Kapitel 4. Kafka mit Kafka-Streams abfragen
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
AATD hat derzeit keinen Echtzeit-Einblick in die Anzahl der Bestellungen oder die erzielten Einnahmen. Das Unternehmen möchte wissen, ob es Spitzen oder Einbrüche in der Anzahl der Bestellungen gibt, damit es im operativen Teil des Geschäfts schneller reagieren kann.
Das AATD-Entwicklungsteam kennt Kafka Streams bereits aus anderen Anwendungen, die es gebaut hat. Deshalb werden wir eine Kafka Streams-App erstellen, die einen HTTP-Endpunkt mit den letzten Bestellungen und Umsätzen anzeigt. Wir werden diese App mit dem Quarkus-Framework erstellen und mit einer naiven Version beginnen. Dann werden wir einige Optimierungen vornehmen. Abschließend fassen wir die Grenzen der Verwendung eines Stream-Prozessors zur Abfrage von Streaming-Daten zusammen.Abbildung 4-1 zeigt, was wir in diesem Kapitel bauen werden.
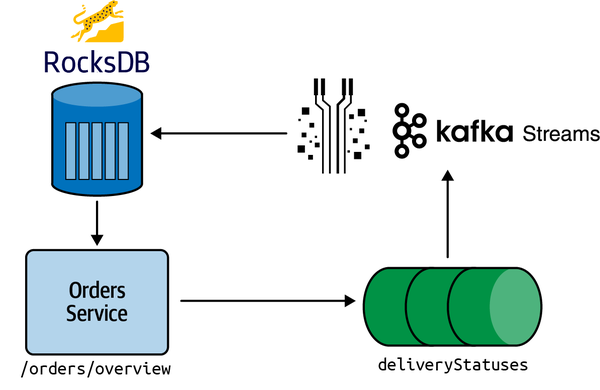
Abbildung 4-1. Architektur von Kafka Streams
Was ist Kafka Streams?
Kafka Streams ist eine Bibliothek zum Erstellen von Streaming-Anwendungen , die Kafka-Themen von der Eingabe in die Ausgabe umwandeln. Sie ist ein Beispiel für die Stream-Prozessor-Komponente des in Kapitel 2 beschriebenen Echtzeit-Analytik-Stacks.
Kafka Streams wird oft zum Verbinden, Filtern und Transformieren von Streams verwendet, aber in diesem Kapitel werden wir es nutzen, um einen bestehenden Stream abzufragen.
Das Herzstück einer Kafka Streams Anwendung ist eine Topologie, die die Stream-Verarbeitungslogik der Anwendung definiert. Eine Topologie beschreibt, wie Daten aus Eingangsstreams (Source) konsumiert und dann in etwas umgewandelt werden, das in Ausgangsstreams (Sink) produziert werden kann.
Genauer gesagt, definiert Jacek Laskowski, Autor von The Internals of Kafka Streams, eine Topologie wie folgt:
Ein gerichteter azyklischer Graph von Stream-Verarbeitungs-Knoten, der die Stream-Verarbeitungslogik einer Kafka-Streams-Anwendung darstellt.
In diesem Diagramm sind die Knoten die Verarbeitungsarbeit und die Beziehungen die Streams. Mit dieser Topologie können wir leistungsstarke Streaming-Anwendungen erstellen, die selbst die komplexesten Datenverarbeitungsaufgaben bewältigen können. Eine Beispieltopologie siehst du in Abbildung 4-2.
Kafka Streams bietet eine domänenspezifische Sprache (DSL), die den Aufbau dieser Topologien vereinfacht.
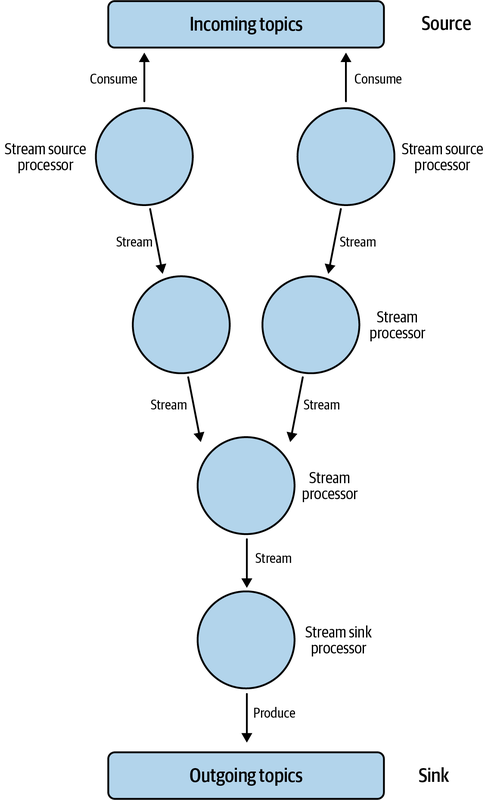
Abbildung 4-2. Kafka Streams Topologie
Gehen wir die Definitionen einiger Kafka-Streams-Abstraktionen durch, die wir in diesem Abschnitt verwenden werden. Die folgenden Definitionen stammen aus der offiziellen Dokumentation:
- KStream
-
Ein KStream ist eine Abstraktion eines Datensatzstroms, bei dem jeder Datensatz ein in sich geschlossenes Datum im unbegrenzten Datensatz darstellt. Die Datensätze in einem KStream werden als "INSERT"-Operationen interpretiert, bei denen jeder Datensatz einen neuen Eintrag in ein "append-only"-Hauptbuch hinzufügt. Mit anderen Worten: Jeder Datensatz stellt ein neues Stück Daten dar, das dem Strom hinzugefügt wird, ohne bestehende Daten mit demselben Schlüssel zu ersetzen.
- KTable
-
Eine KTable ist eine Abstraktion eines Änderungsprotokollstroms, bei dem jeder Datensatz eine Aktualisierung darstellt. Jeder Datensatz in einer KTable stellt eine Aktualisierung des vorherigen Wertes für einen bestimmten Datensatzschlüssel dar, sofern ein solcher existiert. Wenn ein entsprechender Schlüssel noch nicht existiert, wird die Aktualisierung als "INSERT"-Operation behandelt. Mit anderen Worten: Jeder Datensatz in einer KTable stellt eine Aktualisierung der bestehenden Daten mit demselben Schlüssel oder das Hinzufügen eines neuen Datensatzes mit einem neuen Schlüssel-Wert-Paar dar.
- Staatsladen
-
State Stores sind Speicher-Engines zur Verwaltung des Status von Stream-Prozessoren. Sie können den Status im Speicher oder in einer Datenbank wie RocksDB speichern.
Wenn zustandsbehaftete Funktionen wie Aggregations- oder Windowing-Funktionen aufgerufen werden, werden Zwischendaten im State Store gespeichert. Diese Daten können dann von der Leseseite einer Stream-Processing-Anwendung abgefragt werden, um Ausgabeströme oder -tabellen zu erzeugen. State Stores sind eine effiziente Möglichkeit, den Zustand von Stream-Prozessoren zu verwalten und ermöglichen die Erstellung leistungsstarker Stream-Processing-Anwendungen in Kafka Streams.
Was ist Quarkus?
Quarkus ist ein Java-Framework, das für die Entwicklung von Cloud-nativen Anwendungen optimiert ist, die auf Kubernetes bereitgestellt werden. 2019 wurde Quarkus vom Red Hat Engineering Team entwickelt und bietet einen modernen, leichtgewichtigen Ansatz für die Entwicklung von Java-Anwendungen, der ideal auf die Bedürfnisse der Cloud-nativenEntwicklung abgestimmt ist.
Das Framework enthält eine Vielzahl von Erweiterungen für beliebte Technologien wie Camel, Hibernate, MongoDB, Kafka Streams u.v.m. Diese Erweiterungen bieten eine einfache und effiziente Möglichkeit, diese Tools in deine Microservices-Architektur zu integrieren, die Entwicklungszeit zu verkürzen und den Aufbau komplexer verteilter Systeme zu optimieren.
Vor allem die native Kafka-Streams-Integration macht es für uns zu einer guten Wahl.
Quarkus Bewerbung
Jetzt, wo wir die Definitionen aus dem Weg geräumt haben, ist es an der Zeit, mit dem Aufbau unserer Kafka-Streams-App zu beginnen.
Installation der Quarkus CLI
Das Quarkus CLI ist ein leistungsstarkes Werkzeug , mit dem wir Quarkus-Anwendungen von der Kommandozeile aus erstellen und verwalten können. Mit dem Quarkus CLI können wir schnell neue Anwendungen erstellen, Code generieren, Tests durchführen und unsere Anwendungen in verschiedenen Umgebungen bereitstellen. Es gibt viele Möglichkeiten, das CLI zu installieren, so dass du mit Sicherheit eine findest, die dir am besten gefällt.
Ich bin ein großer Fan von SDKMAN, also werde ich es damit installieren. SDKMAN macht es einfach, Software Development Kits (SDKs) zu installieren und zu verwalten. Es hat viele nützliche Funktionen, darunter automatische Updates, Umgebungsverwaltung und Unterstützung für mehrere Plattformen. Ich verwende es, um verschiedene Java-Versionen auf meinem Rechner auszuführen.
Wir können Quarkus mit SDKMAN installieren, indem wir den folgenden Befehl ausführen:
sdkinstallquarkus
Wir können überprüfen, ob sie installiert ist, indem wir den folgenden Befehl ausführen:
quarkus--version
Du solltest eine ähnliche Ausgabe wie in Beispiel 4-1 sehen.
Beispiel 4-1. Quarkus Version
2.13.1.Final
Hinweis
Das Quarkus CLI ist nicht zwingend erforderlich, aber wenn du es installiert hast, wird der Entwicklungsprozess viel reibungsloser, also empfehlen wir dir, es zu installieren!
Erstellen einer Quarkus Anwendung
Jetzt, wo wir das installiert haben, können wir folgenden Befehl ausführen, um unsere Pizzaladen-App zu erstellen:
quarkuscreateapppizzashop--package-namepizzashopcdpizzashop
Dieser Befehl erstellt eine Maven-Anwendung mit den meisten Abhängigkeiten, die wir benötigen, und einer Grundstruktur, mit der wir loslegen können. Das Einzige, was fehlt, sind Kafka-Streams, die wir mit der Erweiterung kafka-streams hinzufügen können:
quarkusextensionadd'kafka-streams'
Jetzt können wir mit der Erstellung unserer Anwendung beginnen.
Erstellen einer Topologie
Als Erstes müssen wir eine Kafka Streams-Topologie erstellen. Eine Quarkus-Anwendung kann eine einzige Topologie definieren, in der wir alle unsere Stream-Operationen festlegen, z. B. das Zusammenfügen von Streams zu einem neuen Stream, das Filtern eines Streams, das Erstellen eines Key-Value-Stores auf der Grundlage eines Streams und vieles mehr.
Sobald wir unsere Topologieklasse haben, erstellen wir ein paar Fensterspeicher, die die Gesamtbestellungen und den Umsatz der letzten Minuten aufzeichnen. So können wir einen HTTP-Endpunkt erstellen, der eine Zusammenfassung der letzten Bestellungen basierend auf den Inhalten dieser Speicher zurückgibt.
Erstelle die Datei src/main/java/pizzashop/streams/Topology.java und füge Folgendes hinzu:
packagepizzashop.streams;importorg.apache.kafka.common.serialization.Serde;importorg.apache.kafka.common.serialization.Serdes;importorg.apache.kafka.common.utils.Bytes;importorg.apache.kafka.streams.StreamsBuilder;importorg.apache.kafka.streams.kstream.*;importorg.apache.kafka.streams.state.WindowStore;importpizzashop.deser.JsonDeserializer;importpizzashop.deser.JsonSerializer;importpizzashop.models.Order;importjavax.enterprise.context.ApplicationScoped;importjavax.enterprise.inject.Produces;importjava.time.Duration;@ApplicationScopedpublicclassTopology{@Producespublicorg.apache.kafka.streams.TopologybuildTopology(){finalSerde<Order>orderSerde=Serdes.serdeFrom(newJsonSerializer<>(),newJsonDeserializer<>(Order.class));// Create a stream over the `orders` topicStreamsBuilderbuilder=newStreamsBuilder();KStream<String,Order>orders=builder.stream("orders",Consumed.with(Serdes.String(),orderSerde));// Defining the window size of our state storeDurationwindowSize=Duration.ofSeconds(60);DurationadvanceSize=Duration.ofSeconds(1);DurationgracePeriod=Duration.ofSeconds(60);TimeWindowstimeWindow=TimeWindows.ofSizeAndGrace(windowSize,gracePeriod).advanceBy(advanceSize);// Create an OrdersCountStore that keeps track of the// number of orders over the last two minutesorders.groupBy((key,value)->"count",Grouped.with(Serdes.String(),orderSerde)).windowedBy(timeWindow).count(Materialized.as("OrdersCountStore"));// Create a RevenueStore that keeps track of the amount of revenue// generated over the last two minutesorders.groupBy((key,value)->"count",Grouped.with(Serdes.String(),orderSerde)).windowedBy(timeWindow).aggregate(()->0.0,(key,value,aggregate)->aggregate+value.price,Materialized.<String,Double,WindowStore<Bytes,byte[]>>as("RevenueStore").withValueSerde(Serdes.Double()));returnbuilder.build();}}
In diesem Code erstellen wir zunächst einen KStream, der auf dem Thema orders basiert, bevor wir OrdersCountStore und RevenueStore erstellen, die ein einminütiges rollierendes Fenster für die Anzahl der Bestellungen und die erzielten Umsätze speichern. Die Karenzzeit wird normalerweise verwendet, um spät eintreffende Ereignisse zu erfassen, aber wir verwenden sie, damit wir Fenster im Wert von zwei Minuten zur Verfügung haben, die wir später benötigen.
Wir haben auch die folgenden Modellklassen, die Ereignisse im orders Stream darstellen:
packagepizzashop.models;importio.quarkus.runtime.annotations.RegisterForReflection;importjava.util.List;@RegisterForReflectionpublicclassOrder{publicOrder(){}publicStringid;publicStringuserId;publicStringcreatedAt;publicdoubleprice;publicdoubledeliveryLat;publicdoubledeliveryLon;publicList<OrderItem>items;}
packagepizzashop.models;publicclassOrderItem{publicStringproductId;publicintquantity;publicdoubleprice;}
Abfrage des Key-Value Store
Als Nächstes erstellen wir die Klasse src/main/java/pizzashop/streams/OrdersQueries.java, die unsere Interaktionen mit OrdersStore abstrahieren wird. Die Abfrage von State Stores (wie OrdersStore) nutzt eine Funktion von Kafka Streams, die interaktive Abfragen genannt wird:
packagepizzashop.streams;importorg.apache.kafka.streams.KafkaStreams;importorg.apache.kafka.streams.KeyValue;importorg.apache.kafka.streams.StoreQueryParameters;importorg.apache.kafka.streams.errors.InvalidStateStoreException;importorg.apache.kafka.streams.state.*;importpizzashop.models.*;importjavax.enterprise.context.ApplicationScoped;importjavax.inject.Inject;importjava.time.Instant;@ApplicationScopedpublicclassOrdersQueries{@InjectKafkaStreamsstreams;publicOrdersSummaryordersSummary(){KStreamsWindowStore<Long>countStore=newKStreamsWindowStore<>(ordersCountsStore());KStreamsWindowStore<Double>revenueStore=newKStreamsWindowStore<>(revenueStore());Instantnow=Instant.now();InstantoneMinuteAgo=now.minusSeconds(60);InstanttwoMinutesAgo=now.minusSeconds(120);longrecentCount=countStore.firstEntry(oneMinuteAgo,now);doublerecentRevenue=revenueStore.firstEntry(oneMinuteAgo,now);longpreviousCount=countStore.firstEntry(twoMinutesAgo,oneMinuteAgo);doublepreviousRevenue=revenueStore.firstEntry(twoMinutesAgo,oneMinuteAgo);TimePeriodcurrentTimePeriod=newTimePeriod(recentCount,recentRevenue);TimePeriodpreviousTimePeriod=newTimePeriod(previousCount,previousRevenue);returnnewOrdersSummary(currentTimePeriod,previousTimePeriod);}privateReadOnlyWindowStore<String,Double>revenueStore(){while(true){try{returnstreams.store(StoreQueryParameters.fromNameAndType("RevenueStore",QueryableStoreTypes.windowStore()));}catch(InvalidStateStoreExceptione){System.out.println("e = "+e);}}}privateReadOnlyWindowStore<String,Long>ordersCountsStore(){while(true){try{returnstreams.store(StoreQueryParameters.fromNameAndType("OrdersCountStore",QueryableStoreTypes.windowStore()));}catch(InvalidStateStoreExceptione){System.out.println("e = "+e);}}}}
Sowohl ordersCountsStore als auch revenueStore geben Daten aus den Fensterspeichern zurück, in denen die Anzahl der Bestellungen bzw. die Höhe der erzielten Einnahmen gespeichert sind. Der Grund für den Codeblock while(true) { try {} catch {} } in beiden Funktionen ist, dass der Speicher möglicherweise nicht verfügbar ist, wenn wir diesen Code aufrufen, bevor der Stream-Thread den Zustand RUNNING erreicht hat. Vorausgesetzt, wir haben keine Fehler in unserem Code, werden wir irgendwann den Zustand RUNNING erreichen; es könnte nur etwas länger dauern, als es dauert, bis der HTTP-Endpunkt startet.
ordersSummary ruft diese beiden Funktionen auf, um die Anzahl der Bestellungen in der letzten Minute und in der Minute davor sowie den Gesamtumsatz in der letzten Minute und in der Minute davor zu ermitteln.
KStreamsWindowStore.java ist hier definiert:
packagepizzashop.models;importorg.apache.kafka.streams.state.ReadOnlyWindowStore;importorg.apache.kafka.streams.state.WindowStoreIterator;importjava.time.Instant;publicclassKStreamsWindowStore<T>{privatefinalReadOnlyWindowStore<String,T>store;publicKStreamsWindowStore(ReadOnlyWindowStore<String,T>store){this.store=store;}publicTfirstEntry(Instantfrom,Instantto){try(WindowStoreIterator<T>iterator=store.fetch("count",from,to)){if(iterator.hasNext()){returniterator.next().value;}}thrownewRuntimeException("No entries found in store between "+from+" and "+to);}}
Die Methode firstEntry findet den ersten Eintrag im Fensterspeicher im angegebenen Datumsbereich und gibt den Wert zurück. Wenn keine Einträge vorhanden sind, wird ein Fehler ausgegeben.
OrdersSummary.java ist hier definiert:
packagepizzashop.models;importio.quarkus.runtime.annotations.RegisterForReflection;@RegisterForReflectionpublicclassOrdersSummary{privateTimePeriodcurrentTimePeriod;privateTimePeriodpreviousTimePeriod;publicOrdersSummary(TimePeriodcurrentTimePeriod,TimePeriodpreviousTimePeriod){this.currentTimePeriod=currentTimePeriod;this.previousTimePeriod=previousTimePeriod;}publicTimePeriodgetCurrentTimePeriod(){returncurrentTimePeriod;}publicTimePeriodgetPreviousTimePeriod(){returnpreviousTimePeriod;}}
Diese Klasse ist ein Datenobjekt, das Aufträge und Einnahmen für den aktuellen und den vorherigen Zeitraum aufzeichnet.
TimePeriod.java ist hier definiert:
packagepizzashop.models;importio.quarkus.runtime.annotations.RegisterForReflection;@RegisterForReflectionpublicclassTimePeriod{privateintorders;privatedoubletotalPrice;publicTimePeriod(longorders,doubletotalPrice){this.orders=orders;this.totalPrice=totalPrice;}publicintgetOrders(){returnorders;}publicdoublegetTotalPrice(){returntotalPrice;}}
Bei dieser Klasse handelt es sich um ein Datenobjekt, das den Überblick über Bestellungen und Einnahmen behält.
Erstellen eines HTTP-Endpunkts
Zum Schluss erstellen wir den HTTP-Endpunkt , der die Übersichtsdaten für unsere Nutzer bereitstellt. Erstelle die Datei src/main/java/pizzashop/rest/OrdersResource.java und füge Folgendes hinzu:
packagepizzashop.rest;importpizzashop.models.OrdersSummary;importpizzashop.streams.InteractiveQueries;importjavax.enterprise.context.ApplicationScoped;importjavax.inject.Inject;importjavax.ws.rs.GET;importjavax.ws.rs.Path;importjavax.ws.rs.core.Response;@ApplicationScoped@Path("/orders")publicclassOrdersResource{@InjectOrdersQueriesordersQueries;@GET@Path("/overview")publicResponseoverview(){OrdersSummaryordersSummary=ordersQueries.ordersSummary();returnResponse.ok(ordersSummary).build();}}
Ausführen der Anwendung
Nachdem wir nun alle Klassen erstellt haben, ist es an der Zeit, die Anwendung zu starten. Dazu führen wir den folgenden Befehl aus:
QUARKUS_KAFKA_STREAMS_BOOTSTRAP_SERVERS=localhost:29092quarkusdev
Wir geben die Umgebungsvariable QUARKUS_KAFKA_STREAMS_BOOTSTRAP_SERVERS ein, damit Quarkus sich mit unserem Kafka-Broker verbinden kann.
Abfrage des HTTP-Endpunkts
Jetzt können wir den HTTP-Endpunkt abfragen, um zu sehen, wie viele Bestellungen unser Online-Service erhält. Der Endpunkt ist auf Port 8080 unter /orders/overview erreichbar:
curlhttp://localhost:8080/orders/overview2>/dev/null|jq'.'
Die Ergebnisse dieses Befehls sind in Beispiel 4-2 dargestellt.
Beispiel 4-2. Letzter Auftragsstatus
{"currentTimePeriod":{"orders":994,"totalPrice":4496973},"previousTimePeriod":{"orders":985,"totalPrice":4535117}}
Erfolg! Wir können die Anzahl der Bestellungen und den Gesamtumsatz im aktuellen und vorherigen Zeitraum sehen.
Einschränkungen von Kafka Streams
Obwohl sich dieser Ansatz für die Abfrage von Streams in vielen Fällen bewährt hat, könnten bestimmte Faktoren seine Effizienz für unseren speziellen Anwendungsfall beeinträchtigen. In diesem Abschnitt werden wir uns diese Einschränkungen genauer ansehen, um besser zu verstehen, wie sie die Leistung dieses Ansatzes beeinflussen könnten.
Die zugrunde liegende Datenbank von Kafka Streams ist RocksDB, ein Key-Value-Store, mit dem du Daten mithilfe von Key-Value-Paaren speichern und abrufen kannst. Dieser Fork von GooglesLevelDB ist für schreibintensive Workloads mit großen Datensätzen optimiert.
Eine der Einschränkungen ist, dass wir nur einen Index pro Key-Value-Store erstellen können. Das bedeutet, dass wir die Topologie aktualisieren müssen, um einen weiteren Key-Value-Store zu erstellen, wenn wir die Daten entlang einer anderen Dimension abfragen wollen. Wenn wir eine Suche ohne Schlüssel durchführen, führt RocksDB einen vollständigen Scan durch, um die passenden Datensätze zu finden, was zu einer hohen Abfragelatenz führt.
Unsere Key-Value-Stores erfassen auch nur Ereignisse, die in der letzten Minute und der Minute davor passiert sind. Wenn wir Daten erfassen wollten, die weiter zurückreichen, müssten wir die Topologie aktualisieren, um mehr Ereignisse zu erfassen. Im Fall von AATD könnten wir uns einen zukünftigen Anwendungsfall vorstellen, in dem wir die Verkaufszahlen von jetzt mit denen der letzten Woche oder des letzten Monats zur gleichen Zeit vergleichen wollen. Das wäre in Kafka Streams schwierig zu realisieren, weil wir historische Daten speichern müssten, was viel Speicherplatz beanspruchen würde.
Auch wenn wir Kafka Streams zum Schreiben von Echtzeit-Analyseabfragen verwenden können und es einen vernünftigen Job macht, müssen wir wahrscheinlich ein Tool finden, das besser zu diesem Problem passt.
Zusammenfassung
In diesem Kapitel haben wir uns angeschaut, wie wir eine HTTP-API auf dem orders Stream aufbauen können, um einen Überblick über die Auftragslage im Unternehmen zu erhalten. Wir haben diese Lösung mit Kafka Streams erstellt, aber wir haben festgestellt, dass dies vielleicht nicht das am besten geeignete Werkzeug für diese Aufgabe ist. Im nächsten Kapitel werden wir erfahren, warum wir eine Serving-Schicht brauchen, um eine skalierbare Echtzeit-Analyseanwendung zu erstellen.
Get Aufbau von Echtzeit-Analysesystemen now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

