Capítulo 1. Fundamentos de Kali Linux
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Kali Linux es una distribución especializada del sistema operativo Linux basada en Ubuntu Linux, que a su vez se basa en Debian Linux. Kali está dirigida a personas que quieran dedicarse a tareas de seguridad. Puede tratarse de pruebas de seguridad, desarrollo de exploits o ingeniería inversa, o análisis forense digital. Una idea a tener en cuenta sobre las distribuciones de Linux es que no son lo mismo. Linux es en realidad sólo el núcleo, el sistema operativo real y el núcleo de la distribución. Cada distribución pone capas de software adicional sobre ese núcleo, lo que la hace única. En el caso de Kali, lo que se superpone no son sólo las utilidades esenciales, sino también cientos de paquetes de software específicos para el trabajo de seguridad.
Una de las características realmente buenas de Linux, especialmente en comparación con otros sistemas operativos, es que es casi completamente personalizable. Esto incluye la selección del intérprete de comandos desde el que ejecutas los programas, que incluye el entorno del terminal donde escribes los comandos, así como el escritorio gráfico que utilizas. Incluso más allá de eso, puedes cambiar el aspecto de cada uno de esos elementos una vez que hayas seleccionado el entorno. Utilizar Linux te permite hacer que el sistema funcione de la forma que tú quieras en beneficio de tu estilo de trabajo, en lugar de que el sistema fuerce tu forma de funcionar por cómo funciona, se ve y se siente.
En realidad, Linux tiene una larga historia, si te remontas a sus inicios. Comprender esta historia te ayudará a entender por qué Linux es como es, especialmente los comandos aparentemente arcanos que se utilizan para gestionar el sistema, manipular archivos y simplemente hacer el trabajo.
Herencia de Linux
Érase una vez, en la época de los dinosaurios o al menos de los ordenadores del tamaño de un frigorífico, un sistema operativo llamado Multics. Este proyecto de sistema operativo, iniciado en 1964, fue desarrollado por el Instituto Tecnológico de Massachusetts (MIT), General Electric (GE) y los Laboratorios Bell. El objetivo de Multics era admitir múltiples usuarios y ofrecer compartimentación de procesos y archivos por usuario. Al fin y al cabo, era una época en la que el hardware informático necesario para ejecutar sistemas operativos como Multics costaba millones de dólares. Como mínimo, el hardware informático costaba cientos de miles de dólares. Como punto de comparación, un sistema de 7 millones de dólares de entonces costaría unos 62 millones en abril de 2023. Tener un sistema que sólo pudiera soportar un único usuario a la vez no era rentable, por lo que los fabricantes de ordenadores como GE estaban interesados en desarrollar Multics junto con organizaciones de investigación como el MIT y los Laboratorios Bell.
Inevitablemente, debido a las complejidades y a los intereses contrapuestos de los participantes, el proyecto se fue desmoronando poco a poco, aunque el sistema operativo acabó publicándose. Uno de los programadores asignados al proyecto desde los Laboratorios Bell volvió a su trabajo habitual y finalmente decidió escribir su propia versión de un sistema operativo para poder jugar a un juego que había escrito originalmente para Multics pero que quería jugar en un PDP-7 que estaba disponible en los Laboratorios Bell. El juego se llamaba Space Travel, y el programador de, Ken Thompson, necesitaba un entorno decente para volver a desarrollar el juego para el PDP-7. En aquellos días, los sistemas eran en gran medida incompatibles. Tenían instrucciones de hardware (códigos de operación) totalmente diferentes, y a veces tenían diferentes tamaños de palabra de memoria, a lo que hoy solemos referirnos como tamaño de bus. Como resultado, los programas escritos para un entorno, sobre todo si se utilizaban lenguajes de muy bajo nivel, no funcionaban en otro entorno. El entorno resultante de recibió el nombre de Unics. Con el tiempo, otros programadores de los Bell Labs se unieron al proyecto, y éste pasó a llamarse Unix.
Unix tenía un diseño sencillo. Como se desarrolló como un entorno de programación para un único usuario a la vez, acabó siendo utilizado, primero dentro de los Laboratorios Bell y luego fuera, por otros programadores. Una de las mayores ventajas de Unix sobre otros sistemas operativos fue que el núcleo se reescribió en el lenguaje de programación C en 1972. Utilizar un lenguaje de más alto nivel que el ensamblador, que era más común entonces, lo hizo portable a través de múltiples sistemas de hardware. En lugar de limitarse al PDP-7, Unix podía funcionar en cualquier sistema que tuviera un compilador de C para compilar el código fuente necesario para construir Unix. Esto permitió disponer de un sistema operativo estándar en numerosas plataformas de hardware.
Nota
El lenguaje ensamblador es lo más parecido a escribir en algo que entienda directamente la máquina sin recurrir al binario. El lenguaje ensamblador comprende mnemónicos, que son la forma en que los humanos se refieren a las operaciones que entiende el procesador. El mnemotécnico suele ser una palabra corta que describe la operación. La instrucción CMP, por ejemplo, compara dos valores. La instrucción MOV mueve datos de una ubicación a otra. El lenguaje ensamblador te da un control total sobre el funcionamiento del programa, ya que se traduce directamente al lenguaje máquina: los valores binarios de las operaciones del procesador y las direcciones de memoria.
Además de tener un diseño sencillo, Unix tenía la ventaja de distribuirse con el código fuente. Esto permitía a los investigadores no sólo leer el código fuente para comprenderlo mejor, sino también ampliarlo y mejorarlo. El lenguaje ensamblador, que se utilizaba antes, puede ser muy difícil de leer sin mucho tiempo y experiencia. Los lenguajes de alto nivel como C facilitan considerablemente la lectura del código fuente. Unix ha engendrado muchos sistemas operativos hijos que se comportaban igual que Unix, con la misma funcionalidad. En algunos casos, estas otras distribuciones de sistemas operativos empezaron con el código fuente de Unix que proporcionó AT&T. En otros casos, Unix se sometió esencialmente a ingeniería inversa basándose en la funcionalidad documentada y fue el punto de partida de dos populares sistemas operativos similares a Unix: BSD y Linux.
Nota
Como verás más adelante, una de las ventajas del diseño Unix -utilizar programas pequeños y sencillos que hacen una cosa pero te permiten introducir la salida de uno en la entrada de otro- es la potencia que proporciona el encadenamiento. Un uso común de esta decisión de diseño es obtener una lista de procesos utilizando una utilidad e introduciendo la salida en otra utilidad que procesará esa salida, buscando específicamente una entrada o manipulando la salida para eliminar parte de ella y hacerla más fácil de entender.
Sobre Linux
A medida que se difundía Unix, la sencillez de su diseño y su enfoque como entorno de programación, aunque principalmente la disponibilidad del código fuente, hizo que se enseñara en los programas de informática de todo el mundo. En los años 80 se escribieron varios libros sobre diseño de sistemas operativos basados en el diseño de Unix. Aunque utilizar el código fuente original violaría los derechos de autor, la extensa documentación y la simplicidad del diseño permitieron desarrollar clones. Una de estas implementaciones fue escrita por Andrew Tannenbaum para su libro Operating Systems: Design and Implementation (Prentice Hall, 1987). Esta implementación, llamada Minix, fue la base para el desarrollo de Linux por parte de Linus Torvalds. Lo que Torvalds desarrolló fue el núcleo Linux, que algunos consideran el sistema operativo. El núcleo permite gestionar el hardware, incluido el procesador, que permite ejecutar procesos a través de la unidad central de procesamiento (CPU). No ofrecía a los usuarios la posibilidad de interactuar con el sistema operativo, es decir, de ejecutar programas.
El Proyecto GNU, iniciado a finales de los 70 por Richard Stallman, tenía una colección de programas que, o bien eran duplicados de las utilidades estándar de Unix, o bien eran funcionalmente iguales con nombres diferentes. El Proyecto GNU escribía programas principalmente en C, lo que significaba que se podían portar fácilmente. Como resultado, Torvalds, y más tarde otros desarrolladores, agruparon las utilidades del Proyecto GNU con su núcleo para crear una distribución completa de software que cualquiera pudiera desarrollar e instalar en su sistema informático. La colección de utilidades GNU se denomina a veces (o al menos históricamente) userland. Las utilidades de userland son la forma en que los usuarios interactúan con el sistema.
Linux heredó la mayoría de los ideales de diseño de Unix, principalmente porque se inició como algo funcionalmente idéntico al Unix estándar que había sido desarrollado por AT&T y fue reimplementado por un pequeño grupo de la Universidad de California en Berkeley como la Berkeley Systems Distribution (BSD). Esto significaba que cualquier persona familiarizada con el funcionamiento de Unix o incluso de BSD podía empezar a utilizar Linux y ser inmediatamente productiva. Durante las décadas transcurridas desde que Torvalds publicó Linux por primera vez, se han iniciado muchos proyectos para aumentar la funcionalidad y facilidad de uso de Linux. Esto incluye varios entornos de escritorio, todos los cuales se asientan sobre el sistema X/Windows, que fue desarrollado por primera vez por el MIT (que, de nuevo, participó en el desarrollo de Multics).
El propio desarrollo de Linux, es decir, el núcleo, ha cambiado la forma de trabajar de los desarrolladores. Por ejemplo, Torvalds no estaba satisfecho con las capacidades de los sistemas de repositorio de software que permitían a los desarrolladores concurrentes trabajar en los mismos archivos al mismo tiempo. Como resultado, Torvalds lideró el desarrollo de Git, un sistema de control de versiones que ha suplantado en gran medida a otros sistemas de control de versiones para el desarrollo de código abierto. Hoy en día, si quieres obtener la versión actual del código fuente de la mayoría de los proyectos de código abierto, es probable que te ofrezcan acceso a través de Git. Además, ahora existen repositorios públicos para que los proyectos almacenen su código que admiten el uso de Git, un gestor de código fuente, para acceder al código. Incluso fuera de los proyectos de código abierto, muchas empresas (si no la mayoría) han trasladado sus sistemas de control de versiones a Git por su enfoque moderno y descentralizado de la gestión del código fuente.
Linux está disponible, generalmente de forma gratuita, en distribuciones. Una distribución de Linux es una colección de paquetes de software que han sido seleccionados por los mantenedores de la distribución. Además, los paquetes de software se han construido de una forma determinada, con características determinadas por el mantenedor del paquete. Estos paquetes de software se adquieren como código fuente, y muchos paquetes pueden tener múltiples opciones -si incluir soporte de base de datos, qué tipo de base de datos, si activar el cifrado- que tienen que activarse cuando se configura y construye el paquete. El responsable del paquete de una distribución puede elegir opciones distintas a las del responsable del paquete de otra distribución.
Las distintas distribuciones también tendrán distintos formatos de paquetes. Por ejemplo, RedHat y sus distribuciones asociadas, como RedHat Enterprise Linux (RHEL) y Fedora Core, utilizan el formato Red Hat Package Manager (RPM). Además, Red Hat utiliza tanto la utilidad RPM como Yellowdog Updater Modified (yum) para gestionar los paquetes del sistema. Otras distribuciones pueden utilizar las diferentes utilidades de gestión de paquetes que utiliza Debian. Debian utiliza la Herramienta avanzada de paquetes (APT) para gestionar los paquetes en el formato de paquetes de Debian. Independientemente de la distribución o del formato del paquete, el objetivo de los paquetes es reunir todos los archivos necesarios para que el software funcione y hacer que esos archivos sean fáciles de colocar para que el software sea funcional. Dado que, en última instancia, Kali Linux hereda de Debian, a través de Ubuntu, Kali también utiliza APT para la gestión de paquetes, tanto desde la perspectiva del formato de paquete que admite como de las herramientas que se utilizan para gestionar los paquetes.
A lo largo de los años, otra diferencia entre distribuciones ha venido con el entorno de escritorio que proporciona por defecto la distribución. En los últimos años, las distribuciones han creado sus propios puntos de vista personalizados sobre los entornos de escritorio existentes. Ya sea el GNU Object Model Environment (GNOME), el K Desktop Environment (KDE), o Xfce, todos pueden personalizarse con temas y fondos de pantalla y organización de menús y paneles. A menudo, las distribuciones ofrecen su propia versión de un entorno de escritorio diferente. Algunas distribuciones, como ElementaryOS, incluso han proporcionado su propio entorno de escritorio, llamado Pantheon.
Aunque al final el resultado de los gestores de paquetes es el mismo, a veces la elección del gestor de paquetes o incluso del entorno de escritorio puede marcar la diferencia para los usuarios. Además, la profundidad del repositorio de paquetes puede marcar la diferencia para algunos usuarios. Puede que quieran tener muchas opciones de software que puedan instalar a través delrepositorio en lugar de intentar construir el software a mano e instalarlo. Las distintas distribuciones pueden tener repositorios más pequeños, aunque se basen en las mismas utilidades y formatos de gestión de paquetes que otras distribuciones. Debido a las dependencias de software que deben instalarse antes de que funcione el software que buscas, los paquetes no siempre son compatibles incluso entre distribuciones relacionadas.
A veces, las distintas distribuciones se centrarán en grupos específicos de usuarios, en lugar de ser distribuciones de uso general para cualquiera que quiera un escritorio. Más allá de eso, distribuciones como Ubuntu tendrán incluso distribuciones de instalación separadas por versión, como una para una instalación de servidor y otra para una instalación de escritorio. Una instalación de escritorio suele incluir una interfaz gráfica de usuario (GUI), mientras que una instalación de servidor no la tendrá y, en consecuencia, instalará muchos menos paquetes. Cuantos menos paquetes, menor exposición a los ataques, y los servidores son a menudo donde se almacena la información sensible; también son sistemas que pueden estar más expuestos a usuarios no autorizados porque proporcionan servicios de red que no suelen encontrarse en los sistemas de escritorio.
Kali Linux es una distribución adaptada específicamente a un tipo concreto de usuario: alguien interesado en la seguridad de la información y en el abanico de capacidades que se engloban bajo ese paraguas increíblemente amplio. Kali Linux, como distribución centrada en funciones de seguridad, entra en la categoría de escritorio, y no hay intención de limitar el número de paquetes que se instalan para que Kali sea más difícil de atacar. Alguien centrado en pruebas de seguridad probablemente necesitará una amplia variedad de paquetes de software, y Kali carga su distribución desde el principio. Esto puede parecer ligeramente irónico, teniendo en cuenta que las distribuciones que se centran en mantener sus sistemas a salvo de ataques (a veces llamadas erróneamente seguras) tienden a limitar los paquetes mediante un proceso llamado hardening. Kali, sin embargo, se centra en las pruebas más que en mantener la distribución a salvo de ataques.
El mantenimiento de Kali Linux corre a cargo de Offensive Security, una empresa de consultoría y formación en seguridad. Además, es conocida por la certificación Offensive Security Certified Professional (OSCP), que se conoce como una certificación muy práctica para las personas interesadas en la seguridad ofensiva: pruebas de penetración y red teaming, por ejemplo.
Adquisición e instalación de Kali Linux
La forma más sencilla de adquirir Kali Linux es visitar su sitio web. Desde allí, puedes obtener información adicional sobre el software, como listas de paquetes instalados. Descargarás una imagen ISO que se puede utilizar como si estuvieras instalando en una máquina virtual (VM), o se puede grabar en un DVD para instalar en una máquina física.
Kali Linux se basa en Debian. Esto no siempre fue así. Hubo un tiempo en que Kali se llamaba BackTrack Linux. BackTrack se basaba en Knoppix Linux, que es principalmente una distribución en vivo, lo que significa que se diseñó para arrancar desde un CD, DVD o memoria USB y ejecutarse desde el medio de origen en lugar de instalarse en un disco duro de destino. Knoppix, a su vez, hereda de Debian. BackTrack era, al igual que Kali Linux, una distribución centrada en las pruebas de penetración y el análisis forense digital. La última versión de BackTrack se publicó en 2012, antes de que el equipo de Seguridad Ofensiva tomara la idea de BackTrack y la reconstruyera para basarla en Debian Linux. Una de las funciones que Kali conserva y que estaba disponible en BackTrack es la capacidad de arranque en vivo. Cuando consigues un medio de arranque para Kali, puedes elegir entre instalar o arrancar en vivo. En la Figura 1-1, puedes ver las opciones de arranque.
Figura 1-1. Pantalla de arranque de Kali Linux
Si arrancas desde el DVD o instalas en un disco duro es algo que depende totalmente de ti. Si arrancas desde el DVD y no tienes un directorio de inicio almacenado en algún soporte grabable, no podrás mantener nada de un arranque a otro. Si no tienes un soporte grabable en el que almacenar la información, empezarás desde cero cada vez que arranques. Esto tiene ventajas si no quieres dejar ningún rastro de lo que hiciste mientras el sistema operativo estaba funcionando. Si personalizas o quieres mantener claves SSH u otras credenciales almacenadas, tendrás que instalar en un medio local.
La instalación de Kali es sencilla. No tienes las opciones que tienen otras distribuciones. No seleccionarás categorías de paquetes. Kali tiene un conjunto definido de paquetes que se instalan. Puedes añadir más o quitar algunos, pero empiezas con un conjunto bastante completo de herramientas para pruebas de seguridad o análisis forenses. Lo que tienes que configurar en es seleccionar un disco en el que instalar y hacer que se particione y formatee. También tienes que configurar la red, incluido el nombre de host y si vas a utilizar una dirección estática en lugar del Protocolo de Configuración Dinámica de Host (DHCP). Una vez que hayas configurado eso y hayas establecido tu zona horaria, así como algunos otros ajustes de configuración fundamentales, se actualizarán los paquetes y estarás listo para arrancar con Linux.
Máquinas virtuales
El enfoque descrito puede funcionar muy bien en una máquina dedicada. Las máquinas dedicadas pueden ser caras. Incluso las máquinas de bajo coste cuestan algo; luego está el espacio y la energía necesarios para que la máquina funcione. En algunos casos, puede que necesites refrigeración, dependiendo del hardware que tengas instalado.
Afortunadamente, Kali no necesita su propio hardware. Funciona perfectamente dentro de una máquina virtual. Si tienes intención de jugar con pruebas de seguridad, y muy especialmente con pruebas de penetración, no es mala idea poner en marcha un laboratorio virtual. He descubierto que Kali funciona bastante bien con 4 GB de memoria y unos 20 GB de espacio en disco. Si quieres almacenar muchos artefactos de tus pruebas, puede que necesites más espacio en disco. Deberías poder arreglártelas con 2 GB de memoria para las tareas básicas, pero, obviamente, cuanta más memoria te sobre, mejor será el rendimiento. Algunos programas necesitarán más memoria para funcionar eficazmente.
Puedes elegir entre muchos hipervisores en función de tu sistema operativo anfitrión. VMware tiene hipervisores tanto para Mac como para PC. Parallels funcionará en Macs. VirtualBox, por otro lado, funciona en PC, Mac, sistemas Linux e incluso Solaris. VirtualBox existe desde 2007, pero fue adquirido por Sun Microsystems en 2008. Como Sun fue adquirida por Oracle, VirtualBox es mantenido actualmente por Oracle. Independientemente de quién lo mantenga, VirtualBox se puede descargar y utilizar gratuitamente. Si te estás iniciando en el mundo de las máquinas virtuales, éste puede ser el lugar adecuado para empezar. Cada hipervisor funciona de forma ligeramente distinta en cuanto a cómo interactúa con los usuarios: Diferentes teclas para salir de la máquina virtual. Diferentes niveles de interacción con el sistema operativo. Soporte diferente para los sistemas operativos invitados, ya que el hipervisor tiene que proporcionar los controladores para el invitado. Al final, todo se reduce a cuánto quieres gastar y con cuál de ellos te sientes cómodo.
Nota
Como posible punto de interés, o al menos de conexión, uno de los principales desarrolladores de BSD fue Bill Joy, que era estudiante de posgrado en la Universidad de California en Berkeley. Joy fue responsable de la primera implementación de TCP/IP en Berkeley Unix. Se convirtió en cofundador de Sun Microsystems en 1982 y, mientras estaba allí, escribió un artículo sobre un lenguaje de programación mejor que C++, que sirvió de inspiración para la creación de Java.
Una consideración son las herramientas que proporciona el hipervisor. Las herramientas son controladores que se instalan en el núcleo para integrarse mejor con el sistema operativo del anfitrión. Esto puede incluir controladores de impresión, controladores para compartir el sistema de archivos del anfitrión en el invitado y un mejor soporte de vídeo. Puedes utilizar las herramientas VMware que son de código abierto y están disponibles en el repositorio Kali Linux. También puedes obtener las herramientas de VirtualBox en el repositorio de Kali. Parallels, por otro lado, proporciona sus propias herramientas. Una ventaja de utilizar VMware es que los controladores de código abierto están disponibles en la mayoría, si no en todas, las distribuciones de Linux. En el pasado he tenido algunos problemas con la instalación de Parallels Tools en algunas versiones de Linux, aunque en general me gusta Parallels. Si no quieres escalar la pantalla automáticamente en la máquina virtual Kali ni compartir documentos entre la máquina anfitriona y la máquina virtual invitada, puede que no te interese ninguna de las herramientas de la máquina virtual.
Informática de bajo coste
Si prefieres no hacer una instalación desde cero pero te interesa utilizar una máquina virtual, puedes descargar una imagen de VMware o VirtualBox. Kali no sólo es compatible con entornos virtuales, sino también con dispositivos basados en Advanced RISC Machine (ARM), como la Raspberry Pi y la BeagleBone. La ventaja de utilizar las imágenes VM es que te permite ponerte en marcha más rápidamente. No tienes que tomarte el tiempo de hacer la instalación. En lugar de eso, descargas la imagen y la cargas en el hipervisor que hayas elegido y ya estás en marcha. Si prefieres utilizar una máquina virtual preconfigurada, puedes encontrar las imágenes en el sitio web de Kali.
Otra opción de bajo coste para ejecutar Kali Linux es una Raspberry Pi. El Pi es un ordenador de bajo coste y pequeño tamaño. Sin embargo, puedes descargar una imagen específica para la Pi. La Pi no utiliza un procesador Intel o AMD como los que verías en la mayoría de los sistemas de sobremesa. En su lugar, utiliza un procesador ARM. Estos procesadores utilizan un conjunto de instrucciones más pequeño y consumen menos energía que los procesadores que verías normalmente en los ordenadores de sobremesa. La Pi viene como una placa muy pequeña que cabe en la palma de la mano. Puedes conseguir varias carcasas en las que insertar la placa y luego equiparla con los periféricos que quieras, como un teclado, un ratón y un monitor.
Una de las ventajas de la Pi es que puede utilizarse en ataques físicos, teniendo en cuenta su pequeño tamaño. Puedes instalar Kali en la Pi y dejarla en un lugar en el que estés haciendo pruebas, pero necesita alimentación y algún tipo de conexión a la red. La Pi tiene una conexión Ethernet incorporada, una interfaz WiFi integrada y puertos USB. Una vez que tengas Kali instalado, podrás realizar ataques locales de forma remota accediendo a tu Pi desde dentro de la red. Hablaremos de ello más adelante.
Subsistema Windows para Linux
Mucha gente de utiliza Windows como sistema operativo principal y con razón, teniendo en cuenta su utilidad para la mayoría de las tareas de escritorio. Aunque las máquinas virtuales son una forma de tener Linux en cualquier sistema, Windows tiene una forma más directa de instalar Linux. En 2016, Windows lanzó el Subsistema Windows para Linux (WSL). Esta función de era una forma de ejecutar binarios en formato ejecutable y enlazable (ELF), que es el formato ejecutable por defecto de Linux, directamente en Windows. Ha habido dos versiones de WSL. La primera era una forma de implementar las llamadas al sistema de Linux directamente en el núcleo de Windows. Como la arquitectura del hardware no está en juego, ya que tanto Windows como los ejecutables de Linux se basan en la arquitectura del procesador Intel, la mayor consideración es la forma en que el núcleo de Linux gestiona el hardware. Esto se hace mediante llamadas al sistema. Las llamadas al sistema de Windows son diferentes de las de Linux. Implementar las llamadas al sistema de Linux en Windows es un paso importante para permitir que los ejecutables de Linux funcionen de forma casi nativa en Windows.
Más recientemente, Microsoft cambió la implementación. Las versiones de escritorio de Windows incluyen ahora un hipervisor ligero, que es una implementación de Hyper-V, antes disponible como hipervisor nativo en los servidores Windows. WSL se implementa ahora utilizando un núcleo Linux que se ejecuta en una máquina Hyper-V. Las aplicaciones Linux hacen llamadas directas al núcleo Linux en lugar de llamar al núcleo Windows. Uno de los motivos es que algunas de las llamadas al sistema Linux acabaron siendo difíciles de implementar en Windows. Implementar WSL en un entorno virtualizado proporciona aislamiento, de modo que las aplicaciones Linux no pueden afectar a las aplicaciones Windows porque se ejecutan en espacios de memoria separados.
Instalar WSL es fácil. Utilizando la línea de comandos, ya sea PowerShell o el antiguo Procesador de Comandos, ejecuta wsl --install. Puedes ver en la Figura 1-2 que Windows instalará por defecto una versión del núcleo de Ubuntu. Si ya tienes instalada una versión anterior de WSL, puedes convertirla a WSL2 utilizando wsl --upgrade. Se te indicará si estás ejecutando una versión antigua cuando intentes hacer muchas cosas con WSL, pero también puedes comprobarlo proactivamente utilizando wsl -l -v desde una ventana de PowerShell o del símbolo del sistema. Una vez instalado el entorno, puedes iniciarlo desde el menú de Windows. El entorno predeterminado de Ubuntu se llamará Ubuntu en el menú.
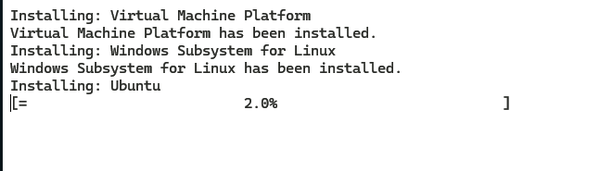
Figura 1-2. Instalación de WSL en PowerShell
Pero no queremos Ubuntu. Queremos Kali. Puedes encontrar Kali en la aplicación Microsoft Store. Si buscas Kali, lo verás como en la Figura 1-3. Sin embargo, al instalarlo no se instala toda la distribución. Instala la capacidad de ejecutar Kali Linux. Al abrir Kali Linux por primera vez en Windows, se instalará la imagen junto con la configuración de usuario que se te pedirá. Se te pedirá un nombre de usuario y una contraseña. Cuando posteriormente ejecutes Kali Linux, iniciarás sesión automáticamente en un intérprete de comandos.
Figura 1-3. Kali Linux en Microsoft Store
La imagen base de Kali en WSL es muy pequeña. No hay mucho instalado. Una gran ventaja de utilizar WSL2 es la posibilidad de ejecutar aplicaciones gráficas directamente en Windows. Esto no siempre fue así. Podías ejecutar programas de línea de comandos en Windows, pero ejecutar programas gráficos requería otro software para alojar esos programas gráficos. Hoy en día, Windows incluye la funcionalidad para alojar esos programas gráficos. Por eso, probablemente querrás instalar algunos metapaquetes para obtener programas adicionales. Para empezar, puede que quieras kali-linux-default. Instalará cientos de paquetes adicionales que te ayudarán a empezar. No tendrás un escritorio gráfico completo, pero podrás ejecutar programas gráficos directamente en Windows. Puedes verlo en la Figura 1-4, donde Ettercap se ejecuta como un programa gráfico fuera de Linux en el escritorio de Windows.
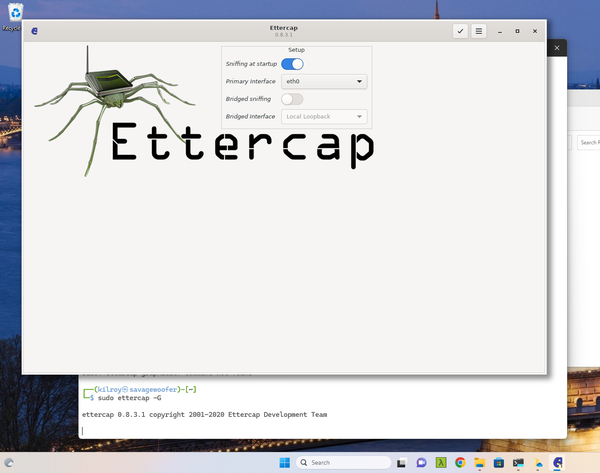
Figura 1-4. Ettercap funcionando en el Escritorio de Windows
WSL tiene algunas limitaciones. Lo notarás sobre todo si pretendes hacer pruebas inalámbricas. Necesitarás un sistema físico o virtual a través del cual puedas pasar una interfaz.
Con tantas opciones para empezar, debería ser fácil poner en marcha una instalación rápidamente. Una vez que tengas la instalación en marcha, querrás familiarizarte con el entorno de escritorio, si utilizas una opción que tenga un entorno de escritorio, para poder empezar a ser productivo.
Sobremesas
En vas a pasar mucho tiempo interactuando con el entorno de escritorio, así que será mejor que consigas algo con lo que te sientas cómodo. A diferencia de los sistemas operativos propietarios como Windows y macOS, Linux tiene múltiples entornos de escritorio. Kali soporta los más populares desde su repositorio sin necesidad de añadir ningún repositorio adicional. Si el entorno de escritorio que se instala por defecto no te satisface, sustituirlo es fácil. Como es probable que pases mucho tiempo en el entorno, lo que realmente quieres es no sólo estar cómodo, sino también ser productivo. Esto significa encontrar el entorno y el conjunto de herramientas adecuados para ti.
Escritorio Xfce
El entorno de escritorio por defecto en Kali en este momento, a mediados de 2023, es Xfce. Suele ser un entorno de escritorio alternativo popular, aunque no suele ser el predeterminado. Una de las razones por las que ha sido popular es que se diseñó para ser bastante ligero para un entorno de escritorio completo y, como resultado, es más sensible. Muchos usuarios hardcore de Linux que he conocido a lo largo de los años han gravitado hacia Xfce como su entorno preferido, si necesitaban un entorno de escritorio. De nuevo, la razón es que tiene un diseño sencillo que es altamente configurable. En la Figura 1-5, puedes ver una configuración básica de Xfce. El panel de la parte inferior del escritorio es totalmente configurable. Puedes cambiar dónde está situado y cómo se comporta, y añadir o quitar elementos según te convenga, en función de cómo prefieras trabajar. Este panel incluye un menú de aplicaciones con las mismas carpetas o categorías que hay en el menú de GNOME.

Figura 1-5. Escritorio Xfce mostrando el menú de aplicaciones
Aunque Xfce se basa en GNOME Toolkit (GTK), no es una bifurcación de GNOME. Se desarrolló sobre una versión anterior de GTK. La intención era crear algo más sencillo que la dirección que estaba tomando GNOME. Xfce pretendía ser más ligero y, como resultado, tener un mejor rendimiento. La sensación era que el escritorio no debería entorpecer el trabajo real que los usuarios quieren hacer.
Al igual que con Windows, si es con lo que estás más familiarizado, tienes un menú de aplicaciones con accesos directos a los programas que se han instalado. En lugar de estar divididos en grupos por proveedor de software o nombre del programa, los programas se presentan en grupos basados en su funcionalidad. Las categorías presentadas, y las que se tratan a lo largo de este libro, son las siguientes:
-
Recogida de información
-
Análisis de vulnerabilidad
-
Análisis de aplicaciones web
-
Evaluación de la base de datos
-
Ataques con contraseña
-
Ataques inalámbricos
-
Ingeniería inversa
-
Herramientas de explotación
-
Sniffing y Spoofing
-
Post Explotación
-
Forense
-
Herramientas de información
-
Herramientas de ingeniería social
-
Servicios del sistema
Junto al menú hay una serie de lanzadores, muy parecidos a los lanzadores rápidos que puedes encontrar en Windows en la barra de menús. Xfce también configura cuatro escritorios virtuales por defecto. Puedes verlos como cuadros numerados en la barra de menús. Cada uno de estos escritorios virtuales pueden ser espacios donde puedes alojar aplicaciones en ejecución. Es una forma de tener lugares separados para mantener tu escritorio menos desordenado.
Escritorio GNOME
GNOME ha sido un entorno de escritorio por defecto en varias distribuciones de Linux. Está disponible como opción en Kali Linux. Este entorno de escritorio formaba parte del Proyecto GNU (GNU's Not Unix, acrónimo recursivo). Red Hat ha sido uno de los principales contribuyentes corporativos y utiliza el escritorio GNOME como interfaz principal para las distribuciones que controla, al igual que Ubuntu y otras varias distribuciones. La Figura 1-6 muestra el entorno de escritorio con el menú principal expandido.
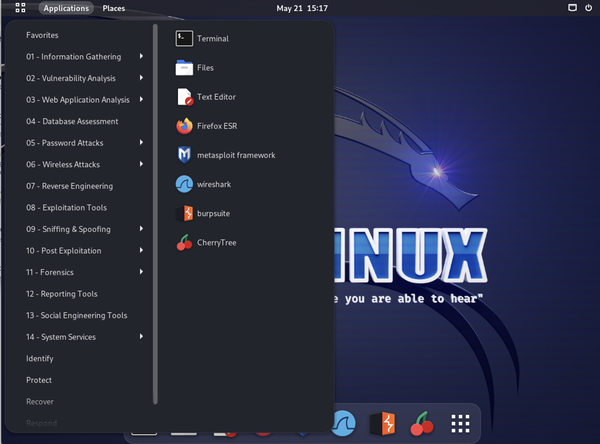
Figura 1-6. Escritorio GNOME para Kali Linux
Al menú principal se accede desde el menú Aplicaciones de la barra superior. Es mínimamente configurable mediante el programa Tweaks, sobre todo en relación con el reloj y el calendario. Además, el menú Lugares te permitirá abrir un explorador de archivos que muestra los contenidos de las ubicaciones del menú Lugares. Por ejemplo, Inicio y Documentos son dos lugares. Si seleccionas cualquiera de ellos, se abrirá un explorador de archivos de tu directorio personal o del directorio Documentos dentro de tu directorio personal. En la parte izquierda del panel superior, puedes abrir el gestor de escritorios virtuales.
Junto con el menú del panel superior, hay un dock en la parte inferior, muy parecido al de macOS. El dock incluye aplicaciones de uso común como el Terminal, Firefox, Metasploit, Wireshark, Burp Suite y Archivos. Al hacer clic una vez en uno de los iconos, se inicia la aplicación. Puedes añadir lanzadores a este dock arrastrándolos fuera de la lista de aplicaciones. Para ello, haz clic en el mosaico con nueve cuadrados situado en la parte derecha del dock. Aparecerán las aplicaciones instaladas en el sistema, mostradas en orden alfabético, como puedes ver en la Figura 1-7. Las aplicaciones que están en el Dock para empezar también aparecen como favoritas en el menú Aplicaciones, accesible desde el panel superior. Mientras que la barra de tareas de Windows se extiende a lo ancho de la pantalla, el dock de GNOME y macOS sólo es tan ancho como sea necesario para almacenar los iconos que se han configurado para que permanezcan allí, además de los de las aplicaciones en ejecución.
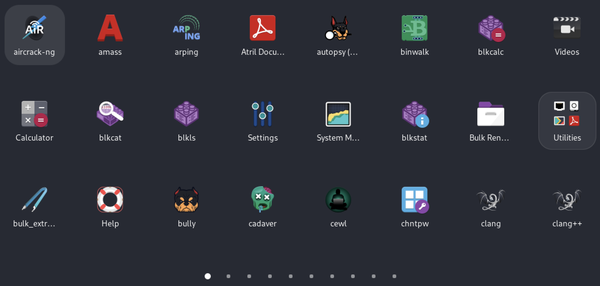
Figura 1-7. Lista de aplicaciones de GNOME
Nota
El dock de macOS procede de la interfaz del sistema operativo NeXTSTEP, que fue diseñado para el ordenador NeXT. Éste es el ordenador para el que Steve Jobs creó una empresa para diseñarlo y construirlo después de que le obligaran a abandonar Apple en la década de 1980. Muchos de los elementos de la interfaz de usuario (IU) de NeXTSTEP se incorporaron a la IU de macOS cuando Apple compró NeXT. Por cierto, NeXTSTEP se construyó sobre un sistema operativo BSD, razón por la cual macOS tiene Unix bajo el capó si abres una ventana de terminal.
Iniciar sesión a través del Desktop Manager
Aunque GNOME es el entorno de escritorio por defecto, hay otros disponibles sin mucho esfuerzo. Si tienes varios entornos de escritorio instalados, podrás seleccionar uno en el gestor de pantalla cuando te conectes. En primer lugar, debes introducir tu nombre de usuario para que el sistema pueda identificar el entorno por defecto que tienes configurado. Éste puede ser el último en el que hayas iniciado sesión. La Figura 1-8 muestra los entornos que puedo seleccionar en uno de mis sistemas Kali Linux.
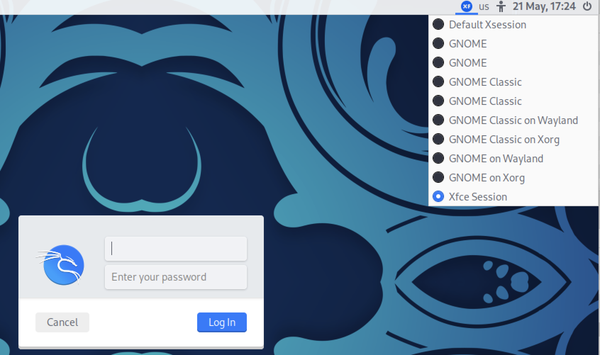
Figura 1-8. Selección de escritorio al iniciar sesión
Ha habido numerosos gestores de pantalla en a lo largo de los años. Inicialmente, la pantalla de inicio de sesión era algo que proporcionaba el gestor de ventanas X, pero se han desarrollado otros gestores de pantalla, ampliando las capacidades. Una de las ventajas de LightDM es que se considera ligero. Esto puede ser especialmente relevante si trabajas en un sistema con menos recursos, como memoria y procesador.
Canela y MATE
Otros dos escritorios de , Cinnamon y MATE, también deben sus orígenes a GNOME. Los responsables de Linux Mint no estaban seguros de GNOME 3 y su shell GNOME, la interfaz de escritorio que lo acompañaba. Por eso desarrollaron Cinnamon, que al principio era sólo un intérprete de comandos sobre GNOME. La segunda versión de Cinnamon se convirtió en un entorno de escritorio por derecho propio. Una de las ventajas de Cinnamon es que se parece mucho a Windows en cuanto a dónde están situadas las cosas y cómo te mueves por él. Puedes ver que hay un botón Menú en la parte inferior izquierda, muy parecido al botón de Windows, así como un reloj y otros widgets del sistema a la derecha de la barra de menú o panel(Figura 1-9). De nuevo, el menú es igual que el que ves en GNOME y Xfce.
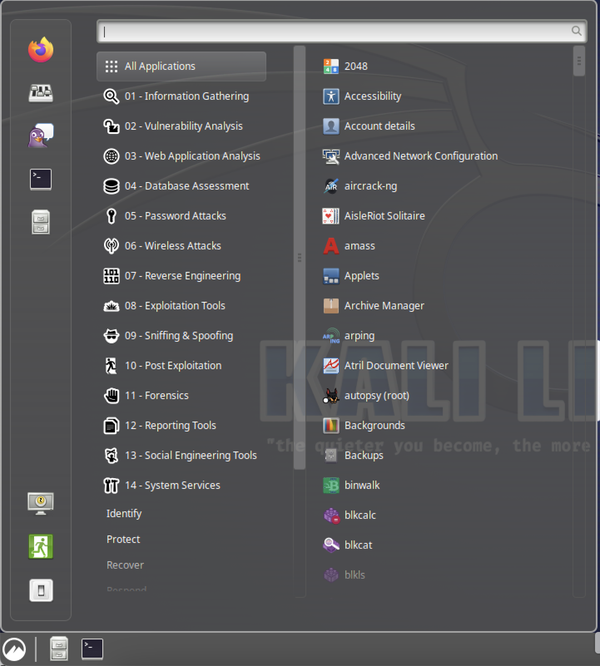
Figura 1-9. Escritorio Cinnamon con menú
Como ya he sugerido, había preocupación por GNOME 3 y el cambio de aspecto y comportamiento del escritorio. Algunos podrían decir que esto era quedarse corto, y la reversión de algunas distribuciones a otros aspectos podría considerarse una prueba de ello. Esto incluye la última implementación de GNOME en Kali Linux. En cualquier caso, Cinnamon fue una respuesta a GNOME 3, creando una interfaz de escritorio que se asentaba sobre la arquitectura subyacente de GNOME 3. MATE, por otro lado, es una bifurcación directa de GNOME 2. Para cualquiera que esté familiarizado con GNOME 2, MATE le resultará familiar. Es una implementación del aspecto clásico de GNOME 2. Puedes verlo ejecutándose en Kali en la Figura 1-10. De nuevo, se muestra el menú para que puedas ver que obtendrás el mismo acceso fácil a las aplicaciones en todos los entornos. Mientras que Xfce, Cinnamon, GNOME y otros entornos de escritorio han evolucionado su aspecto con el tiempo, MATE sigue teniendo prácticamente el mismo aspecto en su implementación Kali que cuando se lanzó por primera vez.
Figura 1-10. Escritorio MATE con su menú
La elección del entorno de escritorio es totalmente personal. Un escritorio que he omitido aquí pero que sigue siendo una opción muy válida es el Entorno de Escritorio K (KDE). Hay dos razones para ello. En primer lugar, KDE siempre me ha parecido bastante pesado, aunque esto se ha igualado un poco con GNOME 3 y los muchos paquetes que trae consigo. KDE nunca me ha parecido tan rápido como GNOME y, desde luego, como Xfce. Sin embargo, a mucha gente le gusta. En segundo lugar, he omitido una imagen del mismo porque se parece a algunas versiones de Windows, así como a algunos de los escritorios alternativos de Linux. Uno de los objetivos de KDE siempre pareció ser clonar el aspecto de Windows para que los usuarios procedentes de esa plataforma se sintieran cómodos.
Si realmente quieres empezar a utilizar Kali y trabajar con él, es posible que quieras pasar algún tiempo jugando con los distintos entornos de escritorio. Es importante que te sientas cómodo y puedas moverte por la interfaz con eficacia. Si tienes un entorno de escritorio que te estorba o es difícil de navegar, probablemente no se adapte bien a ti. Puedes probar con otro. Es bastante fácil instalar entornos adicionales. Cuando lleguemos a la gestión de paquetes un poco más adelante, aprenderás a instalar paquetes adicionales y, como resultado, entornos de escritorio. Puede que incluso descubras algunos entornos de escritorio que no se incluyen en esta discusión.
Utilizar la línea de comandos
En el transcurso de este libro descubrirás que siento una gran afición por la línea de comandos. Hay muchas razones para ello. Para empezar, empecé en la informática cuando los terminales no tenían lo que llamamos pantallas completas. Y desde luego no teníamos entornos de escritorio. Sinceramente, mi primer acceso a un ordenador fue en un teletipo sin pantalla. Cuando teníamos una pantalla, mostraba principalmente líneas de comandos. Como resultado, me acostumbré a teclear. Cuando empecé en los sistemas Unix, lo único que tenía era una línea de comandos, así que tuve que acostumbrarme al conjunto de comandos disponibles allí. Otra razón para sentirse cómodo con la línea de comandos es que no siempre puedes disponer de una interfaz de usuario. Puede que trabajes a distancia y te conectes a través de una red. Esto puede hacer que sólo dispongas de programas de línea de comandos sin trabajo adicional. Por tanto, hacerse amigo de la línea de comandos es útil.
Otra razón para acostumbrarse a la línea de comandos y a las ubicaciones de los elementos del programa es que los programas de la GUI de pueden tener fallos u omitir detalles que podrían ser útiles. Esto puede ser especialmente cierto en el caso de algunas herramientas de seguridad o forenses. Por ejemplo, yo prefiero utilizar The Sleuth Kit (TSK), una colección de programas de línea de comandos, a la interfaz basada en web, Autopsy, que es más visual. Dado que Autopsia se asienta sobre TSK, no es más que una forma diferente de ver la información que TSK es capaz de generar. La diferencia es que con Autopsia no obtienes todos los detalles, sobre todo los de nivel bastante bajo. Si sólo estás aprendiendo a realizar tareas, comprender lo que ocurre puede ser mucho más beneficioso que aprender una GUI. Tus habilidades y conocimientos serán mucho más transferibles a otras situaciones y herramientas. Así que también está eso.
A menudo se denomina shell a la interfaz de usuario. Esto es cierto tanto si te refieres al programa que gestiona el escritorio como al programa que toma los comandos que escribes en una ventana de terminal. El shell por defecto de en Linux ha sido durante mucho tiempo el Bourne Again Shell (bash) en la mayoría de las distribuciones. Se trata de un juego de palabras con el Bourne Shell, que fue uno de los primeros y más antiguos. Sin embargo, el Bourne Shell tenía limitaciones y carecía de funciones. Como resultado, en 1989 se lanzó el Bourne Again Shell. Desde entonces se ha convertido en el shell habitual en las distribuciones de Linux. En hay dos tipos de comandos que se ejecutan en la línea de comandos. Uno se llama incorporado. Es una función del propio intérprete de comandos y no llama a ningún otro programa: el intérprete de comandos se encarga de ello. El otro comando que ejecutarás es un programa que se encuentra en un directorio. El shell tiene un listado de directorios donde se guardan los programas que se proporciona (y es configurable) a través de una variable de entorno.
Actualmente, el shell por defecto en Kali Linux es el shell Z (zsh). Este shell está basado en bash, pero incluye muchas mejoras. En su mayor parte, no notarás mucha diferencia, y desde luego cuando se trata de ejecutar comandos, no hay ninguna diferencia. El intérprete de comandos zsh incluye muchas opciones de personalización, especialmente en lo que respecta a la finalización de la línea de comandos y a la representación del indicador de comandos. El prompt por defecto en Kali usando zsh se muestra en la Figura 1-11.
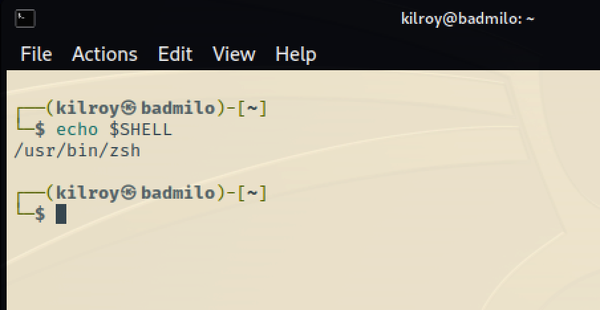
Figura 1-11. prompt zsh
Nota
Ten en cuenta que Unix fue desarrollado por programadores para programadores. Se trataba de crear un entorno que fuera cómodo y útil para los programadores que lo utilizaban. Como resultado, el shell es, tanto como cualquier otra cosa, un lenguaje y un entorno de programación. Cada shell tiene una sintaxis diferente para las sentencias de control que utiliza, pero puedes crear un programa directamente en la línea de comandos porque, como lenguaje de programación, el shell será capaz de ejecutar todas las sentencias.
En resumen, vamos a pasar algún tiempo con la línea de comandos porque es donde empezó Unix y también es potente. Para empezar, querrás moverte por el sistema de archivos y obtener listados de archivos, incluyendo detalles como los permisos. Otros comandos útiles son los que gestionan procesos y las utilidades generales.
Gestión de archivos y directorios
Para empezar, vamos a hablar en sobre cómo conseguir que el intérprete de comandos te indique el directorio en el que te encuentras actualmente. Esto se denomina directorio de trabajo. Para obtener el directorio de trabajo, aquel en el que estamos situados actualmente desde la perspectiva del intérprete de comandos, utilizamos el comando pwd, que es la abreviatura de imprimir directorio de trabajo. En el Ejemplo 1-1, puedes ver el prompt, que termina en $, lo que suele indicar un usuario normal. Si el prompt terminara en #, indicaría un superusuario, o usuario root. $ termina el indicador, al que sigue el comando que se está introduciendo y ejecutando. A continuación, en la línea siguiente, aparecen los resultados del comando.
Ejemplo 1-1. Imprimir tu directorio de trabajo
┌──(kilroy@badmilo)-[~] └─$ pwd /home/kilroy
Nota
Cuando llegues al punto de tener varias máquinas, físicas o virtuales, puede resultarte interesante tener un tema para los nombres de tus sistemas. He conocido a gente que llamaba a sus sistemas como los personajes de La Guía del Autoestopista Galáctico, por ejemplo. También he visto monedas, planetas y otros temas diversos. Desde hace años, mis sistemas llevan nombres de personajes del condado de Bloom. El sistema Kali lleva el nombre de Milo Bloom.
Una vez que sabemos en qué parte del sistema de archivos nos encontramos, que siempre empieza en el directorio raíz (/) y que, cuando se muestra visualmente, parece la raíz de un árbol, podemos obtener un listado de los archivos y directorios. Verás que los comandos de Unix/Linux suelen utilizar un número mínimo de caracteres. Para obtener listados de archivos, el comando es ls. Aunque ls es útil, sólo lista los nombres de archivos y directorios. Puede que quieras detalles adicionales sobre los archivos, incluyendo horas y fechas, así como permisos. Puedes ver esos resultados utilizando el comando ls -la. La l (ell) especifica un listado largo, incluyendo detalles. La a especifica que ls debe mostrar todos los archivos, incluidos los que de otro modo estarían ocultos. Puedes ver la salida en el Ejemplo 1-2.
Ejemplo 1-2. Obtener un listado largo
┌──(kilroy@badmilo)-[~] └─$ ls -la total 192 drwx------ 19 kilroy kilroy 4096 Jun 17 18:54 . drwxr-xr-x 3 root root 4096 Jun 3 07:17 .. -rw-r--r-- 1 kilroy kilroy 220 Jun 3 07:17 .bash_logout -rw-r--r-- 1 kilroy kilroy 5551 Jun 3 07:17 .bashrc -rw-r--r-- 1 kilroy kilroy 3526 Jun 3 07:17 .bashrc.original drwxr-xr-x 8 kilroy kilroy 4096 Jun 3 18:24 .cache drwxr-xr-x 13 kilroy kilroy 4096 Jun 13 17:37 .config drwxr-xr-x 2 kilroy kilroy 4096 Jun 3 07:26 Desktop -rw-r--r-- 1 kilroy kilroy 35 Jun 3 07:44 .dmrc drwxr-xr-x 2 kilroy kilroy 4096 Jun 3 07:26 Documents drwxr-xr-x 5 kilroy kilroy 4096 Jun 12 19:21 Downloads -rw-r--r-- 1 kilroy kilroy 11759 Jun 3 07:17 .face lrwxrwxrwx 1 kilroy kilroy 5 Jun 3 07:17 .face.icon -> .face drwx------ 3 kilroy kilroy 4096 Jun 3 07:26 .gnupg -rw------- 1 kilroy kilroy 0 Jun 3 07:26 .ICEauthority drwxr-xr-x 3 kilroy kilroy 4096 Jun 11 19:25 .ipython drwxr-xr-x 4 kilroy kilroy 4096 Jun 11 12:04 .java -rw------- 1 kilroy kilroy 34 Jun 17 18:53 .lesshst drwxr-xr-x 4 kilroy kilroy 4096 Jun 3 07:26 .local drwx------ 4 kilroy kilroy 4096 Jun 3 18:24 .mozilla drwxr-xr-x 2 kilroy kilroy 4096 Jun 3 07:26 Music -rw-r--r-- 1 kilroy kilroy 33 Jun 17 18:54 myhosts drwxr-xr-x 2 kilroy kilroy 4096 Jun 3 07:26 Pictures -rw-r--r-- 1 kilroy kilroy 807 Jun 3 07:17 .profile drwxr-xr-x 2 kilroy kilroy 4096 Jun 3 07:26 Public -rw-r--r-- 1 kilroy kilroy 37 Jun 3 18:28 pw.txt -rw-r--r-- 1 kilroy kilroy 28672 Jun 17 15:51 .scapy_history -rw-r--r-- 1 kilroy kilroy 0 Jun 3 07:26 .sudo_as_admin_successful drwxr-xr-x 2 kilroy kilroy 4096 Jun 3 07:26 Templates drwxr-xr-x 2 kilroy kilroy 4096 Jun 3 07:26 Videos -rw------- 1 kilroy kilroy 948 Jun 17 18:54 .viminfo drwxr-xr-x 3 kilroy kilroy 4096 Jun 11 12:02 .wpscan -rw------- 1 kilroy kilroy 52 Jun 13 17:23 .Xauthority -rw------- 1 kilroy kilroy 5960 Jun 17 18:36 .xsession-errors -rw------- 1 kilroy kilroy 5385 Jun 12 19:23 .xsession-errors.old drwxr-xr-x 20 kilroy kilroy 4096 Jun 11 13:55 .ZAP -rw------- 1 kilroy kilroy 2716 Jun 14 18:47 .zsh_history -rw-r--r-- 1 kilroy kilroy 10868 Jun 3 07:17 .zshrc
Empezando por la columna de la izquierda, puedes ver los permisos de. Unix tiene un conjunto sencillo de permisos. Cada archivo o directorio tiene un conjunto de permisos asociados al usuario propietario, luego un conjunto de permisos asociados al grupo propietario del archivo y, por último, un conjunto de permisos que pertenecen a todos los demás, denominado mundo. Los directorios se indican con una d en la primera posición. Los demás permisos disponibles son lectura, escritura y ejecución. En los sistemas operativos tipo Unix, un programa obtiene el bit de ejecución para determinar si es ejecutable. Esto es diferente de Windows, donde una extensión de archivo puede hacer esa determinación. El bit de ejecución determina no sólo si un archivo es ejecutable, sino también quién puede ejecutarlo, dependiendo de la categoría en la que se establezca el bit de ejecución (usuario, grupo, mundo).
También puedes ver el propietario (usuario) y el grupo, ambos root en estos casos. A continuación aparece el tamaño del archivo, la última vez que se modificó el archivo o directorio y, por último, el nombre del archivo o directorio. Puede que observes en la parte superior algunos archivos que empiezan con un punto. Los archivos y directorios con punto almacenan configuraciones y registros específicos del usuario. Como son gestionados por las aplicaciones que los crean, por regla general, están ocultos de los listados de directorios normales.
El programa touch puede utilizarse para actualizar la fecha y hora modificadas al momento en que se ejecuta touch. Si el archivo no existe, touch creará un archivo vacío que tendrá la fecha y hora de modificación y creación fijadas al momento en que se ejecutó touch.
Otros comandos relacionados con archivos y directorios que te serán realmente útiles son los relacionados con la configuración de permisos y propietarios de. Cada archivo y directorio tiene un conjunto de permisos, como se ha indicado anteriormente, y tiene un propietario y un grupo. Para establecer permisos en un archivo o directorio, utilizas el comando chmod, que puede tomar un valor numérico para cada uno de los permisos posibles. Se utilizan tres bits, cada uno de ellos activado o desactivado para indicar si el permiso está establecido o no. Puedes pensar en el orden de los permisos como de menor a mayor privilegio: lectura, escritura, ejecución. Sin embargo, como el bit más significativo es el primero, lectura tiene el valor más alto de los tres bits utilizados. El bit más significativo tiene un valor de22, o 4. Escribir tiene el valor de21, o 2. Por último, ejecutar tiene el valor de20, o 1. Como ejemplo, si quieres establecer permisos tanto de lectura como de escritura en un archivo, utilizarías 4 + 2, o 6. El patrón de bits sería 110, si te resulta más fácil verlo así.
Hay tres conjuntos de permisos: propietario, grupo y mundo (todos). Cuando estableces permisos, especifica un valor numérico para cada uno, es decir, un valor de tres dígitos. Por ejemplo, para establecer lectura, escritura y ejecución para el propietario, pero sólo lectura para el grupo y todo el mundo, utiliza chmod 744 nombrearchivo, donde nombrearchivo es el nombre del archivo para el que estás estableciendo los permisos. También puedes especificar simplemente el bit que quieres activar o desactivar, si te resulta más fácil. Por ejemplo, podrías utilizar chmod u+x nombrearchivo para añadir el bit ejecutable para el propietario.
El sistema de archivos de Linux suele estar bien estructurado, por lo que puedes estar seguro de dónde buscar los archivos. Sin embargo, en algunos casos, puede que necesites buscar archivos en. En Windows o macOS, es posible que entiendas cómo buscar archivos, ya que las herramientas necesarias están integradas en los gestores de archivos. Si trabajas desde la línea de comandos, necesitas conocer los medios que puedes utilizar para localizar archivos. El primero es localizar, que se basa en una base de datos del sistema. El programa updatedb actualizará esa base de datos, y cuando utilices locate, el sistema consultará la base de datos para encontrar la ubicación del archivo.
Si buscas un programa, puedes utilizar otra utilidad. El programa que te dirá dónde se encuentra el programa. Esto puede ser útil si tienes varias ubicaciones donde se guardan los ejecutables. Ten en cuenta que which utiliza la variable PATH del entorno del usuario para buscar el programa. Si el ejecutable se encuentra en el PATH, se muestra la ruta completa al ejecutable. Si hay varias instancias de un nombre de archivo en diferentes directorios en la configuración de la ruta, sólo se mostrará la primera.
Un programa más polivalente para la localización es find. Aunque find tiene muchas posibilidades, un enfoque sencillo es utilizar algo como find / -nombre foo -print. No tienes que proporcionar el parámetro -print, ya que imprimir los resultados es el comportamiento por defecto; es sólo la forma en que aprendí a ejecutar el comando, y se me ha quedado grabada. Con find, especifica la ruta en la que deseas buscar. find realiza una búsqueda recursiva, lo que significa que empieza en el directorio especificado y busca en todos los directorios que se encuentran bajo el directorio especificado. En el ejemplo anterior, buscamos el archivo llamado foo. Puedes utilizar expresiones regulares, incluidos comodines, en tu búsqueda. Si quieres encontrar un archivo que empiece por las letras foo, utiliza find / -name "foo*" -print. En el Ejemplo 1-3, puedes ver el uso de find para localizar un archivo en el directorio /etc. Verás errores que indican permiso denegado. Esto es el resultado de buscar en directorios que son propiedad de otro usuario y no tienen permisos de lectura establecidos para otros usuarios. Si utilizas patrones de búsqueda, debes poner la cadena y el patrón entre comillas dobles. Aunque find tiene muchas posibilidades, esto te servirá para empezar.
Ejemplo 1-3. Utilizar hallar
┌──(kilroy@badmilo)-[/etc] └─$ find . -name catalog.xml find: './redis': Permission denied find: './ipsec.d/private': Permission denied find: './openvas/gnupg': Permission denied find: './ssl/private': Permission denied find: './polkit-1/localauthority': Permission denied find: './polkit-1/rules.d': Permission denied ./vmware-tools/vgauth/schemas/catalog.xml find: './vpnc': Permission denied
Gestión de procesos
Cuando ejecutas un programa, inicias un proceso. Puedes pensar en un proceso como una instancia dinámica y en ejecución de un programa, que es estático mientras se encuentra en un medio de almacenamiento. Todo sistema Linux en funcionamiento tiene docenas o cientos de procesos ejecutándose en un momento dado. En la mayoría de los casos, puedes esperar que el sistema operativo gestione los procesos de la mejor manera posible. Sin embargo, a veces puede que quieras involucrarte tú mismo. Por ejemplo, puedes querer comprobar si un proceso se está ejecutando, ya que no todos los procesos se ejecutan en primer plano. Un proceso en primer plano de tiene actualmente la posibilidad de que el usuario lo vea e interactúe con él, en comparación con unproceso en segundo planode, con el que un usuario no podría interactuar a menos que se trajera a primer plano y se diseñara para la interacción del usuario. Por ejemplo, simplemente comprobando el número de procesos que se ejecutaban en un sistema Kali Linux que, por lo demás, estaba inactivo, descubrí 141 procesos, con sólo uno en primer plano. Todos los demás eran servicios de algún tipo.
Para obtener una lista de procesos, puedes utilizar el comando ps. Este comando por sí solo no te proporciona mucho más que la lista de procesos que pertenecen al usuario que ejecuta el programa. Cada proceso, al igual que los archivos, tiene un propietario y un grupo. La razón es que los procesos necesitan interactuar con el sistema de archivos y otros objetos, y tener un propietario y un grupo es la forma en que el sistema operativo determina si se debe permitir el acceso al proceso. En el Ejemplo 1-4, puedes ver qué aspecto tiene la ejecución de ps.
Ejemplo 1-4. Obtener una lista de procesos
┌──(kilroy@badmilo)-[~] └─$ ps PID TTY TIME CMD 4068 pts/1 00:00:00 bash 4091 pts/1 00:00:00 ps
Lo que ves en el Ejemplo 1-4 es el número de identificación del proceso, conocido comúnmente como ID del proceso, o PID, seguido del puerto de teletipo en el que se emitió el comando, la cantidad de tiempo que pasó en el procesador y, por último, el comando. La mayoría de los comandos que verás tienen parámetros que puedes añadir a la línea de comandos, y que cambiarán el comportamiento del programa.
Curiosamente, el Unix de AT&T divergió un poco del Unix de BSD. Esto ha dado lugar a algunas variaciones en los parámetros de la línea de comandos, dependiendo de la derivación de Unix con la que hayas empezado. Para obtener listados de procesos más detallados, que incluyan todos los procesos pertenecientes a todos los usuarios (ya que sin especificar, sólo obtienes los procesos pertenecientes a tu usuario), puedes utilizar ps -ea o ps aux. Cualquiera de los dos te proporcionará la lista completa, aunque habrá diferencias en los detalles proporcionados.
Lo malo de usar ps es que es estático: lo ejecutas una vez y obtienes la lista de procesos. Se puede utilizar otro programa para ver cómo cambia la lista de procesos casi en tiempo real. Aunque también es posible obtener estadísticas como el uso de memoria y del procesador a partir de ps, con top, no tienes que pedirlo. Ejecutando top obtendrás la lista de procesos, refrescada a intervalos regulares. Puedes ver un ejemplo de salida en el Ejemplo 1-5.
Ejemplo 1-5. Utilizar top para listados de procesos
top - 21:54:53 up 63 days, 3:20, 1 user, load average: 0.00, 0.00, 0.00
Tasks: 253 total, 1 running, 252 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.1 us, 0.0 sy, 0.0 ni, 99.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 64033.1 total, 2912.2 free, 1269.2 used, 59851.7 buff/cache
MiB Swap: 8192.0 total, 8180.7 free, 11.2 used. 62114.3 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
419627 kilroy 20 0 7736 3864 3004 R 0.3 0.0 0:00.02 top
1 root 20 0 167732 12648 7668 S 0.0 0.0 1:08.01 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.47 kthreadd
3 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_gp
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_par+
5 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 slub_fl+En además de proporcionar una lista de procesos, la cantidad de memoria que están utilizando y el porcentaje de CPU que se está utilizando, así como otros datos específicos, top muestra detalles sobre el sistema en ejecución, que verás en la parte superior. Cada vez que se actualice la pantalla, la lista de procesos se reordenará, indicando a qué procesos están consumiendo más recursos. Como observarás, el propio top consume cierta cantidad de recursos, y a menudo lo verás cerca de la parte superior de la lista de procesos. Uno de los campos importantes que verás no sólo en top, sino también en ps, es el PID. Además de proporcionar una forma de identificar claramente un proceso de otro, sobre todo cuando el nombre del proceso es el mismo, también proporciona una forma de enviar mensajes al proceso.
Encontrarás dos comandos muy valiosos cuando gestiones procesos. Están estrechamente relacionados y realizan la misma función, aunque ofrecen capacidades ligeramente diferentes. El primer comando es kill, que, como era de esperar, puede matar un proceso en ejecución. Más concretamente, envía una señal al proceso. El sistema operativo interactuará con los procesos enviándoles señales. Las señales son un medio de comunicación entre procesos (IPC). La señal por defecto para kill es la señal TERM (SIGTERM), que significa terminar, pero si especificas una señal diferente, kill enviará esa señal en su lugar. Para enviar una señal diferente, ejecuta kill -# pid, donde # indica el número que equivale a la señal que pretendes enviar, y pid es el número de identificación del proceso que puedes encontrar utilizando ps o top.
El segundo comando con el que debes familiarizarte en es killall. La diferencia entre kill y killall es que con killall no necesitas necesariamente el PID. En su lugar, utilizas el nombre del proceso. Esto puede ser útil, sobre todo cuando un proceso padre ha generado varios procesos hijos. Si quieres matarlos a todos al mismo tiempo, puedes utilizar killall, y hará el trabajo de buscar los PID en la tabla de procesos y emitir la señal adecuada al proceso. Al igual que en el caso de kill, killall tomará un número de señal para enviar al proceso. Si necesitas matar por la fuerza todas las instancias del proceso llamado firefox, por ejemplo, utilizarías killall -9 firefox.
Otras utilidades
Obviamente, en no vamos a repasar toda la lista de comandos disponibles en la línea de comandos de Linux. Sin embargo, algunos adicionales son útiles para que te hagas una idea. Ten en cuenta que Unix se diseñó para tener utilidades sencillas que pudieran encadenarse. Para ello, dispone de tres flujos de entrada/salida estándar: STDIN, STDOUT y STDERR. Cada proceso hereda estos tres flujos cuando se inicia. La entrada se realiza a través de STDIN, la salida a través de STDOUT y los errores se envían a través de STDERR. La ventaja de esto es que si no quieres ver los errores, por ejemplo, puedes enviar el flujo STDERR a algún sitio para que tu salida normal no esté saturada.
Cada uno de estos flujos puede redirigirse. Normalmente, STDOUT y STDERR van al mismo sitio (normalmente, la consola). STDIN se origina en la consola. Si quieres que tu salida vaya a otro sitio, puedes utilizar el operador >. Si, por ejemplo, quisiera enviar la salida de ps a un archivo, podría utilizar ps auxw > ps.out. Esto envía la salida del comando ps al archivo llamado ps.out. Cuando rediriges la salida, ya no la ves en la consola. En este ejemplo, si se produjera un error, lo verías, pero no verías nada en STDOUT. Si quisieras redirigir la entrada, harías lo contrario. En lugar de >, utilizarías <, indicando la dirección en la que quieres que fluya la información.
Comprender los distintos flujos de E/S y la redirección te ayudará a comprender el operador | (tubería). Cuando utilizas |, estás diciendo: "Toma la salida de lo que está a la izquierda y envíala a la entrada de lo que está a la derecha". De hecho, estás colocando un acoplador entre dos aplicaciones, enviando STDOUT a STDIN, sin tener que pasar por ningún dispositivo intermediario.
Una de las funciones más útiles del encadenamiento o canalización de comandos es para buscar o filtrar. Por ejemplo, si tienes una larga lista de procesos del comando ps, puedes utilizar el operador de tubería para enviar la salida de ps a otro programa, grep, que puede utilizarse para buscar cadenas. Otro ejemplo: si quieres encontrar todas las instancias del programa llamado httpd, utiliza ps auxw | grep httpd. El comando grep se utiliza para buscar una cadena de búsqueda en un flujo de entrada. Aunque es útil para filtrar información, también puedes buscar en el contenido de archivos con grep.Por ejemplo, si quieres buscar la cadena wubble en todos los archivos de un directorio, puedes utilizar grep wubble *. Si quieres asegurarte de que la búsqueda sigue todos los directorios, dile a grep que utilice una búsqueda recursiva con grep -R wubble *.
Gestión de usuarios
Aunque Kali solía hacer que iniciaras sesión como root por defecto, no ha sido así en varias versiones. Se te pedirá, como en otras distribuciones de Linux, que crees el usuario que vas a utilizar. A este usuario se le concede la capacidad de obtener temporalmente permisos de superusuario en utilizando la utilidad sudo. Tu usuario se añadirá al grupo sudo. Esto es necesario porque gran parte de lo que harás en Kali requerirá privilegios administrativos.
Puede que quieras añadir usuarios adicionales, así como gestionar usuarios en Kali, igual que con otras distribuciones. Si quieres crear un usuario, puedes utilizar el comando useradd. También puedes utilizar adduser. Ambos consiguen el mismo objetivo. Cuando estés creando usuarios, es útil comprender algunas de las características de los usuarios. Como mínimo, cada usuario debe tener un directorio personal, una shell, un nombre de usuario y un grupo. Si quiero añadir mi nombre de usuario común, por ejemplo, utilizaría useradd -d /home/kilroy -s /bin/bash -g users -m kilroy. Los parámetros indicados especifican el directorio raíz, el intérprete de comandos que debe ejecutar el usuario al iniciar sesión de forma interactiva y el grupo por defecto. La opción -m indica que useradd debe crear el directorio personal. Esto también llenará el directorio raíz con los archivos esqueleto necesarios para los inicios de sesión interactivos.
En el caso del ID de grupo especificado, useradd requiere que el grupo exista. Si quieres que tu usuario tenga su propio grupo, puedes utilizar groupadd para crear un nuevo grupo y luego utilizar useradd para crear el usuario que pertenece al nuevo grupo. Si quieres añadir tu usuario a varios grupos, puedes editar el archivo /etc/group y añadir tu usuario al final de cada línea de grupo de la que quieras que tu usuario sea miembro. Esto es bastante fácil de hacer, pero otras utilidades como usermod también añadirán usuarios a grupos específicos. Para recoger los permisos asociados con el acceso de esos grupos a los archivos, por ejemplo, tienes que cerrar la sesión y volver a iniciarla. Esto recogerá los cambios en tu usuario, incluidos los nuevos grupos.
Una vez creado el usuario, debes establecer una contraseña, utilizando el comando passwd. Si eres root y quieres cambiar la contraseña de otro usuario, utiliza passwd kilroy en el caso del usuario creado en el ejemplo anterior. Si sólo utilizas passwd sin un nombre de usuario, vas a cambiar tu propia contraseña.
Consejo
La shell Z (zsh) sustituye a la Bourne Again Shell (bash) por defecto. Sin embargo, se pueden utilizar otros shells. Si te sientes aventurero, podrías echar un vistazo a otros shells como bash, fish, csh o ksh. El intérprete de comandos bash se comportará de forma muy parecida al zsh con el que se te iniciará. Otros ofrecen otras posibilidades que pueden ser de interés, sobre todo si te gusta experimentar. Si quieres cambiar permanentemente tu shell, puedes editar /etc/passwd o utilizar chsh para que cambie tu shell por ti.
Gestión de servicios
Durante mucho tiempo, en hubo dos estilos de gestión de servicios: el estilo BSD y el estilo AT&T. Esto ya no es así. Ahora hay tres formas de gestionar los servicios. Antes de entrar en la gestión de servicios, deberíamos definir primero un servicio. En este contexto, un servicio es un programa que se ejecuta sin intervención del usuario. El entorno operativo lo pone en marcha automáticamente y se ejecuta en segundo plano. A menos que tengas una lista de procesos, es posible que nunca sepas que se estaba ejecutando. La mayoría de los sistemas tienen un número decente de estos servicios ejecutándose en cualquier momento. Se llaman servicios porque prestan un servicio al sistema, a los usuarios o, a veces, a usuarios remotos.
Puesto que no hay interacción directa del usuario, por lo general, en lo que se refiere al inicio y la finalización de estos servicios, es necesario que haya otra forma de iniciar y detener los servicios que pueda llamarse automáticamente durante el inicio y el apagado del sistema. Con la posibilidad de gestionar los servicios, los usuarios también pueden utilizarla para iniciarlos, detenerlos, reiniciarlos y conocer su estado.
Nota
Los servicios son a nivel de sistema. Gestionarlos requiere privilegios administrativos. Necesitas ser root o utilizar sudo para obtener privilegios temporales de root y poder realizar las funciones de gestión de servicios.
A menudo, las distribuciones de Linux utilizaban el proceso de inicio AT&T init. Esto significaba que los servicios se ejecutaban con un conjunto de scripts que tomaban parámetros estándar. El sistema de inicio init utilizaba niveles de ejecución para determinar qué servicios se iniciaban. El modo monousuario iniciaría un conjunto de servicios diferente al del modo multiusuario. Se iniciaban aún más servicios cuando se utilizaba un gestor de pantalla, para proporcionar interfaces gráficas a los usuarios. Los scripts se almacenaban en /etc/init.d/ y podían gestionarse proporcionando parámetros como inicio, parada, reinicio y estado. Por ejemplo, si querías iniciar el servicio SSH, podías utilizar el comando /etc/init.d/ssh start. Sin embargo, el problema del sistema init era que generalmente era de naturaleza serie. Esto causaba problemas de rendimiento en el arranque del sistema porque cada servicio se iniciaba en secuencia en lugar de iniciarse varios servicios al mismo tiempo. El otro problema delsistema initera que no soportaba bien las dependencias. A menudo, un servicio dependía de otros servicios que debían iniciarse primero.
Llega systemd, desarrollado por desarrolladores de software de Red Hat. El objetivo de systemd era mejorar la eficiencia del sistema init y superar algunas de sus deficiencias. Los servicios pueden declarar dependencias, y los servicios pueden iniciarse en paralelo. Ya no es necesario escribir scripts bash para iniciar los servicios. En su lugar, hay archivos de configuración, y toda la gestión de servicios se maneja con el programa systemctl de. Para gestionar un servicio mediante systemctl, utilizarías systemctl verbo servicio, donde verbo es el comando que pasas y servicio es el nombre del servicio. Por ejemplo, si quisieras activar el servicio SSH y luego iniciarlo, ejecutarías los comandos del Ejemplo 1-6.
Ejemplo 1-6. Activar e iniciar el servicio SSH
┌──(kilroy@badmilo)-[~] └─$ sudo systemctl enable ssh Synchronizing state of ssh.service with SysV service script with /lib/systemd/systemd-sysv-install. Executing: /lib/systemd/systemd-sysv-install enable ssh ┌──(kilroy@badmilo)-[~] └─$ sudo systemctl start ssh
En primer lugar, habilitas el servicio: le estás diciendo a tu sistema que, cuando arranques, quieres que se inicie este servicio. Los distintos modos de inicio del sistema en los que se iniciará el servicio se configuran en el archivo de configuración asociado al servicio. Cada servicio tiene un archivo de configuración. En lugar de utilizar niveles de ejecución, como hacía el antiguo sistema init, systemd utiliza objetivos. Un objetivo es esencialmente lo mismo que un nivel de ejecución, en el sentido de que indica un modo concreto de funcionamiento de tu sistema. El ejemplo 1-7 muestra uno de estos scripts del servicio smartd, que se utiliza para gestionar dispositivos de almacenamiento.
Ejemplo 1-7. Configurar un servicio para systemd
$ cat smartd.service [Unit] Description=Self Monitoring and Reporting Technology (SMART) Daemon Documentation=man:smartd(8) man:smartd.conf(5) # Typically, physical storage devices are managed by the host physical machine # Override it if you are using PCI/USB passthrough ConditionVirtualization=no [Service] Type=notify EnvironmentFile=-/etc/default/smartmontools ExecStart=/usr/sbin/smartd -n $smartd_opts ExecReload=/bin/kill -HUP $MAINPID [Install] WantedBy=multi-user.target Alias=smartd.service
La sección Unidad indica los requisitos y la descripción, así como la documentación. La sección Servicio indica cómo debe iniciarse y gestionarse el servicio. El servicio Instalar indica el objetivo que se va a utilizar. En este caso, syslog está en el objetivo multiusuario.
Kali utiliza un sistema basado en systemd para la inicialización y gestión de servicios, por lo que utilizarás principalmente systemctl para gestionar tus servicios. En raras ocasiones, un servicio instalado no admite la instalación en systemd. En ese caso, instalarás un script de servicio en /etc/init.d/, y tendrás que llamar al script desde allí para iniciar y detener el servicio. Sin embargo, en la mayoría de los casos se trata de situaciones poco frecuentes.
Gestión de paquetes
Aunque Kali viene con un amplio conjunto de paquetes, no todo lo que Kali es capaz de instalar está en la instalación por defecto. En algunos casos, es posible que quieras instalar paquetes. También vas a querer actualizar tu conjunto de paquetes. Para gestionar paquetes, independientemente de lo que intentes hacer, puedes utilizar la herramienta avanzada de paquetes(apt) de. También hay otras formas de gestionar paquetes. Puedes utilizar interfaces, pero al fin y al cabo no son más que programas que se asientan sobre APT. Puedes utilizar el frontend que quieras, pero APT es tan fácil de usar que resulta útil saber cómo utilizarlo. Aunque es una línea de comandos, sigue siendo un gran programa. De hecho, es bastante más fácil de usar que algunas de las interfaces que he visto sobre APT a lo largo de los años.
En primer lugar, puede que quieras actualizar todos los metadatos de tu base de datos de paquetes local. Estos son los detalles sobre los paquetes que tienen los repositorios remotos, incluidos los números de versión. La información sobre la versión es necesaria para determinar si el software que tienes está desactualizado y necesita actualizarse. Para actualizar tu base de datos local de paquetes, le dices a APT que quieres actualizar, como puedes ver en el Ejemplo 1-8.
Ejemplo 1-8. Actualizar la base de datos de paquetes mediante apt
┌──(kilroy@badmilo)-[~] └─$ sudo apt update Get:1 http://kali.localmsp.org/kali kali-rolling InRelease [30.5 kB] Get:2 http://kali.localmsp.org/kali kali-rolling/main amd64 Packages [15.5 MB] Get:3 http://kali.localmsp.org/kali kali-rolling/non-free amd64 Packages [166 kB] Get:4 http://kali.localmsp.org/kali kali-rolling/contrib amd64 Packages [111 kB] Fetched 15.8 MB in 2s (6437 kB/s) Reading package lists... Done Building dependency tree Reading state information... Done 142 packages can be upgraded. Run 'apt list --upgradable' to see them.
Una vez actualizada tu base de datos local de paquetes, APT te dirá si hay actualizaciones disponibles para lo que tienes instalado. En este caso, 142 paquetes necesitan actualizarse. Para actualizar en todo el software de tu sistema, puedes utilizar apt upgrade. Sólo con usar apt upgrade se actualizarán todos los paquetes. Si sólo necesitas actualizar un paquete, puedes utilizar apt upgrade nombrepaquete, donde nombrepaquete es el nombre del paquete que quieres actualizar. El formato de empaquetado utilizado por Debian, y, por extensión, Kali, indica a APT cuáles son los paquetes necesarios. Esta lista de dependencias indica a Kali qué debe instalarse para que funcione un determinado paquete. En el caso de actualizar software, ayuda a determinar el orden en que deben actualizarse los paquetes.
Si necesitas instalar software, es tan fácil como escribiendo apt install packagename. De nuevo, las dependencias son importantes aquí. APT determinará qué software necesita instalarse antes que el paquete que estás pidiendo. Como resultado, cuando pidas que se instale un software, APT te dirá que se necesita otro software. Obtendrás una lista de todo el software necesario y se te preguntará si quieres instalarlo todo. También puedes obtener una lista de paquetes de software opcionales. Los paquetes pueden tener una lista de software relacionado que puede utilizarse con los paquetes que estás instalando. Si quieres instalarlos, tendrás que decirle a APT por separado que quieres instalarlos. Los paquetes opcionales no son necesarios en absoluto.
Para eliminar paquetes se utiliza apt remove packagename. Uno de los problemas de eliminar software es que, aunque haya dependencias para su instalación, el mismo software no necesariamente se elimina, simplemente porque una vez instalado, puede ser utilizado por otros paquetes de software. Sin embargo, APT determinará si los paquetes de software ya no se utilizan. Cuando realices una función utilizando APT, puede indicarte que determinados paquetes podrían eliminarse. Para eliminar paquetes que ya no son necesarios, utiliza apt autoremove.
Todo esto supone que sabes lo que buscas. Puede que no estés totalmente seguro del nombre de un paquete. En ese caso, puedes utilizar apt-cache para buscar paquetes. Puedes utilizar términos de búsqueda que pueden ser nombres parciales de paquetes, ya que a veces los paquetes pueden no llamarse exactamente como esperas. Diferentes distribuciones de Linux pueden nombrar un paquete con un nombre diferente. En el Ejemplo 1-9, he buscado sshd porque el nombre del paquete puede ser sshd, ssh o cualquier otro. Puedes ver los resultados.
Ejemplo 1-9. Buscar paquetes utilizando apt-cache
┌──(kilroy@badmilo)-[~] └─$ apt-cache search sshd fail2ban - ban hosts that cause multiple authentication errors libconfig-model-cursesui-perl - curses interface to edit config data ↩ through Config::Model libconfig-model-openssh-perl - configuration editor for OpenSsh libconfig-model-tkui-perl - Tk GUI to edit config data through Config::Model libnetconf2-2 - NETCONF protocol library [C library] libnetconf2-dev - NETCONF protocol library [C development] libnetconf2-doc - NETCONF protocol library [docs] openssh-server - secure shell (SSH) server, for secure access from remote machines tinysshd - Tiny SSH server - daemon zsnapd - ZFS Snapshot Daemon written in python zsnapd-rcmd - Remote sshd command checker for ZFS Snapshot Daemon
Lo que puedes ver es que el servidor SSH en Kali parece llamarse openssh-server. Si ese paquete no estuviera instalado pero lo quisieras, utilizarías el nombre de paquete openssh-server para instalarlo. Esto supone que sabes qué paquetes están instalados en tu sistema. Con miles de paquetes de software instalados, es poco probable que sepas todo lo que hay. Si quieres saber qué software hay instalado, puedes utilizar dpkg. Se trata de un programa que tiene múltiples usos, entre ellos instalar software desde un archivo .deb. Para obtener la lista de todos los paquetes de software instalados, utiliza dpkg --list. Es lo mismo que utilizar dpkg -l. Ambos te darán una lista de todo el software instalado.
La lista que obtengas te proporcionará el nombre del paquete, así como una descripción del mismo y el número de la versión instalada. También obtendrás la arquitectura de CPU para la que se creó el paquete. Si tienes una CPU de 64 bits y has instalado la versión de 64 bits de Kali, probablemente verás que la mayoría de los paquetes tienen la arquitectura establecida como amd64, aunque también puedes ver algunos marcados como all, lo que puede significar simplemente que no hay ejecutables en el paquete. Cualquier paquete de documentación sería para todas las arquitecturas, como ejemplo.
También puedes utilizar dpkg cuando vayas a instalar software que no esté en el repositorio Kali. Si encuentras un archivo .deb, puedes descargarlo y luego utilizar dpkg -i <nombredelpaquete> para instalarlo. También es posible que quieras eliminar un paquete ya instalado. Aunque puedes utilizar apt para ello, también puedes utilizar dpkg, especialmente si el paquete se instaló de esa forma. Para eliminar un paquete mediante dpkg, utiliza dpkg -r <nombredelpaquete>. Si no estás seguro del nombre del paquete, puedes obtenerlo de la lista de paquetes instalados que utilizaste para obtener dpkg.
Cada paquete de software puede incluir una colección de archivos entre los que se incluyen ejecutables, documentación, archivos de configuración por defecto y las bibliotecas necesarias para el paquete. Si quieres ver el contenido de un paquete, puedes utilizar dpkg -c <nombrearchivo>, donde nombrearchivo es el nombre completo del archivo .deb. En el Ejemplo 1-10, puedes ver el contenido parcial de un paquete de gestión de registros, nxlog. Este paquete no forma parte del repositorio Kali, sino que se ofrece como descarga gratuita para la edición comunitaria. El contenido de este paquete no sólo incluye los archivos, sino también los permisos, incluidos el propietario y el grupo. También puedes ver la fecha y la hora asociadas al archivo desde el paquete.
Ejemplo 1-10. Contenido parcial del paquete nxlog
┌──(kilroy@badmilo)-[~]
└─$ dpkg -c nxlog-ce_3.2.2329_ubuntu22_amd64.deb
drwxr-xr-x root/root 0 2023-04-14 09:14 ./
drwxr-xr-x root/root 0 2023-04-14 09:14 ./etc/
drwxr-xr-x root/root 0 2023-04-14 09:14 ./etc/nxlog/
-rw-r--r-- root/root 1275 2023-04-14 08:49 ./etc/nxlog/nxlog.conf
drwxr-xr-x root/root 0 2023-04-14 09:14 ./lib/
drwxr-xr-x root/root 0 2023-04-14 09:14 ./lib/systemd/
drwxr-xr-x root/root 0 2023-04-14 09:14 ./lib/systemd/system/
-rw-r--r-- root/root 349 2023-04-14 08:49 ./lib/systemd/system/nxlog.service
drwxr-xr-x root/root 0 2023-04-14 09:14 ./usr/
drwxr-xr-x root/root 0 2023-04-14 09:14 ./usr/bin/
-rwxr-xr-x root/root 517232 2023-04-14 09:14 ./usr/bin/nxlog
-rwxr-xr-x root/root 500856 2023-04-14 09:14 ./usr/bin/nxlog-processor
-rwxr-xr-x root/root 455808 2023-04-14 09:14 ./usr/bin/nxlog-stmnt-verifier
drwxr-xr-x root/root 0 2023-04-14 09:14 ./usr/lib/
drwxr-xr-x root/root 0 2023-04-14 09:14 ./usr/lib/nxlog/
drwxr-xr-x root/root 0 2023-04-14 09:14 ./usr/lib/nxlog/modules/
drwxr-xr-x root/root 0 2023-04-14 09:14 ./usr/lib/nxlog/modules/extension/
drwxr-xr-x root/root 0 2023-04-14 09:14 ./usr/lib/nxlog/modules/python/
-rw-r--r-- root/root 15678 2023-04-14 09:14 ./usr/lib/nxlog/modules/python/↩
libpynxlog.aDebes tener en cuenta que las aplicaciones distribuidas en formato de archivo .deb suelen crearse para una distribución concreta. Esto ocurre porque suele haber dependencias que la persona o grupo que crea el paquete sabe que la distribución puede suministrar. Es posible que otras distribuciones no tengan las versiones adecuadas para satisfacer los requisitos del paquete de software. Si ese es el caso, puede que el software no funcione correctamente. dpkg dará un error si no se satisfacen las dependencias. Puedes forzar la instalación utilizando --force-install como parámetro de la línea de comandos además de -i, pero aunque el software se instalará, no hay garantía de que funcione correctamente.
dpkg tiene otras funciones que te permiten buscar paquetes de software, consultar el software instalado y mucho más. Las opciones enumeradas anteriormente te servirán más que de sobra para empezar. Con el gran número de paquetes disponibles en el repositorio Kali, sería inusual, aunque no imposible, que necesitaras hacer instalaciones externas. Sin embargo, sigue siendo útil conocer dpkg y sus capacidades.
Acceso remoto
Los ordenadores conectados en red ofrecen la posibilidad de acceso remoto. Mientras que los sistemas Windows se desarrollaron principalmente para un solo uso, con una persona sentada ante el ordenador, Linux hereda la naturaleza multiusuario de Unix (nótese la ironía del chiste del nombre Unix frente a Multics en un sistema que se ha utilizado durante mucho tiempo para dar soporte a múltiples usuarios). Comúnmente, los usuarios se conectaban a un sistema Unix remoto. Durante muchos años (o décadas), esto se hizo utilizando Telnet. Este protocolo pretende imitar la forma en que se comunicaría un terminal conectado directamente a un gran ordenador, salvo que se comunicaría a través de la red en lugar de a través de una conexión serie cableada. Telnet puede ser confuso porque no es sólo un protocolo, sino también el nombre del cliente y del servidor. En general, Telnet ya no se utiliza porque es un protocolo de texto claro, lo que significa que datos como nombres de usuario y contraseñas se transmiten sin ninguna protección para que puedan ser recogidos a través de la red.
Por otro lado,Secure Shell (SSH), en, está encriptado. Fue desarrollado por el proyecto OpenBSD como una forma de conectarse remotamente a sistemas a través de un canal cifrado. Al igual que Telnet, SSH utiliza un cliente y un servidor. El cliente SSH se conecta al servidor, que inicia una sesión de acceso. Aunque puedes proporcionar tus credenciales de inicio de sesión (nombre de usuario y contraseña), SSH también permite el uso de claves para habilitar la autenticación. Para soportar el cifrado, SSH utiliza un par de claves pública y privada. Estas claves también pueden utilizarse para autenticar a un cliente ante un servidor, ya que la clave pública del cliente sólo debe ser conocida por el usuario propietario de la clave. El Ejemplo 1-11 muestra cómo ssh-keygen genera el par de claves pública y privada.
Ejemplo 1-11. Generar un par de claves pública/privada
kilroy@billthecat:~ $ ssh-keygen Generating public/private rsa key pair. Enter file in which to save the key (/home/kilroy/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/kilroy/.ssh/id_rsa Your public key has been saved in /home/kilroy/.ssh/id_rsa.pub The key fingerprint is: SHA256:sqFcPJ11x8I/ODJ4xAIer885oam287lZo8Cb36fVvOM kilroy@billthecat The key's randomart image is: +---[RSA 3072]----+ | | | + . | | = * o | | . . = * = | | * S = + o | | . o * . +.. + | | o . o .oo.. o| | o+oO.+...| | .=*B.*+.E.| +----[SHA256]-----+
Lo ideal es que establezcas una contraseña en la clave, que sólo tú conozcas. Esto protege la clave del uso/mal uso. Si no estableces una contraseña y alguien consigue la clave, podría utilizarla para hacerse pasar por ti. Para utilizar la clave para autenticarte, tienes que copiar la clave pública en el servidor remoto. Esto puede hacerse automáticamente con ssh-copy-id, como se ve en el Ejemplo 1-12.
Ejemplo 1-12. Copiar la clave pública al servidor remoto
kilroy@billthecat:~ $ ssh-copy-id kilroy@192.168.4.10 /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: ↩ "/home/kilroy/.ssh/id_rsa.pub" /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter ↩ out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are ↩ prompted now it is to install the new keys kilroy@192.168.4.10's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'kilroy@192.168.4.10'" and check to make sure that only the key(s) you wanted were added.
Si no has establecido una contraseña en la clave, la próxima vez que hagas ssh al servidor remoto, iniciarás sesión automáticamente. Si has establecido una contraseña en la clave, se te pedirá la contraseña de la clave, no la del servidor remoto, que debe ser diferente.
SSH también permite una capacidad realmente importante que a menudo se pasa por alto. Como estás creando una sesión cifrada, tienes efectivamente un túnel entre el cliente y el servidor. Podemos explotar esa capacidad de túnel de para pasar tráfico de un sistema o conjunto de sistemas a otro. En el Ejemplo 1-13, puedes ver la configuración del túnel con un oyente creado en el puerto 8080. Cualquier conexión al puerto 8080 en el sistema local será reenviada a www.google.com en el puerto 80, pero ocurrirá a través de la sesión SSH a 192.168.4.10. Lo que esto significa en la práctica es que te conectas al puerto 8080 en el host local, y el tráfico se envía a 192.168.4.10 a través de la sesión SSH, donde se reenvía a www.google.com. El tráfico de retorno se devuelve a través deltúnel.
Ejemplo 1-13. Configurar un túnel SSH
kilroy@billthecat:~ $ ssh -L 8080:www.google.com:80 192.168.4.10 Welcome to Ubuntu 22.04.4 LTS (GNU/Linux 5.15.0-101-generic x86_64) Last login: Sat May 4 23:09:52 2024 from 192.168.4.5 <-- separate session here --> kilroy@billthecat:~ $ telnet 127.0.0.1 8080 Trying 127.0.0.1... Connected to 127.0.0.1. Escape character is '^]'. GET / HTTP/1.0 200 OK Date: Sat, 04 May 2024 23:11:18 GMT Expires: -1 Cache-Control: private, max-age=0 Content-Type: text/html; charset=ISO-8859-1 Content-Security-Policy-Report-Only: object-src ↩ 'none';base-uri 'self';script-src ↩ 'nonce-8jVCtsGFyyU3qD-uOhLDpw' 'strict-dynamic' ↩ 'report-sample' 'unsafe-eval' 'unsafe-inline' ↩ https: http:;report-uri ↩ https://csp.withgoogle.com/csp/gws/other-hp P3P: CP="This is not a P3P policy! See g.co/p3phelp for more info." Server: gws X-XSS-Protection: 0 X-Frame-Options: SAMEORIGIN Set-Cookie: AEC=AQTF6Hysa1Vvt-DXzYNlnEgiCzZ3BznIvFS7ssGrtOtP0qTLmOCL100E0H0; ↩ expires=Thu, 31-Oct-2024 23:11:18 GMT; path=/; domain=.google.com; Secure; ↩ HttpOnly; SameSite=lax
También es posible tener un túnel remoto en el que el tráfico del sistema remoto se envía de vuelta al sistema local. Utilizando estos túneles SSH, puedes pasar tráfico de un sistema o red a otro sistema. Este enfoque puede eludir los cortafuegos si puedes hacer pasar una sesión SSH pero, por ejemplo, el tráfico web está bloqueado en el cortafuegos.
Gestión de registros
En su mayor parte, si estás realizando pruebas de seguridad, puede que nunca necesites realmente mirar los registros de tu sistema. Sin embargo, a lo largo de muchos años, he descubierto que los registros de tienen un valor incalculable. Por muy sólida que sea una distribución como Kali, siempre existe la posibilidad de que algo vaya mal y tengas que investigar. Incluso cuando todo va bien, es posible que quieras ver lo que registra una aplicación. Por eso, necesitas entender el sistema de registro en Linux. Para ello, necesitas saber qué estás utilizando. Unix ha utilizado durante mucho tiempo syslog como registrador del sistema, aunque comenzó su vida como un servicio de registro para el servidor de correo sendmail.
A lo largo de los años, syslog ha tenido muchas implementaciones. Kali Linux no viene con una implementación de syslog común instalada, aunque puedes instalar un registrador de sistema típico como rsyslog. Se trata de una implementación bastante sencilla, y es fácil determinar las ubicaciones de los archivos en los que tendrás que buscar información de registro. En general, todos los registros van a /var/log. Sin embargo, tendrás que buscar en archivos específicos entradas de registro de distintas categorías de información. En Kali, comprobarías el archivo /etc/rsyslog.conf. Además de ver muchos otros ajustes de configuración, verás las entradas que se muestran en el Ejemplo 1-14.
Ejemplo 1-14. Configuración del registro para rsyslog
auth,authpriv.* /var/log/auth.log cron.* -/var/log/cron.log kern.* -/var/log/kern.log mail.* -/var/log/mail.log user.* -/var/log/user.log # # Emergencies are sent to everybody logged in. # *.emerg :omusrmsg:*
Lo que ve en el lado izquierdo es una combinación de instalación y nivel de gravedad. La palabra que precede al punto es la instalación. La instalación se basa en los distintos subsistemas que registran mediante syslog. Puedes observar que syslog se remonta a mucho tiempo atrás, por lo que todavía hay instalaciones identificadas para subsistemas y servicios que es poco probable que veas mucho en la actualidad. En la Tabla 1-1 verás la lista de facilidades definidas para su uso en syslog. La columna Descripción indica para qué se utiliza la instalación en caso de que la propia instalación no te dé esa información.
En junto con la instalación está el valor de gravedad. La gravedad tiene valores potenciales de Emergencia, Alerta, Crítico, Error, Advertencia, Aviso, Informativo y Depuración. Estas severidades se enumeran en orden descendente, con la más severa en primer lugar. Puedes determinar que los registros de Emergencia se envíen a un lugar distinto de donde se envían otros niveles de gravedad. En el Ejemplo 1-14, todas las severidades se envían al registro asociado a cada instalación. El "*" después del nombre de la instalación indica todas las instalaciones. Si quisieras, por ejemplo, enviar los errores de la instalación auth a un archivo de registro específico, utilizarías auth.error e indicarías el archivo que quieres utilizar.
| Número de instalación | Instalación | Descripción |
|---|---|---|
0 |
kern |
Mensajes del núcleo |
1 |
usuario |
Mensajes a nivel de usuario |
2 |
correo |
Sistema de correo |
3 |
demonio |
Dæmons del sistema |
4 |
auth |
Mensajes de seguridad/autorización |
5 |
syslog |
Mensajes generados internamente por syslogd |
6 |
lpr |
Subsistema de impresora de línea |
7 |
noticias |
Subsistema de noticias en red |
8 |
uucp |
Subsistema UUCP |
9 |
Demonio reloj |
|
10 |
authpriv |
Mensajes de seguridad/autorización |
11 |
ftp |
Demonio FTP |
12 |
- |
Subsistema NTP |
13 |
- |
Auditoría de registro |
14 |
- |
Alerta de registro |
15 |
cron |
Demonio de programación |
16 |
local0 |
Uso local 0(local0) |
17 |
local1 |
Uso local 1(local1) |
18 |
local2 |
Uso local 2(local2) |
19 |
local3 |
Uso local 3(local3) |
20 |
local4 |
Uso local 4(local4) |
21 |
local5 |
Uso local 5(local5) |
22 |
local6 |
Uso local 6(local6) |
23 |
local7 |
Uso local 7(local7) |
Una vez que sepas dónde se guardan los registros, necesitas poder leerlos. Afortunadamente, las entradas del registro syslog son bastante fáciles de analizar. El Ejemplo 1-15 muestra una colección de entradas de registro del auth.log de un sistema Kali. Empezando por la izquierda de la entrada, verás la fecha y la hora en que se escribió la entrada de registro. A continuación aparece el nombre del host. Como syslog tiene la capacidad de enviar mensajes de registro a hosts remotos, como un host de registro central, el nombre del host es importante para separar una entrada de otra si estás escribiendo registros de varios hosts en el mismo archivo de registro. Después del nombre de host está el nombre del proceso y el PID. La mayoría de estas entradas proceden del proceso llamado realmd, que tiene un PID de 803.
Ejemplo 1-15. Contenido parcial de auth.log
2023-05-21T18:14:30.094986-04:00 badmilo sudo: pam_unix(sudo:session): ↩ session closed for user root 2023-05-21T18:15:01.783725-04:00 badmilo CRON[41805]: pam_unix(cron:session): ↩ session opened for user root(uid=0) by (uid=0) 2023-05-21T18:15:01.787913-04:00 badmilo CRON[41805]: pam_unix(cron:session): ↩ session closed for user root 2023-05-21T18:16:59.653896-04:00 badmilo sudo: kilroy : TTY=pts/0 ; ↩ PWD=/var/log ; USER=root ; COMMAND=/usr/bin/cat auth.log 2023-05-21T18:16:59.654531-04:00 badmilo sudo: pam_unix(sudo:session): ↩ session opened for user root(uid=0) by (uid=1000)
La parte difícil del registro no es el preámbulo, que crea y escribe el servicio syslog, sino las entradas de la aplicación. Una cosa buena de las entradas syslog es que están escritas en inglés, así que mientras entiendas inglés y conozcas el formato, podrás leer las entradas. Sin embargo, el contenido de las entradas de registro lo crea la propia aplicación, lo que significa que el programador tiene que llamar a funciones que generen y escriban las entradas de registro. Algunos programadores pueden ser mejores que otros a la hora de generar entradas de registro útiles y comprensibles. Cuando te hayas acostumbrado a leer los registros, empezarás a entender lo que dicen. Si te encuentras con una entrada de registro que realmente necesitas pero que no entiendes, los motores de búsqueda de Internet siempre pueden ayudarte a encontrar a alguien que comprenda mejor esa entrada de registro. Alternativamente, puedes pedir ayuda al equipo de desarrollo del software.
No todos los registros pasan por syslog, pero sí todos los relacionados con el sistema. Incluso cuando syslog no gestiona los registros de una aplicación, como en el caso del servidor web Apache, es probable que los registros sigan estando en /var/log/. En algunos casos, puede que tengas que buscar los registros. Esto puede ocurrir con algún software de terceros que se instala en /opt.
Resumen
Linux tiene una larga historia, que se remonta a los tiempos en que los recursos eran muy limitados. Esto ha dado lugar a algunos comandos arcanos cuya finalidad era permitir a los usuarios (principalmente programadores) ser eficientes. Es importante encontrar un entorno que te funcione bien para que tú también puedas ser eficiente en tu trabajo. He aquí algunos puntos clave de que debes aprender de este capítulo:
-
Unix es un entorno creado por programadores para programadores que utiliza la línea de comandos.
-
Unix se creó con herramientas sencillas, de un solo uso, que pueden combinarse para realizar tareas más complejas.
-
Kali Linux tiene varias GUI potenciales que se pueden instalar y utilizar; es importante encontrar aquella con la que te sientas más cómodo.
-
Cada entorno de escritorio tiene muchas opciones de personalización.
-
Kali se basa en systemd, por lo que la gestión de servicios utiliza systemctl.
-
Los procesos pueden gestionarse mediante señales, como interrumpir y matar.
-
Los registros serán tus amigos y te ayudarán a solucionar errores. Los registros suelen almacenarse en /var/log.
-
Los archivos de configuración suelen almacenarse en /etc, aunque los archivos de configuración individuales se almacenan en el directorio home.
Recursos útiles
-
Linux in a Nutshell, 6ª edición, por Ellen Siever et al. (O'Reilly, 2009)
-
Administración práctica de sistemas Linux, de Kenneth Hess (O'Reilly, 2023)
-
Linux eficiente en la línea de comandos por Daniel J. Barrett (O'Reilly, 2022)
-
El sitio web de Kali Linux
-
"Conceptos básicos de administración de sistemas Linux" por Linode
Get Aprendiendo Kali Linux, 2ª Edición now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

