Kapitel 4. Optimierung der Leistung von Eisberg-Tabellen
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Wie du in Kapitel 3 gesehen hast, bieten Apache Iceberg-Tabellen eine Schicht von Metadaten, die es der Abfrage-Engine ermöglichen, intelligentere Abfragepläne für eine bessere Leistung zu erstellen. Diese Metadaten sind jedoch nur der Anfang, wie du die Leistung deiner Daten optimieren kannst.
Dir stehen verschiedene Optimierungshebel zur Verfügung, z. B. die Verringerung der Anzahl der Datendateien, die Datensortierung, die Tabellenpartitionierung, die Behandlung von Aktualisierungen auf Zeilenebene, die Sammlung von Metriken und externe Faktoren. Diese Hebel spielen eine wichtige Rolle bei der Verbesserung der Datenleistung. In diesem Kapitel wird jeder einzelne von ihnen untersucht, um potenzielle Verlangsamungen anzusprechen und Einblicke in die Beschleunigung zu geben. Die Implementierung eines robusten Monitorings mit den bevorzugten Tools ist entscheidend für die Identifizierung von Optimierungsbedarf, einschließlich der Verwendung von Apache Iceberg-Metadaten-Tabellen, die wir in Kapitel 10 behandeln werden.
Verdichtung
Jede Prozedur oder jeder Prozess kostet Zeit, was längere Abfragen und höhere Rechenkosten bedeutet. Anders ausgedrückt: Je mehr Schritte du unternehmen musst, um etwas zu tun, desto länger brauchst du dafür. Wenn du deine Apache Iceberg-Tabellen abfragst, musst du jede einzelne Datei öffnen und scannen und die Datei dann schließen, wenn du fertig bist. Je mehr Dateien du für eine Abfrage scannen musst, desto höher sind die Kosten, die diese Dateioperationen für deine Abfrage verursachen. Dieses Problem wird in der Welt der Streaming- oder "Echtzeit"-Daten noch verschärft, da hier viele Dateien mit jeweils nur wenigen Datensätzen erstellt werden.
Im Gegensatz dazu kannst du bei der Batch-Ingestion, bei der du die Datensätze eines ganzen Tages oder einer Woche in einem einzigen Auftrag einlesen kannst, effizienter planen, wie du die Daten in besser organisierte Dateien schreiben kannst. Auch bei der Batch-Ingestion kann das "Problem der kleinen Dateien" auftreten, bei dem sich zu viele kleine Dateien auf die Geschwindigkeit und Leistung deiner Scans auswirken, weil du mehr Dateioperationen durchführst, viel mehr Metadaten lesen musst (jede Datei enthält Metadaten) und mehr Dateien bei Bereinigungs- und Wartungsarbeiten löschen musst. Abbildung 4-1 zeigt diese beiden Szenarien.
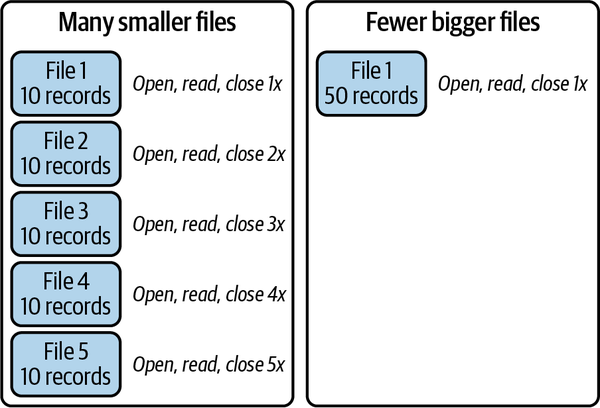
Abbildung 4-1. Viele kleinere Dateien sind langsamer zu lesen als die gleichen Daten in wenigen größeren Dateien
Wenn es um das Lesen von Daten geht, gibt es Fixkosten, die du nicht vermeiden kannst, und variable Kosten, die du mit verschiedenen Strategien vermeiden kannst. Zu den festen Kosten gehört das Lesen der Daten, die für deine Abfrage relevant sind; du kannst nicht vermeiden, dass du die Daten lesen musst, um sie zu verarbeiten. Zu den variablen Kosten gehören zwar auch die Dateioperationen, um auf die Daten zuzugreifen, aber mit vielen der Strategien, die wir in diesem Kapitel besprechen, kannst du diese variablen Kosten so weit wie möglich reduzieren. Wenn du diese Strategien anwendest, brauchst du nur noch die notwendige Rechenleistung, um deine Aufgabe kostengünstiger und schneller zu erledigen (eine schnellere Erledigung der Aufgabe hat den Vorteil, dass du die Rechencluster früher beenden kannst, was ihre Kosten reduziert).
Die Lösung für dieses Problem besteht darin, die Daten in all diesen kleinen Dateien regelmäßig in weniger größere Dateien umzuschreiben (du kannst auch Manifeste umschreiben, wenn es im Verhältnis zur Anzahl deiner Datendateien zu viele Manifeste gibt). Dieser Prozess wird als Verdichtung bezeichnet, da du viele Dateien zu wenigen verdichtest. Die Verdichtung wird in Abbildung 4-2 dargestellt.
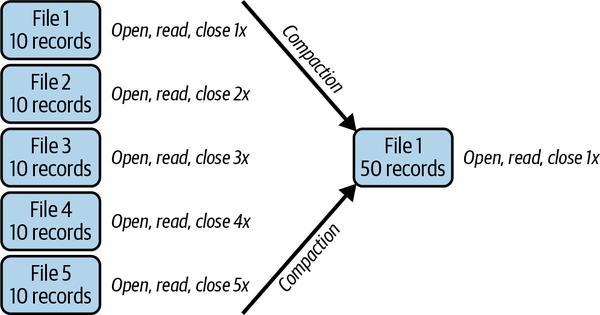
Abbildung 4-2. Bei der Komprimierung werden viele kleinere Dateien zu weniger großen Dateien verarbeitet
Verdichtung zum Anfassen
Du denkst vielleicht, dass die Lösung zwar einfach klingt, aber dass du dafür einen umfangreichen Code in Java oder Python schreiben musst. Glücklicherweise enthält das Actions-Paket von Apache Iceberg mehrere Wartungsprozeduren (das Actions-Paket ist speziell für Apache Spark, aber andere Engines können ihre eigene Implementierung von Wartungsprozeduren erstellen). Dieses Paket wird innerhalb von Spark verwendet, indem du entweder SparkSQL schreibst, wie im Großteil dieses Kapitels gezeigt, oder indem du imperativen Code wie den folgenden schreibst (denke daran, dass diese Aktionen immer noch die gleichen ACID-Garantien wie normale Iceberg-Transaktionen haben):
Tabletable=catalog.loadTable("myTable");SparkActions.get().rewriteDataFiles(table).option("rewrite-job-order","files-desc").execute();
In diesem Snippet haben wir eine neue Instanz unserer Tabelle angelegt und dann rewriteDataFiles ausgelöst, die Spark-Aktion für die Verdichtung. Das von SparkActions verwendete Builder-Muster ermöglicht es uns, Methoden miteinander zu verknüpfen, um den Verdichtungsauftrag fein abzustimmen und damit nicht nur auszudrücken, dass die Verdichtung durchgeführt werden soll, sondern auch wie sie durchgeführt werden soll.
Es gibt mehrere Methoden, die du zwischen dem Aufruf von rewriteDataFiles und der Methode execute, die den Auftrag beginnt, verketten kannst:
binPack-
Setzt die Verdichtungsstrategie auf binpack (wird später besprochen), was die Standardeinstellung ist und nicht explizit angegeben werden muss.
Sort-
Ändert die Verdichtungsstrategie so, dass die umgeschriebenen Daten nach einem oder mehreren Feldern in einer Prioritätsreihenfolge sortiert, die in "Verdichtungsstrategien" näher erläutert wird .
zOrder-
Ändert die Verdichtungsstrategie in eine z-geordnete Sortierung der Daten auf der Grundlage mehrerer Felder mit gleicher Gewichtung, die in "Sortierung" näher erläutert wird .
filter-
Ermöglicht die Übergabe eines Ausdrucks, mit dem du einschränkst, welche Dateien neu geschrieben werden.
optionoptions
Es gibt verschiedene Möglichkeiten, den Auftrag zu konfigurieren; hier sind ein paar wichtige davon:
target-file-size-bytes-
Hier wird die gewünschte Größe der Ausgabedateien festgelegt. Standardmäßig wird dafür die Eigenschaft
write.target.file-size-bytesder Tabelle verwendet, die auf 512 MB voreingestellt ist. max-concurrent-file-group-rewrites-
Dies ist die Obergrenze für die Anzahl der Gruppen, die gleichzeitig schreiben können.
max-file-group-size-bytes-
Die maximale Größe einer Dateigruppe ist nicht eine einzige Datei. Diese Einstellung sollte verwendet werden, wenn es sich um Partitionen handelt, die größer sind als der Speicher, der dem Worker, der eine bestimmte Dateigruppe schreibt, zur Verfügung steht, damit er diese Partition in mehrere Dateigruppen aufteilen kann, die gleichzeitig geschrieben werden.
partial-progress-enabled-
Dadurch können Commits erfolgen, während Dateigruppen verdichtet werden. Bei lang andauernden Verdichtungsvorgängen kann dies dazu führen, dass gleichzeitige Abfragen von bereits verdichteten Dateien profitieren.
partial-progress-max-commits-
Wenn der Teilfortschritt aktiviert ist, wird mit dieser Einstellung die maximale Anzahl von Commits festgelegt, die für den Abschluss des Auftrags zulässig sind.
rewrite-job-order-
Die Reihenfolge zum Schreiben von Dateigruppen, die wichtig sein kann, wenn du den partiellen Fortschritt verwendest, um sicherzustellen, dass die Dateigruppen mit höherer Priorität eher früher als später übertragen werden, kann auf den Gruppen basieren, die nach Bytegröße oder Anzahl der Dateien in einer Gruppe geordnet sind (
bytes-asc,bytes-desc,files-asc,files-desc,none).
Hinweis
Während die Engine die neuen Dateien plant, die im Verdichtungsauftrag geschrieben werden sollen, beginnt sie damit, diese Dateien in Dateigruppen zu gruppieren, die parallel geschrieben werden (d.h. eine Datei aus jeder Gruppe kann gleichzeitig geschrieben werden). In deinen Verdichtungsaufträgen kannst du festlegen, wie groß diese Dateigruppen sein dürfen und wie viele gleichzeitig geschrieben werden sollen, um Speicherprobleme zu vermeiden.
Der folgende Codeschnipsel verwendet mehrere der möglichen Tabellenoptionen in der Praxis:
Table table = catalog.loadTable("myTable");
SparkActions
.get()
.rewriteDataFiles(table)
.sort()
.filter(Expressions.and(
Expressions.greaterThanOrEqual("date", "2023-01-01"),
Expressions.lessThanOrEqual("date", "2023-01-31")))
.option("rewrite-job-order", "files-desc")
.execute();
Im vorangegangenen Beispiel haben wir eine Sortierstrategie implementiert, die sich standardmäßig an die in den Tabelleneigenschaften festgelegte Sortierreihenfolge hält. Außerdem haben wir einen Filter eingebaut, der ausschließlich Daten aus dem Monat Januar umschreibt. Es ist wichtig zu wissen, dass für diesen Filter ein Ausdruck mit der internen Schnittstelle von Apache Iceberg zur Erstellung von Ausdrücken erstellt werden muss. Außerdem haben wir rewrite-job-order so konfiguriert, dass größere Dateigruppen vorrangig umgeschrieben werden. Das bedeutet, dass eine Datei, die aus einer Gruppe von fünf Dateien umgeschrieben wird, vor einer Datei verarbeitet wird, die aus nur zwei Dateien zusammengesetzt ist.
Hinweis
Die Expressions-Bibliothek wurde entwickelt, um die Erstellung von Ausdrücken rund um die Metadatenstrukturen von Apache Iceberg zu erleichtern. Die Bibliothek bietet APIs zum Erstellen und Bearbeiten dieser Ausdrücke, die dann zum Filtern von Daten in Tabellen und für Lesevorgänge verwendet werden können. Icebergs Ausdrücke können auch in Manifestdateien verwendet werden, um die Daten in jeder Datendatei zusammenzufassen. Dadurch kann Iceberg Dateien überspringen, die keine Zeilen enthalten, die einem Filter entsprechen könnten. Dieser Mechanismus ist für die skalierbare Metadaten-Architektur von Iceberg unerlässlich.
Das ist zwar schön und gut, aber mit den Erweiterungen von Spark SQL ist es einfacher, denn sie enthalten Aufrufprozeduren, die mit der folgenden Syntax von Spark SQL aufgerufen werden können:
-- using positional argumentsCALLcatalog.system.procedure(arg1,arg2,arg3)-- using named argumentsCALLcatalog.system.procedure(argkey1=>argval1,argkey2=>argval2)
Die Prozedur rewriteDataFiles würde in dieser Syntax wie in Beispiel 4-1 aussehen.
Beispiel 4-1. Verwendung des rewrite_data_files Verfahrens zur Ausführung von Verdichtungsaufträgen
-- Rewrite Data Files CALL Procedure in SparkSQLCALLcatalog.system.rewrite_data_files(table=>'musicians',strategy=>'binpack',where=>'genre = "rock"',options=>map('rewrite-job-order','bytes-asc','target-file-size-bytes','1073741824',-- 1GB'max-file-group-size-bytes','10737418240'-- 10GB))
In diesem Szenario haben wir vielleicht Daten in unsere Tabelle musicians gestreamt und festgestellt, dass viele kleine Dateien für Rockbands generiert wurden. Anstatt die gesamte Tabelle zu verdichten, was zeitaufwändig sein kann, haben wir nur die problematischen Daten ausgewählt. Außerdem weisen wir Spark an, Dateigruppen mit größeren Bytes zu bevorzugen und Dateien mit einer Größe von jeweils etwa 1 GB zu behalten, wobei jede Dateigruppe etwa 10 GB groß sein sollte. Das Ergebnis dieser Einstellungen kannst du in Abbildung 4-3 sehen.
Tipp
Beachte in Beispiel 4-1 die Verwendung von doppelten Anführungszeichen in unserem where Filter. Da wir den Filter in einfache Anführungszeichen setzen mussten, verwenden wir doppelte Anführungszeichen in der Zeichenfolge, auch wenn SQL normalerweise einfache Anführungszeichen für "rock" verwenden würde. Die Option where ist im Wesentlichen gleichwertig mit der oben erwähnten Filtermethode. Ohne sie würde möglicherweise die gesamte Tabelle neu geschrieben werden.
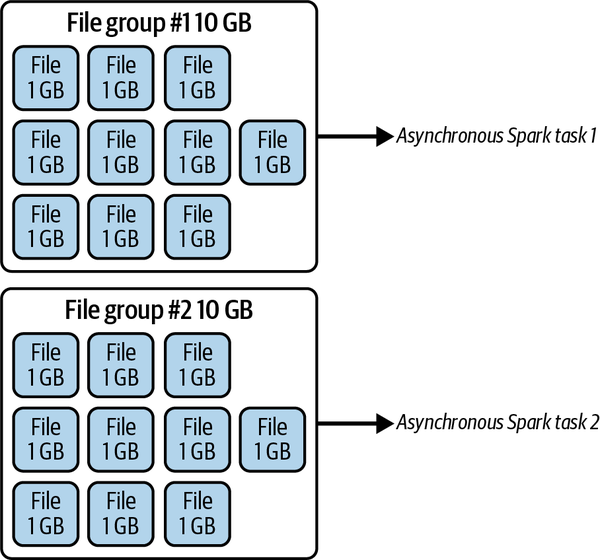
Abbildung 4-3. Das Ergebnis, wenn die maximale Dateigruppe und die maximale Dateigröße auf 10 GB bzw. 1 GB gesetzt werden
Andere Engines können ihre eigenen Verdichtungstools implementieren. Dremio hat z. B. eine eigene Iceberg-Tabellenverwaltung über den Befehl OPTIMIZE, die eine eigene Implementierung ist, aber viele der APIs der Aktion RewriteDataFiles nutzt:
OPTIMIZE TABLE catalog.MyTable
Der vorhergehende Befehl würde die grundlegende binpack Verdichtung erreichen, indem er alle Dateien in weniger, optimalere Dateien komprimiert. Aber wie bei der rewriteDataFiles Prozedur in Spark können wir noch granularer vorgehen.
Hier verdichten wir zum Beispiel nur eine bestimmte Partition:
OPTIMIZE TABLE catalog.MyTable
FOR PARTITIONS sales_year IN (2022, 2023) AND sales_month IN ('JAN', 'FEB',
'MAR')
Und hier komprimieren wir mit bestimmten Dateigrößenparametern:
OPTIMIZE TABLE catalog.MyTable REWRITE DATA (MIN_FILE_SIZE_MB=100, MAX_FILE_SIZE_MB=1000, TARGET_FILE_SIZE_MB=512)
In diesem Codeschnipsel schreiben wir nur die Manifeste um:
OPTIMIZE TABLE catalog.MyTable REWRITE MANIFESTS
Wie du siehst, kannst du Spark oder Dremio verwenden, um die Verdichtung deiner Apache Iceberg-Tabellen zu erreichen .
Strategien zur Verdichtung
Wie bereits erwähnt, gibt es mehrere Verdichtungsstrategien, die du bei der Verwendung des rewriteDataFiles Verfahrens anwenden kannst. Tabelle 4-1 fasst diese Strategien mit ihren Vor- und Nachteilen zusammen. In diesem Abschnitt geht es um die Binpack-Verdichtung; die Standardsortierung und die Sortierung nach z-Reihenfolge werden später in diesem Buch behandelt .
| Strategie | Was sie tut | Profis | Nachteile |
|---|---|---|---|
| Binpack | Kombiniert nur Dateien; keine globale Sortierung (führt lokale Sortierung innerhalb von Aufgaben durch) | Dies bietet die schnellsten Verdichtungsaufträge. | Die Daten sind nicht geclustert. |
| Sortieren | Sortiert vor der Aufgabenzuweisung nach einem oder mehreren Feldern (z. B. nach Feld a sortieren, dann nach Feld b sortieren) | Daten, die nach häufig abgefragten Feldern geclustert sind, können zu viel schnelleren Lesezeiten führen. | Dies führt zu längeren Verdichtungsaufträgen im Vergleich zu binpack. |
| z-order | Sortiert nach mehreren Feldern, die gleich gewichtet sind, bevor die Aufgaben zugewiesen werden (X- und Y-Werte in diesem Bereich sind in einer Gruppierung; die in einem anderen Bereich sind in einer anderen Gruppierung) | Wenn Abfragen häufig auf Filtern für mehrere Felder beruhen, kann dies die Lesezeiten noch weiter verbessern. | Das führt dazu, dass die Verdichtungsaufträge im Vergleich zu binpack länger laufen. |
Die binpack-Strategie ist im Wesentlichen eine reine Verdichtungsstrategie, bei der neben der Größe der Dateien keine weiteren Überlegungen zur Organisation der Daten angestellt werden. Von den drei Strategien ist binpack die schnellste, da sie den Inhalt der kleineren Dateien einfach in eine größere Datei der Zielgröße schreibt, während sort und z-order die Daten sortieren müssen, bevor sie Dateigruppen zum Schreiben zuweisen können. Das ist besonders nützlich, wenn du Daten im Streaming-Verfahren hast und die Verdichtung so schnell laufen muss, dass deine Service Level Agreements (SLAs) eingehalten werden.
Tipp
Wenn in den Einstellungen einer Apache Iceberg-Tabelle eine Sortierreihenfolge festgelegt ist, wird diese Sortierreihenfolge auch bei Verwendung von binpack für die Sortierung der Daten innerhalb einer einzelnen Aufgabe verwendet (lokale Sortierung). Wenn du die Sortier- und Z-Reihenfolge-Strategien verwendest, werden die Daten sortiert, bevor die Abfrage-Engine die Datensätze den verschiedenen Aufgaben zuordnet, um so die Clusterung der Daten über die Aufgaben hinweg zu optimieren.
Wenn du Streaming-Daten einliest, musst du vielleicht eine schnelle Verdichtung der Daten durchführen, die nach jeder Stunde eingelesen werden. Du könntest etwa so vorgehen:
CALLcatalog.system.rewrite_data_files(table=>'streamingtable',strategy=>'binpack',where=>'created_at between "2023-01-26 09:00:00" and "2023-01-26 09:59:59" ',options=>map('rewrite-job-order','bytes-asc','target-file-size-bytes','1073741824','max-file-group-size-bytes','10737418240','partial-progress-enabled','true'))
Bei diesem Verdichtungsauftrag wird die Binpack-Strategie eingesetzt, um die Streaming-SLA-Anforderungen schneller zu erfüllen. Sie zielt speziell darauf ab, die Daten innerhalb eines Zeitrahmens von einer Stunde einzulesen, der dynamisch an die letzte Stunde angepasst werden kann. Die Verwendung von partiellen Fortschritts-Commits stellt sicher, dass Dateigruppen, sobald sie geschrieben werden, sofort übertragen werden, was zu unmittelbaren Leistungsverbesserungen für die Leser führt. Wichtig ist, dass sich dieser Verdichtungsprozess ausschließlich auf bereits geschriebene Daten konzentriert und sie von gleichzeitigen Schreibvorgängen aus Streaming-Operationen isoliert, die neue Datendateien einbringen würden.
Wenn du eine schnellere Strategie für einen begrenzten Datenumfang verwendest, können deine Verdichtungsaufträge viel schneller ausgeführt werden. Natürlich könntest du die Daten wahrscheinlich noch mehr verdichten, wenn du die Verdichtung über eine Stunde hinaus zulassen würdest, aber du musst die Notwendigkeit, den Verdichtungsauftrag schnell auszuführen, mit der Notwendigkeit der Optimierung abwägen. Du kannst einen zusätzlichen Verdichtungsauftrag für die Daten eines Tages über Nacht und einen Verdichtungsauftrag für die Daten einer Woche über das Wochenende durchführen, um die Optimierung in kontinuierlichen Intervallen fortzusetzen und dabei andere Vorgänge so wenig wie möglich zu beeinträchtigen. Denke daran, dass die Verdichtung immer die aktuelle Partitionsspezifikation beachtet. Wenn also Daten aus einer alten Partitionsspezifikation neu geschrieben werden, werden die neuen Partitionierungsregeln angewendet.
Verdichtung automatisieren
Es wäre etwas schwierig, all deine SLAs einzuhalten, wenn du diese Verdichtungsaufträge manuell ausführen müsstest. Daher könnte es von großem Vorteil sein, wenn du diese Prozesse automatisieren könntest. Hier sind ein paar Ansätze, wie du diese Aufträge automatisieren kannst:
-
Du kannst ein Orchestrierungstool wie Airflow, Dagster, Prefect, Argo oder Luigi verwenden, um die richtige SQL an eine Engine wie Spark oder Dremio zu senden, nachdem ein Ingestion-Job abgeschlossen wurde oder zu einem bestimmten Zeitpunkt oder in einem bestimmten Intervall.
-
Du kannst serverlose Funktionen verwenden, um den Auftrag auszulösen, nachdem die Daten in der Cloud Object Speicherung gelandet sind.
-
Du kannst Cron-Jobs einrichten, um die entsprechenden Aufträge zu bestimmten Zeiten auszuführen.
Bei diesen Ansätzen musst du diese Dienste manuell skripten und einsetzen. Es gibt jedoch auch eine Klasse von verwalteten Apache Iceberg-Katalogdiensten, die eine automatische Tabellenpflege und eine Verdichtung beinhalten. Beispiele für diese Art von Diensten sind Dremio Arctic und Tabular .
Sortieren
Bevor wir uns mit den Details der Sortierverdichtungsstrategie befassen, wollen wir erst einmal verstehen, wie sich das Sortieren auf die Optimierung einer Tabelle auswirkt.
Das Sortieren oder "Clustern" deiner Daten hat einen ganz besonderen Vorteil, wenn es um deine Abfragen geht: Es hilft, die Anzahl der Dateien zu begrenzen, die durchsucht werden müssen, um die für eine Abfrage benötigten Daten zu erhalten. Durch das Sortieren der Daten können Daten mit ähnlichen Werten in weniger Dateien konzentriert werden, was eine effizientere Abfrageplanung ermöglicht.
Nehmen wir zum Beispiel an, du hast einen Datensatz mit allen Spielern aller NFL-Teams in 100 Parkettdateien, die nicht besonders sortiert sind. Wenn du eine Abfrage nur nach Spielern der Detroit Lions machst, muss diese Datei zum Abfrageplan hinzugefügt und gescannt werden, selbst wenn eine Datei mit 100 Datensätzen nur einen Datensatz eines Spielers der Detroit Lions enthält. Das bedeutet, dass du möglicherweise bis zu 53 Dateien durchsuchen musst (die maximale Anzahl von Spielern in einem NFL-Team). Wenn du die Daten alphabetisch nach Teamnamen sortiert hast, sollten alle Spieler der Detroit Lions in etwa vier Dateien enthalten sein (100 Dateien geteilt durch 32 NFL-Teams ergibt 3,125), darunter wahrscheinlich auch eine Handvoll Spieler der Green Bay Packers und der Denver Broncos. Durch die Sortierung der Daten hast du also die Anzahl der Dateien, die du durchsuchen musst, von möglicherweise 53 auf 4 reduziert, was, wie wir in "Verdichtungsstrategien" besprochen haben , die Leistung der Abfrage erheblich verbessert. Abbildung 4-4 veranschaulicht die Vorteile des Scannens sortierter Datensätze.
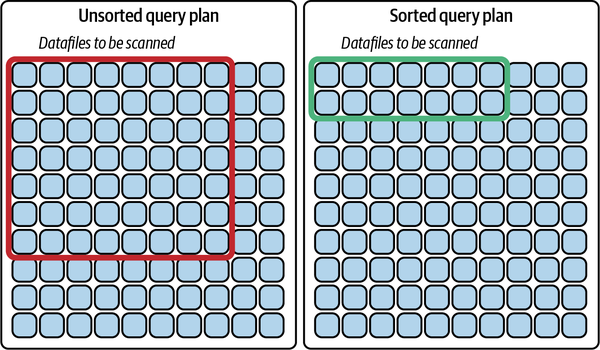
Abbildung 4-4. Sortierte Datensätze führen dazu, dass weniger Datendateien gescannt werden
Sortierte Daten können sehr nützlich sein, wenn die Art und Weise, wie die Daten sortiert werden, typischen Abfragemustern entspricht, wie in diesem Beispiel, in dem du die NFL-Daten regelmäßig nach einem bestimmten Team abfragen kannst. Das Sortieren von Daten in Apache Iceberg kann an vielen verschiedenen Stellen erfolgen, daher solltest du sicherstellen, dass du alle diese Stellen nutzt.
Es gibt zwei Hauptmethoden, um eine Tabelle zu erstellen. Zum einen mit der Standardanweisung CREATE TABLE :
-- Spark SyntaxCREATETABLEcatalog.nfl_players(idbigint,player_namevarchar,teamvarchar,num_of_touchdownsint,num_of_yardsint,player_positionvarchar,player_numberint,)-- Dremio SyntaxCREATETABLEcatalog.nfl_players(idbigint,player_namevarchar,teamvarchar,num_of_touchdownsint,num_of_yardsint,player_positionvarchar,player_numberint,)
Die andere Möglichkeit ist eine CREATE TABLE…AS SELECT (CTAS) Anweisung:
-- Spark SQL & Dremio SyntaxCREATETABLEcatalog.nfl_playersAS(SELECT*FROMnon_iceberg_teams_table);
Nach der Erstellung der Tabelle legst du die Sortierreihenfolge der Tabelle fest, die jede Engine, die diese Eigenschaft unterstützt, zum Sortieren der Daten vor dem Schreiben verwendet und die auch das Standardsortierfeld ist, wenn die Sortierverdichtungsstrategie verwendet wird:
ALTERTABLEcatalog.nfl_teamsWRITEORDEREDBYteam;
Wenn du eine CTAS machst, sortiere die Daten in deiner AS Abfrage:
CREATETABLEcatalog.nfl_teamsAS(SELECT*FROMnon_iceberg_teams_tableORDERBYteam);ALTERTABLEcatalog.nfl_teamsWRITEORDEREDBYteam;
Die Anweisung ALTER TABLE legt eine globale Sortierreihenfolge fest, die für alle zukünftigen Schreibvorgänge von Engines, die die Sortierreihenfolge beachten, verwendet wird. Du könntest auch mit INSERT INTO angeben, etwa so:
INSERTINTOcatalog.nfl_teamsSELECT*FROMstaging_tableORDERBYteam
So wird sichergestellt, dass die Daten beim Schreiben sortiert werden, aber es ist nicht perfekt. Um auf das vorherige Beispiel zurückzukommen: Wenn der NFL-Datensatz jedes Jahr aktualisiert wird, weil sich die Mannschaftsaufstellungen ändern, kann es sein, dass du am Ende viele Dateien hast, in denen die Spieler der Lions und Packers aus mehreren Schreibvorgängen aufgeteilt sind. Das liegt daran, dass du jetzt eine neue Datei mit den neuen Lions-Spielern für das aktuelle Jahr schreiben müsstest. Hier kommt die Strategie der Sortierverdichtung ins Spiel.
Die Sortierverdichtungsstrategie sortiert die Daten über alle Dateien, auf die der Auftrag abzielt. Wenn du also zum Beispiel den gesamten Datensatz mit allen Spielern nach Mannschaften sortiert neu schreiben möchtest, könntest du die folgende Anweisung ausführen:
CALLcatalog.system.rewrite_data_files(table=>'nfl_teams',strategy=>'sort',sort_order=>'team ASC NULLS LAST')
Hier ist eine Aufschlüsselung des Strings, der für die Sortierreihenfolge übergeben wurde:
team-
Sortiert die Daten nach dem Feld
team ASC-
Sortiert die Daten in aufsteigender Reihenfolge (
DESCwürde in absteigender Reihenfolge sortieren) NULLS LAST-
Setzt alle Spieler mit einem Nullwert an das Ende der Sortierung, nach den Washington Commanders (
NULLS FIRSTwürde alle Spieler vor die Arizona Cardinals setzen)
Abbildung 4-5 zeigt das Ergebnis der Sortierung.
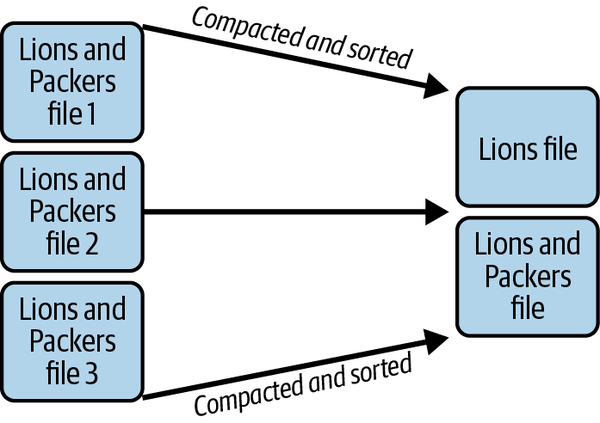
Abbildung 4-5. Komprimieren und Sortieren der Daten in weniger Dateien
Du kannst auch nach weiteren Feldern sortieren. Du möchtest zum Beispiel, dass die Daten nach Teams sortiert werden, aber innerhalb jedes Teams sollen sie alphabetisch nach Namen sortiert werden. Das kannst du erreichen, indem du einen Auftrag mit diesen Parametern ausführst:
CALLcatalog.system.rewrite_data_files(table=>'nfl_teams',strategy=>'sort',sort_order=>'team ASC NULLS LAST, name ASC NULLS FIRST')
Die Sortierung nach Mannschaft hat das größte Gewicht, gefolgt von der Sortierung nach Name. Wahrscheinlich siehst du die Spieler in dieser Reihenfolge in der Datei, wo der Dienstplan der Lions endet und der Dienstplan der Packers beginnt, wie in Abbildung 4-6 dargestellt.
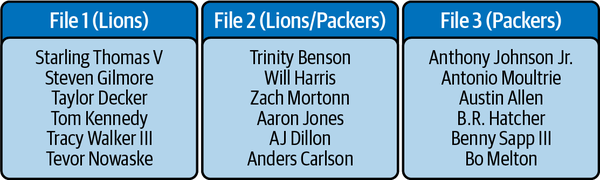
Abbildung 4-6. Sortierte Liste der Spieler über Dateien hinweg
Wenn Endnutzer regelmäßig Fragen stellen wie "Wer sind alle Lions-Spieler, deren Name mit A beginnt", würde diese doppelte Sortierung die Abfrage noch weiter beschleunigen. Wenn du aber fragen würdest: "Wer sind alle NFL-Spieler, deren Name mit A anfängt?", wäre das nicht so hilfreich, da sich alle "A"-Spieler auf mehr Dateien verteilen, als wenn du nur nach Namen sortiert hättest. An dieser Stelle kann die Z-Sortierung nützlich sein.
Die Quintessenz ist, dass du die Art der Fragen, die deine Endnutzer/innen stellen, verstehen musst, um den größten Nutzen aus der Sortierung zu ziehen, damit du die Daten so sortieren kannst, dass du ihre Fragen effektiv beantworten kannst.
Z-Bestellung
Es gibt Fälle, in denen mehrere Felder bei der Abfrage einer Tabelle Priorität haben, und in diesen Fällen kann eine z-order Sortierung sehr hilfreich sein. Mit einer z-order Sortierung sortierst du die Daten nach mehreren Datenpunkten, was es den Suchmaschinen ermöglicht, die Anzahl der gescannten Dateien im endgültigen Abfrageplan zu reduzieren. Nehmen wir an, wir versuchen, den Punkt Z in einem 4 × 4 Raster zu finden(Abbildung 4-7).

Abbildung 4-7. Die Grundlagen der Z-Reihenfolge verstehen
Bei "A" in Abbildung 4-7 haben wir einen Wert (z), der gleich 3,5 ist, und wir wollen den Bereich eingrenzen, den wir in unseren Daten suchen wollen. Wir können unsere Suche eingrenzen, indem wir das Feld in vier Quadranten unterteilen, die auf den Bereichen der X- und Y-Werte basieren, wie in "B" in der Abbildung dargestellt.
Wenn wir also wissen, welche Daten wir anhand der Felder, nach denen wir z-geordnet haben, suchen, können wir möglicherweise vermeiden, große Teile der Daten zu durchsuchen, da sie nach beiden Feldern sortiert sind. Dann können wir diesen Quadranten noch weiter unterteilen und eine weitere Z-Sortierung auf die Daten im Quadranten anwenden, wie in "C" in der Abbildung gezeigt. Da unsere Suche auf mehreren Faktoren basiert (X und Y), können wir mit diesem Ansatz 75 % des durchsuchbaren Bereichs eliminieren.
Du kannst deine Daten in den Datendateien auf ähnliche Weise sortieren und clustern. Nehmen wir an, du hast einen Datensatz mit allen Teilnehmern einer medizinischen Kohortenstudie und möchtest die Ergebnisse der Kohorte nach Alter und Größe ordnen; dann kann es sich lohnen, die Daten nach Z zu sortieren. Du kannst dies in Abbildung 4-8 in Aktion sehen.
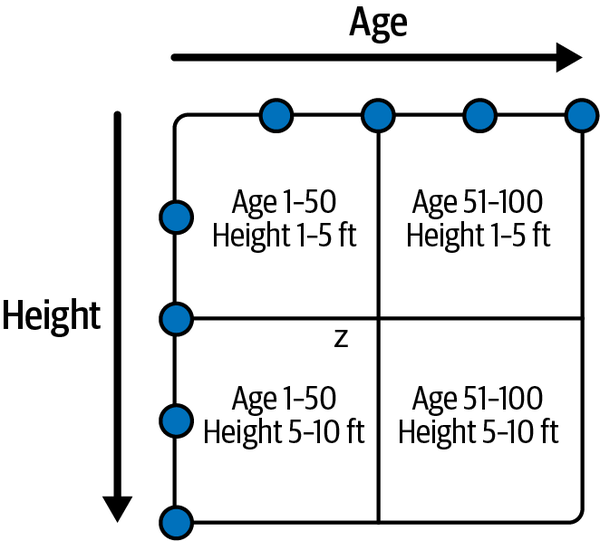
Abbildung 4-8. Z-Reihenfolge basierend auf Alter und Größe
Daten, die in einen bestimmten Quadranten fallen, befinden sich in denselben Datendateien, was die Anzahl der zu durchsuchenden Dateien deutlich verringern kann, wenn du versuchst, Analysen für verschiedene Alters- und Größengruppen durchzuführen. Wenn du nach Personen mit einer Körpergröße von 1,80 m und einem Alter von 60 Jahren suchst, kannst du die Dateien mit Daten aus den anderen drei Quadranten sofort ausschließen.
Das funktioniert, weil die Datendateien in vier Kategorien eingeteilt werden:
-
A: Datei mit Datensätzen, die Alter 1-50 und Größe 1-5 enthalten
-
B: Datei mit Datensätzen, die Alter 51-100 und Größe 1-5 enthalten
-
C: Datei mit Datensätzen, die Alter 1-50 und Größe 5-10 enthalten
-
D: Datei mit Datensätzen, die Alter 51-100 und Größe 5-10 enthalten
Wenn die Suchmaschine weiß, dass du nach einer Person suchst, die 60 Jahre alt und 1,80 m groß ist, und die Apache Iceberg-Metadaten zur Planung der Abfrage verwendet, werden alle Datendateien in den Kategorien A, B und C ausgeschlossen und nie gescannt. Auch wenn du nur nach dem Alter gesucht hättest, würdest du von der Clusterung profitieren, weil du mindestens zwei der vier Quadranten ausschließen könntest.
Um dies zu erreichen, muss ein Verdichtungsauftrag ausgeführt werden:
CALLcatalog.system.rewrite_data_files(table=>'people',strategy=>'sort',sort_order=>'zorder(age,height)')
Mit den Verdichtungsstrategien Sortieren und Z-Reihenfolge kannst du nicht nur die Anzahl der Dateien reduzieren, in denen sich deine Daten befinden, sondern auch dafür sorgen, dass die Reihenfolge der Daten in diesen Dateien eine noch effizientere Abfrageplanung ermöglicht.
Das Sortieren ist zwar effektiv, bringt aber auch einige Herausforderungen mit sich. Erstens werden neue Daten beim Einlesen unsortiert, und bis zum nächsten Verdichtungsauftrag bleiben die Daten über mehrere Dateien verstreut. Das liegt daran, dass neue Daten einer neuen Datei hinzugefügt werden und möglicherweise innerhalb dieser Datei sortiert werden, aber nicht im Zusammenhang mit allen vorherigen Datensätzen. Zweitens können die Dateien immer noch Daten für mehrere Werte des sortierten Feldes enthalten, was für Abfragen, die nur Daten mit einem bestimmten Wert benötigen, ineffizient sein kann. Im Beispiel von vorhin enthielten die Dateien sowohl Daten für Lions- als auch für Packers-Spieler, so dass es ineffizient war, die Packers-Datensätze zu durchsuchen, wenn du nur an den Lions-Spielern interessiert warst.
Aufteilung
Wenn du weißt, dass ein bestimmtes Feld entscheidend dafür ist, wie auf die Daten zugegriffen wird, möchtest du vielleicht über die Sortierung hinausgehen und eine Partitionierung vornehmen. Bei der Partitionierung einer Tabelle wird die Reihenfolge nicht nur nach einem Feld sortiert, sondern es werden Datensätze mit unterschiedlichen Werten des Zielfeldes in eigene Datendateien geschrieben.
In der Politik zum Beispiel wirst du wahrscheinlich oft Wählerdaten nach der Parteizugehörigkeit der Wähler abfragen, so dass dies ein gutes Unterteilungsfeld ist. Das würde bedeuten, dass alle Wähler der "blauen" Partei in anderen Dateien aufgeführt werden als die Wähler der "roten", "gelben" und "grünen" Partei. Wenn du nach Wählern der "gelben" Partei suchen würdest, würde keine der gescannten Datendateien jemanden von einer anderen Partei enthalten. Das siehst du in Abbildung 4-9.

Abbildung 4-9. Partitionierung und Gruppierung von Daten in Dateigruppen
Um eine Tabelle auf der Grundlage abgeleiteter Werte eines bestimmten Feldes aufzuteilen, musste bisher ein zusätzliches Feld angelegt werden, das separat gepflegt werden musste und für dessen Abfrage die Benutzer Kenntnis über dieses separate Feld haben mussten. Ein Beispiel:
-
Für die Aufteilung nach Tag, Monat oder Jahr in einer Zeitstempelspalte musstest du eine zusätzliche Spalte erstellen, die auf dem Zeitstempel basierte und das Jahr, den Monat oder den Tag isoliert ausdrückte.
-
Für die Unterteilung nach dem ersten Buchstaben eines Textwerts musstest du eine zusätzliche Spalte erstellen, die nur diesen Buchstaben enthielt.
-
Die Aufteilung in Buckets (eine festgelegte Anzahl von Unterteilungen, in die Datensätze auf der Grundlage einer Hash-Funktion gleichmäßig verteilt werden) erforderte die Erstellung einer zusätzlichen Spalte, die angab, in welchen Bucket der Datensatz gehörte.
Du würdest dann die Partitionierung bei der Tabellenerstellung so einstellen, dass sie auf den abgeleiteten Feldern basiert, und die Dateien würden in Unterverzeichnissen auf der Grundlage ihrer Partition organisiert werden:
--Spark SQLCREATETABLEMyHiveTable(...)PARTITIONEDBYmonth;
Du müsstest den Wert jedes Mal manuell umwandeln, wenn du Datensätze einfügst:
INSERTINTOMyTable(SELECTMONTH(time)ASmonth,...FROMdata_source);
Bei der Abfrage der Tabelle würde die Engine die Beziehung zwischen dem ursprünglichen Feld und dem abgeleiteten Feld nicht kennen. Das würde bedeuten, dass die folgende Abfrage von der Partitionierung profitieren würde:
SELECT*FROMMYTABLEWHEREtimeBETWEEN'2022-07-01 00:00:00'AND'2022-07-3100:00:00'ANDmonth=7;
Allerdings sind sich die Benutzer oft nicht über diese Umgehungsspalte im Klaren (und das sollte auch nicht nötig sein). Das bedeutet, dass die Benutzer meistens eine Abfrage ähnlich der folgenden stellen, die zu einem vollständigen Tabellenscan führt, wodurch die Abfrage viel länger dauert und viel mehr Ressourcen verbraucht:
SELECT*FROMMYTABLEWHEREtimeBETWEEN'2022-07-01 00:00:00'AND'2022-07-3100:00:00';
Die vorhergehende Abfrage ist für einen Geschäftsanwender oder Datenanalysten, der die Daten verwendet, intuitiver, da er sich der internen Struktur der Tabelle nicht so bewusst ist, was zu vielen versehentlichen vollständigen Tabellendurchsuchungen führt. Hier kommt die versteckte Partitionierungsfunktion von Iceberg ins Spiel.
Entwicklung der Partition
Eine weitere Herausforderung bei der traditionellen Partitionierung besteht darin, dass die physische Struktur der Dateien in Unterverzeichnisse unterteilt ist und eine Änderung der Partitionierung der Tabelle ein Neuschreiben der gesamten Tabelle erfordert. Das wird zu einem unvermeidlichen Problem, wenn sich Daten und Abfragemuster weiterentwickeln und wir die Partitionierung und Sortierung der Daten überdenken müssen.
Apache Iceberg löst auch dieses Problem mit seiner metadatengestützten Partitionierung, denn die Metadaten verfolgen nicht nur die Partitionswerte, sondern auch die historischen Partitionsschemata, sodass sich die Partitionsschemata weiterentwickeln können. Wenn also die Daten in zwei verschiedenen Dateien auf der Grundlage von zwei unterschiedlichen Partitionsschemata geschrieben wurden, würden die Iceberg-Metadaten die Engine darauf aufmerksam machen, so dass sie einen Plan mit Partitionsschema A getrennt von Partitionsschema B erstellen und am Ende einen Gesamtscanplan erstellen könnte.
Angenommen, du hast eine Tabelle mit Mitgliedsdatensätzen, die nach dem Jahr unterteilt sind, in dem sich die Mitglieder angemeldet haben:
CREATETABLEcatalog.members(...)PARTITIONEDBYyears(registration_ts)USINGiceberg;
Dann, einige Jahre später, machte es das Tempo des Mitgliederwachstums sinnvoll, die Datensätze nach Monaten aufzuschlüsseln. Du könntest die Tabelle ändern, um die Aufteilung wie folgt anzupassen:
ALTERTABLEcatalog.membersADDPARTITIONFIELDmonths(registration_ts)
Das Schöne an den datumsbezogenen Partitionstransformationen von Apache Iceberg ist, dass du die weniger granulare Partitionierungsregel nicht entfernen musst, wenn du zu einer granularen Partitionierung übergehst. Wenn du jedoch Bucket oder Truncate verwendest und dich entscheidest, dass du die Tabelle nicht mehr nach einem bestimmten Feld partitionieren willst, kannst du dein Partitionsschema wie folgt aktualisieren:
ALTERTABLEcatalog.membersDROPPARTITIONFIELDbucket(24,id);
Wenn ein Partitionierungsschema aktualisiert wird, gilt es nur für neue Daten, die in die Tabelle geschrieben werden, sodass die vorhandenen Daten nicht neu geschrieben werden müssen. Denk auch daran, dass alle Daten, die durch die rewriteDataFiles Prozedur neu geschrieben werden, mit dem neuen Partitionierungsschema neu geschrieben werden. Wenn du also ältere Daten im alten Schema behalten willst, musst du sicherstellen, dass du die richtigen Filter in deinen Verdichtungsaufträgen verwendest, um sie nicht neu zu schreiben.
Andere Überlegungen zur Aufteilung
Angenommen, du migrierst eine Hive-Tabelle mit der Migrationsprozedur (siehe Kapitel 13). Möglicherweise ist sie derzeit auf Basis einer abgeleiteten Spalte partitioniert (z. B. eine Monatsspalte, die auf einer Zeitstempelspalte in derselben Tabelle basiert), aber du möchtest Apache Iceberg mitteilen, dass sie stattdessen eine Iceberg-Transformation verwenden soll. Für diesen Zweck gibt es den Befehl REPLACE PARTITION :
ALTERTABLEcatalog.membersREPLACEPARTITIONFIELDregistration_dayWITHdays(registration_ts)ASday_of_registration;
Dadurch werden keine Datendateien verändert, aber die Metadaten können die Partitionswerte mithilfe von Iceberg-Transformationen nachverfolgen.
Du kannst Tabellen auf viele Arten optimieren. Wenn du zum Beispiel mit Partitionierung Daten mit eindeutigen Werten in eindeutige Dateien schreibst, die Daten in diesen Dateien sortierst und dann sicherstellst, dass diese Dateien in weniger große Dateien komprimiert werden, bleibt die Leistung deiner Tabelle schön und knackig. Auch wenn es nicht immer um die allgemeine Optimierung geht, gibt es bestimmte Anwendungsfälle, wie z. B. Aktualisierungen und Löschungen auf Zeilenebene, für die du mit Copy-on-Write und Merge-on-Read ebenfalls optimieren kannst.
Copy-on-Write vs. Merge-on-Read
Ein weiterer Aspekt für die Geschwindigkeit deiner Workloads ist die Art und Weise, wie du Aktualisierungen auf Zeilenebene vornimmst. Wenn du neue Daten hinzufügst, werden sie einfach einer neuen Datendatei hinzugefügt. Wenn du aber bereits vorhandene Zeilen aktualisieren oder löschen willst, musst du einige Dinge beachten:
-
In Data Lakes, und damit auch in Apache Iceberg, sind Datendateien unveränderlich, d.h. sie können nicht geändert werden. Das hat viele Vorteile, wie z. B. die Möglichkeit, Snapshots zu isolieren (da Dateien, auf die alte Snapshots verweisen, konsistente Daten haben).
-
Wenn du 10 Zeilen aktualisierst, gibt es keine Garantie, dass sie sich in derselben Datei befinden. Daher musst du möglicherweise 10 Dateien und jede einzelne Datenzeile darin neu schreiben, um 10 Zeilen für den neuen Snapshot zu aktualisieren.
Es gibt drei Ansätze für den Umgang mit Aktualisierungen auf Zeilenebene , die in diesem Abschnitt ausführlich behandelt und in Tabelle 4-2 zusammengefasst werden.
| Stil aktualisieren | Geschwindigkeit lesen | Schreibgeschwindigkeit | Bewährte Methoden |
|---|---|---|---|
| Copy-on-Write | Am schnellsten liest | Langsamste Aktualisierungen/Löschungen | |
| Merge-on-Read (Löschen von Positionen) | Schnell gelesen | Schnelle Aktualisierungen/Löschungen | Nutze die regelmäßige Verdichtung, um die Kosten für das Ablesen zu minimieren. |
| Merge-on-read (Gleichheit löscht) | Langsam liest | Schnellste Aktualisierungen/Löschungen | Verdichte häufiger, um die Ablesekosten zu minimieren . |
Copy-on-Write
Der Standardansatz wird als Copy-on-Write (COW) bezeichnet. Wenn auch nur eine einzige Zeile in einer Datendatei aktualisiert oder gelöscht wird, wird die Datendatei neu geschrieben und die neue Datei nimmt ihren Platz im neuen Snapshot ein. Ein Beispiel dafür siehst du in Abbildung 4-10.
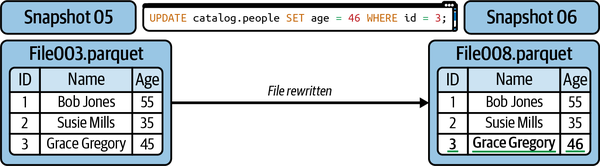
Abbildung 4-10. Die Ergebnisse der Verwendung von Copy-on-Write zum Aktualisieren einer einzelnen Zeile
Dies ist ideal, wenn du für Lesevorgänge optimierst weil Leseabfragen die Daten einfach lesen können, ohne gelöschte oder aktualisierte Dateien abgleichen zu müssen. Wenn deine Arbeitslasten jedoch aus sehr regelmäßigen Aktualisierungen auf Zeilenebene bestehen, kann das Umschreiben ganzer Datendateien für diese Aktualisierungen deine Aktualisierungen über das hinaus verlangsamen, was deine SLAs erlauben. Zu den Vorteilen dieses Ansatzes gehören schnellere Lesevorgänge, zu den Nachteilen dagegen langsamere Aktualisierungen und Löschungen auf Zeilenebene.
Merge-on-Read
Die Alternative zum Copy-on-Write ist das Merge-on-Read (MOR), bei dem du, anstatt eine gesamte Datendatei neu zu schreiben, die zu aktualisierenden Datensätze in der bestehenden Datei in einer Löschdatei erfasst, wobei die Löschdatei festhält, welche Datensätze ignoriert werden sollen.
Wenn du einen Datensatz löschst:
-
Der Datensatz wird in einer Löschdatei aufgeführt.
-
Wenn ein Leser die Tabelle liest, gleicht er die Datendatei mit der Löschdatei ab.
Wenn du einen Datensatz aktualisieren willst:
-
Der zu aktualisierende Datensatz wird in einer Löschdatei nachverfolgt.
-
Es wird eine neue Datendatei erstellt, die nur den aktualisierten Datensatz enthält.
-
Wenn ein Leser die Tabelle liest, wird er die alte Version des Datensatzes aufgrund der Löschdatei ignorieren und die neue Version in der neuen Datendatei verwenden.
Dies ist in Abbildung 4-11 dargestellt.
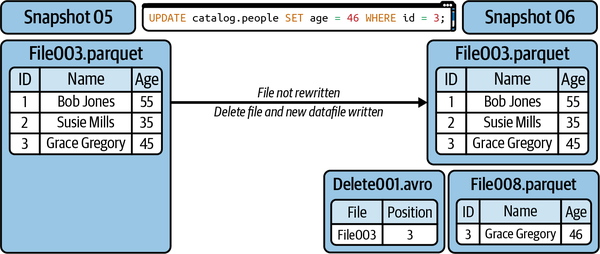
Abbildung 4-11. Die Ergebnisse der Verwendung von Merge-on-Read für die Aktualisierung einer einzelnen Zeile
Dadurch wird vermieden, dass unveränderte Datensätze in neue Dateien umgeschrieben werden müssen, nur weil sie in einer Datendatei mit einem zu aktualisierenden Datensatz vorhanden sind, was den Schreibvorgang beschleunigt. Dies hat jedoch den Nachteil, dass die Lesevorgänge langsamer werden, da die Abfragen die Löschdateien durchsuchen müssen, um zu wissen, welche Datensätze in den richtigen Datendateien ignoriert werden sollen.
Um die Kosten für Lesevorgänge zu minimieren, solltest du regelmäßig Verdichtungsaufträge ausführen. Damit diese Verdichtungsaufträge effizient laufen, solltest du dir einige der Eigenschaften zunutze machen, die du zuvor gelernt hast:
-
Verwende eine
filter/whereKlausel , um die Verdichtung nur für die Dateien durchzuführen, die im letzten Zeitrahmen (Stunde, Tag) aufgenommen wurden. -
Verwende den partiellen Fortschrittsmodus, um Commits zu machen, während Dateigruppen umgeschrieben werden, damit die Leserinnen und Leser die marginalen Verbesserungen eher früher als später sehen können.
Mit diesen Techniken kannst du die Schreibseite von umfangreichen Aktualisierungsaufgaben beschleunigen und gleichzeitig die Kosten für die Leseleistung minimieren. Der Vorteil dieses Ansatzes sind schnellere Aktualisierungen auf Zeilenebene, aber der Nachteil sind langsamere Lesevorgänge, da die Löschdateien abgeglichen werden müssen.
Wenn du MOR-Schreibvorgänge durchführst, kannst du mit Hilfe von Löschdateien feststellen, welche Datensätze in bestehenden Datendateien für zukünftige Lesevorgänge ignoriert werden müssen. Wir verwenden eine Analogie, damit du das Konzept der verschiedenen Arten von Löschdateien besser verstehst. (Behalte im Hinterkopf, welche Arten von Löschdateien geschrieben werden, da dies in der Regel von der Engine für bestimmte Anwendungsfälle entschieden wird und nicht von den Tabelleneinstellungen).
Wenn du eine große Menge an Daten hast und eine bestimmte Zeile herausnehmen möchtest, hast du mehrere Möglichkeiten:
-
Du kannst die Zeilendaten anhand ihrer Position im Datensatz suchen, so als ob du deinen Freund im Kino anhand seiner Sitznummer finden würdest.
-
Du kannst die Zeilendaten danach suchen, woraus sie bestehen, so wie du deinen Freund in einer Menschenmenge erkennen kannst, weil er einen knallroten Hut trägt.
Wenn du die erste Option wählst, verwendest du so genannte positionale Löschdateien. Wenn du jedoch die zweite Option verwendest, musst du Dateien mit Gleichheit löschen. Jede Methode hat ihre eigenen Stärken und Schwächen. Das bedeutet, dass du dich je nach Situation für die eine oder die andere entscheiden kannst. Es kommt darauf an, was für dich am besten funktioniert!
Schauen wir uns diese beiden Arten von Löschdateien an. Bei Positionslöschungen wird festgehalten, welche Zeilen in welchen Dateien ignoriert werden sollen. Die folgende Tabelle ist ein Beispiel dafür, wie diese Daten in einer Positionslöschdatei angeordnet sind:
| Zu löschende Zeile (Position löscht) | |
|---|---|
| Dateipfad | Position |
| 001.Parkett | 0 |
| 001.Parkett | 5 |
| 006.Parkett | 5 |
Beim Lesen der angegebenen Dateien überspringt die Positionslöschdatei die Zeile an der angegebenen Position. Dies verursacht beim Lesen viel geringere Kosten, da es einen ganz bestimmten Punkt gibt, an dem eine Zeile übersprungen werden muss. Dies verursacht jedoch Kosten beim Schreiben, da der Schreiber der Löschdatei die Position des gelöschten Datensatzes kennen muss, was bedeutet, dass er die Datei mit den gelöschten Datensätzen lesen muss, um diese Positionen zu ermitteln.
Gleichheitslöschungen geben stattdessen Werte an, die bei einer Übereinstimmung mit einem Datensatz ignoriert werden sollen. Die folgende Tabelle zeigt, wie die Daten in einer Gleichheitslöschdatei aufgebaut sein können:
| Zu löschende Zeilen (Gleichheitslöschungen) | |
|---|---|
| Team | Staat |
| Gelb | NY |
| Grün | MA |
Dies erfordert keine Schreibzeitkosten, da du keine Dateien öffnen und lesen musst, um die Zielwerte zu verfolgen, aber es hat viel größere Lesezeitkosten. Die Lesezeitkosten entstehen, weil es keine Informationen darüber gibt, wo es Datensätze mit übereinstimmenden Werten gibt. Beim Lesen der Daten muss also ein Vergleich mit jedem Datensatz durchgeführt werden, der möglicherweise einen übereinstimmenden Datensatz enthält. Gleichheitslöschungen sind großartig, wenn du eine möglichst hohe Schreibgeschwindigkeit brauchst, aber es sollte eine aggressive Verdichtung geplant werden, um diese Gleichheitslöschungen abzugleichen und die Auswirkungen auf deine Lesezeiten zu reduzieren.
COW und MOR konfigurieren
Ob eine Tabelle so konfiguriert ist, dass sie Aktualisierungen auf Zeilenebene über COW oder MOR verarbeitet, hängt von Folgendem ab:
-
Die Eigenschaften der Tabelle
-
Ob die Engine, mit der du in Apache Iceberg schreibst, MOR-Writes unterstützt
Die folgenden Tabelleneigenschaften bestimmen, ob eine bestimmte Transaktion über COW oder MOR abgewickelt wird:
write.delete.mode-
Vorgehensweise bei der Löschung von Transaktionen
write.update.mode-
Ansatz zur Verwendung für Update-Transaktionen
write.merge.mode-
Ansatz für die Zusammenführung von Transaktionen
Beachte, dass für diese und alle anderen Apache Iceberg-Tabelleneigenschaften viele zwar Teil der Spezifikation sind, es aber immer noch von der jeweiligen Rechenmaschine abhängt, ob die Spezifikation eingehalten wird. Es kann sein, dass du auf ein unterschiedliches Verhalten stößt, also informiere dich darüber, welche Tabelleneigenschaften von den Engines, die du für bestimmte Aufträge verwendest, beachtet werden. Die Entwickler von Abfrage-Engines sind bestrebt, alle Apache Iceberg-Tabelleneigenschaften zu berücksichtigen, aber das erfordert Implementierungen für die spezifische Architektur der Engine. Mit der Zeit sollten die Engines alle diese Eigenschaften berücksichtigen, damit du in allen Engines das gleiche Verhalten hast.
Da die Unterstützung von Apache Spark für Apache Iceberg innerhalb des Apache Iceberg-Projekts gehandhabt wird, werden alle diese Eigenschaften von Spark beachtet und können bei der Erstellung einer Tabelle in Spark wie folgt festgelegt werden:
CREATETABLEcatalog.people(idint,first_namestring,last_namestring)TBLPROPERTIES('write.delete.mode'='copy-on-write','write.update.mode'='merge-on-read','write.merge.mode'='merge-on-read')USINGiceberg;
Diese Eigenschaft kann auch nach der Erstellung der Tabelle mit einer ALTER TABLE -Anweisung festgelegt werden :
ALTERTABLEcatalog.peopleSETTBLPROPERTIES('write.delete.mode'='merge-on-read','write.update.mode'='copy-on-write','write.merge.mode'='copy-on-write');
So einfach ist das. Aber erinnere dich an Folgendes, wenn du mit Nicht-Apache Spark-Engines arbeitest:
Andere Überlegungen
Abgesehen von deinen Datendateien und deren Organisation gibt es viele Möglichkeiten, die Leistung zu verbessern. Viele davon werden wir in den folgenden Abschnitten besprechen.
Sammlung von Metriken
Wie unter in Kapitel 2 beschrieben, werden im Manifest für jede Gruppe von Datendateien Metriken für jedes Feld in der Tabelle verfolgt, um die Min/Max-Filterung und andere Optimierungen zu unterstützen. Zu den Arten von Metriken auf Spaltenebene, die verfolgt werden, gehören:
-
Zählung von Werten, Nullwerten und eindeutigen Werten
-
Obere und untere Grenzwerte
Wenn du sehr umfangreiche Tabellen hast (d.h. Tabellen mit vielen Feldern, z.B. 100+), kann die Anzahl der Metriken, die verfolgt werden, zu einer Belastung beim Lesen deiner Metadaten werden. Zum Glück kannst du mit den Tabelleneigenschaften von Apache Iceberg genau festlegen, für welche Spalten die Metriken erfasst werden und für welche nicht. Auf diese Weise kannst du die Metriken von Spalten verfolgen, die häufig in Abfragefiltern verwendet werden, und die Metriken von Spalten, die nicht häufig verwendet werden, nicht erfassen, damit ihre Metadaten nicht zu groß werden.
Du kannst die Ebene der Metriksammlung für die gewünschten Spalten anpassen (du musst nicht alle Spalten angeben), indem du die Tabelleneigenschaften wie folgt verwendest:
ALTERTABLEcatalog.db.studentsSETTBLPROPERTIES('write.metadata.metrics.column.col1'='none','write.metadata.metrics.column.col2'='full','write.metadata.metrics.column.col3'='counts','write.metadata.metrics.column.col4'='truncate(16)',);
Wie du siehst, kannst du für jede einzelne Spalte mehrere mögliche Werte festlegen, wie die Metriken gesammelt werden:
none-
Erfasse keine Metriken.
counts-
Sammle nur Zählungen (Werte, eindeutige Werte, Nullwerte).
truncate(XX)-
Zähle und kürze den Wert auf eine bestimmte Anzahl von Zeichen ab und lege die Ober- und Untergrenzen auf dieser Basis fest. So kann z. B. eine String-Spalte auf 16 Zeichen gekürzt werden und die Metadaten-Wertebereiche basieren auf den gekürzten String-Werten.
full-
Beziehe dich bei der Zählung und den oberen/unteren Grenzen auf den vollen Wert.
Du musst dies nicht explizit für jede Spalte einstellen, da Iceberg dies standardmäßig auf truncate(16) setzt.
Manifeste umschreiben
Manchmal liegt das Problem nicht an deinen Datendateien, denn sie haben eine gute Größe und gut sortierte Daten. Das Problem ist, dass sie über mehrere Snapshots hinweg geschrieben wurden, sodass ein einzelnes Manifest mehr Datendateien auflisten könnte. Manifeste sind zwar leichter zu handhaben, aber mehr Manifeste bedeuten immer noch mehr Dateioperationen. Es gibt ein separates rewriteManifests Verfahren, mit dem du nur die Manifestdateien umschreiben kannst, so dass du insgesamt weniger Manifestdateien hast und diese Manifestdateien eine große Anzahl von Datendateien auflisten:
CALLcatalog.system.rewrite_manifests('MyTable')
Wenn du bei diesem Vorgang auf Speicherprobleme stößt, kannst du das Caching von Spark ausschalten, indem du ein zweites Argument übergibst: false. Wenn du viele Manifeste umschreibst und diese von Spark zwischengespeichert werden, könnte dies zu Problemen mit einzelnen Executor-Knoten führen:
CALLcatalog.system.rewrite_manifests('MyTable',false)
Wann dieser Vorgang sinnvoll ist, hängt davon ab, wann die Größe deiner Datendateien optimal ist, die Anzahl der Manifestdateien jedoch nicht. Wenn du zum Beispiel 5 GB Daten in einer Partition hast, die auf 10 Datendateien aufgeteilt sind, aber diese Dateien in fünf Manifestdateien aufgelistet sind, musst du die Datendateien nicht neu schreiben, aber du kannst wahrscheinlich die Auflistung der 10 Dateien in einem Manifest konsolidieren.
Optimierung der Speicherung
Wenn du Aktualisierungen der Tabelle vornimmst oder Verdichtungsaufträge ausführst, werden neue Dateien erstellt, aber alte Dateien werden nicht gelöscht, da diese Dateien mit historischen Snapshots der Tabelle verknüpft sind. Um zu verhindern, dass ein Haufen nicht benötigter Daten gespeichert wird, solltest du die Snapshots regelmäßig ablaufen lassen. Denke daran, dass du nicht zu einem abgelaufenen Snapshot zurückreisen kannst. Während des Ablaufs werden alle Datendateien, die nicht mit noch gültigen Schnappschüssen verknüpft sind, gelöscht.
Du kannst Schnappschüsse ablaufen lassen, die an oder vor einem bestimmten Zeitstempel erstellt wurden:
CALLcatalog.system.expire_snapshots('MyTable',TIMESTAMP'2023-02-0100:00:00.000',100)
Das zweite Argument ist die Mindestanzahl an Snapshots, die aufbewahren soll (standardmäßig werden die Snapshots der letzten fünf Tage aufbewahrt), sodass nur Snapshots verfallen, die an oder vor dem Zeitstempel liegen. Wenn der Schnappschuss jedoch zu den 100 neuesten Schnappschüssen gehört, läuft er nicht ab.
Du kannst auch bestimmte Snapshot-IDs ablaufen lassen:
CALLcatalog.system.expire_snapshots(table=>'MyTable',snapshot_ids=>ARRAY(53))
In diesem Beispiel ist ein Snapshot mit der ID 53 ausgelaufen. Wir können die Snapshot-ID herausfinden, indem wir die Datei metadata.json öffnen und ihren Inhalt untersuchen oder die in Kapitel 10 beschriebenen Metadaten-Tabellen verwenden. Möglicherweise gibt es einen Snapshot, bei dem du versehentlich sensible Daten preisgibst, und du möchtest diesen Snapshot verfallen lassen, um die Datendateien zu bereinigen, die bei dieser Transaktion erstellt wurden. Dies würde dir diese Flexibilität geben. Das Auslaufen ist eine Transaktion, d.h. es wird eine neue metadata.json-Datei mit einer aktualisierten Liste der gültigen Snapshots erstellt .
Es gibt sechs Argumente, die der Prozedur expire_snapshots übergeben werden können:
table-
Tabelle zur Durchführung der Operation auf
older_than-
Alle Schnappschüsse verfallen an oder vor diesem Zeitstempel
retain_last-
Mindestanzahl der aufzubewahrenden Schnappschüsse
snapshot_ids-
Bestimmte Snapshot-IDs, die ablaufen sollen
max_concurrent _deletes-
Anzahl der Threads, die zum Löschen von Dateien verwendet werden
stream_results-
Bei true werden gelöschte Dateien per RDD-Partition (Resilient Distributed Dataset) an den Spark-Treiber gesendet, was nützlich ist, um OOM-Probleme beim Löschen großer Dateien zu vermeiden.
Ein weiterer Aspekt bei der Optimierung der Speicherung sind verwaiste Dateien. Dabei handelt es sich um Dateien und Artefakte, die sich im Datenverzeichnis der Tabelle ansammeln, aber im Metadatenbaum nicht nachverfolgt werden, weil sie von fehlgeschlagenen Aufträgen geschrieben wurden. Diese Dateien werden von ablaufenden Snapshots nicht bereinigt, daher sollte sporadisch eine spezielle Prozedur ausgeführt werden, um dies zu beheben. Diese Prozedur untersucht jede Datei am Standardspeicherort deiner Tabelle und prüft, ob sie sich auf aktive Snapshots bezieht. Das kann ein intensiver Prozess sein (deshalb solltest du ihn nur sporadisch durchführen). Um verwaiste Dateien zu löschen, führst du einen Befehl wie den folgenden aus:
CALLcatalog.system.remove_orphan_files(table=>'MyTable')
Du kannst die folgenden Argumente an die removeOrphanFiles Prozedur übergeben:
table-
Tisch zum Bedienen
older_than-
Löscht nur Dateien, die an oder vor diesem Zeitstempel erstellt wurden
location-
Wo nach verwaisten Dateien gesucht werden soll; standardmäßig wird der Standard-Speicherort der Tabelle verwendet
dry_run-
Boolean bei true; löscht keine Dateien, gibt aber eine Liste der zu löschenden Dateien zurück
max_concurrent_deletes-
Listet die maximale Anzahl von Threads zum Löschen von Dateien auf
Bei den meisten Tabellen befinden sich die Daten an ihrem Standardspeicherort, aber es kann vorkommen, dass du mit dem Verfahren addFiles (siehe Kapitel 13) externe Dateien hinzufügst und später Artefakte in diesen Verzeichnissen bereinigen möchtest. Hier kommt das Argument Speicherort ins Spiel.
Schreibverteilungsmodus
Der Schreibverteilungsmodus erfordert ein Verständnis dafür, wie massiv parallele Verarbeitungssysteme (MPP) mit dem Schreiben von Dateien umgehen. Diese Systeme verteilen die Arbeit auf mehrere Knotenpunkte, von denen jeder einen Auftrag oder eine Aufgabe ausführt. Die Schreibverteilung gibt an, wie die zu schreibenden Datensätze auf diese Aufgaben verteilt werden. Wenn kein bestimmter Schreibverteilungsmodus festgelegt ist, werden die Daten willkürlich verteilt. Die ersten X Datensätze gehen an die erste Aufgabe, die nächsten X Datensätze an die nächste Aufgabe und so weiter.
Jede Aufgabe wird separat verarbeitet, sodass jede Aufgabe mindestens eine Datei für jede Partition erstellt, für die sie mindestens einen Datensatz hat. Wenn du also 10 Datensätze hast, die in Partition A gehören und auf 10 Aufgaben verteilt sind, hast du am Ende 10 Dateien in dieser Partition mit jeweils einem Datensatz, was nicht ideal ist.
Es wäre besser, wenn alle Datensätze für diese Partition denselben Aufgaben zugewiesen würden, damit sie in dieselbe Datei geschrieben werden können. Hier kommt die Schreibverteilung ins Spiel, d.h. wie die Daten auf die Aufgaben verteilt werden. Es gibt drei Möglichkeiten:
none-
Es gibt keine spezielle Verteilung. Sie ist die schnellste bei der Schreibzeit und ideal für vorsortierte Daten.
hash-
Die Daten werden mit einem Hash-Verfahren nach Partitionsschlüssel verteilt.
range-
Die Daten werden nach dem Partitionsschlüssel oder der Sortierreihenfolge aufgeteilt.
Bei einer Hash-Verteilung wird der Wert jedes Datensatzes durch eine Hash-Funktion gejagt und anhand des Ergebnisses in Gruppen zusammengefasst. Basierend auf der Hash-Funktion können mehrere Werte in der gleichen Gruppierung landen. Wenn du zum Beispiel die Werte 1, 2, 3, 4, 5 und 6 in deinen Daten hast, kannst du eine Hash-Verteilung der Daten mit 1 und 4 in Aufgabe A, 2 und 5 in Aufgabe B und 3 und 6 in Aufgabe C erhalten.
Bei einer Bereichsverteilung werden die Daten sortiert und verteilt, so dass du wahrscheinlich die Werte 1 und 2 in Aufgabe A, 3 und 4 in Aufgabe B und 5 und 6 in Aufgabe C hast. Diese Sortierung erfolgt nach dem Partitionswert oder nach dem SortOrder, wenn die Tabelle einen hat. Mit anderen Worten: Wenn eine SortOrder angegeben ist, werden die Daten nicht nur nach dem Partitionswert, sondern auch nach dem Wert des Feldes SortOrder in Aufgaben gruppiert. Das ist ideal für Daten, die von einer Gruppierung nach bestimmten Feldern profitieren können. Die Daten für die Verteilung nacheinander zu sortieren, ist jedoch mit mehr Aufwand verbunden, als die Daten in eine Hash-Funktion zu werfen und sie anhand der Ausgabe zu verteilen.
Es gibt auch eine Eigenschaft für die Schreibverteilung, um das Verhalten für Löschungen, Aktualisierungen und Zusammenführungen festzulegen:
ALTERTABLEcatalog.MyTableSETTBLPROPERTIES('write.distribution-mode'='hash','write.delete.distribution-mode'='none','write.update.distribution-mode'='range','write.merge.distribution-mode'='hash',);
In einer Situation, in der du regelmäßig viele Zeilen aktualisierst, aber nur selten Zeilen löschst, möchtest du vielleicht verschiedene Verteilungsmodi haben, da ein anderer Verteilungsmodus je nach deinen Abfragemustern vorteilhafter sein kann .
Überlegungen zur Speicherung von Objekten
Die Objektspeicherung ist eine einzigartige Art der Datenspeicherung. Anstatt die Dateien in einer übersichtlichen Ordnerstruktur wie in einem herkömmlichen Dateisystem aufzubewahren, werden bei der Speicherung von Objekten alle Daten in sogenannten Buckets abgelegt. Jede Datei wird zu einem Objekt und bekommt eine Reihe von Metadaten mit auf den Weg. Diese Metadaten verraten uns alles Mögliche über die Datei und ermöglichen eine verbesserte Gleichzeitigkeit und Ausfallsicherheit bei der Verwendung von Objektspeicherung, da die zugrunde liegenden Dateien für den regionalen Zugriff oder die Gleichzeitigkeit repliziert werden können, während alle Benutzer/innen einfach nur als "Objekt" mit ihnen interagieren.
Wenn du eine Datei aus der Speicherung holen willst, klickst du dich nicht durch Ordner. Stattdessen verwendest du die APIs. So wie du eine GET oder PUT Anfrage verwendest, um mit einer Website zu interagieren, tust du dasselbe, um auf deine Daten zuzugreifen. Wenn du zum Beispiel mit einer GET Anfrage nach einer Datei fragst, überprüft das System die Metadaten, um die Datei zu finden, und schon hast du deine Daten.
Dieser API-first-Ansatz hilft dem System, mit deinen Daten zu jonglieren, z. B. Kopien an verschiedenen Orten zu erstellen oder eine Vielzahl von Anfragen gleichzeitig zu bearbeiten. Die objektbasierte Speicherung, die von den meisten Cloud-Anbietern bereitgestellt wird, ist ideal für Data Lakes und Data Lakehouses, hat aber einen potenziellen Engpass.
Aufgrund der Architektur und der Art und Weise, wie Objektspeicher mit Parallelität umgehen, gibt es oft Beschränkungen wie viele Anfragen auf Dateien unter demselben "Präfix" gestellt werden können. Wenn du also auf /Präfix1/Datei A.txt und /Präfix1/Datei B.txt zugreifen möchtest, obwohl es sich um unterschiedliche Dateien handelt, wird der Zugriff auf beide auf das Limit für Präfix1 angerechnet. Dies wird bei Partitionen mit vielen Dateien zu einem Problem, da Abfragen zu vielen Anfragen an diese Partitionen führen können und dann auf eine Drosselung stoßen, die die Abfrage verlangsamt .
Der Apache Iceberg ist für dieses Szenario jedoch besonders geeignet, da er sich nicht darauf verlässt, wie die Dateien physisch angeordnet sind, d.h. er kann Dateien über viele Präfixe hinweg in dieselbe Partition schreiben.
Du kannst dies in den Eigenschaften deiner Tabelle wie folgt aktivieren:
ALTERTABLEcatalog.MyTableSETTBLPROPERTIES('write.object-storage.enabled'=true);
Dadurch werden die Dateien in derselben Partition auf viele Präfixe verteilt, einschließlich eines Hashes, um eine mögliche Drosselung zu vermeiden.
Also, stattdessen:
s3://bucket/database/table/field=value1/datafile1.parquet s3://bucket/database/table/field=value1/datafile2.parquet s3://bucket/database/table/field=value1/datafile3.parquet
dann bekommst du das hier:
s3://bucket/4809098/database/table/field=value1/datafile1.parquet s3://bucket/5840329/database/table/field=value1/datafile2.parquet s3://bucket/2342344/database/table/field=value1/datafile3.parquet
Mit dem Hash im Dateipfad wird nun jede Datei in derselben Partition so behandelt, als ob sie unter einem anderen Präfix stünde, wodurch eine Drosselung vermieden wird.
Datendatei-Bloom-Filter
Ein Bloom-Filter ist eine Methode, um herauszufinden, ob ein Wert möglicherweise in einem Datensatz existiert. Stell dir eine Reihe von Bits vor (die 0s und 1s im Binärcode), die alle eine von dir festgelegte Länge haben. Wenn du nun Daten zu deinem Datensatz hinzufügst, lässt du jeden Wert durch einen Prozess laufen, der Hash-Funktion genannt wird. Diese Funktion spuckt eine Stelle in deiner Bitreihe aus, und du drehst dieses Bit von einer 0 zu einer 1. Dieses gedrehte Bit ist wie eine Flagge, die sagt: "Hey, ein Wert, der mit dieser Stelle übereinstimmt, könnte im Datensatz sein."
Nehmen wir zum Beispiel an, wir lassen 1.000 Datensätze durch einen Bloomfilter mit 10 Bits laufen. Am Ende könnte unser Bloomfilter so aussehen:
[0,1,1,0,0,1,1,1,1,0]
Nehmen wir an, wir wollen einen bestimmten Wert finden, nennen wir ihn X. Wir lassen X durch dieselbe Hash-Funktion laufen, und sie zeigt uns die Stelle Nummer 3 in unserer Bitaufstellung. Laut unserem Bloomfilter befindet sich an dieser dritten Stelle eine 1. Das bedeutet, dass die Möglichkeit besteht, dass unser Wert X im Datensatz enthalten ist, weil ein Wert zuvor an dieser Stelle gehasht wurde. Also überprüfen wir den Datensatz, um zu sehen, ob X wirklich vorhanden ist.
Wenn wir Y durch unsere Hash-Funktion laufen lassen, zeigt sie uns auf die vierte Stelle in unserer Bitaufstellung. Aber unser Bloomfilter hat dort eine 0, was bedeutet, dass kein Wert an dieser Stelle gehasht wurde. Wir können also mit Sicherheit sagen, dass Y definitiv nicht in unserem Datensatz enthalten ist, und wir sparen Zeit, indem wir nicht in den Daten wühlen.
Bloom-Filter sind praktisch, weil sie uns helfen können, unnötige Datenabfragen zu vermeiden. Wenn wir sie noch genauer machen wollen, können wir weitere Hash-Funktionen und Bits hinzufügen. Aber denk daran: Je mehr wir hinzufügen, desto größer wird unser Bloomfilter und desto mehr Platz braucht er. Wie bei den meisten Dingen im Leben ist es ein Balanceakt. Alles ist ein Kompromiss.
Du kannst das Schreiben von Bloom-Filtern für eine bestimmte Spalte in deinen Parquet-Dateien (dies kann auch für ORC-Dateien geschehen) über deine Tabelleneigenschaften aktivieren:
ALTERTABLEcatalog.MyTableSETTBLPROPERTIES('write.parquet.bloom-filter-enabled.column.col1'=true,'write.parquet.bloom-filter-max-bytes'=1048576);
Dann können Suchmaschinen, die deine Daten abfragen, diese Bloom-Filter nutzen, um das Lesen der Datendateien noch schneller zu machen, indem sie Datendateien überspringen, bei denen Bloom-Filter eindeutig anzeigen, dass die benötigten Daten nicht vorhanden sind.
Fazit
In diesem Kapitel wurden verschiedene Strategien zur Optimierung der Leistung von Iceberg-Tabellen untersucht. Wir haben uns kritische Methoden zur Optimierung der Tabellenleistung angesehen, wie z. B. Verdichtung, Sortierung, Z-Ordering, Copy-on-Write- versus Merge-on-Read-Mechanismen und versteckte Partitionierung. Jede dieser Komponenten spielt eine entscheidende Rolle bei der Verbesserung der Abfrageeffizienz, der Verringerung der Lese- und Schreibzeiten und der Gewährleistung einer optimalen Ressourcennutzung. Das Verständnis und die effektive Umsetzung dieser Strategien können zu erheblichen Verbesserungen bei der Verwaltung und dem Betrieb von Apache Iceberg Tabellen führen.
In Kapitel 5 werden wir uns mit dem Konzept des Iceberg-Katalogs beschäftigen, mit dem wir sicherstellen können, dass unsere Iceberg-Tabellen portabel sind und von unseren Tools gefunden werden können.
Get Apache Iceberg: Der endgültige Leitfaden now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

