Capítulo 4. La llamada al sistema bpf()
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Como viste en el Capítulo 1, cuando las aplicaciones del espacio de usuario quieren que el kernel haga algo en su nombre, hacen peticiones utilizando la API de llamadas al sistema. Por tanto, tiene sentido que si una aplicación del espacio de usuario quiere cargar un programa eBPF en el núcleo, tenga que haber algunas llamadas al sistema implicadas. De hecho, existe una llamada al sistema llamada bpf(), y en este capítulo te mostraré cómo se utiliza para cargar e interactuar con programas y mapas eBPF.
Vale la pena señalar que el código eBPF que se ejecuta en el núcleo no utiliza syscalls para acceder a los mapas. La interfaz syscall sólo la utilizan las aplicaciones del espacio de usuario. En su lugar, los programas eBPF utilizan funciones de ayuda para leer y escribir en los mapas; ya has visto ejemplos de ello en los dos capítulos anteriores.
Si llegas a escribir tú mismo programas eBPF, es muy probable que no llames directamente a estas llamadas al sistema bpf(). Existen bibliotecas, de las que hablaré más adelante en el libro, que ofrecen abstracciones de alto nivel para facilitarte las cosas. Dicho esto, esas abstracciones suelen corresponderse bastante directamente con los comandos de llamada al sistema subyacentes que verás en este capítulo. Sea cual sea la biblioteca que utilices, necesitarás conocer las operaciones subyacentes -cargar un programa, crear y acceder a mapas, etc.- que verás en este capítulo.
Antes de mostrarte ejemplos de las llamadas al sistema de bpf(), consideremos lo que dice la página de manual de bpf() , que es que bpf() se utiliza para "realizar un comando en un mapa o programa BPF extendido". También nos dice que bpf()'s signature is as follows:
intbpf(intcmd,unionbpf_attr*attr,unsignedintsize);
El primer argumento de bpf(), cmd, especifica qué orden se debe ejecutar. La llamada al sistema bpf() no hace sólo una cosa: hay muchas órdenes distintas que pueden utilizarse para manipular programas y mapas de eBPF. La Figura 4-1 muestra un resumen de algunas de las órdenes más habituales que el código del espacio de usuario puede utilizar para cargar programas eBPF, crear mapas, adjuntar programas a eventos y acceder a los pares clave-valor de un mapa.
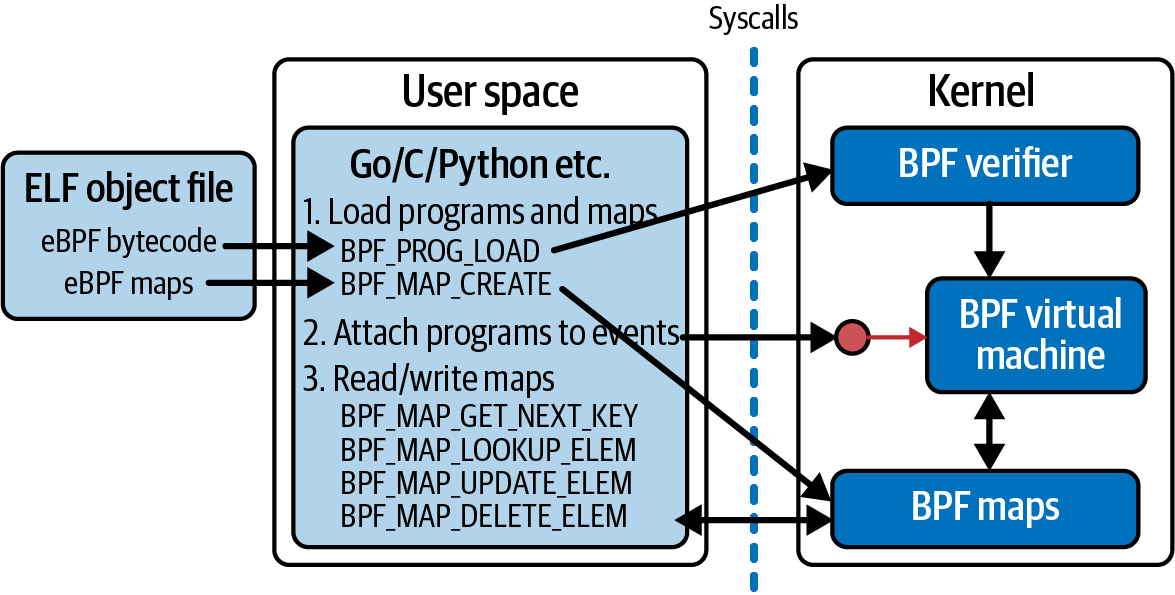
Figura 4-1. Un programa de espacio de usuario interactúa con los programas y mapas eBPF del núcleo mediante syscalls
El argumento attr de la llamada al sistema bpf() contiene los datos necesarios para especificar los parámetros del comando, y size indica cuántos bytes de datos hay en attr.
Ya conociste strace en el Capítulo 1, cuando lo utilicé para mostrar cómo el código del espacio de usuario realiza muchas peticiones a través de la API de la llamada al sistema. En este capítulo lo utilizaré para demostrar cómo se utiliza la llamada al sistema bpf(). La salida de strace incluye los argumentos de cada llamada al sistema, pero para evitar que la salida de ejemplo de este capítulo esté demasiado recargada, omitiré muchos de los detalles de los argumentos de attr a menos que sean especialmente interesantes.
Nota
Encontrarás el código, junto con instrucciones para configurar un entorno en el que ejecutarlo, en github.com/lizrice/learning-ebpf. El código de este capítulo está en el directorio chapter4.
Para este ejemplo voy a utilizar un programa BCC llamado hello-buffer-config.py, que se basa en los ejemplos que viste en el Capítulo 2. Al igual que el ejemplo hello-buffer.py, este programa envía un mensaje al búfer perf cada vez que se ejecuta, transmitiendo información del núcleo al espacio de usuario sobre los eventos de la llamada al sistema execve(). La novedad de esta versión es que permite configurar mensajes distintos para cada ID de usuario.
Aquí tienes el código fuente de eBPF:
structuser_msg_t{charmessage[12];};BPF_HASH(config,u32,structuser_msg_t);BPF_PERF_OUTPUT(output);structdata_t{intpid;intuid;charcommand[16];charmessage[12];};inthello(void*ctx){structdata_tdata={};structuser_msg_t*p;charmessage[12]="Hello World";data.pid=bpf_get_current_pid_tgid()>>32;data.uid=bpf_get_current_uid_gid()&0xFFFFFFFF;bpf_get_current_comm(&data.command,sizeof(data.command));p=config.lookup(&data.uid);if(p!=0){bpf_probe_read_kernel(&data.message,sizeof(data.message),p->message);}else{bpf_probe_read_kernel(&data.message,sizeof(data.message),message);}output.perf_submit(ctx,&data,sizeof(data));return0;}
- Esta línea indica que hay una definición de estructura,
user_msg_t, para contener un mensaje de 12 caracteres. 
- La macro BCC
BPF_HASHse utiliza para definir un mapa de tabla hash llamadoconfig. Contendrá valores de tipouser_msg_t, indexados por claves de tipou32, que es el tamaño adecuado para un ID de usuario. (Si no especificas los tipos para las claves y los valores, BCC utiliza por defectou64para ambos). 
- La salida del búfer perf se define exactamente igual que en el Capítulo 2. Puedes enviar datos arbitrarios a un búfer, por lo que no es necesario especificar aquí ningún tipo de datos...

- ...aunque en la práctica, en este ejemplo el programa siempre presenta una estructura
data_t. Esto tampoco cambia respecto al ejemplo del Capítulo 2. 
- La mayor parte del resto del programa eBPF no ha cambiado respecto a la versión
hello()que has visto antes. 
- La única diferencia es que, habiendo utilizado una función auxiliar para obtener el ID de usuario, el código busca una entrada en el mapa hash
configcon ese ID de usuario como clave. Si hay una entrada que coincide, el valor contiene un mensaje que se utiliza en lugar del predeterminado "Hola Mundo".
El código Python tiene dos líneas adicionales:
b["config"][ct.c_int(0)]=ct.create_string_buffer(b"Hey root!")b["config"][ct.c_int(501)]=ct.create_string_buffer(b"Hi user 501!")
Éstos definen mensajes en la tabla hash config para los ID de usuario 0 y 501, que corresponden al usuario root y a mi ID de usuario en esta máquina virtual. Este código utiliza el paquete ctypes de Python para garantizar que la clave y el valor tienen los mismos tipos que los utilizados en la definición en C de user_msg_t.
Aquí tienes una salida ilustrativa de este ejemplo, junto con los comandos que ejecuté en un segundo terminal para obtenerla:
Terminal 1 Terminal 2 $ ./hello-buffer-config.py 37926 501 bash Hi user 501! ls 37927 501 bash Hi user 501! sudo ls 37929 0 sudo Hey root! 37931 501 bash Hi user 501! sudo -u daemon ls 37933 1 sudo Hello World
Ahora que ya tienes una idea de lo que hace este programa, me gustaría mostrarte las llamadas al sistema bpf() que se utilizan cuando se ejecuta. Lo ejecutaré de nuevo utilizando strace, especificando -e bpf para indicar que sólo me interesa ver la llamada al sistema bpf():
$ strace -e bpf ./hello-buffer-config.py
La salida que verás si lo intentas tú mismo muestra varias llamadas a esta llamada al sistema. Para cada una, verás el comando que indica lo que debe hacer la llamada al sistema bpf(). El esquema general es el siguiente
bpf(BPF_BTF_LOAD, ...) = 3
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_PERF_EVENT_ARRAY…) = 4
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_HASH...) = 5
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_KPROBE,...prog_name="hello",...) = 6
bpf(BPF_MAP_UPDATE_ELEM, ...}
...
Examinémoslas una a una. Ni tú, el lector, ni yo tenemos una paciencia infinita, ¡así que no hablaré de cada argumento de cada llamada! Me centraré en las partes que creo que realmente ayudan a contar la historia de lo que ocurre cuando un programa del espacio de usuario interactúa con un programa eBPF.
Cargar datos BTF
La primera llamada a bpf() que veo tiene este aspecto:
bpf(BPF_BTF_LOAD, {btf="\237\353\1\0...}, 128) = 3
En este caso, el comando que puedes ver en la salida es BPF_BTF_LOAD. Éste es sólo uno de un conjunto de comandos válidos que están (al menos en el momento de escribir esto) más exhaustivamente documentados dentro del código fuente del núcleo.1
Es posible que no veas una llamada con este comando si utilizas un kernel Linux relativamente antiguo, ya que está relacionado con BTF, o Formato de Tipo BPF.2 BTF permite que los programas eBPF sean portables entre distintas versiones del kernel, de modo que puedas compilar un programa en una máquina y utilizarlo en otra, que podría estar utilizando una versión distinta del kernel y, por tanto, tener estructuras de datos del kernel diferentes. Hablaré de esto con más detalle en el Capítulo 5.
Esta llamada a bpf() está cargando un blob de datos BTF en el núcleo, y el código de retorno de la llamada al sistema bpf() (3 en mi ejemplo) es un descriptor de archivo que hace referencia a esos datos.
Nota
Un descriptor de archivo es un identificador de un archivo abierto (u objeto similar a un archivo). Si abres un archivo (con la llamada al sistema open() o openat() ) el código de retorno es un descriptor de archivo, que luego se pasa como argumento a otras llamadas al sistema como read() o write() para realizar operaciones en ese archivo. Aquí el blob de datos no es exactamente un archivo, pero se le da un descriptor de archivo como identificador que puede utilizarse para futuras operaciones que hagan referencia a él.
Crear mapas
La siguiente bpf() crea el mapa del búfer de perf output:
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_PERF_EVENT_ARRAY, , key_size=4,
value_size=4, max_entries=4, ... map_name="output", ...}, 128) = 4
Probablemente puedas adivinar por el nombre del comando BPF_MAP_CREATE que esta llamada crea un mapa eBPF. Puedes ver que el tipo de este mapa es PERF_EVENT_ARRAY y se llama output. Las claves y valores de este mapa de eventos de perf tienen una longitud de 4 bytes. También hay un límite de cuatro pares clave-valor que puede contener este mapa, definido por el campo max_entries; más adelante en este capítulo explicaré por qué hay cuatro entradas en este mapa. El valor de retorno de 4 es el descriptor de archivo para que el código del espacio de usuario acceda al mapa output.
La siguiente llamada al sistema bpf() en la salida crea el mapa config:
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_HASH, key_size=4, value_size=12,
max_entries=10240... map_name="config", ...btf_fd=3,...}, 128) = 5
Este mapa está definido como un mapa de tabla hash, con claves de 4 bytes de longitud (que corresponde a un entero de 32 bits que puede utilizarse para contener un identificador de usuario) y valores de 12 bytes de longitud (que coincide con la longitud de la estructura msg_t ). No especifiqué el tamaño de la tabla, así que se le ha dado el tamaño por defecto de BCC de 10.240 entradas.
Esta llamada al sistema bpf() también devuelve un descriptor de archivo, 5, que se utilizará para hacer referencia a este mapa config en futuras llamadas al sistema.
También puedes ver el campo btf_fd=3, que indica al núcleo que utilice el descriptor de archivo BTF 3 que se obtuvo anteriormente. Como verás en el Capítulo 5, la información BTF describe la disposición de las estructuras de datos, e incluirla en la definición del mapa significa que hay información sobre la disposición de los tipos de clave y valor utilizados en este mapa. Esto lo utilizan herramientas como bpftool para hacer una impresión bonita de los volcados de mapas, haciéndolos legibles para el ser humano; viste un ejemplo de ello en el Capítulo 3.
Cargar un programa
Hasta ahora has visto que el programa de ejemplo utiliza llamadas al sistema para cargar datos BTF en el núcleo y crear algunos mapas eBPF. Lo siguiente que hace es cargar el programa eBPF que se está cargando en el núcleo con la siguiente llamada al sistema bpf():
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_KPROBE, insn_cnt=44,
insns=0xffffa836abe8, license="GPL", ... prog_name="hello", ...
expected_attach_type=BPF_CGROUP_INET_INGRESS, prog_btf_fd=3,...}, 128) = 6
Algunos campos de aquí son interesantes:
El campo
prog_typedescribe el tipo de programa, que aquí indica que está destinado a ser conectado a una kprobe. Aprenderás más sobre los tipos de programa en el Capítulo 7.El campo
insn_cntsignifica "recuento de instrucciones". Es el número de instrucciones bytecode del programa.Las instrucciones bytecode que componen este programa eBPF se guardan en memoria en la dirección especificada en el campo
insns.Este programa se especificó con licencia GPL para que pueda utilizar las funciones de ayuda BPF con licencia GPL.
El nombre del programa es
hello.El
expected_attach_typedeBPF_CGROUP_INET_INGRESSpuede parecer sorprendente, porque suena a algo relacionado con el tráfico de red de entrada, pero sabes que este programa eBPF se va a adjuntar a una kprobe. De hecho, el campoexpected_attach_typesólo se utiliza para algunos tipos de programas, yBPF_PROG_TYPE_KPROBEno es uno de ellos.BPF_CGROUP_INET_INGRESSsólo resulta ser el primero de la lista de tipos de adjuntos BPF,3 por lo que tiene el valor0.El campo
prog_btf_fdindica al núcleo qué blob de datos BTF cargado previamente debe utilizar con este programa. El valor3aquí corresponde al descriptor de archivo que viste devuelto por la llamada al sistemaBPF_BTF_LOAD(y es el mismo blob de datos BTF utilizado para el mapaconfig).
Si el programa hubiera fallado en la verificación (de lo que hablaré en el Capítulo 6), esta llamada al sistema habría devuelto un valor negativo, pero aquí puedes ver que devolvió el descriptor de archivo 6. Para recapitular, en este punto los descriptores de archivo tienen los significados que se muestran en la Tabla 4-1.
| Descriptor de archivo | Representa |
|---|---|
3 |
Datos BTF |
4 |
output mapa del búfer perf |
5 |
config mapa de tabla hash |
6 |
hello Programa eBPF |
Modificar un mapa desde el espacio de usuario
Ya has visto la línea en el código fuente del espacio de usuario de Python que configura los mensajes especiales que se mostrarán para el usuario root con ID de usuario 0, y para el usuario con ID 501:
b["config"][ct.c_int(0)]=ct.create_string_buffer(b"Hey root!")b["config"][ct.c_int(501)]=ct.create_string_buffer(b"Hi user 501!")
Puedes ver cómo se definen estas entradas en el mapa mediante llamadas al sistema como ésta:
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=5, key=0xffffa7842490, value=0xffffa7a2b410,
flags=BPF_ANY}, 128) = 0
El comando BPF_MAP_UPDATE_ELEM actualiza el par clave-valor de un mapa. La bandera BPF_ANY indica que si la clave no existe ya en este mapa, debe crearse. Hay dos de estas llamadas, correspondientes a las dos entradas configuradas para dos ID de usuario diferentes.
El campo map_fd identifica sobre qué mapa se está operando. Puedes ver que en este caso es 5, que es el valor del descriptor de archivo devuelto anteriormente cuando se creó el mapa config.
Los descriptores de archivo son asignados por el núcleo para un proceso concreto, por lo que este valor de 5 sólo es válido para este proceso concreto del espacio de usuario en el que se está ejecutando el programa Python. Sin embargo, varios programas de espacio de usuario (y varios programas eBPF en el núcleo) pueden acceder al mismo mapa. Dos programas de espacio de usuario que accedan a la misma estructura de mapa en el núcleo podrían perfectamente tener asignados valores de descriptor de archivo diferentes; del mismo modo, dos programas de espacio de usuario podrían tener el mismo valor de descriptor de archivo para mapas totalmente distintos.
Tanto la clave como el valor son punteros, por lo que no puedes saber el valor numérico ni de la clave ni del valor a partir de esta salida de strace. Sin embargo, podrías utilizar bpftool para ver el contenido del mapa y ver algo como esto:
$ bpftool map dump name config
[{
"key": 0,
"value": {
"message": "Hey root!"
}
},{
"key": 501,
"value": {
"message": "Hi user 501!"
}
}
]
¿Cómo sabe bpftool cómo formatear esta salida? Por ejemplo, ¿cómo sabe que el valor es una estructura, con un campo llamado message que contiene una cadena? La respuesta es que utiliza las definiciones de la información BTF incluida en la llamada al sistema BPF_MAP_CREATE que definió este mapa. Verás más detalles sobre cómo BTF transmite esta información en el próximo capítulo.
Ya has visto cómo el espacio de usuario interactúa con el núcleo para cargar programas y mapas y para actualizar la información de un mapa. En la secuencia de llamadas al sistema que has visto hasta ahora, el programa aún no se ha asociado a un evento. Este paso tiene que producirse; de lo contrario, el programa nunca se activará.
Advertencia: ¡los distintos tipos de programas eBPF se conectan a los distintos eventos de distintas maneras! Más adelante en este capítulo te mostraré las llamadas al sistema utilizadas en este ejemplo para conectarse al evento kprobe, y en este caso no se utiliza bpf(). En cambio, en los ejercicios del final de este capítulo te mostraré otro ejemplo en el que se utiliza una llamada al sistema bpf() para conectar un programa a un evento tracepoint sin procesar.
Antes de entrar en esos detalles, me gustaría hablar de lo que ocurre cuando dejas de ejecutar el programa. Verás que el programa y los mapas se descargan automáticamente, y esto ocurre porque el núcleo está haciendo un seguimiento de ellos mediante recuentos de referencias.
Programa BPF y referencias cartográficas
Ya sabes que cargar un programa BPF en el núcleo con la llamada al sistema bpf() devuelve un descriptor de archivo. Dentro del núcleo, este descriptor de archivo es una referencia al programa. El proceso del espacio de usuario que realizó la llamada al sistema es el propietario de este descriptor de archivo; cuando ese proceso sale, el descriptor de archivo se libera y el recuento de referencias al programa se reduce. Cuando no quedan referencias a un programa BPF, el núcleo elimina el programa.
Se crea una referencia adicional cuando fijas un programa al sistema de archivos.
Pinning
Ya viste la fijación en acción en el capítulo 3, con el siguiente comando:
bpftool prog load hello.bpf.o /sys/fs/bpf/hello
Nota
Estos objetos anclados no son archivos reales persistentes en disco. Se crean en un pseudo-sistema de archivos, que se comporta como un sistema de archivos normal basado en disco, con directorios y archivos. Pero se mantienen en memoria, lo que significa que no permanecerán en su sitio al reiniciar el sistema.
Si bpftool te permitiera cargar el programa sin anclarlo, no tendría sentido, porque el descriptor de archivo se libera al salir de bpftool, y si hay cero referencias, el programa se borraría, por lo que no se habría conseguido nada útil. Pero fijarlo al sistema de archivos significa que hay una referencia adicional al programa, por lo que el programa permanece cargado una vez finalizado el comando.
El contador de referencia también se incrementa cuando un programa BPF está unido a un gancho que lo activará. El comportamiento de estos contadores de referencia depende del tipo de programa BPF. Aprenderás más sobre estos tipos de programa en el Capítulo 7, pero hay algunos que están relacionados con el rastreo (como kprobes y tracepoints) y siempre están asociados a un proceso del espacio de usuario; para estos tipos de programas eBPF, el contador de referencia del núcleo se decrementa cuando ese proceso sale. Los programas que se adjuntan dentro de la pila de red o cgroups (abreviatura de "grupos de control") no están asociados a ningún proceso del espacio de usuario, por lo que permanecen en su lugar incluso después de que salga el programa del espacio de usuario que los carga. Ya has visto un ejemplo de esto al cargar un programa XDP con el comando ip link:
ip link set dev eth0 xdp obj hello.bpf.o sec xdp
El comando ip se ha completado, y no hay ninguna definición de ubicación fijada, pero sin embargo, bpftool te mostrará que el programa XDP está cargado en el núcleo:
$ bpftool prog list
…
1255: xdp name hello tag 9d0e949f89f1a82c gpl
loaded_at 2022-11-01T19:21:14+0000 uid 0
xlated 48B jited 108B memlock 4096B map_ids 612
El recuento de referencias de este programa es distinto de cero, debido a la vinculación al gancho XDP que persistió después de que finalizara el comando ip link.
Los mapas eBPF también tienen contadores de referencia, y se limpian cuando su recuento de referencias llega a cero. Cada programa eBPF que utiliza un mapa incrementa el contador, al igual que cada descriptor de archivo que los programas del espacio de usuario puedan mantener en el mapa.
Es posible que el código fuente de un programa eBPF defina un mapa al que el programa no haga referencia en realidad. Supongamos que quieres almacenar algunos metadatos sobre un programa; podrías definirlos como una variable global, y como viste en el capítulo anterior, esta información se almacena en un mapa. Si el programa eBPF no hace nada con ese mapa, no habrá automáticamente un recuento de referencias del programa al mapa. Existe una llamada al sistema BPF(BPF_PROG_BIND_MAP) que asocia un mapa a un programa para que el mapa no se limpie en cuanto el programa cargador del espacio de usuario salga y ya no mantenga una referencia de descriptor de archivo al mapa.
Los mapas también se pueden fijar al sistema de archivos, y los programas del espacio de usuario pueden acceder al mapa conociendo la ruta al mapa.
Nota
Alexei Starovoitov escribió una buena descripción de los contadores de referencia BPF y los descriptores de archivo en su entrada del blog "Tiempo de vida de los objetos BPF".
Otra forma de crear una referencia a un programa BPF es con un enlace BPF.
Enlaces BPF
Los enlaces BPF proporcionan una capa de abstracción entre un programa eBPF y el evento al que está vinculado. Un enlace BPF en sí mismo puede anclarse al sistema de archivos, lo que crea una referencia adicional al programa. Esto significa que el proceso del espacio de usuario que cargó el programa en el núcleo puede terminar, dejando el programa cargado. El descriptor de archivo para el programa cargador del espacio de usuario se libera, disminuyendo el recuento de referencias al programa, pero el recuento de referencias será distinto de cero debido al enlace BPF.
Tendrás la oportunidad de ver enlaces BPF en acción si sigues los ejercicios del final de este capítulo. Por ahora, volvamos a la secuencia de llamadas al sistema bpf() que utiliza hello-buffer-config.py.
Otras llamadas al sistema implicadas en el eBPF
Recapitulando, hasta ahora has visto en bpf() las llamadas al sistema que añaden los datos BTF, el programa y los mapas, y los datos de los mapas al núcleo. Lo siguiente que muestra la salida strace está relacionado con la configuración del búfer perf.
Nota
El resto de este capítulo se sumerge con relativa profundidad en las secuencias de syscall implicadas cuando se utilizan perf buffers, ring buffers, kprobes e iteraciones de mapas. No todos los programas eBPF necesitan hacer estas cosas, así que si tienes prisa o te parece demasiado detallado, no dudes en pasar al resumen del capítulo. ¡No me ofenderé!
Inicializar el búfer de rendimiento
Has visto las llamadas a bpf(BPF_MAP_UPDATE_ELEM) que añaden entradas en el mapa config. A continuación, la salida muestra algunas llamadas que tienen este aspecto:
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=4, key=0xffffa7842490, value=0xffffa7a2b410,
flags=BPF_ANY}, 128) = 0
Se parecen mucho a las llamadas que definían las entradas del mapa config, salvo que en este caso el descriptor de archivo del mapa es 4, que representa el mapa de memoria intermedia de perf output.
Como antes, la clave y el valor son punteros, por lo que no puedes saber el valor numérico ni de la clave ni del valor a partir de esta salida de strace. Veo que esta llamada al sistema se repite cuatro veces con valores idénticos para todos los parámetros, aunque no hay forma de saber si los valores que contienen los punteros han cambiado entre cada llamada. Observar estas llamadas a BPF_MAP_UPDATE_ELEM bpf() deja algunas preguntas sin respuesta sobre cómo se configura y utiliza el búfer:
¿Por qué hay cuatro llamadas a
BPF_MAP_UPDATE_ELEM? ¿Tiene esto que ver con el hecho de que el mapaoutputse creó con un máximo de cuatro entradas?Después de estas cuatro instancias de
BPF_MAP_UPDATE_ELEM, no aparecen más llamadas al sistema debpf()en la salida destrace. Esto puede parecer un poco extraño, porque el mapa está ahí para que el programa eBPF pueda escribir datos cada vez que se activa, y has visto que el código del espacio de usuario muestra datos. Está claro que esos datos no se recuperan del mapa con las llamadas al sistemabpf(), así que ¿cómo se obtienen?
Tampoco has visto ninguna prueba de cómo el programa eBPF se une al evento kprobe que lo desencadena. Para obtener la explicación de todas estas preocupaciones, necesito que strace muestre algunas llamadas al sistema más al ejecutar este ejemplo, como ésta:
$ strace -e bpf,perf_event_open,ioctl,ppoll ./hello-buffer-config.py
Por brevedad, voy a ignorar las llamadas a ioctl() que no estén específicamente relacionadas con la funcionalidad eBPF de este ejemplo.
Adjuntar a eventos Kprobe
Has visto que el descriptor de archivo 6 se asignó para representar el hola del programa eBPF una vez cargado en el núcleo. Para asignar el programa eBPF a un evento, también necesitas un descriptor de archivo que represente a ese evento concreto. La siguiente línea de la salida de strace muestra la creación del descriptor de archivo para la kprobe execve():
perf_event_open({type=0x6 /* PERF_TYPE_??? */, ...},...) = 7
Según la página de manual de la llamada al sistema perf_event_open() , "crea un descriptor de archivo que permite medir la información de rendimiento". Puedes ver en la salida que strace no sabe cómo interpretar el parámetro de tipo con el valor 6, pero si examinas más a fondo esa página de manual, describe cómo Linux admite tipos dinámicos de Unidad de medición del rendimiento:
...hay un subdirectorio por cada instancia de PMU en /sys/bus/event_source/devices. En cada subdirectorio hay un archivo de tipo cuyo contenido es un número entero que puede utilizarse en el campo de tipo.
Efectivamente, si miras en ese directorio, encontrarás un archivo kprobe/type:
$ cat /sys/bus/event_source/devices/kprobe/type 6
A partir de esto, puedes ver que la llamada a perf_event_open() tiene un tipo establecido al valor 6 para indicar que es un evento perf de tipo kprobe.
Lamentablemente, strace no muestra los detalles que demostrarían de forma concluyente que la kprobe está conectada a la llamada al sistema execve(), pero espero que aquí haya pruebas suficientes para convencerte de que eso es lo que representa el descriptor de archivo devuelto aquí.
El código de retorno de perf_event_open() es 7, y éste representa el descriptor de archivo del evento perf de kprobe, y sabes que el descriptor de archivo 6 representa el programa hola eBPF. La página de manual de perf_event_open() también explica cómo utilizar ioctl() para crear la unión entre ambos:
PERF_EVENT_IOC_SET_BPF[...] permite adjuntar un programa Berkeley Packet Filter (BPF) a un evento tracepoint kprobe existente. El argumento es un descriptor de archivo de programa BPF creado por una llamada anterior al sistemabpf(2).
Esto explica la siguiente llamada al sistema ioctl() que verás en la salida de strace, con argumentos referidos a los dos descriptores de archivo:
ioctl(7, PERF_EVENT_IOC_SET_BPF, 6) = 0
También hay otra llamada a ioctl() que activa el evento kprobe:
ioctl(7, PERF_EVENT_IOC_ENABLE, 0) = 0
Una vez hecho esto, el programa eBPF debería activarse siempre que se ejecute execve() en esta máquina.
Configuración y lectura de eventos Perf
Ya he mencionado que veo cuatro llamadas a bpf(BPF_MAP_UPDATE_ELEM) relacionadas con el búfer perf de salida. Con las llamadas al sistema adicionales rastreadas, la salida de strace muestra cuatro secuencias, como ésta:
perf_event_open({type=PERF_TYPE_SOFTWARE, size=0 /* PERF_ATTR_SIZE_??? */,
config=PERF_COUNT_SW_BPF_OUTPUT, ...}, -1, X, -1, PERF_FLAG_FD_CLOEXEC) = Y
ioctl(Y, PERF_EVENT_IOC_ENABLE, 0) = 0
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=4, key=0xffffa7842490, value=0xffffa7a2b410,
flags=BPF_ANY}, 128) = 0
He utilizado X para indicar dónde la salida muestra los valores 0, 1, 2, y 3 en las cuatro instancias de esta llamada. Si consultas la página de manual de la llamada al sistema perf_event_open(), verás que se trata de cpu, y que el campo que la precede es pid o ID del proceso. De la página de manual:
pid == -1 y cpu >= 0
Mide todos los procesos/hilos en la CPU especificada.
El hecho de que esta secuencia ocurra cuatro veces corresponde a que hay cuatro núcleos de CPU en mi portátil. Ésta es, por fin, la explicación de por qué hay cuatro entradas en el mapa del búfer perf de "salida": hay una por cada núcleo de CPU. También explica la parte "array" del nombre del tipo de mapa BPF_MAP_TYPE_PERF_EVENT_ARRAY, ya que el mapa no representa sólo un búfer perf ring, sino un array de búferes, uno por cada núcleo.
Si escribes programas eBPF, no tendrás que preocuparte de detalles como el manejo del número de núcleos, ya que de esto se encargará cualquiera de las bibliotecas eBPF que se comentan en el Capítulo 10, pero creo que es un aspecto interesante de las llamadas al sistema que ves cuando utilizas strace en este programa.
Cada una de las llamadas a perf_event_open() devuelve un descriptor de archivo, que he representado como Y; éstos tienen los valores 8, 9, 10 y 11. Las llamadas al sistema ioctl() habilitan la salida perf para cada uno de estos descriptores de archivo. Las llamadas al sistema BPF_MAP_UPDATE_ELEM bpf() establecen la entrada del mapa para que apunte al búfer del anillo perf de cada núcleo de la CPU para indicar dónde puede enviar datos.
A continuación, el código del espacio de usuario puede utilizar ppoll() en los cuatro descriptores de estos archivos de flujo de salida, de modo que pueda obtener la salida de datos, sea cual sea el núcleo que ejecute el programa eBPF hola para cualquier evento kprobe de execve(). Ésta es la llamada del sistema a ppoll():
ppoll([{fd=8, events=POLLIN}, {fd=9, events=POLLIN}, {fd=10, events=POLLIN},
{fd=11, events=POLLIN}], 4, NULL, NULL, 0) = 1 ([{fd=8, revents=POLLIN}])
Como verás si intentas ejecutar tú mismo el programa de ejemplo, estas llamadas a ppoll() se bloquean hasta que hay algo que leer de uno de los descriptores de archivo. No verás el código de retorno escrito en la pantalla hasta que algo active execve(), lo que hace que el programa eBPF escriba los datos que el espacio de usuario recupera mediante esta llamada ppoll().
En el Capítulo 2 mencioné que si tienes un kernel de la versión 5.8 o superior, ahora se prefieren los búferes en anillo BPF a los búferes perf.4 Veamos una versión modificada del mismo código de ejemplo que utiliza una memoria cíclica.
Búferes de anillo
Como se explica en en la documentación del núcleo, se prefieren los búferes en anillo a los búferes perf, en parte por razones de rendimiento, pero también para garantizar que se conserva el orden de los datos, aunque éstos sean enviados por distintos núcleos de la CPU. Sólo hay un búfer, compartido por todos los núcleos.
No son necesarios muchos cambios para convertir hello-buffer-config.py para que utilice un buffer anular. En el repositorio GitHub adjunto encontrarás este ejemplo como chapter4/hello-ring-buffer-config.py. La Tabla 4-2 muestra las diferencias.
| hola-buffer-config.py | hola-anillo-buffer-config.py |
|---|---|
BPF_PERF_OUTPUT(output); |
BPF_RINGBUF_OUTPUT(output, 1); |
output.perf_submit(ctx, &data, sizeof(data)); |
output.ringbuf_output(&data, sizeof(data), 0); |
b["output"]. |
b["output"]. |
b.perf_buffer_poll() |
b.ring_buffer_poll() |
Como era de esperar, dado que estos cambios sólo afectan al búfer output, las llamadas al sistema relacionadas con la carga del programa y del mapa config y la conexión del programa al evento kprobe permanecen sin cambios.
La llamada al sistema bpf() que crea el mapa de búferes de anillo output tiene el siguiente aspecto:
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_RINGBUF, key_size=0, value_size=0,
max_entries=4096, ... map_name="output", ...}, 128) = 4
La principal diferencia en la salida strace es que no hay rastro de la serie de cuatro llamadas al sistema diferentes perf_event_open(), ioctl() y bpf(BPF_MAP_UPDATE_ELEM) que observaste durante la configuración de un búfer perf. Para un búfer en anillo, sólo hay un descriptor de archivo compartido por todos los núcleos de la CPU.
En el momento de escribir esto, BCC utiliza el mecanismo ppoll que mostré antes para los búferes perf, pero utiliza el mecanismo más nuevo epoll para esperar los datos del búfer de anillo. Aprovechemos esto para entender la diferencia entre ppoll y epoll.
En el ejemplo del búfer perf, mostré que hello-buffer-config.py generaba una llamada al sistema ppoll(), como ésta:
ppoll([{fd=8, events=POLLIN}, {fd=9, events=POLLIN}, {fd=10, events=POLLIN},
{fd=11, events=POLLIN}], 4, NULL, NULL, 0) = 1 ([{fd=8, revents=POLLIN}])
Observa que esto pasa el conjunto de descriptores de archivo 8, 9, 10, y 11 de los que el proceso del espacio de usuario quiere recuperar datos. Cada vez que este evento de sondeo devuelve datos, hay que hacer otra llamada a ppoll() para configurar de nuevo el mismo conjunto de descriptores de archivo. Cuando se utiliza epoll, el conjunto de descriptores de archivo se gestiona en un objeto del núcleo.
Puedes verlo en la siguiente secuencia de llamadas al sistema relacionadas con epoll que se realizan cuando hello-ring-buffer-config.py está configurando el acceso al búfer de anillo output.
En primer lugar, el programa del espacio de usuario pide que se cree una nueva instancia de epoll en el núcleo:
epoll_create1(EPOLL_CLOEXEC) = 8
Esto devuelve el descriptor de archivo 8. A continuación, se realiza una llamada a epoll_ctl(), que indica al núcleo que añada el descriptor de archivo 4 (el búfer output ) al conjunto de descriptores de archivo de esa instancia epoll:
epoll_ctl(8, EPOLL_CTL_ADD, 4, {events=EPOLLIN, data={u32=0, u64=0}}) = 0
El programa del espacio de usuario utiliza epoll_pwait() para esperar hasta que los datos estén disponibles en el búfer del anillo. Esta llamada sólo vuelve cuando hay datos disponibles:
epoll_pwait(8, [{events=EPOLLIN, data={u32=0, u64=0}}], 1, -1, NULL, 8) = 1
Por supuesto, si estás escribiendo código utilizando un framework como BCC (o libbpf o cualquiera de las otras bibliotecas que describiré más adelante en este libro), realmente no necesitas conocer estos detalles subyacentes sobre cómo tu aplicación de espacio de usuario obtiene información del núcleo a través de perf o ring buffers. Espero que te haya resultado interesante echar un vistazo bajo las sábanas para ver cómo funcionan estas cosas.
Sin embargo, es muy posible que te encuentres escribiendo código que acceda a un mapa desde el espacio de usuario, y puede ser útil ver un ejemplo de cómo se consigue. Anteriormente en este capítulo, utilicé bpftool para examinar el contenido del mapa config. Como se trata de una utilidad que se ejecuta en el espacio de usuario, utilicemos strace para ver qué llamadas al sistema realiza para recuperar esta información.
Leer información de un mapa
El siguiente comando muestra un extracto de las llamadas al sistema bpf() que realiza bpftool al leer el contenido del mapa config:
$ strace -e bpf bpftool map dump name config
Como verás, la secuencia consta de dos pasos principales:
Recorre todos los mapas buscando los que tengan el nombre
config.Si se encuentra un mapa coincidente, itera por todos los elementos de ese mapa.
Encontrar un mapa
La salida comienza con una secuencia repetida de llamadas similares, a medida que bpftool recorre todos los mapas buscando alguno con el nombre config:
bpf(BPF_MAP_GET_NEXT_ID, {start_id=0,...}, 12) = 0
bpf(BPF_MAP_GET_FD_BY_ID, {map_id=48...}, 12) = 3
bpf(BPF_OBJ_GET_INFO_BY_FD, {info={bpf_fd=3, ...}}, 16) = 0
bpf(BPF_MAP_GET_NEXT_ID, {start_id=48, ...}, 12) = 0
bpf(BPF_MAP_GET_FD_BY_ID, {map_id=116, ...}, 12) = 3
bpf(BPF_OBJ_GET_INFO_BY_FD, {info={bpf_fd=3...}}, 16) = 0
BPF_MAP_GET_NEXT_IDobtiene el ID del siguiente mapa después del valor especificado en .start_idBPF_MAP_GET_FD_BY_IDdevuelve el descriptor de archivo del ID de mapa especificado.BPF_OBJ_GET_INFO_BY_FDrecupera información sobre el objeto (en este caso, el mapa) al que hace referencia el descriptor de archivo. Esta información incluye su nombre para que pueda comprobar si se trata del mapa que está buscando.bpftool- La secuencia se repite, obteniendo el ID del siguiente mapa después del del paso 1.
Hay un grupo de estas tres llamadas al sistema para cada mapa cargado en el núcleo, y también deberías ver que los valores utilizados para start_id y map_id coinciden con los ID de esos mapas. El patrón repetido termina cuando ya no quedan más mapas que consultar, lo que hace que BPF_MAP_GET_NEXT_ID devuelva un valor de ENOENT, como éste:
bpf(BPF_MAP_GET_NEXT_ID, {start_id=133,...}, 12) = -1 ENOENT (No such file or
directory)
Si se ha encontrado un mapa coincidente, bpftool guarda su descriptor de archivo para poder leer los elementos de ese mapa.
Lectura de elementos del mapa
En este punto, bpftool tiene una referencia de descriptor de archivo al mapa o mapas de los que va a leer. Veamos la secuencia de la llamada al sistema para leer esa información:
bpf(BPF_MAP_GET_NEXT_KEY, {map_fd=3, key=NULL,
next_key=0xaaaaf7a63960}, 24) = 0
bpf(BPF_MAP_LOOKUP_ELEM, {map_fd=3, key=0xaaaaf7a63960,
value=0xaaaaf7a63980, flags=BPF_ANY}, 32) = 0
[{
"key": 0,
"value": {
"message": "Hey root!"
}
bpf(BPF_MAP_GET_NEXT_KEY, {map_fd=3, key=0xaaaaf7a63960,
next_key=0xaaaaf7a63960}, 24) = 0
bpf(BPF_MAP_LOOKUP_ELEM, {map_fd=3, key=0xaaaaf7a63960,
value=0xaaaaf7a63980, flags=BPF_ANY}, 32) = 0
},{
"key": 501,
"value": {
"message": "Hi user 501!"
}
bpf(BPF_MAP_GET_NEXT_KEY, {map_fd=3, key=0xaaaaf7a63960,
next_key=0xaaaaf7a63960}, 24) = -1 ENOENT (No such file or directory)
}
]
+++ exited with 0 +++
- En primer lugar, la aplicación necesita encontrar una clave válida que esté presente en el mapa. Para ello, utiliza la versión
BPF_MAP_GET_NEXT_KEYde la llamada al sistemabpf(). El argumentokeyes un puntero a una clave, y la llamada al sistema devolverá la siguiente clave válida después de ésta. Al pasar un puntero NULL, la aplicación está solicitando la primera clave válida del mapa. El núcleo escribe la clave en la ubicación especificada por el punteronext_key. - Dada una clave, la aplicación solicita el valor asociado, que se escribe en la ubicación de memoria especificada por
value. - En este punto,
bpftooltiene el contenido del primer par clave-valor, y escribe esta información en la pantalla. - Aquí,
bpftoolpasa a la siguiente clave del mapa, recupera su valor y escribe este par clave-valor en la pantalla. - La siguiente llamada a
BPF_MAP_GET_NEXT_KEYdevuelveENOENTpara indicar que no hay más entradas en el mapa. - Aquí,
bpftoolfinaliza la salida escrita en pantalla y sale.
Observa que aquí, a bpftool se le ha asignado el descriptor de archivo 3 para que corresponda al mapa config. Éste es el mismo mapa al que hello-buffer-config.py hace referencia con el descriptor de archivo 4. Como ya he mencionado, los descriptores de archivo son específicos de cada proceso.
Este análisis del comportamiento de bpftool muestra cómo un programa de espacio de usuario puede iterar por los mapas disponibles y por los pares clave-valor almacenados en un mapa.
Resumen
En este capítulo has visto cómo el código del espacio de usuario utiliza la llamada al sistema bpf() para cargar programas y mapas eBPF. Has visto cómo se crean programas y mapas utilizando los comandos BPF_PROG_LOAD y BPF_MAP_CREATE.
Aprendiste que el núcleo lleva un registro del número de referencias a programas y mapas eBPF, liberándolos cuando el recuento de referencias desciende a cero. También se te presentaron los conceptos de fijar objetos BPF a un sistema de archivos y utilizar enlaces BPF para crear referencias adicionales.
Has visto un ejemplo de BPF_MAP_UPDATE_ELEM utilizado para crear entradas en un mapa desde el espacio de usuario. Existen comandos similares -BPF_MAP_LOOKUP_ELEM y BPF_MAP_DELETE_ELEM- para recuperar y borrar valores de un mapa. También existe el comando BPF_MAP_GET_NEXT_KEY para encontrar la siguiente clave presente en un mapa. Puedes utilizarlo para recorrer todas las entradas válidas.
Has visto ejemplos de programas de espacio de usuario que utilizan perf_event_open() y ioctl() para adjuntar programas eBPF a eventos kprobe. El método de conexión puede ser muy diferente para otros tipos de programas eBPF, y algunos de ellos incluso utilizan la llamada al sistema bpf(). Por ejemplo, hay una llamada al sistema bpf(BPF_PROG_ATTACH) que puede utilizarse para adjuntar programas cgroup, y bpf(BPF_RAW_TRACEPOINT_OPEN) para tracepoints sin procesar (consulta el Ejercicio 5 al final de este capítulo).
También mostré cómo puedes utilizar BPF_MAP_GET_NEXT_ID, BPF_MAP_GET_FD_BY_ID, y BPF_OBJ_GET_INFO_BY_FD para localizar objetos de mapa (y otros) que tenga el núcleo.
Hay otros comandos de bpf() que no he tratado en este capítulo, pero lo que has visto aquí es suficiente para tener una buena visión general.
También has visto cómo se cargaban algunos datos BTF en el núcleo, y he mencionado que bpftool utiliza esta información para entender el formato de las estructuras de datos y poder imprimirlas bien. Todavía no he explicado qué aspecto tienen los datos BTF ni cómo se utilizan para que los programas eBPF sean portables entre versiones del núcleo. Eso lo veremos en el próximo capítulo.
Ejercicios
Aquí tienes algunas cosas que puedes probar si quieres explorar más a fondo la llamada al sistema bpf():
Confirma que el campo
insn_cntde una llamada al sistemaBPF_PROG_LOADse corresponde con el número de instrucciones que salen si vuelcas el código de bytes eBPF traducido de ese programa utilizandobpftool. (Esto es como se documenta en la página de manual de la llamada al sistemabpf().)Ejecuta dos instancias del programa de ejemplo para que haya dos mapas llamados
config. Si ejecutasbpftool map dump name config, la salida incluirá información sobre los dos mapas diferentes, así como su contenido. Ejecútalo constrace, y sigue el uso de los diferentes descriptores de archivo a través de la salida de la llamada al sistema. ¿Puedes ver dónde está recuperando información sobre un mapa y dónde está recuperando los pares clave-valor almacenados en él?Utiliza
bpftool map updatepara modificar el mapaconfigmientras se ejecuta uno de los programas de ejemplo. Utilizasudo -u usernamepara comprobar que estos cambios de configuración son recogidos por el programa eBPF.Mientras se ejecuta hello-buffer-config.py, utiliza
bpftoolpara fijar el programa al sistema de archivos BPF, de la siguiente manera:bpftool prog pin name hello /sys/fs/bpf/hi
Sal del programa en ejecución y comprueba que el programa hola sigue cargado en el núcleo utilizando
bpftool prog list. Puedes limpiar el enlace eliminando el pin conrm /sys/fs/bpf/hi.Conectarse a un tracepoint sin procesar es considerablemente más sencillo a nivel de llamada al sistema que conectarse a una kprobe, ya que simplemente implica una llamada al sistema
bpf(). Intenta convertir hello-buffer-config.py para adjuntarlo al tracepoint sin procesar parasys_enter, utilizando la macroRAW_TRACEPOINT_PROBEde BCC (si hiciste los ejercicios del Capítulo 2, ya tendrás un programa adecuado que puedes utilizar). No necesitarás adjuntar explícitamente el programa en el código Python, ya que BCC se encargará de ello por ti. Ejecutándolo bajostrace, deberías ver una syscall similar a ésta:bpf(BPF_RAW_TRACEPOINT_OPEN, {raw_tracepoint={name="sys_enter", prog_fd=6}}, 128) = 7El tracepoint en el núcleo tiene el nombre
sys_enter, y se le está adjuntando el programa eBPF con el descriptor de archivo6. A partir de ahora, siempre que la ejecución en el núcleo alcance ese tracepoint, activará el programa eBPF.Ejecuta la aplicación opensnoop del conjunto de herramientas libbpf de BCC. Esta herramienta establece algunos enlaces BPF que puedes ver con
bpftool, como éste:$ bpftool link list 116: perf_event prog 1849 bpf_cookie 0 pids opensnoop(17711) 117: perf_event prog 1851 bpf_cookie 0 pids opensnoop(17711)Confirma que los ID de los programas (1849 y 1851 en mi ejemplo de salida aquí) coinciden con la salida de la lista de los programas eBPF cargados:
$ bpftool prog list ... 1849: tracepoint name tracepoint__syscalls__sys_enter_openat tag 8ee3432dcd98ffc3 gpl run_time_ns 95875 run_cnt 121 loaded_at 2023-01-08T15:49:54+0000 uid 0 xlated 240B jited 264B memlock 4096B map_ids 571,568 btf_id 710 pids opensnoop(17711) 1851: tracepoint name tracepoint__syscalls__sys_exit_openat tag 387291c2fb839ac6 gpl run_time_ns 8515669 run_cnt 120 loaded_at 2023-01-08T15:49:54+0000 uid 0 xlated 696B jited 744B memlock 4096B map_ids 568,571,569 btf_id 710 pids opensnoop(17711)Mientras opensnoop está en marcha, intenta fijar uno de estos enlaces con
bpftool link pin id 116 /sys/fs/bpf/mylink(utilizando uno de los ID de enlace que veas salir debpftool link list). Deberías ver que incluso después de terminar opensnoop, tanto el enlace como el programa correspondiente permanecen cargados en el núcleo.Si pasas al código de ejemplo del Capítulo 5, encontrarás una versión de hello-buffer-config.py escrita utilizando la biblioteca libbpf. Esta biblioteca establece automáticamente un enlace BPF con el programa que carga en el núcleo. Utiliza
stracepara inspeccionar las llamadas al sistemabpf()que realiza, y consulta las llamadas al sistemabpf(BPF_LINK_CREATE).
1 Si quieres ver el conjunto completo de comandos BPF, están documentados en el archivo de cabecera linux/bpf.h.
2 BTF se introdujo en el kernel 5.1, pero ha sido retroportado en algunas distribuciones de Linux, como puedes ver en este debate.
3 Se definen en el enumerador bpf_attach_type de linux/bpf.h.
4 Recuerda que para más información sobre la diferencia, lee la entrada del blog "BPF ring buffer" de Andrii Nakryiko.
Get Aprendizaje eBPF now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

