A key policy decision that network administrators need to make is how to route packets. Application performance, security, and cost can all be affected by these decisions. Routers, in addition to forwarding and receiving data packets, send routing messages that describe where to send those packets. Network administrators use two policy tools to manipulate these routing messages: route filtering and filtering based on characteristics of routes. The first section of this chapter talks about the general issues of implementing routing policies—how filtering the routes distributed by routing protocols can affect network stability and business goals, and the following section goes into the details of making networks robust. After that, we discuss how to implement traffic preferences according to specific objectives and look at the costs incurred when implementing routing policies. Finally, we briefly examine some alternatives to using access lists. This chapter focuses mainly on routing within smaller networks and intranets, but the concepts discussed here are applicable to routing in the Internet and in very large networks, which we’ll talk about in Chapter 6.
In Chapter 3, we saw how access lists can be used to filter packets moving through a router. Packets are not the only types of information that can be monitored by access lists. Routing information, which instructs routers how to forward data packets to their proper destination, are often critical to control. Let’s talk a little about routing basics and the reasons for building router filtering policies for our networks and organizations, which will prepare us for implementing access lists to control the flow of routing information later in the chapter.
When networks grow past a certain size, there is no way that administrators can manually update every router with information about the best way to route packets. Network links change capacity, routers go up and down, and traffic conditions vary. To ensure that all of the routers in a network know about changing network conditions, routers pass routing information between each other in a series of packets called routing updates or route advertisements. Routing updates provide information about the paths going to individual networks so that routers can decide how to forward packets to those networks. Routing information can include the number of router hops to a network, path delay, network congestion, or other information such as flags that routers attached to the routing information. With this information, routers make decisions about the best path to a given network.
In a similar manner to the control of packets we examined in Chapter 3, a router can forward and filter routing information, as shown in Figure 4.1.
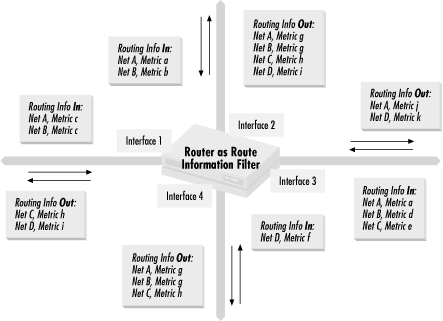
Routing
information comes into the router from several different interfaces,
using a routing protocol with a single metric whose values are shown.
Routing updates about Networks 1 and 2 come into Interfaces 1 and 2.
The updates from Interface 1 have c as the value
of the metric for both networks. The updates coming into interface 2
have the metric for Network 1 as a and the metric
for X as b. Interface 3 sees routing information
that gives Network 1 a metric of a, Network 2 a
metric of d, and Network 3 a metric of
e, while Interface 4 sees that Network 4 has a
metric of f. The router then distributes routing
information about the networks that it received. Network 1 is then
advertised out of Interfaces 2 and 4 with a metric of
g, but it is advertised out of Interface 3 with a
metric of j and not advertised at all out of
Interface 1. Network 2 is advertised with a metric of
g out of Interfaces 2, 3, and 4. Network 3 is
advertised with a metric of h out of Interfaces 1,
2, and 4, while Network 4 is advertised with a metric of
i out of Interfaces 1 and 2 and advertised with a
metric of k out of Interface 3.
As you can see, there are similarities to the flow of information to packet control. Routing information flow differs from packet information flow most significantly in that the router can substantially change the contents of routing information flowing through it.
Let’s talk more about routing information itself. Let’s look at the key elements in any routing information update:
- Network number and mask
The network number and mask determine what network the route information applies. It is also the part of the routing information most commonly used to determine whether a routing update is included in a policy set for further processing.
- Routing protocol and version
The routing protocol is another key piece of information about routing updates. There are a number of different routing protocols for IP, and a router can be configured to listen to more than one. Dealing with different routing protocols and distributing routing information between them is a common thing that network administrators must deal with, and it is one of the most common uses of access lists.
- Next hop
The next key piece of information, next hop, is the IP address where the router is advised to send packets bound for the network advertised. If the router accepts the routing update as the best path to that network, all packets destined to that network are sent to the next hop IP address.
- Source of routing information
Closely related to next hop is the source of routing information. This is the IP address of the router sending the routing update. This router is usually (but not always) the next hop. A network administrator may choose to add routes to a policy set based on next hop information or on the source of routing information. This is an instance of the last network administrator tool mentioned in Chapter 1: controlling routes based on a characteristic of those routes.
- Metric information
Metric information is the information used by a routing protocol to determine the optimal route. There can be a single numerical value, or there can be a series of other values used as metrics, not all of them numeric. Metric information can be used as criteria for placement into a policy set. Once a policy set of routes has been established, a network administrator can manipulate the metric values of the routes in the policy set.
- Other information
Other information is nonmetric information that is in a routing update for the purpose of setting routing policies. Some routing protocols do not have this kind of information. I will talk more about using other information in routing updates in the Chapter 6, when we talk about route maps and the BGP-4 routing protocol.
It is important to keep these elements separate and distinct when thinking about routing updates. Filtering a route to Network A (the network number) is different from filtering routes from routers on Network A (the source of routing information). You can receive routes to Network A from routers that are not directly connected to Network A. In particular, the network number of a route described in a routing update should not be mistaken for any other elements.
Once the policy sets you build based on the elements above are established, a network administrator can program routers to act on them through four actions. First, the administrator can choose to reject routing updates in a policy set so the router ignores the information from those updates. Second, the router can be programmed not to forward the routing updates in a policy set. In this case, the router knows how to send packets to the networks specified, but it does not let other routers know this information. Third, a router can change any of the elements contained in incoming routing updates, so that its own routing table differs from the routing information that it receives. Finally, the router can send out routing information that is different from the routing information in its own routing table.
A desirable property of a network is robustness. A problem in one part of the network shouldn’t affect all of the network, and the network as a whole should keep running even if parts of it are broken. Maintaining network robustness is about modularity and problem isolation. As networks scale in size, different parts of the network are usually run by different organizations. Those parts should be modular: self-contained and thought of and managed as a unit. Breaking down a large network into smaller self-contained units makes a network much more manageable. Once a network has become organized into smaller units, a routing problem or misconfiguration in one unit should not impact everyone in the network, as the problem will be more easily isolated to one modular unit. Let’s look at an example. Figure 4.2 shows a network made of different sites connected through a single router.

In this network, the router in the center connects four different sites. Site L, connected through Interface 1, uses Networks 1, 2, and 3. Site M, connected through Interface 2, uses Networks 4 and 5. Site N, connected through Interface 3, uses Networks 6, 7, and 8, while Site O, connected through Interface 4, uses Networks 9 and 10.
The network administrator managing the router wants to make sure that a routing problem in one site doesn’t impact the other sites. For example, if Site O started advertising routes to Site L’s Networks 1, 2, and 3, the router should not accept these routes and should not forward traffic bound for Site L’s networks to Site O. To provide some modularity in routing and make the network more robust in the case of misconfiguration, the router should only accept a site’s designated routes. Routes for 1, 2, and 3 should be accepted only through Interface 1. Routes 4 and 5 from Site M should only be accepted through Interface 2. Similarly, routes 6, 7, and 8 from Site N should only be accepted through Interface 3, and routes 9 and 10 from Site O only through Interface 4. In this way, sites can advertise any routes they want, but only their designated routes are accepted.
In the previous example, we knew what routes were expected from each site, and that enabled us to make the network much more robust. You might argue that since we had that knowledge, we could have set up static routes to each of the sites, eliminated the use of dynamic routing protocols, and avoided route filtering entirely. Static routing is the practice of explicitly configuring how a router sends traffic. Once the routing is set, the router forwards traffic according to those rules no matter how a network might change. Indeed, static routing is an alternative for simple networks, and I will talk about this alternative later in this chapter. Still, there are reasons you might want to use static routing with dynamic route filtering. If Site L had problems and Networks 1, 2, and 3 became totally unavailable, Site L would signal that problem by not advertising these routes. Traffic for network a would cause a network unreachable message to be sent from the central router instead of being forwarded into Site L, as would be done with static routes. In addition, pure static routing becomes difficult to maintain when a network becomes more complex. Take, for example, a version of the network shown in Figure 4.3.
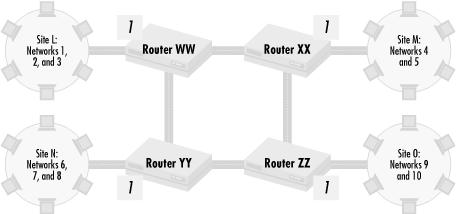
In the network shown in Figure 4.2, one central router forwards all traffic between all four sites, and thus the router itself becomes a critical point of failure. If the router fails, no traffic can be sent between any sites. The network in Figure 4.3 solves this problem, because there are multiple paths between sites. If one router fails, then the site attached to it is cut off from the others, but the rest of the sites can still communicate between each other. Similarly, if one path between routers fails, there are alternate paths that can route traffic. If static routing is used, each of the four routers need to have explicit knowledge about all the paths from that router to each of the networks. That’s a lot of data to manage, and dynamic routing protocols are designed to learn and manage this kind of information automatically.
No matter how complex your organization, with dynamic routing protocols, we make networks robust in the same manner. For instance, in the case of Figure 4.3, we know what networks should be advertised from each site into Interface 1 on the site’s adjacent router. Router WW should allow in route updates only for Networks 1, 2, and 3; Router XX should allow updates only for 4 and 5; Router YY should only allow in updates for Networks 6, 7, and 8; and Router ZZ should only allow in updates for Networks 9 and 10. If any one of the sites advertises a network that it does not own, the bad routing information is not propagated across the network.
So far, I have only talked about filtering incoming routing updates, where the router listening for route updates takes responsibility for making sure the correct routing information is received, accepted, or dropped as necessary. However, senders of routing information can also take responsibility for making sure the proper routing information is distributed. Cisco routers, for example, have the ability to restrict the routes that they send out. Let’s look at an example coming from the network in Figure 4.3. Consider the situation if all of the sites connected to the network of routers via serial lines and Routers WW, XX, YY, and ZZ are managed by different groups than any of the sites they connect. Each site connects to the central network of routers with a configuration similar to that shown in Figure 4.4.

Here’s the problem: Site L knows that it should only send routes to Router WW for Networks 1, 2, and 3. If someone makes a configuration error within Site L, routes other than those for Networks 1, 2, and 3 could be sent to Router WW. Since a different organization maintains Router WW, Site L’s network staff has no assurances that Router WW correctly filters routes. With a situation like this, Site L should restrict route updates sent to Router WW to include only Networks 1, 2, and 3. If Router WW accepts only these routes from Site L, routing still functions properly. If Site L makes a mistake and tries to propagate a route to a network that it doesn’t own, and if for some reason Router WW doesn’t filter incoming route updates, the outgoing route filter will stop the bad route from being advertised. Although it may seem redundant that Site L is ready for the worst from Router WW while Router WW is ready for the worst from Site L, mistakes do happen. Rather than have network traffic totally disrupted if a route is advertised incorrectly, a little paranoia can go a long way to making sure a network stays up and running.
To summarize, the key to ensuring network robustness is to enforce what you know about how routing updates should take place with routing filtering. Don’t accept routes you know you should not accept. Don’t send out routes that you know that you should not send. Don’t assume that the router you are listening to or sending route updates to will do the right thing, especially if that router is controlled by another organization. I’ll show examples later in this chapter that demonstrate how to use access lists to implement routing policies that will help make your network fault-tolerant.
Left alone, routing protocols decide what the best path network traffic will take based on network topology metrics such as bandwidth and router hops. But organizations often want to have more control over the path the traffic takes to get its final destination. In this section, we’ll talk about implementing route preferences driven by an organization’s business goals.
Why would an organization choose traffic preferences different from the ones selected by routing metrics? I discussed a number of the reasons in the scenarios described in Chapter 1. Some paths are more secure than others. Paths over internal networks tend to be more secure than paths over the open Internet. Some paths may be cheaper than others, while some may have more bandwidth and better performance. Whatever the reason, path selection and failover preferences are completely up to the organization, and it falls on network administrators to enforce those policies.
You can picture the general problem of route preferences and business goals as a path selection problem. Figure 4.5 shows two networks, Network 1 and Network 2. There are several ways to get between the two networks through a mesh of routers—Path A is one way, Path B is another, and so on.
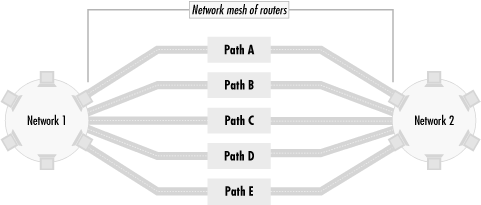
While routing metrics may indicate that traffic between Network 1 and Network 2 should use one path, an organization may prefer that traffic go in another direction. For example, let’s say that routing metrics prefer that traffic from Network 1 to Network 2 go through Path A. If Path A is unavailable, traffic will go through Path B. If Path B is unavailable, traffic will go through Path C, and so on for Paths D and E. The failover sequence is (A, B, C, D, E). Alternatively, the organization may prefer traffic from Network 1 and Network 2 to flow through Path B. It may prefer that the failover sequence be (A, C, D, E, B) or even (B, D, E), which does not allow Paths A or C to be used at all. The organization, in its wisdom, may even decide that no traffic whatsoever should pass between Networks 1 and 2.
I mentioned earlier in the chapter that routers have four possible actions to control routing information: reject routing information, accept but not forward routing information, modify incoming routing information, or modify outgoing routing information. Route preferences are most commonly implemented by rejecting routes or modifying incoming or outgoing routing information.
I’ll start with the first method, rejecting routing information. As in our previous example, we want to specify how traffic flows between Network 2 to Network 1. Figure 4.6 shows routing information for Network 1 coming into a router with a path to Network 2.
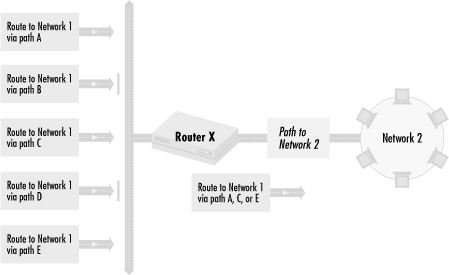
There are five possible paths, A, B, C, D, and E, from Router X to Network 1. We want traffic to go over Path A, C, or E, but not B or D. To do this, Router X rejects routing information about routes going over Paths B and D. Router X will have no information about Paths B and D at all.
The next two options for route preferences modify routing information after it reaches the router. We can do this as routing information comes in or goes out. Figure 4.7 shows how to do this by modifying incoming route information.
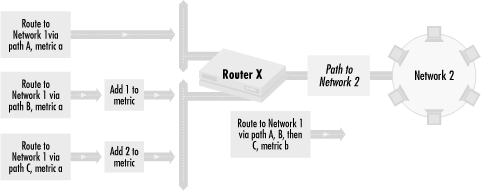
Here, we are trying to control the path that traffic from Network 2
takes to Network 1. In our example, routing metrics in all of the
incoming routing updates, before we modify them in Router X, are
numerical value a. This indicates that the path
from Router X to Network 1 can take either Path A, B, or C with equal
preference. We want to change the path selection preference so that
traffic to Network 1 first goes through Path A. If Path A is
unavailable, traffic should go through Path B, and then if B is
unavailable, through Path C.
To make this happen, we alter the routing metric values of each routing update after each comes into Router X. The metric for the route to Path B is increased by 1. The metric for the route to Path C is increased by 2. Since the original unaltered metrics for the three routes were equal, the metric for the route through A is the lowest, followed by the metric for the route via B and finally by the metric for the route through C. Since routing protocols take the path with the lowest metric, the most preferred Path is A, followed by B and then C.
Similarly, we can alter routing metrics as they go out of the router. This is shown in Figure 4.8.
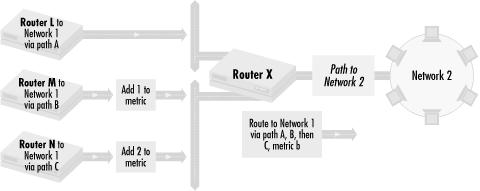
In this figure, we manipulate Routers L, M, and N, and not Router X. As in Figure 4.7, the metrics advertised to Router X for the path to Network 1 are the same for Paths A, B, and C. We want to make traffic prefer routes in the order A, B, then C. To do this, we add 1 to the routing metric of the routing updates from router M, which has Path B to Network 1. We add 2 to the routing metric of the routing updates from router N, which has Path C to Network 1. When the routing information to Network 1 arrive at router X, the path through A has the lowest metric, followed by B then C. Traffic to Network 1 then prefers Path A, B, and then C.
When should you use these different techniques for implementing route preferences? It usually depends on what you want to achieve and what routers you administer. The technique of rejecting incoming routes is best used when you want to completely reject some routes and allow others. It does not allow for explicitly picking failover preferences. Modifying route information must be done when you have to set up a specific order of preferences for route failover. For instance, you would modify incoming routing information when you have control over a router receiving routing updates. On the other hand, if you only have control over the routers’ advertising paths, then you need to modify routing information that is sent out .
Get Cisco IOS Access Lists now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

