Chapter 4. Consuming APIs
Up to this point, we’ve discussed why APIs are important, how to model them, and how to implement the code behind them. In this chapter and the next, we’ll discuss how to best consume APIs.
Identify Clients
Broadly, your clients can fall into one of the following three categories:
- Internal applications
-
Internal microservices that rely on functionality exposed by your APIs
- Digital Experience Platforms
-
Platforms that allow non-technical and semi-technical business users to build experiences for different customers. Grew out of web content management space
- Custom frontends
-
Custom web UIs, native mobile, embedded devices, social media, etc.
These three categories of clients have different requirements that will change how you model, build, and consume APIs.
Start by building an inventory of all known clients. If you have an existing API that you’re replacing, trace the source of all the inbound API calls. Your existing API may have clients you never knew about.
Then, imagine what kinds of clients you’ll see more of. If you’re selling consumer packaged goods, many of your future clients will probably be Internet of Things (IoT) devices, like smart refrigerators. If you’re selling apparel, many of your future clients will probably be magic mirrors and similar devices.
Finally, look at the characteristics and capabilities of each type of client:
- Language
-
What type of language can be used to consume the APIs? Does it have to be plain REST, or can you use SDKs based on Java, .NET, or other languages?
- Latency
-
Where physically is the client relative to the origin of your API? Are you running a custom web UI out of the same physical data center where you have a millisecond of latency, or are you consuming the API from a mobile phone that’s 200 milliseconds from the origin?
- Bandwidth
-
Similar to latency, what are bandwidth constraints? Your end-consumers will get upset if their smart watch consumes hundreds of megabytes every time your app is opened.
- Processing power
-
Some clients may have very limited processing power, which impacts how you call the API. An internet-connected coffee pot that reorders coffee pods will be able to consume APIs very differently than a microservice running on a new data center’s server.
- Security
-
Does your client support the libraries required for common authentication and authorization libraries? Native clients, especially, may severely restrict your ability to include third-party libraries.
- Ability to cache
-
Is the client capable of any client-side caching? To what degree? An internet-connected coffee pot might not be able to cache anything, whereas a full data center server can probably cache hundreds of millions of responses.
The capabilities of each client may force the producer of your API, whether internal or external, to cater to the lowest common denominator.
Let’s look at the three classes of clients and explore what specifically sets them apart and what you should keep in mind.
Internal Applications
By far, the top client for your APIs will be other internal applications. These applications can be legacy back-office applications (OMS, ERP, CRM, etc.), newer cloud-native microservices, or anything in between.
Legacy applications can be excessively chatty with your APIs because they weren’t built to support the number of integrations that are common within enterprises today. The big back-office applications that serve as the backbone of enterprises (OMS, ERP, CRM, etc) once largely operated within their own silos but today are connected by hundreds of touchpoints. To make matters worse, these applications don’t tolerate latency. The world they were built for was deployment to on-premise data centers, with all applications physically deployed next to each other with no latency. Because responses were expected to be instantaneous, there often isn’t any support for asynchronous programming of any sort.
Newer-style cloud-native applications, often backed by microservices, are built for the heavily interconnected world that is common within enterprises today. They are more intelligent about how they call other APIs, often relying on batching or calls that retrieve more data than is immediately required. They are better able to cache data. They support latency, often through advanced asynchronous programming models.
As we discussed in Chapter 2, serialization frameworks like Apache Thrift, Apache Avro, and Google’s protocol buffers sometimes must be used. Clients like internal applications are best able to leverage these frameworks because you can often include the required libraries and have more control over how the APIs are called.
Digital Experience Platforms
Digital Experience Platforms (DXP) allow non- or semi-technical business users to define experiences for customers on different devices. An experience is an interaction with an end consumer, whether it’s a traditional web page view, an alert on a smart watch, or a moment in front of a magic mirror (Figure 4-1).
Figure 4-1. Example of a Digital Experience Platform (Adobe Experience Manager)
Marketing should own these touchpoints with customers because they’re closest to customers. Yet in most organizations, IT owns all digital interactions with customers. DXPs give control of experiences to marketers and other business users. Here’s how Gartner defines these platforms:
A digital experience platform is a rationalized, integrated set of technologies used to provide and improve a wide array of digital experiences to a wide array of audiences. This includes web, mobile and emerging IoT experiences. DXP frameworks evolved from portals and web content management (WCM), yet differ from them with a broad collection of supporting services. Examples include app/API framework, search, analytics, collaboration, social, mobile and UX framework, and may include features like digital commerce or digital marketing.
Gartner, Hype Cycle for Digital Commerce 2017, Gene Phifer, July 2017
Commerce APIs are then injected into the various experiences. In this model, business owns the experiences, and IT owns the APIs that are consumed as part of those experiences.
These platforms are usually deployed to data centers that are near or well connected to where your APIs are served from. You often have your choice of programming language and are able to use third-party libraries, allowing you to use SDKs, serialization frameworks, and security libraries.
Note
Unless you have compelling reasons to build custom UIs, you should use a DXP.
Custom UIs
Custom UIs can be anything. They could be web, mobile, embedded devices, social media, etc. It’s hard to find a device that isn’t capable of facilitating a commerce transaction in some way.
These clients have wide ranges of capabilities, but many times you’re left working directly with REST APIs. Remember to design and deploy your APIs in a way that allows the lowest common denominator of a client.
GraphQL can be of particular value to native clients, where latency and bandwidth are serious constraints. Facebook developed and then later open-sourced GraphQL for precisely this reason.
API Calling Best Practices
As a consumer of an API, what’s behind the API shouldn’t be of concern to you. As a consumer, you’re given a URL, some documentation, and an SLA. The provider of the API should make sure that the API is functional and available. That being said, there are some things you can do to protect yourself from issues on the client side.
Only Request What You Need
It’s easy to over-request data. A simple request to /Product/12345 might result in a response that’s hundreds of kilobytes. A single product may have hundreds of attributes. Unless you’re a merchandiser who’s editing that information in a business administration UI, it is unnecessary for clients to be requesting that much. Displaying a product on a smart watch may only require retrieving three or four properties.
Your SDK may allow you to specify which attributes you’re requesting. Or if you’re making an HTTP request directly to a REST resource, you could simply specify the properties you want as part of the HTTP request:
GET /Product/12345?attributes=id,displayName,imageURL
If you’re using GraphQL, it’s even easier:
query {product(id:"12345") {iddisplayNameimageURL}
However you approach this problem, ensure that every single client is requesting only what is truly necessary.
Don’t Make Too Many Calls
For performance reasons, it’s important to not make too many calls to your APIs. Your clients may be accessing APIs over a mobile internet connection. Like traditional web browsers, your client may have limits on the number of parallel HTTP requests or even open sockets. The farther away your clients are from your APIs, the more you have to worry about this problem.
Note
HTTP/1 only supports one outstanding HTTP request per TCP connection. With browsers supporting only a handful of HTTP requests per distinct origin URL, HTTP/1 suffers from a head-of-line blocking problem whereby one slow response can block the rendering of an entire page.
HTTP/2 is fully multiplexed, meaning it allows multiple HTTP requests in parallel over a single TCP connection. A client can send multiple requests over one connection, and the server can respond as each response becomes available. This makes it dramatically faster and easier to hit dozens of APIs in parallel to render a single page.
You can minimize the number of calls from the client by using some form of an aggregation layer. The layer may be an API gateway of some sort. It may be another application or microservice. It may be GraphQL. What matters is that your remote client isn’t making dozens or even hundreds of API calls to render pages or screens.
Use a Circuit Breaker
Calls from your client to your API should ideally be routed through a circuit breaker. Circuit breakers are a form of bulkheading in that they isolate failures.
If your client calls an API without going through a circuit breaker, and that API is fails, the client is likely to fail as well. Failure is likely because your client’s request-handling threads end up getting stuck waiting on a response from your API. This is easily solved through the use of a circuit breaker (see Figure 4-2).
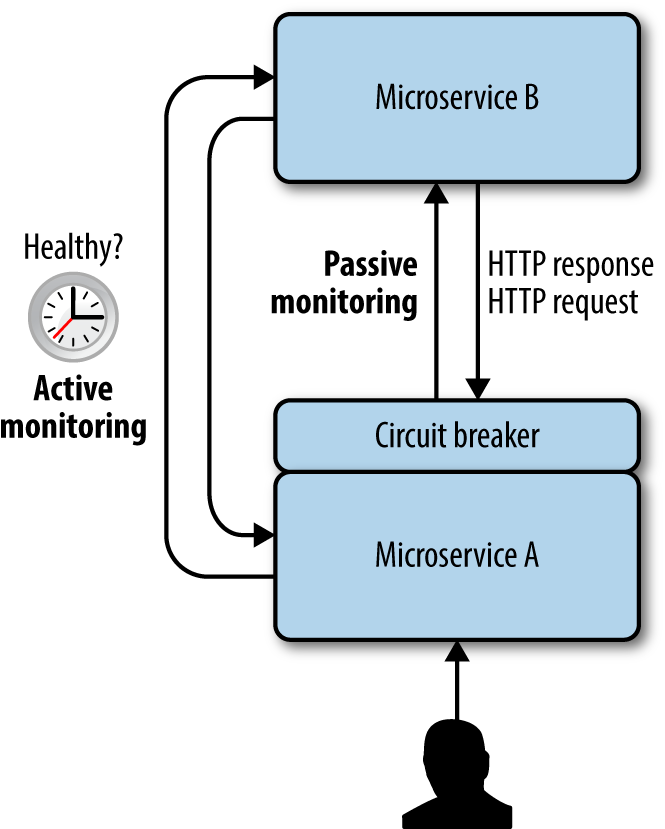
Figure 4-2. Example of the circuit breaker pattern
A circuit breaker uses active, passive, or active-plus-passive monitoring to keep tabs on the health of the microservice you’re calling. Active monitoring can probe the health of a remote microservice on a scheduled basis, whereas passive monitoring can monitor how requests to a remote microservice are performing. If a microservice you’re calling is having trouble, the circuit breaker will stop making calls to it, as seen in Figure 4-3. Calling a resource that is having trouble only exacerbates its problems and ties up valuable request-handling threads.
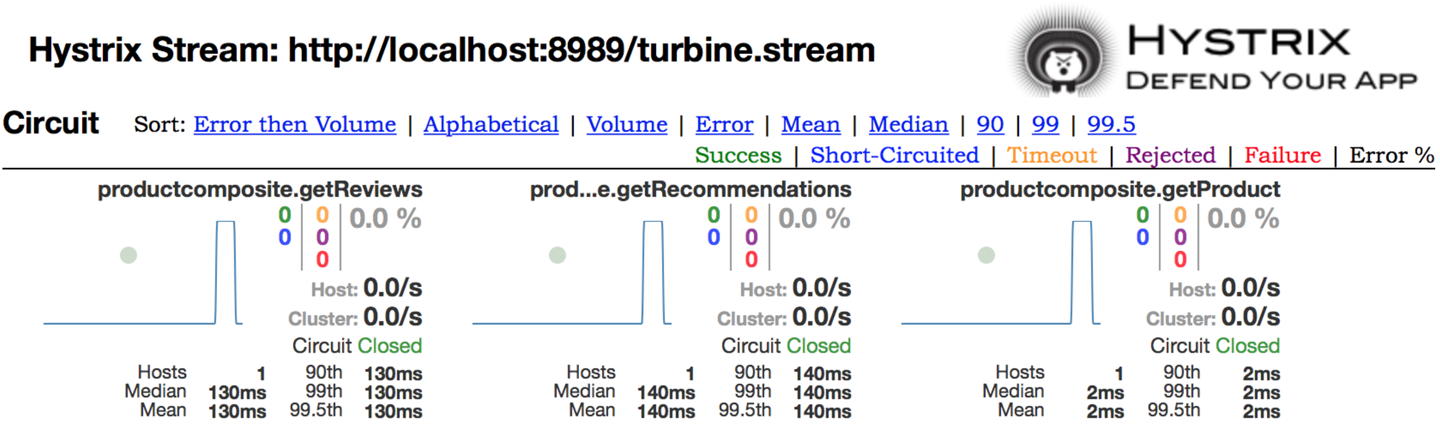
Figure 4-3. Example of Hystrix, the popular circuit breaker from Netflix
To further protect callers from downstream issues, circuit breakers often have their own threadpool. The request-handling thread makes a request to connect to the remote microservice. Upon approval, the circuit breaker itself, using its own thread from its own pool, makes the call. If the call is unsuccessful, the circuit breaker thread ends up being blocked, and the request-handling thread is able to gracefully fail.
The exact technology you use doesn’t matter so much as the fact that you’re using something.
Cache on the Client Side
A client can be anything—a mobile device, a web browser, another application or microservice, an API gateway, etc. For performance reasons, it’s best to cache as aggressively as each client allows, as close to the client as possible.
What’s good about REST APIs, is that they leverage the HTTP stack, which is extremely cacheable. The vast majority of HTTP requests use the GET verb, which is almost entirely cacheable. GET /Product/12345?attributes=id,displayName,imageURL will always return the same JSON or XML document. Through existing ETags and Cache-Control HTTP headers you can finely control how your clients cache responds. Google has a great guide on this topic.
Some clients are essentially transparent passthroughs that make caching transparent. For example, many clients access APIs through a Content Delivery Network. Many APIs are exposed through API gateways. With clients like this, you set up caching and forget about the internals of how it’s handled.
If your client is another application or a custom frontend, you’ll have to deal with caching on your own. In this case, consider using Redis, Memcached, or some other object store to cache entire resources or collections of resources.
Final Thoughts
Now that we’ve discussed consuming APIs, let’s turn our attention to how to extend/customize APIs to suit your specific business needs.
Get APIs for Modern Commerce now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

