Chapter 3. Lifecycle of Write and Read Queries
The Apache Iceberg table format provides high-performance queries during reads and writes, allowing you to run online analytical processing (OLAP) workloads directly on the data lake. What facilitates this performance is the way the various components of the Iceberg table format are designed. It is therefore critical to understand the structure of these components so that query engines can effectively use them for faster query planning and execution. We discussed these architectural components in detail in Chapter 2. At a high level, all these components can be segregated into three different layers, as presented in Figure 3-1.
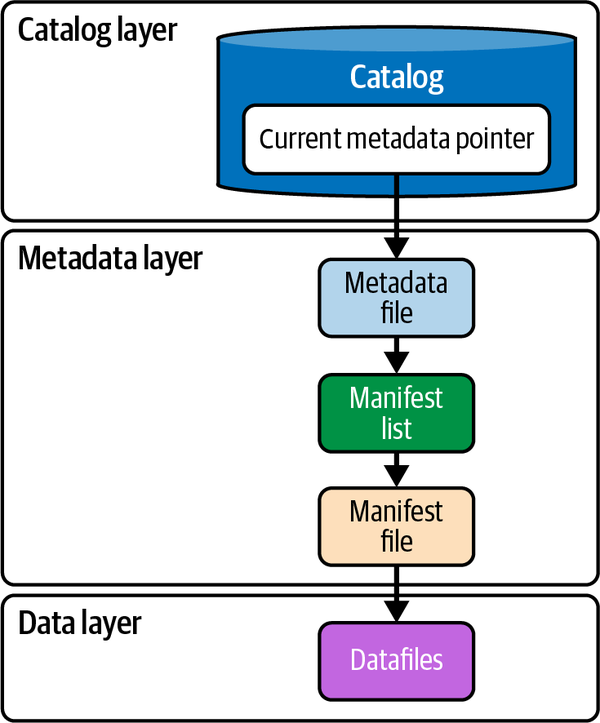
Figure 3-1. Apache Iceberg’s components
Let’s quickly review how a query engine interacts with these components for reads and writes:
- Catalog layer
As you learned in Chapter 2, a catalog holds the references to the current metadata pointer, that is, the latest metadata file for each table. Irrespective of whether you are doing a read operation or a write operation, the catalog is the first component that a query engine interacts with. In the case of reads, the engine reaches out to the catalog to learn about the current state of the table, and for writes, the catalog is used to adhere to the schema defined and to know about the table’s partitioning scheme.
- Metadata layer
The metadata layer in Apache Iceberg ...
Get Apache Iceberg: The Definitive Guide now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

