Capítulo 5. La capa de servicio: Pinot Apache
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
La AATD ha llegado a la conclusión de que va a necesitar introducir una nueva pieza de infraestructura para conseguir análisis escalables en tiempo real, pero aún no está convencida de que sea necesaria una base de datos OLAP completa.
En este capítulo, empezaremos explicando por qué no podemos utilizar simplemente un procesador de flujos para servir consultas sobre flujos, antes de presentar Apache Pinot, una de las nuevas clases de bases de datos OLAP diseñadas para el análisis en tiempo real. Aprenderemos sobre la arquitectura y el modelo de datos de Pinot, antes de ingerir el flujo orders. Después, aprenderemos sobre los índices de marcas de tiempo y cómo escribir consultas contra Pinot utilizando SQL.
La Figura 5-1 muestra cómo vamos a hacer evolucionar nuestra infraestructura en este capítulo.
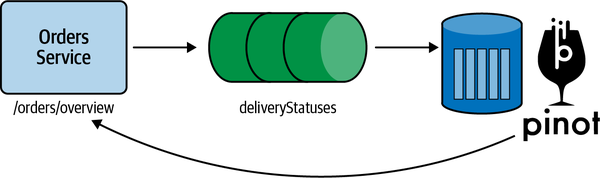
Figura 5-1. Evolución del servicio de pedidos
¿Por qué no podemos utilizar otro procesador de flujo?
Al final del último capítulo, describimos en algunas de las limitaciones de utilizar Kafka Streams para servir consultas sobre flujos. (Véase "Limitaciones de Kafka Streams".) No se trataba en absoluto de una crítica a Kafka Streams como tecnología; es sólo que no la estábamos utilizando realmente para los tipos de problemas ...
Get Creación de sistemas de análisis en tiempo real now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

