Capítulo 4. Conexión en red
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Este capítulo examina cómo los servicios de clúster, como Spark y Hadoop, utilizan la red y cómo ese uso afecta a la arquitectura y la integración de la red. También cubrimos detalles de implementación relevantes para los arquitectos de redes y los creadores de clústeres.
Los servicios como Hadoop son distribuidos, lo que significa que el trabajo en red es una parte fundamental y crítica de la arquitectura general de su sistema. Más que afectar sólo a cómo se accede externamente a un clúster, la conexión en red afecta directamente al rendimiento, escalabilidad, seguridad y disponibilidad de un clúster y de los servicios que presta.
Cómo utilizan los servicios una red
Una plataforma de datos moderna se compone de una serie de servicios en red que se combinan selectivamente para resolver problemas empresariales. Cada servicio proporciona una capacidad única, pero fundamentalmente, cada uno de ellos se construye utilizando un conjunto común de casos de uso de la red.
Llamadas a procedimientos remotos (RPC)
Uno de los casos de uso de red más comunes es cuando los clientes solicitan que un servicio remoto realice una acción. Conocidos como llamadas a procedimientos remotos (RPC), estos mecanismos son una unidad de trabajo fundamental en una red, ya que permiten muchos casos de uso de nivel superior, como el monitoreo, el consenso y las transferencias de datos.
Todos los servicios de la plataforma están distribuidos, por lo que, por definición, todos proporcionan capacidades RPC de una forma u otra. Como era de esperar, la variedad de llamadas remotas disponibles refleja la variedad de los propios servicios: las RPC a algunos servicios duran sólo milisegundos y afectan a un único registro, pero las llamadas a otros servicios instancian complejos trabajos multiservidor que mueven y procesan petabytes de información.
Implementaciones y arquitecturas
La definición de una RPC es amplia y se aplica a muchos lenguajes y bibliotecas diferentes: incluso una simple transferencia HTTP puede considerarse una RPC.
Los servicios de plataforma de datos son una colección de proyectos de código abierto poco afiliados, escritos por diferentes autores. Esto significa que hay muy poca estandarización entre ellos, incluida la elección de la tecnología RPC. Algunos servicios utilizan enfoques estándar de la industria, como REST, y otros utilizan marcos de código abierto, como Apache Thrift. Otros, como Apache Kudu, proporcionan sus propios marcos RPC personalizados, para controlar mejor toda la aplicación de extremo a extremo.
Los servicios también difieren mucho en cuanto a sus arquitecturas subyacentes. Por ejemplo, Apache Oozie proporciona un sencillo modelo cliente-servidor para enviar y monitorizar flujos de trabajo: Oozie interactúa después con otros servicios en tu nombre. En cambio, Apache Impala combina interacciones cliente-servidor a través de JDBC con interacciones servidor-servidor altamente concurrentes, leyendo datos de HDFS y Kudu y enviando datos de tuplas entre demonios Impala para ejecutar una consulta distribuida.
Servicios de plataforma y sus RPC
La Tabla 4-1 muestra ejemplos de RPC en los distintos servicios.
| Servicio | Interacciones cliente-servidor | Interacciones servidor-servidor |
|---|---|---|
ZooKeeper |
Creación, modificación y eliminación de nodos Z |
Elección del líder, réplica del estado |
HDFS |
Creación, modificación y eliminación de archivos y directorios |
Informes de vida útil, gestión de bloques y replicación |
YARN |
Presentación y monitoreo de solicitudes, peticiones de asignación de recursos |
Informes sobre el estado de los contenedores |
Colmena |
Cambios en los metadatos del metastore, envío de consultas mediante JDBC |
Interacciones con YARN y RDBMS de respaldo |
Impala |
Envío de consultas mediante JDBC |
Intercambio de datos de tuplas |
Kudu |
Creación, modificación y eliminación de filas; consultas de exploración basadas en predicados |
Replicación de datos basada en el consenso |
HBase |
Creación, modificación y eliminación de células; exploraciones y recuperación de células |
Informes de actividad |
Kafka |
Publicación y recuperación de mensajes, recuperación de offset y commits |
Replicación de datos |
Oozie |
Envío y control del flujo de trabajo |
Interacciones con otros servicios, como HDFS o YARN, así como RDBMS de respaldo |
Control del proceso
Algunos servicios proporcionan capacidades RPC que permiten iniciar y detener procesos remotos. En el caso de YARN, las aplicaciones enviadas por los usuarios se instancian para realizar diversas cargas de trabajo, como aprendizaje automático, procesamiento de flujos o ETL por lotes, y cada aplicación enviada genera procesos dedicados.
El software de gestión, como Cloudera Manager o Apache Ambari, también utiliza RPCs para instalar, configurar y gestionar los servicios Hadoop, incluyendo su arranque y parada según sea necesario.
Latencia
Cada llamada a un procedimiento remoto pasa por el mismo largo proceso: la llamada crea un paquete, que se convierte en una trama, se almacena en búfer, se envía a un conmutador remoto, se almacena de nuevo en búfer dentro del conmutador, se transfiere al host de destino, se almacena de nuevo en búfer dentro del host, se convierte en un paquete y, finalmente, se entrega a la aplicación de destino.
El tiempo que tarda una RPC en llegar a su destino puede ser significativo, a menudo tarda alrededor de un milisegundo. Las llamadas remotas a menudo requieren que se envíe una respuesta de vuelta al cliente, lo que retrasa aún más la finalización de la interacción. Si un conmutador está muy cargado y sus búferes internos están llenos, puede que tenga que descartar algunas tramas por completo, provocando una retransmisión. Si esto ocurre, una llamada podría tardar bastante más de lo habitual.
Latencia y servicios de clúster
Los servicios del clúster varían en la medida en que pueden tolerar la latencia. Por ejemplo, aunque HDFS puede tolerar una alta latencia al enviar bloques a los clientes, las interacciones entre el NameNode y los JournalNodes (que almacenan de forma fiable los cambios en HDFS en un registro de escritura anticipada basado en el quórum) son más sensibles. El rendimiento de las operaciones de metadatos del HDFS está limitado por la rapidez con la que los JournalNodes pueden almacenar las ediciones.
ZooKeeper es especialmente sensible a la latencia de la red. Rastrea qué clientes están activos escuchando los latidos del corazón, es decir, lasllamadas RPC periódicas. Si esas llamadas se retrasan o se pierden, ZooKeeper asume que el cliente ha fallado y toma las medidas oportunas, como caducar las sesiones. Aumentar los tiempos de espera puede hacer que las aplicaciones sean más resistentes a los picos ocasionales, pero el inconveniente es que aumenta el tiempo necesario para detectar a un cliente que ha fallado.
Aunque la latencia del cliente de ZooKeeper puede deberse a varios factores, como la recogida de basura o un subsistema de disco lento, una red con un rendimiento deficiente puede provocar la caducidad de las sesiones, lo que se traduce en falta de fiabilidad y bajo rendimiento.
Transferencias de datos
Las transferencias de datos son una operación fundamental en cualquier plataforma de gestión de datos, pero la naturaleza distribuida de servicios como Hadoop significa que casi todas las transferencias implican a la red, tanto si se destinan a operaciones de almacenamiento como de procesamiento.
A medida que se amplía un clúster, el ancho de banda de red necesario crece al mismo ritmo: fácilmente hasta cientos de gigabytes por segundo y más. Gran parte de ese ancho de banda se utiliza dentro del clúster, por los nodos servidores que se comunican entre sí, en lugar de comunicarse con los sistemas y clientes externos, el llamado patrón de tráfico este-oeste.
Las transferencias de datos suelen asociarse a unos pocos casos de uso: ingesta y consulta, replicación de datos y barajado de datos.
Replicación
La replicación es una estrategia habitual para mejorar la disponibilidad y fiabilidad en los sistemas distribuidos: si falla un servidor, hay otros disponibles para atender la petición. En los sistemas en los que todas las réplicas están disponibles para su lectura, la replicación también puede aumentar el rendimiento, ya que los clientes eligen leer la réplica más cercana. Si muchas cargas de trabajo necesitan simultáneamente un determinado elemento de datos, la posibilidad de leer varias réplicas puede aumentar el paralelismo.
Veamos cómo se gestiona la replicación en HDFS, Kafka y Kudu:
- HDFS
-
HDFS replica los datos dividiendo los archivos en límites de 128 MB y replicando los bloques resultantes, en lugar de replicar archivos. Una ventaja de esto es que permite leer archivos grandes en paralelo en algunas circunstancias, como cuando se vuelven a replicar datos. Cuando se configura para tener en cuenta los bastidores, HDFS garantiza que los bloques se distribuyan en varios bastidores, manteniendo la disponibilidad de los datos incluso si falla un bastidor o un conmutador completo.
Los bloques se replican durante la escritura inicial del archivo, así como durante las operaciones en curso del clúster. HDFS mantiene la integridad de los datos replicando cualquier bloque corrupto o que falte. Los bloques también se replican durante el reequilibrio, lo que permite que los servidores añadidos a un clúster HDFS existente participen inmediatamente en la gestión de datos responsabilizándose de una parte de los datos existentes.
Durante las escrituras iniciales de archivos, el cliente sólo envía una copia. Los DataNodes forman una cadena, enviando el bloque recién creado a lo largo de la cadena hasta que se escribe correctamente.
Aunque las demandas de replicación de un único archivo son modestas, la carga de trabajo agregada impuesta a HDFS por una aplicación distribuida puede ser inmensa. Aplicaciones como Spark y MapReduce pueden ejecutar fácilmente miles de tareas simultáneas, cada una de las cuales puede estar leyendo o escribiendo simultáneamente en HDFS. Aunque estos marcos de aplicación intentan minimizar las lecturas remotas de HDFS en la medida de lo posible, casi siempre es necesario replicar las escrituras.
- Kafka
-
La ruta de replicación que siguen los mensajes en Kafka es relativamente estática, a diferencia de HDFS, donde la ruta es diferente para cada bloque. Los datos fluyen de los productores a los líderes, pero a partir de ahí son leídos por todos los seguidores de forma independiente: una arquitectura en abanico en lugar de una canalización. Los temas de Kafka tienen un factor de replicación fijo que se define cuando se crea el tema, a diferencia de HDFS, donde cada archivo puede tener un factor de replicación diferente. Como era de esperar, Kafka replica los mensajes en la ingesta.
Las escrituras en Kafka también pueden variar en cuanto a su durabilidad. Los productores pueden enviar mensajes de forma asíncrona utilizando "disparar y olvidar", o pueden elegir escribir de forma síncrona y esperar un acuse de recibo, cambiando rendimiento por durabilidad. El productor también puede elegir si el acuse de recibo representa una recepción correcta sólo en el líder o en todas las réplicas sincronizadas en ese momento.
La replicación también tiene lugar al arrancar un nuevo corredor o cuando un corredor existente vuelve a estar en línea y se pone al día con los últimos mensajes. A diferencia del HDFS, si un intermediario se desconecta, su partición no se replica automáticamente en otro intermediario, pero puede hacerse manualmente.
- Kudu
-
Un clúster Kudu almacena tablas de estilo relacional que resultarán familiares a cualquier desarrollador de bases de datos. Utilizando claves primarias, permite un acceso de baja latencia a escala de milisegundos a filas individuales, al tiempo que almacena los registros en un formato de almacenamiento columnar, lo que hace eficientes los escaneos analíticos profundos.
En lugar de replicar los datos directamente, Kudu replica las operaciones de modificación de datos, como inserciones y borrados. Utiliza el algoritmo de consenso Raft para garantizar que las operaciones de datos se almacenan de forma fiable en al menos dos servidores en registros de escritura anticipada antes de devolver una respuesta al cliente.
Baraja
El análisis de datos depende de las comparaciones. Ya sea comparando los resultados financieros de este año con los del año anterior o midiendo las constantes vitales de la salud de un recién nacido con respecto a las normas esperadas, las comparaciones están en todas partes. Las operaciones de procesamiento de datos, como las agregaciones y uniones, también utilizan comparaciones para encontrar registros coincidentes.
Para comparar los registros, primero hay que colocarlos en la memoria de un único proceso. Esto significa utilizar la red para realizar transferencias de datos como primer paso de una cadena de procesamiento. Marcos como Spark y MapReduce preintegran estas fases de intercambio de datos a gran escala, conocidas como barajadas, lo que permite a los usuarios escribir aplicaciones que ordenan, agrupan y unen terabytes de información de forma masivamente paralela.
Durante una barajada, todos los servidores participantes transfieren datos a todos los demás simultáneamente, lo que convierte a las barajadas en la actividad de red que más ancho de banda consume con diferencia. En la mayoría de las Implementaciones, es la demanda potencial de ancho de banda de las barajadas lo que determina la idoneidad de una arquitectura de red.
Monitoreo
Los sistemas de nivel empresarial requieren casos de uso como reforzar la seguridad mediante auditorías y monitoreo de la actividad, garantizar la disponibilidad y el rendimiento del sistema mediante comprobaciones de estado y métricas proactivas, y permitir diagnósticos remotos mediante funciones de registro y teléfono en casa.
Todos estos casos de uso caen bajo el paraguas del monitoreo, y todos requieren la red. También hay solapamientos entre ellos. Por ejemplo, los registros de monitoreo de la actividad pueden utilizarse tanto para garantizar la seguridad mediante auditorías como para el análisis histórico del rendimiento del trabajo: cada uno es sólo una perspectiva diferente de los mismos datos. La información de monitoreo en un clúster Hadoop adopta la forma de eventos de auditoría, métricas, registros y alertas.
Copia de seguridad
Parte de garantizar la resistencia general del sistema en un sistema de nivel empresarial es asegurarse de que, en caso de fallo catastrófico, los sistemas puedan volver a ponerse en línea y restaurarse. Como se puede ver en el Capítulo 13, estas preocupaciones empresariales tradicionales siguen siendo muy relevantes para las arquitecturas de datos modernas. En la mayoría de los entornos informáticos, las actividades de copia de seguridad se realizan a través de la red, ya que es más fácil y eficaz que visitar físicamente ubicaciones remotas.
Para una arquitectura de clúster moderna que comprenda cientos de servidores, este uso de la red para las copias de seguridad es esencial. El tráfico de red resultante puede ser considerable, pero no todos los servidores necesitan copias de seguridad en su totalidad. Los datos almacenados suelen estar ya replicados, y la automatización de la construcción puede reinstalar con frecuencia el software del sistema necesario. En cualquier caso, procura que los procesos de copia de seguridad no interfieran con las operaciones del clúster, a nivel de red o de otro tipo.
Consenso
Considera un cliente que realiza una RPC pero no recibe respuesta. Sin más información, es imposible saber si esa solicitud se recibió correctamente. Si la solicitud era lo suficientemente importante como para cambiar de algún modo el estado del sistema de destino, ahora no estamos seguros de si el sistema ha cambiado realmente.
Por desgracia, no se trata sólo de un problema académico. La realidad es que ninguna red o sistema puede ser totalmente fiable. Los paquetes se pierden, las fuentes de alimentación fallan, los cabezales de disco se bloquean. Diseñar un sistema para hacer frente a estos fallos significa comprender que los fallos no son sucesos excepcionales y, en consecuencia, escribir software para tener en cuenta -y conciliar- esos fallos.
Una forma de conseguir fiabilidad frente a los fallos es utilizar varios procesos, sustituyendo a los puntos únicos de fallo (SPOF). Sin embargo, esto requiere que los procesos colaboren, intercambiando información sobre su propio estado para llegar a un acuerdo sobre el estado del sistema en su conjunto. Cuando la mayoría de los procesos se ponen de acuerdo sobre ese estado, se dice que tienen quórum, controlando la evolución futura del estado del sistema.
El consenso se utiliza en muchos servicios de clúster para lograr la corrección:
-
HDFS utiliza un sistema de votación por mayoría basado en el quórum para almacenar de forma fiable las ediciones del sistema de archivos en tres JournalNodes diferentes, idealmente desplegados en varios bastidores en dominios de fallo independientes.
-
ZooKeeper utiliza un sistema de consenso basado en el quórum para proporcionar funciones como la elección del líder, el bloqueo distribuido y la puesta en cola a otros servicios y procesos del clúster, como HDFS, Hive y HBase.
-
Kafka utiliza el consenso para saber qué mensajes deben ser visibles para un consumidor. Si un líder acepta escrituras pero el número necesario de réplicas aún no está sincronizado, esos mensajes se retienen de los consumidores hasta que estén suficientemente replicados.
-
Kudu utiliza el algoritmo de consenso Raft para la replicación, garantizando que las inserciones, actualizaciones y eliminaciones persistan en al menos dos nodos antes de responder al cliente.
Arquitecturas de red
Las redes determinan algunas de las cualidades arquitectónicas más importantes de un sistema distribuido, como la fiabilidad, el rendimiento y la seguridad. En esta sección describimos una serie de diseños de red adecuados para todo, desde implementaciones en un solo bastidor hasta gigantes de mil servidores.
Arquitecturas de clústeres pequeños
La primera arquitectura de red de clúster que hay que considerar es la de un único conmutador.
Interruptor único
Aunque casi demasiado simple para ser considerada una arquitectura, el enfoque es, sin embargo, apropiado en muchos casos de uso. La Figura 4-3 ilustra la arquitectura.
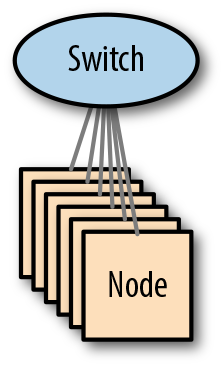
Figura 4-3. Arquitectura de un solo conmutador
Desde el punto de vista del rendimiento, este diseño presenta muy pocos retos. Casi todos los conmutadores modernos son no bloqueantes (lo que significa que todos los puertos pueden utilizarse simultáneamente a plena carga), por lo que el tráfico interno de barajado y replicación debería gestionarse sin esfuerzo.
Sin embargo, aunque sencilla y eficaz, esta arquitectura de red adolece de una falta inherente de escalabilidad: una vez que un conmutador se queda sin puertos, un clúster no puede crecer más. Dado que los puertos de los conmutadores se utilizan a menudo para la conectividad ascendente, así como para los servidores locales, los clusters pequeños con elevados requisitos de ingesta pueden ver restringido aún más su crecimiento.
Otro inconveniente de esta arquitectura es que el conmutador es un SPOF: si falla, el clúster fallará junto con él. No todos los clusters necesitan estar siempre disponibles, pero para los que sí, la única solución es construir una red resistente utilizando varios conmutadores.
Aplicación
Con una arquitectura de conmutador único, debido a la simplicidad inherente del diseño, hay muy pocas opciones en la implementación. El conmutador albergará un único dominio de difusión de Capa 2 dentro de una LAN física o una única LAN virtual (VLAN), y todos los hosts estarán en la misma subred de Capa 3.
Arquitecturas de clústeres medianos
Al construir clústeres que abarcarán varios bastidores, recomendamos encarecidamente las arquitecturas descritas en "Arquitecturas de clústeres grandes", ya que proporcionan los niveles más altos de escalabilidad y rendimiento. Sin embargo, como no todos los clústeres necesitan capacidades tan elevadas, los clústeres más modestos pueden utilizar una de las arquitecturas alternativas descritas en esta sección.
Redes apiladas
Algunos proveedores de redes ofrecen conmutadores que pueden apilarse, es decir, conectarse entre sí con cables propietarios de gran ancho de banda, haciendo que funcionen como un único conmutador. Esto proporciona una opción barata y de baja complejidad para ampliar más allá de un único conmutador. La Figura 4-5 muestra un ejemplo de red apilada.
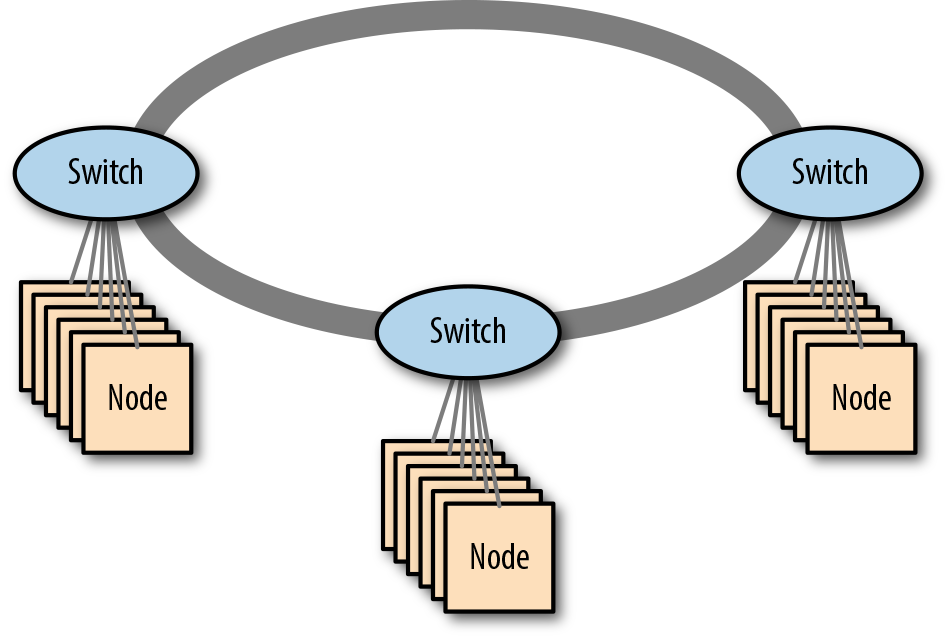
Figura 4-5. Una red apilada de tres conmutadores
Aunque los conmutadores apilables puedan parecer similares al uso de un par de conmutadores de alta disponibilidad (que también pueden funcionar como un único conmutador lógico), en realidad son bastante diferentes. Los conmutadores apilables utilizan sus interconexiones propietarias para transportar grandes volúmenes de datos de usuario, mientras que un par de conmutadores de alta disponibilidad (HA) sólo utiliza la interconexión para gestionar el estado del conmutador. El apilamiento tampoco se limita a un par de conmutadores; muchas implementaciones pueden interconectar hasta siete conmutadores en un solo anillo (aunque, como veremos, esto tiene un gran impacto en la sobresuscripción, afectando gravemente al rendimiento de la red).
Resiliencia
Los conmutadores apilables se conectan mediante una topología de anillo bidireccional. Por tanto, cada participante siempre tiene dos conexiones: en el sentido de las agujas del reloj y en sentido contrario. Esto dota al diseño de resiliencia frente al fallo del enlace en anillo: si falla el enlace en el sentido de las agujas del reloj, el tráfico puede fluir en su lugar a través del enlace en sentido contrario, aunque el ancho de banda total de la red podría verse reducido.
En caso de fallo de un conmutador en el anillo, los demás conmutadores seguirán funcionando, asumiendo el liderazgo del anillo si es necesario (ya que uno de los participantes es el maestro). Los dispositivos que sólo estén conectados a un único conmutador del anillo perderán el servicio de red.
Algunos conmutadores apilables admiten la Agregación de Enlaces Multichasis (ver "Cómo hacer redes en clúster resistentes" en la página 115). Esto permite que los dispositivos sigan recibiendo servicio de red aunque falle uno de los conmutadores del anillo, siempre que los dispositivos se conecten a un par de los conmutadores de la pila. Esta configuración permite crear redes apiladas resistentes (consulta un ejemplo en la Figura 4-6 ).
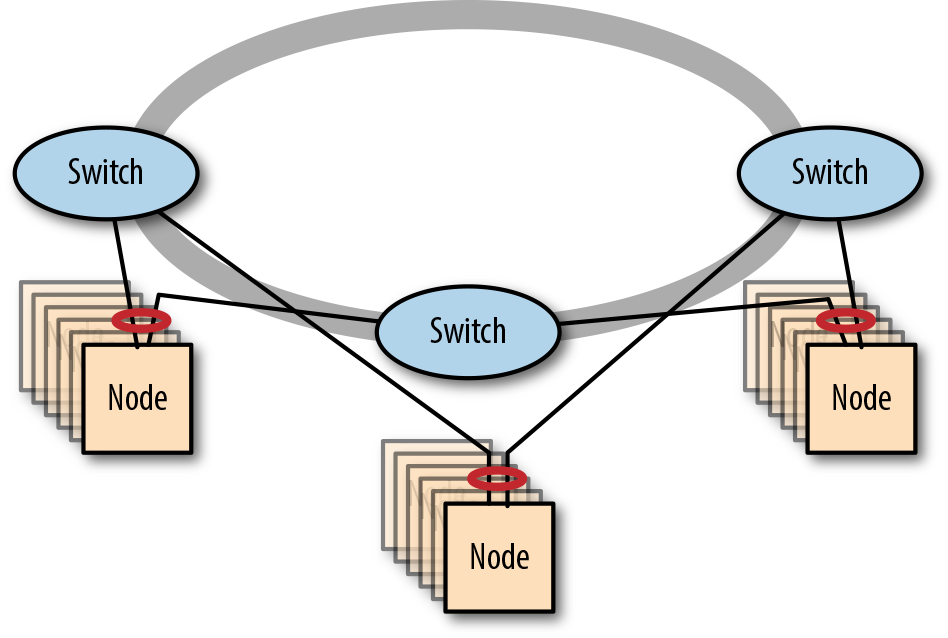
Figura 4-6. Una red apilada resistente de tres conmutadores
En funcionamiento normal, la naturaleza bidireccional de las conexiones en anillo significa que hay dos anillos independientes. En caso de fallo de un enlace o de un conmutador, los conmutadores restantes detectan el fallo y tapan los extremos, dando lugar a un bucle unidireccional en forma de herradura.
Rendimiento
Las interconexiones de apilamiento proporcionan un ancho de banda muy elevado entre los conmutadores, pero cada enlace sigue proporcionando menos ancho de banda que la suma de los puertos, lo que provoca necesariamente una sobresuscripción de la red.
Con sólo dos conmutadores en un anillo, hay dos rutas posibles hacia un conmutador de destino: en el sentido de las agujas del reloj y en el sentido contrario. En cada dirección, el conmutador de destino está conectado directamente. Con tres conmutadores en un anillo, la topología significa que sigue habiendo sólo dos direcciones posibles, pero ahora un conmutador de destino sólo estará conectado directamente en una dirección. En la otra dirección, hay un conmutador intermedio entre la fuente y el objetivo.
La necesidad de que el tráfico atraviese conmutadores intermedios significa que la sobresuscripción aumenta a medida que añadimos conmutadores al anillo. En circunstancias normales, cada conmutador del anillo tiene la opción de enviar tráfico en el sentido de las agujas del reloj o en sentido contrario, y esto también puede afectar al rendimiento de la red.
Determinar la sobresuscripción en redes apiladas
Dentro de una red apilada, ahora hay dos caminos potenciales entre un dispositivo de origen y de destino, lo que hace que la sobresuscripción sea más compleja de determinar, pero conceptualmente el proceso no cambia.
En este primer escenario, examinamos la sobresuscripción entre un par de conmutadores apilados, cada uno de los cuales tiene 48 puertos 10 GbE y enlaces de apilamiento bidireccionales que funcionan a 120 Gb/s (el diagrama de flujo puede verse en la Figura 4-7). Cada conmutador está conectado directamente al otro por dos rutas, lo que da una capacidad total de flujo saliente de 240 Gb/s. Como hay un potencial de 480 Gb/s de entrada desde los puertos, vemos una relación de sobresuscripción de 480:240, o 2:1.
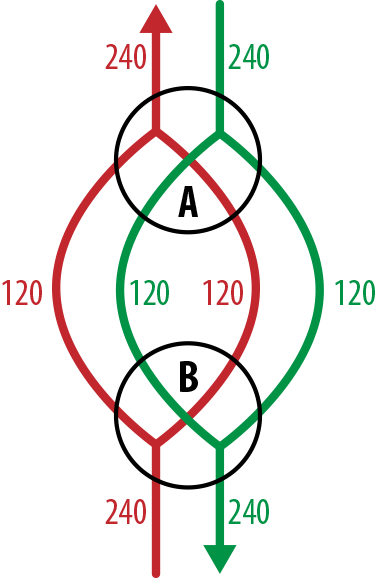
Figura 4-7. Flujos de red entre un par de conmutadores apilados
Con tres conmutadores en el anillo, cada conmutador sigue conectado directamente con los demás, pero el ancho de banda de salida de 240 Gb/s se comparte ahora entre los dos vecinos. La Figura 4-8 muestra los flujos de red que se producen si suponemos que el tráfico está perfectamente equilibrado y los conmutadores toman decisiones perfectas sobre la selección de rutas (asegurándose de que ningún tráfico se envía a través de un conmutador intermedio). En ese escenario, a cada vecino se le envían 120 Gb/s y la salida total es de 240 Gb/s, con lo que la relación de sobresuscripción es de 2:1.
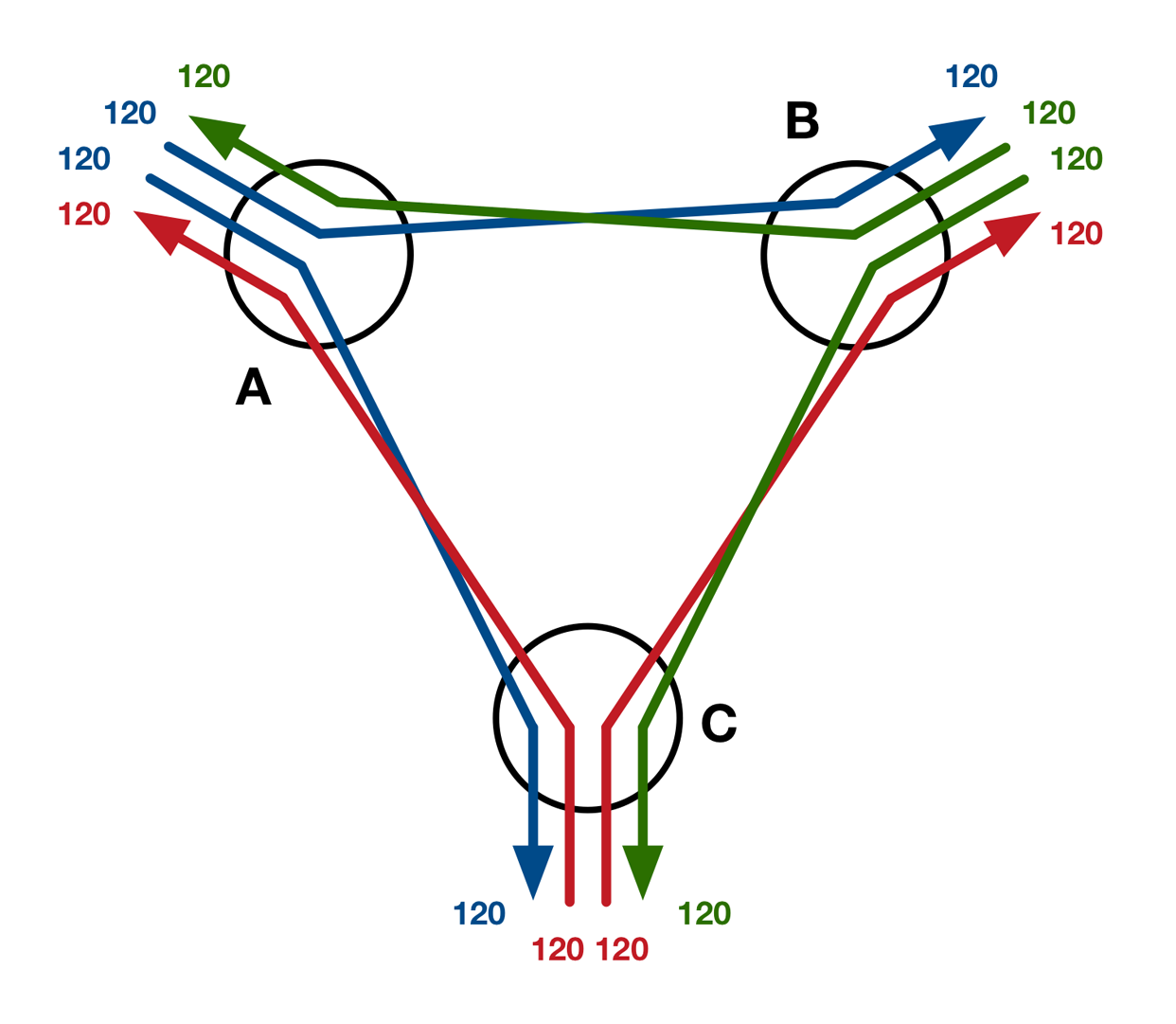
Figura 4-8. Flujos de red en el mejor de los casos entre tres conmutadores apilados
Si de alguna manera los conmutadores apilados hicieran la peor selección de rutas posible (enviando todo el tráfico por la ruta más larga, como se muestra en la Figura 4-9), el ancho de banda efectivo se reduciría porque cada enlace de salida transportaría ahora dos flujos en lugar de uno. Este aumento de la contención reduciría el ancho de banda disponible por flujo a sólo 60 Gb/s, con lo que la relación de sobresuscripción sería de 480:120, o 4:1.
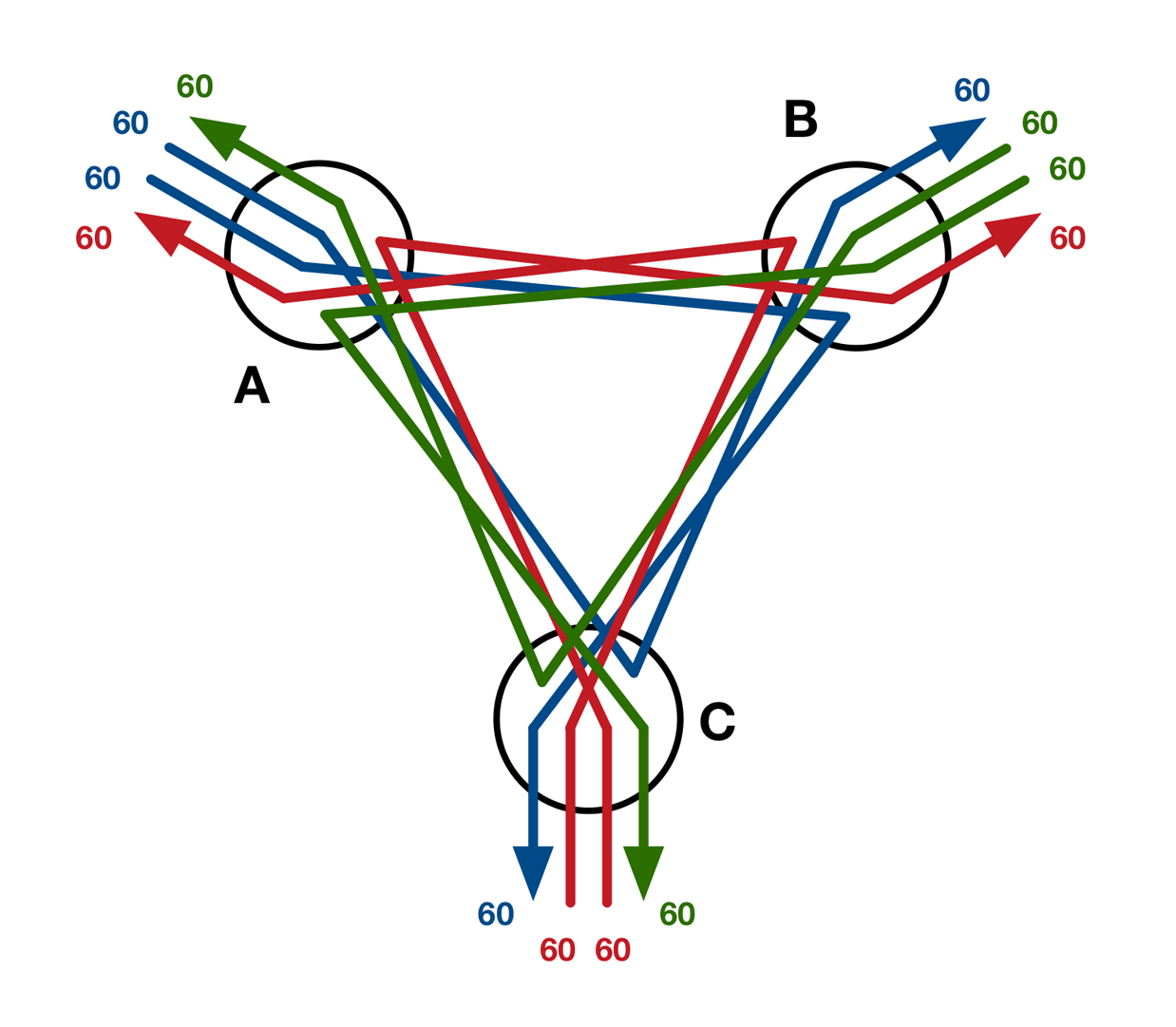
Figura 4-9. Flujos de red en el peor de los casos entre tres conmutadores apilados
Aunque se trata de un ejemplo patológico, demuestra claramente la idea de una relación de sobresuscripción dependiente de la carga. Es casi seguro que una pila de tres conmutadores del mundo real funcionaría mucho más cerca del mejor caso que del peor, y en cualquier caso, incluso una proporción de sobresuscripción de 4:1 sigue siendo una propuesta razonable para un clúster Hadoop.
Con sólo dos conmutadores en la pila, el tráfico en los enlaces de interconexión era siempre directo. Con tres conmutadores, el tráfico sigue siendo mayoritariamente directo, con la posibilidad de algún tráfico indirecto bajo carga elevada.
Cuando el anillo tiene cuatro conmutadores o más, el tráfico indirecto se vuelve completamente inevitable, incluso en condiciones perfectas. A medida que se añaden conmutadores a una pila, el tráfico indirecto empieza a dominar la carga de trabajo, por lo que la sobresuscripción resulta demasiado problemática. Las arquitecturas alternativas se vuelven más apropiadas.
Consideraciones sobre el cableado de redes apiladas
Los cables de apilamiento patentados que se utilizan para formar el anillo son muy cortos -normalmente de sólo un metro o así- y están diseñados para apilar conmutadores en un sentido literal, físico. Es posible colocar los conmutadores de apilamiento en bastidores adyacentes, pero en general es mejor evitarlo, ya que no todos los bastidores permiten el paso de cables entre ellos.
Una forma de sortear la restricción de longitud del cableado en anillo consiste en colocar toda la pila de conmutadores en un único bastidor y utilizar cables más largos entre los conmutadores y los servidores. Sin embargo, esto tiene el inconveniente de que todos los conmutadores se conectan a una única unidad de distribución de energía (PDU), por lo que están sujetos a un único punto de fallo. Si necesitas colocar bastidores en distintos pasillos por falta de espacio, el apilamiento no es para ti.
Aplicación
Con una arquitectura de conmutadores apilados, hay que considerar dos opciones de implementación: desplegar una subred por conmutador o desplegar una única subred en todo el anillo.
La implementación de una subred por conmutador es más adecuada cuando los servidores se conectan a un único conmutador. Esto mantiene el tráfico de difusión local en cada conmutador del anillo. En situaciones en las que los servidores se conectan a varios conmutadores de pila mediante MC-LAG, es más adecuado desplegar una única subred en todo el anillo.
En cualquiera de los dos casos, lo adecuado es una LAN física o una única VLAN por subred.
Redes de árboles gordos
Las redes como la de árbol gordo se construyen conectando varios conmutadores en una estructura jerárquica. Un conmutador mononúcleo se conecta a través de capas de conmutadores de agregación a conmutadores de acceso, que se conectan a servidores.
La arquitectura se conoce como árbol gordo porque los enlaces más cercanos al conmutador central tienen mayor ancho de banda y, por tanto, el árbol se hace más "gordo" a medida que te acercas a la raíz. La Figura 4-10 muestra un ejemplo de red de árbol gordo.
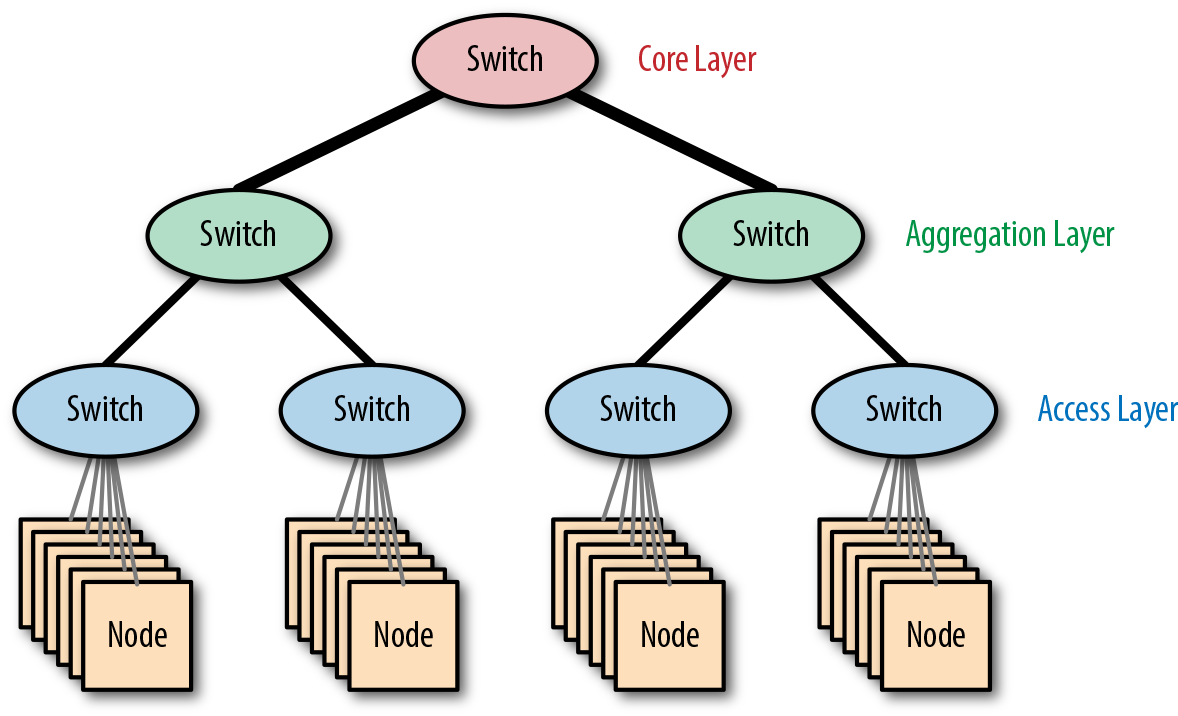
Figura 4-10. La arquitectura de red de árbol grande
Dado que muchos clusters pequeños empiezan utilizando un único conmutador, una red de árbol grande puede considerarse una vía de actualización natural cuando se piensa en ampliar la red. Basta con duplicar el diseño original de un único conmutador, añadir un conmutador central y conectarlo todo.
Escalabilidad
El rendimiento de una red de árbol grande puede determinarse observando el grado de sobresuscripción de la red. Considera el ejemplo de la Figura 4-11.
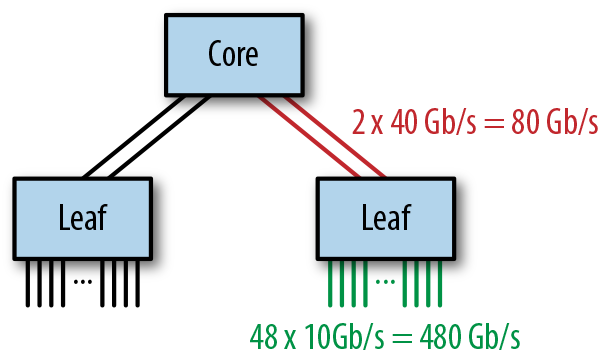
Figura 4-11. Un ejemplo de red de árboles gordos
Los conmutadores de acceso tienen cada uno 48 puertos de 10 GbE conectados a servidores y 2 puertos de 40 GbE conectados al conmutador central, lo que da una relación de sobresuscripción de 480:80, o 6:1, que es considerablemente superior a la recomendada para las cargas de trabajo de Hadoop. Esto puede mejorarse reduciendo el número de servidores por conmutador de acceso o aumentando el ancho de banda entre los conmutadores de acceso y el conmutador central mediante la agregación de enlaces.
Esta arquitectura se amplía añadiendo conmutadores de acceso: cada conmutador adicional aumenta en 48 el número total de puertos. Esto puede repetirse hasta que se alcance la capacidad de puertos del conmutador central, momento en el que sólo se puede conseguir una mayor escala utilizando un conmutador central más grande o una arquitectura diferente.
Resiliencia
Cuando se implementa sin conmutadores redundantes, la fiabilidad de esta arquitectura es limitada debido a los numerosos SPOF. La pérdida de un conmutador de acceso afectaría a una parte importante del clúster, y la pérdida del conmutador central sería catastrófica.
Eliminar los SPOF sustituyendo los conmutadores individuales por pares de conmutadores mejora enormemente la capacidad de recuperación. La Figura 4-12 muestra una red fat-tree construida con agregación de enlaces multichasis.
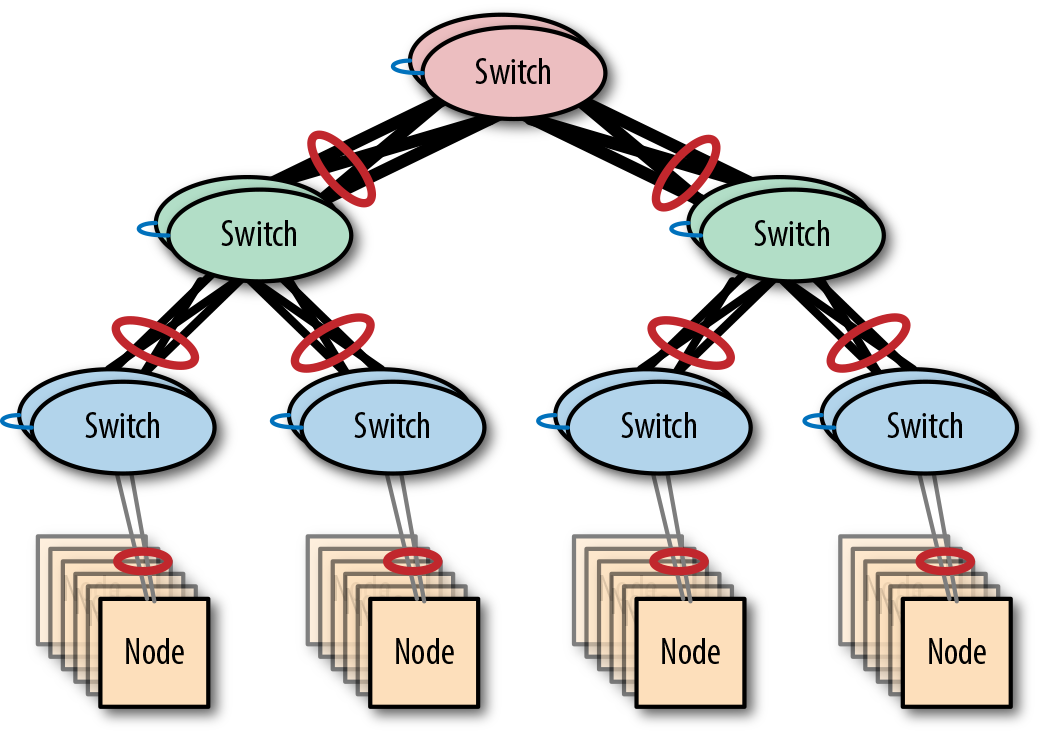
Figura 4-12. Una red resistente de árbol grande
Aplicación
Una red jerárquica puede construirse utilizando una única subred en todo el árbol o utilizando una subred por conmutador. La primera opción es la más fácil de implementar, pero significa que el tráfico de difusión atravesará enlaces más allá de la capa de acceso. La segunda opción es más escalable, pero su implementación es más compleja, ya que requiere que los administradores de red gestionen el enrutamiento, un proceso que puede ser propenso a errores.
Arquitecturas de clústeres grandes
Todas las arquitecturas comentadas hasta ahora han estado limitadas en cuanto a escala o escalabilidad: los conmutadores individuales se quedan rápidamente sin puertos, las redes apiladas están limitadas a unos pocos conmutadores por pila como máximo, y las redes de árbol gordo sólo pueden ampliarse mientras el conmutador central tenga suficientes puertos.
Esta sección trata de los diseños de red que pueden soportar clusters más grandes y/o más escalables.
Conmutadores modulares
En general, sólo hay dos formas de ampliar una red: ampliándola con más conmutadores o reduciéndola con más conmutadores. Tanto la arquitectura de red de árbol grueso como la de red apilada se amplían añadiendo conmutadores. Antes de los conmutadores modulares, ampliar un conmutador verticalmente significaba simplemente sustituirlo por una variante más grande con mayor capacidad de puertos, una opción disruptiva y costosa.
Los conmutadores modulares introdujeron la idea de un chasis ampliable que puede poblarse con varios módulos de conmutación. Como un conmutador modular puede funcionar cuando sólo está parcialmente poblado de módulos, se puede añadir capacidad de red instalando módulos adicionales, siempre que el chasis tenga espacio.
En muchos sentidos, un conmutador modular puede considerarse una versión ampliada de un conmutador único, por lo que puede utilizarse en diversas arquitecturas. Por ejemplo, un conmutador modular es muy adecuado para utilizarlo como conmutador central de un árbol grueso o como conmutador central en una arquitectura de conmutador único. Este último caso se conoce como arquitectura de final de fila, ya que el conmutador modular se despliega literalmente en el extremo físico de una fila de un centro de datos, conectado a los servidores de los muchos bastidores de la fila.
Los conmutadores modulares, como el Cisco 7000, se suelen implementar por parejas para garantizar la resistencia de la arquitectura en la que se utilizan.
Redes espina-hoja
Para conseguir una verdadera escalabilidad a nivel de clúster, es esencial una arquitectura de red que pueda crecer más allá de los límites de un único conmutador, incluso de un monstruoso monstruo modular.
Cuando examinamos la arquitectura de una red de árbol grueso, vimos que la escalabilidad estaba limitada en última instancia por la capacidad del conmutador central en la raíz del árbol. Mientras la sobresuscripción en los conmutadores hoja e intermedios se mantenga a un nivel razonable, podemos seguir escalando el árbol gordo añadiendo conmutadores adicionales hasta que al conmutador central no le quede capacidad.
Este límite puede aumentarse escalando el conmutador central a un modelo mayor (o añadiendo un módulo a un conmutador modular), pero la Figura 4-13 muestra un enfoque alternativo interesante, que consiste simplemente en añadir otro conmutador raíz.
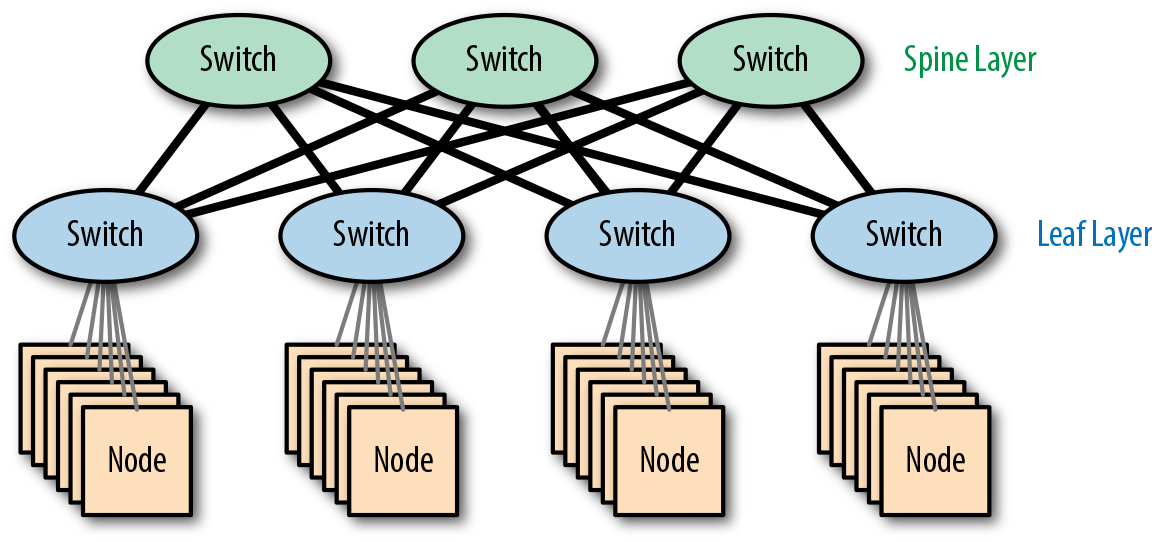
Figura 4-13. Una red espina-hoja
Como no hay un único conmutador raíz, no se trata de una red jerárquica. En términos de topología, el diseño se conoce como una malla parcial -parcialya que los conmutadores hoja sólo se conectan a los conmutadores núcleo y los conmutadores núcleo sólo se conectan a los conmutadores hoja-.
Los conmutadores de núcleo funcionan como la columna vertebral de la red y se denominan conmutadores de columna vertebral, lo que nos da el nombre de hoja de columna vertebral.
Escalabilidad
La ventaja más importante de la arquitectura columna-hoja es la escalabilidad lineal: si se necesita más capacidad, podemos hacer crecer la red añadiendo conmutadores columna y hoja, escalando hacia fuera en lugar de hacia arriba. Esto permite finalmente que la red escale horizontalmente, igual que el software de clúster que soporta.
Como cada conmutador espinal se conecta a cada conmutador hoja, el límite de escalabilidad viene determinado por el número de puertos disponibles en un único conmutador espinal. Si un conmutador espinal tiene 32 puertos, cada uno a 40 Gb/s, y cada conmutador hoja necesita 160 Gb/s para mantener un ratio de sobresuscripción razonable, podemos tener como máximo 8 conmutadores hoja.
Redes espina-hoja resistentes
A la hora de hacer redes resistentes, la técnica principal ha sido utilizar conmutadores redundantes y MC-LAG. Hasta ahora, esto era necesario para todos los conmutadores de una arquitectura, ya que cualquier conmutador sin un compañero redundante se convertiría en un SPOF.
Con la arquitectura spine-leaf, esto ya no es así. Por definición, una red espina-hoja ya tiene varios conmutadores espina, por lo que la capa espina ya es resistente por diseño. La capa de hoja puede hacerse resistente sustituyendo cada conmutador de hoja por un par de conmutadores, como se muestra en la Figura 4-14. Ambos conmutadores se conectan entonces a la red. Estos dos conmutadores se conectan a la capa troncal para los datos y entre sí para la gestión del estado.
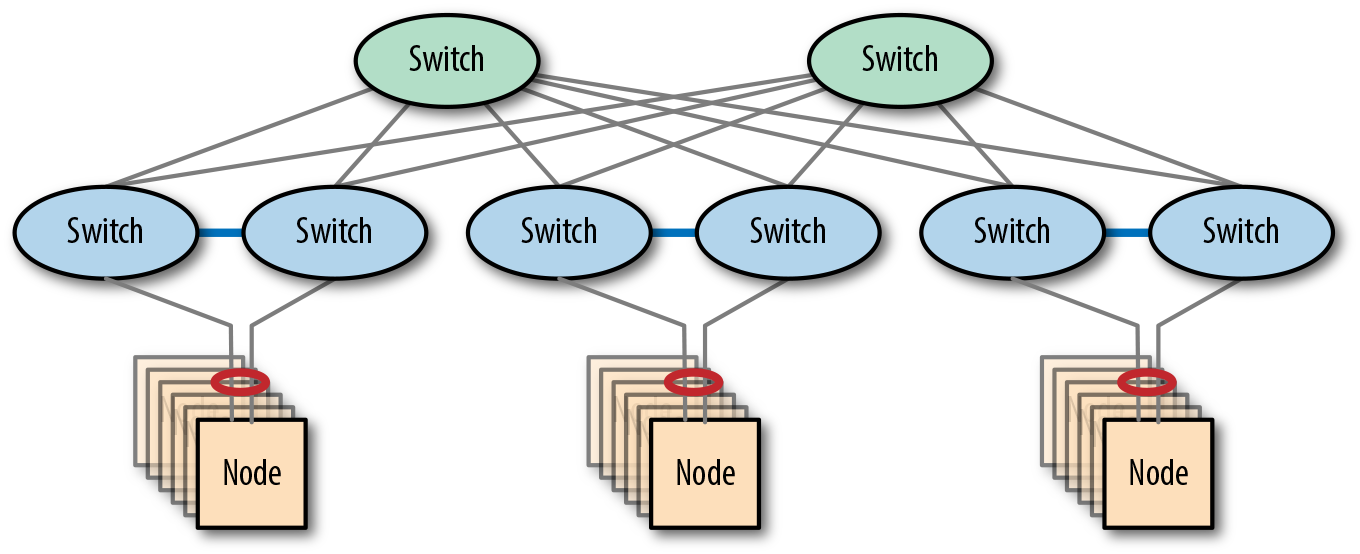
Figura 4-14. Una red espina-hoja resistente
Aplicación
Dado que una arquitectura de hoja en espiral contiene bucles, la opción de implementación de colocar todos los dispositivos en el mismo dominio de difusión ya no es válida. Las tramas de difusión simplemente fluirían alrededor de los bucles, creando una tormenta de difusión, al menos hasta que el Protocolo del Árbol de expansión (STP) desactivara algunos enlaces.
La opción de tener una subred (dominio de difusión) por conmutador hoja sigue existiendo, y es una solución escalable, ya que el tráfico de difusión se limitaría entonces a los conmutadores hoja. Sin embargo, esta opción de implementación requiere de nuevo que los administradores de red gestionen el enrutamiento, lo que puede ser propenso a errores.
Una opción de implementación alternativa interesante es desplegar una red en espina dorsal utilizando un tejido de red en lugar de utilizar el enrutamiento en la capa IP.
Integración en red
Un clúster es una inversión importante que requiere una extensa red, por lo que tiene sentido considerar la arquitectura de la red de un clúster de forma aislada. Sin embargo, una vez establecida la arquitectura de red del clúster, la siguiente tarea es definir cómo se conectará ese clúster con el mundo.
Existen varias posibilidades para integrar una agrupación en una red más amplia. Esta sección describe las opciones disponibles y esboza sus pros y sus contras.
Reutilizar una red existente
El primer enfoque -sólo realmente posible para clusters pequeños- consiste en añadir el cluster a una subred preexistente. Es el enfoque más sencillo, ya que requiere el menor cambio en la infraestructura existente. La Figura 4-15 muestra cómo, a nivel lógico, esta ruta de integración es trivial, ya que sólo estamos añadiendo nuevos servidores de clúster.
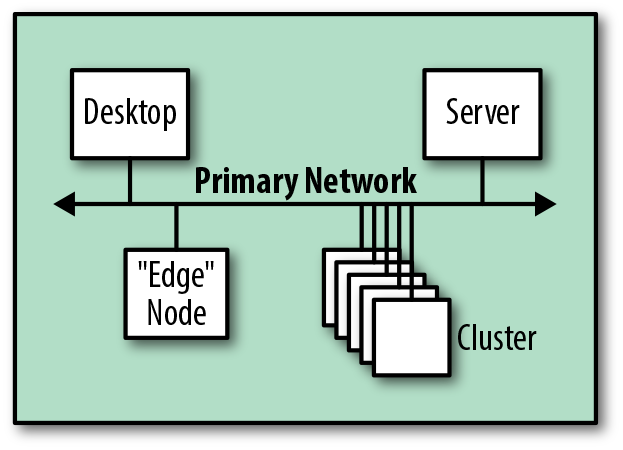
Figura 4-15. Vista lógica de una integración con una red existente
Desde un punto de vista físico, esto podría llevarse a cabo reutilizando los conmutadores existentes, pero a menos que todos los nodos estuvieran situados en el mismo conmutador, esto podría provocar fácilmente problemas de sobresuscripción. Muchas redes están diseñadas más para el acceso que para el rendimiento.
Un plan de implementación mejor es introducir conmutadores adicionales dedicados al clúster, como se muestra en la Figura 4-16. Esto es mejor en términos de aislamiento y rendimiento, ya que el tráfico interno del clúster puede permanecer en el conmutador en lugar de transitar por una red existente.
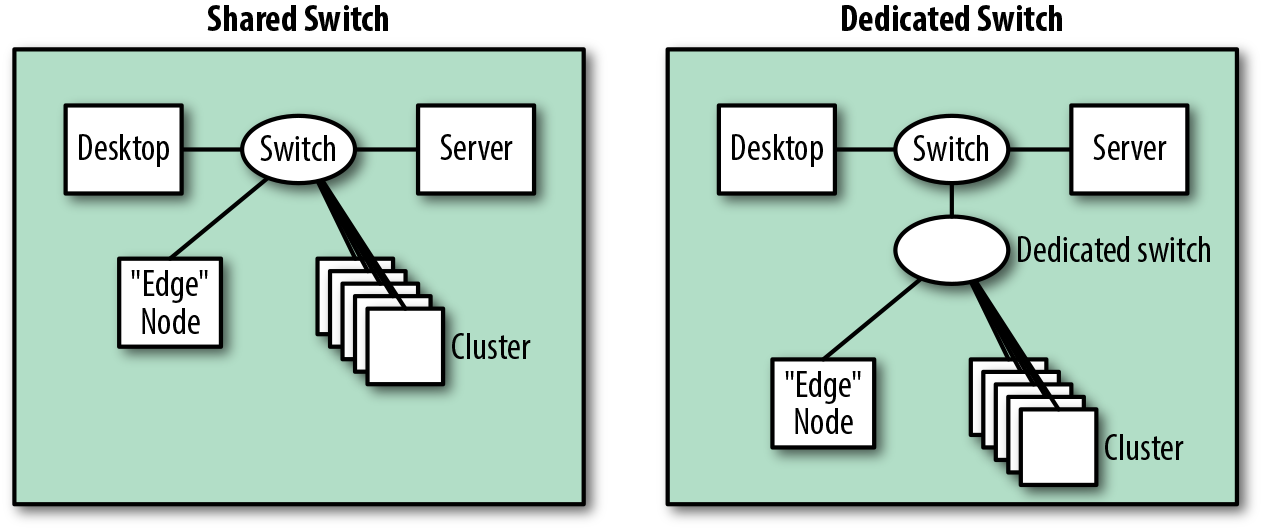
Figura 4-16. Vista física de posibles integraciones con una red existente
Crear una red adicional
El enfoque alternativo consiste en crear subredes adicionales para alojar el nuevo clúster. Esto requiere que se modifique la infraestructura de red existente, tanto en términos de conectividad física como de configuración. La Figura 4-17 muestra cómo, desde una perspectiva lógica, la arquitectura sigue siendo sencilla: añadimos la subred del clúster y nos conectamos a la red principal.
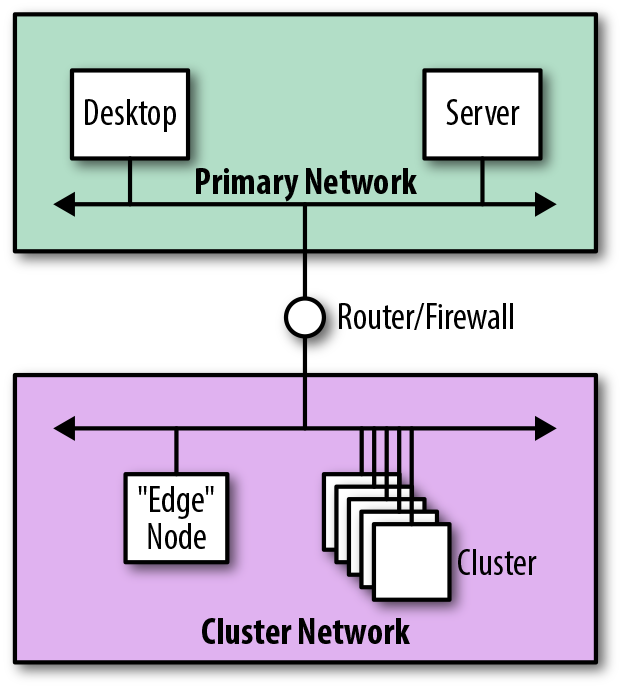
Figura 4-17. Vista lógica de la integración mediante una red adicional
Desde el punto de vista de la seguridad, este enfoque es preferible, ya que el aislamiento adicional mantiene el tráfico de difusión alejado de la red principal. Sustituyendo el router por un cortafuegos, podemos segregar completamente la red del clúster y controlar estrictamente qué servidores y servicios son visibles desde la red principal.
Redes conectadas por perímetros
Los nodos de perímetro suelen ser servidores de clúster que se colocan para proporcionar acceso a los servicios de clúster, ofreciendo acceso SSH, alojando interfaces de usuario web o proporcionando puntos finales JDBC a sistemas de middleware ascendentes. Forman el límite, o perímetro, de los servicios de software proporcionados por un clúster.
La Figura 4-18 muestra cómo, en lugar de conectar un clúster a través de un router o un cortafuegos, los nodos de perímetro podrían proporcionar conectividad de red externa al clúster.
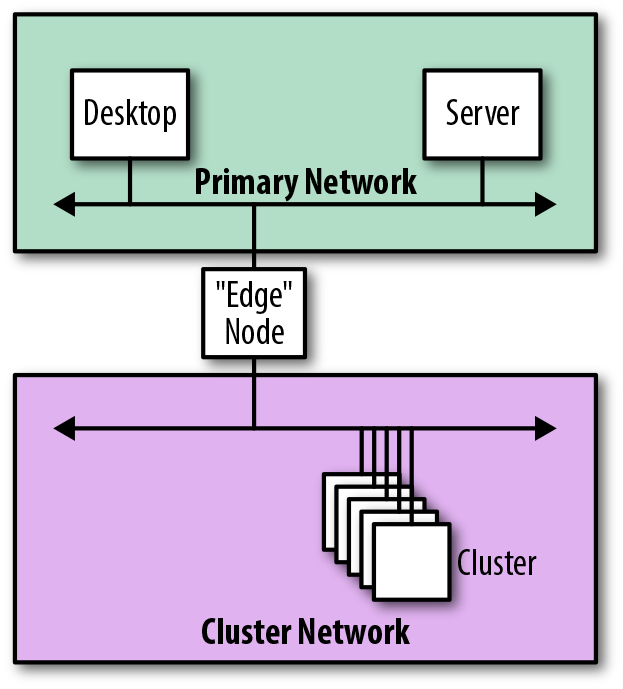
Figura 4-18. Vista lógica de la integración mediante un nodo de perímetro
Cuando se conectan de esta forma, los nodos de perímetro forman literalmente los bordes físicos del clúster, actuando como puerta de enlace a través de la cual se realiza toda la comunicación. El inconveniente de este enfoque es que los nodos de perímetro son multihomed, lo que, en general, no es recomendable.
Consideraciones sobre el diseño de la red
En esta sección se exponen recomendaciones y consideraciones sobre el diseño de la red basadas en arquitecturas de referencia, buenas prácticas conocidas y la experiencia de los autores. La intención es proporcionar algunas directrices de implementación que ayuden a garantizar una implantación satisfactoria.
Recomendaciones Capa 1
Las siguientes recomendaciones se refieren a aspectos de la Capa 1, conocida como capa física. Aquí es donde el caucho se encuentra con el camino, tendiendo un puente entre el mundo lógico del software y el mundo físico de la electrónica y los sistemas de transmisión.
- Utiliza interruptores dedicados
-
Aunque puede ser posible utilizar la infraestructura de red existente para un nuevo clúster, nosotros recomendamos la implementación de conmutadores y enlaces ascendentes dedicados para Hadoop siempre que sea posible. Esto tiene varias ventajas, como el aislamiento y la seguridad, la capacidad de crecimiento del clúster y mayores garantías de que el tráfico de Hadoop y Spark no saturará los enlaces de red existentes.
- Considera un clúster como un aparato
-
Esto está relacionado con el punto anterior, pero es útil pensar en un clúster como un todo, más que como una colección de servidores que se añaden a tu red.
Cuando las organizaciones adquieren un clúster como dispositivo, la instalación se convierte en una cuestión relativamente sencilla de proporcionar espacio, conectividad de red, refrigeración y alimentación; la conectividad interna no suele ser una preocupación. Diseñar y construir tu propio clúster significa que necesariamente tienes que preocuparte de los detalles internos, pero la mentalidad de dispositivo -pensar en el clúster como una sola cosa- sigue siendo apropiada.
- Gestionar la sobresuscripción
-
El rendimiento de cualquier red de clúster depende totalmente del nivel de sobresuscripción en los conmutadores. El software de clúster, como Hadoop y Spark, puede llevar una red al límite de su capacidad, por lo que la red debe diseñarse para minimizar la sobresuscripción. El software de clúster funciona mejor cuando la sobresuscripción se mantiene en torno a 3:1 o mejor.
- Considera cuidadosamente InfiniBand
-
Los clusters Hadoop pueden implementarse utilizando InfiniBand (IB) como tecnología de Capa 1, pero esto es poco habitual fuera de los dispositivos Hadoop.
En el momento de escribir esto, InfiniBand no es compatible de forma nativa con servicios como Hadoop y Spark. Por tanto, funciones como el acceso remoto directo a memoria (RDMA) quedan sin utilizar, lo que hace imprescindible el uso de IP sobre InfiniBand (IPoIB). Como consecuencia, el rendimiento de InfiniBand se reduce significativamente, haciendo que las mayores velocidades de InfiniBand sean menos relevantes.
InfiniBand también introduce una interfaz de red secundaria en los servidores de clúster, convirtiéndolos en multihomed. Como se comenta en "Recomendaciones para la Capa 3", esto debe evitarse. Por último, la relativa escasez de competencias InfiniBand en el mercado y el coste en comparación con Ethernet hacen que la tecnología sea más difícil de adoptar y mantener.
- Utiliza cables de alta velocidad
-
Los clusters se suelen cablear con cables de cobre. Existen varias normas, denominadas categorías, que especifican la longitud máxima del cable y la velocidad máxima a la que puede utilizarse.
Dado que el aumento de coste entre tipos de cable es insignificante en comparación con los servidores y conmutadores, tiene sentido elegir el cable de mayor categoría posible. En el momento de escribir esto, la recomendación es utilizar cable de Categoría 7a, que ofrece velocidades de hasta 40 Gb/s con una distancia máxima de 100 metros (para cables de núcleo sólido; 55 metros para trenzados).
Los cables de fibra óptica ofrecen un rendimiento superior en cuanto a ancho de banda y distancia en comparación con los de cobre, pero a un coste mayor. Pueden utilizarse para cablear servidores, pero se emplean más a menudo para los enlaces de mayor distancia que conectan conmutadores en distintos bastidores. En este momento, la recomendación es utilizar cableado óptico OM3 o superior, que permite velocidades de hasta 100 Gb/s.
- Utiliza redes de alta velocidad
-
Los días en que se conectaban servidores de clúster a 1 Gb/s han quedado atrás. Hoy en día, casi todos los clusters deben conectar los servidores utilizando 10 Gb/s o superior. Para los clústeres más grandes que utilizan varios conmutadores, 40 Gb/s debe considerarse la velocidad mínima para los enlaces que interconectan los conmutadores. Incluso con velocidades de 40 Gb/s, es probable que sea necesaria la agregación de enlaces para mantener un grado aceptable de sobresuscripción.
- Considera la colocación del hardware
-
Recomendamos montar los servidores en ubicaciones predecibles, como colocar siempre los nodos maestros en la parte superior del rack o montar los servidores en orden ascendente de nombre/IP. Esta estrategia puede ayudar a reducir la probabilidad de que se identifique erróneamente un servidor durante las actividades de mantenimiento del clúster. Mejor aún, utiliza etiquetas y mantén actualizada la documentación.
Asegúrate de que los bastidores están colocados cuando consideres redes apiladas, ya que los cables de apilamiento son cortos. Recuerda que, en este caso, puede ser necesario tender cables de red de servidor entre bastidores.
Asegúrate de que los bastidores no estén situados a más de 100 metros de distancia entre sí cuando despliegues el cableado óptico.
- No conectes los clusters a internet
-
Los casos de uso que requieren que un clúster sea direccionable directamente en la Internet pública son raros. Dado que a menudo contienen información valiosa y sensible, la mayoría de los clusters deben implementarse en redes internas seguras, lejos de miradas indiscretas. Una buena política de seguridad de la información dice que hay que minimizar la superficie de ataque de cualquier sistema, y los clusters como Hadoop no son una excepción.
Cuando sea absolutamente necesario, los clusters orientados a Internet deben implementarse con cortafuegos y protegerse con Kerberos, Seguridad de la Capa de Transporte (TLS) y encriptación.
Recomendaciones Capa 2
Las siguientes recomendaciones se refieren a aspectos de la Capa 2, conocida como capa de enlace de datos, que se encarga de enviar y recibir tramas entre dispositivos de una red local. Cada trama incluye las direcciones físicas de hardware del origen y el destino, junto con algunos otros campos.
- Evitar redes de capa 2 sobredimensionadas
-
Aunque las direcciones IP están totalmente determinadas por la configuración de la red, las direcciones MAC son efectivamente aleatorias (excepto por el prefijo del proveedor). Para determinar la dirección MAC asociada a una dirección IP, se utiliza el Protocolo de Resolución de Direcciones (ARP) , que realiza el descubrimiento de direcciones difundiendo una solicitud de dirección a todos los servidores del mismo dominio de difusión.
Utilizar difusiones para el descubrimiento de direcciones significa que las redes de Capa 2 tienen una limitación de escalabilidad. Una regla general práctica es que un único dominio de difusión no debe albergar más de 500 servidores aproximadamente.
- Minimizar el uso de VLAN
-
Las LAN virtuales se diseñaron originalmente para hacer menos costosa la desactivación de enlaces realizada por el Protocolo del Árbol de expansión, permitiendo que los conmutadores y enlaces transportaran simultáneamente varias LAN independientes, cada una de las cuales tiene un árbol de expansión único. La intención era reducir el impacto de la desactivación de enlaces permitiendo que un enlace físico se desactivara en una VLAN mientras seguía activo en otras.
En la práctica, las VLAN casi nunca se utilizan únicamente para limitar el impacto del STP; la naturaleza aislante de las VLAN suele ser mucho más útil para gestionar la visibilidad del servicio, aumentando la seguridad al restringir el alcance de la difusión.
Las VLAN no son necesarias para las redes de clúster: las LAN físicas son perfectamente suficientes, ya que en la mayoría de los casos un clúster dispone de conmutadores dedicados de todos modos. Si se implementan VLAN, su uso debe reducirse, como máximo, a una sola VLAN por clúster o a una sola VLAN por bastidor para los clústeres construidos con enrutamiento de Capa 3. El uso de varias VLAN por servidor es multihoming, lo que generalmente no se recomienda.
- Considera las tramas jumbo
-
Las redes pueden configurarse para enviar tramas más grandes (conocidas como tramas jumbo) aumentando la unidad máxima de transmisión (UTM) de 1.500 a 9.000 bytes. Esto aumenta la eficiencia de las transferencias grandes, ya que se necesitan muchas menos tramas para enviar los mismos datos. Las cargas de trabajo en clúster, como Hadoop y Spark, dependen en gran medida de las transferencias grandes, por lo que las eficiencias que ofrecen las tramas jumbo las convierten en una elección de diseño obvia cuando son compatibles.
En la práctica, las tramas jumbo pueden ser problemáticas porque tienen que ser compatibles con todos los conmutadores y servidores participantes (incluidos los servicios externos, como Active Directory). De lo contrario, la fragmentación puede causar problemas de fiabilidad.
- Considera la resistencia de la red
-
Como ya se ha dicho, una forma de hacer que una red sea resistente a los fallos es utilizar la Agregación de Enlaces Multichasis. Esto se basa en las capacidades de la agregación de enlaces (LAG), permitiendo que los servidores se conecten a un par de conmutadores al mismo tiempo, utilizando una única conexión lógica. De este modo, si uno de los enlaces o conmutadores fallara, la red seguiría funcionando.
Además de sus conexiones ascendentes, los conmutadores redundantes del par deben estar conectados directamente entre sí. Estos enlaces son propietarios (utilizan nombres e implementaciones específicos de cada proveedor), lo que significa que los conmutadores de distintos proveedores (incluso de distintos modelos del mismo proveedor) son incompatibles. Los enlaces propietarios varían en cuanto a si transportan el tráfico del clúster además de los datos de control necesarios del conmutador.
Las Implementaciones de clase empresarial casi siempre tendrán conmutadores gestionados capaces de utilizar LACP, por lo que tiene sentido utilizar esta capacidad siempre que sea posible. LACP negocia automáticamente los ajustes de agregación entre el servidor y un conmutador, por lo que es el enfoque recomendado para la mayoría de las Implementaciones.
Recomendaciones Capa 3
Las siguientes recomendaciones se refieren a aspectos de la Capa 3, conocida como capa de red. Esta capa interconecta varias redes de Capa 2 añadiendo capacidades de direccionamiento lógico y enrutamiento.
- Utiliza subredes dedicadas
-
Recomendamos aislar el tráfico de red al menos en una subred dedicada (y, por tanto, en un dominio de difusión) por clúster. Esto es útil para gestionar la propagación del tráfico de difusión y también puede ayudar a la seguridad del clúster (mediante la segmentación de la red y el uso de cortafuegos). Un rango de subred de tamaño /22 suele ser suficiente para este fin, ya que proporciona 1.024 direcciones; la mayoría de los clusters son más pequeños que esto.
Para clusters más grandes que no utilicen conmutación basada en tejido, una subred dedicada por rack permitirá a los conmutadores enrutar el tráfico en Capa 3 en lugar de limitarse a conmutar tramas. Esto significa que los conmutadores del clúster pueden interconectarse con múltiples enlaces sin riesgo de problemas causados por el STP. Un rango de subred de tamaño /26 es suficiente, ya que proporciona 64 direcciones por rack; la mayoría de los racks tendrán menos servidores que esto.
A cada clúster se le debe asignar una subred única dentro de tu asignación global de red. Esto garantiza que todos los pares de servidores puedan comunicarse, en caso de que haya que copiar datos entre clusters.
- Asignar direcciones IP estáticamente
-
Recomendamos encarecidamente asignar direcciones IP de forma estática a los servidores del clúster durante la fase de creación y configuración del SO, en lugar de utilizar DHCP de forma dinámica en cada arranque. La mayoría de los servicios de clúster esperan que las direcciones IP permanezcan estáticas a lo largo del tiempo. Además, servicios como Spark y Hadoop están escritos en Java, donde el comportamiento por defecto es almacenar en caché las entradas DNS para siempre cuando se instala un gestor de seguridad.
Si se utiliza DHCP, asegúrate de que la asignación de direcciones IP es estable a lo largo del tiempo utilizando un mapeo fijo de direcciones MAC a direcciones IP: de este modo, siempre que se inicie el servidor, recibirá la misma dirección IP, haciendo que la dirección sea efectivamente estática.
- Utilizar rangos de direcciones IP privadas
-
En la mayoría de los casos, las redes internas de una organización deben configurarse para utilizar direcciones IP de los rangos de direcciones IP privadas. Estos rangos están especialmente designados para ser utilizados por las redes internas: los conmutadores de Internet descartarán cualquier paquete dirigido a direcciones privadas o procedente de ellas.
Los múltiples rangos de IP privadas disponibles pueden dividirse en subredes. La Tabla 4-2 muestra los rangos.
Tabla 4-2. Rangos de direcciones IP privadas Rango de direcciones IP Número de direcciones IP Descripción 10.0.0.0–10.255.255.255
16,777,216
Red única de Clase A
172.16.0.0–172.31.255.255
1,048,576
16 redes contiguas de Clase B
192.168.0.0–192.168.255.255
65,536
256 redes contiguas de Clase C
Para clusters como Hadoop, recomendamos encarecidamente el uso de una red privada. Sin embargo, al implementar un clúster, asegúrate de que un rango de red privada sólo se utiliza una vez dentro de una organización: dos clústeres que coincidan en cuanto a direcciones IP no podrán comunicarse.
- Prefiere DNS a /etc/hosts
-
Casi siempre se accede a los servidores de clúster mediante nombres de host en lugar de direcciones IP. Además de ser más fáciles de recordar, los nombres de host son necesarios específicamente cuando se utilizan tecnologías de seguridad como TLS y Kerberos. La resolución de un nombre de host en una dirección IP se realiza a través del Sistema de Nombres de Dominio (DNS) o del archivo de configuración local /etc/hosts.
El archivo de configuración local (que permite definir entradas de forma estática) tiene algunas ventajas sobre el DNS:
- Precedencia
Las entradas locales tienen prioridad sobre las DNS, lo que permite a los administradores anular entradas específicas.
- Disponibilidad
Como servicio de red, el DNS está sujeto a cortes de servicio y de red, pero /etc/hosts siempre está disponible.
- Rendimiento
Las búsquedas DNS requieren como mínimo un viaje de ida y vuelta por la red, pero las búsquedas a través del archivo local son instantáneas.
Incluso con estas ventajas, seguimos recomendando encarecidamente el uso de DNS. Los cambios realizados en DNS se hacen una vez y están disponibles inmediatamente. Como /etc/hosts es un archivo local que existe en todos los dispositivos, cualquier cambio debe hacerse en todas las copias. Como mínimo, esto requerirá la automatización de la implementación para garantizar la corrección, pero si el clúster utiliza Kerberos, los cambios tendrán que hacerse incluso en los clientes. En ese punto, el DNS se convierte en una opción mucho mejor.
Los problemas de disponibilidad y rendimiento de las búsquedas DNS pueden mitigarse utilizando servicios como el Name Service Caching Daemon (NSCD).
Por último, independientemente de cualquier otra consideración, todas las agrupaciones interactuarán con sistemas externos. Por tanto, el DNS es esencial, tanto para el tráfico entrante como para el saliente.
- Proporcionar entradas DNS directas e inversas
-
Además de utilizar DNS para las búsquedas hacia delante que transforman un nombre de host en una dirección IP, también se necesitan entradas DNS inversas que permitan realizar búsquedas para transformar una dirección IP en un nombre de host.
En concreto, las entradas DNS inversas son esenciales para Kerberos, que las utiliza para verificar la identidad del servidor al que se conecta un cliente.
- Nunca resuelvas un nombre de host a 127.0.0.1
-
Es esencial asegurarse de que cada servidor del clúster resuelve su propio nombre de host a una dirección IP enrutable y nunca a la dirección IP localhost 127.0.0.1 -un error de configuración habitual del archivo local /etc/hosts-.
Esto es un problema porque muchos servicios de cluster pasan su dirección IP a sistemas remotos como parte de las interacciones RPC normales. Si se pasa la dirección localhost, el sistema remoto intentará después conectarse a sí mismo de forma incorrecta.
- Evitar IPv6
-
Hoy en día se utilizan dos tipos de direcciones IP: IPv4 e IPv6. IPv4 se diseñó en los años 70, con direcciones que ocupaban 4 bytes. En aquella época, se consideraba que 4.294.967.296 direcciones eran suficientes para el futuro previsible, pero el rápido crecimiento de Internet a lo largo de la década de 1990 llevó al desarrollo de IPv6, que aumentó el tamaño de las direcciones a 16 bytes.
La adopción de IPv6 sigue siendo baja: un informe de 2014 indica que sólo el 3% de los usuarios de Google utilizan el sitio a través de IPv6. Esto se debe en parte a la cantidad de cambios infraestructurales necesarios y al hecho de que las soluciones alternativas, como la Traducción de Direcciones de Red (NAT) y los proxies, funcionan suficientemente bien en muchos casos.
En el momento de escribir esto, los autores aún no han visto ninguna red de cliente -cluster o de otro tipo- que ejecute IPv6. Los rangos de la red privada proporcionan más de 16 millones de direcciones, por lo que IPv6 resuelve un problema que no existe en el espacio empresarial.
Si el IPv6 se adopta más ampliamente en la Internet de los consumidores, puede haber un impulso para estandarizar las redes empresariales para que utilicen la misma pila. Cuando eso ocurra, las plataformas de datos tendrán más en cuenta el IPv6 y se probarán más regularmente con él. Por ahora, tiene más sentido evitar por completo el IPv6.
- Evita el multihoming
-
El multihoming es la práctica de conectar un servidor a varias redes, generalmente con la intención de que algunos o todos los servicios de red sean accesibles desde varias subredes.
Cuando el multihoming se implementa utilizando un enfoque de nombre de host por interfaz, se puede utilizar un único servidor DNS para almacenar las entradas de múltiples nombres de host en un único lugar. Sin embargo, este enfoque no funciona bien con Hadoop cuando se asegura mediante Kerberos, ya que los servicios sólo pueden configurarse para utilizar un único nombre principal de servicio (SPN), y un SPN incluye el nombre de host completo de un servicio.
Cuando se implementa el multihoming utilizando el enfoque de nombre de host por servidor, ya no basta con un único servidor DNS. La dirección IP que necesita un cliente depende ahora de la red en la que se encuentre. Resolver este problema añade una complejidad significativa a la configuración de la red, que suele implicar una combinación tanto de DNS como de /etc/hosts. Este enfoque también añade complejidad cuando se trata de la seguridad Kerberos, ya que es esencial que las búsquedas DNS directas e inversas coincidan exactamente en todos los escenarios de acceso.
El multihoming se ve con más frecuencia en los nodos de perímetro, como se describe en " Redes conectadas a perímetros", donde los servicios de perímetro escuchan en múltiples interfaces las peticiones entrantes. Los nodos de clúster multihoming deben evitarse siempre que sea posible, por las siguientes razones:
-
En el momento de escribir esto, no todos los servicios de clúster admiten el multihoming.
-
El multihoming no está muy implementado en la comunidad de usuarios, por lo que los problemas no se detectan tan rápidamente.
-
Los desarrolladores de código abierto no suelen desarrollar y probar configuraciones multihomed.
-
Resumen
En este capítulo hemos analizado cómo los servicios de clúster como Spark y HDFS utilizan las redes, cómo exigen los más altos niveles de rendimiento y disponibilidad y, en última instancia, cómo esos requisitos impulsan la arquitectura de red y los patrones de integración necesarios.
Equipados con este conocimiento, los arquitectos de redes y sistemas deberían estar en una buena posición para garantizar que el diseño de la red es lo suficientemente robusto como para soportar un clúster en la actualidad, y lo suficientemente flexible como para seguir haciéndolo a medida que un clúster crece.
Get Arquitectura de plataformas de datos modernas now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

