Capítulo 4. Un marco de migración
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
A menos que estés en una startup, es raro que construyas una plataforma de datos desde cero. En lugar de eso, montarás una nueva plataforma de datos migrando cosas a ella desde sistemas heredados. En este capítulo, vamos a examinar el proceso de migración-todas las cosas que debes hacer al emprender el viaje hacia una nueva plataforma de datos. Primero presentaremos un modelo conceptual y un posible marco que deberías seguir al modernizar la plataforma de datos. A continuación, repasaremos cómo una organización puede calcular el coste global de la solución. Discutiremos cómo garantizar la seguridad y la gobernanza de los datos, incluso mientras se lleva a cabo la migración. Por último, hablaremos de la migración de esquemas, datos y conductos. También conocerás las opciones para la capacidad regional, las redes y las limitaciones en la transferencia de datos.
Modernizar los flujos de trabajo de datos
Antes de empezar a crear un plan de migración, debes tener una visión global de por qué lo haces y hacia qué migras.
Visión holística
La transformación de la modernización de los datos debe considerarse de forma holística. Mirándolo a vista de pájaro, podemos identificar tres pilares principales:
- Resultados empresariales
-
Céntrate en los flujos de trabajo que estás modernizando e identifica los resultados empresariales que impulsan esos flujos de trabajo. Esto es fundamental para identificar dónde están las lagunas y dónde las oportunidades. Antes de tomar cualquier decisión tecnológica, limita la migración a los casos de uso que se alineen con los objetivos empresariales identificados por la dirección (normalmente en un horizonte temporal de dos a tres años).
- Partes interesadas
-
Identifica a las personas o funciones (puede que algunos de estos equipos aún no existan) que potencialmente obtendrán acceso a los datos. Tu objetivo con la modernización de datos es democratizar el acceso a los datos. Por lo tanto, estos equipos tendrán que adquirir conocimientos sobre los datos y dominar las herramientas (SQL, Python, cuadros de mando) que las tecnologías de modernización final esperan que utilicen.
- Tecnología
-
Tendrás que definir, implantar y desplegar la arquitectura de datos, el modelado, el almacenamiento, la seguridad, la integración, la operatividad, la documentación, los datos de referencia, la calidad y la gobernanza en consonancia con la estrategia empresarial y las capacidades del equipo.
Asegúrate de que no estás tratando la migración como un proyecto puramente informático o de ciencia de datos, sino como uno en el que el aspecto tecnológico es sólo un subconjunto de un cambio organizativo mayor.
Moderniza los flujos de trabajo
Cuando piensas en un programa de modernización, tu mente gravita naturalmente hacia el dolor que estás experimentando con las herramientas que tienes. Decides que quieres actualizar tu base de datos y hacerla globalmente consistente y escalable, así que la modernizas a Spanner o CockroachDB. Decides que quieres actualizar tu motor de streaming y hacerlo más resistente y fácil de ejecutar, así que eliges Flink o Dataflow. Decides que ya has terminado de ajustar clusters y consultas en tu DWH, así que lo modernizas a BigQuery o Snowflake.
Todos estos son grandes movimientos. Definitivamente, siempre que puedas, deberías cambiar a herramientas más fáciles de usar, más fáciles de ejecutar, mucho más escalables y mucho más resistentes. Sin embargo, si sólo realizas cambios de herramientas similares, acabarás obteniendo mejoras incrementales. No conseguirás un cambio transformador con esas actualizaciones.
Para evitar esta trampa, cuando inicies tu viaje de modernización de datos, oblígate a pensar en flujos de trabajo, no en tecnologías. ¿Qué significa modernizar un flujo de trabajo de datos? Piensa en la tarea general que quiere hacer el usuario final. Quizá quieran identificar clientes de alto valor. Tal vez quiera realizar una campaña de marketing. Tal vez quieran identificar fraudes. Ahora, piensa en este flujo de trabajo en su conjunto y en cómo implementarlo de la forma más barata y sencilla posible.
A continuación, aborda el flujo de trabajo desde los primeros principios. La forma de identificar a los clientes de alto valor es calcular las compras totales de cada usuario a partir de un registro histórico de transacciones. Averigua cómo realizar ese flujo de trabajo con tu moderno conjunto de herramientas. Al hacerlo, apóyate mucho en la automatización:
- Ingesta automatizada de datos
-
No escribas canalizaciones ELT a medida. Utiliza herramientas ELT listas para usar, como Datastream o Fivetran, para aterrizar los datos en un DWH. Es mucho más fácil transformar sobre la marcha, y capturar transformaciones comunes en vistas materializadas, que escribir canalizaciones ETL para cada posible tarea descendente. Además, muchos sistemas SaaS exportan automáticamente a S3, Snowflake, BigQuery, etc.
- Streaming por defecto
-
Aterriza tus datos en un sistema que combine almacenamiento por lotes y streaming para que todas las consultas SQL reflejen los datos más recientes (sujetos a cierta latencia). Lo mismo ocurre con cualquier análisis: busca herramientas de procesamiento de datos que gestionen tanto la transmisión como el procesamiento por lotes utilizando el mismo marco. En nuestro ejemplo, el cálculo del valor de vida puede ser una consulta SQL. Para reutilizarla, conviértela en una vista materializada. De este modo, todos los cálculos son automáticos y los datos están siempre actualizados.
- Escalado automático
-
Cualquier sistema que espere que especifiques previamente el número de máquinas, el tamaño de los almacenes, etc., es un sistema que te obligará a centrarte en el sistema y no en el trabajo a realizar. Quieres que el escalado sea automático, para que puedas centrarte en el flujo de trabajo y no en la herramienta.
- Reescritura de consultas, etapas fusionadas, etc.
-
Quieres poder centrarte en el trabajo a realizar y descomponerlo en pasos comprensibles. No quieres tener que afinar consultas, reescribir consultas, fusionar transformaciones, etc. Deja que los modernos optimizadores integrados en la pila de datos se ocupen de estas cosas.
- Evaluación
-
No quieres escribir tuberías de procesamiento de datos a medida para evaluar el rendimiento del modelo ML. Simplemente quieres poder especificar frecuencias de muestreo y consultas de evaluación, y recibir notificaciones sobre la deriva de características, la deriva de datos y la deriva de modelos. Todas estas capacidades deben estar integradas en los puntos finales de implementación.
- Reentrenamiento
-
Si te encuentras con una deriva del modelo, debes volver a entrenar el modelo 9 de cada 10 veces. Esto también debería automatizarse. Los procesos modernos de ML te proporcionarán un gancho al que puedes llamar y que puedes vincular directamente a tu proceso de evaluación automatizada, para que también puedas automatizar el reentrenamiento.
- Formación continua
-
La deriva del modelo no es la única razón por la que puedes necesitar un reentrenamiento. Querrás volver a entrenar cuando tengas muchos más datos. Quizá cuando lleguen nuevos datos a un cubo de almacenamiento. O cuando tengas una comprobación de código. De nuevo, esto puede automatizarse.
Una vez que te planteas la necesidad de un flujo de trabajo de datos totalmente automatizado, te enfrentas a una configuración bastante planificada que consiste en un conector, un DWH y tuberías ML. Todos ellos pueden funcionar sin servidor, por lo que básicamente sólo te ocuparás de la configuración, no de la gestión del clúster.
Por supuesto, escribirás algunos fragmentos de código específicos:
-
Preparación de datos en SQL
-
Modelos ML en un marco como TensorFlow, PyTorch o langchain
-
Consulta de evaluación para la evaluación continua
El hecho de que podamos reducirnos a una configuración tan sencilla para cada flujo de trabajo explica por qué es tan importante una plataforma integrada de datos e IA.
Transforma el propio flujo de trabajo
Puedes hacer que el propio flujo de trabajo sea mucho más eficaz si lo automatizas utilizando la pila de datos moderna. Pero antes de hacerlo, debes hacerte una pregunta clave: "¿Es necesario que este flujo de trabajo sea precomputado por un ingeniero de datos?".
Porque eso es lo que estás haciendo siempre que construyes un conducto de datos: estás precomputando. Es una optimización, nada más.
En muchos casos, si puedes hacer que el flujo de trabajo sea algo autosuficiente y ad hoc, no tendrás que construirlo con recursos de ingeniería de datos. Como gran parte está automatizada, puedes proporcionar la capacidad de ejecutar cualquier agregación (no sólo el valor de vida útil) en el registro histórico completo de transacciones. Traslada el cálculo del valor de vida a una capa semántica declarativa a la que tus usuarios puedan añadir sus propios cálculos. Esto es lo que te permitirá hacer una herramienta como Looker, por ejemplo. Una vez hecho esto, obtendrás las ventajas de unos KPI coherentes en toda la organización y unos usuarios capacitados para crear una biblioteca de medidas comunes. La capacidad de crear nuevas métricas recae ahora en los equipos empresariales, que es donde esta capacidad debe estar en primer lugar.
Un marco de migración en cuatro pasos
Puedes aplicar un enfoque estandarizado de a muchas de las situaciones que puedas encontrarte en el proceso de construcción de tu plataforma de datos. Este enfoque es, en su mayor parte, independiente del tamaño y la profundidad de la plataforma de datos: lo hemos seguido tanto para modernizar el DWH de una pequeña empresa como para desarrollar una arquitectura de datos totalmente nueva para una empresa multinacional.
Este enfoque se basa en los cuatro pasos principales que se muestran en la Figura 4-1:
- 1. Prepárate y descubre.
-
Todas las partes interesadas deben realizar un análisis preliminar para identificar la lista de cargas de trabajo que hay que migrar y los puntos conflictivos actuales (por ejemplo, incapacidad para escalar, motor de procesos que no se puede actualizar, dependencias no deseadas, etc.).
- 2. Evalúa y planifica.
-
Evalúa la información recopilada en la etapa anterior, define las medidas clave del éxito y planifica la migración de cada componente.
- 3. Ejecuta.
-
Para cada caso de uso identificado, decide si desmantelarlo, migrarlo por completo (datos, esquema, aplicaciones descendentes y ascendentes), o descargarlo (migrando las aplicaciones descendentes a una fuente diferente). Después, prueba y valida cualquier migración realizada.
- 4. Optimiza.
-
Una vez iniciado el proceso, puede ampliarse y mejorarse mediante iteraciones continuas. Un primer paso de modernización podría centrarse sólo en las capacidades básicas.
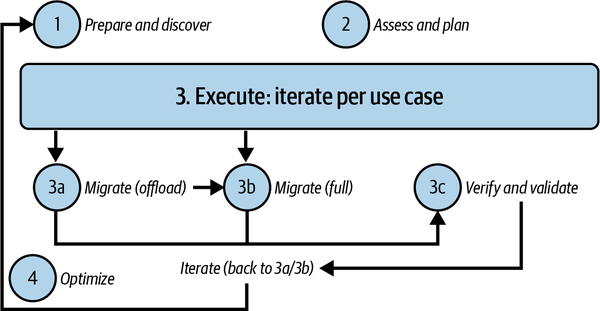
Figura 4-1. Marco de migración en cuatro pasos
Repasemos cada uno de estos pasos.
Prepárate y descubre
El primer paso es preparar y descubrir. Esto implica definir el alcance de la migración y recopilar toda la información relacionada con las cargas de trabajo/casos de uso que se migrarán. Incluye analizar una amplia gama de aportaciones de múltiples partes interesadas de toda la empresa, como el negocio, las finanzas y TI. Pide a esas partes interesadas que
-
Enumera todos los casos de uso y cargas de trabajo, con sus prioridades asociadas, que sean relevantes para la migración. Asegúrate de que incluyen los requisitos de cumplimiento, la sensibilidad a la latencia y otra información relevante.
-
Explícales las ventajas que pueden obtener con el nuevo sistema (por ejemplo, el rendimiento de las consultas, la cantidad de datos que pueden manejar, las capacidades de streaming, etc.).
-
Sugiere soluciones disponibles en el mercado que puedan satisfacer las necesidades de la empresa.
-
Realiza un análisis inicial del coste total de propiedad para estimar el valor de la migración.
-
Identificar las necesidades en materia de formación y contratación para crear una mano de obra capacitada.
Puedes utilizar cuestionarios para recoger estas percepciones de los propietarios de las aplicaciones, los propietarios de los datos y los usuarios finales seleccionados.
Evaluar y planificar
El segundo paso consiste en evaluar los datos recogidos y planificar todas las actividades que deben realizarse para lograr los objetivos identificados. Esto implica
- 1. Evaluación del estado actual
-
Analiza la huella tecnológica actual de cada aplicación, flujo de trabajo o herramienta, recopilando y analizando las configuraciones del servidor, los registros, la actividad de los trabajos, el mapeo del flujo de datos, la volumetría, las consultas y los clusters. A medida que aumenta el tamaño de la huella heredada, esta actividad puede llevar mucho tiempo y ser propensa a errores. Así que busca herramientas (como SnowConvert, CompilerWorks, AWS Schema Conversion Tool, Azure Database Migration Service, Datametica Raven, etc.) que puedan automatizar todo el proceso, desde la recopilación de datos hasta el análisis y la recomendación. Estas herramientas pueden proporcionar desglose de la carga de trabajo, mapeo de dependencias, análisis de complejidad, utilización de recursos, análisis de capacidad, análisis de SLA, linaje de datos de extremo a extremo y diversas recomendaciones de optimización.
- 2. Categorización de la carga de trabajo
-
Utiliza la información recopilada a través del cuestionario utilizado en el paso "Preparar y descubrir", junto con los conocimientos profundos de la fase de evaluación, para clasificar y seleccionar el enfoque de todas las cargas de trabajo identificadas en una de las siguientes opciones:
- Retira
-
La carga de trabajo permanecerá inicialmente en Prem y con el tiempo se desmantelará.
- Conserva
-
La carga de trabajo permanecerá en prem debido a limitaciones técnicas (por ejemplo, se ejecuta en hardware dedicado) o por razones empresariales. Esto puede ser temporal hasta que la carga de trabajo pueda ser refactorizada, o posiblemente trasladada a una instalación de colocación donde los centros de datos deban cerrarse y los servicios no puedan trasladarse.
- Rehost
-
La carga de trabajo se migrará al entorno de la nube, aprovechando sus capacidades de infraestructura como servicio (IaaS). Esto se conoce a menudo como "lift and shift".
- Replataforma
-
La carga de trabajo (o parte de ella) se modificará parcialmente para mejorar su rendimiento o reducir su coste y luego se trasladará a la IaaS; esto se conoce a menudo como "trasladar y mejorar". Optimizar después de hacer una experiencia de traslado y cambio, empezando generalmente por la contenedorización.
- Refactoriza
-
La carga de trabajo (o parte de ella) se migrará a una o varias soluciones de plataforma como servicio (PaaS) totalmente gestionada en la nube (por ejemplo, BigQuery, Redshift, Synapse).
- Sustituye
-
La carga de trabajo se sustituirá completamente por una solución de terceros "off-the-shelf" o SaaS.
- Reconstruye
-
La carga de trabajo se rearquitecta por completo utilizando soluciones totalmente gestionadas en la nube y se reimplementa desde cero. Aquí es donde se replantea la aplicación y se planifica cómo aprovechar lo mejor de los servicios nativos de la nube.
- 3. Clusterización de la carga de trabajo
-
Cluster las cargas de trabajo que no se retirarán/reconstruirán en una serie de grupos basados en su valor empresarial relativo y en el esfuerzo necesario para migrarlas. Esto te ayudará a identificar una priorización que puedes seguir durante la migración. Por ejemplo:
-
Grupo 1: alto valor empresarial, poco esfuerzo para migrar (Prioridad 0-ganancias rápidas)
-
Grupo 2: gran valor empresarial, gran esfuerzo de migración (Prioridad 1)
-
Grupo 3: poco valor empresarial, poco esfuerzo para migrar (Prioridad 2)
-
Grupo 4: escaso valor empresarial, gran esfuerzo de migración (Prioridad 3)
-
En la Figura 4-2 puedes ver un ejemplo de clusterización en el que las cargas de trabajo se han dividido en grupos según los criterios de priorización descritos. En cada grupo, las cargas de trabajo pueden tener diferentes enfoques de migración.
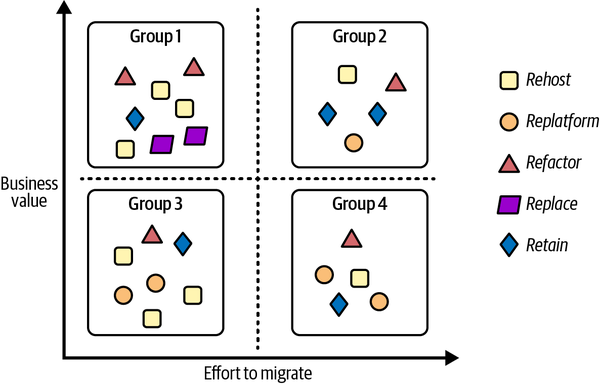
Figura 4-2. Ejemplo de categorización y agrupación de cargas de trabajo
A lo largo de este proceso, te recomendamos que sigas las siguientes prácticas:
- Haz que el proceso sea medible.
-
Asegúrate de que las partes interesadas están de acuerdo y pueden evaluar los resultados de la modernización utilizando algunos KPI empresariales.
- Empieza con un producto mínimo viable (MVP) o una prueba de concepto (PoC).
-
Divide los trabajos grandes en tareas más pequeñas y asegúrate de que existen plantillas estándar para cualquier trabajo que vayas a emprender. Si no es así, realiza una PoC y utilízala como plantilla en el futuro. Estate atento a las ganancias rápidas (cargas de trabajo de Prioridad 0) que puedan aprovecharse no sólo como ejemplo para las demás transformaciones, sino también como demostración a la dirección del impacto que podría introducir dicha modernización.
- Calcula el tiempo total necesario para completar todas las actividades.
-
Crea un plan de proyecto holístico (trabajando con proveedores o consultores si es necesario) para definir el tiempo, el coste y el personal necesarios para la transformación de la carga de trabajo.
- Sobrecomunícate en los hitos.
-
Asegúrate de que las partes interesadas comprenden el plan, cuánto tiempo llevará y cuáles son los componentes clave. Asegúrate de aportar valor e infundir confianza a lo largo del camino con proyectos en la nube finalizados que la gente de la organización pueda empezar a utilizar realmente. Intenta identificar los hitos y envía una comunicación ad hoc recapitulando los detalles del trabajo realizado.
Ahora que conoces bien las tareas que debes realizar para preparar tu próxima migración, veamos cómo debes hacerlo.
Ejecuta
Para cada carga de trabajo, ahora tienes un plan. En concreto, sabes qué se va a migrar (toda la carga de trabajo o sólo una parte), dónde se va a migrar (IaaS, PaaS o SaaS), cómo vas a migrar (rehost, replatform, rebuild, etc.), cómo vas a medir el éxito, qué plantillas vas a seguir, cuánto tiempo va a llevar y en qué hitos vas a comunicarte. Para hacer realidad el plan, te recomendamos que establezcas una zona de aterrizaje, migres a ella y valides las tareas migradas.
Zona de aterrizaje
Primero tienes que construir lo que se denomina la zona de aterrizaje: elentorno de destino donde residirán todas las cargas de trabajo. Esta actividad puede asumir distintos niveles de complejidad en función de tu configuración actual, pero como mínimo tendrás que:
-
Define el proyecto de destino y la organización relacionada (por ejemplo, la jerarquía de organización de Google Cloud)
-
Configura una nueva solución de gestión de identidades o intégrala con una heredada o de terceros (por ejemplo, Azure Active Directory u Okta)
-
Configura los sistemas de autorización (por ejemplo, AWS IAM) y auditoría (por ejemplo, Azure security logging and auditing)
-
Definir y establecer la topología de la red y la configuración correspondiente
Una vez que la zona de aterrizaje esté lista, es hora de que inicies la migración.
Migrar
Por lo general, es aconsejable dividir una migración en varias fases, o iteraciones, a menos que el número de cargas de trabajo que tengas que migrar sea muy pequeño. Esto te permitirá ganar experiencia y confianza en cómo proceder y afrontar los retos y errores a medida que migras un subconjunto de las cargas de trabajo cada vez.
Para cada carga de trabajo, deberás tener en cuenta:
- Migración de esquemas y datos
-
Dependiendo del caso de uso, puede que necesites traducir el modelo de datos o simplemente transferir los datos.
- Consulta transpile
-
En algunos casos, puede que tengas que traducir las consultas de tu sistema de origen al sistema de destino. Si el sistema de destino no admite todas las extensiones, puede que tengas que refactorizar las consultas. Puedes aprovechar herramientas como Datametica Raven o la IA generativa para reducir el esfuerzo manual.
- Migración de canalizaciones de datos
-
Las canalizaciones de datos forman la parte central de una carga de trabajo de datos que prepara los datos para el análisis. Veremos posibles enfoques para abordar dichas migraciones en "Migración de esquemas, canalizaciones y datos".
- Migración de aplicaciones empresariales
-
Una vez que hayas migrado los datos, tienes que migrar las aplicaciones que permiten a los usuarios interactuar con los datos.
- Ajuste del rendimiento
-
Si la carga de trabajo migrada de no funciona como se esperaba, tienes que solucionar el problema y arreglarlo. Puede que la solución de destino no se haya configurado correctamente, que el modelo de datos que has definido no te permita aprovechar todas las capacidades de la plataforma de destino, o que haya un problema en el proceso de transpilación.
Es esencial utilizar herramientas de infraestructura como código, como Ansible o Terraform, ya que pueden automatizar al máximo la gestión de la infraestructura de implementación, acelerando las pruebas y la ejecución de cada iteración.
Valida
Una vez migrada la carga de trabajo, tienes que volver a comprobar si todo se ha completado con éxito. Verifica que el rendimiento de la carga de trabajo, el coste de ejecución, el tiempo de acceso a los datos, etc., se ajustan a tus KPI identificados. Valida que todos los resultados que obtienes se ajustan a tus expectativas (por ejemplo, los resultados de las consultas son los mismos que en el entorno heredado). Una vez que estés seguro de que los resultados se ajustan a tus necesidades, es hora de pasar al segundo caso de uso, y luego al tercero hasta que hayas migrado todo. Si es posible, paraleliza las iteraciones posteriores para acelerar el proceso global.
Siempre es una buena idea anotar al final de cada carga de trabajo los problemas eventuales que puedas tener y el tiempo necesario para completar todas las actividades y las lecciones aprendidas relacionadas para mejorar el proceso en las cargas de trabajo posteriores.
Optimiza
El último paso del marco es la optimización. Aquí no te centrarás en el rendimiento de cada componente migrado. En su lugar, considerarás el nuevo sistema en su conjunto e identificarás posibles nuevos casos de uso que introducir para hacerlo aún más flexible y potente. Deberías reflexionar sobre lo que has obtenido de la migración (por ejemplo, escalabilidad ilimitada, seguridad mejorada, mayor visibilidad, etc.) y lo que harías potencialmente como siguiente paso (por ejemplo, ampliar los límites de la recogida de datos a los perímetros, desarrollar algunas sinergias mejores con los proveedores, empezar a monetizar los datos adecuados, etc.). Puedes partir de la información recopilada en el paso "Preparar y descubrir", averiguar en qué punto de tu recorrido ideal te encuentras y pensar en los siguientes pasos adicionales. Es una historia interminable porque la innovación, como los negocios, nunca duerme, y ayudará a las organizaciones a comprender y aprovechar cada vez mejor sus datos.
Ahora que comprendes mejor cómo enfocar una migración aprovechando el marco de migración en cuatro pasos, profundicemos en cómo estimar el coste global de la solución.
Estimación del coste global de la solución
Acabas de ver un marco general de migración que puede ayudar a las organizaciones a definir el conjunto de actividades que deben llevar a cabo para modernizar una plataforma de datos. La primera pregunta que puede hacerse el director de tecnología, el director general o el director financiero es: "¿Cuál es el coste total que tendremos que presupuestar?". En esta sección, repasaremos cómo suelen abordar las organizaciones este reto y cómo estructuran su trabajo para obtener presupuestos de vendedores y proveedores externos. Ten siempre presente que no se trata sólo del coste de la tecnología: siempre hay que tener en cuenta los costes de las personas y los procesos.
Auditoría de la infraestructura existente
Como has visto, todo empieza con una evaluación del entorno existente. Si no tienes una visión clara de la huella actual, seguramente tendrás dificultades para evaluar correctamente el precio de tu próxima plataforma de datos moderna. Esta actividad puede llevarse a cabo de tres maneras:
- Manualmente por el equipo interno de TI/infraestructuras
-
Muchas organizaciones mantienen una base de datos de gestión de la configuración (CMDB), que puede ser un archivo o una base de datos estándar que contiene toda la información fundamental sobre los componentes de hardware y software utilizados en la organización. Es una especie de instantánea de lo que funciona actualmente en la organización y de la infraestructura subyacente relacionada, destacando incluso las relaciones entre componentes. Las CMDB pueden proporcionar una mejor comprensión de los costes de funcionamiento de todas las aplicaciones y ayudar a cerrar recursos innecesarios o redundantes.
- Automáticamente por el equipo interno de TI/infraestructuras
-
El objetivo es exactamente el mismo descrito en el punto anterior, pero con el fin de aprovechar el software que ayuda a recopilar información de forma automática (datos relacionados con el hardware, las aplicaciones que se ejecutan en los servidores, la relación entre sistemas, etc.). Este tipo de herramientas (por ejemplo, StratoZone, Cloudamize, CloudPhysics, etc.) suelen generar sugerencias relacionadas con los hiperescaladores de nube objetivo más comunes (por ejemplo, AWS, Google Cloud y Azure), como el tamaño de las máquinas y las opciones de optimización (por ejemplo, cuántas horas al día debe estar en funcionamiento un sistema para llevar a cabo su tarea).
- Aprovechar a un tercero
-
Las empresas de consultoría y los proveedores de la nube cuentan con personal experimentado y herramientas de automatización para realizar todas las actividades necesarias para generar la CMDB y los informes detallados descritos en las dos primeras opciones. Esto es lo que recomendamos si tu organización suele subcontratar proyectos informáticos a empresas consultoras.
Solicitud de información/propuesta y presupuesto
Aunque ésta sea la única migración que puedas hacer, y por tanto tengas que aprender sobre la marcha, las empresas de consultoría se ganan la vida con esto y suelen ser mucho más eficientes en la gestión de proyectos de migración. Comprueba, por supuesto, que el equipo que te asignen tenga la experiencia necesaria. Algunos SI pueden incluso realizar evaluaciones y proporcionar estimaciones de costes como inversión si ven una oportunidad futura.
Identificar al mejor socio o proveedor con el que trabajar durante el viaje de modernización puede ser una tarea desalentadora. Hay muchas variables que considerar (los conocimientos, las capacidades, el coste, la experiencia), y puede resultar increíblemente complicado si no se ejecuta de forma rigurosa. Por eso, las organizaciones suelen recurrir a tres tipos de cuestionarios para recabar información de los SI potenciales:
- Solicitud de información (RFI)
-
Cuestionario utilizado para recoger información detallada sobre las soluciones y servicios de los vendedores/posibles socios. Tiene una finalidad educativa.
- Solicitud de propuesta (RFP)
-
Cuestionario utilizado para recopilar información detallada sobre cómo los proveedores/socios aprovecharán sus productos y servicios para resolver un problema concreto de la organización (en este caso, la implantación de la plataforma de datos moderna). Sirve para comparar resultados.
- Solicitud de presupuesto (RFQ)
-
Cuestionario utilizado para recopilar información detallada sobre los precios de diferentes proveedores/posibles socios en función de requisitos específicos. Sirve para cuantificar y normalizar los precios para facilitar futuras comparaciones.
Tu organización probablemente tenga políticas y plantillas sobre cómo hacerlo. Habla con tu departamento jurídico o de compras. Si no, pide a un proveedor que te muestre lo que utilizan habitualmente.
Una vez que hayas recibido todas las respuestas de todos los vendedores/socios potenciales, deberías tener toda la información para elegir el mejor camino a seguir. En algunos casos, especialmente cuando el problema a resolver puede ser increíblemente difuso (por ejemplo, análisis en tiempo real que pueden tener múltiples picos incluso durante un solo día), es un reto incluso para los vendedores/socios potenciales proporcionar detalles claros sobre los costes. Por eso, a veces los vendedores piden trabajar en una PoC o MVP para comprender mejor cómo funciona la solución en un escenario de caso de uso real y facilitar la definición del precio final.
Prueba de concepto/Producto Mínimo Viable
El diseño y el desarrollo de una nueva plataforma de datos puede ser un reto, porque la mayoría de las organizaciones quieren aprovechar la oportunidad de migrar de plataforma de datos para tener algo más que un mero levantar y cambiar: quieren añadir nuevas funciones y capacidades que no estaban disponibles en el mundo antiguo. Como esto es nuevo para ellas, es posible que las organizaciones (y por tanto los proveedores) no tengan una comprensión completa del comportamiento final y, lo que es más importante, de los costes finales en que incurrirá la plataforma.
Para hacer frente a este reto, las organizaciones suelen pedir a los vendedores o socios potenciales seleccionados que pongan en marcha una maqueta inicial de la solución final (o una solución real que funcione, pero con una funcionalidad limitada) como primer paso tras analizar la respuesta a la RFP. Esta maqueta permite a las partes interesadas experimentar cómo se comportará la solución final, de modo que puedan determinar si es necesario algún cambio de alcance. La maqueta también facilita mucho la estimación de costes, aunque es importante tener en cuenta que siempre estamos hablando de estimaciones, no de precios concretos. Es prácticamente imposible tener unos precios claros y definidos definitivamente cuando se adopta un modelo de nube, sobre todo si se quiere aprovechar la elasticidad. La elasticidad, que es una de las principales ventajas de la nube, sólo puede experimentarse en producción.
Hay tres formas de enfocar la idea de la maqueta:
- Prueba de concepto
-
Construye una pequeña parte de la solución para verificar la viabilidad, la integrabilidad, la usabilidad y los posibles puntos débiles. Esto puede ayudar a estimar el precio final. El objetivo no es tocar todas y cada una de las funciones que formarán parte de la plataforma, sino verificar las cosas que puede ser necesario rediseñar. Cuando se trabaja con canalizaciones de streaming, por ejemplo, es una buena práctica crear una PoC variando aleatoriamente la cantidad de datos a procesar. Esto te permitirá ver cómo escala el sistema y te proporcionará mejores datos para estimar el coste final de producción.
- Producto mínimo viable
-
El objetivo de un MVP es desarrollar un producto con un perímetro muy bien definido que tenga todas las características implementadas y que funcione como un producto real y completo que pueda desplegarse en un entorno de producción (por ejemplo, un data mart implementado en un nuevo DWH y conectado a una nueva herramienta de inteligencia empresarial para abordar un caso de uso muy específico). La principal ventaja de los MVP es obtener rápidamente comentarios de usuarios reales, lo que ayuda al equipo a mejorar el producto y a producir mejores estimaciones.
- Híbrido
-
Inicialmente, el equipo desarrollará una PdC general con un perímetro más amplio pero con una profundidad limitada (por ejemplo, una canalización de datos de extremo a extremo para recopilar los datos necesarios para entrenar un algoritmo ML para la clasificación de imágenes), y luego, basándose en los primeros resultados y en la evaluación de costes, el enfoque se trasladará al desarrollo de un MVP que pueda considerarse el primer paso hacia la implementación de la solución completa.
Ahora que ya sabes cómo calcular el coste, vamos a profundizar en la primera parte de cualquier migración: establecer la seguridad y la gobernanza de los datos.
Establecer la seguridad y la gobernanza de los datos
Aunque la propiedad y el control de los datos pasen a las unidades de negocio, la seguridad y la gobernanza siguen siendo una preocupación centralizada en la mayoría de las organizaciones. Esto se debe a que debe haber coherencia en la forma en que se definen las funciones, se protegen los datos y se registran las actividades. En ausencia de esa coherencia, es muy difícil cumplir normativas como la del "derecho al olvido", por la que un cliente puede solicitar que se eliminen todos los registros que le pertenecen.
En este apartado, hablaremos de las capacidades que deben estar presentes en un marco de gobierno de datos centralizado de este tipo. Después, hablaremos de los artefactos que el equipo central necesitará mantener y cómo se reúnen a lo largo del ciclo de vida de los datos.
Marco
Hay tres factores de riesgo que la seguridad y la gobernanza intentan abordar:
- Acceso no autorizado a datos
-
Cuando se almacenan datos de en una infraestructura de nube pública, es necesario protegerse contra el acceso no autorizado a datos sensibles, ya sea información confidencial de la empresa o IPI protegida por la ley.
- Cumplimiento de la normativa
-
Leyes como el Reglamento General de Protección de Datos (RGPD) y el Identificador de Personas Jurídicas (LEI) limitan la ubicación, el tipo y los métodos de análisis de datos.
- Visibilidad
-
Saber qué tipos de datos existen en la organización, quién los utiliza actualmente y cómo los utiliza puede ser necesario para las personas que suministran datos a tu organización. Esto requiere datos actualizados y un catálogo funcional.
Dados estos factores de riesgo, es necesario establecer un marco integral de gobernanza de datos que aborde toda la vida de los datos: ingestión, catalogación, almacenamiento, retención, intercambio, archivo, copia de seguridad, recuperación, prevención de pérdidas y eliminación. Dicho marco debe tener las siguientes capacidades:
- Linaje de los datos
-
La organización necesita poder identificar los activos de datos y registrar las transformaciones que se han aplicado para crear cada activo de datos.
- Clasificación de los datos
-
Necesitamos poder perfilar y clasificar los datos sensibles de para poder determinar qué políticas y procedimientos de gobierno deben aplicarse a cada activo de datos o parte de él.
- Catálogo de datos
-
Necesitamos mantener un catálogo de datos que contenga metadatos estructurales, linaje y clasificación y permita la búsqueda y el descubrimiento.
- Gestión de la calidad de los datos
-
Tiene que haber un proceso para documentar, monitorear e informar sobre la calidad de los datos, de modo que se disponga de datos fiables para el análisis.
- Gestión de accesos
-
Normalmente funcionará en con Cloud IAM para definir roles, especificar derechos de acceso y gestionar claves de acceso.
- Auditoría
-
Las organizaciones y las personas autorizadas de otras organizaciones, como las agencias reguladoras, necesitan poder monitorizar, auditar y realizar un seguimiento de las actividades a un nivel granular exigido por la ley o las convenciones del sector.
- Protección de datos
-
Debe existir la posibilidad de encriptar datos, enmascararlos o borrarlos permanentemente.
Para hacer operativa la gobernanza de datos, tendrás que poner en marcha un marco que permita llevar a cabo estas actividades. Herramientas en la nube como Dataplex en Google Cloud y Purview en Azure proporcionan soluciones unificadas de gobierno de datos para gestionar los activos de datos independientemente de dónde residan (es decir, nube única, nube híbrida o multicloud). Collibra e Informatica son soluciones agnósticas de la nube que proporcionan la capacidad de registrar el linaje, hacer la clasificación de datos, etc.
Según nuestra experiencia, cualquiera de estas herramientas puede funcionar, pero el trabajo duro de la gobernanza de datos no está en la herramienta en sí, sino en su operacionalización. Es importante establecer un modelo operativo -los procesos y procedimientos para la gobernanza de los datos-, así como un consejo que responsabilice a los distintos equipos empresariales del cumplimiento de estos procesos. El consejo también tendrá que encargarse de desarrollar taxonomías y ontologías para que haya coherencia en toda la organización. Lo ideal es que tu organización participe y esté en línea con los organismos de normalización del sector. Las mejores organizaciones también tienen sesiones de educación y formación frecuentes y continuas para garantizar que se cumplen las prácticas de gobierno de datos.
Ahora que hemos discutido qué capacidades deben estar presentes en un marco centralizado de gobierno de datos, vamos a enumerar los artefactos que el equipo central necesitará para mantener.
Artefactos
Para proporcionar las capacidades anteriores a la organización, un equipo central de gobierno de datos necesita mantener los siguientes artefactos:
- Diccionario de empresa
-
Puede ir desde un simple documento en papel hasta una herramienta que automatice (y aplique) determinadas políticas. El diccionario empresarial es un repositorio de los tipos de información que utiliza la organización. Por ejemplo, el código asociado a diversos procedimientos médicos o la información necesaria que hay que recoger sobre cualquier transacción financiera forman parte del diccionario de la empresa. El equipo central podría proporcionar un servicio de validación para garantizar que se cumplen estas condiciones. Un ejemplo sencillo de diccionario empresarial con el que muchos lectores están familiarizados son las API de validación y normalización de direcciones que proporciona el Servicio Postal de EEUU. Las empresas suelen utilizar estas API para asegurarse de que cualquier dirección almacenada en cualquier base de datos de la organización tiene una forma estándar.
- Clases de datos
-
Los distintos tipos de información del diccionario de la empresa pueden agruparse en clases de datos, y las políticas relacionadas con cada clase de datos pueden definirse de forma coherente. Por ejemplo, la política de datos relacionada con las direcciones de los clientes puede ser que el código postal sea visible para una clase de empleados, pero que la información más granular sólo sea visible para el personal de atención al cliente que esté trabajando activamente en un ticket para ese cliente.
- Libro de política
-
Un libro de políticas enumera las clases de datos que se utilizan en la organización, cómo se procesa cada clase de datos, cuánto tiempo se conservan los datos, dónde pueden almacenarse, cómo debe controlarse el acceso a los datos, etc.
- Políticas de casos de uso
-
A menudo, la política que rodea a una clase de datos depende del caso de uso. Como ejemplo sencillo, la dirección de un cliente puede ser utilizada por el departamento de envíos que realiza el pedido del cliente, pero no por el departamento de ventas. Los casos de uso pueden ser mucho más matizados: la dirección de un cliente puede utilizarse para determinar el número de clientes que se encuentran a una distancia en coche de una tienda concreta, pero no para determinar si un cliente concreto se encuentra a una distancia en coche de una tienda concreta.
- Catálogo de datos
-
Se trata de una herramienta para gestionar los metadatos estructurales, el linaje, la calidad de los datos, etc., asociados a los datos. El catálogo de datos funciona como una herramienta eficaz de búsqueda y descubrimiento.
Más allá de los artefactos relacionados con los datos enumerados anteriormente, la organización central también tendrá que mantener una capacidad SSO para proporcionar un mecanismo de autenticación único en toda la organización. Como a muchos servicios automatizados y API se accede mediante claves, y estas claves no deben almacenarse en texto plano, un servicio de gestión de claves suele ser una responsabilidad adicional del equipo central.
Como parte de tu viaje de modernización, es importante también poner en marcha estos artefactos y tenerlos en su sitio para que, a medida que los datos se trasladen a la nube, pasen a formar parte de un marco sólido de gobierno de datos. No pospongas la gobernanza de los datos hasta después de la migración a la nube: las organizaciones que hacen eso tienden a perder rápidamente el control de sus datos.
Veamos ahora cómo se vinculan las capacidades y los artefactos del marco a lo largo de la vida de los datos.
Gobernanza durante la vida de los datos
La gobernanza de los datos implica reunir a personas, procesos y tecnología a lo largo de la vida de los datos.
El ciclo de vida de los datos consta de las siguientes etapas:
- 1. Creación de datos
-
Esta es la etapa en la que creas/capturas los datos. En esta etapa, debes asegurarte de que también se capturan los metadatos. Por ejemplo, al capturar imágenes, es importante anotar también la hora y la ubicación de las fotografías. Del mismo modo, al capturar un flujo de clics, es importante anotar el identificador de sesión del usuario, la página en la que se encuentra, el diseño de la página (si está personalizada para el usuario), etc.
- 2. Procesamiento de datos
-
Cuando capturas los datos, normalmente tienes que limpiarlos, enriquecerlos y cargarlos en un DWH. Es importante capturar estos pasos como parte de un linaje de datos. Junto con el linaje, también hay que registrar los atributos de calidad de los datos.
- 3. Almacenamiento de datos
-
Por lo general, almacenas tanto los datos como los metadatos en un almacén persistente, como un almacenamiento blob (S3, GCS, etc.), una base de datos (Postgres, Aurora, AlloyDB, etc.), una DB de documentos (DynamoDB, Spanner, Cosmos DB, etc.) o un DWH (BigQuery, Redshift, Snowflake, etc.). En este punto, tienes que determinar los requisitos de seguridad para filas y columnas, así como si es necesario cifrar algún campo antes de guardarlo. Esta es la fase en la que la protección de datos ocupa un lugar central en la mente de un equipo de gobierno de datos.
- 4. Catálogo de datos
-
Tienes que introducir los datos persistentes en todas las fases de la transformación en el catálogo de datos de la empresa y habilitar API de descubrimiento para buscarlos. Es esencial documentar los datos y cómo pueden utilizarse.
- 5. Archivo de datos
-
Puedes envejecer datos antiguos de entornos de producción. Si es así, recuerda actualizar el catálogo. Debes tener en cuenta si tal archivado es obligatorio por ley. Lo ideal sería que automatizaras los métodos de archivo de acuerdo con las políticas que se aplican a toda la clase de datos.
- 6. Destrucción de datos
-
Puedes eliminar todos los datos que hayan superado el plazo legal de conservación. Esto también debe formar parte del libro de políticas de la empresa.
Tienes que crear políticas de gobierno de datos para cada una de estas etapas.
Las personas ejecutarán estas etapas, y esas personas necesitan tener ciertos privilegios de acceso para hacerlo. Una misma persona puede tener diferentes responsabilidades y preocupaciones en diferentes partes del ciclo de vida de los datos, por lo que es útil pensar en términos de "sombreros" en lugar de roles:
- Legal
-
Asegura a que el uso de los datos se ajusta a los requisitos contractuales y a la normativa gubernamental/industrial
- Administrador de datos
-
El propietario de los datos, que establece la política para un dato concreto
- Gobernador de datos
-
Establece políticas para las clases de datos e identifica a qué clase pertenece un dato concreto
- Zar de la privacidad
-
Asegura a que los casos de uso no filtran información personal identificable
- Usuario de datos
-
Normalmente un analista o científico de datos que utiliza los datos para tomar decisiones empresariales
Ahora que hemos visto una posible migración y un marco de seguridad y gobernanza, vamos a profundizar en cómo empezar a ejecutar la migración .
Migración de esquemas, canalizaciones y datos
En esta sección, examinaremos más detenidamente los patrones que puedes aprovechar para las migraciones de esquemas y canalizaciones, así como los retos a los que tienes que enfrentarte al transferir los datos.
Migración de esquemas
Cuando empieces a trasladar tu aplicación heredada al nuevo sistema de destino, puede que necesites evolucionar tu esquema para aprovechar todas las funciones que pone a tu disposición el sistema de destino. Es una buena práctica migrar primero el modelo tal cual al sistema de destino, conectando los procesos ascendentes (fuentes de datos y conductos que alimentan el sistema) y descendentes (los scripts, procedimientos y aplicaciones empresariales que se utilizan para procesar, consultar y visualizar los datos) y, a continuación, aprovechar el motor de procesamiento del entorno de destino para realizar todos los cambios. Este enfoque te ayudará a garantizar que tu solución funciona en el nuevo entorno, minimizando el riesgo de tiempo de inactividad y permitiéndote realizar cambios en una segunda fase.
Normalmente puedes aplicar aquí el patrón de fachada -un método de diseño para exponer a los procesos descendentes un conjunto de vistas que enmascaran las tablas subyacentes para ocultar la complejidad de los cambios eventualmente necesarios. Las vistas pueden entonces describir un nuevo esquema que ayude a aprovechar las características ad hoc del sistema de destino, sin perturbar los procesos ascendentes y descendentes que quedan así "protegidos" por esta capa de abstracción. En caso de que no pueda seguirse este tipo de enfoque, los datos deben traducirse y convertirse antes de ser ingeridos en el nuevo sistema. Estas actividades suelen realizarlas los conductos de transformación de datos que están bajo el perímetro de la migración.
Migración de tuberías
Hay dos estrategias diferentes que puedes seguir al migrar de un sistema heredado a la nube:
- Estás descargando la carga de trabajo.
-
En este caso, conservas los conductos de datos ascendentes que alimentan tu sistema fuente, y colocas una copia incremental de los datos en el sistema de destino. Por último, actualizas tus procesos descendentes para que lean del sistema de destino . Entonces puedes continuar la descarga con la siguiente carga de trabajo hasta que llegues al final. Una vez completado, puedes empezar a migrar completamente el canal de datos.
- Estás migrando completamente la carga de trabajo.
-
En este caso, tienes que migrar todo en el nuevo sistema (todo junto con el conducto de datos), y luego eliminar las tablas heredadas correspondientes.
Hay que migrar los datos que alimentan la carga de trabajo. Pueden proceder de diversas fuentes de datos, y podrían requerir transformaciones o uniones particulares para hacerlos utilizables. En general, existen cuatro patrones diferentes de canalización de datos:
- ETL
-
Todas las actividades de transformación, junto con la recogida y la ingestión de datos, las llevará a cabo un sistema ad hoc que disponga de una infraestructura y un lenguaje de programación adecuados (de todos modos, la herramienta puede hacer que las interfaces sean programables con los lenguajes de programación estándar disponibles).
- ELT
-
Similar a ETL, pero con la salvedad de que todas las transformaciones las realizará el motor de procesos donde se ingieran los datos (como hemos visto en los capítulos anteriores, éste es el enfoque preferido cuando se trata de soluciones modernas en la nube).
- Extraer y cargar (EL)
-
Este es el caso más sencillo de, en el que los datos ya están preparados y no requieren más transformaciones.
- Captura de datos de cambios (CDC)
-
Se trata de un patrón utilizado para rastrear los cambios de datos en el sistema de origen y reflejarlos en el de destino. Suele funcionar junto con una solución ETL, ya que almacena el registro original antes de realizar cualquier cambio en el proceso descendente.
Como has visto en la sección anterior, podrías identificar distintos enfoques para la migración de distintas cargas de trabajo. La misma metodología puede aplicarse a las canalizaciones de datos:
- Retira
-
La solución de canalización de datos ya no se utiliza porque se refiere a un caso de uso antiguo o porque ha sido sustituida por una nueva.
- Conserva
-
La solución de canalización de datos permanece en el sistema heredado porque potencialmente puede retirarse muy pronto, por lo que no es económicamente viable embarcarse en un proyecto de migración. También puede darse el caso de que existan algunos requisitos normativos que inhiban el movimiento de datos fuera de los límites corporativos.
- Rehost
-
La solución de canalización de datos se levanta y se traslada al entorno de la nube aprovechando el paradigma IaaS. En este escenario, no estás introduciendo ninguna gran modificación, excepto a nivel de conectividad, donde podría ser necesario establecer una configuración de red ad hoc (normalmente una red privada virtual, o VPN) para permitir la comunicación entre el entorno de la nube y el mundo local. Si los procesos ascendentes están fuera del perímetro corporativo (por ejemplo, terceros proveedores, otros entornos en la nube, etc.), puede que no sea necesaria una VPN, ya que la comunicación puede establecerse de forma segura aprovechando otras tecnologías, como las API REST autenticadas, por ejemplo. Antes de proceder, es necesario validar con el proveedor de la nube si existe alguna limitación tecnológica en el sistema subyacente que impida la correcta ejecución de la solución y volver a comprobar las posibles limitaciones de licencia.
- Replataforma
-
En este escenario, parte de la solución de canalización de datos se transforma antes de la migración para beneficiarse de las características de la nube, como una base de datos PaaS o la tecnología de contenerización. Las consideraciones sobre el lado de la conectividad destacadas en la descripción del "realojamiento" siguen siendo válidas.
- Refactoriza
-
La solución de canalización se migrará a una o varias soluciones PaaS totalmente gestionadas en la nube (por ejemplo, Amazon EMR, Azure HDInsight, Google Cloud Dataproc, Databricks). Cuando se trate de este enfoque, es una buena práctica volver a adoptar el mismo enfoque iterativo que estás adoptando para toda la migración:
-
Prepara y descubre los trabajos y organízalos potencialmente por complejidad.
-
Planifica y evalúa la posible MVP a migrar.
-
Ejecuta la migración y evalúa el resultado en función de los KPI que hayas definido.
-
Iterar con todos los demás trabajos hasta el final.
Siguen siendo válidas las consideraciones sobre la conectividad destacadas en la descripción anterior del "reenganche".
-
- Sustituye
-
La solución de canalización se sustituirá completamente por una solución de terceros lista para usar o SaaS (por ejemplo, Fivetran, Xplenty, Informatica, etc.). Las consideraciones sobre la conectividad destacadas en la sección "Rehost" siguen siendo válidas.
- Reconstruye
-
La solución de canalización está completamente rearquitectada utilizando soluciones totalmente gestionadas en la nube (por ejemplo, AWS Glue, Azure Data Factory, Google Cloud Dataflow). Las consideraciones sobre la conectividad destacadas en la sección "Rehost" siguen siendo válidas.
Durante la fase de migración, especialmente en la integración con el sistema de destino, podrías descubrir que tu solución de canalización de datos no es totalmente compatible con la solución en la nube de destino identificada nada más sacarla de la caja. Podrías necesitar un conector, normalmente denominado a sink, que permita la comunicación entre la solución de canalización de datos (por ejemplo, el sistema ETL) y el entorno de destino. Si no existe el sumidero para esa solución, podrías generar un archivo como salida del proceso y luego ingerir los datos en el paso siguiente. Este enfoque introducirá una complejidad adicional en el proceso, pero es una solución temporal viable en caso de emergencia (mientras esperas un conector del proveedor).
Migración de datos
Ahora que ya tienes listos tu nuevo esquema y tus pipelines, estás preparado para empezar a migrar todos tus datos. Debes centrarte en pensar cómo abordar la transferencia de datos. Puede que quieras migrar todos tus datos locales a la nube, incluso las viejas y polvorientas cintas (puede que algún día alguien necesite esos datos). Puede que te enfrentes a la realidad de que una única conexión FTP durante el fin de semana no será suficiente para llevar a cabo tu tarea.
Planificación
La transferencia de datos requiere planificación. Necesitas identificar e implicar:
- Propietarios técnicos
-
Personas que puedan facilitar el acceso a los recursos que necesitas para realizar la migración (por ejemplo, almacenamiento, TI, redes, etc.).
- Aprobadores
-
Personas que puedan proporcionarte todas las aprobaciones que necesitas para acceder a los datos e iniciar la migración (por ejemplo, propietarios de los datos, asesores jurídicos, administradores de seguridad, etc.).
- Entrega
-
El equipo de migración. Pueden ser personas internas de la organización, si están disponibles, o personas pertenecientes a terceros integradores de sistemas.
A continuación, tienes que recopilar toda la información que puedas para tener una comprensión completa de lo que tienes que hacer, en qué orden (por ejemplo, tal vez tu equipo de migración necesite que se le permita el acceso a un área de almacenamiento de red específica que contenga los datos que quieres migrar), y los posibles bloqueos con los que te puedes encontrar. He aquí una muestra de preguntas (no exhaustiva) que deberías poder responder antes de proceder:
-
¿Cuáles son los conjuntos de datos que necesitas trasladar?
-
¿Dónde se sitúan los datos subyacentes dentro de la organización?
-
¿Cuáles son los conjuntos de datos que puedes mover?
-
¿Hay algún requisito normativo específico que debas respetar?
-
¿Dónde van a ir a parar los datos (por ejemplo, almacén de objetos frente a almacenamiento DWH)?
-
¿Cuál es la región de destino (por ejemplo, Europa, Oriente Medio y África, Reino Unido, EE.UU., etc.)?
-
¿Necesitas realizar alguna transformación antes de la transferencia?
-
¿Cuáles son las políticas de acceso a los datos que quieres aplicar?
-
¿Se trata de una transferencia puntual, o necesitas mover datos con regularidad?
-
¿Cuáles son los recursos disponibles para la transferencia de datos?
-
¿Cuál es el presupuesto asignado?
-
¿Tienes un ancho de banda adecuado para realizar la transferencia, y durante un periodo adecuado?
-
¿Necesitas aprovechar soluciones fuera de línea (por ejemplo, Amazon Snowball, Azure Data Box, Google Transfer Appliance)?
-
¿Cuál es el tiempo necesario para realizar toda la migración de datos?
Una vez que conozcas los atributos de los datos que vas a migrar, tienes que tener en cuenta dos factores clave que afectan a la fiabilidad y el rendimiento de la migración: la capacidad y la red.
Capacidad regional y red a la nube
Cuando se trata de la migración de datos a la nube, normalmente hay dos elementos que deben considerarse cuidadosamente: la capacidad regional y la calidad de la conectividad de la red a la nube.
Un entorno de nube no es infinitamente escalable. La realidad es que el hardware debe ser adquirido, preparado y configurado por los proveedores de la nube en la ubicación regional. Una vez que hayas identificado la arquitectura de destino y los recursos necesarios para manejar la plataforma de datos, también debes presentar un plan regional de capacidad al hiperescalador que hayas elegido, para asegurarte de que la plataforma de datos dispondrá de todo el hardware necesario para satisfacer el uso y el crecimiento futuro de la plataforma. Normalmente querrán saber el volumen de los datos que se migrarán y que se generarán una vez en la nube, la cantidad de computación que necesitarás para procesar los datos y el número de interacciones que tendrás con otros sistemas. Todos estos componentes servirán de entrada a tus hiperescaladores para permitirles estar seguros de que la infraestructura subyacente estará lista desde el día cero para servir a todas tus cargas de trabajo. En caso de desabastecimiento (habitual si tu caso de uso implica GPUs), puede que tengas que elegir el mismo servicio pero en otra región (si no hay implicaciones de cumplimiento/tecnológicas) o aprovechar otros servicios de tipo informático (por ejemplo, IaaS frente a PaaS).
La red, aunque hoy en día se considere una mercancía, desempeña un papel vital en toda infraestructura en la nube: si la red es lenta o no es accesible, partes de tu organización pueden permanecer completamente desconectadas de sus datos empresariales (esto es cierto incluso cuando se aprovecha un entorno local). Al diseñar la plataforma en la nube, algunas de las primeras preguntas en las que debes pensar son: ¿Cómo se conectará mi organización a la nube? ¿A qué socio voy a recurrir para configurar la conectividad? ¿Voy a aprovechar la conexión estándar a Internet (potencialmente con una VPN encima), o quiero pagar por una conexión dedicada adicional que garantice una mayor fiabilidad? Todos estos temas suelen tratarse en los cuestionarios RFI/RFP, pero también deberían formar parte de uno de los primeros talleres que tengas con el proveedor/socio que hayas seleccionado para diseñar e implantar la plataforma.
Hay tres formas principales de conectarse a la nube:
- Conexión pública a Internet
-
Aprovechar las redes públicas de Internet. En este caso, las organizaciones suelen aprovechar una VPN sobre el protocolo de Internet público para proteger sus datos y garantizar un nivel adecuado de fiabilidad. El rendimiento está estrictamente relacionado con la capacidad de la organización para estar cerca del punto de presencia más cercano de los hiperescaladores en la nube seleccionados.
- Interconexión de socios
-
Ésta es una de las conexiones típicas que las organizaciones de pueden aprovechar para sus cargas de trabajo de producción, especialmente cuando necesitan tener un rendimiento garantizado con un alto rendimiento. Esta conexión se realiza entre la organización y el socio seleccionado, que a su vez se encarga de la conexión con los hiperescaladores seleccionados. Aprovechando la omnipresencia de los proveedores de telecomunicaciones, las organizaciones pueden establecer conexiones de alto rendimiento a un precio asequible.
- Interconexión directa
-
Se trata de la mejor conexión posible, en la que la organización se conecta directamente (y físicamente) con la red del proveedor de la nube. (Esto puede ser posible cuando ambas partes tienen routers en la misma ubicación física). La fiabilidad, el rendimiento y el rendimiento general son los mejores, y el precio puede discutirse directamente con los hipervisores seleccionados.
Para más detalles sobre cómo configurar estas tres opciones de conectividad, consulta la documentación en Azure, AWS y Google Cloud.
Normalmente, durante una fase PoC/MVP, se elige la opción de conexión pública a Internet porque es más rápida de configurar. En producción, la interconexión de socios es la más habitual, sobre todo cuando la organización quiere aprovechar un enfoque multicloud.
Opciones de transferencia
Para elegir la forma en que transferirás los datos a la nube, ten en cuenta los siguientes factores:
- Costes
-
Considera los siguientes costes potenciales implicados en la transferencia de datos:
- Red
-
Puede que necesites mejorar tu conectividad antes de proceder a la transferencia de datos. Tal vez no dispongas del ancho de banda adecuado para soportar la migración y necesites negociar con tu proveedor para añadir líneas adicionales.
- Proveedor de la nube
-
Cargar datos a un proveedor de la nube suele ser gratis, pero si exportas datos no sólo de tu entorno local, sino también de otro hiperescalador, puede que te cobren un coste de salida (que suele tener un coste por cada GB exportado) y potencialmente también un coste de lectura.
- Productos
-
Puede que necesites comprar o alquilar aparatos de almacenamiento para acelerar la transferencia de datos.
- Personas
-
El equipo que llevará a cabo la migración.
- Tiempo
-
Es importante conocer la cantidad de datos que tienes que transferir y el ancho de banda del que dispones. Una vez que lo sepas, podrás identificar el tiempo necesario para transferir los datos. Por ejemplo, si tienes que transferir 200 TB de datos y sólo dispones de un ancho de banda de 10 Gbps, necesitarás aproximadamente dos días para completar la transferencia.1 Esto supone que el ancho de banda está totalmente disponible para tu transferencia de datos, lo que puede no ser el caso. Si durante tu análisis descubres que necesitas más ancho de banda, puede que tengas que trabajar con tu proveedor de servicios de Internet (ISP) para solicitar un aumento o determinar la hora del día en que dicho ancho de banda está disponible. También puede ser el momento adecuado para trabajar con tu proveedor de la nube para implantar la conexión directa. Esto evita que tus datos vayan a la Internet pública y puede proporcionar un rendimiento más constante para grandes transferencias de datos (por ejemplo, AWS Direct Connect, Azure ExpressRoute, Google Cloud Direct Interconnect).
- Transferencia offline versus online
-
En algunos casos, una transferencia online es inviable porque llevará demasiado tiempo. En tales casos, selecciona un proceso offline aprovechando el hardware de almacenamiento. Los proveedores de la nube ofrecen este tipo de servicio (por ejemplo, transferencia de datos Amazon Snowball, Azure Data Box, Google Transfer Appliance), que es especialmente útil para transferencias de datos desde cientos de terabytes hasta escala de petabytes. Pides a tu proveedor de la nube un dispositivo físico que tendrá que estar conectado a tu red. Luego copiarás los datos, que estarán encriptados por defecto, y solicitarás un envío a las instalaciones del proveedor más cercanas que estén disponibles. Una vez entregados, los datos se copiarán en el servicio adecuado de la nube (por ejemplo, AWS S3, Azure Blob Storage, Google Cloud Storage) y estarán listos para ser utilizados.
- Herramientas disponibles
-
Una vez que hayas despejado toda la dinámica de la red, debes decidir cómo gestionar la carga de datos. Dependiendo del sistema al que quieras dirigirte (por ejemplo, almacenamiento blob, solución DWH, base de datos, aplicación de terceros, etc.), generalmente tienes las siguientes opciones a tu disposición:
- Herramientas de línea de comandos
-
Herramientas (por ejemplo, AWS CLI, Azure Cloud Shell o Google Cloud SDK) que te permitirán interactuar con todos los servicios del proveedor de la nube. Puedes automatizar y orquestar todos los procesos necesarios para subir los datos al destino deseado. Dependiendo de la herramienta final, puede que tengas que pasar por sistemas intermedios antes de poder subir los datos al destino final (por ejemplo, pasar primero por el almacenamiento blob antes de ingerir los datos en el DWH), pero gracias a la flexibilidad de las distintas herramientas, deberías poder implementar fácilmente tus flujos de trabajo, por ejemplo, aprovechando scripts bash o PowerShell.
- API REST
-
Éstas te permitirán integrar los servicios con las aplicaciones que quieras desarrollar: por ejemplo, herramientas de migración interna que ya hayas implantado y aprovechado o aplicaciones totalmente nuevas que quieras desarrollar con ese fin específico.
- Soluciones físicas
-
Herramientas para la migración fuera de línea, como se ha explicado en la descripción anterior de la transferencia fuera de línea frente a la transferencia en línea.
- Soluciones comerciales de terceros (COTS)
-
Éstas podrían proporcionar más funciones, como estrangulamiento de la red, protocolos avanzados personalizados de transferencia de datos, capacidades avanzadas de orquestación y gestión, y comprobaciones de la integridad de los datos .
Etapas de la migración
Tu migración constará de seis etapas (ver Figura 4-3):
-
Los procesos ascendentes que alimentan las soluciones de datos heredadas actuales se modifican para alimentar el entorno objetivo.
-
Los procesos descendentes que leen del entorno heredado se modifican para leer del entorno de destino.
-
Los datos históricos se migran en bloque al entorno de destino. En este punto, se migran los procesos ascendentes para que también escriban en el entorno de destino.
-
Los procesos descendentes están ahora conectados al entorno de destino.
-
Los datos pueden mantenerse sincronizados entre el entorno heredado y el de destino, aprovechando los pipelines CDC hasta que el antiguo entorno se descarte por completo.
-
Los procesos descendentes pasan a ser plenamente operativos, aprovechando el entorno de destino .
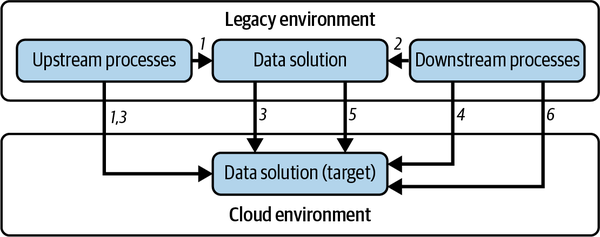
Figura 4-3. Estrategia de migración de datos
Hay algunas comprobaciones finales que debes realizar para asegurarte de que no te encuentras con cuellos de botella o problemas de transferencia de datos:
- Realiza una prueba funcional.
-
Necesitas ejecutar una prueba para validar que toda tu migración de transferencia de datos funciona correctamente. Lo ideal sería ejecutar esta prueba durante la ejecución de tu MVP, seleccionando una cantidad considerable de datos, aprovechando potencialmente todas las herramientas que quieras utilizar durante toda la migración. El objetivo de este paso es principalmente verificar que puedes realizar la transferencia de datos correctamente y, al mismo tiempo, aflorar posibles problemas que detengan el proyecto, como la incapacidad para utilizar las herramientas (por ejemplo, que tu personal no esté formado o que no cuentes con el apoyo adecuado de tu integrador de sistemas) o problemas de red (por ejemplo, rutas de red).
- Realiza una prueba de rendimiento.
-
Necesitas verificar que tu infraestructura actual puede gestionar la migración a escala. Para ello, debes identificar una muestra grande de tus datos (generalmente entre el 3% y el 5%) que se migrarán para confirmar que tu infraestructura y solución de migración se escalan correctamente según las necesidades de migración y que no estás sacando a la luz ningún cuello de botella específico (por ejemplo, un sistema de almacenamiento de origen lento).
- Realiza una comprobación de la integridad de los datos.
-
Uno de los problemas más críticos que puedes encontrarte durante una migración de datos es que los datos migrados al sistema de destino se borren debido a un error o se corrompan y queden inutilizables. Hay algunas formas de proteger tus datos de ese tipo de riesgo:
-
Activa el control de versiones y las copias de seguridad en tu destino para limitar los daños de un borrado accidental.
-
Valida tus datos antes de eliminar los datos de origen.
-
Si aprovechas herramientas estándar para realizar la migración (por ejemplo, CLI o API REST), tendrás que gestionar tú mismo todas estas actividades. Sin embargo, si estás adoptando una aplicación de terceros, como Signiant Media Shuttle o IBM Aspera on Cloud, es probable que ya existan varios tipos de comprobaciones que se hayan implementado por defecto. (Te sugerimos que leas detenidamente las funciones disponibles en la ficha de la aplicación antes de seleccionar la solución.)
Resumen
En este capítulo has visto un enfoque práctico del viaje de modernización de datos y has revisado un marco general de migración tecnológica que puede aplicarse a cualquier migración, desde un entorno heredado a una arquitectura moderna en la nube. Los puntos clave son los siguientes:
-
Céntrate en modernizar tu flujo de trabajo de datos, no sólo en actualizar herramientas individuales. Elegir la herramienta adecuada para el trabajo adecuado te ayudará a reducir costes, sacar el máximo partido a tus herramientas y ser más eficiente.
-
Un posible marco de migración de datos puede aplicarse en cuatro pasos: preparar y descubrir, evaluar y planificar, ejecutar y optimizar.
-
Preparar y descubrir es un paso fundamental en el que te centras en definir el perímetro de la migración y luego en recopilar toda la información relacionada con las distintas cargas de trabajo/casos de uso que has identificado para migrar.
-
Evaluar y planificar es el paso en el que defines y planificas todas las actividades que hay que realizar para lograr el objetivo identificado (por ejemplo, categorización y agrupación de las cargas de trabajo que hay que migrar, definición de los KPI, definición de un posible MVP y definición del plan de migración con los hitos correspondientes).
-
Ejecutar es el paso en el que realizas iterativamente la migración, mejorando el proceso global en cada iteración.
-
Optimizar es el paso en el que consideras el nuevo sistema en su conjunto e identificas posibles nuevos casos de uso que introducir para hacerlo aún más flexible y potente.
-
Comprender la huella actual y cuál será el coste total de la solución final es un paso complejo que puede implicar a múltiples actores. Las organizaciones suelen recurrir a RFI, RFP y RFQ para obtener más información de los vendedores/socios potenciales.
-
La gobernanza y la seguridad siguen siendo una preocupación centralizada en la mayoría de las organizaciones. Esto se debe a que debe haber coherencia en la forma en que se definen las funciones, se protegen los datos y se registran las actividades.
-
El marco de migración tiene que funcionar de acuerdo con un marco de gobernanza muy bien definido, que es fundamental a lo largo de toda la vida de los datos.
-
Al migrar el esquema de tus datos, puede ser útil aprovechar un patrón como el de fachada para facilitar la adopción de las características de la solución de destino.
-
La conectividad y la seguridad de la capacidad regional son fundamentales cuando se utilizan soluciones en la nube. La configuración de la red, la disponibilidad de ancho de banda, el coste, el personal, las herramientas, el rendimiento y la integridad de los datos son los principales puntos que hay que aclarar para cada carga de trabajo.
En los cuatro capítulos anteriores, has aprendido por qué construir una plataforma de datos, una estrategia para llegar a ella, cómo capacitar a tu personal y cómo llevar a cabo una migración. En los próximos capítulos, profundizaremos en los detalles arquitectónicos, empezando por cómo diseñar lagos de datos modernos.
1 Hay varios servicios disponibles gratuitamente en Internet que pueden ayudarte con este ejercicio de estimación; por ejemplo, la calculadora de ancho de banda de Calculator.net.
Get Arquitectura de Plataformas de Datos y Aprendizaje Automático now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

