Chapter 4. Automating Architectural Governance
Architects are tasked with designing the structure of software systems as well as defining many of the development and engineering practices. However, another important job for architects is governing aspects of the building of software, including design principles, good practices, and identified pitfalls to avoid.
Traditionally, architects had few tools to allow them to enforce their governance policies outside manual code reviews, architecture review boards, and other inefficient means. However, with the advent of automated fitness functions, we provide architects with new sets of capabilities. In this chapter, we describe how architects can use the fitness functions created to evolve software to also create automated governance policies.
Fitness Functions as Architectural Governance
The idea that led to this book was the metaphorical mash-up between software architecture and practices from the development of genetic algorithms described in Chapter 2, focusing on the core idea of how architects can create software projects that successfully evolve rather than degrade over time. The results of that initial idea blossomed into the myriad ways we describe fitness functions and their application.
However, while it wasnât part of the original conception, we realized that the mechanics of evolutionary architecture heavily overlap architectural governance, especially the idea of automating governance, which itself represents the evolution of software engineering practices.
In the early 1990s, Kent Beck led a group of forward-looking developers who uncovered one of the driving forces of software engineering advances in the last three decades. He and the developers worked on the C3 project (whose domain isnât important). The team was well versed in the current trends in software development processes but were unimpressedââit seemed that none of the processes that were popular at the time yielded any kind of consistent success. Thus, Kent started the idea of eXtreme Programming (XP): based on past experience, the team took things they knew worked well and did them in the most extreme way. For example, their collective experience was that projects that have higher test coverage tended to have higher-quality code, which led them to evangelize test-driven development, which guarantees that all code is tested because the tests precede the code.
One of their key observations revolved around integration. At that time, a common practice on most software projects was to conduct an integration phase. Developers were expected to code in isolation for weeks or months at a time, then merge their changes during an integration phase. In fact, many version control tools popular at that time forced this isolation at the developer level. The practice of an integration phase was based on the many manufacturing metaphors often misapplied to software. The XP developers noted a correlation from past projects that more frequent integration led to fewer issues, which led them to create continuous integration: every developer commits to the main line of development at least once a day.
What continuous integration and many of the other XP practices illustrated is the power of automation and incremental change. Teams that use continuous integration not only spend less time performing merge tasks regularly, they spend less time overall. When teams use continuous integration, merge conflicts arise and are resolved as quickly as they appear, at least once a day. Projects using a final integration phase allow the combinatorial mass of merge conflicts to grow into a Big Ball of Mud, which they must untangle at the end of the project.
Automation isnât important only for integration; it is also an optimizing force for engineering. Before continuous integration, teams required developers to spend time performing a manual task (integration and merging) over and over; continuous integration (and its associated cadence) automated most of that pain away.
We relearned the benefits of automation in the early 2000s during the DevOps revolution. Teams ran around the operations center installing operating systems, applying patches, and performing other manual tasks, allowing important problems to fall through the cracks. With the advent of automated machine provisioning via tools such as Puppet and Chef, teams can automate infrastructure and enforce consistency.
In many organizations, we observed the same ineffective manual practices recurring with architecture: architects were attempting to perform governance checks via code reviews, architecture review boards, and other manual, bureaucratic processesââand important things fell through the cracks. By tying fitness functions to continuous integration, architects can convert metrics and other governance checks into a regularly applied integrity validation.
In many ways, the marriage of fitness functions and incremental change via continuous integration represents the evolution of engineering practices. Just as teams utilized incremental change for integration and DevOps, we increasingly see the same principles applied to architecture governance.
Fitness functions exist for every facet of architecture, from low-level, code-based analysis up to enterprise architecture. We organize our examples of automating architectural governance in the same manner, starting from the code level, then extending through the software development stack. We cover a number of fitness functions; the illustration in Figure 4-1 provides a road map.
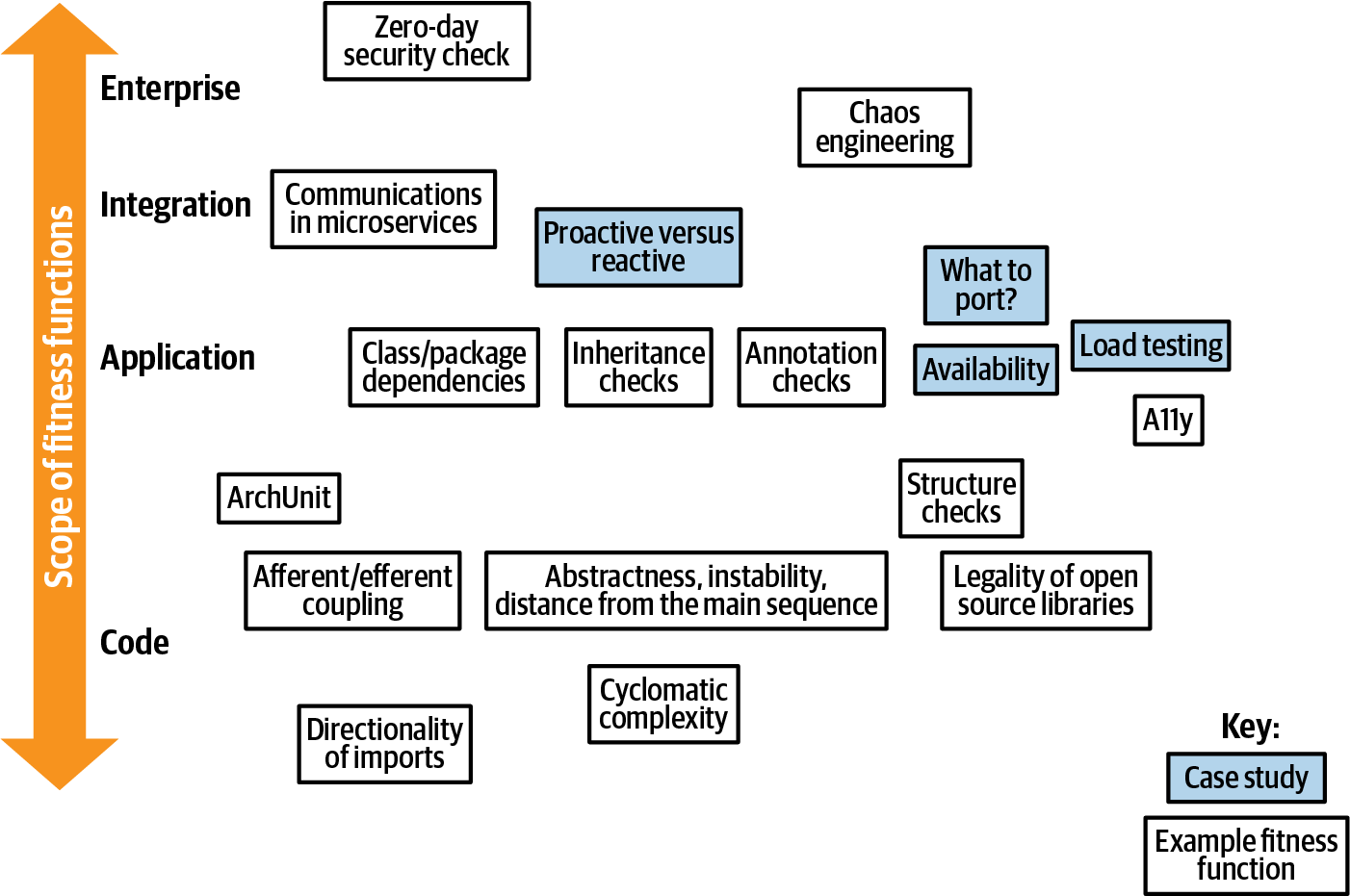
Figure 4-1. Overview of fitness functions
We start at the bottom of the map in Figure 4-1 with code-based fitness functions and make our way gradually to the top.
Code-Based Fitness Functions
Software architects have a fair amount of envy for other engineering disciplines that have built up numerous analysis techniques for predicting how their designs will function. We donât (yet) have anywhere near the level of depth and sophistication of engineering mathematics, especially about architectural analysis.
However, we do have a few tools that architects can use, generally based on code-level metrics. The next few sections highlight some metrics that illustrate something of interest in architecture.
Afferent and Efferent Coupling
In 1979, Edward Yourdon and Larry Constantine published Structured Design: Fundamentals of a Discipline of Computer Program and Systems Design (Prentice-Hall), defining many core concepts, including the metrics afferent and efferent coupling. Afferent coupling measures the number of incoming connections to a code artifact (component, class, function, etc.). Efferent coupling measures the outgoing connections to other code artifacts.
Coupling in architecture is of interest to architects because it constrains and affects so many other architecture characteristics. When architects allow any component to connect to any other with no governance, the result is often a codebase with a dense network of connections that defies understanding. Consider the illustration shown in Figure 4-2 of the metrics output of a real software system (name withheld for obvious reasons).

Figure 4-2. Component-level coupling in a Big-Ball-of-Mud architecture
In Figure 4-2, components appear on the perimeter as single dots, and connectivity between components appears as lines, where the boldness of the line indicates the strength of the connection. This is an example of a dysfunctional codebaseââchanges in any component may ripple out to many other components.
Virtually every platform has tools that allow architects to analyze the coupling characteristics of code in order to assist in restructuring, migrating, or understanding a codebase. Many tools exist for various platforms that provide a matrix view of class and/or component relationships, as illustrated in Figure 4-3.
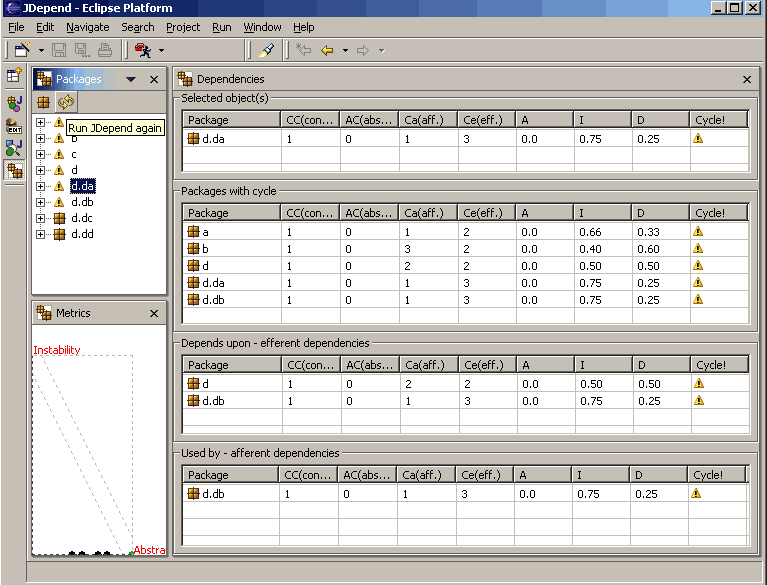
Figure 4-3. JDepend in Eclipse analysis view of coupling relationships
In Figure 4-3, the Eclipse plug-in provides a tabular view of the output of JDepend, which includes coupling analysis per package, along with some aggregate metrics highlighted in the next section.
A number of other tools provide this metric and many of the others we discuss. Notably, IntelliJ for Java, Sonar Qube, JArchitect, and others, based on your preferred platform or technology stack. For example, IntelliJ includes a structure dependency matrix showing a variety of coupling characteristics, as illustrated in Figure 4-4.
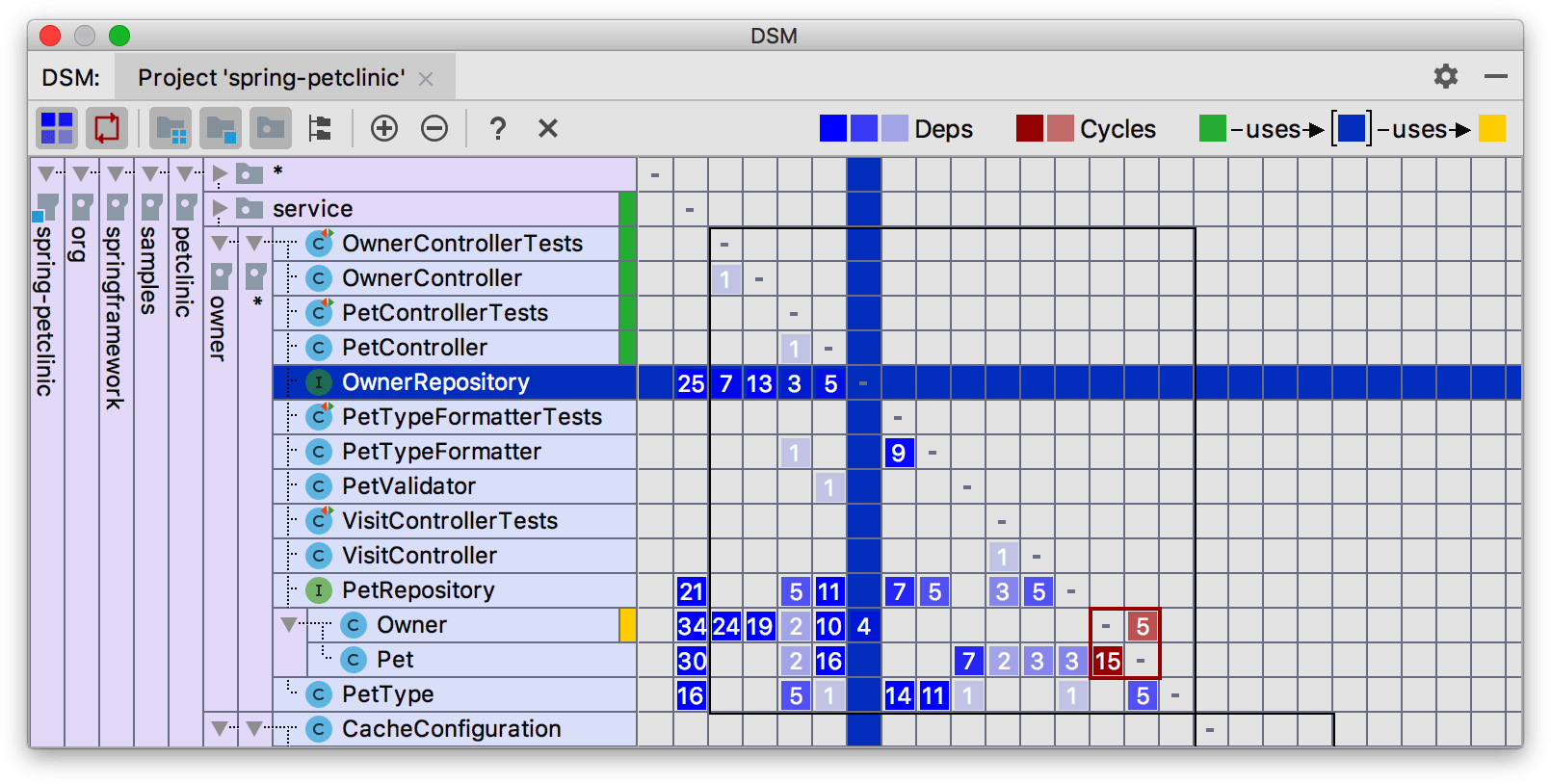
Figure 4-4. Dependency structure matrix from IntelliJ
Abstractness, Instability, and Distance from the Main Sequence
Robert Martin, a well-known figure in the software architecture world, created some derived metrics in the late 1990s which are applicable to any object-oriented language. These metricsââabstractness and instabilityââmeasure the balance of the internal characteristics of a codebase.
Abstractness is the ratio of abstract artifacts (abstract classes, interfaces, etc.) to concrete artifacts (implementation classes). It represents a measure of abstract versus implementation. Abstract elements are features of a codebase that allow developers to better understand the overall function. For example, a codebase consisting of a single main() method and 10,000 lines of code would score nearly zero on this metric and be quite hard to understand.
The formula for abstractness appears in Equation 4-1.
Equation 4-1. Abstractness
In the equation, represents abstract elements (interfaces or abstract classes) within the codebase, and represents concrete elements. Architects calculate abstractness by calculating the ratio of the sum of abstract artifacts to the sum of the concrete ones.
Another derived metric, instability, is the ratio of efferent coupling to the sum of both efferent and afferent coupling, shown in Equation 4-2.
Equation 4-2. Instability
In the equation, represents efferent (or outgoing) coupling, and represents afferent (or incoming) coupling.
The instability metric determines the volatility of a codebase. A codebase that exhibits high degrees of instability breaks more easily when changed because of high coupling. Consider two scenarios, each with of 2. In the first scenario, = 0, yielding an instability score of zero. In the second scenario, = 3, yielding an instability score of 3/5. Thus, the measure of instability for a component reflects how many potential changes might be forced by changes to related components. A component with an instability value near 1 is highly unstable, and a value close to 0 may be either stable or rigid: it is stable if the module or component contains mostly abstract elements and rigid if it is composed of mostly concrete elements. However, the trade-off for high stability is lack of reuseââif every component is self-contained, duplication is likely.
A component with an I value close to 1, we can agree, is highly instable. However, a component with an I value close to 0 may be either stable or rigid. However, if it contains mostly concrete elements, it is rigid.
Thus, in general, it is important to look at the values of I and A together rather than in isolation; they are combined in the next metric, distance from the main sequence.
One of the few holistic metrics architects have for architectural structure is normalized distance from the main sequence, a derived metric based on instability and abstractness, shown in Equation 4-3.
Equation 4-3. Normalized distance from the main sequence
In the equation, A = abstractness and I = instability.
The normalized distance from the main sequence metric imagines an ideal relationship between abstractness and instability; components that fall near this idealized line exhibit a healthy mixture of these two competing concerns. For example, graphing a particular component allows developers to calculate the distance from the main sequence metric, illustrated in Figure 4-5.

Figure 4-5. Normalized distance from the main sequence for a particular component
In Figure 4-5, developers graph the candidate component, then measure the distance from the idealized line. The closer to the line, the better balanced the component. Components that fall too far into the upper-right corner enter into what architects call the zone of uselessness: code that is too abstract becomes difficult to use. Conversely, code that falls into the lower-left corner enters the zone of pain: code with too much implementation and not enough abstraction becomes brittle and hard to maintain, as illustrated in Figure 4-6.
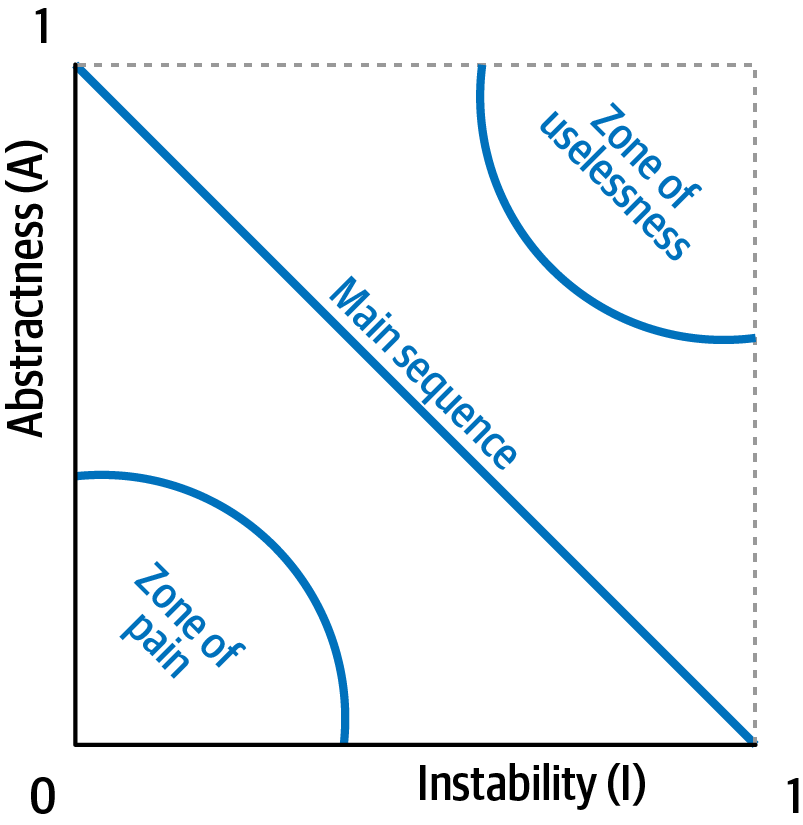
Figure 4-6. Zones of uselessness and pain
This kind of analysis is useful for architects for either evaluation (e.g., to migrate from one architecture style to another) or to set up as a fitness function. Consider the screenshot shown in Figure 4-7, using the commercial tool NDepend applied to the NUnit open source testing tool.
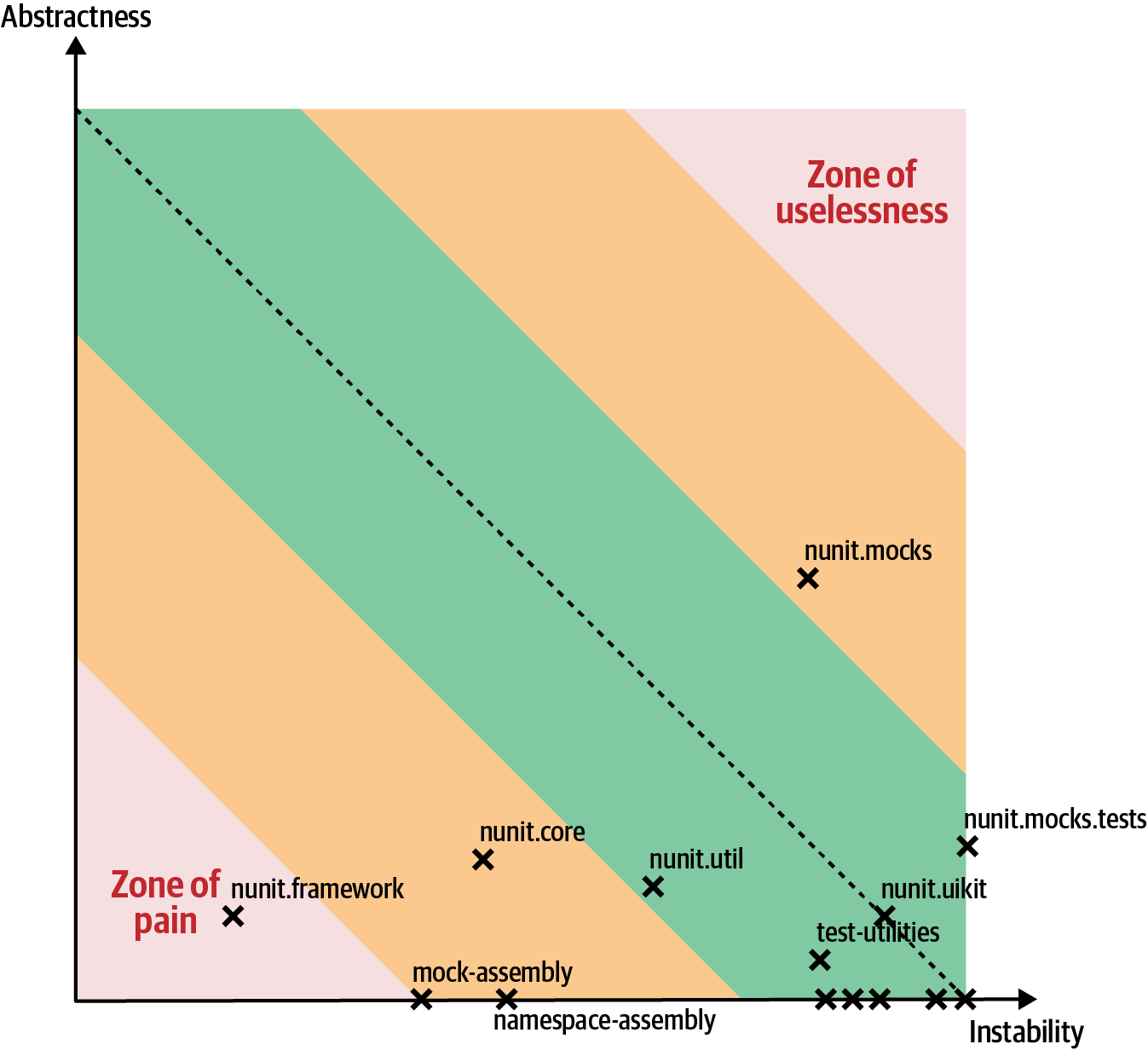
Figure 4-7. NDepend output for distance from the main sequence for the NUnit testing library
In Figure 4-7, the output illustrates that most of the code falls near the main sequence line. The mocks components are tending toward the zone of uselessness: too much abstractness and instability. That makes sense for a set of mocking components, which tend to use indirection to achieve their results. More worrying, the framework code has slipped into the zone of pain: too little abstractness and instability. What does this code look like? Many overly large methods without enough reuse.
How can an architect pull the troublesome code back toward the main sequence line? By using refactoring tools in an IDE: find the large methods that drive this measure and start extracting parts to increase abstractness. As you perform this exercise, you will find duplication among the extracted code, allowing you to remove it and improve instability.
Before performing a restructuring exercise, architects should use metrics like this to analyze and improve the codebase prior to moving it. Just as in building architecture, moving something with an unstable foundation is harder than moving something with a solid one.
Architects also can use this metric as a fitness function to make sure the codebase doesnât degrade to this degree in the first place.
Directionality of Imports
Closely related to the example in Figure 2-3, teams should govern the directionality of imports. In the Java ecosystem, JDepend is a metrics tool that analyzes the coupling characteristics of packages. Because JDepend is written in Java, it has an API that developers can leverage to build their own analysis via unit tests.
Consider the fitness function in Example 4-1, expressed as a JUnit test.
Example 4-1. JDepend test to verify the directionality of package imports
publicvoidtestMatch(){DependencyConstraintconstraint=newDependencyConstraint();JavaPackagepersistence=constraint.addPackage("com.xyz.persistence");JavaPackageweb=constraint.addPackage("com.xyz.web");JavaPackageutil=constraint.addPackage("com.xyz.util");persistence.dependsUpon(util);web.dependsUpon(util);jdepend.analyze();assertEquals("Dependency mismatch",true,jdepend.dependencyMatch(constraint));}
In Example 4-1, we define the packages in our application and then define the rules about imports. If a developer accidentally writes code that imports into util from persistence, this unit test will fail before the code is committed. We prefer building unit tests to catch architecture violations over using strict development guidelines (with the attendant bureaucratic scolding): it allows developers to focus more on the domain problem and less on plumbing concerns. More importantly, it allows architects to consolidate rules as executable artifacts.
Cyclomatic Complexity and âHerdingâ Governance
A common code metric is cyclomatic complexity, a measure of function or method complexity available for all structured programming languages, that has been around for decades.
An obvious measurable aspect of code is complexity, defined by the cyclomatic complexity metric.
Cyclomatic complexity (CC) is a code-level metric designed to provide an object measure for the complexity of code, at the function/method, class, or application level, developed by Thomas McCabe Sr. in 1976.
It is computed by applying graph theory to code, specifically decision points, which cause different execution paths. For example, if a function has no decision statements (such as if statements), then CC = 1. If the function had a single conditional, then
CC = 2 because two possible execution paths exist.
The formula for calculating the cyclomatic complexity for a single function or method is , where N represents nodes (lines of code) and E represents edges (possible decisions). Consider the C-like code shown in Example 4-2.
Example 4-2. Sample code for cyclomatic complexity evaluation
publicvoiddecision(intc1,intc2){if(c1<100)return0;elseif(c1+C2>500)return1;elsereturn-1;}
The cyclomatic complexity for Example 4-2 is 3 (=3 â 2 + 2); the graph appears in Figure 4-8.
The number 2 appearing in the cyclomatic complexity formula represents a simplification for a single function/method. For fan-out calls to other methods (known as connected components in graph theory), the more general formula is , where P represents the number of connected components.
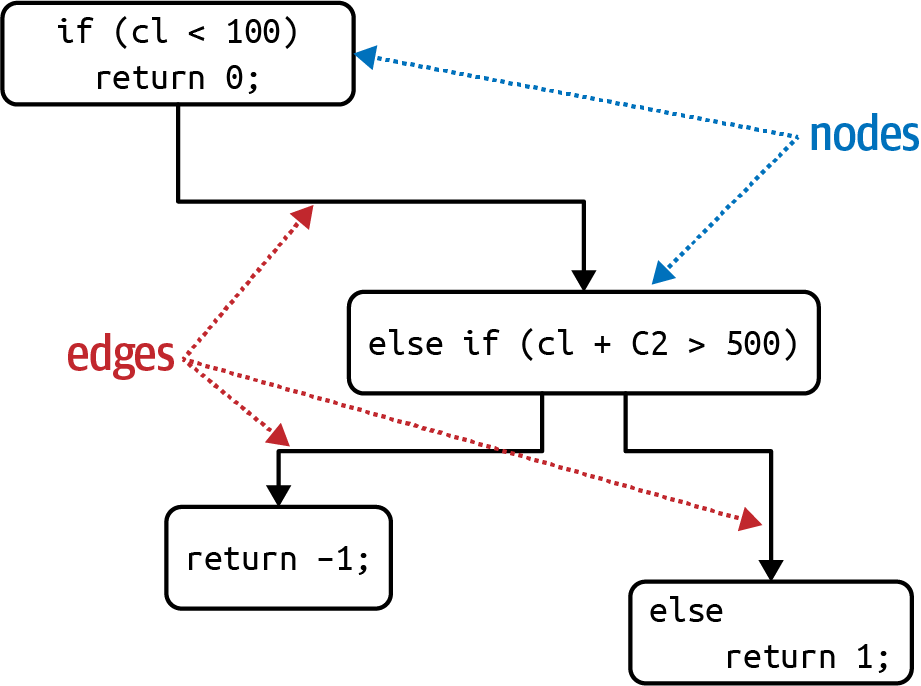
Figure 4-8. Cyclomatic complexity for the decision function
Architects and developers universally agree that overly complex code represents code smell; it harms virtually every one of the desirable characteristics of codebases: modularity, testability, deployability, and so on. Yet, if teams donât keep an eye on gradually growing complexity, that complexity will dominate the codebase.
CC is a good example of a metric architects might want to govern; no one benefits from overly complex codebases. However, what happens on projects where this value has been ignored for a long time?
Rather than set a hard threshold for a fitness function value, you can herd teams toward better values. For example, letâs say that you decided as an organization that the absolute upper limit for CC should be 10, yet when you put that fitness function in place most of your projects fail. Instead of abandoning all hope, you can set up a cascading fitness function that issues a warning for anything past some threshold, which eventually escalates into an error over time. This gives teams time to address technical debt in a controlled, gradual way.
Gradually narrowing to desired values for a variety of metrics-based fitness functions allows teams to both address existing technical debt and, by leaving the fitness functions in place, prevent future degradation. This is the essence of preventing bit rot via governance.
Turnkey Tools
Because all architectures differ, architects struggle to find ready-made tools for complex problems. However, the more common the ecosystem, the more likely you are to find suitable, somewhat generic tools. Here are a few exemplars.
Legality of Open Source Libraries
PenultimateWidgets was working on a project that contained some patented proprietary algorithms, along with a few open source libraries and frameworks. The lawyers became concerned about the development team accidentally using a library whose license requires its users to adopt the same extremely liberal license, which PenultimateWidgets obviously didnât want for their code.
So, the architects gathered up all the licenses from the dependencies and allowed the lawyers to approve them. Then, one of the lawyers asked an awkward question: what happens if one of these dependencies updates the terms of their license during a routine software update? And, being a good lawyer, they had a good example of this happening in the past with some user interface libraries. How can the team make sure that one of the libraries doesnât update a license without them realizing it?
First, the architects should check to see if a tool already exists to do this; as of this writing, the tool Black Duck performs exactly this task. However, at the time, PenultimateWidgetsâ architects couldnât find a tool to suffice.
Thus, they built a fitness function using the following steps:
-
Note the location of each license file within the open source download package in a database.
-
Along with the library version, save the contents (or a hash) of the full license file.
-
When a new version number is detected, the tool reaches into the download package, retrieves the license file, and compares it to the currently saved version.
-
If the versions (or hash) donât match, fail the build and notify the lawyer.
Note that we didnât try to assess the difference between library versions, or build some incredible artificial intelligence to analyze it. As is often the case, the fitness function notifies us of unexpected changes. This is an example of both an automated and a manual fitness function: the detection of change was automated, but the reaction to the changeââapproval by the lawyers of the changed libraryââremains as a manual intervention.
A11y and Other Supported Architecture Characteristics
Sometimes, knowing what to search for leads architects to the correct tool. âA11yâ is developer shorthand for accessibility (derived from a, 11 letters, and y), which determines how well an application supports people with differing capabilities.
Because many companies and government agencies require accessibility, tools to validate this architecture characteristic have blossomed, including tools such as Pa11y, which allows command-line scanning for static web elements to ensure accessibility.
ArchUnit
ArchUnit is a testing tool inspired by and using some of the helpers created for JUnit. However, it is designed for testing architecture features rather than general code structure. We already showed an example of an ArchUnit fitness function in Figure 2-3; here are some more examples of the kinds of governance available.
Package dependencies
Packages delineate components in the Java ecosystem, and architects frequently want to define how packages should be âwiredâ together. Consider the example components illustrated in Figure 4-9.

Figure 4-9. Declarative package dependencies in Java
The ArchUnit code that enforces the dependencies shown in Figure 4-9 appears in Example 4-3.
Example 4-3. Package dependency governance
noClasses().that().resideInAPackage("..source..").should().dependOnClassesThat().resideInAPackage("..foo..")
ArchUnit uses the Hamcrest matchers used in JUnit to allow architects to write very language-like assertions, as shown in Example 4-3, enabling them to define which components may or may not access other components.
Another common governable concern for architects are component dependencies, as illustrated in Figure 4-10.

Figure 4-10. Package dependency governance
In Figure 4-10, the foo shared library should be accessible from source.one but not from other components; an architect can specify the governance rule via ArchUnit as in Example 4-4.
Example 4-4. Allowing and restricting package access
classes().that().resideInAPackage("..foo..").should().onlyHaveDependentClassesThat().resideInAnyPackage("..source.one..","..foo..")
Example 4-4 shows how an architect can control compile-time dependencies between projects.
Class dependency checks
Similar to the rules concerning packages, architects often want to control architectural aspects of class design. For example, an architect may want to restrict dependencies between components to prevent deployment complications. Consider the relationship between classes in Figure 4-11.

Figure 4-11. Dependency checks allowing and disallowing access
ArchUnit allows an architect to codify the rules shown in Figure 4-11 via Example 4-5.
Example 4-5. Class dependency rules in ArchUnit
classes().that().haveNameMatching(".*Bar").should().onlyHaveDependentClassesThat().haveSimpleName("Bar")
ArchUnit allows architects fine-grained control over the âwiringâ of components within an application.
Inheritance checks
Another dependency supported by object-oriented programming languages is inheritance; from an architecture perspective, it is a specialized form of coupling. In a classic example of the perpetual answer âit depends!â the question of whether inheritance is an architectural headache depends on how teams deploy the affected components: if the inheritance is contained with a single component, it has no architectural side effects. On the other hand, if inheritance stretches across component and/or deployment boundaries, architects must take special action to make sure the coupling remains intact.
Inheritance is often an architectural concern; an example of the type of structure requiring governance appears in Figure 4-12.

Figure 4-12. Governing inheritance dependencies
Architects can express the rules appearing in Figure 4-12 through the code in Example 4-6.
Example 4-6. Inheritance governance rule expressed in ArchUnit
classes().that().implement(Connection.class).should().haveSimpleNameEndingWith("Connection")
Annotation checks
A common way architects indicate intent in supported platforms is through tagging annotations (or attributes, depending on your platform). For example, an architect may intend for a particular class to only act as an orchestrater for other servicesââthe intent is that it never takes on nonorchestration behavior. Using an annotation allows the architect to verify intent and correct usage.
ArchUnit allows architects to validate this kind of usage, as shown in Figure 4-13.

Figure 4-13. Governing proper annotation use
Architects can codify the governance rules implied in Figure 4-13 as shown in Example 4-7.
Example 4-7. Governance rules for annotations
classes().that().areAssignableTo(EntityManager.class).should().onlyHaveDependentClassesThat().areAnnotatedWith(Transactional.class)
In Example 4-7, the architect wants to ensure that only annotated classes are allowed to utilize the EntityManager class.
Layer checks
One of the most common usages of a governance tool like ArchUnit is to allow architects to enforce design decisions. Architects often make decisions such as separation of concerns that cause short-term inconvenience for developers but have long-term benefits in terms of evolution and isolation. Consider the illustration in Figure 4-14.
The architect has built a layered architecture to isolate changes between layers. In such an architecture, dependencies should exist only between adjacent layers; the more layers couple to a particular layer, the more rippling side effects occur because of change.
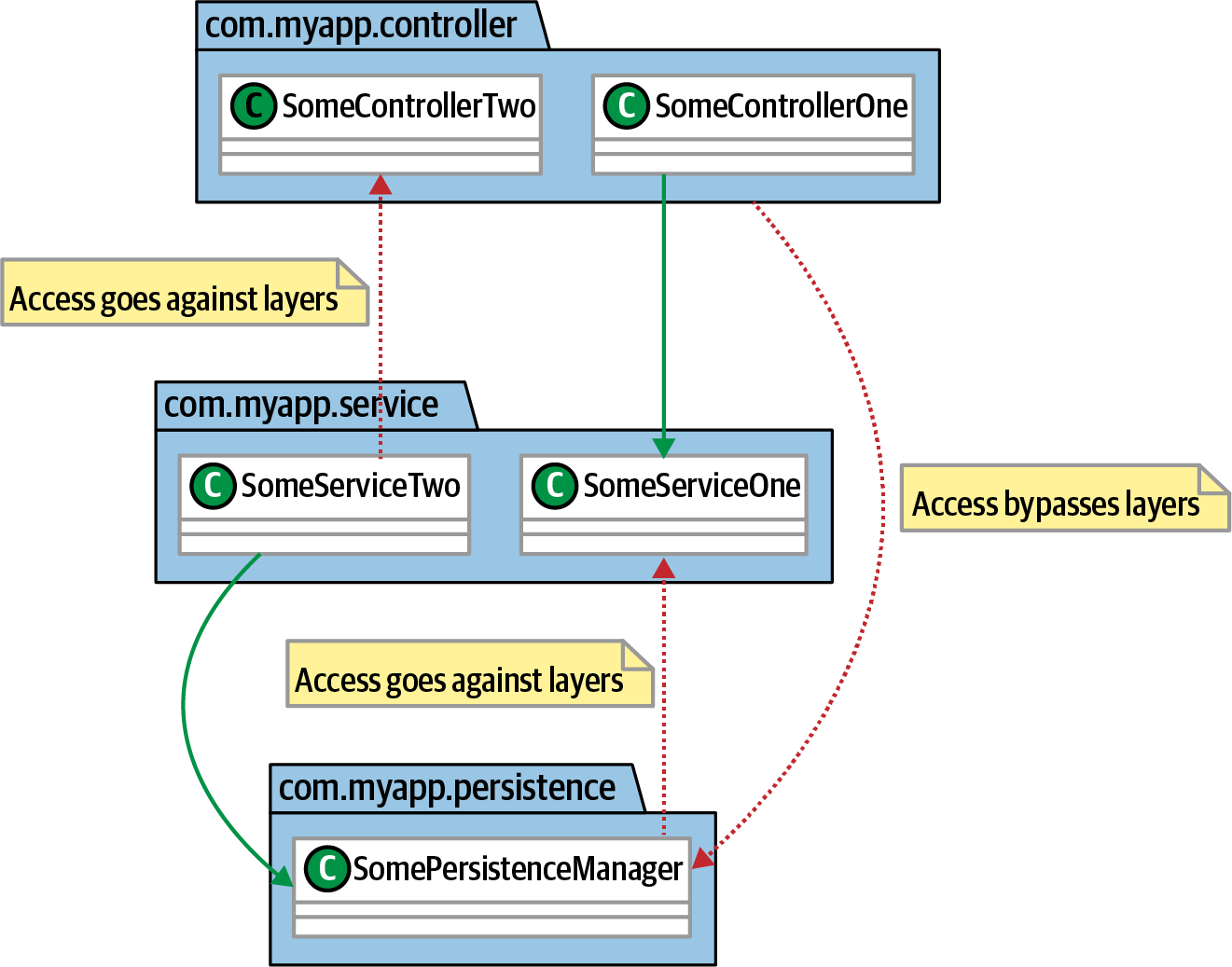
Figure 4-14. Using components to define a layered architecture
A layer governance check fitness function expressed in ArchUnit appears in Example 4-8.
Example 4-8. Layered architecture governance checks
layeredArchitecture().consideringAllDependencies().layer("Controller").definedBy("..controller..").layer("Service").definedBy("..service..").layer("Persistence").definedBy("..persistence..").whereLayer("Controller").mayNotBeAccessedByAnyLayer().whereLayer("Service").mayOnlyBeAccessedByLayers("Controller").whereLayer("Persistence").mayOnlyBeAccessedByLayers("Service")
In Example 4-8, an architect defines layers and access rules for those layers.
Many of you as architects have written the native language versions of many of the principles expressed in the preceding examples in some wiki or other shared information repositoryâand they were read by no one! Itâs great for architects for express principles, but principles without enforcement are aspirational rather than governance. The layered architecture in Example 4-8 is a great exampleââwhile an architect may write a document describing layers and the underlying separation of concerns principle, unless a fitness function validates it, an architect can never have confidence that developers will follow the principles.
Weâve spent a lot of time highlighting ArchUnit, as it is the most mature of many governance-focused testing frameworks. It is obviously applicable only in the Java ecosystem. Fortunately, NetArchTest replicates the same style and basic capabilities of ArchUnit but for the .NET platform.
Linters for Code Governance
A common question we field from salivating architects from platforms other than Java and .NET is whether there is a tool for platform X to ArchUnit that is equivalent. While tools as specific as ArchUnit are rare, most programming languages include a linter, a utility that scans source code to find coding antipatterns and deficiencies. Generally, the linter lexes and parses the source code, providing plug-ins by developers to write checks for syntax. For example, ESLint, the linting tool for JavaScript (technically, the linter for ECMAScript), allows developers to write syntax rules requiring (or not) semicolons, nominally optional braces, and so on. They can also write rules about what function-calling policies architects want to enforce and other governance rules.
Most platforms have linters; for example, C++ is served by Cpplint, Staticcheck is available for the Go language. Thereâs even a variety of linters for SQL, including sql-lint. While they are not as convenient as ArchUnit, architects can still code many structural checks into virtually any codebase.
Case Study: Availability Fitness Function
A common conundrum appears for many architects: should we use a legacy system as an integration point or build a new one? If a particular solution hasnât been tried before, how can architects make objective decisions?
PenultimateWidgets faced this problem when integrating with a legacy system. To that end, the team created a fitness function to stress-test the legacy service, as shown in Figure 4-15.
After setting up the ecosystem, the team measured the percentage of errors compared to total responses from the third-party system using the monitoring tool.
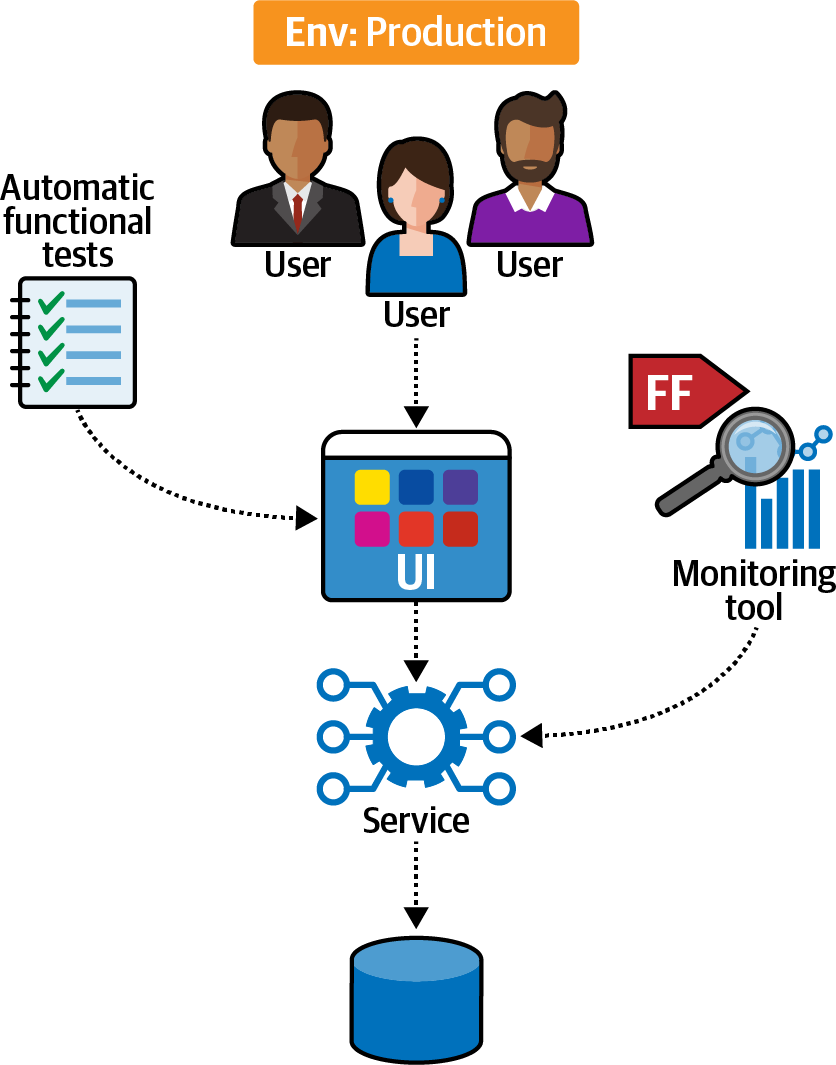
Figure 4-15. Availability verification fitness function
The results of the experiment showed them that the legacy system had no trouble with availability, with plenty of overhead to handle the integration point.
This objective outcome allowed the team to state with confidence that the legacy integration point was sufficient, freeing the resources otherwise dedicated to rewriting that system. This example illustrates how fitness functions help move software development from a gut-feel craft to a measurable engineering discipline.
Case Study: Load-Testing Along with Canary Releases
PenultimateWidgets has a service that currently âlivesâ in a single virtual machine. However, under load, this single instance struggles to keep up with necessary scalability. As a quick fix, the team implements auto-scaling for the service, replicating the single instance with several instances as a stopgap measure because a busy annual sale is fast approaching. However, the skeptics on the team wanted to know how they could prove that the new system was working under load.
The architects on the project created a fitness function tied to a feature flag that allows canary releases or dark launches, which release new behaviors to a small subset of users to test the potential overall impact of the change. For example, when developers of a highly scalable website release a new feature that will consume a lot of bandwidth, they often want to release the change slowly so that they can monitor the impact. This setup appears in Figure 4-16.
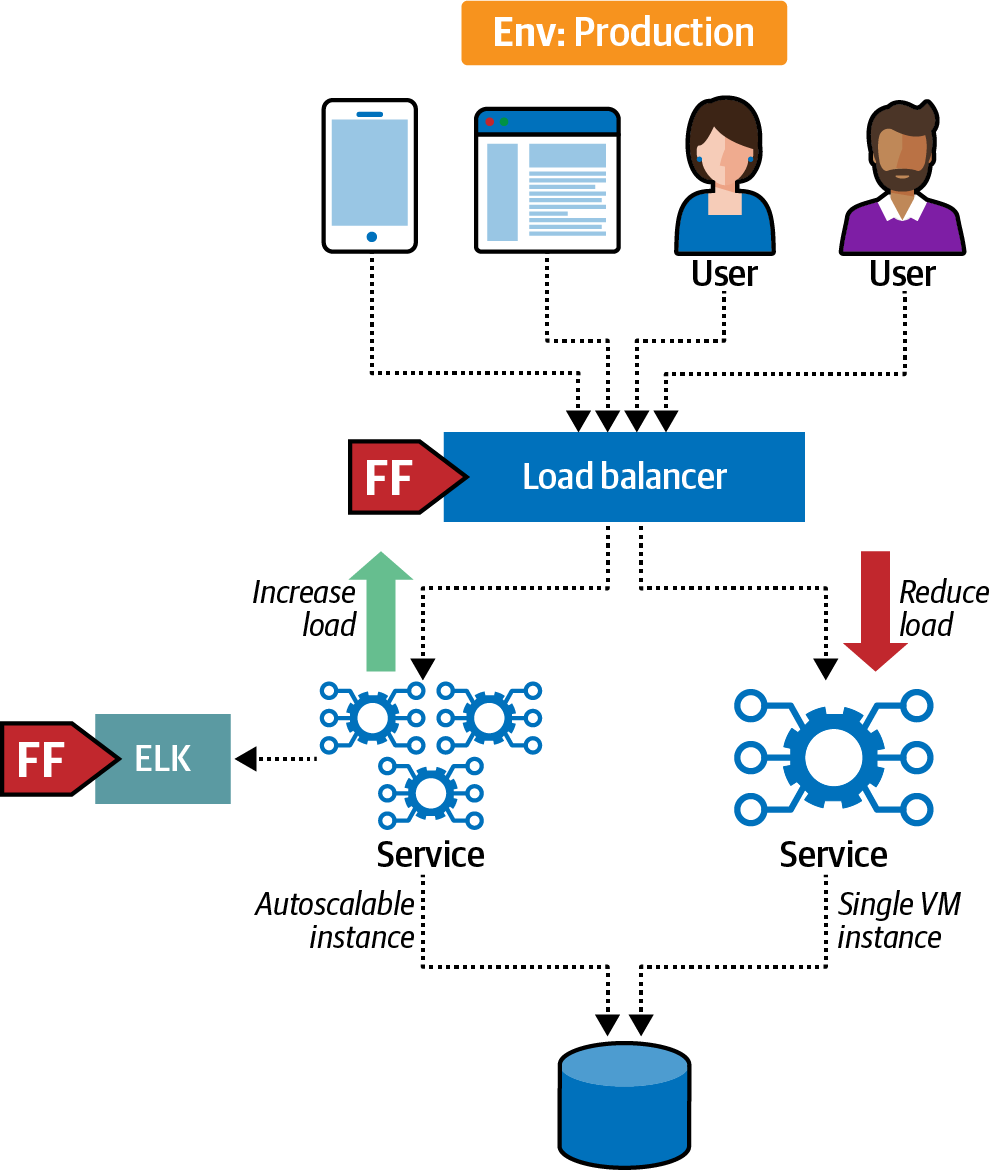
Figure 4-16. Canary-releasing auto-scaling to provide support and increase confidence
For the fitness function shown in Figure 4-16, the team initially released the auto-scaling instances to a small group, then increased the number of users as their monitoring showed continued good performance and support.
This solution will act as scaffolding to allow limited-term expansion while the team develops a better solution. Having the fitness function in place and regularly executed allows the team a better feel for how long this stopgap solution will last.
Case Study: What to Port?
One particular PenultimateWidgets application has been a workhorse, developed as a Java Swing application over the better part of a decade and continually growing new features. The company decided to port it to the web application. However, now the business analysts face a difficult decision: how much of the existing sprawling functionality should they port? And, more practically, in what order should they implement the ported features of the new application to deliver the most functionality quickly?
One of the architects at PenultimateWidgets asked the business analysts what the most popular features were, and they had no idea! Even though they have been specifying the details of the application for years, they had no real understanding of how users used the application. To learn from users, the developers released a new version of the legacy application with logging enabled to track which menu features users actually used.
After a few weeks, they harvested the results, providing an excellent road map of what features to port and in what order. They discovered that the invoicing and customer lookup features were most commonly used. Surprisingly, one subsection of the application that had taken great effort to build had very little use, leading the team to decide to leave that functionality out of the new web application.
Fitness Functions Youâre Already Using
Outside of new tools such as ArchUnit, many of the tools and approaches we outline arenât new. However, teams use them sparsely and inconsistently, on an ad hoc basis. Part of our insight surrounding the fitness function concept unifies a wide variety of tools into a single perspective. Thus, chances are good that you are already using a variety of fitness functions on your projects, and you just donât call them that yet.
Fitness functions include metrics suites such as SonarCube; linting tools such as esLint, pyLint, and cppLint; and a whole family of source-code verification tools, such as PMD.
Just because a team uses monitors to observe traffic doesnât make those measures a fitness function. Setting an objective measure associated with an alert converts measurements into fitness functions.
Tip
To convert a metric or measurement into a fitness function, define objective measures and provide fast feedback for acceptable use.
Using these tools every once in a while doesnât make them fitness functions; wiring them into continuous verification does.
Integration Architecture
While many fitness functions apply to individual applications, they exist in all parts of the architectural ecosystemââany part that may benefit from governance. Inevitably, the more examples move away from application-specific concerns, the fewer generic solutions exist. Integration architecture by its nature integrates different specific parts, defying generic advice. However, some general patterns exist for integration architecture fitness functions.
Communication Governance in Microservices
Many architects see the cycle test shown in Figure 2-3 and fantasize about the same kind of test for distributed architectures such as microservices. However, this desire intersects with the heterogeneous nature of architecture problems. Testing for component cycles is a compile-time check, requiring a single codebase and tool in the appropriate language. However, in microservices, a single tool wonât suffice: each service might be written in a different tech stack, in different repositories, using different communication protocols, and many other variables. Thus, finding a turnkey tool for fitness functions for microservices is unlikely.
Architects often need to write their own fitness functions, but creating an entire framework isnât necessary (and is too much work). Many fitness functions consist of 10 or 15 lines of âglueâ code, often in a different technology stack than the solution.
Consider the governance problem of governing calls between microservices, illustrated in Figure 4-17. The architect designed the OrderOrchestrator as the sole state owner of the workflow. However, if the domain services communicate with each other, the orchestrator canât maintain correct state. Thus, an architect might want to govern the communication between services: domain services can only communicate with the orchestrator.
However, if an architect can ensure a consistent interface between systems (such as logging in a parsable format), they can write a few lines of code in a scripting language to build a governance fitness function. Consider a log message that includes the following information:
-
Service name
-
Username
-
IP address
-
Correlation ID
-
Message received time in UTC
-
Time taken
-
Method name
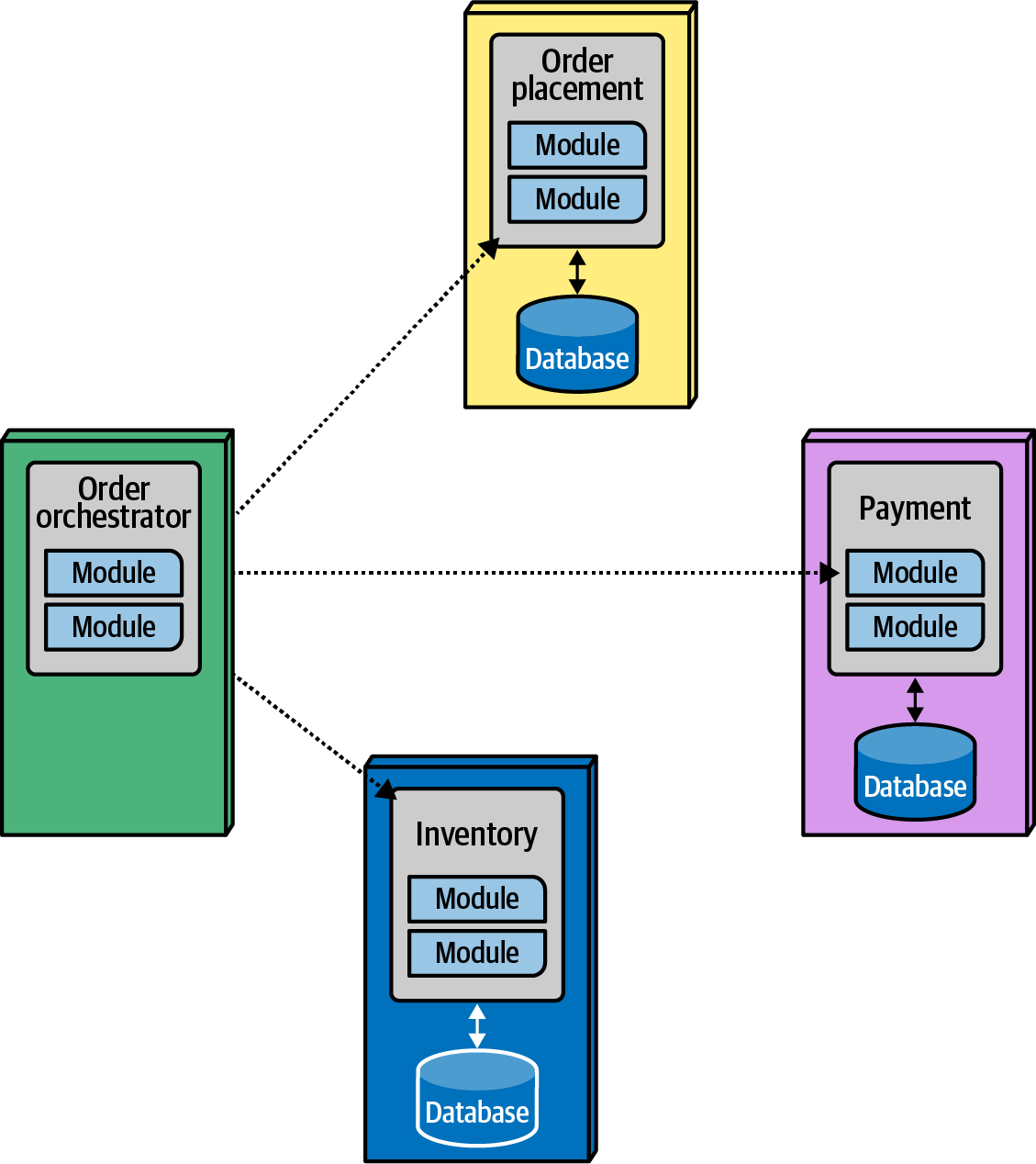
Figure 4-17. Governing communication between microservices
For example, a particular log message might resemble the one shown in Example 4-9.
Example 4-9. Sample microservices log format
["OrderOrchestrator","jdoe","192.16.100.10","ABC123","2021-11-05T08:15:30-05:00","3100ms","updateOrderState()"]
First, an architect can create a fitness function for each project that mandates outputting log messages in the format shown in Example 4-9, regardless of technology stack. This fitness function may be attached to the common container image shared by services.
Second, the architect writes a simple fitness function in a scripting language such as Ruby or Python to harvest the log messages, parse the common format mandated in Example 4-9, and check for approved (or disapproved) communication, as shown in Example 4-10.
Example 4-10. Checking communication between services
list_of_services.each{|service|service.import_logsFor(24.hours)calls_from(service).each{|call|unlesscall.destination.equals("orchestrator")raiseFitnessFunctionFailure.new()}}
In Example 4-10, the architect writes a loop that iterates over all the logfiles harvested for the last 24 hours. For each log entry, they check to ensure that the call destination for each call is only the orchestrator service, not any of the domain services. If one of the services has violated this rule, the fitness function raises an exception.
You may recognize some parts of this example from Chapter 2 in the discussion of triggered versus continual fitness functions; this is a good example of two different ways to implement a fitness function with differing trade-offs. The example shown in Example 4-10 represents a reactive fitness functionââit reacts to the governance check after a time interval (in this case, 24 hours). However, another way to implement this fitness function is proactively, based on real-time monitors for communication, catching violations as they occur.
Each approach has trade-offs. The reactive version doesnât impose any overhead on the runtime characteristics of the architecture, whereas monitors can add a small amount of overhead. However, the proactive version catches violations right away rather than a day later.
Thus, the real trade-off between the two approaches may come down to the criticality of the governance. For example, if the unauthorized communication creates an immediate issue (such as a security concern), architects should implement it proactively. If, however, the purpose is only structural governance, creating the log-based reactive fitness function has less chance of impacting the running system.
Case Study: Choosing How to Implement a Fitness Function
Testing the problem domain is mostly straightforward: as developers implement features in code, they incrementally test those features using one or more testing frameworks. However, architects may find even simple fitness functions have a variety of implementations.
Consider the example shown in Figure 4-18.

Figure 4-18. Grading message governance
In Figure 4-18, a student answers test questions presented by the TestTaker service, which in turn passes messages asynchronously to AutoGrader, which persists the graded test answers. Reliability is a key requirement for this systemââthe system should never âdropâ any answers during this communication. How could an architect design a fitness function for this problem?
At least two solutions present themselves, differing mostly by what trade-offs each offers. Consider the solution illustrated in Figure 4-19.
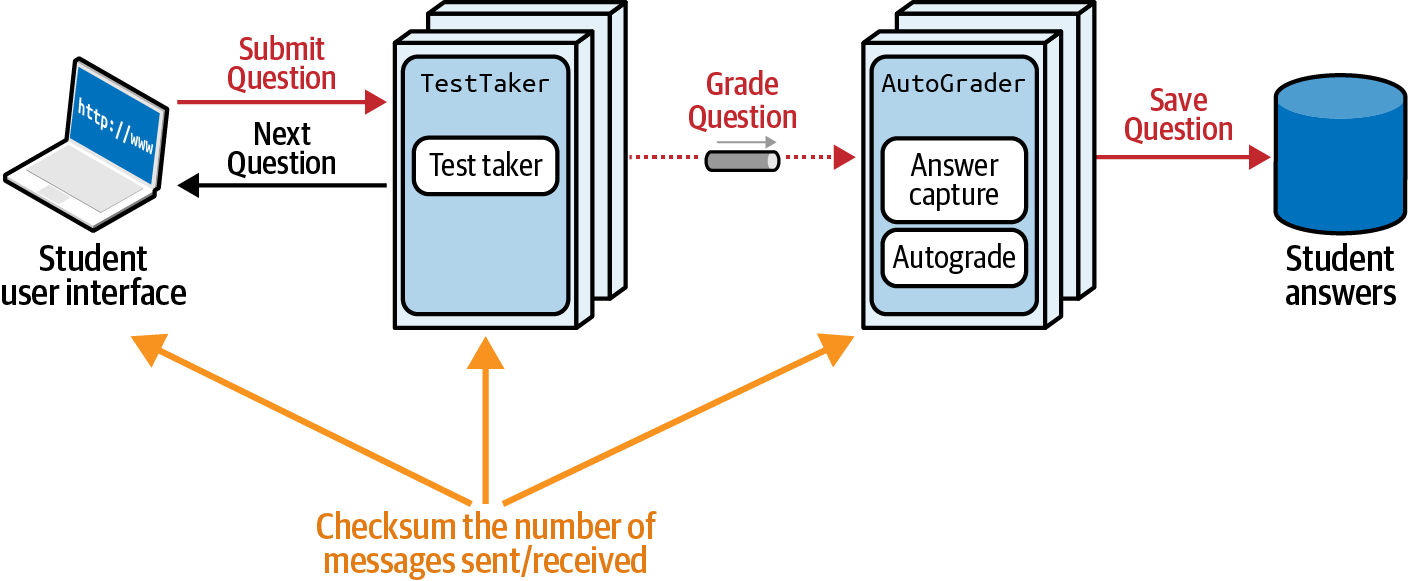
Figure 4-19. Counting the number of messages sent and received
If we can assume a modern microservices architecture, concerns such as message ports are typically managed at the container. A simple way to implement the fitness function shown in Figure 4-19 is to instrument the container to check the number of incoming and outgoing messages, and raise an alarm if the numbers donât match.
This is a simple fitness function, as it is atomic at the service/container level and architects can enforce it via consistent infrastructure. However, it doesnât guarantee end-to-end reliability, only service-level reliability.
An alternative way to implement the fitness function appears in Figure 4-20.

Figure 4-20. Using correlation IDs to ensure reliability
In Figure 4-20, the architect uses correlation IDs, a common technique that tags each request with a unique identifier to allow traceability. To ensure message reliability, each message is assigned a correlation ID at the start of the request, and each ID is checked at the end of the process to make sure it resolved. The second technique provides more holistic assurance of message reliability, but now the architect must maintain state for the entire workflow, making coordination more difficult.
Which is the correct fitness function implementation? Like everything in software architecture, it depends! External forces often dictate which set of trade-offs an architect chooses; the important point is not to get caught up in thinking that there is only one way to implement a fitness function.
The chart shown in Figure 4-21 is an example from a real project that set up exactly this type of fitness function to ensure data reliability.

Figure 4-21. Chart showing the reliability of messages in an orchestrated workflow
As you can see, the fitness function exposed the fact that some messages were not passing through, encouraging the team to perform forensic analysis as to why (and leaving the fitness function in place to ensure future problems donât arise).
DevOps
While most of the fitness functions we cover pertain to architectural structure and related concepts, like software architecture itself, governance concerns may touch all parts of the ecosystem, including a family of DevOps-related fitness functions.
These are fitness functions and not just operational concerns for two reasons. First, they intersect software architecture and the operational concernââchanges to the architecture may impact the operational parts of the system. Second, they represent governance checks with objective outcomes.
Enterprise Architecture
Most of the fitness functions we have shown so far have concerned application or integration architecture, but they are applicable at any part of an architecture that could benefit from governance. One place in particular where enterprise architects have a big impact on the rest of the ecosystem is when they define platforms within their ecosystem to encapsulate business functionality. This effort aligns with our stated desire to keep implementation details at the smallest possible scope.
Consider the example shown in Figure 4-22.

Figure 4-22. Applications as ad hoc compositions of services
In Figure 4-22, applications (shown at the top) consume services from a variety of different parts of the enterprise. Having fine-grained access from applications to services results in implementation details regarding how the parts interact with one another leak into the application, in turn making them more brittle.
Realizing this, many enterprise architects design platforms to encapsulate business functionality behind managed contracts, as illustrated in Figure 4-23.
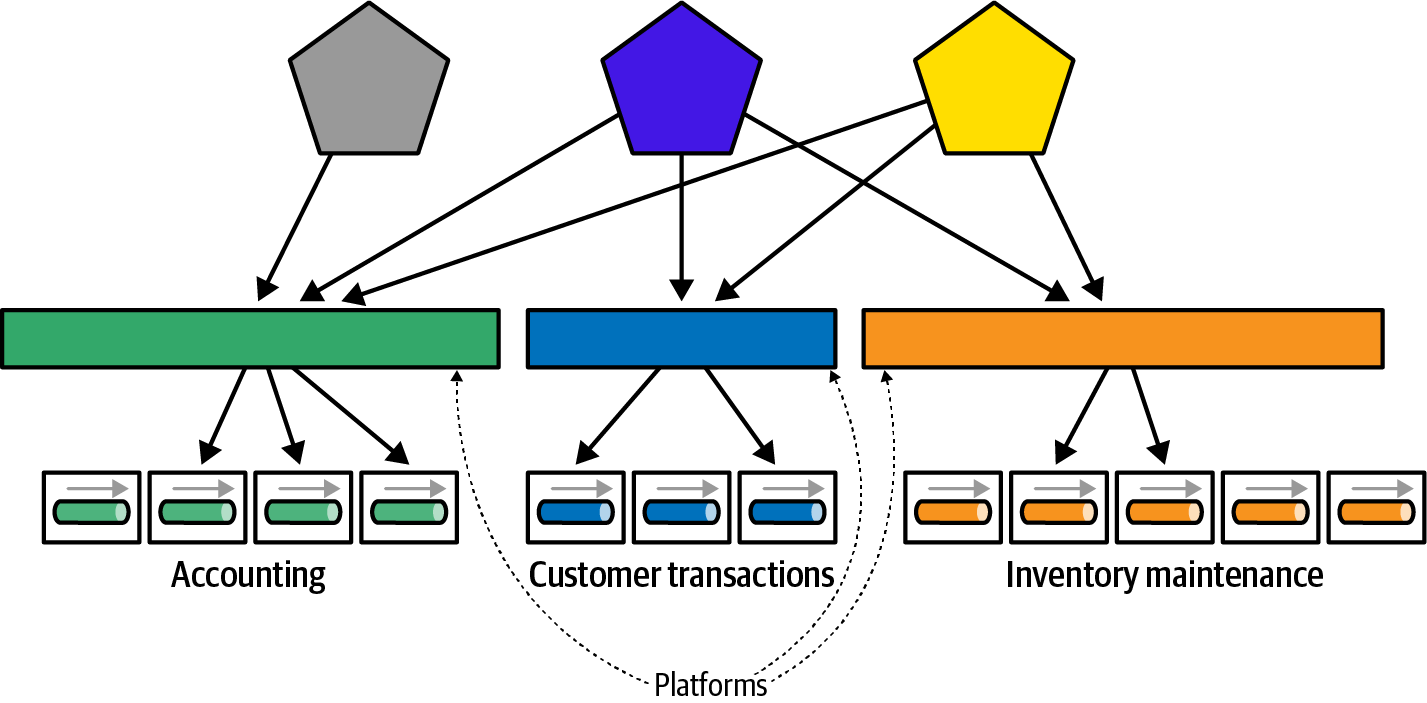
Figure 4-23. Building platforms to hide implementation details
In Figure 4-23, the architects build platforms to hide the way the organization solves problems, instead building a consistent, hopefully slow-changing API that describes the facilities other parts of the ecosystem need via contracts for the platform. By encapsulating the implementation details at the platform level, architects decrease the spread of implementation coupling, in turn making a less brittle architecture.
Enterprise architects define the APIs for these platform and fitness functions to govern the capabilities, structure, and other governable aspects of the platform and its implementation. This, in turn, provides another benefit by keeping enterprise architects away from making technology choices! Instead, they focus on capabilities rather than how to implement them, which solves two problems.
First, enterprise architects are typically far away from implementation details, and thus are not as up-to-date on cutting-edge changes, in the technology landscape and within their own ecosystem; they often suffer from the Frozen Caveman antipattern.
However out of date they may be on current implementation trends, enterprise architects understand best the long-term strategic goals of the organization, which they can codify in fitness functions. Rather than specify technology choices, they instead define concrete fitness functions at the platform level, ensuring that the platform continues to support the appropriate characteristics and behavior. This further explains our advice to decompose architecture characteristics until you can objectively measure themââthings that can be measured can be governed.
Also, allowing enterprise architects to focus on building fitness functions to manage strategic vision frees domain and integration architects to make technology decisions with consequences, protected by the guardrails implemented as fitness functions. This, in turn, allows organizations to grow their next generation of enterprise architects, by allowing lower-tier roles to make decisions and work through the trade-offs.
We have advised several companies that have an enterprise architecture role of evolutionary architect, tasked with looking around the organization for opportunities to find and implement fitness functions (often harvested from a specific project and made more generic) and to build reusable ecosystems with appropriate quantum boundaries and contracts to ensure loose coupling between platforms.
Case Study: Architectural Restructuring While Deploying 60 Times per Day
GitHub is a well-known developer-centric website with aggressive engineering practices, deploying 60 times per day, on average. GitHub describes a problem in its blog âMove Fast and Fix Thingsâ that will make many architects shudder in horror. It turns out that GitHub has long used a shell script wrapped around command-line Git to handle merges, which works correctly but doesnât scale well enough. The Git engineering team built a replacement library for many command-line Git functions called libgit2 and implemented their merge functionality there, thoroughly testing it locally.
But now they must deploy the new solution into production. This behavior has been part of GitHub since its inception and has worked flawlessly. The last thing the developers want to do is introduce bugs in existing functionality, but they must address technical debt as well.
Fortunately, GitHub developers created Scientist, an open source framework written in Ruby that provides holistic, continual testing to vet changes to code. Example 4-11 gives us the structure of a Scientist test.
Example 4-11. Scientist setup for an experiment
require"scientist"classMyWidgetincludeScientistdefallows?(user)science"widget-permissions"do|e|e.use{model.check_user(user).valid?}# old waye.try{user.can?(:read,model)}# new wayend# returns the control valueendend
In Example 4-11, the developer encapsulates the existing behavior with the use block (called the control) and adds the experimental behavior to the try block (called the candidate). The science block handles the following details during the invocation of the code:
- Decides whether to run the
tryblock -
Developers configure Scientist to determine how the experiment runs. For example, in this case studyâthe goal of which was to update the merge functionalityâ1% of random users tried the new merge functionality. In either case, Scientist always returns the results of the
useblock, ensuring the caller always receives the existing behavior in case of differences. - Randomizes the order in which
useandtryblocks run -
Scientist does this to prevent accidentally masking bugs due to unknown dependencies. Sometimes the order or other incidental factors can cause false positives; by randomizing their order, the tool makes those faults less likely.
- Measures the durations of all behaviors
-
Part of Scientistâs job is A/B performance testing, so monitoring performance is built in. In fact, developers can use the framework piecemealââfor example, they can use it to measure calls without performing experiments.
- Compares the result of
tryto the result ofuse -
Because the goal is refactoring existing behavior, Scientist compares and logs the results of each call to see if differences exist.
- Swallows (but logs) any exceptions raised in the
tryblock -
Thereâs always a chance that new code will throw unexpected exceptions. Developers never want end users to see these errors, so the tool makes them invisible to the end user (but logs them for developer analysis).
- Publishes all this information
-
Scientist makes all its data available in a variety of formats.
For the merge refactoring, the GitHub developers used the following invocation to test the new implementation (called create_merge_commit_rugged), as shown in Example 4-12.
Example 4-12. Experimenting with a new merge algorithm
defcreate_merge_commit(author,base,head,options={})commit_message=options[:commit_message]||"Merge#{head}into#{base}"now=Time.currentscience"create_merge_commit"do|e|e.context:base=>base.to_s,:head=>head.to_s,:repo=>repository.nwoe.use{create_merge_commit_git(author,now,base,head,commit_message)}e.try{create_merge_commit_rugged(author,now,base,head,commit_message)}endend
In Example 4-12, the call to create_merge_commit_rugged occurred in 1% of invocations, but, as noted in this case study, at GitHubâs scale, all edge cases appear quickly.
When this code executes, end users always receive the correct result. If the try block returns a different value from use, it is logged, and the use value is returned. Thus, the worse case for end users is exactly what they would have gotten before the refactoring. After running the experiment for 4 days and experiencing no slow cases or mismatched results for 24 hours, they removed the old merge code and left the new code in place.
From our perspective, Scientist is a fitness function. This case study is an outstanding example of the strategic use of a holistic, continuous fitness function to allow developers to refactor a critical part of their infrastructure with confidence. They changed a key part of their architecture by running the new version alongside the existing one, essentially turning the legacy implementation into a consistency test.
Fidelity Fitness Functions
The Scientist tool implements a general type of verification called a fidelity fitness function: preserving the fidelity between a new system and an old one undergoing replacement. Many organizations build important functionality over long periods of time without enough testing or discipline, until eventually the time comes to replace the application with newer technology yet still retain the same behavior as the old one. The older and more poorly documented the old system is, the more difficult it is for teams to replicate the desired behavior.
A fidelity fitness function allows for a side-by-side comparison between old and new. During the replacement process, both systems run in parallel, and a proxy allows teams to call old, new, or both in a controlled way until the team has ported each bit of discrete functionality. Some teams resist building such a mechanism because they realize the complexity of partitioning the old behavior and exact replication, but eventually they succumb to the necessity to achieve confidence.
Fitness Functions as a Checklist, Not a Stick
We realize that we have provided architects a metaphorical sharp stick they can use to poke and torture developers; that is not the point at all. We want to discourage architects from retreating to an ivory tower and devising more and more complex and interlocking fitness functions that increase the burden on developers while not adding corresponding value to the project.
Instead, fitness functions provide a way to enforce architectural principles. Many professions such as surgeons and airline pilots use (sometimes by mandate) checklists as part of their job. Itâs not because they donât understand their job or tend toward absentmindednessâârather, it avoids the natural tendency that people have when performing complex tasks over and over to accidentally skip steps. For example, every developer knows they shouldnât deploy a container with debug ports enabled, but they may forget during a push including many other tasks.
Many architects state architecture and design principles in wikis or other shared knowledge portals, but principles without execution fall by the wayside in the presence of schedule pressure and other constraints. Encoding those design and governance rules as fitness functions ensures they arenât skipped in the face of external forces.
Architects often write fitness functions but should always collaborate with developers, who must understand them and fix them upon occasional breakage. While fitness functions add overhead, they prevent the gradual degradation of a codebase (bit rot), allowing it to continue to evolve into the future.
Documenting Fitness Functions
Tests make good documentation because readers never doubt their honestyââthey can always execute the tests to check results. Trust but verify!
Architects can document fitness functions in a variety of ways, all appropriate with other documentation within their organization. Some architects view the fitness functions themselves as sufficient to document their intent. However, tests (no matter how fluent) are harder for nontechnologists to read.
Many architects like Architectural Decision Records (ADRs) to document architecture decisions. Teams that use fitness functions add a section in the ADR specifying how to govern the enclosed design decisions.
Another alternative is to use a behavior-driven development (BDD) framework such as Cucumber. These tools are designed to map native language to verification code. For example, take a look at the Cucumber test stated in Example 4-13.
Example 4-13. Cucumber assumptions
Feature:IsitFridayyet?Everybodywantstoknowwhenit'sFridayScenario:Sundayisn'tFridayGiventodayisSundayWhenIaskwhetherit'sFridayyetThenIshouldbetold"Nope"
The Feature described in Example 4-13 maps to a programming language method; a Java mapping appears in Example 4-14.
Example 4-14. Cucumber methods that map to descriptions
@Given("today is Sunday")publicvoidtoday_is_sunday(){// Write code here that turns the phrase above into concrete actionsthrownewio.cucumber.java.PendingException();}@When("I ask whether it's Friday yet")publicvoidi_ask_whether_it_s_friday_yet(){// Write code here that turns the phrase above into concrete actionsthrownewio.cucumber.java.PendingException();}@Then("I should be told {string}")publicvoidi_should_be_told(Stringstring){// Write code here that turns the phrase above into concrete actionsthrownewio.cucumber.java.PendingException();}
Architects can use the mapping between native language declarations in Example 4-13 and method definitions in Example 4-14 to define fitness functions in more or less plain native language and map the execution in the corresponding method. This provides architects a way to document their decisions that also executes them.
The downside of using a tool like Cucumber is the impedance mismatch between capturing requirements (its original job) and documenting fitness functions.
Literate programming was an innovation by Donald Knuth that attempted to merge documentation and source code, the goal being to allow cleaner documentation. He built special compilers for the then-current languages but got little support.
However, in modern ecosystems, tools like Mathematica and Jupyter notebooks are popular in disciplines such as data science. Architects can use Jupyter notebooks in particular to document and execute fitness functions.
In one case study, a team created a notebook to check for architectural rules using the structural code analyzer jQAssistant in combination with the graph database Neo4j. jQAssistant scans several artifacts (Java bytecode, Git history, Maven dependencies, etc.) and stores the structural information into the Neo4j database, as shown in Figure 4-24.
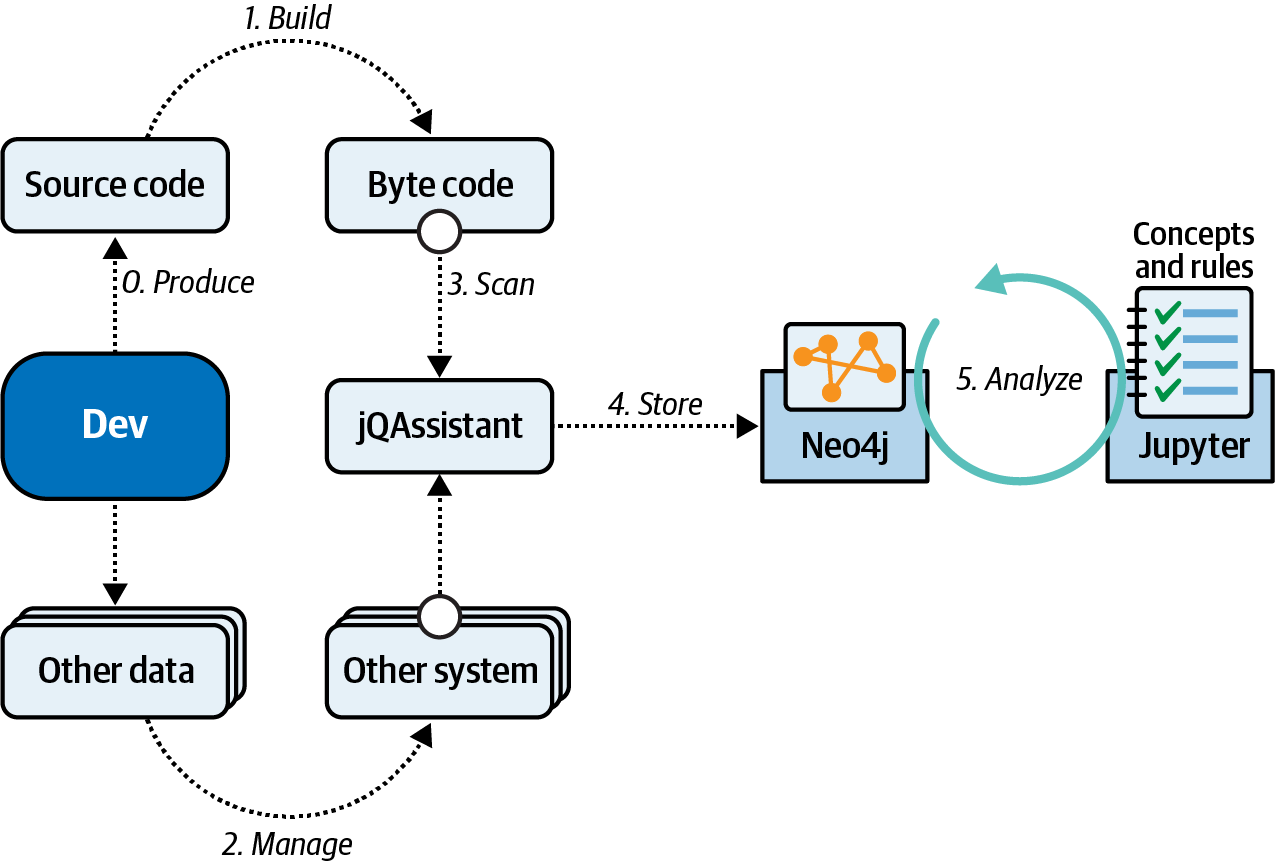
Figure 4-24. Governance workflow with Jupyter notebook
In Figure 4-24, the relationships between parts of the codebase are placed in the graph database, allowing the team to execute queries such as the following:
MATCH(e:Entity)<-[:CONTAINS]-(p:Package)WHEREp.name<>"model"RETURNe.fqnasMisplacedEntity,p.nameasWrongPackage
When executed against a sample PetClinic application, the analysis creates the output shown in Figure 4-25.

Figure 4-25. The output of graph analysis
In Figure 4-25, the results indicate a governance violation, where all classes in the model package should implement an @Entity annotation.
Jupyter notebooks allow architects to define the text of the governance rules along with on-demand execution.
Documenting fitness functions is important because developers must understand why they exist so that fixing them isnât a nuisance. Finding a way to incorporate fitness function definitions within your organizationâs existing documentation framework allows for most consistent access. The execution of the fitness functions remains the top priority, but understandability is also important.
Summary
Fitness functions are to architecture governance as unit tests are to domain changes. However, the implementation of fitness functions varies depending on all the various factors that make up a particular architecture. There is no generic architectureââevery one is a unique combination of decisions and subsequent technologies, often years, or decades, worth. Thus, architects must sometimes be clever in creating fitness functions. However, this isnât an example of needing to write an entire testing framework. Rather, architects often write these fitness functions in scripting languages such as Python or Ruby, writing 10 or 20 lines of âglueâ code to combine the output of other tools. For example, consider Example 4-10, which harvests the output of logfiles and checks for particular string patterns.
One of our colleagues presented a great analogy for fitness functions, shown in Figure 4-26.

Figure 4-26. Fitness functions act as guardrails no matter what the road is made of
In Figure 4-26, the road can be made with a variety of materialââasphalt, cobblestones, gravel, and so on. The guardrails exist to keep travelers on the road regardless of the type of vehicle or type of road. Fitness functions are architecture characteristics guardrails, created by architects to prevent system rot and support evolving systems over time.
Get Building Evolutionary Architectures, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

