Chapter 4. Discovering Micro-Frontend Architectures
In the previous chapter, we learned about decisions framework, the foundation of any micro-frontend architecture. In this chapter, we will review the different architecture choices, applying what we have learned so far.
Micro-Frontend Decisions Framework Applied
The decisions framework helps you to choose the right approach for your micro-frontend project based on its characteristics (see Figure 4-1). Your first decision will be between a horizontal and vertical split.

Figure 4-1. The micro-frontends decisions framework
Tip
The micro-frontends decisions framework helps you determine the best architecture for a project.
Vertical Split
A vertical split offers fewer choices, and because they are likely well known by frontend developers who are used to writing single-page applications (SPAs), only the client-side choice is shown in Figure 4-1. You’ll find a vertical split helpful when your project requires a consistent user interface evolution and a fluid user experience across multiple views. That’s because a vertical split provides the closest developer experience to an SPA, and therefore the tools, best practices, and patterns can be used for the development of a micro-frontend.
Although technically you can serve vertical-split micro-frontends with any composition, so far all the explored implementations have a client-side composition in which an application shell is responsible for mounting and unmounting micro-frontends, leaving us with one composition method to choose from. The relation between a micro-frontend and the application shell is always one to one, so therefore the application shell loads only one micro-frontend at a time. You’ll also want to use client-side routing. The routing is usually split in two parts, with a global routing used for loading different micro-frontends being handled by the application shell (see Figure 4-2).

Figure 4-2. The application shell is responsible for global routing between micro-frontends
Although the local routing between views inside the same micro-frontend is managed by the micro-frontend itself, you’ll have full control of the implementation and evolution of the views present inside it since the team responsible for a micro-frontend is also the subject-matter expert on that business domain of the application (Figure 4-3).
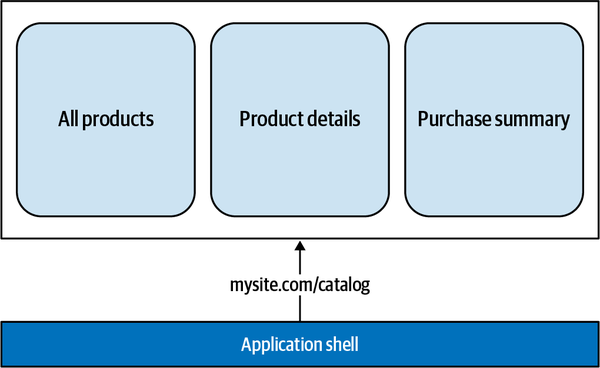
Figure 4-3. A micro-frontend is responsible for routing between views available inside the micro-frontend itself
Finally, for implementing an architecture with a vertical-split micro-frontend, the application shell loads HTML or JavaScript as the entry point. The application shell shouldn’t share any business domain logic with the other micro-frontends and should be technology agnostic to allow future system evolution, so you don’t want to use any specific UI framework for building an application shell. Try Vanilla JavaScript if you built your own implementation.
The application shell is always present during users’ sessions because it’s responsible for orchestrating the web application as well as exposing some life cycle APIs for micro-frontends in order to react when they are fully mounted or unmounted.
When vertical-split micro-frontends have to share information with other micro-frontends, such as tokens or user preferences, we can use query strings for volatile data, or web storages for tokens or user preferences, similar to how the horizontal split ones do between different views.
Horizontal Split
A horizontal split works well when a business subdomain should be presented across several views and therefore reusability of the subdomain becomes key for the project; when search engine optimization is a key requirement of your project and you want to use a server-side rendering approach; when your frontend application requires tens if not hundreds of developers working together and you have to split more granular our subdomains; or when you have a multitenant project with customer customizations in specific parts of your software.
The next decision you’ll make is between client-side, edge-side, and server-side compositions. Client side is a good choice when your teams are more familiar with the frontend ecosystem or when your project is subject to high traffic with significant spikes, for instance. You’ll avoid dealing with scalability challenges on the frontend layer because you can easily cache your micro-frontends, leveraging a content delivery network (CDN).
You can use edge-side composition for a project with static content and high traffic in order to delegate the scalability challenge to the CDN provider instead of having to deal with it in your infrastructure. As we discussed in Chapter 3, embracing this architecture style has some challenges, such as its complicated developer experience and the fact that not all CDNs support it. But projects like online catalog with no personalized content may be a good candidate for this approach.
Server-side composition gives us the most control of our output, which is great for highly indexed websites, such as news sites or ecommerce. It’s also a good choice for websites that require great performance metrics, similar to PayPal and American Express, both of which use server-side composition.
Next is your routing strategy. While you can technically apply any routing to any composition, it’s common to use the routing strategy associated with your chosen composition pattern. If you choose a client-side composition, for example, most of the time, routing will happen at the client-side level. You might use computation logic at the edge (using Lambda@Edge in case of AWS or Workers in CloudFlare) to avoid polluting the application shell’s code with canary releases or to provide an optimized version of your web application to search engine crawlers leveraging the dynamic rendering capability.
On the other hand, an edge-side composition will have an HTML page associated with each view, so every time a user loads a new page, a new page will be composed in the CDN, which will retrieve multiple micro-frontends to create that final view. Finally, with server-side routing, the application server will know which HTML template is associated with a specific route; routing and composition happen on the server side.
Your composition choice will also help narrow your technical solutions for building a micro-frontends project. When you use client-side composition and routing, your best implementation choice is an application shell loading multiple micro-frontends in the same view with the webpack plug-in called Module Federation, with iframes, or with web components, for instance. For the edge-side composition, the only solution available is using edge-side includes (ESI). We are seeing hints that this may change in the future, as cloud providers extend their edge services to provide more computational and storage resources. For now, though, ESI is the only option. And when you decide to use server-side composition, you can use server-side includes (SSI) or one of the many SSR frameworks for your micro-frontend applications. Note that SSRs will give you greater flexibility and control over your implementation.
Missing from the decisions framework is the final pillar: how the micro-frontends will communicate when they are in the same or different views. This is mainly because when you select a horizontal split, you have to avoid sharing any state across micro-frontends; this approach is an antipattern. Instead, you’ll use the techniques mentioned in Chapter 3, such as an event emitter, custom events, or reactive streams using an implementation of the publish/subscribe (pub/sub) pattern for decoupling the micro-frontends and maintaining their independent nature. When you have to communicate between different views, you’ll use a query string parameter to share volatile data, such as product identifiers, and web storage/cookies for persistent data, such as users’ tokens or local users’ settings.
Architecture Analysis
To help you better choose the right architecture for your project, we’ll now analyze the technical implementations, looking at challenges and benefits. We’ll review the different implementations in detail and then assess the characteristics for each architecture. The characteristics we’ll analyze for every implementation:
- Deployability
- Reliability and ease of deploying a micro-frontend in an environment.
- Modularity
- Ease of adding or removing micro-frontends and ease of integrating with shared components hosted by micro-frontends.
- Simplicity
- Ease of being able to understand or do. If a piece of software is considered simple, it has likely been found to be easy to understand and to reason about.
- Testability
- Degree to which a software artifact supports testing in a given test context. If the testability of the software artifact is high, then finding faults in the system by means of testing is easier.
- Performance
- Indicator of how well a micro-frontend would meet the quality of user experience described by web vitals, essential metrics for a healthy site.
- Developer experience
- The experience developers are exposed to when they use your product, be it client libraries, SDKs, frameworks, open source code, tools, API, technology, or services.
- Scalability
- The ability of a process, network, software, or organization to grow and manage increased demand.
- Coordination
- Unification, integration, or synchronization of group members’ efforts in order to provide unity of action in the pursuit of common goals.
Characteristics are rated on a five-point scale, with one point indicating that the specific architecture characteristic isn’t well supported and five points indicating that the architecture characteristic is one of the strongest features in the architectural pattern. The score indicates which architecture characteristic shines better with every approach described. It’s almost impossible having all the characteristics working perfectly in an architecture due to the tension they exercise with each other. Our role would be to find the trade-off suitable for the application we have to build, hence the decision to create a score mechanism to evaluate all of these architectural approaches.
Architecture and Trade-offs
As I pointed out elsewhere in this book, I firmly believe that the perfect architecture doesn’t exist; it’s always a trade-off. The trade-offs are not only technical but also based on business requirements and organizational structure. Modern architecture considers other forces that contribute to the final outcome as well as technical aspects. We must recognize the sociotechnical aspects and optimize for the context we operate in instead of searching for the “perfect architecture” (which doesn’t exist) or borrowing the architecture from another context without researching whether it would be appropriate for our context.
In Fundamentals of Software Architecture, Neal Ford and Mark Richards highlight very well these new architecture practices and invite the readers to optimize for the “least worst” architecture. As they state, “Never shoot for the best architecture, but rather the least worst architecture.”
Before settling on a final architecture, take the time to understand the context you operate in, your teams’ structures, and the communication flows between teams. When we ignore these aspects, we risk creating a great technical proposition that’s completely unsuitable for our company. It’s the same when we read case studies from other companies embracing specific architectures. We need to understand how the company works and how that compares to how our company works. Often the case studies focus on how a company solved a specific problem, which may or may not overlap with your challenges and goals. It’s up to you to find out if the case study’s challenges match your own.
Read widely and talk with different people in the community to understand the forces behind certain decisions. Taking the time to research will help you avoid making wrong assumptions and become more aware of the environment you are working in.
Every architecture is optimized for solving specific technical and organizational challenges, which is why we see so many approaches to micro-frontends. Remember: there isn’t right or wrong in architecture, just the best trade-off for your own context.
Vertical-Split Architectures
For a vertical-split architecture, a client-side composition, client-side routing, and an application shell, as described above, are fantastic for teams with a solid background of building SPAs for their first foray into micro-frontends, because the development experience will be mostly familiar. This is probably also the easiest way to enter the micro-frontend world for developers with a frontend background.
Application Shell
A persistent part of a micro-frontend application, the application shell is the first thing downloaded when an application is requested. It will shepherd a user session from the beginning to the end, loading and unloading micro-frontends based on the endpoint the user requests. The main reasons to load micro-frontends inside an application shell include:
- Handling the initial user state (if any)
- If a user tries to access an authenticated route via a deep link but the user token is invalid, the application shell redirects the user to the sign-in view or a landing page. This process is needed only for the first load, however. After that, every micro-frontend in an authenticated area of a web application should manage the logic for keeping the user authenticated or redirecting them to an unauthenticated page.
- Retrieving global configurations
- When needed, the application shell should first fetch a configuration that contains any information used across the entire user sessions, such as the user’s country if the application provides different experiences based on country.
- Fetching the available routes and associated micro-frontends to load
- To avoid needlessly deploying the application shell, the route configurations should be loaded at runtime with the associated micro-frontends. This will guarantee control of the routing system without deploying the application shell multiple times.
- Setting logging, observability, or marketing libraries
- Because these libraries are usually applied to the entire application, it’s best to instantiate them at the application shell level.
- Handling errors if a micro-frontend cannot be loaded
- Sometimes micro-frontends are unreachable due to a network issue or bug in the system. It’s wise to add an error message (a 404 page, for instance) to the application shell or load a highly available micro-frontend to display errors and suggest possible solutions to the user, like suggesting similar products or asking them to come back later.
You could achieve similar results by using libraries in every micro-frontend rather than using an orchestrator like the application shell. However, ideally you want just one place to manage these things from. Having multiple libraries means ensuring they are always in sync between micro-frontends, which requires more coordination and adds complexity to the entire process. Having multiple libraries also creates risk in the deployment phase, where there are breaking changes, compared to centralizing libraries inside the application shell.
Never use the application shell as a layer to interact constantly with micro-frontends during a user session. The application shell should only be used for edge cases or initialization. Using it as a shared layer for micro-frontends risks having a logical coupling between micro-frontends and the application shell, forcing testing and/or redeployment of all micro-frontends available in an application. This situation is also called a distributed monolith and is a developer’s worst nightmare.
In this pattern, the application shell loads only one micro-frontend at a time. That means you don’t need to create a mechanism for encapsulating conflicting dependencies between micro-frontends because there won’t be any clash between libraries or CSS styles (see Figure 4-4), as long as both are removed from the window object when a micro-frontend is unloaded.
The application shell is nothing more than a simple HTML page with logic wrapped in a JavaScript file. Some CSS styles may or may not be included in the application shell for the initial loading experience, such as for showing a loading animation like a spinner. Every micro-frontend entry point is represented by a single HTML page containing the logic and style of a single view or a small SPA containing several routes that include all the logic needed to allow a user to consume an entire subdomain of the application without a new micro-frontend needing to load. A JavaScript file could be loaded instead as a micro-frontend entry point, but in this case we are limited by the initial customer experience, because we have to wait until the JavaScript file is interpreted before it can add new elements into the domain object model (DOM).

Figure 4-4. Vertical-split architecture with client-side composition and routing using the application shell
The vertical split works well when we want to create a consistent user experience while providing full control to a single team. A clear sign that this may be the right approach for your application is when you don’t have many repetitions of business subdomains across multiple views but every part of the application may be represented by an application itself.
Identifying micro-frontends becomes easy when we have a clear understanding of how users interact with the application. If you use an analytics tool like Google Analytics, you’ll have access to this information. If you don’t have this information, you’ll need to get it before you can determine how to structure the architecture, business domains, and your organization. With this architecture, there isn’t a high reusability of micro-frontends, so it’s unlikely that a vertical-split micro-frontend will be reused in the same application multiple times.
However, inside every micro-frontend we can reuse components (think about a design system), generating a modularity that helps avoid too much duplication. It’s more likely, though, that micro-frontends will be reused in different applications maintained by the same company. Imagine that in a multitenant environment, you have to develop multiple platforms and you want to have a similar user interface with some customizations for part of every platform. You will be able to reuse vertical-split micro-frontends, reducing code fragmentation and evolving the system independently based on the business requirements.
Challenges
Of course, there will be some challenges during the implementation phase, as with any architecture pattern. Apart from domain-specific ones, we’ll have common challenges, some of which have an immediate answer, while others will depend more on context. Let’s look at four major challenges: a sharing state, the micro-frontends composition, a multiframework approach, and the evolution of your architecture.
Sharing state
The first challenge we face when we work with micro-frontends in general is how to share states between micro-frontends. While we don’t need to share information as much with a vertical-split architecture, the need still exists.
Some of the information that we may need to share across multiple micro-frontends are fine when stored via web storage, such as the audio volume level for media the user played or the fonts recently used to edit a document.
When information is more sensitive, such as personal user data or an authentication token, we need a way to retrieve this information from a public API and then share across all the micro-frontends interested in this information. In this case, the first micro-frontend loaded at the beginning of the user’s session would retrieve this data, stored in a web storage with a retrieval time stamp. Then every micro-frontend that requires this data can retrieve it directly from the web storage, and if the time stamp is older than a preset amount of time, the micro-frontend can request the data again. And because the application loads only one micro-frontend at a time and every micro-frontend will have access to the selected web storage, there is no strong requirement to pass through the application shell for storing data in the web storage.
However, let’s say that your application relies heavily on the web storage, and you decide to implement security checks to validate the space available or type of message stored. In this scenario, you may want to instead create an abstraction via the application shell that will expose an API for storing and retrieving data. This will centralize where the data validation happens, providing meaningful errors to every micro-frontend in case a validation fails.
Composing micro-frontends
You have several options for composing vertical-split micro-frontends inside an application shell. Remember, however, that vertical-split micro-frontends are composed and routed on the client side only, so we are limited to what the browser’s standards offer us. There are four techniques for composing micro-frontends on the client side:
- ES modules
-
JavaScript modules can be used to split our applications into smaller files to be loaded at compile time or at runtime, fully implemented in modern browsers. This can be a solid mechanism for composing micro-frontends at runtime using standards. To implement an ES module, we simply define the module attribute in our script tag and the browser will interpret it as a module:
<scripttype="module"src="catalogMFE.js"></script>This module will be always deferred and can implement cross-origin resource sharing (CORS) authentication. ES modules can also be defined for the entire application inside an import map, allowing us to use the syntax to import a module inside the application. As of publication time, the main problem with import maps is that they are not supported by all the browsers. You’ll be limited to Google Chrome, Microsoft Edge (with Chromium engine), and recent versions of Opera, limiting this solution’s viability.
- SystemJS
- This module loader supports import maps specifications, which are not natively available inside the browser. This allows them to be used inside the SystemJS implementation, where the module loader library makes the implementation compatible with all the browsers. This is a handy solution when we want our micro-frontends to load at runtime, because it uses a syntax similar to import maps and allows SystemJS to take care of the browser’s API fragmentation.
- Module Federation
- This is a plug-in introduced in webpack 5 used for loading external modules, libraries, or even entire applications inside another one. The plug-in takes care of the undifferentiated heavy lifting needed for composing micro-frontends, wrapping the micro-frontends’ scope and sharing dependencies between different micro-frontends or handling different versions of the same library without runtime errors. The developer experience and the implementation are so slick that it would seem like writing a normal SPA. Every micro-frontend is imported as a module and then implemented in the same way as a component of a UI framework. The abstraction made by this plug-in makes the entire composition challenge almost completely painless.
- HTML parsing
- When a micro-frontend has an entry point represented by an HTML page, we can use JavaScript for parsing the DOM elements and append the nodes needed inside the application shell’s DOM. At its simplest, an HTML document is really just an XML document with its own defined schema. Given that, we can treat the micro-frontend as an XML document and append the relevant nodes inside the shell’s DOM using the DOMParser object. After parsing the micro-frontend DOM, we then append the DOM nodes using adoptNode or cloneNode methods. However, using cloneNode or adoptNode doesn’t work with the script element, because the browser doesn’t evaluate the script element, so in this case we create a new one, passing the source file found in the micro-frontend’s HTML page. Creating a new script element will trigger the browser to fully evaluate the JavaScript file associated with this element. In this way, you can even simplify the micro-frontend developer experience because your team will provide the final results knowing how the initial DOM will look. This technique is used by some frameworks, such as qiankun, which allows HTML documents to be micro-frontend entry points.
All the major frameworks composed on the client side implement these techniques, and sometimes you even have options to pick from. For example, with single SPA you can use ES modules, SystemJS with import maps, or Module Federation.
All these techniques allow you to implement static or dynamic routes. In the case of static routes, you just need to hardcode the path in your code. With dynamic path, you can retrieve all the routes from a static JSON file to load at the beginning of the application or create something more dynamic by developing an endpoint that can be consumed by the application shell and where you apply logic based on the user’s country or language for returning the final routing list.
Multiframework approach
Using micro-frontends for a multiframework approach is a controversial decision, because many people think that this forces them to use multiple UI frameworks, like React, Angular, Vue, or Svelte. But what is true for frontend applications written in a monolithic way is also true for micro-frontends.
Although technically you can implement multiple UI frameworks in an SPA, it creates performance issues and potential dependency clashes. This applies to micro-frontends as well, so using a multiframework implementation for this architecture style isn’t recommended.
Instead, follow best practices like reducing external dependencies as much as you can, importing only what you use rather than entire packages that may increase the final JavaScript bundle. Many JavaScript tools implement a tree-shaking mechanism to help achieve smaller bundle sizes.
There are some use cases in which the benefits of having a multiframework approach with micro-frontends outweigh the challenges, such as when we can create a healthy flywheel for developers, reducing the time to market of their business logic without affecting production traffic.
Imagine you start porting a frontend application from an SPA to micro-frontends. Working on a micro-frontend and deploying the SPA codebase alongside it would help you to provide value for your business and users.
First, we would have a team finding best practices for approaching the porting (such as identifying libraries to reuse across micro-frontends), setting up the automation pipeline, sharing code between micro-frontends, and so on. Second, after creating the minimum viable product (MVP), the micro-frontend can be shipped to the final user, retrieving metrics and comparing with the older version. In a situation like this, asking a user to download multiple UI frameworks is less problematic than developing the new architecture for several months without understanding if the direction is leading to a better result. Validating your assumptions is crucial for generating the best practices shared by different teams inside your organization. Improving the feedback loop and deploying code to production as fast as possible demonstrates the best approach for overcoming future challenges with microarchitectures in general.
You can apply the same reasoning to other libraries in the same application but with different versions, such as when you have a project with an old version of Angular and you want to upgrade to the latest version.
Remember, the goal is creating the muscles for moving at speed with confidence and reducing the potential mistakes automating what is possible and fostering the right mindset across the teams. Finally, these considerations are applicable to all the micro-frontend architecture shared in this book.
Architecture evolution and code encapsulation
Perfectly defining the subdomains on the first try isn’t always feasible. In particular, using a vertical-split approach may result in coarse-grained micro-frontends that become complicated after several months of work because of broadening project scope as the team’s capabilities grow. Also, we can have new insights into assumptions we made at the beginning of the process. Fear not! This architecture’s modular nature helps you face these challenges and provides a clear path for evolving it alongside the business. When your team’s cognitive load starts to become unsustainable, it may be time to split your micro-frontend. One of the many best practices for splitting a micro-frontend is code encapsulation, which is based on a specific user flow. Let’s explore it!
The concept of encapsulation comes from object-oriented programming (OOP) and is associated with classes and how to handle data. Encapsulation binds together the attributes (data) and the methods (functions and procedures) that manipulate the data in order to protect the data. The general rule, enforced by many languages, is that attributes should only be accessed (that is, retrieved or modified) using methods that are contained (encapsulated) within the class definition.
Imagine your micro-frontend is composed of several views, such as a payment form, sign-up form, sign-in form, and email and password retrieval form, as shown in Figure 4-5.

Figure 4-5. Authentication micro-frontend composed of several views that may create a high cognitive load for the team responsible for this micro-frontend
An existing user accessing this micro-frontend is more likely to sign in to the authenticated area or want to retrieve their account email or password, while a new user is likely to sign up or make a payment. A natural split for this micro-frontend, then, could be one micro-frontend for authentication and another for subscription. In this way, you’ll separate the two according to business logic without having to ask the users to download more code than the flow would require (see Figure 4-6).

Figure 4-6. Splitting the authentication micro-frontend to reduce the cognitive load, following customer experience more than technical constraints
This isn’t the only way to split this micro-frontend, but however you split it, be sure you’re prioritizing a business outcome rather than a technical one. Prioritizing the customer experience is the best way to provide a final output that your users will enjoy.
Encapsulation helps with these situations. For instance, avoid having a unique state representing the entire micro-frontend. Instead, prefer state management libraries that allow composition of state, like MobX-State-Tree does. The data will be expressed in tree structure, which you can compose at will. Spend the time evaluating how to implement the application state, and you may save time later while also reducing your cognitive load. It is always easier to think when the code is well identified inside some boundaries than when it’s spread across multiple parts of the application.
When libraries or even logic are used in multiple domains, such as in a form validation library, you have a few options:
- Duplicate the code
- Code duplication isn’t always a bad practice; it depends on what you are optimizing for and overall impact of the duplicated code. Let’s say that you have a component that has different states based on user status and the view where it’s hosted, and that this component is subject to new requirements more often in one domain than in others. You may want to centralize it. Keep in mind, though, that every time you have a centralized library or component, you have to build a solid governance for making sure that when this shared code is updated, it also gets updated in every micro-frontend that uses this shared code as well. When this happens, you also have to make sure the new version doesn’t break anything inside each micro-frontend and you need to coordinate the activity across multiple teams. In this case, the component isn’t difficult to implement and it will become easier to build for every team that uses it, because there are fewer states to take care of. That allows every implementation to evolve independently at its own speed. Here, we’re optimizing for speed of delivery and reducing the external dependencies for every team. This approach works best when you have a limited amount of duplication. When you have dozens of similar components, this reasoning doesn’t scale anymore; you’ll want to abstract into a library instead.
- Abstract your code into a shared library
- In some situations, you really want to centralize the business logic to ensure that every micro-frontend is using the same implementation, as with integrating payment methods. Imagine implementing in your checkout form multiple payment methods with their validation logic, handling errors, and so on. Duplicating such a complex and delicate part of the system isn’t wise. Creating a shared library instead will help maintain consistency and simplify the integration across the entire platform. Within the automation pipelines, you’ll want to add a version check on every micro-frontend to review the latest library version. Unfortunately, while dealing with distributed systems helps you scale the organization and deliver with speed, sometimes you need to enforce certain practices for the greater good.
- Delegate to a backend API
- The third option is to delegate the common part to be served to all your vertical-split micro-frontends by the backend, thus providing some configuration and implementation of the business logic to each micro-frontend. Imagine you have multiple micro-frontends that are implementing an input field with specific validation that is simple enough to represent with a regular expression. You might be tempted to centralize the logic in a common library, but this would mean enforcing the update of this dependency every time something changes. Considering the logic is easy enough to represent and the common part would be using the same regular expression, you can provide this information as a configuration field when the application loads and make it available to all the micro-frontends via the web storage. That way, if you want to change the regular expression, you won’t need to redeploy every micro-frontend implementing it. You’ll just change the regular expression in the configuration, and all the micro-frontends will automatically use the latest implementation.
It’s important to understand that no solution fits everything. Consider the context your implementation should represent and choose the best trade-off in the guardrails you are operating with. Could you have designed the micro-frontends in this way from the beginning? Potentially, you could have, but the whole point of this architecture is to avoid premature abstractions, optimize for fast delivery, and evolve the architecture when it is required due to complexity or just a change of direction.
Implementing a Design System
In a distributed architecture like micro-frontends, design systems may seem a difficult feature to achieve, but in reality the technical implementation doesn’t differ too much from that of a design system in an SPA. When thinking about a design system applied to micro-frontends, imagine a layered system composed of design tokens, basic components, user interface library, and the micro-frontends that host all these parts together, as shown in Figure 4-7.

Figure 4-7. How a design system fits inside a micro-frontends architecture
The first layer, design tokens, allows you to capture low-level values to then create the styles for your product, such as font families, text colors, text size, and many other characteristics used inside our final user interface. Generally, design tokens are listed in JSON or YAML files, expressing every detail of our design system.
We don’t usually distribute design tokens across different micro-frontends because each team will implement them in their own way, risking the introduction of bugs in some areas of the application and not in others, increasing the code duplication across the system, and, in general, slowing down the maintenance of a design system. However, there are situations when design tokens can be an initial step for creating a level of consistency for iterating later on, with basic components shared across all the micro-frontends. Often, teams do not have enough space for implementing the final design system components inside every micro-frontend. Therefore, make sure if you go down this path that you have the time and space for iterating on the design system.
The next layer is basic components. Usually, these components don’t hold the application business logic and are completely unaware of where they will be used. As a result, they should be as generic as can be, such as a label or button, which will provide the consistency we are looking for and the flexibility to be used in any part of the application.
This is the perfect stage for centralizing the code that will be used across multiple micro-frontends. In this way, we create the consistency needed in the UI to allow every team to use components at the level they need.
The third layer is a UI components library, usually a composition of basic components that contain some business logic that is reusable inside a given domain. We may be tempted to share these components as well, but be cautious in doing so. The governance to maintain and the organization structure may cause many external dependencies across teams, creating more frustration than efficiencies. One exception is when there are complex UI components that require a lot of iterations and there is a centralized team responsible for them. Imagine, for instance, building a complex component such as a video player with several functionalities, such as closed captions, a volume bar, and trick play. Duplicating these components is a waste of time and effort; centralizing and abstracting your code is by far more efficient.
Note, though, that shared components are often not reused as much as we expect, resulting in a wasted effort. Therefore, think twice before centralizing a component. When in doubt, start duplicating the component and, after a few iterations, review whether these components need to be abstracted. The wrong abstraction is way more expensive than duplicated code.
The final layer is the micro-frontend that is hosting the UI components library. Keep in mind the importance of a micro-frontend’s independence. The moment we get more than three or four external dependencies, we are heading toward a distributed monolith. That’s the worst place to be because we are treating a distributed architecture like a monolith that we wanted to move away from, no longer creating independent teams across the organization.
To ensure we are finding the right trade-offs between development speed and independent teams and UI consistency, consider validating the dependencies monthly or every two months throughout the project life cycle. In the past, I’ve worked at companies where this exercise was done every two weeks at the end of every sprint, and it helped many teams postpone tasks that may not have been achievable during a sprint due to blocks from external dependencies. In this way, you’ll reduce your teams’ frustration and increase their performance.
On the technical side, the best investment you can make for creating a design system is in web components. Since you can use web components with any UI framework, should you decide to change the UI framework later, the design system will remain the same, saving you time and effort. There are some situations in which using web components is not viable, such as projects that have to target old browsers. Chances are, though, you won’t have such strong requirements and you can target modern browsers, allowing you to leverage web components with your micro-frontend architecture.
While getting the design system ready to be implemented is half the work, to accomplish the delivery inside your micro-frontends architecture, you’ll need a solid governance to maintain that initial investment. Remember, dealing with a distributed architecture is not as straightforward as you can imagine. Usually, the first implementation happens quite smoothly because there is time allocated to that. The problems come with subsequent updates. Especially when you deal with distributed teams, the best approach is to automate the system design version validation in the continuous integration (CI) phase. Every time a micro-frontend is built, the package.json file should check that the design system library is up to date with the latest version.
Implementing this check in CI allows you to be as strict as needed. You may decide to provide a warning in the logs, asking to update the version as soon as possible, or prevent artifact creation if the micro-frontend is one or more major versions behind.
Some companies have custom dashboards for dealing with this problem, not only for design systems but also for other libraries, such as logging or authentication. In this way, every team can check in real time whether their micro-frontend implements the latest versions.
Finally, let’s consider the team’s structure. Traditionally, in enterprise companies, the design team is centralized, taking care of all the aspects of the design system, from ideation to delivery, and the developers just implement the library the design team provides. However, some companies implement a distributed model wherein the design team is a central authority that provides the core components and direction for the entire design system, but other teams populate the design system with new components or new functionalities of existing ones. In this second approach, we reduce potential bottlenecks by allowing the development teams to contribute to the global design system. Meanwhile, we keep guardrails in place to ensure every component respects the overall plan, such as regular meetings between design and development, office hours during which the design team can guide development teams, or even collaborative sessions where the design team sets the direction but the developers actually implement the code inside the design system.
Developer Experience
For vertical-split micro-frontends, the developer’s experience is very similar to SPAs. However, there are a couple of suggestions that you may find useful to think about up front. First of all, create a command line tool for scaffolding micro-frontends with a basic implementation and common libraries you would like to share in all the micro-frontends such as a logging library. While not an essential tool to have from day one, it’s definitely helpful in the long term, especially for new team members. Also, create a dashboard that summarizes the micro-frontend version you have in different environments. In general, all the tools you are using for developing an SPA are still relevant for a vertical-split micro-frontend architecture. We will discuss this topic more in depth in Chapter 7, where we review how to create automation pipelines for micro-frontend applications.
Search Engine Optimization
Some projects require a strong SEO strategy, including micro-frontend projects. Let’s look at two major options for a good SEO strategy with vertical-split micro-frontends. The first one involves optimizing the application code in a way that is easily indexable by crawlers. In this case, the developer’s job is implementing as many best practices as possible for rendering the entire DOM in a timely manner (usually under five seconds). Time matters with crawlers, because they have to index all the data in a view and also structure the UI in a way that exposes all the meaningful information without hiding behind user interactions. Another option is to create an HTML markup that is meaningful for crawlers to extract the content and categorize it properly. While this isn’t impossible, in the long run, this option may require a bit of effort to maintain for every new feature and project enhancement.
Another option would be using dynamic rendering to provide an optimized version of your web application for all the crawlers trying to index your content. Google introduced dynamic rendering to allow you to redirect crawler requests to an optimized version of your website, usually prerendered, without penalizing the positioning of your website in the search engine results (see Figure 4-8).
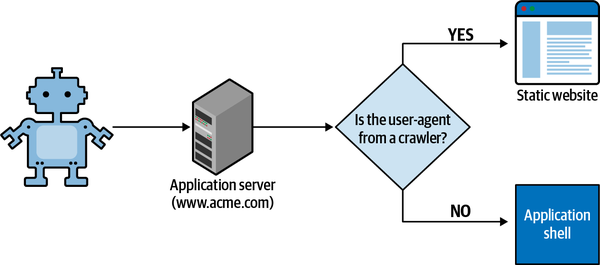
Figure 4-8. When a crawler requests a specific page, the application server should retrieve the user-agent and serve the crawler’s requests to a prerendered version of the website, otherwise serving the micro-frontend implementation
There are a couple of solutions for serving a prerendered version of your application to a crawler. First, for the prerendering phase, you can create a customized version of your website that fetches the same data of the website your users will consume. For instance, you can create a server-side rendering output stored in an objects storage that translates a template into static HTML pages at compile time, maintaining the same user-facing URL structure. Amazon S3 is a good choice for this. You can also decide to server-side render at runtime, eliminating the need to store the static pages and serving the crawlers a just-in-time version created ad hoc for them. Although this solution requires some effort to implement, it allows you the best customization and optimization for improving the final output to the crawler.
A second option would be using an open source solution like Puppeteer or Rendertron to scrape the code from the website created for the users and then deploy a web server that generates static pages regularly.
After generating the static version of your website, you need to know when the request is coming from a browser and when from a crawler. A basic implementation would be using a regular expression that identifies the crawler’s user-agents. A good Node.js library for that is crawler-user-agents. In this case, after identifying the user-agent header, the application server can respond with the correct implementation. This solution can be applied at the edge using technologies like AWS Lambda@Edge or Cloudflare Workers. In this case, CDNs of some cloud providers allow a computation layer after receiving a request. Because there are some constraints on the maximum execution time of these containers, the user-agent identification represents a good reason for using these edge technologies. Moreover, they can be used for additional logic, introducing canary releases or blue-green deployment, as we will see in Chapter 6.
Performance and Micro-Frontends
Is good performance achievable in a micro-frontend architecture? Definitely! Performance of a micro-frontend architecture, like in any other frontend architecture, is key for the success of a web application. And a vertical-split architecture can achieve good performance thanks to the split of domains and, therefore, the code to be shared with a client.
Think for a moment about an SPA. Typically, the user has to download all the code specifically related to the application, the business logic, and the libraries used in the entire application. For simplicity, let’s imagine that an entire application code is 500 KB. The unauthenticated area, composed of sign-in, sign-up, the landing page, customer support, and few other views, requires 100 KB of business logic, while the authenticated area requires 150 KB of business logic. Both use the same bundled dependencies that are each 250 KB (see Figure 4-9).
A new user has to download all 500 KB, despite the action having to fulfill inside the SPA. Maybe one user just wants to understand the business proposition and visits just the landing page, another user wants to see the payment methods available, or an authenticated user is interested mainly in the authenticated area where the service or products are available. No matter what users are trying to achieve, they are forced to download the entire application.

Figure 4-9. Any user of an SPA has to download the entire application regardless of the action they intend to perform in the application
In a vertical-split architecture, however, our unauthenticated user who wants to see the business proposition on the landing page will be able to download the code just for that micro-frontend, while the authenticated user will download only the codebase for the authenticated area. We often don’t realize that our users’ behaviors are different from the way we interpret the application, because we often optimize the application’s performance as a whole rather than by how users interact with the site. Optimizing our site according to user experiences results in a better outcome.
Applying the previous example to a vertical-split architecture, a user interested only in the unauthenticated area will download less than 100 KB of business logic plus the shared dependencies, while an authenticated user will download only the 250 KB plus the shared dependencies.
Clearly a new user who moves beyond the landing page will download almost 500 KB, but this approach will still save some kilobytes if we have properly identified the application boundaries because it’s unlikely a new user will go through every single application view. In the worst-case scenario, the user will download 500 KB as they would for the SPA, but this time not everything up front. Certainly, there is additional logic to download due to the application shell, but usually the size is only in the double digits, making it meaningless for this example. Figure 4-10 shows the advantages of a vertical-split micro-frontend in terms of performance.
A good practice for managing performance on a vertical-split architecture is introducing a performance budget. A performance budget is a limit for micro-frontends that a team is not allowed to exceed. The performance budget includes the final bundle size, multimedia content to load, and even CSS files. Setting a performance budget is an important part of making sure every team optimizes its own micro-frontend properly and can even be enforced during the CI process. You won’t set a performance budget until later in the project, but it should be updated every time there is a meaningful refactoring or additional features introduced in the micro-frontend codebase.

Figure 4-10. A vertical-split micro-frontend enables the user to download only the application code needed to accomplish the action the user is looking for
Time to display the final result to the user is a key performance indicator, and metrics to track include time-to-interactive or first contentful paint, the size of the final artifact, font size, and JavaScript bundle size, as well as metrics like accessibility and SEO. A tool like Lighthouse is useful for analyzing these metrics and is available in a command-line version to be used in the continuous integration process. Although these metrics have been discussed extensively for SPA optimization, bundle size may be trickier when it comes to micro-frontends.
With vertical-split architectures, you can decide either to bundle all the shared libraries together or to bundle the libraries for each micro-frontend. The former can provide greater performance because the user downloads the bundle only once, but you’ll need to coordinate the libraries to update for every change across all the micro-frontends. While this may sound like an easy task, it can be more complicated than you think when it happens regularly. Imagine you have a breaking change on a specific shared UI framework; you can’t update the new version until all the micro-frontends have done extensive tests on the new framework version. So while we gain in performance in this scenario, we must first overcome some organizational challenges. The latter solution—maintaining every micro-frontend independently—reduces the communication overhead for coordinating the shared dependencies but might increase the content the user must download. As seen before, however, a user may decide to stay within the same micro-frontend for the entire session, resulting in the exact same kilobytes downloaded.
Once again, there isn’t right or wrong in any of these strategies. Make a decision on the requirements to fulfill and the context you operate in. Don’t be afraid to make a call and monitor how users interact with your application. You may discover that, overall, the solution you picked, despite some pitfalls, is the right one for the project. Remember, you can easily reverse this decision, so spend the right amount of time thinking which path your project requires, but be aware that you can change direction if a new requirement arises or the decision causes more harm than benefits.
Available Frameworks
There are some frameworks available for embracing this architecture. However, building an application shell on your own won’t require too much effort, as long as you keep the application shell decoupled from any micro-frontend business logic. Polluting the application shell codebase with domain logic is not only a bad practice but also may invalidate all effort and investment of using micro-frontends in the long run due to code and logic coupling.
Two frameworks that are fully embracing this architecture are single-spa and qiankun. The concept behind single-spa is very simple: it’s a lightweight library that provides undifferentiated heavy lifting for the following:
- Registration of micro-frontends
- The library provides a root configuration to associate a micro-frontend to a specific path of your system.
- Life cycle methods
- Every micro-frontend is exposed to many stages when mounted. Single-spa allows a micro-frontend to perform the right task for the life cycle method. For instance, when a micro-frontend is mounted, we can apply logic for fetching an API. When unmounted, we should remove all the listeners and clean up all DOM elements.
Single-spa is a mature library, with years of refinement and many integrations in production. It’s open source and actively maintained and has a great community behind it. In the latest version of the library, you can develop horizontal-split micro-frontends, too, including server-side rendering ones. Qiankun is built on top of single-spa, adding some functionality from the latest releases of single-spa.
Module Federation may also be a good alternative for implementing a vertical-split architecture, considering that the mounting and unmounting mechanism, dependencies management, orchestration between micro-frontends, and many other features are already available to use. Module Federation is typically used for composing multiple micro-frontends in the same view (horizontal split). However, nothing is preventing us from using it for handling vertical-split micro-frontends. Moreover, it’s a webpack plug-in. If your projects are already using webpack, it may help you avoid learning new frameworks for composing and orchestrating your project’s micro-frontends. In the next chapter, we will explore the Module Federation for implementing vertical and horizontal split architectures.
Use Cases
The vertical-split architecture is a good solution when your frontend developers have experience with SPA development. It will also scale up to a certain extent, but if you have hundreds of frontend developers working on the same frontend application, a horizontal split may suit your project better, because you can modularize your application even further.
Vertical-split architecture is also great when you want UI and UX consistency. In this situation, every team is responsible for a specific business domain, and a vertical split will allow them to develop an end-to-end experience without the need to coordinate with other teams.
Another reason to choose this architecture pattern is the level of reusability you want to have across multiple micro-frontends. For instance, if you reuse mainly components of your design system and some libraries, like logging or payments, a vertical split may be a great architecture fit. However, if part of your micro-frontend is replicated in multiple views, a horizontal split may be a better solution. Again, let the context drive the decision for your project.
Finally, this architecture is my first recommendation when you start embracing micro-frontends because it doesn’t introduce too much complexity. It has a smooth learning curve for frontend developers, it distributes the business domains to dozens of frontend developers without any problem, and it doesn’t require huge upfront investment in tools but more in general in the entire developer experience.
Architecture Characteristics
- Deployability (5/5)
- Because every micro-frontend is a single HTML page or an SPA, we can easily deploy our artifacts on a cloud storage or an application server and stick a CDN in front of it. It’s a well-known approach, used for several years by many frontend developers for delivering their web applications. Even better, when we apply a multi-CDN strategy, our content will always be served to our user no matter which fault a CDN provider may have.
- Modularity (2/5)
- This architecture is not the most modular. While we have a certain degree of modularization and reusability, it’s more at the code level, sharing components or libraries but less on the features side. For instance, it’s unlikely a team responsible for the development of the catalog micro-frontend shares it with another micro-frontend. Moreover, when we have to split a vertical-split micro-frontend in two or more parts because of new features, a bigger effort will be required for decoupling all the shared dependencies implemented, since it was designed as a unique logical unit.
- Simplicity (4/5)
- Taking into account that the primary aim of this approach is reducing the team’s cognitive load and creating domain experts using well-known practices for frontend developers, the simplicity is intrinsic. There aren’t too many mindset shifts or new techniques to learn to embrace this architecture. The overhead for starting with single-spa or Module Federation should be minimal for a frontend developer.
- Testability (4/5)
- Compared to SPAs, this approach shows some weakness in the application shell’s end-to-end testing. Apart from that edge case, however, testing vertical-split micro-frontends doesn’t represent a challenge with existing knowledge of unit, integration, or end-to-end testing.
- Performance (4/5)
- You can share the common libraries for a vertical-split architecture, though it requires a minimum of coordination across teams. Since it’s very unlikely that you’ll have hundreds of micro-frontends with this approach, you can easily create a deployment strategy that decouples the common libraries from the micro-frontend business logic and maintains the commonalities in sync across multiple micro-frontends. Compared to other approaches, such as server-side rendering, there is a delay on downloading the code of a micro-frontend because the application shell should initialize the application with some logic. This may impact the load of a micro-frontend when it’s too complex or makes many roundtrips to the server.
- Developer experience (4/5)
- A team familiar with SPA tools won’t need to shift their mindset to embrace the vertical split. There may be some challenges during end-to-end testing, but all the other engineering practices, as well as tools, remain the same. Not all the tools available for SPA projects are suitable for this architecture, so your developers may need to build some internal tools to fill the gaps. However, the out-of-the-box tools available should be enough to start development, allowing your team to defer the decisions to build new tools.
- Scalability (5/5)
- The scalability aspect of this architecture is so great that we can even forget about it when we serve our static content via a CDN. We can also configure the time-to-live according to the assets we are serving, setting a higher time for assets that don’t change often, like fonts or vendor libraries, and a lower time for assets that change often, like the business logic of our micro-frontends. This architecture can scale almost indefinitely based on CDN capacity, which is usually great enough to serve billions of users simultaneously. In certain cases, when you absolutely must avoid a single point of failure, you can even create a multiple-CDN strategy, where your micro-frontends are served by multiple CDN providers. Despite being more complicated, it solves the problem elegantly without investing too much time creating custom solutions.
- Coordination (4/5)
- This architecture, compared to others, enables a strong decentralization of decision making, as well as autonomy of each team. Usually, the touching points between micro-frontends are minimal when the domain boundaries are well defined. Therefore, there isn’t too much coordination needed, apart from an initial investment for defining the application shell APIs and keeping them as domain unaware as possible.
Table 4-1 gathers the architecture characteristics and its associated score for this micro-frontend architecture.
| Architecture characteristics | Score (1 = lowest, 5 = highest) |
|---|---|
| Deployability | 5/5 |
| Modularity | 2/5 |
| Simplicity | 4/5 |
| Testability | 4/5 |
| Performance | 4/5 |
| Developer experience | 4/5 |
| Scalability | 5/5 |
| Coordination | 4/5 |
Horizontal-Split Architectures
Horizontal-split architectures provide a variety of options for almost every need a micro-frontend application has. These architectures have a very granular level of modularization thanks to the possibility to split the work of any view among multiple teams. In this way, you can compose views reusing different micro-frontends built by multiple teams inside your organization. Horizontal-split architectures are suggested not only to companies that already have a sizable engineering department but also to projects that have a high level of code reusability, such as a multitenant business-to-business (B2B) project in which one customer requests a customization or ecommerce with multiple categories with small differences in behaviors and user interface. Your team can easily build a personalized micro-frontend just for that customer and for that domain only. In this way, we reduce the risk of introducing bugs in different parts of the applications, thanks to the isolation and independence that every micro-frontend should maintain.
At the same time, due to this high modularization, horizontal-split architecture is one of the most challenging implementations because it requires solid governance and regular reviews for getting the micro-frontends boundaries rights. Moreover, these architectures challenge the organization’s structure unless they are well thought out up front. It’s very important with these architectures that we review the communication flows and the team’s structure to enable the developers to do their job and avoid too many external dependencies across teams. Also, we need to share best practices and define guidelines to follow to maintain a good level of freedom while providing a unique, consolidated experience for the user.
One of the recommended practices when we use horizontal-split architectures is to reduce the number of micro-frontends in the same view, especially when multiple teams have to merge their work together. This may sound obvious, but there is a real risk of over-engineering the solution to have several tiny micro-frontends living together in the same view, which creates an antipattern. This is because you are blurring the line between a micro-frontend and a component, where the former is a business representation of a subdomain and the latter is a technical solution used for reusability purposes.
Moreover, managing the output of multiple teams in the same view requires additional coordination in several stages of the software development life cycle. Another sign of over-engineering a page is having multiple micro-frontends fetching from the same API. In that case, there is a good chance that you have pushed the division of a view too far and need to refactor. Remember that embracing these architectures provides great power, and therefore we have great responsibility for making the right choices for the project. In the next sections we will review the different implementations of horizontal-split architectures: client side, edge side, and server side.
Client Side
A client-side implementation of the horizontal-split architecture is similar to the vertical-split one in that there is an application shell used for composing the final view. The key difference is that, here, a view is composed of multiple micro-frontends, which can be developed by the same or different teams. Due to the horizontal split’s modular nature, it’s important not to fall into the trap of thinking too much about components. Instead, stick to the business perspective.
Imagine, for example, you are building a video-streaming website and you decide to use a horizontal-split architecture using a client-side composition. There are several teams involved in this project; however, for simplicity, we will only consider two views: the landing page and the catalog. The bulk of work for these two experiences involve the following teams:
- Foundation team
- This team is responsible for the application shell and the design system, working alongside the UX team but from a more technical perspective.
- Landing page team
- The landing page team is responsible for supporting the marketing team to promote the streaming service and creating all the different landing pages needed.
- Catalog team
- This team is responsible for the authenticated area where a user can consume a video on demand. It works in collaboration with other teams for providing a compelling experience to the service subscribers.
- Playback experience team
- Considering the complexity for building a great video player available in multiple platforms, the company decides to have a team dedicated to the playback experience. The team is responsible for the video player, video analytics, implementation of the digital rights management (DRM), and additional security concerns related to the video consumption from unauthorized users.
When it comes to implementing one of the many landing pages, three teams are responsible for the final view presented to every user. The foundation team provides the application shell, footer, and header and composes the other micro-frontends present in the landing page. The landing page team provides the streaming service offering, with additional details about the video platform. The playback experience team provides the video player for delivering the advertising needed to attract new users to the service. Figure 4-11 shows the relationship between these elements.

Figure 4-11. The landing page view is composed by the application shell, which loads two micro-frontends: the service characteristics and the playback experience
This view doesn’t require particular communication between micro-frontends, so once the application shell is loaded, it retrieves the other two micro-frontends and provides the composed view to the user. When a subscriber wants to watch any video content, after being authenticated, they will be presented with the catalog that includes the video player (see Figure 4-12).
In this case, every time a user interacts with a tile to watch the content, the catalog micro-frontend has to communicate with the playback micro-frontend to provide the ID of the video selected by the user. When an error has to be displayed, the catalog team is responsible for triggering a modal with the error message for the user. And when the playback has to trigger an error, the error will need to be communicated to the catalog micro-frontend, which will display it in the view. This means we need a strategy that keeps the two micro-frontends independent but allows communication between them when there is a user interaction or an error occurs.

Figure 4-12. The catalog view is composed by the application shell, which loads two micro-frontends: the playback experience and the catalog itself
There are many strategies available to solve this problem, like using custom events or an event emitter, but we will discuss the different approaches later on in this chapter. Why wasn’t there a specific composition strategy for this example? Mainly because every client-side architecture has its own way of composing a view. Also, in this case we will see, architecture by architecture, the best practice for doing so.
Do you want to discover where the horizontal-split architecture really shines? Let’s fast-forward a few months after the release of the video-streaming platform. The product team asks for a nonauthenticated version of the catalog to improve the discoverability of the platform assets, as well as providing a preview of their best shows to potential customers. This boils down to providing a similar experience of the catalog without the playback experience. The product team would also like to present additional information on the landing page so users can make an informed decision about subscribing to the service. In this case, the foundation team, catalog team, and landing page team will be needed to fulfill this request (see Figure 4-13).

Figure 4-13. This new view is composed by the catalog (owned by the catalog team) and the marketing message (owned by the landing page team)
Evolving a web application is never easy, for both technical and collaboration reasons. Having a way to compose micro-frontends simultaneously and then stitching them together in the same view, with multiple teams collaborating without stepping on each other’s toes, makes life easier for everyone and enables the business to evolve at speed and in any direction.
Challenges
As with every architecture, horizontal splits have benefits and challenges that are important to recognize to ensure they’re a good fit for your organization and projects. Evaluating the trade-offs before embarking on a development puts you one step closer to delivering a successful project.
Micro-frontend communication
Embracing a horizontal-split architecture requires understanding how micro-frontends developed by different teams share information, or states, during the user session. Inevitably, micro-frontends will need to communicate with each other. For some projects, this may be minimal, while in others, it will be more frequent. Either way, you need a clear strategy up front to meet this specific challenge. Many developers may be tempted to share states between micro-frontends, but this results in a socio-technical antipattern. On the technical side, working with a distributed system that has shared code with other micro-frontends owned by different teams means that the shared state requires it to be designed, developed, and maintained by multiple teams (see Figure 4-14).

Figure 4-14. Shared state between multiple micro-frontends represents an antipattern
Every time a team makes a change to the shared state, all the others must validate the change and ensure it won’t impact their micro-frontends. Such a structure breaks the encapsulation micro-frontends provide, creating an underlying coupling between teams that has frequent, if not constant, external dependencies to take care of.
Moreover, we risk jeopardizing the agility and the evolution of our system because a key part of one micro-frontend is now shared among other micro-frontends. Even worse is when a micro-frontend is reused across multiple views and a team is responsible for maintaining multiple shared states with other micro-frontends. On the organization side, this approach risks coupling teams, resulting in the need for a lot of coordination that can be avoided while maintaining intact the boundaries of every micro-frontend.
The coordination between teams doesn’t stop on the design phase, either. It will be even more exasperating during testing and release phases because now all the micro-frontends in the same view depend on the same state that cannot be released independently. Having constant coordination to handle instead of maintaining a micro-frontend’s independent nature can be a team’s worst nightmare. In the microservices world, this is called a distributed monolith: an application deployed like a microservice but built like a monolith.
One of micro-frontends’ main benefits is the strong boundaries that allow every team to move at the speed they need, loosely coupling the organization, reducing the time of coordination, and allowing developers to take destiny in their hands. In the microservices world, to achieve a loose coupling between microservices and therefore between teams, we use the choreography pattern, which uses an asynchronous communication, or event broker, to notify all the consumers interested in a specific event. With this approach we have:
-
Independent microservices that can react to (or not react to) external events triggered by one or more producers
-
Solid, bounded context that doesn’t leak into multiple services
-
Reduced communication overhead for coordinating across teams
-
Agility for every team so they can evolve their microservice based on their customers’ needs
With micro-frontends, we should think in the same way to gain the same benefits. Instead of using a shared state, we maintain our micro-frontends’ boundaries and communicate any event that should be shared on the view using asynchronous messages, something we’re used to dealing with on the frontend.
Other possibilities are implementing either an event emitter or a reactive stream (if you are in favor of the reactive paradigm) and sharing it across all the micro-frontends in a view (see Figure 4-15).

Figure 4-15. Every micro-frontend in the same view should own its own state and should communicate changes via asynchronous communication using an event emitter or CustomEvent or reactive streams
In Figure 4-15, Team Fajitas is working on a micro-frontend (MFE B) that needs to react when a user interacts with an element in another micro-frontend (MFE A), run by Team Burrito. Using an event emitter, Team Fajitas and Team Burrito can define how the event name and the associated payload will look and then implement them, working in parallel (see Figure 4-16).

Figure 4-16. MFE A emits an event using the EventEmitter as a communication bus; all the micro-frontends interested in that event will listen and react accordingly
When the payload changes for additional features implemented in the platform, Team Fajitas will need to make a small change to its logic and can then start integrating these features without waiting for other teams to make any change and maintaining its independence.
The third micro-frontend in our example (MFE C, run by Team Tacos) doesn’t care about any event shared in that view because its content is static and doesn’t need to react to any user interactions. Team Tacos can continue to do its job knowing its part won’t be affected by any state change associated with a view.
A few months later a new team, Team Nachos, is created to build an additional feature in the application. Team Nachos’ micro-frontend (MFE D) lives alongside MFE A and MFE B (see Figure 4-17).

Figure 4-17. A new micro-frontend was added in the same view and has to integrate with the rest of the application reacting to the event emitted by MFE A. Because of the loose coupling nature of this approach, MFE D just listens to the events emitted by MFE A. In this way, all micro-frontends and teams maintain their independence.
Because every micro-frontend is well encapsulated and the only communication protocol is a pub/sub system like the event emitter, the new team can easily listen to all the events it needs to for plugging in the new feature alongside the existing micro-frontends. This approach not only enhances the technical architecture but also provides a loose coupling between teams while allowing them to continue working independently.
Once again, we notice how important our technology choices are when it comes to maintaining independent teams and reducing external dependencies that would cause more frustration than anything else. As well, having the team document all the events in input and output for every horizontal-split micro-frontend will help facilitate the asynchronous communication between teams. Providing an up-to-date, self-explanatory list of contracts for communicating in and out of a micro-frontend will result in clear communication and better governance of the entire system. What these processes help achieve is speed of delivery, independent teams, agility, and a high degree of evolution for every micro-frontend without affecting others.
Clashes with CSS classes and how to avoid them
One potential issue in horizontal-split architecture during implementation is CSS classes clash. When multiple teams work on the same application, there is a strong possibility of having duplicate class names, which would break the final application layout. To avoid this risk, we can prefix each class name for every micro-frontend, creating a strong rule that prevents duplicate names and, therefore, undesired outcomes for our users. Block Element Modifier, or BEM, is a well-known naming convention for creating unique names for CSS classes. As the name suggests, we use three elements to assign to a component in a micro-frontend:
- Block
- An element in a view. For example, an avatar component is composed of an image, the avatar name, and so on.
- Element
- A specific element of a block. In the previous example, the avatar image is an element.
- Modifier
- A state to display. For instance, the avatar image can be active or inactive.
Based on the example described, we can derive the following class names:
.avatar{}.avatar__image{}.avatar__image--active{}.avatar__image--inactive{}
While following BEM can be extremely beneficial for architecting your CSS strategy, it may not be enough for projects with multiple micro-frontends. So we build on the BEM structure by prefixing the micro-frontend name to the class.
For our avatar example, when it’s used in the “My account” micro-frontend, the names become:
.myaccount_avatar{}.myaccount_avatar__image{}.myaccount_avatar__image--active{}.myaccount_avatar__image--inactive{}
Although this makes names long, it guarantees the isolation needed and makes clear what every class refers to. Any other naming convention for CSS class names you want to create is also acceptable, but just remember to add prefixes when used with micro-frontends.
Tip
For a good guide to starting with BEM, check out Inna Belaya’s article “BEM for Beginners: Why You Need BEM” at Smashing magazine. You can read additional content on the topic at Smashing as well.
Multiframework approach
Using multiple frameworks isn’t great for vertical-split architectures due to performance issues. On horizontal-split architectures, it’s even more dangerous. When this problem is not addressed in the design phase, it can cause runtime errors in the final view.
Imagine having multiple versions of React in the same view. It does not lead to a great experience for the user. When the browser downloads two versions for a rendering view, performance issues can crop up. Consider, too, the potential variables clashing when we load the libraries or append new components in the view.
There are many ways to address this problem. For instance, iframes create a sandbox so that what loads inside one iframe doesn’t clash with another iframe. Module Federation allows you to share libraries and provides a mechanism for avoiding clashing dependencies. Import maps allow us to define scopes for every dependency so we can define different versions of the same libraries to different scopes. And web components can “hide” behind the shadow DOM the frameworks need for a micro-frontend.
Still, using a multiframework approach is strongly discouraged due to performance issues. Having more kilobytes to download in order to render a page is not a great customer experience, and our job as developers and architects should be to provide the best user experience possible. Multiframework isn’t acceptable in other frontend architectures, like SPAs, and micro-frontends should not be an exception.
The only acceptable time to use a multiframework strategy is when we have to migrate a legacy application to a new one, resulting in the micro-frontends being iteratively released rather than releasing all at once. In this case, the multiframework strategy allows you to provide customer value and lowers risks in deploying your artifacts.
Authentication
Horizontal-split architectures present an interesting challenge when it comes to system authentication, because, more often than not, multiple teams are working on the same view, and they need to maintain a unique experience for the customer. When a user enters into an authenticated area of a web application, all the micro-frontends composing the page have to communicate with the respective APIs providing tokens.
Let’s say we have three different teams creating a micro-frontend, each composing a view for the customer. These micro-frontends have to fetch data from the backend, which is a distributed system composed of multiple microservices (see Figure 4-18).
How can different micro-frontends retrieve and store a token safely without multiple round trips to the backend? The best option we have is storing the token in the localStorage, the sessionStorage, or a cookie. In this case, all the micro-frontends will retrieve the same token in the defined web storage solution by convention.
Different security restrictions will be applied based on the web storage selected for hosting the token. For instance, if we use localStorage or sessionStorage, all the micro-frontends have to be hosted in the same subdomain; otherwise the localStorage or sessionStorage where the token is stored won’t be accessible. In the case of cookies, we can use multiple subdomains but must use the same domain.
We also have to consider when we have multiple micro-frontends consuming the same API with the same request body that it’s very likely that these micro-frontends can be merged into a unique micro-frontend.
Don’t be afraid to review the domain boundaries of micro-frontends, because they will evolve alongside the business. Additionally, because there isn’t a scientific way to define boundaries, taking a step back and reassessing the direction taken can sometimes be more beneficial than ignoring the problem. The longer we ignore the problem, the more disruption the teams will experience. It’s far better to invest time at the beginning of the project for refactoring a bunch of micro-frontends.
Finally, this approach is applicable also to the vertical-split architecture, and we don’t even have to be worried about multiple teams looking for a token considering we load just one micro-frontend per time.

Figure 4-18. Every micro-frontend in a horizontal-split architecture has to fetch data from an API passing a JWT token to the backend to validate that the user is entitled to retrieve the data requested
Micro-frontends refactoring
Another benefit of the horizontal-split architecture is the ability to refactor specific micro-frontends when the code becomes too complicated to be manageable by a single team or a new team starts owning a micro-frontend they didn’t develop. While you can do this with a vertical split as well, the horizontal-split micro-frontends have far less logic to maintain, making them a great benefit, especially for enterprise organizations that have to work on the same platform for many years.
Because every micro-frontend is independent, refactoring the code to make it more understandable for the team is a benefit because this activity won’t impact anyone else in the company. While you need to keep tech leadership’s guidelines in mind, refactoring a well-designed micro-frontend requires far less time than refactoring a large monolithic codebase. This characteristic makes micro-frontends more maintainable in the long run. Additionally, when a complete rewrite is needed, having the domain experts—the team—in charge of rewriting something they know inside out requires significantly less work than rewriting an unfamiliar application from scratch. And because of the micro-frontends’ nature, you can decide to rewrite them iteratively and ship them in production to gain immediate benefits of your work, instead of working for several months before releasing everything all at once.
I’m not encouraging refactoring or rewriting just because they’re easier. But sometimes the team gains additional business knowledge, or they have to implement a tactical solution due to a hard delivery date; making a refactor or a rewrite from scratch can make life easier in the long run, speeding up new-feature development or reducing the possibility of bugs in the production environment.
Search Engine Optimization
Dynamic rendering is another valid technique for this architecture, especially when we decide to use iframes for encapsulating our micro-frontends. In that situation, redirecting a crawler to an optimized version of static HTML pages helps with the search engine’s ranking. Overall, what has been discussed so far about dynamic rendering is also valid for client-side horizontal-split architectures.
Developer Experience
The developer experience (DX) of the horizontal-split architecture with a client-side composition is very similar to the vertical split when a team is developing its own micro-frontend. However, it becomes more complex when the team needs to test micro-frontends inside a view with other micro-frontends. The main challenge is keeping up with the versions and having a quick turnaround for assembling a view on the developer’s laptop.
As we will describe in Chapter 7, we can use webpack DevServer Proxy for testing locally, with micro-frontends available in testing, staging, or production environments. Often, companies that embrace this architecture create tools for improving their teams’ feedback loop, often in the form of command line tools that can enhance the standard tools available for the frontend developers’ community, like Rollup, webpack, or Snowpack. It’s important to note that it’s very likely this architecture will require some internal investments to create a solid DX. Currently, frameworks and tools (webpack Module Federation, for instance) are trying an opinionated approach; while this isn’t necessarily a bad thing, in large companies, additional effort will most likely be required to maintain the guidelines and standards the tech leadership designed based on the industry the company operates in.
Maintaining control with effective communication
Although horizontal-split architectures are the most versatile, they also present intrinsic implementation challenges from an organizational point of view, with coordinating a final output for the use being the main one. When we have multiple micro-frontends owned by different teams composed in the same view, we have to create a social mechanism for avoiding runtime issues in production due to dependency clashes or CSS classes overriding each other. As well, observability tools must be added to quickly identify which micro-frontends are failing in production and provide the team with clear information so they can diagnose the issue in their micro-frontend.
The best way to avoid issues is to keep the communication channels open and maintain a fast feedback loop that keeps all teams in sync, such as a weekly or biweekly meeting with a member from every micro-frontend team responsible for a view. Synching the work between teams has to happen either in a live meeting or via asynchronous communication, such as emails or instant messaging clients.
We must also reduce the number of teams working on the same page and make one team responsible for the final output presented to the users. This doesn’t mean that the team responsible for the final look and feel of a view should do all the work. However, shared responsibilities often lead to misunderstandings, so having one team lead the effort creates a better experience for your users.
As we saw in our client-side video player example, we have three teams involved in delivering the catalog page. It’s very likely that the catalog team would perform any additional checks on the playback experience because after a user clicks on a movie or a show, it should play in the video player. In this case, then, the catalog team should be responsible for the final outcome and should coordinate the effort with the playback experience team for providing the best output for their users.
When possible, reducing external dependencies should be a periodic job for an engineer manager or a team lead. Don’t blindly accept the status quo. Instead, embrace a continuous improvement mindset and challenge the work done so far to find better ways to serve your customers.
Strongly encourage your teams to document their micro-frontend inputs and outputs, the events a micro-frontend expects to receive, and those that will trigger to keep the teams in sync and to allow the discussion of potential breaking changes. Especially for the latter case, keeping track of breaking changes using requests for comments (RFCs) or similar documents is strongly recommended for several reasons. First, it creates asynchronous communication between teams, which is especially when teams are distributed across time zones. It also maintains a record of decisions with the context the company was operating in when the decision was made. Finally, not everyone performs well during meetings; sometimes one person will monopolize the discussion, preventing others from sharing their opinion. Moving from verbal to written communications helps everyone have their voice be heard.
Use Cases
One reason to embrace the horizontal-split architecture is the micro-frontends’ reusability across the application or multiple applications. Imagine a team responsible for the payment micro-frontend of an ecommerce website, and the micro-frontend contains different states based on the type of view and payments available. The payment micro-frontend is present in every view in which the user wants to perform a payment action, including a landing page, a product detail view, or even a subscription page for another product. This situation is applicable at a larger scale on a B2B application, where similar UX constructs are replicated in several system views.
Another use case for this architecture is for enterprise applications, for which we often deal with dashboards containing a variety of data that we want to collect into different views for different purposes, such as financial and monitoring. New Relic uses this approach to provide monitoring tools for cloud services, as well as a frontend one that implements micro-frontends for scaling the organization, allowing multiple teams to contribute different data representations, all collected into a unique dashboard.
In Figure 4-19, you can see how New Relic divided its application so that a small number of teams work in the same view, reducing the amount of communication needed for composing the final view but allowing the team to be well encapsulated inside its business domain.

Figure 4-19. New Relic micro-frontend implementation. Every team is responsible for their own domain, and when a user selects a dashboard, the related micro-frontend is lazy-loaded inside the application shell.
This approach allows New Relic teams to work on their own micro-frontends, and by following some contracts for deploying micro-frontends in production, they can see the final results in their web application.
The final use case for this architecture is when we are developing a multitenant application for which the vast majority of the interface is the same but allowing customers to build specific features to make the software suitable for their specific organization. For example, let’s say we are developing a digital till system for restaurants, and we want to configure the tables on the floor on a customer-by-customer basis. The application will have the same functionality for every single customer, but a restaurant chain can request specific features in the digital till system. The micro-frontend team responsible for the application can implement these features without forking the code for every customer; instead, they will create a new micro-frontend for handling the specific customer’s needs and deploy it in their tenant.
Module Federation
Micro-frontend architectures received a great gift with the release of webpack 5: a new native plug-in called Module Federation. Module Federation allows chunks of JavaScript code to load synchronously or asynchronously, meaning multiple developers or even teams can work in isolation and take care of the application composition, lazy-loading different JavaScript chunks behind the scenes at runtime, as shown in Figure 4-20.
A Module Federation application is composed of two parts:
- The host
- Represents the container of one or more micro-frontends or libraries loaded.
- The remote
- Represents the micro-frontend or library that will be loaded inside a host at runtime. A remote exposes one or more objects that can be used by the host when the remote is lazy-loaded into an application.
The part of Module Federation that really shines is the simplicity of exposing different micro-frontends, or even shared libraries such as a design system, allowing a simple asynchronous integration. The developer experience is incredibly smooth. As when you’re working with a monolithic codebase, you can import remote micro-frontends and compose a view in the way you need.

Figure 4-20. Module Federation allows multiple micro-frontends to be loaded asynchronously, providing the user with a seamless experience
Testing locally or pointing to a specific endpoint online doesn’t make a difference because we can work in a similar way to handle multiple environments, with webpack having a common configuration augmented by a specific one for every environment (test, stage, or production).
Another important feature of webpack with Module Federation is the ability to share external libraries across multiple micro-frontends without the fear of potential clashes happening at runtime. In fact, we can specify which libraries are shared across multiple micro-frontends, and Module Federation will load just one version for all the micro-frontends using the library.
Imagine that all your micro-frontends are using Vue.js 3.0.0. With Module Federation, you will just need to specify that Vue version 3 is a shared library; at compile time, webpack will export just one Vue version for all the micro-frontends using it. And if you wanted to intentionally work with different versions of Vue in the same project? Module Federation will wrap the two libraries in different scopes to avoid the clashes that could happen at runtime, or you can even specify the scope for a different version of the same library using Module Federation APIs.
Module Federation is available not only when we want to run an application fully client side but also when we want to use it with server-side rendering. In fact, we can asynchronously load different components without needing to deploy the application server that composes the page again and serve the final result to a client request.
Unfortunately, the great simplicity of code sharing across projects is also the weakest point of this plug-in. When you work in a team that’s not disciplined enough, sharing libraries, code snippets, and micro-frontends across multiple views can result in a very complicated architecture to maintain, thanks to the frictionless integration. So it’s critical to create guidelines that follow the micro-frontend decisions framework in order not to regret the freedom Module Federation provides.
Performance
With webpack, you can use a long list of official plug-ins to optimize your code when it is bundled, as well as even more plug-ins from independent developers and companies on GitHub.
Module Federation benefits from this ecosystem because many of these plug-ins can manipulate a micro-frontend’s output and work in conjunction with the plug-in. One of the main challenges we face when working with micro-frontends is how to share dependencies across this distributed architecture, and Module Federation can help there too. Let’s say you have multiple teams working in the same application. Each team owns a single micro-frontend, and the teams have agreed to use the same UI library for the entire application. You can share these libraries automatically with Module Federation from the plug-in configuration, and they’ll be loaded only once at the beginning of the project.
You can also load micro-frontends dynamically inside JavaScript logic instead of defining all of them in the webpack configuration file.
Optimizing the micro-frontends code from webpack is definitely a great option, mainly because, while the tool was created for bundling JavaScript, now it can optimize other static assets, such as CSS or HTML files.
With so many organizations and independent developers using webpack, the ecosystem is more alive than ever, and the community-created enhancements are great for supporting any type of workload.
Composition
Using Module Federation for a micro-frontend architecture is as simple as importing an external JavaScript chunk lazy-loaded inside a project. Composition takes place at runtime either on the client side, when we use an application shell for loading different micro-frontends, or on the server side, when we use server-side rendering. When we load a micro-frontend on an application shell at runtime, we can fetch the micro-frontend directly from a CDN or from an application server. And the same is true when we are working with a server-side rendering architecture. In this case, composition takes place at the origin, and we can load micro-frontends at runtime before serving them to a client request.
In the next chapter, we will dive deeply into Module Federation composition, providing more insights into how to achieve horizontal- and vertical-split composition with code examples.
Developer experience
Webpack with Module Federation makes developers’ lives easier, especially when they’re familiar with the main tool. The people behind the plug-in did an incredible job abstracting all the complexity needed to create a smooth DX, and now developers can load asynchronously or synchronously shared code in the form of libraries or micro-frontends. Even better, Module Federation fits perfectly inside the webpack ecosystem and can be used with other plug-ins or configurations available in the webpack configuration file.
By default, this plug-in produces small JavaScript chunks for every micro-frontend, enabling dependencies to be shared across micro-frontends when specified in the plug-in’s configuration. However, when we use the optimization capability webpack offers out of the box, we can instruct the output to use fewer but larger chunks, maybe dividing our output in vendor and business logic files. These two files can then be cached in different ways, which is valuable since the business logic will be iterated more frequently than a project’s external dependencies will be changed or upgraded.
Use cases
Because this plug-in provides such extensive flexibility, we can apply to it any horizontal- or vertical-split micro-frontend use case. We can compose an application on the client or server side and then easily route using any available routing libraries for our favorite UI framework. Finally, we can use an event emitter library or custom events for communications across micro-frontends. Webpack with Module Federation covers almost all micro-frontends use cases, providing a great DX for every team or developer used to working with webpack.
Architecture characteristics
- Deployability (4/5)
- Webpack divides a micro-frontend into JavaScript chunks, making them easy to deploy in any cloud service from any automation pipeline. And because they are all static files, they are highly cacheable. While we have to handle the scalability of the application servers responding to any client requests in an SSR approach, the ease of integration and rapid feedback are definitely big pluses for this approach.
- Modularity (4/5)
- This plug-in’s level of modularity is very high, but so is its risk. If we’re not careful, we can create many external dependencies across teams; therefore, we have to use Module Federation wisely to avoid creating organizational friction.
- Simplicity (5/5)
- Webpack’s new system solves many problems behind the scenes, but the abstraction created by Module Federation makes the integration of micro-frontends very similar to other, more familiar frontend architectures like SPA or SSR.
- Testability (4/5)
- Although Module Federation offers an initial version of a federated test using Jest for integration testing, we can still apply unit and end-to-end testing similar to how we’re used to working with other frontend architectures.
- Performance (4/5)
- With Module Federation, we gain a set of capabilities, such as sharing common libraries or UI frameworks, that won’t compromise the final artifact’s performance. Bear in mind that the mapping between a micro-frontend and its output files could be one to many, so a micro-frontend may be represented by several small JavaScript files, which may increase the initial chattiness between a client and a CDN performing multiple roundtrips for loading all the files needed for rendering a micro-frontend.
- Developer experience (5/5)
- This is probably one of the best developer experiences currently available for working with micro-frontends. Module Federation integrates very nicely in the webpack ecosystem, hiding the complexity of composing micro-frontends and enabling the implementation of more traditional features, taking care of tedious topics like code sharing and asynchronous import of our static artifacts or libraries.
- Scalability (5/5)
- Module Federation’s approach makes scaling easy, especially when the application is fully client side. The static JavaScript chunks easily served via a CDN make this approach extremely scalable for a vertical-split architecture.
- Coordination (3/5)
- When we follow the decisions framework shared in the first chapters of this book in conjunction with Module Federation, we can really facilitate the life of our enterprise organization. However, the accessible approach provided by this plug-in can lead to abuse of the modularity, resulting in increased coordination and potential refactors in the long term.
Table 4-2 gathers the architecture characteristics and their associated score for this micro-frontend architecture.
| Architecture characteristics | Score (1 = lowest, 5 = highest) |
|---|---|
| Deployability | 4/5 |
| Modularity | 4/5 |
| Simplicity | 5/5 |
| Testability | 4/5 |
| Performance | 4/5 |
| Developer experience | 5/5 |
| Scalability | 5/5 |
| Coordination | 3/5 |
Iframes
Iframes are probably not the first thing that comes to mind in relation to micro-frontends, but they provide an isolation between micro-frontends that none of the other solutions can offer.
An iframe is an inline frame used inside a webpage to load another HTML document inside it. When we want to represent a micro-frontend as an independent artifact completely isolated from the rest of the application, iframes are one of the strongest isolations we can have inside a browser. An iframe gives us granular control over what can run inside it. The less-privileged implementation using the sandbox attribute prevents any JavaScript logic from executing or any forms from being submitted:
<iframesandboxsrc="https://mfe.mywebsite.com/catalog/">
An iframe gives us access to specific functionalities, combining sandbox with other sandbox attribute values, such as allow-forms or allow-scripts, to ease the sandbox attribute restrictions, allowing form submission or JavaScript file execution, respectively:
<iframesandbox="allow-scripts allow-forms"src="https://mfe.mywebsite.com/catalog"/>
Additionally, the iframe can communicate with the host page when we use the postMessage method. In this way, the micro-frontend can notify the broader application when there is a user interaction inside its context, and the application can trigger other activities, such as sharing the event with other iframes or changing part of the UI interface present in the host application.
Iframes aren’t new, but they are still in use for specific reasons and have found a place within the micro-frontend ecosystem. So far, the main use cases for implementing micro-frontends with iframes are coming from desktop applications and B2B applications, when we control the environment where the application is consumed. Note, though, that this approach is strongly discouraged for consumer websites because iframes are really bad for performance. They are CPU-intensive, especially when multiple iframes are used in the same view.
A proposal for adding a ShadowRealm, a sandbox like iframes that is lighter and closer to modern web APIs, is in draft to the TC39, the committee responsible for evolving the ECMAScript programming language and authoring the specification. A ShadowRealm object would abstract the notion of a distinct global environment with its own global object, copy of the standard library, and intrinsics. This is the dynamic equivalent of a same-origin iframe without DOM. Basically, this is a lighter implementation of an iframes sandbox with the same isolation capabilities but without the performance issues that multiple iframes can have when rendered inside the same view.
We can find a list of use cases where ShadowRealms can be used in the proposal repository. Sandboxing is just one of them, and there are some interesting scenarios possible. The proposal may never go beyond the draft stage, but it looks very interesting and could be a great fit for the micro-frontend ecosystem.
Best practices and drawbacks
There are some best practices to follow when we want to compose micro-frontends in a horizontal split with iframes. First, we must define a list of templates where the iframes will be placed; having a few layouts can help simplify managing an application with iframes (see Figure 4-21).
Using templates allows your teams to understand how to implement their micro-frontends’ UI and minimizes edge cases thanks to some guardrails to follow.
Try to avoid too many interactions across micro-frontends; too many interactions can increase the complexity of the code to be maintained. If you need to share a lot of information across micro-frontends, iframes may not be the right approach for the project. This architecture allows teams to build their micro-frontends in isolation without any potential clash between libraries. However, to create a UI consistency, you will need to share the design system at build-time.

Figure 4-21. Different layouts for composing micro-frontends with iframes. Minimizing the number of iframes in a page would result in better performance despite there being an intrinsic performance overhead when we integrate one or more iframes into a view.
Using iframes for responsive websites can be challenging, as dealing with a fluid layout with iframes and their content can be fairly complicated. Try to stick with fixed dimensions as much as you can. If fixed dimensions aren’t possible, one of the other architectures in this chapter may work better for you.
When you have to store data in webstorage or a cookie, use the webstorage or cookie in the application shell to avoid issues with retrieving data across multiple iframes. In this situation, communication between the host page and every micro-frontend living inside an iframe has to be well implemented and thoroughly tested.
When using a pub/sub pattern between iframes and the host page, you have to share an event emitter instance between the main actors of a page. To do this, create an event emitter and append it to the iframe contentWindow object so that you can communicate via the emit or dispatch method across all the micro-frontends listening to it. Alternatively, you can rely on an open source library such as Poster, which abstracts the communication API between the host and every micro-frontend in an iframe:
index.js
variframe=document.getElementById("myIframe");varposter=newPoster(iframe.contentWindow);poster.post("msg","hello, world!");
catalog-mfe.js
varposter=newPoster(window.parent);poster.on("msg",function(msg){console.log("msg = "+msg);// "msg = hello, world"});
Frameworks such as Luigi from SAP provide solutions for the pitfalls listed so far, which we’ll discuss in more depth in the “Available framework” section that follows.
Developer experience
Dealing with iframes makes developers’ lives easier, considering the sandboxed environment they use. One of the main challenges of using this approach is with end-to-end testing, when retrieving objects programmatically across multiple iframes can result in a huge effort due to object nesting. Overall, a micro-frontend will be represented by an HTML entry point, with additional resources loaded such as JavaScript or CSS files—very similar to what we are used to in other frontend architectures, like SPAs.
Available framework
There aren’t many options available for simplifying the developer experience of micro-frontends inside iframes; usually we can create an in-house strategy, or you can use Luigi framework. Luigi from SAP is a micro-frontends framework used for building intranet applications, which simplifies integration with SAP, but it also can be used outside an SAP context and provides a set of libraries for managing common challenges like routing or localization.
The Luigi framework uses iframes for encapsulating micro-frontends and having a true sandbox around the code. Luigi is the main framework for applications that need to extract data from SAP and aggregate it in a more user-friendly interface. These applications are also mainly running in intranet environments, where it’s possible to control which browser version a micro-frontend application runs in without needing to index the content on the main search engines. Given these things, iframes are probably a good fit for using some web standards without the need to create proprietary solutions to handle micro-frontend challenges. In fact, out of the box, Luigi provides a typical implementation for an enterprise application, composed in two main parts:
- Main view
- An application shell that provides an abstraction for handling authentication integration with an authentication provider, navigation between views, localization, and general application settings
- Luigi client
- A micro-frontend that can interact with the main view via a postMessage mechanism abstracted by the Luigi APIs and several other APIs to allow capabilities like web storage integration or life cycle hooks
After implementing these two parts, a developer then can implement a micro-frontend without the risk of interfering with other parts of the application because the implementation uses iframes to create the requested isolation between key elements of the architecture (see Figure 4-22).

Figure 4-22. A micro-frontend architecture (at left) with the Luigi framework is composed of two parts: the main view and a Luigi client. The Luigi.js API provides an abstraction for common operations, such as communication between a micro-frontend and the host.
Use cases
Iframes are definitely not the solution for every project, yet iframes can be handy in certain situations. Iframes shine when there isn’t much communication between micro-frontends and we must enforce the encapsulation of our system using a sandbox for every micro-frontend. The sandboxes release the memory, and there won’t be dependency clashes between micro-frontends, removing some complexities of other implementations.
Drawbacks include accessibility, performance, and lack of indexability by crawlers, so best use cases for iframes are in desktop, B2B, or intranet applications. For example, Spotify used to use iframes to encapsulate its micro-frontends in desktop applications, preventing teams from leaking anything outside an iframe while allowing communication between them via events. That helps a desktop application to not download all the dependencies for rendering a micro-frontend; they are all available with the executable download. If you have a desktop application to develop, then, and multiple teams will contribute to specific domains, iframes might be a possible solution. (Note that Spotify recently decided to add its web modular architecture to the desktop application to unify the codebase and allow reusability across multiple targets.)
Many large organizations also use iframes in intranet applications as strong security boundaries between teams. For instance, when a company has dozens of teams working on the same project and it wants to enforce the teams’ independence, iframes could be a valid solution to avoid code or dependency clashes without creating too many tools to work with.
Imagine you have to build a dashboard where multiple teams will contribute their micro-frontends, composing a final view with a snapshot of different metrics and data points to consult. Iframes can help isolate the different domains without the risk of potential clashes between codebases from different teams. They can even prevent specific features inside an iframe using the sandbox attribute.
The final use case is when we have to maintain a legacy application that isn’t actively developed but is just in support mode and it has to live alongside the development of a new application, which will both have to be presented to users. In this case, the legacy application can be easily isolated in an iframe living alongside a micro-frontends architecture without the risk of polluting it.
Architecture characteristics
- Deployability (5/5)
- The deployability of this architecture is nearly identical to the vertical-split one, with the main difference being we will have more micro-frontends in the horizontal split because we will be dealing with multiple micro-frontends per view.
- Modularity (3/5)
- Iframes provide a good level of modularity, thanks to the ability to organize a view in multiple micro-frontends. At the same time, we will need to find the right balance to avoid abusing this characteristic.
- Simplicity (3/5)
- For a team working on a micro-frontend, iframes are not difficult. The challenge is in communicating across iframes, orchestrating iframe sizes when the page is resized without breaking the layout. In general, dealing with the big picture in absence of frameworks may require a bit of work.
- Testability (3/5)
- Testing in iframes doesn’t have any particular challenges apart from the one described for horizontal-split architectures. However, end-to-end testing may become verbose and challenging due to the DOM tree structure of iframes inside a view.
- Performance (2/5)
- Performance is probably the worst characteristic of this architecture. If not managed correctly, performance with iframes may be far from great. Although iframes solve a huge memory challenge and prevent dependency clashing, these features don’t come free. In fact, iframes aren’t a solution for accessible websites because they aren’t screen-reader-friendly. Moreover, iframes don’t allow search engines to index the content. If either of these is a key requirement for your project, it’s better to use another approach.
- Developer experience (3/5)
- The iframes DX experience is similar to the SPA one. Automation pipelines are set up in a similar manner, and final outputs are static files, like an SPA. The main challenge is creating a solid client-side composition that allows every team working with micro-frontends to test their artifacts in conjunction with other micro-frontends. Some custom tools for speeding up our teams’ DX may be needed. The most challenging part, though, is creating end-to-end testing due to the DOM replication across multiple iframes and the verbosity for selecting an object inside it.
- Scalability (5/5)
- The content served inside an iframe is highly cacheable at the CDN level, so we won’t suffer from scalability challenges at all. At the end, we are serving static content, like CSS, HTML, and JavaScript files.
- Coordination (3/5)
- As with all horizontal-split architectures, it’s important to avoid too many teams collaborating in the same view. Thanks to the sandbox nature of iframes, code clashes aren’t a concern, but we can’t have interactions spanning across the screen when we have multiple iframes, because coordinating these kinds of experiences is definitely not suitable for this architecture.
Table 4-3 gathers the architecture characteristics and their associated score for this micro-frontend architecture.
| Architecture characteristics | Score (1 = lowest, 5 = highest) |
|---|---|
| Deployability | 5/5 |
| Modularity | 3/5 |
| Simplicity | 3/5 |
| Testability | 3/5 |
| Performance | 2/5 |
| Developer experience | 3/5 |
| Scalability | 5/5 |
| Coordination | 3/5 |
Web Components
Web components are a set of web platform APIs that allow you to create custom, reusable, and encapsulated HTML tags for use in web pages and web apps. You may argue that web components are not the first thing that comes to mind when thinking about micro-frontends. However, they have interesting characteristics that make web components a suitable solution for building micro-frontend architecture. For instance, we can encapsulate our styles inside web components without fear of leaking in the main application. As well, all the major UI frameworks, like React, Angular, and Vue, are capable of generating web components, and the number of open source libraries to simplify creating this web standard is increasing, particularly with projects like Svelte, which can compile to web components, and LitElement from Google. Web components are also great tools for creating shared libraries for micro-frontend projects used with the same or different UI framework. In fact, in several 2019 surveys about the state of frontend development, web components were one of the most used solutions for building micro-frontends. They play a pivotal role in micro-frontend architecture, either for sharing components across micro-frontends or for encapsulating micro-frontends.
Web components technologies
Web components consist of three main technologies, which can be used together to create custom elements with encapsulated functionality that can be reused wherever you like without fear of code collisions.
- Custom elements
- They are an extension of HTML components. We can use them as containers of our micro-frontends, allowing us to interact with the external world via callbacks or events, for instance. Moreover, we can configure exposed properties to configure our micro-frontends accordingly when needed.
- Shadow DOM
- A set of JavaScript APIs for attaching an encapsulated “shadow” DOM tree to an element, rendered separately from the main DOM. In this way, you can keep an element’s features private, so they can be scripted and styled without the fear of collision with other parts of the document.
- HTML templates
- The template and slot elements enable you to write markup templates that are not displayed in the rendered page. These can then be reused multiple times as the basis of a custom element’s structure.
Among these three technologies, custom elements and shadow DOM are those that make web components useful for micro-frontend architectures. Both elements allow encapsulation of the code needed in a subdomain without affecting the application shell. Custom elements are used as wrappers of a micro-frontend, while the shadow DOM allows us to encapsulate the micro-frontend’s styles without causing them to override another style of micro-frontend.
An important aspect to consider when we are working with web components as wrappers of our micro-frontends is avoiding domain logic leaks. The moment we are allowing the container of our micro-frontends, wrapped inside web components, to customize their behaviors, we are exposing the domain logic to the external world, causing the container of a micro-frontend to know how to interact with a specific API contract via attributes.
It’s essential to make sure the communication between a micro-frontend wrapped by a web component and the rest of the view happens in a decoupled and unified way. We may risk blurring the line between components and micro-frontends, where the former should be open to extension, while the latter should be close to extension but open to communication.
Compatibility challenges
Before choosing web components for our next micro-frontend project, we need to take into consideration if the requirements are suitable for them. When we have to target many versions of web browsers, including the old ones and Internet Explorer, the only option provided by web components are polyfills. There are two ways for integrating polyfills for web components. The first is including them all. The package size would be quite large, but you are bulletproof, extending the retrocompatibility of your code for older browsers. The second option is loading at runtime only the polyfills needed. In this case, the package size is by far smaller, but it could require a bit of time before loading the right polyfills, considering we have to identify which ones are needed on the browser in which we are running the application.
Another compatibility challenge to be aware of is that there are some bugs on WebKit engine that affect web components’ customized built-in elements. Also, older versions of Safari (7 and 8, for instance) don’t support importNode or cloneNode methods for appending HTML templates to the DOM. For more information about the web components’ fragmentation across all the major browsers divided by vendor and version, I recommend checking out the Can I Use website.
SEO and web components
When our micro-frontend project requires search engine optimization, dealing with web components may be nontrivial. In fact, the best way to allow a crawler indexing the content rendered inside a web component is exposing its content in the light DOM:
<my-account-mfe><h2>Welcome to My Account</h2></my-account-mfe>
In this way, the vast majority of the crawlers available worldwide would be capable of indexing the content of your application. The usage of content inside the shadow DOM is discouraged when you deploy an application that should not be indexed only by major search engines like Google. Therefore, when a SEO is a key requirement for your micro-frontend project, dynamic rendering can be an option if you have to use web components.
Use cases
Embracing web components for your micro-frontend architecture is a great choice when you need to support multitenant environments. Given their broad compatibility with all the major frameworks, web components are the perfect candidate for use in multiple projects with the same or different frontend stack, as with multitenant projects. In multitenant projects, our micro-frontends should be integrated in multiple versions of the same application or even in multiple applications, which makes web components a simple, effective solution.
Let’s say your organization is selling a customer-support solution in which the chat micro-frontend should be live alongside any frontend technology your customers use. Web components can also play an important role in shared libraries. In a design system, for instance, using a web standard allows you to evolve your applications without having to start from scratch every time, because part of the work is reusable no matter what direction your tech teams or business will take. This is a great investment to make.
Architecture characteristics
- Deployability (4/5)
- Loading web components at runtime is easily doable. We just need a CDN for serving them, and they can then be integrated everywhere. They are also easy to integrate with compile time integration; we add them as we import libraries in JavaScript. Although technically you can render them server side, the DX is not as sleek as other solutions proposed by UI frameworks like React.
- Modularity (3/5)
- Web components’ high degree of modularity allows you to decompose an application into well-encapsulated subdomains. Moreover, because they are a web standard, we can use them in several situations without too many problems when we operate inside browsers that support them. The risk of using them as a micro-frontend wrapper is that it can confuse new developers who are joining a project, blurring the line between components and micro-frontends. This often results in a proliferation of “micro-frontends”' in a view, but probably we should call them nano-frontends.
- Simplicity (4/5)
- Using web components should be a simple task for anyone who is familiar with frontend technologies. The main challenge is not splitting our micro-frontends too granularly. Because web components can also be used for building component libraries, the line between micro-frontends and components can be blurred. However, focusing on the business side of our application should lead us to correctly identify micro-frontends from components in our applications.
- Testability (4/5)
- Leveraging different testing strategies using web components doesn’t present too many challenges, but we have to be familiar with their APIs. Web components’ APIs differ from UI frameworks, making it challenging to do what we are used to doing with our favorite framework.
- Performance (4/5)
- One of the main benefits of web components is that we are extending HTML components, meaning we aren’t making them extremely dense with external code from libraries. As a result, they should be one of the best solutions for rendering your micro-frontends client side.
- Developer experience (4/5)
- The DX of your projects shouldn’t be too different from your favorite framework. You have to learn another framework to simplify your life, though there aren’t too many differences in the development life cycle, especially in the syntax, but that’s why there are web component frameworks for simplifying the developer’s life.
- Scalability (5/5)
- Whether we implement our web components at compile or runtime, we will be delivering static files. A simple infrastructure can easily serve millions of customers without the bother of maintaining complex infrastructure solutions to handle traffic.
- Coordination (3/5)
- The main challenge is making sure we have the micro-frontends’ granularity right, because this will impact application delivery speed and avoid external dependencies that may lead to developer frustrations. We need to have a strong sense of discipline when identifying what is represented by a component or by a micro-frontend.
Table 4-4 gathers the architecture characteristics and their associated score for this micro-frontend architecture.
| Architecture characteristics | Score (1 = lowest, 5 = highest) |
|---|---|
| Deployability | 4/5 |
| Modularity | 3/5 |
| Simplicity | 4/5 |
| Testability | 4/5 |
| Performance | 4/5 |
| Developer experience | 4/5 |
| Scalability | 5/5 |
| Coordination | 3/5 |
Server Side
Horizontal-split architectures with a server-side composition are the most flexible and powerful solutions available in the micro-frontend ecosystem, thanks to cloud, which is the perfect environment for developers wanting to focus on the value stream more than infrastructure operationalization. In the cloud, we have the agility to spin up the infrastructure as requests increase and reduce it again when traffic goes back to normal. We can also set up our baseline without too many headaches, focusing on what really matters: the value created for our users.
Server-side composition is usually chosen when our applications have a strong requirement for SEO because this technique speeds up the page load time and the page is fully rendered without the need of any JavaScript logic. Server-side rendering also helps with the position of your application on search engine results pages, considering every search engine takes into account the page load speed.
In a server-side composition, the final view is created on the server side, where we can control the speed of the final output using techniques like caching in different layers (e.g., in a service, in-memory, or CDN), reducing the hops between services to retrieve all the micro-frontends, as well as the type of compute used for running the logic to compose our micro-frontends. Nowadays we have all the tools and resources needed to impact how fast a view is composed and served to our users.
Many of the challenges described in the horizontal split with client-side composition are challenges on the server side too, so rather than repeating them here, let’s focus on a few additional challenges this approach creates.
Scalability and response time
Despite the infrastructure flexibility cloud provides, we have to set up the infrastructure correctly in the first place based on our application’s traffic patterns. While a cloud provider’s auto-scaling functionalities can help you to achieve this goal, the type of compute layer you choose will affect how fast you can ramp up your application. Containers are faster to run than virtual machines, and managed containers like serverless ones delegate the operationalization of our infrastructure to the cloud provider, so we just need to focus on comparing different services’ implementations and plug-and-play options to achieve our goals.
Of course, not all web applications behave in the same way, so there’s a risk that our chosen auto-scaling solution will not be fast enough to copy with our specific traffic surges. A classic example would be the beginning of Black Friday sales or a global live event available only on our platform. In these cases, we would need to ensure that we meet the predictive load by manually increasing our solution’s baseline infrastructure before the users join our platform.
Another challenge we face with this architecture is understanding how we can speed up the response time of services and maybe microservices, and whether we need to consume them every time or if we can cache the response for specific micro-frontends instead of embracing eventual consistency. An in-memory cache solution like Redis can be a great ally in this situation, allowing us to store the microservice response for a short time, thereby increasing our micro-frontend composition’s throughput. We can also store the entire micro-frontend DOM inside an in-memory cache and fetch it from there instead of composing it every time.
Alternatively, we can use a CDN, which can increase a web page’s delivery speed, reducing the latency between the client and the content requested.
Latency, response time, cache eviction, and similar metrics become our measure of success in these situations, but creating the right infrastructure is not a trivial process, especially when there is a lack of knowledge or experience.
Infrastructure ownership
Composition layer ownership is another challenge with this architecture. In the best implementations, a cross-functional team of frontend and backend developers work together to manage the micro-frontend composition layer end to end. In this way, they can collaborate on the best outputs at the composition layer level, improving how data flows through it.
Some companies may decide to split the composition layer from micro-frontend development. The risk here is that a frontend developer will be working in a silo, requiring additional mechanisms to keep the teams in sync to consolidate the integration of the two layers. Frontend developers must clearly understand what’s going on in the composition layer and be able to help enhance it on code, infrastructure, monitoring, and logging levels. In this way, they can optimize the micro-frontend code written based on the implementation made in the composition layer.
Composing micro-frontends
Composing micro-frontends in a server-side architecture may deviate from what we have seen till now, but deviations are in the details, not the substance. As we can see from Figure 4-23, the typical architecture is composed of three layers.

Figure 4-23. A typical high-level architecture for a server-side micro-frontend architecture, where a composer is responsible for stitching together the different micro-frontends at runtime. A CDN can be used for offloading traffic to the origin.
The three layers are as follows:
- Micro-frontends
- These can be deployed as static assets, maybe prepared at compile time during the automation pipeline, or as dynamic assets in which an application server prepares a template and its associated data for every user’s requests.
- Composer
- This layer is used to assemble all the micro-frontends before returning the final view to a user. In this case, we can have an NGINX or HTTPd instance for leveraging SSI’s directives or a more complex scenario leveraging Kubernetes and custom application logic for stitching everything together.
- CDN
- Whenever possible, you should add a CDN layer in front of your application server in order to cache as many requests as possible. And if you can cache a page for a few minutes, you can offload a lot of traffic from the composer and increase your web application’s performance, thanks to the shorter roundtrip for the response.
Many frameworks out there will do the undifferentiated heavy lifting of implementing this type of architecture. To choose the best one for your project, you’ll have to understand the project’s business goals to evaluate the frameworks against the business requirements and architecture characteristics you aim for.
In the next section, I’ll cover some of these frameworks so that you can see how they align with the pattern described above. However, every framework emphasizes different aspects than others, and not all the DXs are first class, so you may end up investing more time streamlining the DX before realizing the expected outcome from your chosen framework.
Micro-frontend communication
When you choose the server-side approach, you likely won’t have many communications inside the view but instead have communication between the view and the APIs. This is because at the end, the page will reload after every significant user action on it. Still, there are situations in which one micro-frontend has to notify another that something happened in the session, such as a user adding a product to the cart. The micro-frontend that owns the domain will need to show the new product on a drop-down to show the user that the change was made in the cart. To accomplish this, we will add some logic on the frontend, and, using an event emitter or custom event, we will keep the micro-frontends loosely coupled while allowing them to communicate when something happens inside the application. In Figure 4-24, we can see how this mechanism works in practice:
-
A user adds a product to the cart. This event is communicated to the backend, which acknowledges the added product within the user’s session.
-
The product micro-frontend notifies the checkout experience micro-frontend that a new product was added to the cart.
-
The checkout experience micro-frontend fetches the new list of products in the cart and displays the new information in the UI.

Figure 4-24. An example of how the product’s micro-frontend notifies the checkout experience micro-frontend to refresh the cart interface when a user adds a product to the cart
There aren’t many of these types of interactions per view in most web applications, so the code won’t negatively impact performance or the maintainability of the final solution.
Available frameworks
Some of the available frameworks for this category include Podium, Mosaic, Puzzle.js, and Ara Framework, with Mosaic probably being one of the most famous because it was one of the first open source frameworks to embrace this architecture style. Mosaic is really a collection of frameworks and tools made famous by Zalando, a fashion ecommerce site, one of the first to leverage the concept of micro-frontends. There are many forks of Tailor.js, the tool used to stitch together different HTML fragments in the Mosaic suite, which testifies how good the solution was. As of publication time, however, Zalando had decided to create a new version of Mosaic with a more opinionated approach based on React and GraphQL.
To implement a micro-frontend architecture with a server-side composition, we explore the high-level architectures of a couple other frameworks that are currently in use by American Express (Amex), OpenTable, and Skyscanner, well-known brands that decided to scale their organizations and frontend development using micro-frontends. Then we’ll spend some time revisiting a well-known approach, SSI, since it falls in this category and there are still organizations leveraging this approach for their micro-frontend applications.
Amex released the open source project OneApp, a Node.js server used for serving server-side rendered micro-frontends on a single HTML page by using Holocron modules, another open source project from Amex. Every module represents a micro-frontend implementation with a set of utilities for simplifying the development experience, as well as for augmenting existing libraries such as Redux for store management. The view is a combination of Holocron modules called the Holocron roots.
As we can see in Figure 4-25, when a user requests a page, OneApp retrieves the associated root module, triggering the retrieval of the associated micro-frontends in order to render the final view. Next, the view is server-side rendered and served to the user. For performance reasons, the OneApp server periodically pulls the modules map JSON from the CDN, storing it in memory as a fast way to retrieve the module associated with a view without introducing too much latency in every request.

Figure 4-25. Holocron is a server-side rendering system for micro-frontends
The pain point of this architecture is the use of Redux as global state management for sharing the application state between micro-frontends. As discussed, every micro-frontend should be completely independent, but in Holocron this isn’t the case. Instead, custom events are used for communication between micro-frontends. Although this isn’t the most common communication technique for React applications, it’s definitely a step closer to fully embracing micro-frontend principles. And because Holocron modules can be stored anywhere and don’t necessarily need to be retrieved from a CDN, a virtual machine, an object storage, or a container may also be a suitable solution.
OpenComponents is another micro-frontend framework for server-side horizontal-split architectures. This opinionated framework provides several features out of the box, including prewarming of a CDN via runtime agents, a micro-frontend registry, and tools for simplifying the DX. Every micro-frontend is encapsulated inside a computational layer completely isolated from the others. This approach enables each team to focus on the implementation of their own domain without taking into account the entire application. Moreover, every micro-frontend has a set of utilities, such as observability, monitoring, or dashboards. For managing burst traffic at specific times of the day, such as from a constant flow of people reserving tables at restaurants, the traffic prewarming the CDN in use is offloaded every time a new micro-frontend is created or when a change to an existing one is made (see Figure 4-26).

Figure 4-26. The OpenComponents architecture shows how a server-side rendered micro-frontend is flowing from development to an environment
Interestingly, OpenComponents allows not only server-side rendering but also client-side rendering, so you can choose the right technique for every use case. When SEO is a key goal of a project, for example, you can choose SSR, while when you need a more SPA-like experience, you can use client-side rendering. Once again, you can see how all these frameworks had to make an investment in the developer experience to accelerate their adoption. As you compare frameworks, keep in mind that the vast majority of the time, these frameworks were built by midsize to large organizations, for which the final benefits definitely overcame the initial investment of resources and time.
SSI are used for dividing a final view into multiple parts, usually called fragments, that are composed by a server before returning a static page to the client request. Back in the 1990s, SSI were used to decouple an HTML page’s static content from other parts that may or not have been dynamic. SSI have directives—placeholders that the server interprets in order to perform a specific action on a page. That action might be including a micro-frontend or running logic, like including different fragments based on specific parameters, such as providing different UIs based on the user status.
SSI directives look like this:
<!--# include virtual="acme.com/mfe/catalog" -->
In particular, the include directive is very important for micro-frontends because when the server interprets this directive, it will add the fragment into the final DOM. Figure 4-27 summarizes how the logic applied by a server, like NGINX or HTTPd, composes micro-frontends using SSI.
Figure 4-27. The sequence diagram shows how a client request is handled by a server when SSI are used
When a client requests a page, the server retrieves the page containing the different directives. The server interprets all the directives and fetches the different fragments in parallel. When the directives are fully loaded, the server returns the final response to the client.
Clearly, when a fragment takes time to return, the page’s time to the first byte is affected. Luckily for us, we can set up timeouts as well as stub content to replace a fragment that times out or returns an empty body. Another challenge of this approach is avoiding overlaps in our CSS classes. As discussed before, creating prefixes for every class can help avoid undesired outcomes for your customers. Finally, it’s important to highlight that SSI won’t enrich your user’s website experience, so you will need to add some JavaScript logic to the page to run on the client side if you want the benefits of both s and page interactivity.
The main benefit of SSI is the server-side composition of the final page, which makes it easier for a search engine crawler to index the page. This is a plus for all server-side composition frameworks, but considering SSI were created several years ago, we can say they were the first technique to integrate this feature out of the box.
Use cases
The typical use cases for this architecture are business-to-consumer (B2C) websites, for which the content has to be highly discoverable by search engines, or B2B solutions with modular layouts, such as dashboards where the user interface doesn’t require too many drifts in the layout, as with a customer-facing solution. A tangible example of these types of implementations is OpenTable, an online restaurant-reservation service company based in San Francisco, with offices all over the world. The platform contains a host of tools that streamline the DX, making it easy to build micro-frontends thanks to OpenComponents.
This architecture is recommended for B2B applications, with many modules that are reused across different views. It’s important, however, that full stack or backend developers with the appropriate skills facilitate the introduction of this implementation. This architecture generally isn’t a good choice for very interactive, fluid layouts, mainly due to the coordination needed across teams to create a cohesive final result or when there are bugs in production that may require more effort in discovering their root cause.
Architecture characteristics
- Deployability (4/5)
- These architectures may be challenging when you have to handle burst traffic or with high-volume traffic. When we decide to deploy a new micro-frontend, we’ll also likely have to deploy some API to fetch the data, creating more infrastructure and configuration to handle. To limit the extra work and avoid production issues, automate repetitive tasks as much as possible.
- Modularity (5/5)
- This architecture key characteristic is the control we have over not only how we compose micro-frontends but also how we manage different levels of caching and final output optimization. Because we can control every aspect of the frontend with this approach, it’s important to modularize the application to fully embrace this approach.
- Simplicity (3/5)
- This architecture isn’t the easiest to implement. There are many moving parts, and observability tools on both the frontend and backend need to be configured so that you’ll understand what’s happening when the application doesn’t behave as expected. Taking into account the architectures seen so far, this is the most powerful and the most challenging, especially on large projects with burst traffic.
- Testability (4/5)
- This is probably the easiest architecture to test, considering it doesn’t differ too much from server-side rendering applications. There may be some challenges when we expect every micro-frontend to hydrate the code on the client side because we’ll have some additional logic to test, but since we’re talking about micro-frontends, it won’t be too much additional effort.
- Performance (5/5)
- With this implementation, we have full control of the final result being served to a client, allowing us to optimize every single aspect of our application, down to the byte. That doesn’t mean optimization is easier with this approach, but it definitely provides all the possibilities needed to make a micro-frontend application highly performant.
- Developer experience (3/5)
- There are frameworks that provide an opinionated way to create a smooth developer experience, but it’s very likely you will need to invest time creating custom tools to improve project management and introducing dashboards, additional command line tools, and so on. Also, a frontend developer may need to boost their backend knowledge, learning how to run servers locally, scale them in production, work in the cloud or on premises efficiently, manage the observability of the composition layer, and more. Full stack developers are more likely to embrace this approach but not always.
- Scalability (3/5)
- Scalability may be a nontrivial task for high-volume projects because you’ll need to scale the backend that composes the final view to the user. A CDN can work, but you will have to deal with different levels of caching. CDNs are helpful with static content, but less so with personalized ones. Moreover, when you need to maintain a low response latency and you aren’t in control of the API you are consuming, you will have another challenge to solve on top of the scalability of the micro-frontend composition layer.
- Coordination (3/5)
- Considering all the moving parts included in this architecture, the coordination has to be well designed. The structure has to enable different teams to work independently, reducing the risks of too many external dependencies that can jeopardize a sprint and cause frustration for developers. Furthermore, developers have to keep both the big picture and the implementation details in mind, making the organization structure a bit more complicated, especially with large organizations and distributed teams.
Table 4-5 gathers the architecture characteristics and their associated score for this micro-frontend architecture.
| Architecture characteristics | Score (1 = lowest, 5 = highest) |
|---|---|
| Deployability | 4/5 |
| Modularity | 5/5 |
| Simplicity | 3/5 |
| Testability | 4/5 |
| Performance | 5/5 |
| Developer experience | 3/5 |
| Scalability | 3/5 |
| Coordination | 3/5 |
Edge Side
Edge Side Includes, or ESI, was created in 2001 by companies like Akamai and Oracle. It’s a markup language used for assembling different HTML fragments into an HTML page and serving the final result to a client. Usually, ESI is performed at the CDN level, where it offers great scalability options because of the CDN’s architecture. Different points of presence across the globe serve every user requesting static content. Every request is redirected to the closest point of presence, reducing the latency between the user and where the content is stored. Additionally, because CDNs are great for caching static assets, this combination of capillarity across the globe and cacheability makes ESI a potential solution for developing micro-frontends that don’t require dynamic content, such as catalog applications.
Another alternative for using ESI is using proxies like NGINX or Varnish, both of which offer ESI implementations. Unfortunately, ESI specifications are not fully supported everywhere. We often find only a subset of the features available in CDN provider or a proxy solution, which may compromise the flexibility needed for a business, reducing the possibility of the frontend architecture evolution. Moreover, the frontend community hasn’t embraced this standard as it has with others, such as React, Vue, or Angular. The fragmentation between vendors, the lack of tools, and the friction on the developer experience have all played a pivotal role in the adoption of this technology.
Implementation details
As we said, every micro-frontend is composed with an HTML page as entry point with either a reverse proxy or a CDN provider. ESI language and composition are very similar to SSI, except that the markup is interpreted before the page is served to a client. ESI is composed by a template containing multiple fragments that represent, in this case at least, our micro-frontends. Here are the main functionalities:
- Inclusion
- ESI can compose pages by assembling included content, which is fetched from the network. The template uses transclusion to replace the placeholder tag within it with the micro-frontend it has retrieved.
- Variable support
- ESI supports the use of variables based on HTTP request attributes. These variables can be used by ESI statements or written directly into the processed markup.
- Conditional processing
- ESI allows conditional logic with Boolean comparisons to influence how a template is processed.
- Exception and error handling
- ESI allows you to handle errors or exceptions with alternative content to create a smoother user experience.
This is how ESI looks before being served to a browser:
<html><body>Welcome to MFE with ESI<esi:includesrc="https://www.myorigin.com/MFE_A.html"/><esi:includesrc="https://www.myorigin.com/MFE_B.html"/></body></html>
When the markup language is interpreted, the final result will be a static HTML page completely renderable by a browser.
Transclusion
ESI uses a technique called transclusion for including existing content inside a new document without the need to duplicate it. In early 2000, this mechanism was used to reduce the cut-and-paste process that every developer was using to create web pages. Now we can use it to reuse content and generate new views based on simple constructs like conditional processing or variable support. This provides a useful mechanism to reduce the time it takes to build websites despite the poor developer experience.
Client-side includes (CSI) also leverage transclusion, such as the h-include. Applying transclusion inside the browser uses the same logic for interpreting an ESI tag. In fact, each <h-include> element will create a request to the URL and replace the innerHTML of the element with the response of the request. Using CSI with ESI will help supplement ESI’s limitation, adding the possibility of serving dynamic content inside a predefined template. In this way, we can use ESI to leverage a CDN’s scalability. When we further combine this with JavaScript’s ability to load HTML fragments directly on the client side, we can make our websites far more interactive.
Challenges
While ESI may seem like a viable option, there are some challenges to be aware of. First, ESI specifications are not implemented in all CDN providers or proxy servers the way Varnish and NGINX are. This lack of adoption increases the chance that you will have to evolve your infrastructure in the future. Your web application requires a certain resilience, and if you are considering a multi-CDN strategy, ESI probably won’t be the right solution for you.
Another problem that ESI won’t solve is the integration of dynamic contents. Let’s say you want to integrate personalized content in your micro-frontends. A caching strategy won’t help because you may end up with a list of personalized content per user, and segmenting your content for a group of users may result in segments too large to be meaningfully cached by a CDN. In these cases, ESI should be integrated in conjunction with JavaScript running inside the browser and consuming some APIs. Depending on the business requirements, you might also use the CSI transclusion mechanism. CSI leverages the same mechanism as ESI but on the client side, so that once the application is loaded inside a browser, a JavaScript code will scan the DOM to find and replace tags and then mount new DOM elements instead of the placeholders. However, you may want to just load some DOM elements or even some external JavaScript files that would run the logic to render personalized content inside an ESI application. Obviously, all these roundtrips may impact micro-frontend application performance, so you’ll want to find the right balance to implement micro-frontends with a combination of ESI and CSI, and you’ll need to spend the time finding the best way to stitch everything together.
Last but not least, ESI doesn’t shine for a frictionless developer experience, with the poor adoption contributing to the lack of investment in this markup language.
Developer experience
The DX is one of ESI’s main challenges. It’s very important to create a smooth, functional environment for developers so that they can concentrate on developing new features, hardening algorithms, and, in general, striving in their daily job. However, ESI requires developers to use different tools to ensure the final result is the one expected by the user.
Imagine we decide to embrace ESI and use Akamai for handling the transclusion at the CDN level. Akamai implements the full specifications for using ESI, but how would you test that locally? Akamai offers an ESI test server provided as a Docker container for local development and for integration with your automation pipelines. The testing server mimics the Akamai servers’ behaviors when receiving a request, fetching the page to serve, interpreting the ESI tags, and serving the final HTML page to a browser. Other CDN providers don’t implement the entire specification, so you risk using a technique that could end up with false positives and invalidate the quick feedback loop for your developers.
Finally, this architecture is not widely embraced by the frontend community, resulting in a lack of documentation, tools, and support compared to more modern solutions described in this chapter.
Use cases
One of the main use cases for edge-side composition is for managing large static websites where multiple teams are contributing to the same final application. The IKEA catalog was implemented in some countries using a combination of ESI and CSI in this way.
Another potential application would be using ESI for the static part of a website and serving the rest with micro-frontends rendered at client side. This technique is also known as micro-caching, but it is complicated to put in place as well as to debug. Because of the poor developer experience, not many companies have implemented this technology, and despite its age, it has never seen the mainstream.
Architecture characteristics
- Deployability (3/5)
- Similar to the client-side composition, this approach guarantees an easy deployment and artifacts consumptions via CDN. Because we are talking about a horizontal split, we need to increase the effort of managing potential network errors that would prevent a micro-frontend from being composed on the CDN level. Finally, not all the CDN supports ESI, which could be a problem in the long run for your project, especially when you have to change CDN providers. However, managing multiple environments and deploying micro-frontends in local environment is not a smooth experience.
- Modularity (4/5)
- Transclusion facilitates modular design, so we can reuse micro-frontends in multiple pages. ESI becomes even more interesting when mixed with CSI, covering the static parts with ESI and the more dynamic ones with CSI.
- Simplicity (2/5)
- If horizontal-split architectures can become quite complex in the long run, the edge-side ones can be even more complex because of the poor developer experience and the need of a CDN or Varnish to test your code.
- Testability (3/5)
- ESI doesn’t shine in testing either. Unit testing may be similar to what we’re used to implementing for other architectures, but to implement an integration and end-to-end testing strategy, we need to rely on a more complex infrastructure, which could slow down the feedback loop for a team.
- Performance (3/5)
- Since ESI is a composition on the CDN level most of the time, the application can have great performance out of the box thanks to the cache for static content. However, we need to consider that when a micro-frontend hangs due to network issues, none of the pages will be served until the request timed out—not exactly the best customer experience.
- Developer experience (2/5)
- The DX of any solution is a key factor in adoption; the more complicated a solution is, the less developers will embrace it. ESI is definitely a complicated solution. To locally test your implementation, you will need a Varnish, NGINX, or Akamai testing server inside a virtual machine or a docker container. And if you are using a CDN, be ready for a long feedback loop on whether your code is behaving correctly. There are other tools available, but it’s still a clunky experience compared to the other architectures.
- Scalability (4/5)
- If your project is static content, ESI is probably one of the best solutions you can have, thanks to the composition at the CDN level. And with a mix of static and dynamic content, using ESI in conjunction with CSI, the scalability of your solution will be bulletproof.
- Coordination (3/5)
- Edge-side composition allows you to leverage micro-frontend principles, allowing you to have independent teams and artifacts. However, due to the poor DX, you may need more coordination across teams, especially when there are changes in the production environment that affect all the teams. Similar to the recommendation for server-side composition, plan your team structure accordingly and be sure to iterate to validate decisions.
Table 4-6 gathers the architecture characteristics and their associated score for this micro-frontend architecture.
| Architecture characteristics | Score (1 = lowest, 5 = highest) |
|---|---|
| Deployability | 3/5 |
| Modularity | 4/5 |
| Simplicity | 2/5 |
| Testability | 3/5 |
| Performance | 3/5 |
| Developer experience | 2/5 |
| Scalability | 4/5 |
| Coordination | 3/5 |
Summary
In this chapter, we have applied the micro-frontend decisions framework to multiple architectures. Defining the four pillars (defining, composing, routing, and communicating) offered by the micro-frontends decisions framework helps us to filter our choices and select the right architecture for a project. We have analyzed different micro-frontend architectures, highlighting their challenges and scoring the architecture characteristics so that we can easily select the right architecture based on what we have to optimize for. Finally, because we understand that the perfect architecture doesn’t exist, we realized that we have to find the less worse architecture based on the context we operate in. In the next chapter, we will analyze a technical implementation and focus our attention on the main challenges we may encounter in a micro-frontend implementation.
Get Building Micro-Frontends now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

