Chapter 4. Additional Cloud and AI Capabilities
Generative AI applications are way more than “just a big model.” As you have already seen, LLMs play a central role, but there are other relevant pieces that complement the capabilities of Azure OpenAI Service: fine-tuning via Azure OpenAI APIs or playgrounds, grounding with Azure Cognitive Search and/or Azure OpenAI embeddings, live search capabilities with Bing Search API, etc.
Additionally, we have new kinds of tools that allow us to expand the capacities of LLMs even more. A curated selection for any generative AI and Azure OpenAI adopter could include plug-ins, LMM integration, databases, and more. Let’s dig into these in more detail.
Plug-ins
One of the most important new terms in AI applications is the notion of “plug-ins.” We can define them as direct interfaces to advanced functionalities, interconnecting Microsoft’s Azure OpenAI (or OpenAI’s ChatGPT) with other systems. For example, there are plug-ins from companies such as Expedia, FiscalNote, Instacart, KAYAK, Klarna, Milo, OpenTable, Shopify, Slack, Speak, Wolfram, and Zapier. They are external to Azure OpenAI, and their nature and business models depend on the developer companies.
Additionally, Microsoft announced in May 2023 its own collection of plug-ins, defining them as “standardized interfaces that allow developers to build and consume APIs to extend the capabilities of large language models (LLMs) and enable a deep integration of GPT across Azure and the Microsoft ecosystem.” These plug-ins include direct interfaces to Bing Search, Azure Cognitive Search, Azure SQL, Azure Cosmos DB, and Microsoft Translator. As a developer, that means that you can connect Azure OpenAI with other Microsoft and Azure-related pieces, with minimal development and integration effort.
LLM Development, Orchestration, and Integration
There are also developer-oriented pieces that enable the combination of existing LLMs with other services, regardless of the programming language. Let’s dig into some of those options now.
LangChain
LangChain is an open source framework that you can use to develop applications that are powered by language models. It provides various language-related utilities and tools (e.g., embeddings, pipelines, agents, plug-ins) and is one of the key components for some of the accelerators you saw earlier in Chapter 3. The official documentation talks about six key areas, noted in increasing order of complexity:
- LLMs and prompts
-
This includes prompt management, prompt optimization, a generic interface for all LLMs, and common utilities for working with LLMs.
- Chains
-
Chains go beyond a single LLM call and involve sequences of calls (whether to an LLM or a different utility). LangChain provides a standard interface for chains, lots of integrations with other tools, and end-to-end chains for common applications.
- Data-augmented generation
-
Data-augmented generation involves specific types of chains that first interact with an external data source to fetch data for use in the generation step. Examples include summarization of long pieces of text and question/answers over specific data sources.
- Agents
-
Agents involve an LLM making decisions about which actions to take, taking that action, seeing an observation, and repeating that until done. LangChain provides a standard interface for agents, a selection of agents to choose from, and examples of end-to-end agents.
- Memory
-
Memory refers to the persisting state between calls of a chain/agent. LangChain provides a standard interface for memory, a collection of memory implementations, and examples of chains/agents that use memory.
- Evaluation
-
Generative models are notoriously hard to evaluate with traditional metrics. One new way of evaluating them is using language models themselves to do the evaluation. LangChain provides some prompts/chains for assisting in this.
The article “Introducing LangChain Agents” by Valentina Alto, a Microsoft AI specialist and author of Modern Generative AI with ChatGPT and OpenAI Models (Packt), explains an implementation example for Azure OpenAI Service with LangChain. You can also check the official integration doc for LangChain and Azure OpenAI Service.
Semantic Kernel
Semantic Kernel is an open source SDK that helps combine Azure OpenAI Service and other LLMs with regular programming languages like C#, Java, and Python. The SDK includes features such as prompt chaining, recursive reasoning, summarization, zero-shot/few-shot learning, contextual memory, long-term memory, embeddings, semantic indexing, planning, retrieval-augmented generation, external knowledge stores, and the “use your own data” option.
The end-to-end notion of the kernel includes the building blocks you can see in Figure 4-1.
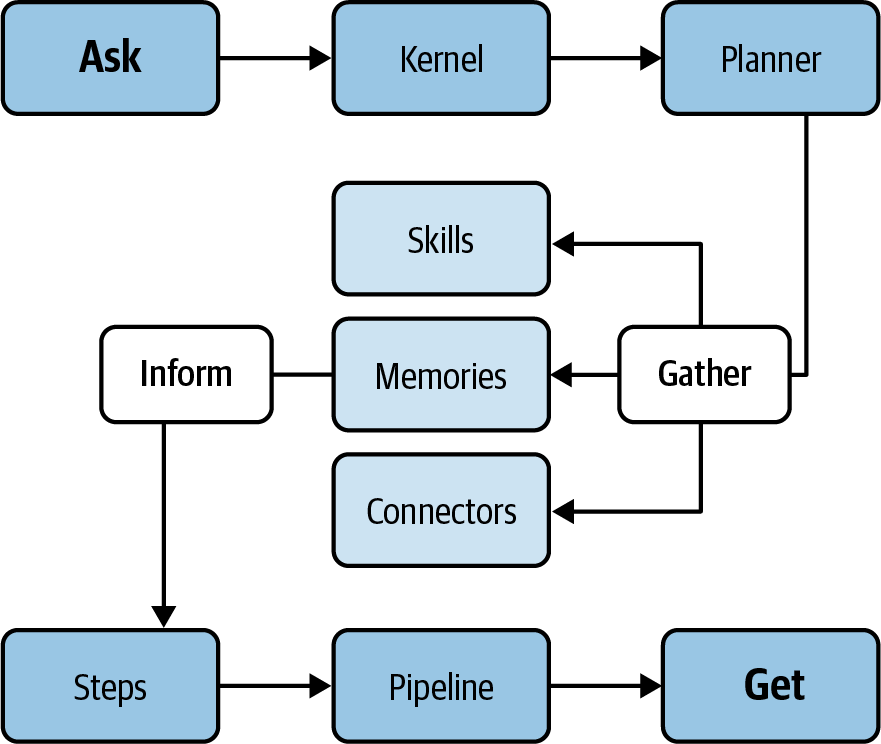
Figure 4-1. Semantic Kernel building blocks (source: adapted from an image by Microsoft)
Let’s look at each part of the figure in more detail:
- ASK
-
Refers to the input you present to the Semantic Kernel, which might be a question or directive in natural language. Examples include inquiries like, “Can you name the tallest mountain in the world?” or commands like, “Condense this piece of text.” Semantic Kernel seeks to interpret your ASK and cater to it using its diverse capabilities.
- Kernel
-
Represents the core processor that manages your ASK, choreographing a blend of AI services, memories, models, and add-ons to craft a response. You have the flexibility to tailor the kernel’s settings and parameters as per your preference.
- Planner
-
An intrinsic facet of the kernel, the planner ingeniously stitches functions together, formulating a strategy to address your ASK. If posed with a request like, “Compose a haiku about the moon,” the planner might amalgamate functions related to topic initiation, rhyming, and poem structuring.
- Gather
-
At this juncture of the plan, the kernel embarks on collating data from an array of outlets including AI models, memory storage, connectors, or even vast external repositories of knowledge. If you’re curious about “the largest mammal on Earth,” the kernel could tap into resources like Bing or Wikipedia for answers.
- Skills
-
Epitomize the proficiency range of Semantic Kernel in addressing your ASKs, harnessing its vast components. Skills might span a spectrum from basic to intricate, contingent on the intricacy of the steps and sources utilized. Examples of skills include areas like elucidation, interpretation, crafting, categorizing, and even answering queries. Consider skills the functional “anatomy” of your AI application.
- Memories
-
The system’s capacity to store, recall, and process information derived from previous interactions, tasks, or externally acquired data. It’s analogous to how human memory works but in a digital format.
- Connectors
-
Connectors serve as bridges, enabling Semantic Kernel to interface with a spectrum of AI platforms, models, memories, or external data troves. Using connectors, one can tap into platforms like OpenAI, Azure OpenAI, or even models like ChatGPT, as well as memory systems or information havens like Encyclopaedia Britannica.
- Inform
-
This phase sees the kernel apprising you of your ASK’s outcome, which could be manifested as text, visuals, audio, or a specific activity. Suppose you prompt, “Illustrate a tranquil forest”; the kernel might respond by curating an image-based query and projecting the resultant picture.
- Steps
-
Constituting the foundational blocks in the plan to address your ASK, each step might be framed as a prompt or an innate function. Prompts entail language-based directives dispatched to Azure OpenAI models. In contrast, native functions refer to standardized coding operations, often scripted in languages like C# or Python. For instance, in response to “Describe the process of photosynthesis,” one step might involve a prompt pinpointing the core mechanisms, while another leverages a native function to align them in a bulleted format.
- Pipeline
-
Essentially a series of actions initiated to address your ASK. Pipelines can either be preset or dynamically crafted by the planner. For a request like, “Pen a narrative on the evolution of technology,” the pipeline could encompass stages such as outlining, crafting an intro, articulating main content, concluding, and final arrangement.
- GET
-
Denotes an operation you can initiate on Semantic Kernel to glean details or data from its constituents. You might, for example, utilize GET to peek into the kernel’s memory bank, exploring its reservoir of past insights.
Last but not least, Semantic Kernel is one of the in-house Microsoft projects for generative AI, an effort led by Dr. John Maeda, and information is available on the official GitHub repository. Here are some additional resources if you want to continue exploring Semantic Kernel:
LlamaIndex
LlamaIndex is a data framework for LLM applications. This is another alternative for your generative AI applications with Azure OpenAI and includes both enterprise and open source options. It offers simplicity through a set of RAG scenarios and orchestration capabilities that combine LLM and internal data sources, and it has good traction with the developer community. Depending on how you use it, it can be an equivalent, alternative, or complement to both Semantic Kernel and LangChain.
Bot Framework
The Microsoft Bot Framework is a classic of the pre-ChatGPT bot era. It does not rely on Azure OpenAI Service, but some adopters are using it for specific scenario integrations (e.g, to deploy GPT-enabled projects within Microsoft Teams or other communication channels), and it includes a set of tools and services intended to help build, test, deploy, and manage intelligent chatbots:
- Bot Framework SDK
-
A modular and extensible software development kit that allows you to build bots in C#, JavaScript, Python, or Java. The SDK provides libraries and templates for common bot scenarios, such as dialogs, state management, authentication, etc.
- Bot Framework Composer
-
An open source visual authoring tool that lets you create bots using a graphical interface and natural language prompts. You can use the Composer to design dialogs, skills, and answers for your bot without writing code.
- Azure Bot Service
-
A cloud service that enables you to host your bot on Azure and connect it to various channels and devices, such as Facebook Messenger, Microsoft Teams, Skype, web chat, etc. Azure Bot Service also provides features such as analytics, debugging, security, etc.
- Bot Framework Emulator
-
A desktop application that allows you to test and debug your bot locally or remotely. You can use the Emulator to send and receive messages from your bot, inspect the bot state and activities, and access the bot logs.
- Bot Framework Connector
-
A service that handles communication between your bot and the channels or users. The Connector defines a REST API and an activity protocol for how your bot can send and receive messages and events.
As you can see, the Microsoft Bot Framework is a complete solution for classic bot (not LLM) scenarios, with Azure Bot Service being part of some of the official Azure OpenAI Accelerators. The full spec is available via its official GitHub repository.
Power Platform, Microsoft Copilot, and AI Builder
Besides the SDKs and development frameworks, there are other pieces for no-code and low-code implementations. The Power Platform suite of tools and services helps build and manage low-code applications, automate workflows, analyze data, and build chatbots, connecting these to any AI-enabled Azure feature, including Azure OpenAI. Microsoft Copilot/Power Virtual Agents (PVAs) is one of the components of Power Platform that allows you to create intelligent chatbots using a low-code graphical interface. You can use PVAs to build bots that can provide answers, perform actions, and interact with users in natural language.
There are three different ways these components can interact with Azure OpenAI for no-code/low-code generative AI applications:
-
By using an Azure OpenAI connector from Microsoft Copilot/PVAs, via Azure OpenAI APIs. An implementation example for that scenario is available online. This is a highly manual option, but still simple to implement.
-
By leveraging the Boost conversations (aka generative answers) feature of PVA. This functionality allows the bot to find and present information from multiple sources. Generative answers can be used as the primary solution in the chatbot, or as a fallback when other authored topics are unable to address a user’s query.
-
Besides these two bot-type applications, you can also leverage Power Platform’s AI Builder component and its integration with Azure OpenAI for automation and apps. A video demo on YouTube illustrates the implementation process.
These development building blocks are your tools to continue evolving your generative AI projects with Azure OpenAI. The list will probably grow over time, but this selection represents some of the most relevant pieces for any generative AI practitioner today. Let’s now check the available vector databases for Azure-first implementations, which will enable your embedding-based projects with Azure OpenAI and allow you save the generated vectors.
Databases and Vector Stores
As previously mentioned, embeddings are a technique that generates mathematical representations of distances between topics, and that information is what we call a “vector.” They have become relevant to the generative AI space because of their ability to connect information that is linguistically related. This is relevant for search engines, document retrieval during chat sessions, etc. For that purpose, we rely on a specific kind of database called a vector database, as it is better suited to store and manage this kind of information.
The main advantage of a vector database is that it allows for fast and accurate similarity search and retrieval of data based on its vector distance or similarity. This means that instead of using traditional methods of querying databases based on exact matches or predefined criteria, you can use a vector database to find the most similar or relevant data based on its semantic or contextual meaning. Vector databases are used to store, search, and retrieve vectors (previously generated via embedding techniques) representing documents, images, and other data types used in machine learning applications.
From an Azure OpenAI Service point of view, there are different native Azure services, or open source pieces deployable via Azure, that will serve as vector databases. Let’s go through those now.
Vector Search from Azure AI Search
Vector search is a recent feature from one of the existing Microsoft Azure AI services, specifically Azure AI Search. This piece is part of the implementation for both embedding- and retrieval-based approaches.
Vector search is a new capability for indexing, storing, and retrieving vector embeddings from a search index. You can use it to enable typical cases such as similarity search, multimodal search, recommendations engines, or grounding/RAG implementations. The main differentiator (based on its creator’s words) is the ability to enable not only classic vector search, but also “a hybrid search approach that harnesses both vector and traditional keyword scores [and] delivers even better retrieval result quality than a single search method alone,” as illustrated in Figure 4-2.
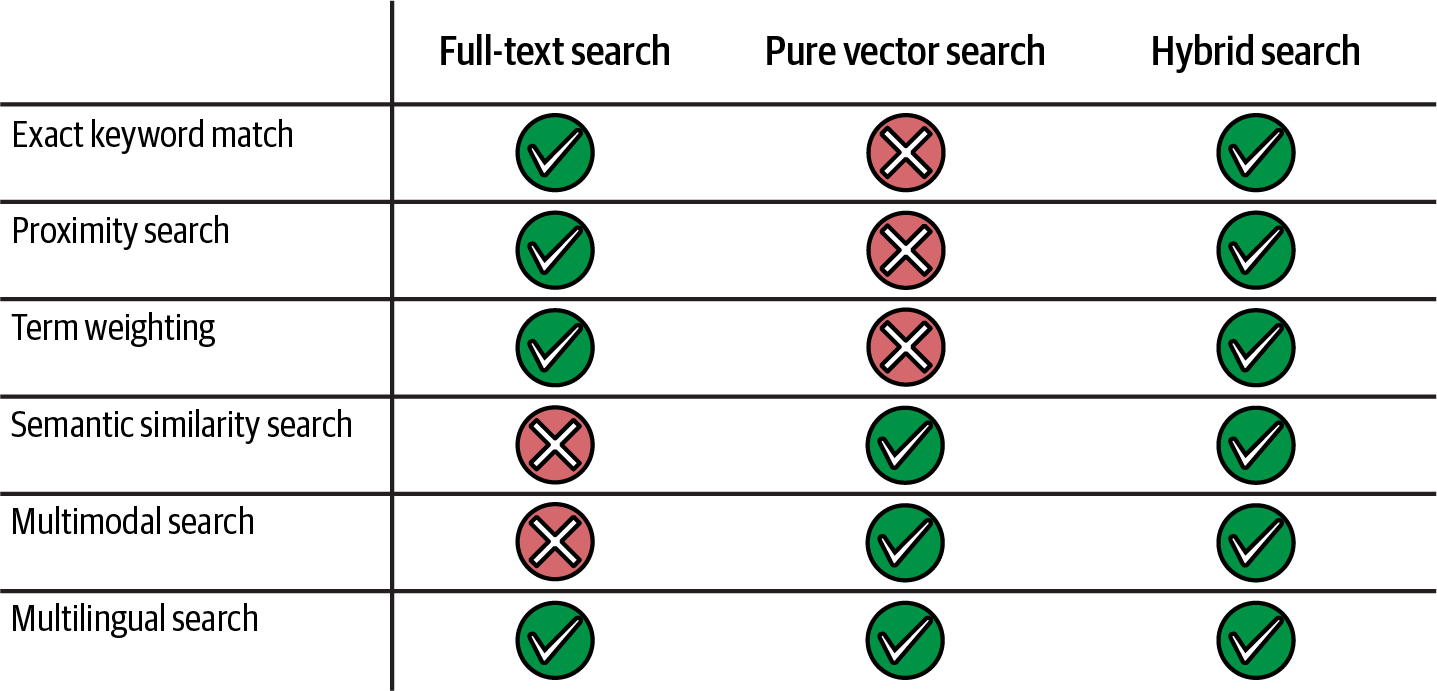
Figure 4-2. Vector and hybrid search features with Azure AI Search (source: adapted from an image by Microsoft)
You can leverage the official documentation for this highly evolving technology, as well as the technical guides on how to save your previously generated vectors and how to perform vector queries via Azure AI Search’s vector search feature.
Vector Search from Cosmos DB
Vector search is a similar vector feature from a different Azure native service, in this case Azure Cosmos DB, which is a managed multitype NoSQL database that supports several types of key-value, column, graph, and document formats. It includes open source options such as PostgreSQL, MongoDB, and Apache Cassandra.
The vector search feature comes from the Azure Cosmos DB for MongoDB vCore product, which provides a fully managed MongoDB-compatible database service in Azure. The new functionality was announced in May 2023, and it’s an alternative to the Azure Cognitive Search option. This is an option for environments where MongoDB is already part of the technology stack. You can view an additional repo with implementation samples, and implementations with Semantic Kernel as the orchestrator.
Azure Databricks Vector Search
As with Azure AI Search and Cosmos DB, there is another excellent native option with Azure Databricks. It offers the Databricks Vector Search feature, which is directly integrated into the serverless engine and into Unity Catalog for data and AI governance. This is a good option if you want to leverage a native end-to-end platform in Azure and connect Azure OpenAI to the vector store by leveraging diverse orchestration engines (e.g., LlamaIndex, LangChain).
Redis Databases on Azure
An alternative option is Azure Cache for Redis, which is a solution to accelerate the data layer of applications through in-memory caching based on Redis open source databases. It contains RediSearch, which is a Redis module that provides full-text search capabilities. The Azure version is built on top of the Redis engine and is designed to be used with Redis Enterprise.
Similar to the previous two options, Azure Cache for Redis has evolved and incorporates a new vector search feature that combines the power of a high-performance caching solution with the versatility of a vector database, opening up new frontiers for developers and businesses. As with Cosmos DB, this option is great for those companies already using Redis or Azure Cache for Redis as part of their technology stack.
Other Relevant Databases (Including Open Source)
There are other options available, including native and open source solutions that you can leverage via Azure:
- pgvector
-
For vector similarity search in Cosmos DB for PostgreSQL and Azure Database for PostgreSQL, the native options for PostgreSQL in Azure.
- Elasticsearch vector database
-
Available in Azure OpenAI Playground, directly integrated to the On Your Data feature.
- Neo4j
-
Enables you to implement RAG patterns with graph data. A good option to leverage the power of knowledge graphs, available in Azure, including accelerators to test it out.
- Pinecone on Azure
-
Available in private preview since July 2023, this allows for the deployment of a Pinecone vector (commercial, fully managed) database directly via Azure. Here is an implementation sample with Azure OpenAI Service and the Pinecone database.
- Milvus
-
An open source project for vector databases, available on Azure. It is one of the main open source contenders, and a graduated project from the Linux Foundation.
- Azure Data Explorer
-
For vector similarity search, another vector store option to store embeddings using an Azure native service. Here is a step-by-step explanation.
- Other vector databases, for deployment via containers (not PaaS)
Additionally, and even if it is not a vector store (just a library that creates an in-memory vector store), you can also explore Faiss, Meta’s library for efficient similarity search and clustering of dense vectors. Its Index Lookup tool via Azure ML Prompt Flow allows querying within a user-provided Faiss-based vector store.
Feel free to explore all these vector store and database options, and others from the OpenAI Cookbook list. The simplest way to start is by leveraging native services such as Azure Cognitive Search or Azure Cosmos DB, but the choice will depend on your implementation approach. Let’s now take a look at some additional technology building blocks you may need for your generative AI projects.
Additional Microsoft Building Blocks for Generative AI
In addition to what we’ve already covered in this chapter, there are some consolidated services and ongoing research projects that we can leverage for our Azure OpenAI projects. Let’s dig into a few of those.
Azure AI Document Intelligence (formerly Azure Form Recognizer) for OCR
Some of the grounding scenarios we previously analyzed rely on images and PDF documents as the main source of knowledge, in addition to the base LLM. If we want to combine the LLM’s knowledge with the information from those images and PDFs, we need to extract the information from those documents in advance, and have it transformed from the source to relevant formats such as JSON or JSONL.
For PDFs, the classic technique that extracts text from the document is OCR (optical character recognition). This is a mature technique that recognizes every character of a document, to read and extract its information for later use.
If we want to leverage native Azure services to perform OCR tasks, there is an Azure AI service called AI Document Intelligence (previously called Form Recognizer). From the official website, it is “an AI service that applies advanced machine learning to extract text, key-value pairs, tables, and structures from documents automatically and accurately.” This is a preliminary step before performing fine-tuning, embeddings, etc. This official article explains the end-to-end process that combines AI Document Intelligence and Azure OpenAI Service to directly launch queries against the document.
Alternatively, the previously mentioned Azure AI Search service includes a similar OCR cognitive skill that works with both images (that contain text) and documents.
Microsoft Fabric’s Lakehouse
This option is a must for any company looking to implement their Microsoft Azure–enabled data strategy for a lakehouse architecture: Microsoft Fabric. This resource could be a topic for a whole new book, but you should know that it is a platform that helps create, use, and govern data insights across an organization. As you can see in Figure 4-3, it includes data integration and science tools, data lakes, governance, and visualization elements. The relationship between Fabric and Azure OpenAI is bidirectional. Data from Microsoft Fabric can serve as a source for RAG patterns, but you can also leverage Azure OpenAI models within Microsoft Fabric data tools. It also contains a GPT-enabled Copilot for data analysis with natural language. If you want to learn more, you can explore the official documentation, specific examples, and the REST API specification.
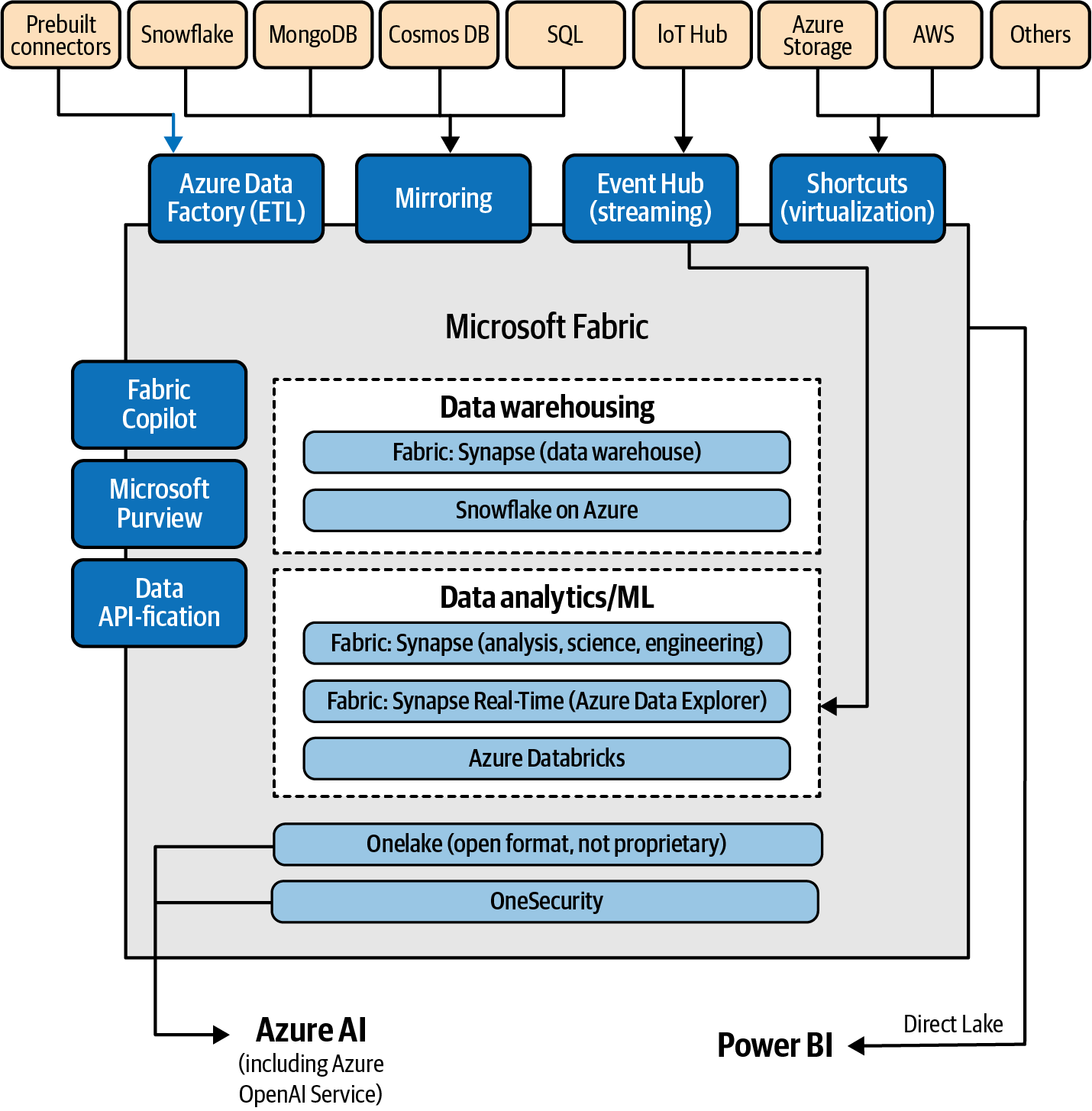
Figure 4-3. Lakehouse with Microsoft Fabric
Microsoft Azure AI Speech
Another complementary service is Azure AI Speech, which includes speech-to-text, text-to-speech, speech translation, and speaker recognition capabilities for voice-enabled features that you can use for your Azure OpenAI–enabled applications. This is very useful for accessible interfaces where users can communicate with the generative AI engine by voice. Also, there are visual avatar functionalities that will help you add virtual faces to your implementations.
Microsoft Azure API Management
Azure API Management is a transversal element that supports all your enterprise-grade Azure OpenAI deployments, allowing you to manage, balance, and monitor your different subscriptions, models, and API keys. It is ideal for cost management and multidepartment chargeback.
Ongoing Microsoft Open Source and Research Projects
In the following we will review a selection of ongoing Microsoft research projects, all of them related to LLM development. Most of them are not production-ready building blocks, but even if they won’t be used by regular generative AI practitioners, you may want to take a look and see the latest generative AI–related developments:
- DeepSpeed
-
A deep learning optimization library developed by Microsoft, designed to help researchers train large-scale models faster and more efficiently, between 10 and 100 times larger than previously possible. Additionally, DeepSpeed Chat is an open system framework for enabling an end-to-end RLHF training experience to generate generative AI models at all scales.
- ONNX Runtime
-
A cross-platform inference and training machine-learning accelerator, intended to improve customer experiences (by providing faster model inference) and to reduce training costs. It was open sourced by Microsoft in 2019, and is based on the ONNX open format (co-developed by Microsoft with Meta and AWS). It includes the DirectML execution provider, a component of ONNX Runtime to accelerate inference of ONNX models.
- JARVIS/HuggingGPT
-
A project to use LLMs as interfaces to connect different AI models from Hugging Face and others for solving complicated AI tasks.
- ToxiGen
-
A large machine-generated dataset for hate speech detection, from Microsoft.
- LLM-Augmenter
-
A project that aims to reduce hallucinations (i.e., LLMs delivering incorrect answers) by utilizing external knowledge for LLMs and automated feedback.
- AdaTest
-
A Microsoft project to find and fix bugs in natural language/machine learning models using adaptive testing.
- LoRA (Low-Rank Adaptation)
-
Helps reduce the number of training parameters for LLMs, making this process less storage and computing intensive.
- Guidance
-
A Microsoft project that enables control of modern language models more effectively and efficiently than traditional prompting or chaining.
- PromptCraft-Robotics
-
A research project that aims to combine ChatGPT and robotic systems such as drones, camera-enabled robots, etc.
- Gorilla LLM
-
A collaboration between Microsoft Research and the University of Berkeley, who have developed an LLM connected to APIs, which means that it can provide appropriate API calls for different topics including PyTorch Hub, TensorFlow Hub, HuggingFace, Kubernetes, OpenAPI, and others. A great step toward a more general kind of intelligence.
- PowerProxy AI
-
A project that helps in monitoring and processing traffic to and from Azure OpenAI Service endpoints.
- AutoGen
-
A framework that enables the development of LLM applications using multiple agents that can converse with each other to solve tasks.
- UniLM
-
A Microsoft repo that contains a series of research papers and links to other LLM-related GitHub repositories.
- LIDA
-
A Microsoft library for automatic generation of visualizations and infographics with LLMs.
- “Algorithm of Thoughts”
-
A research paper that explores potential LLM improvements with human-like reasoning techniques.
- PromptBench
- Promptbase
-
A collection of best practices to obtain the best performance from LLMs.
- AICI
-
An Artificial Intelligence Controller Interface that limits and directs output of LLMs in real time.
- Olive
-
A hardware-aware model optimization tool for compression, optimization, and compilation.
- Phi-3
-
A revolutionary open source small language model (SLM) available via Azure AI Studio and Hugging Face.
- Orca/Orca-2
-
A Microsoft research project to specialize SLMs with domain-specific data.
- PyRIT (Python Risk Identification Tool for generative AI)
-
A powerful framework to enable red team activities for your generative AI applications with Azure OpenAI and other LLMs.
- LLMLingua
-
A prompt compression method that speeds up LLM inference with minimal performance loss, making the models more efficient from a token consumption and latency perspective.
Given that generative AI is a highly evolving area, I aimed to provide you with a quick overview of what the industry is trying to achieve, in addition to the core Azure OpenAI LLM capabilities you already know.
Conclusion
This chapter is a continuation of what we covered in Chapter 3, and it includes an ecosystem of projects and technologies that you can leverage to create very advanced cloud native architectures. Most of them are additional and complementary to Azure OpenAI and required to implement some of the Chapter 3 technical approaches.
This is a highly evolving area, so consider this chapter as an initial toolbox for your generative AI practitioner journey. The next chapter will focus on the notion of LLMOps (LLM operations, an evolution of the DevOps and MLOps concepts), and how to handle production-level topics such as performance, security, and privacy. Let’s explore it together.
Get Azure OpenAI Service for Cloud Native Applications now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

