Kapitel 4. Persistente Daten
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Fast jede Anwendung muss Daten in irgendeiner Form aufbewahren, und Cloud-Anwendungen sind da keine Ausnahme. Die Daten können in einer der folgenden Formen vorliegen:
-
Binär- oder Textdateien, wie z. B. Bilder, Videos, Musik, Apache Avro-, CSV- oder JSON-Formate
-
Strukturierte oder halbstrukturierte Daten, die in relationalen oder NoSQL-Datenbanken gespeichert sind
In Kapitel 3 haben wir über Azure Storage gesprochen, das unstrukturierte Daten wie Blob-Dateien (Text, Binärdateien usw.) speichern kann. In diesem Kapitel werden wir über die Datenbanken sprechen, die Azure für die Speicherung von relationalen und NoSQL-Daten anbietet.
Die erste Option ist die Nutzung von IaaS-Datenbankangeboten. Du kannst eine Azure-VM bereitstellen und jede beliebige Datenbank-Engine installieren, z. B. Microsoft SQL Server, MySQL oder sogar MongoDB. Diese Option bietet dir eine große Flexibilität, da du die zugrunde liegende virtuelle Maschine besitzt, erfordert aber einen hohen Verwaltungsaufwand. Du bist für die Wartung, Sicherung und das Patchen des VM-Betriebssystems und der Datenbank-Engine verantwortlich.
A Die zweite (und bessere) Option, auf die wir uns in diesem Kapitel konzentrieren, sind die verwalteten Datenbanken von Azure. Dabei handelt es sich um PaaS-Angebote (Platform as a Service), die auch als verwaltete Datenbanken bezeichnet werden und mit denen du in wenigen Minuteneine einsatzbereite Datenbank bereitstellen kannst. Azure kümmert sich um die zugrundeliegenden VM-Betriebssysteme, um Patches und Sicherheit sowie um viele andere administrative Aufgaben wie die Skalierung.
Azure SQL, Azure Cosmos DB und Azure Database for PostgreSQL sind einige der Azure PaaS-Datenbanken, die dir zur Verfügung stehen. Durch die native Integration mit anderen Azure-Diensten wie Azure Virtual Networks, Azure Key Vault und Azure Monitor kannst du diese Datenbanken ganz einfach in deine Azure-Lösungen integrieren.
Der Schwerpunkt dieses Kapitels liegt auf den beiden wichtigsten verwalteten Azure-Datenbanken: Azure Cosmos DB und Azure SQL. Zu den Themen, die du kennenlernen wirst, gehören:
-
Aktivieren von kundenverwalteten Schlüsseln für die Cosmos DB-Verschlüsselung im Ruhezustand
-
Arbeiten mit Azure Cosmos DB und Azure SQL Firewalls
-
Gewährung von Cosmos DB-Zugriff auf andere Azure-Dienste mit verwalteten Identitäten und RBAC
-
Konfigurieren der automatischen Skalierung für Azure Cosmos DB
Tipp
Azure verbessert sowohl Azure Cosmos DB als auch Azure SQL Services kontinuierlich. Behalte die Azure-Updates-Seite im Auge, um dich über die neuesten und besten Funktionen zu informieren.
Konfiguration der Arbeitsstation
Bevor du mit den Rezepten in diesem Kapitel beginnst, musst du deine Workstation vorbereiten. Folge dem Abschnitt "Was du brauchst", um deinen Rechner für die Ausführung von Azure CLI-Befehlen einzurichten. Du kannst das GitHub-Repository des Buches mit dem folgenden Befehl klonen:
git clone https://github.com/zaalion/AzureCookbook.git
Erstellen eines Cosmos DB NoSQL API-Kontos
Lösung
Erstelle ein neues Azure Cosmos DB NoSQL API-Konto, erstelle eine Datenbank und speichere deine JSON-Daten in den Containern der Datenbank, wie in Abbildung 4-1 gezeigt.
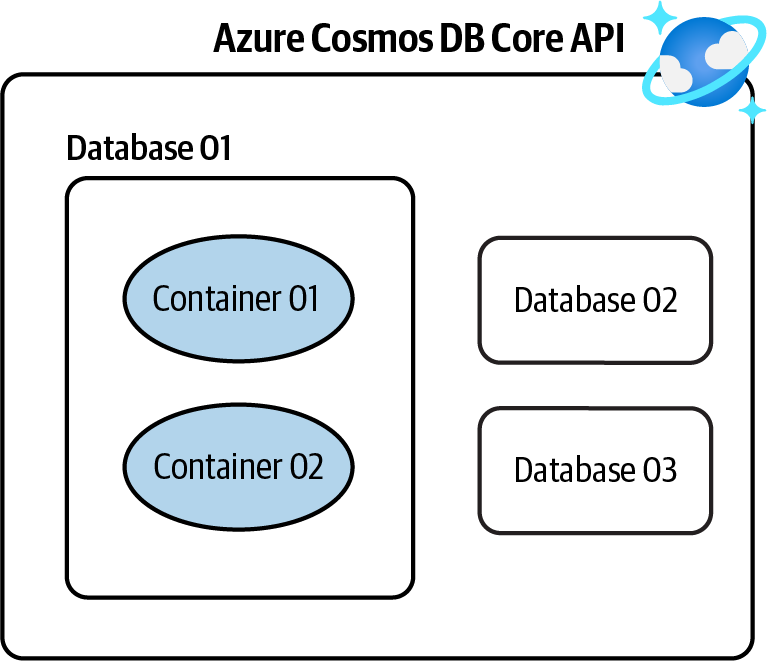
Abbildung 4-1. Speichern von NoSQL-Daten in einem Azure Cosmos DB NoSQL API-Konto
Steps
-
Melde dich in der Rolle des Eigentümers bei deinem Azure-Abonnement an und erstelle eine neue Ressourcengruppe für dieses Rezept. Weitere Informationen findest du unter "Allgemeine Anweisungen zur Einrichtung von Workstations".
-
Erstelle ein neues Azure Cosmos DB NoSQL API-Konto. Ersetze <
cosmos-account-name> durch den gewünschten Cosmos DB-Kontonamen. Dieses Skript konfiguriert außerdem regelmäßige Backups, die alle 240 Minuten (4 Stunden) erstellt und 12 Stunden lang aufbewahrt werden:cosmosAccountName="<cosmos-account-name>" az cosmosdb create \ --name $cosmosAccountName \ --resource-group $rgName \ --backup-policy-type Periodic \ --backup-interval 240 \ --backup-retention 12
-
Als Nächstes musst du eine Datenbank erstellen, in der deine Daten gespeichert werden. Du kannst deiner Datenbank einen festen Durchsatz (RU/s) zuweisen und/oder später den gewünschten Durchsatz auf der Ebene des Containers (Sammlung) festlegen. Einzelheiten findest du in der Azure-Dokumentation. Verwende diesen Befehl, um eine Datenbank namens
MyCompanyDBin deinem Cosmos DB-Konto zu erstellen:az cosmosdb sql database create \ --account-name $cosmosAccountName \ --name MyCompanyDB \ --throughput 1000 \ --resource-group $rgName
Hinweis
Die Zuweisung eines festen (bereitgestellten) Durchsatzes zu einer Datenbank ist nicht zwingend erforderlich. Du hast die Möglichkeit, den Durchsatz später den untergeordneten Containern zuzuweisen. Cosmos DB bietet auch Autoscale- und Serverless-Deployments an, bei denen die Ressourcen auf der Grundlage des Datenverkehrs und der Last angepasst werden. Weitere Informationen findest du in der Cosmos DB-Dokumentation.
-
Unter kannst du nun deinen ersten Container (Sammlung) in deiner Datenbank erstellen. Stell dir einen Container wie eine Tabelle in einer relationalen Datenbank vor. Jeder Container sollte einen Partitionsschlüssel haben, mit dem die Containerdokumente auf logische Partitionen verteilt werden können, um die Leistung zu verbessern. Verwende den folgenden Befehl, um eine neue Sammlung mit dem Namen
Peopleund einem festen Durchsatz von 400 RU/s (Request Units) zu erstellen:MSYS_NO_PATHCONV=1 az cosmosdb sql container create \ --name People \ --partition-key-path "/id" \ --throughput 400 \ --database-name MyCompanyDB \ --account-name $cosmosAccountName \ --resource-group $rgName
Tipp
Setze MSYS_NO_PATHCONV=1 vor den Bash-Befehl, damit /id nicht in einen Linux-Pfad umgewandelt wird.
-
Führe den folgenden Befehl aus, um die Ressourcen zu löschen, die du in diesem Rezept erstellt hast:
az group delete --name $rgName
In diesem Rezept hast du ein Azure Cosmos DB NoSQL API-Konto und eine Datenbank mit einem Container darin erstellt. Jetzt kannst du deine NoSQL-Dokumente in dieser Datenbank persistieren.
Diskussion
Azure Cosmos DB ist das wichtigste NoSQL-Datenbankangebot von Microsoft in der Cloud. Cosmos DB ist eine global verteilte, sichere Multi-Modell-Datenbank. Zum Zeitpunkt der Erstellung dieses Buches bietet Cosmos DB die folgenden APIs (Modelle):
- SQL (Core) API
- Gremlin (Graph) API
-
Wir empfehlen diese API, wenn du die Datenstruktur des Graphen in deiner Datenbank festhalten musst. Das kannst du zum Beispiel für eine Social-Media-Anwendung tun.
- API für MongoDB
-
Verwende diese API, wenn du Daten von MongoDB zu Azure Cosmos DB migrierst und keine oder nur minimale Änderungen an deinem Anwendungscode vornehmen möchtest.
- Kassandra-API
-
Verwende diese API, wenn du von Cassandra zu Azure Cosmos DB migrierst und möchtest, dass deine Anwendung ohne Codeänderungen mit Cosmos DB funktioniert.
- Tabelle API
-
Eine Premium-Alternative für Nutzer von Azure Table Speicherung. Migriere deine Daten zur Azure Cosmos DB Table API und dein Code wird ohne Änderungen funktionieren.
Weitere Informationen findest du in der Azure Cosmos DB SQL (Core) API Dokumentation.
In diesem Rezept haben wir eine SQL (Core) API erstellt. Diese API speichert Daten im JSON-Dokumentenformat. Du hast die volle Kontrolle über die Schnittstelle, den Dienst und die SDK-Client-Bibliotheken.
Cosmos DB bietet außerdem die folgenden Funktionen:
-
Globale Verteilung und multiregionale Schreibvorgänge, so dass die Daten von mit hoher Leistung an Kunden auf der ganzen Welt geliefert werden können
-
Einstellbare Konsistenzstufe für unterschiedliche Konsistenz- undLeistungsanforderungen
-
Zonenredundanz für besseren Schutz vor zonalenAusfällen
-
Sicherheitsfunktionen wie Verschlüsselung im Ruhezustand, Verschlüsselung bei der Übertragung, eine einfach zu konfigurierende Firewall und Unterstützung für Azure Active Directory-Authentifizierung
In diesem Kapitel gehen wir auf verschiedene Funktionen und Möglichkeiten von Cosmos DB ein.
Erstellen eines Cosmos DB Apache Gremlin (Graph) API-Kontos
Lösung
Erstelle ein neues Azure Cosmos DB Gremlin API-Konto, erstelle eine Datenbank und verwende sie, um deine Diagrammobjekte zu speichern. Siehe Abbildung 4-2.
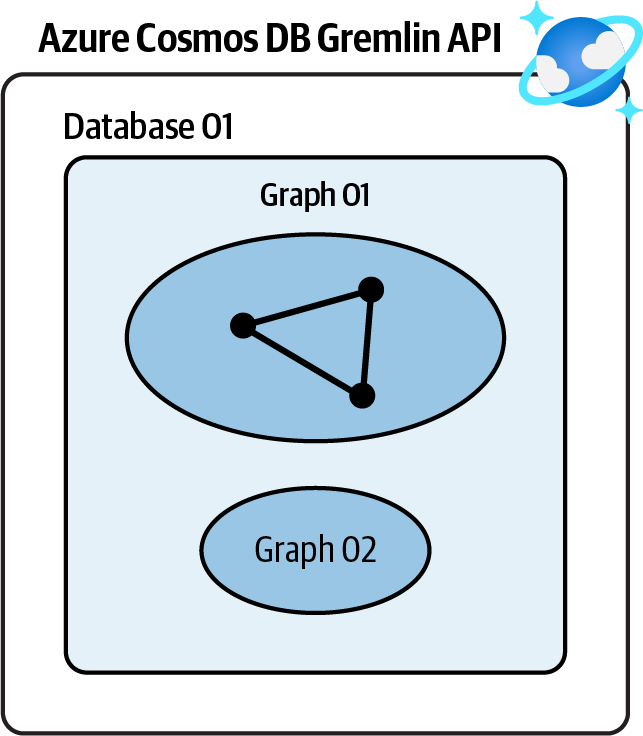
Abbildung 4-2. Speichern von Diagrammdaten in einem Azure Cosmos DB Gremlin API-Konto
Steps
-
Melde dich in der Rolle des Eigentümers bei deinem Azure-Abonnement an und erstelle eine neue Ressourcengruppe für dieses Rezept. Weitere Informationen findest du unter "Allgemeine Anweisungen zur Einrichtung von Workstations".
-
Erstelle ein neues Azure Cosmos DB Gremlin API-Konto. Ersetze <
cosmos-account-name> durch den gewünschten Cosmos DB-Kontonamen:cosmosAccountName="<cosmos-account-name>" az cosmosdb create \ --name $cosmosAccountName \ --resource-group $rgName \ --capabilities EnableGremlin
-
Benutze diesen Befehl, um eine Datenbank namens
MyGraphDBin deinem Cosmos DB-Konto zu erstellen:az cosmosdb gremlin database create \ --account-name $cosmosAccountName \ --resource-group $rgName \ --name MyGraphDB
-
Jetzt kannst du einen oder mehrere Graphen in
MyGraphDBerstellen. Wie bei Containern sollte jeder Graph einen Partitionsschlüssel haben, der die Verteilung der Graphdaten auf logische Partitionen erleichtert und so die Leistung verbessert. Verwende den folgenden Befehl, um einen neuen Graphen mit dem NamenPeoplezu erstellen:MSYS_NO_PATHCONV=1 az cosmosdb gremlin graph create \ --resource-group $rgName \ --account-name $cosmosAccountName \ --database-name MyGraphDB \ --name People \ --partition-key-path "/age"
Tipp
Setze MSYS_NO_PATHCONV=1 vor den Bash-Befehl, damit /id nicht in einen Linux-Pfad umgewandelt wird.
-
Führe den folgenden Befehl aus, um die Ressourcen zu löschen, die du in diesem Rezept erstellt hast:
az group delete --name $rgName
Du hast erfolgreich ein Azure Cosmos DB Gremlin API-Konto und eine Datenbank mit einem Graphen darin erstellt.
Diskussion
Graphdatenbanken sind NoSQL-Datenspeicher, die dafür optimiert sind, die Datenstruktur des Graphen zu erhalten und abzufragen. Azure Cosmos DB Gremlin API ist Microsofts wichtigstes Graphdatenbankangebot in der Cloud. Sie bietet hohe Verfügbarkeit, flexible Konsistenzstufen, globale Verteilung und SDKs für viele Frameworks und Sprachen.
Graphdatenbanken sind ideal für die folgenden Szenarien:
- Internet der Dinge
- Soziale Netzwerke
-
Modelliere die Beziehung zwischen Menschen, Orten und anderen Einheiten
- Empfehlungsmaschinen in der Einzelhandelsbranche
- Geospatial
-
Finde optimierte Routen in standortgebundenen Anwendungen und Produkten
In der Azure Cosmos DB Gremlin-Dokumentation findest du weitere Informationen.
Azure Cosmos DB Firewall konfigurieren
Lösung
Konfiguriere die Azure Cosmos DB Service Firewall so, dass sie den Zugriff von vertrauenswürdigen IP-Adressen, virtuellen Netzwerken und privaten Endpunkten zulässt, während sie allen anderen Datenverkehr abweist (siehe Abbildung 4-3).
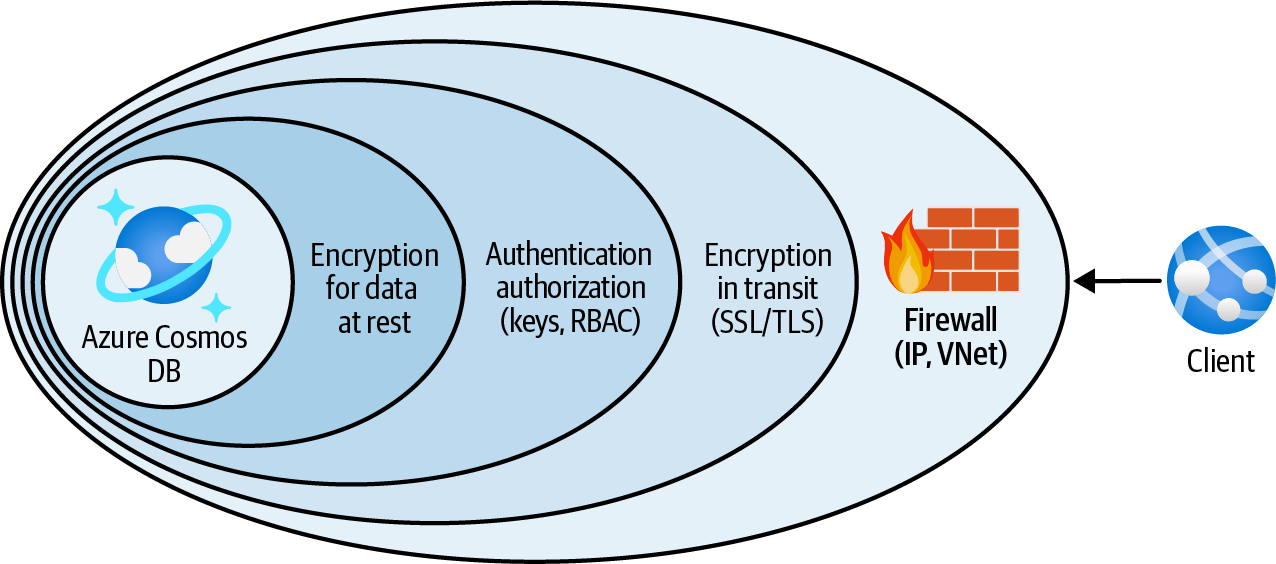
Abbildung 4-3. Schutz von Azure Cosmos DB mit der Service Firewall
Steps
-
Melde dich bei deinem Azure-Abonnement in der Rolle des Eigentümers an und erstelle eine neue Ressourcengruppe für dieses Rezept. Weitere Informationen findest du unter "Allgemeine Anweisungen zur Einrichtung von Workstations".
-
Erstelle ein neues Azure Cosmos DB-Konto. Die Service Firewall ist für alle Cosmos DB APIs verfügbar. In diesem Rezept nehmen wir uns die SQL (Core) API vor. Ersetze <
cosmos-account-name> durch den gewünschten Cosmos DB-Kontonamen:cosmosAccountName="<cosmos-account-name>" az cosmosdb create \ --name $cosmosAccountName \ --resource-group $rgName
-
Zunächst fügen wir unter eine neue IP-Filterregel hinzu. Nachdem wir diese Regel hinzugefügt haben, werden Clients abgewiesen, wenn ihre IP-Adresse nicht in der Regel enthalten ist. Ersetze <
allowed-ip-range> durch einen IP-Bereich, eine kommagetrennte Liste von IPs oder eine einzelne IP-Adresse:allowedIPRange="<allowed-ip-range>" az cosmosdb update \ --resource-group $rgName \ --name $cosmosAccountName \ --ip-range-filter $allowedIPRange
Hinweis
Die Aktualisierung von Azure Cosmos DB kann ein paar Minuten dauern. Bitte warte, bis der Befehl abgeschlossen ist.
-
Du kannst auch Cosmos DB-Netzwerkregeln erstellen, um den Datenverkehr von ausgewählten Azure VNets zuzulassen. Verwende zunächst den folgenden Befehl, um ein neues Azure VNet zu erstellen. Ersetze <
vnet-name> durch deinen gewünschten Netzwerknamen:vnetName="<vnet-name>" az network vnet create \ --resource-group $rgName \ --name $vnetName \ --address-prefix 10.0.0.0/16 \ --subnet-name Subnet01 \ --subnet-prefix 10.0.0.0/26
-
Dein Ziel ist es, dass Clients im angegebenen Subnetz Azure Cosmos DB sehen und nutzen können. Um dies zu erreichen, musst du zunächst den
Microsoft.AzureCosmosDBService-Endpunkt zum Subnetz hinzufügen:az network vnet subnet update \ --resource-group $rgName \ --name Subnet01 \ --vnet-name $vnetName \ --service-endpoints Microsoft.AzureCosmosDB
-
Aktiviere dann die Azure VNet-Filterung für dein Cosmos DB-Konto:
az cosmosdb update \ --resource-group $rgName \ --name $cosmosAccountName \ --enable-virtual-network true
-
Zu diesem Zeitpunkt akzeptiert dein Cosmos DB-Konto nur Datenverkehr von den mit
$allowedIPRangeangegebenen IPs. Jetzt sind die Voraussetzungen dafür geschaffen, dass du Datenverkehr vonSubnet01zulassen kannst:az cosmosdb network-rule add \ --resource-group $rgName \ --virtual-network $vnetName \ --subnet Subnet01 \ --name $cosmosAccountName
Tipp
Es kann ein paar Minuten dauern, bis dieser Befehl ausgeführt wird. Wenn du die Meldung "VirtualNetworkRules sollte nur angegeben werden, wenn IsVirtualNetworkFilterEnabled True ist" erhältst, stelle sicher, dass der vorherige Schritt erfolgreich abgeschlossen wurde.
-
Verwende den folgenden Befehl, um zu bestätigen, dass die Cosmos DB-Netzwerkregelerstellt wurde:
az cosmosdb network-rule list \ --name $cosmosAccountName \ --resource-group $rgName
-
Führe den folgenden Befehl aus, um die Ressourcen zu löschen, die du in diesem Rezept erstellt hast:
az group delete --name $rgName
Du hast die Azure Cosmos DB-Firewall erfolgreich so konfiguriert, dass sie nur Client-Datenverkehr von den gewünschten IP-Adressen und Azure VNets zulässt.
Diskussion
Viele Azure-Dienste bieten Firewalls auf Dienstebene, die deine Daten umfassend schützen. Azure SQL, Azure Storage und Azure Cosmos DB gehören zu diesen Diensten.
Es ist eine gute Sicherheitspraxis, immer Firewalls auf Dienstebene zusätzlich zu anderen Sicherheitsvorkehrungen (wie Azure Active Directory-Authentifizierung) zu konfigurieren. So wird sichergestellt, dass kein unbefugter Nutzer aus dem Internet oder anderen Netzwerken auf deine Azure Cosmos DB-Daten zugreifen kann.
Mit der Azure Cosmos DB Firewall kannst du die folgenden Einschränkungen einzeln oder kombiniert konfigurieren:
-
Datenverkehr auf Basis der IP-Adresse des Clients über IP-Regeln zulassen
-
Datenverkehr basierend auf dem virtuellen Client-Netzwerk zulassen
-
Privaten Datenverkehr über private Azure-Endpunkte zulassen
Verwende IP-Regeln für Clients mit statischen IP-Adressen, wie z. B. öffentliche virtuelle Maschinen, oder wenn du von deinem eigenen lokalen Rechner aus auf Cosmos DB zugreifen musst. Verwende Regeln für virtuelle Netzwerke, um Dienste wie virtuelle Azure-Maschinen oder App Service Environments zuzulassen, die in einem Azure VNet-Subnetz bereitgestellt werden.
Azure Cosmos DB Private Access konfigurieren
Lösung
Erstelle einen privaten Endpunkt für dein Azure Cosmos DB-Konto und deaktiviere dann den öffentlichen Netzwerkzugang für Azure Cosmos DB, wie in Abbildung 4-4 dargestellt.
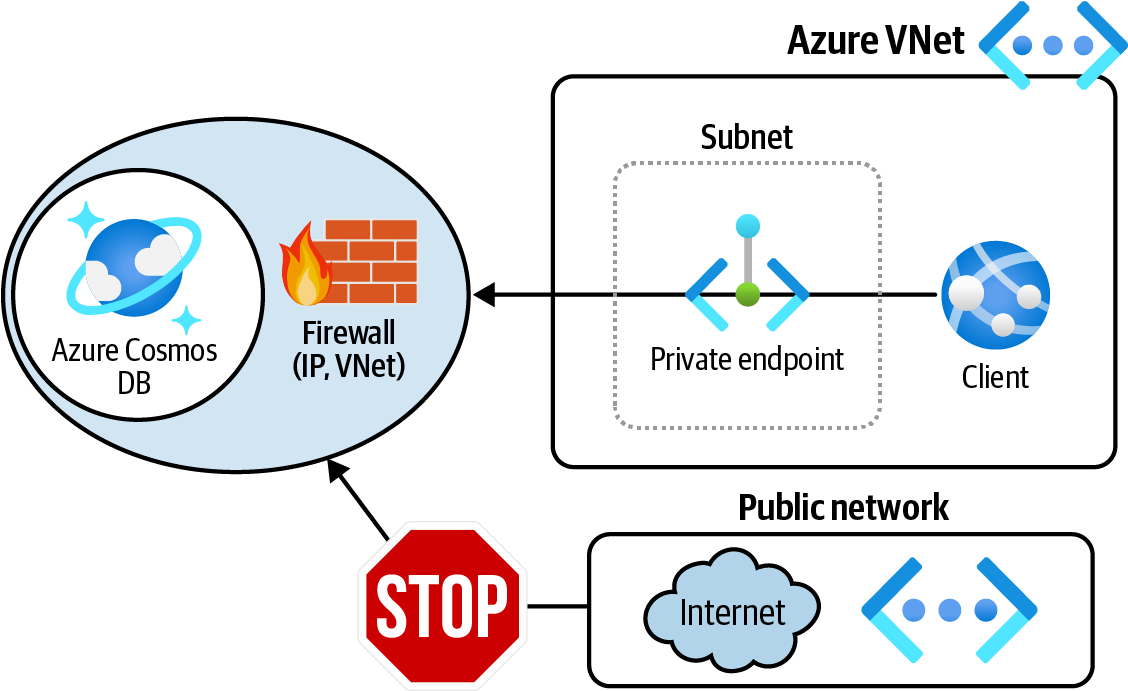
Abbildung 4-4. Nur privaten Datenverkehr zu Azure Cosmos DB über private Endpunkte zulassen
Steps
-
Melde dich bei deinem Azure-Abonnement in der Rolle des Eigentümers an und erstelle eine neue Ressourcengruppe für dieses Rezept. Weitere Informationen findest du unter "Allgemeine Anweisungen zur Einrichtung von Workstations".
-
Erstelle ein neues Azure Cosmos DB-Konto. Die Service Firewall ist für alle Cosmos DB APIs verfügbar. In diesem Rezept nehmen wir uns die SQL (Core) API vor. Ersetze <
cosmos-account-name> durch den gewünschten Cosmos DB-Kontonamen:cosmosAccountName="<cosmos-account-name>" az cosmosdb create \ --name $cosmosAccountName \ --resource-group $rgName
-
Verwende den folgenden Befehl, um ein neues Azure VNet zu erstellen. Ersetze <
vnet-name> durch deinen gewünschten Netzwerknamen:vnetName="<vnet-name>" az network vnet create \ --resource-group $rgName \ --name $vnetName \ --address-prefix 10.0.0.0/20 \ --subnet-name PLSubnet \ --subnet-prefix 10.0.0.0/26
-
Nimm jetzt die Cosmos DB-Konto-ID und speichere sie in einer Variablen. Du wirst die Variable im nächsten Schritt verwenden:
cosmosAccountId=$(az cosmosdb show \ --name $cosmosAccountName \ --resource-group $rgName \ --query id --output tsv)
-
Jetzt kannst du einen privaten Endpunkt für dein Cosmos DB-Konto erstellen:
MSYS_NO_PATHCONV=1 az network private-endpoint create \ --name MyCosmosPrivateEndpoint \ --resource-group $rgName \ --vnet-name $vnetName \ --subnet PLSubnet \ --connection-name MyEndpointConnection \ --private-connection-resource-id $cosmosAccountId \ --group-id Sql
-
Deine Clients können den neuen privaten Endpunkt im PLSubnet-Subnetz verwenden, um mit deinem Cosmos DB-Konto zu kommunizieren, aber dies verhindert nicht den öffentlichen Netzwerkzugang. Verwenden Sie den folgenden Befehl, um den öffentlichen Netzwerkzugang für Ihr Cosmos DB-Konto explizit zu deaktivieren:
az cosmosdb update \ --resource-group $rgName \ --name $cosmosAccountName \ --enable-public-network false
-
Führe den folgenden Befehl aus, um die Ressourcen zu löschen, die du in diesem Rezept erstellt hast:
az group delete --name $rgName
In diesem Rezept hast du die Azure Cosmos DB-Firewall so konfiguriert, dass sie nur Client-Datenverkehr von einem privaten Endpunkt zulässt.
Diskussion
In "Azure Cosmos DB Firewall konfigurieren" haben wir die Azure Cosmos DB Netzwerkzugriffsoptionen besprochen. Wir sprachen über die Beschränkung des Datenverkehrs nach IP-Adresse oder dem Azure VNet des Clients. Beide Optionen erlauben es dem Datenverkehr, über das öffentliche Netzwerk zu gehen, was für viele Unternehmen nicht wünschenswert ist.
In diesem Rezept hast du Azure Cosmos DB so konfiguriert, dass der öffentliche Netzwerkzugang deaktiviert ist und nur Netzwerkverkehr von einem privaten Endpunkt akzeptiert wird. Das ist aus Sicht des Netzwerks die mit Abstand sicherste Option. Weitere Details findest du in der Azure Cosmos DB-Dokumentation.
Microsoft definiert einen privaten Endpunkt als "eine Netzwerkschnittstelle, die eine private IP-Adresse deines virtuellen Netzwerks verwendet". Diese Netzwerkschnittstelle verbindet dich privat mit einem Dienst, der von Azure Private Link betrieben wird. Der Netzwerkverkehr des privaten Endpunkts läuft nicht über das öffentliche Internet, sondern nutzt ausschließlich die private Netzwerkinfrastruktur von Azure. Du kannst private Endpunkte nutzen, um dich mit vielen Diensten zu verbinden:
-
Azure Speicherung
-
Azure Cosmos DB
-
Azure SQL Datenbank
-
Azure App Dienste
-
Azure Function Apps
Funktions-Appsmit RBAC Zugriff auf Cosmos DB gewähren
Lösung
Erstelle eine benutzerdefinierte Cosmos DB-Rollendefinition mit den gewünschten Berechtigungen (Aktionen) und weise sie der Function App-Identität für den Cosmos DB-Kontobereich zu, wie in Abbildung 4-5 dargestellt.
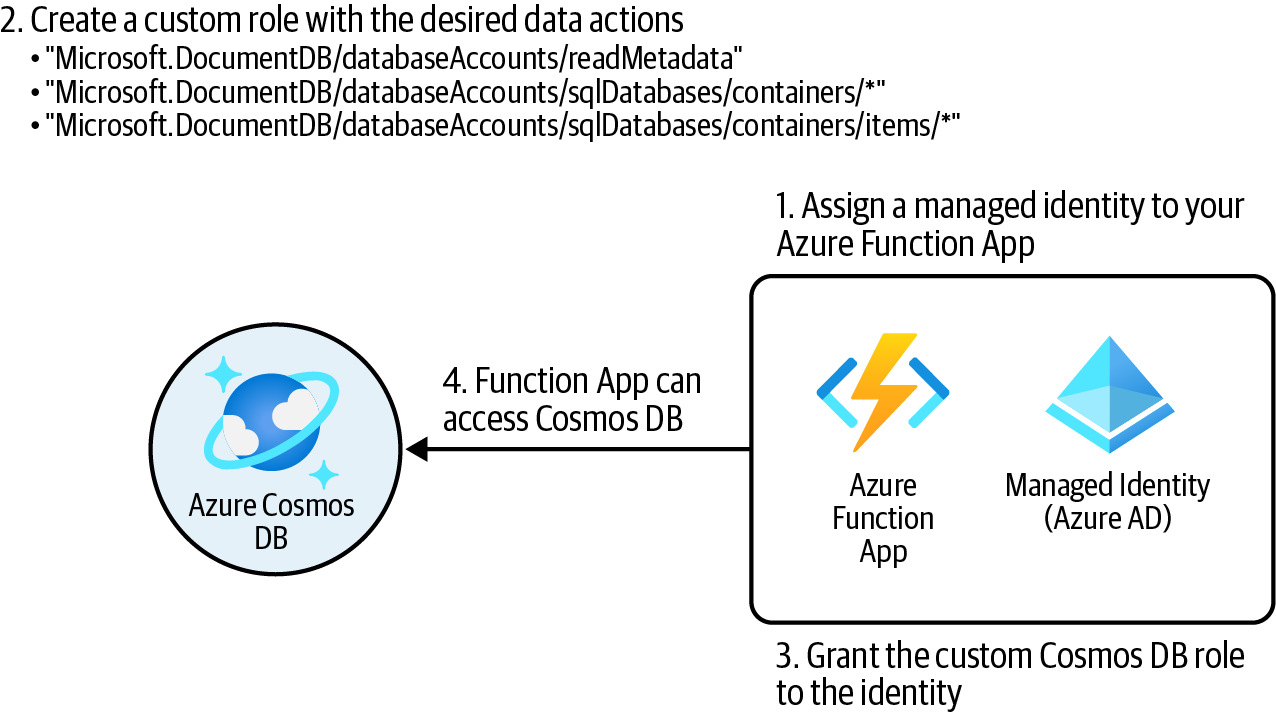
Abbildung 4-5. Zugriff auf Cosmos DB-Daten für die Azure Function App gewähren
Steps
-
Melde dich in der Rolle des Eigentümers bei deinem Azure-Abonnement an und erstelle eine neue Ressourcengruppe für dieses Rezept. Weitere Informationen findest du unter "Allgemeine Anweisungen zur Einrichtung von Workstations".
-
Verwende den folgenden CLI-Befehl, um ein neues Azure Cosmos DB-Konto zu erstellen:
cosmosAccountName="<cosmos-account-name>" az cosmosdb create \ --name $cosmosAccountName \ --resource-group $rgName
-
Verwende den folgenden Befehl, um eine neue Azure Function App zu erstellen und ihr eine vom System zugewiesene verwaltete Identität zuzuweisen:
funcStorageAccount="<func-storage-account-name>" planName="<appservice-plan-name>" funcAppName="<function-app-name>" az storage account create \ --name $funcStorageAccount \ --resource-group $rgName \ --location $region \ --sku Standard_LRS az appservice plan create \ --resource-group $rgName \ --name $planName \ --sku S1 \ --location $region az functionapp create \ --resource-group $rgName \ --name $funcAppName \ --storage-account $funcStorageAccount \ --assign-identity [system] \ --functions-version 3 \ --plan $planName -
Verwende den folgenden Befehl, um die verwaltete Identitäts-ID (GUID) der Function App und die Ressourcen-ID des Cosmos DB-Kontos zu erhalten. Du wirst diese später benötigen:
cosmosAccountId=$(az cosmosdb show \ --name $cosmosAccountName \ --resource-group $rgName \ --query id \ --output tsv) funcObjectId=$(az functionapp show \ --name $funcAppName \ --resource-group $rgName \ --query identity.principalId \ --output tsv) -
Du musst eine benutzerdefinierte RBAC-Rolle mit den gewünschten Cosmos DB-Berechtigungen erstellen. Erstelle zunächst eine JSON-Datei mit dem folgenden Inhalt und nenne sieMyCosmosDBReadWriteRole.json:
{ "RoleName": "MyCosmosDBReadWriteRole", "Type": "CustomRole", "AssignableScopes": ["/"], "Permissions": [ { "DataActions": [ "Microsoft.DocumentDB/databaseAccounts/readMetadata", "Microsoft.DocumentDB/databaseAccounts/sqlDatabases /containers/*", "Microsoft.DocumentDB/databaseAccounts/sqlDatabases /containers/items/*" ] } ] } -
Als nächstes erstellst du die Cosmos DB-Rollendefinition. Ersetze <
path-to-MyCosmosDBReadWriteRole.json> durch den Linux-ähnlichen Pfad zu deiner JSON-Datei, zum Beispiel C:/Data/MyCosmosDBReadWriteRole.json:az cosmosdb sql role definition create \ --account-name $cosmosAccountName \ --resource-group $rgName \ --body <path-to-MyCosmosDBReadWriteRole.json>
-
Jetzt kannst du deiner Funktions-App die neue benutzerdefinierte Rolle MyCosmosDBReadWriteRole zuweisen:
MSYS_NO_PATHCONV=1 az cosmosdb sql role assignment create \ --account-name $cosmosAccountName \ --resource-group $rgName \ --role-definition-name MyCosmosDBReadWriteRole \ --principal-id $funcObjectId \ --scope "/dbs"
Tipp
Du kannst den Geltungsbereich auf eine einzelne Datenbank oder sogar einen Container im Cosmos DB-Konto eingrenzen, wie z.B. /dbs/mydb/colls/mycontainer. In unserem Fall, /dbs, weist du die Rolle allen Datenbanken innerhalb deines Cosmos DB-Kontos zu.
-
Benutze die folgenden Befehle, um die ID der Rollendefinition zu erhalten und sie an
azzu übergeben.cosmosdbsql roledefinition show`, um zu bestätigen, dass deine Rolle erfolgreich zugewiesen wurde:# Assuming there is only one role assignment in this Cosmos DB account roleDefinitionId=$(az cosmosdb sql role assignment list \ --account-name $cosmosAccountName \ --resource-group $rgName \ --query [0].roleDefinitionId --output tsv) # The last 36 characters will be the role definition ID (GUID) roleDefinitionGUID=${roleDefinitionId: -36} az cosmosdb sql role definition show \ --account-name $cosmosAccountName \ --resource-group $rgName \ --id $roleDefinitionGUID
Hinweis
Zum Zeitpunkt der Erstellung dieses Buches kannst du die benutzerdefinierten Rollenzuweisungen von Cosmos DB nicht im Azure-Portal sehen!
-
Führe den folgenden Befehl aus, um die Ressourcen zu löschen, die du in diesem Rezept erstellt hast:
az group delete --name $rgName
Du hast einer Function App erfolgreich Zugriff auf Azure Cosmos DB gewährt, ohne Cosmos DB-Schlüssel zu teilen. Jeder Code, der in deiner Function App eingesetzt wird, kann Lese- und Schreibzugriff auf die Cosmos DB haben, ohne dass du Cosmos DB-Kontoschlüssel bereitstellen musst.
Diskussion
Ähnlich wie Azure Storage unterstützt Azure Cosmos DB die Azure Active Directory (Azure AD)-Authentifizierung über RBAC. Dies ermöglicht es dir, Cosmos DB Zugriff auf Sicherheitsprinzipale zu gewähren, wie z.B. Function App verwaltete Identitäten oder Anwendungsregistrierungen, ohne Cosmos DB-Kontoschlüssel preiszugeben. Dies ist eine empfohlene Sicherheitspraxis.
Azure Cosmos DB unterstützt RBAC-Zugriff auf die folgenden Ebenen:
- Management Ebene
-
Dies ist so , dass der Beauftragte das Azure Cosmos DB-Konto verwalten kann - zum Beispiel, indem er die Sicherung und Wiederherstellung konfiguriert. Der Beauftragte hat keinen Zugriff auf die in der Datenbank gespeicherten Daten. Azure Cosmos DB bietet integrierte Rollen für die Arbeit mit der Verwaltungsebene. Falls nötig, kannst du auch eigene Rollen erstellen.
- Datenebene
-
Dies ist so , dass die zugewiesene Person auf die Daten in der Datenbank zugreifen kann. In diesem Rezept hast du eine benutzerdefinierte RBAC-Rolle für die Datenebene erstellt und sie einem Sicherheitsprinzipal (Azure Function Identität) zugewiesen. Zum Zeitpunkt der Erstellung dieses Buches gibt es zwei eingebaute RBAC-Rollen für den Datenzugriff, Cosmos DB Built-in Data Reader und Cosmos DB Built-in Data Contributor, sowie die Möglichkeit, benutzerdefinierte Rollen zu erstellen.
Wir empfehlen, die eingebauten Cosmos DB RBAC-Rollen für die Verwaltung und die Datenebenen zu testen, bevor du deine eigene benutzerdefinierte Rolle erstellst. Du kannst benutzerdefinierte Rollen erstellen, wenn:
-
Es gibt keine integrierte Rolle für den Zugriff, den du gewähren musst
-
Die eingebauten Rollen geben zu viel Zugriff
Obwohl die Cosmos DB Built-in Data Contributor-Rolle die notwendigen Berechtigungen für unsere Function App gewährt, haben wir uns entschieden, eine benutzerdefinierte RBAC-Rolle für den Zweck des Lernens in diesem Rezept zu erstellen.
Speichern von tabellarischen Daten in Azure Storage Tables
Lösung
Erstelle ein universelles v2-Speicherkonto und speichere deine tabellarischen NoSQL-Daten in Azure-Speichertabellen, wie in Abbildung 4-6 dargestellt.
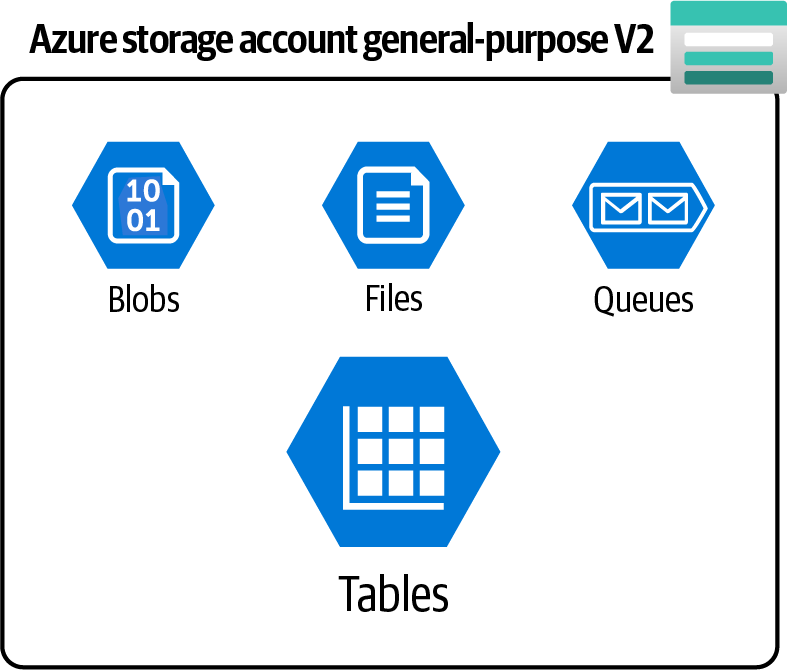
Abbildung 4-6. Azure-Speicherkonto für allgemeine Zwecke v2 bietet Tabellendienst
Steps
-
Melde dich bei deinem Azure-Abonnement in der Rolle des Eigentümers an und erstelle eine neue Ressourcengruppe für dieses Rezept. Weitere Informationen findest du unter "Allgemeine Anweisungen zur Einrichtung von Workstations".
-
Erstelle mit diesem Befehl ein neues Azure-Speicherkonto. Dies wird die Quelle für unsere Migration sein. Ersetze <
storage-account-name> durch den gewünschten, weltweit eindeutigen Namen:storageName="<storage-account-name>" az storage account create \ --name $storageName \ --resource-group $rgName \ --location $region \ --sku Standard_LRS
-
Speichere einen der Schlüssel des Speicherkontos in einer Variablen:
storageKey1=$(az storage account keys list \ --resource-group $rgName \ --account-name $storageName \ --query [0].value \ --output tsv) -
Erstelle nun eine Tabelle in deinem Speicherkonto, nenne sie
Peopleund fülle sie mit zwei Datenzeilen:# creating a table az storage table create \ --account-name $storageName \ --account-key $storageKey1 \ --name People # inserting a new row az storage entity insert \ --account-name $storageName \ --account-key $storageKey1 \ --table-name People \ --entity PartitionKey=Canada RowKey=reza@contoso.com Name=Reza # inserting another new row az storage entity insert \ --account-name $storageName \ --account-key $storageKey1 \ --table-name People \ --entity PartitionKey=U.S.A. RowKey=john@contoso.com Name=John Last=Smith
Hinweis
Jede Datenzeile in einer Azure Speicherungstabelle sollte sowohl PartitionKey als auch RowKey Eigenschaften haben. Zeilen mit der gleichen PartitionKey werden zur besseren Lastverteilung in dieselbe Partition eingeordnet. Die RowKey sollte innerhalb jeder Partition eindeutig sein. Weitere Informationen findest du in der Dokumentation des Azure Table Service Datenmodells. Achte darauf, dass du die richtigen Entitäten auswählst, um heiße oder kalte Partitionen zu vermeiden. In diesem Rezept haben wir den Ländernamen als PartitionKey und die E-Mail-Adresse als RowKey gewählt.
-
Verwende den folgenden Befehl, um zu bestätigen, dass die beiden Zeilen wie erwartet eingefügt wurden:
az storage entity query \ --table-name People \ --account-name $storageName \ --account-key $storageKey1
-
Führe den folgenden Befehl aus, um die Ressourcen zu löschen, die du in diesem Rezept erstellt hast:
az group delete --name $rgName
In diesem Rezept hast du tabellarische Daten in Azure Storage Tabellen gespeichert. Du kannst Azure Storage SDKs, REST APIs und den Azure Storage Explorer verwenden, um deine Tabellen zu verwalten und die Daten zu manipulieren.
Diskussion
Zum Zeitpunkt der Erstellung dieses Buches ( ) bietet Microsoft Azure zwei verwaltete Dienste an, um tabellarische NoSQL-Daten zu speichern: Azure Cosmos DB for Table API und Azure Table Speicherung. Während Cosmos DB erstklassige Leistung, Latenz und SLA (Service Level Agreements) bietet, ist Azure Table für viele Projekte die günstigere Option.
In der Azure-Dokumentation findest du eine detaillierte Liste der Unterschiede zwischen diesen beiden Tabellenangeboten. In der Azure-Dokumentation findest du auch die Einführung von Microsoft Azure zu den Angeboten für die Speicherung von Tabellen.
Du hast mehrere Möglichkeiten, deine Daten von Azure Table Speicherung zu Azure Cosmos DB zu migrieren, um von der globalen Verteilung, dem SLA und der Leistung von Cosmos DB zu profitieren. Je nach Größe und Art deiner Datenmigration kannst du das Cosmos DB Data Migration Tool, die Azure Data Factory oder sogar benutzerdefinierte Migrationen verwenden. Weitere Informationen findest du in der Azure Cosmos DB-Dokumentation.
Konfigurieren von Autoscale für einen Azure Cosmos DB NoSQL API Container
Lösung
Konfiguriere autoscale auf der Cosmos DB-Sammlung (Container) und gib die maximal zulässige RU/s an.
Steps
-
Melde dich bei deinem Azure-Abonnement in der Rolle des Eigentümers an und erstelle eine neue Ressourcengruppe für dieses Rezept. Weitere Informationen findest du unter "Allgemeine Anweisungen zur Einrichtung von Workstations".
-
Verwende den folgenden Befehl, um ein neues Azure Cosmos DB NoSQL API-Konto zu erstellen:
cosmosAccountName="<cosmos-account-name>" az cosmosdb create \ --name $cosmosAccountName \ --resource-group $rgName
-
Erstelle nun eine neue Datenbank in deinem Cosmos DB-Konto. Wir fügen keinen Durchsatz auf der Datenbankebene hinzu:
az cosmosdb sql database create \ --account-name $cosmosAccountName \ --resource-group $rgName \ --name db01
-
Als nächstes erstellst du mit diesem Befehl eine neue Sammlung (Container) in dieser Datenbank und nennst sie
People. Wir erstellen diesen Container mit einem fest eingestellten Durchsatz. Das bedeutet, dass der Container immer 1000 RU/s zur Verfügung hat:MSYS_NO_PATHCONV=1 az cosmosdb sql container create \ --resource-group $rgName \ --account-name $cosmosAccountName \ --database-name db01 \ --name People \ --partition-key-path "/id" \ --throughput "1000"
-
Verwende diesen Befehl, um die Durchsatzdaten des neuen Containers zu sehen. Die Ausgabe sollte zeigen, dass der Wert für die Eigenschaft
throughput1000 RU/s beträgt:az cosmosdb sql container throughput show \ --resource-group $rgName \ --account-name $cosmosAccountName \ --database-name db01 \ --name People
-
In Schritt 4 hätten wir auch den Parameter
--max-throughputanstelle von--throughputübergeben, um die automatische Skalierung des Containers zu aktivieren. Da wir das nicht getan haben, werden wir in diesem Schritt den Container mit folgendem Befehl von einem festen Durchsatz auf Autoscale umstellen:az cosmosdb sql container throughput migrate \ --resource-group $rgName \ --account-name $cosmosAccountName \ --database-name db01 \ --name People \ --throughput "autoscale"
-
Führe den Befehl
az cosmosdb sql container throughput showerneut aus, um die aktualisierten Durchsatzeinstellungen zu sehen. Bestätige, dass die EigenschaftmaxThroughput1.000 RU/s anzeigt:az cosmosdb sql container throughput show \ --resource-group $rgName \ --account-name $cosmosAccountName \ --database-name db01 \ --name People
-
Zum Schluss aktualisieren wir den maximal zulässigen Durchsatz des Containers auf 2.000 RU/s:
az cosmosdb sql container throughput update \ --resource-group $rgName \ --account-name $cosmosAccountName \ --database-name db01 \ --name People \ --max-throughput 2000
-
Führe den folgenden Befehl aus, um die Ressourcen zu löschen, die du in diesem Rezept erstellt hast:
az group delete --name $rgName
In diesem Rezept hast du einen Cosmos DB SQL API-Container mit einem festen Durchsatz erstellt, die automatische Skalierung für ihn aktiviert und schließlich seinen maximal zulässigen Durchsatz festgelegt.
Diskussion
Alle Azure Cosmos DB-APIs, einschließlich der SQL-API, ermöglichen es dir, einen festen Durchsatz sowohl auf Datenbank- als auch auf Containerebene festzulegen. Dies ist ein SLA-gesicherter Durchsatz, der deinen Datenbanken und Containern immer zugewiesen wird.
Wenn du einen festen Durchsatz für Container (und/oder Datenbanken) einrichtest, hast du am Ende des Monats eine vorhersehbare Rechnung, aber Spitzen bei den eingehenden Anfragen können zu einer schlechten Leistung, einer Drosselung der Anfragen oder einem Ausfall führen. Um sicherzustellen, dass deine Cosmos DB-Datenbanken und -Container skalieren können, um mehr Anfragen zu bewältigen, kannst du eine automatische Skalierung für Datenbanken, Container oder beides einrichten.
In diesem Rezept haben wir einen Container mit einem festen Durchsatz erstellt und ihn später in das Autoscale-Modell migriert. Du kannst die minimalen und maximalen RU/s ändern, um deinen Projektanforderungen gerecht zu werden.
Hinweis
Azure Cosmos DB hat auch ein serverloses (verbrauchsbasiertes) Angebot. Wenn du diese Option wählst, musst du dich nicht mehr um die Festlegung von minimalen und maximalen RU/s kümmern. Azure Cosmos DB skaliert auf Basis deines Datenbank-/Container-Traffics nach oben und unten. Weitere Informationen findest du in der Azure Cosmos DB-Dokumentation.
Kosteneinsparungen bei mehreren Azure SQL Single-Datenbanken mit schwankenden und unvorhersehbaren Nutzungsanforderungen
Lösung
Lege deine Einzeldatenbanken in einen Azure SQL Database Elastic Pool. Gepoolte Datenbanken sind eine kostengünstige Alternative zu mehreren einzelnen Datenbanken mit unvorhersehbarem Ressourcenbedarf, wie in Abbildung 4-7 dargestellt.
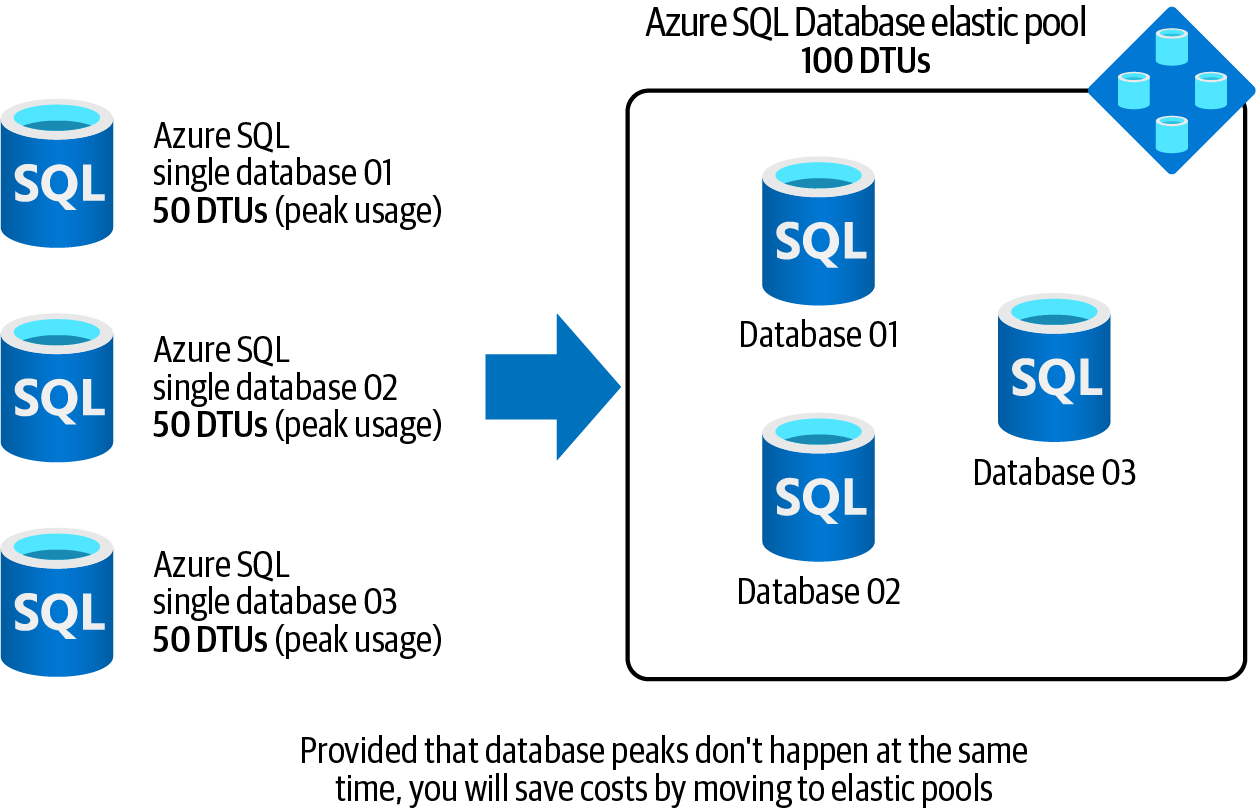
Abbildung 4-7. Azure SQL Database Elastic Pools verwenden, um Kosten zu sparen
Steps
-
Melde dich in der Rolle des Eigentümers bei deinem Azure-Abonnement an und erstelle eine neue Ressourcengruppe für dieses Rezept. Weitere Informationen findest du unter "Allgemeine Anweisungen zur Einrichtung von Workstations".
-
Zuerst musst du einen logischen Azure SQL-Server mit folgendem Befehl bereitstellen. Ersetze <
logical-sql-server-name> durch den gewünschten Servernamen, <admin-user> mit dem Admin-Benutzernamen und <admin-pass> durch das Admin-Kennwort:logicalServerName="<logical-sql-server-name>" sqlAdminUser="<admin-user>" # Use a complex password with numbers, upper case characters and symbols. sqlAdminPass="<admin-pass>" az sql server create \ --resource-group $rgName \ --name $logicalServerName \ --admin-user $sqlAdminUser \ --admin-password $sqlAdminPass
-
Erstellen wir nun einen neuen Elastic Pool. Die Ressourcen, wie Arbeitsspeicher und CPU, werden dem Pool zugewiesen. Verwende den folgenden Befehl, um deinem neuen Pool zwei vCores (virtuelle CPU-Kerne) zuzuweisen:
sqlPoolName="MyPool01" az sql elastic-pool create \ --resource-group $rgName \ --server $logicalServerName \ --name $sqlPoolName \ --edition GeneralPurpose \ --family Gen5 \ --capacity 2
-
Fügen wir nun zwei einzelne Datenbanken zu deinem neuen Pool hinzu. Diese Datenbanken teilen sich die Ressourcen, die dem übergeordneten Pool zugewiesen sind:
az sql db create \ --resource-group $rgName \ --server $logicalServerName \ --name db01 \ --elastic-pool $sqlPoolName az sql db create \ --resource-group $rgName \ --server $logicalServerName \ --name db02 \ --elastic-pool $sqlPoolName
-
Du kannst alle Datenbanken innerhalb eines bestimmten Pools sehen, indem du den folgendenBefehl ausführst:
az sql elastic-pool list-dbs \ --resource-group $rgName \ --name $sqlPoolName \ --server $logicalServerName \ --query [].name
-
Führe den folgenden Befehl aus, um die Ressourcen zu löschen, die du in diesem Rezept erstellt hast:
az group delete --name $rgName
In diesem Rezept hast du einen Azure SQL Database Elastic Pool eingerichtet und ihm zwei Datenbanken hinzugefügt.
Warnung
Azure SQL-Ressourcen können teuer werden. Stelle sicher, dass du die bereitgestellten Ressourcen einschließlich des Elastic Pools nach Abschluss dieses Rezepts bereinigst. Weitere Informationen findest du im Abschnitt "Aufräumen" im Kapitel Repository.
Diskussion
Azure SQL bietet die folgenden Typen an:
-
Azure SQL Einzeldatenbank
-
Azure SQL Database Elastic Pools
-
Azure SQL Managed Instance
Azure SQL Managed Instance ist das kompatibelste Azure SQL-Angebot mit Microsoft SQL Server und liegt außerhalb des Rahmens dieses Rezepts.
Wie der Name schon sagt, ist Azure SQL Single Database eine unabhängige Datenbank, der die Ressourcen wie CPU und Speicher direkt zugewiesen werden. Dies eignet sich perfekt für viele Szenarien, z. B. für eine Datenbank mit einem vorhersehbaren Nutzungsmuster. Du wählst einfach die richtige Ebene(Datenbank-Transaktionseinheit (DTU) oder vCore) und die Datenbank wird wie erwartet funktionieren.
Stell dir nun vor, du hast drei einzelne Datenbanken für Kunden in Japan, der EU und dem Osten der USA. Jede Datenbank benötigt 50 DTUs in der Spitze der Nutzung. Aufgrund der Zeitverschiebung erreicht keine der Datenbanken ihren Spitzenbedarf zur gleichen Zeit, aber du zahlst für 150 DTUs rund um die Uhr, die du nicht vollständig nutzen wirst. Azure SQL Database Elastic Pool ist eine Möglichkeit, dieses Problem zu lösen. (Die andere Möglichkeit ist der Serverless Tier, den wir in "Konfigurieren des Serverless Compute Tier für Azure SQL Single Databases" besprechen) .
Wenn du dich für elastische Pools entscheidest, erstellst du einfach einen neuen elastischen Pool, weist ihm 100 DTUs zu und fügst dann die drei Datenbanken zu dem Pool hinzu. Diese Einrichtung wird gut funktionieren, vorausgesetzt, die drei Datenbanken erreichen nie gleichzeitig ihre Nutzungsspitze.
Konfigurieren der Serverless Compute Tier für Azure SQL Single Databases
Lösung
Stelle deine Azure SQL Single-Datenbanken auf dem Serverless Compute Tier bereit. Azure kümmert sich um die Zuteilung der erforderlichen Ressourcen für deine Datenbank, wie in Abbildung 4-8 dargestellt.
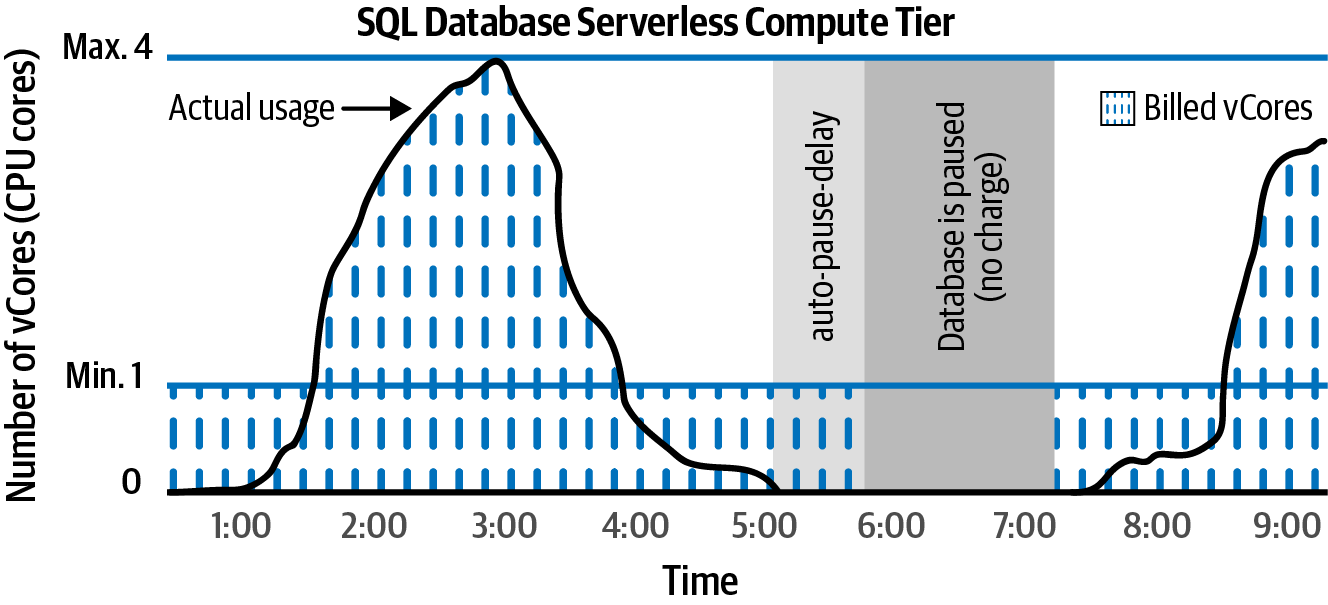
Abbildung 4-8. Azure SQL Single Database Serverless Compute Tier
Steps
-
Melde dich bei deinem Azure-Abonnement in der Rolle des Eigentümers an und erstelle eine neue Ressourcengruppe für dieses Rezept. Weitere Informationen findest du unter "Allgemeine Anweisungen zur Einrichtung von Workstations".
-
Stelle zunächst einen logischen Azure SQL-Server bereit. Ersetze <
logical-sql-server-name>, <admin-user>, und <admin-pass> durch die gewünschten Werte:logicalServerName="<logical-sql-server-name>" sqlAdminUser="<admin-user>" sqlAdminPass="<admin-pass>" az sql server create \ --resource-group $rgName \ --name $logicalServerName \ --admin-user $sqlAdminUser \ --admin-password $sqlAdminPass
-
Erstellen wir nun eine neue einzelne Datenbank. Der folgende Befehl legt die Mindest- und Höchstgrenze für die Anzahl der vCores (CPU-Kerne) fest, die deiner Datenbank zugewiesen werden, und konfiguriert die Datenbank so, dass sie nach zwei Stunden (120 Minuten) Inaktivität pausiert. Die Datenbank wird bei Bedarf automatisch verkleinert und vergrößert:
# The minimum vCore limit is 1 and the maximum is 4. az sql db create \ --resource-group $rgName \ --server $logicalServerName \ --name db01 \ --compute-model Serverless \ --edition GeneralPurpose \ --family Gen5 \ --auto-pause-delay 120 \ --min-capacity 1 \ --capacity 4
Tipp
Zum Zeitpunkt der Erstellung dieses Buches ist der Serverless Compute Tier nur für die Gen5-Hardwarefamilie verfügbar. In der Azure SQL Single Database Dokumentation findest du Details zu den minimal und maximal unterstützten vCores.
-
Verwende schließlich den folgenden Befehl, um die Details deiner neuen Datenbank abzurufen:
az sql db show \ --resource-group $rgName \ --server $logicalServerName \ --name db01 \ --query \ "{Name: name, Sku: currentSku, Edition: edition, MinCapacity: minCapacity}" -
Führe den folgenden Befehl aus, um die Ressourcen zu löschen, die du in diesem Rezept erstellt hast:
az group delete --name $rgName
In diesem Rezept hast du eine einzelne Azure SQL-Datenbank mit dem Serverless Compute Tier provisioniert. Bei Bedarf kannst du auch bestehende Azure SQL Single-Datenbanken von der Provisioned Tier auf die Serverless Tier verschieben. Die Details zu den Befehlen findest du in der Azure SQL-Dokumentation.
Diskussion
Wenn du dich für das vCore-Kaufmodell für deine Azure SQL Single-Datenbank entscheidest (im Gegensatz zu DTU-basiert), hast du zwei Optionen für den Compute-Tier: provisioniert und serverlos.
Der provisioned tier erfordert, dass du deiner Datenbank eine feste Menge an Ressourcen (vCores, Speicher, etc.) zuweist. Diese Ressourcen werden dir auf einer 24x7-Basis in Rechnung gestellt. Die Kosten ändern sich nicht, wenn deine Datenbank zu wenig oder zu viel genutzt wird. Das kann zu Leistungsproblemen führen, wenn deine Datenbank mehr Anfragen erhält als erwartet. Du zahlst auch dann die volle Rechnung, wenn deine Datenbank nicht ausgelastet ist oder sogar komplett stillsteht. Wenn du jedoch das genaue Nutzungsmuster deiner Datenbank kennst oder davon ausgehst, dass die Datenbank die meiste Zeit über voll ausgelastet ist, ist der Provisioned Compute Tier eine gute Option.
Wähle den Serverless Compute Tier, wenn du möchtest, dass Azure die Verantwortung für die Ressourcenzuweisung übernimmt. Du legst die minimalen und maximalen vCores fest, die deiner einzelnen Datenbank zugewiesen werden sollen, und überlässt den Rest Azure. Du kannst auch eine automatische Pausenverzögerung konfigurieren, so dass deine Datenbank pausiert wird, wenn sie für eine bestimmte Zeitspanne nicht genutzt wird. Wenn du dich für den Serverless-Tier entscheidest, wird dir nur dann etwas berechnet, wenn die Datenbank genutzt wird. In der Azure-Dokumentation findest du weitere Informationen zum Serverless Compute Tier.
Konfigurieren der Azure SQL Firewall IP-Regeln
Lösung
Konfiguriere die Azure SQL Service Firewall so, dass nur Clients mit vertrauenswürdigen IP-Adressen zugelassen werden, wie in Abbildung 4-9 dargestellt.
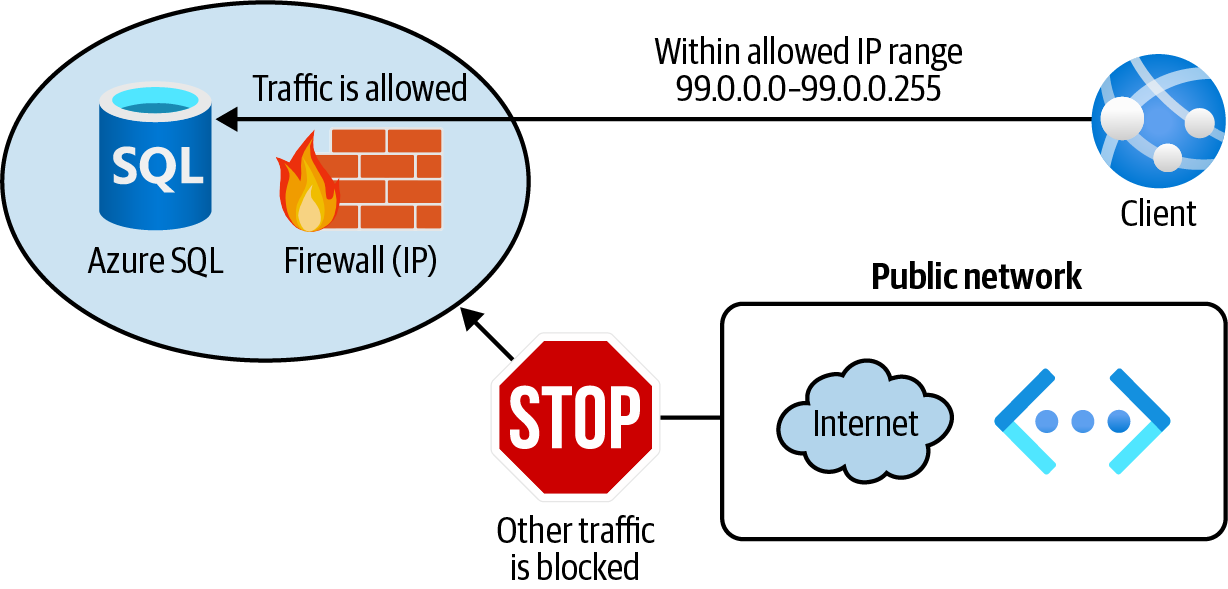
Abbildung 4-9. Schutz einer Azure SQL-Datenbank mit Firewall-IP-Regeln
Steps
-
Melde dich bei deinem Azure-Abonnement in der Rolle des Eigentümers an und erstelle eine neue Ressourcengruppe für dieses Rezept. Weitere Informationen findest du unter "Allgemeine Anweisungen zur Einrichtung von Workstations".
-
Zuerst richten wir einen logischen Azure SQL Server und eine Azure SQL Single Datenbank ein. Ersetze <
logical-sql-server-name>, <admin-user>, und <admin-pass> durch die gewünschten Werte:logicalServerName="<logical-sql-server-name>" sqlAdminUser="<admin-user>" sqlAdminPass="<admin-pass>" az sql server create \ --resource-group $rgName \ --name $logicalServerName \ --admin-user $sqlAdminUser \ --admin-password $sqlAdminPass az sql db create \ --resource-group $rgName \ --server $logicalServerName \ --name db01 \ --compute-model Serverless \ --edition GeneralPurpose \ --family Gen5 \ --auto-pause-delay 60 \ --min-capacity 1 \ --capacity 2
-
Dein Ziel ist es, dass Clients innerhalb eines IP-Bereichs auf Azure SQL zugreifen können. Andere Anfragen sollten abgewiesen werden. Verwende den folgenden Befehl, um die Firewall-Server-Regel zu erstellen:
az sql server firewall-rule create \ --resource-group $rgName \ --server $logicalServerName \ --name allowTrustedClients \ --start-ip-address 99.0.0.0 \ --end-ip-address 99.0.0.255
Tipp
Diese Firewall-Regel wird dem logischen Azure SQL-Server zugewiesen und auf alle untergeordneten Datenbanken dieses Servers angewendet. Du kannst auch IP-Firewall-Regeln nur für die Datenbankebene erstellen, indem du Transact-SQL-Anweisungen verwendest, nachdem die Firewall auf Serverebene konfiguriert wurde. Einzelheiten dazu findest du in der Azure-Dokumentation.
-
Bislang hast du einen vertrauenswürdigen IP-Bereich zugelassen. Was ist, wenn du allen Azure-Diensten den Zugriff auf deine Azure SQL-Datenbanken erlauben willst? Das kannst du mit der speziellen IP-Adresse 0.0.0.0 erreichen. Fügen wir diese Regel mit Azure CLI hinzu:
az sql server firewall-rule create \ --resource-group $rgName \ --server $logicalServerName \ --name allowAzureServices \ --start-ip-address 0.0.0.0 \ --end-ip-address 0.0.0.0
-
Du kannst die Firewall-Regeln, die deinem logischen Azure SQL-Server zugewiesen sind, mit dem folgenden Befehl anzeigen:
az sql server firewall-rule list \ --resource-group $rgName \ --server $logicalServerName
-
Führe den folgenden Befehl aus, um die Ressourcen zu löschen, die du in diesem Rezept erstellt hast:
az group delete --name $rgName
In diesem Rezept hast du die Azure SQL Firewall so konfiguriert, dass sie Clients aus einem vertrauenswürdigen IP-Bereich sowie Verbindungen von IP-Adressen zulässt, die einem beliebigen Azure-Dienst oder -Asset zugeordnet sind.
Diskussion
Mehrere Azure-Datendienste, darunter Azure Storage, Azure Cosmos DB, Azure Synapse Analytics und Azure SQL, bieten eine Firewall auf Dienstebene. Nutze diese Firewall, um die Sicherheitslage deiner Azure-Datendienste zu verbessern. Die Azure SQL-Firewall ist ein leistungsstarkes Werkzeug, um unerwünschte Clients am Zugriff auf deine Daten zu hindern.
Wenn du dem logischen Azure SQL-Server eine Firewall-Regel zuweist, werden auch alle untergeordneten Datenbanken geschützt. Beachte, dass du auch Firewall-Regeln auf Datenbankebene erstellen kannst, so dass nur die Datenbank, für die die Regel erstellt wurde, geschützt wird. Weitere Informationen findest du in der Azure SQL-Dokumentation.
Hinweis
Du kannst auch Datenverkehr aus virtuellen Azure-Netzwerken mithilfe von VNet-Regeln zulassen. Wir besprechen diese Option unter "Azure SQL Firewall VNet-Regeln konfigurieren".
Konfigurieren der Azure SQL Firewall VNet-Regeln
Lösung
Konfiguriere die Azure SQL Service Firewall so, dass sie Clients innerhalb eines vertrauenswürdigen Azure VNet-Subnetzes zulässt, wie in Abbildung 4-10 dargestellt.
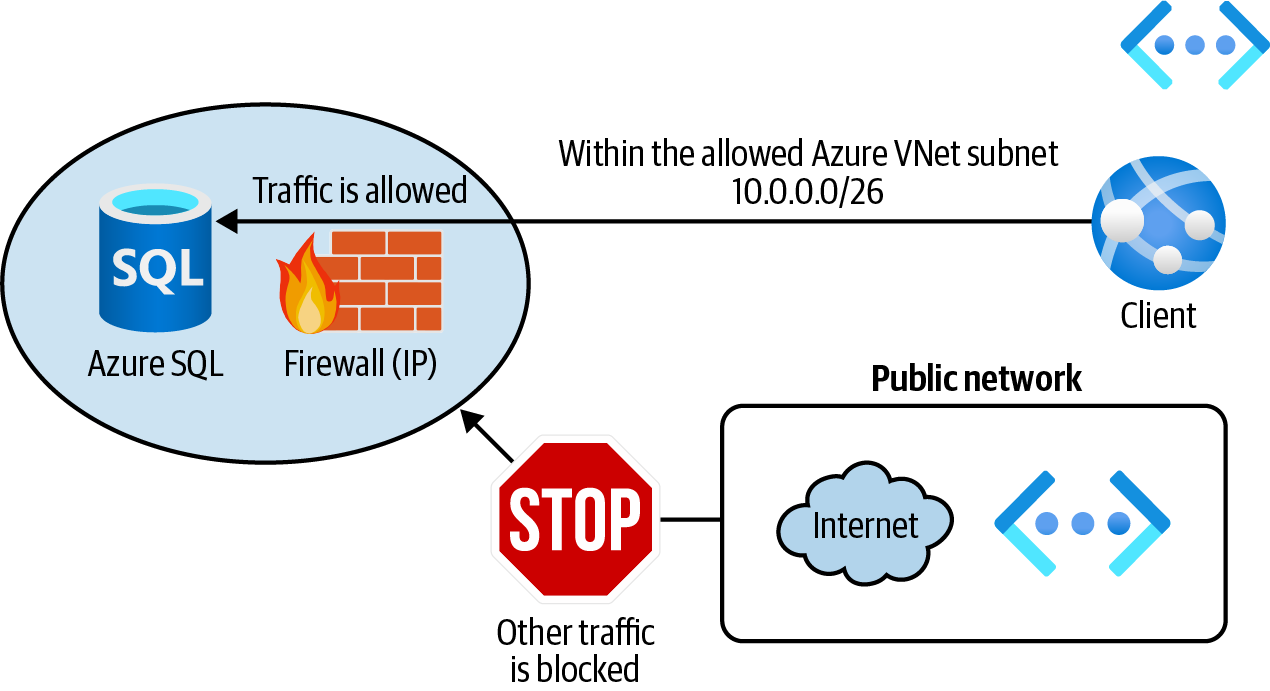
Abbildung 4-10. Schutz einer Azure SQL-Datenbank mithilfe der Firewall-VNet-Regeln
Steps
-
Melde dich bei deinem Azure-Abonnement in der Rolle des Eigentümers an und erstelle eine neue Ressourcengruppe für dieses Rezept. Weitere Informationen findest du unter "Allgemeine Anweisungen zur Einrichtung von Workstations".
-
Befolge Schritt 1 unter "Konfigurieren der Azure SQL Firewall IP-Regeln", um einen neuen logischen Azure SQL-Server und eine einzelne Datenbank zu erstellen.
-
Dein Ziel ist es, dass Clients innerhalb eines vertrauenswürdigen Azure VNet-Subnetzes auf Azure SQL zugreifen können. Lass uns ein neues Azure VNet und ein untergeordnetes Subnetz erstellen:
vnetName="<vnet-name>" az network vnet create \ --resource-group $rgName \ --name $vnetName \ --address-prefix 10.0.0.0/16 \ --subnet-name Subnet01 \ --subnet-prefix 10.0.0.0/26
-
Damit Clients in diesem Subnetz auf die Azure SQL-Datenbank zugreifen können, müssen wir den
Microsoft.SqlService-Endpunkt zum Subnetz hinzufügen:az network vnet subnet update \ --resource-group $rgName \ --name Subnet01 \ --vnet-name $vnetName \ --service-endpoints Microsoft.Sql
-
Verwende schließlich den folgenden Befehl, um eine neue VNet-Regel für
Subnet01zu erstellen:az sql server vnet-rule create \ --resource-group $rgName \ --server $logicalServerName \ --name allowTrustedSubnet \ --vnet-name $vnetName \ --subnet Subnet01
-
Führe den folgenden Befehl aus, um die Ressourcen zu löschen, die du in diesem Rezept erstellt hast:
az group delete --name $rgName
Du hast die Azure SQL-Firewall erfolgreich so konfiguriert, dass Clients innerhalb von Subnet01 mit deiner Azure SQL-Datenbank arbeiten können. Weitere Informationen findest du in der Dokumentation zur Azure SQL Service Firewall.
Diskussion
Verwende Azure SQL Firewall VNet-Regeln mit IP-Regeln, um Schutz vor eingehenden Anfragen auf der Grundlage der IP-Adresse des Clients und des virtuellen Netzwerks zu bieten.
In den Rezepten 4.10 und 4.11 haben wir über die IP- und VNet-Regeln der Azure SQL Firewall gesprochen. Diese Regeln schützen deine Azure SQL-Datenbanken vor eingehenden Anfragen. Die Azure SQL Firewall bietet auch Regeln für ausgehende Anfragen, um den ausgehenden Datenverkehr von deiner Datenbank zu begrenzen. Einzelheiten zur Implementierung findest du in der Azure Firewall-Dokumentation.
Sichern von einzelnen Azure SQL-Datenbanken in Azure Storage Blobs
Lösung
Speichere Azure SQL-Backups mit Azure CLI in Azure Storage Blobs, wie in Abbildung 4-11 dargestellt.

Abbildung 4-11. Sichern einer Azure SQL-Datenbank in Azure Storage Blobs
Steps
-
Melde dich bei deinem Azure-Abonnement in der Rolle des Eigentümers an und erstelle eine neue Ressourcengruppe für dieses Rezept. Weitere Informationen findest du unter "Allgemeine Anweisungen zur Einrichtung von Workstations".
-
Zunächst richten wir eine neue Azure SQL Single-Datenbank ein und bestücken sie mit der AdventureWorks-Beispieldatenbank. Ersetze <
logical-sql-server-name>, <admin-user>, und <admin-pass> durch die gewünschten Werte:logicalServerName="<logical-sql-server-name>" sqlAdminUser="<admin-user>" sqlAdminPass="<admin-pass>" az sql server create \ --resource-group $rgName \ --name $logicalServerName \ --admin-user $sqlAdminUser \ --admin-password $sqlAdminPass az sql db create \ --resource-group $rgName \ --server $logicalServerName \ --name db01 \ --compute-model Serverless \ --edition GeneralPurpose \ --family Gen5 \ --auto-pause-delay 60 \ --min-capacity 0.5 \ --capacity 2 \ --sample-name AdventureWorksLT
-
Du musst den Azure-Diensten den Zugriff auf die neuen Azure SQL-Datenbanken erlauben, damit das Backup erstellt und gespeichert werden kann. Verwende den folgenden Befehl, um die Azure SQL Firewall zu konfigurieren:
az sql server firewall-rule create \ --resource-group $rgName \ --server $logicalServerName \ --name allowAzureServices \ --start-ip-address 0.0.0.0 \ --end-ip-address 0.0.0.0
-
Jetzt musst du ein neues Azure-Speicherkonto und einen untergeordneten Container erstellen:
storageName="<storage-account-name>" bakContainerName="sqlbackups" # we chose the locally redundant storage (LRS) sku but you may need # to choose a better redundancy for your Azure SQL backups. az storage account create \ --name $storageName \ --resource-group $rgName \ --sku Standard_LRS storageKey1=$(az storage account keys list \ --resource-group $rgName \ --account-name $storageName \ --query [0].value \ --output tsv) MSYS_NO_PATHCONV=1 az storage container create \ --name $bakContainerName \ --account-name $storageName \ --account-key $storageKey1 -
Du brauchst eine Schreibberechtigung für deinen Azure Storage Container. Hier verwenden wir den Schlüssel des Speicherkontos zur Authentifizierung. Du kannst auch SAS-Tokens des Speicherkontos als Authentifizierungsmethode verwenden. Weitere Informationen findest du in der Azure CLI-Dokumentation. Verwende den folgenden Befehl, um die Datenbanksicherung zu erstellen:
storageURL= \ "https://$storageName.blob.core.windows.net/\$bakContainerName /sqlbackup01.bacpac" MSYS_NO_PATHCONV=1 az sql db export \ --resource-group $rgName \ --server $logicalServerName \ --name db01 \ --admin-user $sqlAdminUser \ --admin-password $sqlAdminPass \ --storage-key $storageKey1 \ --storage-key-type StorageAccessKey \ --storage-uri $storageURL -
Du kannst bestätigen, dass die Sicherungsdatei erstellt wurde, indem du alle Dateien und ihre Größen im Speicher-Container auflistest:
MSYS_NO_PATHCONV=1 az storage blob list \ --container-name $bakContainerName \ --account-key $storageKey1 \ --account-name $storageName \ --query "[].{Name: name, Length: properties.contentLength}"
Tipp
Da der Schlüssel unseres Speicherkontos einen Schrägstrich (/) enthält, wird er in der Bash-Umgebung in einen Linux-Pfad umgewandelt, was dazu führt, dass der CLI-Befehl fehlschlägt. Deshalb haben wir MSYS_NO_PATHCONV=1 vor den CLI-Skripten verwendet, um dieses Problem zu vermeiden! Du kannst deinen Befehlen alternativ zwei Schrägstriche (//) voranstellen.
-
Führe den folgenden Befehl aus, um die Ressourcen zu löschen, die du in diesem Rezept erstellt hast:
az group delete --name $rgName
In diesem Rezept hast du erfolgreich eine einzelne Azure SQL-Datenbank in einen Azure Storage Container gesichert.
Diskussion
Azure Storage bietet einen erschwinglichen, skalierbaren und sicheren Speicherservice in der Cloud. Wie du in Kapitel 3 gesehen hast, kannst du deine Dateien vor versehentlichem Löschen schützen, indem du den Soft Delete-Schutz aktivierst.
Die Sicherungsdateien können in den Hot-, Cool- oder sogar Archiv-Zugriffsebenen gespeichert werden, um Kosten zu sparen.
In diesem Rezept haben wir die billigste Redundanzoption von Azure Storage verwendet, nämlich die lokal redundante Speicherung (LRS). Wenn du planst, produktive SQL-Datenbanken zu sichern, solltest du eine Option mit besserer Redundanz wählen, wie z.B. zonenredundante Speicherung (ZRS), georedundante Speicherung (GRS) oder geozonenredundante Speicherung (GZRS). Weitere Informationen findest du in Kapitel 3 oder in der Azure Storage Dokumentation.
Get Azure Kochbuch now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

