Kapitel 1. Grundlagen der Sprache
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Dieses Kapitel beschreibt die grundlegenden Eigenschaften und Elemente der Programmiersprache C.
Merkmale von C
C ist eine universelle, prozedurale Programmiersprache. Dennis Ritchie entwickelte C in den 1970er Jahren in den AT&T Bell Laboratories in Murray Hill, New Jersey, um das Unix-Betriebssystem und die Dienstprogramme so unabhängig wie möglich von bestimmten Hardwareplattformen zu implementieren. Die wichtigsten Merkmale der Sprache C sind die Qualitäten, die sie für diesen Zweck geeignet machten :
-
Übertragbarkeit des Quellcodes
-
Die Fähigkeit, "nah an der Maschine" zu arbeiten
-
Effizienz
Daher konnten die Unix-Entwickler den größten Teil des Betriebssystems in C schreiben, so dass nur ein Minimum an systemspezifischer Hardwaremanipulation in Assembler programmiert werden musste.
Die Vorläufer von C sind die typlosen Programmiersprachen BCPL (Basic Combined Programming Language), die von Martin Richards entwickelt wurde, und B, ein Abkömmling von BCPL, der von Ken Thompson entwickelt wurde. Ein neues Merkmal von C war seine Vielfalt an Datentypen: Zeichen, numerische Typen, Arrays, Strukturen und so weiter. Brian Kernighan und Dennis Ritchie veröffentlichten 1978 eine offizielle Beschreibung der Programmiersprache C. Als erster De-facto-Standard wird ihre Beschreibung im Allgemeinen einfach als K&R bezeichnet.1 C verdankt seine hohe Portabilität einer kompakten Kernsprache, die nur wenige hardwareabhängige Elemente enthält. So gibt es in C zum Beispiel keine Anweisungen zum Dateizugriff oder zur dynamischen Speicherverwaltung. Es gibt nicht einmal Anweisungen für die Konsolenein- und -ausgabe. Stattdessen stellt die umfangreiche C-Standardbibliothek die Funktionen für all diese Zwecke bereit.
Durch dieses Sprachdesign ist der C-Compiler relativ kompakt und lässt sich leicht auf neue Systeme portieren. Sobald der Compiler auf einem neuen System läuft, kannst du außerdem die meisten Funktionen der Standardbibliothek ohne weitere Änderungen kompilieren, da sie wiederum in portablem C geschrieben sind.
Da C ausdrücklich für die Systemprogrammierung entwickelt wurde, ist es kaum verwunderlich, dass eine seiner Hauptanwendungen heute die Programmierung eingebetteter Systeme ist. Gleichzeitig verwenden viele Entwickler/innen C aber auch als portable, strukturierte Hochsprache, um Programme wie leistungsstarke Textverarbeitungs-, Datenbank- und Grafikanwendungen zu schreiben .
Die Struktur von C-Programmen
Die prozeduralen Bausteine eines C-Programms sind Funktionen, die sich gegenseitig aufrufen können. Jede Funktion in einem gut konzipierten Programm dient einem bestimmten Zweck. Die Funktionen enthalten Anweisungen, die das Programm nacheinander ausführen soll, und Anweisungen können auch zu Blockanweisungen oder Blöcken gruppiert werden. Als Programmierer kannst du die vorgefertigten Funktionen in der Standardbibliothek verwenden oder deine eigenen schreiben, wenn keine Standardfunktion den gewünschten Zweck erfüllt. Neben der C-Standardbibliothek gibt es viele Spezialbibliotheken, wie z. B. Bibliotheken mit Grafikfunktionen. Wenn du solche nicht standardisierten Bibliotheken verwendest, beschränkst du die Portabilität deines Programms auf die Systeme, auf die die Bibliotheken selbst portiert wurden.
Jedes C-Programm muss mindestens eine eigene Funktion mit dem speziellen Namen main() definieren, die beim Programmstart als erste Funktion aufgerufen wird. Die Funktion main() ist die oberste Steuerungsebene des Programms und kann andere Funktionen als Unterprogramme aufrufen.
Beispiel 1-1 zeigt die Struktur eines einfachen, vollständigen C-Programms. Wir werden die Details von Deklarationen, Funktionsaufrufen, Ausgabeströmen und mehr an anderer Stelle in diesem Buch besprechen. Im Moment geht es uns nur um die allgemeine Struktur des C-Quellcodes. Das Programm in Beispiel 1-1 definiert zwei Funktionen, main() und circularArea(). Die Funktion main() ruft circularArea() auf, um die Fläche eines Kreises mit einem bestimmten Radius zu ermitteln, und ruft dann die Standardbibliotheksfunktion printf() auf, um die Ergebnisse in formatierten Zeichenketten auf der Konsole auszugeben.
Beispiel 1-1. Ein einfaches C-Programm
// circle.c: Calculate and print the areas of circles#include <stdio.h>// Preprocessor directivedoublecircularArea(doubler);// Function declaration (prototype form)intmain()// Definition of main() begins{doubleradius=1.0,area=0.0;printf(" Areas of Circles\n\n");printf(" Radius Area\n""-------------------------\n");area=circularArea(radius);printf("%10.1f %10.2f\n",radius,area);radius=5.0;area=circularArea(radius);printf("%10.1f %10.2f\n",radius,area);return0;}// The function circularArea() calculates the area of a circle// Parameter: The radius of the circle// Return value: The area of the circledoublecircularArea(doubler)// Definition of circularArea() begins{constdoublepi=3.1415926536;// Pi is a constantreturnpi*r*r;}
Ausgabe:
Areas of Circles
Radius Area
-------------------------
1.0 3.14
5.0 78.54
Beachte dass der Compiler für jede aufgerufene Funktion eine vorherige Deklaration verlangt. Der Prototyp von circularArea() in der dritten Zeile von Beispiel 1-1 liefert die Informationen, die benötigt werden, um eine Anweisung zu kompilieren, die diese Funktion aufruft. Die Prototypen der Funktionen der Standardbibliothek befinden sich in den Standard-Header-Dateien. Da die Header-Datei stdio.h den Prototyp der Funktion printf() enthält, deklariert die Präprozessoranweisung #include <stdio.h> die Funktion indirekt, indem sie den Präprozessor des Compilers anweist, den Inhalt dieser Datei einzufügen. (Siehe auch "Wie der C-Compiler arbeitet".)
Du kannst die in einem Programm definierten Funktionen in beliebiger Reihenfolge anordnen. In Beispiel 1-1 hätten wir die Funktion circularArea() genauso gut vor der Funktion main() platzieren können. Dann wäre die Prototypendeklaration von circularArea() überflüssig, weil die Definition der Funktion auch eine Deklaration ist.
Funktionsdefinitionen können nicht ineinander verschachtelt werden: Du kannst eine lokale Variable innerhalb eines Funktionsblocks definieren, aber nicht eine lokale Funktion.
Quelldateien
Die Funktionsdefinitionen, globalen Deklarationen und Vorverarbeitungsanweisungen bilden den Quellcode eines C-Programms. Bei kleinen Programmen wird der Quellcode in einer einzigen Quelldatei geschrieben. Größere C-Programme bestehen aus mehreren Quelldateien. Da die Funktionsdefinitionen in der Regel von Präprozessoranweisungen und globalen Deklarationen abhängen, haben die Quelldateien in der Regel die folgende interne Struktur:
-
Präprozessor-Direktiven
-
Globale Erklärungen
-
Funktionsdefinitionen
C unterstützt die modulare Programmierung, indem es dir erlaubt, ein Programm in beliebig vielen Quell- und Headerdateien zu organisieren und diese separat zu bearbeiten und zu kompilieren. Jede Quelldatei enthält in der Regel Funktionen, die logisch zusammenhängen, wie z. B. die Funktionen der Benutzeroberfläche des Programms. Es ist üblich, C-Quelldateien mit der Dateinamensendung .c zu versehen.
Die Beispiele 1-2 und 1-3 zeigen das gleiche Programm wie Beispiel 1-1, aber aufgeteilt in zwei Quelldateien.
Beispiel 1-2. Die erste Quelldatei, die die main()-Funktion enthält
// circle.c: Prints the areas of circles.// Uses circulararea.c for the math#include <stdio.h>doublecircularArea(doubler);intmain(){/* ... As in Example 1-1... */}
Beispiel 1-3. Die zweite Quelldatei, die die Funktion circularArea() enthält
// circulararea.c: Calculates the areas of circles.// Called by main() in circle.cdoublecircularArea(doubler){/* ... As in Example 1-1... */}
Wenn ein Programm aus mehreren Quelldateien besteht, musst du in vielen der Dateien dieselben Funktionen und globalen Variablen deklarieren und dieselben Makros und Konstanten definieren. Diese Deklarationen und Definitionen bilden also eine Art Dateikopf, der im gesamten Programm mehr oder weniger konstant ist. Der Einfachheit und Konsistenz halber kannst du diese Informationen nur einmal in eine separate Headerdatei schreiben und dann in jeder Quellcodedatei mit einer #include Direktive auf die Headerdatei verweisen. Header-Dateien werden üblicherweise durch die Dateiendung .h gekennzeichnet. Eine Header-Datei, die explizit in eine C-Quelldatei eingebunden ist, kann wiederum andere Dateien einbinden.
Jede C-Quelldatei bildet zusammen mit allen darin enthaltenen Header-Dateien eine Übersetzungseinheit. Der Compiler verarbeitet den Inhalt der Übersetzungseinheit nacheinander und zerlegt den Quellcode in Tokens, die kleinsten semantischen Einheiten, wie Variablennamen und Operatoren. Siehe "Token" für weitere Informationen.
Eine beliebige Anzahl von Leerzeichen kann zwischen zwei aufeinanderfolgenden Token stehen, was dir viel Freiheit bei der Formatierung des Quellcodes gibt. Es gibt keine Regeln für Zeilenumbrüche oder Einrückungen, und du kannst Leerzeichen, Tabulatoren und Leerzeilen großzügig verwenden, um "menschenlesbaren" Quellcode zu erstellen. Die Präprozessor-Direktiven sind etwas weniger flexibel: Eine Präprozessor-Direktive muss immer in einer eigenen Zeile stehen, und vor dem Rautezeichen (#), mit dem die Zeile beginnt, dürfen keine Zeichen außer Leerzeichen oder Tabulatoren stehen.
Es gibt viele verschiedene Konventionen und "Hausstile" für die Formatierung von Quellcode. Die meisten von ihnen enthalten die folgenden gemeinsamen Regeln:
Kommentare
Du solltest Kommentare großzügig im Quellcode verwenden, um deine C-Programme zu dokumentieren. Es gibt zwei Möglichkeiten, einen Kommentar in C einzufügen: Blockkommentare beginnen mit /* und enden mit */, und Zeilenkommentare beginnen mit // und enden mit dem nächsten Zeilenumbruchzeichen.
Du kannst die Begrenzungszeichen /* und */ verwenden, um Kommentare innerhalb einer Zeile zu beginnen und zu beenden und um Kommentare über mehrere Zeilen hinweg einzuschließen. Im folgenden Funktionsprototyp zum Beispiel bedeutet die Ellipse (…), dass die Funktion open() einen dritten, optionalen Parameter hat. Der Kommentar erklärt die Verwendung des optionalen Parameters:
intopen(constchar*name,intmode,.../* int permissions */);
Mit // kannst du Kommentare einfügen, die eine ganze Zeile ausfüllen, oder den Quellcode in einem zweispaltigen Format schreiben, mit Programmcode auf der linken und Kommentaren auf der rechten Seite:
constdoublepi=3.1415926536;// pi is constant
Diese Zeilenkommentare wurden mit dem C99-Standard offiziell in die Sprache C aufgenommen, aber die meisten Compiler unterstützten sie schon vor C99. Sie werden manchmal als Kommentare im "C++-Stil" bezeichnet, obwohl sie ursprünglich aus dem Vorläufer von C, BCPL, stammen.
Innerhalb der Anführungszeichen, die eine Zeichenkonstante oder ein Stringliteral abgrenzen, beginnen die Zeichen /* und // keinen Kommentar. Die folgende Anweisung enthält zum Beispiel keine Kommentare:
printf("Comments in C begin with /* or //.\n");
Das einzige, wonach der Präprozessor bei der Untersuchung der Zeichen in einem Kommentar sucht, ist das Ende des Kommentars; daher ist es nicht möglich, Blockkommentare zu verschachteln. Du kannst jedoch /* und */ einfügen, um einen Teil eines Programms auszukommentieren, der Zeilenkommentare enthält:
/* Temporarily removing two lines:const double pi = 3.1415926536; // pi is constantarea = pi * r * r // Calculate the areaTemporarily removed up to here */
Wenn du einen Teil eines Programms, der Blockkommentare enthält, auskommentieren willst, kannst du eine bedingte Präprozessordirektive verwenden (beschrieben in Kapitel 15):
#if 0const double pi = 3.1415926536; /* pi is constant */area = pi * r * r /* Calculate the area */#endif
Der Präprozessor ersetzt jeden Kommentar durch ein Leerzeichen. Die Zeichenfolge min/*max*/Value wird so zu den beiden Token min Value.
Zeichensätze
C unterscheidet zwischen der Umgebung, in der der Compiler die Quelldateien eines Programms übersetzt (die Übersetzungsumgebung), und der Umgebung, in der das kompilierte Programm ausgeführt wird (die Ausführungsumgebung). Dementsprechend definiert C zwei Zeichensätze: Der Quellzeichensatz ist die Menge der Zeichen, die im C-Quellcode verwendet werden können, und der Ausführungszeichensatz ist die Menge der Zeichen, die vom laufenden Programm interpretiert werden können. In vielen C-Implementierungen sind die beiden Zeichensätze identisch. Wenn das nicht der Fall ist, wandelt der Compiler die Zeichen in Zeichenkonstanten und Stringliteralen im Quellcode in die entsprechenden Elemente des Ausführungszeichensatzes um.
Jeder der beiden Zeichensätze enthält sowohl einen Basiszeichensatz als auch erweiterte Zeichen. In der Sprache C sind die erweiterten Zeichen nicht spezifiziert, da sie in der Regel von der Landessprache abhängig sind. Die erweiterten Zeichen bilden zusammen mit dem Basiszeichensatz den erweiterten Zeichensatz.
Die grundlegenden Quell- und Ausführungszeichensätze enthalten beide die folgenden Arten von Zeichen:
- Die Buchstaben des lateinischen Alphabets
-
A B C D E F G H I J K L M N O P Q R S T U V W X Y Za b c d e f g h i j k l m n o p q r s t u v w x y z - Die Dezimalziffern
-
0 1 2 3 4 5 6 7 8 9 - Die folgenden 29 grafischen Zeichen
-
! " # % & ' () * + , − . / : ; < = > ? [ \ ] ^ _ { | } ~ - Die fünf Whitespace-Zeichen
-
Leerzeichen, horizontaler Tabulator, vertikaler Tabulator, Zeilenumbruch und Seitenvorschub
Der grundlegende Zeichensatz für die Ausführung umfasst auch vier nicht druckbare Zeichen: das Null-Zeichen (das als Abschlusszeichen in einer Zeichenkette fungiert), Alert, Backspace und Carriage Return. Um diese Zeichen in Zeichen- und Zeichenkettenliteralen darzustellen, gibst du die entsprechenden Escape-Sequenzen ein, die mit einem Backslash beginnen: \0 für das Nullzeichen, \a für Alert, \b für Backspace und \r für Carriage Return. In Kapitel 3 findest du weitere Informationen.
Die tatsächlichen numerischen Werte der Zeichen - die Zeichencodes - können von einer C-Implementierung zur anderen variieren. Die Sprache selbst schreibt nur diese Bedingungen vor:
-
Jedes Zeichen des Basiszeichensatzes muss in einem Byte dargestellt werden können.
-
Das Nullzeichen ist ein Byte, in dem alle Bits 0 sind.
-
Der Wert jeder Dezimalstelle nach 0 ist um eins größer als der der vorhergehenden Stelle.
Breitzeichen und Multibyte-Zeichen
C wurde ursprünglich in einer englischsprachigen Umgebung entwickelt, in der der 7-Bit-ASCII-Code der vorherrschende Zeichensatz war. Seitdem ist das 8-Bit-Byte die gebräuchlichste Einheit für die Zeichenkodierung geworden, aber Software für den internationalen Einsatz muss in der Regel mehr verschiedene Zeichen darstellen können, als in einem Byte kodiert werden können. Außerdem werden international seit langem verschiedene Multibyte-Zeichenkodierungssysteme verwendet, um nicht-lateinische Alphabete und die nicht-alphabetischen chinesischen, japanischen und koreanischen Schriftsysteme darzustellen. Mit der Verabschiedung des "Normative Addendum 1" im Jahr 1994 hat ISO C zwei Möglichkeiten zur Darstellung größerer Zeichensätze standardisiert:
-
Breite Zeichen, bei denen für jedes Zeichen in einem Zeichensatz die gleiche Bitbreite verwendet wird
-
Multibyte-Zeichen, bei denen ein bestimmtes Zeichen durch ein oder mehrere Bytes dargestellt werden kann und der Zeichenwert einer bestimmten Bytefolge von ihrem Kontext in einem String oder Stream abhängen kann
Tipp
Obwohl C jetzt abstrakte Mechanismen zur Bearbeitung und Konvertierung der verschiedenen Kodierungsschemata bereitstellt, definiert oder spezifiziert die Sprache selbst keine Kodierungsschemata oder Zeichensätze außer den im vorherigen Abschnitt beschriebenen grundlegenden Quell- und Ausführungszeichensätzen. Mit anderen Worten: Es ist den einzelnen Implementierungen überlassen, wie sie breite Zeichen kodieren und welche Multibyte-Kodierungsschemata sie unterstützen.
Breite Zeichen
Seit , dem Addendum von 1994, bietet C nicht nur den Typ char, sondern auch wchar_t, den Wide Character Type. Dieser Typ, der in der Header-Datei stddef.h definiert ist, ist groß genug, um jedes Element der erweiterten Zeichensätze der jeweiligen Implementierung darzustellen.
Obwohl der C-Standard keine Unterstützung für Unicode-Zeichensätze verlangt, verwenden viele Implementierungen die Unicode-Transformationsformate UTF-16 und UTF-32 (siehe http://www.unicode.org/) für breite Zeichen. Der Unicode-Standard ist weitgehend identisch mit dem ISO/IEC 10646-Standard und stellt eine Obermenge vieler bereits existierender Zeichensätze dar, darunter auch der 7-Bit-ASCII-Code. Wenn der Unicode-Standard implementiert ist, ist der Typ wchar_t mindestens 16 oder 32 Bit breit, und ein Wert vom Typ wchar_t steht für ein Unicode-Zeichen. Die folgende Definition initialisiert zum Beispiel die Variable wc mit dem griechischen Buchstaben α:
wchar_twc='\x3b1';
Die Escape-Sequenz , die mit \x beginnt, gibt einen Zeichencode in hexadezimaler Notation an, der in der Variablen gespeichert werden soll - in diesem Fall der Code für ein Kleinbuchstaben-Alpha.
Für bessere Unicode-Unterstützung führte C11 die zusätzlichen Wide-Character-Typen char16_t und char32_t ein, die als vorzeichenlose Ganzzahltypen in der Header-Datei uchar .h definiert sind. Zeichen des Typs char16_t werden in C-Implementierungen, die das Makro __STDC_UTF_16__ definieren, in UTF-16 kodiert. Ebenso werden in Implementierungen, die das Makro __STDC_UTF_32__ definieren, Zeichen des Typs char32_t in UTF-32 kodiert.
Multibyte-Zeichen
In Multibyte-Zeichensätzen wird jedes Zeichen als eine Folge von einem oder mehreren Bytes kodiert. Sowohl der Quell- als auch der Ausführungszeichensatz können Multibyte-Zeichen enthalten. Wenn dies der Fall ist, belegt jedes Zeichen im Basiszeichensatz nur ein Byte, und kein Multibyte-Zeichen außer dem Null-Zeichen darf ein Byte enthalten, in dem alle Bits 0 sind. Multibyte-Zeichen können in Zeichenkonstanten, String-Literalen, Bezeichnern, Kommentaren und Header-Dateinamen verwendet werden. Viele Multibyte-Zeichensätze wurden zur Unterstützung einer bestimmten Sprache entwickelt, z. B. der Japanese Industrial Standard Character Set (JIS). Der Multibyte-Zeichensatz UTF-8, der vom Unicode Consortium definiert wurde, ist in der Lage, alle Unicode-Zeichen darzustellen. UTF-8 verwendet zwischen einem und vier Bytes, um ein Zeichen darzustellen.
Der Hauptunterschied zwischen Multibyte-Zeichen und Wide-Zeichen (d.h. Zeichen des Typs wchar_t, char16_t oder char32_t) besteht darin, dass Wide-Zeichen alle die gleiche Größe haben, während Multibyte-Zeichen durch eine unterschiedliche Anzahl von Bytes dargestellt werden. Diese Darstellung macht die Verarbeitung von Multibyte-Zeichenfolgen komplizierter als die von Wide-Zeichenfolgen. Obwohl zum Beispiel das Zeichen A in einem einzigen Byte dargestellt werden kann, erfordert das Auffinden des Zeichens in einer Multibyte-Zeichenkette mehr als einen einfachen Byte-zu-Byte-Vergleich, da derselbe Byte-Wert an bestimmten Stellen Teil eines anderen Zeichens sein könnte. Multibyte-Zeichen eignen sich jedoch gut zum Speichern von Text in Dateien (siehe Kapitel 13). Außerdem ist die Kodierung von Multibyte-Zeichen unabhängig von der Systemarchitektur, während die Kodierung von Wide-Zeichen von der Byte-Reihenfolge des jeweiligen Systems abhängt: Das heißt, die Bytes eines Wide-Zeichens können je nach System in Big-Endian- oder Little-Endian-Reihenfolge vorliegen.
Konvertierung
C bietet Standardfunktionen, um den wchar_t Wert eines beliebigen Multibyte-Zeichens zu erhalten und um ein beliebiges Wide-Zeichen in seine Multibyte-Darstellung umzuwandeln. Wenn der C-Compiler zum Beispiel die Unicode-Standards UTF-16 und UTF-8 verwendet, erhält der folgende Aufruf der Funktion wctomb() (lies: "wide character to multibyte") die Multibyte-Darstellung des Zeichens α:
wchar_twc=L'\x3B1';// Greek lowercase alpha,αcharmbStr[10]="";intnBytes=0;nBytes=wctomb(mbStr,wc);if(nBytes<0)puts("Not a valid multibyte character in your locale.");
Nach einem erfolgreichen Funktionsaufruf enthält das Array mbStr das Multibyte-Zeichen, das in diesem Beispiel die Sequenz "\xCE\xB1" ist. Der Rückgabewert der Funktion wctomb(), der hier der Variablen nBytes zugewiesen wird, ist die Anzahl der Bytes, die benötigt werden, um das Multibyte-Zeichen darzustellen, nämlich 2.
Die Standardbibliothek bietet auch Konvertierungsfunktionen für char16_t und char32_t, die neuen Wide-Character-Typen, die in C11 eingeführt wurden, wie z. B. die Funktion c16rtomb(), die das Multibyte-Zeichen zurückgibt, das einem gegebenen Wide-Character des Typs char16_t entspricht (siehe "Multibyte-Zeichen").
Universelle Zeichennamen
C unterstützt auch universelle Zeichennamen, mit denen du den erweiterten Zeichensatz unabhängig von der Kodierung der Implementierung verwenden kannst. Du kannst jedes erweiterte Zeichen durch seinen universellen Zeichennamen angeben, der seinem Unicode-Wert in der Form entspricht:
\uXXXX
oder:
\UXXXXXXXX
wo XXXX oder XXXXXXXX ein Unicode-Codepunkt in hexadezimaler Schreibweise ist. Verwende das Präfix u in Kleinbuchstaben, gefolgt von vier Hexadezimalziffern, oder U in Großbuchstaben, gefolgt von genau acht Hexadezimalziffern. Wenn die ersten vier Hexadezimalziffern Null sind, kann derselbe universelle Zeichenname entweder als \uXXXX oder als\U0000XXXX.
Universelle Zeichennamen sind in Bezeichnern, Zeichenkonstanten und Stringliteralen zulässig. Sie dürfen jedoch nicht verwendet werden, um Zeichen des Basiszeichensatzes darzustellen.
Wenn du ein Zeichen mit seinem universellen Zeichennamen angibst, speichert der Compiler es in dem von der Implementierung verwendeten Zeichensatz. Wenn zum Beispiel der Ausführungszeichensatz in einem lokalisierten Programm ISO 8859-7 (8-Bit-Griechisch) ist, dann initialisiert die folgende Definition die Variable alpha mit dem Code\xE1:
charalpha='\u03B1';
Wenn der Zeichensatz für die Ausführung jedoch UTF-16 ist, musst du die Variable als Wide Character definieren:
wchar_talpha='\u03B1';// or char16_t alpha = u'\u03B1';
In diesem Fall ist der Zeichencodewert, der alpha zugewiesen wird, hexadezimal 3B1, was dem universellen Zeichennamen entspricht.
Tipp
Nicht alle Compiler unterstützen universelle Zeichennamen.
Digraphen und Trigraphen
C bietet alternative Darstellungen für eine Reihe von Interpunktionszeichen, die nicht auf allen Tastaturen verfügbar sind. Sechs davon sind die Digraphen oder Zwei-Zeichen-Marken, die die in Tabelle 1-1 aufgeführten Zeichen darstellen.
| Digraph | Äquivalent |
|---|---|
<: |
[ |
:> |
] |
<% |
{ |
%> |
} |
%: |
# |
%:%: |
## |
Diese Sequenzen werden nicht als Digraphen interpretiert, wenn sie innerhalb von Zeichenkonstanten oder String-Literalen vorkommen. An allen anderen Stellen verhalten sie sich genau wie die Ein-Zeichen-Token, die sie darstellen. Die folgenden Codefragmente sind zum Beispiel vollkommen gleichwertig und erzeugen die gleiche Ausgabe. Mit Digraphen:
intarr<::>=<%10,20,30%>;printf("The second array element is <%d>.\n",arr<:1:>);
Ohne Digraphen:
intarr[]={10,20,30};printf("The second array element is <%d>.\n",arr[1]);
Ausgabe:
Thesecondarrayelementis<20>.
C bietet auch Trigraphen, dreistellige Darstellungen, die alle mit zwei Fragezeichen beginnen. Das dritte Zeichen bestimmt, welches Satzzeichen ein Trigraph darstellt, wie in Tabelle 1-2 gezeigt.
| Trigraph | Äquivalent |
|---|---|
|
[ |
|
] |
|
{ |
|
} |
|
# |
|
\ |
|
| |
|
^ |
|
~ |
Trigraphen ermöglichen es dir, jedes C-Programm nur mit den Zeichen zu schreiben, die in ISO/IEC 646 definiert sind, der Norm von 1991, die dem 7-Bit-ASCII entspricht. Der Präprozessor des Compilers ersetzt die Trigraphen in der ersten Phase der Kompilierung durch ihre Ein-Zeichen-Entsprechungen. Das bedeutet, dass die Trigraphen im Gegensatz zu Digraphen überall, wo sie vorkommen, in ihre einstelligen Entsprechungen übersetzt werden, auch in Zeichenkonstanten, Stringliteralen, Kommentaren und Vorverarbeitungsanweisungen. Zum Beispiel interpretiert der Präprozessor das zweite und dritte Fragezeichen der folgenden Anweisung als Beginn eines Trigraphen:
printf("Cancel???(y/n) ");
Daher erzeugt die Zeile die folgende unbeabsichtigte Präprozessorausgabe:
printf("Cancel?[y/n) ");
Wenn du eine dieser Drei-Zeichen-Sequenzen verwenden musst und nicht möchtest, dass sie als Trigraph interpretiert wird, kannst du die Fragezeichen als Escape-Sequenzen schreiben:
printf("Cancel\?\?\?(y/n) ");
Wenn das Zeichen, das auf zwei Fragezeichen folgt, nicht zu den in Tabelle 1-2 aufgeführten Zeichen gehört, ist die Folge kein Trigraph und bleibt unverändert.
Tipp
Als weiteren Ersatz für Satzzeichen zusätzlich zu den Digraphen und Trigraphen enthält die Header-Datei iso646.h Makros, die alternative Darstellungen der logischen Operatoren und bitweisen Operatoren von C definieren, wie and für && und xor für ^. Für weitere Informationen siehe in Kapitel 16.
Identifikatoren
Der Begriff Bezeichner bezieht sich auf die Namen von Variablen, Funktionen, Makros, Strukturen und anderen Objekten, die in einem C-Programm definiert sind. Bezeichner können die folgenden Zeichen enthalten:
-
Die Buchstaben des Basiszeichensatzes,
a-zundA-Z(Groß- und Kleinschreibung wird beachtet) -
Das Unterstreichungszeichen,
_ -
Die Dezimalziffern
0-9, wobei das erste Zeichen eines Bezeichners keine Ziffer sein darf -
Universelle Zeichennamen, die die Buchstaben und Ziffern anderer Sprachen darstellen
Die zulässigen universellen Zeichen sind in Anhang D der C-Norm definiert und entsprechen den Zeichen, die in der Norm ISO/IEC TR 10176 definiert sind, abzüglich des Basiszeichensatzes.
Multibyte-Zeichen können auch in Bezeichnern zulässig sein. Es liegt jedoch an der jeweiligen C-Implementierung, genau zu bestimmen, welche Multibyte-Zeichen zulässig sind und welchen universellen Zeichennamen sie entsprechen.
Die folgenden 44 Schlüsselwörter sind in C reserviert. Sie haben jeweils eine bestimmte Bedeutung für den Compiler und dürfen nicht als Bezeichner verwendet werden:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Die folgenden Beispiele sind gültige Bezeichner:
x dollar Break error_handler scale64
Die folgenden Identifikatoren sind nicht gültig:
1st_rank switch y/n x-ray
Wenn der Compiler universelle Zeichennamen unterstützt, ist α auch ein Beispiel für einen gültigen Bezeichner, und du kannst eine Variable mit diesem Namen definieren:
doubleα=0.5;
Dein Quellcode-Editor speichert das Zeichen α in der Quelldatei möglicherweise als das universelle Zeichen \u03B1.
Wenn du in deinen Programmen Bezeichner auswählst, erinnere dich daran, dass viele Bezeichner bereits von der C-Standardbibliothek verwendet werden. Dazu gehören die Namen von Funktionen der Standardbibliothek, die du nicht für selbst definierte Funktionen oder globale Variablen verwenden kannst. Siehe Kapitel 16 für weitere Informationen.
Der C-Compiler bietet den vordefinierten Bezeichner __func__ (beachte die vier Unterstriche), den du in jeder Funktion verwenden kannst, um auf eine String-Konstante zuzugreifen, die den Namen der Funktion enthält. Dies ist nützlich für die Protokollierung oder für Debugging-Ausgaben, zum Beispiel:
#include <stdio.h>inttest_func(char*s){if(s==NULL){fprintf(stderr,"%s: received null pointer argument\n",__func__);return-1;}/* ... */}
In diesem Beispiel führt die Übergabe eines Null-Zeigers an die Funktion test_func() zu der folgenden Fehlermeldung:
test_func: received null pointer argument
Es gibt keine Begrenzung für die Länge von Bezeichnern. Die meisten Compiler betrachten jedoch nur eine begrenzte Anzahl von Zeichen in Bezeichnern als signifikant. Das bedeutet, dass ein Compiler möglicherweise nicht zwischen zwei Bezeichnern unterscheiden kann, die mit einer langen identischen Zeichenfolge beginnen. Um dem C-Standard zu entsprechen, muss ein Compiler mindestens die ersten 31 Zeichen in den Namen von Funktionen und globalen Variablen (d. h. Bezeichner mit externer Verknüpfung) und mindestens die ersten 63 Zeichen in allen anderen Bezeichnern als signifikant behandeln.
Kennung Name Leerzeichen
Alle Bezeichner fallen in genau eine der folgenden vier Kategorien, die eigene Namensräume bilden:
-
Label-Namen
-
Tags, die Struktur-, Vereinigungs- und Aufzählungstypen identifizieren
-
Namen der Struktur- oder Unionsmitglieder (jede Struktur oder Union bildet einen eigenen Namensraum für ihre Mitglieder)
-
Alle anderen Identifikatoren, die als gewöhnliche Identifikatoren bezeichnet werden
Bezeichner, die zu verschiedenen Namensräumen gehören, können identisch sein, ohne Konflikte zu verursachen. Mit anderen Worten: Du kannst denselben Namen verwenden, um auf verschiedene Objekte zu verweisen, auch wenn sie von unterschiedlicher Art sind. Der Compiler ist zum Beispiel in der Lage, zwischen einer Variablen und einem Label mit demselben Namen zu unterscheiden. Ebenso kannst du einem Strukturtyp, einem Element in der Struktur und einer Variablen denselben Namen geben, wie das folgende Beispiel zeigt:
structpin{charpin[16];/* ... */};_Boolcheck_pin(structpin*pin){intlen=strlen(pin->pin);/* ... */}
Die erste Zeile des Beispiels definiert einen Strukturtyp, der durch das Tag pin identifiziert wird und ein Zeichenfeld mit dem Namen pin als eines seiner Mitglieder enthält. In der zweiten Zeile ist der Funktionsparameter pin ein Zeiger auf eine Struktur des gerade definierten Typs. Der Ausdruck pin->pin in der vierten Zeile bezeichnet das Mitglied der Struktur, auf das der Parameter der Funktion zeigt. Der Kontext, in dem ein Bezeichner erscheint, bestimmt immer eindeutig seinen Namensraum. Dennoch ist es im Allgemeinen eine gute Idee, alle Bezeichner in einem Programm zu unterscheiden, um den menschlichen Lesern unnötige Verwirrung zu ersparen.
Kennung Geltungsbereich
Der Geltungsbereich eines Bezeichners bezieht sich auf den Teil der Übersetzungseinheit, in dem der Bezeichner sinnvoll ist. Oder anders ausgedrückt: Der Geltungsbereich eines Bezeichners ist der Teil des Programms, der diesen Bezeichner "sehen" kann. Die Art des Geltungsbereichs wird immer durch die Stelle bestimmt, an der du den Bezeichner deklarierst (außer bei Bezeichnern, die immer einen Funktionsbereich haben). Es sind vier Arten von Geltungsbereichen möglich:
- Umfang der Datei
-
Wenn du einen Bezeichner außerhalb aller Blöcke und Parameterlisten deklarierst, hat er Dateigültigkeit. Du kannst den Bezeichner dann überall nach der Deklaration und bis zum Ende der Übersetzungseinheit verwenden.
- Blockumfang
-
Mit Ausnahme von für Labels haben Bezeichner, die innerhalb eines Blocks deklariert werden, einen Blockumfang. Du kannst einen solchen Bezeichner nur von seiner Deklaration bis zum Ende des kleinsten Blocks verwenden, der diese Deklaration enthält. Der kleinste enthaltende Block ist oft, aber nicht unbedingt, der Körper einer Funktionsdefinition. Ab C99 müssen Deklarationen nicht mehr vor allen Anweisungen in einem Funktionsblock stehen. Die Parameternamen im Kopf einer Funktionsdefinition haben ebenfalls Blockumfang und sind innerhalb des entsprechenden Funktionsblocks gültig.
- Umfang des Funktionsprototyps
-
Die Parameternamen in einem Funktionsprototyp haben den Geltungsbereich des Funktionsprototyps. Da diese Parameternamen außerhalb des Prototyps selbst keine Bedeutung haben, sind sie nur als Kommentare sinnvoll und können auch weggelassen werden. In Kapitel 7 findest du weitere Informationen.
- Funktionsumfang
-
Der Geltungsbereich eines Labels ist immer der Funktionsblock, in dem das Label vorkommt, auch wenn es in verschachtelten Blöcken steht. Mit anderen Worten: Du kannst eine
gotoAnweisung verwenden, um von jedem Punkt innerhalb derselben Funktion, die das Label enthält, zu einem Label zu springen. (Das Springen in verschachtelte Blöcke ist allerdings keine gute Idee; mehr dazu in Kapitel 6 ).
Der Geltungsbereich eines Bezeichners beginnt in der Regel nach seiner Deklaration. Die Typnamen - oder Tags - von Struktur-, Unions- und Aufzählungstypen sowie die Namen von Aufzählungskonstanten bilden jedoch eine Ausnahme von dieser Regel: Ihr Geltungsbereich beginnt unmittelbar nach ihrem Erscheinen in der Deklaration, sodass sie in der Deklaration selbst wieder referenziert werden können. (Strukturen und Unions werden in Kapitel 10 ausführlich behandelt; Aufzählungstypen werden in Kapitel 2 beschrieben). In der folgenden Deklaration eines Strukturtyps ist zum Beispiel das letzte Mitglied der Struktur, next, ein Zeiger auf den Strukturtyp, der gerade deklariert wird:
structNode{/* ... */structNode*next;};// Define a structure typevoidprintNode(conststructNode*ptrNode);// Declare a functionintprintList(conststructNode*first)// Begin a function{// definitionstructNode*ptr=first;while(ptr!=NULL){printNode(ptr);ptr=ptr->next;}}
In diesem Codeschnipsel haben die Bezeichner Node, next, printNode und printList alle den Geltungsbereich Datei. Der Parameter ptrNode hat den Geltungsbereich eines Funktionsprototyps, und die Variablen first und ptr haben den Geltungsbereich eines Blocks.
Es ist möglich, einen Bezeichner in einer neuen Deklaration innerhalb seines bestehenden Geltungsbereichs erneut zu verwenden, auch wenn der neue Bezeichner keinen anderen Namensraum hat. Wenn du das tust, muss die neue Deklaration einen Block- oder Funktionsprototyp-Bereich haben und der Block- oder Funktionsprototyp muss eine echte Teilmenge des äußeren Bereichs sein. In solchen Fällen blendet die neue Deklaration desselben Bezeichners die äußere Deklaration aus, so dass die im äußeren Block deklarierte Variable oder Funktion im inneren Bereich nicht sichtbar ist. Die folgenden Deklarationen sind zum Beispiel zulässig:
doublex;// Declare a variable x with file scopelongcalc(doublex);// Declare a new x with function prototype// scopeintmain(){longx=calc(2.5);// Declare a long variable x with block scopeif(x<0)// Here, x refers to the long variable{floatx=0.0F;// Declare a new variable x with block scope/*...*/}x*=2;// Here, x refers to the long variable again/*...*/}
In diesem Beispiel verbirgt die long Variable x, die in der Funktion main() enthalten ist, die globale Variable x mit dem Typ double. Es gibt also keine direkte Möglichkeit, von main() aus auf die Variable double x zuzugreifen. Außerdem verweist x in dem bedingten Block, der von der Anweisung if abhängt, auf die neu deklarierte Variable float, die wiederum die Variable long x verbirgt.
Wie der C-Compiler funktioniert
Sobald du eine Quelldatei mit einem Texteditor geschrieben hast, kannst du einen C-Compiler aufrufen, um sie in Maschinencode zu übersetzen. Der Compiler arbeitet mit einer Übersetzungseinheit, die aus einer Quelldatei und allen Header-Dateien besteht, auf die durch #include Direktiven verwiesen wird. Wenn der Compiler keine Fehler in der Übersetzungseinheit findet, erzeugt er eine Objektdatei, die den entsprechenden Maschinencode enthält. Objektdateien werden in der Regel durch die Dateinamensendung .o oder .obj gekennzeichnet. Darüber hinaus kann der Compiler auch ein Assembler-Listing erstellen (siehe Kapitel 19).
Objektdateien werden auch Module genannt. Eine Bibliothek, wie zum Beispiel die C-Standardbibliothek, enthält kompilierte, schnell zugängliche Module der Standardfunktionen.
Der Compiler übersetzt jede Übersetzungseinheit eines C-Programms - d.h. jede Quelldatei mit den darin enthaltenen Header-Dateien - in eine separate Objektdatei. Anschließend ruft der Compiler den Linker auf, der die Objektdateien und alle verwendeten Bibliotheksfunktionen zu einer ausführbaren Datei zusammenfügt. Abbildung 1-1 veranschaulicht den Prozess des Kompilierens und Linkens eines Programms aus mehreren Quelldateien und Bibliotheken. Die ausführbare Datei enthält auch alle Informationen, die das Zielbetriebssystem benötigt, um sie zu laden und zu starten.
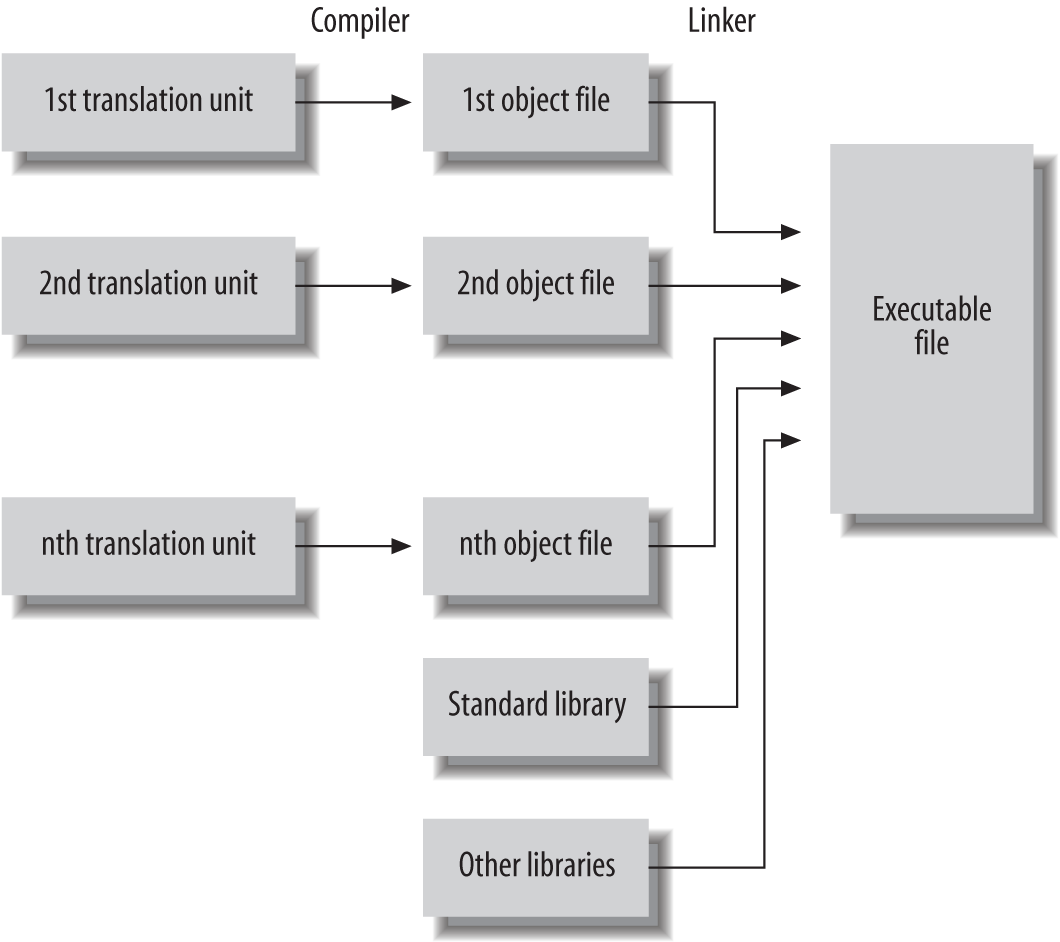
Abbildung 1-1. Vom Quellcode zur ausführbaren Datei
Die Übersetzungsphasen des C-Compilers
Der Kompilierungsprozess von erfolgt in acht logischen Schritten. Ein bestimmter Compiler kann mehrere dieser Schritte kombinieren, solange die Ergebnisse nicht beeinflusst werden. Die Schritte sind:
-
Die Zeichen werden aus der Quelldatei gelesen und, falls erforderlich, in die Zeichen des Quellzeichensatzes umgewandelt. Die Zeilenende-Indikatoren in der Quelldatei werden ersetzt, wenn sie sich vom Zeilenumbruch unterscheiden. Ebenso werden alle Trigraphenfolgen durch die einzelnen Zeichen ersetzt, die sie darstellen. (Digraphen werden jedoch in Ruhe gelassen; sie werden nicht in die entsprechenden Einzelzeichen umgewandelt).
-
Wenn auf einen Backslash unmittelbar ein Zeilenumbruch folgt, löscht der Präprozessor beide. Da ein Zeilenende-Zeichen eine Präprozessor-Direktive beendet, kannst du mit diesem Verarbeitungsschritt einen Backslash an das Ende einer Zeile setzen, um eine Direktive, z. B. eine Makrodefinition, in der nächsten Zeile fortzusetzen.
Tipp
Jede Quelldatei muss, wenn sie nicht komplett leer ist, mit einem Zeilenumbruch enden.
-
Die Quelldatei wird in Präprozessor-Token (siehe "Token") und Sequenzen von Leerzeichen aufgeteilt. Jeder Kommentar wird als ein Leerzeichen behandelt.
-
Die Präprozessor-Direktiven werden ausgeführt und die Makroaufrufe werden erweitert.
Tipp
Die Schritte 1 bis 4 werden auch auf alle Dateien angewendet, die durch
#includeDirektiven eingefügt wurden. Sobald der Compiler die Präprozessor-Direktiven ausgeführt hat, entfernt er sie aus seiner Arbeitskopie des Quellcodes. -
Die Zeichen und Escape-Sequenzen in Zeichenkonstanten und Stringliteralen werden in die entsprechenden Zeichen des Ausführungszeichensatzes umgewandelt.
-
Benachbarte String-Literale werden zu einem einzigen String verkettet.
-
Die eigentliche Kompilierung findet statt: Der Compiler analysiert die Abfolge der Token und erzeugt den entsprechenden Maschinencode.
-
Der Linker löst Verweise auf externe Objekte und Funktionen auf und erzeugt die ausführbare Datei. Wenn ein Modul auf externe Objekte oder Funktionen verweist, die in keiner der Übersetzungseinheiten definiert sind, entnimmt der Linker sie aus der Standardbibliothek oder einer anderen angegebenen Bibliothek. Externe Objekte und Funktionen dürfen nicht mehr als einmal in einem Programm definiert werden.
Bei den meisten Compilern ist der Präprozessor entweder ein separates Programm oder der Compiler bietet Optionen, um nur die Vorverarbeitung durchzuführen (Schritte 1 bis 4 in der vorangegangenen Liste). Auf diese Weise kannst du überprüfen, ob deine Präprozessordirektiven die beabsichtigten Auswirkungen haben. Einen praxisnahen Einblick in den Kompilierprozess findest du in Kapitel 19 unter .
Wertmarken
Ein Token ist entweder ein Schlüsselwort, ein Bezeichner, eine Konstante, ein Stringliteral oder ein Symbol. Symbole in C bestehen aus einem oder mehreren Satzzeichen und fungieren als Operatoren oder Digraphen oder haben eine syntaktische Bedeutung, wie das Semikolon, das eine einfache Anweisung abschließt, oder die geschweiften Klammern { }, die eine Blockanweisung einschließen. Die folgende C-Anweisung besteht zum Beispiel aus fünf Token:
printf("Hello, world.\n");
Die einzelnen Token sind:
printf("Hello, world.\n");
Die vom Präprozessor interpretierten Token werden in der dritten Übersetzungsphase geparst. Diese unterscheiden sich nur geringfügig von den Token, die der Compiler in der siebten Übersetzungsphase interpretiert:
-
Innerhalb einer
#includeDirektive erkennt der Präprozessor die zusätzlichen Token<filename>und"filename". -
In der Vorverarbeitungsphase wurden die Zeichenkonstanten und Stringliterale noch nicht vom Quellzeichensatz in den Ausführungszeichensatz umgewandelt.
-
Im Gegensatz zum eigentlichen Compiler unterscheidet der Präprozessor nicht zwischen Ganzzahlkonstanten und Fließkommakonstanten.
Beim Parsen der Quelldatei in Token wendet der Compiler (oder Präprozessor) immer das folgende Prinzip an: Jedes aufeinanderfolgende Nicht-Leerzeichen muss an das zu lesende Token angehängt werden, es sei denn, das Anhängen würde ein gültiges Token ungültig machen. Diese Regel löst zum Beispiel jede Zweideutigkeit in dem folgenden Ausdruck auf:
a+++b
Da das erste + nicht Teil eines Bezeichners oder Schlüsselworts sein kann, das mit a beginnt, beginnt es ein neues Token. Das zweite +, das an das erste angehängt wird, bildet ein gültiges Token - den Inkrement-Operator -, aber ein drittes + tut dies nicht. Daher muss der Ausdruck geparst werden als:
a+++b
In Kapitel 19 findest du weitere Informationen zum Kompilieren von C Programmen.
1 Die zweite, an den ersten ANSI C-Standard angepasste Ausgabe ist erhältlich als The C Programming Language, 2nd ed., von Brian W. Kernighan und Dennis M. Ritchie (Englewood Cliffs, NJ: Prentice Hall, 1988).
Get C in a Nutshell, 2. Auflage now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

