Capítulo 4. C# avanzado
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
En este capítulo, cubrimos temas avanzados de C# que se basan en conceptos explorados en los Capítulos 2 y 3. Debes leer las cuatro primeras secciones secuencialmente; puedes leer las secciones restantes en cualquier orden.
Delegados
Un delegado es un objeto que sabe cómo llamar a un método.
Un tipo de delegado define el tipo de método al que pueden llamar las instancias delegadas. En concreto, define el tipo de retorno del método y los tipos de sus parámetros. A continuación se define un tipo de delegado llamado Transformer:
delegate int Transformer (int x);
Transformer es compatible con cualquier método con un tipo de retorno int y un único parámetro int, como éste:
static int Square (int x) { return x * x; }
O, más escuetamente:
static int Square (int x) => x * x;
Al asignar un método a una variable delegada, se crea una instancia delegada:
Transformer t = Square;
Puedes invocar una instancia de delegado del mismo modo que un método:
int answer = t(3); // answer is 9
Aquí tienes un ejemplo completo:
delegate int Transformer (int x);
class Test
{
static void Main()
{
Transformer t = Square; // Create delegate instance
int result = t(3); // Invoke delegate
Console.WriteLine (result); // 9
}
static int Square (int x) => x * x;
}
Una instancia de delegado actúa literalmente como delegado del que llama: el que llama invoca al delegado y luego el delegado llama al método de destino. Esta indirección desvincula a la persona que llama del método de destino.
La declaración:
Transformer t = Square;
es la abreviatura de
Transformer t = new Transformer (Square);
Nota
Técnicamente, estamos especificando un grupo de métodos cuando nos referimos a Square sin paréntesis ni argumentos. Si el método está sobrecargado, C# elegirá la sobrecarga correcta basándose en la firma del delegado al que se asigna.
La expresión:
t(3)
es la abreviatura de
t.Invoke(3)
Nota
Un delegado es similar a una llamada de retorno, término general que engloba construcciones como los punteros a funciones C.
Escribir métodos de complemento con delegados
A una variable delegada se le asigna un método en tiempo de ejecución. Esto es útil para escribir métodos complementarios. En este ejemplo, tenemos un método de utilidad llamado Transform que aplica una transformación a cada elemento de una matriz de enteros. El método Transform tiene un parámetro delegado, que puedes utilizar para especificar una transformación de complemento:
public delegate int Transformer (int x);
class Util
{
public static void Transform (int[] values, Transformer t)
{
for (int i = 0; i < values.Length; i++)
values[i] = t (values[i]);
}
}
class Test
{
static void Main()
{
int[] values = { 1, 2, 3 };
Util.Transform (values, Square); // Hook in the Square method
foreach (int i in values)
Console.Write (i + " "); // 1 4 9
}
static int Square (int x) => x * x;
}
Nuestro método Transform es una función de orden superior porque es una función que toma una función como argumento. (Un método que devuelva un delegado también sería una función de orden superior).
Delegados multidifusión
Todas las instancias delegadas tienen capacidad de multidifusión. Esto significa que una instancia de delegado puede hacer referencia no sólo a un único método de destino, sino también a una lista de métodos de destino. Los operadores + y += combinan instancias de delegado:
SomeDelegate d = SomeMethod1; d += SomeMethod2;
La última línea es funcionalmente igual a la siguiente:
d = d + SomeMethod2;
Invocar a d llamará ahora tanto a SomeMethod1 como a SomeMethod2. Los delegados se invocan en el orden en que se añaden.
Los operadores - y -= eliminan el operando delegado derecho del operando delegado izquierdo:
d -= SomeMethod1;
Invocar d hará que ahora sólo se invoque SomeMethod2.
Llamar a + o += sobre una variable delegada con un valor null funciona, y equivale a asignar a la variable un nuevo valor:
SomeDelegate d = null; d += SomeMethod1; // Equivalent (when d is null) to d = SomeMethod1;
Del mismo modo, llamar a -= en una variable delegada con un único objetivo coincidente equivale a asignar null a esa variable.
Nota
Los delegados son inmutables, así que cuando llamas a += o -=, en realidad estás creando una nueva instancia de delegado y asignándola a la variable existente.
Si un delegado multidifusión tiene un tipo de retorno no vacío, la persona que llama recibe el valor de retorno del último método invocado. Los métodos precedentes se siguen invocando, pero sus valores de retorno se descartan. En la mayoría de los casos en los que se utilizan los delegados multidifusión, éstos tienen tipos de retorno void, por lo que esta sutileza no se plantea.
Nota
Todos los tipos de delegado derivan implícitamente de System.MulticastDelegateque hereda de System.Delegate. C# compila las operaciones +, -, +=, y -= realizadas sobre un delegado a los métodos static Combine y Remove de la clase System.Delegate.
Ejemplo de delegado multidifusión
Supón que escribes un método que tarda mucho tiempo en ejecutarse. Ese método podría informar regularmente del progreso a su invocador invocando a un delegado. En este ejemplo, el método HardWork tiene un parámetro delegado ProgressReporter, al que invoca para indicar el progreso:
public delegate void ProgressReporter (int percentComplete);
public class Util
{
public static void HardWork (ProgressReporter p)
{
for (int i = 0; i < 10; i++)
{
p (i * 10); // Invoke delegate
System.Threading.Thread.Sleep (100); // Simulate hard work
}
}
}
Para monitorizar el progreso, el método Main crea una instancia de delegado de multidifusión p, de forma que el progreso sea monitorizado por dos métodos independientes:
class Test
{
static void Main()
{
ProgressReporter p = WriteProgressToConsole;
p += WriteProgressToFile;
Util.HardWork (p);
}
static void WriteProgressToConsole (int percentComplete)
=> Console.WriteLine (percentComplete);
static void WriteProgressToFile (int percentComplete)
=> System.IO.File.WriteAllText ("progress.txt",
percentComplete.ToString());
}
Objetivos de los métodos de instancia frente a los estáticos
Cuando se asigna un método de instancia a un objeto delegado, éste debe mantener una referencia no sólo al método, sino también a la instancia a la que pertenece el método. La propiedad Target de la clase System.Delegate representa esta instancia (y será nula para un delegado que haga referencia a un método estático). He aquí un ejemplo:
public delegate void ProgressReporter (int percentComplete);
class Test
{
static void Main()
{
X x = new X();
ProgressReporter p = x.InstanceProgress;
p(99); // 99
Console.WriteLine (p.Target == x); // True
Console.WriteLine (p.Method); // Void InstanceProgress(Int32)
}
}
class X
{
public void InstanceProgress (int percentComplete)
=> Console.WriteLine (percentComplete);
}
Tipos genéricos de delegados
Un tipo de delegado puede contener parámetros de tipo genérico:
public delegate T Transformer<T> (T arg);
Con esta definición, podemos escribir un método de utilidad generalizado Transform que funcione en cualquier tipo:
public class Util
{
public static void Transform<T> (T[] values, Transformer<T> t)
{
for (int i = 0; i < values.Length; i++)
values[i] = t (values[i]);
}
}
class Test
{
static void Main()
{
int[] values = { 1, 2, 3 };
Util.Transform (values, Square); // Hook in Square
foreach (int i in values)
Console.Write (i + " "); // 1 4 9
}
static int Square (int x) => x * x;
}
Los delegados Func y Acción
Con los delegados genéricos, es posible escribir un pequeño conjunto de tipos de delegados que son tan generales que pueden funcionar para métodos de cualquier tipo de retorno y cualquier número (razonable) de argumentos. Estos delegados son los delegados Func y Action, definidos en el espacio de nombres System (las anotaciones in y out indican varianza, que trataremos en breve en el contexto de los delegados):
delegate TResult Func <out TResult> (); delegate TResult Func <in T, out TResult> (T arg); delegate TResult Func <in T1, in T2, out TResult> (T1 arg1, T2 arg2); ... and so on, up to T16 delegate void Action (); delegate void Action <in T> (T arg); delegate void Action <in T1, in T2> (T1 arg1, T2 arg2); ... and so on, up to T16
Estos delegados son extremadamente generales. El delegado Transformer de nuestro ejemplo anterior puede sustituirse por un delegado Func que tome un único argumento de tipo T y devuelva un valor del mismo tipo:
public static void Transform<T> (T[] values, Func<T,T> transformer)
{
for (int i = 0; i < values.Length; i++)
values[i] = transformer (values[i]);
}
Los únicos supuestos prácticos que no cubren estos delegados son ref/out y los parámetros de puntero.
Nota
Antes de Framework 2.0, los delegados Func y Action no existían (porque no existían los genéricos). Por esta razón histórica, gran parte del Framework utiliza tipos de delegados personalizados en lugar de Func y Action.
Delegados frente a interfaces
Un problema que puedes resolver con un delegado también se puede resolver con una interfaz. Por ejemplo, podemos reescribir nuestro ejemplo original con una interfaz llamada ITransformer en lugar de un delegado:
public interface ITransformer
{
int Transform (int x);
}
public class Util
{
public static void TransformAll (int[] values, ITransformer t)
{
for (int i = 0; i < values.Length; i++)
values[i] = t.Transform (values[i]);
}
}
class Squarer : ITransformer
{
public int Transform (int x) => x * x;
}
...
static void Main()
{
int[] values = { 1, 2, 3 };
Util.TransformAll (values, new Squarer());
foreach (int i in values)
Console.WriteLine (i);
}
Un diseño de delegado puede ser mejor opción que un diseño de interfaz si se cumplen una o varias de estas condiciones:
-
La interfaz sólo define un único método.
-
Se necesita capacidad multidifusión.
-
El abonado tiene que implementar la interfaz varias veces.
En el ejemplo de ITransformer, no necesitamos multidifusión. Sin embargo, la interfaz sólo define un único método. Además, nuestro suscriptor podría tener que implementar ITransformer varias veces, para admitir diferentes transformaciones, como cuadrado o cubo. Con las interfaces, nos vemos obligados a escribir un tipo distinto por cada transformación, porque Test sólo puede implementar ITransformer una vez. Esto es bastante engorroso:
class Squarer : ITransformer
{
public int Transform (int x) => x * x;
}
class Cuber : ITransformer
{
public int Transform (int x) => x * x * x;
}
...
static void Main()
{
int[] values = { 1, 2, 3 };
Util.TransformAll (values, new Cuber());
foreach (int i in values)
Console.WriteLine (i);
}
Compatibilidad de delegados
Compatibilidad de tipos
Los tipos de delegados son incompatibles entre sí, aunque sus firmas sean iguales:
delegate void D1(); delegate void D2(); ... D1 d1 = Method1; D2 d2 = d1; // Compile-time error
Nota
Sin embargo, se permite lo siguiente:
D2 d2 = new D2 (d1);
Las instancias de delegado se consideran iguales si tienen los mismos objetivos de método:
delegate void D(); ... D d1 = Method1; D d2 = Method1; Console.WriteLine (d1 == d2); // True
Los delegados multidifusión se consideran iguales si hacen referencia a los mismos métodos en el mismo orden.
Compatibilidad de parámetros
Cuando llamas a un método, puedes suministrar argumentos que tengan tipos más específicos que los parámetros de ese método. Se trata de un comportamiento polimórfico ordinario. Por la misma razón, un delegado puede tener tipos de parámetros más específicos que el objetivo de su método. Esto se llama contravarianza. He aquí un ejemplo:
delegate void StringAction (string s);
class Test
{
static void Main()
{
StringAction sa = new StringAction (ActOnObject);
sa ("hello");
}
static void ActOnObject (object o) => Console.WriteLine (o); // hello
}
(Al igual que con la varianza de parámetros de tipo, los delegados son variantes sólo para las conversiones de referencia).
Un delegado simplemente llama a un método en nombre de otro. En este caso, se invoca a StringAction con un argumento de tipo string. Cuando el argumento se transmite al método de destino, el argumento se convierte implícitamente en un object.
Nota
El patrón de eventos estándar está diseñado para ayudarte a utilizar la contravarianza mediante el uso de la clase base común EventArgs. Por ejemplo, puedes tener un único método invocado por dos delegados diferentes, uno que pase un MouseEventArgs y otro que pase un KeyEventArgs.
Compatibilidad del tipo de retorno
Si llamas a un método, puede que te devuelva un tipo más específico que el que pediste. Se trata de un comportamiento polimórfico ordinario. Por la misma razón, el método objetivo de un delegado puede devolver un tipo más específico que el descrito por el delegado. Esto se llama covarianza:
delegate object ObjectRetriever();
class Test
{
static void Main()
{
ObjectRetriever o = new ObjectRetriever (RetrieveString);
object result = o();
Console.WriteLine (result); // hello
}
static string RetrieveString() => "hello";
}
ObjectRetriever espera obtener de vuelta un object, pero una subclase de object también servirá: los tipos de retorno de los delegados son covariantes.
Varianza de parámetros de tipo delegado genérico
En el Capítulo 3 vimos cómo las interfaces genéricas admiten parámetros de tipo covariante y contravariante. La misma capacidad existe también para los delegados.
Si estás definiendo un tipo de delegado genérico, es una buena práctica hacer lo siguiente:
-
Marcar como covariante un parámetro de tipo utilizado sólo en el valor de retorno (
out). -
Marca como contravariante cualquier parámetro de tipo utilizado sólo en parámetros (
in).
Esto permite que las conversiones funcionen de forma natural, respetando las relaciones de herencia entre tipos.
El siguiente delegado (definido en el espacio de nombres System ) tiene una covariante TResult:
delegate TResult Func<out TResult>();
permitiendo:
Func<string> x = ...; Func<object> y = x;
El siguiente delegado (definido en el espacio de nombres System ) tiene una contravariante T:
delegate void Action<in T> (T arg);
Action<object> x = ...; Action<string> y = x;
Eventos
Cuando se utilizan delegados, suelen aparecer dos roles emergentes: emisor y abonado.
El emisor es un tipo que contiene un campo delegado. El emisor decide cuándo emitir, invocando al delegado.
Los suscriptores son los destinatarios del método. Un suscriptor decide cuándo empezar y dejar de escuchar llamando a += y -= en el delegado del emisor. Un suscriptor no conoce a otros suscriptores ni interfiere con ellos.
Los eventos son una característica del lenguaje que formaliza este patrón. Un event es una construcción que expone sólo el subconjunto de funciones de delegado necesarias para el modelo emisor/suscriptor. El objetivo principal de los eventos es evitar que los suscriptores interfieran entre sí.
La forma más sencilla de declarar un evento es poner la palabra clave event delante de un miembro delegado:
// Delegate definition
public delegate void PriceChangedHandler (decimal oldPrice,
decimal newPrice);
public class Broadcaster
{
// Event declaration
public event PriceChangedHandler PriceChanged;
}
El código dentro del tipo Broadcaster tiene acceso completo a PriceChanged y puede tratarlo como un delegado. El código fuera de Broadcaster sólo puede realizar operaciones de += y -= en el evento PriceChanged.
Considera el siguiente ejemplo. La clase Stock dispara su evento PriceChanged cada vez que cambia el Price del Stock:
public delegate void PriceChangedHandler (decimal oldPrice,
decimal newPrice);
public class Stock
{
string symbol;
decimal price;
public Stock (string symbol) => this.symbol = symbol;
public event PriceChangedHandler PriceChanged;
public decimal Price
{
get => price;
set
{
if (price == value) return; // Exit if nothing has changed
decimal oldPrice = price;
price = value;
if (PriceChanged != null) // If invocation list not
PriceChanged (oldPrice, price); // empty, fire event.
}
}
}
Si eliminamos la palabra clave event de nuestro ejemplo para que PriceChanged se convierta en un campo delegado ordinario, nuestro ejemplo daría los mismos resultados. Sin embargo, Stock sería menos robusto en la medida en que los suscriptores podrían hacer las siguientes cosas para interferir entre sí:
-
Sustituye a otros abonados reasignando
PriceChanged(en lugar de utilizar el operador+=). -
Borra todos los abonados (configurando
PriceChangedennull). -
Difúndelo a otros abonados invocando al delegado.
Nota
Los eventos de las bibliotecas en tiempo de ejecución de Windows (WinRT) tienen una semántica ligeramente diferente, ya que al asociarse a un evento se devuelve un token, que es necesario para desvincularse del evento. El compilador salva esta diferencia de forma transparente (manteniendo un diccionario interno de tokens) para que puedas consumir eventos WinRT como si fueran eventos CLR ordinarios.
Patrón de eventos estándar
En casi todos los casos en los que se definen eventos en la biblioteca .NET Core, su definición se adhiere a un patrón estándar diseñado para proporcionar coherencia entre la biblioteca y el código de usuario. El núcleo del patrón estándar de eventos es System.EventArgsuna clase Framework predefinida sin miembros (aparte de la propiedad estática Empty ). EventArgs es una clase base para transmitir la información de un evento. En nuestro ejemplo de Stock, subclasificaríamos EventArgs para transmitir los precios antiguo y nuevo cuando se dispara un evento PriceChanged:
public class PriceChangedEventArgs : System.EventArgs
{
public readonly decimal LastPrice;
public readonly decimal NewPrice;
public PriceChangedEventArgs (decimal lastPrice, decimal newPrice)
{
LastPrice = lastPrice;
NewPrice = newPrice;
}
}
Para poder reutilizarla, la subclase EventArgs se denomina según la información que contiene (en lugar del evento para el que se utilizará). Normalmente expone los datos como propiedades o como campos de sólo lectura.
Con una subclase de EventArgs, el siguiente paso es elegir o definir un delegado para el evento. Existen tres reglas:
-
Debe tener un tipo de retorno
void. -
Debe aceptar dos argumentos: el primero de tipo
object, y el segundo una subclase deEventArgs. El primer argumento indica el emisor del evento, y el segundo contiene la información extra que se desea transmitir. -
Su nombre debe terminar en
EventHandler.
El Marco define un delegado genérico llamado System.EventHandler<> que satisface estas reglas:
public delegate void EventHandler<TEventArgs> (object source, TEventArgs e) where TEventArgs : EventArgs;
Nota
Antes de que existieran los genéricos en el lenguaje (antes de C# 2.0), habríamos tenido que escribir en su lugar un delegado personalizado como el siguiente:
public delegate void PriceChangedHandler
(object sender, PriceChangedEventArgs e);
Por razones históricas, la mayoría de los eventos del Marco utilizan delegados definidos de esta forma.
El siguiente paso es definir un evento del tipo de delegado elegido. Aquí utilizamos el delegado genérico EventHandler:
public class Stock
{
...
public event EventHandler<PriceChangedEventArgs> PriceChanged;
}
Por último, el patrón requiere que escribas un método virtual protegido que dispare el evento. El nombre debe coincidir con el nombre del evento, prefijado con la palabra On, y aceptar un único argumento EventArgs:
public class Stock
{
...
public event EventHandler<PriceChangedEventArgs> PriceChanged;
protected virtual void OnPriceChanged (PriceChangedEventArgs e)
{
if (PriceChanged != null) PriceChanged (this, e);
}
}
Nota
Para que funcione con solidez en escenarios multihilo(Capítulo 14), debes asignar el delegado a una variable temporal antes de probarlo e invocarlo:
var temp = PriceChanged;
if (temp != null) temp (this, e);
Podemos conseguir la misma funcionalidad sin la variable temp con el operador condicional nulo:
PriceChanged?.Invoke (this, e);
Al ser a la vez segura para los hilos y sucinta, ésta es la mejor forma general de invocar eventos.
Esto proporciona un punto central desde el que las subclases pueden invocar o anular el evento (suponiendo que la clase no esté sellada).
Aquí tienes el ejemplo completo:
using System;
public class PriceChangedEventArgs : EventArgs
{
public readonly decimal LastPrice;
public readonly decimal NewPrice;
public PriceChangedEventArgs (decimal lastPrice, decimal newPrice)
{
LastPrice = lastPrice; NewPrice = newPrice;
}
}
public class Stock
{
string symbol;
decimal price;
public Stock (string symbol) => this.symbol = symbol;
public event EventHandler<PriceChangedEventArgs> PriceChanged;
protected virtual void OnPriceChanged (PriceChangedEventArgs e)
{
PriceChanged?.Invoke (this, e);
}
public decimal Price
{
get => price;
set
{
if (price == value) return;
decimal oldPrice = price;
price = value;
OnPriceChanged (new PriceChangedEventArgs (oldPrice, price));
}
}
}
class Test
{
static void Main()
{
Stock stock = new Stock ("THPW");
stock.Price = 27.10M;
// Register with the PriceChanged event
stock.PriceChanged += stock_PriceChanged;
stock.Price = 31.59M;
}
static void stock_PriceChanged (object sender, PriceChangedEventArgs e)
{
if ((e.NewPrice - e.LastPrice) / e.LastPrice > 0.1M)
Console.WriteLine ("Alert, 10% stock price increase!");
}
}
El delegado no genérico predefinido EventHandler puede utilizarse cuando un evento no lleva información adicional. En este ejemplo, reescribimos Stock de forma que el evento PriceChanged se dispare después de que cambie el precio, y no sea necesaria ninguna información sobre el evento, aparte de que ha ocurrido. También utilizamos la propiedad EventArgs.Empty para evitar instanciar innecesariamente una instancia de EventArgs:
public class Stock
{
string symbol;
decimal price;
public Stock (string symbol) { this.symbol = symbol; }
public event EventHandler PriceChanged;
protected virtual void OnPriceChanged (EventArgs e)
{
PriceChanged?.Invoke (this, e);
}
public decimal Price
{
get { return price; }
set
{
if (price == value) return;
price = value;
OnPriceChanged (EventArgs.Empty);
}
}
}
Accesorios para eventos
Los accesores de un evento son las implementaciones de sus funciones += y -=. Por omisión, el compilador implementa implícitamente los accesores. Considera esta declaración de evento:
public event EventHandler PriceChanged;
El compilador lo convierte en lo siguiente:
-
Un campo delegado privado
-
Un par de funciones públicas de acceso a eventos (
add_PriceChangedyremove_PriceChanged) cuyas implementaciones reenvían las operaciones+=y-=al campo delegado privado
Puedes encargarte de este proceso definiendo accesores de eventos explícitos. Aquí tienes una implementación manual del evento PriceChanged de nuestro ejemplo anterior:
private EventHandler priceChanged; // Declare a private delegate
public event EventHandler PriceChanged
{
add { priceChanged += value; }
remove { priceChanged -= value; }
}
Este ejemplo es funcionalmente idéntico a la implementación del accesor por defecto de C# (salvo que C# también garantiza la seguridad de los hilos al actualizar el delegado mediante un algoritmo de comparación e intercambio sin bloqueo; consulta http://albahari.com/threading). Al definir nosotros mismos los accesores a eventos, indicamos a C# que no genere la lógica de campos y accesores por defecto.
Con accesores explícitos a eventos, puedes aplicar estrategias más complejas al almacenamiento y acceso del delegado subyacente. Hay tres escenarios para los que esto es útil:
-
Cuando los accesorios del evento son meros repetidores de otra clase que emite el evento.
-
Cuando la clase expone muchos eventos, para los que la mayoría de las veces existen muy pocos suscriptores, como un control de Windows. En estos casos, es mejor almacenar las instancias de delegado del suscriptor en un diccionario, porque un diccionario contendrá menos sobrecarga de almacenamiento que decenas de referencias nulas a campos de delegado.
-
Al implementar explícitamente una interfaz que declara un evento.
He aquí un ejemplo que ilustra este último punto:
public interface IFoo { event EventHandler Ev; }
class Foo : IFoo
{
private EventHandler ev;
event EventHandler IFoo.Ev
{
add { ev += value; }
remove { ev -= value; }
}
}
Nota
Las partes add y remove de un evento se compilan en add_XXX y remove_XXX métodos.
Expresiones lambda
Una expresión lambda es un método sin nombre escrito en lugar de una instancia de delegado. El compilador convierte inmediatamente la expresión lambda en una de las siguientes:
-
Una instancia de delegado.
-
Un árbol de expresión, del tipo
Expression<TDelegate>, que representa el código dentro de la expresión lambda en un modelo de objetos transitable. Esto permite interpretar posteriormente la expresión lambda en tiempo de ejecución (véase "Construcción de expresiones de consulta" en el capítulo 8).
Dado el siguiente tipo de delegado:
delegate int Transformer (int i);
podríamos asignar e invocar la expresión lambda x => x * x del siguiente modo:
Transformer sqr = x => x * x; Console.WriteLine (sqr(3)); // 9
Nota
Internamente, el compilador resuelve las expresiones lambda de este tipo escribiendo un método privado y trasladando el código de la expresión a ese método.
Una expresión lambda tiene la siguiente forma:
(parameters) => expression-or-statement-block
Por comodidad, puedes omitir los paréntesis si y sólo si hay exactamente un parámetro de tipo inferible.
En nuestro ejemplo, hay un único parámetro, x, y la expresión es x * x:
x => x * x;
Cada parámetro de la expresión lambda corresponde a un parámetro del delegado, y el tipo de la expresión (que puede ser void) corresponde al tipo de retorno del delegado.
En nuestro ejemplo, x corresponde al parámetro i, y la expresión x * x corresponde al tipo de retorno int, siendo por tanto compatible con el delegado Transformer:
delegate int Transformer (int i);
El código de una expresión lambda puede ser un bloque de sentencias en lugar de una expresión. Podemos reescribir nuestro ejemplo como sigue:
x => { return x * x; };
Las expresiones lambda se utilizan más comúnmente con los delegados Func y Action, por lo que lo más frecuente es que veas nuestra expresión anterior escrita de la siguiente manera:
Func<int,int> sqr = x => x * x;
Aquí tienes un ejemplo de expresión que acepta dos parámetros:
Func<string,string,int> totalLength = (s1, s2) => s1.Length + s2.Length;
int total = totalLength ("hello", "world"); // total is 10;
Especificación explícita de tipos de parámetros lambda
Normalmente, el compilador puede deducir contextualmente el tipo de los parámetros lambda. Cuando no sea así, deberás especificar explícitamente el tipo de cada parámetro. Considera los dos métodos siguientes:
void Foo<T> (T x) {}
void Bar<T> (Action<T> a) {}
El siguiente código no compilará, porque el compilador no puede deducir el tipo de x:
Bar (x => Foo (x)); // What type is x?
Podemos solucionarlo especificando explícitamente el tipo de xde la siguiente manera:
Bar ((int x) => Foo (x));
Este ejemplo concreto es lo suficientemente sencillo como para que pueda arreglarse de otras dos formas:
Bar<int> (x => Foo (x)); // Specify type parameter for Bar Bar<int> (Foo); // As above, but with method group
Captura de variables externas
Una expresión lambda puede hacer referencia a las variables locales y a los parámetros del método en el que está definida(variables externas):
static void Main()
{
int factor = 2;
Func<int, int> multiplier = n => n * factor;
Console.WriteLine (multiplier (3)); // 6
}
Las variables externas a las que hace referencia una expresión lambda se denominan variables capturadas. Una expresión lambda que captura variables se llama cierre.
Nota
Las variables también pueden ser capturadas por métodos anónimos y métodos locales. Las reglas para las variables capturadas, en estos casos, son las mismas.
Las variables capturadas se evalúan cuando se invoca realmente al delegado, no cuando se capturaron las variables:
int factor = 2; Func<int, int> multiplier = n => n * factor; factor = 10; Console.WriteLine (multiplier (3)); // 30
Las expresiones lambda pueden actualizar por sí mismas variables capturadas:
int seed = 0; Func<int> natural = () => seed++; Console.WriteLine (natural()); // 0 Console.WriteLine (natural()); // 1 Console.WriteLine (seed); // 2
La vida de las variables capturadas se extiende a la del delegado. En el siguiente ejemplo, la variable local seed desaparecería normalmente del ámbito cuando Natural terminara de ejecutarse. Pero como seed ha sido capturada, su tiempo de vida se extiende al del delegado que la captura, natural:
static Func<int> Natural()
{
int seed = 0;
return () => seed++; // Returns a closure
}
static void Main()
{
Func<int> natural = Natural();
Console.WriteLine (natural()); // 0
Console.WriteLine (natural()); // 1
}
Una variable local instanciada dentro de una expresión lambda es única por cada invocación de la instancia delegada. Si refactorizamos nuestro ejemplo anterior para instanciar seed dentro de la expresión lambda, obtendremos un resultado diferente (en este caso, indeseable):
static Func<int> Natural()
{
return() => { int seed = 0; return seed++; };
}
static void Main()
{
Func<int> natural = Natural();
Console.WriteLine (natural()); // 0
Console.WriteLine (natural()); // 0
}
Nota
La captura se implementa internamente "colgando" las variables capturadas en campos de una clase privada. Cuando se llama al método, la clase se instanciará y se vinculará de por vida a la instancia del delegado.
Captura de variables de iteración
Cuando capturas la variable de iteración de un bucle for, C# trata esa variable como si estuviera declarada fuera del bucle. Esto significa que se captura la misma variable en cada iteración. El siguiente programa escribe 333 en lugar de escribir 012:
Action[] actions = new Action[3]; for (int i = 0; i < 3; i++) actions [i] = () => Console.Write (i); foreach (Action a in actions) a(); // 333
Cada cierre (mostrado en negrita) captura la misma variable, i. (En realidad, esto tiene sentido si tienes en cuenta que i es una variable cuyo valor persiste entre iteraciones del bucle; incluso puedes cambiar explícitamente i dentro del cuerpo del bucle si quieres). La consecuencia es que cuando los delegados son invocados posteriormente, cada delegado ve el valor de ien el momento de la invocación, quees 3. Podemos ilustrarlo mejor ampliando el bucle for, como sigue:
Action[] actions = new Action[3]; int i = 0; actions[0] = () => Console.Write (i); i = 1; actions[1] = () => Console.Write (i); i = 2; actions[2] = () => Console.Write (i); i = 3; foreach (Action a in actions) a(); // 333
La solución, si queremos escribir 012, es asignar la variable de iteración a una variable local de ámbito dentro del bucle:
Action[] actions = new Action[3];
for (int i = 0; i < 3; i++)
{
int loopScopedi = i;
actions [i] = () => Console.Write (loopScopedi);
}
foreach (Action a in actions) a(); // 012
Como loopScopedi se crea de nuevo en cada iteración, cada cierre captura una variable diferente.
Nota
Antes de C# 5.0, los bucles foreach funcionaban de la misma manera:
Action[] actions = new Action[3]; int i = 0; foreach (char c in "abc") actions [i++] = () => Console.Write (c); foreach (Action a in actions) a(); // ccc in C# 4.0
Esto causaba bastante confusión: a diferencia de lo que ocurre con un bucle for, la variable de iteración en un bucle foreach es inmutable, por lo que cabría esperar que se tratara como local al cuerpo del bucle. La buena noticia es que se ha corregido desde C# 5.0, y el ejemplo anterior ahora escribe "abc".
Expresiones lambda frente a métodos locales
La funcionalidad de los métodos locales (ver "Métodos locales" en el Capítulo 3) se solapa con la de las expresiones lambda. Los métodos locales tienen las tres ventajas siguientes:
-
Pueden ser recursivos (pueden llamarse a sí mismos), sin hacks feos
-
Evitan el lío de especificar un tipo de delegado
-
Incurren en algo menos de gastos generales
Los métodos locales son más eficientes porque evitan la indirección de un delegado (que cuesta algunos ciclos de CPU y una asignación de memoria). También pueden acceder a las variables locales del método contenedor sin que el compilador tenga que "izar" las variables capturadas a una clase oculta.
Sin embargo, en muchos casos necesitas un delegado, sobre todo cuando llamas a una función de orden superior, es decir, a un método con un parámetro de tipo delegado:
public void Foo (Func<int,bool> predicate) { ... }
(Puedes ver muchos más en el capítulo 8). En tales casos, necesitas un delegado de todos modos, y es precisamente en estos casos en los que las expresiones lambda suelen ser más sencillas y limpias.
Métodos anónimos
Los métodos anónimos son una característica de C# 2.0 que fue subsumida en su mayor parte por las expresiones lambda de C# 3.0. Un método anónimo es como una expresión lambda, pero carece de las siguientes características:
-
Parámetros tipados implícitamente
-
Sintaxis de expresiones (un método anónimo debe ser siempre un bloque de expresiones)
-
La capacidad de compilar a un árbol de expresiones, asignando a
Expression<T>
Para escribir un método anónimo, debes incluir la palabra clave delegate seguida (opcionalmente) de una declaración de parámetros y, a continuación, del cuerpo del método. Por ejemplo, dado este delegado
delegate int Transformer (int i);
podríamos escribir y llamar a un método anónimo de la siguiente forma
Transformer sqr = delegate (int x) {return x * x;};
Console.WriteLine (sqr(3)); // 9
La primera línea es semánticamente equivalente a la siguiente expresión lambda:
Transformer sqr = (int x) => {return x * x;};
O, simplemente:
Transformer sqr = x => x * x;
Los métodos anónimos capturan variables externas del mismo modo que las expresiones lambda.
Nota
Una característica única de los métodos anónimos es que puedes omitir por completo la declaración del parámetro, aunque el delegado lo espere. Esto puede ser útil para declarar eventos con un manejador vacío por defecto:
public event EventHandler Clicked = delegate { };
Esto evita la necesidad de realizar una comprobación de nulos antes de lanzar el evento. Lo siguiente también es legal:
// Notice that we omit the parameters:
Clicked += delegate { Console.WriteLine ("clicked"); };
Sentencias try y excepciones
Una sentencia try especifica un bloque de código sujeto a tratamiento de errores o código de limpieza. El bloque try debe ir seguido de uno o más bloques catch, un bloque finally, o ambos. El bloque catch se ejecuta cuando se produce un error en el bloque try. El bloque finally se ejecuta después de que la ejecución abandone el bloque try (o si está presente, el bloque catch ), para realizar código de limpieza, independientemente de si se ha lanzado una excepción.
Un bloque catch tiene acceso a un objeto Exception que contiene información sobre el error. Utiliza un bloque catch para compensar el error o para volver a lanzar la excepción. Vuelves a lanzar una excepción si sólo quieres registrar el problema o si quieres volver a lanzar un nuevo tipo de excepción de nivel superior.
Un bloque finally añade determinismo a tu programa: el CLR se esfuerza por ejecutarlo siempre. Es útil para tareas de limpieza, como cerrar conexiones de red.
Una declaración try tiene este aspecto:
try
{
... // exception may get thrown within execution of this block
}
catch (ExceptionA ex)
{
... // handle exception of type ExceptionA
}
catch (ExceptionB ex)
{
... // handle exception of type ExceptionB
}
finally
{
... // cleanup code
}
Considera el siguiente programa:
class Test
{
static int Calc (int x) => 10 / x;
static void Main()
{
int y = Calc (0);
Console.WriteLine (y);
}
}
Como x es cero, el tiempo de ejecución lanza una DivideByZeroException, y nuestro programa termina. Podemos evitarlo capturando la excepción del siguiente modo:
class Test
{
static int Calc (int x) => 10 / x;
static void Main()
{
try
{
int y = Calc (0);
Console.WriteLine (y);
}
catch (DivideByZeroException ex)
{
Console.WriteLine ("x cannot be zero");
}
Console.WriteLine ("program completed");
}
}
OUTPUT:
x cannot be zero
program completed
Nota
Éste es un ejemplo sencillo para ilustrar la gestión de excepciones. En la práctica, podríamos tratar mejor esta situación concreta comprobando explícitamente si el divisor es cero antes de llamar a Calc.
La comprobación de errores evitables es preferible a confiar en los bloques try/catch porque las excepciones son relativamente caras de manejar, ya que tardan cientos de ciclos de reloj o más.
Cuando se lanza una excepción dentro de una sentencia try, el CLR realiza una prueba:
¿La declaración try tiene algún bloque compatible catch ?
-
Si es así, la ejecución salta al bloque
catchcompatible, seguido del bloquefinally(si está presente), y luego la ejecución continúa normalmente. -
Si no, la ejecución salta directamente al bloque
finally(si está presente), luego el CLR busca en la pila de llamadas otros bloquestry; si los encuentra, repite la prueba.
Si ninguna función de la pila de llamadas se responsabiliza de la excepción, el programa termina.
La cláusula de captura
Una cláusula catch especifica qué tipo de excepción atrapar. Debe ser System.Exception o una subclase de System.Exception.
Atrapar System.Exception atrapa todos los errores posibles. Esto es útil en las siguientes circunstancias:
-
Tu programa puede recuperarse potencialmente independientemente del tipo específico de excepción.
-
Piensa volver a lanzar la excepción (quizás después de registrarla).
-
Tu manejador de errores es el último recurso, antes de la terminación del programa.
Sin embargo, lo más habitual es que captures tipos de excepción específicos para evitar tener que enfrentarte a circunstancias para las que tu manejador no fue diseñado (por ejemplo, una OutOfMemoryException).
Puedes manejar varios tipos de excepción con varias cláusulas catch (de nuevo, este ejemplo podría escribirse con comprobación explícita de argumentos en lugar de con manejo de excepciones):
class Test
{
static void Main (string[] args)
{
try
{
byte b = byte.Parse (args[0]);
Console.WriteLine (b);
}
catch (IndexOutOfRangeException ex)
{
Console.WriteLine ("Please provide at least one argument");
}
catch (FormatException ex)
{
Console.WriteLine ("That's not a number!");
}
catch (OverflowException ex)
{
Console.WriteLine ("You've given me more than a byte!");
}
}
}
Sólo se ejecuta una cláusula catch para una excepción determinada. Si quieres incluir una red de seguridad para atrapar excepciones más generales (como System.Exception), debes poner primero los manejadores más específicos.
Se puede capturar una excepción sin especificar una variable, si no necesitas acceder a sus propiedades:
catch (OverflowException) // no variable
{
...
}
Además, puedes omitir tanto la variable como el tipo (lo que significa que se capturarán todas las excepciones):
catch { ... }
Filtros de excepción
Puedes especificar un filtro de excepciones en una cláusula catch añadiendo una cláusula when:
catch (WebException ex) when (ex.Status == WebExceptionStatus.Timeout)
{
...
}
Si se lanza un WebException en este ejemplo, se evalúa entonces la expresión booleana que sigue a la palabra clave when. Si el resultado es falso, se ignora el bloque catch en cuestión y se consideran las cláusulas catch posteriores. Con los filtros de excepciones, puede tener sentido volver a capturar el mismo tipo de excepción:
catch (WebException ex) when (ex.Status == WebExceptionStatus.Timeout)
{ ... }
catch (WebException ex) when (ex.Status == WebExceptionStatus.SendFailure)
{ ... }
La expresión booleana de la cláusula when puede tener efectos secundarios, como ocurre con un método que registra la excepción con fines de diagnóstico.
El bloque definitivo
Un bloque finally siempre se ejecuta, independientemente de si se lanza una excepción y de si el bloque try se ejecuta hasta su finalización. Normalmente utilizas los bloques finally para limpiar código.
Un bloque finally se ejecuta después de cualquiera de las siguientes acciones:
-
Un bloque
catchfinaliza (o lanza una nueva excepción) -
El bloque
tryfinaliza (o lanza una excepción para la que no hay bloquecatch) -
El control abandona el bloque
trydebido a una sentenciajump(por ejemplo,returnogoto)
Lo único que puede anular un bloqueo finally es un bucle infinito o que el proceso termine bruscamente.
Un bloque finally ayuda a añadir determinismo a un programa. En el siguiente ejemplo, el archivo que abrimos siempre se cierra, independientemente de si:
-
El bloque
trytermina normalmente -
La ejecución vuelve antes de tiempo porque el archivo está vacío (
EndOfStream) -
Se lanza un
IOExceptional leer el archivo
static void ReadFile()
{
StreamReader reader = null; // In System.IO namespace
try
{
reader = File.OpenText ("file.txt");
if (reader.EndOfStream) return;
Console.WriteLine (reader.ReadToEnd());
}
finally
{
if (reader != null) reader.Dispose();
}
}
En este ejemplo, cerramos el archivo llamando a Dispose en el bloque StreamReader. Llamar a Dispose en un objeto, dentro de un bloque finally, es una convención estándar en todo .NET Core y se admite explícitamente en C# mediante la sentencia using.
La declaración de uso
Muchas clases encapsulan recursos no gestionados, como manejadores de archivos, manejadores gráficos o conexiones a bases de datos. Estas clases implementan System.IDisposable, que define un único método sin parámetros llamado Dispose para limpiar estos recursos. La sentencia using proporciona una elegante sintaxis para llamar a Dispose sobre un objeto IDisposable objeto dentro de un bloque finally. Así:
using (StreamReader reader = File.OpenText ("file.txt"))
{
...
}
es precisamente equivalente a
{
StreamReader reader = File.OpenText ("file.txt");
try
{
...
}
finally
{
if (reader != null)
((IDisposable)reader).Dispose();
}
}
using declaraciones (C# 8)
Si omites los corchetes y el bloque de sentencia que sigue a una sentencia using, se convierte en una declaración de uso. Entonces, el recurso se elimina cuando la ejecución cae fuera del bloque de sentencia que lo encierra:
if (File.Exists ("file.txt"))
{
using var reader = File.OpenText ("file.txt");
Console.WriteLine (reader.ReadLine());
...
}
En este caso, reader se eliminará cuando la ejecución caiga fuera del bloque de sentencia if.
Lanzar excepciones
Las excepciones pueden ser lanzadas por el tiempo de ejecución o en el código de usuario. En este ejemplo, Display lanza una System.ArgumentNullException:
class Test
{
static void Display (string name)
{
if (name == null)
throw new ArgumentNullException (nameof (name));
Console.WriteLine (name);
}
static void Main()
{
try { Display (null); }
catch (ArgumentNullException ex)
{
Console.WriteLine ("Caught the exception");
}
}
}
tirar expresiones
throw también puede aparecer como expresión en funciones con cuerpo de expresión:
public string Foo() => throw new NotImplementedException();
Una expresión throw también puede aparecer en una expresión condicional ternaria:
string ProperCase (string value) =>
value == null ? throw new ArgumentException ("value") :
value == "" ? "" :
char.ToUpper (value[0]) + value.Substring (1);
Volver a lanzar una excepción
Puedes capturar y volver a lanzar una excepción del siguiente modo:
try { ... }
catch (Exception ex)
{
// Log error
...
throw; // Rethrow same exception
}
Nota
Si sustituyéramos throw por throw ex, el ejemplo seguiría funcionando, pero la propiedad StackTrace de la excepción recién propagada ya no reflejaría el error original.
Rechazar de esta forma te permite registrar un error sin tragarlo. También te permite evitar el tratamiento de una excepción si las circunstancias resultan ser mayores de lo que esperabas:
using System.Net; // (See Chapter 16) ... string s = null; using (WebClient wc = new WebClient()) try { s = wc.DownloadString ("http://www.albahari.com/nutshell/"); } catch (WebException ex) { if (ex.Status == WebExceptionStatus.Timeout) Console.WriteLine ("Timeout"); Else throw; // Can't handle other sorts of WebException, so rethrow }
Esto puede escribirse más escuetamente con un filtro de excepciones:
catch (WebException ex) when (ex.Status == WebExceptionStatus.Timeout)
{
Console.WriteLine ("Timeout");
}
El otro escenario habitual es volver a lanzar un tipo de excepción más específico:
try
{
... // Parse a DateTime from XML element data
}
catch (FormatException ex)
{
throw new XmlException ("Invalid DateTime", ex);
}
Observa que cuando construimos XmlException, pasamos la excepción original, ex, como segundo argumento. Este argumento rellena la propiedad InnerException de la nueva excepción y facilita la depuración. Casi todos los tipos de excepción ofrecen un constructor similar.
Volver a lanzar una excepción menos específica es algo que podrías hacer al cruzar un límite de confianza, para no filtrar información técnica a posibles piratas informáticos.
Propiedades clave de System.Exception
Las propiedades más importantes de System.Exception son las siguientes:
StackTrace- Una cadena que representa todos los métodos a los que se llama desde el origen de la excepción hasta el bloque
catch. Message- Una cadena con una descripción del error.
InnerException- La excepción interna (si la hay) que provocó la excepción externa. Ésta, a su vez, puede tener otro
InnerException.
Nota
Todas las excepciones en C# son excepciones en tiempo de ejecución: no hay equivalentes a las excepciones comprobadas en tiempo de compilación de Java.
Tipos comunes de excepción
Los siguientes tipos de excepción se utilizan ampliamente en el CLR y en .NET Core. Puedes lanzarlas tú mismo o utilizarlas como clases base para derivar tipos de excepción personalizados.
System.ArgumentException- Se lanza cuando se llama a una función con un argumento falso. Generalmente indica un error del programa.
System.ArgumentNullException- Subclase de
ArgumentExceptionque se lanza cuando un argumento de una función es (inesperadamente)null. System.ArgumentOutOfRangeException- Subclase de
ArgumentExceptionque se lanza cuando un argumento (normalmente numérico) es demasiado grande o demasiado pequeño. Por ejemplo, se lanza cuando se pasa un número negativo a una función que sólo acepta valores positivos. System.InvalidOperationException- Se lanza cuando el estado de un objeto es inadecuado para que un método se ejecute correctamente, independientemente de los valores de los argumentos. Algunos ejemplos son la lectura de un archivo sin abrir o la obtención del siguiente elemento de un enumerador cuya lista subyacente se ha modificado en parte de la iteración.
System.NotSupportedException- Se lanza para indicar que no se admite una funcionalidad concreta. Un buen ejemplo es llamar al método
Addsobre una colección para la queIsReadOnlydevuelvetrue. System.NotImplementedException- Se lanza para indicar que una función aún no se ha implementado.
System.ObjectDisposedException- Se lanza cuando el objeto sobre el que se llama a la función ha sido eliminado.
Otro tipo de excepción frecuente es NullReferenceException. El CLR lanza esta excepción cuando intentas acceder a un miembro de un objeto cuyo valor es null (lo que indica un error en tu código). Puedes lanzar una excepción NullReferenceException directamente (con fines de prueba) de la siguiente manera:
throw null;
El patrón del método Try XXX
Al escribir un método, tienes la opción, cuando algo va mal, de devolver algún tipo de código de fallo o lanzar una excepción. En general, lanzas una excepción cuando el error está fuera del flujo de trabajo normal, o si esperas que la persona que llama al método no sea capaz de resolverlo. Ocasionalmente, sin embargo, puede ser mejor ofrecer ambas opciones al consumidor. Un ejemplo de ello es el tipo int, que define dos versiones de su método Parse:
public int Parse (string input); public bool TryParse (string input, out int returnValue);
Si falla el análisis, Parse lanza una excepción; TryParse devuelve false.
Puedes aplicar este patrón haciendo que el método XXX llame al método TryXXX método:
public return-type XXX (input-type input)
{
return-type returnValue;
if (!TryXXX (input, out returnValue))
throw new YYYException (...)
return returnValue;
}
Alternativas a las excepciones
Al igual que en int.TryParse, una función puede comunicar un fallo enviando un código de error a la función que la llama a través de un tipo de retorno o un parámetro. Aunque esto puede funcionar con fallos simples y predecibles, se vuelve torpe cuando se extiende a todos los errores, contaminando las firmas de los métodos y creando una complejidad y un desorden innecesarios. Tampoco puede generalizarse a las funciones que no son métodos, como los operadores (por ejemplo, el operador de división) o las propiedades. Una alternativa es colocar el error en un lugar común donde todas las funciones de la pila de llamadas puedan verlo (por ejemplo, un método estático que almacene el error actual por hilo). Esto, sin embargo, requiere que cada función participe en un patrón de propagación de errores, lo cual es engorroso e, irónicamente, propenso en sí mismo a errores.
Enumeración e Iteradores
Enumeración
Un enumerador es un cursor de sólo lectura y sólo hacia adelante sobre una secuencia de valores. C# trata un tipo como enumerador si realiza alguna de las siguientes acciones:
-
Tiene un método público sin parámetros llamado
MoveNexty una propiedad llamadaCurrent
La sentencia foreach itera sobre un objeto enumerable. Un objeto enumerable es la representación lógica de una secuencia. No es en sí mismo un cursor, sino un objeto que produce cursores sobre sí mismo. C# trata un tipo como enumerable si realiza alguna de las siguientes acciones:
El patrón de enumeración es el siguiente
class Enumerator // Typically implements IEnumerator or IEnumerator<T>
{
public IteratorVariableType Current { get {...} }
public bool MoveNext() {...}
}
class Enumerable // Typically implements IEnumerable or IEnumerable<T>
{
public Enumerator GetEnumerator() {...}
}
Ésta es la forma de alto nivel de iterar por los caracteres de la palabra cerveza utilizando una sentencia foreach:
foreach (char c in "beer") Console.WriteLine (c);
Ésta es la forma más sencilla de recorrer los caracteres de la cerveza sin utilizar la sentencia foreach:
using (var enumerator = "beer".GetEnumerator())
while (enumerator.MoveNext())
{
var element = enumerator.Current;
Console.WriteLine (element);
}
Si el enumerador implementa IDisposable, la sentencia foreach también actúa como una sentencia using, disponiendo implícitamente del objeto enumerador.
Enel capítulo 7 se explican con más detalle las interfaces de enumeración.
Inicializadores de colecciones
Puedes instanciar y rellenar un objeto enumerable en un solo paso:
using System.Collections.Generic; ... List<int> list = new List<int> {1, 2, 3};
El compilador traduce esto a lo siguiente:
using System.Collections.Generic; ... List<int> list = new List<int>(); list.Add (1); list.Add (2); list.Add (3);
Esto requiere que el objeto enumerable implemente la interfaz System.Collections.IEnumerable y que tenga un método Add con el número de parámetros adecuado para la llamada. De forma similar, puedes inicializar los diccionarios (ver "Diccionarios" en el Capítulo 7) de la siguiente forma:
var dict = new Dictionary<int, string>()
{
{ 5, "five" },
{ 10, "ten" }
};
O, más sucintamente:
var dict = new Dictionary<int, string>()
{
[3] = "three",
[10] = "ten"
};
Esto último es válido no sólo con los diccionarios, sino con cualquier tipo para el que exista un indexador.
Iteradores
Mientras que una sentencia foreach es un consumidor de un enumerador, un iterador es un productor de un enumerador. En este ejemplo, utilizamos un iterador para devolver una secuencia de números Fibonacci (donde cada número es la suma de los dos anteriores):
using System;
using System.Collections.Generic;
class Test
{
static void Main()
{
foreach (int fib in Fibs(6))
Console.Write (fib + " ");
}
static IEnumerable<int> Fibs (int fibCount)
{
for (int i = 0, prevFib = 1, curFib = 1; i < fibCount; i++)
{
yield return prevFib;
int newFib = prevFib + curFib;
prevFib = curFib;
curFib = newFib;
}
}
}
OUTPUT: 1 1 2 3 5 8
Mientras que una sentencia return expresa "Aquí está el valor que me pediste que devolviera de este método", una sentencia yield return expresa "Aquí está el siguiente elemento que me pediste que devolviera de este enumerador". En cada sentencia yield, el control se devuelve al llamante, pero el estado del llamante se mantiene para que el método pueda seguir ejecutándose en cuanto el llamante enumere el siguiente elemento. El tiempo de vida de este estado está vinculado al enumerador, de modo que el estado pueda liberarse cuando la persona que llama haya terminado de enumerar.
Nota
El compilador convierte los métodos de los iteradores en clases privadas que implementan IEnumerable<T> y/o IEnumerator<T>. La lógica dentro del bloque iterador se "invierte" y se empalma en el método MoveNext y en la propiedad Current de la clase enumeradora escrita por el compilador. Esto significa que cuando llamas a un método iterador, lo único que haces es instanciar la clase escrita por el compilador; ¡en realidad no se ejecuta nada de tu código! Tu código sólo se ejecuta cuando empiezas a enumerar sobre la secuencia resultante, normalmente con una sentencia foreach.
Los iteradores pueden ser métodos locales (consulta "Métodos locales" en el capítulo 3).
Semántica de los iteradores
Un iterador es un método, propiedad o indexador que contiene una o varias sentencias yield. Un iterador debe devolver una de las cuatro interfaces siguientes (de lo contrario, el compilador generará un error):
// Enumerable interfaces System.Collections.IEnumerable System.Collections.Generic.IEnumerable<T> // Enumerator interfaces System.Collections.IEnumerator System.Collections.Generic.IEnumerator<T>
Un iterador tiene una semántica diferente, según devuelva una interfaz enumerable o una interfaz enumeradora. Lo describiremos en el capítulo 7.
Se permitenmúltiples declaraciones de rendimiento:
class Test
{
static void Main()
{
foreach (string s in Foo())
Console.WriteLine(s); // Prints "One","Two","Three"
}
static IEnumerable<string> Foo()
{
yield return "One";
yield return "Two";
yield return "Three";
}
}
interrupción del rendimiento
Una sentencia return es ilegal en un bloque iterador; en su lugar, debes utilizar la sentencia yield break para indicar que el bloque iterador debe salir antes, sin devolver más elementos. Podemos modificar Foo como se indica a continuación para demostrarlo:
static IEnumerable<string> Foo (bool breakEarly)
{
yield return "One";
yield return "Two";
if (breakEarly)
yield break;
yield return "Three";
}
Iteradores y bloques try/catch/finally
Una sentencia yield return no puede aparecer en un bloque try que tenga una cláusula catch:
IEnumerable<string> Foo()
{
try { yield return "One"; } // Illegal
catch { ... }
}
Tampoco puede aparecer yield return en un bloque catch o finally. Estas restricciones se deben a que el compilador debe traducir los iteradores a clases ordinarias con miembros MoveNext, Current y Dispose, y traducir los bloques de gestión de excepciones crearía una complejidad excesiva.
Sin embargo, puedes ceder dentro de un bloque try que tenga (sólo) un bloque finally:
IEnumerable<string> Foo()
{
try { yield return "One"; } // OK
finally { ... }
}
El código del bloque finally se ejecuta cuando el enumerador consumidor llega al final de la secuencia o se desecha. Una sentencia foreach dispone implícitamente del enumerador si se abandona antes de tiempo, lo que hace que ésta sea una forma segura de consumir enumeradores. Cuando se trabaja con enumeradores explícitamente, una trampa es abandonar la enumeración antes de tiempo sin deshacerse de él, eludiendo el bloque finally. Puedes evitar este riesgo envolviendo el uso explícito de enumeradores en una sentencia using:
string firstElement = null;
var sequence = Foo();
using (var enumerator = sequence.GetEnumerator())
if (enumerator.MoveNext())
firstElement = enumerator.Current;
Componer secuencias
Los iteradores son altamente componibles. Podemos ampliar nuestro ejemplo, esta vez para que sólo salgan números pares de Fibonacci:
using System;
using System.Collections.Generic;
class Test
{
static void Main()
{
foreach (int fib in EvenNumbersOnly (Fibs(6)))
Console.WriteLine (fib);
}
static IEnumerable<int> Fibs (int fibCount)
{
for (int i = 0, prevFib = 1, curFib = 1; i < fibCount; i++)
{
yield return prevFib;
int newFib = prevFib + curFib;
prevFib = curFib;
curFib = newFib;
}
}
static IEnumerable<int> EvenNumbersOnly (IEnumerable<int> sequence)
{
foreach (int x in sequence)
if ((x % 2) == 0)
yield return x;
}
}
Cada elemento no se calcula hasta el último momento -cuando lo solicita una MoveNext() operación. La Figura 4-1 muestra las peticiones y salidas de datos a lo largo del tiempo.
La componibilidad del patrón iterador es extremadamente útil en LINQ; volveremos a tratar el tema en el Capítulo 8.
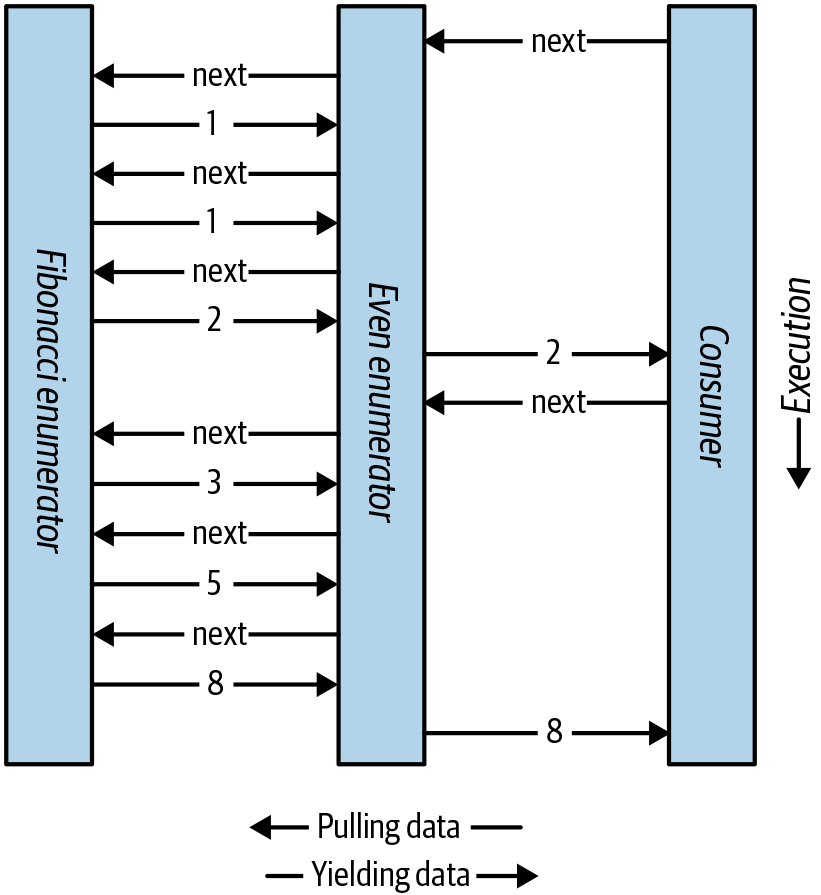
Figura 4-1. Componer secuencias
Tipos de valores anulables
Los tipos de referencia pueden representar un valor inexistente con una referencia nula. Los tipos valor, en cambio, no pueden representar normalmente valores nulos:
string s = null; // OK, reference type int i = null; // Compile error, value type cannot be null
Para representar un nulo en un tipo de valor, debes utilizar una construcción especial llamada tipo anulable. Un tipo anulable se denota con un tipo de valor seguido del símbolo ?:
int? i = null; // OK, nullable type Console.WriteLine (i == null); // True
Nullable<T> Estruct
T? se traduce en , que es una estructura inmutable ligera, que sólo tiene dos campos, para representar y . La esencia de System.Nullable<T> Value HasValueSystem.Nullable<T> es muy sencilla:
public struct Nullable<T> where T : struct
{
public T Value {get;}
public bool HasValue {get;}
public T GetValueOrDefault();
public T GetValueOrDefault (T defaultValue);
...
}
El código:
int? i = null; Console.WriteLine (i == null); // True
se traduce por:
Nullable<int> i = new Nullable<int>(); Console.WriteLine (! i.HasValue); // True
Si se intenta recuperar Value cuando HasValue es falso, se produce un error. InvalidOperationException. GetValueOrDefault() devuelve Value si HasValue es verdadero; en caso contrario, devuelve new T() o un valor predeterminado personalizado especificado.
El valor por defecto de T? es null.
Conversiones anulables implícitas y explícitas
La conversión de T a T? es implícita, y de T? a T es explícita:
int? x = 5; // implicit int y = (int)x; // explicit
El lanzamiento explícito equivale directamente a llamar a la propiedad Value del objeto anulable. Por lo tanto, se lanza un InvalidOperationException si HasValue es falso.
Encajonar y desencajonar valores nulos
Cuando T? está en caja, el valor en caja del montón contiene T, no T?. Esta optimización es posible porque un valor en caja es un tipo de referencia que ya puede expresar nulos.
C# también permite el unboxing de tipos de valor anulables con el operador as. El resultado será null si el reparto falla:
object o = "string"; int? x = o as int?; Console.WriteLine (x.HasValue); // False
Elevación del operario
La estructura Nullable<T> no define operadores como <, >, ni siquiera ==. A pesar de ello, el siguiente código se compila y ejecuta correctamente:
int? x = 5; int? y = 10; bool b = x < y; // true
Esto funciona porque el compilador toma prestado o levanta el operador menor que del tipo de valor subyacente. Semánticamente, traduce la expresión de comparación anterior en esto:
bool b = (x.HasValue && y.HasValue) ? (x.Value < y.Value) : false;
En otras palabras, si tanto x como y tienen valores, los compara mediante el operador menos-que de int; en caso contrario, devuelve false.
La elevación de operadores significa que puedes utilizar implícitamente los operadores de Ten T?. Puedes definir operadores para T? con el fin de proporcionar un comportamiento nulo especial, pero en la gran mayoría de los casos, es mejor confiar en que el compilador aplique automáticamente la lógica nulable sistemática por ti. Aquí tienes algunos ejemplos:
int? x = 5; int? y = null; // Equality operator examples Console.WriteLine (x == y); // False Console.WriteLine (x == null); // False Console.WriteLine (x == 5); // True Console.WriteLine (y == null); // True Console.WriteLine (y == 5); // False Console.WriteLine (y != 5); // True // Relational operator examples Console.WriteLine (x < 6); // True Console.WriteLine (y < 6); // False Console.WriteLine (y > 6); // False // All other operator examples Console.WriteLine (x + 5); // 10 Console.WriteLine (x + y); // null (prints empty line)
El compilador realiza la lógica de nulos de forma diferente según la categoría del operador. Las siguientes secciones explican estas diferentes reglas.
Operadores de igualdad (== y !=)
Los operadores de igualdad elevados tratan los nulos igual que los tipos de referencia. Esto significa que dos valores nulos son iguales:
Console.WriteLine ( null == null); // True Console.WriteLine ((bool?)null == (bool?)null); // True
Además:
-
Si exactamente un operando es nulo, los operandos son desiguales.
-
Si ambos operandos son no nulos, se comparan sus
Values.
Operadores relacionales (<, <=, >=, >)
Los operadores relacionales funcionan según el principio de que no tiene sentido comparar operandos nulos. Esto significa que la comparación de un valor nulo con un valor nulo o no nulo devuelve false:
bool b = x < y; // Translation:
bool b = (x.HasValue && y.HasValue)
? (x.Value < y.Value)
: false;
// b is false (assuming x is 5 and y is null)
Todos los demás operadores (+, -, *, /, %, &, |, ^, <<, >>, +, ++, --, !, ~)
Estos operadores devuelven nulo cuando alguno de los operandos es nulo. Este patrón debería resultar familiar a los usuarios de SQL:
int? c = x + y; // Translation:
int? c = (x.HasValue && y.HasValue)
? (int?) (x.Value + y.Value)
: null;
// c is null (assuming x is 5 and y is null)
Una excepción es cuando los operadores & y | se aplican a bool?, de lo que hablaremos en breve.
bool? con los operadores & y |
Cuando se suministran operandos del tipo bool?, los operadores & y | tratan null como un valor desconocido. Por lo tanto, null | true es verdadero porque
-
Si el valor desconocido es falso, el resultado sería verdadero.
-
Si el valor desconocido es verdadero, el resultado sería verdadero.
Del mismo modo, null & false es falso. Este comportamiento resultará familiar a los usuarios de SQL. El siguiente ejemplo enumera otras combinaciones:
bool? n = null; bool? f = false; bool? t = true; Console.WriteLine (n | n); // (null) Console.WriteLine (n | f); // (null) Console.WriteLine (n | t); // True Console.WriteLine (n & n); // (null) Console.WriteLine (n & f); // False Console.WriteLine (n & t); // (null)
Tipos de valores anulables y operadores nulos
Los tipos de valor anulables funcionan especialmente bien con el operador ?? (consulta "Operador de coalescencia nula" en el Capítulo 2), como se ilustra en este ejemplo:
int? x = null; int y = x ?? 5; // y is 5 int? a = null, b = 1, c = 2; Console.WriteLine (a ?? b ?? c); // 1 (first non-null value)
Utilizar ?? en un tipo de valor anulable es equivalente a llamar a GetValueOrDefault con un valor por defecto explícito, salvo que la expresión para el valor por defecto nunca se evalúa si la variable no es nula.
Los tipos de valor anulables también funcionan bien con el operador condicional nulo (consulta "Operador condicional nulo" en el Capítulo 2). En el siguiente ejemplo, length se evalúa como nulo:
System.Text.StringBuilder sb = null; int? length = sb?.ToString().Length;
Podemos combinarlo con el operador de coalescencia nula para evaluar a cero en lugar de a nulo:
int length = sb?.ToString().Length ?? 0; // Evaluates to 0 if sb is null
Escenarios para tipos de valor anulables
Uno de los escenarios más habituales para los tipos de valores anulables es representar valores desconocidos. Esto ocurre con frecuencia en la programación de bases de datos, donde una clase se asigna a una tabla con columnas anulables. Si estas columnas son cadenas (por ejemplo, una columna EmailAddress en una tabla Customer), no hay problema porque string es un tipo de referencia en el CLR, que puede ser nulo. Sin embargo, la mayoría de los demás tipos de columnas SQL se asignan a tipos struct del CLR, lo que hace que los tipos de valores anulables sean muy útiles al asignar SQL al CLR:
// Maps to a Customer table in a database
public class Customer
{
...
public decimal? AccountBalance;
}
Un tipo anulable también puede utilizarse para representar el campo de respaldo de lo que a veces se denomina una propiedad de ambiente. Una propiedad de entorno, si es nula, devuelve el valor de su padre:
public class Row
{
...
Grid parent;
Color? color;
public Color Color
{
get { return color ?? parent.Color; }
set { color = value == parent.Color ? (Color?)null : value; }
}
}
Alternativas a los tipos de valor anulables
Antes de que los tipos de valor anulables formaran parte del lenguaje C# (es decir, antes de C# 2.0), había muchas estrategias para tratar los tipos de valor anulables, ejemplos de las cuales siguen apareciendo en .NET Core por razones históricas. Una estrategia consiste en designar un determinado valor no nulo como "valor nulo"; un ejemplo lo tenemos en las clases string y array. string.IndexOf devuelve el valor mágico de −1 cuando no se encuentra el carácter:
int i = "Pink".IndexOf ('b');
Console.WriteLine (i); // −1
Sin embargo, Array.IndexOf devuelve −1 sólo si el índice tiene un límite 0. La fórmula más general es que IndexOf devuelve uno menos que el límite inferior de la matriz. En el siguiente ejemplo, IndexOf devuelve 0 cuando no se encuentra un elemento:
// Create an array whose lower bound is 1 instead of 0:
Array a = Array.CreateInstance (typeof (string),
new int[] {2}, new int[] {1});
a.SetValue ("a", 1);
a.SetValue ("b", 2);
Console.WriteLine (Array.IndexOf (a, "c")); // 0
Nombrar un "valor mágico" es problemático por varias razones:
-
Significa que cada tipo de valor tiene una representación diferente de null. En cambio, los tipos de valor anulables proporcionan un patrón común que funciona para todos los tipos de valor.
-
Puede que no haya ningún valor designado razonable. En el ejemplo anterior, no siempre se podía utilizar -1. Lo mismo ocurre con nuestro ejemplo anterior que representa un saldo de cuenta desconocido.
-
Si se olvida comprobar el valor mágico, se obtiene un valor incorrecto que puede pasar desapercibido hasta más adelante en la ejecución, cuando se realiza un truco de magia no intencionado. Sin embargo, si te olvidas de comprobar
HasValueen un valor nulo, se produce un errorInvalidOperationExceptionen el acto. -
La posibilidad de que un valor sea nulo no se recoge en el tipo. Los tipos comunican la intención de un programa, permiten que el compilador compruebe su corrección y hacen posible un conjunto coherente de reglas aplicadas por el compilador.
Tipos de referencia anulables (C# 8)
Mientras que los tipos de valor anulables aportan anulabilidad a los tipos de valor, los tipos de referencia anulables hacen lo contrario y aportan (un grado de) no anulabilidad a los tipos de referencia, con el fin de ayudar a evitar NullReferenceExceptions.
Los tipos de referencia anulables introducen un nivel de seguridad que es aplicado exclusivamente por el compilador, en forma de advertencias cuando detecta código que corre el riesgo de generar un NullReferenceException.
Para activar los tipos de referencia anulables, debes añadir el elemento Nullable a tu archivo de proyecto .csproj (si quieres activarlo para todo el proyecto):
<PropertyGroup> <Nullable>enable</Nullable> </PropertyGroup>
y/o utiliza las siguientes directivas en tu código, en los lugares donde deba surtir efecto:
#nullable enable // enables nullable reference types from this point on #nullable disable // disables nullable reference types from this point on #nullable restore // resets nullable reference types to project setting
Una vez activada, el compilador hace que la no anulabilidad sea el valor por defecto: si quieres que un tipo de referencia acepte nulos, debes aplicar el sufijo ? para indicar un tipo de referencia anulable. En el siguiente ejemplo, s1 es no anulable, mientras que s2 es anulable:
#nullable enable // Enable nullable reference types string s1 = null; // Generates a compiler warning! string? s2 = null; // OK: s2 is nullable reference type
Nota
Como los tipos de referencia anulables son construcciones en tiempo de compilación, no hay diferencia en tiempo de ejecución entre string y string?. En cambio, los tipos de valor anulables introducen algo concreto en el sistema de tipos, a saber, la estructura Nullable<T>.
Lo siguiente también genera una advertencia porque x no está inicializado:
class Foo { string x; }
La advertencia desaparece si inicializas x, ya sea mediante un inicializador de campo o mediante código en el constructor.
El operador que no perdona
El compilador también te avisa al hacer referencia a un tipo de referencia anulable, si cree que puede producirse un NullReferenceException. En el siguiente ejemplo, el acceso a la propiedad Length de la cadena genera una advertencia:
void Foo (string? s) => Console.Write (s.Length);
Puedes eliminar la advertencia con el operador de perdón de nulos (!):
void Foo (string? s) => Console.Write (s!.Length);
En este ejemplo, el uso del operador de perdón de nulos es peligroso, ya que podríamos acabar lanzando el mismo NullReferenceException que intentábamos evitar en primer lugar. Podríamos solucionarlo de la siguiente manera
void Foo (string? s)
{
if (s != null) Console.Write (s.Length);
}
Observa que ahora no necesitamos el operador de perdón de nulos. Esto se debe a que el compilador realiza un análisis estático del flujo y es lo suficientemente inteligente como para deducir -al menos en casos sencillos- cuándo una desreferencia es segura y no existe la posibilidad de que se produzca un error . NullReferenceException.
La capacidad del compilador para detectar y avisar no es a prueba de balas, y también hay límites a lo que es posible en términos de cobertura. Por ejemplo, el compilador no puede saber si se han rellenado los elementos de una matriz, por lo que lo siguiente no genera una advertencia:
var strings = new string[10]; Console.WriteLine (strings[0].Length);
Separar los contextos de anotación y advertencia
Activar los tipos de referencia anulables mediante la directiva #nullable enable (o la configuración del <Nullable>enable</Nullable> del proyecto) hace dos cosas:
-
Activa el contexto de anotación anulable, que indica al compilador que trate todas las declaraciones de variables de tipo referencia como no anulables a menos que vayan acompañadas del símbolo
?. -
Activa el contexto de advertencia anulable, que indica al compilador que genere advertencias al encontrar código con riesgo de lanzar un error
NullReferenceException.
A veces puede ser útil separar estos dos conceptos y activar sólo el contexto de anotación, o (menos útil) sólo el contexto de aviso:
#nullable enable annotations // Enable the annotation context // OR: #nullable enable warnings // Enable the warning context
(El mismo truco funciona con #nullable disable y #nullable restore.)
También puedes hacerlo a través del archivo de proyecto:
<Nullable>annotations</Nullable> <!-- OR --> <Nullable>warnings</Nullable>
Habilitar sólo el contexto de anotación para una clase o conjunto concreto puede ser un buen primer paso para introducir tipos de referencia anulables en una base de código heredada. Al anotar correctamente los miembros públicos, tu clase o conjunto puede actuar como un buen ciudadano para otras clases o conjuntos -de modo que puedan beneficiarse plenamente de los tipos de referencia anulables- sin tener que lidiar con advertencias en tu propia clase o conjunto.
Tratar los avisos anulables como errores
En los proyectos nuevos, tiene sentido activar completamente el contexto anulable desde el principio. Tal vez quieras dar el paso adicional de tratar las advertencias de anulable como errores, de modo que tu proyecto no pueda compilar hasta que se hayan resuelto todas las advertencias de anulable:
<PropertyGroup> <Nullable>enable</Nullable> <WarningsAsErrors>CS8600;CS8602;CS8603</WarningsAsErrors> </PropertyGroup>
Métodos de extensión
Los métodos de extensión permiten ampliar un tipo existente con nuevos métodos sin alterar la definición del tipo original. Un método de extensión es un método estático de una clase estática, en el que el modificador this se aplica al primer parámetro. El tipo del primer parámetro será el tipo extendido:
public static class StringHelper
{
public static bool IsCapitalized (this string s)
{
if (string.IsNullOrEmpty(s)) return false;
return char.IsUpper (s[0]);
}
}
El método de extensión IsCapitalized puede invocarse como si fuera un método de instancia sobre una cadena, del siguiente modo:
Console.WriteLine ("Perth".IsCapitalized());
Una llamada a un método de extensión, cuando se compila, se convierte en una llamada a un método estático normal:
Console.WriteLine (StringHelper.IsCapitalized ("Perth"));
La traducción funciona del siguiente modo:
arg0.Method (arg1, arg2, ...); // Extension method call StaticClass.Method (arg0, arg1, arg2, ...); // Static method call
Las interfaces también se pueden ampliar:
public static T First<T> (this IEnumerable<T> sequence)
{
foreach (T element in sequence)
return element;
throw new InvalidOperationException ("No elements!");
}
...
Console.WriteLine ("Seattle".First()); // S
Encadenamiento de métodos de extensión
Los métodos de extensión, al igual que los métodos de instancia, proporcionan una forma ordenada de encadenar funciones. Considera las dos funciones siguientes:
public static class StringHelper
{
public static string Pluralize (this string s) {...}
public static string Capitalize (this string s) {...}
}
x y y son equivalentes, y ambos evalúan a "Sausages", pero x utiliza métodos de extensión, mientras que y utiliza métodos estáticos:
string x = "sausage".Pluralize().Capitalize();
string y = StringHelper.Capitalize (StringHelper.Pluralize ("sausage"));
Ambigüedad y resolución
Espacios de nombres
No se puede acceder a un método de extensión a menos que su clase esté en el ámbito, normalmente mediante la importación de su espacio de nombres. Considera el método de extensión IsCapitalized en el siguiente ejemplo:
using System;
namespace Utils
{
public static class StringHelper
{
public static bool IsCapitalized (this string s)
{
if (string.IsNullOrEmpty(s)) return false;
return char.IsUpper (s[0]);
}
}
}
Para utilizar IsCapitalized, la siguiente aplicación debe importar Utils para evitar un error de compilación:
namespace MyApp
{
using Utils;
class Test
{
static void Main() => Console.WriteLine ("Perth".IsCapitalized());
}
}
Métodos de extensión frente a métodos de instancia
Cualquier método de instancia compatible siempre tendrá prioridad sobre un método de extensión. En el siguiente ejemplo, el método Test's Foo siempre tendrá preferencia, incluso cuando se llame con un argumento x de tipo int:
class Test
{
public void Foo (object x) { } // This method always wins
}
static class Extensions
{
public static void Foo (this Test t, int x) { }
}
La única forma de llamar al método de extensión en este caso es mediante la sintaxis estática normal; es decir, Extensions.Foo(...).
Métodos de extensión frente a métodos de extensión
Si dos métodos de extensión tienen la misma firma, el método de extensión debe llamarse como un método estático ordinario para desambiguar el método a llamar. Sin embargo, si un método de extensión tiene argumentos más específicos, el método más específico tiene prioridad.
Para ilustrarlo, considera las dos clases siguientes:
static class StringHelper
{
public static bool IsCapitalized (this string s) {...}
}
static class ObjectHelper
{
public static bool IsCapitalized (this object s) {...}
}
El siguiente código llama al método IsCapitalized de StringHelper:
bool test1 = "Perth".IsCapitalized();
Las clases y los structs se consideran más específicos que las interfaces.
Tipos anónimos
Un tipo anónimo es una clase simple creada por el compilador sobre la marcha para almacenar un conjunto de valores. Para crear un tipo anónimo, utiliza la palabra clave new seguida de un inicializador de objeto, especificando las propiedades y valores que contendrá el tipo; por ejemplo:
var dude = new { Name = "Bob", Age = 23 };
El compilador traduce esto a (aproximadamente) lo siguiente:
internal class AnonymousGeneratedTypeName
{
private string name; // Actual field name is irrelevant
private int age; // Actual field name is irrelevant
public AnonymousGeneratedTypeName (string name, int age)
{
this.name = name; this.age = age;
}
public string Name { get { return name; } }
public int Age { get { return age; } }
// The Equals and GetHashCode methods are overridden (see Chapter 6).
// The ToString method is also overridden.
}
...
var dude = new AnonymousGeneratedTypeName ("Bob", 23);
Debes utilizar la palabra clave var para hacer referencia a un tipo anónimo porque no tiene nombre.
El nombre de la propiedad de un tipo anónimo puede deducirse de una expresión que sea a su vez un identificador (o que termine con uno); así:
int Age = 23;
var dude = new { Name = "Bob", Age, Age.ToString().Length };
es equivalente a
var dude = new { Name = "Bob", Age = Age, Length = Age.ToString().Length };
Dos instancias de tipo anónimo declaradas dentro del mismo conjunto tendrán el mismo tipo subyacente si sus elementos se nombran y tipan de forma idéntica:
var a1 = new { X = 2, Y = 4 };
var a2 = new { X = 2, Y = 4 };
Console.WriteLine (a1.GetType() == a2.GetType()); // True
Además, se anula el método Equals para realizar comparaciones de igualdad:
Console.WriteLine (a1 == a2); // False Console.WriteLine (a1.Equals (a2)); // True
Puedes crear matrices de tipos anónimos, como se indica a continuación:
var dudes = new[]
{
new { Name = "Bob", Age = 30 },
new { Name = "Tom", Age = 40 }
};
Un método no puede (útilmente) devolver un objeto de tipo anónimo, porque es ilegal escribir un método cuyo tipo de retorno sea var:
var Foo() => new { Name = "Bob", Age = 30 }; // Not legal!
En su lugar, debes utilizar object o dynamic, y entonces quien llame a Foo deberá confiar en la vinculación dinámica, con pérdida de la seguridad de tipos estática (y de IntelliSense en Visual Studio).
dynamic Foo() => new { Name = "Bob", Age = 30 }; // No static type safety.
Los tipos anónimos son especialmente útiles al escribir consultas LINQ (consulta el capítulo 8).
Tuplas
Al igual que los tipos anónimos, las tuplas proporcionan una forma sencilla de almacenar un conjunto de valores. El objetivo principal de las tuplas es devolver con seguridad varios valores de un método sin recurrir a out parámetros (algo que no puedes hacer con los tipos anónimos).
Nota
Las tuplas hacen casi todo lo que hacen los tipos anónimos y más. Su única desventaja -como verás enseguida- es el borrado de tipos en tiempo de ejecución con elementos con nombre.
La forma más sencilla de crear una tupla literal es enumerar los valores deseados entre paréntesis. Esto crea una tupla con elementos sin nombre, a los que te refieres como Item1, Item2, etc:
var bob = ("Bob", 23); // Allow compiler to infer the element types
Console.WriteLine (bob.Item1); // Bob
Console.WriteLine (bob.Item2); // 23
Las tuplas son tipos de valores, con elementos mutables (lectura/escritura):
var joe = bob; // joe is a *copy* of bob joe.Item1 = "Joe"; // Change joe's Item1 from Bob to Joe Console.WriteLine (bob); // (Bob, 23) Console.WriteLine (joe); // (Joe, 23)
A diferencia de los tipos anónimos, puedes especificar un tipo de tupla explícitamente. Basta con enumerar cada uno de los tipos de elementos entre paréntesis:
(string,int) bob = ("Bob", 23);
Esto significa que puedes devolver útilmente una tupla de un método:
static (string,int) GetPerson() => ("Bob", 23);
static void Main()
{
(string,int) person = GetPerson(); // Could use 'var' instead if we want
Console.WriteLine (person.Item1); // Bob
Console.WriteLine (person.Item2); // 23
}
Las tuplas funcionan bien con los genéricos, por lo que los siguientes tipos son todos legales:
Task<(string,int)> Dictionary<(string,int),Uri> IEnumerable<(int id, string name)> // See below for naming elements
Nombrar elementos de tupla
Opcionalmente, puedes dar nombres significativos a los elementos al crear literales de tupla:
var tuple = (name:"Bob", age:23); Console.WriteLine (tuple.name); // Bob Console.WriteLine (tuple.age); // 23
Puedes hacer lo mismo al especificar tipos de tupla:
static (string name, int age) GetPerson() => ("Bob", 23);
static void Main()
{
var person = GetPerson();
Console.WriteLine (person.name); // Bob
Console.WriteLine (person.age); // 23
}
Ten en cuenta que aún puedes tratar los elementos como sin nombre y referirte a ellos como Item1, Item2, etc. (aunque Visual Studio oculta estos campos del IntelliSense).
Los nombres de los elementos se deducen automáticamente de los nombres de las propiedades o campos:
var now = DateTime.Now; var tuple = (now.Day, now.Month, now.Year); Console.WriteLine (tuple.Day); // OK
Las tuplas son compatibles entre sí si los tipos de sus elementos coinciden (en orden). Sus nombres de elementos no tienen por qué coincidir:
(string name, int age, char sex) bob1 = ("Bob", 23, 'M');
(string age, int sex, char name) bob2 = bob1; // No error!
Nuestro ejemplo particular conduce a resultados confusos:
Console.WriteLine (bob2.name); // M Console.WriteLine (bob2.age); // Bob Console.WriteLine (bob2.sex); // 23
Borrado de tipo
Anteriormente dijimos que el compilador de C# maneja los tipos anónimos construyendo clases personalizadas con propiedades con nombre para cada uno de los elementos. Con las tuplas, C# funciona de forma diferente y utiliza una familia preexistente de structs genéricos:
public struct ValueTuple<T1> public struct ValueTuple<T1,T2> public struct ValueTuple<T1,T2,T3> ...
Cada uno de los structs ValueTuple<> tiene campos denominados Item1, Item2, y así sucesivamente.
Por lo tanto, (string,int) es un alias de ValueTuple<string,int>, y esto significa que los elementos con nombre de tupla no tienen nombres de propiedad correspondientes en los tipos subyacentes. En su lugar, los nombres sólo existen en el código fuente y en la imaginación del compilador. En tiempo de ejecución, los nombres desaparecen en su mayoría, por lo que si descompilas un programa que hace referencia a elementos de tupla con nombre, sólo verás referencias a Item1, Item2, etc. Además, cuando examinas una variable tupla en un depurador después de haberla asignado a un object (o volcarla en LINQPad), los nombres de los elementos no están ahí. Y, en general, no puedes utilizar la reflexión(Capítulo 19) para determinar los nombres de los elementos de una tupla en tiempo de ejecución.
Nota
Hemos dicho que los nombres desaparecen en la mayoría de los casos porque hay una excepción. Con los métodos/propiedades que devuelven tipos de tupla con nombre, el compilador emite los nombres de los elementos aplicando un atributo personalizado llamado TupleElementNamesAttribute (ver "Atributos") al tipo de retorno del miembro. Esto permite que los elementos con nombre funcionen al llamar a métodos de un ensamblado diferente (del que el compilador no tiene el código fuente).
ValueTuple.Crear
También puedes crear tuplas mediante un método de fábrica en el tipo (no genérico) ValueTuple:
ValueTuple<string,int> bob1 = ValueTuple.Create ("Bob", 23);
(string,int) bob2 = ValueTuple.Create ("Bob", 23);
No puedes crear elementos con nombre de esta forma, porque el nombre de los elementos depende de la magia del compilador.
Deconstruir tuplas
Las tuplas admiten implícitamente el patrón de deconstrucción (véase "Deconstructores" en el Capítulo 3), por lo que puedes deconstruir fácilmente una tupla en variables individuales. Así, en lugar de hacer esto
var bob = ("Bob", 23);
string name = bob.Item1;
int age = bob.Item2;
puedes hacerlo:
var bob = ("Bob", 23);
(string name, int age) = bob; // Deconstruct the bob tuple into
// separate variables (name and age).
Console.WriteLine (name);
Console.WriteLine (age);
La sintaxis para la deconstrucción es confusamente similar a la sintaxis para declarar una tupla con elementos con nombre. A continuación se destaca la diferencia:
(string name, int age) = bob; // Deconstructing a tuple (string name, int age) bob2 = bob; // Declaring a new tuple
He aquí otro ejemplo, esta vez al llamar a un método, y con inferencia de tipo (var):
static (string, int, char) GetBob() => ( "Bob", 23, 'M');
static void Main()
{
var (name, age, sex) = GetBob();
Console.WriteLine (name); // Bob
Console.WriteLine (age); // 23
Console.WriteLine (sex); // M
}
Comparación de igualdad
Al igual que con los tipos anónimos, los tipos ValueTuple<> anulan el método Equals para permitir que las comparaciones de igualdad funcionen con sentido:
var t1 = ("one", 1);
var t2 = ("one", 1);
Console.WriteLine (t1.Equals (t2)); // True
Además, ValueTuple<> sobrecarga los operadores == y !=:
Console.WriteLine (t1 == t2); // True (from C# 7.3)
También anulan el método GetHashCode, por lo que resulta práctico utilizar tuplas como claves en los diccionarios. Trataremos en detalle la comparación de igualdades en "Comparación de igualdades", en el Capítulo 6, y en "Diccionarios", en el Capítulo 7.
Los tipos ValueTuple<> también implementan IComparable (véase "Comparación de orden" en el Capítulo 6), lo que permite utilizar tuplas como clave de ordenación.
Las clases System.Tuple
Encontrarás otra familia de tipos genéricos en el espacio de nombres System llamada Tuple (en lugar de ValueTuple). Éstos se introdujeron en .NET Framework 4.0 y son clases (mientras que los tipos ValueTuple son structs). En retrospectiva, definir las tuplas como clases se consideró un error: en los escenarios típicos en los que se utilizan las tuplas, los structs tienen una ligera ventaja de rendimiento (ya que evitan asignaciones de memoria innecesarias), sin apenas inconvenientes. Por eso, cuando Microsoft añadió soporte de lenguaje para tuplas (en C# 7), ignoró los tipos Tuple existentes en favor de los nuevos ValueTuple. Puede que aún te encuentres con las clases Tuple en código escrito antes de C# 7. No tienen soporte especial de lenguaje y se utilizan como sigue:
Tuple<string,int> t = Tuple.Create ("Bob", 23); // Factory method
Console.WriteLine (t.Item1); // Bob
Console.WriteLine (t.Item2); // 23
Patrones
En el capítulo 3, demostramos cómo utilizar el operador is para comprobar si una conversión de referencia tendrá éxito:
if (obj is string) Console.WriteLine (((string)obj).Length);
O, más concisamente:
if (obj is string s) Console.WriteLine (s.Length);
Esto emplea un tipo de patrón llamado patrón de tipo. El operador is también admite otros patrones que se introdujeron en C# 7 y C# 8, como el patrón de propiedades:
if (obj is string { Length:4 })
Console.WriteLine ("A string with 4 characters");
Los patrones se admiten en los siguientes contextos:
-
Después del operador
is(variable is pattern) -
En
switchdeclaraciones -
En
switchexpresiones
Ya hemos tratado el patrón de tipos (y, brevemente, el patrón de tuplas) en "Cambio de tipos", en el Capítulo 2, y en "El operador is", en el Capítulo 3. En esta sección, cubrimos patrones más avanzados que se introdujeron en C# 7 y C# 8. La mayoría de estos patrones están pensados para su uso en declaraciones/expresiones switch, donde hacen lo siguiente:
-
Reduce la necesidad de las cláusulas
when -
Te permite utilizar interruptores donde antes no podías
Nota
Los patrones de esta sección son de leve a moderadamente útiles en algunos casos. Recuerda que siempre puedes sustituir las expresiones switch con patrones muy marcados por simples sentencias if -o, en algunos casos, por el operador condicional ternario- y, a menudo, sin mucho código adicional.
Patrones de propiedades (C# 8)
Un patrón de propiedades coincide con uno o varios valores de las propiedades de un objeto. Anteriormente dimos un ejemplo sencillo en el contexto del operador is:
if (obj is string { Length:4 }) ...
Sin embargo, esto no ahorra mucho respecto a lo siguiente:
if (obj is string s && s.Length == 4) ...
Con las declaraciones y expresiones switch, los patrones de propiedades son más útiles. Considera la clase System.Uri, que representa un URI. Tiene propiedades que incluyen Scheme, Host, Port y IsLoopback. Al escribir un cortafuegos, podríamos decidir si permitir o bloquear una URI empleando una expresión switch que utiliza patrones de propiedades:
bool ShouldAllow (Uri uri) => uri switch
{
{ Scheme: "http", Port: 80 } => true,
{ Scheme: "https", Port: 443 } => true,
{ Scheme: "ftp", Port: 21 } => true,
{ IsLoopback: true } => true,
_ => false
};
Puedes anidar propiedades, por lo que la cláusula siguiente es legal:
{ Scheme: string { Length: 4 }, Port: 80 } => true,
Las coincidencias se basan siempre en el tipo y la igualdad. Si necesitas aplicar algún otro operador (como menos-que), debes utilizar una cláusula when:
{ Scheme: "http", Port: 80 } when uri.Host.Length < 1000 => true,
Puedes combinar el patrón de tipos con el patrón de propiedades:
bool ShouldAllow (object uri) => uri switch
{
Uri { Scheme: "http", Port: 80 } => true,
Uri { Scheme: "https", Port: 443 } => true,
...
Como era de esperar con los patrones de tipos, puedes introducir una variable al final de una cláusula y luego consumir esa variable:
Uri { Scheme: "http", Port: 80 } httpUri => httpUri.Host.Length < 1000,
También puedes utilizar esa variable en una cláusula when:
Uri { Scheme: "http", Port: 80 } httpUri
when httpUri.Host.Length < 1000 => true,
Un giro un tanto extraño de los patrones de propiedades es que también puedes introducir variables a nivel de propiedad:
{ Scheme: "http", Port: 80, Host: string host } => host.Length < 1000,
Se permite la tipificación implícita, por lo que puedes sustituir string por var. Aquí tienes un ejemplo completo:
bool ShouldAllow (Uri uri) => uri switch
{
{ Scheme: "http", Port: 80, Host: var host } => host.Length < 1000,
{ Scheme: "https", Port: 443 } => true,
{ Scheme: "ftp", Port: 21 } => true,
{ IsLoopback: true } => true,
_ => false
};
Es difícil inventar ejemplos en los que esto ahorre más que unos pocos caracteres. En nuestro caso, la alternativa es en realidad más corta:
{ Scheme: "http", Port: 80 } => uri.Host.Length < 1000,
Patrones de tupla (C# 8)
Los patrones de tupla proporcionan un mecanismo sencillo para activar varios valores:
enum Season { Spring, Summer, Fall, Winter };
int AverageCelsiusTemperature (Season season, bool daytime) =>
(season, daytime) switch
{
(Season.Spring, true) => 20,
(Season.Spring, false) => 16,
(Season.Summer, true) => 27,
(Season.Summer, false) => 22,
(Season.Fall, true) => 18,
(Season.Fall, false) => 12,
(Season.Winter, true) => 10,
(Season.Winter, false) => -2,
_ => throw new Exception ("Unexpected combination")
};
Patrones Posicionales (C# 8)
Para los tipos que definen un método Deconstruct (véase "Deconstructores" en el capítulo 3), como la clase Point del ejemplo siguiente:
class Point
{
public readonly int X, Y;
public Point (int x, int y) => (X, Y) = (x, y);
public void Deconstruct (out int x, out int y)
{
x = X; y = Y;
}
}
puedes utilizar las propiedades de posición del objeto para la concordancia de patrones:
var p = new Point (2, 3); Console.WriteLine (p is (2, 3)); // true
Con un interruptor:
string Print (object obj) => obj switch
{
Point (0, 0) => "Empty point",
Point (var x, var y) when x == y => "Diagonal"
...
};
var Patrón
El patrón var se introdujo en C# 7 y es una variación del patrón de tipos por la que sustituyes el nombre del tipo por la palabra clave var. La conversión siempre tiene éxito, por lo que su finalidad es simplemente permitirte reutilizar la variable que sigue:
bool Test (int x, int y) => x * y is var product && product > 10 && product < 100;
Sin esta función, tendrías que hacer esto:
bool Test (int x, int y)
{
int product = x * y;
return product > 10 && product < 100;
}
La posibilidad de introducir y reutilizar una variable intermedia (product, en este caso) en un método con cuerpo de expresión es conveniente. Por desgracia, sólo funciona cuando el método en cuestión tiene un tipo de retorno bool.
Patrón constante
El patrón constante es el pan de cada día de las sentencias switch (y hasta C# 7, era el único patrón admitido). Por coherencia, también puedes utilizar el patrón constante con el operador is de C# 7, con lo que lo siguiente es legal:
void Foo (object obj)
{
// C# won't let you use the == operator, because obj is object.
// However, we can use 'is'
if (obj is 3) ...
}
Esto equivale a lo siguiente
void Foo (object obj)
{
if (obj is int && (int)obj == 3) ...
}
Atributos
Ya estás familiarizado con la noción de atribuir elementos de código de un programa con modificadores, como virtual o ref. Estas construcciones están integradas en el lenguaje. Los atributos son un mecanismo extensible para añadir información personalizada a los elementos de código (conjuntos, tipos, miembros, valores de retorno, parámetros y parámetros de tipo genérico). Esta extensibilidad es útil para servicios que se integran profundamente en el sistema de tipos, sin requerir palabras clave o construcciones especiales en el lenguaje C#.
Un buen escenario para los atributos es la serialización:el proceso de convertir objetos arbitrarios a y desde un formato concreto para su almacenamiento o transmisión. En este escenario, un atributo en un campo puede especificar la traducción entre la representación de C# del campo y la representación del formato del campo.
Clases de atributos
Un atributo lo define una clase que hereda (directa o indirectamente) de la clase abstracta System.Attribute. Para adjuntar un atributo a un elemento de código, especifica el nombre de la clase del atributo entre corchetes, antes del elemento de código. Por ejemplo, lo siguiente adjunta el ObsoleteAttribute a la clase Foo:
[ObsoleteAttribute]
public class Foo {...}
Este atributo concreto es reconocido por el compilador y provocará advertencias del compilador si se hace referencia a un tipo o miembro marcado como obsoleto. Por convención, todos los tipos de atributo terminan en la palabra Atributo. C# lo reconoce y te permite omitir el sufijo al adjuntar un atributo:
[Obsolete]
public class Foo {...}
ObsoleteAttribute es un tipo declarado en el espacio de nombres System como sigue (simplificado para abreviar):
public sealed class ObsoleteAttribute : Attribute {...}
El lenguaje C# y .NET Core incluyen una serie de atributos predefinidos. En el Capítulo 19 describimos cómo escribir tus propios atributos.
Parámetros de Atributos Nombrados y Posicionales
Los atributos pueden tener parámetros. En el siguiente ejemplo, aplicamos XmlTypeAttribute a una clase. Este atributo indica al serializador XML (en System.Xml.Serialization) sobre cómo se representa un objeto en XML y acepta varios parámetros de atributo. El siguiente atributo asigna la clase CustomerEntity a un elemento XML llamado Customer, que pertenece al espacio de nombres http://oreilly.com:
[XmlType ("Customer", Namespace="http://oreilly.com")]
public class CustomerEntity { ... }
Los parámetros de los atributos pertenecen a una de estas dos categorías: posicionales o con nombre. En el ejemplo anterior, el primer argumento es un parámetro posicional; el segundo es un parámetro con nombre. Los parámetros posicionales corresponden a los parámetros de los constructores públicos del tipo de atributo. Los parámetros con nombre corresponden a campos públicos o propiedades públicas del tipo de atributo.
Al especificar un atributo, debes incluir parámetros posicionales que correspondan a uno de los constructores del atributo. Los parámetros con nombre son opcionales.
En el capítulo 19 describimos los tipos de parámetros válidos y las reglas para su evaluación.
Aplicar atributos a conjuntos y campos de respaldo
Implícitamente, el objetivo de un atributo es el elemento de código al que precede inmediatamente, que suele ser un tipo o un miembro de tipo. Pero también puedes adjuntar atributos a un conjunto. Esto requiere que especifiques explícitamente el objetivo del atributo. He aquí cómo puedes utilizar el atributo AssemblyFileVersion para adjuntar una versión al conjunto:
[assembly: AssemblyFileVersion ("1.2.3.4")]
A partir de C# 7.3, puedes utilizar el prefijo field: para aplicar un atributo a los campos de respaldo de una propiedad automática. Esto puede ser útil para controlar la serialización:
[field:NonSerialized]
public int MyProperty { get; set; }
Especificar varios atributos
Puedes especificar varios atributos para un mismo elemento de código. Puedes enumerar cada atributo dentro del mismo par de corchetes (separados por una coma) o en pares de corchetes separados (o una combinación de ambos). Los tres ejemplos siguientes son semánticamente idénticos:
[Serializable, Obsolete, CLSCompliant(false)]
public class Bar {...}
[Serializable] [Obsolete] [CLSCompliant(false)]
public class Bar {...}
[Serializable, Obsolete]
[CLSCompliant(false)]
public class Bar {...}
Atributos de la información de llamada
Puedes etiquetar los parámetros opcionales con uno de los tres atributos de información del autor de la llamada, que indican al compilador que introduzca la información obtenida del código fuente del autor de la llamada en el valor por defecto del parámetro:
-
[CallerMemberName]aplica el nombre del miembro de la persona que llama -
[CallerFilePath]aplica la ruta al archivo de código fuente de la persona que llama -
[CallerLineNumber]aplica el número de línea en el archivo de código fuente de la persona que llama
El método Foo del siguiente programa demuestra las tres cosas:
using System;
using System.Runtime.CompilerServices;
class Program
{
static void Main() => Foo();
static void Foo (
[CallerMemberName] string memberName = null,
[CallerFilePath] string filePath = null,
[CallerLineNumber] int lineNumber = 0)
{
Console.WriteLine (memberName);
Console.WriteLine (filePath);
Console.WriteLine (lineNumber);
}
}
Suponiendo que nuestro programa reside en c:\source\test\Program.cs, la salida sería:
Main c:\source\test\Program.cs 6
Al igual que con los parámetros opcionales estándar, la sustitución se realiza en el sitio de llamada. Por lo tanto, nuestro método Main es azúcar sintáctico para esto:
static void Main() => Foo ("Main", @"c:\source\test\Program.cs", 6);
Los atributos de información de llamada son útiles para el registro y para implementar patrones como disparar un único evento de notificación de cambio cada vez que cambia cualquier propiedad de un objeto. De hecho, existe una interfaz estándar en .NET Core para esto llamada INotifyPropertyChanged (en System.ComponentModel):
public interface INotifyPropertyChanged
{
event PropertyChangedEventHandler PropertyChanged;
}
public delegate void PropertyChangedEventHandler
(object sender, PropertyChangedEventArgs e);
public class PropertyChangedEventArgs : EventArgs
{
public PropertyChangedEventArgs (string propertyName);
public virtual string PropertyName { get; }
}
Observa que PropertyChangedEventArgs requiere el nombre de la propiedad que ha cambiado. Sin embargo, aplicando el atributo [CallerMemberName], podemos implementar esta interfaz e invocar el evento sin especificar nunca los nombres de las propiedades:
public class Foo : INotifyPropertyChanged
{
public event PropertyChangedEventHandler PropertyChanged = delegate { };
void RaisePropertyChanged ([CallerMemberName] string propertyName = null)
{
PropertyChanged (this, new PropertyChangedEventArgs (propertyName));
}
string customerName;
public string CustomerName
{
get { return customerName; }
set
{
if (value == customerName) return;
customerName = value;
RaisePropertyChanged();
// The compiler converts the above line to:
// RaisePropertyChanged ("CustomerName");
}
}
}
Encuadernación dinámica
La vinculación dinámica aplaza la vinculación -elproceso de resolver tipos, miembros y operadores- del tiempo de compilación al tiempo de ejecución. La vinculación dinámica es útil cuando en tiempo de compilación sabes que existe una determinada función, miembro u operación, pero el compilador no. Esto suele ocurrir cuando interoperas con lenguajes dinámicos (como IronPython) y COM, así como en situaciones en las que podrías utilizar la reflexión.
Un tipo dinámico se declara con la palabra clave contextual dynamic:
dynamic d = GetSomeObject(); d.Quack();
Un tipo dinámico indica al compilador que se relaje. Esperamos que el tipo en tiempo de ejecución de d tenga un método Quack. Pero no podemos probarlo estáticamente. Como d es dinámico, el compilador aplaza la vinculación de Quack a d hasta el tiempo de ejecución. Para entender lo que esto significa hay que distinguir entre vinculación estática y vinculación dinámica.
Vinculación estática frente a vinculación dinámica
El ejemplo canónico de vinculación es asignar un nombre a una función concreta al compilar una expresión. Para compilar la siguiente expresión, el compilador necesita encontrar la implementación del método llamado Quack:
d.Quack();
Supongamos que el tipo estático de d es Duck:
Duck d = ... d.Quack();
En el caso más sencillo, el compilador realiza la vinculación buscando un método sin parámetros llamado Quack en Duck. En su defecto, el compilador amplía su búsqueda a métodos que tomen parámetros opcionales, métodos en clases base de Duck, y métodos de extensión que tomen Duck como primer parámetro. Si no se encuentra ninguna coincidencia, obtendrás un error de compilación. Independientemente del método que se vincule, lo esencial es que la vinculación la realiza el compilador, y la vinculación depende totalmente de que se conozcan estáticamente los tipos de los operandos (en este caso, d). Esto lo convierte en una vinculación estática.
Ahora cambiemos el tipo estático de d a object:
object d = ... d.Quack();
Llamar a Quack nos da un error de compilación, porque aunque el valor almacenado en d puede contener un método llamado Quack, el compilador no puede saberlo, porque la única información que tiene es el tipo de la variable, que en este caso es object. Pero cambiemos ahora el tipo estático de d por dynamic:
dynamic d = ... d.Quack();
Un tipo dynamic es como object-es igualmente no descriptivo sobre un tipo. La diferencia es que te permite utilizarlo de formas que no se conocen en tiempo de compilación. Un objeto dinámico se vincula en tiempo de ejecución en función de su tipo en tiempo de ejecución, no de su tipo en tiempo de compilación. Cuando el compilador ve una expresión vinculada dinámicamente (que, en general, es una expresión que contiene cualquier valor del tipo dynamic), se limita a empaquetar la expresión de modo que la vinculación pueda realizarse posteriormente en tiempo de ejecución.
En tiempo de ejecución, si un objeto dinámico implementa IDynamicMetaObjectProvider, se utiliza esa interfaz para realizar la vinculación. Si no, la vinculación se produce casi del mismo modo que si el compilador hubiera conocido el tipo en tiempo de ejecución del objeto dinámico. Estas dos alternativas se denominan enlace personalizado y enlace de lenguaje.
Encuadernación a medida
La vinculación personalizada se produce cuando un objeto dinámico implementa IDynamicMetaObjectProvider (IDMOP). Aunque puedes implementar IDMOP en tipos que escribas en C#, y es útil hacerlo, el caso más común es que hayas adquirido un objeto IDMOP de un lenguaje dinámico que esté implementado en .NET en el Dynamic Language Runtime (DLR), como IronPython o IronRuby. Los objetos de esos lenguajes implementan implícitamente IDMOP como medio para controlar directamente el significado de las operaciones que se realizan sobre ellos.
Hablaremos con más detalle de las carpetas personalizadas en el Capítulo 20, pero de momento vamos a escribir una sencilla para demostrar la función:
using System;
using System.Dynamic;
public class Test
{
static void Main()
{
dynamic d = new Duck();
d.Quack(); // Quack method was called
d.Waddle(); // Waddle method was called
}
}
public class Duck : DynamicObject
{
public override bool TryInvokeMember (
InvokeMemberBinder binder, object[] args, out object result)
{
Console.WriteLine (binder.Name + " method was called");
result = null;
return true;
}
}
La clase Duck no tiene en realidad un método Quack. En su lugar, utiliza un enlace personalizado para interceptar e interpretar todas las llamadas a métodos.
Encuadernación en idiomas
La vinculación lingüística se produce cuando un objeto dinámico no implementa IDMOP. La vinculación de lenguaje es útil cuando se trabaja con tipos imperfectamente diseñados o con limitaciones inherentes al sistema de tipos .NET (exploraremos más escenarios en el Capítulo 20). Un problema típico al utilizar tipos numéricos es que no tienen una interfaz común. Hemos visto que podemos enlazar métodos dinámicamente; lo mismo ocurre con los operadores:
static dynamic Mean (dynamic x, dynamic y) => (x + y) / 2;
static void Main()
{
int x = 3, y = 4;
Console.WriteLine (Mean (x, y));
}
La ventaja es obvia: no necesitas duplicar el código para cada tipo numérico. Sin embargo, pierdes la seguridad de tipo estático, arriesgándote a excepciones en tiempo de ejecución en lugar de errores en tiempo de compilación.
Nota
La vinculación dinámica elude la seguridad de tipos estática, pero no la seguridad de tipos en tiempo de ejecución. A diferencia de lo que ocurre con la reflexión(capítulo 19), con la vinculación dinámica no puedes eludir las normas de accesibilidad de los miembros.
Por diseño, la vinculación en tiempo de ejecución del lenguaje se comporta de la forma más parecida posible a la vinculación estática, si los tipos en tiempo de ejecución de los objetos dinámicos se hubieran conocido en tiempo de compilación. En nuestro ejemplo anterior, el comportamiento de nuestro programa sería idéntico si hubiéramos codificado Mean para que funcionara con el tipo int. La excepción más notable en la paridad entre la vinculación estática y la dinámica son los métodos de extensión, que tratamos en "Funciones invocables".
Nota
La vinculación dinámica también afecta al rendimiento. Sin embargo, gracias a los mecanismos de almacenamiento en caché del DLR, se optimizan las llamadas repetidas a la misma expresión dinámica, lo que te permite llamar eficazmente a expresiones dinámicas en un bucle. Esta optimización reduce a menos de 100 nanosegundos la sobrecarga típica de una expresión dinámica sencilla en el hardware actual.
Representación en tiempo de ejecución de la dinámica
Existe una equivalencia profunda entre los tipos dynamic y object. El tiempo de ejecución trata la siguiente expresión como true:
typeof (dynamic) == typeof (object)
Este principio se extiende a los tipos construidos y a los tipos de matriz:
typeof (List<dynamic>) == typeof (List<object>) typeof (dynamic[]) == typeof (object[])
Al igual que una referencia a un objeto, una referencia dinámica puede apuntar a un objeto de cualquier tipo (excepto de tipo puntero):
dynamic x = "hello"; Console.WriteLine (x.GetType().Name); // String x = 123; // No error (despite same variable) Console.WriteLine (x.GetType().Name); // Int32
Estructuralmente, no hay diferencia entre una referencia a un objeto y una referencia dinámica. Una referencia dinámica simplemente permite realizar operaciones dinámicas sobre el objeto al que apunta. Puedes convertir de object a dynamic para realizar cualquier operación dinámica que desees en un object:
object o = new System.Text.StringBuilder();
dynamic d = o;
d.Append ("hello");
Console.WriteLine (o); // hello
Nota
Si reflexionamos sobre un tipo que expone miembros (públicos) de dynamic, veremos que esos miembros se representan como objects anotados; por ejemplo:
public class Test
{
public dynamic Foo;
}
es equivalente a
public class Test
{
[System.Runtime.CompilerServices.DynamicAttribute]
public object Foo;
}
Esto permite a los consumidores de ese tipo saber que Foo debe tratarse como dinámico, al tiempo que permite a los lenguajes que no admiten la vinculación dinámica recurrir a object.
Conversiones dinámicas
El tipo dynamic tiene conversiones implícitas hacia y desde todos los demás tipos:
int i = 7; dynamic d = i; long j = d; // No cast required (implicit conversion)
Para que la conversión tenga éxito, el tipo en tiempo de ejecución del objeto dinámico debe ser implícitamente convertible al tipo estático de destino. El ejemplo anterior funcionó porque un int es implícitamente convertible a un long.
El siguiente ejemplo lanza un RuntimeBinderException porque un int no es convertible implícitamente en un short:
int i = 7; dynamic d = i; short j = d; // throws RuntimeBinderException
var Versus dinámico
Los tipos var y dynamic tienen un parecido superficial, pero la diferencia es profunda:
-
vardice: "Deja que el compilador averigüe el tipo". -
dynamicdice: "Deja que el tiempo de ejecución averigüe el tipo".
Para ilustrarlo:
dynamic x = "hello"; // Static type is dynamic, runtime type is string var y = "hello"; // Static type is string, runtime type is string int i = x; // Runtime error (cannot convert string to int) int j = y; // Compile-time error (cannot convert string to int)
El tipo estático de una variable declarada con var puede ser dynamic:
dynamic x = "hello"; var y = x; // Static type of y is dynamic int z = y; // Runtime error (cannot convert string to int)
Expresiones dinámicas
Se puede llamar dinámicamente a campos, propiedades, métodos, eventos, constructores, indexadores, operadores y conversiones.
Intentar consumir el resultado de una expresión dinámica con un tipo de retorno void está prohibido, igual que con una expresión tipada estáticamente. La diferencia es que el error se produce en tiempo de ejecución:
dynamic list = new List<int>(); var result = list.Add (5); // RuntimeBinderException thrown
Las expresiones que incluyen operandos dinámicos suelen ser dinámicas en sí mismas, porque el efecto de la ausencia de información de tipo es en cascada:
dynamic x = 2; var y = x * 3; // Static type of y is dynamic
Hay un par de excepciones obvias a esta regla. En primer lugar, si pasas una expresión dinámica a un tipo estático, obtendrás una expresión estática:
dynamic x = 2; var y = (int)x; // Static type of y is int
En segundo lugar, las invocaciones a constructores siempre producen expresiones estáticas, incluso cuando se invocan con argumentos dinámicos. En este ejemplo, x está tipado estáticamente como StringBuilder:
dynamic capacity = 10; var x = new System.Text.StringBuilder (capacity);
Además, hay algunos casos de perímetro en los que una expresión que contiene un argumento dinámico es estática, como pasar un índice a una matriz y las expresiones de creación de delegados.
Llamadas dinámicas sin receptores dinámicos
El caso de uso canónico de dynamic implica un receptor dinámico. Esto significa que un objeto dinámico es el receptor de una llamada a una función dinámica:
dynamic x = ...; x.Foo(); // x is the receiver
Sin embargo, también puedes llamar a funciones conocidas estáticamente con argumentos dinámicos. Tales llamadas están sujetas a la resolución dinámica de sobrecargas, y pueden incluir lo siguiente:
-
Métodos estáticos
-
Constructores de instancia
-
Métodos de instancia en receptores con un tipo conocido estáticamente
En el siguiente ejemplo, el Foo concreto que se vincula dinámicamente depende del tipo en tiempo de ejecución del argumento dinámico:
class Program
{
static void Foo (int x) => Console.WriteLine ("int");
static void Foo (string x) => Console.WriteLine ("string");
static void Main()
{
dynamic x = 5;
dynamic y = "watermelon";
Foo (x); // 1
Foo (y); // 2
}
}
Como no interviene un receptor dinámico, el compilador puede realizar estáticamente una comprobación básica para ver si la llamada dinámica tendrá éxito. Comprueba si existe una función con el nombre y el número de parámetros correctos. Si no encuentra ninguna candidata, obtendrá un error en tiempo de compilación:
class Program
{
static void Foo (int x) => Console.WriteLine ("int");
static void Foo (string x) => Console.WriteLine ("string");
static void Main()
{
dynamic x = 5;
Foo (x, x); // Compiler error - wrong number of parameters
Fook (x); // Compiler error - no such method name
}
}
Tipos estáticos en expresiones dinámicas
Es obvio que los tipos dinámicos se utilizan en la vinculación dinámica. No es tan obvio que los tipos estáticos también se utilicen -siempre que sea posible- en la vinculación dinámica. Piensa en lo siguiente:
class Program
{
static void Foo (object x, object y) { Console.WriteLine ("oo"); }
static void Foo (object x, string y) { Console.WriteLine ("os"); }
static void Foo (string x, object y) { Console.WriteLine ("so"); }
static void Foo (string x, string y) { Console.WriteLine ("ss"); }
static void Main()
{
object o = "hello";
dynamic d = "goodbye";
Foo (o, d); // os
}
}
La llamada a Foo(o,d) está vinculada dinámicamente porque uno de sus argumentos, d, es dynamic. Pero como o se conoce estáticamente, la vinculación -aunque se produzca dinámicamente- hará uso de ella. En este caso, la resolución de sobrecargas elegirá la segunda implementación de Foo debido al tipo estático de o y al tipo en tiempo de ejecución de d. En otras palabras, el compilador es "lo más estático posible".
Funciones no invocables
Algunas funciones no pueden llamarse dinámicamente. No puedes llamar a las siguientes:
-
Métodos de extensión (mediante la sintaxis de los métodos de extensión)
-
Miembros de una interfaz, si para ello necesitas hacer un casting a esa interfaz
-
Miembros base ocultos por una subclase
Entender por qué es así es útil para comprender la vinculación dinámica.
La vinculación dinámica requiere dos datos: el nombre de la función a llamar y el objeto sobre el que llamar a la función. Sin embargo, en cada uno de los tres escenarios invocables, interviene un tipo adicional, que sólo se conoce en tiempo de compilación. En el momento de escribir esto, no hay forma de especificar dinámicamente estos tipos adicionales.
Al llamar a métodos de extensión, ese tipo adicional está implícito. Es la clase estática sobre la que se define el método de extensión. El compilador lo busca a partir de las directivas using de tu código fuente. Esto hace que los métodos de extensión sean conceptos sólo en tiempo de compilación, porque las directivas using desaparecen al compilar (después de que hayan hecho su trabajo en el proceso de enlace al asignar nombres simples a nombres calificados por el espacio de nombres).
Cuando llames a miembros a través de una interfaz, especifica ese tipo adicional mediante un casting implícito o explícito. Hay dos situaciones en las que puedes querer hacer esto: cuando llames a miembros de la interfaz implementados explícitamente, y cuando llames a miembros de la interfaz implementados en un tipo interno de otro conjunto. Podemos ilustrar el primer caso con los dos tipos siguientes:
interface IFoo { void Test(); }
class Foo : IFoo { void IFoo.Test() {} }
Para llamar al método Test, debemos hacer un casting a la interfaz IFoo. Esto es fácil con la tipificación estática:
IFoo f = new Foo(); // Implicit cast to interface f.Test();
Considera ahora la situación con la tipificación dinámica:
IFoo f = new Foo(); dynamic d = f; d.Test(); // Exception thrown
El molde implícito que se muestra en negrita indica al compilador que vincule las siguientes llamadas a miembros de f a IFoo en lugar de a Foo; en otras palabras, que vea ese objeto a través de la lente de la interfaz IFoo. Sin embargo, esa lente se pierde en tiempo de ejecución, por lo que el DLR no puede completar la vinculación. La pérdida se ilustra como sigue:
Console.WriteLine (f.GetType().Name); // Foo
Una situación similar se produce al llamar a un miembro base oculto: debes especificar un tipo adicional mediante un molde o la palabra clave base, y ese tipo adicional se pierde en tiempo de ejecución.
Sobrecarga del operador
Puedes sobrecargar los operadores para proporcionar una sintaxis más natural a los tipos personalizados. La sobrecarga de operadores es más adecuada para implementar structs personalizados que representen tipos de datos bastante primitivos. Por ejemplo, un tipo numérico personalizado es un candidato excelente para la sobrecarga de operadores.
Los siguientes operadores simbólicos pueden sobrecargarse:
+ (unario) |
- (unario) |
! |
~ |
++ |
-- |
+ |
- |
* |
/ |
% |
& |
| |
^ |
<< |
>> |
== |
!= |
> |
< |
>= |
<= |
Los siguientes operadores también son sobrecargables:
-
Conversiones implícitas y explícitas (con las palabras clave
implicityexplicit) -
Los operadores
trueyfalse(no literales).
Los siguientes operadores están sobrecargados indirectamente:
-
Los operadores de asignación compuestos (por ejemplo,
+=,/=) se anulan implícitamente anulando los operadores no compuestos (por ejemplo,+,/). -
Los operadores condicionales
&&y||se anulan implícitamente anulando los operadores bit a bit&y|.
Funciones del operador
Puedes sobrecargar un operador declarando una función de operador. Una función operadora tiene las siguientes reglas:
-
El nombre de la función se especifica con la palabra clave
operatorseguida de un símbolo de operador. -
La función del operador debe estar marcada
staticypublic. -
Los parámetros de la función operador representan los operandos.
-
El tipo de retorno de una función operador representa el resultado de una expresión.
-
Al menos uno de los operandos debe ser del tipo en el que se declara la función operador.
En el siguiente ejemplo, definimos una estructura llamada Note que representa una nota musical y, a continuación, sobrecargamos el operador +:
public struct Note
{
int value;
public Note (int semitonesFromA) { value = semitonesFromA; }
public static Note operator + (Note x, int semitones)
{
return new Note (x.value + semitones);
}
}
Esta sobrecarga nos permite añadir un int a un Note:
Note B = new Note (2); Note CSharp = B + 2;
Al sobrecargar un operador, se sobrecarga automáticamente el operador de asignación compuesta correspondiente. En nuestro ejemplo, como hemos sobrecargado +, también podemos utilizar +=:
CSharp += 2;
Al igual que con los métodos y las propiedades, C# permite que las funciones de operador que comprenden una única expresión se escriban de forma más escueta con la sintaxis con cuerpo de expresión :
public static Note operator + (Note x, int semitones)
=> new Note (x.value + semitones);
Sobrecarga de operadores de igualdad y comparación
Los operadores de igualdad y comparación a veces se sobrecargan al escribir structs, y en raras ocasiones al escribir clases. La sobrecarga de los operadores de igualdad y comparación conlleva reglas y obligaciones especiales, que explicamos en el Capítulo 6. Un resumen de estas reglas es el siguiente:
- Emparejamiento
- El compilador de C# obliga a definir los operadores que son pares lógicos. Estos operadores son (
==!=), (<>), y (<=>=). EqualsyGetHashCode- En la mayoría de los casos, si sobrecargas (
==) y (!=), debes anular los métodosEqualsyGetHashCodedefinidos enobjectpara obtener un comportamiento significativo. El compilador de C# te avisará si no lo haces. (Para más detalles, consulta "Comparación de igualdades" en el Capítulo 6 ). IComparableyIComparable<T>- Si sobrecargas (
< >) y (<= >=), debes implementarIComparableyIComparable<T>.
Conversiones implícitas y explícitas personalizadas
Las conversiones implícitas y explícitas son operadores sobrecargables. Estas conversiones suelen sobrecargarse para que la conversión entre tipos fuertemente relacionados (como los tipos numéricos) sea concisa y natural.
Para convertir entre tipos débilmente relacionados, son más adecuadas las siguientes estrategias:
-
Escribe un constructor que tenga un parámetro del tipo a convertir.
-
Escribe
ToXXXy (estático)FromXXXpara convertir entre tipos.
Como se ha explicado en la discusión sobre los tipos, la razón de ser de las conversiones implícitas es que tienen garantizado el éxito y no pierden información durante la conversión. Por el contrario, una conversión explícita debe ser necesaria cuando las circunstancias del tiempo de ejecución determinen si la conversión tendrá éxito, o si se puede perder información durante la conversión.
Nota
Los operadores as y is ignoran las conversiones personalizadas:
Console.WriteLine (554.37 is Note); // False Note n = 554.37 as Note; // Error
En este ejemplo, definimos conversiones entre nuestro tipo musical Note y un double (que representa la frecuencia en hercios de esa nota):
... // Convert to hertz public static implicit operator double (Note x) => 440 * Math.Pow (2, (double) x.value / 12 ); // Convert from hertz (accurate to the nearest semitone) public static explicit operator Note (double x) => new Note ((int) (0.5 + 12 * (Math.Log (x/440) / Math.Log(2) ) )); ... Note n = (Note)554.37; // explicit conversion double x = n; // implicit conversion
Nota
Siguiendo nuestras propias directrices, este ejemplo podría implementarse mejor con un método ToFrequency (y un método estático FromFrequency en lugar de operadores implícitos y explícitos.
Sobrecarga de verdadero y falso
Los operadores true y false se sobrecargan en el caso extremadamente raro de tipos que son de espíritu booleano, pero que no tienen una conversión a bool. Un ejemplo es un tipo que implemente la lógica de tres estados: sobrecargando true y false, dicho tipo puede trabajar sin problemas con sentencias y operadores condicionales: if, do, while, for, &&, || y ?:. La estructura System.Data.SqlTypes.SqlBoolean proporciona esta funcionalidad:
SqlBoolean a = SqlBoolean.Null;
if (a)
Console.WriteLine ("True");
else if (!a)
Console.WriteLine ("False");
else
Console.WriteLine ("Null");
OUTPUT:
Null
El código siguiente es una reimplementación de las partes de SqlBoolean necesarias para demostrar los operadores true y false:
public struct SqlBoolean
{
public static bool operator true (SqlBoolean x)
=> x.m_value == True.m_value;
public static bool operator false (SqlBoolean x)
=> x.m_value == False.m_value;
public static SqlBoolean operator ! (SqlBoolean x)
{
if (x.m_value == Null.m_value) return Null;
if (x.m_value == False.m_value) return True;
return False;
}
public static readonly SqlBoolean Null = new SqlBoolean(0);
public static readonly SqlBoolean False = new SqlBoolean(1);
public static readonly SqlBoolean True = new SqlBoolean(2);
private SqlBoolean (byte value) { m_value = value; }
private byte m_value;
}
Código inseguro y punteros
C# admite la manipulación directa de la memoria mediante punteros dentro de bloques de código marcados con unsafe y compilados con la opción de compilador /unsafe. Los tipos de punteros son útiles principalmente para la interoperabilidad con las API de C, pero también puedes utilizarlos para acceder a la memoria fuera del montón gestionado o para puntos críticos de rendimiento.
Puntos básicos
Para cada tipo de valor o tipo de referencia V, existe un tipo de puntero V* correspondiente. Una instancia de puntero contiene la dirección de una variable. Los tipos de puntero se pueden convertir (de forma insegura) en cualquier otro tipo de puntero. A continuación se describen los principales operadores de punteros:
| Operario | Significado |
|---|---|
& |
El operador dirección-de devuelve un puntero a la dirección de una variable |
* |
El operador de desreferencia devuelve la variable a la dirección de un puntero |
-> |
El operador puntero a miembro es un atajo sintáctico, en el que x->y equivale a (*x).y |
Código inseguro
Al marcar un tipo, un miembro de tipo o un bloque de sentencia con la palabra clave unsafe, se te permite utilizar tipos de puntero y realizar operaciones de puntero al estilo C++ en la memoria dentro de ese ámbito. He aquí un ejemplo de utilización de punteros para procesar rápidamente un mapa de bits:
unsafe void BlueFilter (int[,] bitmap)
{
int length = bitmap.Length;
fixed (int* b = bitmap)
{
int* p = b;
for (int i = 0; i < length; i++)
*p++ &= 0xFF;
}
}
El código inseguro puede ejecutarse más rápido que su correspondiente implementación segura. En este caso, el código habría requerido un bucle anidado con indexación de matrices y comprobación de límites. Un método C# no seguro también puede ser más rápido que llamar a una función C externa, ya que no hay sobrecarga asociada a la salida del entorno de ejecución gestionado.
La Declaración fija
La sentencia fixed es necesaria para fijar un objeto gestionado, como el mapa de bits del ejemplo anterior. Durante la ejecución de un programa, se asignan y desasignan muchos objetos del montón. Para evitar el desperdicio innecesario o la fragmentación de la memoria, el recolector de basura desplaza los objetos. Señalar un objeto es inútil si su dirección puede cambiar mientras se hace referencia a él, por lo que la sentencia fixed indica al recolector de basura que "fije" el objeto y no lo mueva. Esto puede repercutir en la eficiencia del tiempo de ejecución, por lo que debes utilizar los bloques fixed sólo brevemente, y debes evitar la asignación a la pila dentro del bloque fixed.
Dentro de una sentencia fixed, puedes obtener un puntero a cualquier tipo de valor, a una matriz de tipos de valor o a una cadena. En el caso de las matrices y las cadenas, el puntero apuntará al primer elemento, que es un tipo de valor.
Los tipos de valor declarados en línea dentro de tipos de referencia requieren que el tipo de referencia esté fijado, como se indica a continuación:
class Test
{
int x;
static void Main()
{
Test test = new Test();
unsafe
{
fixed (int* p = &test.x) // Pins test
{
*p = 9;
}
System.Console.WriteLine (test.x);
}
}
}
Describiremos con más detalle la sentencia fixed en "Asignación de una estructura a la memoria no gestionada", en el capítulo 25.
La palabra clave stackalloc
Puedes asignar memoria en un bloque en la pila explícitamente utilizando la palabra clave stackalloc. Como se asigna en la pila, su vida está limitada a la ejecución del método, igual que ocurre con cualquier otra variable local (cuya vida no se haya ampliado por haber sido capturada por una expresión lambda, un bloque iterador o una función asíncrona). El bloque puede utilizar el operador [] para indexar en memoria:
int* a = stackalloc int [10]; for (int i = 0; i < 10; ++i) Console.WriteLine (a[i]); // Print raw memory
En el Capítulo 24, describimos cómo puedes utilizar Span<T> para gestionar la memoria asignada a pilas sin utilizar la palabra clave unsafe:
Span<int> a = stackalloc int [10]; for (int i = 0; i < 10; ++i) Console.WriteLine (a[i]);
Búferes de tamaño fijo
La palabra clave fixed tiene otro uso, que es crear buffers de tamaño fijo dentro de structs (esto puede ser útil cuando se llama a una función no gestionada; ver Capítulo 24):
unsafe struct UnsafeUnicodeString
{
public short Length;
public fixed byte Buffer[30]; // Allocate block of 30 bytes
}
unsafe class UnsafeClass
{
UnsafeUnicodeString uus;
public UnsafeClass (string s)
{
uus.Length = (short)s.Length;
fixed (byte* p = uus.Buffer)
for (int i = 0; i < s.Length; i++)
p[i] = (byte) s[i];
}
}
class Test
{
static void Main() { new UnsafeClass ("Christian Troy"); }
}
Los búferes de tamaño fijo no son matrices: si Buffer fuera una matriz, consistiría en una referencia a un objeto almacenado en el montón (gestionado), en lugar de 30 bytes dentro de la propia estructura.
La palabra clave fixed también se utiliza en este ejemplo para fijar el objeto del montón que contiene el búfer (que será la instancia de UnsafeClass). Por tanto, fixed significa dos cosas distintas: fijo en tamaño y fijo en lugar. Ambas se utilizan a menudo juntas, en el sentido de que un búfer de tamaño fijo debe estar fijo en su lugar para poder ser utilizado.
vacío*
Un puntero vacío (void*) no hace suposiciones sobre el tipo de los datos subyacentes y es útil para funciones que tratan con memoria bruta. Existe una conversión implícita de cualquier tipo de puntero a void*. Un void* no puede ser desreferenciado, y no se pueden realizar operaciones aritméticas con punteros nulos. He aquí un ejemplo:
class Test
{
unsafe static void Main()
{
short[ ] a = {1,1,2,3,5,8,13,21,34,55};
fixed (short* p = a)
{
//sizeof returns size of value-type in bytes
Zap (p, a.Length * sizeof (short));
}
foreach (short x in a)
System.Console.WriteLine (x); // Prints all zeros
}
unsafe static void Zap (void* memory, int byteCount)
{
byte* b = (byte*) memory;
for (int i = 0; i < byteCount; i++)
*b++ = 0;
}
}
Punteros a código no gestionado
Los punteros también son útiles para acceder a datos fuera del montón gestionado (como cuando se interactúa con Bibliotecas de Enlace Dinámico [DLL] de C o con el Modelo de Objetos Componentes [COM]) o cuando se trata de datos que no están en la memoria principal (como la memoria gráfica o un medio de almacenamiento en un dispositivo integrado).
Directivas del preprocesador
Las directivas de preprocesador proporcionan al compilador información adicional sobre regiones de código. Las directivas de preprocesador más comunes son las directivas condicionales, que permiten incluir o excluir regiones de código de la compilación:
#define DEBUG
class MyClass
{
int x;
void Foo()
{
#if DEBUG
Console.WriteLine ("Testing: x = {0}", x);
#endif
}
...
}
En esta clase, la sentencia en Foo se compila como condicionalmente dependiente de la presencia del símbolo DEBUG. Si eliminamos el símbolo DEBUG, la sentencia no se compila. Puedes definir los símbolos del preprocesador dentro de un archivo fuente (como hemos hecho nosotros), o a nivel de proyecto en el archivo .csproj:
<PropertyGroup> <DefineConstants>DEBUG;ANOTHERSYMBOL</DefineConstants> </PropertyGroup>
Con las directivas #if y #elif, puedes utilizar los operadores ||, && y ! para realizar operaciones or, and y not en varios símbolos. La siguiente directiva indica al compilador que incluya el código que sigue si el símbolo TESTMODE está definido y el símbolo DEBUG no lo está:
#if TESTMODE && !DEBUG ...
Ten en cuenta, sin embargo, que no estás construyendo una expresión de C# normal y corriente, y que los símbolos sobre los que operas no tienen ninguna relación con las variables,ya sean estáticaso de otro tipo.
Los símbolos #error y #warning evitan el mal uso accidental de las directivas condicionales haciendo que el compilador genere una advertencia o un error dado un conjunto indeseable de símbolos de compilación. La Tabla 4-1 enumera las directivas del preprocesador.
| Directiva del preprocesador | Acción |
|---|---|
#define symbol |
Define symbol |
#undef symbol |
No define symbol |
#if symbol [operator symbol2]... |
symbol para probar |
operators son ==, !=, &&, y || seguidos de #else, #elif, y #endif |
|
#else |
Ejecuta el código a continuación #endif |
#elif symbol [operator symbol2] |
Combina la rama #else y la prueba #if |
#endif |
Finaliza las directivas condicionales |
#warning text |
text de la advertencia que debe aparecer en la salida del compilador |
#error text |
text del error que aparecerá en la salida del compilador |
#pragma warning [disable | restore] |
Desactiva/restaura la(s) advertencia(s) del compilador |
#line [ number ["file"] | hidden] |
number especifica la línea en el código fuente; file es el nombre de archivo que aparecerá en la salida del ordenador; hidden indica a los depuradores que se salten el código desde este punto hasta la siguiente directiva #line |
#region name |
Marca el inicio de un esquema |
#endregion |
Finaliza una región de contorno |
#nullable option |
Ver "Tipos de referencia anulables (C# 8)" |
Atributos condicionales
Un atributo decorado con el atributo Conditional sólo se compilará si está presente un símbolo de preprocesador determinado:
// file1.cs
#define DEBUG
using System;
using System.Diagnostics;
[Conditional("DEBUG")]
public class TestAttribute : Attribute {}
// file2.cs
#define DEBUG
[Test]
class Foo
{
[Test]
string s;
}
El compilador incorporará los atributos [Test] sólo si el símbolo DEBUG está en el ámbito de file2.cs.
pragma advertencia
El compilador genera una advertencia cuando detecta algo en tu código que parece involuntario. A diferencia de los errores, las advertencias no suelen impedir la compilación de tu aplicación.
Las advertencias del compilador pueden ser muy útiles para detectar errores. Sin embargo, su utilidad se ve mermada cuando recibes advertencias falsas. En una aplicación grande, mantener una buena relación señal-ruido es esencial para que se perciban las advertencias reales.
Para ello, el compilador te permite suprimir selectivamente las advertencias mediante la directiva #pragma warning. En este ejemplo, indicamos al compilador que no nos advierta de que el campo Message no se utiliza:
public class Foo
{
static void Main() { }
#pragma warning disable 414
static string Message = "Hello";
#pragma warning restore 414
}
Omitir el número en la directiva #pragma warning desactiva o restaura todos los códigos de advertencia.
Si eres meticuloso al aplicar esta directiva, puedes compilar con el modificador /warnaserror para que el compilador considere como error cualquier advertencia residual.
Documentación XML
Un comentario de documentación es un fragmento de XML incrustado que documenta un tipo o miembro. Un comentario de documentación aparece inmediatamente antes de la declaración de un tipo o miembro y comienza con tres barras:
/// <summary>Cancels a running query.</summary>
public void Cancel() { ... }
También puedes hacer comentarios multilínea así:
/// <summary>
/// Cancels a running query
/// </summary>
public void Cancel() { ... }
o así (fíjate en la estrella de más al principio):
/**
<summary> Cancels a running query. </summary>
*/
public void Cancel() { ... }
Si añades la siguiente opción a tu archivo .csproj:
<PropertyGroup> <DocumentationFile>SomeFile.xml</DocumentationFile> </PropertyGroup>
el compilador extrae y recopila los comentarios de la documentación en el archivo XML especificado. Esto tiene dos usos principales:
-
Si se coloca en la misma carpeta que el conjunto compilado, herramientas como Visual Studio y LINQPad leen automáticamente el archivo XML y utilizan la información para proporcionar listados de miembros IntelliSense a los consumidores del conjunto del mismo nombre.
-
Herramientas de terceros (como Sandcastle y NDoc) pueden transformar el archivo XML en un archivo de ayuda HTML.
Etiquetas estándar de documentación XML
Éstas son las etiquetas XML estándar que reconocen Visual Studio y los generadores de documentación:
<summary>-
<summary>...</summary>
Indica la información sobre herramientas que IntelliSense debe mostrar para el tipo o miembro; normalmente una sola frase u oración.
<remarks>-
<remarks>...</remarks>
Texto adicional que describe el tipo o miembro. Los generadores de documentación lo recogen y lo integran en el grueso de la descripción de un tipo o miembro.
<param>-
<param name="name">...</param>
Explica un parámetro de un método.
<returns>-
<returns>...</returns>
Explica el valor de retorno de un método.
<exception>-
<exception [cref="type"]>...</exception>
Enumera las excepciones que puede lanzar un método (
crefse refiere al tipo de excepción). <permission>-
<permission [cref="type"]>...</permission>
Indica un tipo
IPermissionrequerido por el tipo o miembro documentado. <example>-
<example>...</example>
Denota un ejemplo (utilizado por los generadores de documentación). Suele contener texto descriptivo y código fuente (el código fuente suele estar dentro de una etiqueta
<c>o<code>). <c>-
<c>...</c>
Indica un fragmento de código en línea. Esta etiqueta suele utilizarse dentro de un bloque
<example>. <code>-
<code>...</code>
Indica una muestra de código multilínea. Esta etiqueta suele utilizarse dentro de un bloque
<example>. <see>-
<see cref="member">...</see>
Inserta una referencia cruzada en línea a otro tipo o miembro. Los generadores de documentación HTML suelen convertirlo en un hipervínculo. El compilador emite una advertencia si el nombre del tipo o miembro no es válido. Para hacer referencia a tipos genéricos, utiliza llaves; por ejemplo,
cref="Foo{T,U}". <seealso>-
<seealso cref="member">...</seealso>
Hace referencia a otro tipo o miembro. Los generadores de documentación suelen escribir esto en una sección separada "Véase también" al final de la página.
<paramref>-
<paramref name="name"/>
Hace referencia a un parámetro desde dentro de una etiqueta
<summary>o<remarks>. <list>-
<list type=[ bullet | number | table ]> <listheader> <term>...</term> <description>...</description> </listheader> <item> <term>...</term> <description>...</description> </item> </list>Indica a los generadores de documentación que emitan una lista con viñetas, numerada o en forma de tabla.
<para>-
<para>...</para>
Indica a los generadores de documentación que formateen el contenido en un párrafo aparte.
<include>-
<include file='filename' path='tagpath[@name="id"]'>...</include>
Fusiona un archivo XML externo que contenga documentación. El atributo
pathdenota una consulta XPath a un elemento concreto de ese archivo.
Etiquetas definidas por el usuario
Las etiquetas XML predefinidas reconocidas por el compilador de C# tienen poco de especial, y eres libre de definir las tuyas propias. El único procesamiento especial que realiza el compilador es sobre la etiqueta <param> (en la que verifica el nombre del parámetro y que todos los parámetros del método estén documentados) y el atributo cref (en el que verifica que el atributo se refiere a un tipo o miembro real y lo expande a un ID de tipo o miembro totalmente cualificado). También puedes utilizar el atributo cref en tus propias etiquetas; se verifica y expande igual que en las etiquetas predefinidas <exception>, <permission>, <see> y <seealso>.
Tipo o miembro Referencias cruzadas
Los nombres de tipo y las referencias cruzadas de tipo o miembro se traducen en ID que definen de forma única el tipo o miembro. Estos nombres se componen de un prefijo que define lo que representa el ID y una firma del tipo o miembro. A continuación se indican los prefijos de los miembros:
| Prefijo de tipo XML | Prefijos ID aplicados a... |
|---|---|
N |
Espacio de nombres |
T |
Tipo (class, struct, enum, interface, delegate) |
F |
Campo |
P |
Propiedad (incluye indexadores) |
M |
Método (incluye métodos especiales) |
E |
Evento |
! |
Error |
Las reglas que describen cómo se generan las firmas están bien documentadas, aunque son bastante complejas.
Aquí tienes un ejemplo de un tipo y los ID que se generan:
// Namespaces do not have independent signatures
namespace NS
{
/// T:NS.MyClass
class MyClass
{
/// F:NS.MyClass.aField
string aField;
/// P:NS.MyClass.aProperty
short aProperty {get {...} set {...}}
/// T:NS.MyClass.NestedType
class NestedType {...};
/// M:NS.MyClass.X()
void X() {...}
/// M:NS.MyClass.Y(System.Int32,System.Double@,System.Decimal@)
void Y(int p1, ref double p2, out decimal p3) {...}
/// M:NS.MyClass.Z(System.Char[ ],System.Single[0:,0:])
void Z(char[ ] p1, float[,] p2) {...}
/// M:NS.MyClass.op_Addition(NS.MyClass,NS.MyClass)
public static MyClass operator+(MyClass c1, MyClass c2) {...}
/// M:NS.MyClass.op_Implicit(NS.MyClass)~System.Int32
public static implicit operator int(MyClass c) {...}
/// M:NS.MyClass.#ctor
MyClass() {...}
/// M:NS.MyClass.Finalize
~MyClass() {...}
/// M:NS.MyClass.#cctor
static MyClass() {...}
}
}
Get C# 8.0 en pocas palabras now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

