Chapter 4. The Cassandra Query Language
In this chapter, youâll gain an understanding of Cassandraâs data model and how that data model is implemented by the Cassandra Query Language (CQL). Weâll show how CQL supports Cassandraâs design goals and look at some general behavior characteristics.
For developers and administrators coming from the relational world, the Cassandra data model can be difficult to understand initially. Some terms, such as keyspace, are completely new, and some, such as column, exist in both worlds but have slightly different meanings. The syntax of CQL is similar in many ways to SQL, but with some important differences. For those familiar with NoSQL technologies such as Dynamo or Bigtable, it can also be confusing, because although Cassandra may be based on those technologies, its own data model is significantly different.
So in this chapter, we start from relational database terminology and introduce Cassandraâs view of the world. Along the way youâll get more familiar with CQL and learn how it implements this data model.
The Relational Data Model
In a relational database, the database itself is the outermost container that might correspond to a single application. The database contains tables. Tables have names and contain one or more columns, which also have names. When you add data to a table, you specify a value for every column defined; if you donât have a value for a particular column, you use null. This new entry adds a row to the table, which you can later read if you know the rowâs unique identifier (primary key), or by using a SQL statement that expresses some criteria that row might meet. If you want to update values in the table, you can update all of the rows or just some of them, depending on the filter you use in a âwhereâ clause of your SQL statement.
After this review, youâre in good shape to look at Cassandraâs data model in terms of its similarities and differences.
Cassandraâs Data Model
In this section, weâll take a bottom-up approach to understanding Cassandraâs data model.
The simplest data store you would conceivably want to work with might be an array or list. It would look like Figure 4-1.

Figure 4-1. A list of values
If you persisted this list, you could query it later, but you would have to either examine each value in order to know what it represented, or always store each value in the same place in the list and then externally maintain documentation about which cell in the array holds which values. That would mean you might have to supply empty placeholder values (nulls) in order to keep the predetermined size of the array in case you didnât have a value for an optional attribute (such as a fax number or apartment number). An array is a clearly useful data structure, but not semantically rich.
Now letâs add a second dimension to this list: names to match the values. Give names to each cell, and now you have a map structure, as shown in Figure 4-2.
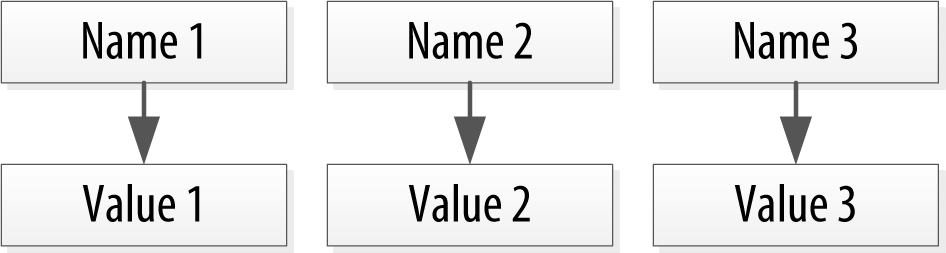
Figure 4-2. A map of name/value pairs
This is an improvement because you can know the names of your values. So if you decided that your map would hold user information, you could have column names like first_name, last_name, phone, email, and so on. This is a somewhat richer structure to work with.
But the structure youâve built so far works only if you have one instance of a given entity, such as a single person, user, hotel, or tweet. It doesnât give you much if you want to store multiple entities with the same structure, which is certainly what you want to do. Thereâs nothing to unify some collection of name/value pairs, and no way to repeat the same column names. So you need something that will group some of the column values together in a distinctly addressable group. You need a key to reference a group of columns that should be treated together as a set. You need rows. Then, if you get a single row, you can get all of the name/value pairs for a single entity at once, or just get the values for the names youâre interested in. You could call these name/value pairs columns. You could call each separate entity that holds some set of columns rows. And the unique identifier for each row could be called a row key or primary key. Figure 4-3 shows the contents of a simple row: a primary key, which is itself one or more columns, and additional columns. Letâs come back to the primary key shortly.
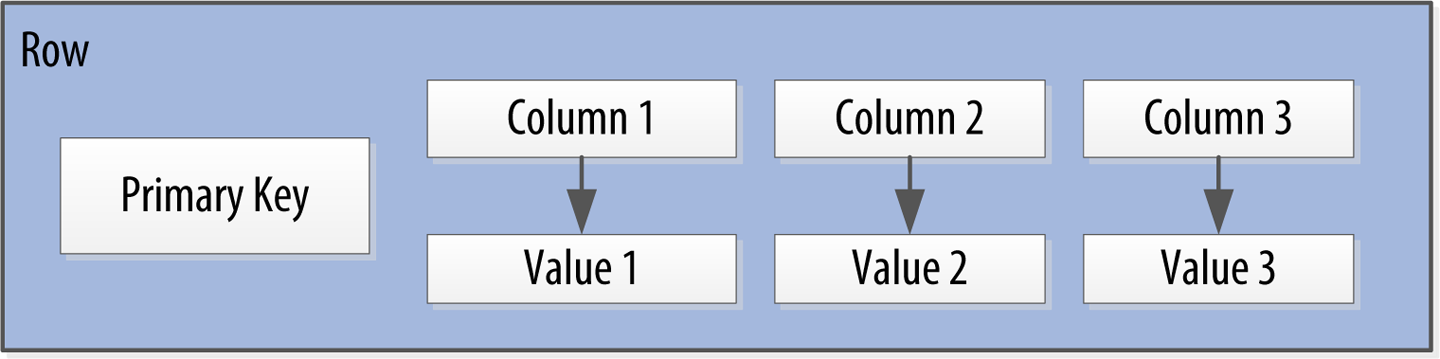
Figure 4-3. A Cassandra row
Cassandra defines a table to be a logical division that associates similar data. For example, you might have a user table, a hotel table, an address book table, and so on. In this way, a Cassandra table is analogous to a table in the relational world.
You donât need to store a value for every column every time you store a new entity. Maybe you donât know the values for every column for a given entity. For example, some people have a second phone number and some donât, and in an online form backed by Cassandra, there may be some fields that are optional and some that are required. Thatâs OK. Instead of storing null for those values you donât know, which would waste space, you just donât store that column at all for that row. So now you have a sparse, multidimensional array structure that looks like Figure 4-4. This flexible data structure is characteristic of Cassandra and other databases classified as wide column stores.
Now letâs return to the discussion of primary keys in Cassandra, as this is a fundamental topic that will affect your understanding of Cassandraâs architecture and data model, how Cassandra reads and writes data, and how it is able to scale.
Cassandra uses a special type of primary key called a composite key (or compound key) to represent groups of related rows, also called partitions. The composite key consists of a partition key, plus an optional set of clustering columns. The partition key is used to determine the nodes on which rows are stored and can itself consist of multiple columns. The clustering columns are used to control how data is sorted for storage within a partition. Cassandra also supports an additional construct called a static column, which is for storing data that is not part of the primary key but is shared by every row in a partition.
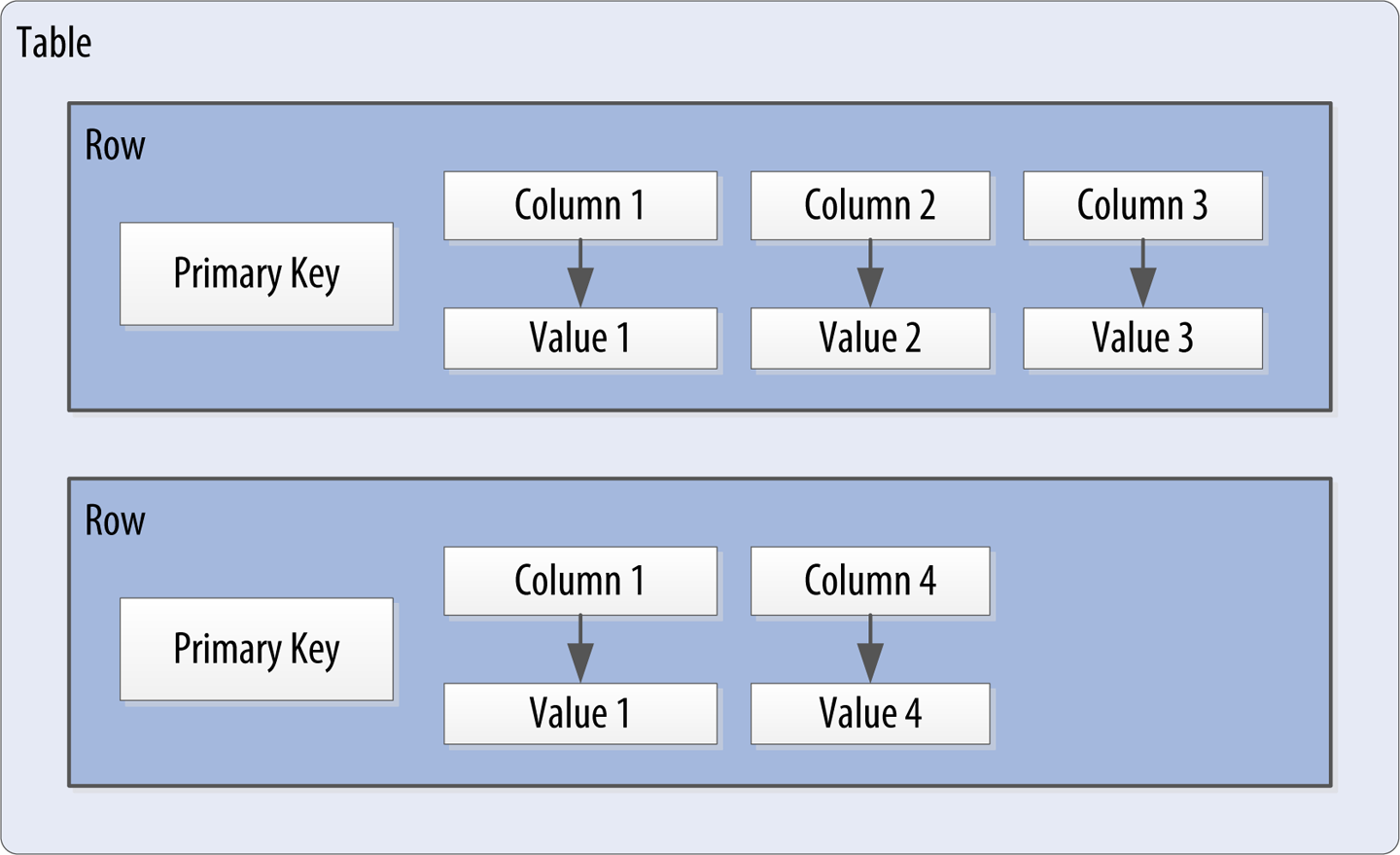
Figure 4-4. A Cassandra table
Figure 4-5 shows how each partition is uniquely identified by a partition key, and how the clustering keys are used to uniquely identify the rows within a partition. Note that in the case where no clustering columns are provided, each partition consists of a single row.
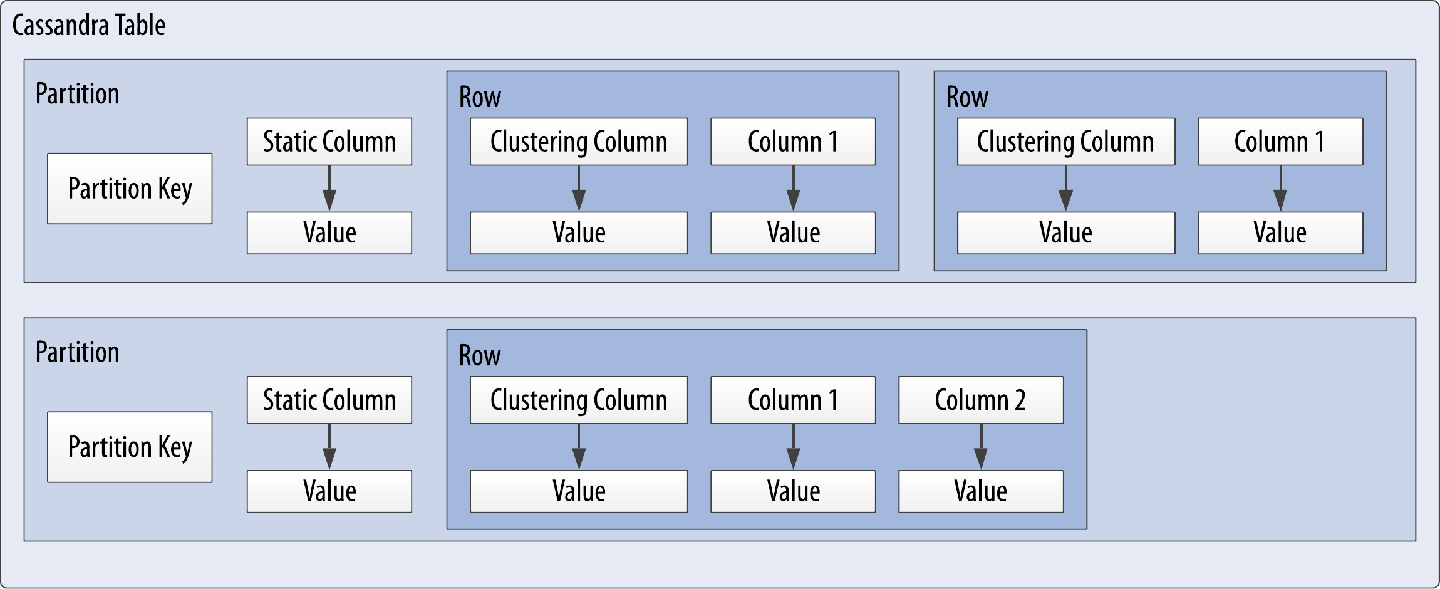
Figure 4-5. A Cassandra table with partitions
Putting these concepts all together, we have the basic Cassandra data structures:
-
The column, which is a name/value pair
-
The row, which is a container for columns referenced by a primary key
-
The partition, which is a group of related rows that are stored together on the same nodes
-
The table, which is a container for rows organized by partitions
-
The keyspace, which is a container for tables
-
The cluster, which is a container for keyspaces that spans one or more nodes
So thatâs the bottom-up approach to looking at Cassandraâs data model. Now that you know the basic terminology, letâs examine each structure in more detail.
Clusters
As previously mentioned, the Cassandra database is specifically designed to be distributed over several machines operating together that appear as a single instance to the end user. So the outermost structure in Cassandra is the cluster, sometimes called the ring, because Cassandra assigns data to nodes in the cluster by arranging them in a ring.
Keyspaces
A cluster is a container for keyspaces. A keyspace is the outermost container for data in Cassandra, corresponding closely to a database in the relational model. In the same way that a database is a container for tables in the relational model, a keyspace is a container for tables in the Cassandra data model. Like a relational database, a keyspace has a name and a set of attributes that define keyspace-wide behavior such as replication.
Because weâre currently focusing on the data model, weâll leave questions about setting up and configuring clusters and keyspaces until later. Weâll examine these topics in Chapter 10.
Tables
A table is a container for an ordered collection of rows, each of which is itself an ordered collection of columns. Rows are organized in partitions and assigned to nodes in a Cassandra cluster according to the column(s) designated as the partition key. The ordering of data within a partition is determined by the clustering columns.
When you write data to a table in Cassandra, you specify values for one or more columns. That collection of values is called a row. You must specify a value for each of the columns contained in the primary key as those columns taken together will uniquely identify the row.
Letâs go back to the user table from the previous chapter. Remember how you wrote a row of data and then read it using the SELECT command in cqlsh:
cqlsh:my_keyspace> SELECT * FROM user where last_name = 'Nguyen';
last_name | first_name | title
-----------+------------+-------
Nguyen | Bill | Mr.
(1 rows)
Youâll notice in the last line of output that one row was returned. It turns out to be the row identified by the last_name âNguyenâ and first_name âBill.â This is the primary key that uniquely identifies this row.
One interesting point about the preceding query is that it is only specifying the partition key, which makes it a query that could potentially return multiple rows. To illustrate this point, letâs add another user with the same last_name and then repeat the SELECT command from above:
cqlsh:my_keyspace> INSERT INTO user (first_name, last_name, title)
VALUES ('Wanda', 'Nguyen', 'Mrs.');
cqlsh:my_keyspace> SELECT * FROM user WHERE last_name='Nguyen';
last_name | first_name | title
-----------+------------+-------
Nguyen | Bill | Mr.
Nguyen | Wanda | Mrs.
(2 rows)
As you can see, by partitioning users by last_name, youâve made it possible to load the entire partition in a single query by providing that last_name. To access just one single row, youâd need to specify the entire primary key:
cqlsh:my_keyspace> SELECT * FROM user WHERE last_name='Nguyen' AND
first_name='Bill';
last_name | first_name | title
-----------+------------+-------
Nguyen | Bill | Mr.
(1 rows)
Data Access Requires a Primary Key
To summmarize this important detail: the SELECT, INSERT, UPDATE, and DELETE commands in CQL all operate in terms of rows. For INSERT and UPDATE commands, all of the primary key columns must be specified using the WHERE clause in order to identify the specific row that is affected. The SELECT and DELETE commands can operate in terms of one or more rows within a partition, an entire partition, or even multiple partitions by using the WHERE and IN clauses. Weâll explore these commands in more detail in Chapter 9.
While you do need to provide a value for each primary key column when you add a new row to the table, you are not required to provide values for nonprimary key columns. To illustrate this, letâs insert another row with no title:
cqlsh:my_keyspace> INSERT INTO user (first_name, last_name)
... VALUES ('Mary', 'Rodriguez');
cqlsh:my_keyspace> SELECT * FROM user WHERE last_name='Rodriguez';
last_name | first_name | title
-----------+------------+-------
Rodriguez | Mary | null
(1 rows)
Since you have not set a value for title, the value returned is null.
Now if you decide later that you would also like to keep track of usersâ middle initials, you can modify the user table using the ALTER TABLE command and then view the results using the DESCRIBE TABLE command:
cqlsh:my_keyspace> ALTER TABLE user ADD middle_initial text;
cqlsh:my_keyspace> DESCRIBE TABLE user;
CREATE TABLE my_keyspace.user (
last_name text,
first_name text,
middle_initial text,
title text,
PRIMARY KEY (last_name, first_name)
) ...
You see that the middle_initial column has been added. Note that weâve shortened the output to omit the various table settings. Youâll learn more about these settings and how to configure them throughout the rest of the book.
Now, letâs write some additional rows, populate different columns for each, and read the results:
cqlsh:my_keyspace> INSERT INTO user (first_name, middle_initial, last_name,
title)
VALUES ('Bill', 'S', 'Nguyen', 'Mr.');
cqlsh:my_keyspace> INSERT INTO user (first_name, middle_initial, last_name,
title)
VALUES ('Bill', 'R', 'Nguyen', 'Mr.');
cqlsh:my_keyspace> SELECT * FROM user WHERE first_name='Bill' AND
last_name='Nguyen';
last_name | first_name | middle_initial | title
-----------+------------+----------------+-------
Nguyen | Bill | R | Mr.
(1 rows)
Was this the result that you expected? If youâre following closely, you may have noticed that both of the INSERT statements here specify a previous row uniquely identified by the primary key columns first_name and last_name. As a result, Cassandra has faithfully updated the row you indicated, and your SELECT will only return the single row that matches that primary key. The two INSERT statements have only served to first set and then overwrite the middle_initial.
Insert, Update, and Upsert
Because Cassandra uses an append model, there is no fundamental difference between the insert and update operations. If you insert a row that has the same primary key as an existing row, the row is replaced. If you update a row and the primary key does not exist, Cassandra creates it.
For this reason, it is often said that Cassandra supports upsert, meaning that inserts and updates are treated the same, with one minor exception that weâll discuss in âLightweight Transactionsâ.
Letâs visualize the data youâve inserted up to this point in Figure 4-6. Notice that there are two partitions, identified by the last_name values of âNguyenâ and âRodriguez.â The âNguyenâ partition contains the two rows, âBillâ and âWanda,â and the row for âBillâ contains values in the title and middle_initial columns, while âWandaâ has only a title and no middle_initial specified.
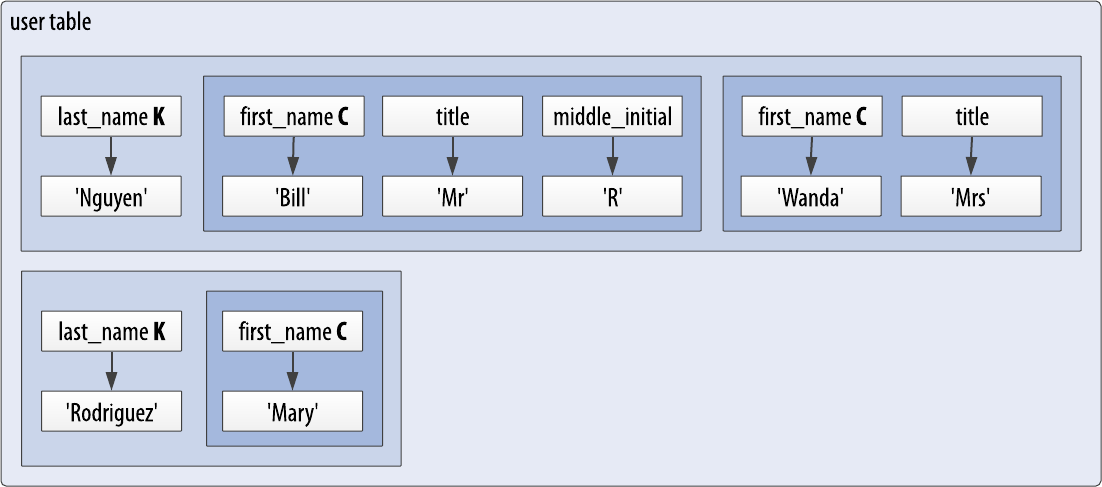
Figure 4-6. Data inserted into the user table
Now that youâve learned more about the structure of a table and done some data modeling, letâs dive deeper into columns.
Columns
A column is the most basic unit of data structure in the Cassandra data model. So far youâve seen that a column contains a name and a value. You constrain each of the values to be of a particular type when you define the column. Youâll want to dig into the various types that are available for each column, but first letâs take a look into some other attributes of a column that we havenât discussed yet: timestamps and time to live. These attributes are key to understanding how Cassandra uses time to keep data current.
Timestamps
Each time you write data into Cassandra, a timestamp, in microseconds, is generated for each column value that is inserted or updated. Internally, Cassandra uses these timestamps for resolving any conflicting changes that are made to the same value, in what is frequently referred to as a last write wins approach.
Letâs view the timestamps that were generated for previous writes by adding the writetime() function to the SELECT command for the title column, plus a couple of other values for context:
cqlsh:my_keyspace> SELECT first_name, last_name, title, writetime(title)
FROM user;
first_name | last_name | title | writetime(title)
------------+-----------+-------+------------------
Mary | Rodriguez | null | null
Bill | Nguyen | Mr. | 1567876680189474
Wanda | Nguyen | Mrs. | 1567874109804754
(3 rows)
As you might expect, there is no timestamp for a column that has not been set. You might expect that if you ask for the timestamp on first_name or last_name, youâd get a similar result to the values obtained for the title column. However, it turns out youâre not allowed to ask for the timestamp on primary key columns:
cqlsh:my_keyspace> SELECT WRITETIME(first_name) FROM user; InvalidRequest: code=2200 [Invalid query] message="Cannot use selection function writeTime on PRIMARY KEY part first_name"
Cassandra also allows you to specify a timestamp you want to use when performing writes. To do this, youâll use the CQL UPDATE command for the first time. Use the optional USING TIMESTAMP option to manually set a timestamp (note that the timestamp must be later than the one from your SELECT command, or the UPDATE will be ignored):
cqlsh:my_keyspace> UPDATE user USING TIMESTAMP 1567886623298243
SET middle_initial = 'Q' WHERE first_name = 'Mary' AND last_name = 'Rodriguez';
cqlsh:my_keyspace> SELECT first_name, middle_initial, last_name,
WRITETIME(middle_initial) FROM user WHERE first_name = 'Mary' AND
last_name = 'Rodriguez';
first_name | middle_initial | last_name | writetime(middle_initial)
------------+----------------+-----------+---------------------------
Mary | Q | Rodriguez | 1567886623298243
(1 rows)
This statement has the effect of adding the middle_initial column and setting the timestamp to the value you provided.
Working with Timestamps
Setting the timestamp is not required for writes. This functionality is typically used for writes in which there is a concern that some of the writes may cause fresh data to be overwritten with stale data. This is advanced behavior and should be used with caution.
There is currently not a way to convert timestamps produced by writetime() into a more friendly format in cqlsh.
Time to live (TTL)
One very powerful feature that Cassandra provides is the ability to expire data that is no longer needed. This expiration is very flexible and works at the level of individual column values. The time to live (or TTL) is a value that Cassandra stores for each column value to indicate how long to keep the value.
The TTL value defaults to null, meaning that data that is written will not expire. Letâs show this by adding the TTL() function to a SELECT command in cqlsh to see the TTL value for Maryâs title:
cqlsh:my_keyspace> SELECT first_name, last_name, TTL(title)
FROM user WHERE first_name = 'Mary' AND last_name = 'Rodriguez';
first_name | last_name | ttl(title)
------------+-----------+------------
Mary | Rodriguez | null
(1 rows)
Now letâs set the TTL on the middle_initial column to an hour (3,600 seconds) by adding the USING TTL option to your UPDATE command:
cqlsh:my_keyspace> UPDATE user USING TTL 3600 SET middle_initial =
'Z' WHERE first_name = 'Mary' AND last_name = 'Rodriguez';
cqlsh:my_keyspace> SELECT first_name, middle_initial,
last_name, TTL(middle_initial)
FROM user WHERE first_name = 'Mary' AND last_name = 'Rodriguez';
first_name | middle_initial | last_name | ttl(middle_initial)
------------+----------------+-----------+---------------------
Mary | Z | Rodriguez | 3574
(1 rows)
As you can see, the clock is already counting down your TTL, reflecting the several seconds it took to type the second command. If you run this command again in an hour, Maryâs middle_initial will be shown as null. You can also set TTL on INSERTS using the same USING TTL option, in which case the entire row will expire.
You can try inserting a row using TTL of 60 seconds and check that the row is initially there:
cqlsh:my_keyspace> INSERT INTO user (first_name, last_name)
VALUES ('Jeff', 'Carpenter') USING TTL 60;
cqlsh:my_keyspace> SELECT * FROM user WHERE first_name='Jeff' AND
last_name='Carpenter';
last_name | first_name | middle_initial | title
-----------+------------+----------------+-------
Carpenter | Jeff | null | null
(1 rows)
After you wait a minute, the row is no longer there:
cqlsh:my_keyspace> SELECT * FROM user WHERE first_name='Jeff' AND last_name='Carpenter'; last_name | first_name | middle_initial | title -----------+------------+----------------+------- (0 rows)
Using TTL
Remember that TTL is stored on a per-column level for nonprimary key columns. There is currently no mechanism for setting TTL at a row level directly after the initial insert; you would instead need to reinsert the row, taking advantage of Cassandraâs upsert behavior. As with the timestamp, there is no way to obtain or set the TTL value of a primary key column, and the TTL can only be set for a column when you provide a value for the column.
The behavior of Cassandraâs TTL feature can be somewhat nonintuitive, especially in cases where you are updating an existing row. Rahul Kumarâs blog âCassandra TTL intricacies and usage by examplesâ does a great job of summarizing the effects of TTL in a number of different cases.
CQL Types
Now that weâve taken a deeper dive into how Cassandra represents columns, including time-based metadata, letâs look at the various types that are available to you for representing values.
As youâve seen previously, each column in a table is of a specified type. Up until this point, youâve only used the varchar type, but there are plenty of other options available in CQL, so letâs explore them.
CQL supports a flexible set of data types, including simple character and numeric types, collections, and user-defined types. Weâll describe these data types and provide some examples of how they might be used to help you learn to make the right choice for your data model.
Numeric Data Types
CQL supports the numeric types youâd expect, including integer and floating-point numbers. These types are similar to standard types in Java and other languages:
intbigintsmallinttinyintvarint-
A variable precision signed integer (equivalent to
java.math.BigInteger) floatdoubledecimal-
A variable precision decimal (equivalent to
java.math.BigDecimal)
Additional Integer Types
The smallint and tinyint types were added in the Cassandra 2.2 release.
While enumerated types are common in many languages, there is no direct equivalent in CQL. A common practice is to store enumerated values as strings. For example, in Java you might use the Enum.name() method to convert an enumerated value to a String for writing to Cassandra as text, and the Enum.valueOf() method to convert from text back to the enumerated value.
Textual Data Types
CQL provides two data types for representing text, one of which youâve made quite a bit of use of already (text):
UTF-8 is the more recent and widely used text standard and supports internationalization, so we recommend using text over ascii when building tables for new data. The ascii type is most useful if you are dealing with legacy data that is in ASCII format.
Setting the Locale in cqlsh
By default, cqlsh prints out control and other unprintable characters using a backslash escape. You can control how cqlsh displays non-ASCII characters by setting the locale with the $LANG environment variable before running the tool. See the cqlsh command HELP TEXT_OUTPUT for more information.
Time and Identity Data Types
The identity of data elements such as rows and partitions is important in any data model in order to be able to access the data. Cassandra provides several types that prove quite useful in defining unique partition keys. Letâs take some time (pun intended) to dig into these:
timestamp-
While we noted earlier that each column has a timestamp indicating when it was last modified, you can also use a timestamp as the value of a column itself. The time can be encoded as a 64-bit signed integer, but it is typically much more useful to input a timestamp using one of several supported ISO 8601 date formats. For example:
2015-06-15 20:05-0700 2015-06-15 20:05:07-0700 2015-06-15 20:05:07.013-0700 2015-06-15T20:05-0700 2015-06-15T20:05:07-0700 2015-06-15T20:05:07.013+-0700
The best practice is to always provide time zones rather than relying on the operating system time zone configuration.
date, time-
Releases through Cassandra 2.1 only had the
timestamptype to represent times, which included both a date and a time of day. The 2.2 release introduceddateandtimetypes that allowed these to be represented independently; that is, a date without a time, and a time of day without reference to a specific date. As withtimestamp, these types support ISO 8601 formats.Although there are new
java.timetypes available in Java 8, thedatetype maps to a custom type in Cassandra in order to preserve compatibility with older JDKs. Thetimetype maps to a Javalongrepresenting the number of nanoseconds since midnight. uuid-
A universally unique identifier (UUID) is a 128-bit value in which the bits conform to one of several types, of which the most commonly used are known as Type 1 and Type 4. The CQL
uuidtype is a Type 4 UUID, which is based entirely on random numbers. UUIDs are typically represented as dash-separated sequences of hex digits. For example:1a6300ca-0572-4736-a393-c0b7229e193e
The
uuidtype is often used as a surrogate key, either by itself or in combination with other values.Because UUIDs are of a finite length, they are not absolutely guaranteed to be unique. However, most operating systems and programming languages provide utilities to generate IDs that provide adequate uniqueness. You can also obtain a Type 4 UUID value via the CQL
uuid()function and use this value in anINSERTorUPDATE. timeuuid-
This is a Type 1 UUID, which is based on the MAC address of the computer, the system time, and a sequence number used to prevent duplicates. This type is frequently used as a conflict-free timestamp. CQL provides several convenience functions for interacting with the
timeuuidtype:now(),dateOf(), andunixTimestampOf().The availability of these convenience functions is one reason why
timeuuidtends to be used more frequently thanuuid.
Building on the previous examples, you might determine that youâd like to assign a unique ID to each user, as first_name is perhaps not a sufficiently unique key for the user table. After all, itâs very likely that youâll run into users with the same first name at some point. If you were starting from scratch, you might have chosen to make this identifier your primary key, but for now youâll add it as another column.
Primary Keys Are Forever
After you create a table, there is no way to modify the primary key, because this controls how data is distributed within the cluster, and even more importantly, how it is stored on disk.
Letâs add the identifier using a uuid:
cqlsh:my_keyspace> ALTER TABLE user ADD id uuid;
Next, insert an ID for Mary using the uuid() function and then view the results:
cqlsh:my_keyspace> UPDATE user SET id = uuid() WHERE first_name =
'Mary' AND last_name = 'Rodriguez';
cqlsh:my_keyspace> SELECT first_name, id FROM user WHERE
first_name = 'Mary' AND last_name = 'Rodriguez';
first_name | id
------------+--------------------------------------
Mary | ebf87fee-b372-4104-8a22-00c1252e3e05
(1 rows)
Notice that the id is in UUID format.
Now you have a more robust table design, which you can extend with even more columns as you learn about more types.
Other Simple Data Types
CQL provides several other simple data types that donât fall nicely into one of the preceding categories:
boolean-
This is a simple true/false value. The
cqlshis case insensitive in accepting these values but outputsTrueorFalse. blob-
A binary large object (blob) is a colloquial computing term for an arbitrary array of bytes. The CQL blob type is useful for storing media or other binary file types. Cassandra does not validate or examine the bytes in a blob. CQL represents the data as hexadecimal digitsâfor example,
0x00000ab83cf0. If you want to encode arbitrary textual data into the blob, you can use thetextAsBlob()function in order to specify values for entry. See thecqlshhelp functionHELP BLOB_INPUTfor more information. inet-
This type represents IPv4 or IPv6 internet addresses.
cqlshaccepts any legal format for defining IPv4 addresses, including dotted or nondotted representations containing decimal, octal, or hexadecimal values. However, the values are represented using the dotted decimal format incqlshoutputâfor example,192.0.2.235.IPv6 addresses are represented as eight groups of four hexadecimal digits, separated by colonsâfor example,
2001:0db8:85a3:0000:0000:8a2e:0370:7334. The IPv6 specification allows the collapsing of consecutive zero hex values, so the preceding value is rendered as follows when read usingSELECT:2001: db8:85a3:a::8a2e:370:7334. counter-
The
counterdata type provides a 64-bit signed integer, whose value cannot be set directly, but only incremented or decremented. Cassandra is one of the few databases that provides race-free increments across data centers. Counters are frequently used for tracking statistics such as numbers of page views, tweets, log messages, and so on. Thecountertype has some special restrictions. It cannot be used as part of a primary key. If a counter is used, all of the columns other than primary key columns must be counters.For example, you could create an additional table to count the number of times a user has visited a website:
cqlsh:my_keyspace> CREATE TABLE user_visits ( user_id uuid PRIMARY KEY, visits counter);
Youâd then increment the value for user âMaryâ according to the unique ID assigned previously each time she visits the site:
cqlsh:my_keyspace> UPDATE user_visits SET visits = visits + 1 WHERE user_id=ebf87fee-b372-4104-8a22-00c1252e3e05;
And you could read out the value of the counter just as you read any other column:
cqlsh:my_keyspace> SELECT visits from user_visits WHERE user_id=ebf87fee-b372-4104-8a22-00c1252e3e05; visits -------- 1 (1 rows)
There is no operation to reset a counter directly, but you can approximate a reset by reading the counter value and decrementing by that value. Unfortunately, this is not guaranteed to work perfectly, as the counter may have been changed elsewhere in between reading and writing.
A Warning About Idempotence
The counter increment and decrement operators are not idempotent. An idempotent operation is one that will produce the same result when executed multiple times. Incrementing and decrementing are not idempotent because executing them multiple times could result in different results as the stored value is increased or decreased.
To see how this is possible, consider that Cassandra is a distributed system in which interactions over a network may fail when a node fails to respond to a request indicating success or failure. A typical client response to this request is to retry the operation. The result of retrying a nonidempotent operation such as incrementing a counter is not predictable. Since it is not known whether the first attempt succeeded, the value may have been incremented twice. This is not a fatal flaw, but something youâll want to be aware of when using counters.
The only other CQL operation that is not idempotent besides incrementing or decrementing a counter is adding an item to a list, which weâll discuss next.
Collections
Letâs say you wanted to extend the user table to support multiple email addresses. One way to do this would be to create additional columns such as email2, email3, and so on. While this approach will work, it does not scale very well and might cause a lot of rework. It is much simpler to deal with the email addresses as a group or âcollection.â CQL provides three collection types to help you with these situations: sets, lists, and maps. Letâs now take a look at each of them:
set-
The
setdata type stores a collection of elements. The elements are unordered when stored, but are returned in sorted order. For example, text values are returned in alphabetical order. Sets can contain the simple types youâve learned previously, as well as user-defined types (which weâll discuss momentarily) and even other collections. One advantage of usingsetis the ability to insert additional items without having to read the contents first.You can modify the
usertable to add a set of email addresses:cqlsh:my_keyspace> ALTER TABLE user ADD emails set<text>;
Then add an email address for Mary and check that it was added successfully:
cqlsh:my_keyspace> UPDATE user SET emails = { 'mary@example.com' } WHERE first_name = 'Mary' AND last_name = 'Rodriguez'; cqlsh:my_keyspace> SELECT emails FROM user WHERE first_name = 'Mary' AND last_name = 'Rodriguez'; emails ---------------------- {'mary@example.com'} (1 rows)Note that in adding that first email address, you replaced the previous contents of the set, which in this case was
null. You can add another email address later without replacing the whole set by using concatenation:cqlsh:my_keyspace> UPDATE user SET emails = emails + {'mary.rodriguez.AZ@gmail.com' } WHERE first_name = 'Mary' AND last_name = 'Rodriguez'; cqlsh:my_keyspace> SELECT emails FROM user WHERE first_name = 'Mary' AND last_name = 'Rodriguez'; emails --------------------------------------------------- {'mary.mcdonald.AZ@gmail.com', 'mary@example.com'} (1 rows)Other Set Operations
You can also clear items from the set by using the subtraction operator:
SET emails = emails - {'mary@example.com'}.Alternatively, you could clear out the entire set by using the empty set notation:
SET emails = {}. list-
The
listdata type contains an ordered list of elements. By default, the values are stored in order of insertion. You can modify theusertable to add a list of phone numbers:cqlsh:my_keyspace> ALTER TABLE user ADD phone_numbers list<text>;
Then add a phone number for Mary and check that it was added successfully:
cqlsh:my_keyspace> UPDATE user SET phone_numbers = ['1-800-999-9999' ] WHERE first_name = 'Mary' AND last_name = 'Rodriguez'; cqlsh:my_keyspace> SELECT phone_numbers FROM user WHERE first_name = 'Mary' AND last_name = 'Rodriguez'; phone_numbers -------------------- ['1-800-999-9999'] (1 rows)
Letâs add a second number by appending it:
cqlsh:my_keyspace> UPDATE user SET phone_numbers = phone_numbers + [ '480-111-1111' ] WHERE first_name = 'Mary' AND last_name = 'Rodriguez'; cqlsh:my_keyspace> SELECT phone_numbers FROM user WHERE first_name = 'Mary' AND last_name = 'Rodriguez'; phone_numbers ------------------------------------ ['1-800-999-9999', '480-111-1111'] (1 rows)
The second number you added now appears at the end of the list.
Note
You could also have prepended the number to the front of the list by reversing the order of the values:
SET phone_numbers = [â4801234567'] + phone_numbers.You can replace an individual item in the list when you reference it by its index:
cqlsh:my_keyspace> UPDATE user SET phone_numbers[1] = '480-111-1111' WHERE first_name = 'Mary' AND last_name = 'Rodriguez';
As with sets, you can also use the subtraction operator to remove items that match a specified value:
cqlsh:my_keyspace> UPDATE user SET phone_numbers = phone_numbers - [ '480-111-1111' ] WHERE first_name = 'Mary' AND last_name = 'Rodriguez';
Finally, you can delete a specific item directly using its index:
cqlsh:my_keyspace> DELETE phone_numbers[0] from user WHERE first_name = 'Mary' AND last_name = 'Rodriguez';
Expensive List Operations
Because a list stores values according to position, there is the potential that updating or deleting a specific item in a list could require Cassandra to read the entire list, perform the requested operation, and write out the entire list again. This could be an expensive operation if you have a large number of values in the list. For this reason, many users prefer to use the set or map types, especially in cases where there is the potential to update the contents of the collection.
map-
The
mapdata type contains a collection of key-value pairs. The keys and the values can be of any type exceptcounter. Letâs try this out by using amapto store information about user logins. Create a column to track login session time, in seconds, with atimeuuidas the key:cqlsh:my_keyspace> ALTER TABLE user ADD login_sessions map<timeuuid, int>;
Then you can add a couple of login sessions for Mary and see the results:
cqlsh:my_keyspace> UPDATE user SET login_sessions = { now(): 13, now(): 18} WHERE first_name = 'Mary' AND last_name = 'Rodriguez'; cqlsh:my_keyspace> SELECT login_sessions FROM user WHERE first_name = 'Mary' AND last_name = 'Rodriguez'; login_sessions ----------------------------------------------- {839b2660-d1c0-11e9-8309-6d2c86545d91: 13, 839b2661-d1c0-11e9-8309-6d2c86545d91: 18} (1 rows)We can also reference an individual item in the map by using its key.
Collection types are very useful in cases where we need to store a variable number of elements within a single column.
Tuples
Now you might decide that you need to keep track of physical addresses for your users. You could just use a single text column to store these values, but that would put the burden of parsing the various components of the address on the application. It would be better if you could define a structure in which to store the addresses to maintain the integrity of the different components.
Fortunately, Cassandra provides two different ways to manage more complex data structures: tuples and user-defined types.
First, letâs have a look at tuples, which provide a way to have a fixed-length set of values of various types. For example, you could add a tuple column to the user table that stores an address. You could have added a tuple to define addresses, assuming a three-line address format and an integer postal code such as a US zip code:
cqlsh:my_keyspace> ALTER TABLE user ADD address tuple<text, text, text, int>;
Then you could populate an address using the following statement:
cqlsh:my_keyspace> UPDATE user SET address =
('7712 E. Broadway', 'Tucson', 'AZ', 85715 )
WHERE first_name = 'Mary' AND last_name = 'Rodriguez';
This does provide you the ability to store an address, but it can be a bit awkward to try to remember the positional values of the various fields of a tuple without having a name associated with each value. There is also no way to update individual fields of a tuple; the entire tuple must be updated. For these reasons, tuples are infrequently used in practice, because Cassandra offers an alternative that provides a way to name and access each value, which weâll examine next.
But first, letâs use the CQL DROP command to get rid of the address column so that you can replace it with something better:
cqlsh:my_keyspace> ALTER TABLE user DROP address;
User-Defined Types
Cassandra gives you a way to define your own types to extend its data model. These user-defined types (UDTs) are easier to use than tuples since you can specify the values by name rather than position. Create your own address type:
cqlsh:my_keyspace> CREATE TYPE address ( street text, city text, state text, zip_code int);
A UDT is scoped by the keyspace in which it is defined. You could have written CREATE TYPE my_keyspace.address. If you run the command DESCRIBE KEYSPACE my_keyspace, youâll see that the address type is part of the keyspace definition.
Now that you have defined the address type, you can use it in the user table. Rather than simply adding a single address, you can use a map to store multiple addresses to which you can give names such as âhome,â âwork,â and so on. However, you immediately run into a problem:
cqlsh:my_keyspace> ALTER TABLE user ADD addresses map<text, address>; InvalidRequest: code=2200 [Invalid query] message="Non-frozen collections are not allowed inside collections: map<text, address>"
What is going on here? It turns out that a user-defined data type is considered a collection, as its implementation is similar to a set, list, or map. Youâve asked Cassandra to nest one collection inside another.
Freezing Collections
Cassandra releases prior to 2.2 do not fully support the nesting of collections. Specifically, the ability to access individual attributes of a nested collection is not yet supported, because the nested collection is serialized as a single object by the implementation. Therefore, the entire nested collection must be read and written in its entirety.
Freezing is a concept that was introduced as a forward compatibility mechanism. For now, you can nest a collection within another collection by marking it as frozen, which means that Cassandra will store that value as a blob of binary data. In the future, when nested collections are fully supported, there will be a mechanism to âunfreezeâ the nested collections, allowing the individual attributes to be accessed.
You can also use a collection as a primary key if it is frozen.
Now that weâve taken a short detour to discuss freezing and nested collections, letâs get back to modifying your table, this time marking the address as frozen:
cqlsh:my_keyspace> ALTER TABLE user ADD addresses map<text, frozen<address>>;
Now letâs add a home address for Mary:
cqlsh:my_keyspace> UPDATE user SET addresses = addresses +
{'home': { street: '7712 E. Broadway', city: 'Tucson',
state: 'AZ', zip_code: 85715 } }
WHERE first_name = 'Mary' AND last_name = 'Rodriguez';
cqlsh:my_keyspace> SELECT addresses FROM user
WHERE first_name = 'Mary' AND last_name = 'Rodriguez';
addresses
---------------------------------------------------------
{'home': {street: '7712 E. Broadway',
city: 'Tucson', state: 'AZ', zip_code: 85715}}
(1 rows)
Now that youâve learned about the various types, letâs take a step back and look at the tables youâve created so far by describing my_keyspace:
cqlsh:my_keyspace> DESCRIBE KEYSPACE my_keyspace ;
CREATE KEYSPACE my_keyspace WITH replication = {'class':
'SimpleStrategy', 'replication_factor': '1') AND
durable_writes = true;
CREATE TYPE my_keyspace.address (
street text,
city text,
state text,
zip_code int
);
CREATE TABLE my_keyspace.user (
last_name text,
first_name text,
addresses map<text, frozen<address>>,
emails set<text>,
id uuid,
login_sessions map<timeuuid, int>,
middle_initial text,
phone_numbers list<text>,
title text,
PRIMARY KEY (last_name, first_name)
) WITH CLUSTERING ORDER BY (first_name ASC)
AND bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'}
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction
.SizeTieredCompactionStrategy', 'max_threshold': '32',
'min_threshold': '4'}
AND compression = {'chunk_length_in_kb': '16', 'class':
'org.apache.cassandra.io.compress.LZ4Compressor'}
AND crc_check_chance = 1.0
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99PERCENTILE';
CREATE TABLE my_keyspace.user_visits (
user_id uuid PRIMARY KEY,
visits counter
) WITH bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'}
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction
.SizeTieredCompactionStrategy', 'max_threshold': '32',
'min_threshold': '4'}
AND compression = {'chunk_length_in_kb': '16', 'class':
'org.apache.cassandra.io.compress.LZ4Compressor'}
AND crc_check_chance = 1.0
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99PERCENTILE';
Practicing CQL Commands
The commands listed in this chapter to operate on the user table are available as a gist on GitHub to make it easier for you to execute them. The file is named cqlsh_intro.cql.
Summary
In this chapter, you took a quick tour of Cassandraâs data model of clusters, keyspaces, tables, keys, rows, and columns. In the process, you learned a lot of CQL syntax and gained more experience working with tables and columns in cqlsh. If youâre interested in diving deeper into CQL, you can read the full language specification.
Get Cassandra: The Definitive Guide, (Revised) Third Edition, 3rd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

