Chapter 1. Today’s Modern Data Stack
Quite often, data teams develop a myopic focus on the pursuit of the “perfect” process. While optimization is important, it’s easy to overlook why companies have sunk millions into data operations. Drawn to the attractiveness of real-time data or the hype of machine learning (ML), AI, and cutting-edge techniques, many seek overly complex solutions when value can be derived from much simpler processes.
The goal of the modern data stack (MDS) is to simplify and democratize access to insight that can enable any organization to improve decision making, delivering value to the business. Working backward to achieve our desired outcome, the tools that support a product-led data team must:
-
Be simple to implement and easy to understand (democratize access to data)
-
Scale with the growth of the company, both in head count and data maturity
-
Limit technical debt and vendor lock-in
In this chapter, we’ll provide a brief overview of the MDS and walk through basic concepts before diving into the creation of a successful data framework. Afterward, we’ll discuss the importance of automation and what data transformation currently lacks.
What Is the MDS?
The MDS is a term pioneered by Fivetran to describe the solutions that comprise an organization’s system for capturing, enriching, and sharing data. We’ve seen tremendous advancement in data processes—only a few years ago, every element of data ingestion and transformation had to be built from scratch or adapted from an open source library.
In the early 2010s, we saw an explosion of services that provided off-the-shelf functionality for data integration (Fivetran, Stitch), cloud data warehousing (BigQuery, Amazon Redshift), transformation (dbt Labs, Matillion), and analytics (Tableau, Looker). Innovation has continued with the maturation of the data warehouse: the separation of storage/compute and rise of serverless architecture. We now have access to mature, cloud native technologies for data warehouses and operational analytics, with a multitude of tools available at every step of the way. While this has been a boon for productivity in storage, compute, and ingestion, transformation and metadata have lagged behind.
In this chapter, we’ll dive into the individual components of the MDS and walk through a framework for building the right data stack. First, it’s necessary to consider how we think about data.
Managing Data as a Product (DaaP)
Traditionally, data has been separate from product: analytics leaders report directly to the CTO or another executive. Under this structure, the data team is isolated. While analysts might be embedded in other product groups, development of infrastructure and initiatives lacks a shared understanding of the business. Frequently, this can lead to silos, specifically between the operational units of a business and the engineering teams.
As one might expect, this structure can result in data that lacks context, even from the best-intentioned engineers. Centralized data ownership can result in obfuscated requirements from product teams. For example, often a single individual will be responsible for data directives, from the top down. It’s quite easy for these teams to focus on outputs rather than outcomes. This diverges from our mandate of value creation: how can engineers contribute when they are isolated from the business?
The solution? Manage data as you would a product. While it might not be feasible to hire a data product manager, there are a number of best practices that can bring a team closer to the product mindset and more focused on the data “consumer:” business users. First proposed by Zhamak Dehghani in her book, Data Mesh (O’Reilly), the DaaP approach revolves around a decentralized framework that includes the following attributes:
- Data services as code
-
Data and query modeling immediately jump to mind, though data teams may also construct data discovery, observability, and product interfaces as APIs to programmatically share information. Codifying data practices can occur at every stage in the MDS, from engineering to analytics/science.
- Data microservices
-
There has been a movement toward microservices in software development, and for good reason. While data teams may necessitate a monolithic element more than other software teams, domain ownership of data is crucial. Those closest are best qualified to understand how and when to leverage analytical data. Microservices bring distributed architecture and decentralized governance to the data space.
- Outcome-oriented teams
-
While activity-oriented teams are effective, they do not effectively scale what matters most: delivering insight built on quality and trustworthy data. Outcome-oriented teams, by contrast, are constructed to deliver business value. The tools data teams leverage must fit this outcome-oriented framework.
- Extensive support for metadata
-
Metadata is the foundation of trust in, as well as understanding and democratization of, data—its importance cannot be overstated. Without accurate documentation, lineage, and governance, the amount of energy spent on triaging issues and answering questions will slowly eclipse the amount contributed to finding insight.
The ultimate goal of a product-first mindset is to deliver value. In the context of data, that means organizing resources, services, and talent in a way that improves the quality of insight derived from data sources.
Of course, a shift from activity- to outcome-oriented teams requires new processes. Data tools and techniques must support cross-disciplinary users, from technical experts to novices, and should support a self-service analytics framework. That is, they should enable business users to access data and democratize information across an organization. The following are some characteristics for a new generation of product-led data initiatives:
- Flexible
-
Data tooling must be malleable. Without flexibility, many will resort to hacky solutions that skirt best practices or opt for building their own solutions.
- Shallow learning curve
-
As solutions mature, the barrier to entry must fall. While some technical proficiency will always be necessary, building outcome-oriented teams requires every member to be able to triage problems and implement solutions. Complex, code-first products limit collaboration to only the most technically advanced users and impose barriers to development and progress.
- User-friendly
-
While the days of the command line are mostly over, some hang on to code-only solutions. Self-service tooling that democratizes access to information requires an element of user-friendliness. While this doesn’t exclude a coding element, it does imply that intuitive graphical user interfaces (GUIs) should be present.
- Metadata-first
-
Like other areas of product, data must be well-documented. Unlike those areas, however, documentation, governance, and lineage is an incredibly expensive task. For data to be valuable, it must be discoverable, understandable, and engaging across all teams in a business. The next generation of data platforms must put metadata first to unlock value.
- Version-controlled
-
For data to be managed as a product, it must be built with software best practices. Tooling, regardless of code volume, should be version-controlled, and data teams should iterate to construct robust, reliable pipelines, business intelligence (BI), and models. Version control enables collaboration at scale.
As the market is flooded with new customers (data teams), solutions must enable a DaaP mindset without the need to build and scale full data engineering, analytics, and science teams. These products will replace in-house solutions and enable drastic productivity gains, further lowering the barrier to entry in analytics, science, and ML, and raising the bar for the average company to compete.
Basic Terms and Concepts in the MDS
The core areas of the MDS are ingestion, storage, transformation, and analytics. We’ll break down each to understand more about how the individual components of the MDS have shaped its trajectory.
Ingestion
Data ingestion refers to the process of extracting and loading data, the first two steps in an ELT (extract, load, transform) architecture. This means that ingestion is the first step to building a data stack. Like the foundation of a house, a rock-solid ingestion framework is essential to the stability of subsequent bricks in the construction of a data warehouse.
Data ingestion solutions are tailored to the problems they solve: where does data originate, and where is it being written? Today, a number of ingestion tools offer pre-built connectors and abstract away the many headaches of custom pipelines. Fivetran is the current market leader, while upstarts like Airbyte and Meltano offer an open-source alternative.
What does this mean for the modern data practitioner? Data ingestion is a developed space with a number of great options. It currently allows a data team to go from 0 to 1 in hours/days instead of weeks/months. Still, there is a need for technical prowess with hard-to-find datasets.
Storage
Data storage is perhaps one of the most mature aspects of the MDS. Products like Snowflake, Redshift, and BigQuery have innovated and helped to spur competition in the online analytical processing (OLAP) space. Modern data warehouses are optimized for analytic processes and can scale to handle loads that older platforms (PostgreSQL, MySQL) simply can’t match, thanks to parallel computing and column-oriented architecture.
When these products first emerged, storage and compute were bundled. Thus, many users found their usage limited by the constraints of the service: they had either plenty of storage but hit analytical limits, or analytical bandwidth but found themselves out of storage. Increasing the availability of both, however, required a tremendous price increase.
Today, storage and compute can be completely separate. The change (and competition) adds much-needed flexibility in data warehouse cost structure. Even the concept of server maintenance has been abstracted away—virtually no infrastructure management is necessary with products like Azure, Redshift Serverless, BigQuery, or Snowflake.
With these changes, many are opting for a data lake architecture, where data is first staged in Amazon Simple Storage Service (Amazon S3) or Google Cloud Storage (GCS), then loaded and transformed in a warehouse mentioned earlier. This approach allows for greater breadth of storage with nice implications for disaster recovery.
What does this mean for the modern data practitioner? Choosing the right platform will always be a difficult decision, but great options like BigQuery, Redshift, and Snowflake are ubiquitous. These are poster children for the MDS: they remove complexity and DevOps from the equation and allow data teams to focus on what matters.
Transformation
Data transformation is the manipulation and enrichment of data to improve access, storage, and analysis. This most frequently occurs on data that has already been structured and stored in a data warehouse. Hence, transformation is accessible to many via SQL and Python. For this reason, we won’t consider upstream frameworks, like PySpark, Dask, and Scala, which are limited to implementation by data and software engineers. While these are important tools, their highly technical nature makes them difficult to democratize. As data volume grows, so does the importance of a solid transformation layer—refining and revealing the most pertinent information to analysts, stakeholders, and data scientists.
Still, transformation is one of the most nascent aspects of the MDS. While dbt was the first in transformation to appropriate software engineering best practices to analytics, many are still operating on some combination of Apache Airflow for orchestration plus dbt Core for execution. While this combination works, it is very technically demanding and does not scale well. Alternatives, like Matillion, are more focused on a GUI, which, while adding simplicity, removes necessary customization and locks users into predefined routines.
Transformation is due for an overhaul. We feel that transformation lacks a metadata-driven element that operates on the column level or, as we say at Coalesce, is column-aware. Furthermore, a more cohesive combination of GUI and code is necessary to include every member of a data team, while allowing the more technically-minded to fine-tune models to their needs. Once this transformation pattern is established, we feel data teams will be prepared to leverage a DAaaS, introduced in Chapter 3, to automate the transformation layer and provide value at scale.
What does this mean for the modern data practitioner? There currently exists a number of established products that allow data teams to transform integrated data. What they lack, however, is the automation of transformation processes: a metadata-driven, column-aware architecture that combines GUI/code and maximizes code reusability. We’ll touch on this more throughout the report.
Analytics
When we say “analytics,” we’re broadly referring to the process of using SQL and GUI platforms to generate visualizations, reports, and insight. Data analytics and BI are separate in many product organizations, but we’ll just call them “analytics” for simplicity’s sake.
Data analysis has a highly human component and is one of the most challenging aspects of deriving value from data—from an entire data lake, an analyst, scientist, or engineer has to think critically to choose the correct data for the task. The upside: improving efficiency in business and product with massive payoff. The downside: potential misinformation and the creation of data silos—negative returns on investment.
BI is another part of the MDS that has been highly refined. Services like Tableau and Looker have been under development for decades (Tableau being released in 2003). While newcomers like Metabase, Apache Superset, Sigma, and ThoughtSpot are challenging the status quo and introducing intuitive new ways of presenting data (at a dramatically lower cost), there are well-established leaders who will continue to serve the majority of the market.
However, the data exploration part of analytics is undergoing a transformation of its own. There are entire websites dedicated to finding the best hosted notebook tool—while a few leaders stand out (Hex, Deepnote), the field is wide open. Hosted notebooks increase efficiency of data science/analytics teams by integrating SQL, Python, and R into the already popular Jupyter Notebook format.
What does this mean for the modern data practitioner? There are a variety of choices in the data analytics space, but some combination of BI plus an exploratory data science/analytics (EDA) platform will be a good fit for most organizations. Many BI products are mature and expensive, but newcomers are looking to disrupt that trend. Newer EDA tooling might lead to a shift in how analytics/science teams operate.
Governance
Data governance is inherently broad, but the umbrella term refers to all under data security, privacy, accuracy, availability, and usability. Data governance carries many benefits but is often overlooked or delayed due to the (seemingly) high cost of implementation. In reality, sound data governance principles will pay dividends far beyond the cost of investment. Three of the most important aspects of data governance are cataloging, observability, and lineage:
- Cataloging
-
Describes the data itself: column names, enum values, and context. It’s the documentation that allows an outside viewer to understand your data without the years of experience working in it. Many transformation platforms have catalog functionality—Coalesce, dbt, Google Dataform, etc. Still, dedicated frameworks for metadata tracking, like Amundsen, are also popular.
- Observability
-
Makes sure that data is reliable and as expected. With more data than ever, how do you know there aren’t silent errors in your pipelines? Data observability solutions fit this niche. Databand, Datafold, and Monte Carlo all provide observability solutions.
- Lineage
-
Describes the path data took, from ingestion to visualization. Many popular tools contain table-level lineage in the form of a directed acyclic graph (DAG) as built-in functionality (see Figure 1-1).
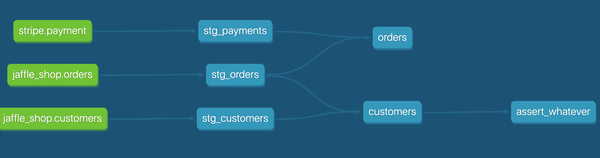
Figure 1-1. An example of table-level data lineage in transformation
What does this mean for the modern data practitioner? Data governance is a far-from-developed part of the MDS. It is a natural fit for part of the transformation step—it’s efficient to document new tables/data at the source when they’re created. Unfortunately, not all data tooling provides column-level lineage, replete metadata tracking, and automation of data governance. We see these as emergent trends in the transformation layer.
Automation in the MDS
From our discussion, it should be clear that some aspects of the MDS are more developed than others. There has been a trend in data processing toward automation: the abstraction of administrative tasks and reduction of operational overhead, which allow data teams to focus on precisely what matters.
For the MDS to deliver what it promises, automation is key. Thus, to address what’s missing in the MDS today you need only compare progress in automation across categories. For example, take data ingestion. While a more constrained problem (taking data from a source and moving it to a target is narrow in scope), the data ingestion problem has been nearly commoditized: you can now find a number of extremely polished products that “just work.”
By contrast, transformation has not yet reached this stage. While the process of transforming data has already undergone a renaissance, it’s due for another. We’ve seen a plateau in the progress of transformation tooling as many companies work to adopt existing solutions. While current solutions are great advancements, each lacks one or more of the components we highlighted as key to truly automating data transformation. A new wave of technologies will complete automation in the MDS by eliminating this current bottleneck.
Summary
Using the guiding principle that data should serve to create value and generate tangible business outcomes, the DaaP framework is a way to think about how your tools of choice should function.
By providing an overview of the MDS as it exists today, we’ve highlighted the strengths and weaknesses of current solutions. Using history as a guide, it is evident that a second renaissance in data processing is here. In this iteration pain points and bottlenecks in data transformation are being overhauled, and data governance is making its way downstream—originating at the column level in the transformation stage.
In Chapter 2, we’ll dive into the specifics of data transformation—examining the pros and cons of transformation frameworks, comparing code and no-code approaches, and ultimately presenting what we like to call the “golden middle” of transformation: a solution that provides just the right balance of flexibility and consistency.
Get Automating Data Transformations now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

