Capítulo 8. Streaming estructurado
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
En capítulos anteriores, aprendiste a utilizar API estructuradas para procesar volúmenes de datos muy grandes pero finitos. Sin embargo, a menudo los datos llegan continuamente y necesitan ser procesados en tiempo real. En este capítulo, veremos cómo utilizar las mismas API estructuradas para procesar también flujos de datos.
Evolución del motor de procesamiento de flujos Apache Spark
El procesamiento de flujos se define como el procesamiento continuo de flujos interminables de datos. Con la llegada de los big data, los sistemas de procesamiento de flujos pasaron de ser motores de procesamiento de un solo nodo a motores de procesamiento distribuido de múltiples nodos. Tradicionalmente, el procesamiento distribuido de flujos se ha implementado con un modelo de procesamiento registro a registro, como se ilustra en la Figura 8-1.
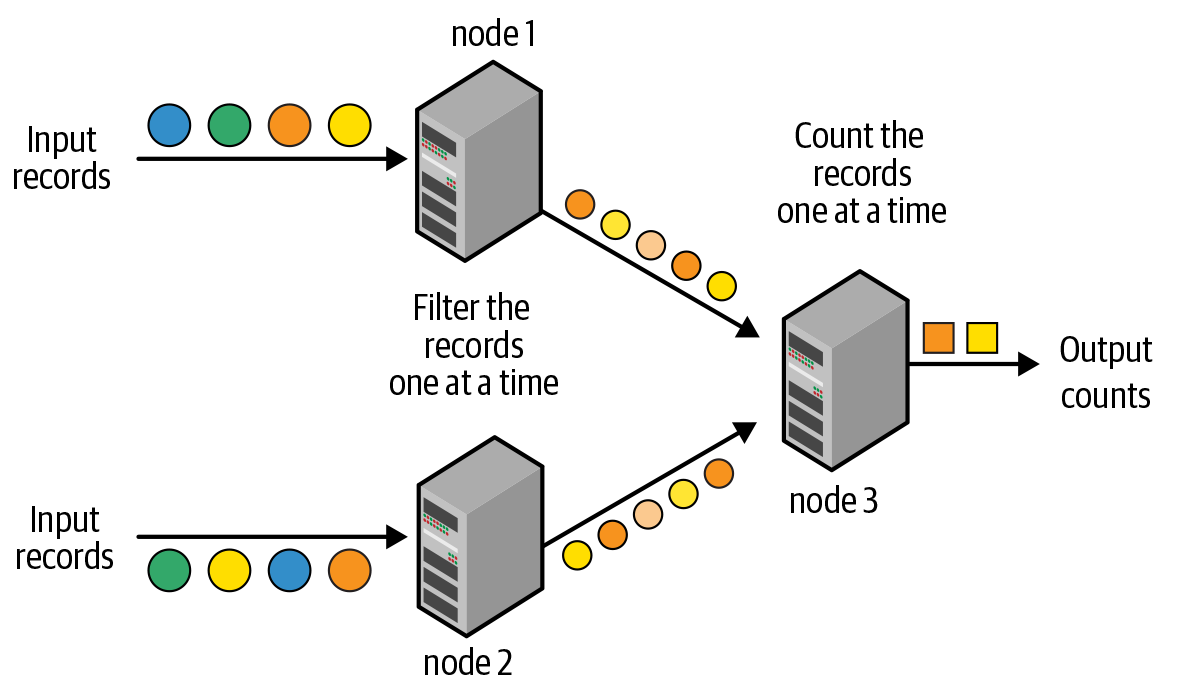
Figura 8-1. Modelo tradicional de procesamiento de registros a la vez
El canal de procesamiento se compone de un grafo dirigido de nodos, como se muestra en la Figura 8-1; cada nodo recibe continuamente un registro cada vez, lo procesa y, a continuación, reenvía el registro o registros generados al siguiente nodo del grafo. Este modelo de procesamiento puede alcanzar latencias muy bajas, es decir, un registro ...
Get Aprender Spark, 2ª Edición now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

