Kapitel 1. Einführung in die Cloud Native Data Infrastructure: Persistenz, Streaming und Batch-Analytik
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Arbeitest du an der Lösung von Datenproblemen und siehst dich mit der Notwendigkeit einer Modernisierung konfrontiert? Ist deine Cloud-native Anwendung auf die Verwendung von Microservices und Service Mesh beschränkt? Wenn du Anwendungen auf Kubernetes (manchmal auch als "K8s" abgekürzt) bereitstellst, ohne Daten mit einzubeziehen, hast du Cloud Native noch nicht vollständig verinnerlicht. Jedes Element deiner Anwendung sollte die Cloud Native-Prinzipien der Skalierbarkeit, Elastizität, Selbstheilung und Beobachtbarkeit verkörpern, auch der Umgang mit Daten.
Ingenieure, die mit Daten arbeiten, befassen sich in erster Linie mit zustandsbehafteten Diensten, und das wird unser Schwerpunkt sein: die Erweiterung deiner Fähigkeiten zur Verwaltung von Daten in Kubernetes. Unser Ziel ist es, mit diesem Buch deine Reise zu Cloud Native Data zu bereichern. Wenn du gerade erst mit Cloud Native Applications beginnst, gibt es keinen besseren Zeitpunkt, um alle Aspekte des Stacks einzubeziehen. Diese Konvergenz ist die Zukunft, wie wir Cloud-Ressourcen nutzen werden.
Wie sieht also diese Zukunft aus, die wir gemeinsam gestalten?
Zu lange haben Daten außerhalb von Kubernetes gelebt, was viel zusätzlichen Aufwand und Komplexität verursacht hat. Wir werden noch auf die Gründe dafür eingehen, aber jetzt ist es an der Zeit, den gesamten Stack zu kombinieren, um Anwendungen schneller und in der benötigten Größe zu entwickeln. Mit der aktuellen Technologie ist das sehr gut möglich. Wir haben uns von der Vergangenheit, in der einzelne Server eingesetzt wurden, in die Zukunft bewegt, in der wir in der Lage sein werden, ganze virtuelle Rechenzentren einzusetzen. Entwicklungszyklen, die früher Monate und Jahre dauerten, können jetzt in Tagen und Wochen bewältigt werden. Open-Source-Komponenten können jetzt in einem einzigen Einsatz auf Kubernetes kombiniert werden, der von deinem Laptop bis zum größten Cloud-Provider portabel ist.
Auch der Open-Source-Beitrag ist kein kleiner Teil davon. Kubernetes und die Projekte, die wir in diesem Buch besprechen, stehen unter der Apache License 2.0, sofern nicht anders angegeben, und das aus gutem Grund. Wenn wir eine Infrastruktur aufbauen, die überall laufen kann, brauchen wir ein Lizenzmodell, das uns die Freiheit der Wahl lässt. Open Source ist sowohl frei wie Bier als auch frei wie Freiheit, und beides zählt beim Aufbau von Cloud-nativen Anwendungen auf Kubernetes. Open Source war der Treibstoff für viele Revolutionen im Infrastrukturbereich, und das ist keine Ausnahme.
Das ist es, was wir bauen: die nahe Zukunft von vollständig realisierten Kubernetes-Anwendungen. Die letzte Komponente ist die wichtigste, und das bist du. Als Leser dieses Buches bist du einer der Menschen, die diese Zukunft gestalten werden. Das ist es, was wir als Ingenieure tun. Wir erfinden die Art und Weise, wie wir komplizierte Infrastrukturen einsetzen, immer wieder neu, um auf die steigende Nachfrage zu reagieren. Als 1960 das erste elektronische Datenbanksystem für American Airlines in Betrieb genommen wurde, sorgte ein kleines Heer von Ingenieuren dafür, dass es rund um die Uhr funktionierte und online blieb. Der Fortschritt führte uns von Mainframes zu Minicomputern, zu Mikrocomputern und schließlich zu unserem heutigen Flottenmanagement. Jetzt setzt sich diese Entwicklung mit Cloud Native und Kubernetes fort.
Dieses Kapitel befasst sich mit den Komponenten von Cloud Native Applications, den Herausforderungen beim Betrieb von Stateful Workloads und den wichtigsten Bereichen, die in diesem Buch behandelt werden. Beginnen wir mit den Bausteinen, aus denen die Dateninfrastruktur besteht.
Infrastruktur-Typen
In den letzten 20 Jahren hat sich der Ansatz für die Infrastruktur langsam in zwei Bereiche geteilt, die die Art und Weise widerspiegeln, wie wir verteilte Anwendungen einsetzen (wie in Abbildung 1-1 dargestellt):
- Zustandslose Dienste
- Dies sind Dienste, die Informationen nur für den unmittelbaren Lebenszyklus der aktiven Anfrage aufbewahren - zum Beispiel ein Dienst, der formatierte Warenkorbinformationen an einen mobilen Client sendet. Ein typisches Beispiel ist ein Anwendungsserver, der die Geschäftslogik für den Einkaufswagen ausführt. Die Informationen über den Inhalt des Warenkorbs befinden sich jedoch außerhalb dieser Dienste. Sie müssen nur für eine kurze Zeitspanne zwischen Anfrage und Antwort online sein. Die Infrastruktur, die für die Bereitstellung des Dienstes verwendet wird, kann leicht wachsen und schrumpfen, ohne dass dies Auswirkungen auf die Gesamtanwendung hat, da die Rechen- und Netzwerkressourcen bei Bedarf skaliert werden. Da wir keine kritischen Daten in den einzelnen Diensten speichern, können diese Daten schnell und mit wenig Koordination erstellt und gelöscht werden. Zustandslose Dienste sind ein entscheidendes Architekturelement in verteilten Systemen.
- Zustandsabhängige Dienste
- Diese Dienste müssen Informationen von einer Anfrage zur nächsten beibehalten. Festplatten und Speicher speichern Daten, die über mehrere Anfragen hinweg verwendet werden können. Ein Beispiel dafür ist eine Datenbank oder ein Dateisystem. Die Skalierung von zustandsbehafteten Diensten ist komplexer, da die Informationen für eine hohe Verfügbarkeit in der Regel repliziert werden müssen. Dies erfordert Konsistenz und Mechanismen, um die Daten zwischen den Replikaten auf dem gleichen Stand zu halten. Diese Dienste haben in der Regel unterschiedliche Skalierungsmethoden, sowohl vertikal als auch horizontal. Daher sind für sie andere Betriebsaufgaben erforderlich als für zustandslose Dienste.
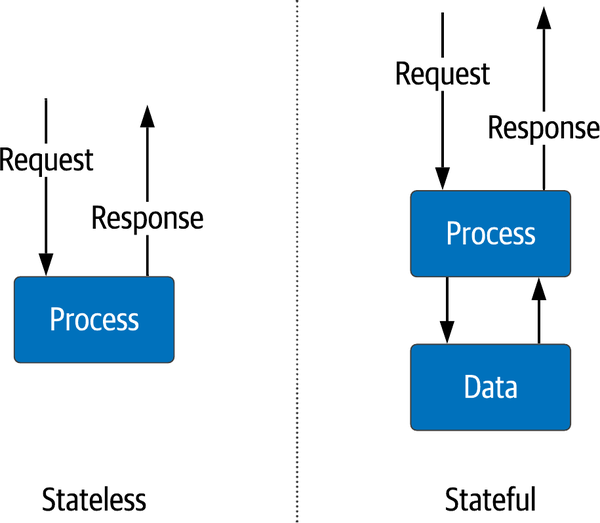
Abbildung 1-1. Zustandslose versus zustandsabhängige Dienste
Nicht nur die Art und Weise, wie Informationen gespeichert werden, sondern auch die Entwicklung von Systemen, die eine automatische Bereitstellung der Infrastruktur ermöglichen, hat sich verändert. Zu diesen jüngsten Fortschritten gehören die folgenden:
Physische Server sind virtuellen Maschinen (VMs) gewichen, die einfach zu installieren und zu warten sind.
VMs wurden vereinfacht und auf bestimmte Anwendungen zu Containern zusammengefasst.
Mit Containern können Infrastrukturingenieure die Anforderungen einer Anwendung an das Betriebssystem in eine einzige ausführbare Datei packen.
Der Einsatz von Containern hat zweifelsohne die Konsistenz von Implementierungen erhöht, was die Bereitstellung und den Betrieb von Infrastrukturen in großen Mengen erleichtert hat. Es gibt nur wenige Systeme, die die Explosion von Containern so gut orchestrieren können wie Kubernetes, was an seinem unglaublichen Wachstum abzulesen ist. Dies spricht dafür, wie gut es das Problem löst. In der offiziellen Dokumentation wird Kubernetes wie folgt beschrieben:
Kubernetes ist eine portable, erweiterbare Open-Source-Plattform für die Verwaltung von Container-Workloads und -Diensten, die sowohl eine deklarative Konfiguration als auch eine Automatisierung ermöglicht. Sie hat ein großes, schnell wachsendes Ökosystem. Kubernetes-Dienste, -Support und -Tools sind weit verbreitet.
Kubernetes wurde ursprünglich für zustandslose Workloads entwickelt, und das ist es auch, was es traditionell am besten kann. Kubernetes hat sich einen Ruf als "Plattform für den Aufbau von Plattformen" in einer cloud-nativen Weise erarbeitet. Es gibt jedoch ein vernünftiges Argument dafür, dass eine vollständige Cloud-native Lösung auch Daten berücksichtigen muss. Das ist das Ziel dieses Buches: Wir wollen herausfinden, wie man mit Kubernetes cloud-native Datenlösungen erstellen kann. Doch zunächst wollen wir klären, was "Cloud Native" bedeutet.
Was sind Cloud Native Data?
Beginnen wir damit, die Aspekte von Cloud Native-Daten zu definieren, die uns bei einer endgültigen Definition helfen können. Beginnen wir mit der Definition von Cloud Native von der Cloud Native Computing Foundation (CNCF):
Cloud-native Technologien ermöglichen es Unternehmen, skalierbare Anwendungen in modernen, dynamischen Umgebungen wie öffentlichen, privaten und hybriden Clouds zu entwickeln und zu betreiben. Container, Service Meshes, Microservices, unveränderliche Infrastruktur und deklarative APIs sind Beispiele für diesen Ansatz.
Diese Techniken ermöglichen lose gekoppelte Systeme, die widerstandsfähig, verwaltbar und beobachtbar sind. In Kombination mit einer robusten Automatisierung ermöglichen sie es den Ingenieuren, mit minimalem Aufwand häufig und vorhersehbar Änderungen vorzunehmen, die große Auswirkungen haben.
Diese Definition beschreibt einen Zielzustand, wünschenswerte Eigenschaften und Beispiele für Technologien, die beides verkörpern. Auf der Grundlage dieser formalen Definition können wir die Eigenschaften zusammenfassen, die eine Cloud Native-Anwendung von anderen Einsatzarten in Bezug auf den Umgang mit Daten unterscheiden. Schauen wir uns diese Eigenschaften genauer an:
- Skalierbarkeit
- Wenn ein Dienst für eine Einheit von Ressourcen eine Einheit von Arbeit produzieren kann, sollte die Menge der Arbeit, die ein Dienst leisten kann, durch Hinzufügen weiterer Ressourcen erhöht werden. Skalierbarkeit beschreibt die Fähigkeit eines Dienstes, zusätzliche Ressourcen einzusetzen, um zusätzliche Arbeit zu leisten. Im Idealfall sollten Dienste unendlich skalierbar sein, wenn sie über eine unendliche Menge an Rechen-, Netzwerk- und Speicherressourcen verfügen. Für Daten bedeutet das, dass sie ohne Ausfallzeiten skaliert werden können. Bei älteren Systemen war eine Wartungsphase erforderlich, in der alle Dienste abgeschaltet werden mussten, um neue Ressourcen hinzuzufügen. Mit den Anforderungen von Cloud-nativen Anwendungen sind Ausfallzeiten nicht mehr akzeptabel.
- Elastizität
Während Skalierbarkeit bedeutet, dass Ressourcen hinzugefügt werden, um den Bedarf zu decken, ist Elastizität die Fähigkeit, diese Ressourcen freizugeben, wenn sie nicht mehr benötigt werden. Der Unterschied zwischen Skalierbarkeit und Elastizität wird in Abbildung 1-2 verdeutlicht. Elastizität kann auch als On-Demand-Infrastruktur bezeichnet werden. In einer eingeschränkten Umgebung wie einem privaten Rechenzentrum ist dies entscheidend für die gemeinsame Nutzung begrenzter Ressourcen. Bei Cloud-Infrastrukturen, die für jede genutzte Ressource Gebühren erheben, kannst du so verhindern, dass du für Dienste bezahlst, die du nicht brauchst. Wenn es um die Verwaltung von Daten geht, müssen wir in der Lage sein, Speicherplatz zurückzugewinnen und die Nutzung zu optimieren, indem wir z. B. ältere Daten auf weniger teure Speicherebenen verschieben.
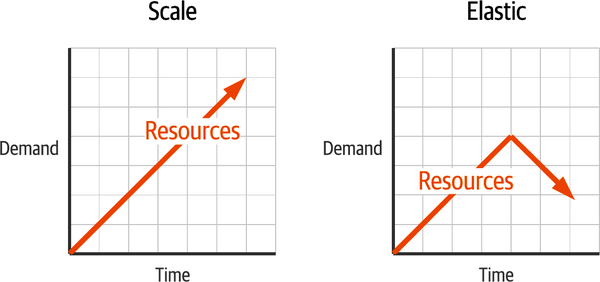
Abbildung 1-2. Skalierbarkeit und Elastizität im Vergleich
- Selbstheilung
- Schlimme Dinge passieren. Wie wird deine Infrastruktur dann reagieren? Eine selbstheilende Infrastruktur leitet den Datenverkehr um, teilt Ressourcen neu zu und hält die Service Level aufrecht. Da immer größere und komplexere verteilte Anwendungen eingesetzt werden, ist dies eine immer wichtigere Eigenschaft einer nativen Cloud-Anwendung. Das ist es, was dich davor bewahrt, um 3 Uhr morgens geweckt zu werden. Für Daten bedeutet dies, dass wir Fähigkeiten brauchen, um Probleme mit Daten wie fehlende Daten und Datenqualität zu erkennen.
- Beobachtbarkeit
- Wenn etwas fehlschlägt und du es nicht überwachst, ist es dann passiert? Leider ist die Antwort nicht nur "Ja", sondern das kann ein noch schlimmeres Szenario sein. Verteilte Anwendungen sind hochdynamisch und der Einblick in jeden Dienst ist entscheidend für die Aufrechterhaltung der Service Levels. Abhängigkeiten können zu komplexen Ausfallszenarien führen. Deshalb ist die Beobachtbarkeit ein wichtiger Bestandteil bei der Entwicklung von Cloud-nativen Anwendungen. In Datensystemen erfordern die alltäglichen Datenmengen effiziente Methoden zur Überwachung des Flusses und des Zustands der Infrastruktur. In den meisten Fällen können Betreiber durch frühzeitige Warnungen vor Problemen kostspielige Ausfallzeiten vermeiden.
Nachdem wir alle vorherigen Definitionen kennen, wollen wir nun eine Definition ausprobieren, die diese Eigenschaften ausdrückt:
Cloud-native Datenansätze befähigen Unternehmen, die die Methodik der Cloud-nativen Anwendungen übernommen haben, Daten ganzheitlich einzubeziehen, anstatt das Erbe von Menschen, Prozessen und Technologien zu nutzen, so dass Daten elastisch nach oben und unten skaliert werden können und Beobachtbarkeit und Selbstheilung gefördert werden. Beispiele dafür sind containerisierte Daten, deklarative Daten, Daten-APIs, Datennetze und Cloud Native Data Infrastructure (d. h. Datenbanken, Streaming- und Analysetechnologien, die selbst als Cloud Native Applications konzipiert sind).
Damit die Dateninfrastruktur mit dem Rest unserer Anwendung mithalten kann, müssen wir jedes Teil integrieren. Dazu gehören die Automatisierung der Skalierung, Elastizität und Selbstheilung. APIs werden benötigt, um Dienste zu entkoppeln und die Entwicklungsgeschwindigkeit zu erhöhen sowie den gesamten Stack deiner Anwendung zu beobachten, um wichtige Entscheidungen zu treffen. Als Ganzes betrachtet, sollten deine Anwendung und deine Dateninfrastruktur als eine Einheit erscheinen.
Mehr Infrastruktur, mehr Probleme
Unabhängig davon, ob deine Infrastruktur in einer Cloud, vor Ort oder beides (gemeinhin als hybrid bezeichnet) betrieben wird, kannst du viel Zeit mit der manuellen Konfiguration verbringen. Dinge in einen Editor einzutippen und unglaublich detaillierte Konfigurationsarbeiten durchzuführen, erfordert tiefgreifende Kenntnisse der jeweiligen Technologie. In den letzten 20 Jahren hat die DevOps-Community erhebliche Fortschritte gemacht, sowohl beim Code als auch bei der Art und Weise, wie wir unsere Infrastruktur bereitstellen. Dies ist ein entscheidender Schritt in der Entwicklung der modernen Infrastruktur. DevOps hat uns bei der Skalierung von Anwendungen einen Vorsprung verschafft, aber nur knapp. Für die vollständige Skripterstellung eines einzelnen Datenbankservers ist wohl die gleiche Menge an Wissen erforderlich. Nur können wir das jetzt mit Templates und Skripten millionenfach tun (falls nötig). Was bisher gefehlt hat, ist die Verbindung zwischen den Komponenten und eine ganzheitliche Sicht auf den gesamten Anwendungsstapel. Lasst uns dieses Problem gemeinsam angehen. (Vorahnung: Das ist ein Problem, das gelöst werden muss.)
Wie bei jedem guten technischen Problem, sollten wir es in überschaubare Teile zerlegen. Der erste Teil ist das Ressourcenmanagement. Unabhängig von den vielen Möglichkeiten, die wir entwickelt haben, um in großem Maßstab zu arbeiten, versuchen wir im Grunde, drei Dinge so effizient wie möglich zu verwalten: Rechenleistung, Netzwerk und Speicherung, wie in Abbildung 1-3 dargestellt. Dies sind die kritischen Ressourcen, die jede Anwendung benötigt, und der Treibstoff, der beim Wachstum verbrannt wird. Es überrascht nicht, dass diese Ressourcen auch die monetäre Komponente für eine laufende Anwendung darstellen. Wir werden belohnt, wenn wir die Ressourcen klug nutzen, und zahlen einen hohen Preis, wenn wir es nicht tun. Egal, wo du deine Anwendung laufen lässt, dies sind die primitivsten Einheiten. Wenn du deine Anwendung vor Ort betreibst, wird alles gekauft und gehört dir. In der Cloud mieten wir sie.
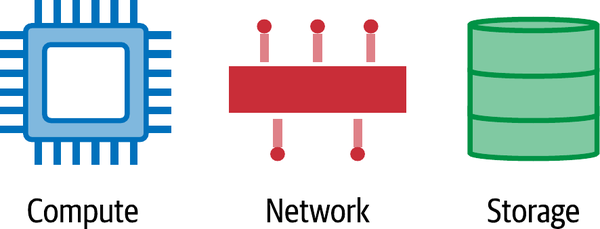
Abbildung 1-3. Grundlegende Ressourcen von Cloud-Anwendungen: Rechenleistung, Netzwerk und Speicherung
Der zweite Teil des Problems besteht darin, dass ein ganzer Stack als eine Einheit agiert. DevOps hat viele Tools für die Verwaltung der einzelnen Komponenten bereitgestellt, aber das Bindegewebe zwischen ihnen bietet das Potenzial für eine unglaubliche Effizienz - ähnlich wie bei der Paketierung von Anwendungen für den Desktop, aber im Maßstab des Rechenzentrums. Dieses Potenzial hat eine ganze Community rund um Cloud Native Applications entstehen lassen. Diese Anwendungen ähneln dem, was wir schon immer eingesetzt haben. Der Unterschied besteht darin, dass moderne Cloud-Anwendungen nicht aus einem einzigen Prozess mit Geschäftslogik bestehen. Sie sind eine komplexe Koordination vieler containerisierter Prozesse, die sicher und zuverlässig kommunizieren müssen. Die Speicherung muss an die aktuellen Anforderungen der Anwendung angepasst werden, ohne dabei zu vergessen, wie sie zur Stabilität der Anwendung beiträgt. Wenn wir daran denken, zustandslose Anwendungen einzusetzen, bei denen die Daten nicht in der gleichen Steuerungsebene verwaltet werden, klingt das unvollständig, weil es so ist. Die Aufteilung deiner Anwendungskomponenten in verschiedene Steuerungsebenen führt zu mehr Komplexität und widerspricht damit den Idealen von Cloud Native.
Kubernetes führt den Weg an
Wie bereits erwähnt, hat uns die DevOps-Automatisierung bei der Erfüllung von Skalierungsanforderungen an die Spitze gebracht. Durch die Containerisierung entstand der Bedarf an einer viel besseren Orchestrierung, und Kubernetes hat diesen Bedarf erfüllt. Für Betreiber ist die Beschreibung eines kompletten Anwendungsstapels in einer Bereitstellungsdatei eine reproduzierbare und portable Infrastruktur. Das liegt daran, dass Kubernetes weit über das einfache Deployment-Management hinausgeht, das in der DevOps-Tooltasche beliebt ist. Die Kubernetes-Kontrollebene wendet die Bereitstellungsanforderung auf die zugrunde liegenden Rechen-, Netzwerk- und Speichereinheiten an, um den gesamten Lebenszyklus der Anwendungsinfrastruktur zu verwalten. Der gewünschte Zustand deiner Anwendung bleibt erhalten, auch wenn sich die zugrunde liegende Hardware ändert. Anstatt VMs einzusetzen, setzen wir jetzt virtuelle Rechenzentren als vollständige Definition ein, wie in Abbildung 1-4 dargestellt.
Die steigende Popularität von Kubernetes hat alle anderen Container-Orchestrierungstools, die in DevOps verwendet werden, in den Schatten gestellt. Sie hat jede andere Art der Infrastrukturbereitstellung überholt und es gibt keine Anzeichen dafür, dass sie langsamer wird. Zu Beginn wurde es jedoch vor allem bei zustandslosen Diensten eingesetzt.
Die Verwaltung von Dateninfrastrukturen in großem Maßstab war schon lange vor der Umstellung auf Container und Kubernetes ein Problem. Stateful-Dienste wie Datenbanken entwickelten sich parallel zur Einführung von Kubernetes anders. Viele Experten rieten, dass Kubernetes der falsche Weg sei, um zustandsbehaftete Dienste zu betreiben, und dass diese Workloads außerhalb von Kubernetes bleiben sollten. Dieser Ansatz funktionierte, bis er nicht mehr funktionierte, und viele dieser Experten treiben nun die notwendigen Änderungen in Kubernetes voran, um den gesamten Stack zu konvergieren.
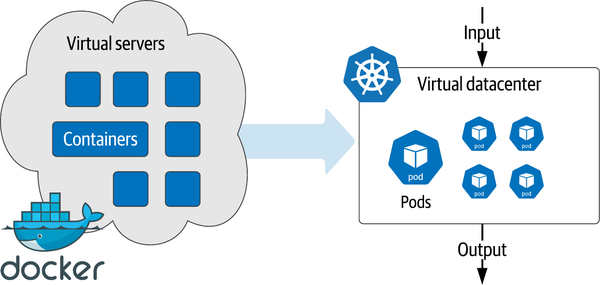
Abbildung 1-4. Wechsel von virtuellen Servern zu virtuellen Rechenzentren
Was sind also die Herausforderungen von Stateful Services? Warum ist es so schwierig, eine Dateninfrastruktur mit Kubernetes einzurichten? Schauen wir uns die einzelnen Komponenten unserer Infrastruktur an.
Compute auf Kubernetes verwalten
In der Dateninfrastruktur hat das Mooresche Gesetz die Aufrüstung zu einem regelmäßigen Ereignis gemacht. Das Mooresche Gesetz sagt voraus, dass sich die Rechenkapazität alle 18 Monate verdoppelt. Wenn sich deine Anforderungen alle 18 Monate verdoppeln, kannst du durch den Austausch von Hardware mithalten. Irgendwann begann sich die reine Rechenleistung zu nivellieren. Die Hersteller fügten immer mehr Prozessoren und Kerne hinzu, um mit dem Mooreschen Gesetz Schritt zu halten. Das führte zu einer gemeinsamen Nutzung von Rechenressourcen auf einem Server mit VMs und Containern und ermöglichte es uns, die riesigen Pools an Rechenleistung anzuzapfen, die in den Inseln der physischen Server stecken. Kubernetes erweiterte den Umfang der Verwaltung von Rechenressourcen, indem es das gesamte Rechenzentrum als einen großen Ressourcenpool über mehrere physische Geräte hinweg betrachtete.
Die gemeinsame Nutzung von Rechenressourcen mit anderen Diensten ist in der Datenwelt ein Tabu. Daten-Workloads sind in der Regel ressourcenintensiv, und die Gefahr, dass ein Dienst einen anderen beeinflusst (bekannt als das Problem der lauten Nachbarn), hat dazu geführt, dass sie von anderen Workloads isoliert werden. Dieser Einheitsansatz schließt die Möglichkeit bedeutenderer Vorteile aus. Erstens wird davon ausgegangen, dass alle Datenservice-Ressourcenanforderungen gleich sind. Apache Pulsar-Broker können weitaus geringere Anforderungen haben als ein Apache Spark-Worker, und beide sind nicht vergleichbar mit einer großen MySQL-Instanz, die für OLAP-Berichte (Online Analytical Processing) verwendet wird. Zweitens bietet die Möglichkeit, die zugrunde liegende Hardware von den laufenden Anwendungen zu entkoppeln, den Betreibern eine Menge unterschätzter Flexibilität. Cloud-native Anwendungen, die Skalierbarkeit, Elastizität und Selbstheilung benötigen, brauchen das, was Kubernetes bieten kann. Daten sind da keine Ausnahme.
Netzwerk in Kubernetes verwalten
Der Aufbau einer verteilten Anwendung erfordert von Natur aus ein zuverlässiges und sicheres Netzwerk. Cloud-native Anwendungen erhöhen die Komplexität des Hinzufügens und Entfernens von Diensten und machen eine dynamische Netzwerkkonfiguration zu einer neuen Anforderung. Kubernetes verwaltet all dies automatisch in deinem virtuellen Rechenzentrum. Wenn neue Dienste online gehen, ist es, als würde ein virtuelles Netzwerkteam in Aktion treten. IP-Adressen werden zugewiesen, Routen erstellt, DNS-Einträge hinzugefügt, das virtuelle Sicherheitsteam stellt sicher, dass Firewall-Regeln vorhanden sind, und wenn gewünscht, sorgen TLS-Zertifikate (Transport Layer Securiity) für eine End-to-End-Verschlüsselung.
Die Dateninfrastruktur ist in der Regel weit weniger dynamisch als Microservices. Für Datenbanken ist eine feste IP mit einem Hostnamen die Norm. Analysesysteme wie Apache Flink sind dynamisch in der Verarbeitung, haben aber eine feste Hardware-Adresszuweisung. Die Servicequalität steht in der Regel ganz oben auf der Anforderungsliste, und deshalb hat der Wunsch nach dedizierter Hardware und dedizierten Netzwerken die Administratoren von Kubernetes abgehalten.
Der Vorteil einer in Kubernetes betriebenen Dateninfrastruktur liegt weniger in den Anforderungen der Vergangenheit als vielmehr in den Anforderungen der Zukunft. Die dynamische Skalierung von Ressourcen kann zu einem Wasserfall von Abhängigkeiten führen. Die Automatisierung ist die einzige Möglichkeit, saubere und effiziente Netzwerke aufrechtzuerhalten, die das Lebenselixier verteilter, zustandsloser Systeme sind. Die Zukunft der Cloud Native Applications wird mehr Komponenten und neue Herausforderungen mit sich bringen, z. B. die Frage, wo die Anwendungen laufen werden. Zu den bisherigen Sorgen um Latenz und Durchsatz kommen nun noch die Einhaltung gesetzlicher Vorschriften und die Datenhoheit hinzu. Die deklarative Natur von Kubernetes-Netzwerken macht es zu einer perfekten Lösung für die Dateninfrastruktur.
Speicherung in Kubernetes verwalten
Jeder Dienst, der Persistenz oder Analysen über große Datenmengen bereitstellt, benötigt die richtige Art von Speicherung. Frühe Versionen von Kubernetes betrachteten die Speicherung als einen grundlegenden Bestandteil des Stacks und gingen davon aus, dass die meisten Arbeitslasten flüchtig sind. Für Daten war das eine große Diskrepanz - du kannst nicht zulassen, dass deine Postgres-Datendateien jedes Mal gelöscht werden, wenn ein Container verschoben wird. Außerdem reichte die zugrundeliegende Speicherung von hochleistungsfähigen NVMe-Platten bis hin zu alten 5400 RPM Spinning Disks, und du konntest nicht immer sicher sein, welche Art von Hardware du bekommen würdest. Glücklicherweise hat sich Kubernetes in den letzten Jahren in diesem Punkt deutlich verbessert.
Mit Funktionen wie StorageClasses ist es möglich, bestimmte Anforderungen an Leistung, Kapazität oder beides zu erfüllen. Mit der Automatisierung können wir den Punkt vermeiden, an dem du von beidem nicht mehr genug hast. Das Vermeiden von Überraschungen ist die Domäne des Kapazitätsmanagements - sowohl die Initialisierung der benötigten Kapazität als auch die Erweiterung bei Bedarf. Wenn die Kapazität deiner Speicherung erschöpft ist, kommt alles zum Stillstand.
Die Verknüpfung der verteilten Natur von Kubernetes mit der Speicherung von Daten eröffnet mehr Möglichkeiten zur Selbstheilung. Automatisierte Backups und Snapshots halten dich für mögliche Datenverluste bereit. Die gemeinsame Nutzung von Compute und Speicherung minimiert das Risiko von Hardwareausfällen und ermöglicht die automatische Wiederherstellung des gewünschten Zustands, wenn der unvermeidliche Ausfall eintritt. All das macht die Aspekte der Datenspeicherung in Kubernetes viel attraktiver.
Cloud Native Datenkomponenten
Nachdem wir nun die Ressourcen definiert haben, die in Cloud-nativen Anwendungen verbraucht werden, wollen wir die Arten von Dateninfrastrukturen klären, die sie betreiben. Anstatt eine umfassende Liste aller möglichen Produkte zu erstellen, werden wir sie in größere Gruppen mit ähnlichen Merkmalen unterteilen:
- Persistenz
- Das ist wahrscheinlich die Kategorie, an die du zuerst denkst, wenn wir über Dateninfrastruktur sprechen. Diese Systeme speichern Daten und ermöglichen den Zugriff durch eine Art der Abfrage: relationale Datenbanken wie MySQL und Postgres und NoSQL-Systeme wie Apache Cassandra und MongoDB. Sie waren die letzten, die auf Kubernetes migriert haben, weil sie einen hohen Ressourcenbedarf und hohe Verfügbarkeitsanforderungen haben. Datenbanken sind in der Regel entscheidend für eine laufende Anwendung und zentral für jeden anderen Teil des Systems.
- Streaming
- Die grundlegendste Funktion von Streaming ist die schnelle Übertragung von Daten von einem Punkt zum anderen. Streaming-Systeme bieten je nach Anwendungsfall eine Vielzahl von Übermittlungssemantiken. In einigen Fällen können die Daten an viele Clients geliefert werden, oder, wenn strenge Kontrollen erforderlich sind, nur einmal. Eine weitere Verbesserung des Streaming ist die zusätzliche Verarbeitung: die Veränderung oder Verbesserung von Daten während des Transports. Der Bedarf an schnelleren Einblicken in die Daten hat die Streaming-Analytik in den Status eines unternehmenskritischen Systems erhoben, das in seiner Bedeutung mit den Persistenzsystemen gleichgezogen hat. Beispiele für Streaming-Systeme, die Daten transportieren, sind Apache Flink und Apache Kafka, Beispiele für Verarbeitungssysteme sind Apache Flink und Apache Storm.
- Batch-Analytik
- Eines der ersten Probleme bei Big Data ist die Analyse großer Datenmengen, um Erkenntnisse zu gewinnen oder neue Daten zu gewinnen. Apache Hadoop war das erste groß angelegte System für Batch-Analysen, das die Erwartungen an die Nutzung großer Rechen- und Speicherkapazitäten, die so koordiniert werden, dass sie die Ergebnisse komplexer Analyseprozesse liefern, festlegte. In der Regel werden diese Aufträge über den gesamten Cluster verteilt, wie es auch bei Spark der Fall ist. Bei diesen Systemen ist die Sorge um die Kosten aufgrund der schieren Menge der benötigten Ressourcen weitaus größer. Orchestrierungssysteme helfen dabei, die Kosten durch intelligente Zuweisung zu senken.
Blick nach vorn
Es gibt eine überzeugende Zukunft mit Cloud Native Data. Welchen Weg wir zwischen dem, was wir heute haben, und dem, was wir in Zukunft haben können, einschlagen, hängt von uns ab: der Gemeinschaft der Verantwortlichen für die Dateninfrastruktur. So wie wir es immer getan haben, sehen wir eine neue Herausforderung und nehmen sie an. Hier gibt es für jeden viel zu tun, aber das Ergebnis könnte ziemlich erstaunlich sein und die Messlatte noch einmal höher legen.
Ricks Punkt bezieht sich speziell auf Datenbanken, aber wir können seinen Handlungsaufruf für unsere Dateninfrastruktur unter Kubernetes extrapolieren. Anders als bei der Bereitstellung einer Datenanwendung auf physischen Servern erfordert die Einführung der Kubernetes-Kontrollebene eine Konversation mit den Diensten, die sie ausführen.
Vorbereitung auf die Revolution
Als Ingenieurinnen und Ingenieure, die Dateninfrastrukturen erstellen und betreiben, müssen wir auf kommende Entwicklungen vorbereitet sein, sowohl in Bezug auf unsere Arbeitsweise als auch auf unsere Einstellung zur Rolle der Dateninfrastruktur. In den folgenden Abschnitten wird beschrieben, was du tun kannst, um für die Zukunft der Cloud Native Data in Kubernetes gerüstet zu sein.
Eine SRE-Mentalität einnehmen
Die Rolle des Site Reliability Engineering (SRE) ist mit der Einführung von Cloud-Native-Methoden gewachsen. Wenn wir wollen, dass unsere Infrastruktur konvergiert, müssen wir als Dateninfrastrukturingenieure neue Fähigkeiten erlernen und neue Praktiken anwenden. Beginnen wir mit der Wikipedia-Definition von SRE:
Site Reliability Engineering ist eine Reihe von Prinzipien und Praktiken, die Aspekte der Softwareentwicklung beinhalten und auf Infrastruktur- und Betriebsprobleme angewendet werden. Das Hauptziel ist es, skalierbare und höchst zuverlässige Softwaresysteme zu schaffen. Site Reliability Engineering steht in engem Zusammenhang mit DevOps, einer Reihe von Praktiken, die Softwareentwicklung und IT-Betrieb miteinander verbinden, und SRE wurde auch als eine spezielle Umsetzung von DevOps beschrieben.
Bei der Bereitstellung von Dateninfrastrukturen geht es in erster Linie um die spezifischen Komponenten, die eingesetzt werden - das "Was". Du kannst dich zum Beispiel darauf konzentrieren, MySQL in großem Umfang einzusetzen oder Spark zu nutzen, um große Datenmengen zu analysieren. Eine SRE-Mentalität bedeutet, dass du über das , was du einsetzt, hinausgehst und dich mehr auf das Wie konzentrierst. Wie werden alle Teile zusammenarbeiten, um die Ziele der Anwendung zu erreichen? Eine ganzheitliche Betrachtung der Bereitstellung berücksichtigt die Art und Weise, wie die einzelnen Komponenten zusammenwirken, den erforderlichen Zugriff, einschließlich der Sicherheit, und die Beobachtbarkeit aller Aspekte, um sicherzustellen, dass die Service Level eingehalten werden.
Wenn deine derzeitige Haupt- oder Nebenrolle die eines Datenbankadministrators (DBA) ist, gibt es keinen besseren Zeitpunkt für einen Wechsel. Der Trend auf LinkedIn zeigt, dass die Zahl der DBAs von Jahr zu Jahr abnimmt und die Zahl der SREs massiv zunimmt. Ingenieure, die die Fähigkeiten erlernt haben, die für den Betrieb einer kritischen Datenbankinfrastruktur erforderlich sind, verfügen über eine wesentliche Grundlage, die sich auf die Anforderungen für die Verwaltung von Cloud Native Data überträgt. Zu diesen Anforderungen gehören die folgenden:
Verfügbarkeit
Latenz
Veränderungsmanagement
Notfallmaßnahmen
Kapazitätsmanagement
Neue Fähigkeiten müssen zu dieser Liste hinzugefügt werden, um der größeren Verantwortung der gesamten Bewerbung besser gerecht zu werden. Das sind Fähigkeiten, die du vielleicht schon hast, aber sie umfassen die folgenden:
- CI/CD-Pipelines
- Verstehe das große Ganze, wenn du den Code vom Repository zur Produktion bringst. Es gibt nichts, was die Anwendungsentwicklung in einem Unternehmen mehr beschleunigt. Continuous Integration (CI) fügt neuen Code in den Anwendungsstapel ein und automatisiert alle Tests, um die Qualität zu gewährleisten. Continuous Delivery (CD) nimmt die vollständig getesteten und zertifizierten Builds und setzt sie automatisch in der Produktion ein. In Kombination (Pipeline) können Unternehmen die Geschwindigkeit und Produktivität ihrer Entwickler drastisch erhöhen.
- Beobachtbarkeit
- DevOps-Praktiker unterscheiden gerne zwischen dem "Was" (dem eigentlichen Dienst, den du bereitstellst) und dem "Wie" (der Methodik zur Bereitstellung dieses Dienstes). Mit dem Monitoring ist jeder vertraut, der Erfahrung mit Infrastruktur hat. Im "Was"-Teil von DevOps geben dir die Eigenschaften, die du überwachst, Aufschluss darüber, ob deine Dienste in Ordnung sind, und liefern dir die nötigen Informationen, um Probleme zu diagnostizieren. Observability erweitert die Überwachung auf das "Wie" deiner Anwendung, indem es alles als Ganzes betrachtet - zum Beispiel die Quelle der Latenz in einer hochgradig verteilten Anwendung aufspüren, indem es Einblick in jeden Hop gibt, den die Daten auf ihrem Weg durch dein System nehmen.
- Den Code kennen
- Wenn in einer großen, verteilten Anwendung etwas schief läuft, ist die Ursache nicht immer ein Prozessfehler. In vielen Fällen kann das Problem ein Fehler im Code oder ein kleines Implementierungsdetail sein. Da du für den gesamten Zustand der Anwendung verantwortlich bist, musst du den Code verstehen, der in der bereitgestellten Umgebung ausgeführt wird. Ordnungsgemäß implementierte Beobachtungsmöglichkeiten werden dir helfen, Probleme zu finden, und dazu gehört auch die Software-Instrumentierung. SREs und Entwicklungsteams brauchen eine klare und regelmäßige Kommunikation, und Code ist eine gemeinsame Basis.
Verteilte Datenverarbeitung nutzen
Wenn du deine Anwendungen in Kubernetes bereitstellst, musst du alle Möglichkeiten des verteilten Computings ausschöpfen. Wenn du es gewohnt bist, in einem einzigen System zu denken, kann diese Umstellung schwierig sein, vor allem, wenn es darum geht, die Erwartungen zu überdenken und zu verstehen, wo Probleme auftauchen. Wenn zum Beispiel jeder Prozess in einem einzigen System stattfindet, ist die Latenzzeit fast gleich null. Das ist es nicht, was du verwalten musst. Hier geht es in erster Linie um CPU- und Speicherressourcen. In den 1990er Jahren war Sun Microsystems führend auf dem wachsenden Gebiet des verteilten Computings und veröffentlichte diese Liste mit den acht häufigsten Irrtümern des verteilten Computings:
Das Netzwerk ist zuverlässig.
Die Latenzzeit ist gleich null.
Die Bandbreite ist unendlich.
Das Netzwerk ist sicher.
Die Topologie ändert sich nicht.
Es gibt einen Verwalter.
Die Transportkosten sind gleich null.
Das Netzwerk ist homogen.
Hinter jedem dieser Trugschlüsse steckt sicherlich die Geschichte eines Entwicklers, der eine falsche Annahme getroffen hat, ein unerwartetes Ergebnis erhielt und unzählige Stunden bei dem Versuch verlor, das falsche Problem zu lösen. Die Einführung verteilter Methoden ist auf lange Sicht die Mühe wert. Sie ermöglichen es uns, groß angelegte Anwendungen zu entwickeln, und das wird auch noch lange so bleiben. Die Herausforderung ist die Belohnung wert, und für diejenigen unter uns, die dies täglich tun, kann es auch eine Menge Spaß machen! Kubernetes-Anwendungen werden jeden dieser Trugschlüsse testen, da sie standardmäßig verteilt sind. Wenn du deinen Einsatz planst, solltest du Dinge wie die Kosten für den Transport von einem Ort zum anderen oder die Auswirkungen auf die Latenzzeit berücksichtigen. Sie ersparen dir eine Menge Zeitverschwendung und Umplanungen.
Grundsätze der Cloud Native Data Infrastructure
Als Ingenieure suchen wir nach Standards und bewährten Methoden, auf denen wir aufbauen können. Um Daten so "cloud-nativ" wie möglich zu machen, müssen wir alle Möglichkeiten von Kubernetes nutzen. Ein wirklich Cloud-nativer Ansatz bedeutet, dass wir die Schlüsselelemente des Kubernetes-Designparadigmas übernehmen und darauf aufbauen. Eine gesamte Cloud Native-Anwendung, die Daten enthält, muss effektiv auf Kubernetes laufen können. Sehen wir uns ein paar Kubernetes-Designprinzipien an, die den Weg weisen.
Grundsatz 1: Nutzung von Datenverarbeitung, Netzwerk und Speicherung als Standard-APIs
Einer der Schlüssel zum Erfolg von Cloud Computing ist die Kommerzialisierung von Rechen-, Netzwerk- und Speicherressourcen, die wir über einfache APIs bereitstellen können. Sieh dir diese Auswahl an AWS-Diensten an:
- Berechne
- Wir weisen VMs über Amazon Elastic Compute Cloud (EC2) und Auto Scaling Groups (ASGs) zu.
- Netzwerk
- Wir verwalten den Datenverkehr mit Elastic Load Balancers (ELB), Route 53 und Virtual Private Cloud (VPC) Peering.
- Speicherung
- Wir nutzen Optionen wie den Simple Storage Service (S3) für die langfristige Speicherung von Objekten oder Elastic Block Store (EBS) Volumes für unsere Compute-Instanzen.
Kubernetes bietet seine eigenen APIs, um ähnliche Dienste für eine Welt der containerisierten Anwendungen bereitzustellen:
- Berechne
- Pods, Deployments und ReplicaSets verwalten das Scheduling und den Lebenszyklus von Containern auf der Computerhardware.
- Netzwerk
- Dienste und Ingress legen die Netzwerkschnittstellen eines Containers offen.
- Speicherung
- PersistentVolumes (PVs) und StatefulSets ermöglichen eine flexible Zuordnung von Containern zur Speicherung.
Kubernetes-Ressourcen fördern die Portabilität von Anwendungen zwischen Kubernetes-Distributionen und Dienstanbietern. Was bedeutet das für Datenbanken? Sie sind einfach Anwendungen, die Rechen-, Netzwerk- und Speicherressourcen nutzen, um die Dienste der Datenpersistenz und -abfrage bereitzustellen:
- Berechne
- Eine Datenbank braucht ausreichend Rechenleistung, um eingehende Daten und Abfragen zu verarbeiten. Jeder Datenbankknoten wird als Pod bereitgestellt und in StatefulSets gruppiert, sodass Kubernetes die Skalierung nach außen und innen verwalten kann.
- Netzwerk
- Eine Datenbank muss Schnittstellen für Daten und Kontrolle bereitstellen. Wir können Kubernetes Services und Ingress-Controller nutzen, um diese Schnittstellen bereitzustellen.
- Speicherung
- Eine Datenbank verwendet PersistentVolumes einer bestimmten StorageClass, um Daten zu speichern und abzurufen.
Wenn du Datenbanken in Bezug auf ihren Bedarf an Rechenleistung, Netzwerk und Speicherung betrachtest, entfällt ein Großteil der Komplexität, die mit der Bereitstellung in Kubernetes verbunden ist.
Prinzip 2: Trenne die Kontroll- und Datenebene
Kubernetes fördert die Trennung von Kontroll- und Datenebene. Der Kubernetes-API-Server ist die Vordertür der Steuerebene. Er bietet die Schnittstelle, über die die Datenebene Rechenressourcen anfordert, während die Steuerebene die Details der Zuordnung dieser Anforderungen zu einer zugrunde liegenden Infrastructure-as-a-Service (IaaS)-Plattform verwaltet.
Wir können dieses Muster auch auf Datenbanken anwenden. Die Datenebene einer Datenbank besteht zum Beispiel aus den Ports, die den Clients zur Verfügung stehen, und bei verteilten Datenbanken aus den Ports, die für die Kommunikation zwischen den Datenbankknoten verwendet werden. Die Steuerebene umfasst Schnittstellen, die von der Datenbank für die Verwaltung und das Sammeln von Metriken bereitgestellt werden, sowie Werkzeuge, die betriebliche Wartungsaufgaben übernehmen. Ein Großteil dieser Funktionen kann und sollte über das Kubernetes-Operator-Muster implementiert werden. Operatoren definieren benutzerdefinierte Ressourcen (CRDs) und stellen Kontrollschleifen bereit, die den Zustand dieser Ressourcen beobachten und Maßnahmen ergreifen, um sie in den gewünschten Zustand zu bringen.
Grundsatz 3: Beobachtbarkeit einfach machen
Die drei Säulen von beobachtbaren Systemen sind Logging, Metriken und Tracing. Kubernetes bietet einen guten Ausgangspunkt, indem es die Logs jedes Containers für Log-Aggregationslösungen von Drittanbietern zugänglich macht. Für Metriken, Tracing und Visualisierung stehen mehrere Lösungen zur Verfügung, von denen wir in diesem Buch einige kennenlernen werden.
Prinzip 4: Mach die Standardkonfiguration sicher
Kubernetes-Netzwerke sind standardmäßig sicher: Ports müssen explizit freigegeben werden, um von außen auf einen Pod zugreifen zu können. Dies ist ein wertvoller Präzedenzfall für den Einsatz von Datenbanken und zwingt uns dazu, sorgfältig zu überlegen, wie jede Schnittstelle der Kontroll- und Datenebene offengelegt werden soll und welche Schnittstellen über einen Kubernetes-Dienst offengelegt werden sollen. Kubernetes bietet auch Funktionen für die Verwaltung von Geheimnissen, die für die gemeinsame Nutzung von Verschlüsselungsschlüsseln und die Konfiguration von Administrationskonten genutzt werden können.
Prinzip 5: Deklarative Konfiguration bevorzugen
Beim deklarativen Ansatz von Kubernetes gibst du den gewünschten Zustand der Ressourcen an, und die Controller manipulieren die zugrunde liegende Infrastruktur, um diesen Zustand zu erreichen. Operatoren für die Dateninfrastruktur können die Details der intelligenten Skalierung verwalten - zum Beispiel die Entscheidung, wie Shards oder Partitionen neu zugewiesen werden, wenn zusätzliche Knoten skaliert werden, oder die Auswahl, welche Knoten entfernt werden sollen, um elastisch zu skalieren.
Die nächste Generation von Operatoren sollte es uns ermöglichen, Regeln für die Größe der gespeicherten Daten, die Anzahl der Transaktionen pro Sekunde oder beides festzulegen. Vielleicht können wir dann auch maximale und minimale Clustergrößen festlegen und bestimmen, wann weniger häufig genutzte Daten in die objektbasierte Speicherung verschoben werden. Das ermöglicht mehr Automatisierung und Effizienz in unserer Dateninfrastruktur.
Zusammenfassung
Wir hoffen, dass du jetzt bereit bist für die spannende Reise auf den nächsten Seiten. Die Umstellung auf Cloud-native Anwendungen muss auch Daten einbeziehen, und dazu werden wir Kuberentes nutzen, um zustandslose und zustandsabhängige Dienste einzubeziehen. In diesem Kapitel ging es um eine Cloud-native Dateninfrastruktur, die elastisch skaliert und keine Ausfallzeiten aufgrund von Systemfehlern zulässt, und darum, wie man solche Systeme aufbaut. Wir Ingenieure müssen uns die Prinzipien der Cloud Native Infrastructure zu eigen machen und in einigen Fällen neue Fähigkeiten erlernen. Herzlichen Glückwunsch - du hast eine fantastische Reise in die Zukunft der Entwicklung Cloud-nativer Anwendungen begonnen. Dreh die Seite um und los geht's!
Get Cloud Native Daten auf Kubernetes verwalten now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

