Kapitel 4. Automatisierte Bedrohungsmodellierung
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Es schien keinen computergesteuerten Prozess zu geben, der nicht von Menschen verbessert werden konnte, die auf der eigentlichen Struktur herumkrabbelten und sie mit Fettstiften beschrifteten.
Neal Stephenson, Atmosphæra Incognita
In Kapitel 1 hast du einen ausführlichen Einblick in die Erstellung verschiedener Systemmodelle "von Hand" bekommen, indem du auf ein Whiteboard gezeichnet oder eine Anwendung wie Visio von Microsoft oder draw.io verwendet hast. Du hast auch gesehen, welche Informationen du beim Erstellen dieser Modelle sammeln musst. In Kapitel 3 hast du einen Überblick über Ansätze zur Bedrohungsmodellierung erhalten, die die von dir erstellten Systemmodelle nutzen, um sicherheitsrelevante Bereiche innerhalb deines zu bewertenden Systems zu identifizieren. Du hast Methoden kennengelernt, die Bedrohungen auf hoher Ebene aufspüren und dabei die Gegner berücksichtigen, die die Fähigkeit und die Absicht haben, einen Angriff auszuführen. Du hast auch Methoden kennengelernt, die tiefer in den "Bedrohungsstapel" blicken, um die Ursachen zu analysieren, die zu Bedrohungen (und gegnerischen Zielen) führen - Schwachstellen und Verwundbarkeiten, die allein oder in Kombination zu einer Katastrophe für die Funktionalität und die Daten deines Systems (sowie für deinen Ruf und deine Marke) führen.
Diese Techniken und Methoden sind ein effektiver Ansatz für die Modellierung von Systemen und Bedrohungen, wenn du die Zeit und Energie hast und dein Unternehmen davon überzeugen kannst, dass dieser Ansatz wichtig ist. Im Zeitalter der kontinuierlichen Entwicklung von allem und jedem als Code wird jedoch ein großer Druck auf die Entwicklungsteams ausgeübt, mehr in weniger Zeit zu liefern. Daher werden Sicherheitspraktiken, die als notwendiges Übel akzeptiert wurden, weil sie mehr als nur ein paar Minuten Entwicklungszeit beanspruchen, als zu kostspielig aufgegeben (ob man sie nun wahrnimmt oder nicht). Das bringt Menschen, die sich mit Sicherheit beschäftigen, in eine schwierige Lage. Versuchst du, dein Unternehmen dazu zu bewegen, in den sauren Apfel zu beißen und strengere Sicherheitsverfahren anzuwenden, oder versuchst du, mit deinen schrumpfenden Ressourcen so viel wie möglich zu erreichen, obwohl du weißt, dass die Qualität deiner Ergebnisse (und damit die Sicherheit des Endprodukts) darunter leiden kann? Wie kannst du hohe Sicherheitsstandards und die Liebe zum Detail aufrechterhalten, die für ein ausgereiftes System notwendig sind?
Eine Möglichkeit, gute Sicherheitstechnik zu fördern, besteht darin, die Notwendigkeit, System- und Bedrohungsmodelle von Hand zu erstellen, einzuschränken und auf Automatisierung zu setzen, um die Belastung für dich zu verringern und die Anforderungen des Unternehmens und des Sicherheitsteams zu erfüllen. Auch wenn das menschliche Element bei der Erstellung von Bedrohungsmodellen zweifellos eine wichtige Rolle spielt, ist die Erstellung und Analyse von Systemmodellen etwas, das ein Computer problemlos bewältigen kann.
Automatisierung hilft dir nicht nur beim Entwurf des Modells, sondern kann auch bei der Beantwortung von Fragen helfen. Wenn du dir zum Beispiel nicht sicher bist, ob der Datenfluss A zwischen den Endpunkten X und Y deine kritischen Daten der mythischen Eva preisgibt,1 kannst du ein Programm benutzen, um das herauszufinden.
In diesem Kapitel erforschen wir eine Entwicklung, die sich gerade vollzieht. Wenn es darum geht, den neuesten Stand der Technik bei der Bedrohungsmodellierung, der Durchführung von Bedrohungsanalysen und der Fehlerermittlung zu schaffen, kannst du Automatisierungstechniken verwenden, die als "Threat Modeling with Code" und "Threat Modeling from Code" bezeichnet werden.2
Du fragst dich vielleicht, wie die Automatisierung der Bedrohungsmodellierung dein Leben einfacher machen kann und nicht nur ein weiteres Werkzeug/einen weiteren Prozess/eine weitere Aufgabe, um die du dich langfristig kümmern musst? Das haben wir uns auch gefragt.
Warum die Bedrohungsmodellierung automatisieren?
Seien wir ehrlich - Bedrohungsmodelle auf herkömmliche Weise zu erstellen, ist aus vielen Gründen schwierig:
-
Man braucht ein seltenes und hochspezialisiertes Talent, um Bedrohungsmodelle gut zu erstellen und die Schwachstellen in einem System herauszufinden. Das erfordert eine Ausbildung (z. B. die Lektüre dieses oder anderer Leitfäden zur Bedrohungsmodellierung) und eine gesunde Portion Pessimismus und kritisches Denken, wenn es darum geht, was ist und was sein könnte (und wie die Dinge schiefgehen könnten).
-
Es gibt eine Menge zu wissen, und das erfordert ein breites und tiefes Wissen und Erfahrungen. Wenn die Komplexität deines Systems zunimmt oder Veränderungen eingeführt werden (wie z.B. die digitale Transformation, die viele Unternehmen heutzutage durchlaufen), bringt der technologische Wandel immer mehr Schwachstellen mit sich: Neue Schwachstellen und Bedrohungen werden identifiziert und neue Angriffsvektoren geschaffen; das Sicherheitspersonal muss ständig lernen.
-
Es gibt unzählige Optionen, aus denen du wählen kannst.3 Dazu gehören Tools und Methoden für die Modellierung und Analyse von Bedrohungen, modellierte Darstellungen und die Aufzeichnung, Entschärfung und Verwaltung der Ergebnisse.
-
Die Stakeholder davon zu überzeugen, dass Bedrohungsmodelle wichtig sind, kann unter anderem aus folgenden Gründen schwierig sein
-
Jeder ist beschäftigt (wie bereits erwähnt).
-
Nicht jeder im Entwicklungsteam versteht das System so, wie es spezifiziert und/oder entworfen wurde. Das, was entworfen wurde, entspricht nicht unbedingt der Spezifikation, und das, was implementiert wurde, stimmt vielleicht auch nicht überein. Es kann schwierig sein, die richtigen Personen zu finden, die den aktuellen Zustand des zu analysierenden Systems korrekt beschreiben können.
-
Nicht alle Architekten und Programmierer haben ein vollständiges Verständnis von dem, woran sie arbeiten. Außer in kleinen, gut funktionierenden Teams werden nicht alle Teammitglieder übergreifende Kenntnisse über die Bereiche der anderen haben. Wir nennen das die Entwicklungsmethodik der drei blinden Männer und des Elefanten.
-
Einige Teammitglieder (hoffentlich nur wenige) haben weniger als perfekte Absichten, d.h. sie können defensiv sein oder absichtlich irreführende Aussagen machen).
-
-
Auch wenn du den Code lesen kannst, zeigt dir das nicht das ganze Bild. Wenn du Code lesen musst, hast du vielleicht die Chance verpasst, potenziell schwerwiegende Fehler zu vermeiden, die durch das Design verursacht werden und die durch den Code nicht abgemildert werden können. Und manchmal kann es schwierig sein, das übergeordnete Design nur aus dem Code abzuleiten.
-
Die Erstellung eines Systemmodells erfordert Zeit und Mühe. Und da nichts jemals statisch ist, braucht auch die Pflege eines Systemmodells Zeit. Das Design eines Systems wird sich ändern, wenn die Systemanforderungen als Reaktion auf die Umsetzung geändert werden, und du musst das Systemmodell mit allen Änderungen synchron halten.
Dies sind einige der Gründe, warum einige langjährige Mitglieder der Sicherheitsgemeinschaft Bedenken über den praktischen Einsatz der Bedrohungsmodellierung als defensive Aktivität während des Entwicklungslebenszyklus geäußert haben.4 Und um ehrlich zu sein, sinddiese Gründe eineHerausforderung.
Aber keine Angst! Die Sicherheits-Community ist ein zäher Haufen, der sich nie scheut, eine Herausforderung anzunehmen, um ein reales Problem zu lösen, vor allem wenn es dir Schmerzen, Ängste und schlaflose Nächte bereitet. Und Automatisierung kann helfen, diese Probleme zu lösen (siehe Abbildung 4-1).
Abbildung 4-1. "Sehr kleines Shell-Skript" (Quelle: https://oreil.ly/W0Lqo)
Das Schwierige an der Automatisierung ist die Komplexität der Systeme und die relative Unfähigkeit eines Programms, etwas zu tun, was das menschliche Gehirn besser kann: Mustererkennung.5 Die Schwierigkeit besteht darin, das System in einer Weise auszudrücken, die ein Computer verstehen kann, ohne das System selbst zu erstellen. Daher gibt es zwei verwandte Ansätze:
- Modellierung von Bedrohungen aus dem Code
-
Erstellen von Computercode in einer Programmiersprache oder in einer neu definierten domänenspezifischen Sprache (DSL), der bei seiner Ausführung dazu führt, dass die Analyse von Bedrohungen an einem Modell durchgeführt wird, das die bereitgestellten Eingabedaten darstellt
- Bedrohungsmodellierung mit Code (auch bekannt als Bedrohungsmodellierung im Code)
-
Verwendung eines Computerprogramms zur Interpretation und Verarbeitung der ihm übermittelten Informationen, um Bedrohungen oder Schwachstellen zu identifizieren
Beide Ansätze können effektiv sein, solange du das GIGO-Problem löst. Die Ergebnisse, die du erhältst, müssen in direktem Zusammenhang mit der Qualität deines Inputs (der Beschreibung des Systems und seiner Eigenschaften) für die Automatisierung stehen. Beide Methoden setzen außerdem voraus, dass die Algorithmen und Regeln, die bei der Analyse verwendet werden, "richtig" sind, so dass ein bestimmter Satz von Eingaben gültige und vertretbare Ausgaben erzeugt. Beide Implementierungen machen es überflüssig, dass spezialisierte Fachkräfte ein Systemmodell interpretieren und Informationen über Elemente, Verbindungen und Daten verstehen müssen, um die Indikatoren für ein potenzielles Sicherheitsproblem zu erkennen. Voraussetzung dafür ist natürlich, dass das Framework oder die Sprache diese Analyse unterstützt und so programmiert ist, dass sie korrekt ausgeführt wird.
Wir werden zunächst über die Erstellung eines Systemmodells in einem maschinenlesbaren Format sprechen und dann die Theorien für jede Art der automatisierten Bedrohungsmodellierung vorstellen und kommerzielle und Open-Source-Projekte nennen, die sie implementieren. Im weiteren Verlauf des Kapitels (und im nächsten Kapitel) nutzen wir diese Konzepte, um Informationen über weitere evolutionäre Bedrohungsmodellierungstechniken zu liefern, die in der sich schnell beschleunigenden Welt von DevOps und CI/CD funktionieren sollen.
Grundsätzlich beruht die Bedrohungsmodellierung auf Eingaben in Form von Informationen, die Daten enthalten oder kodieren, die für die Analyse ausreichen; diese Informationen ermöglichen es dir, Bedrohungen zu identifizieren. Wenn du für die Bedrohungsmodellierung keinen Code, sondern menschliche Intelligenz verwendest, beschreibst du das zu bewertende System (z. B. die Entitäten, Abläufe oder Ereignisfolgen, aus denen ein System besteht, zusammen mit den Metadaten, die für die Analyse und die Dokumentation der Ergebnisse erforderlich sind), und die Anwendung rendert und analysiert die Systemdarstellung, um Ergebnisse zu erzeugen, und stellt die Darstellung optional als Diagramme dar.
Bedrohungsmodellierung aus dem Code
Die Bedrohungsmodellierung aus dem Code verarbeitet Informationen über ein System, die in maschinenlesbarer Form gespeichert sind, um Informationen über Schwachstellen, Verwundbarkeiten und Bedrohungen auszugeben. Dies geschieht auf der Grundlage einer Datenbank oder einer Reihe von Regeln, nach denen gesucht werden sollte, und muss auf unerwartete Eingaben reagieren können (da diese Art von Anwendungen Eingabedaten zur Interpretation benötigen). Mit anderen Worten: Die Bedrohungsmodellierung aus dem Code ist ein interpretierter Ansatz zur Erstellung eines Systemmodells, aus dem Bedrohungen generiert werden.
Die Modellierung von Bedrohungen aus dem Code kann auch als Bedrohungsmodellierung im Code bezeichnet werden, wie zum Beispiel im Fall von Threatspec (beschrieben in "Threatspec").
Hinweis
Der Begriff "Bedrohungsmodellierung aus dem Code" ist eine Weiterentwicklung des Gedankens und kombiniert zwei Konzepte, wie ein System Informationen erfasst, verwaltet und verarbeitet, um Bedrohungen zu identifizieren. Die Idee der Bedrohungsmodellierung im Code stammt aus Gesprächen, die Izar mit Fraser Scott (dem Erfinder von Threatspec, siehe unten) geführt hat. Dabei ging es um die Idee, dass Codemodule die Systemdarstellung und Bedrohungsinformationen zusammen mit dem Code oder anderen Dokumenten speichern und während des gesamten Lebenszyklus pflegen können. Werkzeuge, die diese Informationen verarbeiten, können ausgeführt werden, um aussagekräftige Daten auszugeben. Bei der Bedrohungsmodellierung anhand von Code - entstanden aus einem anderen Gespräch zwischen Izar und dem Erfinder von ThreatPlaybook, Abhay Bhargav - können Bedrohungsinformationen zwar kodiert werden, müssen aber erst "verarbeitet" und in Beziehung gesetzt werden , um aussagekräftig zu sein. Gemeinsam bilden diese Paradigmen die Grundlage für den sich entwickelnden Bereich der Bedrohungsmodellierung als Code, bei dem die Interpretation und Manipulation von Daten aus verschiedenen Quellen die Schlüsseloperationen sind.
Wie es funktioniert
Bei der Bedrohungsmodellierung durch Code nutzt du ein Programm (Code), um Informationen zu analysieren, die in einem maschinenlesbaren Format ( ) erstellt wurden und ein Systemmodell, seine Komponenten und Daten über diese Komponenten beschreiben. Das Programm interpretiert das eingegebene Systemmodell und die Daten und verwendet eine Taxonomie von Bedrohungen und Schwachstellen sowie Erkennungskriterien, um (a) potenzielle Funde zu identifizieren und (b) Ergebnisse zu produzieren, die von einem Menschen interpretiert werden können. In der Regel ist die Ausgabe ein Textdokument oder ein Bericht im PDF-Format.
Threatspec
Threatspec ist ein Open-Source-Projekt, das sich sowohl an Entwicklungsteams als auch an Sicherheitspraktiker richtet. Es bietet eine bequeme Möglichkeit, Informationen über Bedrohungen zusammen mit dem Code zu dokumentieren und so eine Dokumentation oder einen Bericht zu erstellen, der fundierte Risikoentscheidungen ermöglicht. Threatspec wird von Fraser Scott auf https://threatspec.org entwickelt und gepflegt .
Hinweis
Threatspec wird hier in dieser Klasse von Tools genannt, weil es etwas tut, was es nicht tut:
-
Dafür muss es einen Code geben.
-
Es macht die Dokumentation von Bedrohungsinformationen einfacher.
-
Es führt keine eigene Analyse oder Bedrohungserkennung durch.
Die Verwendung von Threatspec hat u.a. folgende Vorteile
-
Bringt Sicherheit für Programmierer durch die Verwendung von Code-Annotationen (mit denen sie wahrscheinlich vertraut sind)
-
Ermöglicht es der Organisation, ein gemeinsames Lexikon der Bedrohungen und andere Strukturen zu definieren, die die Entwicklungsteams verwenden können
-
Erleichtert die Sicherheitsdiskussion über die Modellierung und Analyse von Bedrohungen
-
Erstellt automatisch eine ausführliche und nützliche Dokumentation, einschließlich Diagrammen und Codeschnipseln
Andererseits ist Threatspec zwar ein hervorragendes Tool, mit dem Programmierer ihren Code mit Bedrohungsinformationen versehen und so die Sicherheit stärker in den Entwicklungsprozess einbinden können, aber es hat auch ein paar Nachteile, die es zu beachten gilt.
Erstens setzt das Tool voraus, dass Code vorhanden ist oder zusammen mit Anmerkungen erstellt wird, was bedeuten kann, dass der Entwurf bereits gefestigt ist. In diesem Fall erstellt das Entwicklungsteam hauptsächlich eine Sicherheitsdokumentation, die sehr wertvoll ist, sich aber von der Bedrohungsmodellierung unterscheidet. Bei dieser Art von Projekten wird die Bedrohungsmodellierung "nach rechts verschoben", was in die falsche Richtung geht.
Die Threatspec-Dokumentation macht jedoch deutlich, dass das Tool am produktivsten in Umgebungen eingesetzt werden kann, in denen die DevOps-Mentalität vorherrscht, d.h. in denen alles als Code entwickelt wird. In diesen Umgebungen ist das Henne-Ei-Problem zwischen Design und Code-Entwicklung kein Thema. Threatspec bietet seit kurzem auch die Möglichkeit, Bedrohungen und Anmerkungen zu dokumentieren, ohne Code zu schreiben, indem diese Informationen in Klartextdateien gespeichert werden, die geparst werden können. Dies kann dazu beitragen, dieses potenzielle Problem für Teams zu entschärfen, die ihren Entwicklungszyklus stärker strukturieren oder strengere Systementwicklungsverfahren anwenden.
Zweitens benötigt das Entwicklungsteam Expertenwissen. Das Team braucht die Anleitung eines Experten, der weiß, was eine Bedrohung ist und wie sie zu beschreiben ist. Das bedeutet, dass du das Problem der Skalierbarkeit nicht direkt angehen kannst. Dieser Ansatz eignet sich, wie in der Dokumentation des Tools beschrieben, für Diskussionen oder angeleitete Übungen zwischen dem Entwicklungsteam und dem Sicherheitspersonal. Dabei wird die Skalierbarkeit jedoch weiter in Frage gestellt, da der Engpass des Sicherheitsexperten wieder hinzukommt. Ausführliche Schulungen der Entwicklungsteams können diese Hürde überwinden, oder die Einbindung von Sicherheitsexperten in die Entwicklungsgruppe kann dazu beitragen, dass die Gespräche näher am Ort und Zeitpunkt der Codeentwicklung stattfinden.
Hinweis
In Zukunft könnte Threatspec besonders geeignet sein, um aus den Ergebnissen statischer Code-Analysen Anmerkungen zu erstellen, die die Bedrohungen aus der Natur des Codes beschreiben (und nicht nur das, was die Programmierer selbst dokumentieren können oder wollen). Da Threatspec direkten Zugriff auf den Quellcode hat, kann es als Erweiterung Verifizierungsaktivitäten durchführen und Feedback direkt in den Quellcode geben, wenn es Bedrohungen, Risiken oder Schwachstellen entdeckt. Schließlich kann die Ausweitung der Bedrohungen auf die Bereiche funktionale Sicherheit und Datenschutz einen umfassenden Überblick über die Sicherheit, den Datenschutz und die Sicherheitslage eines Systems geben, was besonders wichtig ist, wenn man mit Compliance-Beauftragten oder Aufsichtsbehörden zu tun hat (z. B. für die Einhaltung von PCI-DSS, GDPR oder anderen Vorschriften) oder um die Ursachen- oder Gefahrenanalyse als Folgemaßnahme zu steuern.
Du kannst Threatspec von GitHub unter https://oreil.ly/NGTI8 beziehen . Es benötigt Python 3 und Graphviz, um zu laufen und Berichte zu erstellen. Der Ersteller/Maintainer von Threatspec ist in der Sicherheits-Community aktiv, insbesondere in der OWASP Threat Modeling Working Group und im Threatspec Slack, und ermutigt zu Beiträgen und Feedback zu dem Tool.
ThreatPlaybook
ThreatPlaybook ist ein Open-Source-Projekt von we45, das von Abhay Bhargav geleitet wird. Es wird als "DevSecOps-Framework [für] kollaborative Bedrohungsmodellierung zur Automatisierung von Anwendungssicherheitstests" vermarktet. Es richtet sich an Entwicklungsteams und bietet eine bequeme Möglichkeit, Bedrohungsinformationen zu dokumentieren und die Automatisierung der Erkennung und Überprüfung von Sicherheitslücken voranzutreiben. ThreatPlaybook hat eine stabile Version (V1) und eine Betaversion (V3); es gibt keine V2-Version.6
Hinweis
Die Spezialität von ThreatPlaybook ist es, die Nutzung von Informationen aus Bedrohungsmodellen zu erleichtern:
-
Es erleichtert die Dokumentation von Bedrohungsinformationen.
-
Es lässt sich mit anderen Sicherheitstools zur Orchestrierung und Validierung von Schwachstellen verbinden, z. B. durch dieAutomatisierung von Sicherheitstests.
-
Es führt keine eigene Analyse oder Bedrohungserkennung durch.
ThreatPlaybook nutzt GraphQL in MongoDB, und YAML-basierte Beschreibungen von Anwendungsfällen und Bedrohungen mit beschreibenden Konstrukten, um die Testorchestrierung für die Überprüfung von Schwachstellen zu unterstützen. Außerdem bietet es eine vollständige API, eine leistungsfähige Client-Anwendung und einen guten Berichtsgenerator. Für die Integration in die Testautomatisierung gibt es zwei Optionen: die ursprünglichen Robot Framework Libraries7 und in V3 die eigene Test Orchestration Framework-Funktionalität. Der Dokumentation ist zu entnehmen, dass ThreatPlaybook eine gute Integration (über das Robot Framework) mit dem OWASP Zed Attack Proxy, der Burp Suite von PortSwigger und npm-audit bietet.
Du kannst ThreatPlaybook von GitHub unter https://oreil.ly/Z2DZd oder über das Python-Dienstprogramm pip beziehen. Auf der Website findest du eine gute, wenn auch etwas spärliche Dokumentation und Videos, die dir erklären, wie du ThreatPlaybook installierst, konfigurierst und benutzt.
Bedrohungsmodellierung mit Code
Im Gegensatz zu den zuvor beschriebenen Threatspec und ThreatPlaybook ( ), die Beispiele für die Verwendung von Code zur Erleichterung der Bedrohungsmodellierung im Lebenszyklus der Systementwicklung sind, wird bei der Bedrohungsmodellierung mit Code eine Architektur- oder Systembeschreibung verwendet, die in einer Form wie einer der zuvor beschriebenen Beschreibungssprachen kodiert ist, und eine Analyse zur automatisierten Identifizierung von Bedrohungen und zur Berichterstattung durchgeführt. Dienstprogramme, die dem Paradigma "mit Code" folgen, sind Werkzeuge, die Systemmodellinformationen lesen und aussagekräftige Ergebnisse erzeugen können, die das Wissen und die Erfahrung von Sicherheitsexperten einschließen und es Sicherheitsexperten ermöglichen, eine größereEntwicklergemeinschaft zu erreichen.
Wie es funktioniert
Ein Benutzer schreibt ein Programm in einer Programmiersprache, um eine Darstellung eines Systems und seiner Komponenten sowie Informationen über diese Komponenten zu erstellen. Dieses Programm beschreibt die Informationen über das System in Form von Code und gibt die Bedingungen für die Durchführung der Analyse vor. Der daraus resultierende Prozess verwendet eine Reihe von APIs (Funktionen), um die Bedrohungsanalyse für den modellierten Systemzustand und die Eigenschaften durchzuführen. Wenn der "Quellcode" kompiliert und ausgeführt wird (oder interpretiert, je nach den Besonderheiten der verwendeten Sprache), liefert das resultierende Programm Erkenntnisse über Sicherheitsbedrohungen, die auf den Eigenschaften und Einschränkungen des modellierten Systems basieren.
Das Konzept, Modelle zu erstellen, ohne sie auf ein Whiteboard zu zeichnen, gibt es mindestens seit 1976, als A. Wayne Wymore, damals Professor an der University of Arizona, Systems Engineering Methodology for Interdisciplinary Teams (Wiley) veröffentlichte. Dieses und andere Bücher, die folgten, legten den Grundstein für den technischen Bereich, der als modellbasierte Systemtechnik (MBSE) bekannt ist. Die Lektionen, die die Industrie aus MBSE gelernt hat, haben die in Kapitel 1 erwähnten Konstrukte zur Systemmodellierung und die Sprachen zur Beschreibung von Systemen für die rechnerische Analyse beeinflusst, die wir kurz besprechen werden.8
Architekturbeschreibungssprachen (ADLs) beschreiben Darstellungen von Systemen. Mit den ADLs verwandt sind die Systementwurfssprachen (SDLs). Innerhalb der ADLs gibt es zwei verwandte Sprachen, die es ermöglichen, Systemmodelle zu erstellen und zu analysieren, um Sicherheitsbedrohungen zu erkennen:9
-
Die Beschreibungssprache Acme für die komponentenbasierte Systemmodellierung
Die Systemtechnik verwendet AADL, das größer und aussagekräftiger ist, wenn Systemmodelle von eingebetteten und Echtzeitsystemen erstellt. Dies gilt vor allem für die Bereiche Avionik und Automobilsysteme, die funktionale Sicherheit erfordern - die Eigenschaft, die Gesundheit und das Leben von Menschen zu schützen, wenn es um das Systemverhalten geht. ACME ist weniger ausdrucksstark und daher besser geeignet für Systeme, die weniger komplex sind oder eine geringere Größe haben (definiert durch die Anzahl der Komponenten und Interaktionen). ACME ist außerdem eine frei verfügbare Sprachspezifikation, während für AADL eine kostenpflichtige Lizenz erforderlich ist, obwohl es kostenloses Schulungsmaterial gibt, mit dem du dich mit der Sprache vertraut machen kannst.10
Diese Sprachen stellen einfache Konzepte vor, die System- und Softwareentwickler/innen auch heute noch verwenden. Vielleicht bemerkst du Ähnlichkeiten zu den Konzepten, die wir in Kapitel 1 beschrieben haben:
- Komponenten
-
Funktionseinheiten wie Prozesse oder Datenspeicher darstellen
- Verbinder
-
Aufbau von Beziehungen und Kommunikationswegen zwischen den Komponenten
- Systeme
-
spezifische Konfigurationen von Komponenten und Anschlüssen darstellen
- Häfen
-
Interaktionspunkte zwischen Komponenten und Anschlüssen
- Rollen
-
Nützliche Einblicke in die Funktion der Elemente innerhalb des Systems zu geben
- Eigenschaften, oder Anmerkungen
-
Informationen zu jedem Konstrukt bereitstellen, die für die Analyse oder Dokumentation verwendet werden können
Hinweis
Sowohl in ACME als auch in AADL existieren Ports als Verbindungspunkte zwischen Objekten und Flüssen. In unserer Diskussion über Modellierungstechniken wird dieses Konzept verwendet, sowohl durch Zeichnungen und manuelle Analysetechniken als auch durch automatisierte Methoden, die Objekte mit Eigenschaften verwenden. Wir empfehlen dies als Erweiterung des traditionellen DFD (wie in Kapitel 1 beschrieben), um die Lesbarkeit des Systemmodells zu verbessern. Dieses Konzept unterstützt auch die Einbeziehung von architektonischen Einschränkungen oder Fähigkeiten in das Systemmodell, da es bei komplexen Systemen mit mehreren Datenflüssen, die schwieriger zu analysieren sind, nicht einfach ist, Protokolle oder Schutzschemata allein auf die Datenflüsse anzuwenden. Die Verwendung von Ports hilft bei dieser Analyse und bei der Darstellung deines Diagramms.
Minimalistische Architekturbeschreibungssprache für die Bedrohungsmodellierung
Welche Informationen sind notwendig, um ein Systemmodell zu beschreiben und zu analysieren? Erinnern wir uns noch einmal an das, was du in Kapitel 1 über das Erstellen einer repräsentativen Zeichnung "von Hand" gelernt hast. Du brauchst Informationen zu den folgenden Punkten:
-
Die Entitäten, die im System existieren
-
Wie diese Einheiten interagieren - welche Elemente über Datenflüsse miteinander verbunden sind
-
Merkmale der Elemente und Datenflüsse
Dies sind die Kernanforderungen für die Beschreibung eines Systemmodells, damit die Automatisierung Muster erkennen kann, die potenzielle Schwächen und Bedrohungen darstellen. Genauer gesagt muss die Sprache oder die Konstrukte, die das System beschreiben, es dir ermöglichen, die grundlegenden Beziehungen zwischen den Entitäten zu spezifizieren und die Haupteinheiten von Elementen (und Sammlungen von Elementen), Ports und Datenflüssen zu beschreiben.
Außerdem solltest du Metadaten in die Eigenschaften der Objekte aufnehmen - das Wer, Was und Warum des Systems und seiner Elemente. Es gibt mehrere Gründe, warum dies notwendig ist, wenn du eine Darstellung des Systems erstellst, denn Metadaten bewirkenFolgendes:
-
Metadaten liefern Hintergrundinformationen, die dabei helfen, Lücken in den Sicherheitskontrollen und -prozessen zu identifizieren und einen Bericht oder ein Dokument zu erstellen, das das Entwicklungsteam verwenden wird. Zu diesen Metadaten gehören Angaben wie der Name des Objekts innerhalb des Systemmodells, der Name der Anwendung oder des Prozesses, wer oder welches Team für seine Implementierung und/oder Wartung verantwortlich ist und der allgemeine Zweck des Objekts innerhalb des Systems.
-
Weist jedem Objekt einen kurzen Bezeichner zu, damit es in Zukunft leichter zu referenzieren ist und um die Dokumentation und die Darstellung von Diagrammen zu erleichtern.
-
Ermöglicht es dir, spezifische Informationen wie den Wert (z. B. den finanziellen Wert oder die Bedeutung der Daten für die Nutzer des Systems) der von dem betreffenden System verwalteten und/oder gespeicherten Daten anzugeben. Du solltest auch angeben, welchen Wert die Funktionen des Systems haben, inwieweit das System die Risikoidentifizierung und -priorisierung unterstützt und andere Informationen, die zur Dokumentation benötigt werden. Diese Informationen sind nicht unbedingt notwendig, um Sicherheitsbedenken zu erkennen, aber sie sollten als notwendig erachtet werden, wenn du eine Risikobewertung, Priorisierung und Berichterstattung durchführst.
Elemente und Sammlungen
Objekte sind mit anderen Objekten innerhalb eines Systems verbunden und haben Eigenschaften, die für die Bedrohungsanalyse relevant sind; werden diese Objekte als Elemente bezeichnet. Elemente können einen Prozess, ein Objekt oder eine Person (Akteur) darstellen. Elemente repräsentieren auch Daten innerhalb eines Systems. Daten sind mit Elementen oder Datenströmen verknüpft (für weitere Informationen siehe "Daten und Datenströme").
Sammlungen sind eine besondere Form von Elementen. Sammlungen bilden eine abstrakte Beziehung Gruppierung von Elementen (und damit auch deren Datenflüsse oder beliebige verwaiste Elemente und/oder Ports), um Gemeinsamkeiten oder einen Bezugspunkt für die Analyse zu schaffen. Sie ermöglichen es dir, eine Gruppe von Elementen darzustellen, deren Wert oder Zweck dir in irgendeiner Weise wichtig ist. Die Gruppierung kann für die Analyse unabhängig von den Mitgliedern der Gruppe hilfreich sein - wenn bestimmte Elemente als Teil einer Gruppe funktionieren oder existieren, kann das Hinweise auf ihre gemeinsame Funktionalität geben, die jedes Element für sich genommen nicht anzeigen würde. Zu den empfohlenen Sammlungen gehören die folgenden:
- System
-
Damit kannst du angeben, dass eine Menge von Elementen zu einem größeren zusammengesetzten Element gehört. Für die Zeichnung und für die Analyse mit unterschiedlichen Granularitätsgraden kann ein System sowohl als Sammlung als auch als Element dargestellt werden. Wie wir in Kapitel 1 besprochen haben, gibt es beim Zeichnen von Systemmodellen ein Verfahren, das mit einem Element beginnt und es in seine repräsentativen Teile zerlegt. Erinnere dich daran, dass bei der Erstellung des Kontexts oder der ersten Ebene, auf der die Hauptkomponenten des Systems dargestellt sind, eine einzelne Form verwendet wurde, um eine Sammlung von Unterkomponenten darzustellen. Bei der Erstellung eines Systemmodells in einer Beschreibungssprache müssen die repräsentativen Teile einzeln angegeben und der Einfachheit halber gruppiert werden (in der Regel durch Zuweisung einer gemeinsamen Bezeichnung oder eines Indikators für ihre Beziehungen zueinander).
- Ausführungskontext
-
Es ist von entscheidender Bedeutung, den Kontext, in dem ein Prozess ausgeführt wird, oder den Umfang einer Dateneinheit, bei der Analyse berücksichtigen zu können. Verwende eine Sammlung von Ausführungskontexten, um Prozesse mit anderen Dingen wie virtuellen oder physischen CPUs, Rechenknoten, Betriebssystemen usw. in dem Bereich, in dem sie ausgeführt werden, zu verknüpfen. Dies hilft dir, kontextübergreifende Probleme und andere Möglichkeiten des Missbrauchs zu erkennen.
- Grenze des Vertrauens
-
Eine Sammlung von Elementen kann rein abstrakt und/oder willkürlich sein und benötigt keine physische oder virtuelle Nachbarschaft, um für dich Bedeutung zu haben. Zum Zeitpunkt der Definition der Objekte im Systemmodell sind möglicherweise noch nicht alle Systemkomponenten bekannt. Daher kann es hilfreich sein, eine Menge von Elementen als Sammlung zu assoziieren, die eine Vertrauensbeziehung teilen oder bei denen sich das Vertrauen zwischen ihnen und anderen Elementen, die nicht in der Sammlung enthalten sind, ändert.
Die mit den Knoten verbundenen Informationen - ein anderer Name für Elemente - werden als Eigenschaften oder Merkmale des Objekts kodiert und liefern wichtige Informationen für die Analyse und Dokumentation. Um die korrekte Überprüfung des Systemmodells und die Analyse von Bedrohungen zu unterstützen, müssen die Elemente grundlegende Eigenschaften haben.11 Ein repräsentatives Beispiel wird hier gezeigt:
Element:containsexposescallsis_type:-cloud.saas-cloud.iaas-cloud.paas-mobile.ios-mobile.android-software-firmware.embedded-firmware.kernel_mod-firmware.driver-firmware-hardware-operating_system-operating_system.windows.10-operating_system.linux-operating_system.linux.fedora.23-operating_system.rtosis_containerizeddeploys_to:-windows-linux-mac_os_x-aws_ec2provides-protection-protection.signed-protection.encrypted-protection.signed.cross-protection.obfuscatedpackaged_as:-source-binary-binary.msi-archivesource_language:-c-cpp-pythonuses.technology:-cryptography-cryptography.aes128-identity-identity.oauth-secure_boot-attestationrequires:-assurance-assurance.privacy-assurance.safety-assurance.thread_safety-assurance.fail_safe-privileges.root-privileges.guestmetadata:-name-label-namespace-created_by-ref.source.source-ref.source.acquisition-source_type.internal-source_type.open_source-source_type.commercial-source_type.commercial.vendor-description

Liste (Array oder Wörterbuch) der Elemente, die mit diesem Element verbunden sind (z. B. für ein System von Systemen), die Daten enthalten können
Liste der Hafenknoten

Ein Element zum anderen, um einen Datenfluss herzustellen

Elemente haben einen Typ (generisch oder spezifisch)

Boolesche Merkmale können Wahr oder Falsch sein, oder (gesetzt) oder (nicht gesetzt)

Generisches Schutzsystem

Nutzung der Microsoft Authenticode Cross-Signatur-Unterstützung

In welcher Form ist das Element in Gebrauch?

Wenn das System Software ist oder enthält, welche Sprache(n) wird/werden verwendet?

Spezifische Technologie oder Fähigkeiten, die von der Komponente genutzt werden

Was braucht das Bauteil, um zu existieren, oder was wird vorausgesetzt?
Setze nur Werte, die zutreffen. Achte auf widersprüchliche Attribute

Allgemeine Informationen für Berichte, Referenzen und andere Unterlagen

Verweis auf den Ort, an dem sich der Quellcode oder die Dokumentation befindet

Hinweis darauf, woher diese Komponente stammt (z. B. Projektstandort)

Diese Komponente war intern Quelle
Elemente sollten bestimmte Beziehungen zu anderen Entitäten oder Objekten unterstützen:
-
Elemente können andere Elemente enthalten.
-
Ein Element kann einen Port zur Verfügung stellen (Ports werden im nächsten Abschnitt beschrieben).
-
Ports sind mit Daten verbunden.
-
-
Elemente können sich über einen Port mit anderen Elementen verbinden und so einen Datenfluss herstellen.
-
Ein Element kann ein anderes Element aufrufen (z. B. wenn eine ausführbare Datei eine gemeinsam genutzte Bibliothek aufruft).
-
Ein Element kann Daten lesen oder schreiben. (Datenobjekte werden in "Daten und Datenflüsse" beschrieben) .
Häfen
Ports bieten einen Zugangs- oder Verbindungspunkt, an dem Interaktionen zwischen Knoten stattfinden. Ports werden von Knoten (insbesondere von Knoten, die Prozesse darstellen) offengelegt und sind mit einem Protokoll verbunden. Ports legen auch Anforderungen an ihre Sicherheit fest, z. B. die Erwartung an die Sicherheit der nachfolgenden Kommunikation, die über den Port läuft. Einige dieser Methoden stammen von dem Knoten, der den Port offenlegt (z. B. ein Knoten, der einen Port für den durch TLS geschützten Datenverkehr öffnet), oder von dem Port selbst (z. B. für eine physisch sichere Schnittstelle).
Für den Konsum und die Lesbarkeit durch ein Computerprogramm,12 ist es unerlässlich, die Kommunikationsflüsse pro Protokoll zu identifizieren und zu trennen. Da verschiedene Protokolle unterschiedliche Konfigurationsmöglichkeiten bieten, die sich auf die Gesamtsicherheit des Entwurfs auswirken können, solltest du eine Überlastung der Kommunikationsflüsse vermeiden. So sollte ein HTTPS-Server, der sowohl RESTful-Interaktionen als auch WebSockets über denselben Dienst und denselben Port zulässt, zwei Kommunikationsflüsse verwenden. Ebenso sollte ein Prozess, der sowohl HTTP als auch HTTPS über dieselbe Schnittstelle unterstützt, im Modell mit unterschiedlichen Kommunikationskanälen beschrieben werden. Das erleichtert die Analyse des Systems.
Zu den Eigenschaften, die sich auf Häfen beziehen, gehören die folgenden:
Port:requires:-security-security.firewallprovides:-confidentiality-integrity-qos-qos.delivery_receiptprotocol:-I2C-DTLS-ipv6-btle-NFSdata:-incoming-outbound-service_name-portmetadata:-name-label-description
Was wird in diesem Hafen benötigt oder erwartet?
Wenn diese Option gesetzt ist, wird erwartet, dass eine Art von Sicherheitsmechanismus zum Schutz des Ports vorhanden ist.
Dieser Port muss durch eine Firewall geschützt sein (als Beispiel für einen speziellen Sicherheitsschutz)
Welche Möglichkeiten bietet der Hafen?
Welches Protokoll verwendet der Anschluss?13
Bluetooth Low Energy
Netzwerk-Dateisystem
Welche Daten sind mit diesem Anschluss verbunden?
Daten, die an diesen Anschluss übermittelt werden (Datenknoten, Liste)
Daten, die von diesem Anschluss übermittelt werden (Datenknoten, Liste)
Beschreibe den Dienst, den du anbietest, vor allem, wenn dieses Objekt einen bekannten Dienst darstellt.14
Numerische Portnummer, falls bekannt (nicht flüchtig)
Allgemeine Informationen für Berichte, Referenzen und andere Unterlagen
Daten und Datenflüsse
Datenflüsse (siehe Kapitel 1 für Beispiele von Datenflüssen) werden manchmal auch als Kanten bezeichnet, weil sie Verbindungslinien in einem Diagramm werden.15 Datenflüsse sind die Pfade, auf denen sich Datenobjekte zwischen Elementen (und durch Ports) bewegen.
Du fragst dich vielleicht, warum es wichtig oder sinnvoll ist, Daten von Datenströmen zu trennen. Die Antwort ist, dass ein Kommunikationskanal in der Regel nur ein Weg oder eine Leitung ist, über die beliebige Informationen fließen können, ähnlich wie eine Autobahn. Der Datenkanal selbst hat normalerweise keinen Zusammenhang mit der Sensibilität der Daten, die durch ihn fließen. Er hat auch keinen Sinn für den Geschäftswert, die Kritikalität oder andere Faktoren, die sich auf die Nutzung oder die Schutzanforderungen auswirken können. Indem du Datenknoten verwendest und sie mit Datenflüssen verbindest, kannst du eine Abstraktion erstellen, die ein System darstellt, das verschiedene Arten von Daten über Datenflüsse weiterleitet.
Es mag offensichtlich sein, aber du solltest die restriktivste Klassifizierung der Daten, die den Datenfluss durchlaufen, als Datenklassifizierung für den Datenfluss selbst festlegen, da dies die Anforderungen an den Datenfluss bestimmt, um die Daten zu schützen, die ihn durchlaufen. Das bedeutet, dass verschiedene Kombinationen von Daten, die mit den Datenströmen verbunden sind, getestet werden können, um vorherzusagen, wann ein Sicherheitsproblem auftreten könnte.
Dies sind einige vorgeschlagene Eigenschaften für Daten:
Data:encoding:-json-protobuf-ascii-utf8-utf16-base64-yaml-xmlprovides:-protection.signed-protection.signed.xmldsig-protection.encryptedrequires:-security-availability-privacy-integrityis_type:-personal-personal.identifiable-personal.health-protected-protected.credit_info-voice-video-securitymetadata:-name-label-description
Art der Daten, die dieses Objekt repräsentiert
Allgemeine Informationen für Berichte, Referenzen und andere Unterlagen
Beliebige benutzerdefinierte Informationen
Dienste, die den Port offenlegen, definieren die Fähigkeiten und Eigenschaften des Datenflusses (der Datenfluss erbt die Eigenschaften, die durch den Port repräsentiert werden). Datenflüsse können dennoch von Metadaten profitieren, die es ihnen ermöglichen, die einzelnen Flüsse zu unterscheiden, wenn sie z. B. ein Diagramm oder einen Bericht erstellen.
Andere Modellbeschreibungssprachen
Um dein Wissen zu vervollständigen, wollen wir noch ein paar andere Sprachen besprechen, von denen einige in die Kategorie SDL passen. Wir ermutigen dich, sie zu erforschen, wenn du interessiert bist.
Das Common Information Model (CIM) ist ein Standard der Distributed Management Task Force (DMTF) zur detaillierten Beschreibung eines Computersystems und seiner Eigenschaften. Du kannst CIM und Varianten wie SBLIM für Linux-Systeme verwenden, um die Konfiguration eines Systems zu verstehen und zu dokumentieren, z. B. für die Orchestrierung von Richtlinien und das Konfigurationsmanagement. Einen Leitfaden für die Art der Daten, die du beim Beschriften von Systemmodellen verwenden kannst, findest du in der Liste der verfügbaren Eigenschaften, die CIM für die in der Spezifikation beschriebenen Systeme anbietet.
Die Unified Modeling Language (UML) ist ein Standard der Object Management Group (OMG) , der sich stark auf die Beschreibung von softwarezentrierten Systemen konzentriert. Du bist vielleicht schon mit der UML vertraut, denn sie wird in der Regel im Rahmen des Informatikunterrichts gelehrt. Das Sequenzdiagramm (das wir in Kapitel 1 besprochen haben) ist ein Teil der UML-Spezifikation. In letzter Zeit wurden auf akademischer Ebene Forschungsarbeiten vorgestellt, in denen die UML eher für die Beschreibung von Softwaresystemen verwendet wird, wenn es darum geht, Bedrohungen zu erkennen, als für die Analyse zur Identifizierung dieser Bedrohungen.16
Die Systems Modeling Language (SysML) ist ebenfalls ein OMG-Standard. Diese Variante der UML ist so konzipiert, dass sie direkter für die Systementwicklung (und nicht nur für die Softwareentwicklung) anwendbar ist als die UML. SysML fügt der UML zwei Diagrammtypen hinzu und ändert einige der anderen Diagrammtypen geringfügig, um softwarespezifische Konstrukte zu entfernen, reduziert aber insgesamt die Anzahl der verfügbaren Diagramme von 13 auf 9.17 Theoretisch wird SysML dadurch "leichter" und funktionaler für die allgemeine Systemtechnik. Unternehmen und Organisationen, die sich auf stark strukturierte Systems-Engineering-Prozesse verlassen, und natürlich auch die Wissenschaft haben Fallstudien darüber veröffentlicht, wie SysML für die Modellierung von Systemen für Bedrohungen eingesetzt werden kann, obwohl zum Zeitpunkt der Erstellung dieses Artikels nur wenige Fallstudien verfügbar sind, die die Automatisierung der Analyse für Bedrohungen zeigen.18,19
Die Arten von Systemmodellen oder Abstraktionen, die sowohl in der UML als auch in der SysML zur Verfügung stehen, und die Daten, die mit ihnen verknüpft werden können, sind entscheidend für die Anwendung im Bereich der Bedrohungsmodellierung, insbesondere der Bedrohungsmodellierung über Code. Beide bieten die Möglichkeit, Objekte und Interaktionen sowie Parameter über diese Objekte und Interaktionen zu spezifizieren. Beide verwenden außerdem XML als Datenaustauschformat. XML ist so konzipiert, dass es von Computeranwendungen verarbeitet werden kann, was es ideal für die Erstellung von Systemmodellen macht, die du auf Bedrohungen analysieren kannst.
Analyse von Diagrammen und Metadaten
Betrachten wir einen Moment lang das einfache Beispiel in Abbildung 4-2.

Abbildung 4-2. Einfaches Client/Server-Systemmodell
Diese Anmerkungen begleiten das Systemdiagramm in Abbildung 4-2:
-
Der Client ist in C geschrieben und ruft den Server auf Port 8080 an, um den Benutzer des Clients zu authentifizieren.
-
Der Server prüft eine interne Datenbank, und wenn die vom Kunden gesendeten Informationen mit den Erwartungen übereinstimmen, sendet der Server ein Autorisierungs-Token an den Kunden zurück.
Setze deinen Sicherheits-Hut auf (siehe Einleitung, wenn du dich über Authentifizierung und andere Schwachstellen informieren willst) und identifiziere die Sicherheitsprobleme in diesem einfachen Systemmodell.20 Denk darüber nach, wie du zu diesem Ergebnis gekommen bist. Du hast dir (wahrscheinlich) das Systemmodell angesehen, die Informationen in Form von Anmerkungen betrachtet und potenzielle Bedrohungen ermittelt. Du hast eine Musteranalyse mit einer Datenbank von Bedrohungsinformationen durchgeführt, die in deinem Gedächtnis gespeichert ist. Das ist eine der Herausforderungen der Skalierbarkeit - es gibt nicht genug "Speicher" und "Rechenleistung" für alle.
Diese Musteranalyse und Extrapolation ist für das menschliche Gehirn leicht zu bewerkstelligen. Mit dem richtigen Wissen kann unser Gehirn leicht Muster erkennen und Hochrechnungen anstellen. Wir haben sogar ein Unterbewusstsein, das uns ein "Bauchgefühl" für unsere Analyse gibt. Wir stellen Verbindungen zu und zwischen Dingen her, die zufällig und mehrdeutig erscheinen. Wir verarbeiten nicht einmal alle Schritte, die unser Gehirn bei der Arbeit macht; unsere Gedanken "passieren einfach". Im Gegensatz zu unserem Gehirn können Computer Dinge schnell erledigen, aber sie müssen sich über jeden Schritt und jeden Prozess bewusst sein, der notwendig ist. Computer können keine Schlüsse ziehen oder Vermutungen anstellen. Was für uns selbstverständlich ist, muss also für Computer programmiert werden.
Wie würde also ein Computerprogramm dieses Szenario analysieren?
Zuerst musst du einen Rahmen für die Analyse entwickeln. Dieser Rahmen muss in der Lage sein, Eingaben (vom Modell) zu akzeptieren und Muster zu analysieren, Schlüsse zu ziehen, Verbindungen herzustellen und gelegentlich zu raten, um ein Ergebnis zu erzielen, das Menschen als sinnvoll interpretieren können. Bist du schon bereit für die KI?
Eigentlich ist es keine große Herausforderung, und das schon seit geraumer Zeit nicht mehr. Der grundlegende Ansatz ist einfach:
-
Erstelle ein Format, um eine Systemdarstellung mit Informationen zu beschreiben, z.B. mit einer ADL.
-
Erstelle ein Programm, das die Informationen des Systemmodells interpretiert.
-
Erweitere das Programm, um eine Analyse auf der Grundlage einer Reihe von Regeln durchzuführen, die die Informationsmuster im Systemmodell bestimmen.
Schauen wir uns also noch einmal das einfache Beispiel in Abbildung 4-3 an.

Abbildung 4-3. Einfaches Client/Server-Systemmodell - neu betrachtet
Nun wollen wir unsere idealisierte Beschreibungssprache vom Anfang des Kapitels verwenden, um die Informationen im Systemmodell zu beschreiben. Um jedes Objekt im Systemmodell eindeutig zu referenzieren, verwenden wir einen Platzhalter für jedes Objekt und verbinden Eigenschaften mit diesem Bezeichner:
# Describe 'Node1' (the client)Node1.name:clientNode1.is_type:softwareNode1.source_language:cNode1.packaged_type:binary# Describe 'Node2' (the server)Node2.name:serverNode2.is_type:software# Describe 'Node3' (an exposed port)Node3.is_type:portNode3.port:8080Node3.protocol:http# Establish the relationshipsNode2.exposes.port:Node3Node1.connects_to:Node3# Describe the data that will be passed on the channelData1.is_type:credentialData1.requires:[confidentiality,integrity,privacy]Data1.metadata.description:"Datacontainsacredentialtobecheckedbytheserver"Data2.is_type:credentialData2.requires:[confidentiality,integrity]Data2.metadata.description:"Datacontainsasessiontokenthatgives/authorizationtoperformactions"Node3.data.incoming = Data1Node3.data.outbound = Data2
In dem vorangegangenen Beispiel (das wir uns komplett ausgedacht und nur zum Zweck der Erklärung erstellt haben), fallen dir vielleicht ein oder zwei Dinge auf, die dir Sorgen bereiten. Dein menschliches Gehirn ist in der Lage, Rückschlüsse auf die Bedeutung der Eigenschaften zu ziehen und darauf, wie das System aussehen könnte. In Kapitel 3 hast du gelernt, wie du einige der Schwachstellen in einem Beispielsystem ermitteln kannst.
Aber wie soll ein Computerprogramm diese Aufgabe erfüllen? Es muss dazu programmiert werden - es braucht eine Reihe von Regeln und Strukturen, um Informationen zusammenzufügen und die für die Analyse notwendigen Ergebnisse zu erzielen.
Um Regeln zu erstellen, muss man sich die verfügbaren Quellen für Bedrohungen ansehen und die "Indikatoren" identifizieren, die auf eine mögliche Bedrohung hinweisen. Die CWE Architectural Concepts Liste oder CAPEC Mechanisms of Attack sind hervorragende Quellen, die duberücksichtigen solltest.
Hinweis
Du hast vielleicht bemerkt, dass wir im gesamten Buch mehrfach auf die Datenbanken CWE und CAPEC verweisen. Wir nutzen diese Datenbanken besonders gerne als zentrale Ressourcen, weil sie offen und öffentlich sind und viele verwertbare und anwendbare Informationen enthalten, die von Experten aus der gesamten Sicherheitsgemeinschaft beigetragen wurden.
Für unsere Demonstration schauen wir uns zwei mögliche Quellen für eine Regel an:
CWE-319 sagt uns, dass die Schwachstelle auftritt, wenn "die Software sensible oder sicherheitskritische Daten im Klartext über einen Kommunikationskanal überträgt, der von Unbefugten abgehört werden kann". Anhand dieser einfachen Beschreibung solltest du in der Lage sein, die Indikatoren zu erkennen, die vorhanden sein müssen, damit eine potenzielle Bedrohung in einem System besteht:
-
Ein Prozess: Dieser führt eine Aktion aus.
-
"Sendet": Die Softwareeinheit kommuniziert mit einer anderen Komponente.
-
"Sensible oder sicherheitskritische Daten": Daten, die für einen Angreifer wertvoll sind.
-
Ohne Verschlüsselung: Auf dem Kanal oder zum direkten Schutz der Datenpakete (eine dieser Bedingungen muss gegeben sein).
-
Auswirkungen: Vertraulichkeit.
CAPEC-157 beschreibt einen Angriff auf sensible Informationen wie folgt: "Bei diesem Angriffsmuster fängt der Angreifer Informationen ab, die zwischen zwei dritten Parteien übertragen werden. Der Angreifer muss in der Lage sein, den Kommunikationsverkehr zu beobachten, zu lesen und/oder zu hören, aber nicht unbedingt die Kommunikation zu blockieren oder ihren Inhalt zu verändern. Theoretisch kann jedes Übertragungsmedium abgehört werden, wenn der Angreifer den Inhalt zwischen Sender und Empfänger untersuchen kann." Aus dieser Beschreibung geht hervor, wie ein Angreifer diesen Angriff durchführen kann:
-
Der Verkehr zwischen zwei Parteien (Endpunkten) wird abgefangen.
-
Der Angriff ist passiv; es wird keine Veränderung oder Denial-of-Service erwartet.
-
Der Angreifer (Akteur) benötigt Zugriff auf den Kommunikationskanal.
Mit diesen beiden Beschreibungen können wir also die folgenden einheitlichen Regeln (im Text) in Betracht ziehen:
-
Der Quell-Endpunkt kommuniziert mit dem Ziel-Endpunkt.
-
Der Datenfluss zwischen den Endpunkten enthält sensible Daten.
-
Der Datenfluss ist nicht für die Vertraulichkeit geschützt.
Die Auswirkungen dieser Bedingungen in einem System würden es einem böswilligen Akteur ermöglichen, sensible Daten durch Sniffing zu erhalten.
Der Code zur Erkennung dieses Musters und zur Anzeige des Vorhandenseins einer Bedrohung könnte wie folgt aussehen (in Pseudocode, ohne alle Sicherheitsüberprüfungen):
defevaluate(noden,"Threat from CWE-319"):ifn.is_typeis"software":foriinrange(0,len(n.exposes)):return(n.exposes[i].p.data.incoming[0].requires.security)and(n.exposes[i].p.provides.confidentiality)
Dies ist ein extrem vereinfachtes Beispiel dafür, was ein Tool oder eine Automatisierung leisten könnte. Sicherlich gibt es effizientere Algorithmen für diesen Musterabgleich, aber ich hoffe, dieses Beispiel gibt dir eine Vorstellung davon, wie die Bedrohungsmodellierung Code zur automatischen Erkennung von Bedrohungen nutzt.
Während die Bedrohungsmodellierung mit Code ein ziemlich toller Trick ist, macht die Bedrohungsmodellierung mit Code die Technologie potenziell leichter zugänglich. Anstatt Code zur Verwaltung von Bedrohungsinformationen zu verwenden oder ein Programm zur Analyse einer textuellen Beschreibung eines Modells "mit Code" einzusetzen, um Konstrukte mit Regeln zur Bestimmung von Bedrohungen abzugleichen, wird ein Programm geschrieben, das bei der Ausführung die Analyse und Darstellung der Bedrohungsmodelle "automatisch" durchführt.
Damit dies möglich ist, muss ein Programmautor Programmlogik und APIs erstellen, um Elemente, Datenflüsse usw. und die Regeln, nach denen sie analysiert werden, zu beschreiben. Die Entwickler nutzen dann die APIs, um ausführbare Programme zu erstellen. Die Ausführung des Programmcodes (mit oder ohne Vorkompilierung, abhängig von der Sprachwahl für die APIs) führt zu diesen grundlegenden Schritten:
-
Übersetze die Direktiven, die Objekte beschreiben, um eine Darstellung des Systems zu erstellen (z. B. einen Graphen, ein Array von Eigenschaften oder eine andere programminterne Darstellung).
-
Lade eine Reihe von Regeln.
-
Gehe den Graphen der Objekte durch, indem du den Musterabgleich mit dem Regelwerk durchführst, um die Ergebnisse zu ermitteln.
-
Erzeuge Ergebnisse auf der Grundlage von Templates für die Erstellung eines Diagramms, das (hoffentlich) für Menschen visuell akzeptabel ist, und für die Ausgabe von Details der Ergebnisse.
Das Schreiben von Code zur automatischen Generierung von Bedrohungsinformationen bietet einige Vorteile:
-
Als Programmierer bist du es bereits gewohnt, Code zu schreiben, also bietet dir das die Möglichkeit, etwas zu deinen Bedingungen zu tun.
-
Die Modellierung von Bedrohungen als Code fügt sich nahtlos in die "Everything as Code"- oder DevOps-Philosophie ein.
-
Du kannst den Code einchecken und unter Revisionskontrolle halten, und zwar mit Tools, an die du als Entwickler/in bereits gewöhnt bist, was sowohl die Übernahme als auch die Verwaltung der Informationen erleichtern sollte.
-
Wenn die APIs und Bibliotheken, die das Wissen und die Erfahrung von Sicherheitsexperten enthalten, die Möglichkeit bieten, Regeln für die Analyse dynamisch zu laden, kann ein und dasselbe Programm mehrere Domänen bedienen. Ein Programm kann ein zuvor im Code beschriebenes System neu analysieren, wenn neue Forschungsergebnisse oder Bedrohungsdaten neue Bedrohungen aufdecken, sodass es immer auf dem neuesten Stand ist, ohne dass das Modell geändert oder die Arbeit wiederholt werden muss.
Diese Methode hat aber auch ein paar Nachteile, die du beachten solltest:
-
Entwickler wie du schreiben bereits jeden Tag Code, um einen Mehrwert für dein Unternehmen oder deine Kunden zu schaffen. Zusätzlichen Code zu schreiben, um deine Architektur zu dokumentieren, mag wie eine zusätzliche Belastung erscheinen.
-
Bei der Vielzahl an Programmiersprachen, die es heutzutage gibt, kann es eine Herausforderung sein, unter ein Codepaket zu finden, das eine Sprache verwendet, die dein Entwicklungsteam nutzt (oder deren Integration unterstützt).
-
Der Schwerpunkt liegt nach wie vor auf den Entwicklern, die als Hüter des Codes Konzepte wie objektorientierte Programmierung und Funktionen (und Aufrufkonventionen usw.) verstehen müssen.
Diese Herausforderungen sind nicht unüberwindbar, aber der Bereich der Bedrohungsmodellierung aus Code ist noch unausgereift. Das beste Beispiel für ein Codemodul und eine API für die Bedrohungsmodellierung aus dem Code ist pytm.
Hinweis
Haftungsausschluss: Wir sind wirklich, wirklich, wirklich voreingenommen gegenüber pytm, als Ersteller/Leiter des Open-Source-Projekts. Wir wollen in diesem Buch allen großartigen Innovationen auf dem Gebiet der Automatisierung von Bedrohungsmodellen gerecht werden. Aber wir sind wirklich der Meinung, dass pytm eine Lücke in den Methoden geschlossen hat, die Sicherheitspraktikern und Entwicklungsteams zur Verfügung stehen, um die Bedrohungsmodellierung für sie praktikabel und effektiv zu machen.
pytm
Einer der Hauptgründe, warum wir dieses Buch geschrieben haben, war der aufrichtige Wunsch, dass Personen, die mit der Entwicklung zu tun haben, sofort zugängliche Informationen erhalten, die ihnen helfen, ihre Sicherheitsfähigkeiten im Lebenszyklus der sicheren Softwareentwicklung weiterzuentwickeln. Deshalb sprechen wir über Schulungen, die Herausforderung, "wie ein Hacker zu denken", Angriffsbäume und Bedrohungsbibliotheken, Regelmaschinen und Diagramme.
Als erfahrene Sicherheitspraktiker haben wir schon viele Argumente von Entwicklungsteams gegen den Einsatz von Bedrohungsmodellierungswerkzeugen gehört: "Es ist zu schwer!", "Es ist nicht plattformunabhängig; ich arbeite mit X, und das Tool funktioniert nur mit Y!", "Ich habe keine Zeit, eine weitere Anwendung zu lernen, und für diese muss ich eine ganz neue Syntax lernen!" Abgesehen von den vielen Ausrufezeichen besteht ein gemeinsames Muster in diesen Erklärungen darin, dass der/die Programmierer/in aufgefordert wird, aus seiner/ihrer unmittelbaren Komfortzone herauszutreten und eine weitere Fähigkeit zu seinem/ihrem Werkzeugkasten hinzuzufügen oder einen vertrauten Arbeitsablauf zu unterbrechen und einen fremden Prozess hinzuzufügen. Wir dachten uns also, was wäre, wenn wir stattdessen versuchen würden, den Prozess der Bedrohungsmodellierung an einen Prozess anzunähern, der den Programmierer/innen bereits vertraut ist?
Ähnlich wie bei der kontinuierlichen Bedrohungsmodellierung (die wir in Kapitel 5 ausführlich beschreiben) hilft der Rückgriff auf Tools und Prozesse, die dem Entwicklungsteam bereits bekannt sind, dabei, Gemeinsamkeit und Vertrauen in den Prozess zu schaffen. Ihr seid bereits mit ihnen vertraut und nutzt sie täglich.
Dann haben wir uns die Automatisierung angesehen. Welche Bereiche der Bedrohungsmodellierung stellten für das Entwicklungsteam die größten Herausforderungen dar? Die üblichen Verdächtigen meldeten sich zu Wort: Bedrohungen identifizieren, Diagramme und Anmerkungen erstellen und das Bedrohungsmodell (und damit auch das Systemmodell) mit minimalem Aufwand aktuell halten. Wir sprachen über Beschreibungssprachen, aber sie fielen in die Kategorie "noch eine Sache, die das Team lernen muss", und ihre Anwendung fühlte sich im Entwicklungsprozess schwer an, während die Teams versuchten, ihn zu vereinfachen. Wie könnten wir dem Entwicklungsteam helfen, sein Ziel (Effizienz/Zuverlässigkeit) zu erreichen und gleichzeitig unser Ziel der Sicherheitsbildung zu verwirklichen?
Dann kam uns der Gedanke: Warum nicht ein System als Sammlung von Objekten objektorientiert beschreiben, und zwar mit einer allgemein bekannten, leicht zugänglichen und vorhandenen Programmiersprache, und daraus Diagramme und Bedrohungen erstellen? Füge Python hinzu, und schon hast du es: eine Python-Bibliothek für die Bedrohungsmodellierung.
Erhältlich unter https://oreil.ly/nuPja (und unter https://oreil.ly/wH-Nl als OWASP Incubator Projekt), hat pytm im ersten Jahr seines Bestehens das Interesse vieler Mitglieder der Threat Modeling Community geweckt. Die interne Anwendung in unseren und anderen Unternehmen, Vorträge und Workshops von Jonathan Marcil auf beliebten Sicherheitskonferenzen wie OWASP Global AppSec DC und Diskussionen auf dem Open Security Summit und sogar die Verwendung durch Trail of Bits in seinem Kubernetes-Bedrohungsmodell zeigen, dass wir uns in die richtige Richtung bewegen!
Hinweis
pytm ist eine Open-Source-Bibliothek, die von den Diskussionen, der Arbeit und Ergänzungen einzelner Personen wie Nick Ozmore und Rohit Shambhuni, die das Tool mitentwickelt haben, sowie Pooja Avhad und Jan Was, die für viele zentrale Patches und Verbesserungen verantwortlich sind, immens profitiert hat. Wir freuen uns auf die aktive Beteiligung der Community, um das Tool zu verbessern. Betrachte dies als einen Aufruf zum Handeln!
Hier ist eine Beispielsystembeschreibung mit pytm:
#!/usr/bin/env python3frompytm.pytmimportTM,Server,Datastore,Dataflow,Boundary,Actor,Lambdatm=TM("my test tm")tm.description="This is a sample threat model of a very simple system - a /web-basedcommentsystem.Theuserenterscommentsandtheseareaddedtoa/databaseanddisplayedbacktotheuser.Thethoughtisthatitis,though/simple,acompleteenoughexampletoexpressmeaningfulthreats."User_Web=Boundary("User/Web")Web_DB=Boundary("Web/DB")user=Actor("User")user.inBoundary=User_Webweb=Server("Web Server")web.OS="CloudOS"web.isHardened=Truedb=Datastore("SQL Database (*)")db.OS="CentOS"db.isHardened=Falsedb.inBoundary=Web_DBdb.isSql=Truedb.inScope=Falsemy_lambda=Lambda("cleanDBevery6hours")my_lambda.hasAccessControl=Truemy_lambda.inBoundary=Web_DBmy_lambda_to_db=Dataflow(my_lambda,db,"(λ)Periodically cleans DB")my_lambda_to_db.protocol="SQL"my_lambda_to_db.dstPort=3306user_to_web=Dataflow(user,web,"User enters comments (*)")user_to_web.protocol="HTTP"user_to_web.dstPort=80user_to_web.data='Comments in HTML or Markdown'user_to_web.order=1web_to_user=Dataflow(web,user,"Comments saved (*)")web_to_user.protocol="HTTP"web_to_user.data='Ack of saving or error message, in JSON'web_to_user.order=2web_to_db=Dataflow(web,db,"Insert query with comments")web_to_db.protocol="MySQL"web_to_db.dstPort=3306web_to_db.data='MySQL insert statement, all literals'web_to_db.order=3db_to_web=Dataflow(db,web,"Comments contents")db_to_web.protocol="MySQL"db_to_web.data='Results of insert op'db_to_web.order=4tm.process()
pytm ist eine Python 3 Bibliothek. Es ist keine Python 2 Version verfügbar.
In pytm dreht sich alles um Elemente. Spezifische Elemente sind
Process,Server,Datastore,Lambda, (Trust)BoundaryundActor. Das ObjektTMenthält alle Metadaten über das Bedrohungsmodell sowie die Rechenleistung. Importiere nur das, was dein Bedrohungsmodell verwenden wird, oder erweitereElementum deine eigenen spezifischen Elemente (und teile sie dann mit uns!)Wir instanziieren ein
TMObjekt, das unsere gesamte Modellbeschreibung enthalten wird.Hier legen wir eine Vertrauensgrenze fest, die wir verwenden werden, um verschiedene Vertrauensbereiche des Modells zu trennen.
Wir instanziieren auch einen generischen Akteur, der den Nutzer des Systems repräsentiert.
Und wir haben es sofort auf die richtige Seite einer Vertrauensgrenze gestellt.
Jedes spezifische Element hat Attribute, die die Bedrohungen beeinflussen, die erzeugt werden können. Alle haben gemeinsame Standardwerte, und wir müssen nur die ändern, die für das System einzigartig sind.
Das Element
Dataflowverbindet zwei zuvor definierte Elemente und enthält Details über die fließenden Informationen, das verwendete Protokoll und die verwendeten Kommunikationsports.Neben dem üblichen DFD kann pytm auch Sequenzdiagramme erstellen. Durch das Hinzufügen eines
.orderAttributs zuDataflowist es möglich, sie so zu organisieren, dass sie in diesem Format Sinn machen.Nachdem wir alle unsere Elemente und ihre Attribute deklariert haben, führt ein Aufruf von
TM.process()die in der Befehlszeile geforderten Operationen aus.
Neben der zeilenweisen Analyse können wir aus diesem Code lernen, dass jedes Bedrohungsmodell ein eigenes Skript ist. Auf diese Weise können bei einem großen Projekt die pytm-Skripte klein gehalten und mit dem Code, den sie repräsentieren, zusammengelegt werden, so dass sie leichter aktualisiert und versioniert werden können. Wenn sich ein bestimmter Teil des Systems ändert, muss nur dieses spezielle Bedrohungsmodell bearbeitet und geändert werden. Dadurch wird der Aufwand auf die Beschreibung der Änderung konzentriert und Fehler werden vermieden, die bei der Bearbeitung eines großen Teils des Codes auftreten können.
Durch den Aufruf von process() hat jedes pytm-Skript den gleichen Satz an Befehlszeilenschaltern und Argumenten:
tm.py[-h][--debug][--dfd][--reportREPORT][--excludeEXCLUDE][--seq]/[--lis][--describeDESCRIBE]optionalarguments:-h,--helpshowthishelpmessageandexit--debugdebugmessages--dfdoutputDFD(default)--reportREPORToutputreportusingthenamedtemplatefile/(sampletemplatefileisunderdocs/template.md)--excludeEXCLUDEspecifythreatIDstobeignored--seqoutputsequentialdiagram--listlistallavailablethreats--describeDESCRIBEdescribethepropertiesavailableforagivenelement
Besonders erwähnenswert sind --dfd und --seq: Sie erzeugen die Diagramme im PNG-Format. Das DFD wird von pytm im Dot-Format erstellt, einem Format, das von Graphviz genutzt wird, und das Sequenzdiagramm von PlantUML. hat auch Multiplattform-Unterstützung. Die Zwischenformate sind textuell, sodass du Änderungen vornehmen kannst, und das Layout wird von den jeweiligen Tools und nicht von pytm bestimmt. Auf diese Weise kann sich jedes Tool auf das konzentrieren, was es am besten kann.21
Siehe Abbildungen 4-4 und 4-5.

Abbildung 4-4. DFD-Darstellung des Beispielcodes

Abbildung 4-5. Derselbe Code, jetzt als Sequenzdiagramm dargestellt
Die Möglichkeit, Diagramme mit der Geschwindigkeit von Code zu erstellen, hat sich als nützliche Eigenschaft von pytm erwiesen. Wir haben erlebt, dass während der ersten Design-Meetings Code notiert wurde, um das System zu beschreiben. pytm ermöglicht es den Teammitgliedern, eine Threat Modeling-Sitzung mit einer funktionalen Darstellung ihrer Idee zu verlassen, die den gleichen Wert hat wie eine Zeichnung auf einem Whiteboard, aber sofort geteilt, bearbeitet und gemeinsam bearbeitet werden kann. Dieser Ansatz vermeidet alle Fallstricke von Whiteboards ("Hat jemand die Marker gesehen? Nein, die schwarzen Marker!", "Kannst du die Kamera ein bisschen bewegen? Sarah ist dafür zuständig, die Zeichnung in eine Visio-Datei zu verwandeln. Moment, wer ist Sarah?", und die gefürchteten "Nicht löschen"-Schilder).
All das ist zwar wertvoll, aber ein Tool zur Bedrohungsmodellierung ist ziemlich unzureichend, wenn es nicht, nun ja, Bedrohungen aufzeigt. pytm verfügt über diese Fähigkeit, wenn auch mit einem Vorbehalt: In diesem Stadium der Entwicklung geht es uns mehr darum, erste Fähigkeiten zu identifizieren, als die Bedrohungen vollständig zu erfassen. Das Projekt begann mit einer Untergruppe von Bedrohungen, die in etwa den Fähigkeiten des in diesem Kapitel beschriebenen Microsoft Threat Modeling Tools entspricht, und fügte einige lambda-bezogene Bedrohungen hinzu. Derzeit erkennt pytm mehr als 100 erkennbare Bedrohungen, die auf einer Teilmenge von CAPEC basieren. Einige der Bedrohungen, die pytm erkennen kann, siehst du hier (und alle Bedrohungen können mit dem Schalter --list aufgelistet werden):
INP01-BufferOverflowviaEnvironmentVariablesINP02-OverflowBuffersINP03-ServerSideInclude(SSI)InjectionCR01-SessionSidejackingINP04-HTTPRequestSplittingCR02-CrossSiteTracingINP05-CommandLineExecutionthroughSQLInjectionINP06-SQLInjectionthroughSOAPParameterTamperingSC01-JSONHijacking(akaJavaScriptHijacking)LB01-APIManipulationAA01-AuthenticationAbuse/ByPassDS01-ExcavationDE01-InterceptionDE02-DoubleEncodingAPI01-ExploitTestAPIsAC01-PrivilegeAbuseINP07-BufferManipulationAC02-SharedDataManipulationDO01-FloodingHA01-PathTraversalAC03-SubvertingEnvironmentVariableValuesDO02-ExcessiveAllocationDS02-TryAllCommonSwitchesINP08-FormatStringInjectionINP09-LDAPInjectionINP10-ParameterInjectionINP11-RelativePathTraversalINP12-Client-sideInjection-inducedBufferOverflowAC04-XMLSchemaPoisoningDO03-XMLPingoftheDeathAC05-ContentSpoofingINP13-CommandDelimitersINP14-InputDataManipulationDE03-SniffingAttacksCR03-Dictionary-basedPasswordAttackAPI02-ExploitScript-BasedAPIsHA02-WhiteBoxReverseEngineeringDS03-FootprintingAC06-UsingMaliciousFilesHA03-WebApplicationFingerprintingSC02-XSSTargetingNon-ScriptElementsAC07-ExploitingIncorrectlyConfiguredAccessControlSecurityLevelsINP15-IMAP/SMTPCommandInjectionHA04-ReverseEngineeringSC03-EmbeddingScriptswithinScriptsINP16-PHPRemoteFileInclusionAA02-PrincipalSpoofCR04-SessionCredentialFalsificationthroughForgingDO04-XMLEntityExpansionDS04-XSSTargetingErrorPagesSC04-XSSUsingAlternateSyntaxCR05-EncryptionBruteForcingAC08-ManipulateRegistryInformationDS05-LiftingSensitiveDataEmbeddedinCache
Wie bereits erwähnt, wird das Format, das pytm zur Definition von Bedrohungen verwendet, derzeit überarbeitet ( ), um eine bessere Regel-Engine zu entwickeln und mehr Informationen bereitzustellen. Derzeit definiert pytm eine Bedrohung als JSON-Struktur mit folgendem Format:
{"SID":"INP01","target":["Lambda","Process"],"description":"Buffer Overflow via Environment Variables","details":"This attack pattern involves causing a buffer overflow through/manipulation of environment variables. Once the attacker finds that they can/modify an environment variable, they may try to overflow associated buffers./This attack leverages implicit trust often placed in environment variables.","Likelihood Of Attack":"High","severity":"High","condition":"target.usesEnvironmentVariables is True and target.sanitizesInput is False and target.checksInputBounds is False","prerequisites":"The application uses environment variables.An environment/variable exposed to the user is vulnerable to a buffer overflow.The vulnerable/environment variable uses untrusted data.Tainted data used in the environment/variables is not properly validated. For instance boundary checking is not /done before copying the input data to a buffer.","mitigations":"Do not expose environment variables to the user.Do not use /untrusted data in your environment variables. Use a language or compiler that /performs automatic bounds checking. There are tools such as Sharefuzz [R.10.3]/which is an environment variable fuzzer for Unix that support loading a shared/library. You can use Sharefuzz to determine if you are exposing an environment/variable vulnerable to buffer overflow.","example":"Attack Example: Buffer Overflow in $HOME A buffer overflow insccw allows local users to gain root access via the $HOMEenvironmental variable. Attack Example: Buffer Overflow in TERM Abuffer overflow in the rlogin program involves its consumption ofthe TERM environment variable.","references":"https://capec.mitre.org/data/definitions/10.html, CVE-1999-0906, CVE-1999-0046, http://cwe.mitre.org/data/definitions/120.html, http://cwe.mitre.org/data/definitions/119.html, http://cwe.mitre.org/data/definitions/680.html"},
Das Zielfeld beschreibt entweder ein einzelnes oder ein Tupel von möglichen Elementen, auf die die Bedrohung wirkt. Das Bedingungsfeld ist ein boolescher Ausdruck, der auf der Grundlage der Werte der Attribute des Zielelements als Wahr (die Bedrohung existiert) oder Falsch (die Bedrohung existiert nicht) ausgewertet wird.
Warnung
Interessanterweise führt die Verwendung der Python-Funktion eval() zur Auswertung des booleschen Ausdrucks in einer Bedingung zu einer möglichen Schwachstelle im System: Wenn pytm beispielsweise systemweit installiert ist, die Berechtigungen der Bedrohungsdatei aber zu freizügig sind und jeder Benutzer neue Bedrohungen schreiben kann, könnte ein Angreifer seinen eigenen Python-Code schreiben und als Bedrohungsbedingung hinzufügen, der dann mit den Rechten des Benutzers ausgeführt wird, der das Skript ausführt. Wir wollen das in naher Zukunft beheben, aber bis dahin seid gewarnt!
Um die anfänglichen Möglichkeiten zu vervollständigen, haben wir eine auf Templates basierende Berichtsfunktion hinzugefügt.22 Der Templating-Mechanismus ist zwar einfach und knapp gehalten, reicht aber aus, um einen brauchbaren Bericht zu erstellen. Er ermöglicht die Erstellung von Berichten in jedem beliebigen textbasierten Format, einschließlich HTML, Markdown, RTF und einfachem Text. Wir haben uns für Markdown entschieden:
#Threat Model Sample ***##System Description {tm.description}##Dataflow Diagram ##Dataflows Name|From|To |Data|Protocol|Port ----|----|---|----|--------|---- {dataflows:repeat:{{item.name}}|{{item.source.name}}|{{item.sink.name}}/ |{{item.data}}|{{item.protocol}}|{{item.dstPort}} }##Potential Threats {findings:repeat:* {{item.description}} on element "{{item.target}}" }
Diese Vorlage, die auf das vorangegangene Skript angewendet wird, würde den Bericht erzeugen, den du in Anhang A siehst.
Wir gehen fest davon aus, dass wir in naher Zukunft weitere Funktionen entwickeln werden, um die Einstiegshürde für Entwicklerteams in die Bedrohungsmodellierung zu senken und gleichzeitig nützliche Ergebnisse zu liefern.
Threagile
Threagile von Christian Schneider ist ein vielversprechendes System, das erst seit Juli 2020 im Bereich der Bedrohungsmodellierung als Code verfügbar ist. Es befindet sich derzeit im Stealth-Modus, wird aber bald als Open Source verfügbar sein!
Ähnlich wie pytm fällt Threagile in die Kategorie der Bedrohungsmodellierung mit Code, verwendet aber eine YAML-Datei, um das System zu beschreiben, das es auswertet. Ein Entwicklungsteam kann die Werkzeuge verwenden, die die Teammitglieder bereits kennen, und zwar in ihrer nativen IDE, und die zusammen mit dem Code des Systems, das es darstellt, gepflegt, versionskontrolliert, geteilt und gemeinsam bearbeitet werden können. Das Tool ist in Go geschrieben.
Da sich das Tool zum Zeitpunkt dieses Artikels noch in der Entwicklung befindet, empfehlen wir dir, die Website des Threagile-Autors zu besuchen, um Beispiele für dieerstellten Berichte und Diagramme zu sehen.
Die wichtigsten Elemente der YAML-Datei, die das Zielsystem beschreibt, sind die Datenbestände, die technischen Bestände, die Kommunikationsverbindungen und die Vertrauensgrenzen. Eine Definition von Datenbeständen sieht zum Beispiel so aus:
Customer Addresses:id:customer-addressesdescription:Customer Addressesusage:businessorigin:Customerowner:Example Companyquantity:manyconfidentiality:confidentialintegrity:mission-criticalavailability:mission-criticaljustification_cia_rating:these have PII of customers and the system /needs these addresses for sending invoices
Derzeit ist die Definition von Datenbeständen der Hauptunterschied im Ansatz zwischen Threagile und pytm, da die Definitionen von technischen Beständen (in pytm Elemente wie Server, Process, etc.), Vertrauensgrenzen und Kommunikationsverbindungen (pytm Datenflüsse) mehr oder weniger dem gleichen Umfang an Informationen über jedes spezifische Element im System folgen.
Die Unterschiede sind insofern deutlicher, als dass Threagile verschiedene Arten von Vertrauensgrenzen wie Network On Prem, Network Cloud-Provider und Network Cloud Security Group (neben vielen anderen) explizit berücksichtigt, während pytm nicht differenziert. Jeder Typ erfordert eine andere Semantik, die bei der Bewertung von Bedrohungen eine Rolle spielt.
Threagile verfügt über ein Plug-in-System zur Unterstützung von Regeln, die den Graphen des durch die YAML-Eingabe beschriebenen Systems analysieren. Zum Zeitpunkt der Erstellung dieses Artikels werden etwa 35 Regeln unterstützt, aber es werden noch weitere hinzugefügt. Eine zufällige Auswahl von Beispielregeln zeigt Folgendes:
-
Cross-Site-Request-Fgery
-
code-backdooring
-
ldap-injection
-
ungeschützter-zugriff-aus-dem-internet
-
service-registry-poisoning
-
unnötige-daten-übertragung
Anders als pytm, das als Kommandozeilenprogramm arbeitet, bietet Threagile auch eine REST-API, die (verschlüsselte) Modelle speichert und es dir ermöglicht, sie zu bearbeiten und auszuführen. Das Threagile-System verwaltet die Eingabe-YAML in einem Repository zusammen mit dem Code, den die YAML beschreibt. Das System kann entweder über die CLI oder die API angewiesen werden, die Verarbeitung durchzuführen. Die Ausgabe von Threagile besteht aus Folgendem:
-
Ein Risikobericht PDF
-
Ein Excel-Tabellenblatt zur Risikoverfolgung
-
Eine Risikozusammenfassung mit Risikodetails als JSON
-
Ein automatisch erstelltes DFD (mit Farbgebung, die die Klassifizierung von Assets, Daten und Kommunikationsverbindungen ausdrückt)
-
Ein Risikodiagramm für Datenbestände
Das letzte Diagramm ist von besonderem Interesse, da es für jedes Datengut angibt, wo es verarbeitet und wo es gespeichert wird, wobei die Farbe den Risikostatus pro Datengut und technischem Gut ausdrückt. Soweit wir wissen, ist dies derzeit das einzige Tool, das diese Ansicht bietet.
Das Format des generierten PDF-Berichts ist äußerst detailliert und enthält alle Informationen, die notwendig sind, um die Risiken an das Management weiterzuleiten oder die Entwickler in die Lage zu versetzen, sie zu mindern. Die STRIDE-Klassifizierung der identifizierten Bedrohungen ist ebenso enthalten wie eine Analyse der Auswirkungen der Risiken pro Kategorie.
Wir freuen uns darauf, mehr von diesem Tool zu sehen und an seiner Entwicklung teilzuhaben. Wir empfehlen dir, einen Blick darauf zu werfen, sobald es für die Öffentlichkeit zugänglich ist.
Ein Überblick über andere Tools zur Bedrohungsmodellierung
Wir haben versucht, diese Tools so unvoreingenommen wie möglich darzustellen, aber es kann schwierig sein, diese Voreingenommenheit zu überwinden. Für etwaige Fehler, Auslassungen oder falsche Darstellungen sind allein wir verantwortlich. Kein Anbieter oder Projekt hat an diesem Bericht mitgewirkt, und wir empfehlen kein Tool gegenüber einem anderen. Die hier präsentierten Informationen dienen lediglich der Aufklärung und sollen dir helfen, deine eigene Recherche zu starten.
IriusRisk
Umgesetzte Methoden: Fragebogenbasiert, Bedrohungsbibliothek
Hauptargument: Die Free/Community-Edition von IriusRisk (siehe Abbildung 4-6) bietet dieselbe Funktionalität wie die Enterprise-Version, allerdings mit einer Einschränkung bei den Berichtsarten und den Elementen, die in ihrem Menü zur Aufnahme in das System angeboten werden. Die kostenlose Version enthält auch keine API, aber sie reicht aus, um die Fähigkeiten des Tools zu zeigen. Abbildung 4-6 zeigt ein Beispiel für die Analyseergebnisse von IriusRisk am Beispiel eines einfachen Browser/Server-Systems. Die Bedrohungsbibliothek von IriusRisk scheint zumindest auf CAPEC zu basieren, denn es werden auch CWE, das Web Application Security Consortium (WASC), die OWASP Top Ten sowie der OWASP Application Security Verification Standard (ASVS) und der OWASP Mobile Application Security Verification Standard (MASVS) erwähnt.
Frische: Ständig aktualisiert
Beziehen von: https://oreil.ly/TzjrQ

Abbildung 4-6. IriusRisk Echtzeit-Analyseergebnisse
Ein typischer Befund in einem IriusRisk-Bericht enthält die Komponente, in der er festgestellt wurde, die Art der Schwachstelle ("Zugriff auf sensible Daten"), eine kurze Erklärung der Bedrohung ("Sensible Daten werden durch Angriffe auf SSL/TLS kompromittiert") und eine grafische/farbliche Darstellung des Risikos und des Fortschritts der Gegenmaßnahmen.
Wenn du eine bestimmte Bedrohung genauer untersuchst, siehst du eine eindeutige ID (mit CAPEC- oder anderen Indexinformationen), eine Aufteilung der Auswirkungen in Vertraulichkeit, Integrität und Verfügbarkeit, eine längere Beschreibung und eine Liste von Referenzen, zugehörigen Schwachstellen und Gegenmaßnahmen, die den Leser darüber informieren, wie er das identifizierte Problem angehen kann.
SD-Elemente
Umgesetzte Methoden: Fragebogenbasiert, Bedrohungsbibliothek
Hauptargument: Zum Zeitpunkt der Erstellung dieses Artikels in Version 5 ist SD Elements eine umfassende Sicherheitsmanagementlösung für dein Unternehmen. Eine der Funktionen, die sie bietet, ist die fragebogenbasierte Bedrohungsmodellierung. Anhand einer vordefinierten Sicherheits- und Compliance-Richtlinie versucht die Anwendung, die Konformität des in der Entwicklung befindlichen Systems mit dieser Richtlinie zu überprüfen, indem sie Gegenmaßnahmen vorschlägt.
Frische: Regelmäßig aktualisiertes kommerzielles Angebot
Beziehen von: https://oreil.ly/On7q2
ThreatModeler
Umgesetzte Methoden: Prozessablaufdiagramme; Visuelle, agile, einfache Bedrohung (VAST); Bedrohungsbibliothek
Hauptargument: ThreatModeler ist eines der ersten kommerziell erhältlichen Diagramm- und Analysetools zur Bedrohungsmodellierung. ThreatModeler verwendet Prozessablaufdiagramme (die wir in Kapitel 1 kurz erwähnt haben) und implementiert den VAST-Modellierungsansatz für die Bedrohungsmodellierung.
Frische: Kommerzielles Angebot
Beziehen von: https://threatmodeler.com
OWASP Threat Dragon
Umgesetzte Methoden: Regelbasierte Bedrohungsbibliothek, STRIDE
Hauptaussage: Threat Dragon ist ein Projekt, das kürzlich den Inkubatorstatus bei OWASP verlassen hat. Es ist eine Online- und Desktop-Anwendung (Windows, Linux und Mac) zur Modellierung von Bedrohungen, die eine Diagrammlösung (Drag & Drop) und eine regelbasierte Analyse der definierten Elemente mit Vorschlägen für Bedrohungen und Abhilfemaßnahmen bietet. Dieses plattformübergreifende, kostenlose Tool ist benutzbar und erweiterbar (siehe Abbildung 4-7).
Frische: In aktiver Entwicklung, geleitet von Mike Goodwin und Jon Gadsden
Beziehen von: https://oreil.ly/-n5uF

Abbildung 4-7. Ein Beispielsystem, verfügbar als Demonstration
In Abbildung 4-7 siehst du, dass die DFD von der im Buch vorgestellten einfachen Symbolik entspricht; jedes Element hat ein Eigenschaftsblatt, das Details und Kontext zu ihm liefert. Das Element wird im Kontext des gesamten Systems dargestellt, und es sind grundlegende Informationen darüber verfügbar, ob es in den Geltungsbereich des Bedrohungsmodells fällt, was es enthält und wie es gespeichert oder verarbeitet wird.
Die Benutzer können auch ihre eigenen Bedrohungen erstellen, was eine Organisation oder ein Team in die Lage versetzt, die Bedrohungen hervorzuheben, die für ihre Umgebung oder die Funktionsweise ihres Systems besonders wichtig sind. Es besteht ein direkter Zusammenhang zwischen der STRIDE-Bedrohungserfassung und einer einfachen Einstufung der Kritikalität (hoch/mittel/niedrig) ohne direkte Korrelation zu einem CVSS-Score.
Threat Dragon bietet eine umfassende Berichtsfunktion, die das Systemdiagramm im Blick behält und eine nach Elementen sortierte Liste aller Feststellungen (mit ihren Abhilfemaßnahmen, falls vorhanden) oder den Grund dafür liefert, wenn ein bestimmtes Element zwar Teil des Diagramms ist, aber für das Bedrohungsmodell nicht in Frage kommt.
Microsoft Threat Modeling Tool
Umgesetzte Methoden: Zeichnen und annotieren, STRIDE
Hauptvorschlag: Das Microsoft Threat Modeling Tool ist ein weiterer wichtiger Beitrag von Adam Shostack und dem SDL-Team auf . Es ist eines der ersten Tools zur Bedrohungsmodellierung, das auf den Markt gekommen ist. Ursprünglich basierte es auf einer Visio-Bibliothek (und erforderte daher eine Lizenz für dieses Programm), doch diese Abhängigkeit wurde inzwischen aufgegeben und das Tool ist nun eine eigenständige Installation. Nach der Installation hast du die Möglichkeit, ein neues Modell oder eine Vorlage hinzuzufügen oder bestehende Vorlagen zu laden. Die Vorlage ist standardmäßig auf Azure ausgerichtet, für Systeme, die nicht Azure-spezifisch sind, gibt es eine generische SDL Vorlage. Microsoft unterstützt auch eine Bibliothek von Templates, die zwar noch nicht sehr umfangreich ist, aber sicherlich einen willkommenen Beitrag zur Landschaft darstellt. Das Tool verwendet eine Annäherung an die DFD-Symbolik, die wir in Kapitel 1 verwendet haben, und bietet Werkzeuge, mit denen du jedes Element mit vordefinierten und benutzerdefinierten Attributen versehen kannst. Auf der Grundlage von vordefinierten Regeln (die in einer XML-Datei gespeichert sind und theoretisch vom Benutzer bearbeitet werden können) erstellt das Tool einen Bedrohungsmodellbericht, der das Diagramm, die identifizierten Bedrohungen (klassifiziert nach STRIDE) und einige Empfehlungen zur Schadensbegrenzung enthält. Obwohl die Elemente und ihre Attribute stark auf Windows ausgerichtet sind, ist das Tool auch für Nicht-Windows-Benutzer interessant (siehe Abbildung 4-8).
Frische: Scheint alle paar Jahre aktualisiert zu werden.
Beziehen von: https://oreil.ly/YL-gI
Ähnlich wie in anderen Tools kann jedes Element bearbeitet werden, um seine Eigenschaften anzugeben. Der Hauptunterschied besteht darin, dass einige Elementeigenschaften sehr Windows-bezogen sind. So enthält das Element OS Process Eigenschaften wie Running As (Ausführen als), mit Administrator als möglichem Wert, oder Code Type (Codetyp): Verwaltet. Wenn das Programm Bedrohungen generiert, ignoriert es Optionen, die auf die Zielumgebung nicht anwendbar sind.
Die Berichterstattung in diesem Tool ist eng mit STRIDE verknüpft, wobei jede Feststellung eine STRIDE-Kategorie hat, zusätzlich zu einer Beschreibung, einer Begründung, einem Zustand der Abschwächung und einerPriorität.

Abbildung 4-8. DFD für das mit dem Tool gelieferte Beispiel-Demosystem
CAIRIS
Umgesetzte Methoden: Asset- und bedrohungsorientiertes Sicherheitsdesign
Hauptaussage: CAIRIS, die Abkürzung für Computer Aided Integration of Requirements and Information Security, wurde von Shamal Faily entwickelt und ist eine Plattform zur Erstellung von Darstellungen sicherer Systeme mit Schwerpunkt auf der Risikoanalyse, die auf Anforderungen und Benutzerfreundlichkeit basiert. Sobald du eine Umgebung definiert hast (d.h. einen Container, in dem das System existiert - eine Kapselung von Vermögenswerten, Aufgaben, Personas und Angreifern, Zielen, Schwachstellen und Bedrohungen), kannst du die Inhalte der Umgebung festlegen. Personas definieren Benutzer, und Aufgaben beschreiben, wie Personas mit dem System interagieren. Personas haben auch Rollen, die Stakeholder, Angreifer, Datenkontrolleure, Datenverarbeiter und Datensubjekte sein können. Personas interagieren mit Assets, die Eigenschaften wie Sicherheit und Datenschutz (wie CIA), Rechenschaftspflicht, Anonymität und Unbeobachtbarkeit haben, die mit Keine, Niedrig, Mittel und Hoch bewertet werden. Aufgaben modellieren die Arbeit, die eine oder mehrere Personas auf dem System in umgebungsspezifischen Vignetten ausführen. CAIRIS ist in der Lage, UML DFDs mit der üblichen Symbolik sowie textuelle Darstellungen eines Systems zu erstellen. Das System ist komplex, und unsere Beschreibung wird ihm niemals gerecht werden, aber im Laufe unserer Recherche hat uns CAIRIS so fasziniert, dass wir es weiter erforschen wollten. Das Buch , in dem das Tool und seine Einsatzmöglichkeiten näher erläutert werden und das einen kompletten Kurs über Security by Design bietet, ist Designing Usable and Secure Software with IRIS and CAIRIS von Shamal Faily (Springer).
Frische: In aktiver Entwicklung
Beziehen von: https://oreil.ly/BfW2l
Mozilla Meeresschwamm
Umgesetzte Methoden: Visuell gesteuert, keine Bedrohungserhebung
Hauptargument: Mozilla SeaSponge ist ein webbasiertes Tool, das auf jedem relativ modernen Browser funktioniert und eine saubere, gut aussehende Benutzeroberfläche bietet, die auch eine intuitive Erfahrung fördert. Derzeit bietet es weder eine Regelmaschine noch eine Berichtsfunktion und die Entwicklung scheint 2015 eingestellt worden zu sein (siehe Abbildung 4-9).
Frische: Die Entwicklung scheint zu stagnieren.
Beziehen von: https://oreil.ly/IOlh8
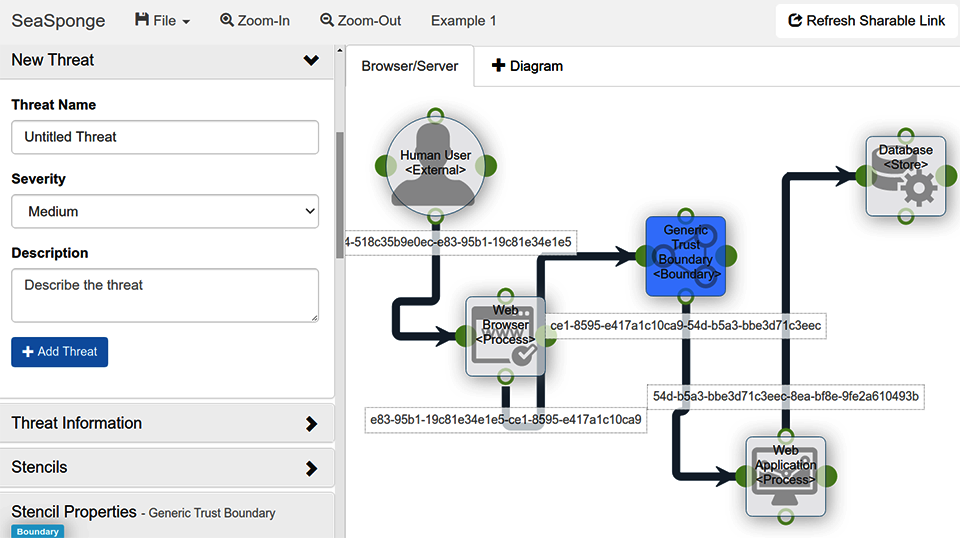
Abbildung 4-9. Mozilla SeaSponge Benutzeroberfläche
Tutamen Threat Model Automator
Umgesetzte Methoden: Visuell gesteuert, STRIDE und Bedrohungsbibliotheken
Hauptangebot: Tutamen Threat Model Automator ist ein kommerzielles Software-as-a-Service (SaaS)-Angebot (ab Oktober 2019 in der kostenlosen Beta-Version) mit einem interessanten Ansatz: Du lädst ein Diagramm deines Systems im draw.io- oder Visio-Format oder eine Excel-Tabelle hoch und erhältst dein Bedrohungsmodell. Du musst deine Daten mit sicherheitsrelevanten Metadaten, Vertrauensbereichen und Berechtigungen versehen, die du den Elementen zuweisen möchtest. Der erstellte Bericht identifiziert die Elemente, die Datenflüsse und die Bedrohungen und schlägt Abhilfemaßnahmen vor.
Frische: Regelmäßig aktualisiertes kommerzielles Angebot
Beziehen von: http://www.tutamantic.com
Bedrohungsmodellierung mit ML und KI
Dies ist das Zeitalter der "KI löst alles".23 In der Sicherheitsbranche sind wir jedoch (noch) nicht bereit, diesen Sprung bei der Bedrohungsmodellierung zu wagen.
Es gibt bereits einige Forschungsarbeiten zum Einsatz von maschinellem Lernen (ML) und KI bei der Modellierung von Bedrohungen. Das ist nur natürlich, denn die heutige KI ist eine Weiterentwicklung der Expertensysteme der (jüngeren) Vergangenheit. Diese Systeme basierten auf Regeln, die von Inferenzmaschinen verarbeitet wurden und versuchten, eine Reihe von Anforderungen zu erfüllen, um das zu modellierende System in einen zufriedenstellenden Zustand zu bringen. Oder die Systeme wiesen auf Unstimmigkeiten hin, die die Lösung unmöglich machten. Klingt vertraut, oder?
Maschinelles Lernen basiert auf der Prämisse, dass sich nach der Klassifizierung einer ausreichenden Anzahl von Daten Muster herausbilden, die es ermöglichen, neue Daten zu klassifizieren. Der Versuch, dies auf den Bereich der Bedrohungsmodellierung zu übertragen, kann knifflig sein. Im Bereich der Netzwerksicherheit ist es zum Beispiel einfach, große Datenmengen mit "gutem" und "schlechtem" Datenverkehr zu erzeugen, um einen Klassifizierungsalgorithmus zu trainieren. Bei der Modellierung von Bedrohungen kann es jedoch sein, dass kein ausreichender Datenbestand vorhanden ist, so dass du keinen Algorithmus trainieren kannst, der Bedrohungen zuverlässig erkennt. Das bringt dich sofort zu dem Ansatz zurück, bei dem eine Bedrohung ein Ausdruck eines unerwünschten Zustands ist, der durch die Konfiguration des Systems in einer bestimmten Konstellation von Elementen und Attributen verursacht wird.
Ansätze des maschinellen Lernens zur Modellierung von Bedrohungen sind in erster Linie immer noch eine akademische Übung, bei der es kaum veröffentlichte Arbeiten oder Proofs of Concept gibt, die es uns ermöglichen würden, ein funktionierendes KI/ML-System zu demonstrieren.24,25 Mindestens ein Patent befasst sich bereits mit einer allgemeinen Bedrohungsmodellierungskette durch maschinelles Lernen, wie sie oben beschrieben wurde, aber bis heute ist uns kein funktionierender Prototyp eines Tools oder eines Datensatzes bekannt, der es unterstützt.
Auch wenn sie zur Verbesserung der Sicherheit in anderen Systemen eingesetzt werden, müssen ML-Systeme für Bedrohungen modelliert werden. Hier sind einige Beispiele aus der Forschung in diesem Bereich:
-
Die NCC Group hat die Ergebnisse ihrer Forschung in diesem Bereich vorgelegt und Bedrohungsmodelle für ML-Systeme entwickelt, die aufzeigen, wie sie von skrupellosen Angreifern angegriffen oder missbraucht werden können.26 Die Forscherinnen und Forscher der NCC Group nutzten für ihre Untersuchungen eines der ältesten Nicht-ML-Tools für die Bedrohungsmodellierung - Microsofts Threat Modeling Tool, 2018 Edition.
-
Forscher am Institut für Technische Informatik der Technischen Universität Wien haben ihr Bedrohungsmodell für das Training von ML-Algorithmen und Inferenzmechanismen veröffentlicht und eine gute Diskussion über Schwachstellen, Ziele der Angreifer und Gegenmaßnahmen zur Entschärfung der identifizierten Bedrohungen geführt.27
-
Das Berryville Institute of Machine Learning, das von dem berühmten Sicherheitswissenschaftler Gary McGraw, PhD, mitbegründet wurde, hat eine architektonische Risikoanalyse von ML-Systemen veröffentlicht, die interessante Problembereiche im Bereich der Sicherheit aufzeigt, wenn sie auf ML-Systeme angewendet werden (von denen einige wiederum zur Erkennung von Sicherheitsproblemen in anderen Systemen verwendet werden können).28
MITREs CWE beginnt, Sicherheitsschwachstellen für maschinelle Lernsysteme mit einzubeziehen. von CWE-1039, "Automated Recognition Mechanism with Inadequate Detection or Handling of Adversarial Input Perturbations".
Zusammenfassung
In diesem Kapitel haben wir einen längeren Blick auf einige der bestehenden Herausforderungen bei der Bedrohungsmodellierung geworfen und wie du sie überwinden kannst. Du hast etwas über Architekturbeschreibungssprachen gelernt und wie sie die Grundlage für die Automatisierung der Bedrohungsmodellierung bilden. Du hast die verschiedenen Möglichkeiten zur Automatisierung der Bedrohungsmodellierung kennengelernt, von der einfachen Erstellung einer besseren Bedrohungsdokumentation bis hin zur vollständigen Modellierung und Analyse durch das Schreiben von Code.
Wir haben Tools besprochen, die Techniken der Bedrohungsmodellierung mit Code und der Bedrohungsmodellierung aus dem Code (in der Branche als "Bedrohungsmodellierung als Code" bezeichnet) verwenden und gleichzeitig die Methoden der Bedrohungsmodellierung aus Kapitel 3 umsetzen. Einige dieser Tools implementieren auch andere Funktionen, wie z. B. die Orchestrierung von Sicherheitstests. Wir haben dir unser Tool zur Bedrohungsmodellierung aus dem Code, pytm, vorgestellt und abschließend kurz die Herausforderung der Anwendung von Algorithmen des maschinellen Lernens auf die Bedrohungsmodellierung besprochen.
Im nächsten Kapitel bekommst du einen Einblick in die nahe Zukunft der Bedrohungsmodellierung mit spannenden neuen Techniken und Technologien.
1 Randall Munroe, "Alice und Bob", xkcd Webcomic, https://xkcd.com/177.
2 Manche verwenden auch den übergreifenden Begriff Threat Modeling as Code, um sich an den DevOps-Jargon anzupassen. Ähnlich wie DevOps (und sein Jargon!) vor ein paar Jahren befindet sich das gesamte Vokabular im Wandel - viele Leute meinen damit viele verschiedene Dinge, aber wir haben das Gefühl, dass sich langsam eine Konvention herausbildet.
3 Bei der letzten Überprüfung haben wir mehr als 20 Methoden und Varianten gezählt.
4 "DtSR Episode 362-Real Security Is Hard", Down the Security Rabbit Hole Podcast, https://oreil.ly/iECWZ.
5 Ophir Tanz, "Kann künstliche Intelligenz Bilder besser erkennen als Menschen?" Entrepreneur, April 2017, https://oreil.ly/Fe9w5.
6 Weitere Informationen findest du in der ThreatPlaybook-Dokumentation unter https://oreil.ly/lhSPc.
7 Siehe das Robot Framework, ein Open-Source-Framework für Tests, unter https://oreil.ly/GWGKP.
8 A. Wymores Autobiografie ist auf dieser Website der University of Arizona verfügbar.
9 Eine Übersicht über ADLs findet sich in "Architecture Description Languages" von Stefan Bjornander, https://oreil.ly/AKo-w.
10 "AADL Resource Pages", Open AADL, http://www.openaadl.org.
11 Es gibt viele Möglichkeiten, Objekte innerhalb eines Systems darzustellen; dies zeigt eine idealisierte oder repräsentative Reihe von Eigenschaften, die auf unserer Forschung basieren. Die Liste wurde für die Platzierung in diesem Text geändert. Das Original findest du unter https://oreil.ly/Vdiws.
12 Wie bei jedem guten Code ist Einfachheit das Beste, damit das Programm für den "nächsten Maintainer" verständlich ist.
13 Für Leser, die mit I2C nicht vertraut sind, siehe Scott Campbells "Grundlagen des I2C-Kommunikationsprotokolls" auf der Seite Circuit Basics.
14 Siehe "Service Name and Transport Protocol Port Number Registry", IANA, https://oreil.ly/1XktB.
15 Für eine Diskussion über Kanten und Graphen, siehe "Graph Theory" von Victor Adamchik, https://oreil.ly/t0bYp.
16 Michael N. Johnstone, "Threat Modelling with Stride and UML," Australian Information Security Management Conference, November 2010, https://oreil.ly/QVU8c.
17 "Was ist die Beziehung zwischen SysML und UML?" SysML Forum, Zugriff im Oktober 2020, https://oreil.ly/xL7l2.
18 Aleksandr Kerzhner et al., "Analyzing Cyber Security Threats on Cyber-Physical Systems Using Model-Based Systems Engineering ", https://oreil.ly/0ToAu.
19 Robert Oates et al., "Security-Aware Model-Based Systems Engineering with SysML ", https://oreil.ly/lri3g.
20 Hinweis: Die Verwendung dieses Systemmodells birgt mindestens fünf potenzielle Bedrohungen wie Spoofing und Diebstahl von Zugangsdaten.
21 Graphviz hat Pakete für alle wichtigen Betriebssysteme.
22 Siehe "The World's Simplest Python Template Engine" von Eric Brehault, https://oreil.ly/BEFIn.
23 Corey Caplette, "Beyond the Hype: Der Wert von maschinellem Lernen und KI (Künstliche Intelligenz) für Unternehmen (Teil 1)", Towards Data Science, Mai 2018, https://oreil.ly/324W3.
24 Mina Hao, "Machine Learning Algorithms Power Security Threat Reasoning and Analysis", NSFOCUS, Mai 2019, https://oreil.ly/pzIQ9.
25 M. Choras und R. Kozik, ScienceDirect, "Machine Learning Techniques for Threat Modeling and Detection," October 6, 2017, https://oreil.ly/PQfUt.
26 "Building Safer Machine Learning Systems-A Threat Model", NCC Group, August 2018, https://oreil.ly/BRgb9.
27 Faiq Khalid et al., "Security for Machine Learning-Based Systems: Attacks and Challenges During Training and Inference," Cornell University, November 2018, https://oreil.ly/2Qgx7.
28 Gary McGraw et al., "An Architectural Risk Analysis of Machine Learning Systems", BIML, https://oreil.ly/_RYwy.
Get Bedrohungsmodellierung now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

