Kapitel 13. Rückkopplungsschleifen
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Jetzt, wo wir eine reibungslose Pipeline haben, um ein maschinelles Lernmodell in die Produktion zu bringen, wollen wir es nicht nur einmal ausführen. Modelle sollten nicht statisch sein, sobald sie eingesetzt werden. Es werden neue Daten gesammelt, die Datenverteilung ändert sich (wie in Kapitel 4 beschrieben), Modelle verändern sich (wie in Kapitel 7 beschrieben) und vor allem möchten wir, dass sich unsere Pipelines kontinuierlich verbessern.
Wenn du eine Art von Feedback in die Maschinenpipeline einbaust, wird sie zu einem Lebenszyklus, wie in Abbildung 13-1 dargestellt. Die Vorhersagen des Modells führen dazu, dass neue Daten gesammelt werden, die das Modell kontinuierlich verbessern.
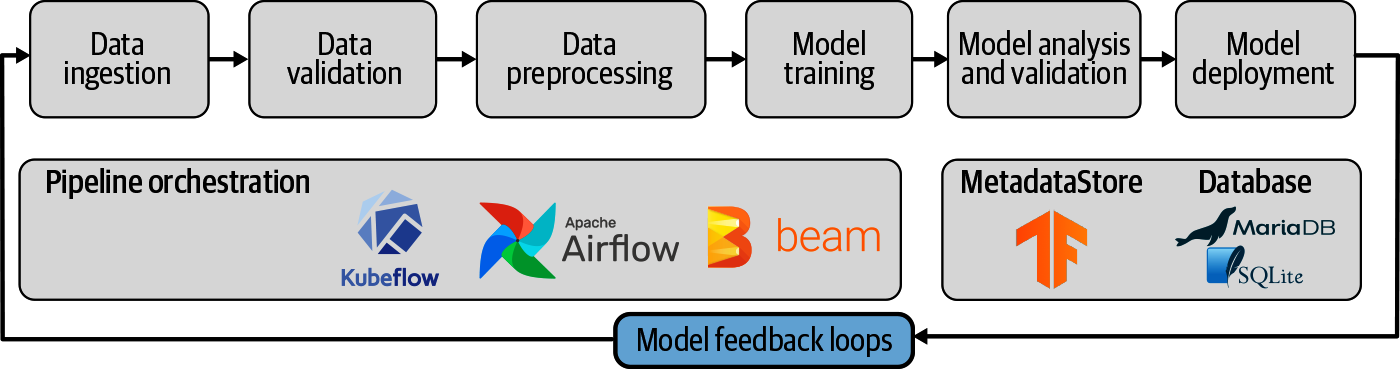
Abbildung 13-1. Modell-Feedback als Teil von ML-Pipelines
Ohne neue Daten kann die Vorhersagekraft eines Modells abnehmen, wenn sich die Eingaben im Laufe der Zeit ändern. Der Einsatz des ML-Modells kann die Trainingsdaten verändern, weil sich die Erfahrungen der Nutzer/innen ändern. In einem Videoempfehlungssystem zum Beispiel führen bessere Empfehlungen des Modells zu einer anderen Auswahl der Videos durch die Nutzer/innen. Feedbackschleifen können uns helfen, neue Daten zu sammeln, um unsere Modelle zu aktualisieren. Sie sind ...
Get Aufbau von Pipelines für maschinelles Lernen now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

