Capítulo 6. Preprocesamiento
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
En el Capítulo 5 vimos cómo crear conjuntos de datos de entrenamiento para el aprendizaje automático. Éste es el primer paso del proceso estándar de procesamiento de imágenes (véase la Figura 6-1). La siguiente etapa consiste en preprocesar las imágenes en bruto para introducirlas en el modelo de entrenamiento o inferencia. En este capítulo, veremos por qué es necesario preprocesar las imágenes, cómo configurar el preprocesamiento para garantizar la reproducibilidad en la producción, y formas de implementar diversas operaciones de preprocesamiento en Keras/TensorFlow.
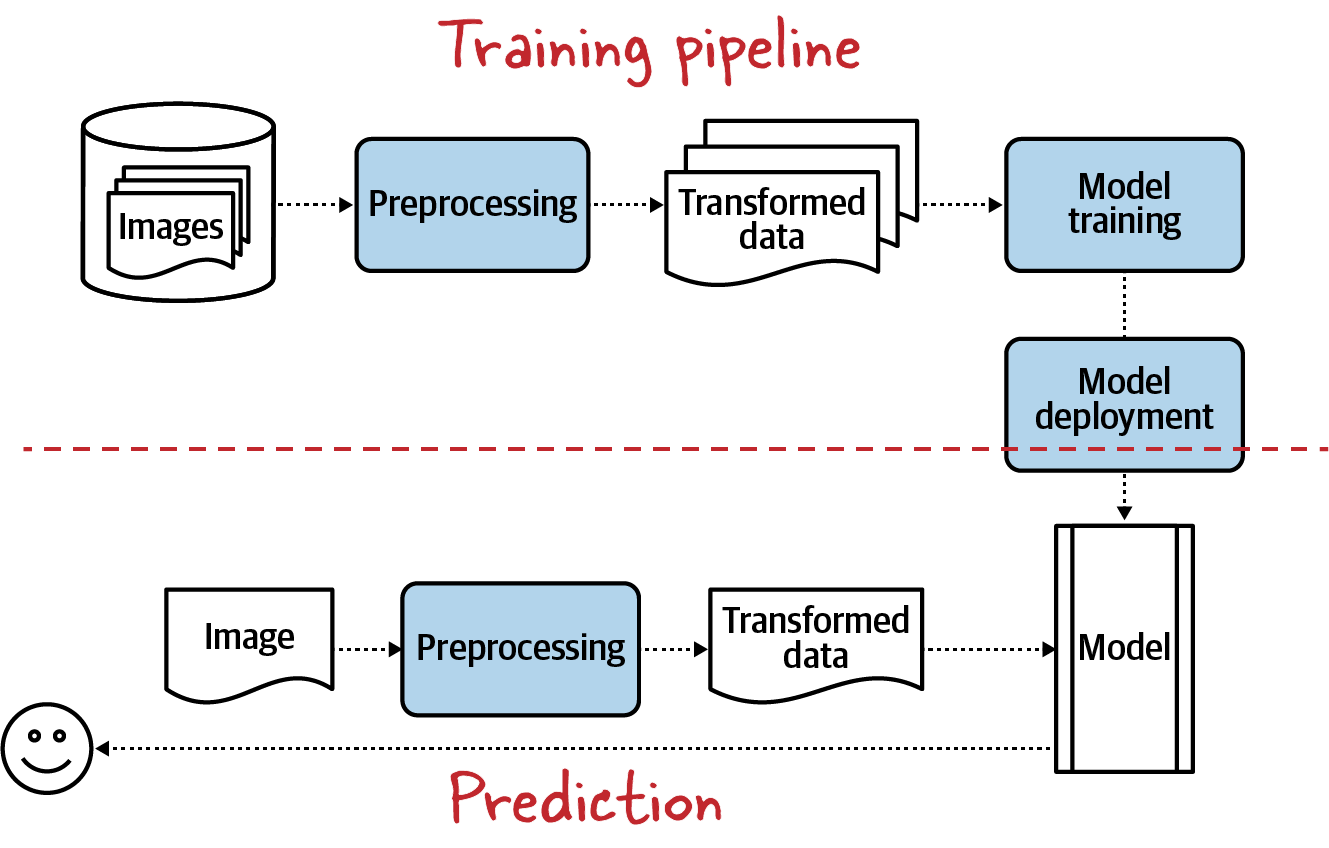
Figura 6-1. Las imágenes en bruto tienen que ser preprocesadas antes de introducirlas en el modelo, tanto durante el entrenamiento (arriba) como durante la predicción (abajo).
Consejo
El código de este capítulo está en la carpeta 06_preprocesamiento del repositorio GitHub del libro. Proporcionaremos los nombres de archivo de los ejemplos de código y de los cuadernos cuando proceda.
Razones para el preprocesamiento
Antes de introducir imágenes en bruto en un modelo de imagen, normalmente hay que preprocesarlas. Este preprocesamiento tiene varios objetivos que se solapan: transformación de la forma, calidad de los datos y calidad del modelo.
Transformación de la forma ...
Get Aprendizaje automático práctico para visión por ordenador now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

