Kapitel 3. Dateneingabe
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Nach der Einrichtung von TFX und dem ML-Metadatenspeicher konzentrieren wir uns in diesem Kapitel darauf, wie du deine Datensätze in eine Pipeline einspeisen kannst, damit sie von den verschiedenen Komponenten genutzt werden können (siehe Abbildung 3-1).
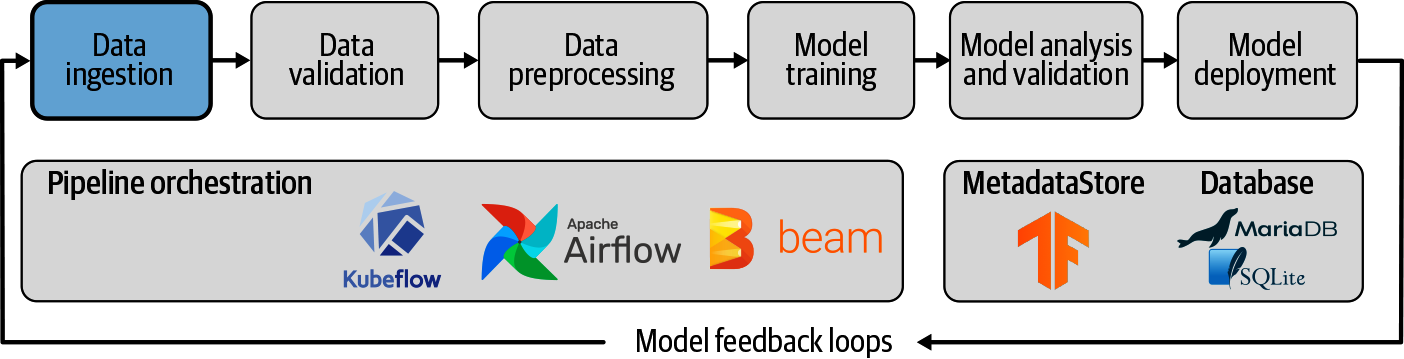
Abbildung 3-1. Dateningestion als Teil von ML-Pipelines
TFX bietet uns Komponenten, um Daten aus Dateien oder Diensten zu importieren. In diesem Kapitel erläutern wir die zugrundeliegenden Konzepte, erklären, wie man die Datensätze in Trainings- und Auswertungsuntergruppen aufteilt, und zeigen, wie man mehrere Datenexporte zu einem umfassenden Datensatz kombiniert. Anschließend erörtern wir einige Strategien zur Aufnahme verschiedener Datenformen (strukturierte Daten, Text und Bilder), die sich in früheren Anwendungsfällen als hilfreich erwiesen haben.
Konzepte für die Dateneingabe
In diesem Schritt unserer Pipeline lesen wir Datendateien oder fordern die Daten für unseren Pipeline-Lauf von einem externen Dienst an (z. B. Google Cloud BigQuery). Bevor wir den eingelesenen Datensatz an die nächste Komponente weitergeben, teilen wir die verfügbaren Daten in separate Datensätze auf (z. B. Trainings- und Validierungsdatensätze) und konvertieren die Datensätze dann in TFRecord-Dateien, ...
Get Aufbau von Pipelines für maschinelles Lernen now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

