Chapter 4. Tokenization
This is our first chapter in the section of NLP from the ground up. In the first three chapters, we walked you through the high-level components of an NLP pipeline. From here till Chapter 9, we’ll be covering a lot of the underlying details to really understand how modern NLP systems work. The main components of this are:
-
Tokenization
-
Embeddings
-
Architectures
Previously, all of these steps were abstracted away in the libraries we
used (spaCy, transformers, and fastai). But now, we’ll
try to understand how these libraries actually work and how
you can modify your code at a low level to build amazing NLP
applications beyond the simple examples we presented in this book.
One thing to note: “low level” is a subjective term. While some may call PyTorch a low-level deep learning library, others may scoff at using that term for anything other than building a custom memory allocator in x86 assembly. It’s a matter of perspective. What we mean by low level here is that after learning about these things, you’ll have enough of an understanding to build useful applications with NLP in the real world and that you’ll also be able to understand and follow the latest research in the field. We won’t be discussing anything that’s too far beyond the scope of NLP. For example, learning about how CUDA works is certainly both interesting and useful, and we’ll do a bit of that in Appendix B. But CUDA itself as a tool is useful for many things outside NLP, so we’d consider that beyond the scope of this book. As much as possible, we’ll try to keep the focus on things that actually improve the performance of your models in production.
Each of the items in the list that we just saw (i.e., tokenizers, embeddings, and models) can be thought of as an independent function. They take in some input and generate some output. Each of these functions then passes on its output to the next stage of the pipeline. To be more specific, we pass tokenized text into the embedding layer, and we pass embeddings into the model. You can treat these functions as black boxes if you would like and choose to focus on only one at a time. We’ll look at each one in isolation, with tokenizers first.
A Minimal Tokenizer
As we start thinking about low-level parts of the deep learning stack, it’s useful to understand components in terms of what their inputs and outputs are.
So what are the inputs and outputs here? The input is text. Usually,
this is provided as a .txt file or something else that is read into a Python object. The output is a sequence of tokens. One of the main
topics of this chapter will be a discussion of what exactly a “token”
is and what it should be doing.
As always, one of the best ways to understand something is to look at the code. So here’s essentially what a tokenizer is:
text=open('example.txt','r').read()words=text.split(" ")tokens={v:kfork,vinenumerate(words)}
tokens{'The': 0,
'quick': 1,
'brown': 2,
'fox': 3,
'jumps': 4,
'over': 5,
'the': 6,
'lazy': 7,
'dog.': 8}
A tokenizer reads in text and returns a mapping between words and indices. Essentially, it creates a dictionary (both figuratively and literally, since the preceding example creates a Python dictionary) that maps words to numbers. This is extremely useful, because we now have a representation of the source text that can be fed into an NLP model:
token_map=map(lambdat:tokens[t],words)list(token_map)
[0, 1, 2, 3, 4, 5, 6, 7, 8]
This was, of course, a drastically oversimplified example. In practice, you’d never want to do tokenization this way. It’s slow, for one thing, and does not account for a lot of intricacies across different languages. Furthermore, this simple tokenizer does not account for punctuation, grammar, or compound word structure (i.e., the fact that words ending in “-ing,” “-ify,” etc., are related) in any meaningful way. Nonetheless, it’s a start.
Here’s a more precise way of stating what a tokenizer should be: a tokenizer is a program that converts a sequence of characters into a sequence of tokens. Tokenizers as a general tool are very useful even outside NLP. Wherever there is a need to parse text, there is probably some form of a tokenizer. Let’s take an example from the world of compilers, because it turns out that tokenization is a very old, fundamental, and useful thing to do.
Tip
So useful, in fact, that there were popular tools like lex and flex invented in the ’80s that generated the C code for a fast tokenizer given a simple description of the token you wanted to parse!
When building a compiler for a programming language, one of the first
things to do is identify and mark keywords like if and for to pass
on to the next stage. Here, the tokenizer reads in a file and builds a
new representation of the source code where the raw ASCII/Unicode
characters are replaced by tokens that represent these keywords, which
can then be used to construct a data structure called a parse tree.
We’re not building a compiler here, so the parse tree isn’t entirely relevant, and in practice, we’ll be using libraries instead of complex code-generation procedures. But we wanted to illustrate an example of how a tokenizer is a very useful and robust program to have, even outside of NLP.
The type of tokenizers we’re interested in as deep learning practitioners, though, usually don’t give us parse trees. What we want is a tokenizer that reads the text and generates a sequence of one-hot vectors.
That is the most important thing to understand about tokenizers from our
top-down perspective. The input is raw text, and the output is a
sequence of vectors. To be even more specific, the vectors, in our case,
are simply one-hot encoded PyTorch tensors that we pass into an
nn.Embedding layer. Once we get to that stage, where we can pass
something to an embedding layer (which we’ll discuss in the
next chapter), we’re done with tokenization.
Now that we understand the input and outputs, let’s jump straight into the implementation, after which we’ll look at some of the new ideas in this space, and examine them in more low-level detail.
In our opinion, there are two tools for tokenization that are superior
to most of the others–spaCy’s tokenizer and the Hugging Face tokenizers library.
spaCy’s tokenizer is more widely used, is older, and is somewhat more reliable. It has its own unique tokenization algorithm that tends to work well for common NLP tasks. The tokenizers library is a slightly more modern package that focuses on implementing the newest algorithms from the newest research.
Warning
Some models like BERT expect certain specific tokens, so you cannot use any tokenizer you like on these models. To work around this, recent versions of spaCy include wrappers around the Hugging Face transformers library, which allows you to combine the rest of your spaCy workflow with transformers. But behind the scenes, this will still use the BERT, not spaCy, tokenizer.
We’ve already used spaCy in Chapters 1 and 3, and will revisit it when we deploys model in Part III. So in this chapter, we’ll focus on the Hugging Face tokenizers library.
Hugging Face Tokenizers
tokenizers is Hugging Face’s official tokenization tool
written in the Rust programming language (which happens to be
Ajay’s favorite programming language at the time of writing),
with bindings to Python and JavaScript. While tokenizers could be used
as a general-purpose tokenizer, it being Hugging Face, it’s
designed to be used specifically for deep learning and NLP, with a
specific focus on fast subword tokenizer (which we’ll look
at in detail once we try out the code first).
Tokenization, unlike other parts of the deep learning pipeline, is typically done on the CPU. But that doesn’t mean it has to be slow! Hugging Face’s library makes good use of the multiple cores you might have on your machine, and can tokenize large datasets at the gigabyte scale (which is fairly large for nonacademic NLP) in under a minute.
The tokenizers library further subdivides the task of tokenizations
into smaller, more manageable steps. Here’s
Hugging Face’s description of the components of the
tokenization process in its library:
- Normalizer
-
Executes all the initial transformations over the initial input string. For example, when you need to lowercase some text, maybe strip it, or even apply one of the common Unicode normalization processes, you will add a Normalizer.
- PreTokenizer
-
In charge of splitting the initial input string. That’s the component that decides where and how to pre-segment the
originstring. The simplest example would be like we saw before, to split on spaces. - Model
-
Handles all the subtoken discovery and generation. This part is trainable and really dependent of your input data.
- Post-Processor
-
Provides advanced construction features to be compatible with some of the Transformer-based SOTA models. For instance, for BERT it would wrap the tokenized sentence around [CLS] and [SEP] tokens.
- Decode
-
In charge of mapping back a tokenized input to the original string. The decoder is usually chosen according to the
PreTokenizerwe used previously. - Trainer
Each of those logical modules has multiple options/implementations in the library:
- Normalizer
-
Lowercase, Unicode (NFD, NFKD, NFC, NFKC), Bert, Strip…
- PreTokenizer
-
ByteLevel, WhitespaceSplit, CharDelimiterSplit, Metaspace, …
- Model
-
WordLevel, BPE, WordPiece, …
- Post-Processor
-
BertProcessor, … - Decoder
-
WordLevel, BPE, WordPiece, …
You have some amount of freedom in choosing these, but more often than not, you’ll be restricted to the components supported by the pretrained model you’re using. In practice, you’ll want to use whatever is suggested on the documentation for your model, so we suggest going through it if/when you encounter bugs.
Installing the library is as simple as running the following:
pip install tokenizers
But of course, we have already included this in our requirements.txt and environment.yml files on the GitHub repo:
importtokenizers
Subword Tokenization
If you continue looking through the documentation for tokenizers,
you’ll notice that there are a lot of different algorithms
that are implemented in the library. But tokenization seems like a fairly straightforward task, right? What gives?
Well, it turns out that there are plenty of ways you can decide to form a “token” from a string of text.
For example, consider the strings "cat" and "cats". One valid
subtokenization of "cats" would be [cat, ##s], where the
double-hashtag represents a prefix subtoken of the initial input. The advantage of this approach is that you get the semantic information that word-based tokenizers provide without incurring the cost of a very large vocabulary. These training algorithms might extract subtokens such as "##ing" and "##ed" over an English corpus.
This approach has pros and cons in terms of computation cost. On the one hand, you’ll have fewer words in your vocabulary, meaning a smaller embedding matrix (discussed in Chapter 5). But on the other hand, one word will now have multiple tokens, so you’ll be able to fit fewer words into a model that accepts a fixed number of tokens.
As illustrated in Figure 4-1, the simplest character-based tokenizers will generally never produce unknown tokens but will also break up a word into many small pieces, which may cause some loss of information. On the other hand, you can fully and accurately represent words with word-level tokenization, but then you’ll need a very large vocabulary, or you risk having many unidentified tokens.
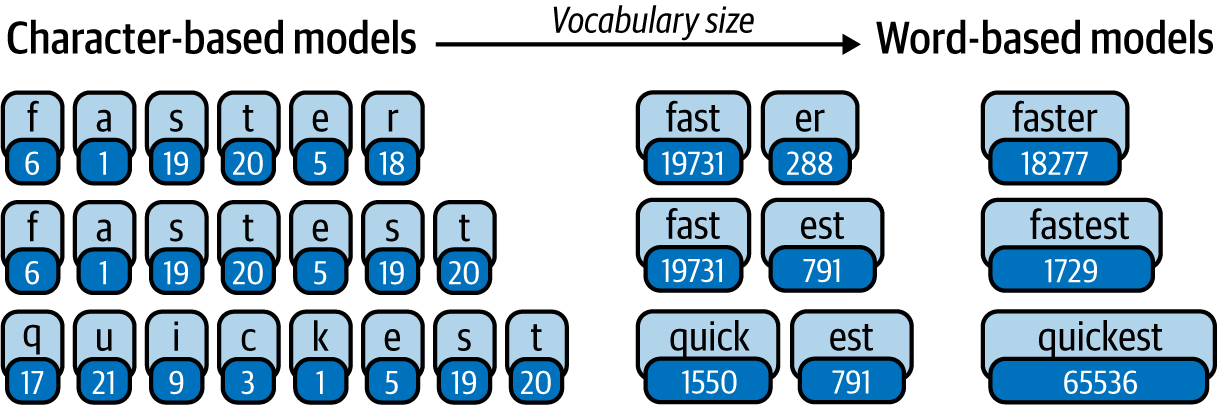
Figure 4-1. Subtokenization
So, the goal here is twofold:
-
Increase the amount of information per token.
-
Decrease the total number of tokens (vocabulary size).
Subword tokenizers achieve this effectively by finding a good balance between characters, subwords, and words.
Note
Subword tokenization algorithms (the newer ones, at least) are not set in stone. There is a “training” phase before we can actually tokenize the text. This is not the training of the language model itself, but rather a process we run to find the optimal balance between character-level and word-level tokenization.
The idea of using prefixes and suffixes is simple enough, and you could
perhaps design a somewhat effective subword tokenizer by coding in rules
for common subwords like "##ing" and "##ed". However, in practice,
there are a number of difficulties with this approach:
-
There are many different languages, each with its own rules. Building a good subword tokenizer would then mean understanding and implementing a new set of rules for each language.
-
There is no guarantee that the rules you make are actually any good. As an extreme example, you might decide to make a subword token for
"super##", but that might never show up in the text. So you’ve essentially wasted a spot in the dictionary. You could evaluate the number of tokens matched and tune your rules again, but at that point you might as well use a training algorithm. -
You as a human reading the text may not be able to capture intricacies in repeated language patterns. It’s much simpler to have a computer read 40+ GB of text and figure out the repeating tokens than it is to actually read 40+ GB of text yourself!
So, the goal of the training procedure, then, is to identify recurring text in a corpus and “refactor” it into a token. If a particular pattern is not repeated often, it is not included as a token.
For example, if your text corpus has an even balance of the strings
"car" and "cat" (along with many other words), then the tokens you
might get would be ["ca##", "r", "t", ...]. But if your corpus has
many more occurrences of "cat" than other words, then it might be
beneficial to condense that into a single token, giving the tokens
["cat", "ca##", "r" ...]. Ideally, we want to avoid chunking entire
words together into a single token like that, since it increases the
vocabulary size, as shown in Figure 4-1. But when
something is repeated often, like the word the, it is more
efficient to chunk that information together into a single token.
Subword tokenization also reduces the impact of the issue where the
model encounters a new word that it’s never seen before. If
your training corpus has the strings swim, play, and playing, a
word-level tokenizer would identify the string swimming as an unknown
word. However, "swimming" is simply a new word constructed on primitive
subwords that the model has seen. So a subword tokenizer could
identify it as ["swim", "##m##", "##ing"] and pass more relevant
information to the model.
Let’s take a look at how these ideas are implemented in the tokenizers library.
Building Your Own Tokenizer
The ready-to-use subword tokenizers are great, but sometimes, you really do need a tokenizer that picks out nuances specific to your text domain. The canonical examples are legal and medical text. These domains usually have a specific set of frequently used terms that are important enough to deserve their own token (think of molecule names or specific sections of legal documents).
Note
Yes, we said “train,” because subword tokenizers need some criteria to decide how to split words, and learning is often the best solution.
If you want to train your own tokenizer, there are a few popular options. Here are some references to the state-of-the-art research in tokenizers:
- Byte pair encoding (BPE)
-
See R. Sennrich et al., “Neural Machine Translation of Rare Words with Subword Units,” arXiv, 2015, https://oreil.ly/dlFNw.
- WordPiece
-
See M. Schuster and K. Nakajima, “Japanese and Korean Voice Search,” International Conference on Acoustics, Speech and Signal Processing, IEEE (2012), https://oreil.ly/fvGTh.
- SentencePiece
-
See T. Kudo and J. Richardson, “SentencePiece: A Simple and Language Independent Subword Tokenizer and Detokenizer for Neural Text Processing,” arXiv, 2018, https://oreil.ly/YNFhP.
Getting real-world medical data is actually quite hard due to regulations and a lack of privacy-preserving machine learning techniques. So for now, we’ll use the WikiText-103 dataset, which is the set of Wikipedia articles we used in Chapter 2. Just know that if your text data represents the typical literary patterns on the internet, you won’t have to train your own tokenizers from scratch most of the time.
First, we need to get the dataset (in case you didn’t download it already):
wget https://s3.amazonaws.com/research.metamind.io/wikitext/ wikitext-103-raw-v1.zip unzip wikitext-103-raw-v1.zip
Using an established tokenizer is quite simple with Hugging Face’s tokenizers library. Here, we first set up a
byte-pair encoding (a form of subword tokenization) tokenizer in a
single line of code:
fromtokenizersimportTokenizerfromtokenizers.modelsimportBPEtokenizer=Tokenizer(BPE(unk_token="[UNK]"))
Next, we initialize a special BpreTrainer object. This is only
required if you’re training a new tokenizer from scratch:
fromtokenizers.trainersimportBpeTrainertrainer=BpeTrainer(special_tokens=["[UNK]","[CLS]","[SEP]","[PAD]","[MASK]"])
Finally, we specify the files and train our BPE tokenizer:
files=[f"data/wikitext-103-raw/wiki.{split}.raw"forsplitin["test","train","valid"]]tokenizer.train(files,trainer)
Conclusion
In this chapter, we looked at the first stage of a lower-level view
of the NLP pipeline—tokenizers. Tokenizers are not the stage of the
stack that most people should be optimizing because different tokenizers
won’t have a significant impact on your
application’s performance in the real world, but they are
nonetheless a vital component. In practice, you should use spacy
or tokenizers since they’ll have the latest versions of
the newest tokenizers from research implemented. If you have a custom
dataset with a lot of domain-specific vocabulary (like in legal or
medical applications) it makes sense to retrain an established
tokenizer algorithm like WordPiece or SentencePiece.
We also explored some of the nuances of developing fast tokenizers. Specifically, we explored how the choice of programming language can have an impact on the performance of your tokenizer.
Now we have a working low-level understanding of tokenizers, and if you want you should be able to build your own from scratch (in practice, of course, it’s not that useful). This allows us to take large text files and generate tokens that our model can use to solve complex NLP problems.
But we can’t pass raw tokens into the model. Tokens are still essentially indices in dictionaries, which is not semantically useful for a deep learning model. Instead, we pass what are called “embeddings” of the tokens, which is what the next chapter is all about.
Get Applied Natural Language Processing in the Enterprise now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

