Kapitel 1. Dienstleistungen
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Die grundlegende Recheneinheit in einer Dapr-fähigen Anwendung ist ein Dienst. Eines der Ziele von Dapr ist es, dir die Möglichkeit zu geben, diese Dienste so zu schreiben, wie du es möchtest, und zwar in der Sprache deiner Wahl. Dapr arbeitet Seite an Seite mit deinen Diensten und bringt die notwendigen Fähigkeiten wie Zustandsverwaltung, Tracing und sichere Kommunikation ein, wenn du sie brauchst. In diesem Kapitel erfährst du, wie die verschiedenen Funktionen von Dapr entstanden sind.
Die Welt vor der Wolke
Um das Jahr 2000 herum arbeitete ich (Haishi) bei einer Finanzsoftwarefirma in San Francisco. Im zweiten Stock gab es einen Serverraum, zu dem man mit einer speziellen Schlüsselkarte Zutritt hatte. Der Raum war immer eiskalt und laut. Er beherbergte alles, was das Unternehmen für den Betrieb brauchte - Domain Controller, Mailserver, Dateiserver, Quellenspeicher, Datenbanken, Testlabore und alle Personalakten. Abgesehen von den Serverschränken war der Raum mit Regalen voller Bänder gefüllt, die bis zur Decke gestapelt waren. Das Unternehmen sicherte die Server regelmäßig, und alle Backups wurden auf diesen Bändern gespeichert. Der Raum war außerdem mit riesigen Tanks mit reinem Stickstoffgas ausgestattet, das im Falle eines Brandes freigesetzt wurde, um den Raum zu retten.
Die IT-Mitarbeiter hüteten die Server sehr. Und sie waren oft genervt von den Aufforderungen der Entwickler, neue Serviceversionen bereitzustellen - schließlich hatte die Aufrechterhaltung der Mailbox des CEOs höhere Priorität. Die Bereitstellung einer neuen Version war ein großer Vorgang: Server wurden gesichert, Datenbanken wurden gesichert, Server wurden gepatcht, Datenmigrationsskripte wurden ausgeführt, Validierungstests wurden durchgeführt. Und wenn die Tests fehlschlugen, wurde alles zurückgesetzt und die IT-Mitarbeiter warfen uns einen bösen Blick zu. Ihre Pager piepten, und sie sagten uns, dass sie erst morgen wieder einsatzbereit sein würden.
Zu dieser Zeit war die Browser/Server-Architektur (B/S) auf dem Vormarsch und sollte die etablierte Client/Server-Architektur (C/S) ersetzen. Das Hauptversprechen der B/S-Architektur bestand darin, dass die Clients so schlank wie ein Webbrowser sein sollten, um eine reibungslose Einführung zu ermöglichen. Da immer mehr Unternehmen versuchten, ein abonnementbasiertes Geschäftsmodell anstelle des traditionellen lizenzbasierten Geschäftsmodells einzuführen, konzentrierte die B/S-Architektur große Mengen an Rechenressourcen wieder auf zentrale Server. Diese Server waren entscheidend für das Geschäft. Ihre Verwaltung wurde jedoch zu einem immer schwierigeren Problem. Die Unternehmen mussten umfangreiche Kapazitätsplanungsprozesse durchlaufen, um sicherzustellen, dass sie genügend Server kaufen konnten, die ihren Anforderungen entsprachen, ohne das Budget zu sprengen. Da die Dienste auch bei Updates und Serverausfällen verfügbar bleiben mussten, brauchten die Unternehmen gleichzeitig die Möglichkeit, ihre Anwendungen schnell und konsistent einzusetzen und zu aktualisieren, ohne die laufenden Dienste zu unterbrechen.
Versprechen und Herausforderungen der Cloud
Ein paar Jahre später stellte sich die Cloud der Herausforderung, hochverfügbare gehostete Dienste zu betreiben. Sie versprach Verfügbarkeit und Elastizität, verbrauchsabhängige Preise und unbegrenzte Kapazität. Diese Versprechen gab es jedoch nicht umsonst. Sie stellten einige neue Anforderungen an die Gestaltung von Anwendungen.
Verfügbarkeit
Cloud Computing erreicht eine hohe Verfügbarkeit durch Redundanz. Cloud-Server sind nicht magisch - sie schlagen genauso fehl wie die Server in deinen eigenen Rechenzentren. Aber wenn ein Cloud-Server fehlschlägt, hat der Anbieter nicht genug Personal, um das Serverproblem sofort zu diagnostizieren und zu beheben. Stattdessen zieht er einfach einen anderen Server aus seinem riesigen Serverpool und migriert deine Anwendung, damit sie wie gewohnt weiterläuft.
Das bedeutet, dass deine Anwendung jederzeit angehalten und auf einer neuen Serverinstanz neu gestartet werden kann. Das bringt einige Herausforderungen für die Gestaltung deiner Dienste mit sich. Wenn du zum Beispiel einen Zustand im Speicher anhäufst, geht dieser Zustand beim Neustart verloren. Wenn dein Dienst lange braucht, um initialisiert zu werden, wird auch die Verfügbarkeit des Dienstes beeinträchtigt. Wenn du außerdem einen Status lokal speicherst, indem du z. B. eine Datei auf ein lokales Laufwerk schreibst, geht dieser Status bei der Migration verloren. Die Migration von Zuständen ist immer problematisch. Deshalb verlangen viele Cloud-Workload-Management-Systeme, dass die Anwendungen zustandslos sind, d. h. sie speichern keinen lokalen Status in der Hosting-Umgebung.
Das Verschieben von Anwendungsteilen von einem Server auf einen anderen braucht Zeit. Wenn eine Anwendung in kleinere Teile zerlegt werden kann, ist das Verschieben und Wiederherstellen dieser kleineren Teile viel effizienter. Die Verwendung dieser kleineren Dienste, die manchmal auch als Microservices bezeichnet werden, wird immer mehr zur Standardmethode für die Zusammenstellung von Anwendungen. Microservices sind in der Regel lose gekoppelt, denn sie sollten funktionsfähig bleiben, während ihre Kollegen verschoben und neu gestartet werden.
Wenn dein Dienst zustandsabhängig sein muss, d.h. er muss einen lokalen Zustand speichern, muss dieser Zustand repliziert werden, um die Verfügbarkeit zu gewährleisten. In solchen Fällen wird oft ein einzelner Writer anstelle mehrerer Writer verwendet, um Datenkonflikte zu vermeiden.
Elastizität
Wenn die Anforderungen eines Dienstes die Kapazität des Hosting-Servers übersteigen, gibt es zwei mögliche Lösungen: kann der Dienst auf einen leistungsfähigeren Server migriert werden, oder es können mehrere Kopien des Dienstes bereitgestellt werden, um die Arbeitslast zu teilen. Der letztere Ansatz, der genannt wird, ist die bevorzugte Methode zur Skalierung in der Cloud. Da Cloud-Provider über eine große Anzahl von Servern verfügen, kann ein Dienst theoretisch unbegrenzt skaliert werden. Auf der anderen Seite kann ein Dienst, wenn die Arbeitslast abnimmt, nach innen skaliert werden, um ungenutzte Rechenkapazität freizugeben. Da du in der Cloud für das bezahlst, was du verbrauchst, kann diese Elastizität eine große Kostenersparnis bedeuten, wenn du saisonal hohe Lasten (wie im Einzelhandel) oder gelegentliche Spitzenlasten (wie in der Nachrichtenbranche) hast.
Bei einfachen Web-APIs ist die Skalierung relativ einfach. Das liegt daran, dass jede Webanforderung oft in sich abgeschlossen ist und die Datenoperationen natürlich nach Transaktionsbereichen segmentiert sind. Bei solchen APIs kann die Skalierung so einfach sein wie das Hinzufügen weiterer Service-Instanzen hinter einem Load Balancer. Aber nicht alle Anwendungen sind für eine Skalierung ausgelegt. Besonders wenn ein Dienst davon ausgeht, dass er die volle Kontrolle über den Systemzustand hat, können mehrere Instanzen des Dienstes widersprüchliche Entscheidungen treffen. Solche Konflikte auszugleichen, ist ein schwieriges Problem, vor allem, wenn es zu einer längeren Netzwerkpartitionierung kommt. Man spricht dann von einem "gespaltenen Gehirn", was oft zu unüberbrückbaren Konflikten und Datenbeschädigungen führt.
Die Partitionierung ist eine effektive Methode, um einen Service zu skalieren. Ein großer Workload kann oft in mehrere Partitionen entlang logischer oder physischer Grenzen aufgeteilt werden, z. B. nach Kunden (oder Mietern), Geschäftsbereichen, geografischen Standorten, Ländern oder Regionen. Jede dieser Partitionen ist ein kleineres System, das je nach Bedarf vergrößert oder verkleinert werden kann. Die Partitionierung ist besonders nützlich, wenn ein zustandsabhängiger Dienst skaliert werden soll. Wie bereits erwähnt, muss der Zustand eines zustandsabhängigen Dienstes repliziert werden, um die Verfügbarkeit zu gewährleisten. Die Partitionierung kontrolliert die Menge der zu replizierenden Daten und ermöglicht eine parallele Replikation, da alle Replikationsvorgänge auf Partitionen beschränkt sind.
Partitionen können entweder statisch oder dynamisch sein. Eine statische Partitionierung ist im Hinblick auf das Routing einfacher, da die Routingregeln im Voraus festgelegt werden können. Allerdings kann die statische Partitionierung zu unausgewogenen Partitionen führen, was wiederum Probleme wie überlastete Hotspots und nicht ausgelastete Serverkapazitäten zur Folge hat. Bei der dynamischen Partitionierung werden die Partitionen mithilfe von Techniken wie dem consistent hashing dynamisch angepasst. Dynamische Partitionierung kann in der Regel eine gleichmäßige Verteilung der Arbeitslasten auf die Partitionen gewährleisten. Es ist jedoch eine partitionsspezifische Routing-Logik erforderlich, um den Benutzerverkehr zu den entsprechenden Partitionen zu leiten. Außerdem ist es schwierig, bei dynamischen Partitionen eine Datentrennung zu gewährleisten, die von einigen Compliance-Standards gefordert wird. Wenn du deine Dienste entwirfst, musst du dich für eine Partitionierungsstrategie entscheiden, die sowohl auf deinen technischen als auch auf deinen nicht-technischen Bedürfnissen basiert, und dich daran halten, denn es ist oft schwierig, die Partitionierungsstrategie später zu ändern, vor allem, wenn du ständig neue Datenströme hast.
Cloud Native Anwendungen
Cloud-native Anwendungen sind dafür konzipiert, in einer Cloud-Umgebung betrieben zu werden. Damit eine Anwendung als "Cloud Native" gilt, sollte sie die folgenden Merkmale aufweisen :
- Automatisch verteilbar
Eine native Cloud-Anwendung kann bei Bedarf immer wieder neu bereitgestellt werden. Diese Funktion ist erforderlich, wenn die automatische Ausfallsicherung aktiviert ist, um eine hohe Verfügbarkeit zu gewährleisten. Virtualisierung und Containerisierung ermöglichen es, Anwendungen als eigenständige Pakete zu schnüren, die auf verschiedenen Hosting-Knoten eingesetzt werden können, ohne dass es zu Konflikten bei externen Abhängigkeiten kommt. Diese Pakete müssen ohne menschliches Zutun bereitgestellt werden können, denn der Failover-Mechanismus kann jederzeit durch verschiedene Umstände ausgelöst werden, z. B. durch den Ausfall von Rechnern oder die Neuverteilung von Rechenressourcen.
Wie bereits erwähnt, ist das Verschieben eines zustandslosen Dienstes auf eine neue Maschine einfacher als das Verschieben eines zustandsbehafteten Dienstes, und die Möglichkeit, eine neue Dienstinstanz schnell zu starten, ist der Schlüssel zur Verbesserung der Verfügbarkeit. Die Zustandslosigkeit ist jedoch keine zwingende Voraussetzung für eine native Cloud-Anwendung. Techniken wie die Partitionierung ermöglichen es, auch zustandsabhängige Dienste effizient zu verschieben.
- Isolierung zwischen den Komponenten
Eine Komponente in einer nativen Multikomponenten-Anwendung sollte weiterhin funktionieren, wenn andere Komponenten fehlschlagen. Auch wenn die Komponente möglicherweise nicht in der Lage ist, die erforderliche Funktionalität zu liefern, sollte sie in der Lage sein, einen voll funktionsfähigen Zustand wiederherzustellen, wenn alle abhängigen Dienste wieder online sind. Mit anderen Worten: Eine fehlschlagende oder neu startende Komponente sollte keine Kaskadenfehler in anderen Komponenten verursachen.
Eine solche Isolierung wird in der Regel durch eine Kombination aus klar definierten APIs, Client-Bibliotheken mit automatischer Rücknahme und einem lose gekoppelten Design durch Messaging erreicht.
Isolation zwischen den Komponenten bedeutet auch, dass die Komponenten individuell skalierbar sein sollten. Das verbrauchsbasierte Modell erfordert, dass die Betreiber von Cloud Native Applications den Ressourcenverbrauch der einzelnen Komponenten genau abstimmen, um die Anforderungen bei minimalem Ressourcenverbrauch besser zu erfüllen. Dies erfordert, dass die Komponenten an Änderungen der Arbeitslast angepasst werden können, wenn verwandte Komponenten skaliert werden.
Cloud-native Anwendungen bestehen in der Regel aus Microservices (tatsächlich werden die beiden Begriffe oft als Synonym betrachtet). Trotz des Namens müssen Microservices nicht klein sein - bei dem Konzept dreht sich alles um den Betrieb. Microservices-Anwendungen sind isoliert, durchgängig einsetzbar und leicht zu skalieren, wodurch sie sich ideal für eine Cloud-Umgebung eignen.
Infrastruktur ist langweilig
Damit eine Cloud-Plattform das Versprechen von Verfügbarkeit und Elastizität erfüllen kann, müssen die Workloads von der zugrunde liegenden Infrastruktur getrennt werden, damit die Infrastruktur bei Bedarf für gängige Cloud-Vorgänge wie Failover und Skalierung mobilisiert werden kann. Infrastrukturfragen sollten das Letzte sein, woran ein Entwickler denken sollte. Projekte wie Open Application Model (OAM, siehe weiter unten in diesem Kapitel) und Dapr zielen darauf ab, Entwicklern Werkzeuge und Abstraktionen zur Verfügung zu stellen, mit denen sie Anwendungen entwerfen und entwickeln können, die unabhängig von der zugrunde liegenden Infrastruktur sind, sowohl für den Einsatz in der Cloud als auch an den Kanten.
Dapr und Container
Die Containerisierung bietet einen leichtgewichtigen Isolationsmechanismus für Workloads, und Kubernetes bietet eine leistungsstarke Workload-Orchestrierung auf geclusterten Rechenknoten. Dapr ist so konzipiert, dass es nativ mit Containern und Kubernetes funktioniert. Wie du im vorherigen Kapitel gesehen hast, funktioniert Dapr aber auch in Umgebungen ohne Container. Der Hauptgrund für dieses Design ist die Unterstützung von IoT-Szenarien und Legacy-Szenarien, in denen keine Container verwendet werden. Ein Altsystem, das auf einer virtuellen Maschine oder einem physischen Server läuft, kann zum Beispiel einen Dapr-Prozess verwenden, der als Windows-Dienst oder Linux-Daemon konfiguriert werden kann. Die Dapr-Laufzeitumgebung kann auch als unabhängiger Container ausgeführt werden, und da sie leichtgewichtig ist, kann sie leicht auf Geräten mit geringerer Kapazität eingesetzt werden.
Unabhängig davon, wie du deine Dapr-Sidecars einsetzt, bieten die Sidecars lokale Service-Endpunkte, die deiner Anwendung verschiedene Fähigkeiten verleihen, die du nutzen kannst, ohne dich um infrastrukturelle Details kümmern zu müssen - das ist der wichtigste Wert von Dapr. Eine native Cloud-Anwendung nutzt oft verschiedene Cloud-basierte Dienste, wie z. B. Speicherungen, geheime Speicher, Authentifizierungsserver, Messaging-Backbones und mehr. Dapr abstrahiert diese Dienste zu einfachen Schnittstellen, so dass deine Anwendungen so konfiguriert werden können, dass sie verschiedene Dienstimplementierungen, einschließlich containerisierter und gehosteter Dienste, in unterschiedlichen Bereitstellungsumgebungen nutzen können.
IaaS, PaaS, SaaS und serverlos
Viele Cloud-Projekte beginnen mit einer Debatte darüber, welche Ebene der Cloud - IaaS, PaaS oder SaaS - der Einstiegspunkt sein soll. Wir nehmen SaaS (Software as a Service) vorerst aus der Diskussion heraus, denn aus Sicht einer Anwendung bedeutet die Nutzung von SaaS den Aufruf einer gehosteten API. Das hat keinen Einfluss darauf, wie die Anwendung selbst gehostet wird.
Mit IaaS (Infrastructure as a Service) hast du die flexibelste Kontrolle über die Rechenressourcen, die du in der Cloud bereitstellst. Da du auf der Infrastrukturebene arbeitest, kannst du deine Hosting-Umgebung genau so gestalten, wie du es möchtest. Du kannst die Netzwerktopologie, das Betriebssystem, die Laufzeitumgebung, die Frameworks und vieles mehr auswählen. Dann stellst du deine Anwendung auf der angegebenen Infrastruktur bereit und verwaltest sie genauso wie in einem lokalen Rechenzentrum. Die Arbeit auf Infrastrukturebene macht es jedoch schwieriger, die Vorteile der Verfügbarkeit und Elastizität der Cloud zu nutzen. Obwohl dein Cloud-Provider zum Beispiel eine fehlgeschlagene virtuelle Maschine automatisch wiederherstellen und eine Neuverteilung deiner Anwendung veranlassen kann, kann der Aufbau der Umgebung sehr lange dauern und unerwartete Ausfälle verursachen.
PaaS (Platform as a Service) ist etwas eigenwilliger. Wenn du dich an die Programmiermodelle einer PaaS-Plattform hältst, werden dir viele infrastrukturelle Lasten abgenommen. Dapr ist so konzipiert, dass es mit verschiedenen PaaS-Plattformen zusammenarbeitet. Architektonisch gesehen ist Dapr nur eine Reihe von Service-Endpunkten, die deine Anwendung nutzen kann. In gewisser Weise ist es ein "lokaler SaaS", den deine Anwendung nutzen kann. Dapr schreibt nicht vor, wie deine Anwendung geschrieben wird oder welche Frameworks deine Anwendung nutzt.
Da Dapr als Sidecar läuft, funktioniert es mit jeder serverlosen Plattform, die das Konzept der gruppierten Container unterstützt. Dazu gehören verschiedene Varianten von verwalteten Kubernetes-Clustern sowie Azure Container Instances (ACI), die Container-Gruppen unterstützen. Um auf einer serverlosen Plattform zu arbeiten, die keine Containergruppen unterstützt, kannst du den Dapr-Prozess als Teil deines Anwendungscontainers verpacken.
Mit diesen Überlegungen im Hinterkopf stellen wir nun vor, wie Dapr Abstraktionen für Serviceaufrufe zwischen verteilten Komponenten bereitstellt. Die Funktion des Dienstaufrufs bietet die grundlegende Unterstützung, die es den Komponenten in einer Microservices-Anwendung ermöglicht, miteinander zu kommunizieren.
Dienstaufruf
Mehrere Dienste können über Dapr-Sidecars miteinander kommunizieren, wie in Abbildung 1-1 dargestellt. Wenn Dienst a, der durch ein Dapr-Sidecar mit dem Namen dapr-a repräsentiert wird, versucht, eine Methode foo aufzurufen, die von Dienst b, der durch ein Dapr-Sidecar mit dem Namen dapr-b repräsentiert wird, definiert wurde, durchläuft die Anfrage die folgenden Schritte:
Dienst a sendet eine Anfrage an seinen eigenen Dapr-Sidecar über localhost:3500 (vorausgesetzt, der Sidecar hört auf Port 3500) mit dem Pfad /v1.0/invoke/<Ziel-Dapr-ID>/method/<Ziel-Methode>. Beachte, dass ein Dienst die Aufrufanforderung immer über localhost an sein eigenes Dapr-Sidecar sendet.
Der dapr-a Sidecar löst die Adresse des dapr-b Sidecars auf und leitet die Anfrage an den Aufrufendpunkt von dapr-bweiter.
Der dapr-b-Sidecar ruft die
/fooRoute von Dienst bauf.
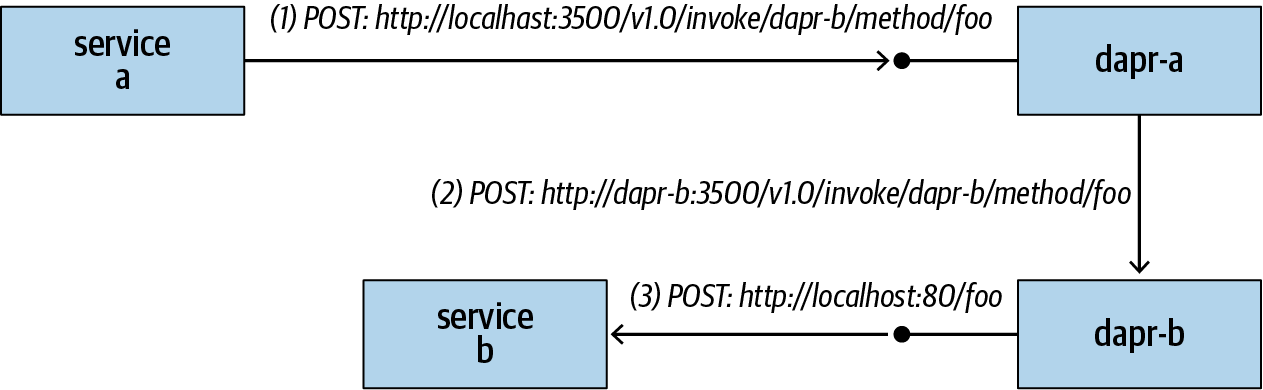
Abbildung 1-1. Dienstaufruf durch Dapr-Sidecars
Name Auflösung
Der erste Schritt, um einen anderen Dienst aufzurufen, besteht darin, den Dienst zu finden. Jeder Dapr-Sidecar wird durch eine String-ID identifiziert. Die Aufgabe der Namensauflösung besteht darin, die Dapr-ID auf eine routingfähige Adresse abzubilden. Standardmäßig verwendet Dapr den Kubernetes-Namensauflösungsmechanismus, wenn es auf Kubernetes läuft, und es verwendet Multicast-DNS (mDNS), wenn es im lokalen Modus läuft. Dapr erlaubt es auch, andere Namensauflöser als Komponente in die Laufzeitumgebung einzubinden.
Kubernetes
Wenn du einen Pod mit Dapr-Annotationen bereitstellst, injiziert Dapr automatisch einen Dapr-Sidecar-Container in deinen Pod. Außerdem wird ein ClusterIP Service mit einem -dapr Postfix erstellt. Um dies zu überprüfen, verwende kubectl, um die folgende Pod-Spezifikation aus dem Dapr-Beispielrepository zu deployen:
apiVersion: apps/v1
kind: Deployment
metadata:
name: pythonapp
labels:
app: python
spec:
replicas: 1
selector:
matchLabels:
app: python
template:
metadata:
labels:
app: python
annotations:
dapr.io/enabled: "true"
dapr.io/id: "pythonapp"
spec:
containers:
- name: python
image: dapriosamples/hello-k8s-python
Dann kannst du kubectl verwenden, um den erstellten Dienst anzusehen:
kubectl get svc pythonapp-dapr NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE pythonapp-dapr ClusterIP 10.0.79.144 <none> 80/TCP,50001/TCP 11m
Standardmäßig verwendet Kubernetes CoreDNS für die Namensauflösung. Die folgenden Befehle erstellen einen busybox Pod in deinem Cluster und überprüfen die Standardkonfiguration der Namensauflösung :
kubectl apply -f https://k8s.io/examples/admin/dns/busybox.yaml kubectl exec busybox cat /etc/resolv.conf
In unserer Umgebung, die auf Azure Kubernetes Service (AKS) gehostet wird, erzeugt die folgende Ausgabe:
nameserver 10.0.0.10 search default.svc.cluster.local svc.cluster.local cluster.local vvdjj2huljtelaqnqfod0pbtwh.xx.internal.cloudapp.net options ndots:5
Du kannst die Dienstadresse mit dem folgenden Befehl manuell nachschlagen:
kubectl exec -ti busybox -- nslookup pythonapp-dapr
Dieser Befehl erzeugt in unserer Umgebung die folgende Ausgabe. Du solltest in deiner Umgebung ähnliche Ergebnisse erhalten, mit Ausnahme der aufgelösten Dienst-IP. Die Ausgabe zeigt, wie Dapr die Dapr-ID, pythonapp-dapr, in den entsprechenden aufzurufenden Dienst auflösen kann:
Server: 10.0.0.10 Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local Name: pythonapp-dapr Address 1: 10.0.79.144 pythonapp-dapr.default.svc.cluster.local
Wenn der Pod verkleinert wird, wird der Verkehr zum Dienst gleichmäßig auf die Instanzen verteilt - so skaliert ein Dapr-Sidecar.
mDNS
Das Multicast-DNS-Protokoll wird verwendet, um Hostnamen in IP-Adressen in einem kleinen Netzwerk aufzulösen, indem UDP-Pakete gesendet werden. Im Wesentlichen kündigt jeder Teilnehmer seine eigene Adresse an und aktualisiert seinen DNS-Lookup-Cache auf der Grundlage der Ankündigungen der anderen Teilnehmer. Wenn Dapr im lokalen Modus läuft, verwendet es mDNS für die Namensauflösung.
Wenn mehrere Dapr-Sidecars auf demselben Host laufen, müssen sie auf verschiedene HTTP/gRPC-Ports hören, um Portkonflikte zu vermeiden. In solchen Fällen löst mDNS den spezifischen Port auf, den die Dapr-Instanz abhört. Zum Beispiel kann die Dapr-ID dapr-a auf localhost:3500 aufgelöst werden und die Dapr-ID dapr-d auf localhost:3600.
Hinweis
Zum Zeitpunkt der Erstellung dieses Artikels ist die mDNS-Implementierung von Dapr auf einen einzigen Host beschränkt. Wenn du diesen Text liest, wird die Implementierung wahrscheinlich so erweitert sein, dass sie mehrere Rechner im selben lokalen Netzwerk unterstützt. Bis dahin unterstützt der lokale Modus von Dapr nur Dapr-Sidecars, die auf demselben Host laufen und an verschiedenen Ports lauschen. Nach der Erweiterung können sich Dapr-Sidecars, die im selben lokalen Netzwerk laufen, gegenseitig über Dapr-IDs ansprechen.
Anfragen und Antworten
Dapr leitet alle Anfrage-Header sowie Abfrageparameter für HTTP-Anfragen, und alle mit gRPC-Anfragen verbundenen Metadaten weiter. Obwohl Dienste entweder über HTTP oder gRPC mit Dapr kommunizieren können, kommunizieren Dapr-Sidecars untereinander immer über gRPC. Wenn eine HTTP-Anfrage in eine gRPC-Anfrage umgewandelt wird, werden alle HTTP-Header in das headers Metadatenelement der gRPC-Anfrage kodiert. Dapr unterstützt die gängigen HTTP-Verben wie GET, POST, DELETE und PUT.
Dapr verwendet gegenseitiges TLS, um die Kommunikation zwischen den Sidecars zu sichern. Dapr-Sidecars authentifizieren sich gegenseitig mit Sidecar-spezifischen Zertifikaten, die auf eine CA auf Clusterebene (wenn sie auf Kubernetes laufen) oder ein vom Kunden bereitgestelltes Root-Zertifikat verweisen - siehe Kapitel 4 für weitere Details. Die Kommunikation zwischen einem Dienst und dem zugehörigen Sidecar ist oft ungeschützt, da davon ausgegangen wird, dass sich das Sidecar in der gleichen Sicherheitsdomäne wie der Dienst befindet, aber du kannst über Dapr eine Ende-zu-Ende-Verschlüsselung zwischen zwei Diensten konfigurieren.
Gleichzeitigkeitskontrolle
Die Dapr-Laufzeitumgebung unterstützt einen max-concurrency Schalter. Wenn dieser Schalter auf einen positiven Wert gesetzt ist, bestimmt er, wie viele gleichzeitige Anfragen an einen Benutzerdienst gesendet werden können. Sobald die Anzahl der gleichzeitigen Anfragen den angegebenen Schwellenwert überschreitet, werden weitere Anfragen zurückgehalten, bis zusätzliche Verarbeitungskapazität frei wird. Das bedeutet, dass eine Kundenanfrage aufgrund eines ausgelasteten Dienstes eine Zeitüberschreitung verursachen kann.
Experiment Dienstaufruf
In diesem Abschnitt werden wir ein kleines Experiment zum Aufruf von Diensten durchführen. Wir verwenden hier PHP, aber denk daran, dass du jede beliebige Sprache wählen kannst. Du musst nur einen einfachen Webserver ohne Dapr-spezifische Logik oder Bibliotheken schreiben.
Erstellen des PHP-Dienstes
Der erste Schritt besteht darin, einen einfachen PHP-Webdienst zu erstellen. Dieser Dienst antwortet auf auf alle angeforderten Routen und gibt die Anfragemethode, den Anforderungspfad und die Kopfzeilen der Anfrage zurück:
Erstelle einen neuen Ordner namens php-app.
Erstelle im Ordner php-app eine neue PHP-Skriptdatei namens app.php mit folgendem Inhalt:
<?php $method = $_SERVER[’REQUEST_METHOD’]; $uri = $_SERVER[’REQUEST_URI’]; $headers = array(); foreach ($_SERVER as $key => $value) { if (strpos($key, ’HTTP_’) == 0 && strlen($key) >5) { $header = str_replace(’ ’, ’-’, ucwords(str_replace(’_’, ’ ’, strtolower(substr($key, 5))))); $headers[$header] = $value; } } echo json_encode(array(’method’=>$method, ’uri’ => $uri, ’headers’ => $headers)); ?>Erstelle im selben Ordner ein Dockerfile mit diesem Inhalt:
FROM php:7.4-cli COPY . /usr/src/myapp WORKDIR /usr/src/myapp CMD ["php", "-S", "0.0.0.0:8000", "app.php"]
Erstelle und verteile das Docker-Image:
docker build -t
<image tag>. docker push<image tag>
Den Dienst einrichten
Im nächsten Schritt erstellst du eine Kubernetes Deployment Spec, um den PHP-Dienst bereitzustellen. Außerdem definierst du einen LoadBalancer Dienst, damit du über eine öffentliche IP auf den Dienst zugreifen kannst:
Erstelle eine neue php-app.yaml-Datei mit dem folgenden Inhalt:
kind: Service apiVersion: v1 metadata: name: phpapp labels: app: php spec: selector: app: php ports: - protocol: TCP port: 80 targetPort: 8000 type: LoadBalancer --- apiVersion: apps/v1 kind: Deployment metadata: name: phpapp labels: app: php spec: replicas: 1 selector: matchLabels: app: php template: metadata: labels: app: php annotations: dapr.io/enabled: "true" dapr.io/id: "phpapp" dapr.io/port: "8000" spec: containers: - name: php image:<image tag>ports: - containerPort: 8000 imagePullPolicy: AlwaysStelle die Datei mit
kubectlbereit. Rufe dann die öffentliche IP desphpappDienstes ab:kubectl apply -f php-app.yaml kubectl get svc phpapp
Verwende einen Browser oder Postman, um eine Anfrage an http://<Ihre Dienst-IP>/abc/def?param=123 zu senden. Du solltest ein JSON-Dokument erhalten, das ähnlich wie das folgende aussieht:
{ "method":"GET", "uri":"\/abc\/def?param=123", "headers":{ ... } }
Den Dienst -dapr freigeben
Wie bereits erwähnt, erstellt Dapr beim Deployment eines Pods mit Dapr-Annotationen einen -dapr ClusterIP Service. Für dieses Experiment bearbeitest du den Dienst, um seinen Typ in LoadBalancer zu ändern, was bedeutet, dass ihm eine öffentliche IP über den Load Balancer zugewiesen wird:
kubectl edit svc phpapp-dapr
Ersetze ClusterIP in dieser Datei durch LoadBalancer und speichere dann die Datei. kubectl sollte melden, dass der Dienst bearbeitet wurde:
service/phpapp-dapr edited
Warte darauf, dass phpapp-dapr eine öffentliche IP zugewiesen wird. Dann kannst du den PHP-Dienst über den exponierten Dapr-Dienst aufrufen:
http://<dapr service IP>/v1.0/invoke/phpapp/method/foo
Du kannst mit verschiedenen Kombinationen von Anfragepfaden, Parametern und Anfrage-Headern experimentieren. So kannst du beobachten, wie Dapr die Metadaten an den PHP-Dienst weiterleitet.
Der universelle Namensraum
Zum Zeitpunkt der Erstellung dieses Artikels entwickeln wir eine neue Dapr-Fähigkeit mit dem vorläufigen Namen " Universal Namespace". Bislang funktionieren die Namensauflösung und die Kommunikation in Dapr nur in einem einzigen Cluster. Wir möchten Dapr jedoch so erweitern, dass es die Namensauflösung und Kommunikation zwischen mehreren Clustern unterstützt.
Die Idee des universellen Namensraums ist es, den Nutzern die Möglichkeit zu geben, Dienstnamen mit Cluster-Identifikatoren zu versehen, so dass Dienste auf verschiedenen Clustern sich gegenseitig über Namen wie <service name>.<cluster identifier>. Um zum Beispiel eine Methode foo auf service-1 auf cluster1 aufzurufen, würde ein Client einfach eine POST-Anfrage an einen Dapr-Endpunkt auf http://localhost:3500/v1.0/invoke/service-1.cluster1/foo senden .
Da Dapr-Sidecars oft als ClusterIP Dienste angeboten werden, planen wir die Einführung eines neuen Dapr-Gateway-Dienstes, der mit einer öffentlichen IP verbunden werden kann. Bei der Namensauflösung über DNS wird die Adresse des Gateway-Dienstes ermittelt, und der Gateway leitet die Anfrage an die lokalen Dienste weiter. Wenn du dich dafür entscheidest, einen Dapr-Dienst mit einer öffentlichen IP-Adresse bereitzustellen, können die DNS-Einträge auf dem anderen Cluster natürlich aktualisiert werden, um den Datenverkehr direkt an den Zieldienst weiterzuleiten, ohne den Umweg über das Gateway zu nehmen.
Um die Kommunikation zwischen den Clustern zu sichern, werden die Stammzertifikate der Cluster (oder ein gemeinsames Stammzertifikat) zur gegenseitigen TLS-Authentifizierung ausgetauscht.
Hinweis
Wir werden in Kapitel 7 mehr über diese und andere zukünftige Funktionen von Dapr sprechen.
Kneipe/Verleih
Microservices-Architekturen plädieren für lose gekoppelte Dienste. Wenn ein Dienst einen anderen Dienst über Dapr aufruft, muss er die physische Dienstadresse nicht selbst auflösen. Stattdessen kann er einfach über die entsprechende Dapr-ID auf einen anderen Dienst verweisen. Dieses Design ermöglicht eine große Flexibilität bei der Platzierung von Diensten. Allerdings muss der aufrufende Dienst immer noch den genauen Namen des Zieldienstes kennen.
Viele moderne Anwendungen bestehen aus mehreren Diensten, die von verschiedenen Teams entwickelt und betrieben werden. Vor allem in großen Unternehmensumgebungen können verschiedene Dienste unterschiedliche Lebenszyklen haben und ein Dienst kann durch einen völlig anderen Dienst ersetzt werden. Die Aufrechterhaltung direkter Verbindungen zwischen diesen Diensten kann schwierig, wenn nicht gar unmöglich sein. Deshalb brauchen wir Möglichkeiten, um die Dienste lose zu koppeln, aber effizient in eine Gesamtanwendung zu integrieren.
Um eine bessere lose Kopplung zu erreichen, unterstützt Dapr nachrichtenbasierte Integrationsmuster. Bevor wir uns ansehen, wie Dapr Messaging unterstützt, wollen wir die Vorteile dieses Ansatzes noch einmal zusammenfassen.
Vorteile der nachrichtenbasierten Integration
Die nachrichtenbasierte Integration ermöglicht es den Diensten, Nachrichten über einen Messaging-Backbone auszutauschen, wie in Abbildung 1-2 dargestellt. Anstatt Anfragen direkt aneinander zu senden, kommunizieren alle Dienste miteinander, indem sie Nachrichten über den Messaging-Backbone austauschen. Diese zusätzliche Ebene der Indirektion bringt viele wünschenswerte Eigenschaften mit sich, die in den folgenden Unterabschnitten zusammengefasst werden .
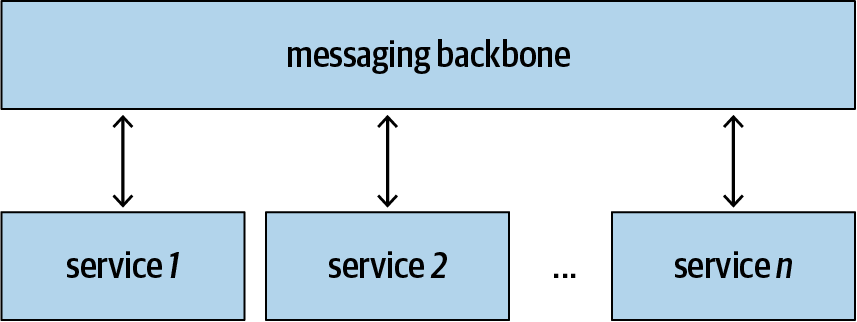
Abbildung 1-2. Nachrichtenbasierte Integration
Leistungsunterschiede abmildern
Verschiedene Dienste haben unterschiedliche Durchsatzraten. Wenn alle Dienste durch direkte Aufrufe miteinander verknüpft sind, wird der Gesamtdurchsatz des Systems durch den langsamsten Dienst in der Kette bestimmt. Das ist in der Regel inakzeptabel. Ein Webservice sollte zum Beispiel weiterhin neue Bestellungen entgegennehmen, während der Backend-Dienst die Bestellungen bearbeitet, was viel länger dauern kann.
In solchen Fällen kann der Frontend-Dienst eine neue Bestellung annehmen, sie in eine Bearbeitungswarteschlange stellen und sich auf die nächste Bestellung vorbereiten. Gleichzeitig kann der Backend-Dienst die Aufträge in seinem eigenen Tempo aufnehmen und bearbeiten, ohne die Reaktionsfähigkeit des Frontend-Dienstes zu beeinträchtigen. Außerdem kann der Backend-Dienst unabhängig skaliert werden, um die Bearbeitungswarteschlange schneller zu leeren.
Erweiterte Warteschlangenfunktionen wie Deduplizierung (Entfernen doppelter Anfragen), Prioritätswarteschlangen (Verschieben von Anfragen mit höherer Priorität an den Anfang der Warteschlange) und Batching (Zusammenfassen von Anfragen zu einer einzigen Transaktion) können helfen, das System weiter zu optimieren.
Verbesserung der Verfügbarkeit
Die nachrichtenbasierte Integration kann in einigen Fällen auch dazu beitragen, die Systemverfügbarkeit zu verbessern. Wenn zum Beispiel das Backend wegen Wartungsarbeiten oder Upgrades heruntergefahren wird, kann das Frontend weiterhin neue Anfragen entgegennehmen und in die Warteschlange stellen.
Mit einem global redundanten Messaging-Backbone kann dein System sogar regionale Ausfälle überstehen, denn die Anfragen in der Warteschlange bleiben auch dann verfügbar, wenn alle deine Systemkomponenten fehlschlagen. Sie können abgeholt werden, wenn das System neu startet.
Einige Warteschlangensysteme erlauben das Auschecken eines Workitems, ohne es aus der Warteschlange zu entfernen. Sobald das Workitem ausgecheckt ist, erhält der Bearbeiter ein Zeitfenster, um es zu bearbeiten und dann aus der Warteschlange zu entfernen. Wenn der Bearbeiter dies nicht in der vorgegebenen Zeit schafft, wird das Workitem für andere zum Auschecken freigegeben. Auf diese Weise wird sichergestellt, dass ein Workitem mindestens ein Mal bearbeitet wird.
Flexible Integrationstopologie
Durch die nachrichtenbasierte Integration kannst du verschiedene Servicetopologien implementieren: pub/sub, bursting to cloud, content-based routing, scatter-gather, competing consumer, dead letter channel, message broker und viele mehr.
Beim Pub/Sub-Muster veröffentlichen Publisher Nachrichten in einem Topic, das von Subscribern abonniert wird. Abbildung 1-3 veranschaulicht einige der Integrationstopologien, die du mit pub/sub erreichen kannst.
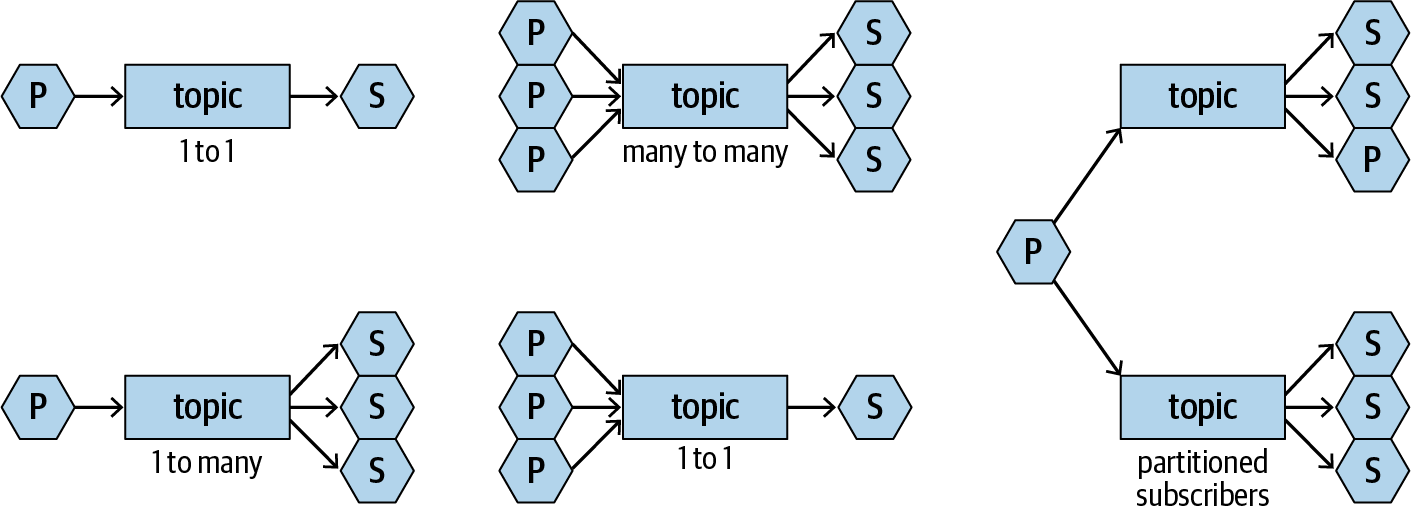
Abbildung 1-3. Integrationsmuster mit pub/sub
Einer der Hauptvorteile von Pub/Sub ist, dass die Verleger und Abonnenten völlig entkoppelt sind (um genau zu sein, sind sie immer noch durch das Nachrichtenformat gekoppelt, aber wir sprechen hier nur über die Topologie). Einem Verleger ist es egal, wie viele Abonnenten das Thema, das er veröffentlicht, abonniert haben, oder wer die Abonnenten sind. Das Gleiche gilt für die Abonnenten. Das bedeutet, dass Verleger und Abonnenten jederzeit weiterentwickelt oder ersetzt werden können, ohne sich gegenseitig zu beeinflussen. Das ist sehr leistungsstark, vor allem wenn mehrere Teams zusammenarbeiten, um eine komplexe Anwendung zu erstellen.
Pub/Sub mit Dapr
Um Themen zu abonnieren, sollte deine Anwendung eine GET-Anfrage an den Dapr-Sidecar mit einer Liste von Themen und entsprechenden Routen als JSON-Array senden, wie im folgenden Node.js-Beispielcode gezeigt:
app.get(’/dapr/subscribe’, (_req, res) => {
res.json([
{
topic: "A",
route: "A"
},
{
topic: "B",
route: "B"
}
]);
});
Der Sidecar sendet dir dann Ereignisse durch POST-Anfragen, wenn Publisher Inhalte in den abonnierten Themen veröffentlichen:
app.post(’/A’, (req, res) => {
console.log("A: ", req.body);
res.sendStatus(200);
});
Um ein Thema zu veröffentlichen, sollte deine Anwendung eine POST-Anfrage an einen /publish/<topic> Endpunkt deines Dapr-Sidecars senden, wobei die zu sendende Nachricht als POST-Body und als CloudEvent verpackt ist (mehr dazu im folgenden Abschnitt):
const publishUrl = `http://localhost:3500/v1.0/publish/<topic>`; request( { uri: publishUrl, method: ’POST’, json:<message>} );
Hinweis
Du kannst den Quellcode eines vollständigen Pub/Sub-Beispiels aus dem Dapr-Beispiel-Repository erhalten.
Wie Pub/Sub funktioniert
Pub/sub braucht ein Messaging-Backbone. Wie in der Einführung erläutert, ist es jedoch eines der Designprinzipien von Dapr, das Rad nicht neu zu erfinden. Anstatt also einen neuen Messaging-Backbone zu entwickeln, ist Dapr so konzipiert, dass es in viele gängige Messaging-Backbones integriert werden kann, darunter Redis Streams, NATS, Azure Service Bus, RabbitMQ, Kafka und andere (eine vollständige Liste findest du im Dapr-Repository).
Dapr verwendet Redis Streams als Standard-Backbone für die Nachrichtenübermittlung. Der Stream ist eine Datenstruktur, die mit Redis 5.0 eingeführt wurde und nur aus Anhängen besteht. Du kannst XADD verwenden, um Datenelemente in einen Stream einzufügen, und du kannst APIs wie BLPOP verwenden, um Daten abzurufen. Jedem Abonnenten wird eine eigene Verbrauchergruppe zugewiesen, damit er seine eigenen Kopien von Nachrichten parallel verarbeiten kann.
Dapr folgt der CloudEvents v1.0 Spezifikation. CloudEvents ist ein Projekt der Cloud Native Computing Foundation (CNCF) auf Sandbox-Ebene. Sein Ziel ist es, eine einheitliche Methode zur Beschreibung von Ereignissen zu schaffen, die von allen Ereignisproduzenten und -konsumenten verwendet werden kann. Dapr implementiert alle erforderlichen Attribute: id source , specversion und type. Außerdem implementiert es die optionalen Attribute datacontenttype und subject. Tabelle 1-1 zeigt, wie diese Attribute ausgefüllt werden.
| Attribut | Wert |
|---|---|
data |
Nutzlast der Nachricht |
datacontenttype |
application/cloudevent+json, text/plain, application/json |
id |
UUID |
source |
Absender Dapr ID |
specversion |
1.0 |
subject |
Abo-Thema |
type |
com.dapr.event.sent |
Dapr Komponenten
Dapr fasst verschiedene Funktionalitäten wie Pub/Sub, den State Store, Middleware und Secrets als Komponenten (auch bekannt als Bausteine) zusammen. Dapr wird mit Standardimplementierungen ausgeliefert, aber du kannst auch andere Implementierungen einfügen, wenn du möchtest.
Eine Komponente wird durch eine Metadaten-Datei im Kubernetes CRD-Format definiert. Die folgende Datei definiert zum Beispiel einen Redis-Status-Speicher mit dem kreativen Namen statestore:
apiVersion: dapr.io/v1alpha1
kind: Component
metadata:
name: statestore
spec:
type: state.redis
metadata:
- name: redisHost
value: <YOUR_REDIS_HOST_HERE>:6379
- name: redisPassword
value: <YOUR_REDIS_KEY_HERE>
Im lokalen Modus sucht Dapr nach einem ./components-Ordner in deinem Dapr-Installationsordner (der mit --component-path überschrieben werden kann) und lädt alle Komponentendateien, die in diesem Ordner gefunden werden. Wenn Dapr im Kubernetes-Modus läuft, sollten diese Dateien als CRDs in deinem Kubernetes-Cluster deployed werden. Um zum Beispiel die obige State-Store-Definition anzuwenden, würdest du Folgendes verwenden:
kubectl apply -f ./redis.yaml
Im Folgenden findest du eine Definition einer OAuth 2.0 Autorisierungs-Middleware:
apiVersion: dapr.io/v1alpha1
kind: Component
metadata:
name: oauth2
spec:
type: middleware.http.oauth2
metadata:
- name: clientId
value: "<your client ID>"
- name: clientSecret
value: "<your client secret>"
- name: scopes
value: "https://www.googleapis.com/auth/userinfo.email"
- name: authURL
value: "https://accounts.google.com/o/oauth2/v2/auth"
- name: tokenURL
value: "https://accounts.google.com/o/oauth2/token"
- name: redirectURL
value: "http://dummy.com"
- name: authHeaderName
value: "authorization"
Diese Datei definiert eine Komponente des Typs middleware.http.oauth2 mit dem Namen oauth2. Du kannst mehrere Middleware-Komponenten zu einer benutzerdefinierten Pipeline zusammenstellen, indem du eine benutzerdefinierte Konfiguration definierst, wie im Folgenden beschrieben.
Dapr-Konfigurationen
Ein Dapr-Sidecar kann mit einer benutzerdefinierten Konfiguration gestartet werden, die im lokalen Modus eine Datei oder im Kubernetes-Modus ein Konfigurationsobjekt ist. Eine Dapr-Konfiguration verwendet wiederum die Kubernetes-CRD-Semantik, so dass dieselbe Konfiguration sowohl im lokalen Modus als auch im Kubernetes-Modus verwendet werden kann.
Zum Zeitpunkt der Erstellung dieses Artikels kannst du Dapr-Konfigurationen verwenden, um das verteilte Tracing anzupassen und eigene Pipelines zu erstellen. Das Schema wird wahrscheinlich in zukünftigen Versionen erweitert werden; schaue in der Online-Dokumentation von Dapr nach, um aktuelle Informationen zu erhalten. Das folgende Beispiel zeigt eine Konfiguration, die verteiltes Tracing aktiviert und eine benutzerdefinierte Pipeline mit der OAuth Middleware definiert:
apiVersion: dapr.io/v1alpha1
kind: Configuration
metadata:
name: pipeline
spec:
tracing:
samplingRate: "1"
httpPipeline:
handlers:
- type: middleware.http.oauth2
name: oauth2
Um diese Konfiguration anzuwenden, verwende kubectl (vorausgesetzt, der Dateiname lautet pipeline.yaml):
kubectl apply -f ./pipeline.yaml
Hinweis
Zum Zeitpunkt der Erstellung dieses Artikels musst du deine Pods neu starten, um die neuen Konfigurationsänderungen zu übernehmen.
Um die benutzerdefinierte Konfiguration anzuwenden, musst du eine dapr.io/config Anmerkung zu deiner Pod-Spezifikation hinzufügen:
apiVersion: apps/v1
kind: Deployment
metadata:
name: echoapp
labels:
app: echo
spec:
replicas: 1
selector:
matchLabels:
app: echo
template:
metadata:
labels:
app: echo
annotations:
dapr.io/enabled: "true"
dapr.io/id: "echoapp"
dapr.io/port: "3000"
dapr.io/config: "pipeline"
spec:
containers:
- name: echo
image: <your Docker image tag>
ports:
- containerPort: 3000
imagePullPolicy: Always
Benutzerdefinierte Pipelines
Middleware, die in einer benutzerdefinierten Pipeline definiert ist, wird in der Reihenfolge angewendet, in der sie in der benutzerdefinierten Konfigurationsdatei auf der Anfrageseite und in umgekehrter Reihenfolge auf der Antwortseite erscheint. Eine Middleware-Implementierung kann entweder an der Ingress-Pipe, der Egress-Pipe oder an beiden teilnehmen, wie in Abbildung 1-4 dargestellt.
Zusätzlich zur benutzerdefinierten Middleware lädt Dapr immer zwei Middlewares am Anfang der Kette: die verteilte Tracing-Middleware und die CORS-Middleware. Wir werden im nächsten Abschnitt über die verteilte Nachverfolgung sprechen. CORS wird durch einen Laufzeitschalter, allowed-origins, konfiguriert, der eine durch Komma getrennte Liste der zulässigen Anfragestämme enthält. Dieser Schalter kann in zukünftigen Versionen in die Dapr-Konfiguration integriert werden.
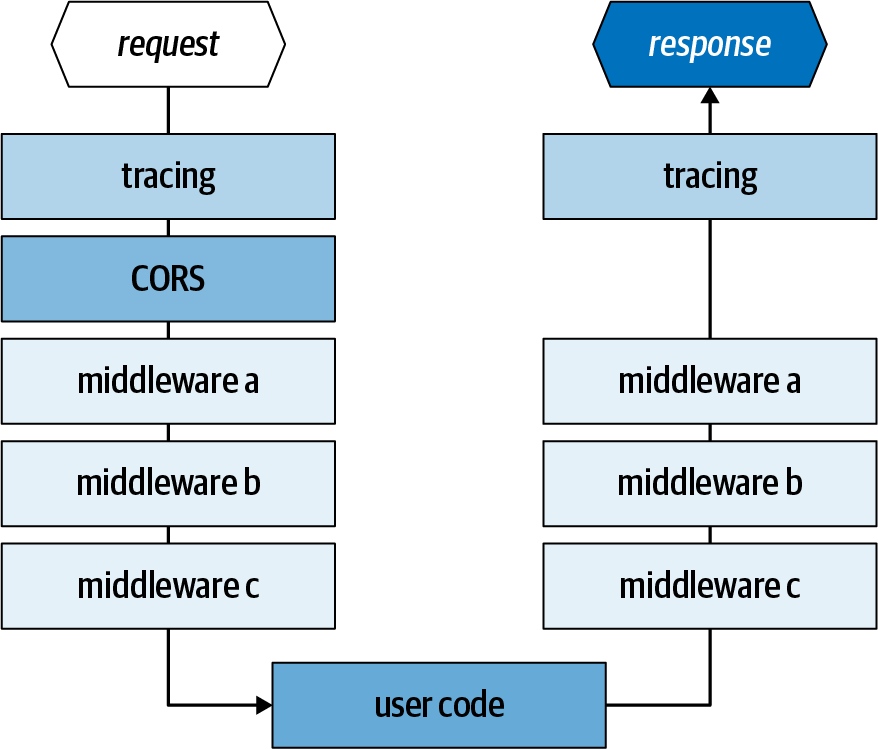
Abbildung 1-4. Eine benutzerdefinierte Pipeline
Benutzerdefiniertes Pipeline-Experiment
Im folgenden Experiment erstellst du eine benutzerdefinierte Pipeline mit einer seltsamen Middleware, die alle Request Bodies in Großbuchstaben ändert. Wir haben die Middleware zu Testzwecken erstellt; du kannst sie verwenden, um zu überprüfen, ob deine benutzerdefinierte Pipeline richtig funktioniert.
Da wir bisher für jedes der Beispiele eine andere Programmiersprache verwendet haben, wechseln wir für diese Übung zu Rust. Du kannst natürlich auch eine andere Sprache und ein anderes Web-Framework wählen, um die App zu schreiben, die einfach zurückgibt, was empfangen wird. Im Folgenden wird davon ausgegangen, dass du Rust auf deinem Rechner installiert und konfiguriert hast.
Die Rust-App erstellen
Erstelle zunächst die Rust-App:
Erstelle ein neues Rust-Projekt mit
cargo:cargo new rust-web cd rust-web
Ändere deine Cargo.toml-Datei so, dass sie die notwendigen Abhängigkeiten enthält:
[dependencies] actix-web = "2.0" actix-rt = "1.0.0" actix-service = "1.0.0" serde = "1.0" bytes = "0.5.2" json = "*"
Ändere die Datei src/main.rs so, dass sie den folgenden Code enthält:
use actix_web::{ web, App, Error, HttpResponse, HttpServer, }; use json::JsonValue; use bytes::{Bytes}; async fn echo(body: Bytes) -> Result<HttpResponse, Error> { let result = json::parse(std::str::from_utf8(&body).unwrap()); // return result let injson: JsonValue = match result { Ok(v) => v, Err(e) => json::object! {"err" => e.to_string() }, }; Ok(HttpResponse::Ok() .content_type("application/json") .body(injson.dump())) } #[actix_rt::main] async fn main() -> std::io::Result<()> { HttpServer::new(|| { App::new() .data(web::JsonConfig::default().limit(4096)) .service(web::resource("/echo").route(web::post().to(echo))) }) .bind("127.0.0.1:8088")? .run() .await }Starte die Anwendung und stelle sicher, dass sie funktioniert:
cargo run
Verwende ein Web-Testing-Tool wie Postman, um eine POST-Anfrage mit einer JSON-Nutzlast an den Webserver zu senden. Du solltest sehen, dass der Payload in der Antwort wiedergegeben wird.
Definiere die benutzerdefinierte Pipeline
In diesem Teil der Übung wirst du zwei Manifestdateien erstellen, eine Dapr-Konfigurationsdatei und eine Middleware-Definitionsdatei:
Erstelle einen neuen Komponentenordner unter deinem Anwendungsordner.
Füge unter diesem Ordner eine neue Datei uppercase .yaml mit folgendem Inhalt hinzu. Die Datei definiert eine Middleware
middleware.http.uppercase, die keine Metadaten hat:apiVersion: dapr.io/v1alpha1 kind: Component metadata: name: uppercase spec: type: middleware.http.uppercase
Definiere eine pipeline.yaml Datei unter deinem Anwendungsordner mit folgendem Inhalt. Diese Konfiguration definiert eine benutzerdefinierte Pipeline mit einer einzigen
middleware.http.uppercaseMiddleware:apiVersion: dapr.io/v1alpha1 kind: Configuration metadata: name: pipeline spec: httpPipeline: handlers: - type: middleware.http.uppercase name: uppercase
Testen
Um die Anwendung lokal zu testen, starte die Rust-Anwendung mit einem Dapr-Sidecar aus deinem Anwendungsordner:
dapr run --app-id rust-web --app-port 8088 --port 8080 --config ./pipeline.yaml cargo run
Verwende dann Postman, um eine POST-Anfrage mit einer JSON-Nutzlast an die folgende Adresse zu senden:
http://localhost:8080/v1.0/invoke/rust-web/method/echo
Du solltest sehen, dass das Antwort-JSON-Dokument nur Großbuchstaben enthält.
Hinweis
Das Testen von Kubernetes bleibt als Übung für interessierte Leser.
OAuth 2.0 Autorisierung
Die OAuth 2.0 Autorisierungs-Middleware ist eine der Middleware-Komponenten, die mit Dapr ausgeliefert werden. Sie ermöglicht den OAuth 2.0 Authorization Code Grant Flow. Wenn der Dapr-Sidecar mit aktivierter OAuth 2.0-Middleware eine Anfrage erhält, laufen die folgenden Schritte ab:
Der Dapr-Sidecar prüft, ob ein Autorisierungs-Token existiert. Wenn nicht, leitet Dapr den Browser an den konfigurierten Autorisierungsserver weiter.
Der Benutzer meldet sich an und gewährt Zugang zur Anwendung. Die Anfrage wird mit einem Autorisierungscode zurück an den Dapr-Sidecar weitergeleitet.
Dapr tauscht den Autorisierungscode gegen ein Zugangs-Token aus.
Der Sidecar fügt das Token in einen konfigurierten Header ein und leitet die Anfrage an die Benutzeranwendung weiter.
Hinweis
Zum Zeitpunkt der Erstellung dieses Artikels unterstützt die Middleware keine Refresh-Tokens.
Abbildung 1-5 zeigt, wie die OAuth-Middleware konfiguriert werden kann, um einer Anwendung die OAuth-Autorisierung zu ermöglichen.
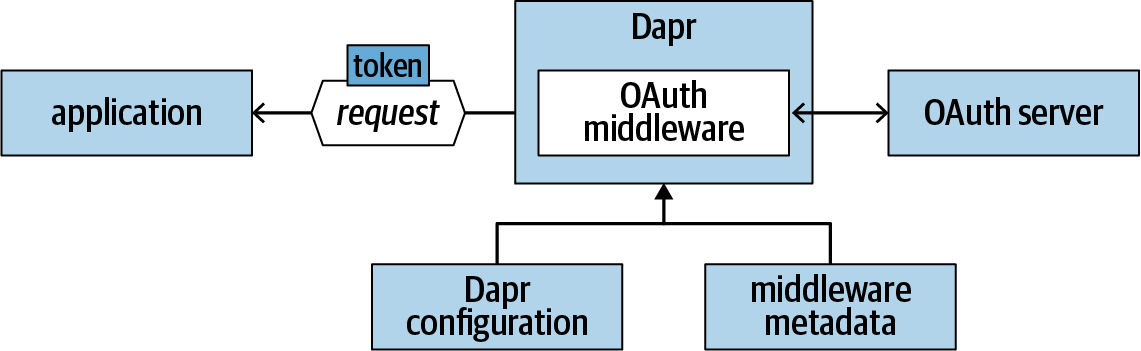
Abbildung 1-5. Benutzerdefinierte Pipeline mit OAuth-Middleware
OAuth ist ein beliebtes Protokoll, das von vielen Autorisierungsservern unterstützt wird, darunter Azure AAD, Facebook, Fitbit, GitHub, Google APIs, Slack, Twitter und viele mehr. Um mit diesen Autorisierungsservern zu arbeiten, musst du deine Anwendung bei den Servern registrieren, die du nutzen möchtest. Verschiedene Server bieten unterschiedliche Registrierungsmöglichkeiten. Am Ende musst du die folgenden Informationen sammeln:
Kundengeheimnis
Autorisierungs-URL
Token URL
In Tabelle 1-2 sind die Autorisierungs- und Token-URLs einiger gängiger Autorisierungsserver aufgeführt.
| Server | Autorisierungs-URL | Token URL |
|---|---|---|
| Azure AAD | https://oreil.ly/M_5KZ | https://oreil.ly/3p0-u |
| GitHub | https://oreil.ly/tbgaL | https://oreil.ly/N2a_1 |
| Google APIs | https://oreil.ly/H79ez | https://oreil.ly/zN1NP https://oreil.ly/SerId |
| https://oreil.ly/FJKKk | https://oreil.ly/WtvKZ |
Sobald du die erforderlichen Informationen gesammelt hast, kannst du die OAuth-Middleware und deine eigene Pipeline definieren. Die Middleware folgt dem OAuth-Flow und fügt das Access Token in den konfigurierten authHeaderName Header ein.
Erstellen einer benutzerdefinierten Middleware
Der HTTP-Server von Dapr verwendet FastHTTP, so dass die Dapr HTTP Middleware auch als FastHTTP-Handler geschrieben wird. Dapr definiert eine einfache Middleware-Schnittstelle, die aus einer GetHandler Methode besteht, die eine fasthttp.RequestHandler zurückgibt:
type Middleware interface {
GetHandler(metadata Metadata) (func(h fasthttp.RequestHandler)
fasthttp.RequestHandler, error)
}
Deine Implementierung sollte eine Funktion zurückgeben, die den Downstream Request Handler aufnimmt und einen neuen Request Handler zurückgibt. Dann kannst du eine eingehende oder ausgehende Logik um den Downstream-Handler herum einfügen, wie im folgenden Codeschnipsel gezeigt:
func GetHandler(metadata Metadata) fasthttp.RequestHandler {
return func(h fasthttp.RequestHandler) fasthttp.RequestHandler {
return func(ctx *fasthttp.RequestCtx) {
//inbound logic
h(ctx) //call the downstream handler
//outbound logic
}
}
}
Deine benutzerdefinierte Middleware sollte, wie andere benutzerdefinierte Komponenten auch, in das Repositorycomponents-contrib von Dapr unter dem Ordner /middleware eingebracht werden. Dann musst du einen weiteren Pull Request für das Haupt-Repository einreichen, um den neuen Middleware-Typ zu registrieren. Du musst auch den Registrierungsprozess befolgen, um deine Middleware zu registrieren .
Hinweis
Der hier beschriebene Registrierungsprozess wird wahrscheinlich in zukünftigen Versionen abgeschafft. Zum Zeitpunkt der Erstellung dieses Dokuments wird nur HTTP-Middleware unterstützt, aber wir planen, in zukünftigen Versionen auch gRPC-Middleware zu unterstützen.
Verteilte Rückverfolgung
Die Diagnose von Problemen in einer verteilten Anwendung ist eine Herausforderung. Du musst Traces von mehreren Diensten sammeln und Korrelationen zwischen den Protokolleinträgen herstellen, um die komplette Aufrufkette zu ermitteln. Das ist eine gewaltige Aufgabe, vor allem in einem großen System mit Dutzenden oder sogar Hunderten von Diensten und Millionen von Transaktionen pro Sekunde.
Dapr macht deine Anwendungstopologie komplexer, weil es Sidecars um alle beteiligten Dienste herum einfügt. Andererseits kann Dapr durch das Einfügen von Sidecars bei der Diagnose helfen. Da der gesamte Datenverkehr durch Dapr-Sidecars fließt, kann Dapr automatisch Korrelationen zwischen den Anfragen herstellen und verteilte Traces in einer einheitlichen Ansicht sammeln. Dapr nutzt OpenTelemetry, um dies zu erreichen.
Ein weiterer Vorteil des verteilten Tracings von Dapr ist, dass dein Servicecode nicht instrumentiert werden muss und dass du keine Tracing-Bibliotheken einbinden musst. Alle Methodenaufrufe werden automatisch von Dapr getraced. Und da die Tracing-Konfiguration völlig unabhängig ist, hat eine Änderung oder Neukonfiguration des Tracing-Systems keine Auswirkungen auf deine laufenden Anwendungen. Zum Zeitpunkt der Erstellung dieses Dokuments stellt Dapr den Benutzerdiensten keine Tracing-API für zusätzliche Tracing-Anforderungen zur Verfügung. Es wurde jedoch diskutiert, eine solche API in Dapr zu implementieren.
Verfolgung von Middleware
Dapr Distributed Tracing ist eine Middleware, die in jeden Dapr-Sidecar eingebunden werden kann. Sie funktioniert sowohl mit dem HTTP- als auch mit dem gRPC-Protokoll. Die Middleware basiert auf zwei Schlüsselkonzepten: dem Span und der Korrelations-ID.
Spannweite
Ein Span repräsentiert eine einzelne Operation, wie z.B. eine HTTP-Anfrage oder einen gRPC-Aufruf. Ein Span kann einen Parent-Span und mehrere Child-Spans haben. Ein Span ohne Elternteil wird als Root-Span bezeichnet. Ein Span wird durch eine Span-ID identifiziert. Dapr speichert zwei Arten von Spans: Server-Spans und Client-Spans. Wenn ein Dienst eine Anfrage erhält, erstellt Dapr einen Server-Span. Wenn ein Dienst einen anderen Dienst aufruft, erstellt Dapr einen Client-Span. Die Spant-Typen helfen Tracing-Systemen, verschiedene Rollen bei einem Dienstaufruf zu verfolgen.
Dapr extrahiert den Methodennamen aus dem Anforderungspfad und verwendet ihn als Span-Namen, und es verwendet den Span-Status, um das Anrufergebnis aufzuzeichnen. Dapr ordnet die HTTP-Antwortcodes einigen Span-Status zu, die in Tabelle 1-3 zusammengefasst sind.
| HTTP-Antwortcode | Spannweite Status |
|---|---|
| 200 | OK |
| 201 | OK |
| 400 | Ungültiges Argument |
| 403 | Erlaubnis verweigert |
| 404 | Nicht gefunden |
| 500 | Intern |
| Andere | Aufnehmen wie es ist |
Korrelation ID
Dapr verwendet eine Korrelations-ID, um eine Aufrufkette über mehrere Dienste hinweg zu verfolgen. Wenn eine Anfrage eingeht, sucht Dapr nach einem X-Correlation-ID Header in den HTTP-Anfrage-Headern oder gRPC-Metadaten. Wenn die ID existiert, verknüpft Dapr neue Tracing-Spans mit der bestehenden Korrelations-ID. Wenn nicht, betrachtet Dapr die Anfrage als neue, vom Kunden initiierte Anfrage und startet eine neue Aufrufkette.
Exporteure
Zum Zeitpunkt der Erstellung dieses Artikels nutzt Dapr OpenCensus, das in OpenTelemetry aufgeht, zum Sammeln von verteilten Traces. OpenCensus unterstützt das Konzept der Exporter, die Traces und Metriken an verschiedene Tracing-Backends senden. Exporteure sind die Erweiterungspunkte von OpenCensus und werden von Dapr verwendet, um sich mit verschiedenen Backend-Systemen wie Zipkin und Azure Monitor zu verbinden. Zum Zeitpunkt der Erstellung dieses Artikels unterstützt Dapr den nativen OpenTelemetry-Exporter, einen Zipkin-Exporter und einen String-Exporter für Testzwecke.
Nachverfolgung mit Zipkin
Zipkin ist ein beliebtes verteiltes Tracing-System. Die folgende Anleitung zeigt dir die Schritte zur Konfiguration des verteilten Dapr-Tracing mit Zipkin.
Konfigurationsdateien erstellen
Du musst zwei Artefakte definieren, eine Zipkin-Exportkomponente und eine Dapr-Konfiguration mit aktiviertem Tracing:
Erstelle eine zipkin.yaml-Datei. Jede Exporter-Komponente hat ein
enabled-Attribut, mit dem du den Exporter ein- oder ausschalten kannst. Andere Attribute sind spezifisch für den Exporteur. Der Zipkin-Exporter benötigt ein einzigesexporterAddress-Attribut, das auf den Zipkin-API-Endpunkt verweist:apiVersion: dapr.io/v1alpha1 kind: Component metadata: name: zipkin spec: type: exporters.zipkin metadata: - name: enabled value: "true" - name: exporterAddress value: "http://zipkin.default.svc.cluster.local:9411/api/v2/spans"Erstelle eine Dapr-Konfigurationsdatei namens tracing.yaml. Die Konfiguration enthält einen
samplingRateSchalter, der steuert, wie oft die Traces abgetastet werden sollen (die Einstellung"0"deaktiviert das Tracing):apiVersion: dapr.io/v1alpha1 kind: Configuration metadata: name: tracing spec: tracing: samplingRate: "1"
Bereitstellen einer Zipkin-Instanz
Verwende den folgenden Befehl, um eine Zipkin-Instanz lokal in einem Docker-Container bereitzustellen :
docker run -d -p 9411:9411 openzipkin/zipkin
Um eine Zipkin-Instanz in deinem Kubernetes-Cluster einzusetzen, verwende diese Befehle:
kubectl run zipkin --image openzipkin/zipkin --port 9411 kubectl expose deploy zipkin --type ClusterIP --port 9411
Aktivieren und Anzeigen der Ablaufverfolgung in Kubernetes
Befolge diese Schritte, um Tracing in Kubernetes zu aktivieren:
Wende die Exporter-Komponente und die Dapr-Konfiguration an:
kubectl apply -f tracing.yaml kubectl apply -f zipkin.yaml
Ändere deine Pod-Spezifikation so, dass sie eine Annotation enthält, die eine benutzerdefinierte Dapr-Konfiguration verwendet :
annotations: dapr.io/config: "tracing"
Setze deinen Pod ein oder starte ihn neu und betreibe deinen Dienst wie gewohnt. Traces werden automatisch gesammelt und an den Zipkin-Endpunkt gesendet.
Du kannst die Zipkin-Benutzeroberfläche verwenden, um die Verfolgungsdaten einzusehen. Um auf die Benutzeroberfläche zuzugreifen, kannst du eine Portweiterleitung über
kubectleinrichten und dann http://localhost:9411 verwenden, um die Verfolgungsdaten anzuzeigen:kubectl port-forward svc/zipkin 9411:9411
Lokale Verfolgung aktivieren und anzeigen
Um die Nachverfolgung lokal zu aktivieren, befolge diese Schritte:
Starte eine lokale Zipkin-Instanz als Docker-Container:
docker run -d -p 9411:9411 openzipkin/zipkin
Ändere die Datei zipkin.yaml so, dass sie auf den lokalen Zipkin-Endpunkt verweist:
apiVersion: dapr.io/v1alpha1 kind: Component metadata: name: zipkin spec: type: exporters.zipkin metadata: - name: enabled value: "true" - name: exporterAddress value: "http://localhost:9411/api/v2/spans"Erstelle einen Komponentenordner unter deinem Anwendungsordner und verschiebe die Datei zipkin.yaml in diesen Ordner.
Starte deinen Dienst mit einem Dapr-Sidecar mit dem folgenden Befehl:
dapr run --app-id mynode --app-port 3000 --config ./tracing.yaml
<command to launch your service>Nutze deinen Dienst wie gewohnt. Du kannst die Tracing-Daten mit der Zipkin-Benutzeroberfläche unter http://localhost:9411 einsehen .
Nachverfolgung mit Azure Monitor
Zum Zeitpunkt der Erstellung dieses Artikels nutzt Dapr einen Local Forwarder, der OpenCensus Traces und Telemetriedaten sammelt und an Application Insights weiterleitet. Dapr bietet einen vorgefertigten Container, daprio/dapr-localforwarder, der den Konfigurationsprozess erleichtert. Sobald der Container läuft, kannst du den Local Forwarder ähnlich wie Zipkin als ClusterIP Dienst in deinem Kubernetes-Cluster konfigurieren. Sobald der Local Forwarder konfiguriert ist, gibst du den Endpunkt des Local Forwarder-Agenten in die Konfigurationsdatei deines nativen Exporters ein:
apiVersion: dapr.io/v1alpha1
kind: Component
metadata:
name: native
spec:
type: exporters.native
metadata:
- name: enabled
value: "true"
- name: agentEndpoint
value: "<Local Forwarder address, for example: 50.140.60.170:6789>"
Anschließend kannst du die umfangreichen Funktionen von Azure Monitor nutzen, um deine gesammelten Tracing-Daten anzuzeigen und zu analysieren. Abbildung 1-6 zeigt ein Beispiel für die Azure Monitor UI, das eine Anwendung mit mehreren Diensten zeigt, die sich gegenseitig aufrufen.
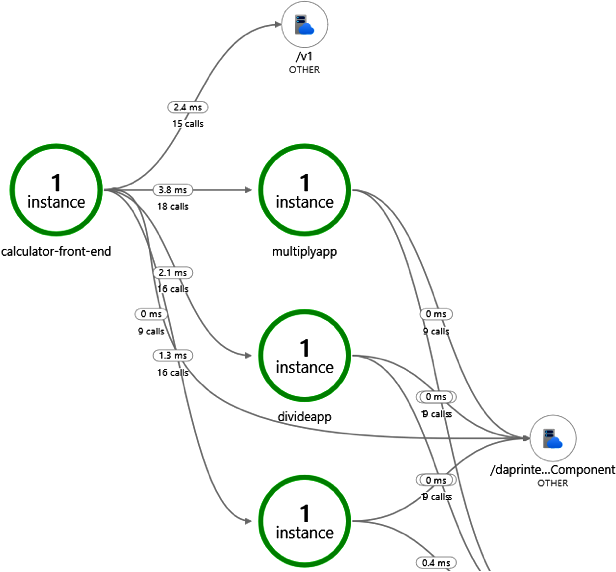
Abbildung 1-6. Anzeigen von Tracing-Daten in Azure Monitor
Du kannst mehrere Exporteure gleichzeitig einsetzen. Dapr leitet die Spuren an alle Exporteure weiter.
Dienstbetrieb
Als verteiltes Programmiermodell und Laufzeitsystem kümmert sich Dapr nicht um den Betrieb von Diensten. Dapr ist jedoch darauf ausgelegt, mit bestehenden Kubernetes-Toolchains und neuen Open-Source-Projekten wie OAM zusammenzuarbeiten, um Anwendungen zu verwalten, die aus mehreren Diensten bestehen. Dieser Abschnitt soll keine umfassende Einführung sein, sondern ein Verzeichnis der entsprechenden Ressourcen.
Dienstbereitstellung und Upgrade
Wenn Dapr unter Kubernetes läuft, verwendet es den Sidecar-Injector, der automatisch Dapr-Sidecar-Container in Pods injiziert, die mit dem Attribut dapr.io/enabled annotiert sind. Du verwaltest deine Pods dann wie gewohnt mit gängigen Kubernetes-Tools wie kubectl. Die folgende YAML-Datei beschreibt zum Beispiel ein Deployment mit einem einzelnen Container und einem lastverteilten Dienst (dieses Beispiel stammt aus dem Beispiel für einen verteilten Rechner, das du im Beispiel-Repository von Dapr finden kannst):
kind: Service
apiVersion: v1
metadata:
name: calculator-front-end
labels:
app: calculator-front-end
spec:
selector:
app: calculator-front-end
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: calculator-front-end
labels:
app: calculator-front-end
spec:
replicas: 1
selector:
matchLabels:
app: calculator-front-end
template:
metadata:
labels:
app: calculator-front-end
annotations:
dapr.io/enabled: "true"
dapr.io/id: "calculator-front-end"
dapr.io/port: "8080"
spec:
containers:
- name: calculator-front-end
image: dapriosamples/distributed-calculator-react-calculator
ports:
- containerPort: 8080
imagePullPolicy: Always
Du kannst kubectl verwenden, um die Bereitstellung durchzuführen:
kubectl apply -f calculator-front-end.yaml
Sobald der Einsatz erstellt ist, kannst du ihn mit kubectl auf mehrere Replikate skalieren:
kubectl scale deployment calculator-front-end --replicas=3
Du kannst kubectl auch verwenden, um eine Bereitstellung auf eine neue Image-Version zu aktualisieren - zum Beispiel:
kubectl set image deployment.v1.apps/calculator-front-end calculator-front-end
=dapriosamples/distributed-calculator-react-calculator:<version tag>
Hinweis
Weitere Informationen zur Verwaltung von Kubernetes-Einsätzen findest du in der Dokumentation.
OAM
Open Application Model (OAM) ist ein Open-Source-Projekt , das eine plattformunabhängige Modellierungssprache für native Cloud-Anwendungen bereitstellen will. OAM beschreibt die Topologie einer Anwendung, die sich aus mehreren miteinander verbundenen Komponenten zusammensetzt. Es befasst sich mit der Anwendungstopologie, aber nicht damit, wie die einzelnen Dienste geschrieben werden. Dapr geht tiefer und bietet ein gemeinsames Programmiermodell und die dazugehörige Laufzeitumgebung für Cloud Native Applications. Wie du bereits in diesem Kapitel gesehen hast, kann Dapr die Auflösung von Dienstnamen und das Routing von Aufrufen übernehmen. Gleichzeitig kann Dapr so konfiguriert werden, dass es mit bestehenden Service-Mesh-Systemen verwendet werden kann, um eine fein abgestimmte Verkehrssteuerung zwischen den Diensten zu ermöglichen. Abbildung 1-7 zeigt, wie die logische Topologie von OAM, die Dapr-Routen und die Service-Mesh-Richtlinien übereinander liegen.
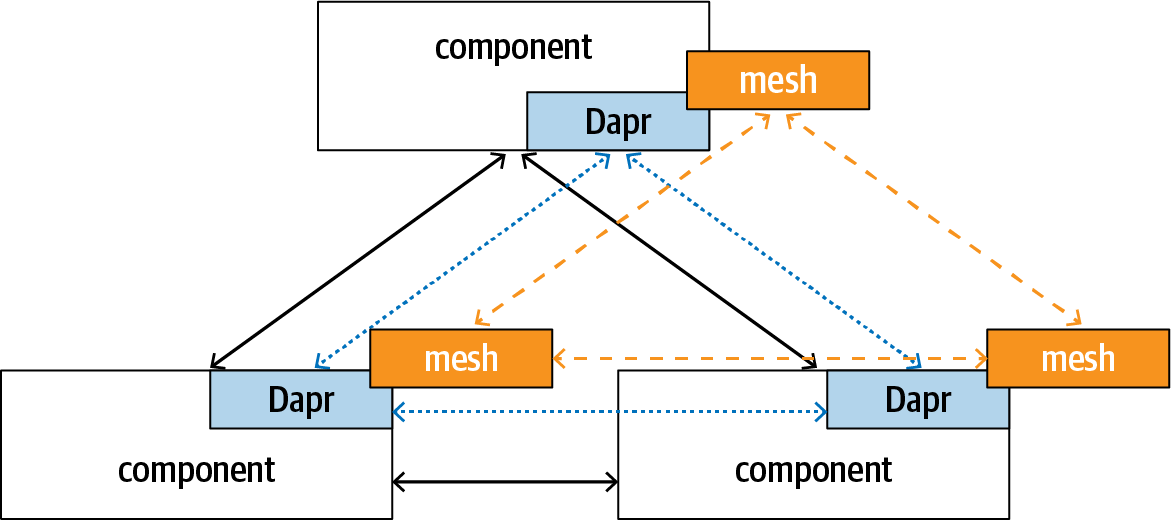
Abbildung 1-7. Beziehung zwischen OAM und Dapr
Mit OAM kannst du jeder Komponente Traits zuweisen, um ein Verhalten wie die Skalierung zu steuern. Der folgende manuelle Skalierungs-Trait skaliert zum Beispiel eine Komponente frontend auf fünf Replikate:
apiVersion: core.oam.dev/v1alpha1
kind: ApplicationConfiguration
metadata:
name: custom-single-app
annotations:
version: v1.0.0
description: "Customized version of single-app"
spec:
variables:
components:
- componentName: frontend
instanceName: web-front-end
parameterValues:
traits:
- name: ManualScaler
properties:
replicaCount: 5
Du kannst mehrere Komponenten in einem Bereich gruppieren und du kannst Bereiche, Komponenten und Traits über eine Anwendungskonfiguration miteinander verknüpfen. Der Kerngedanke hinter diesem Design ist die Trennung von Belangen. Das Ziel von OAM ist es, Entwicklern eine Möglichkeit zu geben, eine Anwendung unabhängig von infrastrukturellen Belangen zu beschreiben, den Anwendungsbetreibern eine Möglichkeit zu geben, Anwendungen so zu konfigurieren, dass sie den geschäftlichen Anforderungen entsprechen, und den Infrastrukturbetreibern eine Möglichkeit zu geben, zu beschreiben, wie die gewünschte Topologie und Konfiguration auf einer bestimmten Plattform realisiert wird.
Eine gängige Form der Komponente ist ein Container, der als Kubernetes Pod eingesetzt wird. Das bedeutet, dass du Dapr-Annotationen zu deiner Komponente hinzufügen kannst und der Dapr Sidecar Injector Dapr Sidecars in deine Pods injizieren kann.
Die Kombination von OAM und Dapr bietet eine Komplettlösung für das Schreiben von plattformunabhängigen Anwendungen - OAM liefert die plattformunabhängige Modellierungssprache und Dapr bietet abstrakte gemeinsame APIs für Zustand, Serviceaufrufe, Pub/Sub, Sicherheit und Bindungen. Zum Zeitpunkt der Erstellung dieses Artikels befinden sich sowohl OAM als auch Dapr in der aktiven Entwicklung. Es ist zu erwarten, dass in zukünftigen Versionen weitere Integrationen hinzukommen werden.
Warum glauben wir, dass es wichtig ist, plattformunabhängige Anwendungen zu schreiben? Weil wir uns eine Zukunft des allgegenwärtigen Computings vorstellen, in der die Datenverarbeitung im Kontext der Daten stattfindet. Eine Anwendung sollte sich daran anpassen, wo sich die Daten befinden. Das bedeutet, dass Anwendungen auf verschiedenen Cloud-Plattformen und On-Premises-Systemen sowie in hybriden Umgebungen funktionieren müssen, die sich über Cloud und Kanten erstrecken.
Zusammenfassung
In diesem Kapitel wurde ausführlich erläutert, wie Dapr die Kommunikation von Diensten untereinander durch direkte Aufrufe und Messaging ermöglicht. Du hast auch gesehen, wie Dapr den Aufbau von benutzerdefinierten Verarbeitungspipelines durch Middleware ermöglicht. Du kannst mehrere Middlewares miteinander verknüpfen, um eine benutzerdefinierte Pipeline zu bilden, die entweder den Ingress- oder den Egress-Datenverkehr abfangen und umwandeln kann.
Dapr bietet integrierte Unterstützung für verteiltes Tracing über die Protokolle HTTP und gRPC. Verteiltes Tracing ist eine obligatorische Funktion eines verteilten Frameworks, um eine verteilte Anwendung effizient zu diagnostizieren. Dapr nutzt OpenTelemetry zur Integration mit verschiedenen Tracing-Backends.
Ziel von OAM und Dapr ist es, eine Komplettlösung für die Entwicklung plattformunabhängiger nativer Cloud-Anwendungen anzubieten. OAM bietet eine plattformunabhängige Modellierungssprache zur Beschreibung der Anwendungstopologie. Dapr bietet HTTP/gRPC-basierte APIs, die gängige Aufgaben wie die Auflösung und den Aufruf von Diensten, Pub/Sub, Zustandsverwaltung, Sicherheitsmanagement und Bindungen an externe Dienste abstrahieren.
Im nächsten Kapitel stellen wir die Dapr State API vor.
Get Dapr lernen now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

