Kapitel 4. Automatisierung der Datenbankbereitstellung in Kubernetes mit Helm
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Im vorigen Kapitel hast du gelernt, wie du Datenbanken mit einem oder mehreren Knoten in Kubernetes einrichten kannst, indem du ein Element nach dem anderen erstellst. Wir haben das absichtlich auf die "harte Tour" gemacht, damit du besser verstehst, wie du mit den Kubernetes-Primitiven die Rechen-, Netzwerk- und Speicherressourcen einrichten kannst, die eine Datenbank benötigt. Das entspricht natürlich nicht der Erfahrung, die man beim Betrieb von Datenbanken unter Kubernetes macht, und zwar aus mehreren Gründen.
Erstens stellen Teams ihre Datenbanken in der Regel nicht von Hand ein, eine YAML-Datei nach der anderen. Das kann ziemlich mühsam werden. Und selbst das Zusammenfassen der Konfigurationen in einer einzigen Datei kann ziemlich kompliziert werden, vor allem bei komplexeren Bereitstellungen. Denk daran, dass der Konfigurationsaufwand in Kapitel 3 für Cassandra als Multinode-Datenbank höher ist als für den Einsatz von MySQL mit nur einem Knoten. Das ist für große Unternehmen nicht praktikabel.
Zweitens: Eine Datenbank einzurichten ist zwar toll, aber wie sieht es damit aus, sie über einen längeren Zeitraum am Laufen zu halten? Deine Dateninfrastruktur muss auf lange Sicht zuverlässig und leistungsfähig bleiben, und Dateninfrastrukturen sind dafür bekannt, dass sie viel Aufmerksamkeit und Pflege brauchen. Anders ausgedrückt: Die Aufgabe, ein System zu betreiben, wird oft unterteilt in den "ersten Tag" (den freudigen Tag, an dem du eine Anwendung in Betrieb nimmst) und den "zweiten Tag" (jeden Tag nach dem ersten Tag, an dem du deine Anwendung betreiben und weiterentwickeln und gleichzeitig eine hohe Verfügbarkeit aufrechterhalten musst).
Diese Überlegungen zum Datenbankeinsatz und -betrieb spiegeln den allgemeinen Branchentrend zu DevOps wider, einem Ansatz, bei dem Entwicklungsteams eine aktivere Rolle bei der Unterstützung von Anwendungen in der Produktion übernehmen. Zu den DevOps-Praktiken gehört der Einsatz von Automatisierungstools für CI/CD von Anwendungen, um die Zeit zu verkürzen, die es braucht, bis der Code vom Desktop des Entwicklers in die Produktion gelangt.
In diesem Kapitel befassen wir uns mit Tools, die dabei helfen, die Bereitstellung von Datenbanken und anderen Anwendungen zu standardisieren. Diese Tools verfolgen einen Infrastructure as Code (IaC)-Ansatz, der es dir ermöglicht, Software-Installations- und Konfigurationsoptionen in einem Format darzustellen, das automatisch ausgeführt werden kann, sodass du weniger Konfigurationscode schreiben musst. In den nächsten beiden Kapiteln werden wir uns mit dem Betrieb von Dateninfrastrukturen befassen und dieses Thema im weiteren Verlauf des Buches fortführen.
Einsatz von Anwendungen mit Helm Charts
Werfen wir zunächst einen Blick auf ein Tool, das dir hilft, die Komplexität der Verwaltung von Konfigurationen zu bewältigen: Helm. Dieser Paketmanager für Kubernetes ist Open Source und ein von der CNCF unterstütztes Projekt. Das Konzept eines Paketmanagers ist in vielen Programmiersprachen verbreitet, z. B. pip für Python, der Node Package Manager (NPM) für JavaScript und die Gems-Funktion von Ruby. Es gibt auch Paketmanager für bestimmte Betriebssysteme, wie z. B. Apt für Linux oder Homebrew für macOS. Wie in Abbildung 4-1 dargestellt, sind die wesentlichen Elemente eines Paketverwaltungssystems die Pakete, die Registrierungsstellen, in denen die Pakete gespeichert werden, und die Paketverwaltungsanwendung (oder der Client), die den Kartenentwicklern bei der Registrierung der Karten hilft und den Kartennutzern ermöglicht, die Pakete auf ihren lokalen Systemen zu finden, zu installieren und zu aktualisieren.
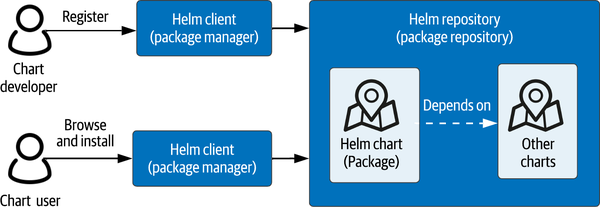
Abbildung 4-1. Helm, ein Paketmanager für Kubernetes
Helm überträgt das Konzept der Paketverwaltung auf Kubernetes, allerdings mit einigen interessanten Unterschieden. Wenn du mit einem der zuvor genannten Paketmanager gearbeitet hast, wirst du mit der Idee vertraut sein, dass ein Paket aus einer Binärdatei (ausführbarer Code) sowie aus Metadaten besteht, die die Binärdatei beschreiben, z. B. ihre Funktionalität, API und Installationsanweisungen. In Helm werden die Pakete Charts genannt. Charts beschreiben, wie eine Kubernetes-Anwendung Stück für Stück aufgebaut wird, indem die in den vorherigen Kapiteln vorgestellten Kubernetes-Ressourcen für die Berechnung, das Netzwerk und die Speicherung verwendet werden, z. B. Pods, Services und PersistentVolumeClaims. Für Compute-Workloads verweisen die Beschreibungen auf Container-Images, die sich in öffentlichen oder privaten Container-Registries befinden.
Helm erlaubt es Diagrammen, auf andere Diagramme als Abhängigkeiten zu verweisen, was eine großartige Möglichkeit bietet, Anwendungen zu erstellen, indem du Diagramme zusammenfügst. Du könntest zum Beispiel eine Anwendung wie das WordPress/MySQL-Beispiel aus dem vorherigen Kapitel definieren, indem du ein Diagramm für deinen WordPress-Einsatz definierst, das auf ein Diagramm verweist, das einen MySQL-Einsatz definiert, den du wiederverwenden möchtest. Oder du könntest sogar ein Helm-Diagramm finden, das eine ganze WordPress-Anwendung einschließlich der Datenbank definiert.
Voraussetzungen für die Kubernetes-Umgebung
Die Beispiele in diesem Kapitel gehen davon aus, dass du Zugang zu einem Kubernetes-Cluster mit einigen Eigenschaften hast:
Der Cluster sollte mindestens drei Worker Nodes haben, um die Mechanismen von Kubernetes zu demonstrieren, die es dir ermöglichen, Pods über einen Cluster zu verteilen. Du kannst einen einfachen Cluster auf deinem Desktop erstellen, indem du die Open-Source-Distribution kind verwendest. In der kind-Kurzanleitung findest du Anweisungen zur Installation von kind und zur Erstellung eines Multinode-Clusters. Der Code für dieses Beispiel enthält auch eine Konfigurationsdatei, die dir helfen kann, einen einfachen kind-Cluster mit drei Knoten zu erstellen.
Außerdem brauchst du eine StorageClass, die dynamische Provisionierung unterstützt. Du kannst die Anweisungen unter "StorageClasses" befolgen, um eine einfache StorageClass und einen Provisioner zu installieren, die eine lokale Speicherung ermöglichen.
MySQL mit Helm bereitstellen
Um die Sache etwas konkreter zu machen, wollen wir Helm verwenden, um die Datenbanken, mit denen du in Kapitel 3 gearbeitet hast, einzusetzen. Wenn Helm noch nicht auf deinem System installiert ist, musst du es zunächst mit Hilfe der Dokumentation auf der Helm-Website installieren. Als nächstes fügst du das Bitnami Helm Repository hinzu:
helm repo add bitnami https://charts.bitnami.com/bitnami
Das Bitnami Helm Repository enthält eine Vielzahl von Helm-Diagrammen, die dir bei der Bereitstellung von Infrastrukturen wie Datenbanken, Analyse-Engines und Log-Management-Systemen sowie von Anwendungen wie E-Commerce, Customer Relationship Management (CRM) und - du hast es erraten - WordPress helfen: WordPress. Den Quellcode für die Charts findest du im Bitnami Charts Repository auf GitHub. Das README für dieses Repository enthält hilfreiche Anweisungen für die Verwendung der Charts in verschiedenen Kubernetes-Distributionen.
Verwenden wir nun das Helm-Diagramm aus dem bitnami Repository, um MySQL einzusetzen. In der Terminologie von Helm wird jeder Einsatz als Release bezeichnet. Die einfachste Version, die du mit diesem Diagramm erstellen könntest, würde etwa so aussehen:
# don’t execute me yet! helm install mysql bitnami/mysql
Wenn du diesen Befehl ausführst, wird eine Version namens mysql erstellt, die das Bitnami MySQL Helm-Diagramm mit seinen Standardeinstellungen verwendet. Als Ergebnis hättest du einen einzelnen MySQL-Knoten. Da du in Kapitel 3 bereits einen einzelnen MySQL-Knoten manuell eingerichtet hast, wollen wir dieses Mal etwas Interessanteres tun und einen MySQL-Cluster erstellen. Dazu erstellst du eine values.yaml-Datei mit folgendem Inhalt oder du verwendest das Beispiel im Quellcode:
architecture: replication secondary: replicaCount: 2
Die Einstellungen in dieser values.yaml-Datei teilen Helm mit, dass du die Optionen im Bitnami MySQL Helm-Diagramm verwenden willst, um MySQL in einer replizierten Architektur einzusetzen, in der es einen primären und zwei sekundäre Knoten gibt.
MySQL Helm Chart Konfigurationsoptionen
Wenn du dir die Dateivalues.yaml ansiehst, die mit dem Bitnami MySQL Helm-Diagramm geliefert wird, siehst du eine ganze Reihe von Optionen, die über die hier gezeigte einfache Auswahl hinausgehen. Zu den konfigurierbaren Werten gehören die folgenden:
Zu ziehende Bilder und ihre Standorte
Die Kubernetes StorageClass, die zur Erzeugung von PersistentVolumes verwendet wird
Sicherheitsnachweise für Benutzer- und Administratorkonten
MySQL-Konfigurationseinstellungen für primäre und sekundäre Replikate
Anzahl der zu erstellenden sekundären Replikate
Details zu Liveness, Bereitschaftstests
Einstellungen für Affinität und Anti-Affinität
Verwaltung der Hochverfügbarkeit der Datenbank mithilfe von Budgets für Pod-Unterbrechungen
Viele dieser Konzepte wirst du bereits kennen, andere wie Affinität und Pod-Störungsbudgets werden später in diesem Buch behandelt.
Sobald du die Datei values.yaml erstellt hast, kannst du den Cluster mit diesem Befehl starten :
helm install mysql bitnami/mysql -f values.yaml
Nachdem du den Befehl ausgeführt hast, siehst du den Status der Installation von Helm sowie die Anweisungen, die mit der Karte unter NOTES bereitgestellt werden:
NAME: mysql LAST DEPLOYED: Thu Oct 21 20:39:19 2021 NAMESPACE: default STATUS: deployed REVISION: 1 TEST SUITE: None NOTES: …
Wir haben die Notizen hier weggelassen, da sie etwas langatmig sind. Sie beschreiben vorgeschlagene Befehle, um den Status der MySQL-Initialisierung zu überwachen, wie sich Clients und Administratoren mit der Datenbank verbinden können, wie man die Datenbank aktualisiert und vieles mehr.
Benutze Namensräume, um Ressourcen zu isolieren
Da wir keinen Namespace angegeben haben, wurde das Helm-Release im Standard-Kubernetes-Namespace installiert, es sei denn, du hast einen eigenen Namespace in deiner kubeconfig konfiguriert. Wenn du ein Helm-Release in seinem eigenen Namespace installieren willst, um effektiver mit seinen Ressourcen arbeiten zu können, kannst du etwas wie das Folgende ausführen:
helm install mysql bitnami/mysql \ --namespace mysql --create-namespace
Dadurch wird ein Namensraum namens mysql erstellt und die Version mysql darin installiert.
Um Informationen über die von dir erstellten Helm-Versionen zu erhalten, verwende den Befehl helm list, der eine Ausgabe wie die folgende erzeugt (zur besseren Lesbarkeit formatiert):
helm list NAME NAMESPACE REVISION UPDATED mysql default 1 2021-10-21 20:39:19 STATUS CHART APP VERSION deployed mysql-8.8.8 8.0.26
Wenn du die Version nicht in einem eigenen Namespace installiert hast, kannst du die Rechenressourcen, die Helm für dich erstellt hat, ganz einfach sehen, indem du kubectl get all aufrufst, da sie alle mit dem Namen deiner Version gekennzeichnet sind. Es kann einige Minuten dauern, bis alle Ressourcen initialisiert sind, aber wenn das geschehen ist, sieht es ungefähr so aus:
kubectl get all NAME READY STATUS RESTARTS AGE pod/mysql-primary-0 1/1 Running 0 3h40m pod/mysql-secondary-0 1/1 Running 0 3h40m pod/mysql-secondary-1 1/1 Running 0 3h38m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT service/mysql-primary ClusterIP 10.96.107.156 <none> ... service/mysql-primary-headless ClusterIP None <none> ... service/mysql-secondary ClusterIP 10.96.250.52 <none> ... service/mysql-secondary-headless ClusterIP None <none> ... NAME READY AGE statefulset.apps/mysql-primary 1/1 3h40m statefulset.apps/mysql-secondary 2/2 3h40m
Wie du sehen kannst, hat Helm zwei StatefulSets erstellt, eines für primäre Replikate und eines für sekundäre Replikate. Das StatefulSet mysql-primary verwaltet einen einzelnen MySQL Pod mit einem primären Replikat, während das StatefulSet mysql-secondary zwei MySQL Pods mit sekundären Replikaten verwaltet. Versuche mit dem Befehl kubectl describe pod herauszufinden, auf welchem Kubernetes-Worker-Knoten die einzelnen MySQL-Replikate laufen.
In der vorangegangenen Ausgabe siehst du auch, dass für jedes StatefulSet zwei Dienste erstellt wurden, einer davon ist ein Headless Service und der andere hat eine eigene IP-Adresse. Da kubectl get all nur Rechenressourcen und Dienste anzeigt, fragst du dich vielleicht auch nach den Speicherressourcen. Um diese zu überprüfen, führe den Befehl kubectl get pv aus. Wenn du eine StorageClass installiert hast, die Dynamic Provisioning unterstützt, solltest du PersistentVolumes sehen, die an PersistentVolumeClaims mit den Namen data-mysql-primary-0, data-mysql-secondary-0 und data-mysql-secondary-1 gebunden sind.
Zusätzlich zu den Ressourcen, die wir besprochen haben, wurden durch die Installation der Karte noch einige weitere Ressourcen geschaffen, die wir im nächsten Schritt untersuchen werden.
Namensräume und Kubernetes-Ressourcenumfang
Wenn du dich entschieden hast, deine Helm-Version in einem Namespace zu installieren, musst du den Namespace bei den meisten deiner kubectl get Befehle angeben, um die erstellten Ressourcen zu sehen. Die Ausnahme ist kubectl get pv, denn PersistentVolumes gehören zu den Kubernetes-Ressourcen, die nicht mit einem Namespace versehen sind, d.h. sie können von Pods in jedem Namensraum verwendet werden. Um mehr darüber zu erfahren, welche Kubernetes-Ressourcen in deinem Cluster Namespaced sind und welche nicht, rufe den Befehl kubectl api-resources auf.
Wie Helm funktioniert
Hast du dich gefragt, was passiert, wenn du den Befehl helm install mit einer bereitgestellten Wertedatei ausführst? Um zu verstehen, was vor sich geht, sehen wir uns den Inhalt eines Helm-Diagramms an, wie in Abbildung 4-2 dargestellt. Während wir diese Inhalte besprechen, ist es auch hilfreich, sich den Quellcode des MySQL Helm-Diagramms anzusehen, das du gerade installiert hast.
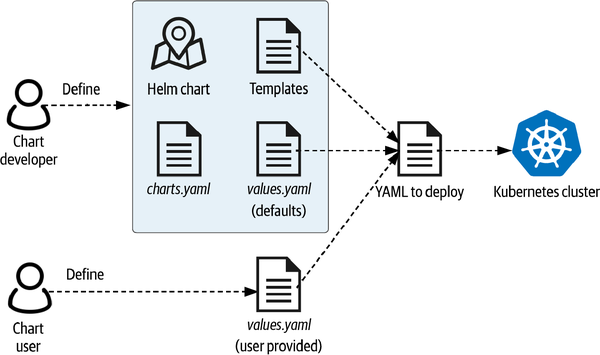
Abbildung 4-2. Anpassen einer Helm-Freigabe mithilfe einer values.yaml-Datei
Wenn du dir den Inhalt einer Helm-Karte ansiehst, wirst du Folgendes feststellen:
- README-Datei
- Hier wird erklärt, wie du die Tabelle verwenden kannst. Diese Anleitung wird zusammen mit der Karte in den Registern bereitgestellt.
- Chart.yaml Datei
- Sie enthält Metadaten über das Diagramm wie Name, Herausgeber, Version, Schlüsselwörter und Abhängigkeiten von anderen Diagrammen. Diese Eigenschaften sind nützlich, wenn du Helm-Registrierungen nach Karten durchsuchst.
- values.yaml Datei
- Hier werden die konfigurierbaren Werte, die von der Karte unterstützt werden, und ihre Standardwerte aufgelistet. Diese Dateien enthalten in der Regel eine Reihe von Kommentaren, die die verfügbaren Optionen erklären. Für das Bitnami MySQL Helm-Diagramm sind viele Optionen verfügbar, wie wir bereits festgestellt haben.
- Templating-Verzeichnis
- Diese enthält Go-Vorlagen, die das Diagramm definieren. Zu den Templates gehören eine Notes.txt-Datei, mit der die Ausgabe generiert wird, die du zuvor nach der Ausführung des
helm install-Befehls gesehen hast, und eine oder mehrere YAML-Dateien, die ein Muster für eine Kubernetes-Ressource beschreiben. Diese YAML-Dateien können in Unterverzeichnissen organisiert sein (z. B. die Vorlage, die ein StatefulSet für primäre MySQL-Replikate definiert). Schließlich beschreibt eine _helpers.tpl-Datei, wie die Templates verwendet werden können. Einige der Templates können je nach den gewählten Konfigurationswerten mehrfach oder gar nicht verwendet werden.
Wenn du den Befehl helm install ausführst, stellt der Helm-Client sicher, dass er eine aktuelle Kopie des von dir benannten Diagramms hat, indem er das Quell-Repository überprüft. Dann verwendet er die Vorlage, um YAML-Konfigurationscode zu generieren, wobei er die Standardwerte aus der Datei values.yaml des Diagramms mit den von dir angegebenen Werten überschreibt. Anschließend wendet es diese Konfiguration mit dem Befehl kubectl auf deinen aktuell konfigurierten Kubernetes-Cluster an.
Wenn du die Konfiguration sehen möchtest, die ein Helm-Diagramm erzeugt, bevor du es anwendest, kannst du den praktischen Befehl template verwenden. Er unterstützt die gleiche Syntax wie der Befehl install:
helm template mysql bitnami/mysql -f values.yaml
Wenn du diesen Befehl ausführst, werden ziemlich viele Daten ausgegeben. Du solltest sie daher in eine Datei umleiten (hänge > values-template.yaml an den Befehl an), damit du sie dir genauer ansehen kannst. Alternativ kannst du dir auch die Kopie ansehen, die wir im Quellcode-Repository gespeichert haben.
Du wirst feststellen, dass mehrere Arten von Ressourcen erstellt werden, wie in Abbildung 4-3 zusammengefasst. Viele der gezeigten Ressourcen wurden bereits besprochen, darunter die StatefulSets für die Verwaltung der primären und sekundären Replikate, die jeweils über einen eigenen Dienst verfügen (das Diagramm erstellt auch Headless Services, die in der Abbildung nicht gezeigt werden). Jeder Pod hat seinen eigenen PersistentVolumeClaim, der auf ein eindeutiges PersistentVolume abgebildet wird.
Abbildung 4-3 enthält auch Ressourcentypen, die wir bisher noch nicht besprochen haben. Beachte zunächst, dass jedes StatefulSet eine zugehörige ConfigMap hat, die verwendet wird, um den Pods einen gemeinsamen Satz von Konfigurationseinstellungen zur Verfügung zu stellen. Als Nächstes ist das Secret mit dem Namen mysql zu beachten, in dem Passwörter für den Zugriff auf verschiedene Schnittstellen der Datenbankknoten gespeichert werden. Schließlich wird jedem Pod, der mit dieser Helm-Version erstellt wird, eine ServiceAccount-Ressource zugewiesen.
Konzentrieren wir uns auf einige interessante Aspekte dieses Einsatzes, darunter die Verwendung von Labels, ServiceAccounts, Secrets und ConfigMaps.
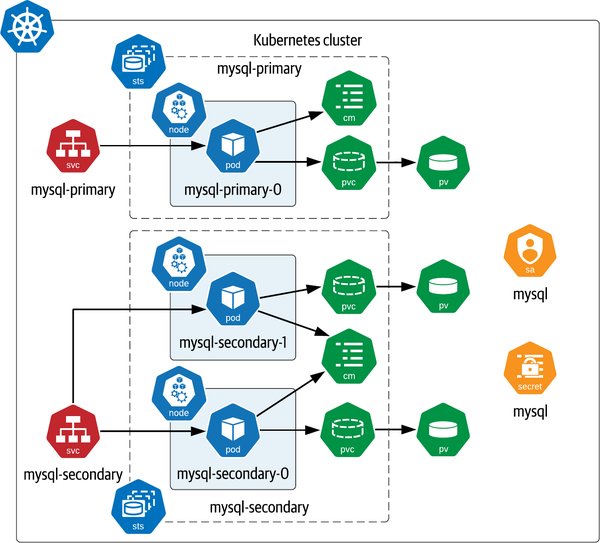
Abbildung 4-3. Bereitstellen von MySQL mit dem Bitnami Helm-Diagramm
Etiketten
Wenn du dir die Ausgabe von helm template ansiehst, wirst du feststellen, dass die Ressourcen einen gemeinsamen Satz von Bezeichnungen haben:
labels:
app.kubernetes.io/name: mysql
helm.sh/chart: mysql-8.8.8
app.kubernetes.io/instance: mysql
app.kubernetes.io/managed-by: Helm
Diese Kennzeichnungen helfen dabei, die Ressourcen als Teil der Anwendung mysql zu identifizieren und zeigen an, dass sie von Helm mit einer bestimmten Diagrammversion verwaltet werden. Die Beschriftungen sind nützlich, um Ressourcen auszuwählen, was oft bei der Festlegung von Konfigurationen für andere Ressourcen hilfreich ist.
ServiceAccounts
In Kubernetes-Clustern wird bei der Zugriffskontrolle zwischen menschlichen Nutzern und Anwendungen unterschieden. Ein ServiceAccount ist eine Kubernetes-Ressource, die eine Anwendung repräsentiert und auf die sie zugreifen darf. Einem ServiceAccount kann zum Beispiel der Zugriff auf einige Teile der Kubernetes-API oder auf ein oder mehrere Geheimnisse mit privilegierten Informationen wie Anmeldedaten gewährt werden. Letztere Fähigkeit wird in deiner Helm-Installation von MySQL genutzt, um Anmeldedaten zwischen Pods auszutauschen.
Jedem Pod, der in Kubernetes erstellt wird, ist ein ServiceAccount zugewiesen. Wenn du keinen angibst, wird der Standard-ServiceAccount verwendet. Die Installation des MySQL Helm Charts erstellt einen ServiceAccount namens mysql. Die Angaben für diese Ressource kannst du in der generierten Vorlage sehen:
apiVersion: v1 kind: ServiceAccount metadata: name: mysql namespace: default labels: ... annotations: secrets: - name: mysql
Wie du siehst, hat dieser ServiceAccount Zugriff auf ein Secret namens mysql, auf das wir gleich noch eingehen werden. Ein ServiceAccount kann auch einen zusätzlichen Secret-Typ haben, der imagePullSecret genannt wird. Diese Secrets werden verwendet, wenn eine Anwendung Bilder aus einer privaten Registry verwenden muss.
Standardmäßig hat ein ServiceAccount keinen Zugriff auf die Kubernetes-API. Um diesem ServiceAccount den nötigen Zugriff zu geben, erstellt das MySQL Helm-Diagramm eine Rolle, die die Kubernetes-Ressourcen und -Operationen spezifiziert, sowie eine Rollenbindung, um den ServiceAccount mit der Rolle zu verknüpfen. Wir werden ServiceAccounts und rollenbasierten Zugriff in Kapitel 5 besprechen.
Geheimnisse
Wie du in Kapitel 2 gelernt hast, bietet ein Secret sicheren Zugang zu Informationen, die du geheim halten musst. Deine mysql Helm-Version enthält ein Secret namens mysql, das die Anmeldedaten für die MySQL-Instanzen selbst enthält:
apiVersion: v1 kind: Secret metadata: name: mysql namespace: default labels: ... type: Opaque data: mysql-root-password: "VzhyNEhIcmdTTQ==" mysql-password: "R2ZtNkFHNDhpOQ==" mysql-replication-password: "bDBiTWVzVmVORA=="
Die drei Passwörter stehen für unterschiedliche Zugriffsarten: Das mysql-root-password ermöglicht den administrativen Zugriff auf den MySQL-Knoten, während das mysql-replication-password von den Knoten für die Kommunikation zur Datenreplikation zwischen den Knoten verwendet wird. Das mysql-password wird von Client-Anwendungen verwendet, um auf die Datenbank zuzugreifen und Daten zu schreiben und zu lesen.
ConfigMaps
Das Bitnami MySQL Helm-Diagramm erstellt Kubernetes ConfigMap-Ressourcen, um die Konfigurationseinstellungen für Pods darzustellen, auf denen die primären und sekundären MySQL-Replikat-Knoten laufen. ConfigMaps speichern Konfigurationsdaten als Schlüssel-Werte-Paare. Die ConfigMap, die vom Helm-Chart für die primären Replikate erstellt wurde, sieht zum Beispiel so aus:
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql-primary
namespace: default
labels: ...
data:
my.cnf: |-
[mysqld]
default_authentication_plugin=mysql_native_password
...
In diesem Fall ist der Schlüssel der Name my.cnf, der einen Dateinamen darstellt, und der Wert ist ein mehrzeiliger Satz von Konfigurationseinstellungen, die den Inhalt einer Konfigurationsdatei darstellen (die wir hier abgekürzt haben). Als Nächstes sehen wir uns die Definition des StatefulSet für die primären Replikate an. Beachte, dass der Inhalt der ConfigMap gemäß der Pod-Spezifikation für das StatefulSet als schreibgeschützte Datei in jede Vorlage eingebunden wird (auch hier haben wir einige Details weggelassen, um uns auf die wichtigsten Bereiche zu konzentrieren):
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql-primary
namespace: default
labels: ...
spec:
replicas: 1
selector:
matchLabels: ...
serviceName: mysql-primary
template:
metadata:
annotations: ...
labels: ...
spec:
...
serviceAccountName: mysql
containers:
- name: mysql
image: docker.io/bitnami/mysql:8.0.26-debian-10-r60
volumeMounts:
- name: data
mountPath: /bitnami/mysql
- name: config
mountPath: /opt/bitnami/mysql/conf/my.cnf
subPath: my.cnf
volumes:
- name: config
configMap:
name: mysql-primary
Das Mounten der ConfigMap als Volume in einem Container führt dazu, dass eine schreibgeschützte Datei im Mount-Verzeichnis erstellt wird, die nach dem Schlüssel benannt ist und den Wert als Inhalt hat. In unserem Beispiel führt das Mounten der ConfigMap in den mysql Container des Pods zur Erstellung der Datei /opt/bitnami/mysql/conf/my.cnf.
Dies ist eine von mehreren Möglichkeiten, wie ConfigMaps in Kubernetes-Anwendungen genutzt werden können:
Wie in der Kubernetes-Dokumentation beschrieben, kannst du Konfigurationsdaten auch in detaillierteren Schlüssel-Wert-Paaren speichern, was den Zugriff auf einzelne Werte in deiner Anwendung erleichtert.
Du kannst auch einzelne Schlüssel-Wert-Paare als Umgebungsvariablen referenzieren, die du an einen Container übergibst.
Schließlich können Anwendungen über die Kubernetes-API auf die Inhalte der ConfigMap zugreifen.
Mehr Konfigurationsoptionen
Jetzt, wo du ein Helm-Release mit einem funktionierenden MySQL-Cluster hast, kannst du eine Anwendung darauf verweisen, z. B. WordPress. Warum versuchst du nicht, den WordPress-Einsatz aus Kapitel 3 so anzupassen, dass er auf den MySQL-Cluster verweist, den du hier erstellt hast?
Um weiter zu lernen, kannst du deine Konfiguration auch mit der des Bitnami WordPress Helm Diagramms vergleichen, das MariaDB statt MySQL verwendet, aber ansonsten recht ähnlich ist.
Aktualisieren von Steuerkarten
Wenn du ein Helm-Release in einer Produktionsumgebung einsetzt, ist es wahrscheinlich, dass du es im Laufe der Zeit pflegen musst. Es kann sein, dass du ein Helm-Release aus verschiedenen Gründen aktualisieren möchtest:
Eine neue Version einer Karte ist verfügbar.
Eine neue Version eines von deiner Anwendung verwendeten Bildes ist verfügbar.
Du möchtest die ausgewählten Optionen ändern.
Um nach einer neuen Version einer Karte zu suchen, führe den Befehl helm repo update aus. Wenn du diesen Befehl ohne Optionen ausführst, wird in allen Karten-Repositories, die du für deinen Helm-Client konfiguriert hast, nach Aktualisierungen gesucht:
helm repo update Hang tight while we grab the latest from your chart repositories... ...Successfully got an update from the "bitnami" chart repository Update Complete. ⎈Happy Helming!⎈
Als Nächstes musst du alle gewünschten Aktualisierungen an deinen konfigurierten Werten vornehmen. Wenn du ein Upgrade auf eine neue Version einer Karte durchführst, solltest du dir die Versionshinweise und die Dokumentation der konfigurierbaren Werte ansehen. Es ist eine gute Idee, ein Upgrade zu testen, bevor du es anwendest. Mit der Option --dry-run kannst du dies tun und erhältst ähnliche Werte wie mit dem Befehl helm template:
helm upgrade mysql bitnami/mysql -f values.yaml --dry-run
Verwendung einer Overlay-Konfigurationsdatei
Eine nützliche Option für das Upgrade ist es, die Werte, die du überschreiben möchtest, in einer neuen Konfigurationsdatei anzugeben und sowohl die neue als auch die alte Datei anzuwenden, etwa so:
helm upgrade mysql bitnami/mysql \ -f values.yaml -f new-values.yaml
Die Konfigurationsdateien werden in der Reihenfolge angewendet, in der sie in der Befehlszeile erscheinen. Wenn du also diesen Ansatz verwendest, musst du sicherstellen, dass deine überschriebene Wertedatei nach deiner ursprünglichen Wertedatei erscheint.
Sobald du das Upgrade durchgeführt hast, macht sich Helm an die Arbeit und aktualisiert nur die Ressourcen in der Version, die von deinen Konfigurationsänderungen betroffen sind. Wenn du Änderungen an der Pod-Vorlage für ein StatefulSet vorgenommen hast, werden die Pods gemäß der für das StatefulSet festgelegten Aktualisierungsrichtlinie neu gestartet, wie wir im Abschnitt "StatefulSet-Lebenszyklusmanagement" erläutert haben .
Helm Charts deinstallieren
Wenn du deine Helm-Version nicht mehr verwendest, kannst du sie nach Namen deinstallieren:
helm uninstall mysql
Beachte, dass Helm die PersistentVolumeClaims oder PersistentVolumes, die für dieses Helm-Diagramm erstellt wurden, nicht entfernt. Dies entspricht dem in Kapitel 3 beschriebenen Verhalten von StatefulSets.
Einsatz von Helm für Apache Cassandra
Schalten wir nun einen Gang höher und schauen uns den Einsatz von Apache Cassandra mit Helm an. In diesem Abschnitt verwendest du ein anderes Diagramm, das von Bitnami bereitgestellt wird, sodass du kein weiteres Repository hinzufügen musst. Die Implementierung dieses Diagramms findest du auf GitHub. Helm bietet eine schnelle Möglichkeit, die Metadaten zu diesem Diagramm einzusehen:
helm show chart bitnami/cassandra
Nachdem du dir die Metadaten angesehen hast, solltest du dich auch über die konfigurierbaren Werte informieren. Du kannst die Dateivalues.yaml im GitHub Repo einsehen oder eine andere Option im show Befehl verwenden:
helm show values bitnami/cassandra
Die Liste der Optionen für dieses Diagramm ist kürzer als die Liste für das MySQL-Diagramm, da Cassandra nicht über das Konzept der primären und sekundären Replikate verfügt. Du wirst aber sicherlich ähnliche Optionen für Images, StorageClasses, Sicherheit, Liveness- und Readiness-Probes usw. finden. Einige Konfigurationsoptionen gibt es nur bei Cassandra, z. B. für die JVM-Einstellungen und die Seed Nodes (siehe Kapitel 3).
Eine interessante Funktion dieses Diagramms ist die Möglichkeit, Metriken von Cassandra-Knoten zu exportieren. Wenn du metrics.enabled=true einstellst, injiziert das Diagramm einen Sidecar-Container in jeden Cassandra Pod, der einen Port zur Verfügung stellt, der von Prometheus abgefragt werden kann. Andere Werte unter metrics legen fest, welche Metriken exportiert werden, wie oft sie gesammelt werden und vieles mehr. Auch wenn wir diese Funktion hier nicht nutzen werden, ist die Berichterstattung über Metriken ein wichtiger Bestandteil der Verwaltung der Dateninfrastruktur, die wir in Kapitel 6 behandeln werden.
Für eine einfache Cassandra-Konfiguration mit drei Knoten könntest du die Anzahl der Replikate auf 3 setzen und die anderen Konfigurationswerte auf ihre Standardwerte setzen. Da du jedoch nur einen einzigen Konfigurationswert überschreibst, ist dies ein guter Zeitpunkt, um Helm's Unterstützung für das Setzen von Werten auf der Kommandozeile zu nutzen, anstatt eine values.yaml-Datei bereitzustellen:
helm install cassandra bitnami/cassandra --set replicaCount=3
Wie bereits erwähnt, kannst du den Befehl helm template verwenden, um die Konfiguration vor der Installation zu überprüfen, oder du siehst dir die Datei an, die wir auf GitHub gespeichert haben. Da du die Version jedoch bereits erstellt hast, kannst du auch diesen Befehl verwenden:
helm get manifest cassandra
Wenn du dir die Ressourcen in der YAML ansiehst, wirst du feststellen, dass eine ähnliche Infrastruktur eingerichtet wurde, wie in Abbildung 4-4 dargestellt.
Die Konfiguration umfasst die folgenden Punkte:
Ein ServiceAccount, der auf ein Secret verweist, das das Passwort für das
cassandraAdministratorkonto enthält.Ein einzelnes StatefulSet mit einem Headless Service, der die Pods referenziert. Die Pods sind gleichmäßig auf die verfügbaren Kubernetes Worker Nodes verteilt, auf die wir im nächsten Abschnitt eingehen werden. Der Service stellt Cassandra-Ports zur Verfügung, die für die Kommunikation innerhalb des Kubernetes-Knotens (
7000, mit7001für die sichere Kommunikation über TLS), die Verwaltung über JMX (7199) und den Client-Zugriff über CQL (9042) verwendet werden.
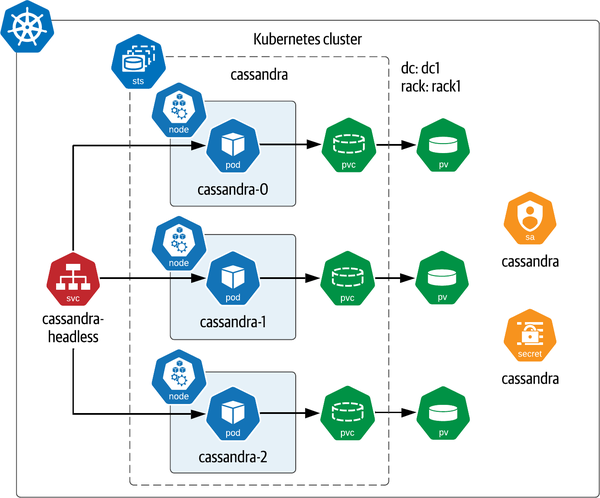
Abbildung 4-4. Bereitstellen von Apache Cassandra mit dem Bitnami Helm-Diagramm
Diese Konfiguration stellt eine einfache Cassandra-Topologie dar, bei der sich alle drei Knoten in einem einzigen Rechenzentrum und Rack befinden. Diese einfache Topologie spiegelt eine der Einschränkungen dieses Diagramms wider: Es bietet nicht die Möglichkeit, einen Cassandra-Cluster zu erstellen, der aus mehreren Rechenzentren und Racks besteht. Um einen komplexeren Einsatz zu erstellen, müsstest du mehrere Helm-Versionen mit demselben clusterName (in diesem Fall verwendest du den Standardnamen cassandra), aber mit einem anderen Rechenzentrum und Rack pro Einsatz installieren. Außerdem musst du die IP-Adresse einiger Knoten im ersten Rechenzentrum ermitteln, um sie als additionalSeeds zu verwenden, wenn du die Versionen für die anderen Racks konfigurierst.
Affinität und Anti-Affinität
Wie in Abbildung 4-4 zu sehen ist, sind die Cassandra-Knoten gleichmäßig auf die Worker Nodes in deinem Cluster verteilt. Um dies in deiner eigenen Cassandra-Version zu überprüfen, könntest du etwas wie das Folgende ausführen:
kubectl describe pods | grep "^Name:" -A 3 Name: cassandra-0 Namespace: default Priority: 0 Node: kind-worker/172.20.0.7 -- Name: cassandra-1 Namespace: default Priority: 0 Node: kind-worker2/172.20.0.6 -- Name: cassandra-2 Namespace: default Priority: 0 Node: kind-worker3/172.20.0.5
Wie du sehen kannst, läuft jeder Cassandra-Knoten auf einem anderen Worker Node. Wenn dein Kubernetes-Cluster mindestens drei Worker Nodes und keine anderen Workloads hat, wirst du wahrscheinlich ein ähnliches Verhalten beobachten. Es stimmt zwar, dass diese gleichmäßige Verteilung in einem Cluster mit gleichmäßiger Auslastung der Worker Nodes natürlich vorkommen kann, aber das ist in deiner Produktionsumgebung wahrscheinlich nicht der Fall. Um die maximale Verfügbarkeit deiner Daten zu gewährleisten, wollen wir jedoch versuchen, die Absicht der Cassandra-Architektur zu respektieren, die Knoten auf verschiedenen Rechnern zu betreiben, um eine hohe Verfügbarkeit zu gewährleisten.
Um diese Isolierung zu gewährleisten, nutzt das Bitnami Helm-Diagramm die Affinitätsfunktionen von Kubernetes, insbesondere die Anti-Affinität. Wenn du dir die generierte Konfiguration für das Cassandra StatefulSet ansiehst, wirst du Folgendes sehen:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: cassandra
namespace: default
labels: ...
spec:
...
template:
metadata:
labels: ...
spec:
...
affinity:
podAffinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchLabels:
app.kubernetes.io/name: cassandra
app.kubernetes.io/instance: cassandra
namespaces:
- "default"
topologyKey: kubernetes.io/hostname
weight: 1
nodeAffinity:
Wie hier zu sehen ist, listet die Pod-Vorlagenspezifikation drei mögliche Arten von Affinität auf, wobei nur die podAntiAffinity definiert ist. Was bedeuten diese Konzepte?
- Pod-Affinität
- Die Vorliebe, einen Pod auf einem Knoten einzuplanen, auf dem ein anderer bestimmter Pod läuft. Die Pod-Affinität kann z.B. genutzt werden, um einen Webserver mit seinem Cache zusammenzulegen.
- Pods Anti-Affinität
- Das Gegenteil von Pod-Affinität, d.h. die Vorgabe, dass ein Pod nicht auf einem Knoten geplant wird, auf dem ein anderer identifizierter Pod läuft. Das ist die Einschränkung, die in diesem Beispiel verwendet wird, wie wir gleich sehen werden.
- Knotenpunkt-Affinität
- Eine Vorgabe, dass ein Pod auf einem Knoten mit bestimmten Eigenschaften ausgeführt werden soll.
Jede Art von Affinität kann entweder als harte oder als weiche Beschränkung ausgedrückt werden. Diese sind als requiredDuringSchedulingIgnoredDuringExecution und preferredDuringSchedulingIgnoredDuringExecution bekannt. Die erste Bedingung legt Regeln fest, die erfüllt werden müssen, bevor ein Pod auf einem Knoten eingeplant wird, während die zweite Bedingung eine Präferenz angibt, die das Zeitplannungsprogramm zu erfüllen versucht, aber gegebenenfalls lockern kann, um den Pod einzuplanen.
IgnoredDuringExcecution bedeutet, dass die Einschränkungen nur gelten, wenn die Pods zum ersten Mal eingeplant werden. In Zukunft werden neue RequiredDuringExecution Optionen namens requiredDuringSchedulingRequiredDuringExecution und requiredDuringSchedulingRequiredDuringExecution hinzugefügt. Mit diesen Optionen wird Kubernetes aufgefordert, Pods zu evakuieren (d.h. auf einen anderen Knoten zu verschieben), die die Kriterien nicht mehr erfüllen - z.B. durch eine Änderung ihrer Labels.
Im vorangegangenen Beispiel ist in der Pod-Template-Spezifikation für das Cassandra StatefulSet eine Anti-Affinitätsregel festgelegt, die die Labels verwendet, die auf jeden Cassandra Pod angewendet werden. Das bedeutet, dass Kubernetes versucht, die Pods auf die verfügbaren Worker Nodes zu verteilen.
Das sind die wichtigsten Punkte, die du in der Bitnami Helm-Tabelle für Cassandra siehst. Um die Dinge zu bereinigen, deinstalliere die Cassandra-Version:
helm uninstall cassandra
Wenn du nicht mehr mit Bitnami Helm Charts arbeiten möchtest, kannst du das Repository auch aus deinem Helm-Client entfernen:
helm repo remove bitnami
Mehr Kubernetes Zeitplannungsprogramm-Einschränkungen
Kubernetes unterstützt zusätzliche Mechanismen, um dem Zeitplannungsprogramm Hinweise zur Platzierung von Pods zu geben. Einer der einfachsten ist NodeSelectors, der der Node-Affinität sehr ähnlich ist, aber mit einer weniger ausdrucksstarken Syntax, die mit einem oder mehreren Labels übereinstimmen kann, indem sie AND-Logik verwendet. Da du möglicherweise nicht über die erforderlichen Berechtigungen verfügst, um den Worker Nodes in deinem Cluster Labels zuzuweisen, ist die Pod-Affinität oft die bessere Option. Taints und Toleranzen sind ein weiterer Mechanismus, mit dem du Worker Nodes so konfigurieren kannst, dass bestimmte Pods nicht auf diesen Nodes eingeplant werden können.
Generell solltest du darauf achten, alle Einschränkungen zu verstehen, die du dem Zeitplannungsprogramm von Kubernetes durch verschiedene Workloads auferlegst, um seine Fähigkeit, Pods zu platzieren, nicht zu sehr einzuschränken. In der Kubernetes-Dokumentation findest du weitere Informationen zu Zeitplannungsprogrammen. In "Alternative Zeitplannungsprogramme für Kubernetes" werden wir uns außerdem ansehen, wie du verschiedene Zeitplannungsprogramme in Kubernetes einbinden kannst .
Helm, CI/CD und Betrieb
Helm ist ein leistungsstarkes Tool, das sich auf eine Hauptaufgabe konzentriert: die Bereitstellung komplexer Anwendungen in Kubernetes-Clustern. Um den größten Nutzen aus Helm zu ziehen, solltest du dir überlegen, wie es in dein größeres CI/CD-Toolset passt:
Automatisierungsserver wie Jenkins erstellen, testen und verteilen Software automatisch anhand von Skripten, die als Aufträge bezeichnet werden. Diese Aufträge werden in der Regel auf der Grundlage vordefinierter Auslöser ausgeführt, z. B. einer Übergabe an ein Quellcode-Repository. Helm-Diagramme können in Aufträgen referenziert werden, um eine zu testende Anwendung und ihre unterstützende Infrastruktur in einem Kubernetes-Cluster zu installieren.
IaC-Automatisierungstools wie Terraform ermöglichen es dir, Templates und Skripte zu definieren, die beschreiben, wie die Infrastruktur in einer Vielzahl von Cloud-Umgebungen erstellt wird. Du könntest zum Beispiel ein Terraform-Skript schreiben, das die Erstellung einer neuen VPC bei einem bestimmten Cloud-Provider und die Erstellung eines neuen Kubernetes-Clusters in dieser VPC automatisiert. Das Skript könnte dann Helm nutzen, um Anwendungen innerhalb des Kubernetes-Clusters zu installieren.
Zwar gibt es Überschneidungen bei den Funktionen dieser Tools, aber du solltest bei der Zusammenstellung deines Toolsets die Stärken und Grenzen der einzelnen Tools berücksichtigen. Aus diesem Grund möchten wir darauf hinweisen, dass Helm bei der Verwaltung des Betriebs von Anwendungen, die es einsetzt, seine Grenzen hat. Um uns ein Bild von den damit verbundenen Herausforderungen zu machen, haben wir mit einem Praktiker gesprochen, der Helm-Diagramme erstellt hat, um eine komplexe Datenbankbereitstellung zu verwalten. In dieser Diskussion werden Konzepte wie Kubernetes Custom Resource Definitions (CRDs) und das Operator-Pattern vorgestellt, die wir beide in Kapitel 5 ausführlich behandeln werden.
Wie John Sanda in seinem Kommentar anmerkt, ist Helm ein leistungsfähiges Tool für die Skripterstellung von Anwendungen, die aus mehreren Kubernetes-Ressourcen bestehen, kann aber bei der Verwaltung komplexerer betrieblicher Aufgaben weniger effektiv sein. Wie du in den folgenden Kapiteln sehen wirst, wird für Dateninfrastrukturen und andere komplexe Anwendungen häufig ein Helm-Diagramm verwendet, um einen Operator einzusetzen, der dann wiederum sowohl die Bereitstellung als auch den Lebenszyklus der Anwendung verwalten kann.
Zusammenfassung
In diesem Kapitel hast du gelernt, wie ein Paketmanagement-Tool wie Helm dir helfen kann, den Einsatz von Anwendungen auf Kubernetes zu verwalten, einschließlich deiner Datenbankinfrastruktur. Nebenbei hast du auch gelernt, wie du zusätzliche Kubernetes-Ressourcen wie ServiceAccounts, Secrets und ConfigMaps nutzen kannst. Jetzt ist es an der Zeit, unsere Diskussion über den Betrieb von Datenbanken in Kubernetes abzurunden. Im nächsten Kapitel werden wir tiefer in die Verwaltung von Datenbankoperationen in Kubernetes eintauchen, indem wir das Operator-Muster verwenden.
Get Cloud Native Daten auf Kubernetes verwalten now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

