Capítulo 4. Automatizar la gobernanza arquitectónica
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Los arquitectos se encargan de diseñar la estructura de los sistemas de software, así como de definir muchas de las prácticas de desarrollo e ingeniería. Sin embargo, otra labor importante de los arquitectos es regir los aspectos de la construcción de software, incluidos los principios de diseño, las buenas prácticas y los escollos identificados que hay que evitar.
Tradicionalmente, los arquitectos disponían de pocas herramientas que les permitieran hacer cumplir sus políticas de gobernanza fuera de las revisiones manuales del código, las juntas de revisión de la arquitectura y otros medios ineficaces. Sin embargo, con la llegada de las funciones de adecuación automatizadas, proporcionamos a los arquitectos nuevos conjuntos de capacidades. En este capítulo, describimos cómo los arquitectos pueden utilizar las funciones de adecuación creadas para evolucionar el software para crear también políticas de gobierno automatizadas.
Funciones de Adecuación como Gobernanza Arquitectónica
La idea que dio lugar a este libro fue la mezcla metafórica entre la arquitectura de software y las prácticas del desarrollo de algoritmos genéticos descritas en el Capítulo 2, centrándose en la idea central de cómo los arquitectos pueden crear proyectos de software que evolucionen con éxito en lugar de degradarse con el tiempo. Los resultados de esa idea inicial florecieron en las innumerables formas en que describimos las funciones de aptitud y su aplicación.
Sin embargo, aunque no formaba parte de la concepción original, nos dimos cuenta de que la mecánica de la arquitectura evolutiva se solapa en gran medida con la gobernanza arquitectónica, especialmente con la idea de automatizar la gobernanza, que a su vez representa la evolución de las prácticas de ingeniería de software.
A principios de los 90, Kent Beck lideró un grupo de desarrolladores con visión de futuro que descubrieron una de las fuerzas motrices de los avances en ingeniería de software de las últimas tres décadas. Él y los desarrolladores trabajaban en el proyecto C3 (cuyo dominio no es importante). El equipo conocía bien las tendencias actuales en procesos de desarrollo de software, pero no estaban impresionados: parecía que ninguno de los procesos populares en aquel momento producía ningún tipo de éxito consistente. Así, Kent puso en marcha la idea de la Programación eXtrema (XP): basándose en experiencias pasadas, el equipo tomó cosas que sabían que funcionaban bien y las hizo de la forma más extrema. Por ejemplo, su experiencia colectiva era que los proyectos que tenían una mayor cobertura de pruebas tendían a tener un código de mayor calidad, lo que les llevó a evangelizar el desarrollo dirigido por pruebas, que garantiza que todo el código se prueba porque las pruebas preceden al código.
Una de sus observaciones clave giraba en torno a la integración. En aquella época, una práctica habitual en la mayoría de los proyectos de software era llevar a cabo una fase de integración. Se esperaba que los desarrolladores codificaran de forma aislada durante semanas o meses, para luego fusionar sus cambios durante una fase de integración. De hecho, muchas herramientas de control de versiones populares en aquella época forzaban este aislamiento a nivel del desarrollador. La práctica de una fase de integración se basaba en las muchas metáforas de fabricación que a menudo se aplican erróneamente al software. Los desarrolladores de XP observaron una correlación de proyectos anteriores según la cual una integración más frecuente conducía a menos problemas, lo que les llevó a crear la integración continua: cada desarrollador se compromete con la línea principal de desarrollo al menos una vez al día.
Lo que la integración continua y muchas de las demás prácticas de XP ilustran es el poder de la automatización y el cambio incremental. Los equipos que utilizan la integración continua no sólo dedican menos tiempo a realizar tareas de fusión con regularidad, sino que dedican menos tiempo en general. Cuando los equipos utilizan la integración continua, los conflictos de fusión surgen y se resuelven tan rápido como aparecen, al menos una vez al día. Los proyectos que utilizan una fase de integración final permiten que la masa combinatoria de conflictos de fusión crezca hasta convertirse en una Gran Bola de Barro, que deben desenredar al final del proyecto.
La automatización no es importante sólo para la integración; también es una fuerza optimizadora para la ingeniería. Antes de la integración continua, los equipos necesitaban que los desarrolladores dedicaran tiempo a realizar una tarea manual (integración y fusión) una y otra vez; la integración continua (y su cadencia asociada) automatizó la mayor parte de ese dolor.
Volvimos a aprender las ventajas de la automatización a principios de la década de 2000, durante la revolución DevOps. Los equipos corrían por el centro de operaciones instalando sistemas operativos, aplicando parches y realizando otras tareas manuales, lo que permitía que los problemas importantes quedaran en el olvido. Con la llegada del aprovisionamiento automatizado de máquinas mediante herramientas como Puppet y Chef, los equipos pueden automatizar la infraestructura e imponer la coherencia.
En muchas organizaciones, observamos las mismas prácticas manuales ineficaces que se repetían con la arquitectura: los arquitectos intentaban realizar comprobaciones de gobernanza mediante revisiones del código, juntas de revisión de la arquitectura y otros procesos manuales y burocráticos, y las cosas importantes se les escapaban de las manos. Vinculando las funciones de adecuación a la integración continua, los arquitectos pueden convertir las métricas y otras comprobaciones de gobernanza en una validación de integridad aplicada con regularidad.
En muchos sentidos, la unión de las funciones de adecuación y el cambio incremental mediante la integración continua representa la evolución de las prácticas de ingeniería. Al igual que los equipos utilizaron el cambio incremental para la integración y DevOps, cada vez vemos más los mismos principios aplicados a la gobernanza de la arquitectura.
Existen funciones de adecuación para cada faceta de la arquitectura, desde el análisis de bajo nivel basado en el código hasta la arquitectura empresarial. Organizamos nuestros ejemplos de automatización de la gobernanza arquitectónica de la misma manera, empezando por el nivel de código y extendiéndonos después por la pila de desarrollo de software. Abarcamos una serie de funciones de adecuación; la ilustración de la Figura 4-1 proporciona una hoja de ruta.
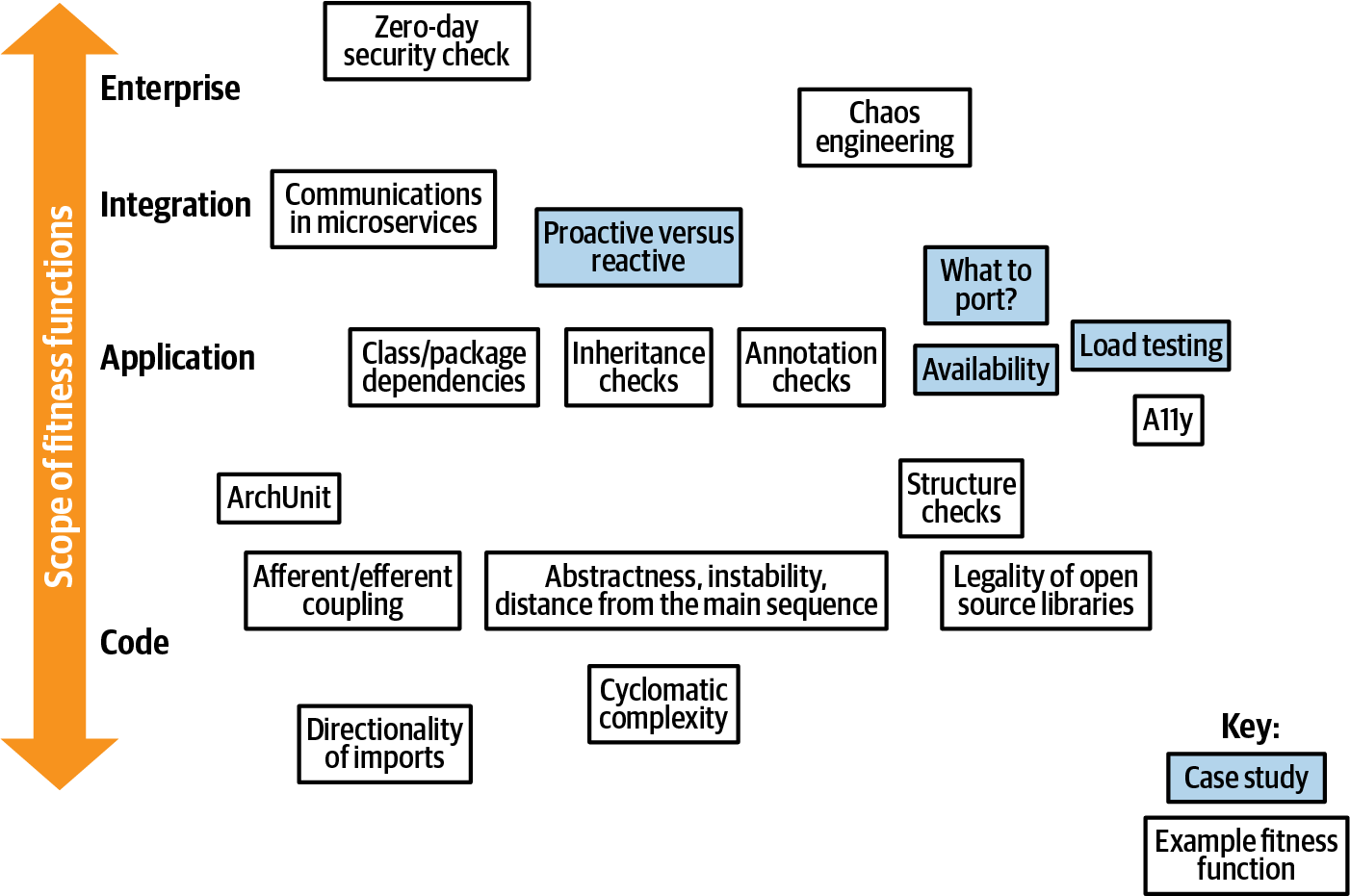
Figura 4-1. Visión general de las funciones de aptitud
Empezaremos por la parte inferior del mapa de la Figura 4-1, con funciones de adecuación basadas en códigos, y nos iremos abriendo camino gradualmente hacia la parte superior.
Funciones de aptitud basadas en códigos
Los arquitectos de software envidian bastante a otras disciplinas de la ingeniería que han desarrollado numerosas técnicas de análisis para predecir cómo funcionarán sus diseños. No tenemos (todavía) ni de lejos el nivel de profundidad y sofisticación de las matemáticas de la ingeniería, especialmente sobre el análisis arquitectónico.
Sin embargo, disponemos de algunas herramientas que pueden utilizar los arquitectos, generalmente basadas en métricas a nivel de código. Las siguientes secciones destacan algunas métricas que ilustran algo de interés en arquitectura.
Acoplamiento aferente y eferente
En 1979, Edward Yourdon y Larry Constantine publicaron Diseño estructurado: Fundamentals of a Discipline of Computer Program and Systems Design (Prentice-Hall), en el que definen muchos conceptos básicos, como las métricas de acoplamiento aferente y eferente. El acoplamiento aferente mide el número de conexiones entrantes a un artefacto de código (componente, clase, función, etc.). El acoplamiento eferente mide las conexiones salientes a otros artefactos de código.
El acoplamiento en arquitectura interesa a los arquitectos porque limita y afecta a muchas otras características de la arquitectura. Cuando los arquitectos permiten que cualquier componente se conecte a cualquier otro sin ningún tipo de control, el resultado suele ser una base de código con una densa red de conexiones que desafía la comprensión. Considera la ilustración de la Figura 4-2 de los resultados de las métricas de un sistema de software real (nombre oculto por razones obvias).

Figura 4-2. Acoplamiento a nivel de componentes en una arquitectura Big-Ball-of-Mud
En la Figura 4-2, los componentes aparecen en el perímetro como puntos individuales, y la conectividad entre componentes aparece como líneas, donde la negrita de la línea indica la fuerza de la conexión. Éste es un ejemplo de una base de código disfuncional: los cambios en cualquier componente pueden extenderse a muchos otros componentes.
Prácticamente todas las plataformas disponen de herramientas que permiten a los arquitectos analizar las características de acoplamiento del código para ayudarles a reestructurar, migrar o comprender una base de código. Existen muchas herramientas para diversas plataformas que proporcionan una vista matricial de las relaciones entre clases y/o componentes, como se ilustra en la Figura 4-3.
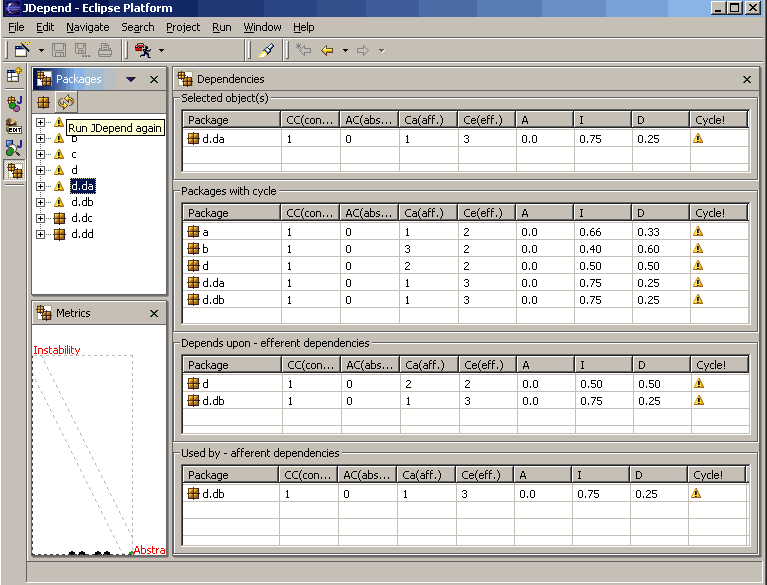
Figura 4-3. Vista de análisis de JDepend en Eclipse de las relaciones de acoplamiento
En la Figura 4-3, el complemento de Eclipse proporciona una vista tabular de los resultados de JDepend, que incluye el análisis de acoplamiento por paquete, junto con algunas métricas agregadas que se destacan en la sección siguiente.
Otras herramientas proporcionan esta métrica y muchas de las otras que comentamos. En particular, IntelliJ para Java, Sonar Qube, JArchitect y otras, en función de tu plataforma o pila tecnológica preferida. Por ejemplo, IntelliJ incluye una matriz de dependencia de estructuras que muestra diversas características de acoplamiento, como se ilustra en la Figura 4-4.
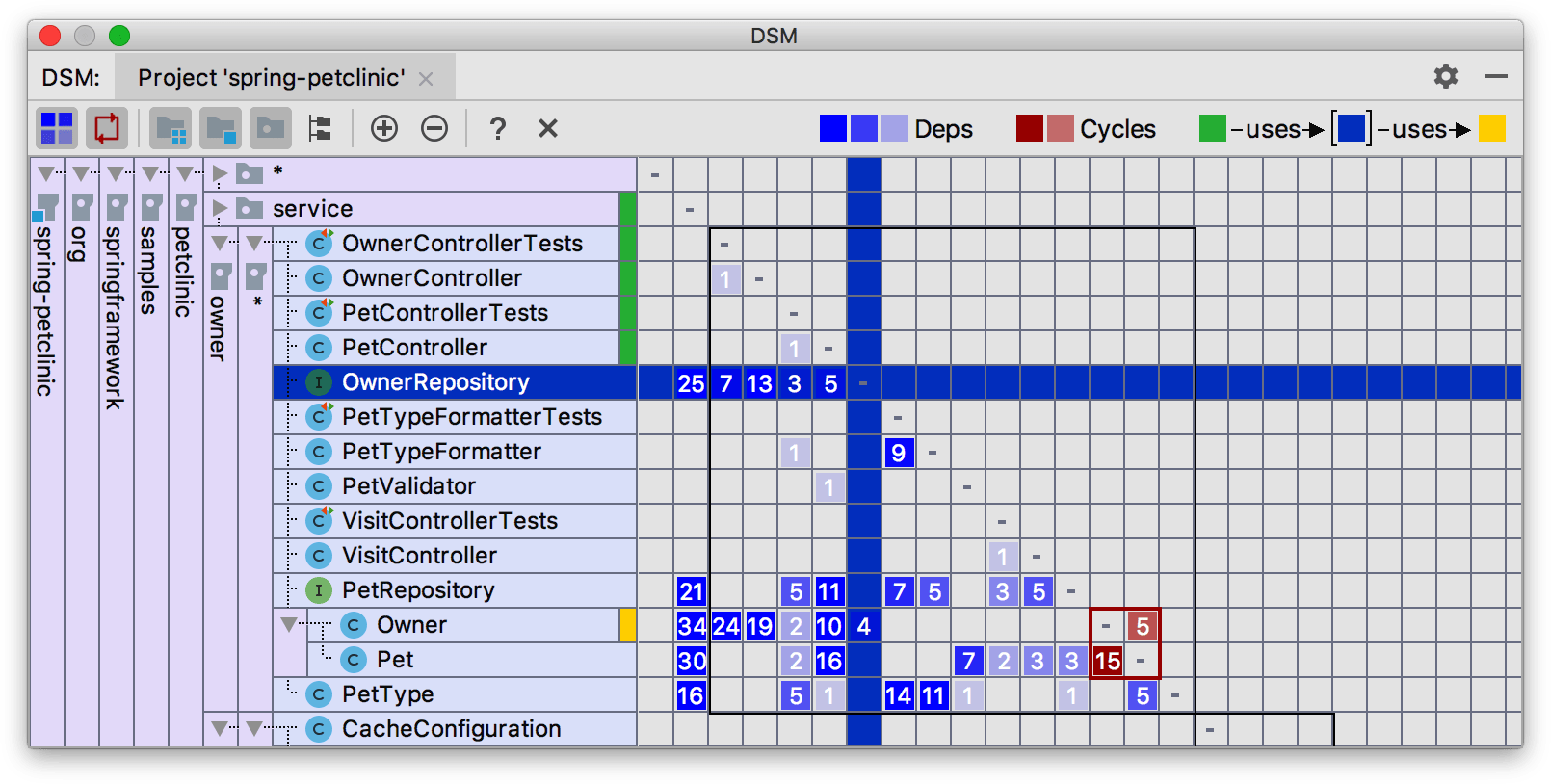
Figura 4-4. Matriz de estructura de dependencias de IntelliJ
Abstracción, inestabilidad y distancia de la secuencia principal
Robert Martin, una figura muy conocida en el mundo de la arquitectura del software, creó a finales de los 90 algunas métricas derivadas que son aplicables a cualquier lenguaje orientado a objetos. Estas métricas -abstracción e inestabilidad- miden el equilibrio de las características internas de una base de código.
La abstracción es la relación entre artefactos abstractos (clases abstractas, interfaces, etc.) y artefactos concretos (clases de implementación). Representa una medida de la abstracción frente a la implementación. Los elementos abstractos son características de una base de código que permiten a los desarrolladores comprender mejor la función global. Por ejemplo, una base de código formada por un único método main() y 10.000 líneas de código tendría una puntuación de casi cero en esta métrica y sería bastante difícil de entender.
La fórmula de la abstracción aparece en la Ecuación 4-1.
Ecuación 4-1. Abstracción
En la ecuación representa los elementos abstractos (interfaces o clases abstractas) dentro de la base de código, y representa los elementos concretos. Los arquitectos calculan la abstracción calculando la relación entre la suma de artefactos abstractos y la suma de los concretos.
Otra métrica derivada, la inestabilidad, es la relación entre el acoplamiento eferente y la suma del acoplamiento eferente y aferente, que se muestra en la ecuación 4-2.
Ecuación 4-2. Inestabilidad
En la ecuación representa el acoplamiento eferente (o saliente), y representa el acoplamiento aferente (o entrante).
La métrica de inestabilidad determina la volatilidad de una base de código. Una base de código que presenta altos grados de inestabilidad se rompe más fácilmente cuando se modifica, debido a su elevado acoplamiento. Considera dos escenarios, cada uno con de 2. En el primer escenario = 0, lo que da una puntuación de inestabilidad de cero. En el segundo escenario = 3, se obtiene una puntuación de inestabilidad de 3/5. Así, la medida de inestabilidad de un componente refleja cuántos cambios potenciales podrían verse forzados por cambios en componentes relacionados. Un componente con un valor de inestabilidad cercano a 1 es muy inestable, y un valor cercano a 0 puede ser estable o rígido: es estable si el módulo o componente contiene mayoritariamente elementos abstractos y rígido si está compuesto mayoritariamente por elementos concretos. Sin embargo, la contrapartida de una alta estabilidad es la falta de reutilización: si cada componente es autónomo, es probable que se duplique.
Un componente con un valor I próximo a 1, podemos estar de acuerdo, es altamente inestable. Sin embargo, un componente con un valor I próximo a 0 puede ser estable o rígido. Sin embargo, si contiene principalmente elementos de hormigón, es rígido.
Así pues, en general, es importante observar los valores de I y A conjuntamente y no de forma aislada; se combinan en la siguiente métrica, la distancia a la secuencia principal.
Una de las pocas métricas holísticas que tienen los arquitectos para la estructura arquitectónica es la distancia normalizada a la secuencia principal, una métrica derivada basada en la inestabilidad y la abstracción, que se muestra en la Ecuación 4-3.
Ecuación 4-3. Distancia normalizada a la secuencia principal
En la ecuación, A = abstracción e I = inestabilidad.
La distancia normalizada desde la métrica de la secuencia principal imagina una relación ideal entre abstracción e inestabilidad; los componentes que caen cerca de esta línea idealizada muestran una mezcla saludable de estas dos preocupaciones contrapuestas. Por ejemplo, graficar un componente concreto permite a los desarrolladores calcular la distancia respecto a la métrica de la secuencia principal, ilustrada en la Figura 4-5.
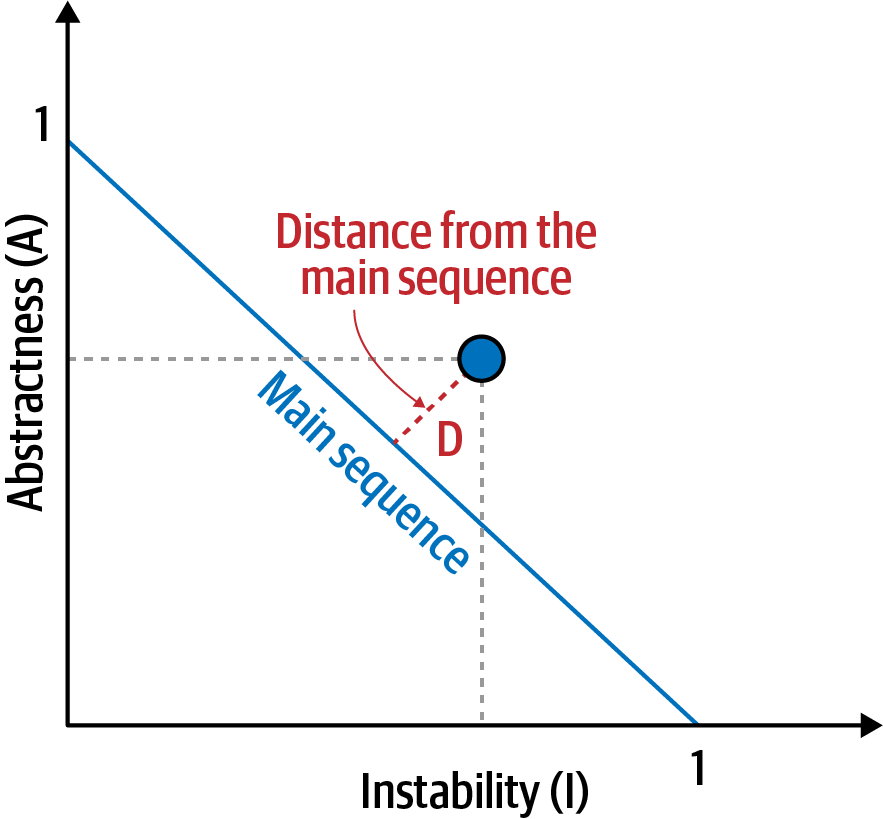
Figura 4-5. Distancia normalizada a la secuencia principal para un componente concreto
En la Figura 4-5, los desarrolladores grafican el componente candidato y luego miden la distancia a la línea idealizada. Cuanto más se acerque a la línea, mejor equilibrado estará el componente. Los componentes que caen demasiado lejos de la esquina superior derecha entran en lo que los arquitectos llaman la zona de la inutilidad: el código demasiado abstracto se vuelve difícil de usar. A la inversa, el código que cae en la esquina inferior izquierda entra en la zona del dolor: el código con demasiada implementación y poca abstracción se vuelve quebradizo y difícil de mantener, como se ilustra en la Figura 4-6.
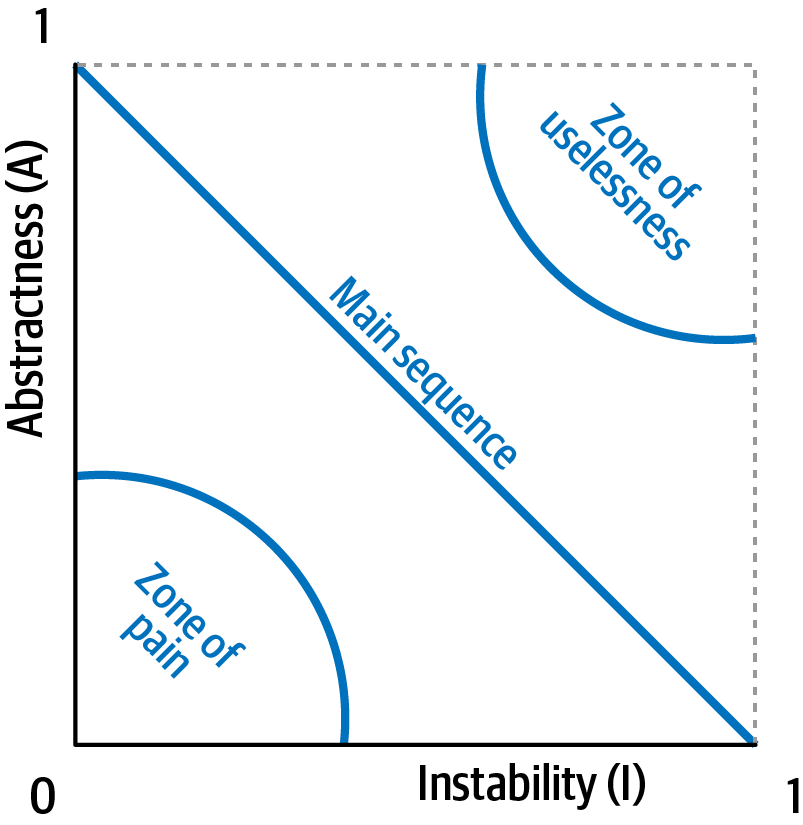
Figura 4-6. Zonas de inutilidad y dolor
Este tipo de análisis es útil para los arquitectos, ya sea para evaluar (por ejemplo, para migrar de un estilo de arquitectura a otro) o para establecer una función de adecuación. Considera la captura de pantalla que se muestra en la Figura 4-7, utilizando la herramienta comercial NDepend aplicada a la herramienta de pruebas de código abierto NUnit.
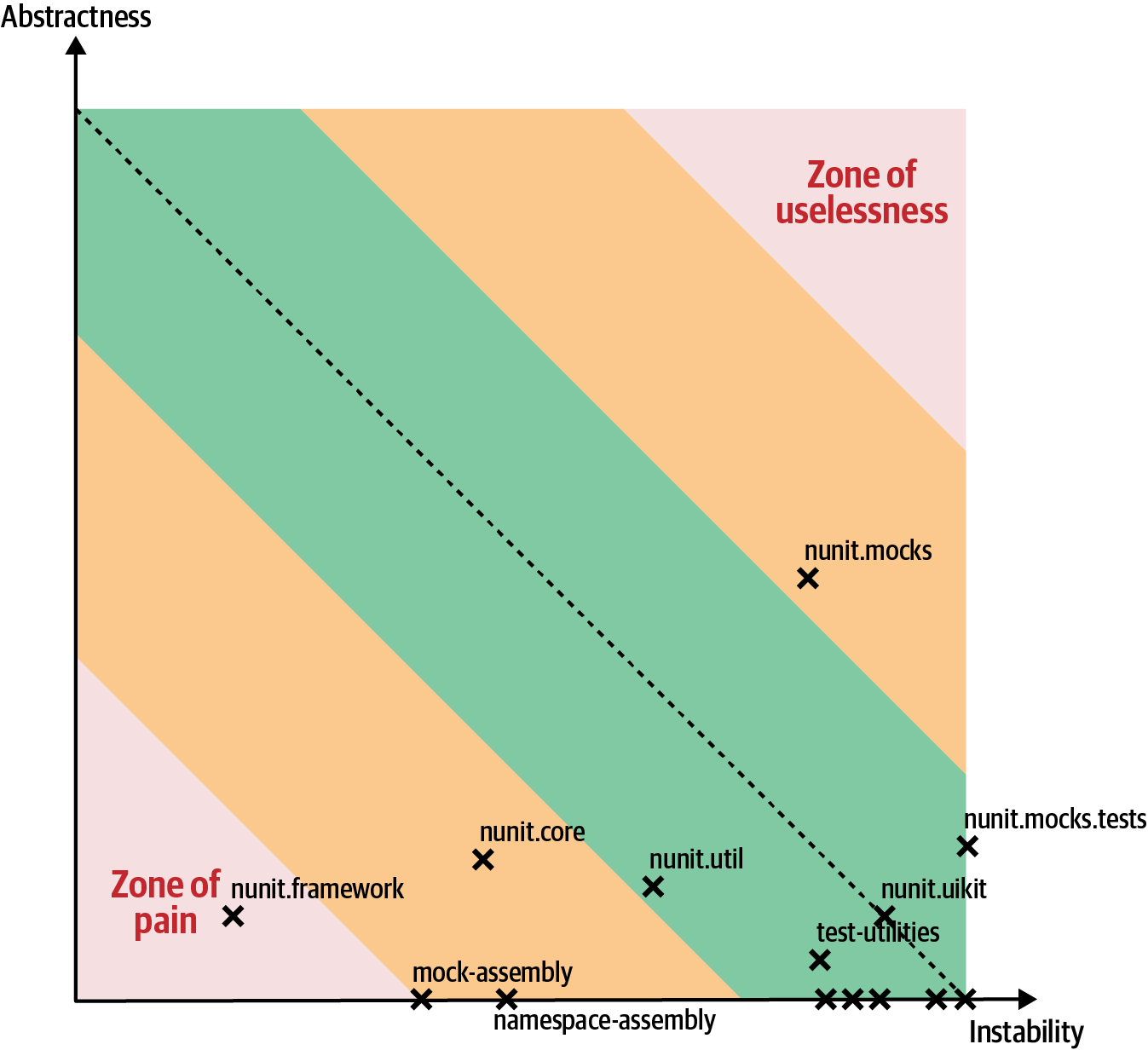
Figura 4-7. Salida de NDepend para la distancia desde la secuencia principal para la biblioteca de pruebas NUnit
En la Figura 4-7, el resultado ilustra que la mayor parte del código cae cerca de la línea de la secuencia principal. Los componentes de mocks tienden hacia la zona de inutilidad: demasiada abstracción e inestabilidad. Eso tiene sentido para un conjunto de componentes burlones, que tienden a utilizar la indirección para conseguir sus resultados. Lo que es más preocupante, el código de framework se ha deslizado hacia la zona de dolor: demasiada poca abstracción e inestabilidad. ¿Qué aspecto tiene este código? Muchos métodos demasiado grandes sin suficiente reutilización.
¿Cómo puede un arquitecto tirar del código problemático hacia la línea de secuencia principal? Utilizando herramientas de refactorización en un IDE: encuentra los grandes métodos que impulsan esta medida y empieza a extraer partes para aumentar la abstracción. Al realizar este ejercicio, encontrarás duplicidades entre el código extraído, lo que te permitirá eliminarlas y mejorar la inestabilidad.
Antes de realizar un ejercicio de reestructuración, los arquitectos deben utilizar métricas como ésta para analizar y mejorar el código base antes de trasladarlo. Al igual que en la arquitectura de edificios, trasladar algo con cimientos inestables es más difícil que trasladar algo con cimientos sólidos.
Los arquitectos también pueden utilizar esta métrica como una función de aptitud para asegurarse de que el código base no se degrade hasta este grado en primer lugar.
Direccionalidad de las importaciones
En estrecha relación con el ejemplo de la Figura 2-3, los equipos deben gobernar la direccionalidad de las importaciones. En el ecosistema Java, JDepend es una herramienta de métricas que analiza las características de acoplamiento de los paquetes. Como JDepend está escrito en Java, tiene una API que los desarrolladores pueden aprovechar para construir sus propios análisis mediante pruebas unitarias.
Considera la función de adecuación del Ejemplo 4-1, expresada como una prueba JUnit.
Ejemplo 4-1. Prueba JDepend para verificar la direccionalidad de las importaciones de paquetes
publicvoidtestMatch(){DependencyConstraintconstraint=newDependencyConstraint();JavaPackagepersistence=constraint.addPackage("com.xyz.persistence");JavaPackageweb=constraint.addPackage("com.xyz.web");JavaPackageutil=constraint.addPackage("com.xyz.util");persistence.dependsUpon(util);web.dependsUpon(util);jdepend.analyze();assertEquals("Dependency mismatch",true,jdepend.dependencyMatch(constraint));}
En el Ejemplo 4-1, definimos los paquetes de nuestra aplicación y, a continuación, definimos las reglas sobre importaciones. Si un desarrollador escribe accidentalmente código que importa a util desde persistence, esta prueba unitaria fallará antes de que se confirme el código. Preferimos crear pruebas unitarias para detectar infracciones de la arquitectura que utilizar directrices de desarrollo estrictas (con la consiguiente reprimenda burocrática): permite a los desarrolladores centrarse más en el problema del dominio y menos en las preocupaciones de fontanería. Y lo que es más importante, permite a los arquitectos consolidar las normas como artefactos ejecutables.
Complejidad ciclomática y gobernanza "en manada
Una métrica de código habitual es la complejidad ciclomática, una medida de la complejidad de las funciones o métodos disponible para todos los lenguajes de programación estructurados, que existe desde hace décadas.
Un aspecto medible obvio del código es la complejidad, definida por la métrica de la complejidad ciclomática.
La complejidad ciclomática (CC) es una métrica a nivel de código diseñada para proporcionar una medida objetiva de la complejidad del código, a nivel de función/método, clase o aplicación, desarrollada por Thomas McCabe Sr. en 1976.
Se calcula aplicando la teoría de grafos al código, concretamente a los puntos de decisión, que provocan distintas rutas de ejecución. Por ejemplo, si una función no tiene sentencias de decisión (como las sentencias if ), entonces CC = 1. Si la función tuviera una única condicional, entoncesCC = 2 porque existen dos posibles caminos de ejecución.
La fórmula para calcular la complejidad ciclomática de una única función o método es donde N representa nodos (líneas de código) y E representa perímetros (posibles decisiones). Considera el código tipo C que se muestra en el Ejemplo 4-2.
Ejemplo 4-2. Ejemplo de código para la evaluación de la complejidad ciclomática
publicvoiddecision(intc1,intc2){if(c1<100)return0;elseif(c1+C2>500)return1;elsereturn-1;}
La complejidad ciclomática del Ejemplo 4-2 es 3 (=3 - 2 + 2); el gráfico aparece en la Figura 4-8.
El número 2 que aparece en la fórmula de complejidad ciclomática representa una simplificación para una sola función/método. Para llamadas en abanico a otros métodos (conocidos como componentes conectados en la teoría de grafos), la fórmula más general es donde P representa el número de componentes conectados.
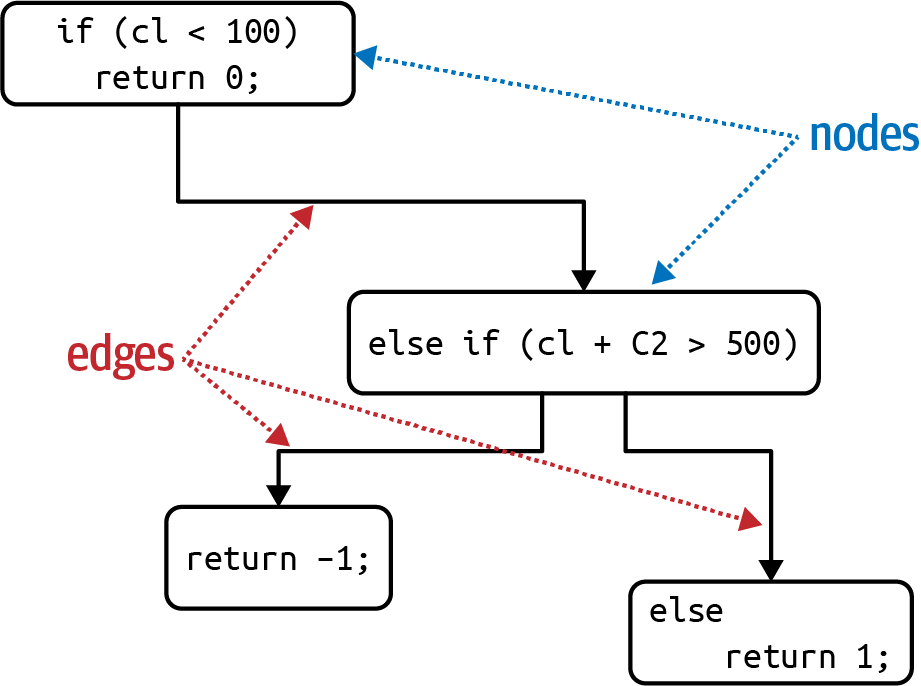
Figura 4-8. Complejidad ciclomática de la función de decisión
Arquitectos y desarrolladores están universalmente de acuerdo en que un código demasiado complejo representa olor a código; perjudica prácticamente a todas y cada una de las características deseables de las bases de código: modularidad, comprobabilidad, capacidad de implementación, etc. Sin embargo, si los equipos no vigilan que la complejidad aumente gradualmente, esa complejidad dominará la base de código.
CC es un buen ejemplo de una métrica que los arquitectos podrían querer gobernar; nadie se beneficia de bases de código demasiado complejas. Sin embargo, ¿qué ocurre en los proyectos en los que este valor se ha ignorado durante mucho tiempo?
En lugar de establecer un umbral duro para el valor de una función de aptitud, puedes guiar a los equipos hacia valores mejores. Por ejemplo, supongamos que has decidido como organización que el límite superior absoluto para CC debe ser 10, pero cuando pones en marcha esa función de aptitud la mayoría de tus proyectos fracasan. En lugar de abandonar toda esperanza, puedes establecer una función de adecuación en cascada que emita una advertencia para todo lo que supere algún umbral, que con el tiempo se convierta en un error. Esto da tiempo a los equipos para abordar la deuda técnica de forma controlada y gradual.
La reducción gradual a los valores deseados de una serie de funciones de adecuación basadas en métricas permite a los equipos tanto abordar la deuda técnica existente como, al dejar las funciones de adecuación en su sitio, prevenir la degradación futura. Esta es la esencia de la prevención de la podredumbre de bits mediante la gobernanza.
Herramientas llave en mano
Como todas las arquitecturas son diferentes, a los arquitectos les cuesta encontrar herramientas ya hechas para problemas complejos. Sin embargo, cuanto más común sea el ecosistema, más probabilidades tendrás de encontrar herramientas adecuadas y algo genéricas. He aquí algunos ejemplos.
Legalidad de las bibliotecas de código abierto
PenultimateWidgets estaba trabajando en un proyecto que contenía algunos algoritmos patentados de su propiedad, junto con algunas bibliotecas y marcos de código abierto. A los abogados les preocupaba que el equipo de desarrollo utilizara accidentalmente una biblioteca cuya licencia exige que sus usuarios adopten la misma licencia extremadamente liberal, que PenultimateWidgets obviamente no quería para su código.
Así que los arquitectos reunieron todas las licencias de las dependencias y permitieron que los abogados las aprobaran. Entonces, uno de los abogados hizo una pregunta incómoda: ¿qué ocurre si una de estas dependencias actualiza los términos de su licencia durante una actualización rutinaria del software? Y, como buenos abogados, tenían un buen ejemplo de que esto había ocurrido en el pasado con algunas bibliotecas de interfaz de usuario. ¿Cómo puede el equipo asegurarse de que una de las bibliotecas no actualiza una licencia sin que ellos se den cuenta?
En primer lugar, los arquitectos deberían comprobar si ya existe una herramienta para hacer esto; en el momento de escribir esto, la herramienta Black Duck realiza exactamente esta tarea. Sin embargo, en ese momento, los arquitectos de PenultimateWidgets no pudieron encontrar una herramienta que fuera suficiente.
Así, construyeron una función de adecuación utilizando los siguientes pasos:
-
Anota en una base de datos la ubicación de cada archivo de licencia dentro del paquete de descarga de código abierto.
-
Junto con la versión de la biblioteca, guarda el contenido (o un hash) del archivo de licencia completo.
-
Cuando se detecta un nuevo número de versión, la herramienta accede al paquete de descarga, recupera el archivo de licencia y lo compara con la versión guardada actualmente.
-
Si las versiones (o el hash) no coinciden, falla la compilación y notifica al abogado.
Ten en cuenta que no intentamos evaluar la diferencia entre las versiones de las bibliotecas, ni construimos una increíble inteligencia artificial para analizarla. Como suele ocurrir, la función de adecuación nos notifica los cambios inesperados. Este es un ejemplo tanto de una función de adecuación automatizada como de una manual: la detección del cambio se automatizó, pero la reacción al cambio -la aprobación por parte de los abogados de la biblioteca modificada- sigue siendo una intervención manual.
A11y y otras características de arquitectura compatibles
A veces, saber qué buscar lleva a los arquitectos a la herramienta correcta. "A11y" es la abreviatura para desarrolladores de accesibilidad (derivado de a, 11 letras e y), que determina lo bien que una aplicación es compatible con personas con capacidades diferentes.
Dado que muchas empresas y organismos gubernamentales exigen accesibilidad, han florecido herramientas para validar esta característica de la arquitectura, incluidas herramientas como Pa11y, que permite escanear desde la línea de comandos los elementos estáticos de la web para garantizar la accesibilidad.
ArchUnit
ArchUnit es una herramienta de pruebas inspirada en algunos de los ayudantes creados para JUnit y que los utiliza. Sin embargo, está diseñada para probar características de la arquitectura en lugar de la estructura general del código. Ya mostramos un ejemplo de función de adecuación de ArchUnit en la Figura 2-3; aquí tienes más ejemplos de los tipos de gobernanza disponibles.
Dependencias de los paquetes
Los paquetes delimitan los componentes en el ecosistema Java, y los arquitectos suelen querer definir cómo deben "conectarse" los paquetes entre sí. Considera los componentes de ejemplo ilustrados en la Figura 4-9.

Figura 4-9. Dependencias declarativas de paquetes en Java
El código ArchUnit que aplica las dependencias mostradas en la Figura 4-9 aparece en el Ejemplo 4-3.
Ejemplo 4-3. Gobierno de la dependencia de paquetes
noClasses().that().resideInAPackage("..source..").should().dependOnClassesThat().resideInAPackage("..foo..")
ArchUnit utiliza los emparejadores Hamcrest utilizados en JUnit para permitir a los arquitectos escribir aserciones muy similares a las del lenguaje, como se muestra en el Ejemplo 4-3, que les permiten definir qué componentes pueden o no acceder a otros componentes.
Otra preocupación gobernable común para los arquitectos son las dependencias de los componentes, como se ilustra en la Figura 4-10.
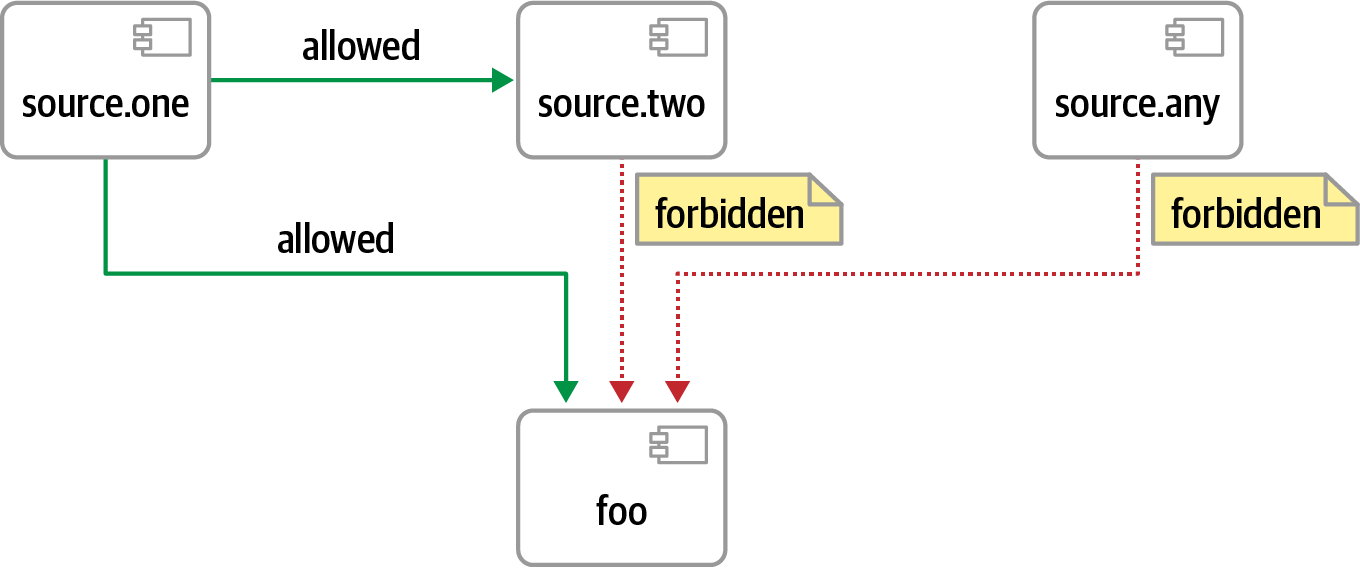
Figura 4-10. Gobierno de la dependencia de paquetes
En la Figura 4-10, la biblioteca compartida foo debe ser accesible desde source.one, pero no desde otros componentes; un arquitecto puede especificar la regla de gobierno mediante ArchUnit, como en el Ejemplo 4-4.
Ejemplo 4-4. Permitir y restringir el acceso a paquetes
classes().that().resideInAPackage("..foo..").should().onlyHaveDependentClassesThat().resideInAnyPackage("..source.one..","..foo..")
El Ejemplo 4-4 muestra cómo un arquitecto puede controlar las dependencias en tiempo de compilación entre proyectos.
Comprobaciones de dependencia de clases
De forma similar a las normas relativas a los paquetes, los arquitectos suelen querer controlar los aspectos arquitectónicos del diseño de las clases. Por ejemplo, un arquitecto puede querer restringir las dependencias entre componentes para evitar complicaciones en la implementación. Considera la relación entre clases de la Figura 4-11.
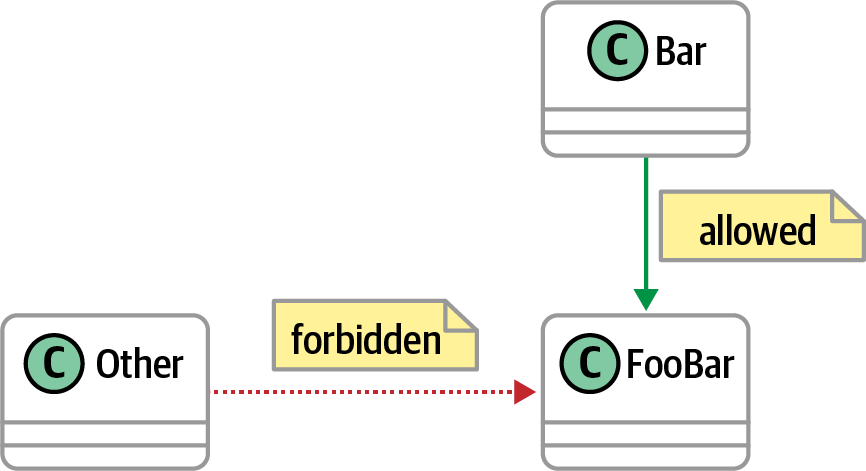
Figura 4-11. Comprobaciones de dependencia que permiten y deniegan el acceso
ArchUnit permite a un arquitecto codificar las reglas que se muestran en la Figura 4-11 medianteel Ejemplo 4-5.
Ejemplo 4-5. Reglas de dependencia de clases en ArchUnit
classes().that().haveNameMatching(".*Bar").should().onlyHaveDependentClassesThat().haveSimpleName("Bar")
ArchUnit permite a los arquitectos un control detallado del "cableado" de los componentes de una aplicación.
Comprobaciones de herencia
Otra dependencia soportada por los lenguajes de programación orientados a objetos es la herencia; desde el punto de vista de la arquitectura, es una forma especializada de acoplamiento. En un ejemplo clásico de la respuesta perpetua "¡depende!", la cuestión de si la herencia es un quebradero de cabeza arquitectónico depende de cómo desplieguen los equipos los componentes afectados: si la herencia está contenida en un único componente, no tiene efectos secundarios arquitectónicos. Por otra parte, si la herencia se extiende a través de los límites de los componentes y/o de la implementación, los arquitectos deben tomar medidas especiales para asegurarse de que el acoplamiento permanece intacto.
La herencia suele ser una preocupación arquitectónica; en la Figura 4-12 aparece un ejemplo del tipo de estructura que requiere gobernanza.
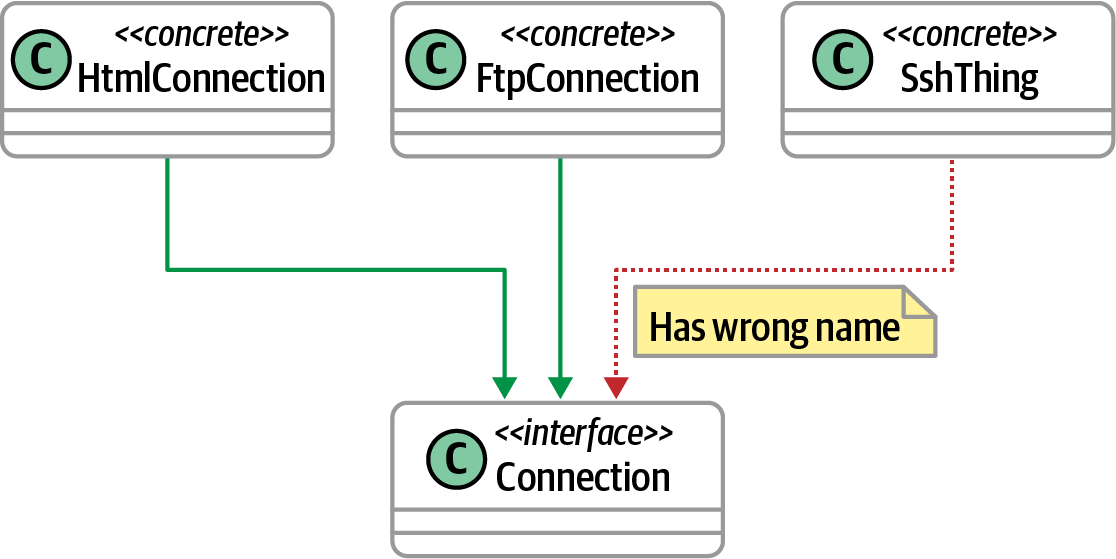
Figura 4-12. Gobernar las dependencias de la herencia
Los arquitectos pueden expresar las reglas que aparecen en la Figura 4-12 mediante el código delEjemplo 4-6.
Ejemplo 4-6. Regla de gobierno de la herencia expresada en ArchUnit
classes().that().implement(Connection.class).should().haveSimpleNameEndingWith("Connection")
Comprobaciones de anotación
Una forma habitual en que los arquitectos indican la intención en las plataformas compatibles es mediante anotaciones de etiquetado (o atributos, según tu plataforma). Por ejemplo, un arquitecto puede tener la intención de que una clase determinada sólo actúe como orquestadora de otros servicios: la intención es que nunca adopte un comportamiento que no sea de orquestación. Utilizar una anotación permite al arquitecto verificar la intención y el uso correcto.
ArchUnit permite a los arquitectos validar este tipo de uso, como se muestra en la Figura 4-13.
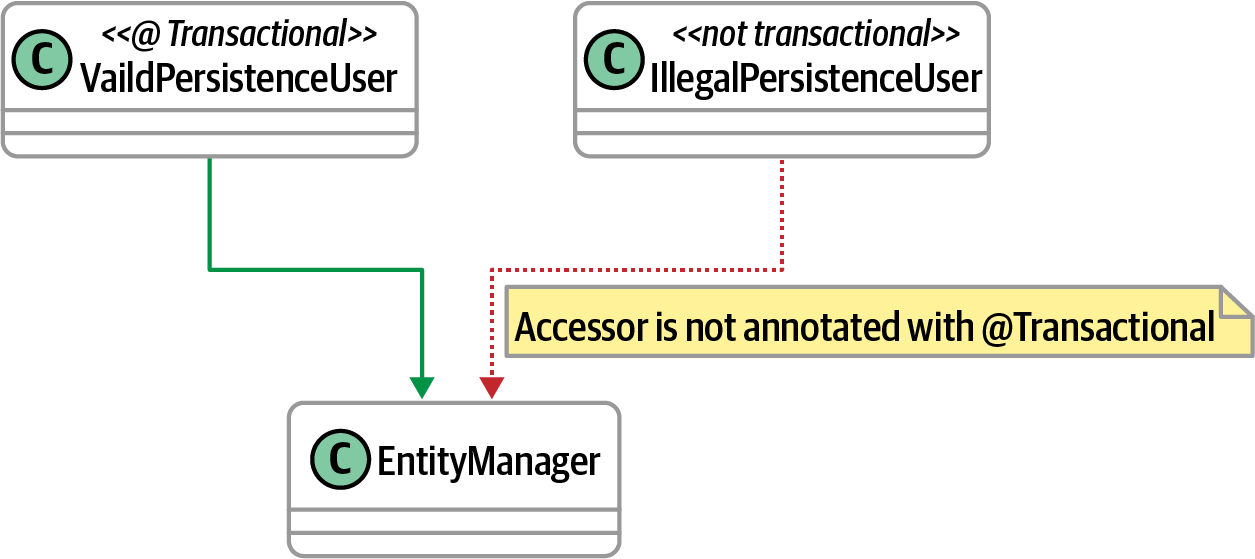
Figura 4-13. Regulación del uso adecuado de las anotaciones
Los arquitectos pueden codificar las reglas de gobierno implícitas en la Figura 4-13, como se muestra en el Ejemplo 4-7.
Ejemplo 4-7. Reglas de gobierno para las anotaciones
classes().that().areAssignableTo(EntityManager.class).should().onlyHaveDependentClassesThat().areAnnotatedWith(Transactional.class)
En el Ejemplo 4-7, el arquitecto quiere asegurarse de que sólo las clases anotadas puedan utilizar la clase EntityManager.
Comprobación de capas
Uno de los usos más comunes de una herramienta de gobierno como ArchUnit es permitir a los arquitectos imponer decisiones de diseño. Los arquitectos suelen tomar decisiones, como la separación de preocupaciones, que causan molestias a corto plazo a los desarrolladores, pero tienen beneficios a largo plazo en términos de evolución y aislamiento. Considera la ilustración de la Figura 4-14.
El arquitecto ha construido una arquitectura por capas para aislar los cambios entre capas. En una arquitectura de este tipo, las dependencias sólo deben existir entre capas adyacentes; cuantas más capas se acoplen a una determinada capa, más efectos secundarios ondulantes se producirán a causa de los cambios.
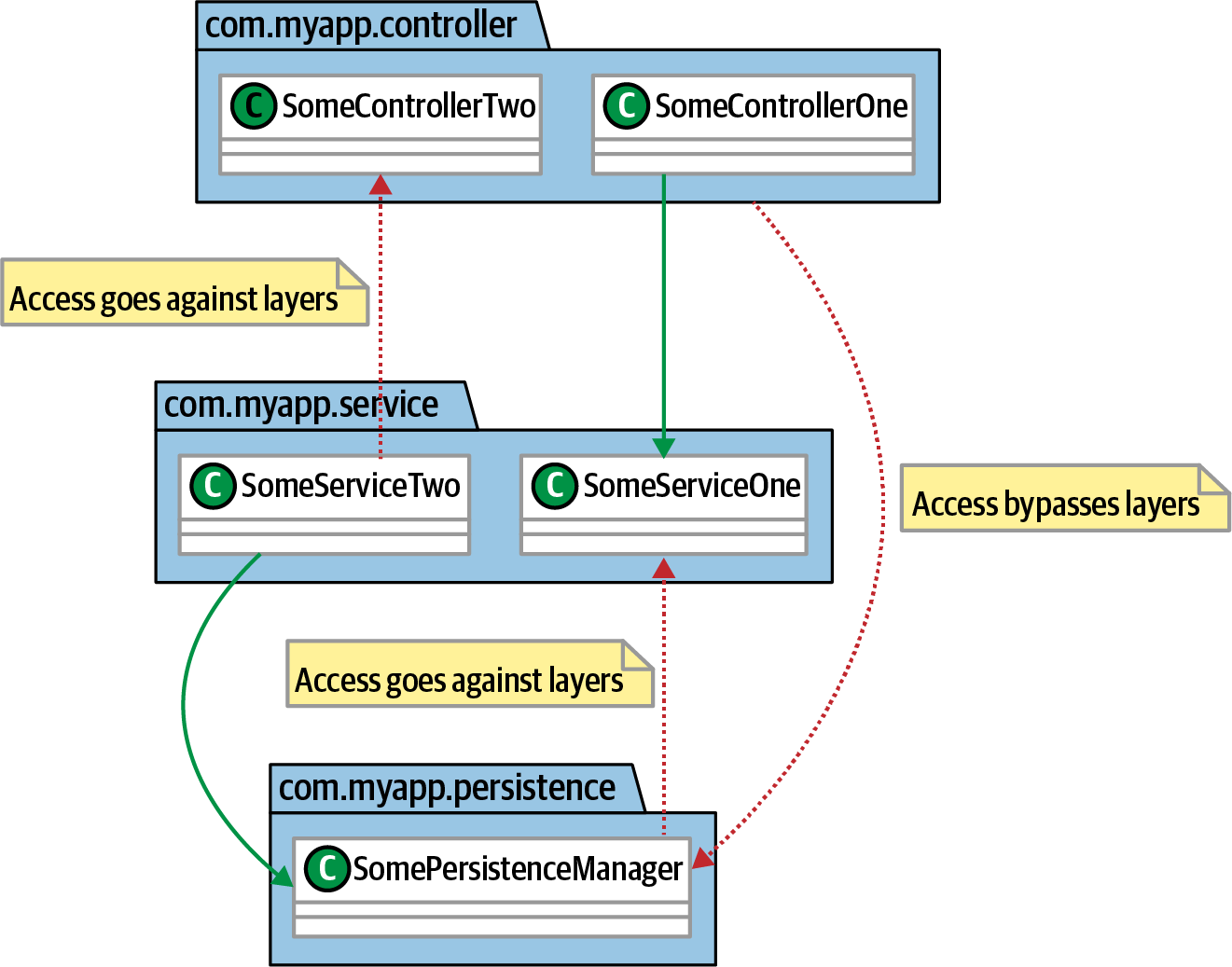
Figura 4-14. Utilizar componentes para definir una arquitectura por capas
En elEjemplo 4-8 aparece una función de aptitud de comprobación de gobernanza de capas expresada en ArchUnit.
Ejemplo 4-8. Comprobaciones de gobernanza de la arquitectura por niveles
layeredArchitecture().consideringAllDependencies().layer("Controller").definedBy("..controller..").layer("Service").definedBy("..service..").layer("Persistence").definedBy("..persistence..").whereLayer("Controller").mayNotBeAccessedByAnyLayer().whereLayer("Service").mayOnlyBeAccessedByLayers("Controller").whereLayer("Persistence").mayOnlyBeAccessedByLayers("Service")
En el Ejemplo 4-8, un arquitecto define capas y reglas de acceso para esas capas.
Muchos de vosotros, como arquitectos, habéis escrito las versiones en vuestra lengua materna de muchos de los principios expresados en los ejemplos anteriores en alguna wiki u otro repositorio de información compartida, ¡y nadie las ha leído! Es estupendo que los arquitectos expresen principios, pero los principios sin aplicación son aspiraciones más que gobernanza. La arquitectura por capas del Ejemplo 4-8 es un gran ejemplo: aunque un arquitecto puede escribir un documento que describa las capas y el principio subyacente de separación de intereses, a menos que una función de adecuación lo valide, un arquitecto nunca podrá confiar en que los desarrolladores seguirán los principios.
Hemos dedicado mucho tiempo a destacar ArchUnit, ya que es el más maduro de los muchos marcos de pruebas centrados en la gobernanza. Obviamente, sólo es aplicable en el ecosistema Java. Afortunadamente, NetArchTest reproduce el mismo estilo y las capacidades básicas de ArchUnit, pero para la plataforma .NET.
Linters para la Gobernanza del Código
Una pregunta habitual que nos hacen los arquitectos salivadores de plataformas distintas de Java y .NET es si existe una herramienta equivalente a ArchUnit para la plataforma X. Aunque son raras las herramientas tan específicas como ArchUnit, la mayoría de los lenguajes de programación incluyen un linter, una utilidad que escanea el código fuente para encontrar antipatrones y deficiencias de codificación. Generalmente, el linter léxica y analiza el código fuente, proporcionando plug-ins por parte de los desarrolladores para escribir comprobaciones de sintaxis. Por ejemplo, ESLint, la herramienta de linting para JavaScript (técnicamente, el linter para ECMAScript), permite a los desarrolladores escribir reglas sintácticas que requieran (o no) punto y coma, llaves nominalmente opcionales, etc. También pueden escribir reglas sobre qué políticas de llamada a funciones quieren aplicar los arquitectos y otras reglas de gobernanza.
La mayoría de las plataformas tienen linters; por ejemplo, C++ está servido por Cpplint, Staticcheck está disponible para el lenguaje Go. Incluso hay una variedad de linters para SQL, incluido sql-lint. Aunque no son tan prácticos como ArchUnit, los arquitectos pueden codificar muchas comprobaciones estructurales en prácticamente cualquier código base.
Caso práctico: Función de adecuación a la disponibilidad
Para muchos arquitectos aparece un enigma común: ¿debemos utilizar un sistema heredado como punto de integración o construir uno nuevo? Si no se ha probado antes una solución concreta, ¿cómo pueden los arquitectos tomar decisiones objetivas?
PenultimateWidgets se enfrentó a este problema al integrarse con un sistema heredado. Para ello, el equipo creó una función de adecuación para probar el estrés del servicio heredado, como se muestra en la Figura 4-15.
Tras configurar el ecosistema, el equipo midió el porcentaje de errores en comparación con el total de respuestas del sistema de terceros mediante la herramienta de monitoreo.
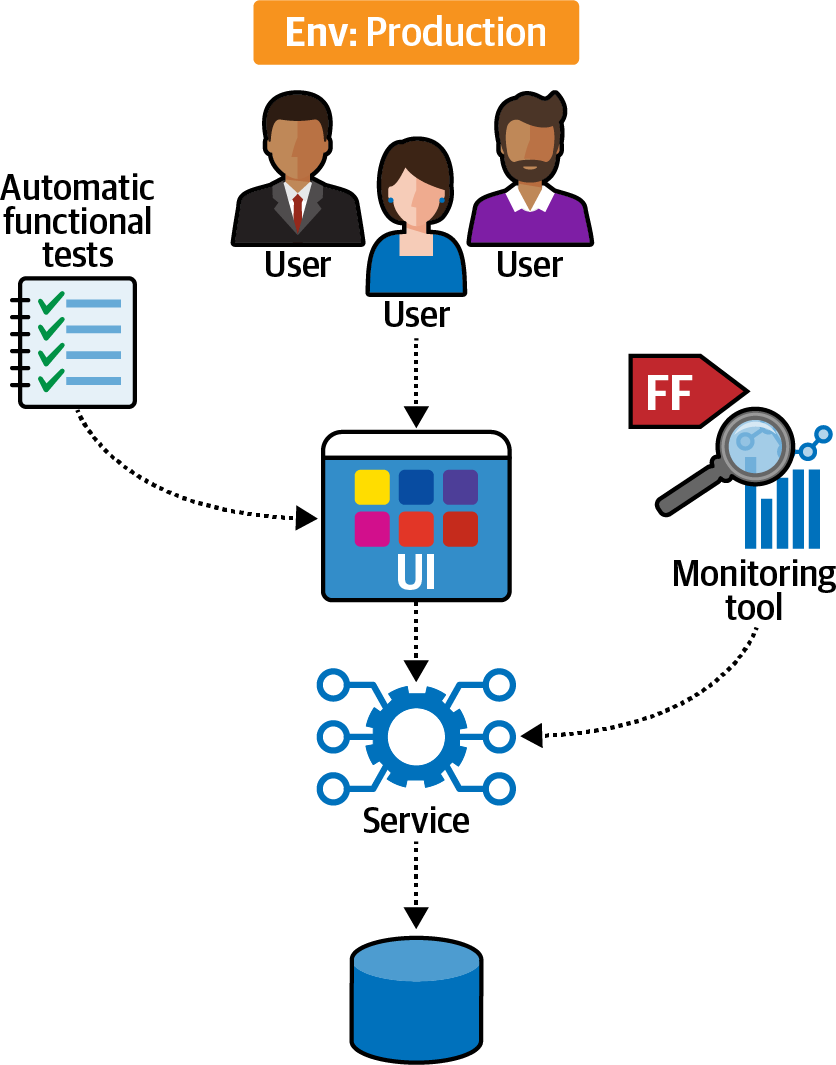
Figura 4-15. Función de adecuación de la verificación de la disponibilidad
Los resultados del experimento les mostraron que el sistema heredado no tenía problemas de disponibilidad, con sobrecarga suficiente para manejar el punto de integración.
Este resultado objetivo permitió al equipo afirmar con seguridad que el punto de integración heredado era suficiente, liberando los recursos que de otro modo se dedicarían a reescribir ese sistema. Este ejemplo ilustra cómo las funciones de adecuación ayudan a que el desarrollo de software pase de ser un arte visceral a una disciplina de ingeniería mensurable.
Caso práctico: Pruebas de carga junto con Canary Releases
PenultimateWidgets tiene un servicio que actualmente "vive" en una única máquina virtual. Sin embargo, bajo carga, esta única instancia tiene dificultades para mantener la escalabilidad necesaria. Como solución rápida, el equipo implementa el autoescalado para el servicio, replicando la instancia única con varias instancias como medida provisional, ya que se acerca rápidamente una ajetreada venta anual. Sin embargo, los escépticos del equipo querían saber cómo podían demostrar que el nuevo sistema funcionaba bajo carga.
Los arquitectos del proyecto crearon una función de adecuación vinculada a una bandera de característica que permite lanzamientos canarios o lanzamientos oscuros, que liberan nuevos comportamientos a un pequeño subconjunto de usuarios para probar el posible impacto global del cambio. Por ejemplo, cuando los desarrolladores de un sitio web altamente escalable lanzan una nueva función que consumirá mucho ancho de banda, a menudo quieren lanzar el cambio lentamente para poder monitorear el impacto. Esta configuración aparece en la Figura 4-16.
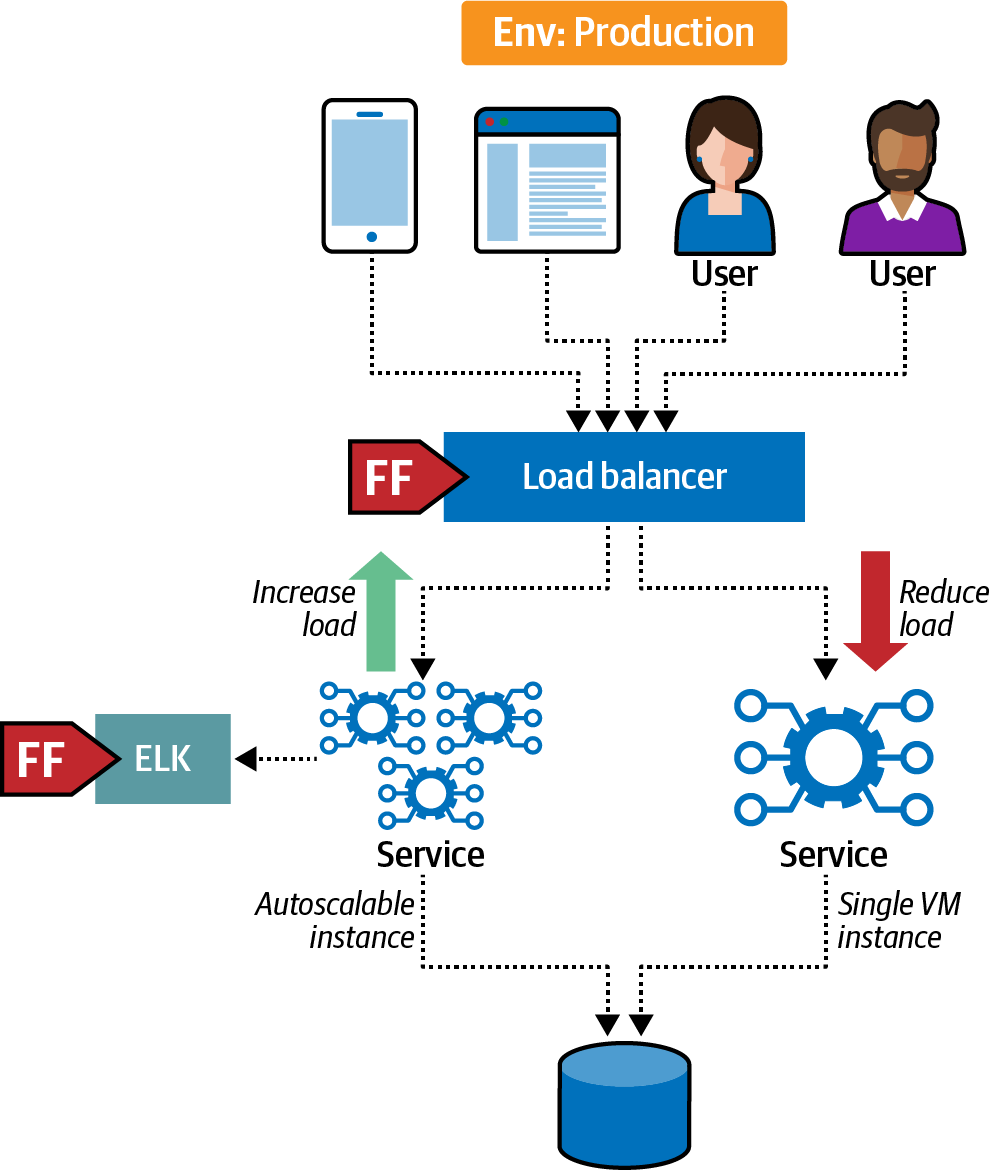
Figura 4-16. Autoescalado canario para proporcionar apoyo y aumentar la confianza
Para la función de adecuación mostrada en la Figura 4-16, el equipo lanzó inicialmente las instancias de autoescalado a un pequeño grupo, y luego aumentó el número de usuarios a medida que su monitoreo mostraba un buen rendimiento y apoyo continuados.
Esta solución actuará como andamiaje para permitir una expansión a plazo limitado mientras el equipo desarrolla una solución mejor. Tener la función de adecuación en su sitio y ejecutarla regularmente permite al equipo tener una mejor idea de cuánto durará esta solución provisional.
Caso práctico: ¿Qué portar?
Una aplicación concreta de PenultimateWidgets ha sido un caballo de batalla, desarrollada como aplicación Java Swing durante casi una década y con nuevas funciones en continuo crecimiento. La empresa decidió portarla a la aplicación web. Sin embargo, ahora los analistas empresariales se enfrentan a una difícil decisión: ¿qué parte de la extensa funcionalidad existente deben portar? Y, lo que es más práctico, ¿en qué orden deben implementar las funciones portadas de la nueva aplicación para ofrecer la mayor funcionalidad rápidamente?
Uno de los arquitectos de PenultimateWidgets preguntó a los analistas de negocio cuáles eran las funciones más populares, ¡y no tenían ni idea! Aunque llevaban años especificando los detalles de la aplicación, no sabían realmente cómo la utilizaban los usuarios. Para aprender de los usuarios, los desarrolladores lanzaron una nueva versión de la aplicación heredada con el registro activado para rastrear qué funciones del menú utilizaban realmente los usuarios.
Al cabo de unas semanas, cosecharon los resultados, que les proporcionaron una excelente hoja de ruta sobre qué funciones portar y en qué orden. Descubrieron que las funciones de facturación y búsqueda de clientes eran las más utilizadas. Sorprendentemente, una subsección de la aplicación que había costado un gran esfuerzo construir se utilizaba muy poco, lo que llevó al equipo a decidir dejar esa funcionalidad fuera de la nueva aplicación web.
Funciones de fitness que ya utilizas
Aparte de nuevas herramientas como ArchUnit, muchas de las herramientas y enfoques que esbozamos no son nuevos. Sin embargo, los equipos las utilizan de forma dispersa e incoherente, ad hoc. Parte de nuestra visión en torno al concepto de función de adecuación unifica una amplia variedad de herramientas en una única perspectiva. Por tanto, es muy probable que ya estés utilizando diversas funciones de adecuación en tus proyectos, sólo que aún no las llamas así.
Las funciones de adecuación incluyen suites de métricas como SonarCube; herramientas de linting como esLint, pyLint y cppLint; y toda una familia de herramientas de verificación del código fuente, como PMD.
Que un equipo utilice monitores para observar el tráfico no convierte esas medidas en una función de aptitud. Establecer una medida objetiva asociada a una alerta convierte las medidas en funciones de aptitud.
Consejo
Para convertir una métrica o medida en una función de adecuación, define medidas objetivas y proporciona información rápida para un uso aceptable.
Utilizar estas herramientas de vez en cuando no las convierte en funciones de fitness, sino que las incorpora a la verificación continua.
Arquitectura de integración
Aunque muchas funciones de adecuación se aplican a aplicaciones individuales, existen en todas las partes del ecosistema arquitectónico: cualquier parte que pueda beneficiarse de la gobernanza. Inevitablemente, cuanto más se alejan los ejemplos de las preocupaciones específicas de la aplicación, menos soluciones genéricas existen. La arquitectura de integración, por su naturaleza, integra diferentes partes específicas, lo que desafía los consejos genéricos. Sin embargo, existen algunos patrones generales para las funciones de adecuación de la arquitectura de integración.
Gobernanza de la comunicación en los microservicios
Muchos arquitectos ven la prueba de ciclo que se muestra en la Figura 2-3 y fantasean con el mismo tipo de prueba para arquitecturas distribuidas como los microservicios. Sin embargo, este deseo se cruza con la naturaleza heterogénea de los problemas de arquitectura. La prueba de ciclos de componentes es una comprobación en tiempo de compilación, que requiere una única base de código y una herramienta en el lenguaje apropiado. Sin embargo, en los microservicios, una única herramienta no será suficiente: cada servicio puede estar escrito en una pila tecnológica diferente, en repositorios distintos, utilizando protocolos de comunicación diferentes, y muchas otras variables. Por tanto, encontrar una herramienta llave en mano para funciones de adecuación para microservicios es poco probable.
Los arquitectos a menudo necesitan escribir sus propias funciones de adecuación, pero no es necesario crear un marco completo (y es demasiado trabajo). Muchas funciones de adecuación constan de 10 ó 15 líneas de código "pegamento", a menudo en una pila tecnológica diferente a la de la solución.
Considera el problema de gobierno de las llamadas entre microservicios, ilustrado en la Figura 4-17. El arquitecto diseñó el OrderOrchestrator como único propietario del estado del flujo de trabajo. Sin embargo, si los servicios de dominio se comunican entre sí, el orquestador no puede mantener el estado correcto. Por ello, un arquitecto puede querer gobernar la comunicación entre servicios: los servicios de dominio sólo pueden comunicarse con el orquestador.
Sin embargo, si un arquitecto puede garantizar una interfaz coherente entre sistemas (como el registro en un formato analizable), puede escribir unas pocas líneas de código en un lenguaje de scripting para construir una función de aptitud de gobierno. Considera un mensaje de registro que incluya la siguiente información:
-
Nombre del servicio
-
Nombre de usuario
-
Dirección IP
-
ID de correlación
-
Hora de recepción del mensaje en UTC
-
Tiempo empleado
-
Nombre del método
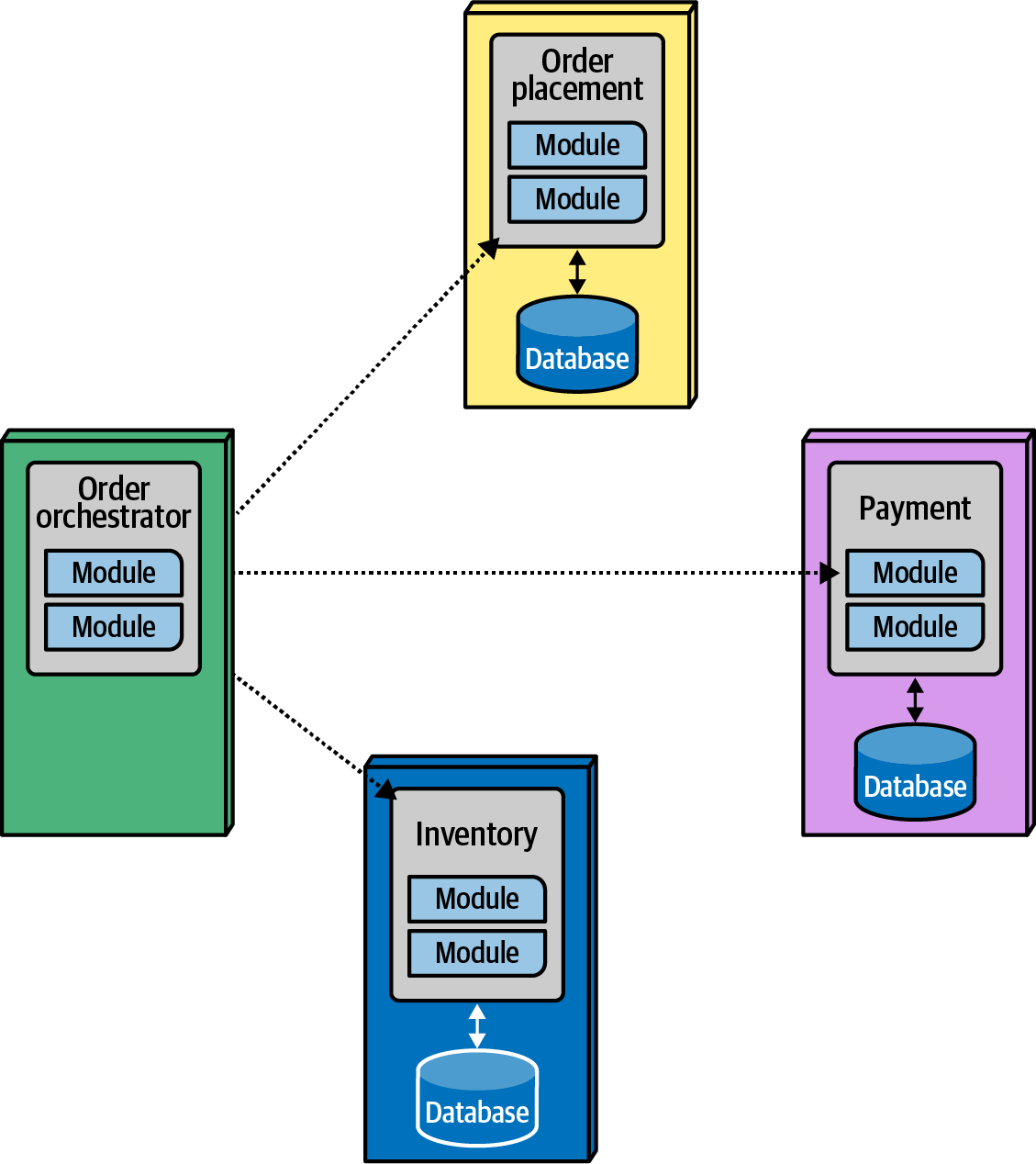
Figura 4-17. Gobernar la comunicación entre microservicios
Por ejemplo, un mensaje de registro concreto podría parecerse al que se muestra en el Ejemplo 4-9.
Ejemplo 4-9. Ejemplo de formato de registro de microservicios
["OrderOrchestrator","jdoe","192.16.100.10","ABC123","2021-11-05T08:15:30-05:00","3100ms","updateOrderState()"]
En primer lugar, un arquitecto puede crear una función de idoneidad para cada proyecto que obligue a emitir mensajes de registro en el formato mostrado en el Ejemplo 4-9, independientemente de la pila tecnológica. Esta función de idoneidad puede adjuntarse a la imagen de contenedor común compartida por los servicios.
En segundo lugar, el arquitecto escribe una sencilla función de adecuación en un lenguaje de scripting como Ruby o Python para recoger los mensajes de registro, analizar el formato común que se indica en el Ejemplo 4-9 y comprobar si la comunicación está aprobada (o desaprobada), como se muestra en el Ejemplo 4-10.
Ejemplo 4-10. Comprobar la comunicación entre servicios
list_of_services.each{|service|service.import_logsFor(24.hours)calls_from(service).each{|call|unlesscall.destination.equals("orchestrator")raiseFitnessFunctionFailure.new()}}
En el Ejemplo 4-10, el arquitecto escribe un bucle que itera sobre todos los archivos de registro recogidos durante las últimas 24 horas. Para cada entrada de registro, comprueba que el destino de cada llamada sea sólo el servicio orquestador, y no ninguno de los servicios del dominio. Si uno de los servicios ha infringido esta regla, la función de adecuación lanza una excepción.
Puede que reconozcas algunas partes de este ejemplo del Capítulo 2 en la discusión sobre las funciones de aptitud activadas frente a las continuas; es un buen ejemplo de dos formas distintas de implementar una función de aptitud con distintas compensaciones. El ejemplo mostrado en el Ejemplo 4-10 representa una función de aptitud reactiva: reacciona a la comprobación de gobierno tras un intervalo de tiempo (en este caso, 24 horas). Sin embargo, otra forma de implementar esta función de idoneidad es de forma proactiva, basándose en el monitoreo en tiempo real de la comunicación, detectando las infracciones en el momento en que se producen.
Cada enfoque tiene ventajas y desventajas. La versión reactiva no impone ninguna sobrecarga a las características de tiempo de ejecución de la arquitectura, mientras que los monitores pueden añadir una pequeña cantidad de sobrecarga. Sin embargo, la versión proactiva detecta las infracciones de inmediato, en lugar de un día después.
Así pues, el verdadero equilibrio entre ambos enfoques puede reducirse a la criticidad de la gobernanza. Por ejemplo, si la comunicación no autorizada crea un problema inmediato (como un problema de seguridad), los arquitectos deberían aplicarla de forma proactiva. Si, por el contrario, el objetivo es sólo la gobernanza estructural, crear la función de adecuación reactiva basada en registros tiene menos posibilidades de afectar al sistema en funcionamiento.
Caso práctico: Elegir cómo implementar una función de aptitud
Probar el dominio del problema es, en su mayor parte, sencillo: a medida que los desarrolladores implementan funciones en el código, las prueban de forma incremental utilizando uno o varios marcos de pruebas. Sin embargo, los arquitectos pueden descubrir que incluso las funciones de aptitud más sencillas tienen diversas implementaciones.
Considera el ejemplo de la Figura 4-18.
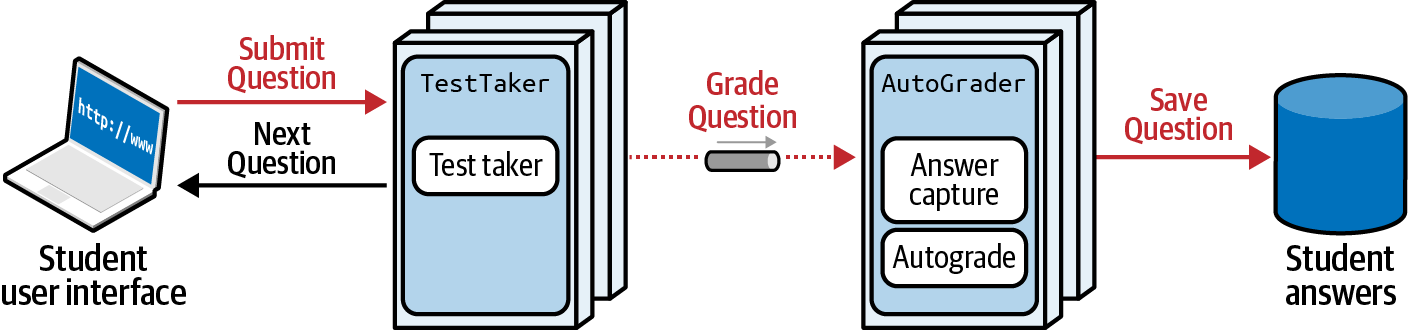
Figura 4-18. Clasificación de la gobernanza de los mensajes
En la Figura 4-18, un alumno responde a las preguntas del examen presentadas por el servicio TestTaker, que a su vez pasa mensajes de forma asíncrona a AutoGrader, que persiste las respuestas calificadas del examen. La fiabilidad es un requisito clave para este sistema: el sistema nunca debe "dejar caer" ninguna respuesta durante esta comunicación. ¿Cómo podría un arquitecto diseñar una función de adecuación para este problema?
Se presentan al menos dos soluciones, que se diferencian sobre todo por las contrapartidas que ofrece cada una. Considera la solución ilustrada en la Figura 4-19.
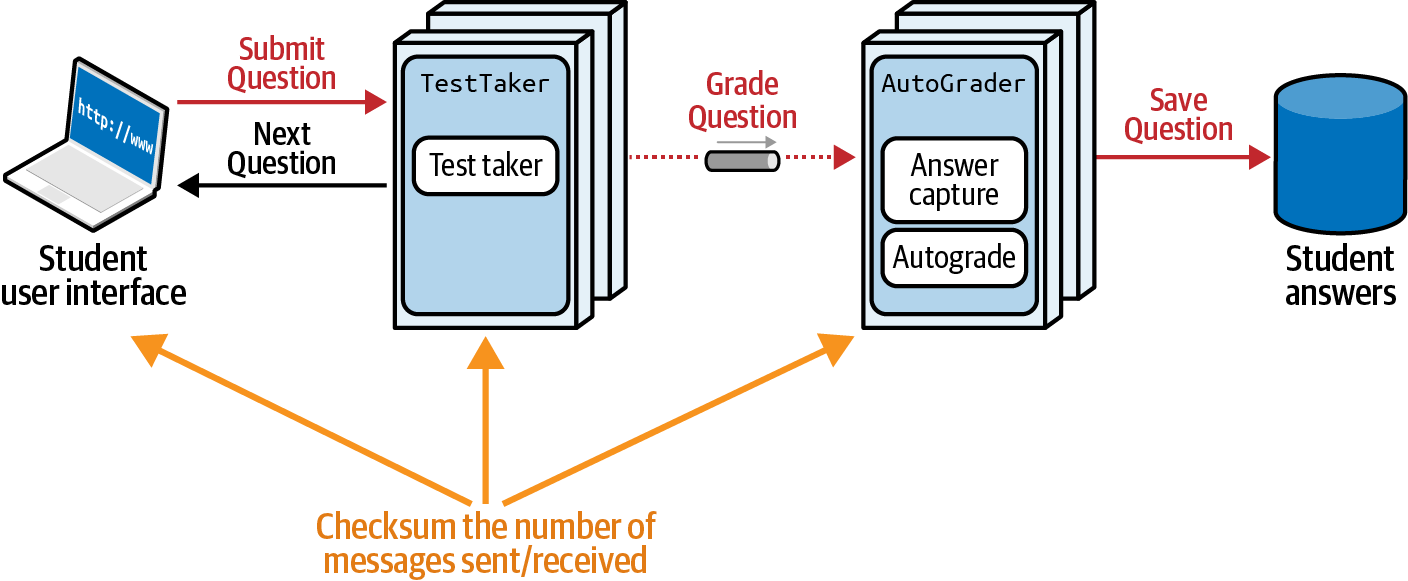
Figura 4-19. Contar el número de mensajes enviados y recibidos
Si podemos suponer una arquitectura de microservicios moderna, preocupaciones como los puertos de mensajes suelen gestionarse en el contenedor. Una forma sencilla de implementar la función de adecuación mostrada en la Figura 4-19 es instrumentar el contenedor para comprobar el número de mensajes entrantes y salientes, y lanzar una alarma si los números no coinciden.
Se trata de una función de adecuación sencilla, ya que es atómica a nivel de servicio/contenedor y los arquitectos pueden aplicarla mediante una infraestructura coherente. Sin embargo, no garantiza la fiabilidad de extremo a extremo, sólo la fiabilidad a nivel de servicio.
En la Figura 4-20 aparece una forma alternativa de aplicar la función de adecuación.
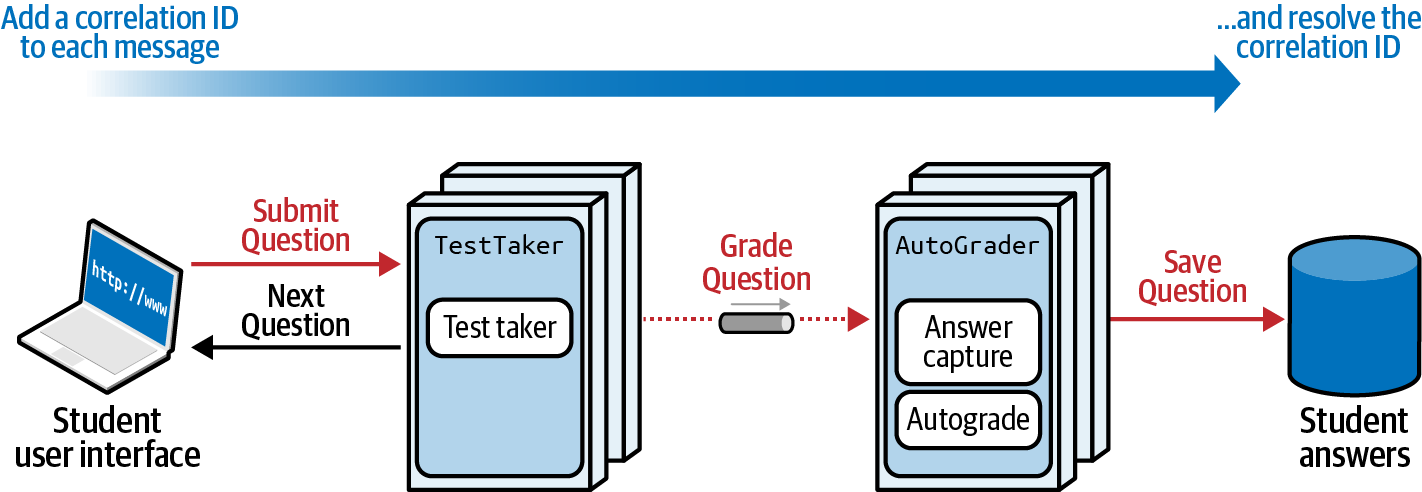
Figura 4-20. Utilizar IDs de correlación para garantizar la fiabilidad
En la Figura 4-20, el arquitecto utiliza IDs de correlación, una técnica habitual que etiqueta cada solicitud con un identificador único para permitir su trazabilidad. Para garantizar la fiabilidad del mensaje, a cada mensaje se le asigna un ID de correlación al inicio de la solicitud, y cada ID se comprueba al final del proceso para asegurarse de que se ha resuelto. La segunda técnica proporciona una garantía más holística de la fiabilidad de los mensajes, pero ahora el arquitecto debe mantener el estado de todo el flujo de trabajo, lo que dificulta la coordinación.
¿Cuál es la implementación correcta de la función fitness? Como todo en arquitectura de software, ¡depende! Las fuerzas externas a menudo dictan qué conjunto de compensaciones elige un arquitecto; lo importante es no quedarse atrapado pensando que sólo hay una forma de implementar una función de fitness.
El gráfico de la Figura 4-21 es un ejemplo de un proyecto real que estableció exactamente este tipo de función de adecuación para garantizar la fiabilidad de los datos.
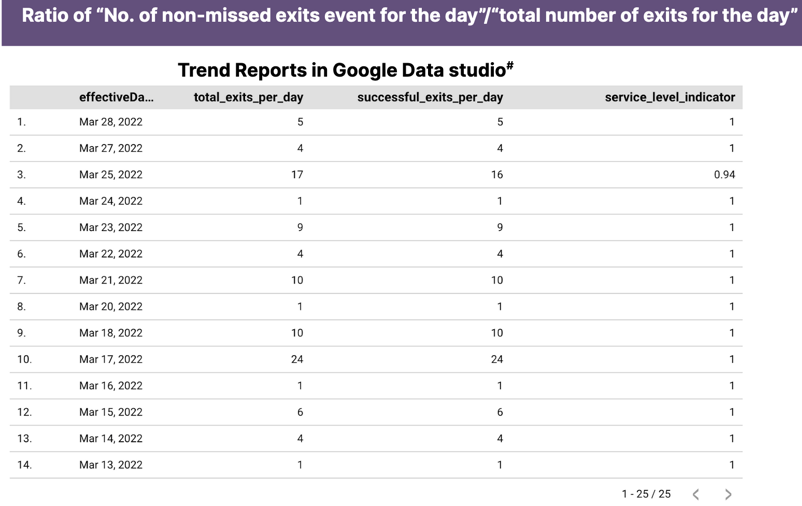
Figura 4-21. Gráfico que muestra la fiabilidad de los mensajes en un flujo de trabajo orquestado
Como puedes ver, la función de adecuación puso al descubierto el hecho de que algunos mensajes no pasaban, lo que animó al equipo a realizar un análisis forense del motivo (y a dejar la función de adecuación en su sitio para garantizar que no surjan problemas en el futuro).
DevOps
Aunque la mayoría de las funciones de adecuación que cubrimos pertenecen a la estructura arquitectónica y conceptos relacionados, como la propia arquitectura de software, las preocupaciones de gobernanza pueden tocar todas las partes del ecosistema, incluida una familia de funciones de adecuación relacionadas con DevOps.
Se trata de funciones de aptitud y no sólo de preocupaciones operativas por dos motivos. En primer lugar, entrecruzan la arquitectura del software y la preocupación operativa: los cambios en la arquitectura pueden afectar a las partes operativas del sistema. En segundo lugar, representan controles de gobernanza con resultados objetivos.
Arquitectura empresarial
La mayoría de las funciones de adecuación que hemos mostrado hasta ahora se han referido a la arquitectura de aplicaciones o de integración, pero son aplicables a cualquier parte de una arquitectura que pueda beneficiarse de la gobernanza. Un lugar en particular donde los arquitectos empresariales tienen un gran impacto en el resto del ecosistema es cuando definen plataformas dentro de su ecosistema para encapsular la funcionalidad empresarial. Este esfuerzo se alinea con nuestro deseo declarado de mantener los detalles de implementación en el ámbito más pequeño posible.
Considera el ejemplo de la Figura 4-22.
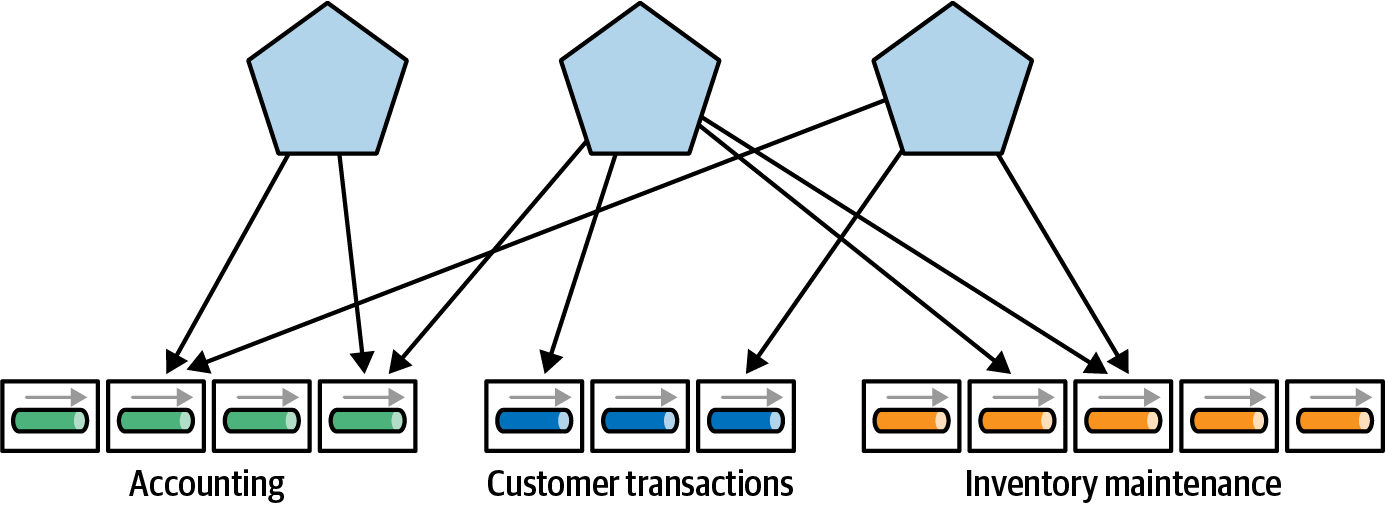
Figura 4-22. Las aplicaciones como composiciones ad hoc de servicios
En la Figura 4-22, las aplicaciones (mostradas en la parte superior) consumen servicios de distintas partes de la empresa. Tener un acceso de grano fino de las aplicaciones a los servicios provoca que los detalles de implementación sobre cómo interactúan las partes entre sí se filtren en la aplicación, haciéndolas a su vez más frágiles.
Al darse cuenta de esto, muchos arquitectos empresariales diseñan plataformas para encapsular la funcionalidad empresarial detrás de contratos gestionados, como se ilustra en la Figura 4-23.
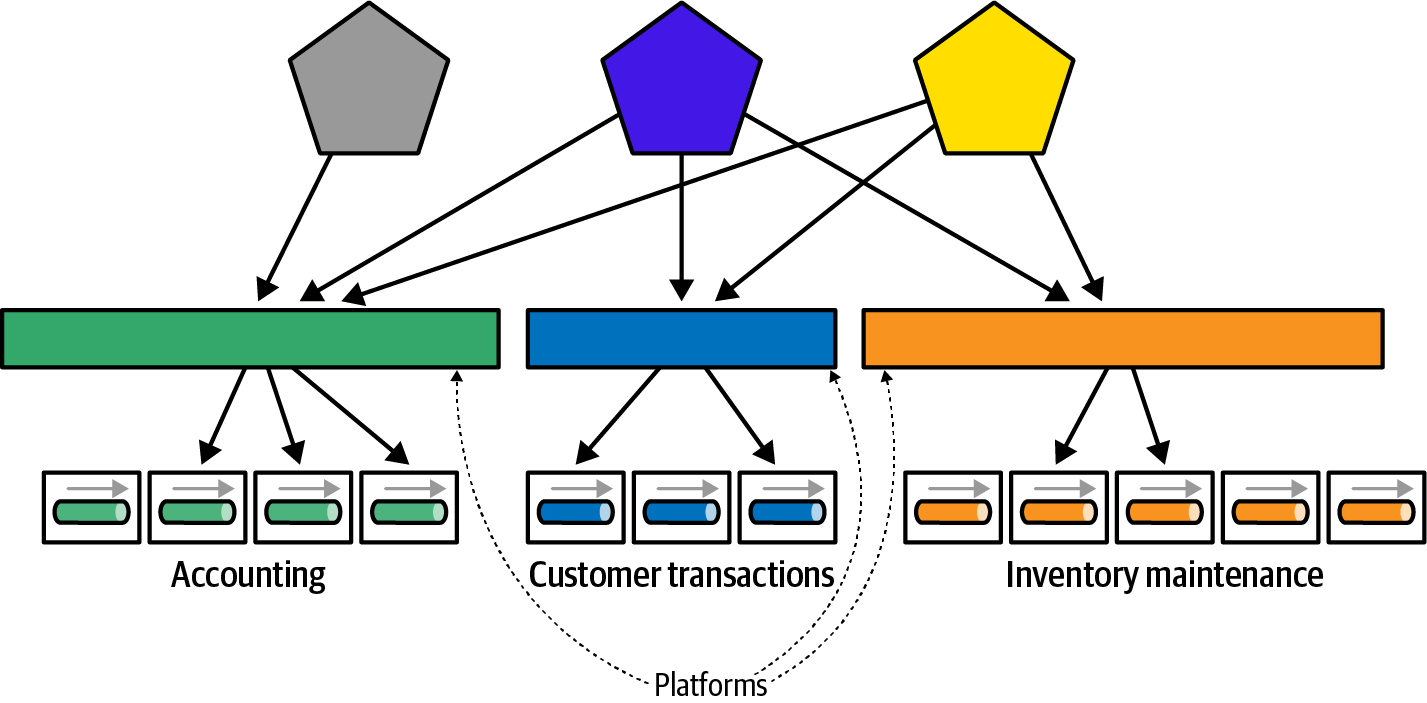
Figura 4-23. Construir plataformas para ocultar detalles de implementación
En la Figura 4-23, los arquitectos construyen plataformas para ocultar la forma en que la organización resuelve los problemas, construyendo en su lugar una API coherente y, con suerte, de cambio lento, que describe las facilidades que otras partes del ecosistema necesitan mediante contratos para la plataforma. Al encapsular los detalles de implementación en el nivel de la plataforma, los arquitectos disminuyen la propagación del acoplamiento de la implementación, haciendo a su vez una arquitectura menos frágil.
Los arquitectos empresariales definen las API de estas funciones de plataforma y adecuación para gobernar las capacidades, la estructura y otros aspectos gobernables de la plataforma y su implementación. Esto, a su vez, proporciona otra ventaja, ¡al mantener a los arquitectos empresariales alejados de la toma de decisiones tecnológicas! En su lugar, se centran en las capacidades y no en cómo implementarlas, lo que resuelve dos problemas.
En primer lugar, los arquitectos empresariales suelen estar alejados de los detalles de la implementación, y por tanto no están tan al día de los cambios de perímetro, en el panorama tecnológico y dentro de su propio ecosistema; a menudo sufren el antipatrón del Cavernícola Congelado.
Por muy desfasados que estén en cuanto a las tendencias de implantación actuales, los arquitectos empresariales son los que mejor entienden los objetivos estratégicos a largo plazo de la organización, que pueden codificar en funciones de adecuación. En lugar de especificar las opciones tecnológicas, definen funciones de adecuación concretas a nivel de plataforma, garantizando que la plataforma siga soportando las características y el comportamiento adecuados. Esto explica aún más nuestro consejo de descomponer las características de la arquitectura hasta que puedas medirlas objetivamente: las cosas que se pueden medir se pueden gobernar.
Además, permitir que los arquitectos empresariales se centren en crear funciones de adecuación para gestionar la visión estratégica libera a los arquitectos de dominio e integración para tomar decisiones tecnológicas con consecuencias, protegidos por los guardarraíles implementados como funciones de adecuación. Esto, a su vez, permite a las organizaciones hacer crecer su próxima generación de arquitectos empresariales, al permitir que las funciones de nivel inferior tomen decisiones y trabajen en las compensaciones.
Hemos asesorado a varias empresas que tienen un papel de arquitecto evolutivo en la arquitectura empresarial, encargado de buscar en la organización oportunidades para encontrar e implantar funciones de adecuación (a menudo cosechadas de un proyecto específico y hechas más genéricas) y construir ecosistemas reutilizables con límites cuánticos y contratos adecuados para garantizar un acoplamiento laxo entre plataformas.
Caso práctico: Reestructuración arquitectónica mientras se implementa 60 vecesal día
GitHub es un conocido sitio web centrado en los desarrolladores, con prácticas de ingeniería agresivas, que despliega 60 veces al día, de media. GitHub describe un problema en su blog "Move Fast and Fix Things" que hará estremecerse de horror a muchos arquitectos. Resulta que GitHub ha utilizado durante mucho tiempo un script de shell envuelto en la línea de comandos de Git para gestionar las fusiones, que funciona correctamente pero no escala lo suficientemente bien. El equipo de ingenieros de Git construyó una biblioteca de sustitución para muchas funciones de Git de la línea de comandos llamada libgit2 e implementó allí su funcionalidad de fusión, probándola a fondo localmente.
Pero ahora deben implementar la nueva solución en producción. Este comportamiento ha formado parte de GitHub desde sus inicios y ha funcionado a la perfección. Lo último que quieren hacer los desarrolladores es introducir errores en la funcionalidad existente, pero también deben abordar la deuda técnica.
Afortunadamente, los desarrolladores de GitHub crearon Scientist, un framework de código abierto escrito en Ruby que proporciona pruebas holísticas y continuas para examinar los cambios en el código. El ejemplo 4-11 nos muestra la estructura de una prueba Scientist.
Ejemplo 4-11. Configuración del científico para un experimento
require"scientist"classMyWidgetincludeScientistdefallows?(user)science"widget-permissions"do|e|e.use{model.check_user(user).valid?}# old waye.try{user.can?(:read,model)}# new wayend# returns the control valueendend
En el Ejemplo 4-11, el programador encapsula el comportamiento existente con el bloque use (llamado control) y añade el comportamiento experimental al bloque try (llamado candidato). El bloque science gestiona los siguientes detalles durante la invocación del código:
- Decide si se ejecuta el bloque
try -
Los desarrolladores configuran el Científico para determinar cómo se ejecuta el experimento. Por ejemplo, en este estudio de caso -cuyo objetivo era actualizar la funcionalidad de fusión-, el 1% de los usuarios aleatorios probaron la nueva funcionalidad de fusión. En cualquier caso, Scientist siempre devuelve los resultados del bloque
use, garantizando que la persona que llama siempre reciba el comportamiento existente en caso de diferencias. - Aleatoriza el orden de ejecución de los bloques
useytry -
El Científico hace esto para evitar enmascarar accidentalmente fallos debidos a dependencias desconocidas. A veces, el orden u otros factores incidentales pueden causar falsos positivos; al aleatorizar su orden, la herramienta hace que esos fallos sean menos probables.
- Mide las duraciones de todas las conductas
-
Parte del trabajo de Scientist consiste en realizar pruebas de rendimiento A/B, por lo que el monitoreo del rendimiento está integrado. De hecho, los desarrolladores pueden utilizar el framework de forma fragmentada: por ejemplo, pueden utilizarlo para medir las llamadas sin realizar experimentos.
- Compara el resultado de
trycon el resultado deuse -
Como el objetivo es refactorizar el comportamiento existente, el Científico compara y registra los resultados de cada llamada para ver si existen diferencias.
- Traga (pero registra) las excepciones que se produzcan en el bloque
try -
Siempre existe la posibilidad de que un código nuevo lance excepciones inesperadas. Los desarrolladores nunca quieren que los usuarios finales vean estos errores, así que la herramienta los hace invisibles para el usuario final (pero los registra para que los analicen los desarrolladores).
- Publica toda esta información
-
Scientist pone a disposición todos sus datos en diversos formatos.
Para la refactorización de la fusión, los desarrolladores de GitHub utilizaron la siguiente invocación para probar la nueva implementación (llamada create_merge_commit_rugged), como se muestra en el Ejemplo 4-12.
Ejemplo 4-12. Experimentar con un nuevo algoritmo de fusión
defcreate_merge_commit(author,base,head,options={})commit_message=options[:commit_message]||"Merge#{head}into#{base}"now=Time.currentscience"create_merge_commit"do|e|e.context:base=>base.to_s,:head=>head.to_s,:repo=>repository.nwoe.use{create_merge_commit_git(author,now,base,head,commit_message)}e.try{create_merge_commit_rugged(author,now,base,head,commit_message)}endend
En el Ejemplo 4-12, la llamada a create_merge_commit_rugged se produjo en el 1% de las invocaciones, pero, como se ha señalado en este estudio de caso, a la escala de GitHub, todos los casos de perímetro aparecen rápidamente.
Cuando se ejecuta este código, los usuarios finales siempre reciben el resultado correcto. Si el bloque try devuelve un valor distinto de use, se registra, y se devuelve el valor use. Por tanto, el peor caso para los usuarios finales es exactamente el que habrían obtenido antes de la refactorización. Tras ejecutar el experimento durante 4 días y no experimentar casos lentos ni resultados erróneos durante 24 horas, eliminaron el antiguo código de fusión y dejaron el nuevo código en su lugar.
Desde nuestra perspectiva, Científico es una función de adecuación. Este caso práctico es un ejemplo excepcional del uso estratégico de una función de adecuación holística y continua para permitir a los desarrolladores refactorizar una parte crítica de su infraestructura con confianza. Cambiaron una parte clave de su arquitectura ejecutando la nueva versión junto a la existente, convirtiendo esencialmente la implementación heredada en una prueba de coherencia.
Funciones de aptitud de fidelidad
La herramienta Científico implementa un tipo general de verificación denominada función de adecuación a la fidelidad: preservar la fidelidad entre un sistema nuevo y uno antiguo en proceso de sustitución. Muchas organizaciones construyen funcionalidades importantes durante largos periodos de tiempo, sin suficientes pruebas ni disciplina, hasta que llega el momento de sustituir la aplicación por una tecnología más reciente, pero conservando el mismo comportamiento que la antigua. Cuanto más antiguo y peor documentado sea el sistema antiguo, más difícil será para los equipos replicar el comportamiento deseado.
Una función de adecuación de la fidelidad permite una comparación en paralelo entre lo antiguo y lo nuevo. Durante el proceso de sustitución, ambos sistemas se ejecutan en paralelo, y un proxy permite a los equipos llamar a old, new, o both de forma controlada hasta que el equipo haya portado cada bit de funcionalidad discreta. Algunos equipos se resisten a construir un mecanismo de este tipo porque se dan cuenta de la complejidad de la partición del comportamiento antiguo y la replicación exacta, pero al final sucumben a la necesidad de lograr la confianza.
La aptitud funciona como una lista de comprobación, no como un palo
Somos conscientes de que hemos proporcionado a los arquitectos un palo metafóricamente afilado que pueden utilizar para pinchar y torturar a los desarrolladores; no se trata de eso en absoluto. Queremos disuadir a los arquitectos de retirarse a una torre de marfil e idear funciones de adecuación cada vez más complejas y entrelazadas que aumenten la carga de los desarrolladores sin añadir el valor correspondiente al proyecto.
En cambio, las funciones de adecuación proporcionan una forma de hacer cumplir los principios arquitectónicos. Muchas profesiones, como los cirujanos y los pilotos de avión, utilizan (a veces por mandato) listas de comprobación como parte de su trabajo. No es porque no entiendan su trabajo o tiendan al despiste, sino para evitar la tendencia natural que tienen las personas a saltarse pasos accidentalmente cuando realizan tareas complejas una y otra vez. Por ejemplo, todos los desarrolladores saben que no deben implementar un contenedor con los puertos de depuración activados, pero pueden olvidarlo durante una implementación que incluya muchas otras tareas.
Muchos arquitectos enuncian principios de arquitectura y diseño en wikis u otros portales de conocimiento compartido, pero los principios sin ejecución se quedan por el camino ante la presión de los plazos y otras limitaciones. Codificar esas reglas de diseño y gobernanza como funciones de adecuación garantiza que no se omitan ante fuerzas externas.
Los arquitectos suelen escribir funciones de aptitud, pero siempre deben colaborar con los desarrolladores, que deben entenderlas y arreglarlas en caso de rotura ocasional. Aunque las funciones de aptitud añaden sobrecarga, evitan la degradación gradual de una base de código(putrefacción de bits), permitiéndole seguir evolucionando en el futuro.
Documentar las funciones de aptitud
Las pruebas son una buena documentación porque los lectores nunca dudan de su honestidad: siempre pueden ejecutar las pruebas para comprobar los resultados. ¡Confía pero verifica!
Los arquitectos pueden documentar las funciones de idoneidad de diversas formas, todas ellas apropiadas con otra documentación dentro de su organización. Algunos arquitectos consideran que las propias funciones de adecuación son suficientes para documentar su intención. Sin embargo, las pruebas (por muy fluidas que sean) son más difíciles de leer para los no tecnólogos.
A muchos arquitectos les gustan los Registros de Decisiones Arquitectónicas (ADR) para documentar las decisiones arquitectónicas. Los equipos que utilizan funciones de adecuación añaden una sección en el ADR que especifica cómo gobernar las decisiones de diseño adjuntas.
Otra alternativa es utilizar un marco de desarrollo basado en el comportamiento (BDD), como Cucumber. Estas herramientas están diseñadas para mapear el lenguaje nativo al código de verificación. Por ejemplo, echa un vistazo a la prueba Cucumber indicada en el Ejemplo 4-13.
Ejemplo 4-13. Suposiciones de Cucumber
Feature:IsitFridayyet?Everybodywantstoknowwhenit'sFridayScenario:Sundayisn'tFridayGiventodayisSundayWhenIaskwhetherit'sFridayyetThenIshouldbetold"Nope"
El Feature descrito en el Ejemplo 4-13 se mapea a un método del lenguaje de programación; en el Ejemplo 4-14 aparece un mapeo Java.
Ejemplo 4-14. Métodos de Cucumber que se asignan a descripciones
@Given("today is Sunday")publicvoidtoday_is_sunday(){// Write code here that turns the phrase above into concrete actionsthrownewio.cucumber.java.PendingException();}@When("I ask whether it's Friday yet")publicvoidi_ask_whether_it_s_friday_yet(){// Write code here that turns the phrase above into concrete actionsthrownewio.cucumber.java.PendingException();}@Then("I should be told {string}")publicvoidi_should_be_told(Stringstring){// Write code here that turns the phrase above into concrete actionsthrownewio.cucumber.java.PendingException();}
Los arquitectos pueden utilizar el mapeo entre las declaraciones en lenguaje nativo del Ejemplo 4-13 y las definiciones de métodos del Ejemplo 4-14 para definir funciones de fitness en lenguaje nativo más o menos llano y mapear la ejecución en el método correspondiente. Esto proporciona a los arquitectos una forma de documentar sus decisiones que también las ejecuta.
El inconveniente de utilizar una herramienta como Cucumber es el desajuste de impedancia entre la captura de requisitos (su trabajo original) y la documentación de las funciones de aptitud.
La programación literaria fue una innovación de Donald Knuth que intentó fusionar la documentación y el código fuente, con el objetivo de permitir una documentación más limpia. Construyó compiladores especiales para los lenguajes entonces vigentes, pero obtuvo poco apoyo.
Sin embargo, en los ecosistemas modernos, herramientas como Mathematica y los cuadernos Jupyter son populares en disciplinas como la ciencia de datos. Los arquitectos pueden utilizar los cuadernos Jupyter en particular para documentar y ejecutar funciones de adecuación.
En un estudio de caso, un equipo creó un cuaderno para comprobar las reglas arquitectónicas utilizando el analizador de código estructural jQAssistant en combinación con la base de datos de grafos Neo4j. jQAssistant escanea varios artefactos (código de bytes Java, historial Git, dependencias Maven, etc.) y almacena la información estructural en la base de datos Neo4j, como se muestra en la Figura 4-24.
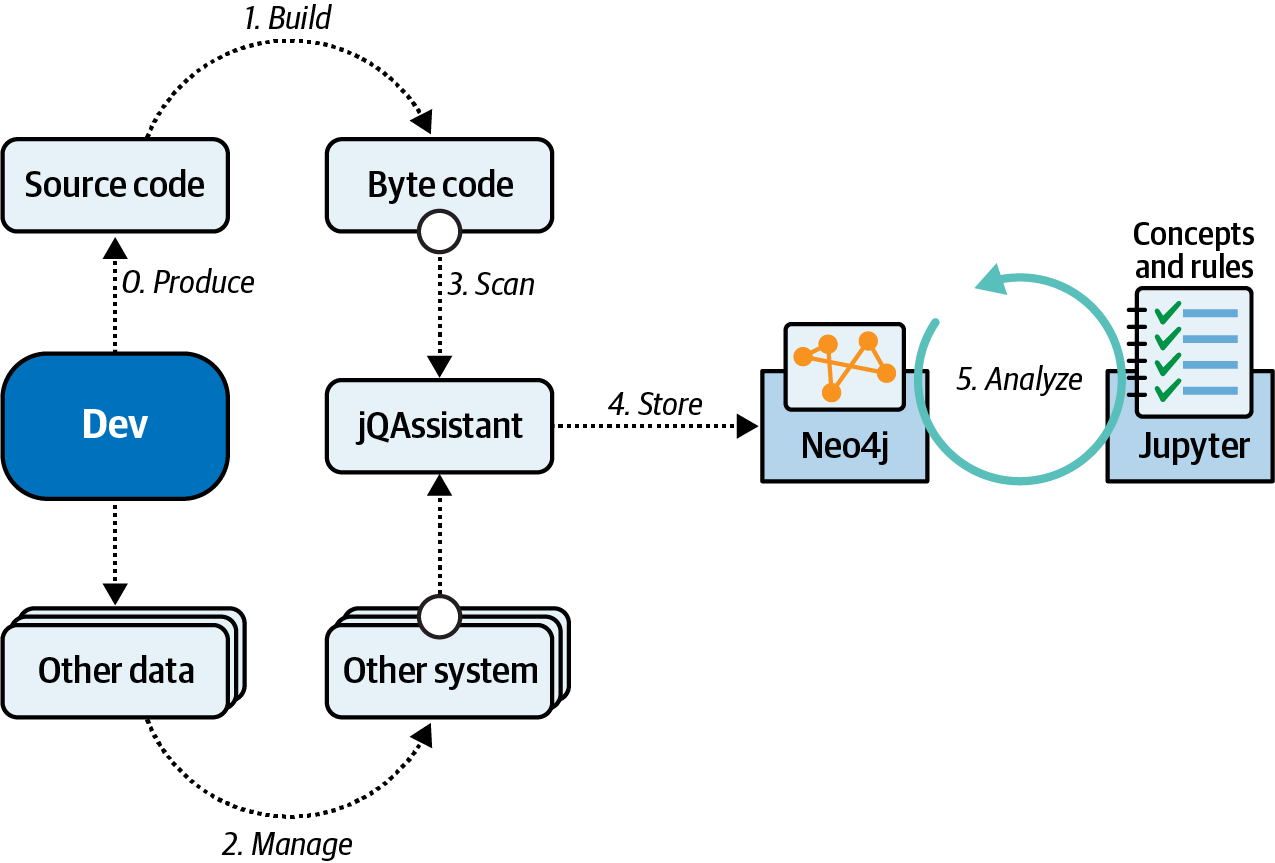
Figura 4-24. Flujo de trabajo de gobernanza con el cuaderno Jupyter
En la Figura 4-24, las relaciones entre las partes de la base de código se colocan en la base de datos gráfica, lo que permite al equipo ejecutar consultas como las siguientes:
MATCH(e:Entity)<-[:CONTAINS]-(p:Package)WHEREp.name<>"model"RETURNe.fqnasMisplacedEntity,p.nameasWrongPackage
Cuando se ejecuta contra una aplicación PetClinic de muestra, el análisis crea la salida que se muestra en la Figura 4-25.

Figura 4-25. Salida del análisis gráfico
En la Figura 4-25, los resultados indican una violación de la gobernanza, ya que todas las clases del paquete model deberían implementar una anotación @Entity.
Los cuadernos Jupyter permiten a los arquitectos definir el texto de las reglas de gobierno junto con la ejecución bajo demanda.
Documentar las funciones de aptitud es importante porque los desarrolladores deben entender por qué existen para que arreglarlas no sea una molestia. Encontrar una forma de incorporar las definiciones de las funciones de fitness dentro del marco de documentación existente en tu organización permite un acceso más coherente. La ejecución de las funciones de aptitud sigue siendo la máxima prioridad, pero la comprensibilidad también es importante.
Resumen
Las funciones de adecuación son a la gobernanza de la arquitectura lo que las pruebas unitarias son a los cambios de dominio. Sin embargo, la aplicación de las funciones de adecuación varía en función de los diversos factores que componen una arquitectura concreta. No existe una arquitectura genérica: cada una es una combinación única de decisiones y tecnologías posteriores, a menudo de años, o décadas. Por ello, los arquitectos a veces deben ser inteligentes a la hora de crear funciones de adecuación. Sin embargo, éste no es un ejemplo de necesidad de escribir todo un marco de pruebas. Más bien, los arquitectos suelen escribir estas funciones de adecuación en lenguajes de scripting como Python o Ruby, escribiendo 10 ó 20 líneas de código "pegamento" para combinar la salida de otras herramientas. Por ejemplo, considera el Ejemplo 4-10, que recoge la salida de los archivos de registro y busca determinados patrones de cadenas.
Uno de nuestros colegas presentó una gran analogía para las funciones de aptitud, que se muestra en la Figura 4-26.

Figura 4-26. Las funciones de aptitud actúan como guardarraíles independientemente de cómo esté hecho el camino
En la Figura 4-26, la carretera puede estar hecha de diversos materiales: asfalto, adoquines, grava, etc. Las barandillas existen para mantener a los viajeros en la carretera, independientemente del tipo de vehículo o del tipo de carretera. Las funciones de aptitud son barandillas de características arquitectónicas, creadas por arquitectos para evitar la putrefacción del sistema y soportar la evolución de los sistemas a lo largo del tiempo.
Get Construyendo Arquitecturas Evolutivas, 2ª Edición now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

