Kapitel 4. Aufbereitung von Textdaten für Statistik und maschinelles Lernen
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Technisch gesehen ist jedes Textdokument nur eine Folge von Zeichen. Um Modelle für den Inhalt zu erstellen, müssen wir einen Text in eine Abfolge von Wörtern oder, allgemeiner gesagt, in sinnvolle Zeichenfolgen, sogenannte Tokens, umwandeln. Aber das allein reicht nicht aus. Denk an die Wortfolge New York, die als eine einzige benannte Einheit behandelt werden sollte. Um solche Wortfolgen korrekt als zusammengesetzte Strukturen zu erkennen, ist eine ausgefeilte linguistische Verarbeitung erforderlich.
Die Datenaufbereitung oder Datenvorverarbeitung umfasst im Allgemeinen nicht nur die Umwandlung der Daten in eine Form, die als Grundlage für die Analyse dienen kann, sondern auch die Entfernung von störendem Rauschen. Was Rauschen ist und was nicht, hängt immer von der Analyse ab, die du durchführen willst. Wenn du mit Text arbeitest, gibt es verschiedene Arten von Rauschen. Die Rohdaten können HTML-Tags oder Sonderzeichen enthalten, die in den meisten Fällen entfernt werden sollten. Aber auch häufige Wörter mit geringer Bedeutung, die sogenannten Stoppwörter, bringen Rauschen in das maschinelle Lernen und die Datenanalyse, weil sie die Erkennung von Mustern erschweren.
Was du lernen wirst und was wir bauen werden
In diesem Kapitel werden wir Entwürfe für eine Textvorverarbeitungspipeline entwickeln. Die Pipeline nimmt den Rohtext als Eingabe, bereinigt ihn, transformiert ihn und extrahiert die grundlegenden Merkmale des Textinhalts. Wir beginnen mit regulären Ausdrücken zur Datenbereinigung und Tokenisierung und konzentrieren uns dann auf linguistische Verarbeitung mit spaCy. spaCy ist eine leistungsstarke NLP-Bibliothek mit einer modernen API und modernsten Modellen. Für einige Operationen werden wir auf textacy zurückgreifen, eine Bibliothek, die einige nützliche Zusatzfunktionen speziell für die Datenvorverarbeitung bietet. Wir werden auch auf NLTK und andere Bibliotheken verweisen, wann immer es hilfreich erscheint.
Nach der Lektüre dieses Kapitels kennst du die erforderlichen und optionalen Schritte der Datenaufbereitung. Du weißt, wie du reguläre Ausdrücke für die Datenbereinigung verwendest und wie du SpaCy für die Merkmalsextraktion nutzen kannst. Mit den mitgelieferten Vorlagen kannst du schnell eine Datenaufbereitungspipeline für dein eigenes Projekt einrichten.
Eine Pipeline für die Datenvorverarbeitung
Die Datenvorverarbeitung umfasst in der Regel eine Abfolge von Schritten. Oft wird diese Abfolge als Pipeline bezeichnet, weil man die Rohdaten in die Pipeline einspeist und die umgewandelten und vorverarbeiteten Daten herausbekommt. In Kapitel 1 haben wir bereits eine einfache Datenverarbeitungspipeline aufgebaut, die Tokenisierung und Stoppwortentfernung beinhaltet. In diesem Kapitel werden wir den Begriff Pipeline als allgemeinen Begriff für eine Abfolge von Verarbeitungsschritten verwenden. Abbildung 4-1 gibt einen Überblick über die Blaupausen, die wir in diesem Kapitel für die Vorverarbeitungspipeline erstellen werden.
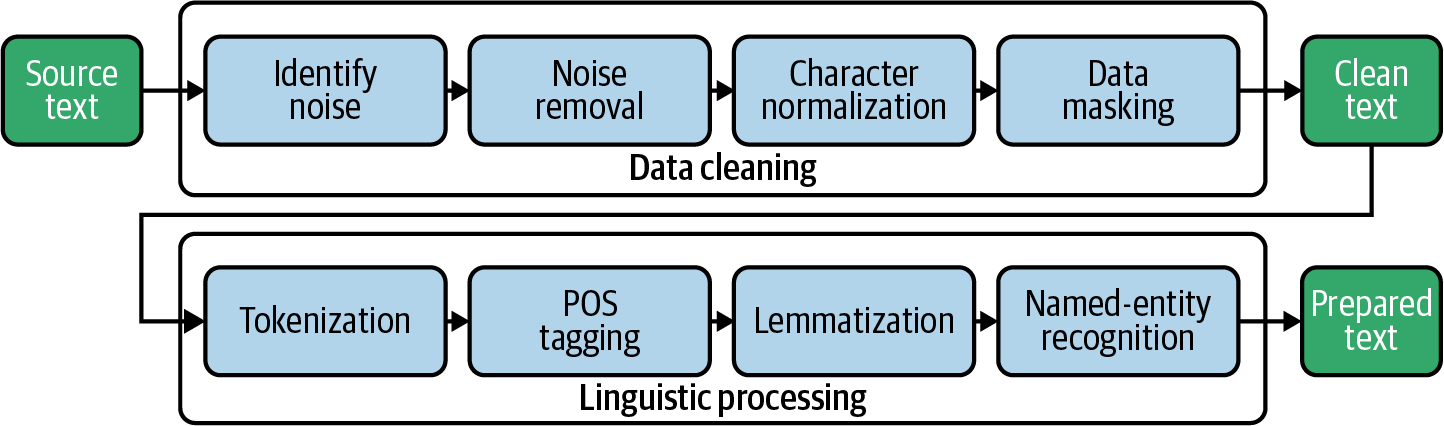
Abbildung 4-1. Eine Pipeline mit typischen Vorverarbeitungsschritten für textuelle Daten.
Der erste große Block in unserer Pipeline ist die Datenbereinigung. Wir beginnen damit, Störfaktoren im Text wie HTML-Tags und nicht druckbare Zeichen zu identifizieren und zu entfernen. Bei der Zeichennormalisierung werden Sonderzeichen wie Akzente und Bindestriche in eine Standarddarstellung umgewandelt. Schließlich können wir Identifikatoren wie URLs oder E-Mail-Adressen maskieren oder entfernen, wenn sie für die Analyse nicht relevant sind oder wenn es Probleme mit dem Datenschutz gibt. Jetzt ist der Text sauber genug, um mit der linguistischen Verarbeitung zu beginnen.
Bei der Tokenisierung wird ein Dokument in eine Liste von einzelnen Token wie Wörtern und Satzzeichen Zeichen aufgeteilt. Beim Part-of-Speech-Tagging (POS-Tagging) wird die Wortklasse bestimmt, also ob es sich um ein Substantiv, ein Verb, einen Artikel usw. handelt. Die Lemmatisierung ordnet flektierte Wörter ihrer unflektierten Wurzel, dem Lemma, zu (z. B. "sind" → "sein"). Das Ziel der Named-Entity-Erkennung ist die Identifizierung von Verweisen auf Personen, Organisationen, Orte usw. im Text.
Am Ende wollen wir eine Datenbank mit vorbereiteten Daten für die Analyse und das maschinelle Lernen erstellen. Daher sind die erforderlichen Vorbereitungsschritte von Projekt zu Projekt unterschiedlich. Es liegt an dir zu entscheiden, welche der folgenden Blaupausen du in deine problemspezifische Pipeline einbauen musst.
Wir stellen den Datensatz vor: Reddit Self-Posts
Die Aufbereitung von Textdaten ist eine besondere Herausforderung, wenn du mit nutzergenerierten Inhalten (UGC) arbeitest. Im Gegensatz zu gut redigierten Texten aus professionellen Berichten, Nachrichten und Blogs sind Nutzerbeiträge in sozialen Medien meist kurz und enthalten viele Abkürzungen, Hashtags, Emojis und Tippfehler. Daher verwenden wir den Reddit Self-Posts-Datensatz, der auf bei Kaggle zu finden ist. Der vollständige Datensatz enthält etwa 1 Million Nutzerbeiträge mit Titel und Inhalt, die in 1.013 verschiedenen Subreddits mit jeweils 1.000 Datensätzen angeordnet sind. Wir werden nur eine Teilmenge von 20.000 Beiträgen aus der Kategorie "Autos" verwenden. Der Datensatz, den wir in diesem Kapitel aufbereiten, ist die Grundlage für die Analyse der Worteinbettungen in Kapitel 10.
Daten in Pandas laden
Der ursprüngliche Datensatz besteht aus zwei separaten CSV-Dateien, eine mit den Beiträgen und die andere mit einigen Metadaten für die Subreddits, einschließlich Kategorieinformationen. Beide Dateien werden von pd.read_csv() in ein Pandas DataFrame geladen und dann zu einem einzigen DataFrame zusammengefügt.
importpandasaspdposts_file="rspct.tsv.gz"posts_df=pd.read_csv(posts_file,sep='\t')subred_file="subreddit_info.csv.gz"subred_df=pd.read_csv(subred_file).set_index(['subreddit'])df=posts_df.join(subred_df,on='subreddit')
Blueprint: Standardisierung von Attribut-Namen
Bevor wir mit den Daten arbeiten, werden wir die datensatzspezifischen Spaltennamen in allgemeinere Namen ändern. Wir empfehlen, die Hauptspalte immer DataFrame df zu nennen und die Spalte mit dem zu analysierenden Text text zu benennen. Solche Namenskonventionen für gemeinsame Variablen und Attributnamen machen es einfacher, den Code der Blueprints in verschiedenen Projekten wiederzuverwenden.
Werfen wir einen Blick auf die Spaltenliste dieses Datensatzes:
(df.columns)
Out:
Index(['id', 'subreddit', 'title', 'selftext', 'category_1', 'category_2',
'category_3', 'in_data', 'reason_for_exclusion'],
dtype='object')
Für die Spaltenumbenennung und -auswahl definieren wir ein Wörterbuch column_mapping, in dem jeder Eintrag eine Zuordnung vom aktuellen Spaltennamen zu einem neuen Namen definiert. Spalten, die auf None abgebildet werden, und nicht erwähnte Spalten werden gelöscht. Ein Wörterbuch ist die perfekte Dokumentation für eine solche Umwandlung und lässt sich leicht wiederverwenden. Dieses Wörterbuch wird dann verwendet, um die Spalten auszuwählen und umzubenennen, die wir behalten wollen.
column_mapping={'id':'id','subreddit':'subreddit','title':'title','selftext':'text','category_1':'category','category_2':'subcategory','category_3':None,# no data'in_data':None,# not needed'reason_for_exclusion':None# not needed}# define remaining columnscolumns=[cforcincolumn_mapping.keys()ifcolumn_mapping[c]!=None]# select and rename those columnsdf=df[columns].rename(columns=column_mapping)
Wie bereits erwähnt, beschränken wir die Daten auf die Kategorie "Autos":
df=df[df['category']=='autos']
Werfen wir einen kurzen Blick auf einen Beispieldatensatz, um einen ersten Eindruck von den Daten zu bekommen:
df.sample(1).T
| 14356 | |
|---|---|
| id | 7jc2k4 |
| subreddit | volt |
| Titel | Dashcam für 2017 volt |
| Text | Hallo.<lb>Ich überlege, mir eine Dashcam zuzulegen. <lb>Hat jemand eine Empfehlung? <lb><lb>Ich suche generell nach einer aufladbaren, damit ich keine Kabel zum Zigarettenanzünder verlegen muss. <lb>Es sei denn, es gibt eine Anleitung, wie man sie richtig verkabelt, ohne dass Kabel zu sehen sind. <lb><lb><lb>Danke! |
| Kategorie | autos |
| Unterkategorie | chevrolet |
Speichern und Laden eines Datenrahmens
Nach jedem Schritt der Datenaufbereitung ist es hilfreich, den jeweiligen DataFrame als Checkpoint auf die Festplatte zu schreiben. Pandas unterstützt direkt eine Reihe von Serialisierungsoptionen. Textbasierte Formate wie CSV oder JSON können problemlos in die meisten anderen Tools importiert werden. Allerdings gehen dabei Informationen über Datentypen verloren (CSV) oder werden nur rudimentär gespeichert (JSON). Das standardmäßige Serialisierungsformat von Python, pickle, wird von Pandas unterstützt und ist daher eine praktikable Option. Es ist schnell und bewahrt alle Informationen, kann aber nur von Python verarbeitet werden. Das "Picken" eines Datenrahmens ist einfach; du musst nur den Dateinamen angeben:
df.to_pickle("reddit_dataframe.pkl")
Wir bevorzugen jedoch die Speicherung von Datenrahmen in SQL-Datenbanken, weil sie dir alle Vorteile von SQL bieten, z. B. Filter, Joins und einfachen Zugriff aus vielen Tools. Aber im Gegensatz zu pickle werden nur SQL-Datentypen unterstützt. Spalten, die z. B. Objekte oder Listen enthalten, können nicht einfach auf diese Weise gespeichert werden und müssen manuell serialisiert werden.
In unseren Beispielen werden wir SQLite verwenden, um Datenrahmen zu speichern. SQLite ist gut mit Python integriert. Außerdem ist es nur eine Bibliothek und benötigt keinen Server, sodass die Dateien in sich abgeschlossen sind und leicht zwischen verschiedenen Teammitgliedern ausgetauscht werden können. Für mehr Leistung und Sicherheit empfehlen wir eine serverbasierte SQL-Datenbank.
Wir verwenden pd.to_sql(), um unsere DataFrame als Tabelle posts in einer SQLite-Datenbank zu speichern. Der Index DataFrame wird nicht gespeichert und alle vorhandenen Daten werden überschrieben:
importsqlite3db_name="reddit-selfposts.db"con=sqlite3.connect(db_name)df.to_sql("posts",con,index=False,if_exists="replace")con.close()
Die DataFrame kann leicht mit pd.read_sql() wiederhergestellt werden:
con=sqlite3.connect(db_name)df=pd.read_sql("select * from posts",con)con.close()
Textdaten bereinigen
Wenn du mit Nutzeranfragen oder Kommentaren arbeitest und nicht mit gut redigierten Artikeln, musst du dich in der Regel mit einer Reihe von Qualitätsproblemen auseinandersetzen:
- Spezielle Formatierung und Programmcode
- Der Text kann noch Sonderzeichen, HTML-Entities, Markdown-Tags und Ähnliches enthalten. Diese Artefakte sollten im Voraus bereinigt werden, da sie die Tokenisierung erschweren und Rauschen verursachen.
- Anreden, Unterschriften, Adressen, etc.
- Persönliche Kommunikation enthält oft bedeutungslose Höflichkeitsfloskeln und namentliche Begrüßungen, die für die Analyse meist irrelevant sind.
- Antworten
- Wenn dein Text Antworten enthält, die den Fragentext wiederholen, musst du die doppelten Fragen löschen. Wenn du sie beibehältst, werden Modell und Statistik verfälscht.
In diesem Abschnitt zeigen wir , wie man reguläre Ausdrücke verwendet, um unerwünschte Muster in den Daten zu erkennen und zu entfernen. In der folgenden Seitenleiste findest du weitere Informationen über reguläre Ausdrücke in Python.
Wirf einen Blick auf das folgende Textbeispiel aus dem Reddit-Datensatz:
text="""After viewing the [PINKIEPOOL Trailer](https://www.youtu.be/watch?v=ieHRoHUg)it got me thinking about the best match ups.<lb>Here's my take:<lb><lb>[](/sp)[](/ppseesyou) Deadpool<lb>[](/sp)[](/ajsly)Captain America<lb>"""
Es wird die Ergebnisse definitiv verbessern, wenn dieser Text etwas aufgeräumt und poliert wird. Einige Tags sind nur Artefakte aus dem Web Scraping, also werden wir sie loswerden. Und da wir an den URLs und anderen Links nicht interessiert sind, werden wir sie ebenfalls entfernen.
Blaupause: Rauschen mit regulären Ausdrücken identifizieren
Die Identifizierung von Qualitätsproblemen in einem großen Datensatz kann knifflig sein. Natürlich kannst und solltest du einen Blick auf eine Stichprobe der Daten werfen. Aber die Wahrscheinlichkeit ist hoch, dass du nicht alle Probleme finden wirst. Besser ist es, grobe Muster zu definieren, die auf wahrscheinliche Probleme hinweisen, und den gesamten Datensatz programmatisch zu überprüfen.
Die folgende Funktion kann dir helfen, Rauschen in Textdaten zu erkennen. Mit Rauschen meinen wir alles, was kein reiner Text ist und daher die weitere Analyse stören könnte. Die Funktion verwendet einen regulären Ausdruck, um nach einer Reihe verdächtiger Zeichen zu suchen, und gibt deren Anteil an allen Zeichen als Wert für die Unreinheit zurück. Sehr kurze Texte (weniger als min_len Zeichen) werden ignoriert, da hier ein einziges Sonderzeichen zu einer erheblichen Verunreinigung führen und das Ergebnis verfälschen würde.
importreRE_SUSPICIOUS=re.compile(r'[&#<>{}\[\]\\]')defimpurity(text,min_len=10):"""returns the share of suspicious characters in a text"""iftext==Noneorlen(text)<min_len:return0else:returnlen(RE_SUSPICIOUS.findall(text))/len(text)(impurity(text))
Out:
0.09009009009009009
Diese Zeichen sind in gut redigierten Texten fast nie zu finden, daher sollten die Werte im Allgemeinen sehr gering sein. Bei dem vorherigen Beispieltext sind etwa 9 % der Zeichen nach unserer Definition "verdächtig". Das Suchmuster muss natürlich für Korpora angepasst werden, die Hashtags oder ähnliche Token mit Sonderzeichen enthalten. Es muss jedoch nicht perfekt sein, sondern nur gut genug, um potenzielle Qualitätsprobleme zu erkennen.
Für die Reddit-Daten können wir mit den folgenden beiden Anweisungen die "unsaubersten" Datensätze erhalten. Beachte, dass wir Pandas apply() anstelle des ähnlichen map() verwenden, weil wir damit zusätzliche Parameter wie min_len an die angewandte Funktion weitergeben können.1
# add new column to data framedf['impurity']=df['text'].apply(impurity,min_len=10)# get the top 3 recordsdf[['text','impurity']].sort_values(by='impurity',ascending=False).head(3)
| Text | Verunreinigung | |
|---|---|---|
| 19682 | Ich möchte einen 335i mit 39.000 Kilometern und noch 11 Monaten CPO-Garantie kaufen. Ich habe nach dem Deal gefragt... | 0.21 |
| 12357 | Ich bin auf der Suche nach einem a4 Premium Plus Automatik mit dem Nav-Paket.<lb><lb>Fahrzeugpreis:<ta... | 0.17 |
| 2730 | Nachfolgende Aufschlüsselung:<lb><lb>Elantra GT<lb><lb>2.0L 4-Zylinder<lb><lb>6-Gang Schaltgetriebe<lb>... | 0.14 |
Offensichtlich sind viele Tags wie <lb> (Zeilenumbruch) und <tab> enthalten. Überprüfen wir, ob es noch andere gibt, indem wir unseren Wortzählungsplan aus Kapitel 1 in Kombination mit einem einfachen Regex-Tokenizer für solche Tags verwenden:
fromblueprints.explorationimportcount_wordscount_words(df,column='text',preprocess=lambdat:re.findall(r'<[\w/]*>',t))
| freq | Token |
|---|---|
| <lb> | 100729 |
| <tab> | 642 |
Jetzt wissen wir, dass diese beiden Tags zwar häufig vorkommen, aber nicht die einzigen sind.
Blaupause: Rauschen mit regulären Ausdrücken beseitigen
Unser Ansatz zur Datenbereinigung besteht darin, eine Reihe von regulären Ausdrücken zu definieren und problematische Muster und entsprechende Ersetzungsregeln zu identifizieren.2 Die Blueprint-Funktion ersetzt zunächst alle HTML-Escapes (z. B. &) durch ihre Klartextdarstellung und ersetzt dann bestimmte Muster durch Leerzeichen. Schließlich werden Sequenzen von Leerzeichen entfernt:
importhtmldefclean(text):# convert html escapes like & to characters.text=html.unescape(text)# tags like <tab>text=re.sub(r'<[^<>]*>',' ',text)# markdown URLs like [Some text](https://....)text=re.sub(r'\[([^\[\]]*)\]\([^\(\)]*\)',r'\1',text)# text or code in brackets like [0]text=re.sub(r'\[[^\[\]]*\]',' ',text)# standalone sequences of specials, matches &# but not #cooltext=re.sub(r'(?:^|\s)[&#<>{}\[\]+|\\:-]{1,}(?:\s|$)',' ',text)# standalone sequences of hyphens like --- or ==text=re.sub(r'(?:^|\s)[\-=\+]{2,}(?:\s|$)',' ',text)# sequences of white spacestext=re.sub(r'\s+',' ',text)returntext.strip()
Warnung
Sei vorsichtig: Wenn deine regulären Ausdrücke nicht genau genug definiert sind, kannst du während dieses Vorgangs versehentlich wertvolle Informationen löschen, ohne es zu merken! Die Wiederholungen + und * können besonders gefährlich sein, weil sie auf unbegrenzte Zeichenfolgen passen und große Teile des Textes löschen können.
Wenden wir die Funktion clean auf den vorherigen Beispieltext an und überprüfen wir das Ergebnis:
clean_text=clean(text)(clean_text)("Impurity:",impurity(clean_text))
Out:
After viewing the PINKIEPOOL Trailer it got me thinking about the best match ups. Here's my take: Deadpool Captain America Impurity: 0.0
Das sieht ziemlich gut aus. Wenn du die ersten Muster behandelt hast, solltest du die Verunreinigung des gereinigten Textes noch einmal überprüfen und gegebenenfalls weitere Reinigungsschritte hinzufügen:
df['clean_text']=df['text'].map(clean)df['impurity']=df['clean_text'].apply(impurity,min_len=20)
df[['clean_text','impurity']].sort_values(by='impurity',ascending=False)\.head(3)
| sauber_text | Verunreinigung | |
|---|---|---|
| 14058 | Mustang 2018, 2019, oder 2020? Must Haves!! 1. Eine Kreditwürdigkeit von 780+ für die besten niedrigen Zinssätze! 2. Tritt einer Credit Union bei, um das Fahrzeug zu finanzieren! 3. Oder finde einen Kreditgeber für die Finanzierung des Fahrzeugs... | 0.03 |
| 18934 | Im Autohaus wurde eine Option für eine Fußraumbeleuchtung angeboten, aber ich kann online keinen Hinweis darauf finden. Hat sie jemand bekommen? Wie sieht sie aus? Hat jemand Bilder. Ich weiß nicht, ob das... | 0.03 |
| 16505 | Ich schaue mir vier Caymans an, die alle in einer ähnlichen Preisklasse liegen. Die größten Unterschiede sind die Kilometerzahl, das Baujahr und einer ist kein S. https://www.cargurus.com/Cars/inventorylisting/viewDetailsFilterV... | 0.02 |
Selbst die schmutzigsten Datensätze sehen nach unserem regulären Ausdruck jetzt ziemlich sauber aus. Aber neben diesen groben Mustern, nach denen wir gesucht haben, gibt es auch subtilere Variationen von Zeichen, die Probleme verursachen können.
Blaupause: Zeichen-Normalisierung mit Textacy
Sieh dir den folgenden Satz auf an, der typische Probleme im Zusammenhang mit Varianten von Buchstaben und Anführungszeichen enthält:
text = "The café “Saint-Raphaël” is loca-\nted on Côte dʼAzur."
Die akzentuierten Zeichen können ein Problem darstellen, weil die Menschen sie nicht konsequent verwenden. Zum Beispiel werden die Token Saint-Raphaël und Saint-Raphael nicht als identisch erkannt. Außerdem enthalten Texte aufgrund des automatischen Zeilenumbruchs oft Wörter, die durch einen Bindestrich getrennt sind. Ausgefallene Unicode-Bindestriche und Apostrophe, wie sie im Text verwendet werden, können ein Problem für die Tokenisierung darstellen. Bei all diesen Problemen ist es sinnvoll, den Text zu normalisieren und Akzente und ausgefallene Zeichen durch ASCII-Entsprechungen zu ersetzen.
Wir werden textacy für diesen Zweck verwenden. textacy ist eine NLP-Bibliothek, die für die Zusammenarbeit mit spaCy entwickelt wurde. Sie überlässt den linguistischen Teil SpaCy und konzentriert sich auf die Vor- und Nachbearbeitung. So umfasst das Vorverarbeitungsmodul eine schöne Sammlung von Funktionen zur Normalisierung von Zeichen und zur Behandlung gängiger Muster wie URLs, E-Mail-Adressen, Telefonnummern usw., die wir im Folgenden unter verwenden werden. Tabelle 4-1 zeigt eine Auswahl der Vorverarbeitungsfunktionen von textacy . Alle diese Funktionen arbeiten mit einfachem Text und sind völlig unabhängig von SpaCy.
| Funktion | Beschreibung |
|---|---|
normalize_hyphenated_words |
Setzt Wörter wieder zusammen, die durch einen Zeilenumbruch getrennt wurden |
normalize_quotation_marks |
Ersetzt alle ausgefallenen Anführungszeichen durch ein ASCII-Äquivalent |
normalize_unicode |
Vereinheitlicht verschiedene Codes für akzentuierte Zeichen in Unicode |
remove_accents |
Ersetzt akzentuierte Zeichen durch ASCII, wenn möglich, oder lässt sie weg |
replace_urls |
Ähnliches gilt für URLs wie https://xyz.com |
replace_emails |
Ersetzt Emails durch _EMAIL_ |
replace_hashtags |
Ähnlich für Tags wie #sunshine |
replace_numbers |
Ähnlich für Zahlen wie 1235 |
replace_phone_numbers |
Ähnlich für Telefonnummern +1 800 456-6553 |
replace_user_handles |
Ähnlich für Benutzerhandles wie @pete |
replace_emojis |
Ersetzt Smileys etc. durch _EMOJI_ |
Unsere hier gezeigte Blueprint-Funktion standardisiert ausgefallene Bindestriche und Anführungszeichen und entfernt Akzente mit Hilfe von textacy:
importtextacy.preprocessingastprepdefnormalize(text):text=tprep.normalize_hyphenated_words(text)text=tprep.normalize_quotation_marks(text)text=tprep.normalize_unicode(text)text=tprep.remove_accents(text)returntext
Wenn wir dies auf den vorherigen Beispielsatz anwenden, erhalten wir folgendes Ergebnis:
(normalize(text))
Out:
The cafe "Saint-Raphael" is located on Cote d'Azur.
Hinweis
Da die Unicode-Normalisierung viele Facetten hat, kannst du dir auch andere Bibliotheken ansehen. unidecode zum Beispiel leistet hier hervorragende Arbeit .
Blaupause: Musterbasierte Datenmaskierung mit textacy
Text, insbesondere von Nutzern geschriebene Inhalte, enthält oft nicht nur gewöhnliche Wörter, sondern auch verschiedene Arten von Identifikatoren, wie URLs, E-Mail-Adressen oder Telefonnummern. Manchmal sind wir besonders an diesen Elementen interessiert, zum Beispiel, um die am häufigsten genannten URLs zu analysieren. In vielen Fällen ist es jedoch besser, diese Informationen zu entfernen oder auszublenden, entweder weil sie nicht relevant sind oder aus Datenschutzgründen.
textacy verfügt über einige praktische replace Funktionen zum Maskieren von Daten (siehe Tabelle 4-1). Die meisten Funktionen basieren auf den regulären Ausdrücken von , die über den offenen Quellcode leicht zugänglich sind. Wann immer du also eines dieser Elemente behandeln musst, hat textacy einen regulären Ausdruck dafür, den du direkt verwenden oder an deine Bedürfnisse anpassen kannst. Veranschaulichen wir uns das anhand eines einfachen Aufrufs, um die am häufigsten verwendeten URLs im Korpus zu finden:
fromtextacy.preprocessing.resourcesimportRE_URLcount_words(df,column='clean_text',preprocess=RE_URL.findall).head(3)
| Token | freq |
|---|---|
| www.getlowered.com | 3 |
| http://www.ecolamautomotive.com/#!2/kv7fq | 2 |
| https://www.reddit.com/r/Jeep/comments/4ux232/just_ordered_an_android_head_unit_joying_jeep/ | 2 |
Für die Analyse, die wir mit diesem Datensatz durchführen wollen (in Kapitel 10), sind wir nicht an diesen URLs interessiert. Sie stellen vielmehr ein störendes Artefakt dar. Daher werden wir alle URLs in unserem Text durch replace_urls ersetzen, was eigentlich nur ein Aufruf von RE_URL.sub ist. Die Standard-Ersetzung für alle Ersetzungsfunktionen von textacy ist ein generisches, von Unterstrichen umschlossenes Tag wie _URL_. Du kannst deine eigene Ersetzung wählen, indem du den Parameter replace_with angibst. Oft ist es sinnvoll, diese Elemente nicht vollständig zu entfernen, weil dadurch die Struktur der Sätze intakt bleibt. Der folgende Aufruf veranschaulicht die Funktionalität:
fromtextacy.preprocessing.replaceimportreplace_urlstext="Check out https://spacy.io/usage/spacy-101"# using default substitution _URL_(replace_urls(text))
Out:
Check out _URL_
Um die Datenbereinigung auf abzuschließen, wenden wir die Normalisierungs- und Datenmaskierungsfunktionen auf unsere Daten an:
df['clean_text']=df['clean_text'].map(replace_urls)df['clean_text']=df['clean_text'].map(normalize)
Datenbereinigung ist wie ein Hausputz. Du wirst immer ein paar schmutzige Ecken finden und dein Haus wird nie ganz sauber werden. Also hörst du auf zu putzen, wenn es ausreichend sauber ist. Davon gehen wir im Moment bei unseren Daten aus. Später, wenn die Analyseergebnisse unter dem verbleibenden Rauschen leiden, müssen wir vielleicht zur Datenbereinigung zurückkommen.
Schließlich benennen wir die Textspalten um, so dass clean_text zu text wird, lassen die Verunreinigungsspalte weg und speichern die neue Version von DataFrame in der Datenbank .
df.rename(columns={'text':'raw_text','clean_text':'text'},inplace=True)df.drop(columns=['impurity'],inplace=True)con=sqlite3.connect(db_name)df.to_sql("posts_cleaned",con,index=False,if_exists="replace")con.close()
Tokenisierung
Wir haben bereits in Kapitel 1 einen Regex-Tokenizer vorgestellt, der eine einfache Regel verwendet. In der Praxis kann die Tokenisierung jedoch ziemlich komplex sein, wenn wir alles richtig behandeln wollen. Betrachte das folgende Stück Text als Beispiel:
text="""2019-08-10 23:32: @pete/@louis - I don't have a well-designedsolution for today's problem. The code of module AC68 should be -1.Have to think a bit... #goodnight ;-) 😩😬"""
Offensichtlich sind die Regeln zur Definition von Wort- und Satzgrenzen nicht so einfach. Also was genau ist ein Token? Leider gibt es keine klare Definition. Wir könnten sagen, dass ein Token eine sprachliche Einheit ist, die für die Analyse semantisch nützlich ist. Diese Definition impliziert, dass die Tokenisierung bis zu einem gewissen Grad anwendungsabhängig ist. In vielen Fällen können wir zum Beispiel Satzzeichen einfach weglassen, aber nicht, wenn wir Emoticons wie :-) für die Stimmungsanalyse behalten wollen. Das Gleiche gilt für Token, die Zahlen oder Hashtags enthalten. Auch wenn die meisten Tokenizer, einschließlich der in NLTK und spaCy verwendeten, auf regulären Ausdrücken basieren, wenden sie recht komplexe und manchmal sprachspezifische Regeln an.
Wir werden zunächst unseren eigenen Entwurf für Tokenisierungs-basierte reguläre Ausdrücke entwickeln, bevor wir die Tokenizer von NLTK kurz vorstellen. Die Tokenisierung in spaCy wird im nächsten Abschnitt dieses Kapitels als Teil des integrierten Prozesses von spaCy behandelt.
Blaupause: Tokenisierung mit regulären Ausdrücken
Nützliche Funktionen für die Tokenisierung sind re.split() und re.findall(). Die erste teilt eine Zeichenkette an übereinstimmenden Ausdrücken auf, während die zweite alle Zeichensequenzen extrahiert, die einem bestimmten Muster entsprechen. In Kapitel 1 haben wir zum Beispiel die Bibliothek regex mit dem POSIX-Muster [\w-]*\p{L}[\w-]* verwendet, um Sequenzen von alphanumerischen Zeichen mit mindestens einem Buchstaben zu finden. Die scikit-learn CountVectorizer verwendet das Muster \w\w+ für seine Standard-Tokenisierung. Es findet alle Sequenzen mit zwei oder mehr alphanumerischen Zeichen. Angewandt auf unseren Beispielsatz ergibt dies das folgende Ergebnis:3
tokens=re.findall(r'\w\w+',text)(*tokens,sep='|')
Out:
2019|08|10|23|32|pete|louis|don|have|well|designed|solution|for|today problem|The|code|of|module|AC68|should|be|Have|to|think|bit|goodnight
Leider gehen dabei alle Sonderzeichen und die Emojis verloren. Um das Ergebnis zu verbessern, fügen wir einige zusätzliche Ausdrücke für die Emojis hinzu und erstellen einen wiederverwendbaren regulären Ausdruck RE_TOKEN. Die Option VERBOSE ermöglicht eine lesbare Formatierung von komplexen Ausdrücken. Die folgende tokenize Funktion und das Beispiel veranschaulichen die Verwendung:
RE_TOKEN=re.compile(r"""( [#]?[@\w'’\.\-\:]*\w # words, hashtags and email addresses| [:;<]\-?[\)\(3] # coarse pattern for basic text emojis| [\U0001F100-\U0001FFFF] # coarse code range for unicode emojis)""",re.VERBOSE)deftokenize(text):returnRE_TOKEN.findall(text)tokens=tokenize(text)(*tokens,sep='|')
Out:
2019-08-10|23:32|@pete|@louis|I|don't|have|a|well-designed|solution for|today's|problem|The|code|of|module|AC68|should|be|-1|Have|to|think a|bit|#goodnight|;-)|😩|😬
Dieser Ausdruck sollte bei den meisten nutzergenerierten Inhalten recht gute Ergebnisse liefern. Sie kann verwendet werden, um Text für die Datenexploration schnell zu tokenisieren, wie in Kapitel 1 erklärt. Er ist auch eine gute Alternative für die Standard-Tokenisierung der scikit-learn Vektorisierer, die im nächsten Kapitel vorgestellt wird.
Tokenisierung mit NLTK
Werfen wir einen kurzen Blick auf die Tokenizer von NLTK, da NLTK häufig für die Tokenisierung verwendet wird. Der Standard-NLTK-Tokenizer kann mit dem Kürzel word_tokenize aufgerufen werden. Er liefert das folgende Ergebnis für unseren Beispieltext:
importnltktokens=nltk.tokenize.word_tokenize(text)(*tokens,sep='|')
Out:
2019-08-10|23:32|:|@|pete/|@|louis|-|I|do|n't|have|a|well-designed solution|for|today|'s|problem|.|The|code|of|module|AC68|should|be|-1|. Have|to|think|a|bit|...|#|goodnight|;|-|)||😩😬
Die Funktion verwendet intern die TreebankWordTokenizer in Kombination mit der PunktSentenceTokenizer. Sie funktioniert gut für Standardtext, hat aber ihre Schwächen bei Hashtags oder Text-Emojis. NLTK bietet auch RegexpTokenizer an, das im Grunde ein Wrapper für re.findall() ist und einige zusätzliche Komfortfunktionen bietet. Außerdem gibt es noch andere auf regulären Ausdrücken basierende Tokenizer in NLTK, wie den TweetTokenizer oder den mehrsprachigen ToktokTokenizer, die du im Notebook auf GitHub für dieses Kapitel nachlesen kannst.
Empfehlungen für die Tokenisierung
Du wirst wahrscheinlich benutzerdefinierte reguläre Ausdrücke verwenden müssen, wenn du eine hohe Präzision bei domänenspezifischen Token-Mustern anstrebst. Glücklicherweise kannst du in Open-Source-Bibliotheken reguläre Ausdrücke für viele gängige Muster finden und sie an deine Bedürfnisse anpassen.4
Generell solltest du dir der folgenden Problemfälle in deiner Bewerbung bewusst sein und festlegen, wie du sie behandelst:5
- Token, die Punkte enthalten, wie
Dr.,Mrs.,U.,xyz.com - Bindestriche, wie in
rule-based - Klitika (zusammenhängende Wortabkürzungen), wie in
couldn't,we'veoderje t'aime - Numerische Ausdrücke, wie z.B. Telefonnummern (
(123) 456-7890) oder Daten (August 7th, 2019) - Emojis, Hashtags, E-Mail-Adressen oder URLs
Die Tokenizer in den gängigen Bibliotheken unterscheiden sich vor allem in Bezug auf diese Token.
Linguistische Verarbeitung mit spaCy
spaCy ist eine leistungsstarke Bibliothek für die Verarbeitung linguistischer Daten. Sie bietet eine integrierte Pipeline von Verarbeitungskomponenten, standardmäßig einen Tokenizer, einen Part-of-Speech Tagger, einen Dependency Parser und einen Named-Entity Recognizer (siehe Abbildung 4-2). Die Tokenisierung basiert auf komplexen sprachabhängigen Regeln und regulären Ausdrücken, während alle nachfolgenden Schritte vortrainierte neuronale Modelle verwenden.

Abbildung 4-2. Die NLP-Pipeline von SpaCy.
Die Philosophie von spaCy ist, dass der Originaltext während des gesamten Prozesses erhalten bleibt. Anstatt ihn umzuwandeln, fügt spaCy Informationen hinzu. Das Hauptobjekt, das den verarbeiteten Text darstellt, ist ein Doc Objekt, das wiederum eine Liste von Token Objekten enthält. Jede Bereichsauswahl von Token erzeugt ein Span. Jeder dieser Objekttypen hat Eigenschaften, die Schritt für Schritt festgelegt werden.
In diesem Abschnitt erklären wir , wie man ein Dokument mit spaCy verarbeitet, wie man mit Token und ihren Attributen arbeitet, wie man Part-of-Speech-Tags verwendet und wie man benannte Entitäten extrahiert. In Kapitel 12 werden wir noch tiefer in die fortgeschrittenen Konzepte von spaCy eintauchen. Dort schreiben wir unsere eigenen Pipeline-Komponenten, erstellen benutzerdefinierte Attribute und arbeiten mit dem vom Parser generierten Abhängigkeitsbaum zur Wissensextraktion.
Warnung
Für die Entwicklung der Beispiele in diesem Buch haben wir spaCy Version 2.3.2 verwendet. Wenn du bereits spaCy 3.0 verwendest, das sich zum Zeitpunkt des Schreibens noch in der Entwicklung befindet, können deine Ergebnisse etwas anders aussehen.
Instanziierung einer Pipeline
Fangen wir mit spaCy an. Als ersten Schritt müssen wir ein Objekt der Klasse Language von spaCy instanziieren, indem wir spacy.load() zusammen mit dem Namen der zu verwendenden Modelldatei aufrufen.6 In diesem Kapitel werden wir das kleine englische Sprachmodell en_core_web_sm verwenden. Die Variable für das Language Objekt wird normalerweise nlp genannt:
importspacynlp=spacy.load('en_core_web_sm')
Dieses Language Objekt enthält nun das gemeinsame Vokabular, das Modell und die Verarbeitungspipeline. Du kannst die Komponenten der Pipeline über diese Eigenschaft des Objekts überprüfen:
nlp.pipeline
Out:
[('tagger', <spacy.pipeline.pipes.Tagger at 0x7fbd766f84c0>),
('parser', <spacy.pipeline.pipes.DependencyParser at 0x7fbd813184c0>),
('ner', <spacy.pipeline.pipes.EntityRecognizer at 0x7fbd81318400>)]
Die Standard-Pipeline besteht aus einem Tagger, einem Parser und einem Named-Entity-Recognizer (ner), die alle sprachabhängig sind. Der Tokenizer ist nicht explizit aufgeführt, da dieser Schritt immer notwendig ist.
Der Tokenizer von spaCy ist ziemlich schnell, aber alle anderen Schritte basieren auf neuronalen Modellen und verbrauchen eine erhebliche Menge an Zeit. Im Vergleich zu anderen Bibliotheken sind die Modelle von spaCy jedoch mit am schnellsten. Die Verarbeitung der gesamten Pipeline dauert etwa 10-20 Mal so lange wie die reine Tokenisierung, wobei jeder Schritt einen ähnlichen Anteil an der Gesamtzeit benötigt. Wenn die Tokenisierung von 1.000 Dokumenten z. B. eine Sekunde dauert, können Tagging, Parsing und NER jeweils weitere fünf Sekunden in Anspruch nehmen. Das kann zu einem Problem werden, wenn du große Datensätze verarbeitest. Es ist also besser, die Teile auszuschalten, die du nicht brauchst.
Oft brauchst du nur den Tokenizer und den Part-of-Speech-Tagger. In diesem Fall solltest du den Parser und die Named-Entity-Erkennung wie folgt deaktivieren:
nlp=spacy.load("en_core_web_sm",disable=["parser","ner"])
Wenn du nur den Tokenizer und sonst nichts brauchst, kannst du auch einfach nlp.make_doc für einen Text aufrufen.
Textverarbeitung
Die Pipeline wird durch den Aufruf des nlp Objekts ausgeführt. Der Aufruf gibt ein Objekt vom Typ spacy.tokens.doc.Doc zurück, einen Container für den Zugriff auf die Token, Spans (Bereiche von Token) und ihre linguistischen Annotationen.
nlp=spacy.load("en_core_web_sm")text="My best friend Ryan Peters likes fancy adventure games."doc=nlp(text)
spaCy ist objektorientiert und nicht-destruktiv. Der ursprüngliche Text bleibt immer erhalten. Wenn du das Objekt doc ausdruckst, verwendet es doc.text, die Eigenschaft, die den Originaltext enthält. Aber doc ist auch ein Container-Objekt für die Token, und du kannst es als Iterator für sie verwenden:
fortokenindoc:(token,end="|")
Out:
My|best|friend|Ryan|Peters|likes|fancy|adventure|games|.|
Jedes Token ist eigentlich ein Objekt der Klasse Token von SpaCy. Sowohl Token als auch Docs haben eine Reihe interessanter Eigenschaften für die Verarbeitung von Sprachen. Tabelle 4-2 zeigt, welche dieser Eigenschaften von jeder Pipeline-Komponente erzeugt werden.7
| Komponente | Erzeugt |
|---|---|
| Tokenizer | Token.is_punct, Token.is_alpha, Token.like_email, Token.like_url |
| Part-of-Speech Tagger | Token.pos_ |
| Abhängigkeits-Parser | Token.dep_, Token.head, Doc.sents, Doc.noun_chunks |
| Erkennung von benannten Personen | Doc.ents, Token.ent_iob_, Token.ent_type_ |
Wir stellen eine kleine Hilfsfunktion, display_nlp, zur Verfügung, um eine Tabelle mit den Token und ihren Attributen zu erstellen. Intern erstellen wir dafür eine DataFrame und verwenden die Position des Tokens im Dokument als Index. Interpunktionszeichen werden bei dieser Funktion standardmäßig übersprungen. Tabelle 4-3 zeigt die Ausgabe dieser Funktion für unseren Beispielsatz:
defdisplay_nlp(doc,include_punct=False):"""Generate data frame for visualization of spaCy tokens."""rows=[]fori,tinenumerate(doc):ifnott.is_punctorinclude_punct:row={'token':i,'text':t.text,'lemma_':t.lemma_,'is_stop':t.is_stop,'is_alpha':t.is_alpha,'pos_':t.pos_,'dep_':t.dep_,'ent_type_':t.ent_type_,'ent_iob_':t.ent_iob_}rows.append(row)df=pd.DataFrame(rows).set_index('token')df.index.name=Nonereturndf
| Text | lemma_ | is_stop | is_alpha | pos_ | dep_ | ent_type_ | ent_iob_ | |
|---|---|---|---|---|---|---|---|---|
| 0 | Mein | -PRON- | Wahr | Wahr | DET | eventuell | O | |
| 1 | beste | gut | Falsch | Wahr | ADJ | amod | O | |
| 2 | Freund | Freund | Falsch | Wahr | NOUN | nsubj | O | |
| 3 | Ryan | Ryan | Falsch | Wahr | PROPN | Verbindung | PERSON | B |
| 4 | Peters | Peters | Falsch | Wahr | PROPN | appos | PERSON | I |
| 5 | mag | wie | Falsch | Wahr | VERB | ROOT | O | |
| 6 | schick | schick | Falsch | Wahr | ADJ | amod | O | |
| 7 | Abenteuer | Abenteuer | Falsch | Wahr | NOUN | Verbindung | O | |
| 8 | Spiele | Spiel | Falsch | Wahr | NOUN | dobj | O |
Für jedes Token findest du das Lemma, einige beschreibende Flags, das Part-of-Speech-Tag, das Dependency-Tag (hier nicht verwendet, aber in Kapitel 12) und möglicherweise einige Informationen über den Entity-Typ. Die is_<something> Flags werden auf der Grundlage von Regeln erstellt, aber alle Part-of-Speech-, Dependency- und Named-Entity-Attribute basieren auf neuronalen Netzwerkmodellen. Diese Informationen sind also immer mit einem gewissen Grad an Unsicherheit behaftet. Die zum Training verwendeten Korpora enthalten eine Mischung aus Nachrichten- und Online-Artikeln. Die Vorhersagen des Modells sind ziemlich genau, wenn deine Daten ähnliche linguistische Merkmale aufweisen. Wenn deine Daten jedoch sehr unterschiedlich sind - wenn du zum Beispiel mit Twitter-Daten oder IT-Service-Desk-Tickets arbeitest - solltest du dir bewusst sein, dass diese Informationen unzuverlässig sind.
Warnung
spaCy verwendet die Konvention, dass Token-Attribute mit einem Unterstrich wie pos_ die lesbare Textdarstellung liefern. pos ohne Unterstrich liefert spaCy den numerischen Bezeichner eines Part-of-Speech-Tags.8 Die numerischen Bezeichner können als Konstanten importiert werden, z.B. spacy.symbols.VERB. Achte darauf, sie nicht zu verwechseln!
Blaupause: Tokenisierung anpassen
Die Tokenisierung ist der erste Schritt in der Pipeline, und alles hängt von den richtigen Token ab. Der Tokenizer von spaCy leistet in den meisten Fällen gute Arbeit, aber er spaltet sich bei Rautezeichen, Bindestrichen und Unterstrichen auf, was manchmal nicht das ist, was du willst. Daher kann es notwendig sein, sein Verhalten anzupassen. Schauen wir uns den folgenden Text als Beispiel an:
text="@Pete: choose low-carb #food #eat-smart. _url_ ;-) 😋👍"doc=nlp(text)fortokenindoc:(token,end="|")
Out:
@Pete|:|choose|low|-|carb|#|food|#|eat|-|smart|.|_|url|_|;-)|😋|👍|
Der Tokenizer von spaCy ist vollständig regelbasiert. Zunächst wird der Text anhand von Leerzeichen zerlegt. Dann verwendet er prefix, suffix und infix splitting rules, die durch reguläre Ausdrücke definiert sind, um die verbleibenden Token weiter aufzuteilen. Ausnahmeregeln werden verwendet, um sprachspezifische Ausnahmen wie can't zu behandeln, die mit den Lemmata can und not in ca und n't aufgeteilt werden sollten.9
Wie du im Beispiel sehen kannst, enthält der englische Tokenizer von spaCy eine Infix-Regel für Trennungen an Bindestrichen. Außerdem hat er eine Präfix-Regel, um Zeichen wie # oder _ abzutrennen. Er funktioniert aber auch gut für Token, denen @ und Emojis vorangestellt sind.
Eine Möglichkeit ist, die Token in einem Nachbearbeitungsschritt mit doc.retokenize zusammenzuführen. Dadurch werden jedoch keine falsch berechneten Part-of-Speech-Tags und syntaktischen Abhängigkeiten korrigiert, da diese auf der Tokenisierung basieren. Daher ist es vielleicht besser, die Tokenisierungsregeln zu ändern und von vornherein korrekte Token zu erstellen.
Am besten ist es, wenn du deine eigene Variante des Tokenizers mit individuellen Regeln für Infix-, Präfix- und Suffixsplitting erstellst.10 Die folgende Funktion erstellt ein Tokenizer-Objekt mit individuellen Regeln auf eine "minimalinvasive" Weise: Wir lassen einfach die entsprechenden Muster aus den Standardregeln von SpaCy weg, behalten aber den größten Teil der Logik bei:
fromspacy.tokenizerimportTokenizerfromspacy.utilimportcompile_prefix_regex,\compile_infix_regex,compile_suffix_regexdefcustom_tokenizer(nlp):# use default patterns except the ones matched by re.searchprefixes=[patternforpatterninnlp.Defaults.prefixesifpatternnotin['-','_','#']]suffixes=[patternforpatterninnlp.Defaults.suffixesifpatternnotin['_']]infixes=[patternforpatterninnlp.Defaults.infixesifnotre.search(pattern,'xx-xx')]returnTokenizer(vocab=nlp.vocab,rules=nlp.Defaults.tokenizer_exceptions,prefix_search=compile_prefix_regex(prefixes).search,suffix_search=compile_suffix_regex(suffixes).search,infix_finditer=compile_infix_regex(infixes).finditer,token_match=nlp.Defaults.token_match)nlp=spacy.load('en_core_web_sm')nlp.tokenizer=custom_tokenizer(nlp)doc=nlp(text)fortokenindoc:(token,end="|")
Out:
@Pete|:|choose|low-carb|#food|#eat-smart|.|_url_|;-)|😋|👍|
Warnung
Sei vorsichtig mit Änderungen an der Tokenisierung, denn ihre Auswirkungen können subtil sein und die Korrektur einer Gruppe von Fällen kann eine andere Gruppe von Fällen zerstören. Mit unserer Änderung werden zum Beispiel Token wie Chicago-based nicht mehr geteilt. Außerdem gibt es mehrere Unicode-Zeichen für Bindestriche und Gedankenstriche, die Probleme verursachen können, wenn sie nicht normalisiert wurden.
Blaupause: Mit Stopp-Wörtern arbeiten
spaCy verwendet sprachspezifische Stoppwortlisten, um die Eigenschaft is_stop für jedes Token direkt nach der Tokenisierung zu setzen. So ist es einfach, Stoppwörter (und ähnliche Satzzeichen) herauszufiltern:
text="Dear Ryan, we need to sit down and talk. Regards, Pete"doc=nlp(text)non_stop=[tfortindocifnott.is_stopandnott.is_punct](non_stop)
Out:
[Dear, Ryan, need, sit, talk, Regards, Pete]
Die Liste der englischen Stoppwörter mit mehr als 300 Einträgen kann durch den Import von spacy.lang.en.STOP_WORDS aufgerufen werden. Wenn ein nlp Objekt erstellt wird, wird diese Liste geladen und unter nlp.Defaults.stop_words gespeichert. Wir können das Standardverhalten von spaCy ändern, indem wir die is_stop Eigenschaft der entsprechenden Wörter im spaCy Vokabular setzen:11
nlp=spacy.load('en_core_web_sm')nlp.vocab['down'].is_stop=Falsenlp.vocab['Dear'].is_stop=Truenlp.vocab['Regards'].is_stop=True
Wenn wir das vorherige Beispiel wiederholen, erhalten wir das folgende Ergebnis:
[Ryan, need, sit, down, talk, Pete]
Blaupause: Lemmata anhand der Wortart extrahieren
Lemmatisierung ist die Zuordnung eines Wortes zu seinem unflektierten Wortstamm. Die Gleichsetzung von Wörtern wie "Haus", " untergebracht" und " Haus" hat viele Vorteile für Statistik, maschinelles Lernen und Information Retrieval. Es kann nicht nur die Qualität der Modelle verbessern, sondern auch die Trainingszeit und die Modellgröße verringern, da der Wortschatz viel kleiner ist, wenn nur die unflektierten Formen beibehalten werden. Außerdem ist es oft hilfreich, die verwendeten Wortarten auf bestimmte Kategorien zu beschränken, z. B. Nomen, Verben und Adjektive. Diese Wortarten werden Part-of-Speech-Tags genannt.
Werfen wir zunächst einen genaueren Blick auf die Lemmatisierung. Auf das Lemma eines Tokens oder einer Spanne kann über die Eigenschaft lemma_ zugegriffen werden, wie im folgenden Beispiel gezeigt wird:
text="My best friend Ryan Peters likes fancy adventure games."doc=nlp(text)(*[t.lemma_fortindoc],sep='|')
Out:
-PRON-|good|friend|Ryan|Peters|like|fancy|adventure|game|.
Die richtige Zuordnung des Lemmas erfordert ein Nachschlagewörterbuch und Wissen über die Wortart eines Wortes. Zum Beispiel ist das Lemma des Substantivs Meeting Meeting, während das Lemma des Verbs meet ist. Im Englischen ist spaCy in der Lage, diese Unterscheidung zu treffen. In den meisten anderen Sprachen ist die Lemmatisierung jedoch rein wörterbuchbasiert und ignoriert die Part-of-Speech-Abhängigkeit. Beachte, dass Personalpronomen wie ich, ich, du und sie in spaCy immer das Lemma -PRON- erhalten.
Das andere Token-Attribut, das wir in diesem Blueprint verwenden werden, ist das Part-of-Speech-Tag.Tabelle 4-3 zeigt, dass jedes Token in einem spaCy-Dokument zwei Part-of-Speech-Attribute hat: pos_ und tag_. tag_ ist das Tag aus dem Tagset, mit dem das Modell trainiert wurde. Für die englischen Modelle von spaCy, die auf dem OntoNotes 5-Korpus trainiert wurden, ist dies das Penn Treebank-Tagset. Für ein deutsches Modell wäre dies das Stuttgart-Tübingen-Tagset. Das Attribut pos_ enthält das vereinfachte Tag des universellen Part-of-Speech-Tagsatzes .12 Wir empfehlen die Verwendung dieses Attributs, da die Werte über verschiedene Modelle hinweg stabil bleiben.Tabelle 4-4 zeigt die vollständigen Beschreibungen der Tag-Sets.
| Tag | Beschreibung | Beispiele |
|---|---|---|
| ADJ | Adjektive (beschreiben Substantive) | groß, grün, afrikanisch |
| ADP | Adpositionen (Präpositionen und Postpositionen) | in, an |
| ADV | Adverbien (modifizieren Verben oder Adjektive) | sehr, genau, immer |
| AUX | Auxiliar (begleitet das Verb) | kann (tun), tut (tun) |
| CCONJ | Konjunktion verbinden | und, oder, aber |
| DET | Bestimmungswort (in Bezug auf Substantive) | die, a, alle (Dinge), deine (Idee) |
| INTJ | Zwischenruf (eigenständiges Wort, Ausruf, Ausdruck von Gefühlen) | Hallo, ja |
| NOUN | Nomen (gewöhnliche und Eigennamen) | Haus, Computer |
| NUM | Kardinalzahlen | neun, 9, IX |
| PROPN | Eigenname, Name oder Teil eines Namens | Peter, Berlin |
| PRON | Pronomen, Ersatz für Substantiv | Ich, du, ich, der |
| TEIL | Partikel (macht nur mit anderem Wort Sinn) | |
| PUNCT | Interpunktionszeichen | , . ; |
| SCONJ | Unterordnende Konjunktion | vor, da, wenn |
| SYM | Symbole (wortähnlich) | $, © |
| VERB | Verben (alle Zeitformen und Modi) | gehen, ging, denken |
| X | Alles, was nicht zugeordnet werden kann | grlmpf |
Part-of-Speech-Tags sind eine hervorragende Alternative zu Stoppwörtern als Wortfilter. In der Linguistik werden Pronomen, Präpositionen, Konjunktionen und Determinatoren als Funktionswörter bezeichnet, weil ihre Hauptfunktion darin besteht, grammatikalische Beziehungen innerhalb eines Satzes herzustellen. Nomen, Verben, Adjektive und Adverbien sind Inhaltswörter, von denen die Bedeutung eines Satzes hauptsächlich abhängt.
Oft sind wir nur an den Inhaltswörtern interessiert. Anstatt eine Stoppwortliste zu verwenden, können wir mit Hilfe von Part-of-Speech-Tags die Wortarten auswählen, an denen wir interessiert sind, und den Rest verwerfen. Eine Liste, die nur die Substantive und Eigennamen in einer doc enthält, kann zum Beispiel so erstellt werden:
text="My best friend Ryan Peters likes fancy adventure games."doc=nlp(text)nouns=[tfortindocift.pos_in['NOUN','PROPN']](nouns)
Out:
[friend, Ryan, Peters, adventure, games]
Wir könnten zu diesem Zweck leicht eine allgemeinere Filterfunktion definieren, aber die Funktion von textacy extract.words bietet diese Funktionalität. Sie ermöglicht es uns auch, nach der Wortart und zusätzlichen Tokeneigenschaften wie is_punct oder is_stop zu filtern. Die Filterfunktion ermöglicht also sowohl die Auswahl der Wortart als auch die Filterung von Stoppwörtern. Intern funktioniert sie genauso wie der zuvor gezeigte Substantivfilter.
Das folgende Beispiel zeigt, wie man Token für Adjektive und Substantive aus dem Beispielsatz extrahiert:
importtextacytokens=textacy.extract.words(doc,filter_stops=True,# default True, no stopwordsfilter_punct=True,# default True, no punctuationfilter_nums=True,# default False, no numbersinclude_pos=['ADJ','NOUN'],# default None = include allexclude_pos=None,# default None = exclude nonemin_freq=1)# minimum frequency of words(*[tfortintokens],sep='|')
Out:
best|friend|fancy|adventure|games
Unsere Blueprint-Funktion zum Extrahieren einer gefilterten Liste von Wortlemmata ist letztendlich nur ein kleiner Wrapper um diese Funktion. Durch die Weiterleitung der Schlüsselwortargumente (**kwargs) akzeptiert diese Funktion die gleichen Parameter wie die extract.words von Textacy.
defextract_lemmas(doc,**kwargs):return[t.lemma_fortintextacy.extract.words(doc,**kwargs)]lemmas=extract_lemmas(doc,include_pos=['ADJ','NOUN'])(*lemmas,sep='|')
Out:
good|friend|fancy|adventure|game
Hinweis
Die Verwendung von Lemmata anstelle von flektierten Wörtern ist oft eine gute Idee, aber nicht immer. Es kann sich zum Beispiel negativ auf die Stimmungsanalyse auswirken, wo "gut" und "am besten" einen Unterschied machen.
Blaupause: Nomenphrasen extrahieren
In Kapitel 1 haben wir gezeigt, wie man n-Gramme für die Analyse verwendet. n-Gramme sind einfache Aufzählungen von Unterfolgen von n Wörtern in einem Satz. Der Satz, den wir zuvor verwendet haben, enthält zum Beispiel die folgenden Bigramme:
My_best|best_friend|friend_Ryan|Ryan_Peters|Peters_likes|likes_fancy fancy_adventure|adventure_games
Viele dieser Bigramme sind für die Analyse nicht sehr nützlich, zum Beispiel likes_fancy oder my_best. Bei Trigrammen wäre es noch schlimmer. Aber wie können wir Wortfolgen erkennen, die eine echte Bedeutung haben? Eine Möglichkeit ist die Anwendung von pattern-matching auf die Part-of-Speech-Tags. spaCy verfügt über einen recht leistungsfähigen regelbasierten Matcher, und textacy bietet einen praktischen Wrapper für die musterbasierte Phrasenextraktion. Das folgende Muster extrahiert Sequenzen von Substantiven mit einem vorangehenden Adjektiv:
text="My best friend Ryan Peters likes fancy adventure games."doc=nlp(text)patterns=["POS:ADJ POS:NOUN:+"]spans=textacy.extract.matches(doc,patterns=patterns)(*[s.lemma_forsinspans],sep='|')
Out:
good friend|fancy adventure|fancy adventure game
Alternativ könntest du auch die Funktion doc.noun_chunks von SpaCy für die Extraktion von Substantivphrasen verwenden. Da die zurückgegebenen Chunks aber auch Pronomen und Determinatoren enthalten können, eignet sich diese Funktion weniger für die Merkmalsextraktion:
(*doc.noun_chunks,sep='|')
Out:
My best friend|Ryan Peters|fancy adventure games
So definieren wir unseren Entwurf für die Extraktion von Substantivphrasen auf der Grundlage von Part-of-Speech-Mustern. Die Funktion benötigt ein doc, eine Liste von Part-of-Speech-Tags und ein Trennzeichen, um die Wörter der Substantivphrase zu verbinden. Das konstruierte Muster sucht nach Folgen von Substantiven, denen ein Token mit einem der angegebenen Part-of-Speech-Tags vorausgeht. Zurückgegeben werden die Lemmata. Unser Beispiel extrahiert alle Phrasen, die aus einem Adjektiv oder einem Substantiv bestehen, gefolgt von einer Sequenz von Substantiven:
defextract_noun_phrases(doc,preceding_pos=['NOUN'],sep='_'):patterns=[]forposinpreceding_pos:patterns.append(f"POS:{pos} POS:NOUN:+")spans=textacy.extract.matches(doc,patterns=patterns)return[sep.join([t.lemma_fortins])forsinspans](*extract_noun_phrases(doc,['ADJ','NOUN']),sep='|')
Out:
good_friend|fancy_adventure|fancy_adventure_game|adventure_game
Blaupause: Benannte Entitäten extrahieren
Named-Entity-Erkennung bezeichnet die Erkennung von Entitäten wie Personen, Orten oder Organisationen in Texten. Jede Entität kann aus einem oder mehreren Token bestehen, wie zum Beispiel San Francisco. Daher werden benannte Entitäten durch Span Objekte repräsentiert. Wie bei Substantivphrasen kann es hilfreich sein, eine Liste von benannten Entitäten für die weitere Analyse zu erstellen.
Wenn du dir Tabelle 4-3 noch einmal ansiehst, siehst du die Token-Attribute für die Named-Entity-Erkennung, ent_type_ und ent_iob_. ent_iob_ enthält die Information, ob ein Token mit einer Entität beginnt (B), sich innerhalb einer Entität befindet (I) oder außerhalb (O). Anstatt durch die Token zu iterieren, können wir mit doc.ents auch direkt auf die benannten Entitäten zugreifen. Hier heißt die Eigenschaft für den Entitätstyp label_. Veranschaulichen wir uns das anhand eines Beispiels:
text="James O'Neill, chairman of World Cargo Inc, lives in San Francisco."doc=nlp(text)forentindoc.ents:(f"({ent.text}, {ent.label_})",end=" ")
Out:
(James O'Neill, PERSON) (World Cargo Inc, ORG) (San Francisco, GPE)
Das displacy Modul von spaCy bietet auch eine Visualisierung für die Named-Entity-Erkennung, die das Ergebnis viel besser lesbar macht und die Identifizierung von falsch klassifizierten Entitäten visuell unterstützt:
fromspacyimportdisplacydisplacy.render(doc,style='ent')

Die benannten Entitäten wurden korrekt als eine Person, eine Organisation und eine geopolitische Entität (GPE) identifiziert. Sei dir aber bewusst, dass die Genauigkeit der Named-Entity-Erkennung möglicherweise nicht sehr gut ist, wenn deinem Korpus eine klare grammatikalische Struktur fehlt. Unter "Named-Entity Recognition" findest du eine ausführliche Diskussion .
Für die Extraktion von benannten Entitäten bestimmter Typen nutzen wir wieder eine der praktischen Funktionen von Textacy:
defextract_entities(doc,include_types=None,sep='_'):ents=textacy.extract.entities(doc,include_types=include_types,exclude_types=None,drop_determiners=True,min_freq=1)return[sep.join([t.lemma_fortine])+'/'+e.label_foreinents]
Mit dieser Funktion können wir z.B. die benannten Entitäten der Typen PERSON und GPE (geopolitische Entität) wie folgt abrufen:
(extract_entities(doc,['PERSON','GPE']))
Out:
["James_O'Neill/PERSON", 'San_Francisco/GPE']
Merkmalsextraktion in einem großen Datensatz
Jetzt, da wir die Werkzeuge kennen, die SpaCy zur Verfügung stellt, können wir endlich unseren linguistischen Feature Extractor erstellen. Abbildung 4-3 veranschaulicht, wie wir vorgehen werden. Am Ende wollen wir einen Datensatz erstellen, der als Input für statistische Analysen und verschiedene maschinelle Lernalgorithmen verwendet werden kann. Nach der Extraktion werden wir die vorverarbeiteten Daten "gebrauchsfertig" in einer Datenbank aufbewahren.
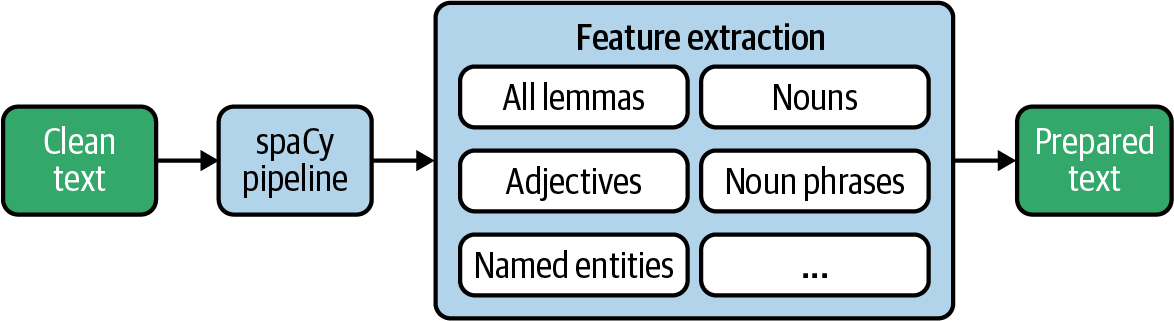
Abbildung 4-3. Merkmalsextraktion aus Text mit spaCy.
Blaupause: Eine Funktion schaffen, um alles zu bekommen
Diese Blueprint-Funktion fasst alle Extraktionsfunktionen aus dem vorherigen Abschnitt zusammen. Sie fasst alles, was wir extrahieren wollen, an einer Stelle im Code zusammen, sodass die nachfolgenden Schritte nicht angepasst werden müssen, wenn du hier etwas hinzufügst oder änderst:
defextract_nlp(doc):return{'lemmas':extract_lemmas(doc,exclude_pos=['PART','PUNCT','DET','PRON','SYM','SPACE'],filter_stops=False),'adjs_verbs':extract_lemmas(doc,include_pos=['ADJ','VERB']),'nouns':extract_lemmas(doc,include_pos=['NOUN','PROPN']),'noun_phrases':extract_noun_phrases(doc,['NOUN']),'adj_noun_phrases':extract_noun_phrases(doc,['ADJ']),'entities':extract_entities(doc,['PERSON','ORG','GPE','LOC'])}
Die Funktion gibt ein Wörterbuch mit allen Informationen zurück, die wir extrahieren wollen, wie in diesem Beispiel gezeigt:
text="My best friend Ryan Peters likes fancy adventure games."doc=nlp(text)forcol,valuesinextract_nlp(doc).items():(f"{col}: {values}")
Out:
lemmas: ['good', 'friend', 'Ryan', 'Peters', 'like', 'fancy', 'adventure', \
'game']
adjs_verbs: ['good', 'like', 'fancy']
nouns: ['friend', 'Ryan', 'Peters', 'adventure', 'game']
noun_phrases: ['adventure_game']
adj_noun_phrases: ['good_friend', 'fancy_adventure', 'fancy_adventure_game']
entities: ['Ryan_Peters/PERSON']
Die Liste der zurückgegebenen Spaltennamen wird für die nächsten Schritte benötigt. Anstatt sie fest zu codieren, rufen wir einfach extract_nlp mit einem leeren Dokument auf, um die Liste abzurufen:
nlp_columns=list(extract_nlp(nlp.make_doc('')).keys())(nlp_columns)
Out:
['lemmas', 'adjs_verbs', 'nouns', 'noun_phrases', 'adj_noun_phrases', 'entities']
Blaupause: Anwendung von SpaCy auf einen großen Datensatz
Jetzt können wir diese Funktion verwenden, um Merkmale aus allen Datensätzen eines Datensatzes zu extrahieren. Wir nehmen die bereinigten Texte, die wir am Anfang dieses Kapitels erstellt und gespeichert haben, und fügen die Titel hinzu:
db_name="reddit-selfposts.db"con=sqlite3.connect(db_name)df=pd.read_sql("select * from posts_cleaned",con)con.close()df['text']=df['title']+': '+df['text']
Bevor wir mit der NLP-Verarbeitung beginnen, initialisieren wir die neuen DataFrame Spalten, die wir mit Werten füllen wollen:
forcolinnlp_columns:df[col]=None
Die neuronalen Modelle von spaCy profitieren von auf der GPU. Daher versuchen wir, das Modell auf den Grafikprozessor zu laden, bevor wir beginnen:
ifspacy.prefer_gpu():("Working on GPU.")else:("No GPU found, working on CPU.")
Jetzt müssen wir entscheiden, welches Modell und welche der Pipeline-Komponenten wir verwenden wollen. Erinnere dich daran, nicht benötigte Komponenten zu deaktivieren, um die Laufzeit zu verbessern! Wir entscheiden uns für das kleine englische Modell mit der Standard-Pipeline und verwenden unseren benutzerdefinierten Tokenizer, der Bindestriche aufspaltet:
nlp=spacy.load('en_core_web_sm',disable=[])nlp.tokenizer=custom_tokenizer(nlp)# optional
Bei der Verarbeitung größerer Datensätze wird empfohlen, die Stapelverarbeitung von SpaCy zu verwenden, um einen erheblichen Leistungsgewinn zu erzielen (etwa Faktor 2 bei unserem Datensatz). Die Funktion nlp.pipe nimmt eine iterable von Texten, verarbeitet sie intern als Stapel und liefert eine Liste von verarbeiteten Doc Objekten in der gleichen Reihenfolge wie die Eingabedaten.
Um sie zu nutzen, müssen wir zunächst eine Losgröße festlegen. Dann können wir eine Schleife über die Stapel ziehen und nlp.pipe aufrufen.
batch_size=50foriinrange(0,len(df),batch_size):docs=nlp.pipe(df['text'][i:i+batch_size])forj,docinenumerate(docs):forcol,valuesinextract_nlp(doc).items():df[col].iloc[i+j]=values
In der inneren Schleife extrahieren wir die Merkmale aus den verarbeiteten doc und schreiben die Werte zurück in die DataFrame. Der gesamte Prozess dauert etwa sechs bis acht Minuten auf dem Datensatz ohne GPU und etwa drei bis vier Minuten mit der GPU auf Colab.
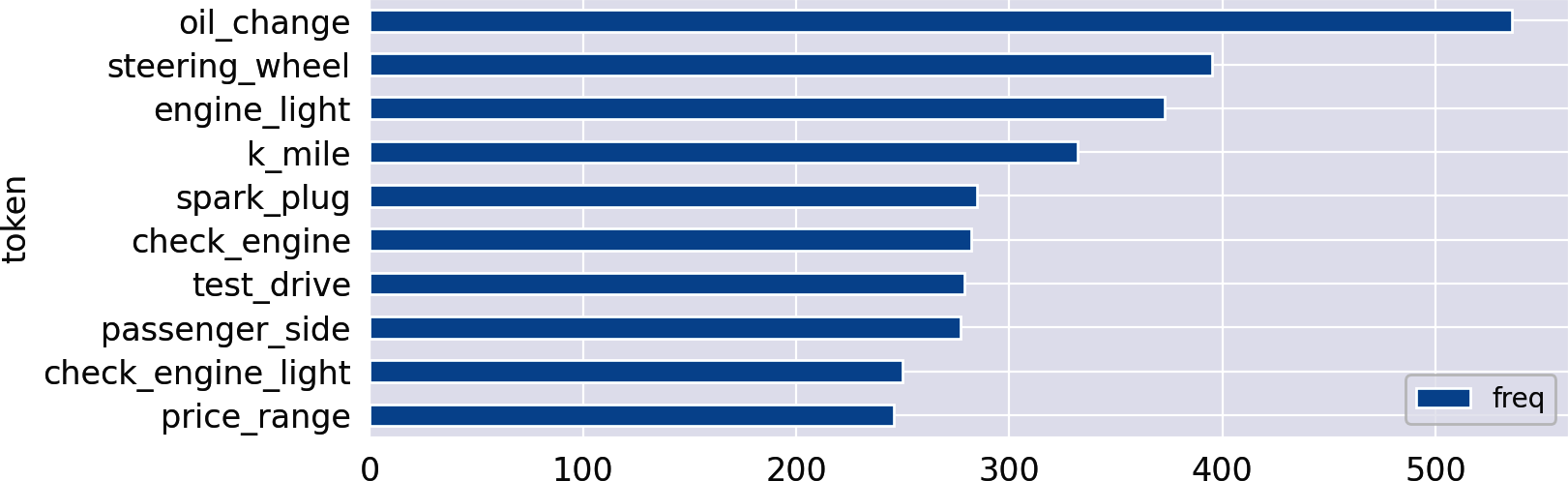
Die neu erstellten Spalten eignen sich perfekt für die Häufigkeitsanalyse mit den Funktionen aus Kapitel 1. Lass uns nach den am häufigsten genannten Substantivphrasen in der Kategorie Autos suchen:
count_words(df,'noun_phrases').head(10).plot(kind='barh').invert_yaxis()
Out:
Das Ergebnis festhalten
Schließlich wir die komplette DataFrame in SQLite speichern. Dazu müssen wir die extrahierten Listen in durch Leerzeichen getrennte Strings serialisieren, da Listen von den meisten Datenbanken nicht unterstützt werden:
df[nlp_columns]=df[nlp_columns].applymap(lambdaitems:' '.join(items))con=sqlite3.connect(db_name)df.to_sql("posts_nlp",con,index=False,if_exists="replace")con.close()
Die resultierende Tabelle bietet eine solide und gebrauchsfertige Grundlage für weitere Analysen. Tatsächlich werden wir diese Daten in Kapitel 10 erneut verwenden, um mit den extrahierten Lemmata Worteinbettungen zu trainieren. Die Vorverarbeitungsschritte hängen natürlich davon ab, was du mit den Daten machen willst. Die Arbeit mit Wortsätzen, wie sie unser Blueprint erzeugt hat, eignet sich perfekt für jede Art von statistischer Analyse der Worthäufigkeiten und für maschinelles Lernen auf der Grundlage einer Bag-of-Words-Vektorisierung. Für Algorithmen, die auf dem Wissen über Wortfolgen basieren, musst du die Schritte anpassen.
Ein Hinweis zur Ausführungszeit
Die komplette linguistische Verarbeitung ist sehr zeitaufwändig. Tatsächlich dauert die Verarbeitung von allein der 20.000 Reddit-Beiträge mit SpaCy mehrere Minuten. Ein einfacher Regexp-Tokenizer braucht dagegen nur ein paar Sekunden, um alle Einträge auf demselben Rechner zu tokenisieren. Es ist das Tagging, Parsing und Named-Entity-Erkennung, die teuer ist, auch wenn spaCy im Vergleich zu anderen Bibliotheken sehr schnell ist. Wenn du also keine benannten Entitäten brauchst, solltest du den Parser und die Namenserkennung deaktivieren, um mehr als 60 % der Laufzeit zu sparen.
Die Verarbeitung der Daten in Stapeln mit nlp.pipe und unter Verwendung von GPUs ist eine Möglichkeit, die Datenverarbeitung für SpaCy zu beschleunigen. Aber auch die Datenaufbereitung im Allgemeinen ist ein perfekter Kandidat für die Parallelisierung. Eine Möglichkeit, Aufgaben in Python zu parallelisieren, ist die Verwendung der Bibliothek multiprocessingSpeziell für die Parallelisierung von Operationen auf Datenrahmen gibt es einige skalierbare Alternativen zu Pandas, nämlich Dask, Modin und Vaex. pandarallel ist eine Bibliothek, die Pandas direkt um parallele Anwendungsoperatoren erweitert.
In jedem Fall ist es hilfreich, den Fortschritt zu beobachten und eine Laufzeitschätzung zu erhalten. Wie bereits in Kapitel 1 erwähnt, ist die tqdm-Bibliothek ein großartiges Werkzeug für diesen Zweck, denn sie bietet Fortschrittsbalken für Iteratoren und Datenrahmen-Operationen. Unsere Notebooks auf GitHub verwenden tqdm wann immer möglich.
Es gibt mehr
Wir haben mit der Datenbereinigung begonnen und sind dann durch eine ganze Pipeline der linguistischen Verarbeitung gegangen. Dennoch gibt es einige Aspekte, die wir nicht im Detail behandelt haben, die aber für deine Projekte hilfreich oder sogar notwendig sein könnten.
Erkennung von Sprachen
Viele Korpora enthalten Text in verschiedenen Sprachen. Wann immer du mit einem mehrsprachigen Korpus arbeitest, musst du dich für eine dieser Optionen entscheiden:
- Ignoriere andere Sprachen, wenn sie eine vernachlässigbare Minderheit darstellen, und behandle jeden Text so, als wäre er in der Hauptsprache des Korpus, z. B. in Englisch.
- Übersetze alle Texte in die Hauptsprache, zum Beispiel mit Google Translate.
- Bestimme die Sprache und führe in den nächsten Schritten sprachabhängige Vorverarbeitungen durch.
Es gibt gute Bibliotheken für die Spracherkennung. Unsere Empfehlung ist Facebooks fastText-Bibliothek. fastText bietet ein vortrainiertes Modell, das 176 Sprachen wirklich schnell und genau identifiziert. Im GitHub-Repository zu diesem Kapitel findest du einen zusätzlichen Entwurf für die Spracherkennung mit fastText.
Die Funktion make_spacy_doc von textacy ermöglicht es dir, automatisch das entsprechende Sprachmodell für die linguistische Verarbeitung zu laden, falls verfügbar. Standardmäßig wird ein Spracherkennungsmodell verwendet, das auf dem Compact Language Detector v3 von Google basiert, aber du kannst auch eine beliebige Spracherkennungsfunktion einbinden (z. B. fastText).
Rechtschreibprüfung
Die von Nutzern erstellten Inhalte von weisen eine Menge Rechtschreibfehler auf. Es wäre toll, wenn eine Rechtschreibprüfung diese Fehler automatisch korrigieren könnte. SymSpell ist eine beliebte Rechtschreibprüfung mit einer Python-Portierung. Wie du jedoch von deinem Smartphone weißt, kann die automatische Rechtschreibkorrektur selbst lustige Artefakte erzeugen. Du solltest also unbedingt prüfen, ob sich die Qualität wirklich verbessert.
Token-Normalisierung
Oft gibt es unterschiedliche Schreibweisen für identische Begriffe oder Variationen von Begriffen, die du identisch behandeln und vor allem zählen möchtest. In diesem Fall ist es sinnvoll, diese Begriffe zu normalisieren und sie einem gemeinsamen Standard zuzuordnen. Hier sind einige Beispiele:
- U.S.A. oder U.S. → USA
- Dot-Com-Blase → Dot-Com-Blase
- München → München
Du könntest verwenden, um diese Art der Normalisierung als Nachbearbeitungsschritt in den Phrase Matcher von spaCy zu integrieren. Wenn du spaCy nicht verwendest, kannst du ein einfaches Python-Wörterbuch verwenden, um verschiedene Schreibweisen auf ihre normalisierten Formen abzubilden.
Schlussbemerkungen und Empfehlungen
"Garbage in, garbage out" ist ein häufig genanntes Problem bei Datenprojekten. Das gilt besonders für Textdaten, die von Natur aus verrauscht sind. Deshalb ist die Datenbereinigung eine der wichtigsten Aufgaben in jedem Textanalyseprojekt. Investiere genug Aufwand, um eine hohe Datenqualität zu gewährleisten, und überprüfe sie systematisch. In diesem Abschnitt haben wir viele Lösungen zur Identifizierung und Behebung von Qualitätsproblemen vorgestellt.
Die zweite Voraussetzung für zuverlässige Analysen und robuste Modelle ist die Normalisierung. Viele Algorithmen des maschinellen Lernens für Text basieren auf dem Bag-of-Words-Modell, das eine Vorstellung von der Ähnlichkeit zwischen Dokumenten auf der Grundlage von Worthäufigkeiten erzeugt. Im Allgemeinen bist du mit lemmatisiertem Text besser dran, wenn du Textklassifizierung, Themenmodellierung oder Clustering auf Basis von TF-IDF durchführst. Bei komplexeren Aufgaben des maschinellen Lernens wie Textzusammenfassung, maschinelle Übersetzung oder Beantwortung von Fragen, bei denen das Modell die Vielfalt der Sprache widerspiegeln muss, solltest du diese Arten der Normalisierung oder die Entfernung von Stoppwörtern vermeiden oder nur sparsam einsetzen.
1 Die Pandas-Operationen map und apply wurden in "Blueprint" erklärt : Aufbau einer einfachen Textvorverarbeitungspipeline" erklärt.
2 Auf HTML-Datenbereinigung spezialisierte Bibliotheken wie Beautiful Soup wurden in Kapitel 3 vorgestellt.
3 Der Asterisk-Operator (*) entpackt die Liste in separate Argumente für print.
4 Schau dir zum Beispiel den Tweet-Tokenizer von NLTK für reguläre Ausdrücke für Text-Emoticons und URLs an, oder sieh dir die Compile Regexes von textacy an.
5 Ein guter Überblick ist "The Art of Tokenization" von Craig Trim.
6 Eine Liste der verfügbaren Modelle findest du auf der Website von SpaCy.
7 Eine vollständige Liste findest du in der API von SpaCy.
8 Eine vollständige Liste der Attribute findest du in der API von SpaCy.
9 Details und ein anschauliches Beispiel findest du in den spaCy-Dokumenten zur Verwendung von Tokenization.
10 Details findest du in den spaCy-Dokumenten zur Verwendung des Tokenizers.
11 Das Ändern der Stoppwortliste auf diese Weise wird wahrscheinlich mit spaCy 3.0 veraltet sein. Stattdessen wird empfohlen, eine modifizierte Unterklasse der jeweiligen Sprachklasse zu erstellen. Weitere Informationen findest du im GitHub-Notizbuch zu diesem Kapitel.
12 Siehe Universal Part-of-Speech-Tags für mehr.
Get Blaupausen für Textanalyse mit Python now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

