Kapitel 1. Einführung in Apache Iceberg
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Daten sind das wichtigste Kapital, aus dem Unternehmen die Informationen und Erkenntnisse gewinnen, die sie für wichtige Geschäftsentscheidungen benötigen. Egal, ob sie genutzt werden, um Trends bei den jährlichen Verkaufszahlen eines bestimmten Produkts zu analysieren oder um zukünftige Marktchancen vorherzusagen, Daten geben die Richtung vor, die Unternehmen einschlagen müssen, um erfolgreich zu sein. Außerdem sind Daten heute nicht mehr nur ein Nice-to-have. Sie sind eine Voraussetzung, nicht nur um auf dem Markt zu gewinnen, sondern um im Wettbewerb zu bestehen. Angesichts des enormen Informationsbedarfs wurden enorme Anstrengungen unternommen, um die von den verschiedenen Systemen in einem Unternehmen erzeugten Daten zu sammeln und daraus Erkenntnisse abzuleiten.
Gleichzeitig ist die Geschwindigkeit, mit der betriebliche und analytische Systeme Daten erzeugen, in die Höhe geschnellt. Während mehr Daten den Unternehmen die Möglichkeit bieten, fundiertere Entscheidungen zu treffen, besteht auch ein dringender Bedarf an einer Plattform, die all diese Daten speichert und analysiert, damit sie für die Erstellung von Analyseprodukten wie Business Intelligence (BI)-Berichten und Machine Learning (ML)-Modellen zur Unterstützung der Entscheidungsfindung verwendet werden können. Die Lakehouse-Architektur, auf die wir in diesem Kapitel näher eingehen werden, entkoppelt die Datenspeicherung von der Datenverarbeitung und bietet so mehr Flexibilität. In diesem Kapitel werden wir die Geschichte und Entwicklung von Datenplattformen aus praktischer Sicht erläutern und die Vorteile einer Lakehouse-Architektur mit den offenen Tabellenformaten von Apache Iceberg vorstellen.
Wie sind wir hierher gekommen? Eine kurze Geschichte
Was die Speicherung und die Verarbeitungssysteme angeht, so sind relationale Datenbankmanagementsysteme (RDBMS) seit langem eine Standardoption für Unternehmen, um alle ihre Transaktionsdaten zu speichern. Nehmen wir an, du betreibst ein Transportunternehmen und möchtest Informationen über neue Buchungen deiner Kunden aufbewahren. In diesem Fall würde jede neue Buchung eine neue Zeile in einem RDBMS darstellen. RDBMS, die für diesen Zweck verwendet werden, unterstützen eine bestimmte Datenverarbeitungskategorie, die als Online Transaction Processing (OLTP) bezeichnet wird. Beispiele für OLTP-optimierte RDBMS sind PostgreSQL, MySQL und Microsoft SQL Server. Diese Systeme sind so konzipiert und optimiert, dass du sehr schnell mit einer oder wenigen Datenzeilen gleichzeitig arbeiten kannst, und eignen sich gut zur Unterstützung des Tagesgeschäfts eines Unternehmens.
Aber nehmen wir an, du wolltest wissen, wie hoch der durchschnittliche Gewinn ist, den du mit all deinen neuen Buchungen aus dem vorangegangenen Quartal gemacht hast. In diesem Fall hätte die Verwendung von Daten, die in einem OLTP-optimierten RDBMS gespeichert sind, zu erheblichen Leistungsproblemen geführt, sobald deine Daten groß genug waren. Einige der Gründe dafür sind die folgenden:
Transaktionssysteme konzentrieren sich auf das Einfügen, Aktualisieren und Lesen einer kleinen Teilmenge von Zeilen in einer Tabelle, daher ist die Speicherung der Daten in einem zeilenbasierten Format ideal. Analysesysteme hingegen konzentrieren sich in der Regel darauf, bestimmte Spalten zu aggregieren oder mit allen Zeilen einer Tabelle zu arbeiten, weshalb eine spaltenbasierte Struktur vorteilhafter ist.
Der Betrieb von Transaktions- und Analyse-Workloads auf derselben Infrastruktur kann zu einem Wettbewerb um Ressourcen führen.
Transaktionale Workloads profitieren von der Normalisierung der Daten in mehrere zusammenhängende Tabellen, die bei Bedarf zusammengefügt werden, während analytische Workloads möglicherweise besser abschneiden, wenn die Daten in dieselbe Tabelle denormalisiert werden, um umfangreiche Join-Operationen zu vermeiden.
Stellen Sie sich nun vor, Ihr Unternehmen hätte eine große Anzahl betrieblicher Systeme, die eine riesige Menge an Daten erzeugen, und Ihr Analyseteam wollte Dashboards erstellen, die auf der Aggregation der Daten aus diesen verschiedenen Datenquellen (d.h. Anwendungsdatenbanken) beruhen. Leider sind OLTP-Systeme nicht dafür ausgelegt, komplexe aggregierte Abfragen mit einer großen Anzahl historischer Datensätze zu verarbeiten. Diese Workloads werden als Online Analytical Processing (OLAP) Workloads bezeichnet. Um diese Einschränkung zu beheben, brauchst du ein anderes System, das für OLAP-Arbeitslasten optimiert ist. Dieser Bedarf war der Grund für die Eingabeaufforderung zur Entwicklung der Lakehouse-Architektur.
Grundlegende Komponenten eines Systems für OLAP-Workloads
Ein für OLAP-Workloads konzipiertes System besteht aus einer Reihe von technologischen Komponenten, die die Unterstützung moderner analytischer Workloads ermöglichen, wie in Abbildung 1-1 dargestellt und in den folgenden Unterabschnitten beschrieben.
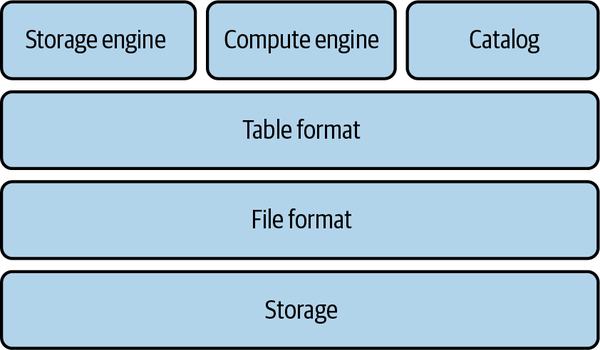
Abbildung 1-1. Technische Komponenten zur Unterstützung analytischer Workloads
Speicherung
Um historische Daten aus einer Vielzahl von Quellen zu analysieren, brauchst du ein System, mit dem du große bis sehr große Datenmengen speichern kannst. Daher ist die Speicherung die erste Komponente, die du in einem System brauchst, das mit analytischen Abfragen großer Datenmengen umgehen kann. Es gibt viele Möglichkeiten für die Speicherung, z. B. ein lokales Dateisystem auf einem Direct-Attached Storage (DAS) ; ein verteiltes Dateisystem auf einer Reihe von Knoten, die du betreibst, wie das Hadoop Distributed File System (HDFS); und Objektspeicher, der von Cloud-Providern als Service angeboten wird, wie Amazon Simple Storage Service (Amazon S3).
Was die Art der Speicherung angeht, so kannst du zeilenorientierte Datenbanken oder spaltenorientierte Datenbanken verwenden oder in manchen Systemen beide Varianten kombinieren. In den letzten Jahren haben sich spaltenorientierte Datenbanken stark durchgesetzt, da sie sich beim Umgang mit großen Datenmengen als effizienter erwiesen haben.
Dateiformat
Für die Speicherung müssen deine Rohdaten in einem bestimmten Dateiformat organisiert werden. Die Wahl des Dateiformats wirkt sich unter anderem auf die Komprimierung der Dateien, die Datenstruktur und die Leistung eines bestimmten Workloads aus.
Dateiformate lassen sich im Allgemeinen in drei übergeordnete Kategorien einteilen: strukturierte (CSV), semistrukturierte (JSON) und unstrukturierte (Textdateien) . In den strukturierten und semistrukturierten Kategorien können Dateiformate zeilenorientiert oder spaltenorientiert (columnar) sein. Zeilenorientierte Dateiformate speichern alle Spalten einer bestimmten Zeile zusammen, während spaltenorientierte Dateiformate alle Zeilen einer bestimmten Spalte zusammen speichern. Zwei gängige Beispiele für zeilenorientierte Dateiformate sind Comma-Separated Values (CSV) und Apache Avro. Beispiele für spaltenorientierte Dateiformate sind Apache Parquet und Apache ORC.
Je nach Anwendungsfall können bestimmte Dateiformate vorteilhafter sein als andere. So sind zeilenorientierte Dateiformate in der Regel besser, wenn du mit einer kleinen Anzahl von Datensätzen zu tun hast. Im Vergleich dazu sind spaltenorientierte Dateiformate in der Regel besser, wenn du es mit einer großen Anzahl von Datensätzen zu tun hast.
Tabellenformat
Das Tabellenformat ist eine weitere kritische Komponente für ein System, das analytische Arbeitslasten mit aggregierten Abfragen auf einer riesigen Datenmenge unterstützen kann. Das Tabellenformat fungiert wie eine Metadatenschicht über dem Dateiformat und ist dafür verantwortlich, wie die Datendateien in der Speicherung angeordnet werden sollen.
Letztendlich besteht das Ziel eines Tabellenformats darin, die Komplexität der physischen Datenstruktur zu abstrahieren und Funktionen wie Data Manipulation Language (DML) Operationen (z. B. Einfügen, Aktualisieren und Löschen) und das Ändern des Tabellenschemas zu erleichtern. Moderne Tabellenformate bieten auch die Atomaritäts- und Konsistenzgarantien, die für die sichere Ausführung von DML-Operationen auf den Daten erforderlich sind.
Speicher-Engine
Die Speicherung ist das System, das dafür verantwortlich ist, die Daten in der vom Tabellenformat vorgegebenen Form anzulegen und alle Dateien und Datenstrukturen mit den neuen Daten auf dem neuesten Stand zu halten. Die Speicher-Engines übernehmen einige wichtige Aufgaben, wie die physische Optimierung der Daten, die Indexpflege und die Beseitigung alter Daten.
Katalog
Wenn du mit Daten aus verschiedenen Quellen und in größerem Umfang arbeitest, ist es wichtig, die Daten, die du für deine Analyse brauchst, schnell zu identifizieren. Die Aufgabe eines Katalogs ist es, dieses Problem zu lösen, indem er Metadaten zur Identifizierung von Datensätzen nutzt. Der Katalog ist der zentrale Ort, an dem Rechenmaschinen und Nutzer/innen herausfinden können, ob eine Tabelle vorhanden ist und welche zusätzlichen Informationen sie enthält, z. B. den Tabellennamen, das Tabellenschema und den Ort, an dem die Tabellendaten auf dem Speichersystem gespeichert sind. Einige Kataloge sind systemintern und können nur direkt über die Engine des Systems angesprochen werden. Beispiele für solche Kataloge sind Postgres und Snowflake. Andere Kataloge, wie Hive und Project Nessie, können von jedem System genutzt werden. Beachte, dass diese Metadatenkataloge nicht dasselbe sind wie Kataloge für die menschliche Datensuche, wie Colibra, Atlan und der interne Katalog von Dremio Software.
Compute Engine
Die Compute Engine ist die letzte Komponente, die benötigt wird, um eine große Menge an Daten, die in einem Speichersystem gespeichert sind, effizient zu verarbeiten. Die Aufgabe der Compute Engine in einem solchen System besteht darin, die Daten mit Benutzer-Workloads zu verarbeiten. Je nach Datenmenge, Rechenlast und Art des Workloads kannst du eine oder mehrere Compute Engines für diese Aufgabe einsetzen. Wenn du mit großen Datenmengen und/oder hohen Rechenanforderungen zu tun hast, musst du möglicherweise eine verteilte Rechenmaschine in einem Verarbeitungsparadigma verwenden, das als massiv parallele Verarbeitung (MPP) bezeichnet wird. Einige Beispiele für MPP-basierte Compute Engines sind Apache Spark, Snowflake und Dremio.
Alles unter einen Hut bringen
Für OLAP-Workloads werden diese technischen Komponenten traditionell eng mit einem einzigen System, dem Data Warehouse, verbunden. Data Warehouses ermöglichen es Unternehmen, Daten aus einer Vielzahl von Quellen zu speichern und auf diesen Daten analytische Arbeitslasten auszuführen. Im nächsten Abschnitt werden wir die Funktionen eines Data Warehouse, die Integration der technischen Komponenten und die Vor- und Nachteile der Verwendung eines solchen Systems im Detail erörtern .
Das Data Warehouse
Ein Data Warehouse oder eine OLAP-Datenbank ist ein zentraler Speicher, in dem große Datenmengen gespeichert werden, die aus verschiedenen Quellen wie operativen Systemen, Anwendungsdatenbanken und Protokollen stammen. Abbildung 1-2 zeigt einen architektonischen Überblick über die technischen Komponenten eines Data Warehouses.
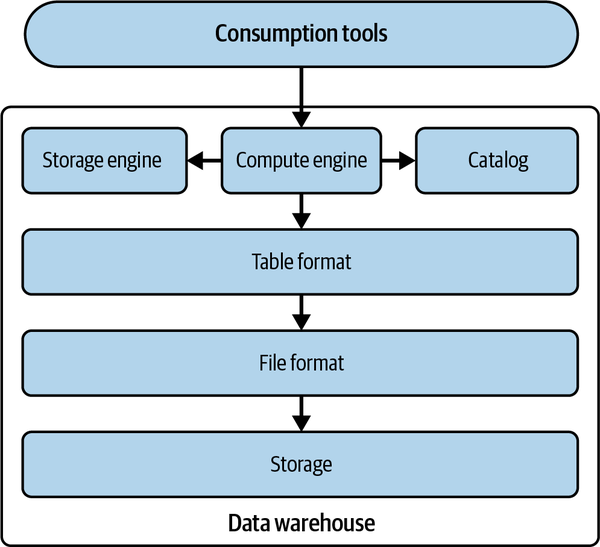
Abbildung 1-2. Technische Komponenten eines Data Warehouse
Ein Data Warehouse verfügt über alle technischen Komponenten in einem einzigen System. Das heißt, alle Daten werden in eigenen Datei- und Tabellenformaten auf einem eigenen Speichersystem gespeichert. Diese Daten werden dann ausschließlich von der Speicher-Engine des Data Warehouse verwaltet, in seinem Katalog registriert und können nur von den Nutzern oder analytischen Engines über seine Compute Engine abgerufen werden.
Eine kurze Geschichte
Bis etwa 2015 waren in den meisten Data Warehouses die Speicher- und Rechenkomponenten eng miteinander gekoppelt, da sie meist in den Räumlichkeiten des Unternehmens entwickelt und betrieben wurden. Dies führte jedoch zu einer Reihe von Problemen. Die Skalierung wurde zu einem großen Problem, da das Datenvolumen immer schneller wuchs und die Anzahl und Intensität der Arbeitslasten (d.h. der Rechenaufgaben, die auf dem Warehouse laufen) ebenfalls zunahm. Es gab keine Möglichkeit, die Rechenressourcen und die Speicherung je nach Aufgabe zu erhöhen. Wenn dein Bedarf an Speicherung schneller wuchs als der Bedarf an Rechenleistung, spielte das keine Rolle. Du musstest immer noch für zusätzliche Rechenleistung bezahlen, auch wenn du sie nicht brauchtest.
Dies führte dazu, dass die nächste Generation von Data Warehouses mit einem großen Fokus auf die Cloud entwickelt wurde. Diese Data Warehouses gewannen um 2015 an Bedeutung, als das Cloud-native Computing aufkam, das die Trennung von Rechen- und Speicherkomponenten und die Skalierung dieser Ressourcen je nach Aufgabenstellung ermöglichte. Du konntest sogar die Rechenleistung abschalten, wenn du sie nicht gebraucht hast, ohne deine Speicherung zu verlieren.
Vor- und Nachteile eines Data Warehouse
Obwohl Data Warehouses, egal ob vor Ort oder in der Cloud, es Unternehmen leicht machen, schnell einen Überblick über alle ihre historischen Daten zu bekommen, gibt es bestimmte Bereiche, in denen ein Warehouse noch Probleme verursacht. Tabelle 1-1 listet die Vor- und Nachteile eines Data Warehouses auf.
| Profis | Nachteile |
|---|---|
| Dient als einzige Quelle der Wahrheit, da es die Speicherung und Abfrage von Daten aus verschiedenen Quellen ermöglicht | Sperrt die Daten in ein anbieterspezifisches System, das nur von der Compute Engine des Lagers genutzt werden kann |
| Unterstützt die Abfrage großer Mengen historischer Daten, damit analytische Arbeitslasten schnell ausgeführt werden können | Teuer in Bezug auf Speicherung und Berechnung; mit zunehmender Arbeitslast werden die Kosten schwer zu bewältigen |
| Stellt wirksame Data-Governance-Richtlinien bereit, um sicherzustellen, dass die Daten verfügbar und nutzbar sind und mit den Sicherheitsrichtlinien übereinstimmen | Unterstützt vor allem strukturierte Daten |
| Organisiert das Datenlayout für dich und stellt sicher, dass es für Abfragen optimiert ist | Ermöglicht es Unternehmen nicht, fortgeschrittene analytische Workloads wie ML nativ auszuführen |
| Stellt sicher, dass die in eine Tabelle geschriebenen Daten mit dem technischen Schema übereinstimmen |
Ein Data Warehouse dient Unternehmen als zentraler Speicher für alle Daten, die aus einer Vielzahl von Quellen stammen. So können Datenkonsumenten wie Analysten und BI-Ingenieure einfach und schnell aus einer einzigen Quelle auf die Daten zugreifen und ihre Analysen starten. Darüber hinaus ermöglichen die technologischen Komponenten eines Data Warehouse den Zugriff auf riesige Datenmengen und unterstützen gleichzeitig BI Workloads, die darauf laufen.
Obwohl Data Warehouses eine wichtige Rolle bei der Demokratisierung von Daten gespielt haben und es Unternehmen ermöglichen, historische Erkenntnisse aus verschiedenen Datenquellen zu gewinnen, sind sie in erster Linie auf relationale Arbeitslasten beschränkt. Um auf das Beispiel des Transportunternehmens von vorhin zurückzukommen: Angenommen, du möchtest herausfinden, wie hoch dein Gesamtumsatz im nächsten Quartal sein wird. In diesem Fall müsstest du ein Prognosemodell mit historischen Daten erstellen. Mit einem Data Warehouse kannst du diese Fähigkeit jedoch nicht erreichen, da die Rechenmaschine und die anderen technischen Komponenten nicht für ML-basierte Aufgaben ausgelegt sind. Deine wichtigste Option wäre also, die Daten aus dem Data Warehouse auf andere Plattformen zu verschieben oder zu exportieren, die ML-Workloads unterstützen. Das bedeutet, dass du die Daten in mehreren Kopien vorliegen hast und dass du für jede Datenverschiebung Pipelines erstellen musst, was zu kritischen Problemen wie dem Datendrift und dem Modellverfall führen kann, wenn Pipelines Daten falsch oder inkonsistent verschieben.
Ein weiteres Hindernis für die Ausführung fortschrittlicher analytischer Workloads auf einem Data Warehouse ist, dass ein Data Warehouse nur strukturierte Daten unterstützt. Durch die schnelle Generierung und Verfügbarkeit anderer Datentypen, wie z. B. semistrukturierter und unstrukturierter Daten (JSON, Bilder, Text usw.), können ML-Modelle jedoch interessante Erkenntnisse liefern. In unserem Beispiel könnte das bedeuten, dass wir die Stimmungen aller neuen Buchungsrezensionen aus dem vorangegangenen Quartal verstehen. Dies würde sich letztendlich auf die Fähigkeit eines Unternehmens auswirken, zukunftsorientierte Entscheidungen zu treffen.
Es gibt auch spezifische Herausforderungen bei der Gestaltung eines Data Warehouses. Wenn du zu Abbildung 1-2 zurückkehrst, siehst du, dass alle sechs technischen Komponenten in einem Data Warehouse eng miteinander verbunden sind. Bevor du verstehst, was das bedeutet, solltest du unbedingt beachten, dass sowohl die Datei- als auch die Tabellenformate intern für ein bestimmtes Data Warehouse sind. Dieses Entwurfsmuster führt zu einer geschlossenen Form der Datenarchitektur. Das bedeutet, dass der Zugriff auf die eigentlichen Daten nur über die Compute Engine des Data Warehouses möglich ist, die speziell für die Interaktion mit den Tabellen- und Dateiformaten des Warehouses entwickelt wurde. Bei dieser Art von Architektur haben Unternehmen ein großes Problem mit eingeschlossenen Daten. Mit der Zunahme der Arbeitslasten und den riesigen Datenmengen, die im Laufe der Zeit in ein Warehouse eingespeist werden, bist du an diese bestimmte Plattform gebunden. Das bedeutet, dass deine analytischen Workloads, wie BI und alle zukünftigen Tools, die du einführen willst, nur auf diesem speziellen Data Warehouse laufen können. Das hindert dich auch daran, auf eine andere Datenplattform zu migrieren, die speziell auf deine Anforderungen zugeschnitten ist.
Außerdem ist die Speicherung von Daten in einem Data Warehouse und die Nutzung von Rechenressourcen zur Verarbeitung der Daten mit einem erheblichen Kostenfaktor verbunden. Diese Kosten steigen mit der Zeit, wenn du die Anzahl der Workloads in deiner Umgebung erhöhst und dadurch mehr Rechenressourcen beanspruchst. Zusätzlich zu den monetären Kosten gibt es noch andere Gemeinkosten, wie z.B. die Notwendigkeit für Entwicklungsteams, zahlreiche Pipelines zu erstellen und zu verwalten, um Daten aus den operativen Systemen zu übertragen, und eine verzögerte Time-to-Intelligence auf Seiten der Datenkonsumenten. Diese Herausforderungen haben die Unternehmen dazu veranlasst, nach alternativen Datenplattformen zu suchen, die es ihnen ermöglichen, die Kontrolle über die Daten zu behalten und sie in offenen Dateiformaten zu speichern, so dass nachgelagerte Anwendungen wie BI und ML parallel zu deutlich geringeren Kosten laufen können. Dies führte zum Entstehen von Data Lakes.
Der Datensee
Data Warehouses boten zwar einen Mechanismus für die Analyse strukturierter Daten, hatten aber immer noch einige Probleme:
Ein Data Warehouse kann nur strukturierte Daten speichern.
Die Speicherung in einem Data Warehouse ist in der Regel teurer als On-Prem-Hadoop-Cluster oder Cloud-Objektspeicher.
In traditionellen On-Prem-Data-Warehouses sind Speicherung und Rechenleistung oft miteinander vermischt und können daher nicht getrennt skaliert werden. Mehr Kosten für die Speicherung gingen mit mehr Kosten für die Rechenleistung einher, unabhängig davon, ob man die Rechenleistung benötigte oder nicht.
Um diese Probleme zu lösen, musste eine alternative Speicherung gefunden werden, die billiger war und alle Daten speichern konnte, ohne dass sie einem festen Schema entsprechen mussten. Diese alternative Lösung war der Data Lake.
Eine kurze Geschichte
Ursprünglich hast du Hadoop , ein Open-Source-Framework für verteiltes Rechnen, und dessen Dateisystemkomponente HDFS verwendet, um große Mengen strukturierter und unstrukturierter Datensätze in Clustern von kostengünstigen Computern zu speichern und zu verarbeiten. Aber es reichte nicht aus, all diese Daten nur zu speichern. Du wolltest auch Analysen damit durchführen.
Zum Hadoop-Ökosystem gehörte auch MapReduce, ein Analyse-Framework, mit dem du Analyseaufträge in Java schreiben und sie auf dem Hadoop-Cluster ausführen konntest. Das Schreiben von MapReduce-Aufträgen war langwierig und komplex, und viele Analysten sind mit SQL besser vertraut als mit Java. Deshalb wurde Hive entwickelt, um SQL-Anweisungen in MapReduce-Aufträge umzuwandeln.
Um SQL zu schreiben, brauchte man einen Mechanismus, um zu unterscheiden, welche Dateien in der Speicherung zu einem bestimmten Datensatz oder einer Tabelle gehören. So entstand das Tabellenformat Hive, das ein Verzeichnis und die darin enthaltenen Dateien als Tabelle erkennt.
Im Laufe der Zeit wurde von Hadoop-Clustern auf die Cloud-Objektspeicherung (z. B. Amazon S3, Minio, Azure Blob Storage) umgestellt, da diese einfacher zu verwalten und kostengünstiger ist. Auch MapReduce wurde zugunsten anderer verteilter Abfrage-Engines wie Apache Spark, Presto und Dremio nicht mehr verwendet. Das Hive-Tabellenformat blieb jedoch bestehen und wurde zum Standard für die Erkennung von Dateien in deiner Speicherung als einzelne Tabellen, auf denen du Analysen durchführen kannst. Allerdings erforderte die Speicherung in der Cloud mehr Netzwerkkosten für den Zugriff auf diese Dateien, was die Architektur des Hive-Formats nicht vorsah und zu übermäßigen Netzwerkaufrufen führte, da Hive von der Ordnerstruktur der Tabelle abhängig war.
Ein Merkmal, das einen Data Lake von einem Data Warehouse unterscheidet, ist die Möglichkeit, verschiedene Compute Engines für unterschiedliche Arbeitslasten zu nutzen. Das ist wichtig, denn es hat noch nie einen Königsweg gegeben, der für jede Arbeitslast am besten geeignet ist und die Rechenleistung unabhängig von der Speicherung skalieren kann. Das liegt einfach in der Natur der Datenverarbeitung, denn es gibt immer Kompromisse, und die Entscheidung, welche Kompromisse man eingeht, bestimmt, wofür ein bestimmtes System gut und wofür es weniger gut geeignet ist.
Beachte, dass es in Data Lakes eigentlich keinen Dienst gibt, der die Anforderungen der Funktion der Speicher-Engine erfüllt. In der Regel entscheidet die Compute Engine, wie die Daten geschrieben werden sollen, und dann werden die Daten in der Regel nicht mehr überprüft und optimiert, es sei denn, ganze Tabellen oder Partitionen werden neu geschrieben, was in der Regel auf Ad-hoc-Basis geschieht. Abbildung 1-3 zeigt, wie die Komponenten eines Data Lakes miteinander interagieren.
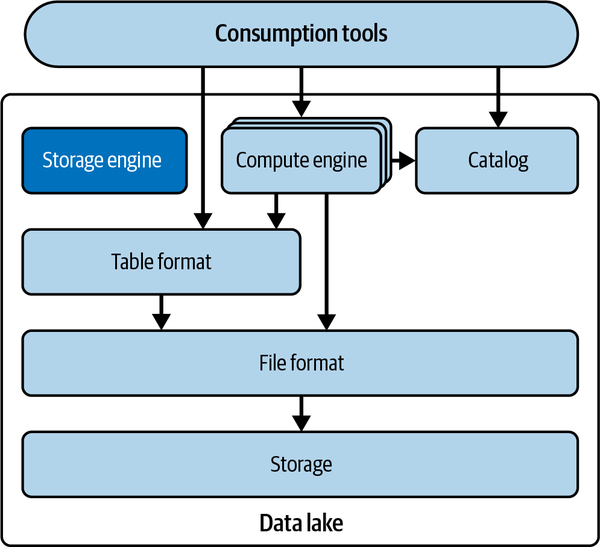
Abbildung 1-3. Technische Komponenten eines Data Lake
Vor- und Nachteile eines Data Lake
Natürlich ist kein Architekturmuster perfekt, und das gilt auch für Data Lakes. Data Lakes bieten zwar viele Vorteile, haben aber auch einige Einschränkungen. Die folgenden sind die Vorteile:
- Niedrigere Kosten
Die Kosten für die Speicherung von Daten und die Ausführung von Abfragen in einem Data Lake sind viel geringer als in einem Data Warehouse. Das macht einen Data Lake besonders nützlich für Analysen von Daten, deren Priorität nicht hoch genug ist, um die Kosten für ein Data Warehouse zu rechtfertigen, und ermöglicht eine größere analytische Reichweite.
- Speichert Daten in offenen Formaten
In einem Data Lake kannst du die Daten in jedem beliebigen Dateiformat speichern, während du in einem Data Warehouse keinen Einfluss darauf hast, wie die Daten gespeichert werden, da es sich dabei in der Regel um ein proprietäres Format handelt, das für dieses spezielle Data Warehouse entwickelt wurde. So hast du mehr Kontrolle über die Daten und kannst sie mit einer größeren Vielfalt von Tools nutzen, die diese offenen Formate unterstützen.
- Verarbeitet unstrukturierte Daten
Data Warehouses können keine unstrukturierten Daten wie Sensordaten, E-Mail-Anhänge und Logfiles verarbeiten. Wenn du also Analysen auf unstrukturierten Daten durchführen wolltest, war der Data Lake die einzige Option.
Das sind die Grenzen:
- Leistung
Da jede Komponente eines Data Lakes entkoppelt ist, fehlen viele der Optimierungen die es in eng gekoppelten Systemen gibt, wie z.B. Indizes und ACID (Atomicity, Consistency, Isolation, Durability) Garantien. Sie können zwar nachgebildet werden, aber es ist ein großer Aufwand, die Komponenten (Speicherung, Dateiformat, Tabellenformat, Engines) so zusammenzuschustern, dass die Leistung mit der eines Data Warehouse vergleichbar wird. Das machte Data Lakes für Datenanalysen mit hoher Priorität, bei denen Leistung und Zeit eine Rolle spielen, unerwünscht.
- Erfordert viel Konfiguration
Wie bereits erwähnt, würde eine engere Kopplung der von dir gewählten Komponenten mit dem Optimierungsgrad, den du von einem Data Warehouse erwartest, einen erheblichen technischen Aufwand erfordern. Dies würde dazu führen, dass viele Dateningenieure benötigt werden, um all diese Tools zu konfigurieren, was ebenfalls kostspielig sein kann.
- Fehlen von ACID-Transaktionen
Ein bemerkenswerter Nachteil von Data Lakes ist das Fehlen von eingebauten ACID Transaktionsgarantien, die in traditionellen relationalen Datenbanken üblich sind. In Data Lakes werden die Daten oft nach dem Schema-on-read-Verfahren eingelesen, d.h. die Schemavalidierung und Konsistenzprüfung erfolgt während der Datenverarbeitung und nicht zum Zeitpunkt des Einlesens. Dies kann für Anwendungen, die eine hohe Transaktionsintegrität erfordern, wie z. B. Finanzsysteme oder Anwendungen, die mit sensiblen Daten arbeiten, eine Herausforderung darstellen. Um ähnliche Transaktionsgarantien in einem Data Lake zu erreichen, müssen in der Regel komplexe Datenverarbeitungspipelines und Koordinationsmechanismen implementiert werden, was den technischen Aufwand für kritische Anwendungsfälle erhöht. Data Lakes zeichnen sich zwar durch Skalierbarkeit und Flexibilität aus, sind aber möglicherweise nicht die ideale Wahl, wenn die strikte Einhaltung von ACID eine Hauptanforderung ist.
Tabelle 1-2 fasst diese Vor- und Nachteile zusammen.
| Profis | Nachteile |
|---|---|
| Geringere Kosten Speichert Daten in offenen Formaten Verarbeitet unstrukturierte Daten Unterstützt ML-Anwendungsfälle |
Leistung Fehlende ACID-Garantien Viel Konfiguration erforderlich |
Sollte ich Analysen auf einem Data Lake oder einem Data Warehouse durchführen ?
Obwohl Data Lakes ein großartiger Ort sind, um alle strukturierten und unstrukturierten Daten zu sammeln, gibt es immer noch Unzulänglichkeiten. Nachdem du ETL (Extrahieren, Transformieren und Laden) ausgeführt hast, um deine Daten in deinem Data Lake zu speichern, musstest du in der Regel einen von zwei Wegen einschlagen, um Analysen durchzuführen.
Du könntest zum Beispiel eine zusätzliche ETL-Pipeline einrichten, um eine Kopie einer kuratierten Teilmenge von Daten zu erstellen, die für Analysen mit hoher Priorität bestimmt ist, und diese im Warehouse speichern, um die Leistung und Flexibilität des Data Warehouse zu nutzen.
Dies führt jedoch zu einigen Problemen:
Zusätzliche Rechenkosten für die zusätzliche ETL-Arbeit und die Kosten für die Speicherung einer Kopie der Daten, die du bereits in einem Data Warehouse speicherst, wo die Kosten für die Speicherung oft höher sind
Zusätzliche Kopien der Daten, die möglicherweise benötigt werden, um Data Marts für verschiedene Geschäftsbereiche zu füllen, und noch mehr Kopien, da Analysten physische Kopien von Datenuntergruppen in Form von BI-Extrakten erstellen, um Dashboards zu beschleunigen, was zu einem Netz von Datenkopien führt, die schwer zu verwalten, zu verfolgen und synchron zu halten sind
Alternativ kannst du Abfrage-Engines verwenden, die Data-Lake-Workloads unterstützen, wie Dremio, Presto, Apache Spark, Trino und Apache Impala, um Abfragen im Data Lake auszuführen. Diese Engines sind in der Regel gut für Nur-Lese-Arbeitslasten geeignet. Aufgrund der Einschränkungen des Hive-Tabellenformats ist es jedoch schwierig, die Daten aus dem Data Lake sicher zu aktualisieren.
Wie du siehst, haben Data Lakes und Data Warehouses ihre eigenen Vorteile und Einschränkungen. Daher war es notwendig, eine neue Architektur zu entwickeln, die ihre Vorteile bietet und gleichzeitig ihre Fehler minimiert. Diese Architektur wird als Data Lakeshouse bezeichnet.
Das Daten-See-Haus
Während uns die Nutzung eines Data Warehouse Leistung und Benutzerfreundlichkeit bescherte, ermöglichte uns die Analyse in Data Lakes niedrigere Kosten, Flexibilität durch die Verwendung offener Formate, die Möglichkeit, unstrukturierte Daten zu nutzen, und vieles mehr. Der Wunsch, den Bogen zu spannen, führt zu großen Fortschritten und Innovationen, die zu dem führen, was wir heute als Data Lakes kennen.
Die Data-Lake-House-Architektur entkoppelt die Speicherung und Berechnung von Data Lakes und bringt Mechanismen ein, die mehr Data-Warehouse-ähnliche Funktionen ermöglichen (ACID-Transaktionen, bessere Leistung, Konsistenz usw.). Ermöglicht wird diese Funktionalität durch Data-Lake-Tabellenformate, die alle bisherigen Probleme mit dem Hive-Tabellenformat beseitigen. Du speicherst die Daten an denselben Orten, an denen du sie auch in einem Data Lake speichern würdest, du verwendest die Abfrage-Engines, die du auch in einem Data Lake verwenden würdest, und deine Daten werden in denselben Formaten gespeichert, in denen sie auch in einem Data Lake gespeichert werden würden. Was deine Welt wirklich von "Nur-Lese-Daten" in ein "Zentrum meiner Datenwelt"-Data-Lakehouse verwandelt, ist das Tabellenformat, das eine Metadaten-/Abstraktionsschicht zwischen der Engine und der Speicherung bildet, damit sie intelligenter interagieren können (siehe Abbildung 1-4).
Tabellenformate schaffen eine Abstraktionsschicht über der Speicherung von Dateien, die bessere Konsistenz-, Leistungs- und ACID-Garantien bei der Arbeit mit Daten direkt in der Data Lake Speicherung ermöglicht:
- Weniger Kopien = weniger Abdrift
Mit ACID-Garantien und besserer Leistung kannst du jetzt Arbeitslasten, die normalerweise für das Data Warehouse aufbewahrt werden, wie z. B. Aktualisierungen und andere Datenmanipulationen, in das Data Lakehouse verlagern und so Kosten und Datenbewegungen reduzieren. Wenn du deine Daten in das Lakehouse verschiebst, kannst du eine schlankere Architektur mit weniger Kopien haben. Weniger Kopien bedeuten geringere Speicherkosten, geringere Rechenkosten durch die Verlagerung von Daten in ein Data Warehouse, weniger Drift (das Datenmodell ändert/bricht über verschiedene Versionen derselben Daten) und eine bessere Verwaltung deiner Daten, um die Einhaltung von Vorschriften und internen Kontrollen zu gewährleisten.
- Schnellere Abfragen = schnellere Erkenntnisse
Das Endziel ist immer, durch hochwertige Erkenntnisse aus unseren Daten einen geschäftlichen Nutzen zu erzielen. Alles andere sind nur Schritte auf dem Weg dorthin. Wenn du schnellere Abfragen machen kannst, bedeutet das, dass du schneller Erkenntnisse gewinnen kannst. Data Lakes ermöglichen schnellere Abfragen als Data Lakes und vergleichbare Data Warehouses, indem sie Optimierungen an der Abfrage-Engine (kostenbasierte Optimierer, Caching), am Tabellenformat (besseres Überspringen von Dateien und Abfrageplanung mithilfe von Metadaten) und am Dateiformat (Sortierung und Komprimierung) vornehmen.
- Historische Datenschnappschüsse = Fehler, die nicht wehtun
Data Lakehouse-Tabellenformate speichern historische Daten-Snapshots und ermöglichen es, Tabellen mit ihren früheren Snapshots abzufragen und wiederherzustellen. Du kannst mit deinen Daten arbeiten, ohne dich nachts fragen zu müssen, ob ein Fehler zu stundenlangem Prüfen, Reparieren und Wiederherstellen führen wird.
- Erschwingliche Architektur = Geschäftswert
Es gibt zwei Möglichkeiten, den Gewinn zu steigern: den Umsatz erhöhen und die Kosten senken. Und Data Lakehouses helfen dir nicht nur dabei, Geschäftseinblicke zu gewinnen, um deinen Umsatz zu steigern, sondern sie können dir auch helfen, die Kosten zu senken. Das bedeutet, dass du die Speicherkosten senken kannst, indem du die Duplizierung deiner Daten vermeidest, zusätzliche Rechenkosten durch zusätzliche ETL-Arbeiten zum Verschieben von Daten vermeidest und niedrigere Preise für die Speicherung und den Rechenaufwand im Vergleich zu typischen Data Warehouse-Tarifen erzielst.
- Offene Architektur = Sorglosigkeit
Data Lakehouses basieren auf offenen Formaten, wie Apache Iceberg als Tabellenformat und Apache Parquet als Dateiformat. Viele Tools können diese Formate lesen und schreiben, wodurch du eine Herstellerbindung vermeiden kannst. Die Abhängigkeit von einem bestimmten Anbieter führt dazu, dass die Kosten in die Höhe schießen und deine Daten in Formaten vorliegen, auf die die Tools nicht zugreifen können. Wenn du offene Formate verwendest, kannst du beruhigt sein, denn du weißt, dass deine Daten nicht in einer begrenzten Anzahl von Tools gespeichert werden.
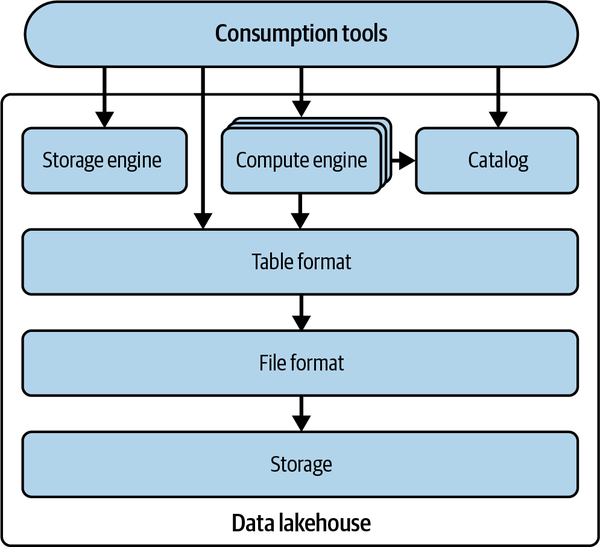
Abbildung 1-4. Technische Komponenten eines Data Lakehouse
Zusammenfassend lässt sich sagen, dass mit den modernen Innovationen aus den zuvor besprochenen offenen Standards die beste aller Welten existieren kann, wenn man ausschließlich mit dem Data Lake arbeitet. Die Schlüsselkomponente, die all das möglich macht, ist das Tabellenformat, das den Engines die Garantien und die verbesserte Leistung gegenüber Data Lakes bietet, wenn sie mit Daten arbeiten, die es vorher einfach nicht gab. Wenden wir uns nun dem Apache Iceberg Tabellenformat zu.
Was ist ein Tabellenformat?
Ein Tabellenformat ist eine Methode, um die Dateien eines Datensatzes so zu strukturieren, dass sie als eine einheitliche "Tabelle" dargestellt werden. Aus der Sicht des Nutzers kann es als Antwort auf die Frage "Welche Daten sind in dieser Tabelle?" definiert werden.
Diese einfache Antwort ermöglicht es mehreren Personen, Teams und Tools, gleichzeitig mit den Daten in der Tabelle zu interagieren, egal ob sie daraus lesen oder in sie schreiben. Der Hauptzweck eines Tabellenformats besteht darin, den Nutzern und Werkzeugen eine Abstraktion der Tabelle zur Verfügung zu stellen, die es ihnen erleichtert, effizient mit den zugrunde liegenden Daten zu interagieren.
Tabellenformate gibt es seit den Anfängen der RDBMS wie System R, Multics und Oracle, die das relationale Modell von Edgar Codd erstmals umsetzten, obwohl der Begriff Tabellenformat damals noch nicht verwendet wurde. In diesen Systemen konnten die Benutzer/innen einen Datensatz als Tabelle bezeichnen, und die Datenbank-Engine war für die Verwaltung des Byte-Layouts des Datensatzes auf der Festplatte in Form von Dateien zuständig, während sie auch komplexe Vorgänge wie Transaktionen abwickelte.
Alle Interaktionen mit den Daten in diesen RDBMS, wie das Lesen und Schreiben, werden von der Speicher-Engine der Datenbank verwaltet. Keine andere Engine kann direkt mit den Dateien interagieren, ohne eine Beschädigung des Systems zu riskieren. Die Details, wie die Daten gespeichert werden, werden abstrahiert, und die Nutzer/innen gehen davon aus, dass die Plattform weiß, wo sich die Daten einer bestimmten Tabelle befinden und wie sie darauf zugreifen können.
In der heutigen Big-Data-Welt ist es jedoch nicht mehr praktikabel, sich auf eine einzige geschlossene Engine zu verlassen, die den gesamten Zugriff auf die zugrunde liegenden Daten verwaltet. Deine Daten brauchen Zugang zu einer Vielzahl von Compute Engines, die für verschiedene Anwendungsfälle wie BI oder ML optimiert sind.
In einem Data Lake werden alle Daten als Dateien in einer Speicherlösung (z.B. Amazon S3, Azure Data Lake Storage [ADLS], Google Cloud Storage [GCS]) gespeichert, so dass eine einzige Tabelle aus Dutzenden, Hunderten, Tausenden oder sogar Millionen von einzelnen Dateien auf diesem Speicher bestehen kann. Wenn wir SQL mit unseren bevorzugten Analysetools verwenden oder Ad-hoc-Skripte in Sprachen wie Java, Scala, Python und Rust schreiben, möchten wir nicht ständig festlegen, welche dieser Dateien in der Tabelle sind und welche nicht. Das wäre nicht nur mühsam, sondern würde wahrscheinlich auch zu Inkonsistenzen bei der unterschiedlichen Verwendung der Daten führen.
Die Lösung bestand also darin, eine Standardmethode zu entwickeln, um zu verstehen, "welche Daten in dieser Tabelle sind", wie in Abbildung 1-5 dargestellt.
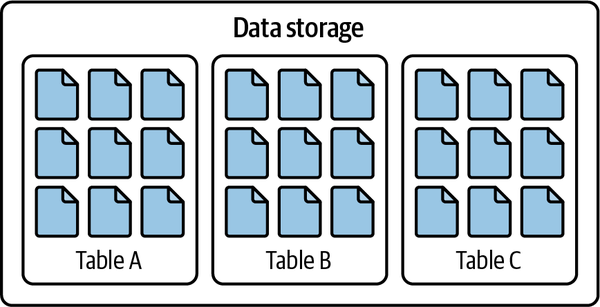
Abbildung 1-5. In einem Tabellenformat organisierte Datendateien
Hive: Das ursprüngliche Tabellenformat
Als es darum ging, Analysen auf Hadoop-Datenseen durchzuführen, wurde das MapReduce-Framework verwendet, das von den Nutzern verlangte, komplexe und langwierige Java-Aufträge zu schreiben, was für viele Analysten nicht zugänglich war. Facebook erkannte diese Situation und entwickelte im Jahr 2009 ein Framework namens Hive. Hive bot einen entscheidenden Vorteil, der die Analyse in Hadoop erheblich erleichterte: die Möglichkeit, SQL statt MapReduce-Aufträge direkt zu schreiben.
Das Hive-Framework nimmt SQL-Anweisungen und wandelt sie in MapReduce-Aufträge um, die dann ausgeführt werden können. Um SQL-Anweisungen schreiben zu können, brauchte man einen Mechanismus, um zu verstehen, welche Daten in der Hadoop Speicherung eine eindeutige Tabelle darstellen, und so entstanden das Hive-Tabellenformat und der Hive-Metastore zur Verfolgung dieser Tabellen.
Das Hive-Tabellenformat definiert eine Tabelle als alle Dateien innerhalb eines bestimmten Verzeichnisses (oder Präfixe für die Speicherung von Objekten). Die Partitionen dieser Tabellen sind dann die Unterverzeichnisse. Diese Verzeichnispfade, die die Tabelle definieren, werden von einem Dienst namens Hive Metastore verfolgt, auf den Abfrageprogramme zugreifen können, um zu wissen, wo sie die für ihre Abfrage relevanten Daten finden. Dies ist in Abbildung 1-6 dargestellt.
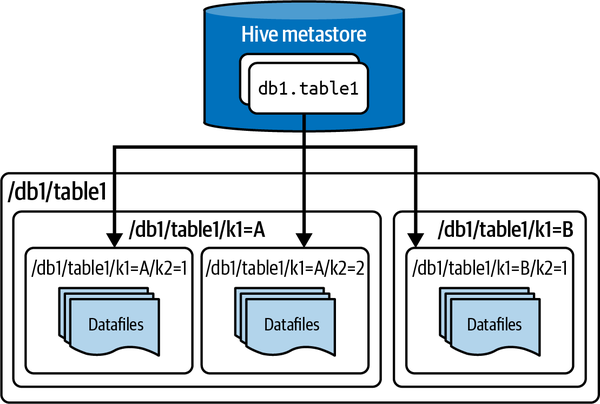
Abbildung 1-6. Die Architektur einer Tabelle, die im Hive-Tabellenformat gespeichert wird
Das Hive-Tabellenformat hatte mehrere Vorteile:
Sie ermöglichte effizientere Abfragemuster als vollständige Tabellenscans. Techniken wie Partitionierung (Aufteilung der Daten anhand eines Partitionierungsschlüssels) und Bucketing (ein Ansatz zur Partitionierung oder Clusterung/Sortierung, bei dem eine Hash-Funktion zur gleichmäßigen Verteilung der Werte verwendet wird) machten es möglich, das Scannen jeder Datei zu vermeiden und so schnellere Abfragen zu ermöglichen.
Es war unabhängig vom Dateiformat, sodass die Datengemeinschaft im Laufe der Zeit bessere Dateiformate wie Apache Parquet entwickeln und in ihren Hive-Tabellen verwenden konnte. Außerdem mussten die Daten nicht umgewandelt werden, bevor sie in einer Hive-Tabelle verfügbar waren (z. B. Avro, CSV/TSV).
Durch atomare Swaps des aufgelisteten Verzeichnisses im Hive Metastore kannst du Alles-oder-Nichts-(atomare) Änderungen an einer einzelnen Partition in der Tabelle vornehmen.
Mit der Zeit wurde dies zum De-facto-Standard, der mit den meisten Datentools funktioniert und eine einheitliche Antwort auf die Frage "Welche Daten sind in dieser Tabelle?" liefert.
Obwohl diese Vorteile bedeutend waren, gab es auch viele Einschränkungen, die mit der Zeit deutlich wurden:
Änderungen auf Dateiebene sind ineffizient, da es keinen Mechanismus gibt, um eine Datei auf die gleiche Weise zu tauschen wie den Hive Metastore, um ein Partitionsverzeichnis zu tauschen. Es bleibt dir also nichts anderes übrig, als Swaps auf Partitionsebene durchzuführen, um eine einzelne Datei atomar zu aktualisieren.
Während du eine Partition atomar austauschen konntest, gab es keinen Mechanismus, um mehrere Partitionen in einer Transaktion atomar zu aktualisieren. Dadurch besteht die Möglichkeit, dass die Endnutzer inkonsistente Daten zwischen Transaktionen sehen, die mehrere Partitionen aktualisieren.
Es gibt keine guten Mechanismen, um gleichzeitige Aktualisierungen zu ermöglichen, vor allem nicht mit Tools außerhalb von Hive selbst.
Eine Engine, die Dateien und Verzeichnisse auflistet, war zeitaufwändig und verlangsamte Abfragen. Das Lesen und Auflisten von Dateien und Verzeichnissen, die in der resultierenden Abfrage möglicherweise nicht gescannt werden müssen, hat seinen Preis.
Partitionsspalten wurden oft von anderen Spalten abgeleitet, z. B. eine Monatsspalte von einem Zeitstempel. Die Partitionierung half nur, wenn du nach der Partitionsspalte gefiltert hast, und jemand, der einen Filter für die Zeitstempelspalte hat, weiß vielleicht nicht intuitiv, dass er auch nach der abgeleiteten Monatsspalte filtern muss, was zu einer vollständigen Tabellendurchsuchung führt, da die Partitionierung nicht genutzt wurde.
Die Tabellenstatistiken wurden durch asynchrone Aufträge gesammelt, was oft dazu führte, dass die Tabellenstatistiken nur in einem bestimmten Zustand waren, wenn überhaupt Statistiken verfügbar waren. Das machte es für Abfrage-Engines schwierig, Abfragen weiter zu optimieren.
Da die Speicherung von Objekten Anfragen oft auf ein und dasselbe Präfix drosselt (ein Präfix für die Speicherung von Objekten ist vergleichbar mit einem Dateiverzeichnis), kann es bei Abfragen von Tabellen mit einer großen Anzahl von Dateien in einer einzigen Partition (so dass alle Dateien in einem Präfix enthalten wären) zu Leistungsproblemen kommen.
Je größer der Umfang der Datensätze und Anwendungsfälle, desto mehr würden sich diese Probleme verstärken. Das führte dazu, dass man eine neue Lösung brauchte, so dass neuere Tabellenformate erstellt wurden.
Moderne Data Lake Tabellenformate
Bei dem Versuch, die Grenzen des Hive-Tabellenformats zu überwinden, entstand eine neue Generation von Tabellenformaten mit unterschiedlichen Ansätzen zur Lösung der Probleme mit Hive.
Die Entwickler moderner Tabellenformate erkannten, dass der Fehler, der zu Problemen mit dem Hive-Tabellenformat führte, darin bestand, dass die Definition der Tabelle auf dem Inhalt der Verzeichnisse basierte und nicht auf den einzelnen Datendateien. Moderne Tabellenformate wie Apache Iceberg, Apache Hudi und Delta Lake verfolgen alle den Ansatz, Tabellen als kanonische Liste von Dateien zu definieren und Metadaten für Suchmaschinen bereitzustellen, die angeben, aus welchen Dateien die Tabelle besteht und nicht aus welchen Verzeichnissen. Dieser detailliertere Ansatz zur Definition von "was ist eine Tabelle" öffnete die Tür zu Funktionen wie ACID-Transaktionen, Zeitreisen und mehr.
Moderne Tabellenformate bieten alle eine Reihe von Vorteilen gegenüber dem Hive-Tabellenformat:
Sie ermöglichen ACID-Transaktionen, d.h. sichere Transaktionen, die entweder vollständig abgeschlossen oder abgebrochen werden. In älteren Formaten wie dem Hive-Tabellenformat konnten viele Transaktionen diese Garantien nicht haben.
Sie ermöglichen sichere Transaktionen wenn es mehrere Writer gibt. Wenn zwei oder mehr Writer in eine Tabelle schreiben, gibt es einen Mechanismus, der sicherstellt, dass der Writer, der seinen Schreibvorgang als zweiter abschließt, weiß und berücksichtigt, was die anderen Writer getan haben, um die Daten konsistent zu halten.
Sie bieten eine bessere Sammlung von Tabellenstatistiken und Metadaten, die es einer Abfrage-Engine ermöglichen, Scans effizienter zu planen, so dass sie weniger Dateien scannen muss .
Wir wollen herausfinden, was der Apache Iceberg ist und wie er entstanden ist.
Was ist ein Apache-Eisberg?
Apache Iceberg ist ein Tabellenformat, das 2017 von den Netflix-Mitarbeitern Ryan Blue und Daniel Weeks entwickelt wurde. Es entstand aus dem Bedürfnis heraus, Herausforderungen in Bezug auf Leistung, Konsistenz und viele der zuvor genannten Probleme mit dem Tabellenformat Hive zu überwinden. Im Jahr 2018 wurde das Projekt als Open Source veröffentlicht und der Apache Software Foundation übergeben, wo sich viele andere Unternehmen daran beteiligten, darunter Apple, Dremio, AWS, Tencent, LinkedIn und Stripe. Seitdem haben viele weitere Unternehmen zu dem Projekt beigetragen.
Wie der Apache Iceberg entstanden ist
Netflix kam bei der Erstellung des späteren Apache Iceberg-Formats zu dem Schluss, dass viele der Probleme mit dem Hive-Format auf einen einfachen, aber grundlegenden Fehler zurückzuführen sind: Jede Tabelle wird als Verzeichnisse und Unterverzeichnisse verfolgt, was die Granularität einschränkt, die notwendig ist, um Konsistenzgarantien, eine bessere Gleichzeitigkeit und einige der Funktionen zu bieten, die in Data Warehouses oft verfügbar sind.
Vor diesem Hintergrund hat Netflix ein neues Tabellenformat entwickelt und dabei mehrere Ziele verfolgt:
- Konsistenz
Wenn Aktualisierungen einer Tabelle über mehrere Partitionen hinweg erfolgen, darf es für die Endnutzer nicht möglich sein, dass die Daten, die sie sehen, inkonsistent sind. Eine Aktualisierung einer Tabelle über mehrere Partitionen hinweg sollte schnell und atomar erfolgen, damit die Daten für die Endnutzer konsistent sind. Sie sehen die Daten entweder vor der Aktualisierung oder nach der Aktualisierung und nicht dazwischen.
- Leistung
Aufgrund des Engpasses bei der Auflistung von Dateien und Verzeichnissen in Hive würde die Abfrageplanung übermäßig lange dauern, bevor die Abfrage tatsächlich ausgeführt wird. Die Tabelle sollte Metadaten bereitstellen und ein übermäßiges Dateilisting vermeiden, damit die Abfrageplanung nicht nur schneller abläuft, sondern auch die daraus resultierenden Pläne schneller ausgeführt werden können, da sie nur die für die Abfrage erforderlichen Dateien durchsuchen.
- Einfach zu bedienen
Um die Vorteile von Techniken wie der Partitionierung zu nutzen, sollten die Endnutzer die physische Struktur der Tabelle nicht kennen müssen. Die Tabelle sollte in der Lage sein, den Nutzern die Vorteile der Partitionierung auf der Grundlage von natürlich intuitiven Abfragen zu bieten und nicht von der Filterung zusätzlicher Partitionsspalten abhängig zu sein, die von einer Spalte abgeleitet sind, nach der sie bereits filtern (z. B. die Filterung nach einer Monatsspalte, wenn du bereits den Zeitstempel gefiltert hast, von dem sie abgeleitet ist).
- Evolvierbarkeit
Die Aktualisierung von Schemata von Hive-Tabellen könnte zu unsicheren Transaktionen führen, und die Aktualisierung der Partitionierung einer Tabelle würde dazu führen, dass die gesamte Tabelle neu geschrieben werden müsste. Eine Tabelle sollte in der Lage sein, ihr Schema und ihr Partitionierungsschema sicher und ohne Neuschreiben zu entwickeln.
- Skalierbarkeit
Alle oben genannten Ziele sollten in der Lage sein, die Petabyte-Größe der Daten von Netflix zu erreichen.
Also begann das Team mit der Entwicklung des Iceberg-Formats, das sich darauf konzentriert, eine Tabelle als eine kanonische Liste von Dateien zu definieren, anstatt eine Tabelle als eine Liste von Verzeichnissen und Unterverzeichnissen zu verfolgen. Das Apache Iceberg Projekt ist eine Spezifikation oder ein Standard dafür, wie Metadaten, die eine Data Lakehouse Tabelle definieren, über mehrere Dateien hinweg geschrieben werden sollten. Um die Einführung dieses Standards zu unterstützen, bietet Apache Iceberg zahlreiche Bibliotheken an, die den Benutzern bei der Arbeit mit dem Format oder bei der Implementierung von Compute Engines helfen. Neben diesen Bibliotheken hat das Projekt auch Implementierungen für Open Source Compute Engines wie Apache Spark und Apache Flink entwickelt.
Apache Iceberg zielt darauf ab, dass bestehende Tools den Standard übernehmen, und ist so konzipiert, dass es die Vorteile bestehender, beliebter Speicherlösungen und Compute Engines nutzt, in der Hoffnung, dass die bestehenden Optionen die Arbeit mit dem Standard unterstützen. Dieser Ansatz zielt darauf ab, dass das Ökosystem bestehender Datentools die Unterstützung für Apache Iceberg-Tabellen ausbaut und Iceberg zum Standard dafür wird, wie Engines Tabellen im Data Lake erkennen und mit ihnen arbeiten können. Das Ziel ist, dass Apache Iceberg im Ökosystem so allgegenwärtig wird, dass es zu einem weiteren Implementierungsdetail wird, über das viele Nutzer nicht nachdenken müssen. Sie wissen einfach, dass sie mit Tabellen arbeiten und müssen sich darüber hinaus keine Gedanken machen, unabhängig davon, welches Tool sie für die Interaktion mit der Tabelle verwenden. Das ist bereits Realität, denn viele Tools ermöglichen es den Endnutzern, so einfach mit Apache Iceberg-Tabellen zu arbeiten, dass sie das zugrunde liegende Iceberg-Format nicht verstehen müssen. Mit automatisierten Tabellenoptimierungs- und Ingestion-Tools werden sogar technischere Nutzer wie Dateningenieure nicht mehr so viel über das zugrundeliegende Format nachdenken müssen und in der Lage sein, mit ihrer Data Lake Speicherung so zu arbeiten, wie sie es von Data Warehouses gewohnt sind, ohne sich jemals direkt mit der Speicherschicht auseinanderzusetzen.
Die Apache Eisberg Architektur
Apache Iceberg verfolgt die Partitionierung einer Tabelle, die Sortierung, das Schema im Laufe der Zeit und vieles mehr mithilfe eines Baums von Metadaten, die eine Engine nutzen kann, um Abfragen zu einem Bruchteil der Zeit zu planen, die sie mit herkömmlichen Data Lake-Mustern benötigen würde. Abbildung 1-7 zeigt diesen Baum von Metadaten.
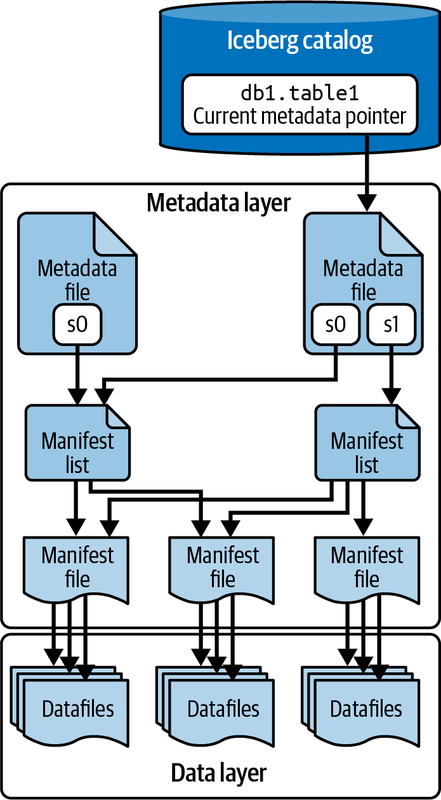
Abbildung 1-7. Die Apache Iceberg Architektur
Dieser Metadatenbaum unterteilt die Metadaten der Tabelle in vier Komponenten:
- Manifest-Datei
Eine Liste von Datendateien, die den Speicherort/Pfad jeder Datendatei und wichtige Metadaten über diese Datendateien enthält, was die Erstellung effizienterer Ausführungspläne ermöglicht.
- Manifest-Liste
Dateien, die einen einzelnen Snapshot der Tabelle als Liste von Manifestdateien zusammen mit Statistiken zu diesen Manifesten definieren, die die Erstellung effizienterer Ausführungspläne ermöglichen.
- Metadaten-Datei
Dateien, die die Struktur einer Tabelle definieren, einschließlich des Schemas, des Partitionierungsschemas und einer Liste der Snapshots.
- Katalog
Verfolgt den Speicherort der Tabelle (ähnlich wie der Hive Metastore), aber statt einer Zuordnung von Tabellenname -> Verzeichnissatz enthält er eine Zuordnung von Tabellenname -> Speicherort der letzten Metadaten-Datei der Tabelle. Mehrere Tools, darunter auch ein Hive Metastore, können als Katalog verwendet werden. Wir haben diesem Thema Kapitel 5 gewidmet .
Jede dieser Dateien wird in Kapitel 2 ausführlicher behandelt.
Hauptmerkmale von Apache Iceberg
Die einzigartige Architektur von Apache Iceberg ermöglicht eine ständig wachsende Zahl von Funktionen, die über die Lösung der Herausforderungen von Hive hinausgehen und stattdessen völlig neue Funktionen für Data Lakes und Data Lakehouse-Workloads freischalten. In diesem Abschnitt geben wir einen allgemeinen Überblick über die wichtigsten Funktionen von Apache Iceberg. In späteren Kapiteln werden wir auf diese Funktionen näher eingehen.
ACID-Transaktionen
Apache Iceberg verwendet eine optimistische Gleichzeitigkeitssteuerung, um ACID zu garantieren, auch wenn Transaktionen von mehreren Lesern und Schreibern bearbeitet werden. Die optimistische Gleichzeitigkeitssteuerung geht davon aus, dass Transaktionen nicht miteinander kollidieren, und prüft nur bei Bedarf auf Konflikte, um Sperren zu minimieren und die Leistung zu verbessern. Auf diese Weise kannst du Transaktionen in deinem Data Lakehouse ausführen, die entweder bestätigt werden oder fehlschlagen und nichts dazwischen. Ein pessimistisches Gleichzeitigkeitsmodell, das Sperren einsetzt, um Konflikte zwischen Transaktionen zu verhindern, weil es davon ausgeht, dass Konflikte auftreten werden, war zum Zeitpunkt der Erstellung dieses Artikels in Apache Iceberg noch nicht verfügbar, wird aber möglicherweise in Zukunft verfügbar sein.
Die Gleichzeitigkeitsgarantien werden vom Katalog übernommen, da dieser typischerweise einen Mechanismus mit eingebauten ACID-Garantien darstellt. Dadurch können Transaktionen auf Iceberg-Tabellen atomar sein und die Korrektheit garantieren. Wäre dies nicht der Fall, könnten zwei verschiedene Systeme widersprüchliche Aktualisierungen vornehmen, was zu Datenverlusten führen würde.
Entwicklung der Partition
Ein großes Problem bei Data Lakes vor Apache Iceberg war die Notwendigkeit, die physische Optimierung der Tabelle zu ändern. Wenn die Partitionierung geändert werden muss, bleibt dir oft nur die Möglichkeit, die gesamte Tabelle neu zu schreiben, was bei einer großen Anzahl von Tabellen sehr teuer werden kann. Die Alternative ist, mit dem bestehenden Partitionierungsschema zu leben und auf die Leistungsverbesserungen zu verzichten, die ein besseres Partitionierungsschema bieten kann.
Mit Apache Iceberg kannst du die Partitionierung der Tabelle jederzeit aktualisieren, ohne dass du die Tabelle und alle Daten neu schreiben musst. Da die Partitionierung nur mit den Metadaten zu tun hat, sind die für diese Änderung der Tabellenstruktur erforderlichen Operationen schnell und kostengünstig.
Abbildung 1-8 zeigt eine Tabelle, die zunächst nach Monaten partitioniert war und dann in Zukunft nach Tagen partitioniert wurde. Die zuvor geschriebenen Daten verbleiben in den Monatspartitionen, während neue Daten in die Tagespartitionen geschrieben werden. Bei einer Abfrage erstellt die Engine einen Plan für jede Partition, der auf dem angewendeten Partitionsschema basiert.
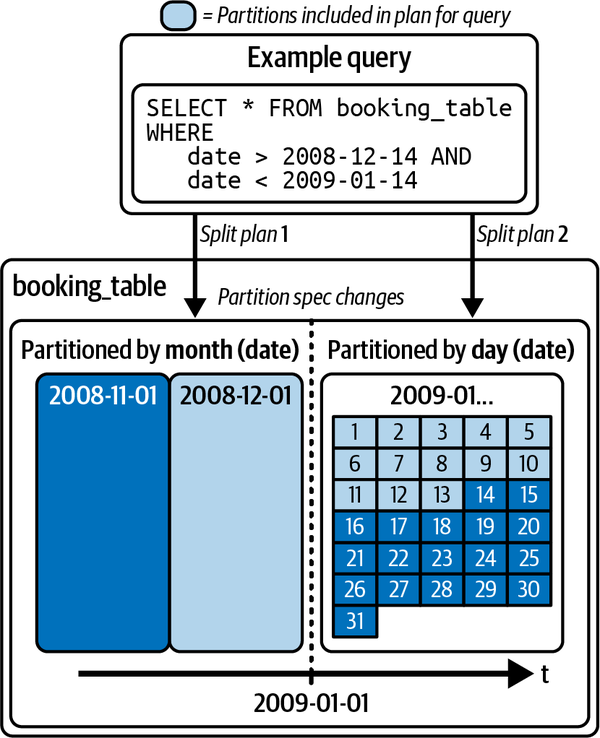
Abbildung 1-8. Entwicklung der Partition
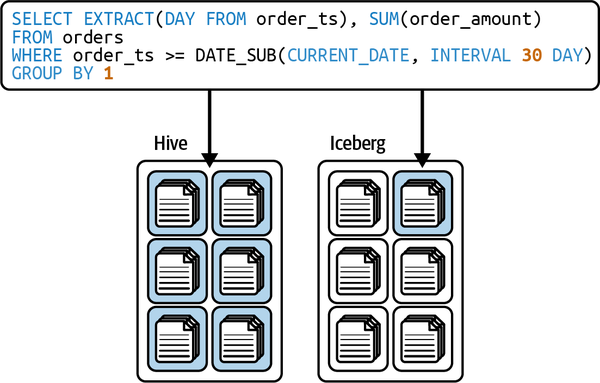
Tabellenoperationen auf Zeilenebene
Du kannst die Aktualisierungsmuster auf Zeilenebene der Tabelle auf eine von zwei Formen optimieren: copy-on-write (COW) oder merge-on-read (MOR). Bei COW wird bei einer Änderung einer beliebigen Zeile in einer bestimmten Datendatei die gesamte Datei neu geschrieben (mit der Änderung auf Zeilenebene in der neuen Datei), auch wenn nur ein einziger Datensatz darin aktualisiert wird. Bei der Verwendung von MOR wird bei Aktualisierungen auf Zeilenebene nur eine neue Datei geschrieben, die die Änderungen an der betroffenen Zeile enthält, die beim Lesen abgeglichen wird. Das gibt dir die Flexibilität, schwere Aktualisierungs- und Löschvorgänge zu beschleunigen.
Zeitreise
Apache Iceberg bietet unveränderliche Snapshots, so dass die Informationen über den historischen Zustand der Tabelle zugänglich sind und du Abfragen über den Zustand der Tabelle zu einem bestimmten Zeitpunkt in der Vergangenheit durchführen kannst. Das kann hilfreich sein, wenn du z. B. Berichte zum Quartalsende erstellen willst, ohne die Daten der Tabelle an einem anderen Ort duplizieren zu müssen, oder wenn du die Ausgabe eines ML-Modells zu einem bestimmten Zeitpunkt reproduzieren willst. Dies wird in Abbildung 1-10 veranschaulicht.
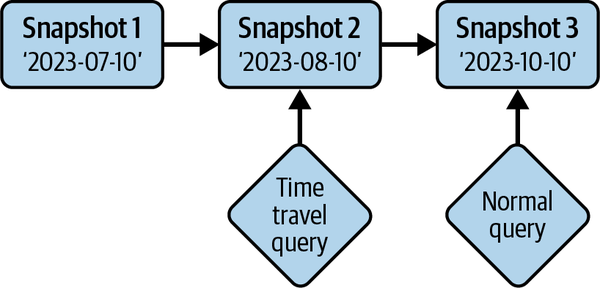
Abbildung 1-10. Abfrage der Tabelle, wie sie bei der Zeitreise war
Version Rollback
Die Isolierung von Icebergs Snapshot ermöglicht es dir nicht nur, die Daten so abzufragen, wie sie sind, sondern setzt auch den aktuellen Zustand der Tabelle auf jeden dieser früheren Snapshots zurück. Daher ist das Rückgängigmachen von Fehlern so einfach wie ein Rollback (siehe Abbildung 1-11).
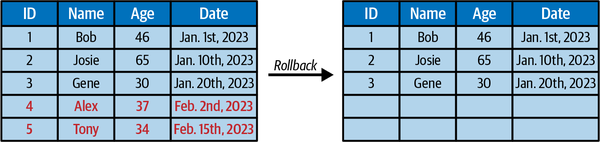
Abbildung 1-11. Verschieben des Zustands der Tabelle zu einem früheren Zeitpunkt durch Rollback
Schema-Entwicklung
Tabellen ändern sich, sei es durch das Hinzufügen/Entfernen einer Spalte, das Umbenennen einer Spalte oder das Ändern des Datentyps einer Spalte. Unabhängig davon, wie sich deine Tabelle entwickeln muss, bietet dir Apache Iceberg robuste Funktionen für die Schemaentwicklung - zum Beispiel die Aktualisierung einer int Spalte zu einer long Spalte, wenn die Werte in der Spalte größer werden.
Fazit
In diesem Kapitel hast du gelernt, dass Apache Iceberg ein Data Lakehouse-Tabellenformat ist, das entwickelt wurde, um viele der Bereiche zu verbessern, in denen Hive-Tabellen unzureichend waren. Durch die Entkopplung von der physischen Dateistruktur und dem mehrstufigen Metadatenbaum bietet Iceberg Hive-Transaktionen, ACID-Garantien, Schema-Evolution, Partitions-Evolution und verschiedene andere Funktionen, die das Data Lakehouse ermöglichen. Das Apache Iceberg Projekt ermöglicht dies, indem es eine Spezifikation und unterstützende Bibliotheken entwickelt, die es bestehenden Datentools ermöglichen, das offene Tabellenformat zu unterstützen.
In Kapitel 2 tauchen wir tief in die Architektur von Apache Iceberg ein, die all das möglich macht.
Get Apache Iceberg: Der endgültige Leitfaden now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

