Chapter 1. Introducing Knowledge Graphs
We’re overwhelmed by data. It’s everywhere and being collected at a fantastic rate and stored at substantial cost. But we’re not necessarily getting value from that data, though there is significant value in it, if only we could understand it.
All is not lost. Over the last decade, a new category of technology based on graphs has moved from obscurity to prominence. Graphs have come to underpin everything from consumer-facing systems like navigation and social networks to critical infrastructure like supply chains and power grids.
These important graph use cases have reached a common conclusion: applying knowledge in context is the most powerful tool that most businesses have. A set of patterns and practices called knowledge graphs has been emerging to help understand data in context, where the context is represented as a graph of connected data items. With knowledge graphs, there is hope that you can distill business value from data. This book is an attempt to show how it can be done.
Knowledge graphs are useful because they provide contextualized understanding of data. Context derives from the layer of metadata (graph topology and other features) that provides rules for structure and interpretation. This book shows how the connected context provided by knowledge graphs enables you to extract greater value from existing data, drive automation and process optimization, improve predictions, and support an agile response to changing business environments.
We wrote this book for technology professionals who are interested in building and operating knowledge graphs within their businesses. In a way, it’s a sequel to or expansion of O’Reilly’s Knowledge Graphs: Data in Context for Responsive Businesses, which we had the pleasure of writing in 2021. That report was intended for chief information officers (CIOs) and chief data officers (CDOs), helping them to understand the benefits of knowledge graphs. This time we’re aiming at data and software professionals who build sophisticated information systems.
The book is arranged in two parts. The first part deals with graph fundamentals, including graph databases, query languages, data wrangling, and graph data science. It teaches technical practitioners the fundamental tooling needed to understand the second part of this book, which tackles significant knowledge graph use cases and how to implement them, complete with code examples and system architectures.
For data and software professionals, this book provides an on-ramp to the world of knowledge graphs and a language for discussing their implementation with your peers and management. It also gives deep examples for how to build and use knowledge graphs—from graph basics all the way to graph machine learning.
For CIOs or CDOs, this book may still be useful since it provides a good overview of knowledge graphs and how they are delivered. You can skim the earlier chapters and code examples if that’s not your thing, but you’ll still be able to understand what your practitioner colleagues are doing and why.
This chapter explains the background and motivation for knowledge graphs. Here we’ll introduce the notions of graphs and graph data and start to show how to build smarter systems with knowledge graphs.
What Are Graphs?
Knowledge graphs are a type of graph, so it’s important to have a basic understanding of graphs. Graphs are simple structures that use nodes (or vertices) connected by relationships (or edges) to create high-fidelity models of a domain. To avoid any confusion, the graphs in this book have nothing to do with visualizing data as histograms or plotting a function, which are called charts, as shown in Figure 1-1.
Figure 1-1. Graphs versus charts
The graphs in this book are sometimes referred to as networks. They are a simple but powerful way of showing how things connect.
Graphs are not new. In fact, graph theory was invented by Swiss mathematician Leonhard Euler in the 18th century to help compute the minimum distance that the emperor of Prussia had to walk to see the town of Königsberg (modern-day Kaliningrad) by ensuring that each of its seven bridges was crossed only once, as shown in Figure 1-2.
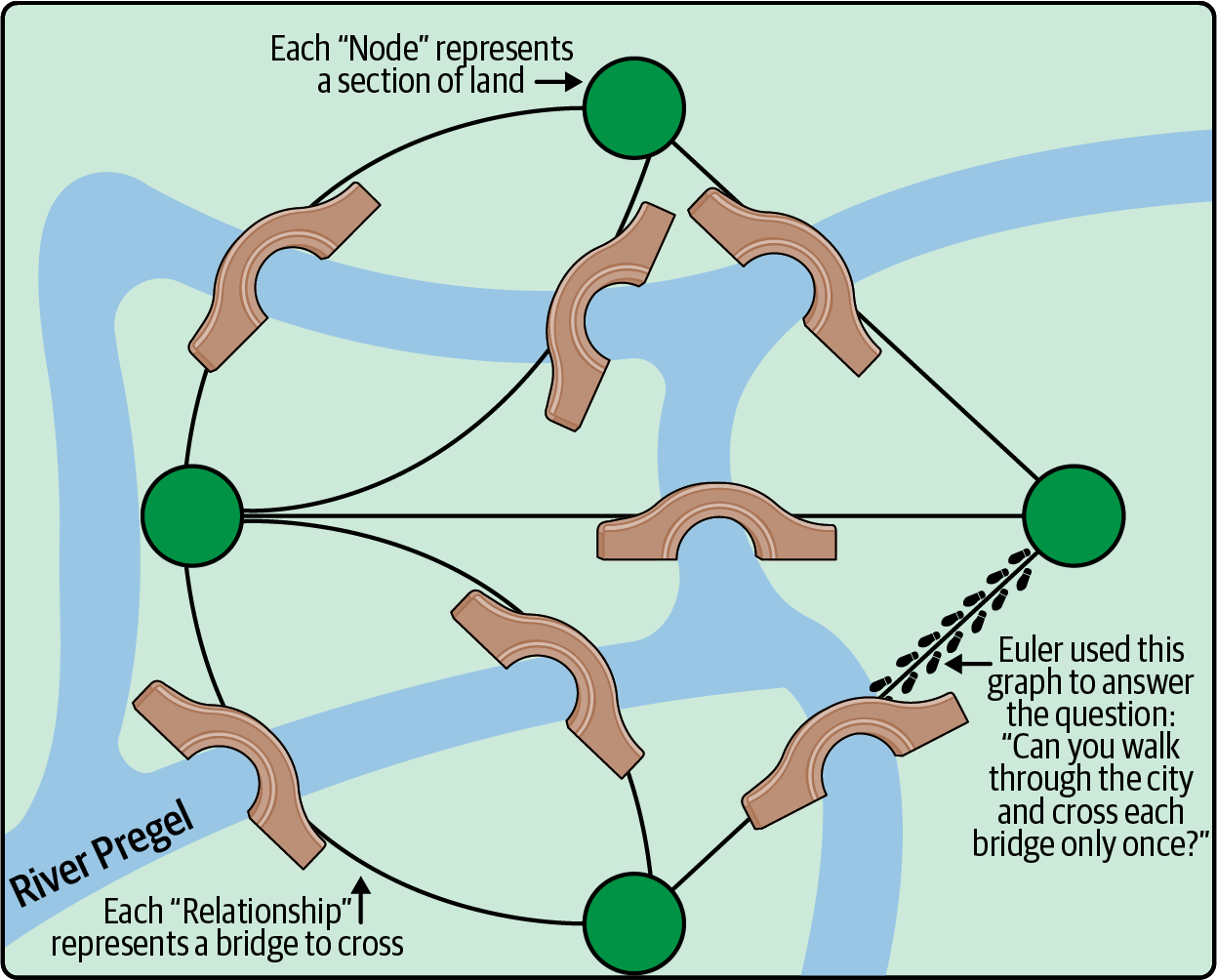
Figure 1-2. A graphical representation of Königsberg and its seven bridges across the Pregel River
Euler’s insight was that the problem shown in Figure 1-2 could be reduced to a logical form, stripping out all the noise of the real world and concentrating solely on how things are connected. He was able to demonstrate that the problem didn’t need to involve bridges, islands, or emperors. He proved that in fact the physical geography of Königsberg was completely irrelevant.
Note
To us, Euler’s approach is similar to modern software development. The inherent noise of the real world is stripped away so that a more valuable logical representation—the software—remains. For software professionals, this feels comfortingly familiar.
You can use the superimposed graph in Figure 1-2 to figure out the shortest route for walking around Königsberg without having to put on your walking boots and try it for real. In fact, Euler proved that the emperor could not walk the whole town crossing each bridge only once, since there would have needed to be (at least) one island (node) with an even number of connecting bridges (relationships) from which the emperor could start his walk. No such island existed in Königsberg, so no such route (path) is possible.
Building on Euler’s work, mathematicians have studied various graph models, all variations on the theme of nodes connected by relationships. Some models allow relationships to be directed, where they have an explicit start and end node, while some have undirected relationships connecting nodes. Some models, like hypergraphs, allow relationships to connect multiple nodes.
In theory, there’s no single best graph model to choose (though you can usually transform from one model to another). But there are better or worse models in practice, especially for building computer systems. In this book we’ve chosen the labeled property graph model as the foundation. It’s a popular model that is simple for software and data professionals to understand. It is expressive enough to represent even the most complicated domains and is information rich (unlike the graphs beloved of mathematicians).
Figure 1-3 shows a small social graph, but compared to the example in Figure 1-2, this graph holds much more information.
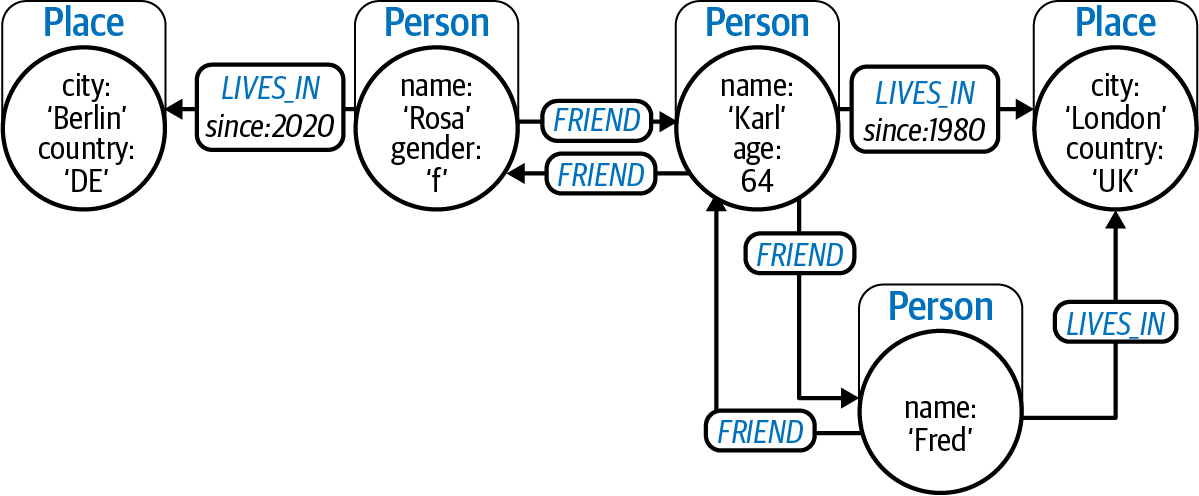
Figure 1-3. A graph representing people, their friendships, and their locations
In Figure 1-3 each node has a label that represents its role in the graph.
Some nodes are labeled Person and some are labeled Place, representing people and places respectively.
Stored inside those nodes are properties.
For example, one node has name:'Rosa' and gender:'f' that you can interpret as being a female person called Rosa.
Note that the Karl and Fred nodes have slightly different properties on them, which is a perfectly fine tool as it accommodates the messiness of the real world.
Tip
The property graph model does not enforce any schemas based on labels or relationship types. It’s deliberately intended to be flexible and accommodating to help develop high-fidelity models. If you really need to ensure that nodes with certain labels have certain properties, you can apply constraints to the label to ensure those properties exist, are unique, and so on. You can view this not as schema or schemaless, but schema-ish. The idea is to use schema-like constraints just where you need them rather than eagerly locking down the whole data model. Those schema-like constraints, like everything else in a graph data model, can change over time. Real-world data is often uneven and incomplete, so your knowledge graphs should reflect this reality.
Between the nodes in Figure 1-3 you see relationships. The relationships are richer than in Figure 1-2 since they have a type, a direction, and optional properties. Relationships cannot “dangle”; they always have a start node and an end node, even if the start and end nodes are the same.
For instance, there is a Person node with the property name:'Rosa' that has an outgoing LIVES_IN relationship with the property since: 2020 to the Place node with the property city:'Berlin'.
You can read this as “Rosa has lived in Berlin since 2020,” based on the direction of the relationships.
You can also see that Fred is a FRIEND of Karl and that Karl is a FRIEND of Fred.
Rosa and Karl are also friends, but Rosa and Fred are not.
In the property graph model, there are no limits on the number of nodes or the number or type of relationships that interconnect them. Some nodes are densely connected while others are sparsely connected. All that matters is that the model matches the problem domain. Similarly, some nodes have lots of properties, while some have few or none. Some relationships have lots of properties, but many have none at all. This is all perfectly normal for knowledge graphs.
It’s easy to see how the graph in Figure 1-3 can answer questions about friendships and who lives where. Extending the model to include other data like hobbies, publications, or jobs is also straightforward: just keep adding nodes and relationships to match your problem domain. Creating large, complex graphs with millions or billions of connections isn’t a problem for modern graph databases and graph-processing software, so building even very large knowledge graphs is achievable.
Graph data models can comfortably represent complex networks of relationships in a way that is both human readable and machine friendly. Graphs might seem very technical at first, but they are created from very simple primitives, making them very accessible in practice. In fact the combination of a simple data model and the ease of algorithmic processing to discover connections, patterns, and features is what has made graphs so popular. It’s a powerful combination you will also exploit in your knowledge graphs.
The Motivation for Knowledge Graphs
Interest in knowledge graphs has exploded, with a myriad of research papers, solutions, analyst reports, groups, and conferences on this topic. Knowledge graphs have become so popular partly because graph technology has accelerated in recent years but also because there is strong demand to make sense of data.
External factors have undoubtedly accelerated knowledge graphs to greater prominence. Stresses from the COVID-19 pandemic and fallout from geopolitics have strained some organizations to the point of breaking. Decision making has never needed to be more rapid. At the same time, businesses are hampered by the lack of timely and accurate insight.
Now businesses are reconfiguring their operations and processes to flex rapidly. As historical knowledge ages faster and is invalidated by market dynamics, many organizations need new ways of capturing, analyzing, and learning from data. Businesses need rapid insights and recommendations, from customer experience and patient outcomes to product innovation, fraud detection, and automation. They need contextualized data to generate knowledge.
Knowledge Graphs: A Definition
Now you know a little about graphs and the motivation for using knowledge graphs. But clearly not all graphs are knowledge graphs (despite the hype). Knowledge graphs are a specific type of graph with an emphasis on contextual understanding. Knowledge graphs are interlinked sets of facts that describe real-world entities, events, or things and their interrelations in a human- and machine-understandable format.
Critically, knowledge graphs must have an organizing principle so that a user (or a computer system) can reason about the underlying data. The organizing principle provides an additional layer of structure that adds context to support knowledge discovery. The organizing principle makes the data itself smarter. This idea runs contrary to the norm where intelligence resides in applications and data is dumb, just something to be mined and refined. Having smarter data both simplifies systems and encourages broad reuse.
Summary
Organizing principles, reasoning, and knowledge discovery might seem complicated at first. But in reality, you can think of knowledge graphs as a rich index over data that provides curation, much like a skilled librarian recommending books and journals to a researcher.
From here on things get a little more technical. In Chapter 2 you’ll learn how we can extend the definition of an organizing principle to act as a contract between a knowledge graph and its consuming users and systems. You’ll also learn about several different options for creating organizing principles.
Get Building Knowledge Graphs now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

