Kapitel 4. Fortgeschrittene C#
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
In diesem Kapitel behandeln wir fortgeschrittene C#-Themen, die auf den Konzepten aufbauen, die in den Kapiteln 2 und 3 behandelt wurden. Du solltest die ersten vier Abschnitte der Reihe nach lesen; die restlichen Abschnitte kannst du in beliebiger Reihenfolge lesen.
Delegierte
Ein Delegat ist ein Objekt, das weiß, wie man eine Methode aufruft.
Ein Delegatentyp definiert die Art der Methode, die Delegat-Instanzen aufrufen können. Insbesondere definiert er den Rückgabetyp der Methode und ihre Parametertypen. Im Folgenden wird ein Delegatentyp namens Transformer definiert:
delegate int Transformer (int x);
Transformer ist mit jeder Methode kompatibel, die einen int Rückgabetyp und einen einzelnen int Parameter hat, wie zum Beispiel diese:
static int Square (int x) { return x * x; }
Oder, noch kürzer:
static int Square (int x) => x * x;
Die Zuweisung einer Methode an eine Delegiertenvariable erzeugt eine Delegierteninstanz:
Transformer t = Square;
Du kannst eine Delegateninstanz auf die gleiche Weise wie eine Methode aufrufen:
int answer = t(3); // answer is 9
Hier ist ein vollständiges Beispiel:
delegate int Transformer (int x);
class Test
{
static void Main()
{
Transformer t = Square; // Create delegate instance
int result = t(3); // Invoke delegate
Console.WriteLine (result); // 9
}
static int Square (int x) => x * x;
}
Eine Delegateninstanz fungiert buchstäblich als Delegierter für den Aufrufer: Der Aufrufer ruft den Delegaten auf und der Delegat ruft dann die Zielmethode auf. Durch diese Umleitung wird der Aufrufer von der Zielmethode entkoppelt.
Die Erklärung:
Transformer t = Square;
ist die Kurzform für:
Transformer t = new Transformer (Square);
Hinweis
Technisch gesehen geben wir eine Methodengruppe an, wenn wir auf Square ohne Klammern oder Argumente verweisen. Wenn die Methode überladen ist, wählt C# anhand der Signatur des Delegaten, dem sie zugewiesen wird, die richtige Überladung aus.
Der Ausdruck:
t(3)
ist die Kurzform für:
t.Invoke(3)
Hinweis
Ein Delegat ist ähnlich wie ein Callback, ein allgemeiner Begriff, der Konstrukte wie C-Funktionszeiger umfasst.
Plug-in-Methoden mit Delegaten schreiben
Einer Delegiertenvariable wird zur Laufzeit eine Methode zugewiesen. Das ist nützlich, um Plug-in-Methoden zu schreiben. In diesem Beispiel haben wir eine Utility-Methode namens Transform, die eine Transformation auf jedes Element in einem Integer-Array anwendet. Die Methode Transform hat einen Delegate-Parameter, den du für die Angabe einer Plug-in-Transformation verwenden kannst:
public delegate int Transformer (int x);
class Util
{
public static void Transform (int[] values, Transformer t)
{
for (int i = 0; i < values.Length; i++)
values[i] = t (values[i]);
}
}
class Test
{
static void Main()
{
int[] values = { 1, 2, 3 };
Util.Transform (values, Square); // Hook in the Square method
foreach (int i in values)
Console.Write (i + " "); // 1 4 9
}
static int Square (int x) => x * x;
}
Unsere Methode Transform ist eine Funktion höherer Ordnung, weil sie eine Funktion ist, die eine Funktion als Argument annimmt. (Eine Methode, die einen Delegaten zurückgibt, wäre auch eine Funktion höherer Ordnung).
Multicast-Delegierte
Alle Delegateninstanzen sind multicastfähig. Das bedeutet, dass eine Delegateninstanz nicht nur eine einzelne Zielmethode referenzieren kann, sondern auch eine Liste von Zielmethoden. Die Operatoren + und += kombinieren Delegateninstanzen:
SomeDelegate d = SomeMethod1; d += SomeMethod2;
Die letzte Zeile ist funktionell die gleiche wie die folgende:
d = d + SomeMethod2;
Wenn du d aufrufst, werden nun sowohl SomeMethod1 als auch SomeMethod2 aufgerufen. Die Delegierten werden in der Reihenfolge aufgerufen, in der sie hinzugefügt werden.
Die Operatoren - und -= entfernen den rechten Delegatenoperanden vom linken Delegatenoperanden:
d -= SomeMethod1;
Wenn du d aufrufst, wird jetzt nur noch SomeMethod2 aufgerufen.
Der Aufruf von + oder += für eine Delegiertenvariable mit dem Wert null funktioniert und ist gleichbedeutend damit, der Variablen einen neuen Wert zuzuweisen:
SomeDelegate d = null; d += SomeMethod1; // Equivalent (when d is null) to d = SomeMethod1;
Ebenso ist der Aufruf von -= für eine Delegiertenvariable mit einem einzigen passenden Ziel gleichbedeutend mit der Zuweisung von null an diese Variable.
Hinweis
Delegaten sind unveränderlich. Wenn du also += oder -= aufrufst, erstellst du in Wirklichkeit eine neue Delegateninstanz und weist sie der vorhandenen Variablen zu.
Wenn ein Multicast-Delegat einen nicht-leeren Rückgabetyp hat, erhält der Aufrufer den Rückgabewert der zuletzt aufgerufenen Methode. Die vorangegangenen Methoden werden weiterhin aufgerufen, aber ihre Rückgabewerte werden verworfen. In den meisten Szenarien, in denen Multicast-Delegierte verwendet werden, haben sie void Rückgabetypen, so dass diese Spitzfindigkeit nicht auftritt.
Hinweis
Alle Delegatentypen leiten sich implizit von System.MulticastDelegateab, der von System.Delegate erbt. C# kompiliert +, -, += und -= Operationen, die auf einem Delegaten ausgeführt werden, mit den statischen Combine und Remove Methoden der Klasse System.Delegate.
Beispiel für einen Multicast-Delegierten
Angenommen, du hast eine Methode geschrieben, die sehr lange zur Ausführung braucht. Diese Methode könnte ihrem Aufrufer regelmäßig den Fortschritt melden, indem sie einen Delegaten aufruft. In diesem Beispiel hat die Methode HardWork einen ProgressReporter Delegatenparameter, den sie aufruft, um den Fortschritt anzuzeigen:
public delegate void ProgressReporter (int percentComplete);
public class Util
{
public static void HardWork (ProgressReporter p)
{
for (int i = 0; i < 10; i++)
{
p (i * 10); // Invoke delegate
System.Threading.Thread.Sleep (100); // Simulate hard work
}
}
}
Um den Fortschritt zu überwachen, erstellt die Methode Main eine Multicast-Delegate-Instanz p, so dass der Fortschritt von zwei unabhängigen Methoden überwacht wird:
class Test
{
static void Main()
{
ProgressReporter p = WriteProgressToConsole;
p += WriteProgressToFile;
Util.HardWork (p);
}
static void WriteProgressToConsole (int percentComplete)
=> Console.WriteLine (percentComplete);
static void WriteProgressToFile (int percentComplete)
=> System.IO.File.WriteAllText ("progress.txt",
percentComplete.ToString());
}
Instanz- versus statische Methodenziele
Wenn eine Instanzmethode einem Delegatenobjekt zugewiesen wird, muss letzteres nicht nur einen Verweis auf die Methode, sondern auch auf die Instanz, zu der die Methode gehört, erhalten. Die Eigenschaft Target der Klasse System.Delegate stellt diese Instanz dar (und ist bei einem Delegaten, der eine statische Methode referenziert, null). Hier ist ein Beispiel:
public delegate void ProgressReporter (int percentComplete);
class Test
{
static void Main()
{
X x = new X();
ProgressReporter p = x.InstanceProgress;
p(99); // 99
Console.WriteLine (p.Target == x); // True
Console.WriteLine (p.Method); // Void InstanceProgress(Int32)
}
}
class X
{
public void InstanceProgress (int percentComplete)
=> Console.WriteLine (percentComplete);
}
Generische Delegatentypen
Ein Delegatentyp kann generische Typparameter enthalten:
public delegate T Transformer<T> (T arg);
Mit dieser Definition können wir eine verallgemeinerte Transform Utility-Methode schreiben, die mit jedem Typ funktioniert:
public class Util
{
public static void Transform<T> (T[] values, Transformer<T> t)
{
for (int i = 0; i < values.Length; i++)
values[i] = t (values[i]);
}
}
class Test
{
static void Main()
{
int[] values = { 1, 2, 3 };
Util.Transform (values, Square); // Hook in Square
foreach (int i in values)
Console.Write (i + " "); // 1 4 9
}
static int Square (int x) => x * x;
}
Die Func- und Action-Delegierten
Mit generischen Delegaten ist es möglich, eine kleine Gruppe von Delegatetypen zu schreiben, die so allgemein sind, dass sie für Methoden mit beliebigem Rückgabetyp und beliebiger (vernünftiger) Anzahl von Argumenten funktionieren. Diese Delegaten sind die Func und Action Delegaten, die im System Namensraum definiert sind (die in und out Annotationen weisen auf die Varianz hin, die wir im Zusammenhang mit Delegaten kurz behandeln):
delegate TResult Func <out TResult> (); delegate TResult Func <in T, out TResult> (T arg); delegate TResult Func <in T1, in T2, out TResult> (T1 arg1, T2 arg2); ... and so on, up to T16 delegate void Action (); delegate void Action <in T> (T arg); delegate void Action <in T1, in T2> (T1 arg1, T2 arg2); ... and so on, up to T16
Diese Delegaten sind extrem allgemein. Der Delegat Transformer in unserem vorherigen Beispiel kann durch einen Delegaten Func ersetzt werden, der ein einzelnes Argument vom Typ T annimmt und einen Wert desselben Typs zurückgibt:
public static void Transform<T> (T[] values, Func<T,T> transformer)
{
for (int i = 0; i < values.Length; i++)
values[i] = transformer (values[i]);
}
Die einzigen praktischen Szenarien, die von diesen Delegierten nicht abgedeckt werden, sind ref/out und Zeigerparameter.
Hinweis
Vor dem Framework 2.0 gab es die Delegaten Func und Action nicht (weil es keine Generics gab). Aus diesem historischen Grund verwendet ein Großteil des Frameworks benutzerdefinierte Delegatetypen anstelle von Func und Action.
Delegierte versus Schnittstellen
Ein Problem, das du mit einem Delegaten lösen kannst, kann auch mit einer Schnittstelle gelöst werden. Wir können zum Beispiel unser ursprüngliches Beispiel mit einer Schnittstelle namens ITransformer statt mit einem Delegaten:
public interface ITransformer
{
int Transform (int x);
}
public class Util
{
public static void TransformAll (int[] values, ITransformer t)
{
for (int i = 0; i < values.Length; i++)
values[i] = t.Transform (values[i]);
}
}
class Squarer : ITransformer
{
public int Transform (int x) => x * x;
}
...
static void Main()
{
int[] values = { 1, 2, 3 };
Util.TransformAll (values, new Squarer());
foreach (int i in values)
Console.WriteLine (i);
}
Ein Delegatendesign ist möglicherweise die bessere Wahl als ein Schnittstellendesign, wenn eine oder mehrere dieser Bedingungen erfüllt sind:
-
Die Schnittstelle definiert nur eine einzige Methode.
-
Multicast-Fähigkeit ist erforderlich.
-
Der Abonnent muss die Schnittstelle mehrfach implementieren.
Im Beispiel von ITransformer brauchen wir kein Multicasting. Die Schnittstelle definiert jedoch nur eine einzige Methode. Außerdem muss unser Abonnent ITransformer möglicherweise mehrfach implementieren, um verschiedene Transformationen zu unterstützen, z. B. Quadrat oder Würfel. Bei Schnittstellen sind wir gezwungen, für jede Transformation einen eigenen Typ zu schreiben, denn Test kann ITransformer nur einmal implementieren. Das ist ziemlich umständlich:
class Squarer : ITransformer
{
public int Transform (int x) => x * x;
}
class Cuber : ITransformer
{
public int Transform (int x) => x * x * x;
}
...
static void Main()
{
int[] values = { 1, 2, 3 };
Util.TransformAll (values, new Cuber());
foreach (int i in values)
Console.WriteLine (i);
}
Kompatibilität der Delegierten
Typenkompatibilität
Delegate Typen sind alle nicht miteinander kompatibel, auch wenn ihre Signaturen gleich sind:
delegate void D1(); delegate void D2(); ... D1 d1 = Method1; D2 d2 = d1; // Compile-time error
Hinweis
Das Folgende ist jedoch erlaubt:
D2 d2 = new D2 (d1);
Delegateninstanzen werden als gleich angesehen, wenn sie die gleichen Methodenziele haben:
delegate void D(); ... D d1 = Method1; D d2 = Method1; Console.WriteLine (d1 == d2); // True
Multicast-Delegierte werden als gleichwertig angesehen, wenn sie die gleichen Methoden in der gleichen Reihenfolge referenzieren.
Parameter Kompatibilität
Wenn du eine Methode aufrufst, kannst du Argumente liefern, die spezifischere Typen haben als die Parameter der Methode. Das ist normales polymorphes Verhalten. Aus demselben Grund kann ein Delegat spezifischere Parametertypen haben als sein Methodenziel. Das nennt man Kontravarianz. Hier ist ein Beispiel:
delegate void StringAction (string s);
class Test
{
static void Main()
{
StringAction sa = new StringAction (ActOnObject);
sa ("hello");
}
static void ActOnObject (object o) => Console.WriteLine (o); // hello
}
(Wie bei der Abweichung von Typparametern sind Delegierte nur für Referenzumwandlungen eine Variante).
Ein Delegat ruft lediglich eine Methode im Namen einer anderen Person auf. In diesem Fall wird die Methode StringAction mit einem Argument vom Typ string aufgerufen. Wenn das Argument dann an die Zielmethode weitergegeben wird, wird das Argument implizit zu einem object umgewandelt.
Hinweis
Das Standard-Ereignismuster soll dir helfen, die Kontravarianz zu nutzen, indem es die gemeinsame Basisklasse EventArgs verwendet. Du kannst zum Beispiel eine einzige Methode von zwei verschiedenen Delegierten aufrufen lassen, wobei der eine eine MouseEventArgs und der andere eine KeyEventArgs übergibt.
Kompatibilität der Rückgabearten
Wenn du eine Methode aufrufst, kann es sein, dass du einen Typ zurückbekommst, der spezifischer ist als der, nach dem du gefragt hast. Das ist ein normales polymorphes Verhalten. Aus demselben Grund kann die Zielmethode eines Delegaten einen spezifischeren Typ zurückgeben, als der Delegat beschreibt. Das nennt man Kovarianz:
delegate object ObjectRetriever();
class Test
{
static void Main()
{
ObjectRetriever o = new ObjectRetriever (RetrieveString);
object result = o();
Console.WriteLine (result); // hello
}
static string RetrieveString() => "hello";
}
ObjectRetriever erwartet, ein object zurückzubekommen, aber eine object Unterklasse tut es auch: Die Rückgabetypen von Delegaten sind kovariant.
Generischer Delegatentyp Parameterabweichung
In Kapitel 3 haben wir gesehen, wie generische Schnittstellen kovariante und kontravariante Typparameter unterstützen. Die gleiche Möglichkeit gibt es auch für Delegierte.
Wenn du einen generischen Delegatentyp definierst, ist es sinnvoll, Folgendes zu tun:
-
Kennzeichne einen Typparameter, der nur für den Rückgabewert verwendet wird, als kovariant (
out). -
Markiere alle Typ-Parameter, die nur für Parameter verwendet werden, als kontravariant (
in).
Auf diese Weise können Konvertierungen auf natürliche Weise funktionieren, da die Vererbungsbeziehungen zwischen den Typen berücksichtigt werden.
Der folgende Delegierte (definiert im Namensraum System ) hat eine Kovariante TResult:
delegate TResult Func<out TResult>();
erlaubt:
Func<string> x = ...; Func<object> y = x;
Der folgende Delegat (definiert im Namensraum System ) hat eine kontravariante T:
delegate void Action<in T> (T arg);
Action<object> x = ...; Action<string> y = x;
Veranstaltungen
Bei der Verwendung von Delegierten gibt es in der Regel zwei auftauchende Rollen: Sender und Teilnehmer.
Der Broadcaster ist ein Typ, der ein Delegatenfeld enthält. Der Broadcaster entscheidet, wann die Sendung gesendet wird, indem er den Delegaten aufruft.
Die Abonnenten sind die Zielempfänger der Methode. Ein Abonnent entscheidet, wann er das Zuhören beginnt und beendet, indem er += und -= auf dem Delegierten des Senders aufruft. Ein Abonnent weiß nichts von anderen Abonnenten und stört diese nicht.
Ereignisse sind ein Sprachmerkmal, das dieses Muster formalisiert. Ein event ist ein Konstrukt, das nur die Teilmenge der Delegiertenfunktionen bereitstellt, die für das Sender-/Teilnehmermodell erforderlich sind. Der Hauptzweck von Ereignissen ist es, zu verhindern, dass sich die Teilnehmer gegenseitig stören.
Der einfachste Weg, ein Ereignis zu deklarieren, ist, das Schlüsselwort event vor ein Delegiertenmitglied zu setzen:
// Delegate definition
public delegate void PriceChangedHandler (decimal oldPrice,
decimal newPrice);
public class Broadcaster
{
// Event declaration
public event PriceChangedHandler PriceChanged;
}
Code innerhalb des Typs Broadcaster hat vollen Zugriff auf PriceChanged und kann es wie einen Delegaten behandeln. Code außerhalb von Broadcaster kann nur += und -= Operationen auf das Ereignis PriceChanged ausführen.
Betrachte das folgende Beispiel. Die Klasse Stock feuert ihr Ereignis PriceChanged jedes Mal ab, wenn sich das Price der Klasse Stock ändert:
public delegate void PriceChangedHandler (decimal oldPrice,
decimal newPrice);
public class Stock
{
string symbol;
decimal price;
public Stock (string symbol) => this.symbol = symbol;
public event PriceChangedHandler PriceChanged;
public decimal Price
{
get => price;
set
{
if (price == value) return; // Exit if nothing has changed
decimal oldPrice = price;
price = value;
if (PriceChanged != null) // If invocation list not
PriceChanged (oldPrice, price); // empty, fire event.
}
}
}
Wenn wir das Schlüsselwort event aus unserem Beispiel entfernen, so dass PriceChanged ein gewöhnliches Delegiertenfeld wird, würde unser Beispiel die gleichen Ergebnisse liefern. Allerdings wäre Stock weniger robust, da sich die Teilnehmer/innen durch die folgenden Dinge gegenseitig stören könnten:
-
Ersetze andere Teilnehmer, indem du
PriceChangedneu zuordnest (anstatt den+=Operator zu verwenden). -
Lösche alle Abonnenten (indem du
PriceChangedaufnullsetzt). -
Sende an andere Abonnenten, indem du den Delegierten aufrufst.
Hinweis
Ereignisse in Windows Runtime (WinRT)-Bibliotheken haben eine etwas andere Semantik, da das Anhängen an ein Ereignis ein Token zurückgibt, das benötigt wird, um sich von dem Ereignis zu lösen. Der Compiler überbrückt diese Lücke auf transparente Weise (indem er ein internes Token-Wörterbuch verwaltet), so dass du WinRT-Ereignisse wie gewöhnliche CLR-Ereignisse konsumieren kannst.
Standard-Ereignis-Muster
In fast allen Fällen, in denen Ereignisse in der .NET Core-Bibliothek definiert sind, folgt ihre Definition einem Standardmuster, das für Konsistenz zwischen Bibliotheks- und Benutzercode sorgen soll. Der Kern des Standard-Ereignismusters ist System.EventArgsEmpty EventArgs ist eine Basisklasse, die die Informationen für ein Ereignis übermittelt. In unserem Beispiel würden wir die Unterklasse verwenden, um den alten und den neuen Preis zu übermitteln, wenn ein Ereignis ausgelöst wird: Stock EventArgs PriceChanged
public class PriceChangedEventArgs : System.EventArgs
{
public readonly decimal LastPrice;
public readonly decimal NewPrice;
public PriceChangedEventArgs (decimal lastPrice, decimal newPrice)
{
LastPrice = lastPrice;
NewPrice = newPrice;
}
}
Damit sie wiederverwendet werden kann, wird die Unterklasse EventArgs nach den Informationen benannt, die sie enthält (und nicht nach dem Ereignis, für das sie verwendet wird). Normalerweise werden die Daten als Eigenschaften oder schreibgeschützte Felder angezeigt.
Wenn du eine EventArgs Unterklasse erstellt hast, ist der nächste Schritt, einen Delegierten für das Ereignis auszuwählen oder zu definieren. Es gibt drei Regeln:
-
Sie muss einen Rückgabetyp
voidhaben. -
Sie muss zwei Argumente akzeptieren: das erste vom Typ
objectund das zweite eine Unterklasse vonEventArgs. Das erste Argument gibt den Ereignissender an, und das zweite Argument enthält die zu übermittelnden Zusatzinformationen. -
Sein Name muss mit
EventHandlerenden.
Das Framework definiert einen generischen Delegierten namens System.EventHandler<>, der diese Regeln erfüllt:
public delegate void EventHandler<TEventArgs> (object source, TEventArgs e) where TEventArgs : EventArgs;
Hinweis
Bevor es Generics in der Sprache gab (vor C# 2.0), hätten wir stattdessen einen benutzerdefinierten Delegaten wie folgt schreiben müssen:
public delegate void PriceChangedHandler
(object sender, PriceChangedEventArgs e);
Aus historischen Gründen werden bei den meisten Ereignissen innerhalb der Rahmenregelung Delegierte auf diese Weise definiert.
Der nächste Schritt besteht darin, ein Ereignis des gewählten Delegatentyps zu definieren. Hier verwenden wir den allgemeinen Delegatentyp EventHandler:
public class Stock
{
...
public event EventHandler<PriceChangedEventArgs> PriceChanged;
}
Schließlich verlangt das Muster, dass du eine geschützte virtuelle Methode schreibst, die das Ereignis auslöst. Der Name muss mit dem Namen des Ereignisses übereinstimmen, dem das Wort On vorangestellt ist, und dann ein einzelnes EventArgs Argument akzeptieren:
public class Stock
{
...
public event EventHandler<PriceChangedEventArgs> PriceChanged;
protected virtual void OnPriceChanged (PriceChangedEventArgs e)
{
if (PriceChanged != null) PriceChanged (this, e);
}
}
Hinweis
Um in Multithreading-Szenarien stabil zu arbeiten(Kapitel 14), musst du den Delegaten einer temporären Variablen zuweisen, bevor du ihn testest und aufrufst:
var temp = PriceChanged;
if (temp != null) temp (this, e);
Mit dem Null-Bedingungs-Operator können wir die gleiche Funktionalität ohne die Variable temp erreichen:
PriceChanged?.Invoke (this, e);
Da sie sowohl thread-sicher als auch prägnant ist, ist dies der beste allgemeine Weg, um Ereignisse aufzurufen.
Dies bietet einen zentralen Punkt, von dem aus Unterklassen das Ereignis aufrufen oder überschreiben können (vorausgesetzt, die Klasse ist nicht versiegelt).
Hier ist das vollständige Beispiel:
using System;
public class PriceChangedEventArgs : EventArgs
{
public readonly decimal LastPrice;
public readonly decimal NewPrice;
public PriceChangedEventArgs (decimal lastPrice, decimal newPrice)
{
LastPrice = lastPrice; NewPrice = newPrice;
}
}
public class Stock
{
string symbol;
decimal price;
public Stock (string symbol) => this.symbol = symbol;
public event EventHandler<PriceChangedEventArgs> PriceChanged;
protected virtual void OnPriceChanged (PriceChangedEventArgs e)
{
PriceChanged?.Invoke (this, e);
}
public decimal Price
{
get => price;
set
{
if (price == value) return;
decimal oldPrice = price;
price = value;
OnPriceChanged (new PriceChangedEventArgs (oldPrice, price));
}
}
}
class Test
{
static void Main()
{
Stock stock = new Stock ("THPW");
stock.Price = 27.10M;
// Register with the PriceChanged event
stock.PriceChanged += stock_PriceChanged;
stock.Price = 31.59M;
}
static void stock_PriceChanged (object sender, PriceChangedEventArgs e)
{
if ((e.NewPrice - e.LastPrice) / e.LastPrice > 0.1M)
Console.WriteLine ("Alert, 10% stock price increase!");
}
}
Der vordefinierte nicht-generische EventHandler Delegat kann verwendet werden, wenn ein Ereignis keine zusätzlichen Informationen enthält. In diesem Beispiel schreiben wir Stock so um, dass das PriceChanged Ereignis ausgelöst wird, nachdem sich der Preis geändert hat, und keine weiteren Informationen über das Ereignis notwendig sind, außer dass es passiert ist. Außerdem verwenden wir die EventArgs.Empty Eigenschaft, um zu vermeiden, dass unnötigerweise eine Instanz von EventArgs:
public class Stock
{
string symbol;
decimal price;
public Stock (string symbol) { this.symbol = symbol; }
public event EventHandler PriceChanged;
protected virtual void OnPriceChanged (EventArgs e)
{
PriceChanged?.Invoke (this, e);
}
public decimal Price
{
get { return price; }
set
{
if (price == value) return;
price = value;
OnPriceChanged (EventArgs.Empty);
}
}
}
Ereignis-Accessoren
Die Accessors eines Ereignisses sind die Implementierungen der Funktionen += und -=. Standardmäßig werden die Accessors implizit vom Compiler implementiert. Betrachte diese Ereignisdeklaration:
public event EventHandler PriceChanged;
Der Compiler wandelt dies in das Folgende um:
-
Ein privates Delegiertenfeld
-
Ein öffentliches Paar von Ereignis-Accessor-Funktionen (
add_PriceChangedundremove_PriceChanged), deren Implementierungen die Operationen+=und-=an das private Delegatenfeld weiterleiten
Du kannst diesen Prozess übernehmen, indem du explizite Ereignis-Accessors definierst. Hier ist eine manuelle Implementierung des Ereignisses PriceChanged aus unserem vorherigen Beispiel:
private EventHandler priceChanged; // Declare a private delegate
public event EventHandler PriceChanged
{
add { priceChanged += value; }
remove { priceChanged -= value; }
}
Dieses Beispiel ist funktional identisch mit der Standard-Accessor-Implementierung von C# (mit der Ausnahme, dass C# auch die Thread-Sicherheit bei der Aktualisierung des Delegaten durch einen sperrfreien Compare-and-Swap-Algorithmus gewährleistet; siehe http://albahari.com/threading). Indem wir die Ereignis-Accessors selbst definieren, weisen wir C# an, keine Standard-Feld- und Accessor-Logik zu erzeugen.
Mit expliziten Ereignis-Accessors kannst du komplexere Strategien für die Speicherung und den Zugriff auf den zugrunde liegenden Delegaten anwenden. Es gibt drei Szenarien, für die dies nützlich ist:
-
Wenn die Ereignis-Accessoren nur Relais für eine andere Klasse sind, die das Ereignis sendet.
-
Wenn die Klasse viele Ereignisse auslöst, für die es meist nur wenige Abonnenten gibt, wie z. B. ein Windows-Steuerelement. In solchen Fällen ist es besser, die Delegateninstanzen des Abonnenten in einem Wörterbuch zu speichern, da ein Wörterbuch weniger Speicherplatz beansprucht als Dutzende von Null-Delegatenfeldreferenzen.
-
Wenn du explizit eine Schnittstelle implementierst, die ein Ereignis deklariert.
Hier ist ein Beispiel, das den letzten Punkt verdeutlicht:
public interface IFoo { event EventHandler Ev; }
class Foo : IFoo
{
private EventHandler ev;
event EventHandler IFoo.Ev
{
add { ev += value; }
remove { ev -= value; }
}
}
Hinweis
Die add und remove Teile eines Ereignisses werden zu add_XXX und remove_XXX Methoden.
Lambda-Ausdrücke
Ein Lambda-Ausdruck ist eine unbenannte Methode, die anstelle einer Delegateninstanz geschrieben wird. Der Compiler wandelt den Lambda-Ausdruck sofort in eine der folgenden Möglichkeiten um:
-
Eine Delegateninstanz.
-
Ein Ausdrucksbaum vom Typ
Expression<TDelegate>, der den Code innerhalb des Lambda-Ausdrucks in einem durchsuchbaren Objektmodell darstellt. So kann der Lambda-Ausdruck später zur Laufzeit interpretiert werden (siehe "Aufbau von Abfrageausdrücken" in Kapitel 8).
Gegeben ist der folgende Delegatentyp:
delegate int Transformer (int i);
können wir den Lambda-Ausdruck x => x * x wie folgt zuweisen und aufrufen:
Transformer sqr = x => x * x; Console.WriteLine (sqr(3)); // 9
Hinweis
Intern löst der Compiler Lambda-Ausdrücke dieses Typs auf, indem er eine private Methode schreibt und dann den Code des Ausdrucks in diese Methode verschiebt.
Ein Lambda-Ausdruck hat die folgende Form:
(parameters) => expression-or-statement-block
Der Einfachheit halber kannst du die Klammern nur dann weglassen, wenn es genau einen Parameter mit einem ableitbaren Typ gibt.
In unserem Beispiel gibt es einen einzigen Parameter, x, und der Ausdruck lautet x * x:
x => x * x;
Jeder Parameter des Lambda-Ausdrucks entspricht einem Delegaten-Parameter, und der Typ des Ausdrucks (der void sein kann) entspricht dem Rückgabetyp des Delegaten.
In unserem Beispiel entspricht x dem Parameter i, und der Ausdruck x * x entspricht dem Rückgabetyp int und ist somit mit dem Delegaten Transformer kompatibel:
delegate int Transformer (int i);
Der Code eines Lambda-Ausdrucks kann ein Anweisungsblock statt eines Ausdrucks sein. Wir können unser Beispiel wie folgt umschreiben:
x => { return x * x; };
Lambda-Ausdrücke werden am häufigsten mit den Delegierten Func und Action verwendet, so dass du unseren früheren Ausdruck meist wie folgt geschrieben siehst:
Func<int,int> sqr = x => x * x;
Hier ist ein Beispiel für einen Ausdruck, der zwei Parameter akzeptiert:
Func<string,string,int> totalLength = (s1, s2) => s1.Length + s2.Length;
int total = totalLength ("hello", "world"); // total is 10;
Explizite Angabe von Lambda-Parametertypen
Normalerweise kann der Compiler den Typ von Lambda-Parametern aus dem Kontext ableiten. Wenn das nicht der Fall ist, musst du den Typ jedes Parameters explizit angeben. Betrachte die folgenden zwei Methoden:
void Foo<T> (T x) {}
void Bar<T> (Action<T> a) {}
Die Kompilierung des folgenden Codes schlägt fehl, weil der Compiler den Typ von x nicht ableiten kann:
Bar (x => Foo (x)); // What type is x?
Wir können dies beheben, indem wir den Typ von xwie folgt explizit angeben:
Bar ((int x) => Foo (x));
Dieses Beispiel ist so einfach, dass es auf zwei andere Arten gelöst werden kann:
Bar<int> (x => Foo (x)); // Specify type parameter for Bar Bar<int> (Foo); // As above, but with method group
Erfassen äußerer Variablen
Ein Lambda-Ausdruck kann die lokalen Variablen und Parameter der Methode referenzieren, in der er definiert ist(äußere Variablen):
static void Main()
{
int factor = 2;
Func<int, int> multiplier = n => n * factor;
Console.WriteLine (multiplier (3)); // 6
}
Äußere Variablen, die von einem Lambda-Ausdruck referenziert werden, heißen gefangene Variablen. Ein Lambda-Ausdruck, der Variablen einfängt, wird als Closure bezeichnet.
Hinweis
Variablen können auch von anonymen Methoden und lokalen Methoden erfasst werden. Die Regeln für erfasste Variablen sind in diesen Fällen dieselben.
Erfasste Variablen werden ausgewertet, wenn der Delegierte tatsächlich aufgerufen wird, nicht wenn die Variablen erfasst wurden:
int factor = 2; Func<int, int> multiplier = n => n * factor; factor = 10; Console.WriteLine (multiplier (3)); // 30
Lambda-Ausdrücke können selbst erfasste Variablen aktualisieren:
int seed = 0; Func<int> natural = () => seed++; Console.WriteLine (natural()); // 0 Console.WriteLine (natural()); // 1 Console.WriteLine (seed); // 2
Die Lebensdauer der gefangenen Variablen wird auf die Lebensdauer des Delegaten verlängert. Im folgenden Beispiel würde die lokale Variable seed normalerweise aus dem Geltungsbereich verschwinden, wenn Natural die Ausführung beendet. Da seed jedoch gefangen wurde, wird ihre Lebensdauer auf die des fangenden Delegaten natural verlängert:
static Func<int> Natural()
{
int seed = 0;
return () => seed++; // Returns a closure
}
static void Main()
{
Func<int> natural = Natural();
Console.WriteLine (natural()); // 0
Console.WriteLine (natural()); // 1
}
Eine lokale Variable , die innerhalb eines Lambda-Ausdrucks instanziiert wird, ist pro Aufruf der Delegateninstanz eindeutig. Wenn wir unser vorheriges Beispiel so umgestalten, dass seed innerhalb des Lambda-Ausdrucks instanziiert wird, erhalten wir ein anderes (in diesem Fall unerwünschtes) Ergebnis:
static Func<int> Natural()
{
return() => { int seed = 0; return seed++; };
}
static void Main()
{
Func<int> natural = Natural();
Console.WriteLine (natural()); // 0
Console.WriteLine (natural()); // 0
}
Hinweis
Das Capturing wird intern implementiert, indem die erfassten Variablen in Felder einer privaten Klasse "gehievt" werden. Wenn die Methode aufgerufen wird, wird die Klasse instanziiert und lebenslang an die Instanz des Delegaten gebunden.
Erfassen von Iterationsvariablen
Wenn du die Iterationsvariable einer for Schleife erfasst, behandelt C# diese Variable so, als ob sie außerhalb der Schleife deklariert wäre. Das bedeutet, dass in jeder Iteration die gleiche Variable erfasst wird. Das folgende Programm schreibt 333, anstatt 012 zu schreiben:
Action[] actions = new Action[3]; for (int i = 0; i < 3; i++) actions [i] = () => Console.Write (i); foreach (Action a in actions) a(); // 333
Jede Closure (fett gedruckt) erfasst dieselbe Variable, i. (Das macht Sinn, wenn du bedenkst, dass i eine Variable ist, deren Wert zwischen den Iterationen der Schleife bestehen bleibt; du kannst sogar i innerhalb des Schleifenkörpers explizit ändern, wenn du willst.) Wenn die Delegaten später aufgerufen werden, sieht jeder Delegat den Wert von izum Zeitpunkt des Aufrufs - also3. Wir können dies besser veranschaulichen, indem wir die for Schleife wie folgt erweitern:
Action[] actions = new Action[3]; int i = 0; actions[0] = () => Console.Write (i); i = 1; actions[1] = () => Console.Write (i); i = 2; actions[2] = () => Console.Write (i); i = 3; foreach (Action a in actions) a(); // 333
Die Lösung, wenn wir 012 schreiben wollen, besteht darin, die Iterationsvariable einer lokalen Variable zuzuweisen, die innerhalb der Schleife skaliert ist:
Action[] actions = new Action[3];
for (int i = 0; i < 3; i++)
{
int loopScopedi = i;
actions [i] = () => Console.Write (loopScopedi);
}
foreach (Action a in actions) a(); // 012
Da loopScopedi bei jeder Iteration neu erstellt wird, erfasst jeder Abschluss eine andere Variable.
Hinweis
Vor C# 5.0 funktionierten die foreach Schleifen auf die gleiche Weise:
Action[] actions = new Action[3]; int i = 0; foreach (char c in "abc") actions [i++] = () => Console.Write (c); foreach (Action a in actions) a(); // ccc in C# 4.0
Dies führte zu erheblicher Verwirrung: Anders als bei einer for -Schleife ist die Iterationsvariable in einer foreach -Schleife unveränderlich, so dass man erwarten würde, dass sie als lokal für den Schleifenkörper behandelt wird. Die gute Nachricht ist, dass dies seit C# 5.0 behoben wurde und das vorangegangene Beispiel nun "abc" schreibt.
Lambda-Ausdrücke vs. lokale Methoden
Die Funktionalität von lokalen Methoden (siehe "Lokale Methoden" in Kapitel 3) überschneidet sich mit der von Lambda-Ausdrücken. Lokale Methoden haben die folgenden drei Vorteile:
-
Sie können rekursiv sein (sie können sich selbst aufrufen), ohne hässliche Hacks
-
Sie vermeiden das Durcheinander der Angabe eines Delegatentyps
-
Sie verursachen etwas weniger Gemeinkosten
Lokale Methoden sind effizienter, weil sie den Umweg über einen Delegaten vermeiden (der einige CPU-Zyklen und eine Speicherzuweisung kostet). Außerdem können sie auf lokale Variablen der enthaltenen Methode zugreifen, ohne dass der Compiler die erfassten Variablen in eine versteckte Klasse "hieven" muss.
In vielen Fällen brauchst du jedoch einen Delegierten - vor allem, wenn du eine Funktion höherer Ordnung aufrufst, d.h. eine Methode mit einem Parameter vom Typ Delegierter:
public void Foo (Func<int,bool> predicate) { ... }
(In Kapitel 8 findest du viele weitere Beispiele). In solchen Fällen brauchst du sowieso einen Delegaten, und genau in diesen Fällen sind Lambda-Ausdrücke normalerweise kürzer und sauberer.
Anonyme Methoden
Anonyme Methoden sind ein Feature von C# 2.0, das größtenteils von den Lambda-Ausdrücken von C# 3.0 verdrängt wurde. Eine anonyme Methode ist wie ein Lambda-Ausdruck, hat aber die folgenden Eigenschaften nicht:
-
Implizit typisierte Parameter
-
Ausdruckssyntax (eine anonyme Methode muss immer ein Anweisungsblock sein)
-
Die Möglichkeit, einen Ausdrucksbaum zu kompilieren, indem man ihn
Expression<T>
Um eine anonyme Methode zu schreiben, fügst du das Schlüsselwort delegate ein, gefolgt (optional) von einer Parameterdeklaration und einem Methodenkörper. Nehmen wir zum Beispiel diesen Delegaten:
delegate int Transformer (int i);
könnten wir eine anonyme Methode schreiben und wie folgt aufrufen:
Transformer sqr = delegate (int x) {return x * x;};
Console.WriteLine (sqr(3)); // 9
Die erste Zeile ist semantisch gleichbedeutend mit dem folgenden Lambda-Ausdruck:
Transformer sqr = (int x) => {return x * x;};
Oder, ganz einfach:
Transformer sqr = x => x * x;
Anonyme Methoden erfassen äußere Variablen auf dieselbe Weise wie Lambda-Ausdrücke.
Hinweis
Eine einzigartige Eigenschaft anonymer Methoden ist, dass du die Parameterdeklaration ganz weglassen kannst - auch wenn der Delegat sie erwartet. Das kann bei der Deklaration von Ereignissen mit einem leeren Standard-Handler nützlich sein:
public event EventHandler Clicked = delegate { };
Dadurch wird eine Nullprüfung vor dem Auslösen des Ereignisses überflüssig. Das Folgende ist auch legal:
// Notice that we omit the parameters:
Clicked += delegate { Console.WriteLine ("clicked"); };
try-Anweisungen und Ausnahmen
Eine try Anweisung gibt einen Codeblock an, der einer Fehlerbehandlung oder einem Bereinigungscode unterliegt. Auf den try Block muss ein oder mehrere catch Blöcke, ein finally Block oder beides folgen. Der catch -Block wird ausgeführt, wenn im try -Block ein Fehler auftritt. Der finally -Block wird ausgeführt, nachdem die Ausführung den try -Block (oder, falls vorhanden, den catch -Block) verlassen hat, um Bereinigungscode auszuführen, unabhängig davon, ob eine Ausnahme ausgelöst wurde.
Ein catch Block hat Zugriff auf ein Exception Objekt, das Informationen über den Fehler enthält. Du verwendest einen catch Block, um entweder den Fehler zu kompensieren oder die Ausnahme erneut auszulösen. Du löst eine Ausnahme erneut aus, wenn du das Problem lediglich protokollieren oder einen neuen, höheren Ausnahmetyp auslösen willst.
Ein finally Block verleiht deinem Programm Determinismus: Die CLR bemüht sich, ihn immer auszuführen. Er ist nützlich für Aufräumarbeiten wie das Schließen von Netzwerkverbindungen.
Ein try Statement sieht so aus:
try
{
... // exception may get thrown within execution of this block
}
catch (ExceptionA ex)
{
... // handle exception of type ExceptionA
}
catch (ExceptionB ex)
{
... // handle exception of type ExceptionB
}
finally
{
... // cleanup code
}
Betrachte das folgende Programm:
class Test
{
static int Calc (int x) => 10 / x;
static void Main()
{
int y = Calc (0);
Console.WriteLine (y);
}
}
Da x gleich Null ist, löst die Laufzeit eine DivideByZeroException aus, und unser Programm bricht ab. Wir können dies verhindern, indem wir die Ausnahme wie folgt abfangen:
class Test
{
static int Calc (int x) => 10 / x;
static void Main()
{
try
{
int y = Calc (0);
Console.WriteLine (y);
}
catch (DivideByZeroException ex)
{
Console.WriteLine ("x cannot be zero");
}
Console.WriteLine ("program completed");
}
}
OUTPUT:
x cannot be zero
program completed
Hinweis
Dies ist ein einfaches Beispiel, um die Behandlung von Ausnahmen zu veranschaulichen. In der Praxis könnten wir mit diesem speziellen Szenario besser umgehen, indem wir vor dem Aufruf von Calc explizit prüfen, ob der Divisor Null ist.
Die Überprüfung auf vermeidbare Fehler ist besser, als sich auf try/catch Blöcke zu verlassen, da die Behandlung von Ausnahmen relativ teuer ist und Hunderte von Taktzyklen oder mehr dauert.
Wenn eine Ausnahme innerhalb einer try Anweisung ausgelöst wird, führt die CLR einen Test durch:
Gibt es in der Anweisung try kompatible Blöcke catch ?
-
Wenn dies der Fall ist, springt die Ausführung zum kompatiblen
catchBlock, gefolgt vomfinallyBlock (falls vorhanden), und setzt dann die Ausführung normal fort. -
Falls nicht, springt die Ausführung direkt zum
finallyBlock (falls vorhanden), dann sucht die CLR auf dem Aufrufstapel nach anderentryBlöcken; falls gefunden, wird der Test wiederholt.
Wenn keine Funktion im Aufrufstapel die Verantwortung für die Ausnahme übernimmt, wird das Programm beendet.
Die Fangklausel
Eine catch Klausel gibt an, welche Art von Ausnahme abgefangen werden soll. Diese muss entweder System.Exception oder eine Unterklasse von System.Exception sein.
Catching System.Exception fängt alle möglichen Fehler ab. Dies ist in den folgenden Fällen nützlich:
-
Dein Programm kann sich möglicherweise unabhängig von der Art der Ausnahme erholen.
-
Du hast vor, die Exception wieder zurückzuwerfen (vielleicht nachdem du sie protokolliert hast).
-
Dein Error-Handler ist die letzte Instanz, bevor das Programm beendet wird.
In der Regel fängst du jedoch bestimmte Ausnahmetypen ab, um zu vermeiden, dass du dich mit Umständen auseinandersetzen musst, für die dein Handler nicht konzipiert wurde (z. B. ein OutOfMemoryException).
Du kannst mehrere Ausnahmetypen mit mehreren catch Klauseln behandeln (auch dieses Beispiel könnte mit einer expliziten Argumentprüfung statt mit Ausnahmebehandlung geschrieben werden):
class Test
{
static void Main (string[] args)
{
try
{
byte b = byte.Parse (args[0]);
Console.WriteLine (b);
}
catch (IndexOutOfRangeException ex)
{
Console.WriteLine ("Please provide at least one argument");
}
catch (FormatException ex)
{
Console.WriteLine ("That's not a number!");
}
catch (OverflowException ex)
{
Console.WriteLine ("You've given me more than a byte!");
}
}
}
Für eine bestimmte Ausnahme wird nur eine catch Klausel ausgeführt. Wenn du ein Sicherheitsnetz einbauen willst, um allgemeinere Ausnahmen (wie System.Exception) abzufangen, musst du die spezifischeren Handler zuerst einfügen.
Eine Ausnahme kann ohne Angabe einer Variablen abgefangen werden, wenn du nicht auf ihre Eigenschaften zugreifen musst:
catch (OverflowException) // no variable
{
...
}
Außerdem kannst du sowohl die Variable als auch den Typ weglassen (was bedeutet, dass alle Ausnahmen abgefangen werden):
catch { ... }
Ausnahmefilter
Du kannst einen Ausnahmefilter in einer catch Klausel angeben, indem du eine when Klausel hinzufügst:
catch (WebException ex) when (ex.Status == WebExceptionStatus.Timeout)
{
...
}
Wenn in diesem Beispiel ein WebException ausgelöst wird, wird der boolesche Ausdruck nach dem when Schlüsselwort ausgewertet. Wenn das Ergebnis false ist, wird der betreffende catch Block ignoriert und alle nachfolgenden catch Klauseln werden berücksichtigt. Mit Ausnahmefiltern kann es sinnvoll sein, denselben Ausnahmetyp erneut abzufangen:
catch (WebException ex) when (ex.Status == WebExceptionStatus.Timeout)
{ ... }
catch (WebException ex) when (ex.Status == WebExceptionStatus.SendFailure)
{ ... }
Der boolesche Ausdruck in der when Klausel kann eine Nebenwirkung haben, wie bei einer Methode, die die Ausnahme zu Diagnosezwecken protokolliert.
Der letzte Block
Ein finally -Block wird immer ausgeführt - unabhängig davon, ob eine Ausnahme ausgelöst wird und ob der try -Block zu Ende ausgeführt wird. Du verwendest finally Blöcke normalerweise für Aufräumarbeiten.
Ein finally Block wird nach einem der folgenden Punkte ausgeführt:
-
Ein
catchBlock wird beendet (oder löst eine neue Ausnahme aus) -
Der
tryBlock wird beendet (oder es wird eine Ausnahme geworfen, für die es keinencatchBlock gibt) -
Die Kontrolle verlässt den
tryBlock aufgrund einerjumpAnweisung (z.B.returnodergoto)
Die einzigen Dinge, die einen finally Block aushebeln können, sind eine Endlosschleife oder ein abruptes Ende des Prozesses.
Ein finally Block hilft dabei, einem Programm Determinismus zu verleihen. Im folgenden Beispiel wird die Datei, die wir öffnen, immer geschlossen, unabhängig davon, ob:
-
Der
tryBlock wird normal beendet -
Die Ausführung wird vorzeitig abgebrochen, weil die Datei leer ist (
EndOfStream) -
Beim Lesen der Datei wird ein
IOExceptionausgelöst
static void ReadFile()
{
StreamReader reader = null; // In System.IO namespace
try
{
reader = File.OpenText ("file.txt");
if (reader.EndOfStream) return;
Console.WriteLine (reader.ReadToEnd());
}
finally
{
if (reader != null) reader.Dispose();
}
}
In diesem Beispiel haben wir die Datei durch den Aufruf von Dispose auf StreamReader geschlossen. Der Aufruf von Dispose auf ein Objekt innerhalb eines finally Blocks ist eine Standardkonvention in .NET Core und wird in C# explizit durch die using Anweisung unterstützt.
Die using-Anweisung
Viele Klassen kapseln nicht verwaltete Ressourcen, wie z. B. Datei- und Grafik-Handles oder Datenbankverbindungen. Diese Klassen implementieren System.IDisposable, die eine einzelne parameterlose Methode namens Dispose definiert, um diese Ressourcen aufzuräumen. Die Anweisung using bietet eine elegante Syntax für den Aufruf von Dispose für ein IDisposable Objekt innerhalb eines finally Blocks aufzurufen. So:
using (StreamReader reader = File.OpenText ("file.txt"))
{
...
}
ist genau gleichbedeutend mit:
{
StreamReader reader = File.OpenText ("file.txt");
try
{
...
}
finally
{
if (reader != null)
((IDisposable)reader).Dispose();
}
}
using Deklarationen (C# 8)
Wenn du die Klammern und den Anweisungsblock nach einer using Anweisung weglässt, wird sie zu einer using-Deklaration. Die Ressource wird dann entsorgt, wenn die Ausführung außerhalb des einschließenden Anweisungsblocks erfolgt:
if (File.Exists ("file.txt"))
{
using var reader = File.OpenText ("file.txt");
Console.WriteLine (reader.ReadLine());
...
}
In diesem Fall wird reader entsorgt, wenn die Ausführung außerhalb des if Anweisungsblocks erfolgt.
Das Werfen von Ausnahmen
Ausnahmen können entweder von der Laufzeit oder im Benutzercode ausgelöst werden. In diesem Beispiel löst Display eine System.ArgumentNullException aus:
class Test
{
static void Display (string name)
{
if (name == null)
throw new ArgumentNullException (nameof (name));
Console.WriteLine (name);
}
static void Main()
{
try { Display (null); }
catch (ArgumentNullException ex)
{
Console.WriteLine ("Caught the exception");
}
}
}
Ausdrücke werfen
throw kann auch als Ausdruck in ausdrucksbehafteten Funktionen erscheinen:
public string Foo() => throw new NotImplementedException();
Ein throw Ausdruck kann auch in einem ternären bedingten Ausdruck vorkommen:
string ProperCase (string value) =>
value == null ? throw new ArgumentException ("value") :
value == "" ? "" :
char.ToUpper (value[0]) + value.Substring (1);
Eine Ausnahme zurückwerfen
Du kannst eine Ausnahme wie folgt einfangen und wieder auslösen:
try { ... }
catch (Exception ex)
{
// Log error
...
throw; // Rethrow same exception
}
Hinweis
Wenn wir throw durch throw ex ersetzen würden, würde das Beispiel immer noch funktionieren, aber die Eigenschaft StackTrace der neu propagierten Ausnahme würde nicht mehr den ursprünglichen Fehler widerspiegeln.
Mit diesem Rethrow kannst du einen Fehler protokollieren, ohne ihn zu schlucken. Außerdem kannst du auf diese Weise die Behandlung einer Ausnahme abbrechen, wenn sich herausstellt, dass die Umstände anders sind, als du erwartet hast:
using System.Net; // (See Chapter 16) ... string s = null; using (WebClient wc = new WebClient()) try { s = wc.DownloadString ("http://www.albahari.com/nutshell/"); } catch (WebException ex) { if (ex.Status == WebExceptionStatus.Timeout) Console.WriteLine ("Timeout"); Else throw; // Can't handle other sorts of WebException, so rethrow }
Das kann mit einem Ausnahmefilter noch kürzer geschrieben werden:
catch (WebException ex) when (ex.Status == WebExceptionStatus.Timeout)
{
Console.WriteLine ("Timeout");
}
Das andere häufige Szenario ist das Zurückwerfen eines spezifischeren Ausnahmetyps:
try
{
... // Parse a DateTime from XML element data
}
catch (FormatException ex)
{
throw new XmlException ("Invalid DateTime", ex);
}
Beachte, dass wir bei der Konstruktion von XmlException die ursprüngliche Ausnahme, ex, als zweites Argument mitgegeben haben. Dieses Argument füllt die Eigenschaft InnerException der neuen Exception auf und hilft bei der Fehlersuche. Fast alle Ausnahmetypen bieten einen ähnlichen Konstruktor.
Das Zurückwerfen einer weniger spezifischen Ausnahme ist etwas, was du tun könntest, wenn du eine Vertrauensgrenze überschreitest, um technische Informationen nicht an potenzielle Hacker weiterzugeben.
Wichtige Eigenschaften von System.Exception
Die wichtigsten Eigenschaften von System.Exception sind die folgenden:
StackTrace- Eine Zeichenkette mit allen Methoden, die vom Ursprung der Ausnahme bis zum
catchBlock aufgerufen werden. Message- Eine Zeichenkette mit einer Beschreibung des Fehlers.
InnerException- Die innere Ausnahme (falls vorhanden), die die äußere Ausnahme verursacht hat. Diese kann wiederum eine andere
InnerExceptionhaben.
Hinweis
Alle Ausnahmen in C# sind Laufzeitausnahmen - es gibt kein Äquivalent zu den compile-time checked exceptions von Java.
Häufige Ausnahmetypen
Die folgenden Ausnahmetypen werden in der CLR und in .NET Core häufig verwendet. Du kannst sie selbst auslösen oder sie als Basisklassen für die Ableitung eigener Ausnahmetypen verwenden.
System.ArgumentException- Wird ausgelöst, wenn eine Funktion mit einem falschen Argument aufgerufen wird. Dies weist in der Regel auf einen Programmfehler hin.
System.ArgumentNullException- Unterklasse von
ArgumentException, die ausgelöst wird, wenn ein Funktionsargument (unerwartet)nullist. System.ArgumentOutOfRangeException- Unterklasse von
ArgumentException, die ausgelöst wird, wenn ein (meist numerisches) Argument zu groß oder zu klein ist. Sie wird zum Beispiel ausgelöst, wenn eine negative Zahl an eine Funktion übergeben wird, die nur positive Werte akzeptiert. System.InvalidOperationException- Wird ausgelöst, wenn der Zustand eines Objekts für die erfolgreiche Ausführung einer Methode ungeeignet ist, unabhängig von bestimmten Argumentwerten. Beispiele dafür sind das Lesen einer ungeöffneten Datei oder das Abrufen des nächsten Elements aus einem Enumerator, bei dem die zugrundeliegende Liste während der Iteration teilweise geändert worden ist.
System.NotSupportedException- Wird geworfen, um anzuzeigen, dass eine bestimmte Funktionalität nicht unterstützt wird. Ein gutes Beispiel ist der Aufruf der Methode
Addfür eine Sammlung, für dieIsReadOnlytruezurückgibt. System.NotImplementedException- Wird ausgelöst, um anzuzeigen, dass eine Funktion noch nicht implementiert wurde.
System.ObjectDisposedException- Wird ausgelöst, wenn das Objekt, auf dem die Funktion aufgerufen wird, entsorgt wurde.
Ein weiterer häufig auftretender Ausnahmetyp ist NullReferenceException. Die CLR löst diese Ausnahme aus, wenn du versuchst, auf ein Mitglied eines Objekts zuzugreifen, dessen Wert null ist (was auf einen Fehler in deinem Code hinweist). Du kannst eine NullReferenceException direkt (zu Testzwecken) wie folgt auslösen:
throw null;
Das Muster der Try XXX Methode
Wenn du eine Methode schreibst, hast du die Wahl, ob du einen Fehlercode zurückgibst oder eine Ausnahme auslöst, wenn etwas schief läuft. Im Allgemeinen wirfst du eine Ausnahme, wenn der Fehler außerhalb des normalen Arbeitsablaufs liegt - oder wenn du davon ausgehst, dass der unmittelbare Aufrufer nicht in der Lage ist, ihn zu bewältigen. Gelegentlich kann es jedoch sinnvoll sein, dem Verbraucher beide Möglichkeiten anzubieten. Ein Beispiel dafür ist der Typ int, der zwei Versionen seiner Methode Parse definiert:
public int Parse (string input); public bool TryParse (string input, out int returnValue);
Wenn das Parsen fehlschlägt, löst Parse eine Ausnahme aus; TryParse gibt false zurück.
Du kannst dieses Muster implementieren, indem du die XXX Methode den Aufruf der TryXXX Methode aufruft:
public return-type XXX (input-type input)
{
return-type returnValue;
if (!TryXXX (input, out returnValue))
throw new YYYException (...)
return returnValue;
}
Alternativen zu Ausnahmen
Wie bei int.TryParse kann eine Funktion einen Fehler mitteilen, indem sie über einen Rückgabetyp oder Parameter einen Fehlercode an die aufrufende Funktion zurücksendet. Obwohl dies bei einfachen und vorhersehbaren Fehlern funktionieren kann, wird es schwerfällig, wenn es auf alle Fehler ausgedehnt wird, die Methodensignaturen verschmutzt und unnötige Komplexität und Unordnung schafft. Sie kann auch nicht auf Funktionen verallgemeinert werden, die keine Methoden sind, wie z. B. Operatoren (z. B. der Divisionsoperator) oder Eigenschaften. Eine Alternative ist, den Fehler an einem gemeinsamen Ort zu platzieren, an dem alle Funktionen im Aufrufstapel ihn sehen können (z. B. eine statische Methode, die den aktuellen Fehler pro Thread speichert). Dies erfordert jedoch, dass jede Funktion an einem Fehlerfortpflanzungsmuster teilnimmt, was umständlich und ironischerweise selbst fehleranfällig ist.
Aufzählung und Iteratoren
Aufzählung
Ein Enumerator ist ein schreibgeschützter, vorwärtsgerichteter Cursor über eine Folge von Werten. C# behandelt einen Typ als Enumerator, wenn er einen der folgenden Punkte erfüllt:
-
Hat eine öffentliche Methode ohne Parameter namens
MoveNextund eine Eigenschaft namensCurrent
Die Anweisung foreach iteriert über ein aufzählbares Objekt. Ein aufzählbares Objekt ist die logische Darstellung einer Sequenz. Es ist nicht selbst ein Cursor, sondern ein Objekt, das Cursor über sich selbst erzeugt. C# behandelt einen Typ als aufzählbar, wenn er einen der folgenden Punkte erfüllt:
Das Aufzählungsmuster sieht folgendermaßen aus:
class Enumerator // Typically implements IEnumerator or IEnumerator<T>
{
public IteratorVariableType Current { get {...} }
public bool MoveNext() {...}
}
class Enumerable // Typically implements IEnumerable or IEnumerable<T>
{
public Enumerator GetEnumerator() {...}
}
Hier siehst du, wie du mit der Anweisung foreach durch die Zeichen im Wort "Bier" iterierst:
foreach (char c in "beer") Console.WriteLine (c);
Hier ist der einfache Weg, um durch die Zeichen in beer zu iterieren, ohne eine foreach Anweisung zu verwenden:
using (var enumerator = "beer".GetEnumerator())
while (enumerator.MoveNext())
{
var element = enumerator.Current;
Console.WriteLine (element);
}
Wenn der Enumerator IDisposable implementiert, fungiert die Anweisung foreach auch als Anweisung using, die das Enumerator-Objekt implizit entsorgt.
In Kapitel 7 werden die Aufzählungsschnittstellen näher erläutert.
Sammlung Initializer
Du kannst ein aufzählbares Objekt in einem einzigen Schritt instanziieren und auffüllen:
using System.Collections.Generic; ... List<int> list = new List<int> {1, 2, 3};
Der Compiler übersetzt dies folgendermaßen:
using System.Collections.Generic; ... List<int> list = new List<int>(); list.Add (1); list.Add (2); list.Add (3);
Dies setzt voraus, dass das enumerable Objekt die System.Collections.IEnumerable Schnittstelle implementiert und dass es eine Add Methode hat, die die entsprechende Anzahl von Parametern für den Aufruf hat. Auf ähnliche Weise kannst du Wörterbücher (siehe "Wörterbücher" in Kapitel 7) wie folgt initialisieren:
var dict = new Dictionary<int, string>()
{
{ 5, "five" },
{ 10, "ten" }
};
Oder, um es kurz zu fassen:
var dict = new Dictionary<int, string>()
{
[3] = "three",
[10] = "ten"
};
Letzteres gilt nicht nur für Wörterbücher, sondern für jeden Typ, für den ein Indexer existiert.
Iteratoren
Während eine foreach Anweisung einen Enumerator konsumiert, ist ein Iterator ein Produzent eines Enumerators. In diesem Beispiel verwenden wir einen Iterator, um eine Folge von Fibonacci-Zahlen zurückzugeben (wobei jede Zahl die Summe der beiden vorherigen ist):
using System;
using System.Collections.Generic;
class Test
{
static void Main()
{
foreach (int fib in Fibs(6))
Console.Write (fib + " ");
}
static IEnumerable<int> Fibs (int fibCount)
{
for (int i = 0, prevFib = 1, curFib = 1; i < fibCount; i++)
{
yield return prevFib;
int newFib = prevFib + curFib;
prevFib = curFib;
curFib = newFib;
}
}
}
OUTPUT: 1 1 2 3 5 8
Während eine return -Anweisung ausdrückt: "Hier ist der Wert, den ich von dieser Methode zurückgeben soll", drückt eine yield return -Anweisung aus: "Hier ist das nächste Element, das ich von diesem Enumerator liefern soll." Bei jeder yield Anweisung wird die Kontrolle an den Aufrufer zurückgegeben, aber der Zustand des Aufrufers wird beibehalten, damit die Methode weiter ausgeführt werden kann, sobald der Aufrufer das nächste Element aufzählt. Die Lebensdauer dieses Zustands ist an den Enumerator gebunden, so dass der Zustand freigegeben werden kann, wenn der Aufrufer die Aufzählung beendet hat.
Hinweis
Der Compiler wandelt Iterator-Methoden in private Klassen um, die IEnumerable<T> und/oder IEnumerator<T> implementieren. Die Logik innerhalb des Iterator-Blocks wird "invertiert" und in die Methode MoveNext und die Eigenschaft Current der vom Compiler geschriebenen Enumerator-Klasse eingefügt. Das heißt, wenn du eine Iterator-Methode aufrufst, instanziierst du lediglich die vom Compiler geschriebene Klasse; kein einziger Code wird tatsächlich ausgeführt! Dein Code wird erst ausgeführt, wenn du mit der Aufzählung der resultierenden Sequenz beginnst, normalerweise mit einer foreach Anweisung.
Iteratoren können lokale Methoden sein (siehe "Lokale Methoden" in Kapitel 3).
Iterator-Semantik
Ein Iterator ist eine Methode, Eigenschaft oder ein Indexer, der eine oder mehrere yield Anweisungen enthält. Ein Iterator muss eine der folgenden vier Schnittstellen zurückgeben (sonst erzeugt der Compiler einen Fehler):
// Enumerable interfaces System.Collections.IEnumerable System.Collections.Generic.IEnumerable<T> // Enumerator interfaces System.Collections.IEnumerator System.Collections.Generic.IEnumerator<T>
Ein Iterator hat eine unterschiedliche Semantik, je nachdem, ob er eine Aufzählungsschnittstelle oder eine Aufzählerschnittstelle zurückgibt. Wir beschreiben dies in Kapitel 7.
Mehrere Ausbeuteerklärungen sind zulässig:
class Test
{
static void Main()
{
foreach (string s in Foo())
Console.WriteLine(s); // Prints "One","Two","Three"
}
static IEnumerable<string> Foo()
{
yield return "One";
yield return "Two";
yield return "Three";
}
}
Ertragspause
Die Anweisung return ist in einem Iterator-Block nicht zulässig; stattdessen musst du die Anweisung yield break verwenden, um anzugeben, dass der Iterator-Block vorzeitig beendet werden soll, ohne weitere Elemente zurückzugeben. Zur Veranschaulichung können wir Foo wie folgt abändern:
static IEnumerable<string> Foo (bool breakEarly)
{
yield return "One";
yield return "Two";
if (breakEarly)
yield break;
yield return "Three";
}
Iteratoren und try/catch/finally-Blöcke
Eine yield return Anweisung kann nicht in einem try Block erscheinen, der eine catch Klausel enthält:
IEnumerable<string> Foo()
{
try { yield return "One"; } // Illegal
catch { ... }
}
Auch yield return kann nicht in einem catch oder finally Block erscheinen. Diese Einschränkungen sind darauf zurückzuführen, dass der Compiler Iteratoren in gewöhnliche Klassen mit MoveNext, Current und Dispose übersetzen muss und die Übersetzung von Ausnahmebehandlungsblöcken zu viel Komplexität verursachen würde.
Du kannst jedoch innerhalb eines try Blocks, der (nur) einen finally Block hat, nachgeben:
IEnumerable<string> Foo()
{
try { yield return "One"; } // OK
finally { ... }
}
Der Code im finally Block wird ausgeführt, wenn der konsumierende Enumerator das Ende der Sequenz erreicht oder entsorgt wird. Eine foreach Anweisung entsorgt den Enumerator implizit, wenn du zu früh abbrichst, was dies zu einem sicheren Weg macht, Enumeratoren zu konsumieren. Wenn du explizit mit Aufzählungszeichen arbeitest, besteht die Gefahr, dass du die Aufzählung vorzeitig abbrichst, ohne sie zu entsorgen, und so den finally Block umgehst. Du kannst dieses Risiko vermeiden, indem du die explizite Verwendung von Aufzählungszeichen in eine using Anweisung verpackst:
string firstElement = null;
var sequence = Foo();
using (var enumerator = sequence.GetEnumerator())
if (enumerator.MoveNext())
firstElement = enumerator.Current;
Sequenzen komponieren
Iteratoren sind sehr kompositionsfähig. Wir können unser Beispiel erweitern, diesmal so, dass nur gerade Fibonacci-Zahlen ausgegeben werden:
using System;
using System.Collections.Generic;
class Test
{
static void Main()
{
foreach (int fib in EvenNumbersOnly (Fibs(6)))
Console.WriteLine (fib);
}
static IEnumerable<int> Fibs (int fibCount)
{
for (int i = 0, prevFib = 1, curFib = 1; i < fibCount; i++)
{
yield return prevFib;
int newFib = prevFib + curFib;
prevFib = curFib;
curFib = newFib;
}
}
static IEnumerable<int> EvenNumbersOnly (IEnumerable<int> sequence)
{
foreach (int x in sequence)
if ((x % 2) == 0)
yield return x;
}
}
Jedes Element wird erst im letzten Moment berechnet - wenn es von einer MoveNext() Vorgang. Abbildung 4-1 zeigt die Datenanforderungen und -ausgaben im Zeitverlauf.
Die Kompositionsfähigkeit des Iterator-Patterns ist in LINQ äußerst nützlich; wir besprechen das Thema noch einmal in Kapitel 8.
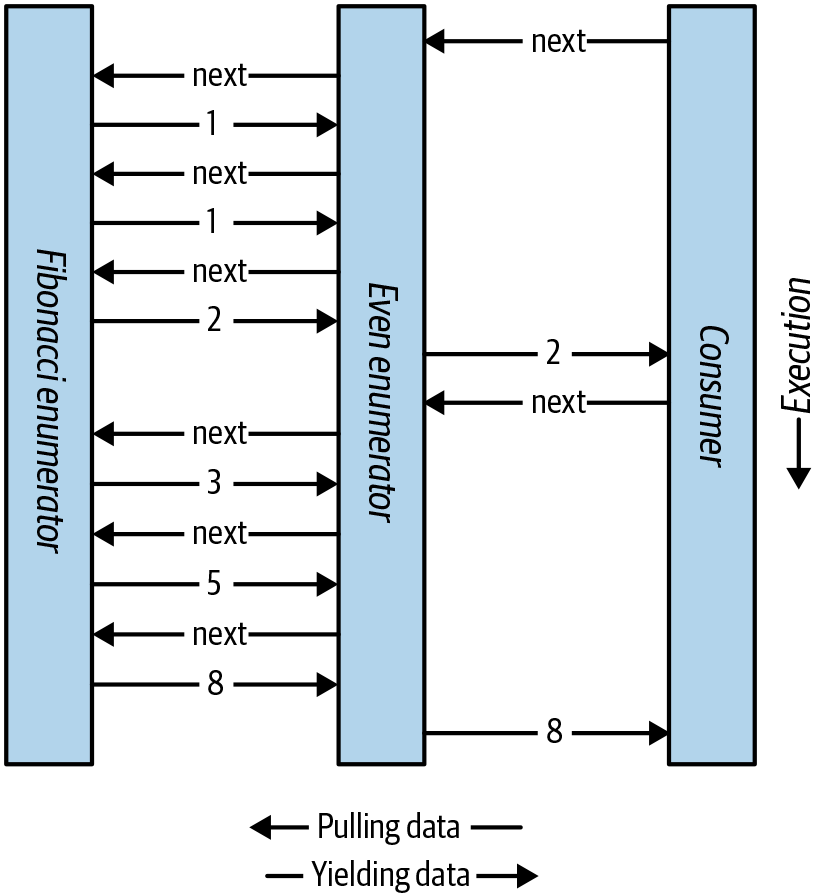
Abbildung 4-1. Sequenzen zusammenstellen
Nullbare Werttypen
Referenztypen können einen nicht existierenden Wert mit einer Null-Referenz darstellen. Wertetypen hingegen können normalerweise keine Nullwerte darstellen:
string s = null; // OK, reference type int i = null; // Compile error, value type cannot be null
Um null in einem Wertetyp darzustellen, musst du ein spezielles Konstrukt verwenden, das nullable type genannt wird. Ein nullbarer Typ wird mit einem Wertetyp gefolgt von dem Symbol ? bezeichnet:
int? i = null; // OK, nullable type Console.WriteLine (i == null); // True
Nullable<T> Struktur
T? wird in übersetzt, eine leichtgewichtige, unveränderliche Struktur mit nur zwei Feldern, die und repräsentieren. Die Essenz von System.Nullable<T> Value HasValueSystem.Nullable<T> ist sehr einfach:
public struct Nullable<T> where T : struct
{
public T Value {get;}
public bool HasValue {get;}
public T GetValueOrDefault();
public T GetValueOrDefault (T defaultValue);
...
}
Der Code:
int? i = null; Console.WriteLine (i == null); // True
übersetzt zu:
Nullable<int> i = new Nullable<int>(); Console.WriteLine (! i.HasValue); // True
Der Versuch, Value abzurufen, wenn HasValue falsch ist, führt zu einer Fehlermeldung. InvalidOperationException. GetValueOrDefault() gibt Value zurück, wenn HasValue wahr ist; andernfalls gibt es new T() oder einen benutzerdefinierten Standardwert zurück.
Der Standardwert von T? ist null.
Implizite und explizite nullbare Konvertierungen
Die Umwandlung von T in T? ist implizit, die von T? in T explizit:
int? x = 5; // implicit int y = (int)x; // explicit
Der explizite Cast ist direkt gleichbedeutend mit dem Aufruf der Value Eigenschaft des nullbaren Objekts. Daher wird ein InvalidOperationException ausgelöst, wenn HasValue falsch ist.
Boxing und Unboxing von nullbaren Werten
Wenn T? geboxt ist, enthält der geboxte Wert auf dem Heap T, nicht T?. Diese Optimierung ist möglich, weil ein gepackter Wert ein Referenztyp ist, der bereits Null ausdrücken kann.
C# erlaubt auch das Unboxing von nullbaren Werttypen mit dem as Operator. Wenn der Cast fehlschlägt, lautet das Ergebnis null:
object o = "string"; int? x = o as int?; Console.WriteLine (x.HasValue); // False
Bediener Heben
In der Struktur Nullable<T> sind keine Operatoren wie <, > oder sogar == definiert. Trotzdem lässt sich der folgende Code kompilieren und wird korrekt ausgeführt:
int? x = 5; int? y = 10; bool b = x < y; // true
Das funktioniert, weil der Compiler den Kleiner-als-Operator vom zugrundeliegenden Wertetyp entlehnt oder aufhebt. Semantisch übersetzt er den vorangegangenen Vergleichsausdruck in diesen:
bool b = (x.HasValue && y.HasValue) ? (x.Value < y.Value) : false;
Mit anderen Worten: Wenn sowohl x als auch y einen Wert haben, wird mit dem Kleiner-als-Operator von intverglichen; andernfalls wird false zurückgegeben.
Operator Lifting bedeutet, dass du die Operatoren von Timplizit auf T? verwenden kannst. Du kannst Operatoren für T? definieren, um ein spezielles Null-Verhalten zu erreichen, aber in den meisten Fällen ist es am besten, wenn du dich darauf verlässt, dass der Compiler automatisch eine systematische Null-Logik für dich anwendet. Hier sind einige Beispiele:
int? x = 5; int? y = null; // Equality operator examples Console.WriteLine (x == y); // False Console.WriteLine (x == null); // False Console.WriteLine (x == 5); // True Console.WriteLine (y == null); // True Console.WriteLine (y == 5); // False Console.WriteLine (y != 5); // True // Relational operator examples Console.WriteLine (x < 6); // True Console.WriteLine (y < 6); // False Console.WriteLine (y > 6); // False // All other operator examples Console.WriteLine (x + 5); // 10 Console.WriteLine (x + y); // null (prints empty line)
Der Compiler führt die Null-Logik je nach Kategorie des Operators unterschiedlich aus. Die folgenden Abschnitte erklären diese unterschiedlichen Regeln.
Gleichheitsoperatoren (== und !=)
Gehobene Gleichheitsoperatoren behandeln Nullen genauso wie Referenztypen. Das bedeutet, dass zwei Nullwerte gleich sind:
Console.WriteLine ( null == null); // True Console.WriteLine ((bool?)null == (bool?)null); // True
Weiter:
-
Wenn genau ein Operand Null ist, sind die Operanden ungleich.
-
Wenn beide Operanden nicht Null sind, werden ihre
Values verglichen.
Relationale Operatoren (<, <=, >=, >)
Die relationalen Operatoren arbeiten nach dem Prinzip, dass es sinnlos ist, Null-Operanden zu vergleichen. Das bedeutet, dass der Vergleich eines Null-Wertes mit einem Null-Wert oder einem Nicht-Null-Wert false ergibt:
bool b = x < y; // Translation:
bool b = (x.HasValue && y.HasValue)
? (x.Value < y.Value)
: false;
// b is false (assuming x is 5 and y is null)
Alle anderen Operatoren (+, -, *, /, %, &, |, ^, <<, >>, +, ++, --, !, ~)
Diese Operatoren geben null zurück, wenn einer der Operanden null ist. Dieses Muster sollte SQL-Benutzern vertraut sein:
int? c = x + y; // Translation:
int? c = (x.HasValue && y.HasValue)
? (int?) (x.Value + y.Value)
: null;
// c is null (assuming x is 5 and y is null)
Eine Ausnahme ist, wenn die Operatoren & und | auf bool? angewendet werden, worauf wir gleich eingehen.
bool? mit & und | Operatoren
Bei Operanden des Typs bool? behandeln die Operatoren & und | null als unbekannten Wert. null | true ist also wahr, weil:
-
Wenn der unbekannte Wert falsch ist, wäre das Ergebnis wahr.
-
Wenn der unbekannte Wert wahr ist, würde das Ergebnis wahr sein.
In ähnlicher Weise ist null & false falsch. Dieses Verhalten dürfte SQL-Benutzern vertraut sein. Das folgende Beispiel listet weitere Kombinationen auf:
bool? n = null; bool? f = false; bool? t = true; Console.WriteLine (n | n); // (null) Console.WriteLine (n | f); // (null) Console.WriteLine (n | t); // True Console.WriteLine (n & n); // (null) Console.WriteLine (n & f); // False Console.WriteLine (n & t); // (null)
Nullbare Wertetypen & Null-Operatoren
Nullbare Wertetypen funktionieren besonders gut mit dem ?? Operator (siehe "Null-Coalescing Operator" in Kapitel 2), wie in diesem Beispiel gezeigt wird:
int? x = null; int y = x ?? 5; // y is 5 int? a = null, b = 1, c = 2; Console.WriteLine (a ?? b ?? c); // 1 (first non-null value)
Die Verwendung von ?? für einen nullbaren Werttyp entspricht dem Aufruf von GetValueOrDefault mit einem expliziten Standardwert, mit dem Unterschied, dass der Ausdruck für den Standardwert nie ausgewertet wird, wenn die Variable nicht null ist.
Nullbare Wertetypen funktionieren auch gut mit dem Null-Bedingungsoperator (siehe "Null-Bedingungsoperator" in Kapitel 2). Im folgenden Beispiel wird length als Null ausgewertet:
System.Text.StringBuilder sb = null; int? length = sb?.ToString().Length;
Wir können dies mit dem Null-Koaleszenz-Operator kombinieren, damit die Auswertung Null statt Null ergibt:
int length = sb?.ToString().Length ?? 0; // Evaluates to 0 if sb is null
Szenarien für nullbare Werttypen
Eines der häufigsten Szenarien für nullbare Wertetypen ist die Darstellung unbekannter Werte. Dies geschieht häufig in der Datenbankprogrammierung, wenn eine Klasse auf eine Tabelle mit löschbaren Spalten abgebildet wird. Wenn es sich bei diesen Spalten um Strings handelt (z. B. eine EmailAddress-Spalte in einer Kundentabelle), gibt es kein Problem, da string in der CLR ein Referenztyp ist, der null sein kann. Die meisten anderen SQL-Spaltentypen lassen sich jedoch auf CLR-Strukturtypen abbilden, sodass nullbare Wertetypen bei der Abbildung von SQL auf die CLR sehr nützlich sind:
// Maps to a Customer table in a database
public class Customer
{
...
public decimal? AccountBalance;
}
Ein nullable-Typ kann auch verwendet werden, um das Hintergrundfeld einer so genannten Umgebungseigenschaft darzustellen. Eine Umgebungseigenschaft gibt den Wert ihrer übergeordneten Eigenschaft zurück, wenn sie null ist:
public class Row
{
...
Grid parent;
Color? color;
public Color Color
{
get { return color ?? parent.Color; }
set { color = value == parent.Color ? (Color?)null : value; }
}
}
Alternativen zu nullbaren Werttypen
Bevor nullbare Wertetypen Teil der Sprache C# waren (d.h. vor C# 2.0), gab es viele Strategien, um mit nullbaren Wertetypen umzugehen, von denen es aus historischen Gründen immer noch Beispiele in .NET Core gibt. Eine Strategie besteht darin, einen bestimmten Nicht-Null-Wert als "Null-Wert" zu bezeichnen; ein Beispiel dafür sind die Klassen string und array. string.IndexOf gibt den magischen Wert von −1 zurück, wenn das Zeichen nicht gefunden wird:
int i = "Pink".IndexOf ('b');
Console.WriteLine (i); // −1
Array.IndexOf gibt jedoch nur dann −1 zurück, wenn der Index 0-begrenzt ist. Die allgemeinere Formel lautet, dass IndexOf einen Wert kleiner als die untere Grenze des Arrays zurückgibt. Im nächsten Beispiel gibt IndexOf 0 zurück, wenn ein Element nicht gefunden wird:
// Create an array whose lower bound is 1 instead of 0:
Array a = Array.CreateInstance (typeof (string),
new int[] {2}, new int[] {1});
a.SetValue ("a", 1);
a.SetValue ("b", 2);
Console.WriteLine (Array.IndexOf (a, "c")); // 0
Die Benennung eines "magischen Wertes" ist aus mehreren Gründen problematisch:
-
Das bedeutet, dass jeder Wertetyp eine andere Darstellung von null hat. Im Gegensatz dazu bieten nullable Wertetypen ein gemeinsames Muster, das für alle Wertetypen gilt.
-
Es kann sein, dass es keinen vernünftigen festgelegten Wert gibt. Im vorherigen Beispiel konnte -1 nicht immer verwendet werden. Dasselbe gilt für unser früheres Beispiel, das einen unbekannten Kontostand darstellt.
-
Wenn du vergisst, auf den magischen Wert zu testen, entsteht ein falscher Wert, der vielleicht erst später in der Ausführung bemerkt wird - wenn er einen ungewollten Zaubertrick ausführt. Wenn du jedoch vergisst,
HasValueauf einen Nullwert zu testen, wird einInvalidOperationExceptionauf der Stelle. -
Die Möglichkeit, dass ein Wert null sein kann, wird nicht im Typ erfasst. Typen kommunizieren die Intention eines Programms, ermöglichen dem Compiler, die Korrektheit zu prüfen, und ermöglichen einen konsistenten Satz von Regeln, die der Compiler durchsetzt.
Nullbare Referenztypen (C# 8)
Während nullbare Wertetypen Wertetypen nullbar machen, bewirken nullbare Referenztypen das Gegenteil und machen Referenztypen (bis zu einem gewissen Grad) nicht-nullbar, um NullReferenceExceptions zu vermeiden.
Nullable-Referenztypen führen eine Sicherheitsebene ein, die ausschließlich vom Compiler durchgesetzt wird, und zwar in Form von Warnungen, wenn er Code entdeckt, der Gefahr läuft, ein NullReferenceException zu erzeugen.
Um nullbare Referenztypen zu aktivieren, musst du entweder das Element Nullable zu deiner .csproj-Projektdatei hinzufügen (wenn du es für das gesamte Projekt aktivieren willst):
<PropertyGroup> <Nullable>enable</Nullable> </PropertyGroup>
und/oder verwende die folgenden Direktiven in deinem Code, an den Stellen, an denen sie wirksam werden sollen:
#nullable enable // enables nullable reference types from this point on #nullable disable // disables nullable reference types from this point on #nullable restore // resets nullable reference types to project setting
Nach der Aktivierung macht der Compiler die Nicht-Nullbarkeit zum Standard: Wenn du willst, dass ein Referenztyp Nullen akzeptiert, musst du das Suffix ? hinzufügen, um einen nullbaren Referenztyp anzugeben. Im folgenden Beispiel ist s1 nicht-nullbar, während s2 nullbar ist:
#nullable enable // Enable nullable reference types string s1 = null; // Generates a compiler warning! string? s2 = null; // OK: s2 is nullable reference type
Hinweis
Da nullbare Referenztypen Konstrukte zur Kompilierzeit sind, gibt es keinen Laufzeitunterschied zwischen string und string?. Im Gegensatz dazu führen nullbare Werttypen etwas Konkretes in das Typsystem ein, nämlich die Nullable<T> Struktur.
Das Folgende erzeugt ebenfalls eine Warnung, weil x nicht initialisiert ist:
class Foo { string x; }
Die Warnung verschwindet, wenn du x initialisierst, entweder über einen Feldinitialisierer oder über Code im Konstruktor.
Der Null-Vergabe-Operator
Der Compiler warnt dich auch beim Dereferenzieren eines nullbaren Referenztyps, wenn er denkt, dass ein NullReferenceException auftreten könnte. Im folgenden Beispiel führt der Zugriff auf die Eigenschaft Length des Strings zu einer Warnung:
void Foo (string? s) => Console.Write (s.Length);
Du kannst die Warnung mit dem Null-Forgiving-Operator (!) entfernen:
void Foo (string? s) => Console.Write (s!.Length);
Die Verwendung des Null-Vergabe-Operators in diesem Beispiel ist insofern gefährlich, als dass wir am Ende genau die NullReferenceException auslösen könnten, die wir eigentlich vermeiden wollten. Wir könnten es wie folgt lösen:
void Foo (string? s)
{
if (s != null) Console.Write (s.Length);
}
Beachte, dass wir den Null-Vergabe-Operator jetzt nicht mehr brauchen. Das liegt daran, dass der Compiler eine statische Flussanalyse durchführt und schlau genug ist, um - zumindest in einfachen Fällen - abzuleiten, wann eine Dereferenzierung sicher ist und es keine Möglichkeit gibt, eine NullReferenceException.
Die Fähigkeit des Compilers, zu erkennen und zu warnen, ist nicht kugelsicher, und es gibt auch Grenzen, was die Abdeckung angeht. So kann der Compiler zum Beispiel nicht wissen, ob die Elemente eines Arrays gefüllt wurden, und deshalb gibt es keine Warnung:
var strings = new string[10]; Console.WriteLine (strings[0].Length);
Trennung der Kontexte für Anmerkungen und Warnungen
Das Aktivieren von löschbaren Referenztypen über die Direktive #nullable enable (oder die <Nullable>enable</Nullable> Projekteinstellung) bewirkt zwei Dinge:
-
Er aktiviert den Annotationskontext nullable, der den Compiler anweist, alle referenzartigen Variablendeklarationen als nicht-nullbar zu behandeln, sofern sie nicht durch das Symbol
?ergänzt werden. -
Er aktiviert den nullbaren Warnkontext, der den Compiler anweist, Warnungen zu generieren, wenn er auf Code stößt, bei dem die Gefahr besteht, dass er eine
NullReferenceException.
Manchmal kann es sinnvoll sein, diese beiden Konzepte zu trennen und nur den Anmerkungskontext oder (weniger sinnvoll) nur den Warnkontext zu aktivieren:
#nullable enable annotations // Enable the annotation context // OR: #nullable enable warnings // Enable the warning context
(Der gleiche Trick funktioniert mit #nullable disable und #nullable restore.)
Du kannst es auch über die Projektdatei machen:
<Nullable>annotations</Nullable> <!-- OR --> <Nullable>warnings</Nullable>
Die Aktivierung des Annotationskontextes für eine bestimmte Klasse oder Assembly kann ein guter erster Schritt sein, um nullbare Referenztypen in eine Legacy-Codebasis einzuführen. Indem du öffentliche Mitglieder korrekt annotierst, kann deine Klasse oder Assembly als guter Bürger für andere Klassen oder Assemblies fungieren, so dass diese in vollem Umfang von nullbaren Referenztypen profitieren können, ohne dass du dich mit Warnungen in deiner eigenen Klasse oder Assembly auseinandersetzen musst.
Nullbare Warnungen als Fehler behandeln
Bei neuen Projekten ist es sinnvoll, den Nullable-Kontext von Anfang an vollständig zu aktivieren. Vielleicht möchtest du zusätzlich Warnungen vor Nullen als Fehler behandeln, damit dein Projekt erst kompiliert werden kann, wenn alle Null-Warnungen behoben sind:
<PropertyGroup> <Nullable>enable</Nullable> <WarningsAsErrors>CS8600;CS8602;CS8603</WarningsAsErrors> </PropertyGroup>
Erweiterungsmethoden
Mit Erweiterungsmethoden kann ein bestehender Typ um neue Methoden erweitert werden, ohne die Definition des ursprünglichen Typs zu ändern. Eine Erweiterungsmethode ist eine statische Methode einer statischen Klasse, bei der der this Modifikator auf den ersten Parameter angewendet wird. Der Typ des ersten Parameters ist der Typ, der erweitert wird:
public static class StringHelper
{
public static bool IsCapitalized (this string s)
{
if (string.IsNullOrEmpty(s)) return false;
return char.IsUpper (s[0]);
}
}
Die Erweiterungsmethode IsCapitalized kann wie eine Instanzmethode für eine Zeichenkette aufgerufen werden, und zwar wie folgt:
Console.WriteLine ("Perth".IsCapitalized());
Ein Aufruf einer Erweiterungsmethode wird beim Kompilieren in einen normalen statischen Methodenaufruf zurückübersetzt:
Console.WriteLine (StringHelper.IsCapitalized ("Perth"));
Die Übersetzung funktioniert folgendermaßen:
arg0.Method (arg1, arg2, ...); // Extension method call StaticClass.Method (arg0, arg1, arg2, ...); // Static method call
Auch die Schnittstellen können erweitert werden:
public static T First<T> (this IEnumerable<T> sequence)
{
foreach (T element in sequence)
return element;
throw new InvalidOperationException ("No elements!");
}
...
Console.WriteLine ("Seattle".First()); // S
Verkettung von Erweiterungsmethoden
Erweiterungsmethoden bieten, genau wie Instanzmethoden, eine ordentliche Möglichkeit, Funktionen zu verketten. Betrachte die folgenden zwei Funktionen:
public static class StringHelper
{
public static string Pluralize (this string s) {...}
public static string Capitalize (this string s) {...}
}
x und y sind gleichwertig und werden beide zu "Sausages" ausgewertet, aber x verwendet Erweiterungsmethoden, während y statische Methoden verwendet:
string x = "sausage".Pluralize().Capitalize();
string y = StringHelper.Capitalize (StringHelper.Pluralize ("sausage"));
Zweideutigkeit und Auflösung
Namensräume
Auf eine Erweiterungsmethode kann nur dann zugegriffen werden, wenn ihre Klasse im Geltungsbereich liegt, in der Regel, indem ihr Namensraum importiert wird. Betrachte die Erweiterungsmethode IsCapitalized im folgenden Beispiel:
using System;
namespace Utils
{
public static class StringHelper
{
public static bool IsCapitalized (this string s)
{
if (string.IsNullOrEmpty(s)) return false;
return char.IsUpper (s[0]);
}
}
}
Um IsCapitalized zu verwenden, muss die folgende Anwendung Utils importieren, um einen Kompilierfehler zu vermeiden:
namespace MyApp
{
using Utils;
class Test
{
static void Main() => Console.WriteLine ("Perth".IsCapitalized());
}
}
Erweiterungsmethoden versus Instanzmethoden
Jede kompatible Instanzmethode hat immer Vorrang vor einer Erweiterungsmethode. Im folgenden Beispiel hat die Methode Foo von Testimmer Vorrang, auch wenn sie mit einem Argument x vom Typ int aufgerufen wird:
class Test
{
public void Foo (object x) { } // This method always wins
}
static class Extensions
{
public static void Foo (this Test t, int x) { }
}
Die einzige Möglichkeit, die Erweiterungsmethode in diesem Fall aufzurufen, ist über die normale statische Syntax, also Extensions.Foo(...).
Erweiterungsmethoden versus Erweiterungsmethoden
Wenn zwei Erweiterungsmethoden die gleiche Signatur haben, muss die Erweiterungsmethode als gewöhnliche statische Methode aufgerufen werden, um die aufzurufende Methode eindeutig zu bestimmen. Wenn eine Erweiterungsmethode jedoch spezifischere Argumente hat, hat die spezifischere Methode Vorrang.
Zur Veranschaulichung betrachten wir die folgenden zwei Klassen:
static class StringHelper
{
public static bool IsCapitalized (this string s) {...}
}
static class ObjectHelper
{
public static bool IsCapitalized (this object s) {...}
}
Der folgende Code ruft die Methode StringHelper' IsCapitalized auf:
bool test1 = "Perth".IsCapitalized();
Klassen und Strukturen werden als spezifischer angesehen als Schnittstellen.
Anonyme Typen
Ein anonymer Typ ist eine einfache Klasse, die vom Compiler im Handumdrehen erstellt wird, um eine Reihe von Werten zu speichern. Um einen anonymen Typ zu erstellen, verwendest du das Schlüsselwort new, gefolgt von einem Objektinitialisierer, der die Eigenschaften und Werte angibt, die der Typ enthalten soll, z. B:
var dude = new { Name = "Bob", Age = 23 };
Der Compiler übersetzt dies (ungefähr) wie folgt:
internal class AnonymousGeneratedTypeName
{
private string name; // Actual field name is irrelevant
private int age; // Actual field name is irrelevant
public AnonymousGeneratedTypeName (string name, int age)
{
this.name = name; this.age = age;
}
public string Name { get { return name; } }
public int Age { get { return age; } }
// The Equals and GetHashCode methods are overridden (see Chapter 6).
// The ToString method is also overridden.
}
...
var dude = new AnonymousGeneratedTypeName ("Bob", 23);
Du musst das Schlüsselwort var verwenden, um einen anonymen Typ zu referenzieren, weil er keinen Namen hat.
Der Eigenschaftsname eines anonymen Typs kann aus einem Ausdruck abgeleitet werden, der selbst ein Bezeichner ist (oder mit einem Bezeichner endet); also:
int Age = 23;
var dude = new { Name = "Bob", Age, Age.ToString().Length };
ist gleichbedeutend mit:
var dude = new { Name = "Bob", Age = Age, Length = Age.ToString().Length };
Zwei anonyme Typinstanzen, die in derselben Assembly deklariert sind, haben denselben zugrunde liegenden Typ, wenn ihre Elemente identisch benannt und typisiert sind:
var a1 = new { X = 2, Y = 4 };
var a2 = new { X = 2, Y = 4 };
Console.WriteLine (a1.GetType() == a2.GetType()); // True
Außerdem wird die Methode Equals außer Kraft gesetzt, um Gleichheitsvergleiche durchzuführen:
Console.WriteLine (a1 == a2); // False Console.WriteLine (a1.Equals (a2)); // True
Du kannst Arrays von anonymen Typen wie folgt erstellen:
var dudes = new[]
{
new { Name = "Bob", Age = 30 },
new { Name = "Tom", Age = 40 }
};
Eine Methode kann (sinnvollerweise) kein anonym typisiertes Objekt zurückgeben, da es illegal ist, eine Methode zu schreiben, deren Rückgabetyp var ist:
var Foo() => new { Name = "Bob", Age = 30 }; // Not legal!
Stattdessen musst du object oder dynamic verwenden. Wer dann Foo aufruft, muss sich auf die dynamische Bindung verlassen, wobei die statische Typsicherheit (und IntelliSense in Visual Studio) verloren geht.
dynamic Foo() => new { Name = "Bob", Age = 30 }; // No static type safety.
Anonyme Typen sind besonders nützlich beim Schreiben von LINQ-Abfragen (siehe Kapitel 8).
Tupel
Wie anonyme Typen bieten auch Tupel eine einfache Möglichkeit, eine Reihe von Werten zu speichern. Der Hauptzweck von Tupeln ist die sichere Rückgabe mehrerer Werte aus einer Methode, ohne auf out Parameter zurückgreifen zu müssen (was bei anonymen Typen nicht möglich ist).
Hinweis
Tupel können fast alles, was anonyme Typen können, und noch mehr. Ihr einziger Nachteil ist - wie du gleich sehen wirst - das Löschen von Typen mit benannten Elementen zur Laufzeit.
Die einfachste Art, ein Tupel-Literal zu erstellen, besteht darin, die gewünschten Werte in Klammern aufzulisten. So entsteht ein Tupel mit unbenannten Elementen, die du als Item1, Item2, usw. bezeichnest:
var bob = ("Bob", 23); // Allow compiler to infer the element types
Console.WriteLine (bob.Item1); // Bob
Console.WriteLine (bob.Item2); // 23
Tupel sind Wertetypen mit veränderbaren (lesbaren/schreibbaren) Elementen:
var joe = bob; // joe is a *copy* of bob joe.Item1 = "Joe"; // Change joe's Item1 from Bob to Joe Console.WriteLine (bob); // (Bob, 23) Console.WriteLine (joe); // (Joe, 23)
Anders als bei anonymen Typen kannst du einen Tupeltyp explizit angeben. Führe einfach alle Elementtypen in Klammern auf:
(string,int) bob = ("Bob", 23);
Das bedeutet, dass du sinnvollerweise ein Tupel aus einer Methode zurückgeben kannst:
static (string,int) GetPerson() => ("Bob", 23);
static void Main()
{
(string,int) person = GetPerson(); // Could use 'var' instead if we want
Console.WriteLine (person.Item1); // Bob
Console.WriteLine (person.Item2); // 23
}
Tupel lassen sich gut mit Generika kombinieren, sodass die folgenden Typen alle zulässig sind:
Task<(string,int)> Dictionary<(string,int),Uri> IEnumerable<(int id, string name)> // See below for naming elements
Tupel-Elemente benennen
Bei der Erstellung von Tupelliteralen kannst du den Elementen optional aussagekräftige Namen geben:
var tuple = (name:"Bob", age:23); Console.WriteLine (tuple.name); // Bob Console.WriteLine (tuple.age); // 23
Du kannst dasselbe tun, wenn du Tupeltypen angibst:
static (string name, int age) GetPerson() => ("Bob", 23);
static void Main()
{
var person = GetPerson();
Console.WriteLine (person.name); // Bob
Console.WriteLine (person.age); // 23
}
Beachte, dass du die Elemente immer noch als unbenannt behandeln und auf sie als Item1, Item2 usw. verweisen kannst (obwohl Visual Studio diese Felder vor IntelliSense verbirgt).
Elementnamen werden automatisch aus Eigenschafts- oder Feldnamen abgeleitet:
var now = DateTime.Now; var tuple = (now.Day, now.Month, now.Year); Console.WriteLine (tuple.Day); // OK
Tupel sind miteinander typkompatibel, wenn ihre Elementtypen (in der Reihenfolge) übereinstimmen. Ihre Elementnamen müssen nicht übereinstimmen:
(string name, int age, char sex) bob1 = ("Bob", 23, 'M');
(string age, int sex, char name) bob2 = bob1; // No error!
Unser spezielles Beispiel führt zu verwirrenden Ergebnissen:
Console.WriteLine (bob2.name); // M Console.WriteLine (bob2.age); // Bob Console.WriteLine (bob2.sex); // 23
Typ Löschung
Wir haben bereits erwähnt, dass der C#-Compiler anonyme Typen behandelt, indem er benutzerdefinierte Klassen mit benannten Eigenschaften für jedes der Elemente erstellt. Bei Tupeln arbeitet C# anders und verwendet eine bereits vorhandene Familie von generischen Strukturen:
public struct ValueTuple<T1> public struct ValueTuple<T1,T2> public struct ValueTuple<T1,T2,T3> ...
Jede der ValueTuple<> -Strukturen hat Felder mit den Namen Item1, Item2 und so weiter.
Daher ist (string,int) ein Alias für ValueTuple<string,int>, und das bedeutet, dass benannte Tupel-Elemente keine entsprechenden Eigenschaftsnamen in den zugrunde liegenden Typen haben. Stattdessen existieren die Namen nur im Quellcode und in der Vorstellung des Compilers. Wenn du also ein Programm dekompilierst, das sich auf benannte Tupel-Elemente bezieht, siehst du nur Verweise auf Item1, Item2 und so weiter. Wenn du eine Tupelvariable in einem Debugger untersuchst, nachdem du sie einem object zugewiesen hast (oder sie in LINQPad löschen willst), sind die Elementnamen nicht mehr vorhanden. Und in den meisten Fällen kannst du Reflection(Kapitel 19) nicht verwenden, um die Elementnamen eines Tupels zur Laufzeit zu ermitteln.
Hinweis
Wir haben gesagt, dass die Namen meistens verschwinden, weil es eine Ausnahme gibt. Bei Methoden/Eigenschaften, die benannte Tupeltypen zurückgeben, gibt der Compiler die Elementnamen aus, indem er ein benutzerdefiniertes Attribut namens TupleElementNamesAttribute (siehe "Attribute") auf den Rückgabetyp des Elements anwendet. Dadurch können benannte Elemente beim Aufruf von Methoden in einer anderen Assembly (für die der Compiler keinen Quellcode hat) funktionieren.
ValueTuple.Create
Du kannst Tupel auch über eine Factory-Methode für den (nicht generischen) Typ ValueTuple erstellen:
ValueTuple<string,int> bob1 = ValueTuple.Create ("Bob", 23);
(string,int) bob2 = ValueTuple.Create ("Bob", 23);
Du kannst auf diese Weise keine benannten Elemente erstellen, weil die Benennung von Elementen auf der Magie des Compilers beruht.
Tupel dekonstruieren
Tupel unterstützen implizit das Dekonstruktionsmuster (siehe "Dekonstruktoren" in Kapitel 3), sodass du ein Tupel leicht in einzelne Variablen zerlegen kannst. Anstatt dies also zu tun:
var bob = ("Bob", 23);
string name = bob.Item1;
int age = bob.Item2;
kannst du das tun:
var bob = ("Bob", 23);
(string name, int age) = bob; // Deconstruct the bob tuple into
// separate variables (name and age).
Console.WriteLine (name);
Console.WriteLine (age);
Die Syntax für die Dekonstruktion ist der Syntax für die Deklaration eines Tupels mit benannten Elementen zum Verwechseln ähnlich. Im Folgenden wird der Unterschied deutlich:
(string name, int age) = bob; // Deconstructing a tuple (string name, int age) bob2 = bob; // Declaring a new tuple
Hier ist ein weiteres Beispiel, dieses Mal beim Aufruf einer Methode und mit Typinferenz (var):
static (string, int, char) GetBob() => ( "Bob", 23, 'M');
static void Main()
{
var (name, age, sex) = GetBob();
Console.WriteLine (name); // Bob
Console.WriteLine (age); // 23
Console.WriteLine (sex); // M
}
Gleichheit im Vergleich
Wie bei anonymen Typen überschreiben die ValueTuple<> Typen die Equals Methode, damit Gleichheitsvergleiche sinnvoll funktionieren:
var t1 = ("one", 1);
var t2 = ("one", 1);
Console.WriteLine (t1.Equals (t2)); // True
Darüber hinaus überlastet ValueTuple<> die Operatoren == und !=:
Console.WriteLine (t1 == t2); // True (from C# 7.3)
Sie setzen auch die Methode GetHashCode außer Kraft, so dass es praktisch ist, Tupel als Schlüssel in Wörterbüchern zu verwenden. Wir behandeln den Gleichheitsvergleich im Detail in "Gleichheitsvergleich" in Kapitel 6 und "Wörterbücher" in Kapitel 7.
Die ValueTuple<> Typen implementieren auch IComparable (siehe "Ordnungsvergleich" in Kapitel 6), wodurch es möglich ist, Tupel als Sortierschlüssel zu verwenden.
Die System.Tupel-Klassen
Im Namensraum System findest du eine weitere Familie von generischen Typen mit dem Namen Tuple (statt ValueTuple). Diese wurden im .NET Framework 4.0 eingeführt und sind Klassen (während die ValueTuple Typen Structs sind). Tupel als Klassen zu definieren, wurde im Nachhinein als Fehler angesehen: In den typischen Szenarien, in denen Tupel verwendet werden, haben Structs einen leichten Leistungsvorteil (da sie unnötige Speicherzuweisungen vermeiden), aber fast keinen Nachteil. Als Microsoft die Sprachunterstützung für Tupel (in C# 7) hinzufügte, wurden daher die bestehenden Tuple Typen zugunsten der neuen ValueTuple ignoriert. In Code, der vor C# 7 geschrieben wurde, kannst du noch auf die Tuple Klassen stoßen. Sie haben keine spezielle Sprachunterstützung und werden wie folgt verwendet:
Tuple<string,int> t = Tuple.Create ("Bob", 23); // Factory method
Console.WriteLine (t.Item1); // Bob
Console.WriteLine (t.Item2); // 23
Muster
In Kapitel 3 haben wir gezeigt, wie du mit dem is Operator testen kannst, ob eine Referenzkonvertierung erfolgreich sein wird:
if (obj is string) Console.WriteLine (((string)obj).Length);
Oder, noch knapper ausgedrückt:
if (obj is string s) Console.WriteLine (s.Length);
Dabei wird eine Art von Muster verwendet, das sogenannte Typmuster. Der is Operator unterstützt auch andere Muster, die in C# 7 und C# 8 eingeführt wurden, wie z.B. das Eigenschaftsmuster:
if (obj is string { Length:4 })
Console.WriteLine ("A string with 4 characters");
Muster werden in den folgenden Kontexten unterstützt:
-
Nach dem
isOperator (variable is pattern) -
In
switchAussagen -
In
switchAusdrücke
Wir haben das Typ-Muster (und kurz das Tupel-Muster) bereits in Kapitel 2, "Umschalten von Typen", und in Kapitel 3 , "Der is-Operator", behandelt. In diesem Abschnitt behandeln wir fortgeschrittenere Muster, die in C# 7 und C# 8 eingeführt wurden. Die meisten dieser Muster sind für die Verwendung in switch Anweisungen/Ausdrücken gedacht, wo sie Folgendes tun:
-
Reduziere den Bedarf an
whenKlauseln -
Du kannst Schalter benutzen, die du vorher nicht benutzen konntest
Hinweis
Die Muster in diesem Abschnitt sind in einigen Szenarien leicht bis mittelmäßig nützlich. Erinnere dich daran, dass du stark gemusterte switch Ausdrücke immer durch einfache if Anweisungen - oder in manchen Fällen durch den ternären Bedingungsoperator - ersetzen kannst, und das oft ohne viel zusätzlichen Code.
Property Patterns (C# 8)
Ein Eigenschaftsmuster passt auf einen oder mehrere Eigenschaftswerte eines Objekts. Wir haben bereits ein einfaches Beispiel im Zusammenhang mit dem Operator is gegeben:
if (obj is string { Length:4 }) ...
Das spart aber nicht viel gegenüber den folgenden Punkten:
if (obj is string s && s.Length == 4) ...
Bei switch Anweisungen und Ausdrücken sind die Eigenschaftsmuster nützlicher. Nehmen wir die Klasse System.Uri, die einen URI darstellt. Sie hat Eigenschaften wie Scheme, Host, Port und IsLoopback. Wenn wir eine Firewall schreiben, können wir entscheiden, ob wir einen URI zulassen oder blockieren, indem wir einen Ausdruck switch verwenden, der Eigenschaftsmuster verwendet:
bool ShouldAllow (Uri uri) => uri switch
{
{ Scheme: "http", Port: 80 } => true,
{ Scheme: "https", Port: 443 } => true,
{ Scheme: "ftp", Port: 21 } => true,
{ IsLoopback: true } => true,
_ => false
};
Du kannst Eigenschaften verschachteln, wodurch die folgende Klausel legal ist:
{ Scheme: string { Length: 4 }, Port: 80 } => true,
Das Matching basiert immer auf Typ und Gleichheit. Solltest du einen anderen Operator (z.B. kleiner-als) anwenden müssen, musst du eine when Klausel verwenden:
{ Scheme: "http", Port: 80 } when uri.Host.Length < 1000 => true,
Du kannst das Typmuster mit dem Eigenschaftsmuster kombinieren:
bool ShouldAllow (object uri) => uri switch
{
Uri { Scheme: "http", Port: 80 } => true,
Uri { Scheme: "https", Port: 443 } => true,
...
Wie bei Typmustern nicht anders zu erwarten, kannst du am Ende einer Klausel eine Variable einführen und diese dann verbrauchen:
Uri { Scheme: "http", Port: 80 } httpUri => httpUri.Host.Length < 1000,
Du kannst diese Variable auch in einer when Klausel verwenden:
Uri { Scheme: "http", Port: 80 } httpUri
when httpUri.Host.Length < 1000 => true,
Eine etwas bizarre Wendung bei den Eigenschaftsmustern ist, dass du auch Variablen auf der Ebene der Eigenschaft einführen kannst:
{ Scheme: "http", Port: 80, Host: string host } => host.Length < 1000,
Implizite Typisierung ist erlaubt, du kannst also string durch var ersetzen. Hier ist ein vollständiges Beispiel:
bool ShouldAllow (Uri uri) => uri switch
{
{ Scheme: "http", Port: 80, Host: var host } => host.Length < 1000,
{ Scheme: "https", Port: 443 } => true,
{ Scheme: "ftp", Port: 21 } => true,
{ IsLoopback: true } => true,
_ => false
};
Es ist schwierig, Beispiele zu finden, bei denen das mehr als ein paar Zeichen spart. In unserem Fall ist die Alternative sogar kürzer:
{ Scheme: "http", Port: 80 } => uri.Host.Length < 1000,
Tupel-Muster (C# 8)
Tupel-Muster bieten einen einfachen Mechanismus zum Einschalten mehrerer Werte:
enum Season { Spring, Summer, Fall, Winter };
int AverageCelsiusTemperature (Season season, bool daytime) =>
(season, daytime) switch
{
(Season.Spring, true) => 20,
(Season.Spring, false) => 16,
(Season.Summer, true) => 27,
(Season.Summer, false) => 22,
(Season.Fall, true) => 18,
(Season.Fall, false) => 12,
(Season.Winter, true) => 10,
(Season.Winter, false) => -2,
_ => throw new Exception ("Unexpected combination")
};
Positional Patterns (C# 8)
Für Typen, die eine Deconstruct Methode definieren (siehe "Dekonstruktoren" in Kapitel 3), wie die Klasse Point im folgenden Beispiel:
class Point
{
public readonly int X, Y;
public Point (int x, int y) => (X, Y) = (x, y);
public void Deconstruct (out int x, out int y)
{
x = X; y = Y;
}
}
kannst du die Positionseigenschaften des Objekts für den Mustervergleich verwenden:
var p = new Point (2, 3); Console.WriteLine (p is (2, 3)); // true
Mit einem Schalter:
string Print (object obj) => obj switch
{
Point (0, 0) => "Empty point",
Point (var x, var y) when x == y => "Diagonal"
...
};
var Muster
Das var Muster wurde in C# 7 eingeführt und ist eine Variante des Typmusters, bei der du den Typnamen durch das var Schlüsselwort ersetzt. Die Konvertierung ist immer erfolgreich, so dass sie nur dazu dient, die nachfolgende Variable wiederzuverwenden:
bool Test (int x, int y) => x * y is var product && product > 10 && product < 100;
Ohne diese Funktion müsstest du das tun:
bool Test (int x, int y)
{
int product = x * y;
return product > 10 && product < 100;
}
Die Möglichkeit, eine Zwischenvariable (in diesem Fallproduct) in einer Methode mit Ausdruck einzuführen und wiederzuverwenden, ist praktisch. Leider funktioniert dies nur, wenn die betreffende Methode einen bool Rückgabetyp hat.
Konstantes Muster
Das Konstantenmuster ist das A und O der switch Anweisungen (und bis C# 7 war es das einzige unterstützte Muster). Aus Gründen der Konsistenz kannst du das Konstantenmuster auch mit dem is Operator aus C# 7 verwenden, so dass die folgenden Anweisungen legal sind:
void Foo (object obj)
{
// C# won't let you use the == operator, because obj is object.
// However, we can use 'is'
if (obj is 3) ...
}
Dies ist gleichbedeutend mit dem Folgenden:
void Foo (object obj)
{
if (obj is int && (int)obj == 3) ...
}
Attribute
Du kennst bereits das Konzept, Code-Elemente eines Programms mit Modifikatoren wie virtual oder ref zu versehen. Diese Konstrukte sind in die Sprache eingebaut. Attribute sind ein erweiterbarer Mechanismus zum Hinzufügen von benutzerdefinierten Informationen zu Codeelementen (Assemblies, Typen, Member, Rückgabewerte, Parameter und generische Typparameter). Diese Erweiterbarkeit ist nützlich für Dienste, die tief in das Typsystem integriert sind, ohne dass spezielle Schlüsselwörter oder Konstrukte in der Sprache C# erforderlich sind.
Ein gutes Szenario für Attribute ist die Serialisierung - derProzess der Konvertierung beliebiger Objekte in ein bestimmtes Format zur Speicherung oder Übertragung. In diesem Szenario kann ein Attribut für ein Feld die Übersetzung zwischen der C#-Darstellung des Feldes und der Darstellung des Feldes in dem Format festlegen.
Attribut-Klassen
Ein Attribut wird von einer Klasse definiert, die (direkt oder indirekt) von der abstrakten Klasse System.Attribute erbt. Um ein Attribut an ein Codeelement anzuhängen, gibst du den Typnamen des Attributs in eckigen Klammern an, bevor du das Codeelement angibst. Im folgenden Beispiel wird das Attribut ObsoleteAttribute an die Klasse Foo angehängt:
[ObsoleteAttribute]
public class Foo {...}
Dieses besondere Attribut wird vom Compiler erkannt und führt zu Compiler-Warnungen, wenn auf einen als veraltet gekennzeichneten Typ oder Member verwiesen wird. Konventionell enden alle Attributtypen mit dem Wort Attribut. C# erkennt dies und erlaubt dir, das Suffix wegzulassen, wenn du ein Attribut anfügst:
[Obsolete]
public class Foo {...}
ObsoleteAttribute ist ein Typ, der im Namespace System wie folgt deklariert ist (der Kürze halber vereinfacht):
public sealed class ObsoleteAttribute : Attribute {...}
Die Sprache C# und .NET Core enthalten eine Reihe von vordefinierten Attributen. Wie du deine eigenen Attribute schreiben kannst, wird in Kapitel 19 beschrieben.
Benannte und positionale Attributparameter
Attribute können Parameter haben. Im folgenden Beispiel wenden wir XmlTypeAttribute auf eine Klasse an. Dieses Attribut weist den XML-Serialisierer (in System.Xml.Serialization) an, wie ein Objekt in XML dargestellt wird und akzeptiert mehrere Attributparameter. Das folgende Attribut bildet die Klasse CustomerEntity auf ein XML-Element mit dem Namen Customer ab, das zum Namensraum http://oreilly.com gehört:
[XmlType ("Customer", Namespace="http://oreilly.com")]
public class CustomerEntity { ... }
Attributparameter fallen in eine von zwei Kategorien: Positionsparameter oder benannte Parameter. Im obigen Beispiel ist das erste Argument ein Positionsparameter, das zweite ein benannter Parameter. Positionale Parameter entsprechen den Parametern der öffentlichen Konstruktoren des Attributtyps. Benannte Parameter entsprechen öffentlichen Feldern oder öffentlichen Eigenschaften des Attributtyps.
Wenn du ein Attribut angibst, musst du Positionsparameter angeben, die einem der Konstruktoren des Attributs entsprechen. Benannte Parameter sind optional.
In Kapitel 19 beschreiben wir die gültigen Parametertypen und Regeln für ihre Auswertung.
Anwenden von Attributen auf Baugruppen und Unterlegfelder
Implizit ist das Ziel eines Attributs das Codeelement, dem es unmittelbar vorausgeht, also in der Regel ein Typ oder ein Typ-Member. Du kannst Attribute aber auch an eine Assembly anhängen. Dazu musst du das Ziel des Attributs explizit angeben. So kannst du das Attribut AssemblyFileVersion verwenden, um eine Version an die Assembly anzuhängen:
[assembly: AssemblyFileVersion ("1.2.3.4")]
Ab C# 7.3 kannst du das Präfix field: verwenden, um ein Attribut auf die hinteren Felder einer automatischen Eigenschaft anzuwenden. Dies kann bei der Steuerung der Serialisierung nützlich sein:
[field:NonSerialized]
public int MyProperty { get; set; }
Mehrere Attribute spezifizieren
Du kannst mehrere Attribute für ein einzelnes Code-Element angeben. Du kannst jedes Attribut entweder innerhalb desselben Paars eckiger Klammern (durch ein Komma getrennt) oder in separaten Paaren eckiger Klammern (oder einer Kombination aus beidem) auflisten. Die folgenden drei Beispiele sind semantisch identisch:
[Serializable, Obsolete, CLSCompliant(false)]
public class Bar {...}
[Serializable] [Obsolete] [CLSCompliant(false)]
public class Bar {...}
[Serializable, Obsolete]
[CLSCompliant(false)]
public class Bar {...}
Anrufer-Info-Attribute
Du kannst optionale Parameter mit einem von drei Caller-Info-Attributen versehen, die den Compiler anweisen, Informationen aus dem Quellcode des Aufrufers in den Standardwert des Parameters zu übernehmen:
-
[CallerMemberName]wendet den Mitgliedsnamen des Anrufers an -
[CallerFilePath]wendet den Pfad zur Quellcode-Datei des Aufrufers an -
[CallerLineNumber]wendet die Zeilennummer in der Quellcodedatei des Aufrufers an
Die Methode Foo im folgenden Programm demonstriert alle drei:
using System;
using System.Runtime.CompilerServices;
class Program
{
static void Main() => Foo();
static void Foo (
[CallerMemberName] string memberName = null,
[CallerFilePath] string filePath = null,
[CallerLineNumber] int lineNumber = 0)
{
Console.WriteLine (memberName);
Console.WriteLine (filePath);
Console.WriteLine (lineNumber);
}
}
Angenommen, unser Programm befindet sich in c:\source\test\Program.cs, dann würde die Ausgabe lauten:
Main c:\source\test\Program.cs 6
Wie bei den optionalen Standardparametern wird die Ersetzung auf der aufrufenden Seite vorgenommen. Daher ist unsere Methode Main ein syntaktischer Zucker für diese Aufgabe:
static void Main() => Foo ("Main", @"c:\source\test\Program.cs", 6);
Caller-Info-Attribute sind nützlich für die Protokollierung und für die Implementierung von Mustern wie dem Auslösen eines einzelnen Änderungsbenachrichtigungsereignisses, wenn sich eine Eigenschaft eines Objekts ändert. In .NET Core gibt es dafür sogar eine Standardschnittstelle namens INotifyPropertyChanged (in System.ComponentModel):
public interface INotifyPropertyChanged
{
event PropertyChangedEventHandler PropertyChanged;
}
public delegate void PropertyChangedEventHandler
(object sender, PropertyChangedEventArgs e);
public class PropertyChangedEventArgs : EventArgs
{
public PropertyChangedEventArgs (string propertyName);
public virtual string PropertyName { get; }
}
Beachte, dass PropertyChangedEventArgs den Namen der Eigenschaft benötigt, die sich geändert hat. Mit dem Attribut [CallerMemberName] können wir diese Schnittstelle jedoch implementieren und das Ereignis aufrufen, ohne die Eigenschaftsnamen anzugeben:
public class Foo : INotifyPropertyChanged
{
public event PropertyChangedEventHandler PropertyChanged = delegate { };
void RaisePropertyChanged ([CallerMemberName] string propertyName = null)
{
PropertyChanged (this, new PropertyChangedEventArgs (propertyName));
}
string customerName;
public string CustomerName
{
get { return customerName; }
set
{
if (value == customerName) return;
customerName = value;
RaisePropertyChanged();
// The compiler converts the above line to:
// RaisePropertyChanged ("CustomerName");
}
}
}
Dynamische Bindung
Dynamische Bindung verschiebt die Bindung - also dieAuflösung von Typen, Membern und Operatoren - von der Kompilierzeit auf die Laufzeit. Dynamisches Binden ist nützlich, wenn du zur Kompilierzeit weißt, dass eine bestimmte Funktion, ein Member oder eine Operation existiert, der Compiler aber nicht. Das kommt häufig vor, wenn du mit dynamischen Sprachen (z. B. IronPython) und COM zusammenarbeitest, aber auch in Szenarien, in denen du sonst Reflection verwenden würdest.
Ein dynamischer Typ wird mit dem kontextuellen Schlüsselwort dynamic deklariert:
dynamic d = GetSomeObject(); d.Quack();
Ein dynamischer Typ sagt dem Compiler, dass er sich entspannen soll. Wir erwarten, dass der Laufzeittyp von d eine Quack Methode hat. Wir können es nur nicht statisch beweisen. Da d dynamisch ist, verschiebt der Compiler die Bindung von Quack an d bis zur Laufzeit. Um zu verstehen, was das bedeutet, muss man zwischen statischer Bindung und dynamischer Bindung unterscheiden.
Statische Bindung versus dynamische Bindung
Das kanonische Beispiel für eine Bindung ist die Zuordnung eines Namens zu einer bestimmten Funktion beim Kompilieren eines Ausdrucks. Um den folgenden Ausdruck zu kompilieren, muss der Compiler die Implementierung der Methode mit dem Namen Quack finden:
d.Quack();
Nehmen wir an, dass der statische Typ von d Duck ist:
Duck d = ... d.Quack();
Im einfachsten Fall sucht der Compiler für die Bindung nach einer parameterlosen Methode namens Quack auf Duck. Fehlschlägt dies, erweitert der Compiler seine Suche auf Methoden mit optionalen Parametern, auf Methoden der Basisklassen von Duck und auf Erweiterungsmethoden, die Duck als ersten Parameter haben. Wenn keine Übereinstimmung gefunden wird, bekommst du einen Kompilierungsfehler. Unabhängig davon, welche Methode gebunden ist, wird die Bindung vom Compiler vorgenommen, und die Bindung hängt vollständig davon ab, dass die Typen der Operanden (in diesem Fall d) statisch bekannt sind. Es handelt sich also um statische Bindung.
Ändern wir nun den statischen Typ von d in object:
object d = ... d.Quack();
Der Aufruf von Quack führt zu einem Kompilierungsfehler, denn obwohl der in d gespeicherte Wert eine Methode namens Quack enthalten kann, kann der Compiler das nicht wissen, denn die einzige Information, die er hat, ist der Typ der Variablen, der in diesem Fall object ist. Ändern wir nun aber den statischen Typ von d in dynamic:
dynamic d = ... d.Quack();
Ein dynamic Typ ist wie object- er ist genauso wenig beschreibend für einen Typ. Der Unterschied besteht darin, dass du ihn auf eine Weise verwenden kannst, die zur Kompilierzeit nicht bekannt ist. Ein dynamisches Objekt wird zur Laufzeit auf der Grundlage seines Laufzeittyps gebunden, nicht auf der Grundlage seines Kompilierzeittyps. Wenn der Compiler einen dynamisch gebundenen Ausdruck sieht (was im Allgemeinen ein Ausdruck ist, der einen beliebigen Wert des Typs dynamic enthält), verpackt er den Ausdruck lediglich so, dass die Bindung später zur Laufzeit erfolgen kann.
Wenn ein dynamisches Objekt zur Laufzeit IDynamicMetaObjectProvider implementiert, wird diese Schnittstelle für die Bindung verwendet. Ist dies nicht der Fall, erfolgt die Bindung auf fast dieselbe Weise, wie wenn der Compiler den Laufzeittyp des dynamischen Objekts gekannt hätte. Diese beiden Alternativen werden als Custom Binding und Language Binding bezeichnet.
Individuelle Bindung
Custom Binding tritt auf, wenn ein dynamisches Objekt die IDynamicMetaObjectProvider (IDMOP) IMPLEMENTIERT. Obwohl du IDMOP auf Typen implementieren kannst, die du in C# schreibst, und das ist auch sinnvoll, ist der häufigere Fall, dass du ein IDMOP-Objekt aus einer dynamischen Sprache erworben hast, die in .NET auf der Dynamic Language Runtime (DLR) implementiert ist, wie IronPython oder IronRuby. Objekte aus diesen Sprachen implementieren IDMOP implizit als Mittel, um die Bedeutung von Operationen, die mit ihnen durchgeführt werden, direkt zu steuern.
In Kapitel 20 gehen wir ausführlicher auf benutzerdefinierte Binder ein, aber jetzt wollen wir erst einmal einen einfachen Binder schreiben, um die Funktion zu demonstrieren:
using System;
using System.Dynamic;
public class Test
{
static void Main()
{
dynamic d = new Duck();
d.Quack(); // Quack method was called
d.Waddle(); // Waddle method was called
}
}
public class Duck : DynamicObject
{
public override bool TryInvokeMember (
InvokeMemberBinder binder, object[] args, out object result)
{
Console.WriteLine (binder.Name + " method was called");
result = null;
return true;
}
}
Die Klasse Duck hat eigentlich keine Methode Quack. Stattdessen verwendet sie eine eigene Bindung, um alle Methodenaufrufe abzufangen und zu interpretieren.
Sprache Bindung
Sprachbindung tritt auf, wenn ein dynamisches Objekt IDMOP nicht implementiert. Sprachbindung ist nützlich, wenn es darum geht, unvollkommene Typen oder inhärente Beschränkungen des .NET-Typensystems zu umgehen (weitere Szenarien werden in Kapitel 20 behandelt). Ein typisches Problem bei der Verwendung von numerischen Typen ist, dass sie keine gemeinsame Schnittstelle haben. Wir haben gesehen, dass wir Methoden dynamisch binden können; dasselbe gilt für Operatoren:
static dynamic Mean (dynamic x, dynamic y) => (x + y) / 2;
static void Main()
{
int x = 3, y = 4;
Console.WriteLine (Mean (x, y));
}
Der Vorteil liegt auf der Hand: Du musst den Code nicht für jeden numerischen Typ duplizieren. Allerdings verlierst du die statische Typsicherheit und riskierst Laufzeitausnahmen statt Kompilierfehler.
Hinweis
Dynamisches Binden umgeht die statische Typsicherheit, aber nicht die Laufzeittypsicherheit. Anders als bei der Reflexion(Kapitel 19) kannst du bei der dynamischen Bindung die Regeln für die Zugänglichkeit von Mitgliedern nicht umgehen.
Die Laufzeitbindung von Sprachen verhält sich so ähnlich wie die statische Bindung, wenn die Laufzeittypen der dynamischen Objekte zur Kompilierungszeit bekannt wären. In unserem vorangegangenen Beispiel wäre das Verhalten unseres Programms identisch, wenn wir Mean für die Arbeit mit dem Typ int fest kodiert hätten. Die bemerkenswerteste Ausnahme bei der Gleichheit zwischen statischer und dynamischer Bindung sind die Erweiterungsmethoden, die wir in "Nicht aufrufbare Funktionen" besprechen .
Hinweis
Dynamische Bindungen führen auch zu Leistungseinbußen. Durch die Caching-Mechanismen des DLR werden jedoch wiederholte Aufrufe desselben dynamischen Ausdrucks optimiert, so dass du dynamische Ausdrücke effizient in einer Schleife aufrufen kannst. Durch diese Optimierung sinkt der typische Overhead für einen einfachen dynamischen Ausdruck auf heutiger Hardware auf weniger als 100 Nanosekunden.
RuntimeBinderException
Wenn die Bindung eines Mitglieds fehlschlägt, wird ein RuntimeBinderException ausgelöst. Du kannst dir das wie einen Kompilierfehler zur Laufzeit vorstellen:
dynamic d = 5; d.Hello(); // throws RuntimeBinderException
Die Ausnahme wird ausgelöst, weil der Typ int keine Methode Hello hat.
Laufzeitdarstellung von dynamischen
Es besteht eine tiefe Äquivalenz zwischen den Typen dynamic und object. Die Laufzeit behandelt den folgenden Ausdruck als true:
typeof (dynamic) == typeof (object)
Dieses Prinzip gilt auch für konstruierte Typen und Array-Typen:
typeof (List<dynamic>) == typeof (List<object>) typeof (dynamic[]) == typeof (object[])
Wie eine Objektreferenz kann auch eine dynamische Referenz auf ein Objekt beliebigen Typs verweisen (mit Ausnahme von Zeigertypen):
dynamic x = "hello"; Console.WriteLine (x.GetType().Name); // String x = 123; // No error (despite same variable) Console.WriteLine (x.GetType().Name); // Int32
Strukturell gibt es keinen Unterschied zwischen einer Objektreferenz und einer dynamischen Referenz. Eine dynamische Referenz ermöglicht lediglich dynamische Operationen mit dem Objekt, auf das sie zeigt. Du kannst von object nach dynamic konvertieren, um jede beliebige dynamische Operation an einem object durchzuführen:
object o = new System.Text.StringBuilder();
dynamic d = o;
d.Append ("hello");
Console.WriteLine (o); // hello
Hinweis
Wenn du über einen Typ nachdenkst, der (öffentliche) dynamic Mitglieder hat, siehst du, dass diese Mitglieder als kommentierte objects dargestellt werden; zum Beispiel:
public class Test
{
public dynamic Foo;
}
ist gleichbedeutend mit:
public class Test
{
[System.Runtime.CompilerServices.DynamicAttribute]
public object Foo;
}
So können Verbraucher dieses Typs wissen, dass Foo als dynamisch behandelt werden sollte, während Sprachen, die keine dynamische Bindung unterstützen, auf object zurückgreifen können.
Dynamische Umrechnungen
Der Typ dynamic hat implizite Konvertierungen in und aus allen anderen Typen:
int i = 7; dynamic d = i; long j = d; // No cast required (implicit conversion)
Damit die Konvertierung erfolgreich ist, muss der Laufzeittyp des dynamischen Objekts implizit in den statischen Zieltyp konvertierbar sein. Das vorangegangene Beispiel hat funktioniert, weil ein int implizit in ein long konvertierbar ist.
Das folgende Beispiel löst ein RuntimeBinderException aus, weil ein int nicht implizit in ein short konvertierbar ist:
int i = 7; dynamic d = i; short j = d; // throws RuntimeBinderException
var Versus dynamic
Die Typen var und dynamic haben eine oberflächliche Ähnlichkeit, aber der Unterschied ist tief:
-
varsagt: "Lass den Compiler den Typ herausfinden". -
dynamicsagt: "Lass die Laufzeit den Typ herausfinden."
Zur Veranschaulichung:
dynamic x = "hello"; // Static type is dynamic, runtime type is string var y = "hello"; // Static type is string, runtime type is string int i = x; // Runtime error (cannot convert string to int) int j = y; // Compile-time error (cannot convert string to int)
Der statische Typ einer mit var deklarierten Variablen kann dynamic sein:
dynamic x = "hello"; var y = x; // Static type of y is dynamic int z = y; // Runtime error (cannot convert string to int)
Dynamische Ausdrücke
Felder, Eigenschaften, Methoden, Ereignisse, Konstruktoren, Indexer, Operatoren und Konvertierungen können alle dynamisch aufgerufen werden.
Der Versuch, das Ergebnis eines dynamischen Ausdrucks mit einem void Rückgabetyp zu konsumieren, ist verboten - genau wie bei einem statisch typisierten Ausdruck. Der Unterschied ist, dass der Fehler zur Laufzeit auftritt:
dynamic list = new List<int>(); var result = list.Add (5); // RuntimeBinderException thrown
Ausdrücke mit dynamischen Operanden sind in der Regel selbst dynamisch, da fehlende Typinformationen sich kaskadierend auswirken:
dynamic x = 2; var y = x * 3; // Static type of y is dynamic
Es gibt ein paar offensichtliche Ausnahmen von dieser Regel. Erstens ergibt das Casting eines dynamischen Ausdrucks in einen statischen Typ einen statischen Ausdruck:
dynamic x = 2; var y = (int)x; // Static type of y is int
Zweitens ergeben Konstruktoraufrufe immer statische Ausdrücke - auch wenn sie mit dynamischen Argumenten aufgerufen werden. In diesem Beispiel ist x statisch auf StringBuilder typisiert:
dynamic capacity = 10; var x = new System.Text.StringBuilder (capacity);
Außerdem gibt es einige Kanten, bei denen ein Ausdruck, der ein dynamisches Argument enthält, statisch ist, z. B. bei der Übergabe eines Index an ein Array und bei Ausdrücken zur Erstellung von Delegaten.
Dynamische Anrufe ohne dynamische Empfänger
Der kanonische Anwendungsfall für dynamic betrifft einen dynamischen Empfänger. Das bedeutet, dass ein dynamisches Objekt der Empfänger eines dynamischen Funktionsaufrufs ist:
dynamic x = ...; x.Foo(); // x is the receiver
Du kannst aber auch statisch bekannte Funktionen mit dynamischen Argumenten aufrufen. Solche Aufrufe unterliegen der dynamischen Überladungsauflösung und können Folgendes beinhalten:
-
Statische Methoden
-
Instanz-Konstruktoren
-
Instanzmethoden auf Empfängern mit einem statisch bekannten Typ
Im folgenden Beispiel hängt der Foo, der dynamisch gebunden wird, vom Laufzeittyp des dynamischen Arguments ab:
class Program
{
static void Foo (int x) => Console.WriteLine ("int");
static void Foo (string x) => Console.WriteLine ("string");
static void Main()
{
dynamic x = 5;
dynamic y = "watermelon";
Foo (x); // 1
Foo (y); // 2
}
}
Da es sich nicht um einen dynamischen Empfänger handelt, kann der Compiler statisch eine grundlegende Prüfung durchführen, um festzustellen, ob der dynamische Aufruf erfolgreich sein wird. Er prüft, ob eine Funktion mit dem richtigen Namen und der richtigen Anzahl von Parametern existiert. Wenn kein Kandidat gefunden wird, erhältst du einen Kompilierfehler:
class Program
{
static void Foo (int x) => Console.WriteLine ("int");
static void Foo (string x) => Console.WriteLine ("string");
static void Main()
{
dynamic x = 5;
Foo (x, x); // Compiler error - wrong number of parameters
Fook (x); // Compiler error - no such method name
}
}
Statische Typen in dynamischen Ausdrücken
Es ist offensichtlich, dass dynamische Typen in der dynamischen Bindung verwendet werden. Es ist nicht so offensichtlich, dass statische Typen auch in der dynamischen Bindung verwendet werden, wo immer dies möglich ist. Betrachte das Folgende:
class Program
{
static void Foo (object x, object y) { Console.WriteLine ("oo"); }
static void Foo (object x, string y) { Console.WriteLine ("os"); }
static void Foo (string x, object y) { Console.WriteLine ("so"); }
static void Foo (string x, string y) { Console.WriteLine ("ss"); }
static void Main()
{
object o = "hello";
dynamic d = "goodbye";
Foo (o, d); // os
}
}
Der Aufruf von Foo(o,d) ist dynamisch gebunden, weil eines seiner Argumente, d, dynamic ist. Da o jedoch statisch bekannt ist, wird die Bindung - auch wenn sie dynamisch erfolgt - von diesem Typ Gebrauch machen. In diesem Fall wählt die Überladungsauflösung aufgrund des statischen Typs von o und des Laufzeittyps von d die zweite Implementierung von Foo. Mit anderen Worten: Der Compiler ist "so statisch, wie er nur sein kann".
Nicht aufrufbare Funktionen
Einige Funktionen können nicht dynamisch aufgerufen werden. Die folgenden Funktionen kannst du nicht aufrufen:
-
Erweiterungsmethoden (über die Syntax der Erweiterungsmethode)
-
Mitglieder einer Schnittstelle, wenn du dafür einen Cast auf diese Schnittstelle durchführen musst
-
Basismitglieder, die von einer Unterklasse versteckt werden
Zu verstehen, warum das so ist, ist hilfreich, um die dynamische Bindung zu verstehen.
Die dynamische Bindung erfordert zwei Informationen: den Namen der aufzurufenden Funktion und das Objekt, mit dem die Funktion aufgerufen werden soll. In jedem der drei nicht aufrufbaren Szenarien ist jedoch ein zusätzlicher Typ beteiligt, der nur zur Kompilierzeit bekannt ist. Bislang gibt es keine Möglichkeit, diese zusätzlichen Typen dynamisch zu definieren.
Wenn du Erweiterungsmethoden aufrufst, ist dieser zusätzliche Typ implizit. Es ist die statische Klasse, für die die Erweiterungsmethode definiert ist. Der Compiler sucht ihn anhand der using Direktiven in deinem Quellcode. Das macht Erweiterungsmethoden zu reinen Kompilierkonzepten, da die using Direktiven bei der Kompilierung verschwinden (nachdem sie ihre Aufgabe im Bindungsprozess erfüllt haben, indem sie einfache Namen auf Namensraum-qualifizierte Namen abbilden).
Wenn du Mitglieder über eine Schnittstelle aufrufst, gibst du diesen zusätzlichen Typ über einen impliziten oder expliziten Cast an. Es gibt zwei Szenarien, in denen du dies tun solltest: beim Aufruf von explizit implementierten Schnittstellenmitgliedern und beim Aufruf von Schnittstellenmitgliedern, die in einem internen Typ einer anderen Assembly implementiert sind. Ersteres können wir anhand der folgenden zwei Typen veranschaulichen:
interface IFoo { void Test(); }
class Foo : IFoo { void IFoo.Test() {} }
Um die Methode Test aufzurufen, müssen wir auf die Schnittstelle IFoo casten. Mit statischer Typisierung ist das ganz einfach:
IFoo f = new Foo(); // Implicit cast to interface f.Test();
Betrachte nun die Situation mit der dynamischen Typisierung:
IFoo f = new Foo(); dynamic d = f; d.Test(); // Exception thrown
Der fettgedruckte implizite Cast weist den Compiler an, nachfolgende Memberaufrufe von f an IFoo und nicht an Foozu binden, d.h. das Objekt durch die Linse der Schnittstelle IFoo zu betrachten. Diese Linse geht jedoch zur Laufzeit verloren, sodass das DLR die Bindung nicht vollenden kann. Der Verlust wird wie folgt veranschaulicht:
Console.WriteLine (f.GetType().Name); // Foo
Eine ähnliche Situation entsteht, wenn du ein verstecktes Basismitglied aufrufst: Du musst einen zusätzlichen Typ entweder über einen Cast oder das Schlüsselwort base angeben - und dieser zusätzliche Typ ist zur Laufzeit verloren.
Operator Überlastung
Du kannst Operatoren überladen, um eine natürlichere Syntax für benutzerdefinierte Typen zu erhalten. Das Überladen von Operatoren eignet sich am besten für die Implementierung benutzerdefinierter Strukturen, die relativ primitive Datentypen darstellen. Ein benutzerdefinierter numerischer Typ ist zum Beispiel ein hervorragender Kandidat für die Überladung von Operatoren.
Die folgenden symbolischen Operatoren können überladen werden:
+ (unär) |
- (unär) |
! |
~ |
++ |
-- |
+ |
- |
* |
/ |
% |
& |
| |
^ |
<< |
>> |
== |
!= |
> |
< |
>= |
<= |
Die folgenden Operatoren sind ebenfalls überladbar:
-
Implizite und explizite Konvertierungen (mit den Schlüsselwörtern
implicitundexplicit) -
Die Operatoren
trueundfalse(keine Literale).
Die folgenden Operatoren sind indirekt überladen:
-
Die zusammengesetzten Zuweisungsoperatoren (z. B.
+=,/=) werden implizit überschrieben, indem die nicht zusammengesetzten Operatoren (z. B.+,/) überschrieben werden. -
Die bedingten Operatoren
&&und||werden implizit überschrieben, indem die bitweisen Operatoren&und|überschrieben werden.
Bedienerfunktionen
Du überlädst einen Operator, indem du eine Operatorfunktion deklarierst. Für eine Operatorfunktion gelten die folgenden Regeln:
-
Der Name der Funktion wird mit dem Schlüsselwort
operatorangegeben, gefolgt von einem Operator-Symbol. -
Die Betreiberfunktion muss mit
staticundpublicgekennzeichnet sein. -
Die Parameter der Operatorfunktion stellen die Operanden dar.
-
Der Rückgabetyp einer Operatorfunktion stellt das Ergebnis eines Ausdrucks dar.
-
Mindestens einer der Operanden muss der Typ sein, in dem die Operatorfunktion deklariert ist.
Im folgenden Beispiel definieren wir eine Struktur namens Note, die eine Musiknote darstellt, und überladen dann den + Operator:
public struct Note
{
int value;
public Note (int semitonesFromA) { value = semitonesFromA; }
public static Note operator + (Note x, int semitones)
{
return new Note (x.value + semitones);
}
}
Diese Überladung ermöglicht es uns, eine int zu einer Note hinzuzufügen:
Note B = new Note (2); Note CSharp = B + 2;
Durch das Überladen eines Operators wird automatisch der entsprechende zusammengesetzte Zuweisungsoperator überladen. Da wir in unserem Beispiel + überladen haben, können wir auch += verwenden:
CSharp += 2;
Genau wie bei den Methoden und Eigenschaften können in C# Operatorfunktionen, die aus einem einzigen Ausdruck bestehen, mit der ausdrucksbasierten Syntax kürzer geschrieben werden:
public static Note operator + (Note x, int semitones)
=> new Note (x.value + semitones);
Überladen von Gleichheits- und Vergleichsoperatoren
Gleichheits- und Vergleichsoperatoren werden manchmal beim Schreiben von Structs und in seltenen Fällen beim Schreiben von Klassen überschrieben. Mit dem Überladen der Gleichheits- und Vergleichsoperatoren sind besondere Regeln und Verpflichtungen verbunden, die wir in Kapitel 6 erklären. Eine Zusammenfassung dieser Regeln lautet wie folgt:
- Paarung
- Der C#-Compiler erzwingt, dass Operatoren, die logische Paare sind, beide definiert werden. Diese Operatoren sind (
==!=), (<>), und (<=>=). EqualsundGetHashCode- Wenn du (
==) und (!=) überlädst, musst du in den meisten Fällen die MethodenEqualsundGetHashCodeüberschreiben, die aufobjectdefiniert sind, um ein sinnvolles Verhalten zu erhalten. Der C#-Compiler gibt eine Warnung aus, wenn du das nicht tust. (Siehe "Gleichheitsvergleich" in Kapitel 6 für weitere Details). IComparableundIComparable<T>- Wenn du (
< >) und (<= >=) überlädst, solltest duIComparableundIComparable<T>implementieren.
Benutzerdefinierte implizite und explizite Umrechnungen
Implizite und explizite Konvertierungen sind überladbare Operatoren. Diese Konvertierungen werden in der Regel überladen, um die Konvertierung zwischen stark verwandten Typen (z. B. numerischen Typen) übersichtlich und natürlich zu gestalten.
Um zwischen schwach verwandten Typen zu konvertieren, sind die folgenden Strategien besser geeignet:
-
Schreibe einen Konstruktor, der einen Parameter des Typs hat, aus dem konvertiert werden soll.
-
Schreiben Sie
ToXXXund (statische)FromXXXMethoden, um zwischen Typen zu konvertieren.
Wie in der Diskussion über Typen erläutert, ist der Grundgedanke hinter impliziten Konvertierungen, dass sie garantiert erfolgreich sind und keine Informationen während der Konvertierung verloren gehen. Umgekehrt sollte eine explizite Konvertierung erforderlich sein, wenn entweder die Laufzeitumstände bestimmen, ob die Konvertierung erfolgreich ist, oder wenn während der Konvertierung Informationen verloren gehen könnten.
Hinweis
Benutzerdefinierte Konvertierungen werden von den Operatoren as und is ignoriert:
Console.WriteLine (554.37 is Note); // False Note n = 554.37 as Note; // Error
In diesem Beispiel definieren wir Umwandlungen zwischen unserem musikalischen Note Typ und einem double (der die Frequenz in Hertz dieser Note darstellt):
... // Convert to hertz public static implicit operator double (Note x) => 440 * Math.Pow (2, (double) x.value / 12 ); // Convert from hertz (accurate to the nearest semitone) public static explicit operator Note (double x) => new Note ((int) (0.5 + 12 * (Math.Log (x/440) / Math.Log(2) ) )); ... Note n = (Note)554.37; // explicit conversion double x = n; // implicit conversion
Hinweis
Unseren eigenen Richtlinien folgend, könnte dieses Beispiel besser mit einer ToFrequency Methode (und einer statischen FromFrequency Methode) anstelle von impliziten und expliziten Operatoren.
Überladen von true und false
Die Operatoren true und false werden in dem extrem seltenen Fall von Typen überladen, die zwar boolesch sind, aber keine Umwandlung in bool haben. Ein Beispiel ist ein Typ, der eine Logik mit drei Zuständen implementiert: Durch Überladen von true und false kann ein solcher Typ nahtlos mit bedingten Anweisungen und Operatoren arbeiten - nämlich if, do, while, for, &&, || und ?:. Die Struktur System.Data.SqlTypes.SqlBoolean bietet diese Funktionalität:
SqlBoolean a = SqlBoolean.Null;
if (a)
Console.WriteLine ("True");
else if (!a)
Console.WriteLine ("False");
else
Console.WriteLine ("Null");
OUTPUT:
Null
Der folgende Code ist eine Neuimplementierung der Teile von SqlBoolean, die notwendig sind, um die Operatoren true und false zu demonstrieren:
public struct SqlBoolean
{
public static bool operator true (SqlBoolean x)
=> x.m_value == True.m_value;
public static bool operator false (SqlBoolean x)
=> x.m_value == False.m_value;
public static SqlBoolean operator ! (SqlBoolean x)
{
if (x.m_value == Null.m_value) return Null;
if (x.m_value == False.m_value) return True;
return False;
}
public static readonly SqlBoolean Null = new SqlBoolean(0);
public static readonly SqlBoolean False = new SqlBoolean(1);
public static readonly SqlBoolean True = new SqlBoolean(2);
private SqlBoolean (byte value) { m_value = value; }
private byte m_value;
}
Unsicherer Code und Zeiger
C# unterstützt die direkte Speichermanipulation über Zeiger innerhalb von Codeblöcken, die mit unsafe gekennzeichnet und mit der Compileroption /unsafe kompiliert wurden. Zeigertypen sind in erster Linie für die Interoperabilität mit C-APIs nützlich, aber du kannst sie auch für den Zugriff auf Speicher außerhalb des verwalteten Heaps oder für leistungsrelevante Hotspots verwenden.
Zeiger-Grundlagen
Für jeden Werttyp oder Referenztyp V gibt es einen entsprechenden Zeigertyp V*. Eine Zeigerinstanz enthält die Adresse einer Variablen. Zeigertypen können (unsicher) in jeden anderen Zeigertyp umgewandelt werden. Im Folgenden sind die wichtigsten Zeigeroperatoren aufgeführt:
| Betreiber | Bedeutung |
|---|---|
& |
Der address-of-Operator gibt einen Zeiger auf die Adresse einer Variablen zurück |
* |
Der Dereferenzierungsoperator gibt die Variable an der Adresse eines Zeigers zurück |
-> |
Der Pointer-to-member-Operator ist eine syntaktische Abkürzung, bei der x->y gleichbedeutend ist mit (*x).y |
Unsicherer Code
Wenn du einen Typ, ein Typ-Member oder einen Anweisungsblock mit dem Schlüsselwort unsafe markierst, darfst du Zeigertypen verwenden und Zeigeroperationen im Stil von C++ auf den Speicher innerhalb dieses Bereichs ausführen. Hier ist ein Beispiel für die Verwendung von Zeigern, um eine Bitmap schnell zu verarbeiten:
unsafe void BlueFilter (int[,] bitmap)
{
int length = bitmap.Length;
fixed (int* b = bitmap)
{
int* p = b;
for (int i = 0; i < length; i++)
*p++ &= 0xFF;
}
}
Unsicherer Code kann schneller laufen als eine entsprechende sichere Implementierung. In diesem Fall hätte der Code eine verschachtelte Schleife mit Array-Indizierung und Bound-Checking erfordert. Eine unsichere C#-Methode kann auch schneller sein als der Aufruf einer externen C-Funktion, da kein Overhead beim Verlassen der verwalteten Ausführungsumgebung anfällt.
Die feste Aussage
Die Anweisung fixed ist erforderlich, um ein verwaltetes Objekt, wie die Bitmap im vorherigen Beispiel, zu pinnen. Während der Ausführung eines Programms werden viele Objekte aus dem Heap zugewiesen und freigegeben. Um eine unnötige Verschwendung oder Fragmentierung des Speichers zu vermeiden, verschiebt der Garbage Collector die Objekte. Auf ein Objekt zu zeigen ist sinnlos, wenn sich seine Adresse während des Verweises ändern könnte. Deshalb weist die Anweisung fixed den Garbage Collector an, das Objekt "festzunageln" und nicht zu verschieben. Das kann sich auf die Effizienz der Laufzeit auswirken. Deshalb solltest du fixed Blöcke nur kurz verwenden und eine Heap-Allokation innerhalb des fixed Blocks vermeiden.
In einer fixed Anweisung kannst du einen Zeiger auf einen beliebigen Werttyp, ein Array von Werttypen oder einen String erhalten. Im Fall von Arrays und Strings zeigt der Zeiger auf das erste Element, das ein Wertetyp ist.
Wertetypen, die inline innerhalb von Referenztypen deklariert werden, erfordern, dass der Referenztyp gepinnt wird, wie folgt:
class Test
{
int x;
static void Main()
{
Test test = new Test();
unsafe
{
fixed (int* p = &test.x) // Pins test
{
*p = 9;
}
System.Console.WriteLine (test.x);
}
}
}
Die Anweisung fixed wird in Kapitel 25, "Zuordnung einer Struktur zum nicht verwalteten Speicher", näher beschrieben.
Das Schlüsselwort stackalloc
Du kannst Speicher in einem Block auf dem Stack explizit mit dem Schlüsselwort stackalloc zuweisen. Da er auf dem Stack zugewiesen wird, ist seine Lebensdauer auf die Ausführung der Methode beschränkt, genau wie bei jeder anderen lokalen Variablen (deren Lebensdauer nicht durch einen Lambda-Ausdruck, einen Iteratorblock oder eine asynchrone Funktion verlängert wurde). Der Block kann den Operator [] verwenden, um in den Speicher zu indizieren:
int* a = stackalloc int [10]; for (int i = 0; i < 10; ++i) Console.WriteLine (a[i]); // Print raw memory
In Kapitel 24 wird beschrieben, wie du Span<T> verwenden kannst, um den vom Stack zugewiesenen Speicher zu verwalten, ohne das Schlüsselwort unsafe zu verwenden:
Span<int> a = stackalloc int [10]; for (int i = 0; i < 10; ++i) Console.WriteLine (a[i]);
Puffer mit fester Größe
Das Schlüsselwort fixed hat noch eine weitere Funktion, nämlich die Erstellung von Puffern mit fester Größe innerhalb von Structs (dies kann beim Aufruf einer nicht verwalteten Funktion nützlich sein; siehe Kapitel 24):
unsafe struct UnsafeUnicodeString
{
public short Length;
public fixed byte Buffer[30]; // Allocate block of 30 bytes
}
unsafe class UnsafeClass
{
UnsafeUnicodeString uus;
public UnsafeClass (string s)
{
uus.Length = (short)s.Length;
fixed (byte* p = uus.Buffer)
for (int i = 0; i < s.Length; i++)
p[i] = (byte) s[i];
}
}
class Test
{
static void Main() { new UnsafeClass ("Christian Troy"); }
}
Puffer mit fester Größe sind keine Arrays: Wenn Buffer ein Array wäre, würde es aus einem Verweis auf ein Objekt bestehen, das auf dem (verwalteten) Heap gespeichert ist, und nicht aus 30 Bytes in der Struktur selbst.
Das Schlüsselwort fixed wird in diesem Beispiel auch verwendet, um das Objekt auf dem Heap festzulegen, das den Puffer enthält (das wird die Instanz von UnsafeClass sein). fixed bedeutet also zwei verschiedene Dinge: feste Größe und fester Ort. Die beiden Begriffe werden oft zusammen verwendet, da ein Puffer mit fester Größe an einem bestimmten Ort fixiert sein muss, um verwendet werden zu können.
void*
Ein ungültiger Zeiger (void*) macht keine Annahmen über den Typ der zugrunde liegenden Daten und ist nützlich für Funktionen, die mit Rohspeicher arbeiten. Es gibt eine implizite Umwandlung von jedem Zeigertyp in void*. Ein void* kann nicht dereferenziert werden, und arithmetische Operationen können nicht mit ungültigen Zeigern durchgeführt werden. Hier ist ein Beispiel:
class Test
{
unsafe static void Main()
{
short[ ] a = {1,1,2,3,5,8,13,21,34,55};
fixed (short* p = a)
{
//sizeof returns size of value-type in bytes
Zap (p, a.Length * sizeof (short));
}
foreach (short x in a)
System.Console.WriteLine (x); // Prints all zeros
}
unsafe static void Zap (void* memory, int byteCount)
{
byte* b = (byte*) memory;
for (int i = 0; i < byteCount; i++)
*b++ = 0;
}
}
Zeiger auf nicht verwalteten Code
Zeiger sind auch nützlich, um auf Daten außerhalb des verwalteten Heaps zuzugreifen (z. B. bei der Interaktion mit C Dynamic-Link Libraries [DLLs] oder Component Object Model [COM]) oder wenn es um Daten geht, die sich nicht im Hauptspeicher befinden (z. B. Grafikspeicher oder ein Speichermedium auf einem Embedded Device).
Präprozessor-Direktiven
Präprozessor-Direktiven versorgen den Compiler mit zusätzlichen Informationen über Codebereiche. Die gebräuchlichsten Präprozessordirektiven sind die bedingten Direktiven, die es ermöglichen, Codebereiche in die Kompilierung einzubeziehen oder auszuschließen:
#define DEBUG
class MyClass
{
int x;
void Foo()
{
#if DEBUG
Console.WriteLine ("Testing: x = {0}", x);
#endif
}
...
}
In dieser Klasse wird die Anweisung in Foo als bedingt abhängig vom Vorhandensein des Symbols DEBUG kompiliert. Wenn wir das Symbol DEBUG entfernen, wird die Anweisung nicht kompiliert. Du kannst Präprozessorsymbole innerhalb einer Quelldatei (wie wir es getan haben) oder auf Projektebene in der .csproj-Datei definieren:
<PropertyGroup> <DefineConstants>DEBUG;ANOTHERSYMBOL</DefineConstants> </PropertyGroup>
Mit den Direktiven #if und #elif kannst du die Operatoren ||, && und ! verwenden, um die Operationen or, and und not auf mehrere Symbole anzuwenden. Die folgende Anweisung weist den Compiler an, den folgenden Code einzubinden, wenn das Symbol TESTMODE definiert ist und das Symbol DEBUG nicht definiert ist:
#if TESTMODE && !DEBUG ...
Behalte jedoch im Hinterkopf, dass du keinen gewöhnlichen C#-Ausdruck erstellst und dass die Symbole, mit denen du operierst, absolut keine Verbindung zu Variablenhaben - weder zu statischennoch zu anderen.
Die Symbole #error und #warning verhindern den versehentlichen Missbrauch von bedingten Direktiven, indem sie den Compiler veranlassen, bei einer unerwünschten Menge von Kompiliersymbolen eine Warnung oder einen Fehler zu erzeugen. Tabelle 4-1 listet die Präprozessor-Direktiven auf.
| Präprozessor-Direktive | Aktion |
|---|---|
#define symbol |
Definiert symbol |
#undef symbol |
Undefiniert symbol |
#if symbol [operator symbol2]... |
symbol zum Test |
operators sind ==, !=, &&, und || gefolgt von #else, #elif und #endif |
|
#else |
Führt Code aus, um anschließend #endif |
#elif symbol [operator symbol2] |
Kombiniert #else branch und #if test |
#endif |
Beendet bedingte Direktiven |
#warning text |
text der Warnung, die in der Compiler-Ausgabe erscheinen soll |
#error text |
text des Fehlers, der in der Compiler-Ausgabe erscheinen soll |
#pragma warning [disable | restore] |
Deaktiviert/stellt die Compiler-Warnung(en) wieder her |
#line [ number ["file"] | hidden] |
number gibt die Zeile im Quellcode an; file ist der Dateiname, der in der Computerausgabe erscheinen soll; hidden weist den Debugger an, den Code ab dieser Stelle bis zur nächsten #line Anweisung zu überspringen. |
#region name |
Markiert den Anfang einer Gliederung |
#endregion |
Beendet eine Gliederungsregion |
#nullable option |
Siehe "Nullable Reference Types (C# 8)" |
Bedingte Attribute
Ein Attribut, das mit dem Attribut Conditional dekoriert ist, wird nur kompiliert, wenn ein bestimmtes Präprozessorsymbol vorhanden ist:
// file1.cs
#define DEBUG
using System;
using System.Diagnostics;
[Conditional("DEBUG")]
public class TestAttribute : Attribute {}
// file2.cs
#define DEBUG
[Test]
class Foo
{
[Test]
string s;
}
Der Compiler übernimmt die Attribute [Test] nur dann, wenn das Symbol DEBUG im Geltungsbereich von file2.cs liegt.
pragma Warnung
Der Compiler erzeugt eine Warnung, wenn er etwas in deinem Code entdeckt, das ungewollt ist. Im Gegensatz zu Fehlern verhindern Warnungen normalerweise nicht, dass deine Anwendung kompiliert wird.
Compiler-Warnungen können sehr nützlich sein, um Fehler zu finden. Ihre Nützlichkeit wird jedoch untergraben, wenn du falsche Warnungen erhältst. In einer großen Anwendung ist es wichtig, ein gutes Signal-Rausch-Verhältnis aufrechtzuerhalten, damit die echten Warnungen bemerkt werden.
Zu diesem Zweck ermöglicht der Compiler die selektive Unterdrückung von Warnungen mit der Direktive #pragma warning. In diesem Beispiel weisen wir den Compiler an, uns nicht zu warnen, wenn das Feld Message nicht verwendet wird:
public class Foo
{
static void Main() { }
#pragma warning disable 414
static string Message = "Hello";
#pragma warning restore 414
}
Wenn du die Nummer in der Anweisung #pragma warning weglässt, werden alle Warncodes deaktiviert oder wiederhergestellt.
Wenn du diese Direktive sorgfältig anwendest, kannst du beim Kompilieren den /warnaserror Schalter kompilieren - dies weist den Compiler an, alle verbleibenden Warnungen als Fehler zu behandeln.
XML-Dokumentation
Ein Dokumentationskommentar ist ein Stück eingebettetes XML, das einen Typ oder ein Mitglied dokumentiert. Ein Dokumentationskommentar steht unmittelbar vor einer Typ- oder Member-Deklaration und beginnt mit drei Schrägstrichen:
/// <summary>Cancels a running query.</summary>
public void Cancel() { ... }
Du kannst mehrzeilige Kommentare auch so machen:
/// <summary>
/// Cancels a running query
/// </summary>
public void Cancel() { ... }
oder so (beachte den zusätzlichen Stern am Anfang):
/**
<summary> Cancels a running query. </summary>
*/
public void Cancel() { ... }
Wenn du die folgende Option zu deiner .csproj-Datei hinzufügst:
<PropertyGroup> <DocumentationFile>SomeFile.xml</DocumentationFile> </PropertyGroup>
extrahiert der Compiler Dokumentationskommentare und stellt sie in der angegebenen XML-Datei zusammen. Dies hat zwei Hauptzwecke:
-
Wenn sie sich im gleichen Ordner wie die kompilierte Assembly befindet, lesen Tools wie Visual Studio und LINQPad die XML-Datei automatisch und verwenden die Informationen, um den Benutzern der gleichnamigen Assembly IntelliSense-Member-Listen zur Verfügung zu stellen.
-
Tools von Drittanbietern (wie Sandcastle und NDoc) können die XML-Datei in eine HTML-Hilfedatei umwandeln.
Standard-XML-Dokumentations-Tags
Hier sind die Standard-XML-Tags, die Visual Studio und die Dokumentationsgeneratoren erkennen:
<summary>-
<summary>...</summary>
Gibt den Tooltipp an, den IntelliSense für den Typ oder das Mitglied anzeigen soll; in der Regel eine einzelne Phrase oder ein Satz.
<remarks>-
<remarks>...</remarks>
Zusätzlicher Text, der den Typ oder das Mitglied beschreibt. Dokumentationsgeneratoren nehmen diesen Text auf und fügen ihn in den Hauptteil der Beschreibung eines Typs oder Mitglieds ein.
<param>-
<param name="name">...</param>
Erläutert einen Parameter einer Methode.
<returns>-
<returns>...</returns>
Erklärt den Rückgabewert für eine Methode.
<exception>-
<exception [cref="type"]>...</exception>
Listet eine Ausnahme auf, die eine Methode auslösen kann (
crefbezieht sich auf den Ausnahmetyp). <permission>-
<permission [cref="type"]>...</permission>
Gibt einen
IPermissionTyp an, der für den dokumentierten Typ oder das Mitglied erforderlich ist. <example>-
<example>...</example>
Bezeichnet ein Beispiel (wird von Dokumentationsgeneratoren verwendet). Es enthält in der Regel sowohl den Beschreibungstext als auch den Quellcode (der Quellcode befindet sich normalerweise in einem
<c>oder<code>Tag). <c>-
<c>...</c>
Zeigt einen Inline-Codeausschnitt an. Dieses Tag wird normalerweise innerhalb eines
<example>Blocks verwendet. <code>-
<code>...</code>
Zeigt ein mehrzeiliges Codebeispiel an. Dieses Tag wird normalerweise innerhalb eines
<example>Blocks verwendet. <see>-
<see cref="member">...</see>
Fügt einen Inline-Querverweis zu einem anderen Typ oder Mitglied ein. HTML-Dokumentationsgeneratoren wandeln dies normalerweise in einen Hyperlink um. Der Compiler gibt eine Warnung aus, wenn der Typ- oder Membername ungültig ist. Um auf generische Typen zu verweisen, verwendest du geschweifte Klammern, zum Beispiel
cref="Foo{T,U}". <seealso>-
<seealso cref="member">...</seealso>
Ein Querverweis auf einen anderen Typ oder ein anderes Mitglied. Dokumentationsersteller schreiben dies normalerweise in einen separaten Abschnitt "Siehe auch" am Ende der Seite.
<paramref>-
<paramref name="name"/>
Verweist auf einen Parameter innerhalb eines
<summary>oder<remarks>Tags. <list>-
<list type=[ bullet | number | table ]> <listheader> <term>...</term> <description>...</description> </listheader> <item> <term>...</term> <description>...</description> </item> </list>Weist die Dokumentationsgeneratoren an, eine Aufzählung, Nummerierung oder Tabelle auszugeben.
<para>-
<para>...</para>
Weist die Dokumentationsersteller an, den Inhalt in einem eigenen Absatz zu formatieren.
<include>-
<include file='filename' path='tagpath[@name="id"]'>...</include>
Führt eine externe XML-Datei zusammen, die Dokumentation enthält. Das Attribut
pathbezeichnet eine XPath-Abfrage zu einem bestimmten Element in dieser Datei.
Benutzerdefinierte Tags
Bei den vordefinierten XML-Tags, die der C#-Compiler erkennt, gibt es kaum Besonderheiten, und es steht dir frei, deine eigenen zu definieren. Die einzige besondere Verarbeitung, die der Compiler vornimmt, ist das <param> Tag (in dem er den Parameternamen überprüft und sicherstellt, dass alle Parameter der Methode dokumentiert sind) und das cref Attribut (in dem er überprüft, dass sich das Attribut auf einen echten Typ oder ein echtes Mitglied bezieht und es zu einer voll qualifizierten Typ- oder Mitgliedskennung erweitert). Du kannst das Attribut cref auch in deinen eigenen Tags verwenden; es wird genauso überprüft und erweitert wie in den vordefinierten Tags <exception>, <permission>, <see> und <seealso>.
Typ oder Mitglied Querverweise
Typnamen und Typ- oder Member-Querverweise werden in IDs übersetzt, die den Typ oder das Member eindeutig definieren. Diese Namen bestehen aus einem Präfix, das definiert, wofür die ID steht, und einer Signatur des Typs oder Mitglieds. Im Folgenden sind die Präfixe der Mitglieder aufgeführt:
| XML-Typ-Präfix | ID-Präfixe, die auf... |
|---|---|
N |
Namensraum |
T |
Typ (Klasse, Struktur, Enum, Schnittstelle, Delegat) |
F |
Feld |
P |
Eigentum (einschließlich Indexer) |
M |
Methode (einschließlich spezieller Methoden) |
E |
Veranstaltung |
! |
Fehler |
Die Regeln, die beschreiben, wie die Signaturen erstellt werden, sind gut dokumentiert, wenn auch ziemlich komplex.
Hier ist ein Beispiel für einen Typ und die IDs, die erzeugt werden:
// Namespaces do not have independent signatures
namespace NS
{
/// T:NS.MyClass
class MyClass
{
/// F:NS.MyClass.aField
string aField;
/// P:NS.MyClass.aProperty
short aProperty {get {...} set {...}}
/// T:NS.MyClass.NestedType
class NestedType {...};
/// M:NS.MyClass.X()
void X() {...}
/// M:NS.MyClass.Y(System.Int32,System.Double@,System.Decimal@)
void Y(int p1, ref double p2, out decimal p3) {...}
/// M:NS.MyClass.Z(System.Char[ ],System.Single[0:,0:])
void Z(char[ ] p1, float[,] p2) {...}
/// M:NS.MyClass.op_Addition(NS.MyClass,NS.MyClass)
public static MyClass operator+(MyClass c1, MyClass c2) {...}
/// M:NS.MyClass.op_Implicit(NS.MyClass)~System.Int32
public static implicit operator int(MyClass c) {...}
/// M:NS.MyClass.#ctor
MyClass() {...}
/// M:NS.MyClass.Finalize
~MyClass() {...}
/// M:NS.MyClass.#cctor
static MyClass() {...}
}
}
Get C# 8.0 in einer Kurzfassung now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

