Capítulo 4. Diseñar conductos de datos eficaces
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
En este capítulo, aprenderás a construir canalizaciones de datos resistentes y eficaces utilizando Kafka Connect. Explicamos los conceptos clave y los puntos de decisión que los ingenieros y arquitectos de datos deben comprender al ensamblar los componentes que introdujimos en el Capítulo 3.
En la primera mitad de este capítulo, veremos cómo elegir plug-ins conectores para tus canalizaciones. Necesitas un conector, un conversor y, opcionalmente, algunas transformaciones y predicados. Discutimos cómo evaluar los conectores e identificar el que satisface tus requisitos de producción entre los cientos que están disponibles en la comunidad. Luego discutiremos cómo modelar tus datos a medida que fluyen por la tubería y las opciones de formato de que dispones.
La segunda mitad de este capítulo se centra en las características de resistencia de Kafka Connect. Antes de construir tu canalización, tienes que identificar la semántica que necesitas en función de tus casos de uso. Por ejemplo, ¿necesitas garantizar que se entregan todos los datos, o es aceptable perder algunos datos en favor de un mayor rendimiento? Primero nos sumergimos en el funcionamiento interno de Kafka Connect, explicando por qué es un entorno robusto capaz de gestionar fallos. A continuación, examinamos la semántica que pueden alcanzar las canalizaciones de origen y destino, y las distintas opciones de configuración y compensaciones disponibles para orientar tus casos de uso específicos.
Elegir un conector
Cuando construyas una canalización de datos que utilice Kafka Connect, primero tendrás que decidir qué conector instalar. Dado que Kafka es una tecnología muy popular, existen muchos conectores entre los que puedes elegir. En lugar de reinventar la rueda, a menudo es mejor utilizar un conector existente, pero sólo si cumple tus requisitos. He aquí algunas cosas que debes tener en cuenta a la hora de elegir si utilizas un conector específico como parte de tu canalización:
-
Dirección de la tubería (fuente o sumidero)
-
Licencias y asistencia
-
Características del conector
Dirección de la tubería
En primer lugar, comprueba que el conector hace fluir los datos en la dirección correcta. ¿Es un conector fuente que produce datos hacia Kafka o un conector sumidero que consume de Kafka? La mayoría de los conectores incluyen este detalle como parte del nombre, y suele quedar claro en la documentación. Si no es así, puedes instalar el conector en un entorno Kafka Connect y utilizar la API REST para recuperar su tipo.
$curllocalhost:8083/connector-plugins[{"class":"org.apache.kafka.connect.mirror.MirrorCheckpointConnector","type":"source","version":"3.5.0"},{"class":"org.apache.kafka.connect.mirror.MirrorHeartbeatConnector","type":"source","version":"3.5.0"},{"class":"org.apache.kafka.connect.mirror.MirrorSourceConnector","type":"source","version":"3.5.0"}]
El campo type indica el tipo de conector.
Algunos proyectos proporcionan una única descarga que incluye un conector fuente y un conector sumidero, pero otros proyectos pueden proporcionar sólo uno u otro.
Licencias y asistencia
Antes de utilizar un conector, asegúrate de que comprueba lo que permite su licencia. Que el código fuente de un conector sea público o se pueda descargar libremente no significa que la licencia sea permisiva. También debes considerar el nivel de mantenimiento y soporte que esperas. La comunidad Kafka trabaja duro para asegurarse de que los conectores más antiguos sean compatibles con las versiones más recientes del tiempo de ejecución; sin embargo, no todos los conectores se mantienen o actualizan con la misma regularidad. Sea cual sea el conector que elijas, de código abierto o propietario, asegúrate de saber con qué frecuencia se actualiza el conector con las últimas API de Kafka y cómo abordan los desarrolladores las vulnerabilidades de seguridad.
El nivel de soporte que obtienes para un conector concreto varía mucho. Muchas empresas ofrecen asistencia de pago para los conectores, ya sean propietarios o de código abierto. Esto incluye normalmente un canal de comunicación dedicado si tienes problemas y acceso a expertos del sector para que te asesoren sobre la configuración. Dicho esto, muchas comunidades de código abierto también responden rápidamente a los informes de errores y proporcionan sus propios canales de comunicación dedicados, lo que, dependiendo de tus casos de uso, puede ser una alternativa al soporte de pago.
Nota
Dado que un único conector se utiliza a menudo para muchos casos de uso diferentes, puede que no haya uno que se adapte perfectamente a tus necesidades. Si ese es el caso, en lugar de escribir uno desde cero, te animamos a que veas si existe un conector de código abierto al que puedas contribuir. Seguirás necesitando que se acepten tus cambios, pero la mayoría de los proyectos de código abierto aceptan nuevos colaboradores.
Características del conector
Una vez que hayas identificado los posibles conectores para tus tuberías, tienes que examinar más detenidamente las características que ofrecen esos conectores. Para empezar, ¿soporta el conector el tipo de conexión que necesitas? Por ejemplo, puede que tu sistema externo requiera una conexión cifrada, alguna forma de autenticación o que los datos estén en un formato específico. También debes comprobar si el conector es adecuado para su uso en producción. Por ejemplo, ¿proporciona métricas para monitorear su estado y registros que te ayuden a depurar problemas? Revisa la documentación -y, en el caso de un conector de código abierto, el código- para ver cómo funciona el conector y evaluar las funciones que ofrece.
En el Capítulo 3, presentamos las opciones de configuración comunes a todos los conectores: topics para los conectores de sumidero y tasks.max tanto para los de origen como para los de sumidero. La mayoría de los conectores ofrecen opciones adicionales para configurar sus características específicas. Para un conector concreto, puedes utilizar la API REST para listar todas las opciones de configuración disponibles y validar su configuración antes de iniciar el conector.
Utilizar la API REST es especialmente útil si el código no está disponible, pero ten en cuenta que esto depende de que el desarrollador documente correctamente su configuración. Algunos campos podrían estar marcados incorrectamente como opcionales u obligatorios. Del mismo modo, la validación es útil para verificar que la configuración del conector será aceptada, pero una solicitud de validación correcta no garantiza que tu conector funcione.
Utiliza el punto final GET /connector-plugins/<CONNECTOR_PLUGIN>/config para enumerar las opciones de configuración y el punto final PUT /connector-plugins/<CONNECTOR_PLUGIN>/config/validate para validar una configuración concreta.
En el capítulo 7 describimos detalladamente los puntos finales de la API REST.
Definición de modelos de datos
No hay dos pipelines idénticos. Aunque cumplan un caso de uso similar o utilicen los mismos componentes, los datos reales y cómo evolucionan esos datos varía de una canalización a otra. Cuando diseñes tu pipeline en , deberás tener en cuenta cuándo y cómo cambiará cada entrada de datos individual, así como la relación entre las entradas individuales. La forma en que agrupes o dividas (shard) tus datos afectará a lo bien que puedas escalar tu pipeline a medida que aumente la cantidad de datos que procesa. Para examinar estas ideas con más detalle, primero discutiremos cuándo aplicar la transformación de datos en Kafka Connect utilizando transformaciones y predicados, y después discutiremos técnicas para mapear datos entre Kafka Connect y otros sistemas.
Transformación de datos
Hay dos patrones comunes que se utilizan en para hacer evolucionar los datos a medida que fluyen por una tubería: ETL (Extraer-Transformar-Cargar) y ELT (Extraer-Cargar-Transformar). En estos patrones de , la palabra "Transformar" no se refiere sólo a actualizar el formato. La transformación podría incluir la limpieza de los datos para eliminar la información sensible, cotejar los datos con otros flujos de datos o realizar análisis más avanzados.
Ambos enfoques tienen sus ventajas e inconvenientes. En los sistemas en los que el almacenamiento está restringido, es mejor utilizar el enfoque ETL y transformar los datos antes de cargarlos en el almacenamiento. Esto facilita la consulta de los datos porque ya han sido preparados para el análisis. Sin embargo, puede ser difícil actualizar la canalización si se descubre un nuevo caso de uso que requiera una transformación diferente. En cambio, ELT mantiene los datos lo más genéricos posible durante el mayor tiempo posible, dando la oportunidad de que los datos se reutilicen para otros fines. El patrón ELT ha ido ganando popularidad y ahora hay muchas herramientas dedicadas al procesamiento y análisis de datos que están construidas para soportarlo. Algunos ejemplos de estas herramientas son Kafka Streams, Apache Spark, Apache Flink, Apache Druid y Apache Pinot.
Entonces, ¿dónde encajan las transformaciones de Kafka Connect en este flujo? En Kafka Connect, hay un rico conjunto de transformaciones que puedes realizar en tus datos mientras están en vuelo, lo que encaja de forma natural en el patrón ETL. Utilizar Kafka Connect para tus transformaciones elimina la necesidad de una herramienta independiente para transformar los datos antes de cargarlos. Puesto que tú eliges el conjunto específico de transformaciones a aplicar y Kafka Connect te permite añadir otras personalizadas, las posibilidades son infinitas. Sin embargo, las transformaciones de Kafka Connect tienen sus limitaciones, porque se aplican a cada dato de forma independiente. Esto significa que no puedes realizar transformaciones más avanzadas, como fusionar dos flujos de datos o agregar datos a lo largo del tiempo. En su lugar, debes utilizar una de las tecnologías dedicadas al procesamiento de flujos para este tipo de operaciones.
Aunque decidas utilizar una tecnología dedicada para el grueso de tu procesamiento y análisis de datos, puedes seguir haciendo uso de las transformaciones de Kafka Connect. Algunas transformaciones concretas que quizá quieras tener en cuenta son las que eliminan o renombran campos y pueden eliminar registros. Éstas son muy útiles para garantizar que los datos sensibles no se envían más adelante en la cadena y para eliminar datos que podrían causar problemas de procesamiento más adelante. Si tienes varias fuentes diferentes que deben agregarse en pasos posteriores, también puedes utilizar las transformaciones de Kafka Connect para alinear primero los datos para que tengan campos comunes. La Figura 4-1 muestra este tipo de flujo.
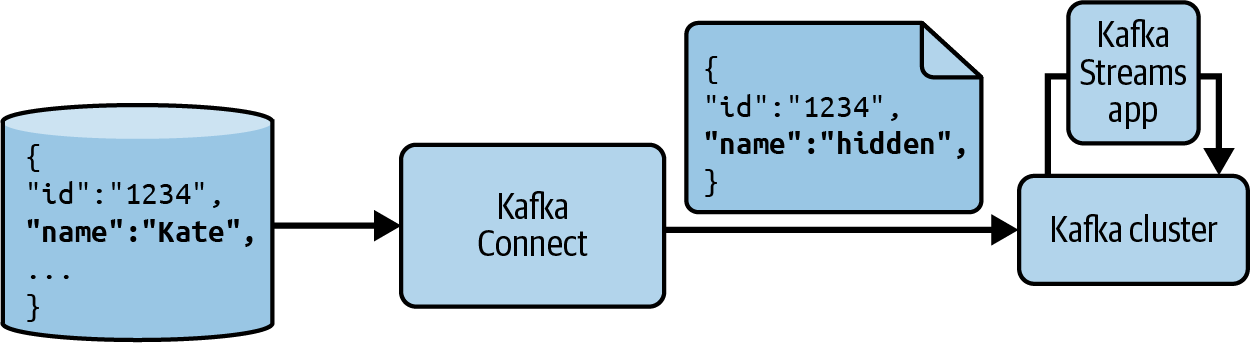
Figura 4-1. Canalización de datos utilizando transformaciones de Kafka Connect para eliminar datos sensibles y Kafka Streams para realizar el procesamiento posterior
Mapeo de datos entre sistemas
Hemos hablado de cómo puedes transformar las entradas de datos individuales, pero ¿qué pasa con la estructura general de tus datos a medida que pasan a lo largo de la cadena?
Una de las cosas más difíciles de razonar en cuando se construye una canalización de datos es cómo mapear las estructuras de datos entre diferentes sistemas. Más que el formato de las entradas individuales, el modo en que deben agruparse y almacenarse los datos, el orden necesario y lo que ocurre cuando hay que escalar la canalización son consideraciones estructurales. En Kafka Connect, muchas de estas decisiones las toma por ti el desarrollador que escribió el conector, pero aun así debes ser consciente de los mecanismos que están disponibles para que los conectores los utilicen al mapear datos entre Kafka y otros sistemas. Si comprendes estos mecanismos, estarás mejor equipado para evaluar un conector que quieras utilizar y configurarlo correctamente para tu caso de uso.
Para entender cómo los conectores pueden agrupar y asignar datos, debes considerar la interacción entre las tareas de Kafka Connect y las particiones de Kafka. En el Capítulo 3, presentamos las tareas como el mecanismo que Kafka Connect utiliza para realizar el trabajo real de transferir datos de un lugar a otro. En el Capítulo 2, hablamos de las particiones y destacamos el hecho de que Kafka proporciona garantías de ordenación dentro de una única partición. Ambos mecanismos proporcionan una forma de fragmentar los datos.
Veamos primero el impacto de las tareas en los conectores fuente. Cuando un conector fuente lee datos de un sistema externo, cada tarea está leyendo datos en paralelo. Corresponde al conector decidir cómo repartir estos datos entre las tareas disponibles para garantizar que no haya duplicados. Un conector sencillo podría ejecutar una única tarea y evitar el problema de la fragmentación de los datos que están en el sistema externo. Esto es en realidad cómo funciona FileStreamSourceConnector, que viene empaquetado con Kafka. Mira la Figura 4-2 para ver un ejemplo.

Figura 4-2. Una sola tarea en FileStreamSourceConnector lee el archivo línea por línea
Aunque aumentes la configuración de tasks.max, seguirá ejecutando una sola tarea porque no tiene un mecanismo sensato para repartir los datos. La mayoría de los conectores son más avanzados que FileStreamSourceConnector y tienen mecanismos integrados para asignar los datos entre las tareas. La Figura 4-3 muestra un ejemplo de un conector de este tipo que permite que distintas tareas lean diferentes líneas de una tabla.
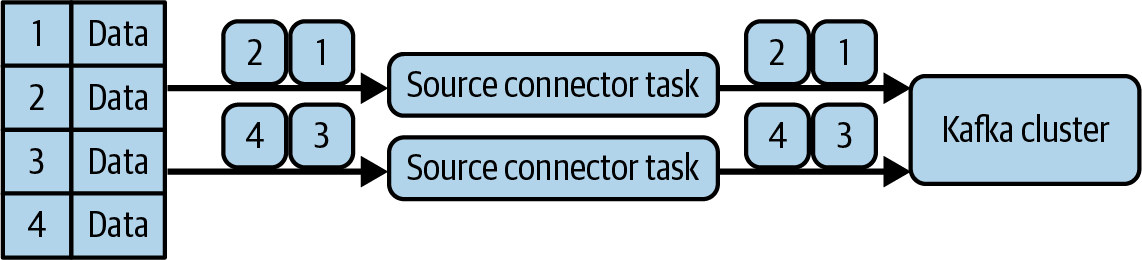
Figura 4-3. Múltiples tareas que leen cada una un subconjunto de los datos, evitando duplicados en Kafka
Consideremos las particiones. Un conector fuente individual de puede elegir qué registros deben ir a qué particiones o confiar en la estrategia de particionado configurada. Muchos conectores utilizan claves para identificar los datos que deben enviarse a las mismas particiones. Por ejemplo, las actualizaciones de estado que se aplican a una entidad concreta podrían utilizar el ID de la entidad como clave. La Figura 4-4 muestra un ejemplo de tareas que envían datos a las particiones.
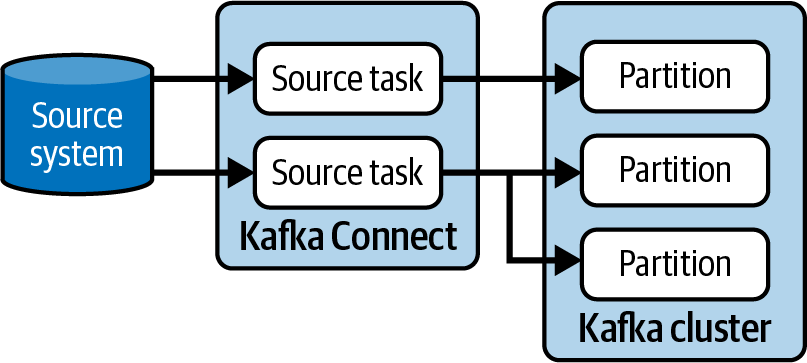
Figura 4-4. Las tareas fuente pueden enviar sus datos a una o varias particiones
La forma en que un conector fuente particiona sus datos afecta a la siguiente etapa del pipeline, tanto si esa siguiente etapa es un conector sumidero como si es sólo un consumidor de Kafka, debido a la forma en que Kafka distribuye las particiones entre las tareas sumidero y los consumidores de un grupo. Cada partición sólo puede asignarse a una única tarea sumidero de un conector sumidero concreto, y del mismo modo a un único consumidor dentro de un grupo concreto, por lo que cualquier dato que deba ser leído por una única tarea o consumidor debe ser enviado a la misma partición por el conector de origen.
Consideremos ahora los conectores de sumidero. En los conectores sumidero, las tareas también se ejecutan en paralelo. Esto puede afectar a el orden en que se envían los datos al sistema externo. Puedes estar seguro de que cada tarea escribirá sus propios datos en orden, pero no existe ninguna coordinación de orden entre tareas. La forma en que las tareas sumidero interactúan con las particiones también influye en el número de tareas sumidero que puedes ejecutar. Si tienes una partición y dos tareas, sólo una tarea recibirá datos, así que cuando crees una canalización de datos con un conector de sumidero, asegúrate de que tienes en cuenta el número de particiones de los temas de los que lee el conector. La Figura 4-5 muestra dos tareas sumidero que leen datos de tres particiones.
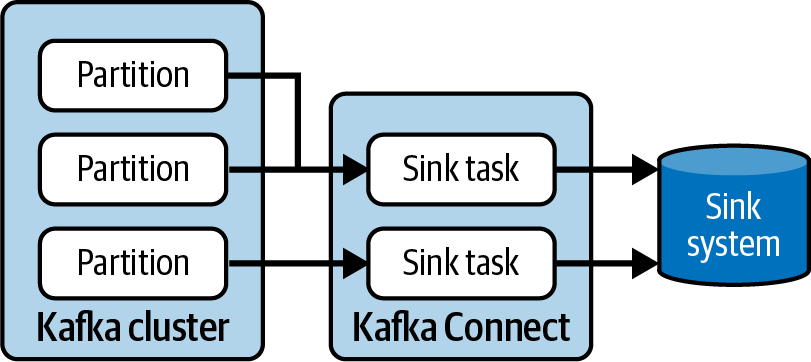
Figura 4-5. Cada partición sólo puede ser leída por una tarea de sumidero para un conector concreto
Como puedes imaginar, la combinación de tareas y particiones significa que hay múltiples formas de agrupar y ordenar los datos a medida que fluyen por el sistema. Cuando estés diseñando tu canalización de datos de Kafka Connect, asegúrate de pensar en estas opciones y no dejes las opciones de configuración de tasks.max y las particiones como una ocurrencia tardía.
Ahora que hemos visto cómo pueden transformarse y mapearse los datos a alto nivel entre sistemas, veamos en cómo puedes controlar el formato específico de los datos en una canalización de Kafka Connect.
Formatear datos
En el Capítulo 3, hablamos de los convertidores y de cómo serializan y deserializan los datos cuando entran y salen de Kafka. También tratamos brevemente por qué necesitas alinear tus convertidores con el serializador y deserializador de los productores y consumidores que también interactúan con los datos. Aquí tratamos con más detalle las diferencias entre convertidores, transformaciones y conectores, y cómo afectan al formato de los datos a lo largo del canal. También veremos cómo puedes reforzar esta estructura con esquemas y un registro de esquemas.
Formatos de datos
En una canalización de Kafka Connect, el formato de los datos y su evolución dependen del conector, de las transformaciones configuradas y del conversor. Veamos cada uno de ellos y cómo afectan al formato de los datos.
En primer lugar, consideremos el conector. En un flujo fuente, el conector se ejecuta primero; lee los datos del sistema externo y crea un objeto Java llamado ConnectRecord. El conector decide qué partes de los datos del registro deben conservarse y cómo asignarlas a ConnectRecord. Los detalles de esta asignación pueden diferir entre conectores, aunque sean para el mismo sistema, así que asegúrate de que el conector que elijas conserva las partes de los datos que son importantes para ti.
En un flujo sumidero, el conector se ejecuta en último lugar en vez de en primer lugar. Toma los objetos de ConnectRecord y los convierte en objetos de datos que puede enviar al sistema externo. Esto significa que un conector sumidero tiene la última palabra sobre qué datos llegan al sistema externo.
Veamos ahora la diferencia entre los convertidores y las transformaciones de en lo que se refiere a su entrada y salida:
-
Las transformaciones tienen como entrada y salida objetos de
ConnectRecord. -
Los conversores convierten entre objetos
ConnectRecordy los bytes brutos que Kafka envía y recibe. Se ejecutan en último lugar en las cadenas de origen y en primer lugar en las cadenas de destino.
La Figura 4-6 muestra los distintos tipos de datos que se pasan entre conectores, transformaciones y convertidores.
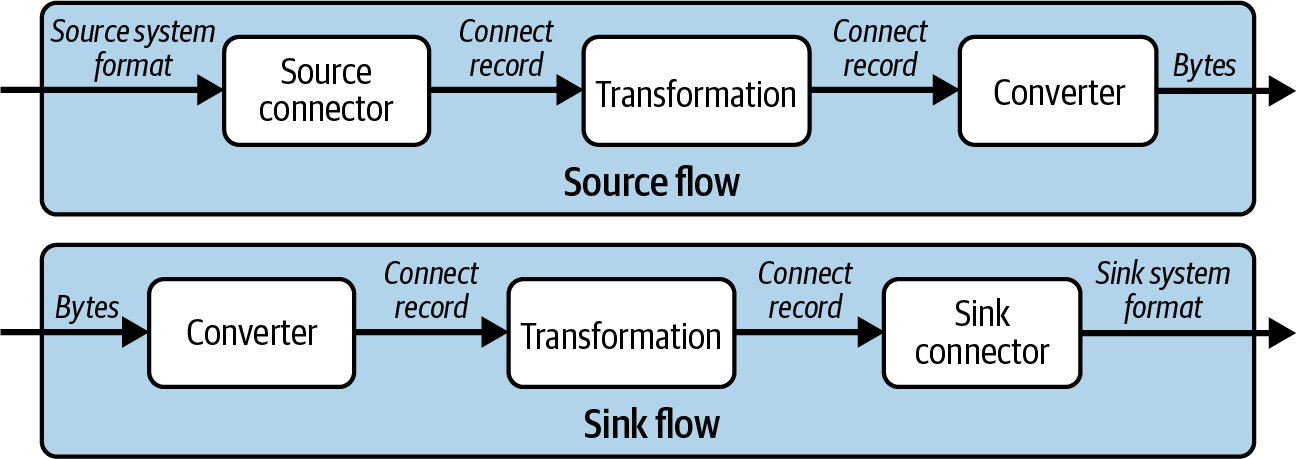
Figura 4-6. Tipos de datos en los flujos fuente y sumidero
Las transformaciones y los convertidores son pasos separados para permitir la componibilidad que ofrece Kafka Connect. Podrías escribir un conversor JSON que manipulara el contenido del registro antes de enviarlo a Kafka. Si quisieras una canalización que manipulara los datos del mismo modo pero utilizara un formato como Avro, necesitarías un nuevo conversor. Sería mejor crear una transformación que manipule los datos y luego utilizar dos conversores, uno para JSON y otro para Avro.
Las transformaciones se pueden encadenar, de modo que en lugar de tener que escribir una transformación personalizada, puedes ejecutar varias transformaciones sencillas para satisfacer tus necesidades. Si no encuentras transformaciones o convertidores que se ajusten a tus requisitos, puedes escribir los tuyos propios (consulta el Capítulo 12).
Ahora que entiendes las funciones de los conectores, las transformaciones y los convertidores, y el orden en que pueden ejecutarse, puedes tomar una decisión mejor informada sobre qué bibliotecas utilizar en tu canalización para obtener el formato de datos exacto que necesitas en cada etapa. Al igual que al elegir los conectores, asegúrate de tener en cuenta los requisitos de licencia y soporte al elegir las transformaciones y los convertidores.
Esquemas
Un esquema proporciona un plano para la forma de los datos. Por ejemplo, un esquema puede especificar qué campos son obligatorios y qué tipos deben estar presentes. Utilizar esquemas es importante cuando construyes un canal de datos, porque la mayoría de los datos son complejos y contienen múltiples campos de distintos tipos. Sin esquemas que den contexto a los datos, es muy difícil que las aplicaciones realicen de forma fiable los pasos para procesarlos y analizarlos.
Casi todos los sistemas de gestión de datos tienen un mecanismo para definir esquemas. Los esquemas específicos de tus sistemas variarán, pero he aquí cómo las canalizaciones de Kafka Connect suelen hacer uso de los esquemas. Como vimos en la sección anterior, los datos transitan entre dos formatos diferentes mientras pasan por Kafka Connect: el ConnectRecord y el de bytes brutos. Cada formato tiene un mecanismo de configuración diferente.
Esquemas de registro de Kafka Connect
Un ConnectRecord contiene un objeto opcional Schema tanto para la clave como para el valor. Schema es una clase Java que forma parte de la API de Kafka Connect y que utilizan los conectores, las transformaciones y los conversores cuando los datos viajan a través de Kafka Connect. Veamos cómo se utiliza Schema en los pipelines de origen y de destino.
Un conector de origen es responsable de construir el objeto ConnectRecord inicial y tiene control sobre el Schema que se añade. La forma en que se define el Schema depende del conector. FileStreamSourceConnector siempre utiliza el STRING_SCHEMA, independientemente del formato que utilice el archivo. Puedes ver esto en el código fuente:
privatestaticfinalSchemaVALUE_SCHEMA=Schema.STRING_SCHEMA;@OverridepublicList<SourceRecord>poll()throwsInterruptedException{...records.add(newSourceRecord(offsetKey(filename),offsetValue(streamOffset),topic,null,null,null,VALUE_SCHEMA,line,System.currentTimeMillis()));...}
La mayoría de los conectores son más complejos que FileStreamSourceConnector y utilizan esquemas proporcionados por el sistema para construir el objeto Schema. Por ejemplo, los conectores Debezium que leen los registros de cambios de la base de datos toman nota de los cambios del esquema de la base de datos y utilizan esa información para construir el ConnectRecord. Los objetos ConnectRecord y Schema incluido se pasan entonces a cualquier transformación y al conversor. Las transformaciones y los conversores pueden utilizar el Schema para analizar el ConnectRecord y realizar su trabajo respectivo.
En un conducto sumidero, es el conversor que construye el ConnectRecord, y, por tanto, el Schema; las transformaciones utilizan esta información para analizar el contenido. Los conectores de sumidero utilizan el ConnectRecord para construir el objeto que se envía al sistema externo, lo que significa que pueden elegir cómo interpretar el Schema que se incluye en el ConnectRecord. Por ejemplo, FileStreamSinkConnector ignora completamente el Schema, pero eso es sólo porque está escribiendo en un archivo. La mayoría de los conectores del sumidero utilizan la información de Schema para construir los datos del sistema externo.
Esquemas de registro Kafka
Las canalizaciones de Kafka Connect también pueden utilizar esquemas para describir los datos almacenados en Kafka. Estos esquemas de son utilizados por los convertidores para entender cómo serializar y deserializar los datos enviados a y desde Kafka. En una canalización de destino, el esquema que utiliza Kafka Connect para deserializar los datos es el mismo que utilizaron las aplicaciones para producir esos datos. En un canal de origen, el esquema que utiliza Kafka Connect para serializar los datos también lo utilizan las aplicaciones consumidoras o los conectores de destino para deserializarlos más adelante en el canal.
El objeto ConnectRecord tiene soporte incorporado para esquemas, pero como los registros en Kafka son bytes en bruto, tienes que decidir un mecanismo para incluir el esquema. El enfoque ingenuo es poner el esquema junto a la carga útil en el valor del registro. Esto es lo que hace JsonConverter por defecto.
Si ejecutas FileStreamSourceConnector con JsonConverter contra un archivo con el siguiente contenido:
This is a string Another string A third string The final string
El JsonConverter utiliza el esquema String que proporciona el conector y construye registros Kafka con los valores como:
{"schema":{"type":"string","optional":false},"payload":"This is a string"}{"schema":{"type":"string","optional":false},"payload":"Another string"}{"schema":{"type":"string","optional":false},"payload":"A third string"}{"schema":{"type":"string","optional":false},"payload":"The final string"}
Aunque esto facilita la transmisión de un esquema a los consumidores, significa que cada registro debe incluir el esquema. Este ejemplo es sencillo, por lo que el esquema es pequeño, pero cuanto más complejo sea el esquema, mayor será la sobrecarga para cada registro.
Un enfoque mejor es incluir sólo un pequeño identificador del esquema en cada registro y almacenar los esquemas en otro lugar. Esto te proporciona las ventajas de tener esquemas a lo largo de tu pipeline con una sobrecarga insignificante. Esto es lo que hacen la mayoría de las herramientas convertidoras, serializadoras y deserializadoras existentes, y suelen poner el identificador del esquema en uno de estos dos lugares: en la cabecera de un registro o al principio del valor serializado.
Si estás construyendo un flujo fuente, asegúrate de elegir un conversor que almacene el ID en un lugar esperado por las aplicaciones posteriores que consumirán el registro. Del mismo modo, si estás construyendo un flujo receptor, elige un conversor que sepa en qué parte del registro buscar el ID. Es relativamente fácil construir un sistema para almacenar esquemas que puedan ser recuperados por tus aplicaciones; por lo demás, esto es exactamente para lo que se construyen los registros de esquemas.
Un registro de esquemas suele constar de dos partes: un servidor que almacena esquemas y expone API para recuperarlos y administrarlos, y bibliotecas serializadoras/deserializadoras/convertidoras para utilizar en tus clientes. Los registros de esquemas suelen incluir funciones adicionales para ayudarte a administrar tus esquemas. Por ejemplo, muchos registros aplican la compatibilidad y te permiten controlar el ciclo de vida de tus esquemas. Esto es útil para las aplicaciones, ya que puede evitar que se introduzcan cambios de última hora y permite a los administradores informar a los desarrolladores de aplicaciones cuando un esquema ha quedado obsoleto.
Los dos registros de esquemas más utilizados con Kafka son el Confluent Schema Registry y el Apicurio Registry. Ambos te permiten utilizar Kafka como almacén de respaldo para el registro, eliminando la necesidad de una base de datos independiente u otro sistema de almacenamiento. Además, ambos admiten los formatos de esquema más comunes que se utilizan con Kafka: Avro, Esquema JSON y Protobuf.
Una comparación detallada de los formatos de esquemas y registros de esquemas disponibles para Kafka queda fuera del alcance de este libro, pero podemos dar indicaciones. Para elegir un formato, asegúrate de tener en cuenta las herramientas y bibliotecas que acompañan a cada uno. Por ejemplo, ¿soportan el lenguaje que deseas y proporcionan opciones de generación de código? Si utilizas un registro de esquemas, asegúrate de que el conversor y el serializador/deserializador de aplicaciones que has elegido son compatibles con el registro. El registro de esquemas de Confluent sólo funcionará con las bibliotecas de Confluent, mientras que Apicurio Registry viene con una API de compatibilidad, lo que significa que puedes utilizar las bibliotecas dedicadas de Apicurio Registry o las de Confluent.
Explorar las funciones internas de Kafka Connect
Para comprender cómo Kafka Connect en modo distribuido puede soportar fallos, debes saber cómo almacena su estado con una mezcla de temas internos y pertenencia a grupos. En segundo lugar, debes estar familiarizado con el protocolo de reequilibrio que utiliza Kafka Connect para repartir las tareas entre los trabajadores y detectar los fallos de éstos.
Temas internos
Como se mencionó en el Capítulo 3, Kafka Connect en modo distribuido utiliza temas para almacenar el estado, que son:
-
Tema de configuración, especificado mediante
config.storage.topic -
Tema de desplazamiento, especificado mediante
offset.storage.topic -
Tema de estado, especificado mediante
status.storage.topic
En el tema de configuración, Kafka Connect almacena la configuración de todos los conectores y tareas que han iniciado los usuarios. Cada vez que los usuarios actualizan la configuración de un conector o un conector solicita una reconfiguración (por ejemplo, cuando detecta que puede iniciar más tareas), se emite un registro a este tema. Este tema está compactado, por lo que siempre conserva el último estado de cada entidad, al tiempo que garantiza que no utiliza mucho almacenamiento.
En el tema offset, Kafka Connect almacena offsets de los conectores de origen. (Este tema está compactado por las mismas razones.) Por defecto, Kafka Connect crea este tema con varias particiones, ya que cada tarea de origen lo utiliza regularmente para escribir su posición. Los desplazamientos de los conectores de destino se almacenan utilizando grupos de consumidores Kafka normales.
En el tema de estado, Kafka Connect almacena en el estado actual de los conectores y las tareas. Este tema es el lugar central para los datos consultados por los usuarios de la API REST. Permite a los usuarios consultar cualquier trabajador y obtener el estado de todos los conectores en ejecución. También está compactado y debe tener varias particiones.
Al iniciarse, Kafka Connect crea automáticamente estos temas si aún no existen. Todos los trabajadores de un clúster de Kafka Connect deben utilizar los mismos temas, pero si estás ejecutando varios clústeres de Kafka Connect, cada clúster necesita sus propios temas independientes. Los datos de los tres temas se almacenan en JSON, por lo que pueden visualizarse utilizando un consumidor normal.
Por ejemplo, con la herramienta kafka-console-consumer.sh, así es como puedes ver el contenido del tema de estado:
$./bin/kafka-console-consumer.sh--bootstrap-serverlocalhost:9092\--topicconnect-status\--from-beginning\--propertyprint.key=truestatus-connector-file-source{"state":"RUNNING","trace":null,"worker_id":"192.168.1.12:8083","generation":5}
En este ejemplo, el tiempo de ejecución tiene status.storage.topic establecido en connect-status. Los registros de este tema muestran el estado de un conector llamado file-source y Kafka Connect utiliza ese nombre para derivar la clave, status-connector-file-source, para los registros relacionados con el conector.
Afiliación al Grupo
Además de los temas, Kafka Connect hace un amplio uso de la API de pertenencia a grupos de Kafka en .
En primer lugar, para cada conector de sumidero, el tiempo de ejecución de Kafka Connect ejecuta un grupo consumidor regular que consume registros de Kafka para pasarlos al conector. Por defecto, los grupos reciben el nombre del conector; por ejemplo, para un conector llamado file-sink, el grupo es connect-file-sink. Cada consumidor del grupo proporciona registros a una única tarea. Estos grupos y sus desplazamientos pueden recuperarse utilizando las herramientas habituales de grupos de consumidores, como kafka-consumer-groups.sh.
Además, Kafka Connect utiliza la API de pertenencia a grupos para asignar conectores y tareas a los trabajadores y garantizar que cada partición de usuario sólo sea consumida por una única tarea de sumidero por conector. Al iniciarse, Kafka Connect crea un grupo utilizando el valor group.id de su configuración. Este grupo no es directamente visible por las herramientas de grupos de consumidores, ya que no es un grupo de consumidores, pero funciona esencialmente de la misma manera. Por eso, todos los trabajadores con el mismo valor group.id pasan a formar parte del mismo grupo de Kafka Connect.
Para ser miembro de un grupo, los trabajadores, al igual que los consumidores normales, tienen que hacer heartbeat regularmente. Un latido es una solicitud que contiene el nombre del grupo, el ID del miembro y algunos campos más para identificar al remitente. Es enviada a intervalos regulares (especificados por heartbeat.interval.ms, con un valor por defecto de tres segundos) por todos los trabajadores al coordinador del grupo. Si un trabajador deja de enviar latidos, el coordinador lo detecta, lo retira del grupo y desencadena un reequilibrio. Durante un reequilibrio, las tareas se asignan a los trabajadores mediante un protocolo de reequilibrio.
Protocolos de reequilibrio
Los detalles de los protocolos de reequilibrio (o rebalanceo) suelen ser difíciles de comprender. Afortunadamente, para utilizar Kafka Connect con eficacia, basta con entender el proceso de alto nivel que se describe en esta sección.
Kafka Connect quiere asegurarse de que todas las tareas se están ejecutando, de que cada tarea la ejecuta un único trabajador y de que las tareas se reparten uniformemente entre todos los trabajadores. La distribución de tareas tiene que actualizarse cada vez que cambien los recursos gestionados por Kafka Connect, como cuando un trabajador se une o abandona el grupo, o cuando se añaden o eliminan tareas de un conector. Cuando cambian los recursos, Kafka Connect tiene que reequilibrar las tareas entre los trabajadores.
El mecanismo que utiliza Kafka Connect para los reequilibrios ha cambiado con el tiempo. Hasta Kafka 2.3, durante un reequilibrio, Kafka Connect simplemente detenía todas las tareas y las reasignaba todas a los trabajadores disponibles. Esto se denomina protocolo de reequilibrio eager, también llamado "parar el mundo". El principal problema de este protocolo es que Kafka Connect puede ejecutar un conjunto de conectores independientes, y cada vez que uno de estos conectores decide crear o eliminar tareas, se detienen todos los conectores y tareas, se reasignan a los trabajadores y se reinician. En un clúster de Kafka Connect muy ocupado, esto puede causar pausas largas y repetitivas en el procesamiento de datos. También hace que los reinicios continuos sean muy caros, ya que cada trabajador provoca dos reequilibrios: uno cuando se apaga y otro cuando se reinicia.
En Kafka 2.3, Connect introdujo un protocolo de reequilibrio cooperativo incremental llamado compatible. La idea es evitar detener todos los conectores y tareas cada vez que se produce un reequilibrio y, en su lugar, reequilibrar sólo los recursos que necesitan ser reequilibrados (de forma incremental, si es posible). Por ejemplo, si desaparece un trabajador, Kafka Connect espera un poco antes de reequilibrar nada. Esto se debe a que los trabajadores no suelen experimentar fallos destructivos y se reiniciarán inmediatamente. Si un trabajador se reincorpora rápidamente, conserva las tareas que poseía antes y no es necesario reequilibrar nada. Si el trabajador no se reincorpora lo suficientemente rápido -la duración se especifica a través de scheduled.rebalance.max.delay.ms, con un valor por defecto de cinco minutos-, las tareas que antes ejecutaba se reasignan a los trabajadores disponibles.
Desde Kafka 2.4, el protocolo de reequilibrio por defecto es sessioned. En cuanto al comportamiento del reequilibrio, funciona exactamente igual que compatible, pero además garantiza que las comunicaciones intracluster estén aseguradas. Al igual que compatible, sessioned sólo está activo si todos los trabajadores lo soportan; de lo contrario, se utiliza por defecto el protocolo común compartido por todos los trabajadores.
El protocolo de reequilibrio utilizado por Kafka Connect se especifica en la configuración de connect.protocol. Los usuarios deben mantener el valor predeterminado para la versión que utilicen y sólo considerar la posibilidad de degradar a eager si dependen de su comportamiento específico.
Nota
Para más detalles sobre la historia de cada protocolo, puedes leer los KIP respectivos. El protocolo de reequilibrio compatible fue introducido por el KIP-415. El protocolo de reequilibrio sessioned fue introducido por el KIP-507.
Gestión de fallos en Kafka Connect
Ahora que entiendes cómo gestiona Kafka Connect su estado, echemos un vistazo a los tipos de fallos más comunes y cómo gestionarlos.
Para construir una canalización resistente, es clave comprender cómo gestionan los fallos todos los componentes de tu sistema. En esta sección, nos centramos en Kafka Connect y en cómo gestiona los fallos, ignorando otros componentes como el sistema operativo, el entorno de ejecución e implementación o el hardware.
Cubrimos las siguientes averías:
-
Fallo del trabajador
-
Fallo del conector/tarea
-
Fallo de Kafka/sistemas externos
También hablaremos de cómo puedes utilizar las colas de letra muerta para tratar los registros no procesables.
Fallo del trabajador
En modo distribuido, Kafka Connect puede ejecutarse a través de varios trabajadores. Recomendamos utilizar al menos dos trabajadores para ser resistentes a los fallos de los trabajadores.
Por ejemplo, si tenemos tres trabajadores que ejecutan dos conectores (C1 y C2), las distintas tareas podrían repartirse como en la Figura 4-7.
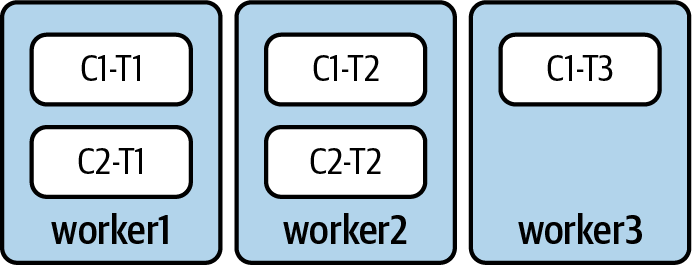
Figura 4-7. Ejemplo de un cluster Kafka Connect con tres trabajadores. El conector C1 tiene tres tareas (T1, T2, T3) y el C2 tiene dos tareas (T1 y T2).
En este caso, si worker2 se desconecta -ya sea porque se ha bloqueado o por mantenimiento- Kafka deja de recibir su latido. Tras un breve intervalo, expulsa automáticamente al trabajador2 del grupo, lo que obliga a Kafka Connect a reequilibrar todas las tareas en ejecución en los trabajadores restantes.
Tras el reequilibrio, la asignación de tareas puede parecerse a la Figura 4-8.
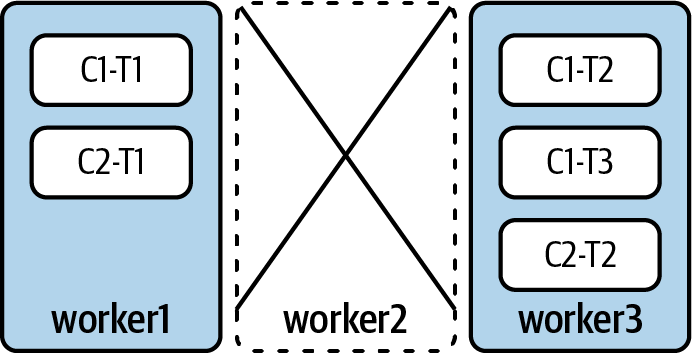
Figura 4-8. Kafka Connect ha reasignado todas las tareas a los trabajadores restantes
Mientras se produce el reequilibrio, las tareas que estaban en el trabajador2 no se ejecutan. Este mecanismo se activa y se completa en unos cinco minutos. El tiempo real que tarda depende sobre todo de las siguientes configuraciones:
-
session.timeout.mses la duración máxima entre dos latidos consecutivos de los trabajadores -
rebalance.timeout.mses la duración máxima que pueden tardar los trabajadores en reincorporarse al grupo cuando se produce un reequilibrio -
scheduled.rebalance.max.delay.mses el tiempo que hay que esperar antes de reasignar los conectores y las tareas de los trabajadores que se han caído del grupo desde el último reequilibrio
Cuando un trabajador no se detiene limpiamente, es posible que sus tareas no hayan consignado los desplazamientos de todos los registros que estaban procesando. Así que, al reiniciarse, algunas tareas pueden volver a procesar algunos registros. Discutiremos este problema más adelante en este capítulo.
Para que Kafka Connect pueda gestionar los fallos de los trabajadores, debes asegurarte de que tienes capacidad suficiente para acomodar la redistribución de tareas. Kafka Connect no tiene ningún mecanismo para limitar el número de tareas que se pueden asignar a un trabajador durante un reequilibrio. Si a un trabajador se le asignan demasiadas tareas, su rendimiento se degrada y, finalmente, las tareas no progresarán. Como mínimo, debes tener siempre capacidad suficiente para gestionar el fallo de un único trabajador, a fin de gestionar de forma fiable los reinicios continuos de trabajadores de .
Fallo de conector/tarea
Otro tipo común de fallo es el fallo de uno de los conectores o de una de sus tareas. Hasta ahora, hemos simplificado lo que ocurre exactamente cuando Kafka Connect ejecuta un conector. En realidad, tiene que ejecutar una instancia del conector y cero o más instancias de tareas. Kafka Connect realiza un seguimiento del estado de ambos y los asocia a un estado, que puede ser:
UNASSIGNEDTodavía no se ha asignado un conector o tarea a un trabajador
RUNNINGUn conector o tarea se ejecuta correctamente en un trabajador
PAUSEDUn conector o tarea ha sido pausado por un usuario a través de la API REST
FAILEDUn conector o tarea ha encontrado un error y se ha bloqueado
RESTARTINGEl conector/tarea se está reiniciando activamente o se espera que se reinicie pronto
STOPPEDUn usuario ha detenido un conector a través de la API REST
El estado de los conectores y las tareas puede recuperarse a través de la API REST. La Figura 4-9 muestra las transiciones más habituales entre los distintos estados.
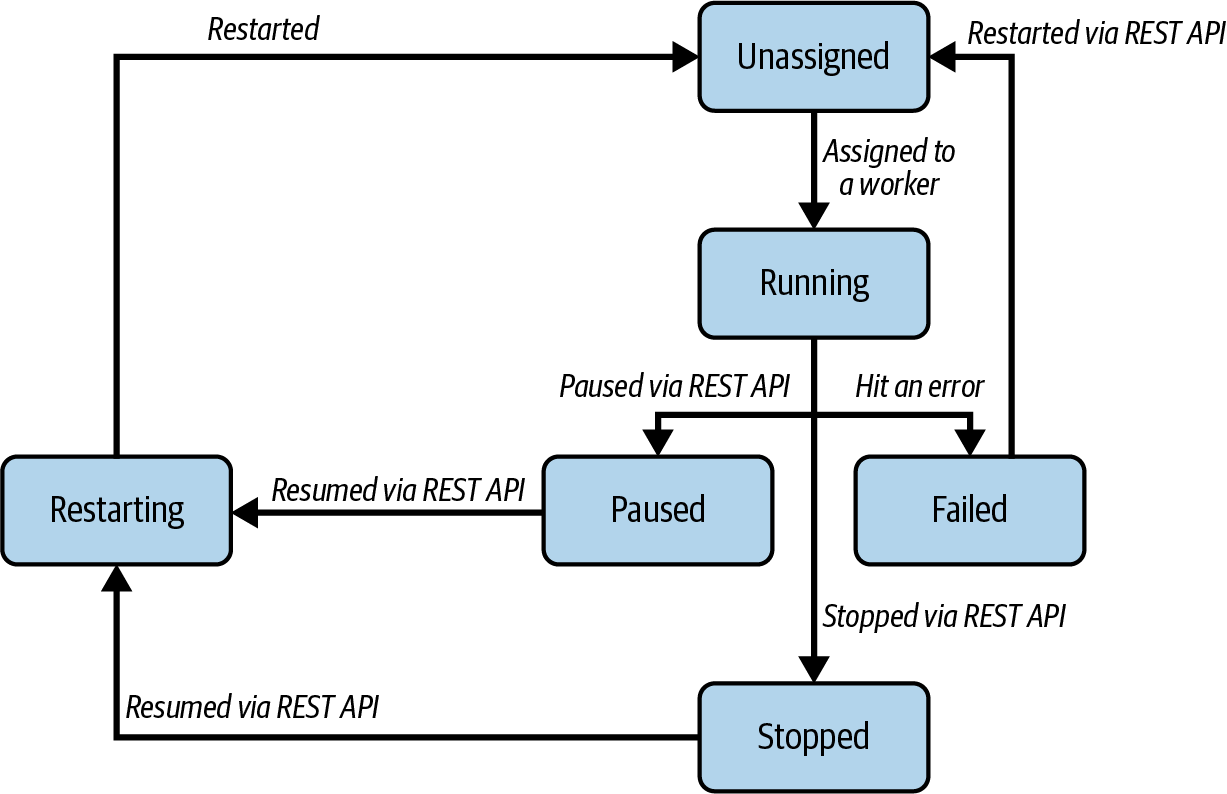
Figura 4-9. Transiciones de estado más comunes para conectores y tareas
Consejo
Kafka Connect emite métricas detalladas que rastrean el tiempo pasado en cada estado por cada conector. Consulta el Capítulo 9 para saber cómo recuperar y monitorizar las métricas.
Los estados del conector y de las tareas se determinan de forma independiente. Por ejemplo, algunos conectores pueden realizar una lógica adicional, como conectarse a su sistema de destino para descubrir recursos cuando se ponen en marcha. Mientras esto ocurre, el conector estará en estado RUNNING, pero no se creará ninguna tarea.
Cada tarea también puede encontrar un error (y ser marcada FAILED) por separado del conector. Por defecto, si una tarea tiene un problema, Kafka Connect deja que se bloquee, la marca como FAILED, y no intenta reiniciarla automáticamente. Kafka Connect emite métricas sobre el estado de las tareas, que los administradores tienen que monitorizar para identificar fallos. El fallo de una tarea no desencadena un reequilibrio.
En caso de un fallo puntual, los administradores pueden reiniciar las tareas a través de la API REST. La API REST también puede utilizarse para recuperar la excepción que bloqueó la tarea y su rastro de pila. En caso de un fallo sistemático, como un registro imposible de procesar, Kafka Connect ofrece la opción de omitirlo (y opcionalmente emitir un mensaje de registro detallado) en lugar de hacer fallar la tarea. Esto puede configurarse por conector utilizando la configuración errors.tolerance.
Fallo de Kafka/Sistemas externos
Como Kafka Connect hace fluir datos entre Kafka y sistemas externos, los fallos en cualquiera de ellos pueden afectar a Kafka Connect.
Como se detalla en el Capítulo 2, Kafka puede ser muy resistente. Para tener una implementación de producción resistente, los clusters de Kafka deben tener varios brokers y estar configurados para ofrecer la máxima disponibilidad. Además, Kafka Connect debe configurarse para crear sus temas con múltiples réplicas, de modo que no se vea afectado negativamente por el fallo de un único intermediario. Esto es importante para los temas que son fuente o sumidero de conectores, los temas internos de Kafka Connect y los temas de __consumer_offsets y __transaction_state.
Por otro lado, un fallo externo del sistema debe ser gestionado por el conector. Dependiendo del sistema y de la implementación del conector, puede gestionarse automáticamente o puede colapsar las tareas y requerir una intervención manual para recuperarse.
Antes de construir una canalización de Kafka Connect, es importante leer la documentación del conector y comprender los modos de fallo del sistema externo para calibrar la resistencia de la canalización. A veces hay varias implementaciones comunitarias para los mismos conectores y tendrás que elegir la que satisfaga tus necesidades. Luego tendrás que realizar pruebas de resistencia para determinar si el conector proporciona la resistencia necesaria para tus casos de uso. Por último, es importante monitorizar las métricas y los registros adecuados, tanto del sistema externo como del conector, que se describen en el Capítulo 9.
Colas de Letras Muertas
Cuando se trata de un registro no procesable, para los conectores de sumidero, Kafka Connect puede utilizar una cola de letra muerta en lugar de tener que omitir el registro o fallar. Una cola de letra muerta, a menudo abreviada DLQ, es un concepto de los sistemas de mensajería tradicionales: básicamente, un lugar para almacenar registros que no se pueden procesar o entregar. En Kafka Connect, la cola de letra muerta es un tema (especificado a través de errors.deadletterqueue.topic.name en la configuración del conector) donde se escriben los registros no procesables. Sin embargo, Kafka Connect no proporciona un mecanismo similar para los conectores de origen, porque no puede convertir el registro no entregable del sistema externo en un registro Kafka.
Nota
La compatibilidad con colas de letra muerta para conectores de sumidero se introdujo por primera vez mediante KIP-298 y se mejoró en Kafka 2.6 mediante KIP-610.
Veamos un ejemplo de uso de una cola de letra muerta. Al ejecutar el conector de sumidero S3 de Confluent, el tiempo de ejecución de Kafka Connect está leyendo registros de un tema de Kafka antes de pasarlos al conector. Como se espera que el tema contenga registros Avro, configuramos el conector con un conversor Avro. Sin embargo, si un único registro del tema no está en formato Avro, el conector no puede gestionar ese registro. En lugar de fallar el conector o perder este registro, Kafka Connect puede reenviarlo a una cola de letra muerta y seguir procesando los demás registros del tema. La configuración del conector contendría los siguientes ajustes:
{"connector.class":"io.confluent.connect.s3.S3SinkConnector","value.converter":"io.confluent.connect.avro.AvroConverter","errors.tolerance":"all","errors.deadletterqueue.topic.name":"my-dlq"}
Esto permite que el contenido del tema de la cola de letra muerta sea procesado por otro mecanismo, por ejemplo otro conector o una aplicación consumidora.
La Figura 4-10 muestra un ejemplo de utilización de una cola de letra muerta.
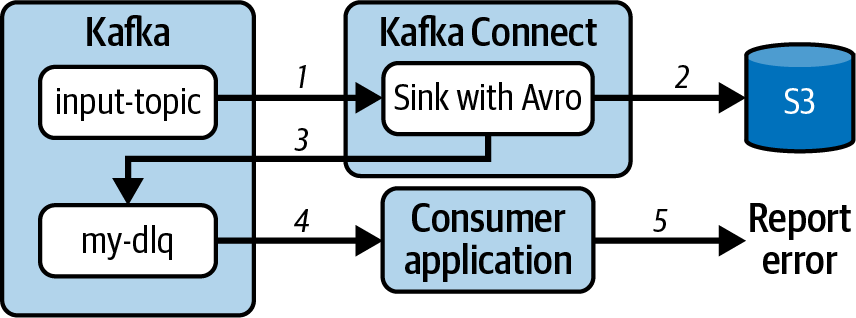
Figura 4-10. Los registros no procesables se envían a una cola de letra muerta para ser procesados por otro mecanismo
El flujo comienza con el conector S3 sink configurado con Avro recibiendo registros del tema de entrada (1). Los registros Avro se procesan correctamente y se envían a S3 (2). Si un registro no se puede procesar debido a fallos en la fase de conversión, transformación o entrega de la tarea de sumidero, se envía a la cola de letra muerta configurada para el conector (3). En este ejemplo, otra aplicación recibe registros de la cola de letra muerta (4), los procesa e informa de los errores (5).
Comprender la semántica del procesamiento
La semántica de procesamiento define en el tipo de garantías que se ofrecen cuando un mensaje fluye a través de una canalización de Kafka Connect. Puede ser uno de estos tres tipos:
- Al menos una vez
Un mensaje que entra en el canal llega al sistema de destino al menos una vez como una o varias copias. Las copias adicionales de un mensaje se denominan duplicados.
- Al menos una vez
Un mensaje que entra en la canalización puede no llegar al sistema de destino, y nunca se duplicará.
- Exactamente una vez
Un mensaje que entra en el canal es procesado por los lectores posteriores exactamente una vez.
La semántica exacta que proporciona una canalización de Kafka Connect depende de varios aspectos, como el conector que se utiliza, cómo está configurado y la configuración del tiempo de ejecución.
Veamos cada tipo de conector y veamos cómo entender la semántica que puede proporcionar.
Conectores de fregadero
Para recapitular, estos son los pasos que constituyen una tubería de sumidero:
-
El tiempo de ejecución consume registros del tema Kafka
-
Los registros se pasan al convertidor configurado
-
Los registros se pasan a las transformaciones configuradas
-
Los registros se pasan al conector del sumidero que los escribe en el sistema del sumidero
La Figura 4-11 muestra este flujo.

Figura 4-11. Pasos en una tubería de sumidero
Para determinar la semántica de una canalización sink, hay que tener en cuenta algunos elementos diferentes:
-
El valor de
errors.tolerance -
Tanto si utilizas un DLQ
-
El comportamiento del conector
-
Las características del sistema objetivo
Consideremos en primer lugar errors.tolerance. Esta configuración indica al tiempo de ejecución de Kafka Connect qué hacer si el conversor, las transformaciones o el conector informan de un error. El valor por defecto es none, que hace que la tarea falle. En este caso, la tarea falla sin comprometer las compensaciones para el registro que causó el error, por lo que cuando se reinicia, ese registro es consumido de nuevo por la tarea. Esta configuración siempre proporciona una semántica de al menos una vez; que proporcione exactamente una vez depende del comportamiento específico del conector (trataremos esas consideraciones más adelante en esta sección).
A veces no es necesario que la tarea falle si encuentra un error. Si un registro concreto no se puede procesar (lo que se conoce como píldora venenosa), puede hacer que la tarea falle repetidamente. En su lugar, puedes establecer errors.tolerance en all para que el tiempo de ejecución omita los registros que provocan fallos. Esto es bueno para mantener tus tareas en ejecución, pero poco útil si tu objetivo es la semántica de exactamente una vez o al menos una vez.
Si utilizas errors.tolerance configurado en all y quieres una semántica de exactamente una vez o al menos una vez, una opción es configurar una cola de letra muerta. Con una DLQ, si se produce un fallo, el tiempo de ejecución se asegura de que no se pierda ningún registro y reenvía automáticamente los registros afectados a la DLQ. Este enfoque te permite obtener la semántica at-least-once en la mayoría de los casos, aunque cabe señalar que Kafka Connect no reintenta al enviar registros a la DLQ.
Por último, debes tener en cuenta el propio conector en combinación con las características del sistema de destino. La diferencia entre la semántica "al menos una vez" y "exactamente una vez" a menudo se reduce a cómo se envían los datos al sistema de destino. Como los registros en Kafka son inmutables, si los mismos registros se procesan dos veces, el conector puede emitir exactamente los mismos registros al sistema de destino. En los sistemas que ofrecen escrituras idempotentes -por ejemplo, almacenando los registros en función de su clave-, pueden eliminar los registros duplicados y conservar sólo una copia, con lo que se consigue una semántica exactamente igual.
El comportamiento del conector también determina si tienes una semántica de más de una vez o de menos de una vez. Cada vez que se inicia una tarea, se reinicia desde el último desplazamiento consignado. Por defecto, el tiempo de ejecución sólo consigna los desplazamientos de los registros que se han pasado correctamente al conector y no han dado lugar a un error. Esto significa que si el conector escribe datos en el sistema externo de forma asíncrona, debe utilizar los ganchos proporcionados para influir en los desplazamientos que el tiempo de ejecución puede consignar. De lo contrario, si la tarea se bloqueara antes de que el conector escribiera correctamente el registro y después de que se confirmara el desplazamiento, este registro se omitiría al reiniciarse la tarea.
En resumen, la configuración errors.tolerance es importante a la hora de determinar la semántica de una canalización de sumideros. Si se establece en all, el tiempo de ejecución omite los registros no procesables. Si quieres evitar perder ningún registro y maximizar la disponibilidad de una canalización de sumideros, considera la posibilidad de utilizar una cola de letra muerta, pero ten en cuenta el coste operativo adicional que requiere. Además, aunque algunos pasos pueden causar duplicados, algunos sistemas externos son capaces de gestionarlos y proporciona efectivamente una semántica de extremo a extremo exactamente una vez para las canalizaciones de sumidero.
Conectores de origen
Como resumen rápido, estos son los pasos de que constituyen una canalización de origen, como se muestra en la Figura 4-12:
-
El conector consume registros del sistema externo
-
Los registros se pasan a las transformaciones configuradas
-
Los registros se pasan al convertidor configurado
-
Los registros se pasan al tiempo de ejecución que los produce a un tema Kafka

Figura 4-12. Pasos de una cadena de fuentes
Para determinar la semántica de una canalización de origen, debes tener en cuenta lo siguiente:
-
Uso de compensaciones del conector de origen
-
El valor de
errors.tolerance -
El comportamiento del productor
-
Si está activada la función "exactamente una vez
De forma similar al consumidor que recupera registros en una canalización de sumidero, en una canalización de origen el conector tiene que decidir qué datos recuperar del sistema externo. No todos los sistemas externos disponen de un mecanismo como los offsets en Kafka que les permita identificar directamente un registro. Por eso, los conectores de origen pueden asociar una asignación arbitraria de claves a valores -el campo sourceOffset en los objetos SourceRecord - para expresar su posición actual. Este objeto arbitrario puede ser recuperado por las tareas según sea necesario. Es responsabilidad del conector asegurarse de que este objeto contiene la información adecuada para recuperar correctamente los registros del sistema externo. El tiempo de ejecución de Kafka Connect almacena automáticamente este objeto en el tema de offset y también proporciona un mecanismo para que los conectores sepan cuándo está consignando offsets en caso de que quieran hacer su propio seguimiento de offset en el sistema de destino. En la mayoría de las cadenas de conectores de origen, las compensaciones se consignan después de producir registros en Kafka, por lo que es posible que un trabajador produzca registros en Kafka con éxito, pero falle antes de poder consignar sus compensaciones. Dependiendo de cómo funcione el conector, este paso puede causar algún reprocesamiento de registros, lo que da lugar a una semántica de "al menos una vez".
En caso de que se produzca algún error en las transformaciones, los pasos del conversor o en el productor utilizado por el tiempo de ejecución, el valor del ajuste errors.tolerance determina si la tarea se marca como FAILED o si se omite el registro que falla. Las tareas fuente no pueden confiar en las colas de letra muerta, por lo que tolerar errores hace que estos pasos proporcionen una semántica de "al menos una vez" en caso de errores.
Los registros de un canal de origen se envían a Kafka a través de un productor desde el tiempo de ejecución. A partir de Kafka 3.1.0, los productores están configurados para ofrecer al menos una vez por defecto, pero esto puede anularse en la configuración del conector.
En Kafka 3.3 se añadió mediante KIP-618 la compatibilidad con exactamente una vez en los conectores de origen. Cuando está activada, el tiempo de ejecución utiliza un productor transaccional para consignar desvíos y producir en Kafka como parte de una única transacción. En el Capítulo 8, explicamos las configuraciones del trabajador y del conector necesarias para activar esta función. No todos los conectores de origen admiten exactamente una vez, así que asegúrate de consultar la documentación del conector. También explicamos cómo escribir un conector que admita exactly-once en el Capítulo 11. Puedes utilizar esta información para escribir tu propio conector o para evaluar la semántica de uno existente.
Advertencia
La semántica "exactamente una vez" para los conectores fuente no está disponible en modo autónomo.
En resumen, la forma en que los conectores de origen gestionan los offsets y cómo se envían a Kafka son factores clave en la semántica de las canalizaciones de origen. Al igual que con las canalizaciones de sumidero, la configuración de errors.tolerance también desempeña un papel; sin embargo, a diferencia de las canalizaciones de sumidero, no puedes hacer uso de las colas de letra muerta para atrapar los registros omitidos.
Resumen
En este capítulo, hemos visto los distintos aspectos que hay que tener en cuenta para construir canalizaciones de datos resistentes con Kafka Connect.
Primero examinamos la selección de los conectores adecuados entre los cientos de conectores creados por la comunidad Kafka. Tienes que tener en cuenta la dirección de la canalización, si cumple tus requisitos de características y si viene con un nivel de asistencia adecuado.
Luego nos centramos en los modelos y formatos de datos y en las opciones que tienes para mapear datos entre sistemas. Sea cual sea tu elección, tienes que comprender la estructura de tus datos en cada etapa del proceso y tomar decisiones conscientes sobre la transformación y el formato. Estas decisiones informan tu elección de conversor, transformaciones y predicados. También destacamos las ventajas de utilizar esquemas y un registro de esquemas para definir, aplicar y gestionar adecuadamente la estructura de los datos.
A continuación, examinamos los retos que plantea la gestión de los muchos tipos de fallos que pueden surgir, desde caídas de los trabajadores hasta errores en las tareas. Aunque, en general, se considera que Kafka Connect es resistente, no puede recuperarse de todos los fallos, por lo que debes comprender las palancas de las que hemos hablado y cómo utilizarlas en respuesta a los fallos.
Por último, detallamos cómo todas las decisiones tomadas en relación con los modelos de datos, la gestión de errores, el tiempo de ejecución y las configuraciones de los conectores repercuten directamente en la semántica de procesamiento que pueden conseguir las canalizaciones de Kafka Connect. Para las canalizaciones de sumideros, las colas de letra muerta son una potente característica para evitar la pérdida de datos, y es posible conseguir una semántica exactamente una vez con sistemas descendentes capaces. Desde Kafka 3.3, las canalizaciones de origen también pueden conseguir exactamente una vez con conectores que admitan esta función.
Get Conexión Kafka now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

