Kapitel 1. Frühe Einblicke aus Textdaten gewinnen
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Eine der ersten Aufgaben bei jedem Datenanalyse- und Machine Learning-Projekt ist es, sich mit den Daten vertraut zu machen. Tatsächlich ist es immer wichtig, ein grundlegendes Verständnis der Daten zu haben, um zuverlässige Ergebnisse zu erzielen. Deskriptive Statistiken liefern zuverlässige und robuste Erkenntnisse und helfen dabei, die Datenqualität und -verteilung zu beurteilen.
Bei der Betrachtung von Texten ist die Häufigkeitsanalyse von Wörtern und Phrasen eine der wichtigsten Methoden zur Datenerforschung. Absolute Worthäufigkeiten sind meist nicht sehr interessant, relative oder gewichtete Häufigkeiten hingegen schon. Wenn du zum Beispiel einen Text über Politik analysierst, werden die häufigsten Wörter wahrscheinlich viele offensichtliche und wenig überraschende Begriffe wie Volk, Land, Regierung usw. enthalten. Aber wenn du die relativen Worthäufigkeiten in Texten verschiedener politischer Parteien oder sogar von Politikern derselben Partei vergleichst, kannst du viel aus den Unterschieden lernen.
Was du lernen wirst und was wir bauen werden
In diesem Kapitel werden die Grundlagen für die statistische Analyse von Texten vorgestellt. Es ermöglicht dir einen schnellen Einstieg und führt in grundlegende Konzepte ein, die du in den folgenden Kapiteln kennen musst. Wir beginnen mit der Analyse von kategorialen Metadaten und konzentrieren uns dann auf die Analyse der Worthäufigkeit und die Visualisierung.
Nach der Lektüre dieses Kapitels verfügst du über grundlegende Kenntnisse zur Textverarbeitung und -analyse. Du wirst wissen, wie man Text tokenisiert, Stoppwörter filtert und Textinhalte mit Häufigkeitsdiagrammen und Wortwolken analysiert. Außerdem stellen wir die TF-IDF-Gewichtung als wichtiges Konzept vor, das später im Buch für die Textvektorisierung aufgegriffen wird.
Die Blaupausen in diesem Kapitel konzentrieren sich auf schnelle Ergebnisse und folgen dem KISS-Prinzip: "Keep it simple, stupid!" Daher verwenden wir in erster Linie Pandas als Bibliothek der Wahl für die Datenanalyse in Kombination mit regulären Ausdrücken und den Kernfunktionen von Python. In Kapitel 4 geht es um fortgeschrittene linguistische Methoden zur Datenaufbereitung.
Explorative Datenanalyse
Die explorative Datenanalyse ist der Prozess der systematischen Untersuchung von Daten auf einer aggregierten Ebene. Typische Methoden sind zusammenfassende Statistiken für numerische Merkmale sowie Häufigkeitsauszählungen für kategorische Merkmale. Histogramme und Boxplots veranschaulichen die Verteilung der Werte, und Zeitreihenplots zeigen ihre Entwicklung.
Ein Datensatz, der aus Textdokumenten wie Nachrichten, Tweets, E-Mails oder Serviceanrufen besteht, wird in der natürlichen Sprachverarbeitung als Korpus bezeichnet. Die statistische Erforschung eines solchen Korpus hat verschiedene Facetten. Einige Analysen konzentrieren sich auf Metadatenattribute, während andere sich mit dem Textinhalt befassen. Abbildung 1-1 zeigt typische Attribute eines Textkorpus, von denen einige in der Datenquelle enthalten sind, während andere berechnet oder abgeleitet werden können. Die Metadaten eines Dokuments bestehen aus mehreren beschreibenden Attributen, die für die Aggregation und Filterung nützlich sind. Zeitbezogene Attribute sind wichtig, um die Entwicklung des Korpus zu verstehen. Falls vorhanden, ermöglichen dir autorenbezogene Attribute, Gruppen von Autoren zu analysieren und diese Gruppen miteinander zu vergleichen.
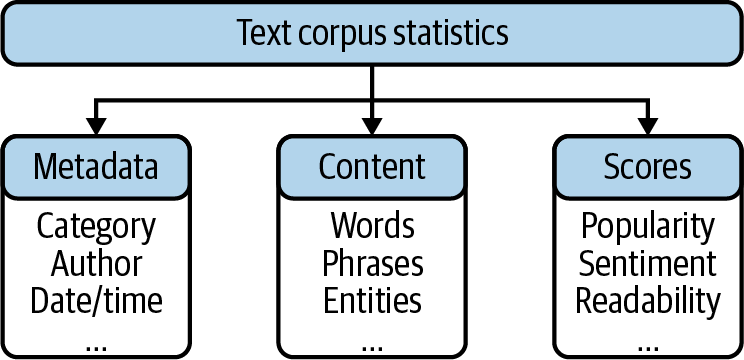
Abbildung 1-1. Statistische Merkmale für die Untersuchung von Textdaten.
Die statistische Analyse des Inhalts basiert auf den Häufigkeiten von Wörtern und Phrasen. Mit den in Kapitel 4 beschriebenen linguistischen Datenvorverarbeitungsmethoden werden wir den Analyseraum auf bestimmte Wortarten und benannte Entitäten erweitern. Außerdem können die beschreibenden Scores für die Dokumente in den Datensatz aufgenommen oder durch eine Art von Feature Modeling abgeleitet werden. Zum Beispiel könnte die Anzahl der Antworten auf den Beitrag eines Nutzers als Maß für die Popularität genommen werden. Schließlich können interessante Softfacts wie Sentiment- oder Emotionalitätswerte mit einer der später in diesem Buch beschriebenen Methoden ermittelt werden.
Beachte, dass absolute Zahlen bei der Arbeit mit Text im Allgemeinen nicht sehr interessant sind. Die bloße Tatsache, dass das Wort Problem hundertmal vorkommt, enthält keine relevanten Informationen. Aber die Tatsache, dass sich die relative Häufigkeit des Problems innerhalb einer Woche verdoppelt hat kann bemerkenswert sein.
Einführung in den Datensatz
Die Analyse von politischen Texten, seien es Nachrichten oder Programme politischer Parteien oder Parlamentsdebatten, kann interessante Einblicke in nationale und internationale Themen geben. Oft ist Text aus vielen Jahren öffentlich zugänglich, so dass ein Einblick in den Zeitgeist gewonnen werden kann. Versetzen wir uns in die Rolle eines politischen Analysten, der ein Gefühl für das analytische Potenzial eines solchen Datensatzes bekommen möchte.
Dazu arbeiten wir mit dem UN General Debate Dataset. Der Korpus besteht aus 7.507 Reden, die auf den jährlichen Sitzungen der Generalversammlung der Vereinten Nationen von 1970 bis 2016 gehalten wurden. Er wurde 2017 von Mikhaylov, Baturo und Dasandi in Harvard erstellt, "um die Präferenzen der Staaten in der Weltpolitik zu verstehen und zu messen". Jedes der fast 200 Länder in den Vereinten Nationen hat die Möglichkeit, bei der jährlichen Generaldebatte seine Ansichten zu globalen Themen wie internationalen Konflikten, Terrorismus oder Klimawandel darzulegen.
Der Originaldatensatz auf Kaggle wird in Form von zwei CSV-Dateien zur Verfügung gestellt, eine große mit den Reden und eine kleinere mit Informationen über die Redner. Um die Sache zu vereinfachen, haben wir eine einzige gezippte CSV-Datei erstellt, die alle Informationen enthält. Den Code für die Vorbereitung sowie die resultierende Datei findest du in unserem GitHub-Repository.
In Pandas kann eine CSV-Datei mit pd.read_csv() geladen werden. Lass uns die Datei laden und zwei zufällige Datensätze der DataFrame anzeigen:
file="un-general-debates-blueprint.csv"df=pd.read_csv(file)df.sample(2)
Out:
| Sitzung | Jahr | Land | land_name | Sprecher | Position | Text | |
|---|---|---|---|---|---|---|---|
| 3871 | 51 | 1996 | PER | Peru | Francisco Tudela Van Breughel Douglas | Minister für auswärtige Angelegenheiten | Erlauben Sie mir zunächst, Ihnen und dieser Versammlung die Grüße und Glückwünsche des peruanischen Volkes sowie seiner... |
| 4697 | 56 | 2001 | GBR | Vereinigtes Königreich | Jack Straw | Minister für auswärtige Angelegenheiten | Erlauben Sie mir, Ihnen herzlich zur Übernahme des Vorsitzes der sechsundfünfzigsten Tagung der Generalversammlung zu gratulieren... |
Die erste Spalte enthält den Index der Datensätze. Die Kombination aus Sitzungsnummer und Jahr kann als logischer Primärschlüssel der Tabelle betrachtet werden. Die Spalte country enthält einen standardisierten dreibuchstabigen ISO-Ländercode, gefolgt von der textlichen Beschreibung. Dann folgen zwei Spalten über den Sprecher und seine Position. Die letzte Spalte enthält den eigentlichen Text der Rede.
Unser Datensatz ist klein; er enthält nur ein paar tausend Datensätze. Dieser Datensatz eignet sich hervorragend, da wir keine Leistungsprobleme haben werden. Wenn dein Datensatz größer ist, findest du unter "Arbeiten mit großen Datensätzen" weitere Optionen.
Blueprint: Mit Pandas einen Überblick über die Daten gewinnen
In unserem ersten Entwurf verwenden wir nur die Metadaten und die Anzahl der Datensätze, um die Datenverteilung und -qualität zu untersuchen; wir werden uns den textlichen Inhalt noch nicht ansehen. Wir werden die folgenden Schritte durcharbeiten:
- Berechne zusammenfassende Statistiken.
- Prüfe auf fehlende Werte.
- Zeichne Verteilungen interessanter Eigenschaften auf.
- Vergleiche die Verteilungen zwischen den Kategorien.
- Visualisiere Entwicklungen im Laufe der Zeit.
Bevor wir mit der Analyse der Daten beginnen können, brauchen wir zumindest einige Informationen über die Struktur der DataFrame . Tabelle 1-1 zeigt einige wichtige beschreibende Eigenschaften oder Funktionen.
df.columns |
Liste der Spaltennamen | |
df.dtypes |
Tupel (Spaltenname, Datentyp) | Strings werden in Versionen vor Pandas 1.0 als Objekt dargestellt. |
df.info() |
D-Typen plus Speicherverbrauch | Verwende memory_usage='deep' für gute Schätzungen im Text. |
df.describe() |
Zusammenfassende Statistik | Verwende include='O' für kategoriale Daten. |
Berechnung der zusammenfassenden Statistik für Spalten
Die Funktion describe von Pandas berechnet statistische Zusammenfassungen für die Spalten von DataFrame. Sie funktioniert sowohl für eine einzelne Reihe als auch für die gesamte DataFrame. Im letzteren Fall ist die Standardausgabe auf numerische Spalten beschränkt. Derzeit enthält unsere DataFrame nur die Sitzungsnummer und das Jahr als numerische Daten. Fügen wir dem DataFrame eine neue numerische Spalte hinzu, die die Textlänge enthält, um zusätzliche Informationen über die Verteilung der Redelängen zu erhalten. Wir empfehlen, das Ergebnis mit describe().T zu transponieren, um Zeilen und Spalten in der Darstellung zu vertauschen:
df['length']=df['text'].str.len()df.describe().T
Out:
| zählen | mittlere | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| Sitzung | 7507.00 | 49.61 | 12.89 | 25.00 | 39.00 | 51.00 | 61.00 | 70.00 |
| Jahr | 7507.00 | 1994.61 | 12.89 | 1970.00 | 1984.00 | 1996.00 | 2006.00 | 2015.00 |
| Länge | 7507.00 | 17967.28 | 7860.04 | 2362.00 | 12077.00 | 16424.00 | 22479.50 | 72041.00 |
describe()berechnet ohne zusätzliche Parameter die Gesamtzahl der Werte, deren Mittelwert und Standardabweichung sowie eine fünfstellige Zusammenfassung nur der numerischen Spalten. Die DataFrame enthält 7.507 Einträge für session, year und length. Mittelwert und Standardabweichung sind für year und session, aber Minimum und Maximum sind trotzdem interessant. Unser Datensatz enthält Reden von der 25. bis zur 70. UN-Generaldebatte, also aus den Jahren 1970 bis 2015.
Eine Zusammenfassung für nicht numerische Spalten kann durch die Angabe von include='O' (der Alias für np.object) erstellt werden. In diesem Fall erhalten wir auch die Anzahl, die Anzahl der eindeutigen Werte, das oberste Element (oder eines davon, wenn es viele mit der gleichen Anzahl von Vorkommen gibt) und seine Häufigkeit. Da die Anzahl der eindeutigen Werte bei Textdaten nicht sinnvoll ist, analysieren wir nur die Spalten country und speaker:
df[['country','speaker']].describe(include='O').T
Out:
| zählen | einzigartig | top | freq | |
|---|---|---|---|---|
| Land | 7507 | 199 | ITA | 46 |
| Sprecher | 7480 | 5428 | Seyoum Mesfin | 12 |
Der Datensatz enthält Daten aus 199 eindeutigen Ländern und offenbar 5.428 Sprechern. Die Anzahl der Länder ist gültig, da diese Spalte standardisierte ISO-Codes enthält. Aber das Zählen der eindeutigen Werte von Textspalten wie speaker liefert normalerweise keine gültigen Ergebnisse, wie wir im nächsten Abschnitt zeigen werden.
Prüfen auf fehlende Daten
Anhand der Zählungen in der vorherigen Tabelle können wir sehen, dass in der Spalte speaker Werte fehlen. Prüfen wir also alle Spalten auf fehlende Werte, indem wir df.isna() (den Alias für df.isnull()) verwenden und eine Zusammenfassung des Ergebnisses berechnen:
df.isna().sum()
Out:
session 0 year 0 country 0 country_name 0 speaker 27 position 3005 text 0 length 0 dtype: int64
Bei der Verwendung der Spalten speaker und position müssen wir vorsichtig sein, denn die Ausgabe zeigt uns, dass diese Informationen nicht immer verfügbar sind! Um Probleme zu vermeiden, können wir die fehlenden Werte durch einen generischen Wert wie unknown speaker oder unknown position oder einfach durch eine leere Zeichenkette ersetzen.
Pandas stellt dafür die Funktion df.fillna() zur Verfügung:
df['speaker'].fillna('unknown',inplace=True)
Aber auch die vorhandenen Werte können problematisch sein, weil der Name desselben Sprechers manchmal unterschiedlich oder sogar mehrdeutig geschrieben wird. Die folgende Anweisung berechnet die Anzahl der Datensätze pro Sprecher für alle Dokumente, die Bush in der Spalte Sprecher enthalten:
df[df['speaker'].str.contains('Bush')]['speaker'].value_counts()
Out:
George W. Bush 4 Mr. George W. Bush 2 George Bush 1 Mr. George W Bush 1 Bush 1 Name: speaker, dtype: int64
Jede Analyse von Sprechernamen würde zu falschen Ergebnissen führen, wenn wir diese Mehrdeutigkeiten nicht auflösen. Deshalb sollten wir lieber die eindeutigen Werte der kategorischen Attribute überprüfen. Aus diesem Grund ignorieren wir hier die Sprecherinformationen.
Plotten von Wertverteilungen
Eine Möglichkeit, die fünfstellige Zusammenfassung einer numerischen Verteilung zu visualisieren, ist ein Boxplot. Er kann mit der in Pandas eingebauten Plot-Funktion einfach erstellt werden. Werfen wir einen Blick auf das Boxplot für die Spalte length:
df['length'].plot(kind='box',vert=False)
Out:

Wie diese Grafik zeigt, haben 50 % der Reden (das Kästchen in der Mitte) eine Länge zwischen etwa 12.000 und 22.000 Zeichen, wobei der Median bei etwa 16.000 liegt und ein langer Schwanz mit vielen Ausreißern nach rechts. Die Verteilung ist offensichtlich linksschief. Mit einem Histogramm können wir noch mehr Details herausfinden:
df['length'].plot(kind='hist',bins=30)
Out:
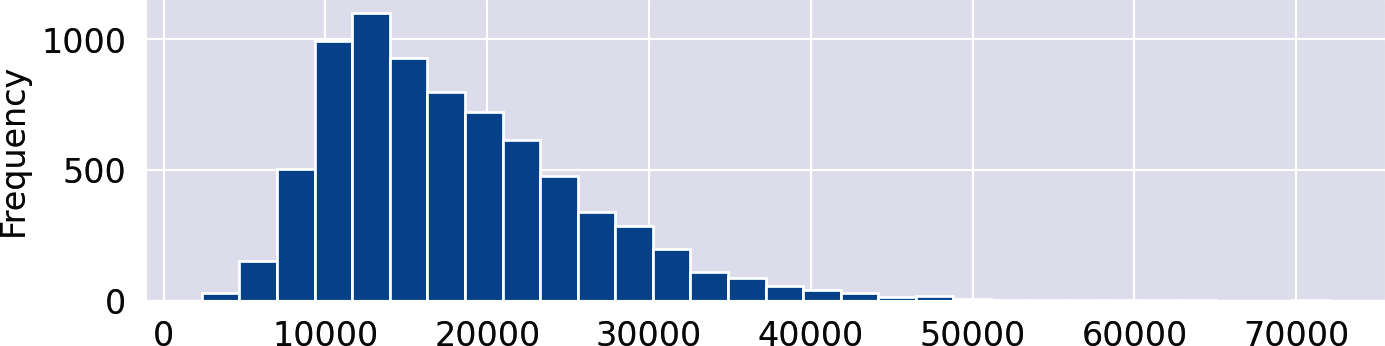
Für das Histogramm wird der Wertebereich der Spalte length in 30 gleich breite Intervalle, die Bins, unterteilt. Die y-Achse zeigt die Anzahl der Dokumente, die in jeden dieser Bins fallen.
Vergleich von Wertverteilungen in verschiedenen Kategorien
Auffälligkeiten in den Daten werden oft sichtbar, wenn verschiedene Untergruppen der Daten untersucht werden. Eine schöne Visualisierung, um Verteilungen über verschiedene Kategorien hinweg zu vergleichen, ist Seaborns catplot.
Wir zeigen Box- und Violinplots, um die Verteilungen der Redelänge der fünf ständigen Mitglieder des UN-Sicherheitsrats zu vergleichen(Abbildung 1-2). Die Kategorie für die x-Achse von sns.catplot ist also country:
where=df['country'].isin(['USA','FRA','GBR','CHN','RUS'])sns.catplot(data=df[where],x="country",y="length",kind='box')sns.catplot(data=df[where],x="country",y="length",kind='violin')
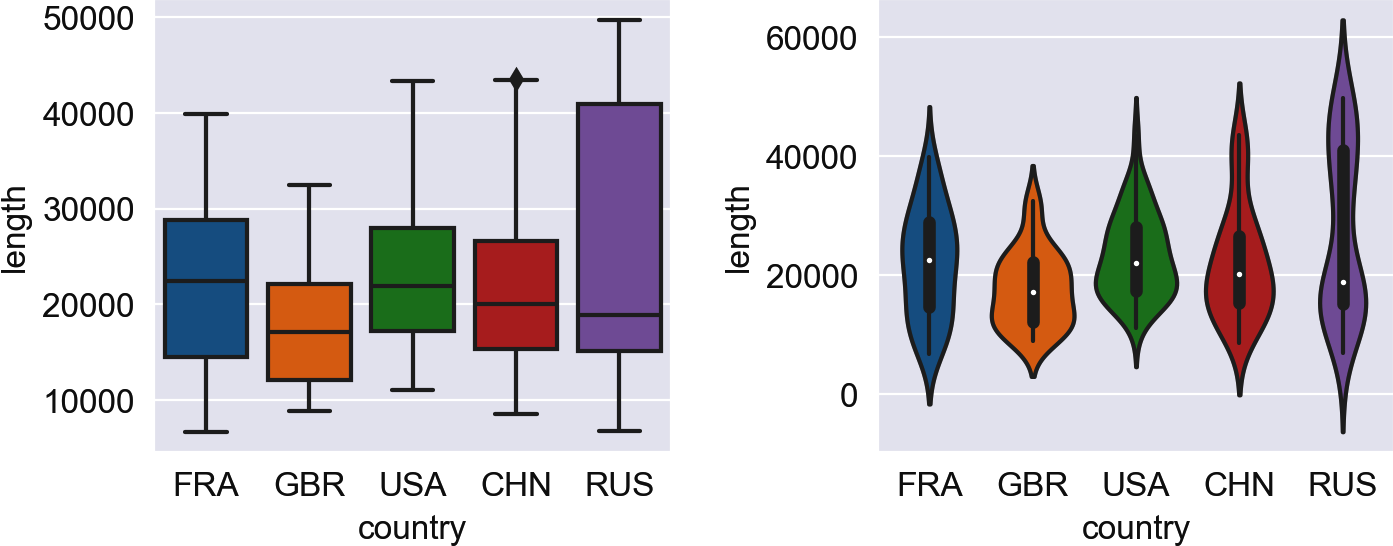
Abbildung 1-2. Box Plots (links) und Violin Plots (rechts) zur Visualisierung der Verteilung der Redelängen für ausgewählte Länder.
Der Violinplot ist die "geglättete" Version eines Boxplots. Die Frequenzen werden durch die Breite des Geigenkörpers visualisiert, während der Kasten innerhalb der Geige weiterhin sichtbar ist. Beide Diagramme zeigen, dass die Streuung der Werte, in diesem Fall die Länge der Reden, für Russland viel größer ist als für Großbritannien. Das Vorhandensein mehrerer Spitzen, wie in Russland, wird jedoch nur in der Geigengrafik deutlich.
Entwicklungen im Laufe der Zeit visualisieren
Wenn deine Daten Datums- oder Zeitattribute enthalten, ist es immer interessant, einige Entwicklungen innerhalb der Daten im Laufe der Zeit zu visualisieren. Eine erste Zeitreihe kann erstellt werden, indem die Anzahl der Reden pro Jahr analysiert wird. Wir können die Pandas Gruppierungsfunktion size() verwenden, um die Anzahl der Zeilen pro Gruppe zu ermitteln. Durch einfaches Anhängen von plot() können wir die resultierende DataFrame visualisieren(Abbildung 1-3, links):
df.groupby('year').size().plot(title="Number of Countries")
Die Zeitleiste spiegelt die Entwicklung der Anzahl der Länder in der UNO wider, da jedes Land nur eine Rede pro Jahr halten darf. Tatsächlich hat die UNO heute 193 Mitglieder. Interessanterweise musste die Länge der Rede abnehmen, je mehr Länder an den Debatten teilnehmen, wie die folgende Analyse zeigt(Abbildung 1-3, rechts):
df.groupby('year').agg({'length':'mean'})\.plot(title="Avg. Speech Length",ylim=(0,30000))
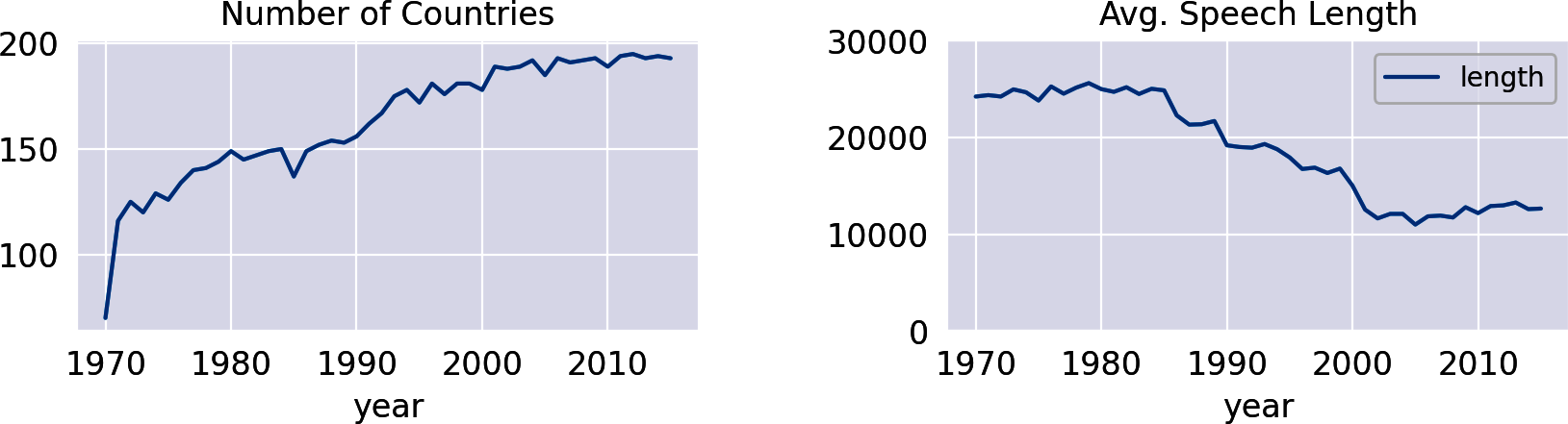
Abbildung 1-3. Anzahl der Länder und durchschnittliche Redelänge im Zeitverlauf.
Hinweis
Pandas Datenrahmen lassen sich nicht nur leicht in Jupyter-Notizbüchern visualisieren, sondern können auch mit eingebauten Funktionen nach Excel (.xlsx), HTML, CSV, LaTeX und in viele andere Formate exportiert werden. Unter gibt es sogar eine to_clipboard() Funktion. Details findest du in der Dokumentation.
Blaupause: Aufbau einer einfachen Textvorverarbeitungspipeline
Die Analyse von Metadaten wie Kategorien, Zeit, Autoren und anderen Attributen gibt einen ersten Einblick in den Korpus. Viel interessanter ist es jedoch, tiefer in den eigentlichen Inhalt einzudringen und häufige Wörter in verschiedenen Teilmengen oder Zeiträumen zu untersuchen. In diesem Abschnitt entwickeln wir einen grundlegenden Plan, um Text für eine erste schnelle Analyse vorzubereiten, die aus einer einfachen Abfolge von Schritten besteht(Abbildung 1-4). Da die Ausgabe eines Vorgangs die Eingabe für den nächsten bildet, wird eine solche Abfolge auch als Verarbeitungspipeline bezeichnet, die den Originaltext in eine Reihe von Token umwandelt.

Abbildung 1-4. Einfache Vorverarbeitungspipeline.
Die hier vorgestellte Pipeline besteht aus drei Schritten: Groß- und Kleinschreibung, Tokenisierung und Stoppwortentfernung. Diese Schritte werden in Kapitel 4, in dem wir spaCy verwenden, ausführlich besprochen und erweitert. Um es schnell und einfach zu halten, bauen wir hier unseren eigenen Tokenizer, der auf regulären Ausdrücken basiert, und zeigen, wie wir eine beliebige Stoppwortliste verwenden können.
Durchführen der Tokenisierung mit regulären Ausdrücken
Tokenisierung ist der Prozess der Extraktion von Wörtern aus einer Folge von Zeichen. In westlichen Sprachen werden Wörter oft durch Leerzeichen und Satzzeichen getrennt. Der einfachste und schnellste Tokenizer ist daher Pythons native str.split() Methode von Python, die nach Leerzeichen trennt. Eine flexiblere Methode ist die Verwendung von regulären Ausdrücken.
Reguläre Ausdrücke und die Python-Bibliotheken re und regex werden in Kapitel 4 ausführlicher vorgestellt. Hier wollen wir ein einfaches Muster anwenden, das Wörtern entspricht. Wörter in unserer Definition bestehen aus mindestens einem Buchstaben sowie aus Ziffern und Bindestrichen. Reine Zahlen werden übersprungen, da sie in diesem Korpus fast ausschließlich Datumsangaben, Sprach- oder Sitzungskennungen darstellen.
Der häufig verwendete Ausdruck [A-Za-z] ist keine gute Option für das Abgleichen von Buchstaben, da er akzentuierte Buchstaben wie ä oder â nicht berücksichtigt. Viel besser ist die POSIX-Zeichenklasse \p{L}, die alle Unicode-Buchstaben auswählt. Beachte, dass wir die Bibliothekregex anstelle von re benötigen, um mit POSIX-Zeichenklassen zu arbeiten. Der folgende Ausdruck passt auf Token , die aus mindestens einem Buchstaben (\p{L}) bestehen, dem eine beliebige Folge von alphanumerischen Zeichen (\w enthält Ziffern, Buchstaben und Unterstriche) und Bindestrichen (- ) vorausgeht und folgt :
importregexasredeftokenize(text):returnre.findall(r'[\w-]*\p{L}[\w-]*',text)
Lass uns das mit einem Beispielsatz aus dem Korpus ausprobieren:
text="Let's defeat SARS-CoV-2 together in 2020!"tokens=tokenize(text)("|".join(tokens))
Out:
Let|s|defeat|SARS-CoV-2|together|in
Behandlung von Stopp-Wörtern
Die häufigsten Wörter in einem Text sind gebräuchliche Wörter wie Determinatoren, Hilfsverben, Pronomen, Adverbien und so weiter. Diese Wörter werden als Stoppwörter bezeichnet. Stoppwörter enthalten in der Regel nicht viele Informationen, verbergen aber aufgrund ihrer hohen Häufigkeit interessante Inhalte. Deshalb werden Stoppwörter oft vor der Datenanalyse oder dem Modelltraining entfernt.
In diesem Abschnitt zeigen wir, wie man Stoppwörter, die in einer vordefinierten Liste enthalten sind, verwirft. Gängige Stoppwortlisten gibt es für viele Sprachen und sie sind in fast jeder NLP-Bibliothek integriert. Wir werden hier mit der Stoppwortliste von NLTK arbeiten, aber du kannst jede beliebige Wortliste als Filter verwenden.2 Um schnell nachzuschlagen, solltest du eine Liste immer in eine Menge umwandeln. Mengen sind Hash-basierte Strukturen wie Wörterbücher mit nahezu konstanter Suchzeit:
importnltkstopwords=set(nltk.corpus.stopwords.words('english'))
Unser Ansatz zum Entfernen von Stoppwörtern aus einer gegebenen Liste, der in der hier gezeigten kleinen Funktion verpackt ist, besteht aus einem einfachen Listenverständnis. Für die Prüfung werden die Token in Kleinbuchstaben umgewandelt, da die NLTK-Liste nur klein geschriebene Wörter enthält:
defremove_stop(tokens):return[tfortintokensift.lower()notinstopwords]
Oft musst du die vordefinierte Liste um domänenspezifische Stoppwörter ergänzen. Wenn du zum Beispiel E-Mails analysierst, werden die Begriffe lieb und grüß wahrscheinlich in fast jedem Dokument vorkommen. Andererseits möchtest du vielleicht einige der Wörter in der vordefinierten Liste nicht als Stoppwörter behandeln. Wir können zusätzliche Stoppwörter hinzufügen und andere aus der Liste ausschließen, indem wir zwei von Pythons Mengenoperatoren verwenden: | (Vereinigung/Oder) und - (Differenz):
include_stopwords={'dear','regards','must','would','also'}exclude_stopwords={'against'}stopwords|=include_stopwordsstopwords-=exclude_stopwords
Die Stoppwortliste von NLTK ist konservativ und enthält nur 179 Wörter. Überraschenderweise wird would nicht als Stoppwort betrachtet, wouldn't hingegen schon. Dies verdeutlicht ein häufiges Problem mit vordefinierten Stoppwortlisten: Inkonsistenz. Beachte, dass das Entfernen von Stoppwörtern die Leistung von semantisch gezielten Analysen erheblich beeinträchtigen kann, wie in "Warum das Entfernen von Stoppwörtern gefährlich sein kann" erklärt wird .
Zusätzlich zu oder anstelle einer festen Liste von Stoppwörtern kann es hilfreich sein, jedes Wort, das in mehr als, sagen wir, 80% der Dokumente vorkommt, als Stoppwort zu behandeln. Solche häufigen Wörter erschweren die Unterscheidung von Inhalten. Der Parameter max_df der scikit-learn Vektorisierer, der in Kapitel 5 behandelt wird, tut genau dies. Eine andere Methode ist das Filtern von Wörtern auf der Grundlage der Wortart (Part of Speech). Dieses Konzept wird in Kapitel 4 erklärt.
Verarbeitung einer Pipeline mit einer Codezeile
Kommen wir zurück zu DataFrame, das die Dokumente unseres Korpus enthält. Wir wollen eine neue Spalte namens tokens erstellen, die den klein geschriebenen, tokenisierten Text ohne Stoppwörter für jedes Dokument enthält. Dazu verwenden wir ein erweiterbares Muster für eine Verarbeitungspipeline. In unserem Fall werden wir den gesamten Text in Kleinbuchstaben ändern, ihn tokenisieren und Stoppwörter entfernen. Andere Operationen können durch einfache Erweiterung der Pipeline hinzugefügt werden:
pipeline=[str.lower,tokenize,remove_stop]defprepare(text,pipeline):tokens=textfortransforminpipeline:tokens=transform(tokens)returntokens
Wenn wir all das in eine Funktion packen, wird daraus ein perfekter Anwendungsfall für die map oder apply Operation von Pandas. Funktionen wie map und apply, die andere Funktionen als Parameter annehmen, werden in der Mathematik und Informatik Funktionen höherer Ordnung genannt.
| Funktion | Beschreibung |
|---|---|
Series.map |
Arbeitet Element für Element an einem Pandas Series |
Series.apply |
Wie map, erlaubt aber zusätzliche Parameter |
DataFrame.applymap |
Element für Element auf einem Pandas DataFrame (dasselbe wie map auf Series) |
DataFrame.apply |
Arbeitet mit Zeilen oder Spalten einer DataFrame und unterstützt Aggregation |
Pandas unterstützt die verschiedenen Funktionen höherer Ordnung für Serien und Datenrahmen(Tabelle 1-2). Mit diesen Funktionen kannst du nicht nur eine Reihe von funktionalen Datentransformationen auf verständliche Weise angeben, sondern sie lassen sich auch leicht parallelisieren. Das Python-Paket pandarallelbietet zum Beispiel parallele Versionen von map und apply.
Skalierbare Frameworks wie Apache Spark unterstützen ähnliche Operationen auf Datenrahmen sogar noch eleganter. Tatsächlich beruhen die Map- und Reduce-Operationen in der verteilten Programmierung auf demselben Prinzip der funktionalen Programmierung. Darüber hinaus verfügen viele Programmiersprachen, darunter Python und JavaScript, über eine native Map-Operation für Listen oder Arrays.
Wenn du eine der Pandas-Operationen höherer Ordnung verwendest, wird die Anwendung einer funktionalen Transformation zu einem Einzeiler:
df['tokens']=df['text'].apply(prepare,pipeline=pipeline)
Die Spalte tokens besteht nun aus Python-Listen, die die extrahierten Token für jedes Dokument enthalten. Natürlich verdoppelt diese zusätzliche Spalte im Grunde den Speicherverbrauch der DataFrame, aber sie ermöglicht es dir, für die weitere Analyse schnell direkt auf die Token zuzugreifen. Die folgenden Blueprints sind jedoch so konzipiert, dass die Tokenisierung auch während der Analyse im laufenden Betrieb durchgeführt werden kann. Auf diese Weise kann die Leistung gegen den Speicherverbrauch eingetauscht werden: Entweder Tokenisierung einmal vor der Analyse und Speicherverbrauch oder Tokenisierung on the fly und warten.
Außerdem fügen wir eine weitere Spalte hinzu, die die Länge der Token-Liste für spätere Zusammenfassungen enthält:
df['num_tokens']=df['tokens'].map(len)
Hinweis
tqdm (ausgesprochen taqadum für "Fortschritt" auf Arabisch) ist eine großartige Bibliothek für Fortschrittsbalken in Python. Sie unterstützt konventionelle Schleifen, z. B. durch die Verwendung von tqdm_range anstelle von range, und sie unterstützt Pandas durch die Bereitstellung von progress_map und progress_apply Operationen auf Datenrahmen.3 Unsere begleitenden Notebooks auf GitHub verwenden diese Operationen, aber wir bleiben hier im Buch bei plain Pandas.
Blaupausen für die Worthäufigkeitsanalyse
Häufig verwendete Wörter und Phrasen können uns ein grundlegendes Verständnis der besprochenen Themen vermitteln. Die Worthäufigkeitsanalyse ignoriert jedoch die Reihenfolge und den Kontext der Wörter. Das ist die Idee des berühmten bag-of-words-Modells (siehe auch Kapitel 5): Alle Wörter werden in eine Tüte geworfen, in der sie durcheinandergeraten. Die ursprüngliche Anordnung im Text geht dabei verloren; es wird nur die Häufigkeit der Begriffe berücksichtigt. Dieses Modell eignet sich nicht für komplexe Aufgaben wie Sentiment-Analysen oder die Beantwortung von Fragen, aber es funktioniert erstaunlich gut für die Klassifizierung und Themenmodellierung. Darüber hinaus ist es ein guter Ausgangspunkt, um zu verstehen, worum es in den Texten geht.
In diesem Abschnitt entwickeln wir eine Reihe von Konzepten zur Berechnung und Visualisierung von Worthäufigkeiten. Da rohe Häufigkeiten unwichtige, aber häufige Wörter überbewerten, werden wir am Ende des Prozesses auch TF-IDF einführen. Wir werden die Häufigkeitsberechnung mit Hilfe von Counter durchführen, weil das einfach und extrem schnell ist.
Blaupause: Wörter zählen mit einem Zähler
Pythons Standardbibliothek hat eine eingebaute Klasse Counter, die genau das tut, was du vielleicht denkst: Sie zählt Dinge.4 Der einfachste Weg, mit einem Zähler zu arbeiten, ist, ihn aus einer Liste von Elementen zu erstellen, in unserem Fall aus Strings, die Wörter oder Token darstellen. Der resultierende Zähler ist im Grunde ein Wörterbuchobjekt, das diese Elemente als Schlüssel und ihre Häufigkeit als Wert enthält.
Lass uns die Funktionsweise anhand eines einfachen Beispiels veranschaulichen:
fromcollectionsimportCountertokens=tokenize("She likes my cats and my cats like my sofa.")counter=Counter(tokens)(counter)
Out:
Counter({'my': 3, 'cats': 2, 'She': 1, 'likes': 1, 'and': 1, 'like': 1,
'sofa': 1})
Der Zähler benötigt eine Liste als Eingabe, also muss jeder Text im Voraus in Token umgewandelt werden. Das Schöne an dem Zähler ist, dass er schrittweise mit einer Liste von Token aus einem zweiten Dokument aktualisiert werden kann:
more_tokens=tokenize("She likes dogs and cats.")counter.update(more_tokens)(counter)
Out:
Counter({'my': 3, 'cats': 3, 'She': 2, 'likes': 2, 'and': 2, 'like': 1,
'sofa': 1, 'dogs': 1})
Um die häufigsten Wörter in einem Korpus zu finden, müssen wir einen Zähler aus der Liste aller Wörter in allen Dokumenten erstellen. Ein naiver Ansatz wäre es, alle Dokumente zu einer einzigen, riesigen Liste von Token zu verketten, aber das ist für größere Datensätze nicht geeignet. Es ist viel effizienter, die Funktion update des Zählerobjekts für jedes einzelne Dokument aufzurufen.
counter=Counter()df['tokens'].map(counter.update)
Wir machen hier einen kleinen Trick und setzen counter.update in die Funktion map. Die Magie passiert innerhalb der update Funktion unter der Haube. Der gesamte Aufruf von map läuft extrem schnell; er braucht nur etwa drei Sekunden für die 7.500 UN-Sprüche und skaliert linear mit der Gesamtzahl der Token. Der Grund dafür ist, dass Wörterbücher im Allgemeinen und Zähler im Besonderen als Hashtabellen implementiert sind. Ein einzelner Zähler ist im Vergleich zum gesamten Korpus ziemlich kompakt: Er enthält jedes Wort nur einmal, zusammen mit seiner Häufigkeit.
Jetzt können wir die häufigsten Wörter im Text mit der entsprechenden Zählerfunktion abrufen:
(counter.most_common(5))
Out:
[('nations', 124508),
('united', 120763),
('international', 117223),
('world', 89421),
('countries', 85734)]
Für die weitere Verarbeitung und Analyse ist es viel bequemer, den Zähler in eine Pandas DataFrame umzuwandeln, und genau das macht die folgende Blueprint-Funktion schließlich. Die Token bilden den Index der DataFrame, während die Häufigkeitswerte in einer Spalte namens freq gespeichert werden. Die Zeilen werden so sortiert, dass die häufigsten Wörter am Anfang stehen:
defcount_words(df,column='tokens',preprocess=None,min_freq=2):# process tokens and update counterdefupdate(doc):tokens=docifpreprocessisNoneelsepreprocess(doc)counter.update(tokens)# create counter and run through all datacounter=Counter()df[column].map(update)# transform counter into a DataFramefreq_df=pd.DataFrame.from_dict(counter,orient='index',columns=['freq'])freq_df=freq_df.query('freq >= @min_freq')freq_df.index.name='token'returnfreq_df.sort_values('freq',ascending=False)
Die Funktion nimmt als ersten Parameter ein Pandas DataFrame und als zweiten Parameter den Spaltennamen mit den Token oder dem Text. Da wir die vorbereiteten Token bereits in der Spalte tokens der DataFrame mit den Reden gespeichert haben, können wir die folgenden zwei Codezeilen verwenden, um die DataFrame mit den Worthäufigkeiten zu berechnen und die fünf wichtigsten Token anzuzeigen:
freq_df=count_words(df)freq_df.head(5)
Out:
| Token | freq |
|---|---|
| Nationen | 124508 |
| vereinigt | 120763 |
| international | 117223 |
| Welt | 89421 |
| Länder | 85734 |
Wenn wir keine vorberechneten Token für eine spezielle Analyse verwenden wollen, können wir den Text mit einer benutzerdefinierten Vorverarbeitungsfunktion als drittem Parameter "on the fly" tokenisieren. Mit dieser On-the-Fly-Tokenisierung des Textes könnten wir zum Beispiel alle Wörter mit 10 oder mehr Zeichen erzeugen und zählen:
count_words(df, column='text',
preprocess=lambda text: re.findall(r"\w{10,}", text))
Der letzte Parameter von count_words legt die Mindesthäufigkeit der Token fest, die in das Ergebnis aufgenommen werden. Der Standardwert ist 2, um den langen Schwanz von Hapaxen, d. h. Token, die nur einmal vorkommen, zu reduzieren.
Blaupause: Erstellen eines Frequenzdiagramms
Es gibt Dutzende von Möglichkeiten, Tabellen und Diagramme in Python zu erstellen. Wir bevorzugen Pandas mit seiner eingebauten Plot-Funktionalität, weil es einfacher zu benutzen ist als die einfache Matplotlib. Wir gehen von einem DataFrame freq_df aus, das mit dem vorherigen Blueprint zur Visualisierung erstellt wurde. Die Erstellung eines Häufigkeitsdiagramms, das auf einem solchen DataFrame basiert, wird nun im Grunde zu einem Einzeiler. Wir fügen zwei weitere Zeilen für die Formatierung hinzu:
ax=freq_df.head(15).plot(kind='barh',width=0.95)ax.invert_yaxis()ax.set(xlabel='Frequency',ylabel='Token',title='Top Words')
Out:
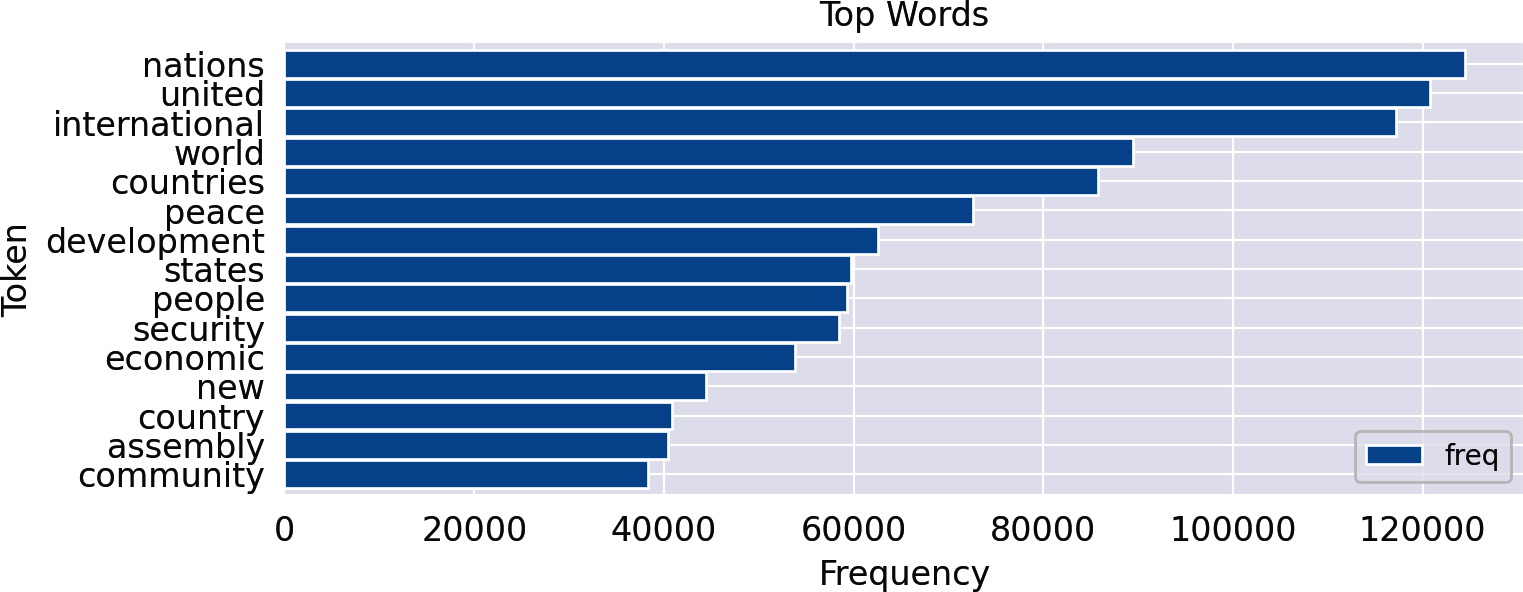
Die Verwendung von horizontalen Balken (barh) für die Worthäufigkeiten verbessert die Lesbarkeit erheblich, da die Wörter horizontal auf der y-Achse in einer lesbaren Form erscheinen. Die y-Achse wird invertiert, damit die wichtigsten Wörter oben im Diagramm erscheinen. Die Achsenbeschriftungen und der Titel können optional geändert werden.
Blaupause: Wortwolken erstellen
Diagramme von Häufigkeitsverteilungen wie die zuvor gezeigten geben detaillierte Informationen über die Häufigkeit von Token. Aber es ist ziemlich schwierig, Häufigkeitsdiagramme für verschiedene Zeiträume, Kategorien, Autoren usw. zu vergleichen. Wortwolken hingegen visualisieren die Häufigkeiten durch unterschiedliche Schriftgrößen. Sie sind viel leichter zu verstehen und zu vergleichen, aber ihnen fehlt die Präzision von Tabellen und Balkendiagrammen. Du solltest bedenken, dass lange Wörter oder Wörter mit Großbuchstaben eine unverhältnismäßig hohe Anziehungskraft haben.
Das Python-Modul wordcloud erzeugt schöne Wortwolken aus Texten oder Zählern. Am einfachsten ist es, ein Wortwolken-Objekt mit einigen Optionen zu instanziieren, z. B. der maximalen Anzahl von Wörtern und einer Stoppwortliste, und dann das wordcloud Modul mit der Tokenisierung und der Stoppwortentfernung zu beauftragen. Der folgende Code zeigt, wie man eine Wortwolke für den Text der US-Rede von 2015 erstellt und das Ergebnis mit Matplotlib anzeigt:
fromwordcloudimportWordCloudfrommatplotlibimportpyplotasplttext=df.query("year==2015 and country=='USA'")['text'].values[0]wc=WordCloud(max_words=100,stopwords=stopwords)wc.generate(text)plt.imshow(wc,interpolation='bilinear')plt.axis("off")
Dies funktioniert jedoch nur für einen einzelnen Text und nicht für eine (potenziell große) Menge von Dokumenten. Für letzteren Anwendungsfall ist es viel schneller, zuerst einen Häufigkeitszähler zu erstellen und dann die Funktion generate_from_frequencies() zu verwenden.
Unser Blueprint ist ein kleiner Wrapper um diese Funktion herum, um auch eine Pandas Series mit Frequenzwerten zu unterstützen, wie sie von count_words erstellt werden. Die Klasse WordCloud verfügt bereits über eine Vielzahl von Optionen zur Feinabstimmung des Ergebnisses. Wir verwenden einige davon in der folgenden Funktion, um mögliche Anpassungen zu demonstrieren, aber für Details solltest du die Dokumentation lesen:
defwordcloud(word_freq,title=None,max_words=200,stopwords=None):wc=WordCloud(width=800,height=400,background_color="black",colormap="Paired",max_font_size=150,max_words=max_words)# convert DataFrame into dictiftype(word_freq)==pd.Series:counter=Counter(word_freq.fillna(0).to_dict())else:counter=word_freq# filter stop words in frequency counterifstopwordsisnotNone:counter={token:freqfor(token,freq)incounter.items()iftokennotinstopwords}wc.generate_from_frequencies(counter)plt.title(title)plt.imshow(wc,interpolation='bilinear')plt.axis("off")
Die Funktion hat zwei praktische Parameter, um Wörter zu filtern. skip_n überspringt die obersten n Wörter der Liste. In einem UN-Korpus stehen natürlich Wörter wie "United", "Nations" oder " International" an erster Stelle der Liste. Es könnte interessanter sein, zu sehen, was als nächstes kommt. Der zweite Filter ist eine (zusätzliche) Liste von Stoppwörtern. Manchmal ist es hilfreich, bestimmte häufige, aber uninteressante Wörter nur für die Visualisierung herauszufiltern.5
Werfen wir also einen Blick auf die Reden von 2015(Abbildung 1-5). Die linke Wortwolke visualisiert die häufigsten Wörter ungefiltert. In der rechten Wortwolke werden stattdessen die 50 häufigsten Wörter des gesamten Korpus als Stoppwörter behandelt:
freq_2015_df=count_words(df[df['year']==2015])plt.figure()wordcloud(freq_2015_df['freq'],max_words=100)wordcloud(freq_2015_df['freq'],max_words=100,stopwords=freq_df.head(50).index)
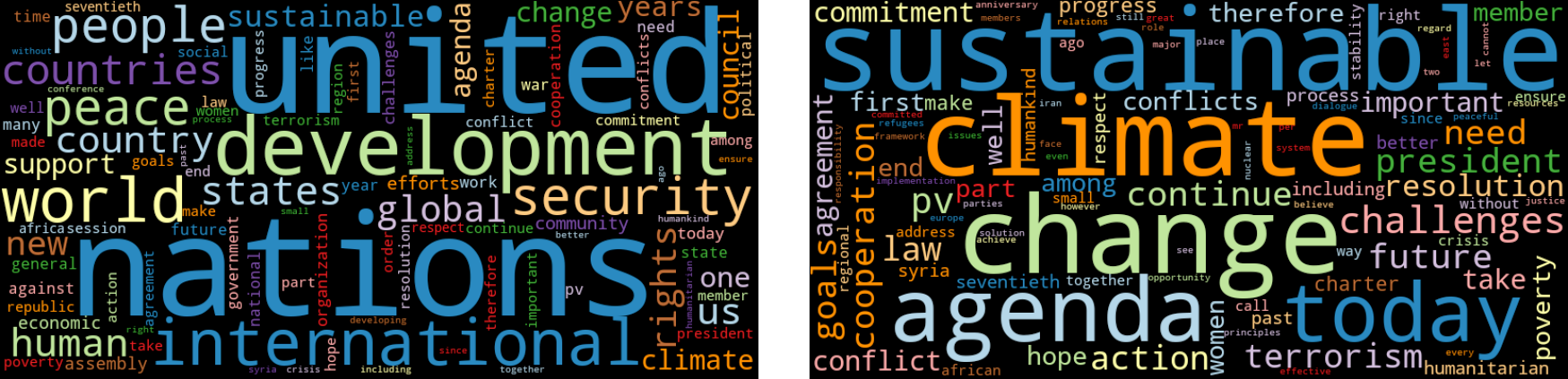
Abbildung 1-5. Wortwolken für die Reden 2015 mit allen Wörtern (links) und ohne die 50 häufigsten Wörter (rechts).
Es ist klar, dass die rechte Wortwolke ohne die häufigsten Wörter des Korpus einen viel besseren Eindruck von den Themen des Jahres 2015 vermittelt, aber es gibt immer noch häufige und unspezifische Wörter wie heute oder Herausforderungen. Wir brauchen eine Möglichkeit, diesen Wörtern weniger Gewicht zu geben, wie im nächsten Abschnitt auf gezeigt wird.
Blaupause: Ranking mit TF-IDF
Wie in Abbildung 1-5 dargestellt, bringt die Visualisierung der häufigsten Wörter in der Regel nicht viel Aufschluss. Selbst wenn Stoppwörter entfernt werden, sind die häufigsten Wörter in der Regel offensichtliche domänenspezifische Begriffe, die in jeder Teilmenge (Slice) der Daten recht ähnlich sind. Wir möchten jedoch den Wörtern mehr Bedeutung beimessen, die in einer bestimmten Teilmenge der Daten häufiger als "gewöhnlich" vorkommen. Ein solcher Ausschnitt kann eine beliebige Teilmenge des Datenkorpus sein, z. B. eine einzelne Rede, die Reden eines bestimmten Jahrzehnts oder die Reden aus einem Land.
Wir wollen Wörter hervorheben, deren tatsächliche Worthäufigkeit in einem Slice höher ist, als es ihre Gesamtwahrscheinlichkeit vermuten ließe. Es gibt eine Reihe von Algorithmen, um den "Überraschungsfaktor" eines Wortes zu messen. Einer der einfachsten, aber am besten funktionierenden Ansätze ist die Ergänzung der Begriffshäufigkeit durch die inverse Dokumentenhäufigkeit (siehe Seitenleiste).
Definieren wir eine Funktion, um die IDF für alle Begriffe im Korpus zu berechnen. ist fast identisch mit count_words, außer dass jedes Token nur einmal pro Dokument gezählt wird (counter.update(set(tokens))) und die IDF-Werte nach der Zählung berechnet werden. Der Parameter min_df dient als Filter für den Long Tail der seltenen Wörter. Das Ergebnis dieser Funktion ist wiederum DataFrame:
defcompute_idf(df,column='tokens',preprocess=None,min_df=2):defupdate(doc):tokens=docifpreprocessisNoneelsepreprocess(doc)counter.update(set(tokens))# count tokenscounter=Counter()df[column].map(update)# create DataFrame and compute idfidf_df=pd.DataFrame.from_dict(counter,orient='index',columns=['df'])idf_df=idf_df.query('df >= @min_df')idf_df['idf']=np.log(len(df)/idf_df['df'])+0.1idf_df.index.name='token'returnidf_df
Die IDF-Werte müssen einmal für den gesamten Korpus berechnet werden (verwende hier keine Teilmenge!) und können dann für alle Arten von Analysen verwendet werden. Mit dieser Funktion erstellen wir eine DataFrame mit den IDF-Werten für jedes Token (idf_df):
idf_df=compute_idf(df)
Da sowohl die IDF als auch die Häufigkeit DataFrame einen Index haben, der aus den Token besteht, können wir die Spalten beider DataFrameeinfach multiplizieren, um den TF-IDF-Score für die Begriffe zu berechnen:
freq_df['tfidf']=freq_df['freq']*idf_df['idf']
Unter vergleichen wir die Wortwolken, die nur auf der Anzahl der Wörter (Termhäufigkeiten) basieren, und die TF-IDF-Scores für die Reden des ersten und des letzten Jahres im Korpus. Wir entfernen einige weitere Stoppwörter, die für die Nummern der jeweiligen Debatten stehen.
freq_1970=count_words(df[df['year']==1970])freq_2015=count_words(df[df['year']==2015])freq_1970['tfidf']=freq_1970['freq']*idf_df['idf']freq_2015['tfidf']=freq_2015['freq']*idf_df['idf']#wordcloud(freq_df['freq'], title='All years', subplot=(1,3,1))wordcloud(freq_1970['freq'],title='1970 - TF',stopwords=['twenty-fifth','twenty-five'])wordcloud(freq_2015['freq'],title='2015 - TF',stopwords=['seventieth'])wordcloud(freq_1970['tfidf'],title='1970 - TF-IDF',stopwords=['twenty-fifth','twenty-five','twenty','fifth'])wordcloud(freq_2015['tfidf'],title='2015 - TF-IDF',stopwords=['seventieth'])
Die Wortwolken in Abbildung 1-6 zeigen eindrucksvoll die Leistungsfähigkeit der TF-IDF-Gewichtung. Während die häufigsten Wörter in den Jahren 1970 und 2015 fast identisch sind, heben die TF-IDF-gewichteten Visualisierungen die Unterschiede der politischen Themen hervor.

Abbildung 1-6. Nach Klartext gewichtete Wörter (oben) und TF-IDF (unten) für Reden in zwei ausgewählten Jahren.
Der erfahrene Leser fragt sich vielleicht, warum wir Funktionen zum Zählen von Wörtern und Berechnen von IDF-Werten selbst implementiert haben, anstatt die Klassen CountVectorizer und TfidfVectorizer von scikit-learn zu verwenden. Dafür gibt es eigentlich zwei Gründe. Erstens erzeugen die Vektorisierer einen Vektor mit gewichteten Termhäufigkeiten für jedes einzelne Dokument und nicht für beliebige Teilmengen des Datensatzes. Zweitens sind die Ergebnisse Matrizen (gut für maschinelles Lernen) und keine Datenrahmen (gut für Slicing, Aggregation und Visualisierung). Wir müssten am Ende etwa die gleiche Anzahl von Codezeilen schreiben, um die Ergebnisse in Abbildung 1-6 zu erzeugen, verpassen aber die Gelegenheit, dieses wichtige Konzept von Grund auf einzuführen. Die Scikit-Learn-Vektorisierer werden in Kapitel 5 ausführlich besprochen.
Blaupause: Ein Schlüsselwort im Kontext finden
Wortwolken und Häufigkeitsdiagramme sind großartige Instrumente, um Textdaten visuell zusammenzufassen. Allerdings werfen sie oft auch Fragen darüber auf, warum ein bestimmter Begriff so prominent erscheint. In der TF-IDF-Wortwolke aus dem Jahr 2015, die wir bereits besprochen haben, tauchen zum Beispiel die Begriffe pv, sdgs oder sids auf, deren Bedeutung du wahrscheinlich nicht kennst. Um das herauszufinden, brauchen wir eine Möglichkeit, die tatsächlichen Vorkommen dieser Wörter im ursprünglichen, unvorbereiteten Text zu untersuchen. Eine einfache, aber raffinierte Methode für eine solche Untersuchung ist die Keyword-in-Context (KWIC)-Analyse. Sie erstellt eine Liste von gleich langen Textfragmenten, die den linken und rechten Kontext eines Schlüsselworts zeigen. Hier ist ein Beispiel für die KWIC-Liste für sdgs, die uns eine Erklärung für diesen Begriff liefert:
5 random samples out of 73 contexts for 'sdgs': of our planet and its people. The SDGs are a tangible manifestation of th nd, we are expected to achieve the SDGs and to demonstrate dramatic develo ead by example in implementing the SDGs in Bangladesh. Attaching due impor the Sustainable Development Goals ( SDGs ). We applaud all the Chairs of the new Sustainable Development Goals ( SDGs ) aspire to that same vision. The A
Offensichtlich ist sdgs die kleingeschriebene Version von SDGs, die für "nachhaltige Entwicklungsziele" steht. Mit der gleichen Analyse können wir herausfinden, dass sids für "small island developing states" steht. Das sind wichtige Informationen, um die Themen des Jahres 2015 zu interpretieren! pv ist jedoch ein Tokenisierungs-Artefakt. Es ist eigentlich der Rest von Zitaten wie (A/70/PV.28), was für "Assembly 70, Process Verbal 28" steht, also für die Rede 28 der 70.
Hinweis
Schau dir immer die Details an, wenn du auf Token stößt, die du nicht kennst oder die für dich keinen Sinn ergeben! Oft enthalten sie wichtige Informationen (wie sdgs), die du als Analytiker interpretieren können solltest. Aber du wirst auch oft Artefakte wie pv finden. Diese sollten verworfen werden, wenn sie irrelevant sind oder richtig behandelt werden.
Die KWIC-Analyse ist in NLTK und textacy implementiert. Wir werden die FunktionKWIC von textacy verwenden, weil sie schnell ist und mit dem unkommentierten Text arbeitet. So können wir nach Zeichenketten suchen, die mehrere Token umfassen, wie z. B. "Klimawandel", was NLTK nicht kann. Sowohl NLTK als auch die KWIC-Funktionen von Textacy arbeiten nur mit einem einzigen Dokument. Um die Analyse auf eine Reihe von Dokumenten in einer DataFrame zu erweitern, bieten wir die folgende Funktion an :
fromtextacy.text_utilsimportKWICdefkwic(doc_series,keyword,window=35,print_samples=5):defadd_kwic(text):kwic_list.extend(KWIC(text,keyword,ignore_case=True,window_width=window,print_only=False))kwic_list=[]doc_series.map(add_kwic)ifprint_samplesisNoneorprint_samples==0:returnkwic_listelse:k=min(print_samples,len(kwic_list))(f"{k} random samples out of {len(kwic_list)} "+\f"contexts for '{keyword}':")forsampleinrandom.sample(list(kwic_list),k):(re.sub(r'[\n\t]',' ',sample[0])+' '+\sample[1]+' '+\re.sub(r'[\n\t]',' ',sample[2]))
Die Funktion sammelt iterativ die Schlüsselwortkontexte, indem die Funktion add_kwic auf jedes Dokument mit map anwendet. Dieser Trick, den wir bereits in den Word Count Blueprints verwendet haben, ist sehr effizient und ermöglicht die KWIC-Analyse auch für größere Korpora. Standardmäßig gibt die Funktion eine Liste von Tupeln der Form (left context, keyword, right context) zurück. Wenn print_samples größer als 0 ist, wird eine Zufallsstichprobe der Ergebnisse ausgegeben.8 Die Stichprobe ist besonders nützlich, wenn du mit vielen Dokumenten arbeitest, weil die ersten Einträge der Liste sonst von einem einzigen oder einer sehr kleinen Anzahl von Dokumenten stammen würden.
Die KWIC-Liste für sdgs von früher wurde durch diesen Aufruf erstellt:
kwic(df[df['year']==2015]['text'],'sdgs',print_samples=5)
Blaupause: N-Gramme analysieren
Nur zu wissen, dass Klima ein häufiges Wort ist, sagt uns nicht allzu viel über das Thema der Diskussion, denn zum Beispiel haben Klimawandel und politisches Klima völlig unterschiedliche Bedeutungen. Auch Klimawandel ist nicht dasselbe wie Klimawandel. Deshalb kann es hilfreich sein, Häufigkeitsanalysen von einzelnen Wörtern auf kurze Sequenzen von zwei oder drei Wörtern auszuweiten.
Im Grunde suchen wir nach zwei Arten von Wortfolgen: Verbindungen und Kollokationen. Eine Verbindung ist eine Kombination aus zwei oder mehr Wörtern mit einer bestimmten Bedeutung. Im Englischen gibt es Verbindungen in geschlossener Form, wie Erdbeben, in Form von Bindestrichen, wie selbstbewusst, und in offener Form, wie Klimawandel. Es kann also sein, dass wir zwei Token als eine einzige semantische Einheit betrachten müssen. Kollokationen hingegen sind Wörter, die häufig zusammen verwendet werden. Oft bestehen sie aus einem Adjektiv oder Verb und einem Substantiv, wie roter Teppich oder Vereinte Nationen.
In der Textverarbeitung arbeiten wir normalerweise mit Bigrammen (Sequenzen der Länge 2), manchmal sogar mit Trigrammen (Länge 3). n-Gramme der Größe 1 sind einzelne Wörter, auch Unigramme genannt. Der Grund, warum wir uns an zu halten, ist, dass die Anzahl der verschiedenen n-Gramme exponentiell mit n zunimmt, während ihre Häufigkeit auf die gleiche Weise abnimmt. Die meisten Trigramme kommen nur einmal in einem Korpus vor.
Die folgende Funktion erzeugt auf elegante Weise die Menge der n-Gramme für eine Folge von Token:9
defngrams(tokens,n=2,sep=' '):return[sep.join(ngram)forngraminzip(*[tokens[i:]foriinrange(n)])]text="the visible manifestation of the global climate change"tokens=tokenize(text)("|".join(ngrams(tokens,2)))
Out:
the visible|visible manifestation|manifestation of|of the|the global| global climate|climate change
Wie du sehen kannst, enthalten die meisten Bigramme Stoppwörter wie Präpositionen und Determinatoren. Daher ist es ratsam, Bigramme ohne Stoppwörter zu bilden. Aber wir müssen vorsichtig sein: Wenn wir zuerst die Stoppwörter entfernen und dann die Bigramme bilden, erzeugen wir Bigramme, die im Originaltext nicht existieren, wie im Beispiel "manifestation global". Daher erstellen wir die Bigramme auf allen Token, behalten aber nur die, die keine Stoppwörter enthalten, mit dieser modifizierten ngrams Funktion:
defngrams(tokens,n=2,sep=' ',stopwords=set()):return[sep.join(ngram)forngraminzip(*[tokens[i:]foriinrange(n)])iflen([tfortinngramiftinstopwords])==0]("Bigrams:","|".join(ngrams(tokens,2,stopwords=stopwords)))("Trigrams:","|".join(ngrams(tokens,3,stopwords=stopwords)))
Out:
Bigrams: visible manifestation|global climate|climate change Trigrams: global climate change
Mit dieser ngrams Funktion können wir eine Spalte mit allen Bigrammen zu unserer DataFrame hinzufügen und die Wortzählung anwenden, um die fünf wichtigsten Bigramme zu ermitteln:
df['bigrams']=df['text'].apply(prepare,pipeline=[str.lower,tokenize])\.apply(ngrams,n=2,stopwords=stopwords)count_words(df,'bigrams').head(5)
Out:
| Token | freq |
|---|---|
| Vereinte Nationen | 103236 |
| internationale Gemeinschaft | 27786 |
| Generalversammlung | 27096 |
| Sicherheitsrat | 20961 |
| menschenrechte | 19856 |
Du hast vielleicht bemerkt, dass wir bei der Tokenisierung die Satzgrenzen ignoriert haben. Daher werden wir Nonsens-Bigramme mit dem letzten Wort eines Satzes und dem ersten Wort des nächsten Satzes erzeugen. Diese Bigramme kommen nicht sehr häufig vor und sind daher für die Datenexploration nicht wirklich wichtig. Wenn wir das verhindern wollten, müssten wir die Satzgrenzen identifizieren, was viel komplizierter ist als die Tokenisierung von Wörtern und den Aufwand hier nicht wert ist.
Erweitern wir nun unsere TF-IDF-basierte Unigramm-Analyse aus dem vorherigen Abschnitt und beziehen Bigramme mit ein. Wir addieren die IDF-Werte der Bigramme, berechnen die TF-IDF-gewichteten Bigram-Häufigkeiten für alle Reden aus dem Jahr 2015 und erstellen eine Wortwolke aus den resultierenden DataFrame:
# concatenate existing IDF DataFrame with bigram IDFsidf_df=pd.concat([idf_df,compute_idf(df,'bigrams',min_df=10)])freq_df=count_words(df[df['year']==2015],'bigrams')freq_df['tfidf']=freq_df['freq']*idf_df['idf']wordcloud(freq_df['tfidf'],title='all bigrams',max_words=50)
Wie wir in der Wortwolke links in Abbildung 1-7 sehen können, war der Klimawandel im Jahr 2015 ein häufiges Bigramm. Um die verschiedenen Kontexte von Klima zu verstehen, ist es interessant, einen Blick auf die Bigramme zu werfen, die nur Klima enthalten. Dazu können wir einen Textfilter auf Klima anwenden und das Ergebnis erneut als Wortwolke darstellen(Abbildung 1-7, rechts):
where=freq_df.index.str.contains('climate')wordcloud(freq_df[where]['freq'],title='"climate" bigrams',max_words=50)
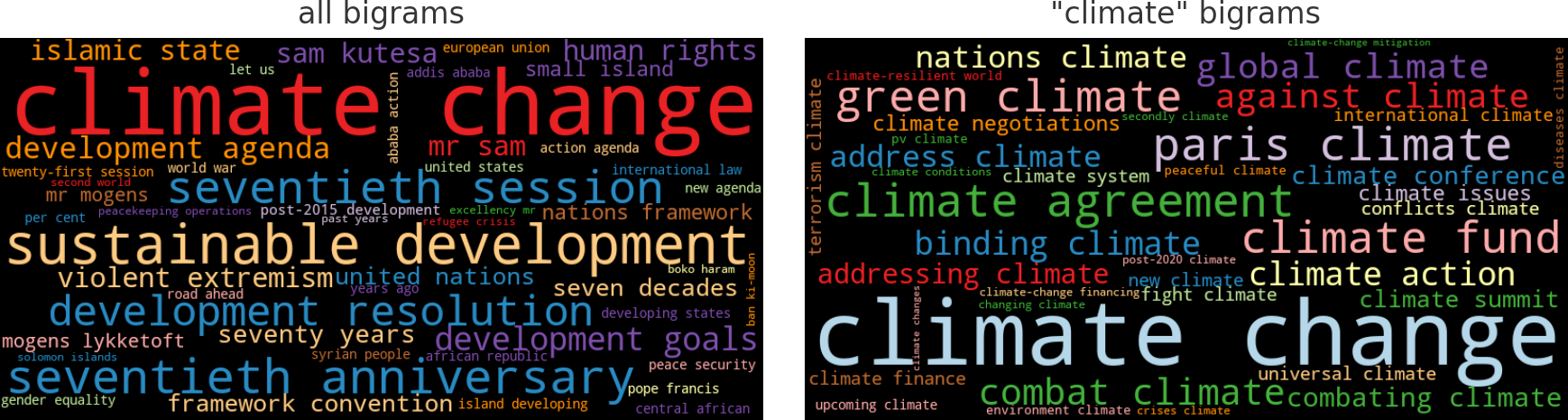
Abbildung 1-7. Wortwolken für alle Bigramme und Bigramme, die das Wort Klima enthalten.
Der hier vorgestellte Ansatz erstellt und gewichtet alle n-Gramme, die keine Stoppwörter enthalten. Für eine erste Analyse sehen die Ergebnisse recht gut aus. Wir kümmern uns nur nicht um den langen Schwanz der seltenen Bigramme. Anspruchsvollere, aber auch rechenintensivere Algorithmen zur Identifizierung von Kollokationen gibt es z. B. im Kollokationsfinder von NLTK. Wir werden in den Kapiteln 4 und 10 Alternativen zur Identifizierung sinnvoller Phrasen aufzeigen.
Blaupause: Vergleich von Häufigkeiten über Zeitintervalle und Kategorien hinweg
Du kennst sicher Google Trends, wo du die Entwicklung einer Reihe von Suchbegriffen im Laufe der Zeit verfolgen kannst. Diese Art der Trendanalyse berechnet die Häufigkeiten pro Tag und stellt sie in einem Liniendiagramm dar. Wir wollen die Entwicklung bestimmter Suchbegriffe im Laufe der Jahre in unserem UN-Debatten-Datensatz verfolgen, um einen Eindruck von der wachsenden oder sinkenden Bedeutung von Themen wie Klimawandel, Terrorismus oder Migration zu bekommen.
Frequenz-Zeitleisten erstellen
Unser Ansatz besteht darin, die Häufigkeiten der gegebenen Schlüsselwörter pro Dokument zu berechnen und diese Häufigkeiten dann mit der Funktion groupby von Pandas zu aggregieren. Die folgende Funktion ist für die erste Aufgabe gedacht. Sie extrahiert die Anzahl der gegebenen Schlüsselwörter aus einer Liste von Token:
defcount_keywords(tokens,keywords):tokens=[tfortintokensiftinkeywords]counter=Counter(tokens)return[counter.get(k,0)forkinkeywords]
Lass uns die Funktionalität anhand eines kleinen Beispiels demonstrieren:
keywords=['nuclear','terrorism','climate','freedom']tokens=['nuclear','climate','climate','freedom','climate','freedom'](count_keywords(tokens,keywords))
Out:
[1, 0, 3, 2]
Wie du siehst, gibt die Funktion eine Liste oder einen Vektor der Wortanzahl zurück. Es handelt sich also um einen sehr einfachen Zählvektor für Schlüsselwörter. Wenn wir diese Funktion auf jedes Dokument in unserem DataFrame anwenden, erhalten wir eine Matrix von Zählungen. Die nachfolgend gezeigte Blueprint-Funktion count_keywords_by macht genau das in einem ersten Schritt. Die Matrix wird dann wieder in eine DataFrame umgewandelt, die schließlich aggregiert und nach der angegebenen Gruppierungsspalte sortiert wird.
defcount_keywords_by(df,by,keywords,column='tokens'):freq_matrix=df[column].apply(count_keywords,keywords=keywords)freq_df=pd.DataFrame.from_records(freq_matrix,columns=keywords)freq_df[by]=df[by]# copy the grouping column(s)returnfreq_df.groupby(by=by).sum().sort_values(by)
Diese Funktion ist sehr schnell, weil sie sich nur um die Schlüsselwörter kümmern muss. Das Zählen der vier Schlüsselwörter von vorhin im UN-Korpus dauert auf einem Laptop nur zwei Sekunden. Werfen wir einen Blick auf das Ergebnis:
freq_df=count_keywords_by(df,by='year',keywords=keywords)
Out:
| Atomkraft | terrorismus | Klima | Freiheit | Jahr |
|---|---|---|---|---|
| 1970 | 192 | 7 | 18 | 128 |
| 1971 | 275 | 9 | 35 | 205 |
| ... | ... | ... | ... | ... |
| 2014 | 144 | 404 | 654 | 129 |
| 2015 | 246 | 378 | 662 | 148 |
Hinweis
Auch wenn wir in unseren Beispielen nur das Attribut year als Gruppierungskriterium verwenden, kannst du mit der Blueprint-Funktion die Worthäufigkeiten für jedes beliebige diskrete Attribut vergleichen, z. B. Land, Kategorie, Autor - was immer du willst. Du könntest sogar eine Liste von Gruppierungsattributen angeben, um z. B. die Anzahl pro Land und Jahr zu berechnen.
Die resultierende DataFrame ist bereits perfekt für das Plotten vorbereitet, da wir eine Datenreihe pro Schlüsselwort haben. Mit der Funktion plot von Pandas erhalten wir ein schönes Liniendiagramm, das dem von Google Trends ähnelt(Abbildung 1-8):
freq_df.plot(kind='line')
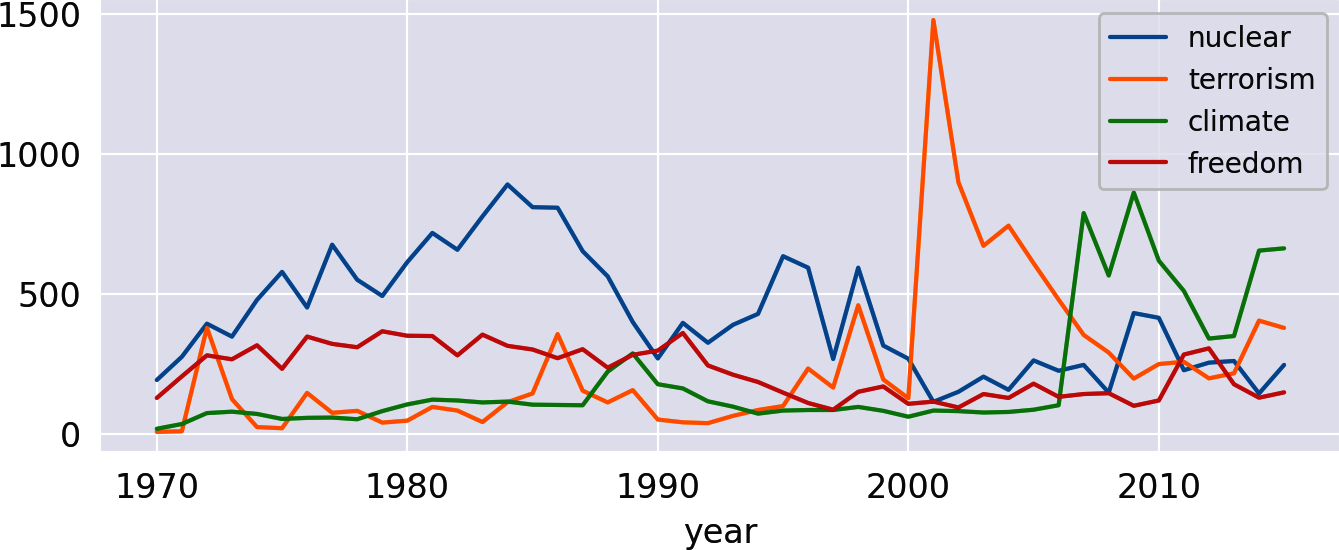
Abbildung 1-8. Häufigkeit der ausgewählten Wörter pro Jahr.
Beachte den Höhepunkt der Atomkraft in den 1980er Jahren, der auf das Wettrüsten hinweist, und den Höhepunkt des Terrorismus im Jahr 2001. Es ist irgendwie bemerkenswert, dass das Thema Klima schon in den 1970er und 1980er Jahren einige Aufmerksamkeit bekam. Hat es das wirklich? Nun, wenn du mit einer KWIC-Analyse ("Blueprint: Finding a Keyword-in-Context") nachschaust, wirst du herausfinden, dass das Wort Klima in diesen Jahrzehnten fast ausschließlich im übertragenen Sinne verwendet wurde .
Frequenz-Heatmaps erstellen
Nehmen wir an, wir wollen die historischen Entwicklungen von globalen Krisen wie dem Kalten Krieg, dem Terrorismus und dem Klimawandel analysieren. Wir könnten eine Auswahl bedeutender Wörter treffen und ihre Zeitlinien durch Liniendiagramme visualisieren, wie im vorherigen Beispiel. Aber Liniendiagramme werden verwirrend, wenn du mehr als vier oder fünf Zeilen hast. Eine alternative Visualisierung ohne diese Einschränkung ist eine Heatmap, wie sie von der Seaborn-Bibliothek bereitgestellt wird. Fügen wir also ein paar weitere Schlüsselwörter zu unserem Filter hinzu und zeigen das Ergebnis als Heatmap an(Abbildung 1-9).
keywords=['terrorism','terrorist','nuclear','war','oil','syria','syrian','refugees','migration','peacekeeping','humanitarian','climate','change','sustainable','sdgs']freq_df=count_keywords_by(df,by='year',keywords=keywords)# compute relative frequencies based on total number of tokens per yearfreq_df=freq_df.div(df.groupby('year')['num_tokens'].sum(),axis=0)# apply square root as sublinear filter for better contrastfreq_df=freq_df.apply(np.sqrt)sns.heatmap(data=freq_df.T,xticklabels=True,yticklabels=True,cbar=False,cmap="Reds")

Abbildung 1-9. Worthäufigkeiten im Zeitverlauf als Heatmap.
Bei dieser Art von Analyse gibt es einige Dinge zu beachten:
- Ziehe relative Häufigkeiten für jede Art von Vergleich vor.
- Absolute Begriffshäufigkeiten sind problematisch, wenn die Gesamtzahl der Token pro Jahr oder Kategorie nicht stabil ist. Zum Beispiel steigen die absoluten Häufigkeiten natürlich an, wenn in unserem Beispiel Jahr für Jahr mehr Länder sprechen.
- Sei vorsichtig bei der Interpretation von Häufigkeitsdiagrammen, die auf Stichwortlisten basieren.
- Obwohl das Diagramm wie eine Verteilung der Themen aussieht, ist es das nicht! Es kann andere Wörter geben, die dasselbe Thema bezeichnen, aber nicht in der Liste enthalten sind. Schlagwörter können auch unterschiedliche Bedeutungen haben (z. B. "Klima der Diskussion"). Fortgeschrittene Techniken wie Topic Modeling(Kapitel 8) und Word Embeddings(Kapitel 10) können hier helfen.
- Verwende eine sublineare Skalierung.
- Da die Frequenzwerte sehr unterschiedlich sind, kann es schwierig sein, eine Veränderung bei weniger häufigen Token zu erkennen. Deshalb solltest du die Frequenzen sublinear skalieren (wir haben die Quadratwurzel
np.sqrtangewendet). Der visuelle Effekt ist ähnlich wie bei , wenn du den Kontrast senkst.
Schlussbemerkungen
Wir haben gezeigt, wie man mit der Analyse von Textdaten beginnt. Das Verfahren zur Textaufbereitung und Tokenisierung wurde einfach gehalten, um schnelle Ergebnisse zu erzielen. In Kapitel 4 werden wir anspruchsvollere Methoden vorstellen und die Vor- und Nachteile der verschiedenen Ansätze diskutieren.
Die Datenexploration sollte nicht nur erste Erkenntnisse liefern, sondern auch dazu beitragen, Vertrauen in deine Daten zu entwickeln. Eine Sache, die du im Hinterkopf behalten solltest, ist, dass du immer die Ursache für auftauchende seltsame Token identifizieren solltest. Die KWIC-Analyse ist ein gutes Werkzeug, um nach solchen Token zu suchen.
Für eine erste Analyse des Inhalts haben wir mehrere Entwürfe für die Worthäufigkeitsanalyse eingeführt. Die Gewichtung der Begriffe basiert entweder auf der Termhäufigkeit allein oder auf der Kombination aus Termhäufigkeit und inverser Dokumentenhäufigkeit (TF-IDF). Diese Konzepte werden später in Kapitel 5 aufgegriffen, denn die TF-IDF-Gewichtung ist eine Standardmethode zur Vektorisierung von Dokumenten für das maschinelle Lernen.
Es gibt viele Aspekte der Textanalyse, die wir in diesem Kapitel nicht behandelt haben:
- Autorenbezogene Informationen können dabei helfen, einflussreiche Autorinnen und Autoren zu identifizieren, wenn das eines deiner Projektziele ist. Autoren können nach Aktivität, sozialer Bewertung, Schreibstil usw. unterschieden werden.
- Manchmal ist es interessant, Autoren oder verschiedene Korpora zum gleichen Thema anhand ihrer Lesbarkeit zu vergleichen. Die Bibliothek
textacyhat eine Funktion namenstextstats, die verschiedene Lesbarkeitsbewertungen und andere Statistiken in einem einzigen Durchgang über den Text berechnet. - Ein interessantes Tool zur Identifizierung und Visualisierung von Unterscheidungsmerkmalen zwischen Kategorien (z. B. politischen Parteien) ist Jason Kessler's
ScattertextBibliothek. - Neben einfachem Python kannst du auch interaktive visuelle Tools für die Datenanalyse verwenden. Microsofts PowerBI hat ein schönes Wortwolken-Add-on und viele andere Optionen, um interaktive Diagramme zu erstellen. Wir erwähnen es, weil es in der Desktop-Version kostenlos ist und Python und R für die Datenaufbereitung und -visualisierung unterstützt.
- Für größere Projekte empfehlen wir, eine Suchmaschine wie Apache SOLR, Elasticsearch oder Tantivy einzurichten. Diese Plattformen erstellen spezielle Indizes (auch mit TF-IDF-Gewichtung) für eine schnelle Volltextsuche. Für alle diese Plattformen gibt es Python-APIs.
1 Eine vollständige Liste findest du in der Pandas-Dokumentation.
2 Die Liste von spaCy kannst du ähnlich mit spacy.lang.en.STOP_WORDS ansprechen.
3 In der Dokumentation findest du weitere Informationen.
4 Die NLTK-Klasse FreqDist ist von Counter abgeleitet und fügt einige Komfortfunktionen hinzu.
5 Beachte, dass das Modul wordcloud die Stoppwortliste ignoriert, wenn generate_from_frequencies aufgerufen wird. Deshalb wenden wir einen zusätzlichen Filter an.
6 Zum Beispiel fügt scikit-learns TfIdfVectorizer +1 hinzu.
7 Eine andere Möglichkeit ist, +1 im Nenner hinzuzufügen, um eine Division durch Null für ungesehene Terme mit df(t) = 0 zu verhindern. Diese Technik wird Glättung genannt.
8 Der Parameter print_only in der Funktion KWIC von textacy funktioniert ähnlich, aber ohne Stichproben.
9 Eine Erklärung findest du im Blogbeitrag von Scott Triglia.
Get Blaupausen für Textanalyse mit Python now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

