Capítulo 1. ¿Qué es sin servidor?
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Latecnología sin servidor se ha promocionado en como una tecnología transformadora, ha sido utilizada como marca por varias plataformas de desarrollo y etiquetada como docenas de servicios por los principales proveedores de la nube. Promete la capacidad de enviar código muchas veces al día, crear prototipos de nuevas aplicaciones con unas pocas docenas de líneas de código y escalar a los mayores problemas de aplicación. También ha sido utilizado con éxito para aplicaciones de producción por empresas que van desde Snap (la aplicación principal de Snapchat) a iRobot (que gestiona las comunicaciones de cientos de miles de electrodomésticos) y Microsoft (una amplia variedad de sitios web y portales).
Como se menciona en el Prefacio, el término "sin servidor" se ha aplicado no sólo a los servicios de infraestructura informática, sino también al almacenamiento, la mensajería y otros sistemas. Las definiciones ayudan a explicar qué es y qué no es "sin servidor". Dado que este libro se centra en cómo crear aplicaciones utilizando la infraestructura sin servidor, muchos capítulos se concentran en cómo diseñar y programar las capas informáticas. Sin embargo, nuestra definición también debe servir de ayuda a los equipos de infraestructura que estén pensando en construir abstracciones no informáticas sin servidor. Para ello, voy a utilizar la siguiente definición de sin servidor:
Sin servidor es un patrón de diseño y ejecución de aplicaciones distribuidas que divide la carga en unidades de trabajo independientes y, a continuación, programa y ejecuta ese trabajo automáticamente en un número de instancias escalado automáticamente.
En general1 el patrón sin servidor consiste en escalar automáticamente el número de procesos informáticos en función de la cantidad de trabajo disponible, como se muestra en la Figura 1-1.
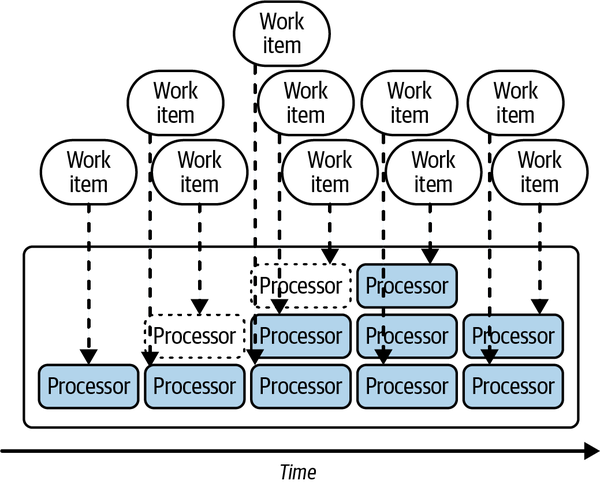
Figura 1-1. El modelo sin servidor
Observarás que esta definición es bastante amplia; no abarca sólo plataformas FaaS como AWS Lambda o Cloudflare Workers, sino que también podría abarcar sistemas como GitHub Actions (acciones de construcción e integración continua [CI]), service workers en Chrome (hilos en segundo plano que se coordinan entre el navegador y el servidor), o incluso funciones definidas por el usuario en una plataforma de consulta como BigQuery de Google (almacén SQL distribuido). También abarca plataformas de almacenamiento de objetos como Amazon Simple Storage Service, o S3 (una unidad de trabajo es almacenar un blob), e incluso podría abarcar marcos de actores que escalaran automáticamente el número de instancias que gestionan el estado de los actores.
En este libro, generalmente sacaré ejemplos delproyecto de código abierto Knative para ejemplificar los principios sin servidor, pero de vez en cuando me extenderé y hablaré de otras plataformas sin servidor cuando tenga sentido. Voy a centrarme en Knative por tres razones:
-
Como proyecto de código abierto, está disponible en una amplia variedad de plataformas, desde proveedores de la nube hasta ordenadores de placa única como la Raspberry Pi.
-
Al ser un proyecto de código abierto, el código fuente está disponible para la experimentación. Puedes añadir líneas de depuración o integrarlo en un proyecto o plataforma mayor ya existente. Muchas plataformas sin servidor son ofertas comerciales en la nube que están vinculadas a un proveedor concreto, y no suelen permitirte modificar o sustituir suplataforma.
-
Está en el título del libro, y supongo que algunos de vosotros os sentiríais decepcionados si no lo mencionara. También tengo cinco años de experiencia trabajando con la comunidad Knative, construyendo software y comunidad, y respondiendo preguntas. Mi experiencia en Knative es al menos tan profunda como mi experiencia con otras plataformas.
¿Por qué se llama sin servidor?
A los críticos de sillón de serverless les gusta señalar una "trampa" en el nombre: aunque el nombre es "serverless", en realidad sigue siendo una forma de ejecutar el código de tu aplicación en servidores, en algún lugar. Entonces, ¿cómo surgió este nombre y cómo encaja la tecnología sin servidor en el arco de los sistemas informáticos de los últimos 50 años?
En las décadas de 1960 y 1970, los ordenadores centrales eran raros, caros y completamente centrales para la informática. Los años 70 y 80 trajeron ordenadores cada vez más pequeños y baratos, hasta el punto de que, a mediados de los 90, a menudo era más barato conectar en red varios ordenadores pequeños para realizar una tarea que comprar un único ordenador más caro. La coordinación eficaz de estos ordenadores es la base de la informática distribuida. (Para una historia más completa de la informática sin servidor, consulta el Capítulo 11.) Para una historia de cómo ha evolucionado el nombre sin servidor, consulta "Sin servidor alojado en la nube").
Aunque hay muchas formas de conectar ordenadores para resolver problemas mediante la informática distribuida, la tecnología sin servidor se centra en facilitar la resolución de problemas que se ajustan a patrones bien conocidos de distribución del trabajo. Gran parte de esto se alinea con el movimiento de microservicios que comenzó alrededor de 2010, cuyo objetivo era dividir las aplicaciones monolíticas existentes en componentes independientes capaces de ser escritos y gestionados por equipos más pequeños. Sin servidor complementa (pero no requiere) una arquitectura de microservicios simplificando la implementación de microservicios individuales.
Consejo
El objetivo de serverless es hacer que los desarrolladores ya no necesiten pensar en términos de unidades de servidor cuando construyan y escalen aplicaciones,2 sino que utilicen unidades de escalado que tengan sentido para la aplicación.
Al adoptar patrones bien conocidos, las plataformas sin servidor pueden automatizar procesos difíciles pero comunes, como la conmutación por error, la replicación o el enrutamiento de solicitudes, el "trabajo pesado indiferenciado" de la informática distribuida (acuñado por Jeff Bezos en 2006 al describir las ventajas de la plataforma de computación en nube de Amazon). Un modelo sin servidor popular desde 2011 es el modelo de aplicación de doce factores, que describe varios patrones que la mayoría de las plataformas sin servidor adoptan, incluidas las aplicaciones sin estado con almacenamiento gestionado por servicios externos o por la plataforma y una clara separación de la configuración y el código de la aplicación.
A estas alturas, debería estar claro que adoptar una mentalidad de desarrollo sin servidor no significa tirar por la ventana un montón de hardware caro; de hecho, las plataformas sin servidor a menudo necesitan trabajar junto a los sistemas de software existentes e integrarse con ellos, incluidos los sistemas mainframe con un linaje que se remonta a la década de 1960.
Knative, en en particular, es una buena opción para integrar capacidades sin servidor en una plataforma informática existente, porque se basa en las capacidades de Kubernetes e incorpora de forma nativa dichas capacidades. De este modo, Knative zanja la cuestión de "sin servidor frente a contenedores", que ha sido una fuente popular de discusión desde la introducción de AWS Lambda y Kubernetes en 2014.
Un poco de terminología
Mientras describa los sistemas sin servidor y los compare con los sistemas informáticos tradicionales, utilizaré algunos términos específicos a lo largo del libro. Intentaré utilizar estas palabras de forma coherente, ya que hay muchas formas de implementar un sistema sin servidor, y merece la pena tener un lenguaje preciso que sea distinto de los productos específicos que podemos utilizar para describir cómo nuestros modelos mentales se corresponden con una implementación concreta:
- Proceso
-
Utilizo el término proceso en el sentido Unix de la palabra: un programa en ejecución con uno o más hilos que comparten un espacio de memoria común y una interfaz con un núcleo. La mayoría de los sistemas sin servidor se basan en el núcleo de Linux, ya que es popular y gratuito, pero otros sistemas sin servidor se basan en el núcleo de Windows o en el tiempo de ejecución de JavaScript expuesto a través de WebAssembly (Wasm). El mecanismo de proceso sin servidor más común en el momento de escribir este libro es el núcleo Linux a través del subsistema de contenedores, utilizado tanto por Lambda a través de la biblioteca Firecracker VM como por varios proyectos de código abierto como Knative utilizando el programador Kubernetes y la Interfaz de Tiempo de Ejecución de Contenedores (CRI).
- Instancia
-
Una instancia es un entorno de ejecución sin servidor junto con cualquier infraestructura de sistema externa que se necesite para gestionar el proceso raíz en ese entorno. La instancia es la unidad más pequeña de programación y computación disponible en un sistema sin servidor, y a menudo se utiliza como clave en sistemas como el registro, el monitoreo y el rastreo para permitir correlaciones. Los sistemas sin servidor tratan las instancias como efímeras y se encargan de crearlas y destruirlas automáticamente en respuesta a la carga del sistema. Dependiendo del entorno sin servidor, puede ser posible ejecutar múltiples procesos dentro de una única instancia, pero el sistema sin servidor externo ve la instancia como la unidad de escalado y ejecución.
- Artefacto
-
Un artefacto (o artefacto de código) es un conjunto de código informático que está listo para ser ejecutado por una instancia. Puede ser un archivo ZIP de código fuente, un JAR compilado, una imagen contenedora o un fragmento Wasm. Normalmente, cada instancia ejecutará código utilizando un artefacto concreto, y cuando un nuevo artefacto esté listo, se pondrán en marcha nuevas instancias y se eliminarán las antiguas. Este método de despliegue de código es diferente de los sistemas tradicionales que aprovisionan máquinas virtuales y luego las reutilizan para ejecutar muchos artefactos o versiones diferentes de un artefacto, y tiene propiedades beneficiosas de las que hablaremos más adelante.
- Aplicación
-
Una aplicación es un conjunto diseñado y coordinado de procesos y sistemas de almacenamiento que se ensamblan para lograr algún tipo de valor para el usuario. Mientras que las aplicaciones sencillas pueden contener sólo un tipo de instancia, la mayoría de las aplicaciones sin servidor contienen múltiples microservicios, cada uno de los cuales ejecuta sus propios tipos de instancias. Tambiénes habitual que las aplicaciones se construyan con una mezcla de componentes sin servidor y sin servidor -consulta el Capítulo 5 para más detalles sobre cómo integrar arquitecturas sin servidor y tradicionales en una misma aplicación-.
Estos componentes, así como algunos otros como el programador, se ilustran enla Figura 1-2.
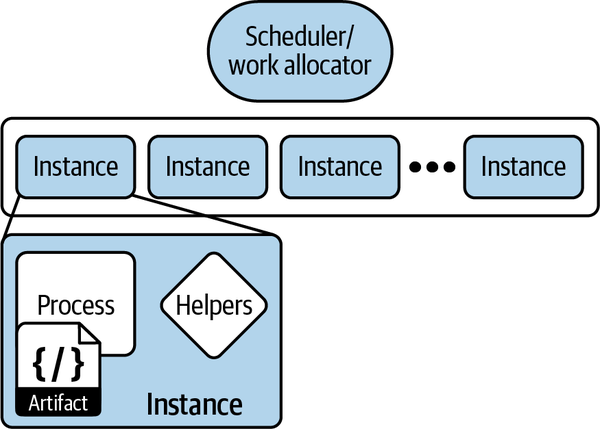
Figura 1-2. Componentes de una aplicación sin servidor
¿Qué es una "Unidad de Trabajo"?
Serverless escala por unidades de trabajo y puede escalar a cero instancias cuando no hay trabajo. Pero, te preguntarás, ¿qué es una unidad de trabajo? Una unidad de trabajo es una petición sin estado, independiente, que puede ser satisfecha utilizando una cierta cantidad de cálculo (y más peticiones de red) por una sola instancia. Vamos a desglosarlo:
- Sin estado
-
Cada solicitud contiene todo el trabajo que debe realizarse y no depende de que la instancia haya gestionado partes anteriores de la solicitud o de otras solicitudes también en curso. Esto también significa que un proceso sin servidor no puede almacenar datos en memoria para trabajos futuros ni suponer que se ejecutarán procesos entre unidades de trabajo para hacer cosas como gestionar temporizadores en proceso. En realidad, esta definición permite mucho margen de maniobra: puedes enlazar con las salidas de unidades de trabajo que podrían procesarse antes, o tu trabajo puede ser un flujo de datos como "Aquí hay un segmento de vídeo que contiene movimiento (hasta que el movimiento se detiene)". A grandes rasgos, puedes pensar en una unidad de trabajo como la entrada a una función; si puedes procesar las entradas a la función sin estado local (como una función no asociada a una clase o a valores globales), entonces eres lo suficientemente sin estado como para ser serverless.
- Independiente
-
Poder referenciar sólo el trabajo que está completo en otro lugar permite a los sistemas sin servidor escalar horizontalmente añadiendo más nodos, ya que cada unidad de trabajo no depende directamente de que se ejecute otra. Además, la independencia significa que el trabajo puede dirigirse a "una instancia que esté preparada para hacer el trabajo" (incluida una instancia de nueva creación), y que las instancias pueden cerrarse cuando no haya suficiente trabajo para repartir.
- Solicita
-
Al igual que los sistemas reactivos, los sistemas sin servidor deben realizar trabajo sólo cuando se les solicite. Estas solicitudes de trabajo pueden adoptar muchas formas: pueden ser eventos que hay que gestionar, solicitudes HTTP, filas que hay que procesar o incluso correos electrónicos que llegan a un sistema. El punto clave aquí es que el trabajo puede dividirse en trozos discretos, y el sistema puede medir cuántos trozos de trabajo hay y utilizar esa medida para determinar cuántas instancias debe aprovisionar.
He aquí algunos ejemplos de unidades de trabajo que los sistemas sin servidor podríanescalar.
Conexiones
Un sistema podría tratar cada solicitud de conexión TCP entrante como una unidad de trabajo. Cuando llega una conexión, se adjunta a una instancia, y esa instancia hablará un protocolo (propietario) hasta que un lado u otro cuelgue la conexión.
Como se muestra en la Figura 1-3, CockroachDB utiliza un modelo como éste para gestionar las "cabezas" de PostgreSQL (Postgres) en su base de datos3-cada conexión a la base de datos de un cliente se enruta mediante un proxy de conexión especial a un procesador SQL específico de ese cliente, que se encarga de hablar el protocolo Postgres, interpretar las consultas SQL, convertirlas en planes de consulta contra el almacenamiento backend (compartido), ejecutar los planes de consulta y, a continuación, marshalear los resultados de nuevo al protocolo Postgres y devolverlos al cliente. Si no hay conexiones abiertas para un cliente concreto, el conjunto de procesadores SQL se reduce a cero.
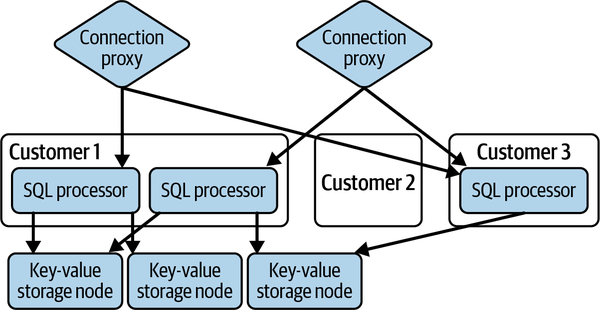
Figura 1-3. Arquitectura sin servidor de CockroachDB
Al utilizar el paradigma sin servidor, CochroachDB puede cobrar a los clientes por el uso sólo cuando una conexión a la base de datos está realmente activa y ofrecer un nivel de servicio gratuito razonable para los clientes pequeños que, en su mayoría, no utilizan el servicio. Por supuesto, el servicio de almacenamiento backend para esto no es sin servidor: los datos se almacenan en un almacén de valores clave compartido, y a los clientes se les cobra por el almacenamiento de datos mensualmente, independientemente del número de conexiones y consultas ejecutadas. Hablaremos más sobre este modelo en "Almacenamiento clave-valor".
Solicita
En un nivel superior, un sistema sin servidor podría entender un protocolo de aplicación concreto, como HTTP, SMTP (correo electrónico) o un mecanismo RPC, e interpretar cada intercambio de protocolo como una unidad de trabajo individual. Muchos protocolos admiten la reutilización o multiplexación de solicitudes de aplicación en una única conexión TCP; al permitir que el sistema sin servidor comprenda los mensajes de aplicación, el trabajo puede dividirse en trozos más pequeños, lo que tiene las siguientes ventajas:
-
Es más probable que las solicitudes más pequeñas tengan un tamaño uniforme y un tiempo más limitado. En los protocolos que permiten transmitir más de una petición a través de un flujo TCP, es de suponer que la mayoría de las peticiones terminan antes que el flujo TCP, y el trabajo para ejecutar una petición es menor, lo que permite un equilibrio de carga más preciso entre instancias.
-
Interpretar las peticiones de la aplicación permite desacoplar la vida útil de la conexión y la vida útil de la instancia. Cuando una conexión TCP es la unidad de trabajo, desplegar un nuevo artefacto de código requiere iniciar nuevas instancias para nuevas conexiones y luego esperar a que se completen las conexiones existentes (lo que evocativamente se llama "drenar" las instancias). Si el drenaje tarda cinco minutos en lugar de un minuto, los despliegues de aplicaciones y los cambios de configuración tardan cinco veces más en completarse. Muchos ajustes (como las variables de entorno) sólo pueden establecerse cuando se inicia un proceso (instancia), por lo que esto limita la velocidad a la que los equipos pueden cambiar el código o la configuración.
-
Dependiendo del protocolo, es posible que una sola conexión tenga cero, una o muchas solicitudes en vuelo a la vez. Interpretando las solicitudes de las aplicaciones al programar las unidades de trabajo, los sistemas sin servidor pueden lograr una mayor eficiencia y una menor latencia, distribuyendo las solicitudes entre varias instancias cuando se realizan en paralelo o evitando iniciar instancias para conexiones que no tienen ninguna solicitud en curso.
-
Al definir los límites de las solicitudes a nivel de aplicación, los sistemas sin servidor pueden proporcionar una telemetría y un servicio de mayor calidad. Cuando el sistema puede medir la duración de una solicitud, puede medir la latencia, el tamaño de las solicitudes y otras métricas, y puede habilitar y hacer cumplir los plazos de solicitud a nivel de aplicación y el rastreo desde fuera del proceso específico que está gestionando una solicitud. Esto puede permitir que los sistemas sin servidor se recuperen y respondan a los fallos de la aplicación del mismo modo que las pasarelas API y otros enrutadores HTTP.
Eventos
A un alto nivel , los eventos y las peticiones son prácticamente lo mismo. A otro nivel, los eventos son un elemento fundamental de las arquitecturas reactivas y asíncronas. Los eventos declaran: "En este momento, ocurrió esto". Sería posible modelar todo un sistema sin servidor en base a eventos; podrías tener un evento para "Ha ocurrido esta solicitud HTTP", "Se ha escaneado esta fila de la base de datos" o "Se ha recibido este elemento de la cola de trabajo". Esta es una forma muy inteligente de encajar la comunicación síncrona y asíncrona en un único modelo. Por desgracia, convertir las solicitudes síncronas en eventos asíncronos y "eventos de respuesta" correlacionados con el evento de solicitud introduce algunos problemas:
- Tiempos muertos
-
Hacer cumplir los tiempos de espera en sistemas asíncronos puede ser mucho más difícil, sobre todo si un mensaje que necesita tiempo de espera puede estar en alguna cola de mensajes, esperando a que un proceso se dé cuenta de que el tiempo de espera ha terminado.
- Notificación de errores
-
Más allá de los tiempos de espera y los bloqueos de la aplicación, las peticiones síncronas pueden provocar a veces condiciones de error en la aplicación subyacente. Las condiciones de error pueden ser cualquier cosa, desde "Has solicitado un archivo sobre el que no tienes permiso" hasta "Has enviado una petición de búsqueda sin una consulta", pasando por "Esta entrada ha provocado una excepción debido a un error de codificación". Todas estas condiciones de error deben reflejarse a la persona que hizo la llamada original de forma que pueda comprender qué hizo mal en su solicitud, si es que hizo algo mal, y decidir qué hacer en el futuro.
- Cardinalidad y correlación
-
Aunque modelar "Se ha recibido una solicitud" y "Se ha enviado una respuesta" como eventos puede ser beneficioso, utilizar esos eventos como un bus de mensajes para decir "Por favor, envía esta respuesta a este evento" pierde el sentido de los eventos como observaciones de un sistema externo. En términos más prácticos, ¿cuál es el significado previsto de un segundo "Por favor, envía esta respuesta a este evento" que se correlaciona con el mismo evento de solicitud? Suponiendo que el protocolo de aplicación sólo prevea una única respuesta, es probable que el segundo evento acabe descartándose. Descartar el evento puede requerir, a su vez, una notificación adicional al organizador del evento infractor para indicarle que su mensaje ha sido ignorado, otro caso del problema de notificación de errores mencionado anteriormente.
En mi opinión, estos costes no compensan los beneficios de un "gran modelo unificado de eventos sin servidor". A veces las llamadas síncronas son la respuesta correcta, a veces las llamadas asíncronas son la respuesta correcta, y corresponde a los desarrolladores de aplicaciones elegir inteligentemente entre las dos.
No se trata (sólo) de la báscula
El escalado automático de está bien, pero construir un tiempo de ejecución en torno a unidades de trabajo tiene más ventajas. Una vez que la capa de infraestructura comprende lo que hace que la aplicación se ejecute, es posible inyectar andamiaje adicional alrededor de la aplicación para medir y gestionar lo bien que hace su trabajo. Cuanto más detalladas sean las unidades de trabajo, más ayuda podrá proporcionar la plataforma en términos de comprensión, control e incluso seguridad de la aplicación sobre ella.
En el mundo de las aplicaciones de escritorio y de los navegadores web, esta revolución se produjo a finales de los 90 (escritorio) y en la década de 2000 (navegadores), donde los bucles de eventos o mensajes de las aplicaciones fueron sustituidos lentamente por marcos que utilizaban sistemas basados en llamadas de retorno para dirigir automáticamente las entradas del usuario a los widgets y controles apropiados dentro de una ventana. En los servidores HTTP, en los años 90 se desarrolló un marco similar de un solo sistema llamado CGI (Common Gateway Interface). En muchos sentidos, fue el antepasado de los modernos sistemas sin servidor: permitía escribir un programa que respondiera a una única solicitud HTTP y gestionara automáticamente gran parte de los detalles de la comunicación de red. (Para más detalles sobre CGI y su influencia en los sistemas sin servidor, consultael Capítulo 11).
Al igual que la especificación CGI, los sistemas modernos sin servidor pueden simplificar muchas de las buenas prácticas de programación rutinarias en torno al manejo de una unidad de trabajo y hacerlo de forma agnóstica a la programación. La computación en nube llama a este tipo de asistencias "trabajo pesado indiferenciado", es decir, cada programa las necesita, pero cada programa está bien si se hacen de la misma manera.
La siguiente no es una lista exhaustiva de funciones; es muy posible que el conjunto de funciones que permiten las unidades de trabajo de comprensión siga ampliándose a medida que se añadan más herramientas y capacidades a los entornos en tiempo de ejecución.
Azul y Verde: Despliegue, retroceso y día a día
La mayoría de los sistemas sin servidor de incluyen la noción de actualizar o cambiar el artefacto de código o la configuración de ejecución de instancias de forma coordinada. El sistema también entiende lo que es una unidad de trabajo y tiene alguna forma (interna) de dirigir las peticiones a una o más instancias que ejecutan un artefacto de código especificado. Algunos sistemas exponen estos detalles a los operadores de la aplicación y permiten a esos operadores controlar explícitamente la asignación del trabajo entrante entre las distintas versiones de un artefacto de código.
Si ampliamos la imagen, el proceso sin servidor de iniciar nuevas instancias con una versión específica de un artefacto de código y permitir que las instancias antiguas se recojan cuando ya no se utilicen se parece mucho al patrón de implementación azul-verde sin servidor: se inicia un segundo banco de servidores con el código "verde" mientras se permite que los servidores "azules" sigan funcionando hasta que los servidores verdes estén en funcionamiento y el tráfico se haya redirigido de los servidores azules a los verdes. Con el enrutamiento de peticiones sin servidor y el escalado automático, estas transiciones pueden hacerse muy rápidamente, a veces en menos de un segundo para aplicaciones pequeñas y en menos de cinco minutos incluso para aplicaciones muy grandes.
Más allá del patrón de despliegue azul-verde, también es posible controlar la asignación de trabajo a las distintas versiones de una aplicación sobre una base porcentual (proporcional). Este permite tanto las implantaciones incrementales (el trabajo se desplaza lentamente de una versión a otra, por ejemplo, para permitir que se llenen las cachés de la nueva versión) como las implantaciones canarias (un pequeño porcentaje del trabajo se dirige a una nueva aplicación para ver cómo reacciona ésta a las peticiones reales de los usuarios).
Mientras que las implantaciones incrementales tienen que ver sobre todo con la gestión de la escala, las implantaciones azul-verde y canaria tienen que ver sobre todo con la gestión del riesgo de implantación. Una de las partes más arriesgadas del funcionamiento de un servicio es la implementación de nuevo código de aplicación o configuración: cambiar un sistema que ya funciona introduce el riesgo de que el nuevo estado del sistema no funcione. Al facilitar la rápida puesta en marcha de nuevas instancias con una versión específica, la tecnología sin servidor hace que sea más rápido y fácil volver a una versión existente (que funcione). Esto se traduce en un menor tiempo medio de recuperación (MTTR), unamétrica común de recuperación en caso de desastre.
Al hacer efímeras las instancias individuales y escalarlas automáticamente en función del trabajo entrante, la tecnología sin servidor puede reducir el riesgo de "copos de nieve de infraestructura", es decir,sistemas especialmente configurados a mano con configuraciones artesanales que pueden ser difíciles de replicar o reparar. Cuando las instancias se sustituyen y se vuelven a desplegar automáticamente como parte de las operaciones regulares de la infraestructura, la recuperación y la inicialización de las instancias se prueban continuamente, lo que tiende a garantizar que cualquier deficiencia se solucione con bastante rapidez.
Reemplazar o rehacer continuamente las instancias de la infraestructura también puede tener ventajas para la seguridad: una instancia que haya sido corrompida por un atacante se restablecerá de la misma forma que una instancia corrompida por un fallo de software. Las instancias efímeras pueden mejorar la postura defensiva de una aplicación al dificultar que los atacantes mantengan la persistencia, obligándoles a comprometer la misma infraestructura repetidamente. La necesidad de ejecutar repetidamente un compromiso aumenta las probabilidades de detectar el ataque y cerrar la vulnerabilidad .
Consejo
Serverless trata las instancias individuales como fungibles,es decir, cada instancia es igualmente sustituible por otra. La solución a una instancia rota es simplemente tirarla y conseguir otra. La respuesta a "¿Cuántas instancias para X?" es siempre "El número que necesites", porque es fácil añadir o eliminar instancias. Apoyarse en este patrón de instancias reemplazables simplifica muchos problemas operativos.
Comodidades de las criaturas: Levantamiento Pesado Indiferenciado
Como describió anteriormente en "¿Por qué se llama sin servidor?", uno de los beneficios de una plataforma sin servidor es proporcionar capacidades comunes que pueden ser difíciles o repetitivas de implementar en cada aplicación.
Como se menciona en "No se trata (sólo) de la escala", una vez que el trabajo entrante al sistema ha sido desglosado y reconocido por la infraestructura, es fácil utilizar ese andamiaje para empezar a ayudar con el trabajo pesado indiferenciado que, de otro modo, requeriría código de aplicación. Un ejemplo de esto es la observabilidad: una aplicación tradicional necesita instrumentación que mida cada vez que se realiza una solicitud (unidad de trabajo) y cuánto tiempo se tarda en completar esa solicitud. Con una infraestructura sin servidor que gestione las unidades de trabajo por ti, es fácil que la infraestructura ponga en marcha un tic-tac del reloj cuando el trabajo se entrega a tu aplicación y registre una medición de latencia cuando tu aplicación completa el trabajo.
Aunque todavía puede ser necesario proporcionar métricas más detalladas desde dentro de tu aplicación (por ejemplo, el número de registros escaneados para responder a una solicitud de trabajo), el monitoreo automático, la visualización e incluso las alertas sobre el rendimiento y la latencia de las unidades de trabajo pueden proporcionar a los equipos de aplicación un "esfuerzo cero" sencillo demonitoreo. Esto no sólo puede ahorrar tiempo de desarrollo de la aplicación, sino que también puede proporcionar barandillas en la implementación de la aplicación para los equipos que no tienen tiempo o ganas de desarrollar experiencia en el monitoreo y la observabilidad.
Del mismo modo, la infraestructura sin servidor puede necesitar y querer implementar el rastreo de aplicaciones en las unidades de trabajo gestionadas por la infraestructura. Este rastreo sirve para dos propósitos diferentes:
-
Proporciona a los usuarios de la infraestructura una forma de investigar y determinar el origen de la latencia de la aplicación, incluida la latencia inducida por la plataforma y la latencia debida al inicio de la aplicación (cuando proceda).
-
Proporciona a los operadores de infraestructura información más rica sobre los cuellos de botella de la plataforma subyacente, incluso en el escalado de aplicaciones y la latencia general observada.
Otras funciones comunes de observabilidad son la recopilación y agregación de registros, la creación de perfiles de rendimiento y el rastreo de pila. El Capítulo 10 profundiza en los detalles de la utilización de estas herramientas para depurar aplicaciones sin servidor en el entorno efímero en vivo. Al controlar el entorno adyacente (y, en algunos casos, el proceso de creación de la aplicación), los entornos sin servidor pueden ejecutar fácilmente agentes de observabilidad junto al proceso de aplicación para recopilar estos tipos de datos.
La Figura 1-4 ofrece una visualización de los puntos de medición que pueden implementarse en un sistema sin servidor.
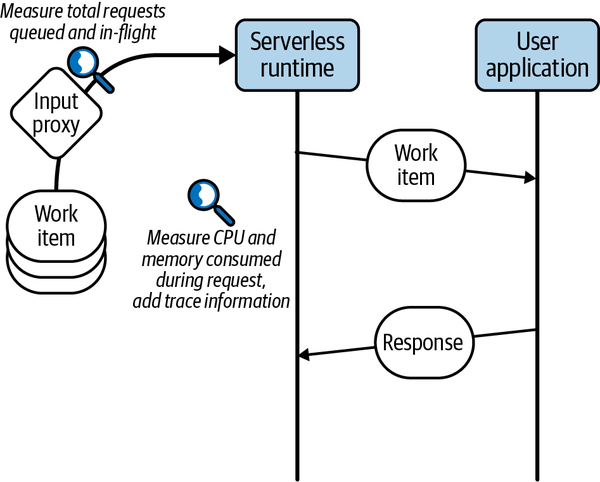
Figura 1-4. Capacidades comunes
Comodidades para las criaturas: Gestión de Entradas
Dado que los entornos sin servidor de proporcionan un punto de entrada controlado por la infraestructura para las unidades de trabajo, la propia infraestructura puede utilizarse para aplicar buenas prácticas para exponer los servicios al resto del mundo. Un ejemplo de ello es la configuración automática de TLS (incluidos los cifrados admitidos y la obtención y rotación de certificados válidos si es necesario) para los servicios sin servidor que puedan ser llamados a través de HTTPS u otros protocolos de servidor. Trasladar estas responsabilidades a la capa sin servidor permite al proveedor de infraestructura emplear a un equipo especializado que pueda garantizar que se siguen las buenas prácticas; el trabajo de este equipo se amortiza entonces entre todos los consumidores sin servidor que utilicen la plataforma. Otras capacidades comunes que pueden ir más allá del "trabajo pesado no diferenciado" son la autorización, la aplicación de políticas y latraducción de protocolos.
Para una representación visual de las transformaciones de entrada realizadas por Knative, consulta la Figura 1-5.
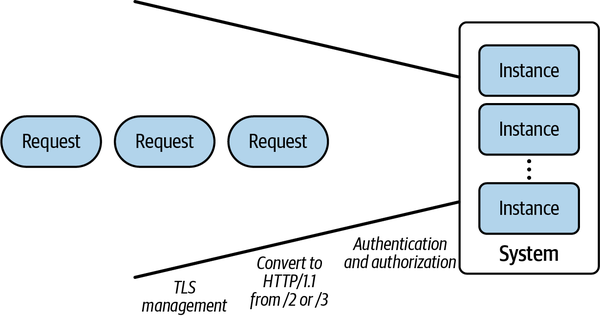
Figura 1-5. Gestión de las entradas
La autorización y la aplicación de políticas es una capacidad crucial en muchos escenarios de aplicación. En una arquitectura tradicional, esta capa podría delegarse en un cortafuegos o proxy externo de la aplicación o en un middleware específico del idioma. El middleware funciona bien para ecosistemas de un solo idioma, pero mantener un nivel común de capacidad en el middleware para varios idiomas es difícil. Los cortafuegos y los proxies extraen este middleware en una capa de servicio común, pero la aplicación protegida sigue necesitando validar que las solicitudes han sido enviadas por el cortafuegos, y no por algún otro atacante interno. Como las plataformas sin servidor controlan la ruta de las peticiones hasta la entrega del trabajo ala aplicación, los autores de las aplicaciones no tienen que preocuparse de confirmar quelas peticiones han sido gestionadas correctamente por la infraestructura: otra mejora de la calidad de vida.
La última mejora de la calidad de vida del desarrollador de aplicaciones consiste en la oportunidad de traducir las peticiones externas a unidades de trabajo que puedan ser consumidas más fácilmente por las aplicaciones de destino. Muchos protocolos modernos son complicados y requieren bibliotecas sustanciales para implementarlos correcta y eficientemente. Al implementar la traducción de protocolo de un protocolo complejo (como HTTP/3 sobre UDP) a uno más sencillo (por ejemplo, HTTP/1.1, que se entiende ampliamente), los desarrolladores de aplicaciones pueden elegir entre una gama más amplia de bibliotecas de aplicaciones y lenguajes de programación .
Comodidades de criatura: Gestión del Ciclo de Vida de los Procesos
Como parte del escalado y la distribución del trabajo de , las instancias sin servidor desempeñan un papel activo en la gestión del ciclo de vida del proceso de la aplicación, así como de los procesos de ayuda que pueda generar la propia plataforma. Dependiendo de la plataforma y de la cantidad de trabajo en vuelo, la plataforma puede necesitar detener (poner en cola) ese trabajo hasta que una instancia esté disponible para gestionar la solicitud. Conocido como un arranque en frío, esto puede ocurrir incluso cuando ya hay instancias de aplicación activas (por ejemplo, una ráfaga repentina de trabajo podría superar la capacidad de las instancias provisionadas). Algunas plataformas sin servidor pueden optar por sobreaprovisionar instancias para actuar como amortiguador en estos casos, mientras que otras pueden minimizar el número de instancias adicionales para reducir costes.
Normalmente, un proceso de aplicación dentro de una instancia sin servidor pasará por las siguientes etapas del ciclo de vida:
- 1. Colocación
Antes de iniciar un proceso en , la instancia debe asignarse a un nodo servidor real. Es una vieja broma que en realidad haya servidores en serverless, pero las plataformas serverless tendrán en cuenta varias de las siguientes condiciones:
- Disponibilidad de recursos: Dependiendo del modelo y del grado de sobresuscripción permitido, algunos nodos pueden no ser un destino adecuado para una nueva instancia.
- Artefactos compartidos: Generalmente, dos instancias en el mismo nodo servidor pueden compartir artefactos de código de aplicación. Dependiendo del tamaño de la aplicación compilada, esto puede acelerar sustancialmente el tiempo de inicio de la aplicación, ya que hay que traer menos datos al nodo.
- Adyacencia: Si dos instancias de la misma aplicación están presentes en el mismo nodo, puede ser posible compartir algunos recursos en el nodo (asignaciones de memoria para bibliotecas compartidas, código compilado justo a tiempo [JIT], etc.). Según el lenguaje y la implementación, este ahorro puede ser considerable o casi inexistente.
- Contención y efectos adversarios: En un entorno multiaplicación, algunas aplicaciones pueden competir por los recursos limitados de los nodos (por ejemplo, la caché L2 o el ancho de banda de la memoria). Las plataformas sofisticadas sin servidor pueden detectar estas aplicaciones y programarlas en nodos diferentes. Ten en cuenta que una aplicación especialmente optimizada puede convertirse en su propio adversario si utiliza una gran cantidad de un recurso no compartido.
- Programación de inquilinos: En algunos entornos, puede haber normas estrictas sobre qué inquilinos pueden compartir recursos físicos con otros inquilinos. Los fuertes controles de sandbox dentro de un nodo físico aún no pueden proteger contra ataques novedosos como Spectre o Rowhammer que eluden el modelo de seguridad .
- 2. Inicialización
Una vez colocada la instancia en un nodo, ésta necesita preparar el entorno de la aplicación. Esto puede incluir lo siguiente:
- Obtención de artefactos de código: Si no están ya presentes, los artefactos de código tendrán que ser recuperados antes de que el proceso de aplicación pueda comenzar.
- Obtener configuración: Además del código, algunas instancias pueden necesitar información de configuración específica (incluyendo secretos a nivel de instancia o compartidos) cargada en el sistema de archivos local.
- Montaje de sistemas de archivos: Algunos sistemas sin servidor permiten montar sistemas de archivos compartidos (de sólo lectura o de lectura-escritura) en las instancias para gestionar los datos compartidos. Otros requieren que la instancia recupere los datos durante el arranque.
- Configuración de la red: Las instancias recién creadas tendrán que registrarse de algún modo en el equilibrador de carga entrante para poder recibir tráfico. Esto puede ser un problema de difusión, dependiendo del número de equilibradores de carga. En algunos sistemas, las instancias también necesitan registrarse con un proveedor de traducción de direcciones de red (NAT) para el tráfico saliente.
- Aislamiento de recursos: La instancia puede necesitar configurar mecanismos de aislamiento como Linux
cgroupspara garantizar que la aplicación utiliza una cantidad justa de recursos del nodo. - Aislamiento de seguridad: En un sistema multiarrendatario, puede ser necesario establecer sandboxes o máquinas virtuales ligeras para evitar que los usuarios pongan en peligro a los arrendatarios adyacentes.
- Procesos auxiliares: El entorno sin servidor puede ofrecer servicios adicionales, como la recopilación de registros o métricas, proxies de servicios o agentes de identidad. Normalmente, estos procesos deben estar configurados y listos antes de que se inicie el proceso principal de la aplicación.
- Políticas de seguridad: Pueden abarcar las políticas de tráfico de red entrante y saliente que restringen los servicios que el proceso de aplicación puede ver en la red.
- 3. Puesta en marcha
Una vez que el entorno está listo, se inicia el proceso de la aplicación. Normalmente, la aplicación debe realizar algún tipo de configuración e inicialización interna antes de estar lista para gestionar el trabajo. Esto suele indicarse mediante una comprobación de preparación, que puede ser una llamada del proceso al entorno externo o una solicitud de comprobación de estado del entorno al proceso.
Mientras que las fases de colocación e inicialización son en gran medida responsabilidad de la plataforma sin servidor, la fase de arranque es en gran medida responsabilidad del programador de la aplicación. Para algunas implementaciones de lenguajes, la fase de inicio de la aplicación puede suponer la mayor parte del retraso atribuible a los arranques en frío.
- 4. Servir
Una vez que el proceso de solicitud ha indicado que está listo para recibir trabajo, recibe unidades de trabajo en función de las políticas de la plataforma. Algunas plataformas limitan el trabajo en vuelo en un proceso a una sola solicitud cada vez, mientras que otras permiten varias unidades de trabajo en vuelo a la vez.
Normalmente, una vez que un proceso entra en el estado de servicio, gestionará varios elementos de trabajo (en paralelo o secuencialmente) antes de terminar. Reutilizar un proceso servidor activo de este modo ayuda a amortizar el coste de colocación, inicialización y puesta en marcha, y contribuye a reducir el número de arranques en frío que experimenta la aplicación.
- 5. Apaga
Una vez que el proceso de la aplicación ya no sea necesario, la plataforma indicará que el proceso debe salir. Una plataforma puede proporcionar algunas de estas garantías:
- Vaciado: Antes de señalar la finalización, la instancia se asegurará de que no hay unidades de trabajo en vuelo. Esto simplifica el cierre de la aplicación, ya que no necesita bloquear ningún trabajo activo en vuelo.
- Apagado gradual: Algunas plataformas sin servidor pueden ofrecer a un proceso en ejecución la oportunidad de realizar acciones antes de apagarse, como vaciar cachés, actualizar instantáneas o registrar métricas finales de la aplicación. No todas las plataformas sin servidor ofrecen un periodo de apagado graceful, por lo que es importante saber si este tipo de actividades están garantizadas en la plataforma elegida.
- 6. Terminación
Una vez que se haya enviado la señal de apagado y haya transcurrido cualquier periodo de apagado graceful, el proceso se terminará, y todos los procesos ayudantes, políticas de seguridad y otros recursos asignados durante la inicialización se limpiarán (posiblemente pasando por sus propias fases de apagado graceful). En las plataformas que facturan por recursos utilizados, suele ser en este momento cuando se detiene la facturación. Hasta que se complete la terminación, los recursos de la instancia se consideran generalmente "reclamados" por el programador, por lo que la rápida rotación de las instancias puede afectar a las decisiones del programador sin servidor .
Resumen
La informática sin servidor y las plataformas sin servidor asumen determinados comportamientos de las aplicaciones, y no sustituirán por completo a los sistemas existentes y pueden no ser una buena opción para todas las aplicaciones. Para una variedad de patrones de aplicación comunes, las plataformas sin servidor ofrecen ventajas técnicas sustanciales, y espero que la fracción de organizaciones y aplicaciones que incorporan la computación sin servidor siga aumentando. Con un poco de teoría a nuestras espaldas, el siguiente capítulo se centra en construir una pequeña aplicación sin servidor para que puedas hacerte una idea de cómo se aplica esta teoría en la práctica.
1 En "Colas de tareas", hablaremos brevemente de escalar el trabajo en el tiempo en lugar de en el recuento de instancias.
2 Las "unidades de servidor" pueden representar máquinas virtuales/físicas o procesos de servidor que se ejecutan en una única instancia. En ambos casos, el objetivo de la tecnología sin servidor es que los desarrolladores no tengan que pensar en ninguna de las dos cosas.
3 Esto se describe en la entrada del blog de Andy Kimball "Cómo construimos una base de datos SQL sin servidor", que describe la arquitectura de CockroachDB sin servidor (que he resumido).
Get Construir aplicaciones sin servidor en Knative now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

