Chapter 4. Data Transformation with dbt
The primary purpose of dbt is to help you transform the data of your data platforms in an easy and integrated way by simply writing SQL statements. When we place dbt in an ELT workflow, it matches the activities during the transformation stage, providing you with additional components—such as version control, documentation, tests, or automated deployment—that simplify the overall work of a data specialist. Does this remind you of the actual activities of an analytics engineer? Well, that’s because dbt is one of the modern tools that defines what analytics engineers do, giving them the instruments integrated with the platform, which reduces the need to set up additional services to answer specific problems and decreases the overall system complexity.
dbt supports the tasks described for an analytics engineer, empowering them to run the code in their data platform collaboratively for a single source of truth for metrics and business definitions. It promotes central and modular analytics code, leveraging DRY code with Jinja templating language, macros, or packages. In parallel, dbt also provides the security that we typically find in software engineering best practices, such as collaborate on data models, version them, and test and document your queries before safely deploying them to production, with monitoring and visibility.
We’ve provided a thorough introduction to dbt. However, within this chapter, we will delve even deeper into the specifics of dbt and clarify its importance in the world of data analytics. We will discuss the dbt design philosophy, the principles behind this transformation tool, and the data lifecycle with dbt at its core, presenting how dbt transforms raw data into structured models for easy consumption. We will explore the dbt project structure by outlining its various features, such as building models, documentation, and tests, as well as detailing other dbt artifacts, such as YAML files. By the end of this chapter, you will have a comprehensive understanding of dbt and its capabilities, which will enable you to implement it effectively in your data analytics workflow.
dbt Design Philosophy
As data engineering and analytics workflows become increasingly complex, tools that streamline the process while maintaining data quality and reliability are essential. dbt has emerged as a concentrated solution with a well-defined design philosophy that underpins its approach to data modeling and analytics engineering.
In summary, dbt design philosophy relies on the following points:
- Code-centric approach
-
At the core of dbt’s design philosophy is a code-centric approach to data modeling and transformation. Instead of relying on GUI-based interfaces or manual SQL scripts, dbt encourages users to define data transformations using code. This shift to code-driven development promotes collaboration, version control, and automation.
- Modularity for reusability
-
dbt promotes modularity, allowing data practitioners to create reusable code components. Models, macros, and tests can be organized into packages, which facilitates code maintenance and scalability. This modular approach aligns with best practices and enhances code reusability.
- Transformations as SQL
SELECTstatements -
dbt models are defined as SQL
SELECTstatements, making them accessible to analysts and engineers with SQL skills. This design choice simplifies development and ensures that data modeling closely follows SQL best practices. - Declarative language
-
dbt uses a declarative language for defining data transformations. Analysts specify the desired outcome, and dbt handles the underlying implementation. This abstraction reduces the complexity of writing complex SQL code and enhances readability.
- Incremental builds
-
Efficiency is a key focus of dbt’s design. It supports incremental builds, which allows data engineers to update only the affected pieces of the data pipeline rather than reprocessing the entire dataset. This accelerates development and reduces processing time.
- Documentation as code
-
dbt advocates for documenting data models and transformations as code. Descriptions, explanations, and metadata are stored alongside the project code, making it easier for team members to understand and collaborate effectively.
- Data quality, testing, and validation
-
dbt places a significant emphasis on data testing. It provides a testing framework that enables analysts to define data quality checks and validation rules. This includes data reliability and quality throughout the pipeline, thus ensuring that data meets predefined criteria and adheres to business rules.
- Version control integration
-
Seamless integration with version control systems like Git is a fundamental aspect of dbt. This feature enables collaborative development, change tracking, and the ability to roll back changes, ensuring that data pipelines remain under version control.
- Native integration with data platforms
-
dbt is designed to work seamlessly with popular data platforms such as Snowflake, BigQuery, and Redshift. It leverages the native capabilities of these platforms for scalability and performance.
- Open source and extensible
-
dbt is an open source tool with a thriving community. Users can extend its functionality by creating custom macros and packages. This extensibility allows organizations to tailor dbt to their specific data needs.
- Separation of transformation and loading
-
dbt separates the transformation and loading steps in the data pipeline. Data is transformed within dbt and then loaded into the data platform.
In essence, dbt’s design philosophy is rooted in creating a collaborative, code-centric, and modular environment for data engineers, analysts, and data scientists to efficiently transform data, ensure data quality, and generate valuable insights. dbt empowers organizations to harness the full potential of their data by simplifying the complexities of data modeling and analytics engineering.
dbt Data Flow
Figure 4-1 shows the big picture of a data flow. It identifies where dbt and its features fit in the overall data landscape.

Figure 4-1. Typical data flow with dbt that helps you transform your data from BigQuery, Snowflake, Databricks, and Redshift, among others (see the dbt documentation for supported data platforms)
As mentioned, the primary purpose of dbt is to help you transform the data of your data platforms, and for that, dbt offers two tools for achieving that goal:
-
dbt Cloud
-
dbt Core, an open source CLI tool, maintained by dbt Labs, that you can set up on your managed environments or run locally
Let’s look at an example to see how dbt works in real life and what it can do. Imagine that we are working on a pipeline that periodically extracts data from a data platform such as BigQuery. Then, it transforms the data by combining tables (Figure 4-2).
We’ll combine the first two tables into one, applying several transformation techniques, such as data cleaning or consolidation. This phase takes place in dbt, so we’ll need to create a dbt project to accomplish this merge. We will get there, but let’s first get familiar with dbt Cloud and how to set up our working environment.
Note
For this book, we will use dbt Cloud to write our code since it is the fastest and most reliable way to start with dbt, from development to writing tests, scheduling, deployments, and investigating data models. Also, dbt Cloud runs on top of dbt Core, so while we work on dbt Cloud, we will become familiar with the same commands used in dbt Core’s CLI tool.

Figure 4-2. Data pipeline use case with dbt
dbt Cloud
dbt Cloud is a cloud-based version of dbt that offers a wide range of features and services to write and productize your analytics code. dbt Cloud allows you to schedule your dbt jobs, monitor their progress, and view logs and metrics in real time. dbt Cloud also provides advanced collaboration features, including version control, testing, and documentation. Moreover, dbt Cloud integrates with various cloud data warehouses, such as Snowflake, BigQuery, and Redshift, which allows you to easily transform your data.
You can use dbt Core with the majority of the stated features, but it will require configuration and setup on your infrastructure, similar to running your own server or an Amazon Elastic Compute Cloud (EC2) instance for tools like Airflow. This means you’ll need to maintain and manage it autonomously, similar to managing a virtual machine (VM) on EC2.
In contrast, dbt Cloud operates like a managed service, similar to Amazon Managed Workflows for Apache Airflow (MWAA). It offers convenience and ease of use, as many operational aspects are handled for you, allowing you to focus more on your analytics tasks and less on infrastructure management.
Setting Up dbt Cloud with BigQuery and GitHub
There is nothing better than learning a specific technology by practicing it, so let’s set up the environment we will use to apply our knowledge. To start, let’s first register for a dbt account.
After registering, we will land on the Complete Project Setup page (Figure 4-3).

Figure 4-3. dbt landing page to complete the project setup
This page has multiple sections to properly configure our dbt project, including connections to our desired data platform and to our code repository. We will use BigQuery as the data platform and GitHub to store our code.
The first step in BigQuery is to set up a new project. In GCP, search for Create a Project in the search bar and click it (Figure 4-4).

Figure 4-4. BigQuery project setup, step 1
A screen similar to Figure 4-5 is presented, where you can set up the project. We’ve named it dbt-analytics-engineer.

Figure 4-5. BigQuery project setup, step 2
After configuration, go into your BigQuery IDE—you can use the search bar again. It should look similar to Figure 4-6.
Figure 4-6. BigQuery IDE
Finally, test the dbt public dataset to ensure that BigQuery is working correctly. For that, copy the code in Example 4-1 into BigQuery and then click Run.
Example 4-1. dbt public datasets in BigQuery
select*from`dbt-tutorial.jaffle_shop.customers`;select*from`dbt-tutorial.jaffle_shop.orders`;select*from`dbt-tutorial.stripe.payment`;
If you see the page in Figure 4-7, then you did it!
Note
Since we’ve executed three queries simultaneously, we won’t see the output results. For that, click View Results to inspect the query output individually.

Figure 4-7. BigQuery dataset output
Now let’s connect dbt with BigQuery and execute these queries inside the dbt IDE. To let dbt connect to your data platform, you’ll need to generate a keyfile, similar to using a database username and password in most other data platforms.
Go to the BigQuery console. Before proceeding with the next steps, make sure you select the new project in the header. If you do not see your account or project, click your profile picture to the right and verify that you are using the correct email account:
-
Go to IAM & Admin and select Service Accounts.
-
Click Create Service Account.
-
In the name field, type
dbt-userand then click Create and Continue. -
On “Grant this service account access to project” select BigQuery Admin in the role field. Click Continue.
-
Leave fields blank in the “Grant users access to this service account” section and click Done.
The screen should look like Figure 4-8.

Figure 4-8. BigQuery Service Accounts screen
Moving on, proceed with the remaining steps:
-
Click the service account that you just created.
-
Select Keys.
-
Click Add Key; then select “Create new key.”
-
Select JSON as the key type; then click Create.
-
You should be prompted to download the JSON file. Save it locally to an easy-to-remember spot with a clear filename—for example, dbt-analytics-engineer-keys.json.
Now let’s get back into the dbt Cloud for the final setup:
-
On the project setup screen, give a more verbose name to your project. In our case, we chose dbt-analytics-engineer.
-
On the “Choose a warehouse” screen, click the BigQuery icon and Next.
-
Upload the JSON file generated previously. To do this, click the “Upload a Service Account JSON file” button, visible in Figure 4-9.
Last but not least, after you upload the file, apply the remaining step:
-
Go to the bottom and click “test.” If you see “Your test completed successfully,” as Figure 4-10 shows, you’re good to go! Now click Next. On the other hand, if the test fails, there’s a good chance you’ve encountered an issue with your BigQuery credentials. Try to regenerate them again.

Figure 4-9. dbt Cloud, submit BigQuery Service Account screen
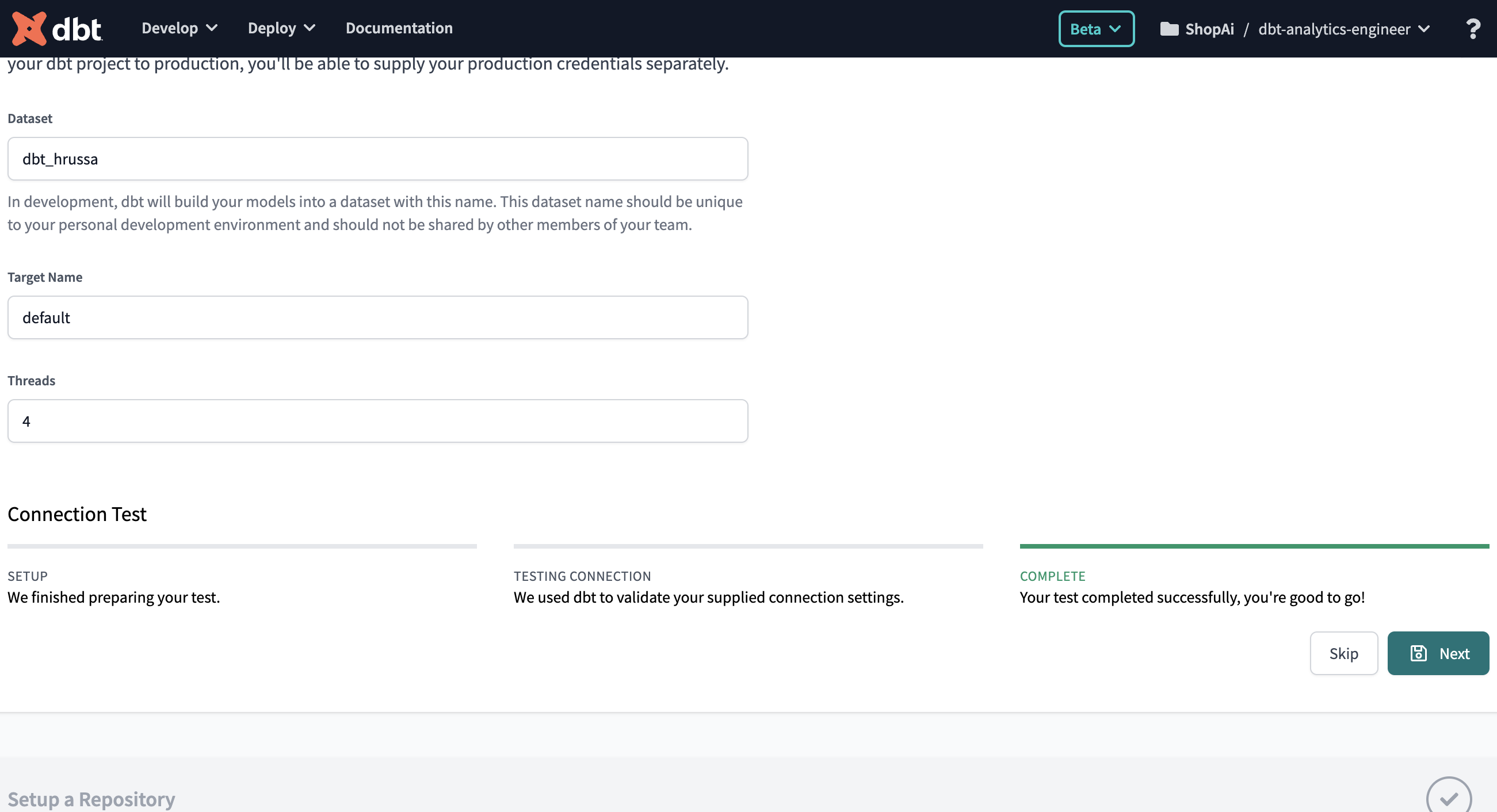
Figure 4-10. dbt and BigQuery connection test
The final step is setting up GitHub, but first, let’s understand what we are discussing here. GitHub is a popular version control platform that hosts Git repositories that allow you to track changes in your code and collaborate with others effectively. To correctly use Git, sticking to these principles and best practices is essential:
- Commit often, commit early
-
Make frequent commits, even for small changes. This helps in tracking your progress and simplifies debugging. Each commit should represent a logical change or feature.
- Use meaningful commit messages
-
Write concise and descriptive commit messages. A good commit message should explain what was changed and why it was changed.
- Follow a branching strategy
-
Use branches for different features, bug fixes, or development tasks.
- Pull before push
-
Always pull the latest changes from the remote repository (e.g.,
git pull) before pushing your changes. This reduces conflicts and ensures that your changes are based on the latest code. - Review code before committing
-
If your team practices code reviews, make sure to review and test your changes before committing. It helps maintain code quality.
- Use .gitignore
-
Create a .gitignore file to specify files and directories that should be excluded from version control (e.g., build artifacts, temporary files).
- Use atomic commits
-
Keep commits focused on a single, specific change. Avoid mixing unrelated changes in the same commit.
- Rebase instead of merge
-
Use
git rebaseto integrate changes from a feature branch into the main branch instead of traditional merging. This results in a cleaner commit history. - Keep commit history clean
-
Avoid committing “work in progress” or debugging statements. Use tools like
git stashto temporarily save unfinished work. - Use tags
-
Create tags, such as version tags, to mark important points in your project’s history, like releases or major milestones.
- Collaborate and communicate
-
Communicate with your team about Git workflows and conventions. Establish guidelines for handling issues, pull requests, and conflict resolution.
- Know how to undo changes
-
Learn how to revert commits (
git revert), reset branches (git reset), and recover lost work (git reflog) when needed. - Document
-
Document your project’s Git workflow and conventions in a README or contributing guidelines to effectively onboard new team members.
- Use backup and remote repositories
-
Regularly back up your Git repositories and use remote repositories like GitHub for collaboration and redundancy.
- Continue learning
-
Git is a great tool with many features. Keep learning and exploring advanced Git concepts like cherry-picking, interactive rebasing, and custom hooks to improve your workflow.
To better understand in practice some of the common Git terms and commands, let’s have a look at Table 4-1.
| Term/command | Definition | Git command (if applicable) |
|---|---|---|
Repository (repo) |
This is similar to a project folder and contains all the files, history, and branches of your project. |
- |
Branch |
A branch is a separate line of development. It allows you to work on new features or fixes without affecting the main codebase. |
|
Pull request (PR) |
A pull request is a proposed change that you want to merge into the main branch. It’s a way to collaborate and review code changes with your team. |
- |
Stash |
|
|
Commit |
A commit is a snapshot of your code at a specific point in time. It represents a set of changes you’ve made to your files. |
|
Add |
|
To stage all changes, the git command is |
Fork |
Forking a repository means creating your copy of someone else’s project on GitHub. You can make changes to your forked repository without affecting the original. |
- |
Clone |
Cloning a repository means making a local copy of a remote repository. You can work on your code locally and push changes to the remote repository. |
|
Push |
|
|
Pull |
|
|
Status |
|
|
Log |
|
|
Diff |
The |
|
Merge |
The |
|
Rebase |
Rebase allows you to move or combine a sequence of commits to a new base commit. |
|
Checkout |
The |
|
These Git commands and terms provide the foundation for version control in your projects. Nevertheless, Git commands often have many additional arguments and options, allowing for fine-tuned control over your version control tasks. While we’ve covered some essential commands here, it’s essential to note that Git’s versatility extends far beyond what we’ve outlined.
For a more comprehensive list of Git commands and the diverse array of arguments they can accept, we recommend referring to the official Git documentation.
Now that you understand what Git and GitHub are and their role within the project, let’s establish a connection to GitHub. For that, you need to do the following:
-
Register for a GitHub account if you don’t already have one.
-
Click New to create a new repository, which is where you will version your analytics code. On the “Create a new repository screen,” give your repository a name; then click “Create repository.”
-
With the repository created, let’s get back to dbt. In the Setup a Repository section, select GitHub and then connect the GitHub account.
-
Click Configure GitHub Integration to open a new window where you can select the location to install the dbt Cloud. Then choose the repository you want to install.
Now click “Start developing in the IDE.” Figure 4-11 is what you should expect to see.
Figure 4-11. dbt IDE
We will give an overview of the dbt Cloud Integrated Development Environment (IDE) in “Using the dbt Cloud IDE” and cover it in more detail in “Structure of a dbt Project”.
Click “Initialize dbt project” on the top left. Now, you should be able to see the screen as it looks in Figure 4-12.

Figure 4-12. dbt after project initialization
We will detail each folder and file in “Structure of a dbt Project”. For now, let’s see if the queries work. Run them again by copying the Example 4-2 code and click Preview.
Example 4-2. dbt public datasets in BigQuery, dbt test
--select * from `dbt-tutorial.jaffle_shop.customers`;--select * from `dbt-tutorial.jaffle_shop.orders`;select*from`dbt-tutorial.stripe.payment`;
If the output looks similar to Figure 4-13, that means your connection works. You can then submit queries to your data platform, which in our case is BigQuery.
Note
The steps provided here are part of the documentation for the BigQuery adapter in dbt. As technologies evolve and improve, these steps and configurations may also change. To ensure that you have the most up-to-date information, refer to the latest dbt documentation for BigQuery. This resource will provide you with the most current guidance and instructions for working with dbt and BigQuery.
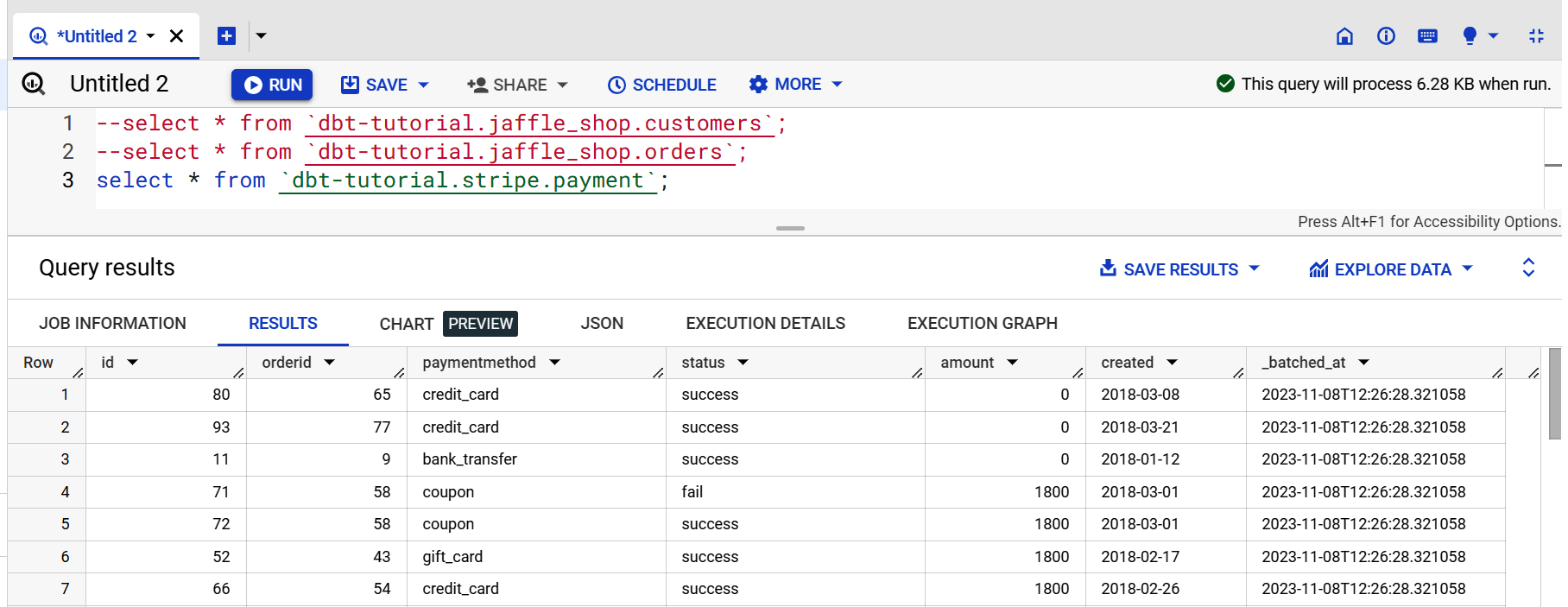
Figure 4-13. dbt output of BigQuery public dataset
Finally, let’s test whether your GitHub integration is working as expected by carrying out your first “Commit and push.” Click the button with the same description, visible in Figure 4-14, at the left. A popup screen, the image to the right in Figure 4-14, will appear where you can write your commit message. Click Commit Changes.

Figure 4-14. Commit and push to GitHub
Since we didn’t create a Git branch, it will version our code inside the main branch. Go into the GitHub repository you made during this setup and see if your dbt project exists. Figure 4-15 should be similar to what you see on your GitHub repository.

Figure 4-15. dbt GitHub repository, first commit check
Using the dbt Cloud UI
When you sign in to dbt Cloud, the initial page displays a welcome message and a summary of your job’s execution history. As Figure 4-16 shows, the page is empty at first but once we create and run our first jobs, we will start seeing information. In “Jobs and Deployment”, we detail a job’s execution in more detail.

Figure 4-16. dbt landing page
On the top bar, you will see several options. Starting from the left, you can access the Develop page, where you will develop all your analytics code and create your models, tests, and documentation. It is the core of dbt development, and we will give you more insights into this section in “Using the dbt Cloud IDE”, and deep dive into each component in “Structure of a dbt Project”.
Right next to the Develop option is the Deploy menu, as shown in Figure 4-17. From this menu, you can configure jobs and monitor their execution via Run History, configure the development environments, and verify the source freshness of your snapshots via Data Sources.

Figure 4-17. dbt Deploy menu
The Deploy menu’s first option is Run History, which opens the page shown in Figure 4-18. Here you can see your job’s run history. In the context of dbt, jobs are automated tasks or processes that you configure to perform specific actions, such as running models, tests, or generating documentation. These jobs are an integral part of orchestrating dbt, which involves managing and automating various data transformation and analytics tasks.

Figure 4-18. dbt Run History page
Suppose you have jobs configured that had executions already in this section. In that case, you can inspect each job’s invocation and status. A wealth of information is available in the job’s run history, including its status, duration, the environment in which the job executed, and other useful details. You can access information about the steps the job went through, including respective logs for each step. Additionally, you can find artifacts generated by the job, such as models, tests, or documentation.
The Deploy menu’s next option is Jobs. This opens a page for configuring all your automation, including CI/CD pipelines, run tests, and other exciting behaviors, without running dbt commands manually from the command line.
Figure 4-19 shows the empty Jobs landing page. We have a whole section dedicated to Jobs in “Jobs and Deployment”.

Figure 4-19. dbt Jobs page
The third Deploy menu option is Environments. Inside dbt, we have two main types of environment: development and deployment. Out of the box, dbt configures the development environment for you, which is visible right after you set up your dbt project. Figure 4-20 shows you the Environments landing page, which should be similar to yours if you followed the steps in “Setting Up dbt Cloud with BigQuery and GitHub”.

Figure 4-20. dbt Environments page
Finally, we have the Data Sources option. This page, shown in Figure 4-21, is populated automatically by dbt Cloud once you configure a job to snapshot source-data freshness. Here you will see the state of the most recent snapshots, allowing you to analyze if your source data freshness is meeting the service-level agreements (SLAs) you’ve defined with your organization. We will give you a better idea of data freshness in “Source freshness” and how to test it in “Testing sources”.

Figure 4-21. dbt Data Sources page
Next is the Documentation option, and as long as you and your team create routines to ensure that your dbt project is correctly documented, this step will have a particular level of significance. Proper documentation can answer questions like these:
-
What does this data mean?
-
Where does this data come from?
-
How are these metrics calculated?
Figure 4-22 shows the Documentation page for your project. We will explain how to leverage and write documentation inside your dbt project while writing your code in “Documentation”.

Figure 4-22. dbt Documentation page
The top-right menu allows you to select your dbt project (Figure 4-23). This short menu makes it simple to move around between dbt projects.

Figure 4-23. dbt Select Account menu
The dbt Help menu (Figure 4-24) can be found by clicking the question mark symbol. Here you can speak directly with the dbt team through chat, provide feedback, and access dbt documentation. Finally, via the Help menu, you can join the Slack dbt community or GitHub dbt discussions.
Figure 4-24. dbt Help menu
The Settings menu, Figure 4-25, is where you can configure everything related to your account, profile, or even notifications.

Figure 4-25. dbt Settings menu
Once you click one of the three options, you will land on the Settings page, similar to Figure 4-26. On the first page, Account Settings, you can edit and create new dbt projects, manage users and their access control level (if you are an owner), and manage the billing.

Figure 4-26. dbt Account Settings page
The second menu option, Profile Settings, accesses the Your Profile page (Figure 4-27). On this page, you can review all your personal information and manage linked accounts, such as GitHub or GitLab, Slack, and single sign-on (SSO) tools. You can also review and edit the credentials you defined for your data platform and the API access key.
Figure 4-27. dbt Your Profile page
Finally, the Notification Settings option accesses the Notifications center (Figure 4-28), where you can configure alerts to be received in a chosen Slack channel or email when a job run succeeds, fails, or is canceled.

Figure 4-28. dbt Notifications center
Using the dbt Cloud IDE
One of the essential parts of the dbt Cloud is the IDE, where all your analytics code can be written, along with tests and documentation. Figure 4-29 shows the main sections of the dbt IDE.

Figure 4-29. dbt IDE—annotated
Next, you can find a detailed explanation of what each section represents and its relevance inside the integrated development environment:
-
Git controls and documentation
This menu is where you interact with Git. Here you can see what changed since your previous commit and what’s new. All Git commands in the IDE are here, and you can decide whether to commit and push or revert your code. Also, in the top right of this window, you can see the documentation icon. Once documentation is generated, you can click this shortcut to access your project documentation.
-
File Explorer
The File Explorer gives you the main overview of your dbt project. Here you can check how your dbt project is built—generally in the form of .sql, .yml, and other compatible file types.
-
Text editor
This section of the IDE is where your analytics code is written and becomes mature. Here you can also edit and create other relevant files for your project, such as the YAML files. If you select those files from File Explorer, they will pop up here. Multiple files can be opened simultaneously.
-
Information window and code Preview, Compile, and Build
This menu will show your results once you click the Preview or Compile buttons. Preview will compile and run your query against your data platform and display the results in the Results tab at the bottom of your screen. On the other hand, Compile will convert any Jinja into pure SQL. This will be displayed in the information window in the Compiled Code tab at the bottom of your screen. Preview or Compile buttons apply to statements and SQL files.
Build is a special button that pops up only in specific files. Depending on what type of build you choose, the run results will include information about all models, tests, seeds, and snapshots that were selected to build, combined into one file.
The information window is also helpful for troubleshooting errors during development or using the Lineage tab to check the data lineage of the model currently open in the text editor and its ancestors and dependencies.
-
Command line
The command line is where you can execute specific dbt commands such as
dbt runordbt test. During or after the execution of the command, it also displays a pop-up screen to show the results as they are processed—for that, click the arrow at the beginning of the command line. Logs can also be viewed here. Figure 4-30 shows the command line expanded; the command to be executed is at the top, and the log of the execution follows.

Figure 4-30. dbt command line expanded
Structure of a dbt Project
A dbt project is a directory composed of folders and files, programming patterns, and naming conventions. All your analytics code, tests, documentation, and parametrizations that will tell dbt how to operate will be in those files and folders. It will use those naming conventions and programming patterns. The way you organize your folders and file directory is your dbt project structure.
Building a proper dbt project takes effort. To be well implemented, it needs to bring together the company domains and departments, leveraging their particular expertise to map the goals and needs of the whole company. As such, defining a set of conventions and patterns that are clear, comprehensive, and consistent is relevant. Accomplishing that will ensure that the project remains accessible and maintainable as your company scales, while using dbt to empower and benefit as many people as possible.
How you organize your dbt project can vary and might be subject to changes defined by you or company guidelines. That’s not a problem. What’s important is that you explicitly declare those changes in a rigorous and accessible way for all contributors and, above all, stay consistent with it. For the sake of this book, we will keep the basic structure of the dbt project that you encounter once you initialize (Example 4-3).
Example 4-3. Initial structure of a dbt project
root/ ├─ analyses/ ├─ dbt_packages/ ├─ logs/ ├─ macros/ ├─ models/ │ ├─ example/ │ │ ├─ schema.yml │ │ ├─ my_second_dbt_model.sql │ │ ├─ my_first_dbt_model.sql ├─ seeds/ ├─ snapshots/ ├─ target/ ├─ tests/ ├─ .gitignore ├─ dbt_project.yml ├─ README.md
Each folder and file will be explained in the subsequent sections in this chapter and Chapter 5. Some will have more emphasis and will be used more regularly than others. Yet, it is essential to have a broader idea of their purpose:
- analyses folder
-
Detailed in “Analyses”, this folder is commonly used to store queries for auditing purposes. For example, you may want to find discrepancies during logic migration from another system into dbt and still leverage the capabilities of dbt, such as the use of Jinja and version control, without including it in your built models inside your data platform.
- dbt_packages folder
-
Is where you will install your dbt packages. We will cover the concept of packages in “dbt Packages”. Still, the idea is that packages are standalone dbt projects that tackle specific problems and can be reused and shared across organizations. This promotes a DRY-er code since you aren’t implementing the same logic over and over.
- logs folder
-
Is where all your project logs will be written by default, unless you configure them differently in your dbt_project.yml.
- macros folder
-
Is where your DRY-ing up transformations code will be stored. Macros, analogous to functions in other programming languages, are pieces of Jinja code that can be reused multiple times. We will devote an entire section in “Using SQL Macros” to detailing them.
- models folder
-
Is one of the mandatory folders in dbt. Generally speaking, a model is a SQL file that contains a
SELECTstatement with a modular piece of logic that will take your raw data and build it into the final transformed data. In dbt, the model’s name indicates the name of a future table or view, or neither if configured as an ephemeral model. This subject will be detailed in “Models”. - seeds folder
-
Is where our lookup tables will be stored. We will discuss this in “Seeds”. The general idea is that seeds are CSV files that change infrequently, and are used for modeling data that doesn’t exist in any source system. Some helpful use cases could be mapping zip codes to states or a list of test emails we need to exclude from the analysis.
- snapshots folder
-
Contains all snapshot models for your project, which must be separated from the models folder. The dbt snapshot feature records change to a mutable table over time. It applies the type 2 slowly changing dimension (SCDs), which identifies how a row in a table changes during the time. This is covered in detail in “Snapshots”.
- target folder
-
Contains the compiled SQL files that will be written when you run the
dbt run,dbt compile, ordbt testcommands. You can optionally configure in dbt_project.yml to be written into another folder. - tests folder
-
Serves the purpose of testing multiple specific tables simultaneously. This will not be the solo folder where your tests will be written. A good number will still be under your model’s folder inside the YAML files, or through macros. Yet, the tests folder is more suited for singular tests, which report the results of how several specific models interact or relate to one another. We will cover this topic in depth in “Tests”.
- dbt_project.yml
-
Is the core of every dbt project. This is how dbt knows a directory is a dbt project, and it contains important information that tells dbt how to operate on your project. We will cover this file throughout the course of this book. It’s also covered in “dbt_project.yml”.
- .gitignore and README.md
-
Are files typically used for your Git projects. While gitignore specifies intentional files that Git should ignore during your commit and push, the README file is an essential guide that gives other developers a detailed description of your Git project.
We’ll cover these folders in more detail in this chapter and Chapter 5 while going deeper into the dbt project and features.
Jaffle Shop Database
In this book, we will give a set of practical examples of how to work with the components and features of dbt. In most cases, we will need to develop SQL queries to give you the best idea of what we want to show. So, it is essential to have a database that we can work with. That database is the Jaffle Shop.
The Jaffle Shop database is a simple database composed of two tables, for customers and orders. To give more context, we will have a side database, from Stripe, with the payments connected with the orders. All three tables will be our raw data.
The reason we use this database is that it is already publicly available, in BigQuery, by dbt Labs. It is one of the main databases used for their documentation and courses, so we hope it will simplify the overall learning curve of the dbt platform at this stage of the book.
Figure 4-31 shows you the ERD representing our raw data with customers, orders, and payments.

Figure 4-31. A Jaffle Shop raw data ERD, which we read as follows: single customer (1) can have multiple orders (N), and a single order (1) can have multiple processing payments (N)
YAML Files
YAML is a human-readable data-serialization language commonly used for configuration files and in applications where data is being stored or transmitted. In dbt, YAML is used to define properties and some configurations of the components of your dbt project: models, snapshots, seeds, tests, sources, or even the actual dbt project, dbt_project.yml.
Apart from the top-level YAML files, such as dbt_project.yml and packages.yml, that need to be specifically named and in specific locations, the way you organize the other YAML files inside your dbt project is up to you. Remember that, as with other aspects of structuring your dbt project, the most important guidelines are to keep consistent, be clear on your intentions, and document how and why it is organized that way. It is important to balance centralization and file size to make specific configurations as easy to find as possible. Following are a set of recommendations on how to organize, structure, and name your YAML files:
-
As mentioned, balancing the configuration’s centralization and file size is particularly relevant. Having all configurations within a single file might make it challenging to find a specific one as your project scales (though you technically can use one file). Change management with Git will also be complicated because of the repetitive nature of the file.
-
As per the previous point, if we follow a config per folder approach, it is better to maintain all your configurations in the long run. In other words, in each model’s folder directory, it is recommended to have a YAML file that will facilitate the configurations of all the models in that directory. Extend this rule by separating the model’s configuration file, having a specific file for your sources configurations inside the same directory (Example 4-4).
In this structure, we’ve used the staging models to represent what’s being discussed, since it covers most cases, such as sources, YAML files. Here you can see the config per folder system, where source and model configurations are divided. It also introduces the Markdown files for documentation, which we will discuss in more detail in “Documentation”. Finally, the underscore at the beginning puts all these files at the top of their respective directory so they are easier to find.
Example 4-4. dbt YAML files in the model directory
root/ ├─ models/ │ ├─ staging/ │ │ ├─ jaffle_shop/ │ │ │ ├─ _jaffle_shop_docs.md │ │ │ ├─ _jaffle_shop_models.yml │ │ │ ├─ _jaffle_shop_sources.yml │ │ │ ├─ stg_jaffle_shop_customers.sql │ │ │ ├─ stg_jaffle_shop_orders.sql │ │ ├─ stripe/ │ │ │ ├─ _stripe_docs.md │ │ │ ├─ _stripe_models.yml │ │ │ ├─ _stripe_sources.yml │ │ │ ├─ stg_stripe_order_payments.sql ├─ dbt_project.yml
-
When using documentation blocks, also follow the same approach by creating one Markdown file (
.md) per models directory. In “Documentation”, we will get to know this type of file better.
It is recommended that you set up default configurations of your dbt project in your dbt_project.yml file at the directory level and use the cascading scope priority to define variations of these configurations. This can help you streamline your dbt project management and ensure that your configurations are consistent and easily maintainable. For example, leveraging Example 4-4, imagine that all our staging models would be configured to be materialized as a view by default. That would be in your dbt_project.yml. But if you have a specific use case where you need to change the materialization configuration for your jaffle_shop staging models, you can do so by modifying the _jaffle_shop_models.yml file. This way, you can customize the materialization configuration for this specific set of models while keeping the rest of your project configurations unchanged.
The ability to override the default configurations for specific models is made possible by the cascading scope priority used in the dbt project build. While all staging models would be materialized as views because this is the default configuration, the staging jaffle_shop models would be materialized as tables because we overrode the default by updating the specific _jaffle_shop_models.yml YAML file.
dbt_project.yml
One of the most critical files in dbt is dbt_project.yml. This file must be in the root of the project and it is the main configuration file for your project, containing pertinent information for dbt to properly operate.
The dbt_project.yml file also has some relevancy while writing your DRY-er analytics code. Generally speaking, your project default configurations will be stored here, and all objects will inherit from it unless overridden at the model level.
Here are some of the most important fields that you will encounter in this file:
- name
-
(Mandatory.) The name of the dbt project. We recommend changing this configuration to your project name. Also, remember to change it in the model’s section and the dbt_project.yml file. In our case, we name it dbt_analytics_engineer_book.
- version
-
(Mandatory.) Core version of your project. Different from dbt version.
- config-version
-
(Mandatory.) Version 2 is the currently available version.
- profile
-
(Mandatory.) Profile within dbt is used to connect to your data platform.
- [folder]-paths
-
(Optional.) Where [folder] is the list of folders in the dbt project. It can be a model, seed, test, analysis, macro, snapshot, log, etc. For example, the model-paths will state the directory of your models and sources. The macro-paths is where your macros code lives, and so on.
- target-path
-
(Optional.) This path will store the compiled SQL file.
- clean-targets
-
(Optional.) List of directories containing artifacts to be removed by the
dbt cleancommand. - models
-
(Optional.) Default configuration of the models. In Example 4-5, we want all models inside the staging folder to be materialized as views.
Example 4-5. dbt_project.yml, model configuration
models:dbt_analytics_engineer_book:staging:materialized:view
packages.yml
Packages are standalone dbt projects that tackle specific problems and can be reused and shared across organizations. They are projects with models and macros; by adding them to your project, those models and macros will become part of it.
To access those packages, you first need to define them in the packages.yml file. The detailed steps are as follows:
-
You must ensure that the packages.yml file is in your dbt project. If not, please create it at the same level as your dbt_project.yml file.
-
Inside the dbt packages.yml file, define the packages you want to have available for use inside your dbt project. You can install packages from sources like the dbt Hub; Git repositories, such as GitHub or GitLab; or even packages you have stored locally. Example 4-6 shows you the syntax required for each of these scenarios.
-
Run
dbt depsto install the defined packages. Unless you configure differently, by default those packages get installed in the dbt_packages directory.
Example 4-6. Syntax to install packages from the dbt hub, Git, or locally
packages:-package:dbt-labs/dbt_utilsversion:1.1.1-git:"https://github.com/dbt-labs/dbt-utils.git"revision:1.1.1-local:/opt/dbt/bigquery
profiles.yml
If you decide to use the dbt CLI and run your dbt project locally, you will need to set up a profiles.yml, which is not needed if you use dbt Cloud. This file contains the database connection that dbt will use to connect to the data platform. Because of its sensitive content, this file lives outside the project to avoid credentials being versioned into your code repository. You can safely use code versioning if your credentials are stored under environment variables.
Once you invoke dbt from your local environment, dbt parses your dbt_project.yml file and gets the profile name, which dbt needs to connect to your data platform. You can have multiple profiles as needed, yet it is common to have one profile per dbt project or per data platform. even using dbt Cloud for this book, and the profiles configuration not being necessary. We’re showing a sample of the profiles.yml if you are curious or prefer to use dbt CLI with BigQuery.
The typical YAML schema file for profiles.yml is shown in Example 4-7. We are using dbt Cloud for this book, meaning the profiles configuration is not necessary. However, we’re showing a sample of profiles.yml if you are curious or prefer to use the dbt CLI with BigQuery.
Example 4-7. profiles.yml
dbt_analytics_engineer_book:target:devoutputs:dev:type:bigquerymethod:service-accountproject:[GCP project id]dataset:[the name of your dbt dataset]threads:[1 or more]keyfile:[/path/to/bigquery/keyfile.json]<optional_config>:<value>
The most common structure of profiles.yaml has the following components:
- profile_name
-
The profile’s name must be equal to the name found in your dbt_project.yml. In our case, we’ve named it
dbt_analytics_engineer_book. - target
-
This is how you have different configurations for different environments. For instance, you would want separate datasets/databases to work on when developing locally. But when deploying to production, it is best to have all tables in a single dataset/database. By default, the target is set up to be
dev. - type
-
The type of data platform you want to connect: BigQuery, Snowflake, Redshift, among others.
- database-specific connection details
-
Example 4-7 includes attributes like
method,project,dataset, andkeyfilethat are required to set up a connection to BigQuery, using this approach. - threads
-
Number of threads the dbt project will run on. It creates a DAG of links between models. The number of threads represents the maximum number of paths through the graph that dbt may work in parallel. For example, if you specify
threads: 1, dbt will start building only one resource (models, tests, etc.) and finish it before moving on to the next. On the other hand, if you havethreads: 4, dbt will work on up to four models at once without violating dependencies.
Note
The overall idea of the profiles.yml file is presented here. We will not go further than this nor give a detailed setup guide on configuring your dbt local project with BigQuery. Most of the tasks were already described, such as keyfile generation in “Setting Up dbt Cloud with BigQuery and GitHub”, but there might be some nuances. If you want to learn more, dbt provides a comprehensive guide.
Models
Models are where you, as a data specialist, will spend most of your time inside the dbt ecosystem. They are typically written as select statements, saved as .sql, and are one of the most important pieces in dbt that will help you transform your data inside your data platform.
To properly build your models and create a clear and consistent project structure, you need to be comfortable with the data modeling concept and techniques. This is core knowledge if your goal is to become an analytics engineer or, generically speaking, someone who wants to work with data.
As we saw in Chapter 2, data modeling is the process that, by analyzing and defining the data requirements, creates data models that support the business processes in your organization. It shapes your source data, the data your company collects and produces, into transformed data, answering the data needs of your company domains and departments and generating added value.
In line with data modeling, and also as introduced in Chapter 2, modularity is another concept that is vital to properly structuring your dbt project and organizing your models while keeping your code DRY-er. Conceptually speaking, modularity is the process of decomposing a problem into a set of modules that can be separated and recombined, which reduces the overall complexity of the system, often with the benefit of flexibility and variety of use. In analytics, this is no different. While building a data product, we don’t write the code all at once. Instead, we make it piece by piece until we reach the final data artifacts.
Since we will try to have modularity present from the beginning, our initial models will also be built with modularity in mind and in accordance with what we’ve discussed in Chapter 2. Following a typical dbt data transformation flow, there will be three layers in our model’s directory:
- Staging layer
-
Our initial modular building blocks are within the staging layer of our dbt project. In this layer, we establish an interface with our source systems, similar to how an API interacts with external data sources. Here, data is reordered, cleaned up, and prepared for downstream processing. This includes tasks like data standardization and minor transformations that set the stage for more advanced data processing further downstream.
- Intermediate layer
-
This layer consists of models between the staging layer and the marts layer. These models are built on top of our staging models and are used to conduct extensive data transformations, as well as data consolidation from multiple sources, which creates varied intermediate tables that will serve distinct purposes.
- Marts layer
-
Depending on your data modeling technique, marts bring together all modular pieces to give a broader vision of the entities your company cares about. If, for example, we choose a dimensional modeling technique, the marts layer contains your fact and dimension tables. In this context, facts are occurrences that keep happening over time, such as orders, page clicks, or inventory changes, with their respective measures. Dimensions are attributes, such as customers, products, and geography, that can describe those facts. Marts can be described as subsets of data inside your data platform that are oriented to specific domains or departments, such as finance, marketing, logistics, customer service, etc. It can also be a good practice to have a mart called “core,” for example, that isn’t oriented to a specific domain but is instead the core business facts and dimensions.
With the introductions made, let’s now build our first models, initially only on our staging layer. Create a new folder inside your models folder, named staging, and the respective folders per source, jaffle_shop and stripe, inside the staging folder. Then create the necessary SQL files, one for stg_stripe_order_payments.sql (Example 4-8), another for stg_jaffle_shop_customers.sql (Example 4-9), and finally one for stg_jaffle_shop_orders.sql (Example 4-10). In the end, delete the example folder inside your models. It is unnecessary, so it would create unneeded visual noise while coding. The folder structure should be similar to Example 4-11.
Example 4-8. stg_stripe_order_payments.sql
selectidaspayment_id,orderidasorder_id,paymentmethodaspayment_method,casewhenpaymentmethodin('stripe','paypal','credit_card','gift_card')then'credit'else'cash'endaspayment_type,status,amount,casewhenstatus='success'thentrueelsefalseendasis_completed_payment,createdascreated_datefrom`dbt-tutorial.stripe.payment`
Example 4-9. stg_jaffle_shop_customers.sql
selectidascustomer_id,first_name,last_namefrom`dbt-tutorial.jaffle_shop.customers`
Example 4-10. stg_jaffle_shop_orders.sql
selectidasorder_id,user_idascustomer_id,order_date,status,_etl_loaded_atfrom`dbt-tutorial.jaffle_shop.orders`
Example 4-11. Staging models’ folder structure
root/ ├─ models/ │ ├─ staging/ │ │ ├─ jaffle_shop/ │ │ │ ├─ stg_jaffle_shop_customers.sql │ │ │ ├─ stg_jaffle_shop_orders.sql │ │ ├─ stripe/ │ │ │ ├─ stg_stripe_order_payments.sql ├─ dbt_project.yml
Now let’s execute and validate what we did. Typically, typing dbt run in your command line is enough, but at BigQuery, you may need to type dbt run --full-refresh. After, look at your logs by using the arrow to the left of your command line. The logs should look similar to Figure 4-32.

Figure 4-32. dbt system logs
Tip
Your logs should also give you a good idea of the issue if something goes wrong. In Figure 4-32, we present a logs summary, but you can also check the detailed logs for more verbosity.
Expecting that you have received the “Completed successfully” message, let’s now take a look at BigQuery, where you should see all three models materialized, as Figure 4-33 shows.

Figure 4-33. dbt BigQuery models
By default, dbt materializes your models inside your data platform as views. Still, you can easily configure this in the configuration block at the top of the model file (Example 4-12).
Example 4-12. Materialization config inside the model file
{{config(materialized='table')}}SELECTidascustomer_id,first_name,last_nameFROM`dbt-tutorial.jaffle_shop.customers`
Now that we have created our first models, let’s move to the next steps. Rearrange the code using the YAML files, and follow the best practices recommended in “YAML Files”. Let’s take the code block from there and configure our materializations inside our YAML files (Example 4-12). The first file we will change is dbt_project.yml. This should be the core YAML file for default configurations. As such, let’s change the model’s configuration inside with the code presented in Example 4-13 and then execute dbt run again.
Example 4-13. Materialize models as views and as tables
models:dbt_analytics_engineer_book:staging:jaffle_shop:+materialized:viewstripe:+materialized:table
Note
The + prefix is a dbt syntax enhancement, introduced with dbt v0.17.0, designed to clarify resource paths and configurations within dbt_project.yml files.
Since Example 4-13 forced all staging Stripe models to be materialized as a table, BigQuery should look like Figure 4-34.
Figure 4-34. dbt BigQuery models with materialized table
Example 4-13 shows how to configure, per folder, the specific desired materializations inside dbt_project.yml. Your staging models will be kept by default as views, so overriding this configuration can be done at the model’s folder level, leveraging the cascading scope priority on the project build. First, let’s change our dbt_project.yml to set all staging models to be materialized as views, as Example 4-14 shows.
Example 4-14. Staging models to be materialized as views
models:dbt_analytics_engineer_book:staging:+materialized:view
Now let’s create the separate YAML file for stg_jaffle_shop_customers, stating that it needs to be materialized as a table. For that, create the respective YAML file, with the name _jaffle_shop_models.yml, inside the staging/jaffle_shop directory and copy the code in Example 4-15.
Example 4-15. Defining that the model will be materialized as a table
version:2models:-name:stg_jaffle_shop_customersconfig:materialized:table
After you rerun dbt, take a look at BigQuery. It should be similar to Figure 4-35.

Figure 4-35. dbt BigQuery customers model materialized into a table
This is a simple example of using the YAML files, playing with table materializations, and seeing what the cascading scope priority means in practice. There is still a lot to do and see, and some of what we’re discussing will have even more applicability as we move onward. For now, we would just ask you to change your model inside _jaffle_shop_models.yml to be materialized as a view. This will be your default configuration.
Hopefully, at this stage, you’ve developed your first models and understand roughly the overall purpose of the YAML files and the cascading scope priority. The following steps will be to create our intermediate and mart models while learning about ref() functions. This will be our first use of Jinja, which we will cover in more detail in “Dynamic SQL with Jinja”.
First things first: our use case. With our models inside our staging area, we need to know what we want to do with them. As we mentioned at the start of this section, you need to define the data requirements that support the business processes in your organization. As a business user, multiple streams can be taken from our data. One of them, which will be our use case, is to analyze our orders per customer, presenting the total amount paid per successful order and the total amount per successful order type (cash and credit).
Since we have some transformations here that require a granularity change from payment type level to order grain, it justifies isolating this complex operation before we reach the marts layer. This is where the intermediate layer lands. In your models folder, create a new folder named intermediate. Inside, create a new SQL file named int_payment_type_amount_per_order.sql and copy the code in Example 4-16.
Example 4-16. int_payment_type_amount_per_order.sql
withorder_paymentsas(select*from{{ref('stg_stripe_order_payments')}})selectorder_id,sum(casewhenpayment_type='cash'andstatus='success'thenamountelse0end)ascash_amount,sum(casewhenpayment_type='credit'andstatus='success'thenamountelse0end)ascredit_amount,sum(casewhenstatus='success'thenamountend)astotal_amountfromorder_paymentsgroupby1
As you can see while creating the order_payments CTE, we gather the data from stg_stripe_order_payments by using the ref() function. This function references the upstream tables and views that were building your data platform. We’ll use this function as a standard while we implement our analytics code due to the benefits, such as:
-
It allows you to build dependencies among models in a flexible way that can be shared in a common codebase since it compiles the name of the database object during the
dbt run, gathering it from the environment configuration when you create the project. This means that in your environment, the code will be compiled considering your environment configurations, available in your particular development environment, but different from that of your teammate who is using a different development environment but shares the same codebase. -
You can build lineage graphs in which you can visualize a specific model’s data flow and dependencies. We will discuss this later in this chapter, and it’s also covered in “Documentation”.
Finally, while acknowledging that the preceding code may seem like an antipattern, because of the sense of repetitiveness of CASE WHEN conditions, it’s essential to clarify that the entire dataset includes all orders, regardless of their payment status. However, for this example, we chose to conduct financial analysis only on payments associated with orders that have reached the “success” status.
With the intermediate table built, let’s move to the final layer. Considering the use case described, we need to analyze the orders from the customer’s perspective. This means we must create a customer dimension that connects with our fact table. Since the current use case can fulfill multiple departments, we will not create a specific department folder but one named core. So, to start, let’s create, in our models folder, the marts/core directory. Then copy Example 4-17 into a new file named dim_customers.sql and Example 4-18 into a new file named fct_orders.sql.
Example 4-17. dim_customers.sql
withcustomersas(select*from{{ref('stg_jaffle_shop_customers')}})selectcustomers.customer_id,customers.first_name,customers.last_namefromcustomers
Example 4-18. fct_orders.sql
withordersas(select*from{{ref('stg_jaffle_shop_orders')}}),payment_type_ordersas(select*from{{ref('int_payment_type_amount_per_order')}})selectord.order_id,ord.customer_id,ord.order_date,pto.cash_amount,pto.credit_amount,pto.total_amount,casewhenstatus='completed'then1else0endasis_order_completedfromordersasordleftjoinpayment_type_ordersasptoONord.order_id=pto.order_id
With all files created, let’s just set our default configurations inside dbt_project.yml, as shown in Example 4-19, and then execute dbt run, or potentially dbt run --full-refresh on BigQuery.
Example 4-19. Model configuration, per layer, inside dbt_project.yml
models:dbt_analytics_engineer_book:staging:+materialized:viewintermediate:+materialized:viewmarts:+materialized:table
Tip
If you are receiving an error message similar to “Compilation Error in rpc request…depends on a node named int_payment_type_amount_per_order which was not found,” this means that you have a model, dependent on the one that you are trying to preview, that is not yet inside your data platform—in our case int_payment_type_amount_per_order. To solve this, go to that particular model and execute the dbt run --select MODEL_NAME command, replacing MODEL_NAME with the respective model name.
If everything ran successfully, your data platform should be fully updated with all dbt models. Just look at BigQuery, which should be similar to Figure 4-36.

Figure 4-36. dbt BigQuery with all models
Finally, open fct_orders.sql and look at the Lineage option inside the information window (Figure 4-37). This is one of the great features we will cover in “Documentation”, giving us a good idea of the data flow that feeds a specific model and its upstream and downstream dependencies.

Figure 4-37. dbt fct_orders data lineage
Sources
In dbt, sources are the raw data available in your data platform, captured using a generic extract-and-load (EL) tool. It is essential to distinguish dbt sources from traditional data sources. A traditional data source can be either internal or external. Internal data sources provide the transactional data that supports the daily business operations inside your organization. Customer, sales, and product data are examples of potential content from an internal data source. On the other hand, external data sources provide data that originated outside your organization, such as data collected from your business partners, the internet, and market research, among others. Often this is data related to competitors, economics, customer demographics, etc.
dbt sources rely on internal and external data upon business demand but differ in definition. As mentioned, dbt sources are the raw data inside your data platform. This raw data is typically brought by the data engineering teams, using an EL tool, into your data platform and will be the foundation that allows your analytical platform to operate.
In our models, from “Models”, we’ve referred to our sources by using hardcoded strings such as dbt-tutorial.stripe.payment or dbt-tutorial.jaffle_shop.customers. Even if this works, consider that if your raw data changes, such as its location or the table name to follow specific naming conventions, making the changes across multiple files can be difficult and time-consuming. This is where dbt sources come in. They allow you to document those source tables inside a YAML file, where you can reference your source database, the schema, and tables.
Let’s put this into practice. By following the recommended best practices in “YAML Files”, let’s now create a new YAML file in the models/staging/jaffle_shop directory, named _jaffle_shop_sources.yml, and copy the code from Example 4-20. Then create another YAML file, now in the models/staging/stripe directory, named _stripe_sources.yml, copying the code in Example 4-21.
Example 4-20. _jaffle_shop_sources.yml—sources parametrization file for all tables under the Jaffle Shop schema
version:2sources:-name:jaffle_shopdatabase:dbt-tutorialschema:jaffle_shoptables:-name:customers-name:orders
Example 4-21. _stripe_sources.yml—sources parametrization file for all tables under the stripe schema
version:2sources:-name:stripedatabase:dbt-tutorialschema:stripetables:-name:payment
With our YAML files configured, we need to make a final change inside our models. Instead of having our sources hardcoded, we will use a new function named source(). This works like the ref() function that we introduced in “Referencing data models”, but instead of {{ ref("stg_stripe_order_payments") }}, to configure a source we now pass something like {{ source("stripe", "payment") }}, which, in this particular case, will reference the YAML file that we’ve created in Example 4-21.
Let’s now get our hands dirty. Take all the SQL staging model code you created earlier, and replace it with the respective code in Example 4-22.
Example 4-22. Payments, orders, and customers staging models with the source() function
-- REPLACE IT IN stg_stripe_order_payments.sqlselectidaspayment_id,orderidasorder_id,paymentmethodaspayment_method,casewhenpaymentmethodin('stripe','paypal','credit_card','gift_card')then'credit'else'cash'endaspayment_type,status,amount,casewhenstatus='success'thentrueelsefalseendasis_completed_payment,createdascreated_datefrom{{source('stripe','payment')}}-- REPLACE IT IN stg_jaffle_shop_customers.sql fileselectidascustomer_id,first_name,last_namefrom{{source('jaffle_shop','customers')}}-- REPLACE IT IN stg_jaffle_shop_orders.sqlselectidasorder_id,user_idascustomer_id,order_date,status,_etl_loaded_atfrom{{source('jaffle_shop','orders')}}
After you switch your models with our source() function, you can check how your code executes in your data platform by running dbt compile or clicking the Compile button in your IDE. In the backend, dbt will look to the referenced YAML file and replace the source() function with the direct table reference, as shown in Figure 4-38.

Figure 4-38. dbt customers staging model with source() function and respective code compiled. The compiled code is what will run inside your data platform.
Another benefit of using the source() function is that now you can see the sources in the lineage graph. Just take a look, for example, at the fct_orders.sql lineage. The same lineage shown in Figure 4-37 should now look like Figure 4-39.

Figure 4-39. dbt fct_orders data lineage with sources
Source freshness
The freshness of your data is an essential aspect of data quality. If the data isn’t up-to-date, it is obsolete, which could cause significant issues in your company’s decision-making process since it could lead to inaccurate insights.
dbt allows you to mitigate this situation with the source freshness test. For that, we need to have an audit field that states the loaded timestamp of a specific data artifact in your data platform. With it, dbt will be able to test how old the data is and trigger a warning or an error, depending on the specified conditions.
To achieve this, let’s get back to our source YAML files. For this particular example, we will use the orders data in our data platform, so by inference, we will replace the code in _jaffle_shop_sources.yml with the code in Example 4-23.
Example 4-23. _jaffle_shop_sources.yml—sources parametrization file for all tables under Jaffle Shop schema, with source freshness test
version:2sources:-name:jaffle_shopdatabase:dbt-tutorialschema:jaffle_shoptables:-name:customers-name:ordersloaded_at_field:_etl_loaded_atfreshness:warn_after:{count:12,period:hour}error_after:{count:24,period:hour}
As you can see, we’ve used the _etl_loaded_at field in our data platform. We didn’t have to bring it to our transformation process since it had no added value for forward models. This isn’t an issue because we are testing our upstream data, which in our case is our raw data. In the YAML file, we’ve created two additional properties: loaded_at_field, which represents the field to be monitored under the source freshness test, and freshness, with the actual rules to monitor the source freshness. Inside the freshness property, we’ve configured it to raise a warning if the data is 12 hours outdated with the warn_after property and raise an actual error if the data wasn’t refreshed in the past 24 hours with the error_after property.
Finally, let’s see what happens if we execute the command dbt source freshness. In our case, we got a warning, as you can see in Figure 4-40.

Figure 4-40. dbt orders raw data and source freshness test logs
If you check the log details, you can see the query executed in your data platform and troubleshoot. This particular warning was expected. The _etl_loaded_at was built to take 16 hours from the current time, so anything lower than that will raise a warning. If you want to keep playing around, change your warn_after to something higher, like 17 hours. All your tests should pass.
Hopefully, the source freshness concept is now clear. We will get back to it later in the book and show you how to automate and snapshot the source freshness tests. In the meantime, it is essential to understand its purpose in the overall test landscape, how to configure it, and how important this test could be to mitigate data quality issues.
Tests
As an analytics engineer, you must ensure that data is accurate and reliable to build trust in the analytics you deliver and provide objective insights for your organization. Everyone agrees with this, yet even if you follow all the engineering state-of-the-art best practices, there will always be exceptions—even more so when you have to deal with the volatility that is working with data, its variations, type, structure, etc.
There are many ways to capture those exceptions. Nonetheless, when you work with significant amounts of data, you need to think of a scalable approach to analyzing large datasets and quickly identifying those exceptions. This is where dbt comes in.
dbt allows you to rapidly and easily scale tests across your data workflow so that you can identify when things break before anyone else does. In a development environment, you can use tests to ensure that your analytics code produces the desired output. In a deployment/production environment, you can automate tests and set up an alert to tell you when a specific test fails so you can quickly react to it and fix it before it generates a more extreme consequence.
As a data practitioner, it’s important to understand that tests in dbt can be summarized as assertions about your data. When you run tests on top of your data models, you assert that those data models produce the expected output, which is a crucial step in ensuring data quality and reliability. These tests are a form of verification similar to confirming that your data follows specific patterns and meets predefined criteria.
However, it’s essential to note that dbt tests are just one type of testing within the broader landscape of data testing. In software testing, tests are often differentiated between verification and validation. dbt tests primarily focus on verification by confirming that data adheres to established patterns and structures. They are not designed for testing the finer details of logic within your data transformations, comparable to what unit tests do in software development.
Furthermore, dbt tests can assist with the integration of data components to some extent, particularly when multiple components are run together. Nevertheless, it’s crucial to recognize that dbt tests have their limitations and may not cover all testing use cases. For comprehensive testing in data projects, you may need to employ other testing methods and tools tailored to specific validation and verification needs.
With this in mind, let’s focus on which tests can be employed with dbt. There are two main classifications of tests in dbt: singular and generic. Let’s get to know a bit more about both types, their purpose, and how we can leverage them.
Generic tests
The simplest yet highly scalable tests in dbt are generic tests. With these tests, you usually don’t need to write any new logic, yet custom generic tests are also an option. Nevertheless, you typically write a couple of YAML lines of code and then test a particular model or column, depending on the test. dbt comes with four built-in generic tests:
uniquetest-
Verifies that every value in a specific column is unique
not_nulltest-
Verifies that every value in a specific column is not null
accepted_valuestest-
Ensures that every value in a specific column exists in a given predefined list
relationshipstest-
Ensures that every value in a specific column exists in a column in another model, and so we grant referential integrity
Now that we have some context about the generic tests, let’s try them. We can choose the model we want, but to simplify, let’s pick one to which we can apply all the tests. For that, we’ve chosen the stg_jaffle_shop_orders.sql model. Here we will be able to test unique and not_null in fields like customer_id and order_id. We can use accepted_values to check whether all orders status are in a predefined list. Finally, we will use the relationships test to check whether all values from the customer_id are in the stg_jaffle_shop_customers.sql model. Let’s start by replacing our _jaffle_shop_models.yml with the code in Example 4-24.
Example 4-24. _jaffle_shop_models.yml parametrizations with generic tests
version:2models:-name:stg_jaffle_shop_customersconfig:materialized:viewcolumns:-name:customer_idtests:-unique-not_null-name:stg_jaffle_shop_ordersconfig:materialized:viewcolumns:-name:order_idtests:-unique-not_null-name:statustests:-accepted_values:values:-completed-shipped-returned-placed-name:customer_idtests:-relationships:to:ref('stg_jaffle_shop_customers')field:customer_id
Now, in your command line, type dbt test and take a look at the logs. If the test failed in the accepted_values, you did everything right. It was supposed to fail. Let’s debug to understand the potential root cause of the failure. Open the logs and expand the test that failed. Then click Details. You’ll see the query executed to test the data, as Figure 4-41 shows.

Figure 4-41. Generic test, dbt logs with accepted_values failed test
Let’s copy this query to your text editor—keep only the inner query and then execute it. You should have a similar output as in Figure 4-42.

Figure 4-42. Generic test debug
And voilá. We found the issue. The additional status return_pending is missing from our test list. Let’s add it and rerun our dbt test command. All the tests should pass now, as shown in Figure 4-43.

Figure 4-43. Generic test with all tests being successfully executed
Note
In addition to the generic tests within dbt Core, a lot more are in the dbt ecosystem. These tests are found in dbt packages because they are an extension of the generic tests built inside dbt. “dbt Packages” will detail the concept of packages and how to install them, but for extended testing capabilities, packages such as dbt_utils from the dbt team, or dbt_expectations from the Python library Great Expectations, are clear examples of the excellent usage of packages and a must-have in any dbt project. Finally, custom generic tests are another dbt feature that enables you to define your own data validation rules and checks, tailored to your specific project requirements.
Singular tests
Unlike the generic tests, singular tests are defined in .sql files under the tests directory. Typically, these tests are helpful when you want to test a specific attribute inside a particular model, but the traditional tests built inside dbt don’t fit your needs.
Looking into our data model, a good test is to check that no order has a negative total amount. We could perform this test in one of the three layers—staging, intermediate, or marts. We’ve chosen the intermediate layer since we did some transformations that could influence the data. To start, create a file named assert_total_payment_amount_is_positive.sql in the tests directory and copy the code in Example 4-25.
Example 4-25. assert_total_payment_amount_is_positive.sql singular test to check if the total_amount attribute inside int_payment_type_amount_per_order has only non-negative values
selectorder_id,sum(total_amount)astotal_amountfrom{{ref('int_payment_type_amount_per_order')}}groupby1havingtotal_amount<0
Now you can execute one of the following commands to run your test, which should pass:
dbt test-
Executes all your tests
dbt test --select test_type:singular-
Executes only singular tests
dbt test --select int_payment_type_amount_per_order-
Executes all tests for the
int_payment_type_amount_per_ordermodel dbt test --select assert_total_payment_amount_is_positive-
Executes only the specific test we created
These commands offer the ability to selectively run tests according to your requirements. Whether you need to run all tests, tests of a specific type, tests for a particular model, or even a single specific test, dbt allows you to leverage various selection syntax options within your commands. This variety of choices ensures that you can precisely target the tests, along with other dbt resources, that you wish to execute. In “dbt Commands and Selection Syntax”, we’ll provide a comprehensive overview of the available dbt commands and investigate how to efficiently use selection syntax to specify resources.
Testing sources
To test your models in your dbt project, you can also extend those tests to your sources. You already did this with the source freshness test in “Source freshness”. Still, you can also potentiate generic and singular tests for that purpose. Using the test capabilities in your sources will give us confidence that the raw data is built to fit our expectations.
In the same way that you configure tests in your models, you can also do so for your sources. Either in YAML files for generic tests, or .sql files for singular tests, the norm remains the same. Let’s take a look at one example for each type of test.
Starting with generic tests, you will need to edit the specific YAML file of the sources. Let’s keep the same unique, not_null, and accepted_values tests as we have for the customers and orders staging tables, but now you will test their sources. So, to make this happen, replace the _jaffle_shop_sources.yml code with the code from Example 4-26.
Example 4-26. _jaffle_shop_sources.yml—parametrizations with generic tests
version:2sources:-name:jaffle_shopdatabase:dbt-tutorialschema:jaffle_shoptables:-name:customerscolumns:-name:idtests:-unique-not_null-name:ordersloaded_at_field:_etl_loaded_atfreshness:warn_after:{count:17,period:hour}error_after:{count:24,period:hour}columns:-name:idtests:-unique-not_null-name:statustests:-accepted_values:values:-completed-shipped-returned-placed-return_pending
Once you have your new code in the YAML file, you can run dbt test or, to be more exact, execute the command that will test only the source for which we’ve created these tests, dbt test --select source:jaffle_shop. All your tests should pass.
Finally, you can also implement singular tests as you did before. Let’s replicate the singular test we performed earlier in Example 4-25. Create a new file named assert_source_total_payment_amount_is_positive.sql in your tests directory and copy the code from Example 4-27. This test checks whether the sum of the amount attribute, per order, inside the payment source table has only nonnegative values.
Example 4-27. assert_source_total_payment_amount_is_positive.sql singular test
selectorderidasorder_id,sum(amount)astotal_amountfrom{{source('stripe','payment')}}groupby1havingtotal_amount<0
Execute dbt test or dbt test --select source:stripe, since we look into the Stripe source in this case. Everything should pass as well.
Analyses
The analyses folder can store your ad hoc queries, audit queries, training queries, or refactoring queries, used, for example, to check how your code will look before affecting your models.
Analyses are templated SQL files that you can’t execute during dbt run, but since you can use Jinja on your analyses, you can still use dbt compile to see how your code will look while preserving your code under version control. Considering its purpose, let’s look into one use case where we can leverage the analyses folder.
Imagine that you don’t want to build a whole new model but still want to keep a piece of information for future needs by leveraging the code versioning. With analyses, you can do just that. For our use case, let’s analyze the top 10 most valuable customers in terms of the total amount paid, considering only orders “completed” status. To see this, inside the analyses directory, create a new file named most_valuable_customers.sql and copy the code from Example 4-28.
Example 4-28. most_valuable_customers.sql analyses, which output the top 10 most valuable customers based on completed orders
withfct_ordersas(select*from{{ref('fct_orders')}}),dim_customersas(select*from{{ref('dim_customers')}})selectcust.customer_id,cust.first_name,SUM(total_amount)asglobal_paid_amountfromfct_ordersasordleftjoindim_customersascustONord.customer_id=cust.customer_idwhereord.is_order_completed=1groupbycust.customer_id,first_nameorderby3desclimit10
Now execute the code and check the results. It will give you the top 10 most valuable customers if everything goes well, as Figure 4-44 shows.

Figure 4-44. Top 10 most valuable customers, based on the total global amount paid with completed orders
Seeds
Seeds are CSV files within your dbt platform with a small amount of nonvolatile data to be materialized as a table inside your data platform. By simply typing dbt seed in your command line, seeds can be used in your models in the standard way, like all the other models, using the ref() function.
We can find multiple applications for seeds, from mapping country codes (for example, PT to Portugal or US to United States), zip codes to states, dummy email addresses to be excluded from our analyses, or even other complex analyses, like price range classification. What’s important is to remember that seeds shouldn’t have large or frequently changing data. If that is the case, rethink your data capture approach—for example, using an SFTP (SSH File Transfer Protocol) or an API.
To better understand how to use seeds, let’s follow the next use case. Taking into account what we did in “Analyses”, we want to not only see the top 10 most valuable customers, based on paid orders completed, but also classify all customers with orders as regular, bronze, silver, or gold, considering the total_amount paid. As a start, let’s create our seed. For that, create a new file named customer_range_per_paid_amount.csv in your seeds folder and copy the Example 4-29 data.
Example 4-29. seed_customer_range_per_paid_amount.csv with ranges mapping
min_range,max_range,classification 0,9.999,Regular 10,29.999,Bronze 30,49.999,Silver 50,9999999,Gold
After you complete this, execute dbt seed. It will materialize your CSV file into a table in your data platform. Finally, in the analyses directory, let’s make a new file named customer_range_based_on_total_paid_amount.sql and copy the code from Example 4-30.
Example 4-30. customer_range_based_on_total_paid_amount.sql shows you, based on the completed orders and the total amount paid, the customer classification range
withfct_ordersas(select*from{{ref('fct_orders')}}),dim_customersas(select*from{{ref('dim_customers')}}),total_amount_per_customer_on_orders_completeas(selectcust.customer_id,cust.first_name,SUM(total_amount)asglobal_paid_amountfromfct_ordersasordleftjoindim_customersascustONord.customer_id=cust.customer_idwhereord.is_order_completed=1groupbycust.customer_id,first_name),customer_range_per_paid_amountas(select*from{{ref('seed_customer_range_per_paid_amount')}})selecttac.customer_id,tac.first_name,tac.global_paid_amount,crp.classificationfromtotal_amount_per_customer_on_orders_completeastacleftjoincustomer_range_per_paid_amountascrpontac.global_paid_amount>=crp.min_rangeandtac.global_paid_amount<=crp.max_range
Let’s now execute our code and see the results. It will give each customer the total amount paid and its corresponding range (Figure 4-45).

Figure 4-45. Customers’ range, based on the total global amount paid with completed orders
Documentation
Documentation is critical in the global software engineering landscape, yet it seems like a taboo. Some teams do it, others don’t, or it is incomplete. It can become too bureaucratic or complex, or be seen as an overhead to the developer’s to-do list, and thus avoided at all costs. You might hear a giant list of reasons to justify not creating documentation or postponing it to a less demanding time. No one says documentation is nonessential. It’s just that “we won’t do it,” “not now,” or “we don’t have time.”
Here are several reasons to justify creating and using documentation:
-
Facilitates the onboarding, handover, and hiring processes. With proper documentation, any new team member will have the safeguard that they are not being “thrown to the wolves.” The new colleague will have the onboarding process and technical documentation in writing, which reduces their learning curve on the current team processes, concepts, standards, and technological developments. The same applies to employee turnover and the knowledge-sharing transition.
-
It will empower a single source of the truth. From business definitions, processes, and how-to articles, to letting users answer self-service questions, having documentation will save your team time and energy trying to reach that information.
-
Sharing knowledge through documentation will mitigate duplicate or redundant work. If the documentation was done already, it could be reused without the need to start from scratch.
-
It promotes a sense of shared responsibility, ensuring that critical knowledge is not confined to a single individual. This shared ownership is crucial in preventing disruptions when key team members are unavailable.
-
It is essential when you want to establish quality, process control, and meet compliance regulations. Having documentation will enable your team to work toward cohesion and alignment across the company.
One reason that justifies the lack of motivation to create documentation is that it is a parallel stream from the actual development flow, like using one tool for development and another for the documentation. With dbt, this is different. You build your project documentation while developing your analytics code, tests, and connecting to sources, among other tasks. Everything is inside dbt, not in a separate interface.
The way dbt handles documentation enables you to create it while building your code. Typically, a good part of the documentation is already dynamically generated, such as the lineage graphs we’ve introduced before, requiring only that you configure your ref() and source() functions appropriately. The other part is partially automated, needing you to give your manual inputs of what a particular model or column represents. Yet, once again, everything is done inside dbt, directly in the YAML or Markdown files.
Let’s get started with our documentation. The use case we want to achieve is to document our models and respective columns of fct_orders and dim_customers. We will use the models’ YAML files, and for richer documentation, we will use doc blocks inside the Markdown files. Since we still need to create a YAML file for the core models inside the marts directory, let’s do so with the name _core_models.yml.
Copy Example 4-31. Then, create a Markdown file in the same directory folder named _code_docs.md, copying Example 4-32.
Example 4-31. _core_models.yml—YAML file with description parameter
version:2models:-name:fct_ordersdescription:Analytical orders data.columns:-name:order_iddescription:Primary key of the orders.-name:customer_iddescription:Foreign key of customers_id at dim_customers.-name:order_datedescription:Date that order was placed by the customer.-name:cash_amountdescription:Total amount paid in cash by the customer with "success" paymentstatus.-name:credit_amountdescription:Total amount paid in credit by the customer with "success"payment status.-name:total_amountdescription:Total amount paid by the customer with "success" payment status.-name:is_order_completeddescription:"{{doc('is_order_completed_docblock')}}"-name:dim_customersdescription:Customer data. It allows you to analyze customers perspective linkedfacts.columns:-name:customer_iddescription:Primary key of the customers.-name:first_namedescription:Customer first name.-name:last_namedescription:Customer last name.
Example 4-32. _core_doc.md—markdown file with a doc block
{% docs is_order_completed_docblock %}Before generating the documentation, let’s try to understand what we did. By analyzing the YAML file _core_models.yml, you can see we’ve added a new property: description. This basic property allows you to complement the documentation with your manual inputs. These manual inputs can be text, as we used in most cases, but can also reference doc blocks inside Markdown files, as done in fct_orders, column is_order_completed. We first created the doc block inside the Markdown file _code_docs.md and named it is_order_completed_docblock. This name is the one that we’ve used to reference the doc block inside the description field: "{{ doc('is_order_completed_docblock') }}".
Let’s generate our documentation by typing dbt docs generate in your command line. After it finishes successfully, you can navigate through the documentation page.
Reaching the documentation page is simple. After you execute dbt docs generate successfully, inside the IDE, at the top left of the screen, you can click the Documentation site book icon right next to the Git branch information (Figure 4-46).

Figure 4-46. View documentation
Once you enter the documentation page, you will see the overview page, similar to Figure 4-47. For now, you have the default information provided by dbt, but this page is also fully customizable.

Figure 4-47. Documentation landing page
Looking on the overview page, you can see your project structure to the left (Figure 4-48) with tests, seeds, and models, among others, that you can navigate freely.

Figure 4-48. dbt project structure inside the documentation
Now choose one of our developed models and look at its respective documentation. We’ve selected the fct_orders model. Once we click its file, the screen will show you several layers of information on the model, as shown in Figure 4-49.

Figure 4-49. fct_orders documentation page
At the top, the Details section gives you information about table metadata, such as the table type (also known as materialization). The language used, the number of rows, and the approximate table size are other available details.
Right after, we have the Description of the model. As you may recall, it was the one we configured in the _core_models.yml file for the fct_orders table.
Finally, we have the Columns information related to fct_orders. This documentation is partially automated (for example, the column type), but also receives manual inputs (such as the column descriptions). We gave those inputs already filling the description properties and provided comprehensive information using doc blocks for the is_order_completed attribute. To see the written doc block on the documentation page, click in the is_order_completed field, which should expand and present the desired information (Figure 4-50).

Figure 4-50. is_order_completed column showing the configured doc block
After the Columns information, we have the downstream and upstream dependencies of the model, with the Referenced By and Depends On sections, respectively. These dependencies are also shown in Figure 4-51.

Figure 4-51. fct_orders dependencies in the documentation
At the bottom of the fct_orders documentation page is the Code that generated the specific model. You can visualize the source code in a raw format, with Jinja, or the compiled code. Figure 4-52 shows its raw form.
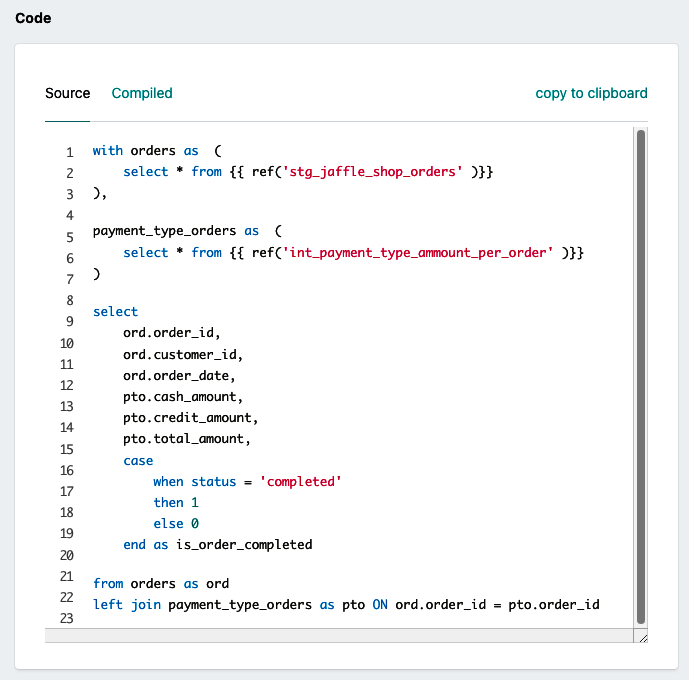
Figure 4-52. fct_orders source code
Finally, if you look at the bottom right of your documentation page, you’ll see a blue button. Clicking this button accesses the lineage graph for the respective model you are visualizing. We have selected the fct_orders lineage graph,
where you can see the upstream dependencies, such as the source tables or the intermediate tables, as well as the downstream dependencies, like the analysis files shown in Figure 4-53. The lineage graph is powerful since it provides a holistic view of how data moves from the moment you consume it until you transform and serve it.
Another interesting aspect of dbt documentation worth mentioning is the ability to persist column- and table-level descriptions directly to the database by using the persist_docs configuration. This feature is valuable for all users of your data
warehouse, including those who may not have access to dbt Cloud. It ensures that essential metadata and descriptions are readily available to data consumers, facilitating better understanding and utilization of your data assets.

Figure 4-53. fct_orders lineage graph
dbt Commands and Selection Syntax
We’ve already introduced several dbt commands, such as dbt run and dbt test, and how we interact with the CLI to execute them. In this section, we’ll explore the essential dbt commands and selection syntax that allow you to execute, manage, and control various aspects of your dbt project. Whether running transformations, executing tests, or generating documentation, these commands are your toolkit for effective project management.
Let’s start at the beginning. At its core, dbt is a command-line tool designed to streamline your data transformation workflows. It provides a set of commands that enable you to interact with your dbt project efficiently. Let’s explore each of these commands in more detail.
dbt run
The dbt run command is your go-to tool for executing data transformations defined in your dbt models. It works with your project’s configuration files, such as dbt_project.yml, to understand which models to run and in what order. This command will identify the models that must be executed based on their dependencies and run them in the appropriate order.
dbt docs
Adequate documentation is essential for collaborative data projects. dbt docs automates the documentation generation for your dbt project, including model descriptions, column descriptions, and relationships between models. To generate the documentation, you need to execute dbt docs generate.
dbt build
Before running your dbt project, compiling it is often necessary. The dbt build command performs this task, creating the required artifacts for execution. This step is essential for optimizing the execution process and ensuring everything is in its proper place. Once your project compiles successfully, you can proceed with other commands like dbt run with more confidence.
Other commands
Although the preceding commands may be the most used, you should be aware of other dbt commands, such as these:
dbt seed-
Loads raw data or reference data into your project
dbt clean-
Deletes artifacts generated by
dbt build dbt snapshot-
Takes a snapshot of your data for versioning
dbt archive-
Archives tables or models to cold storage
dbt deps-
Installs project dependencies defined in packages.yml
dbt run-operation-
Runs a custom operation defined in your project
dbt source snapshot-freshness-
Checks the freshness of your source data
dbt ls-
Lists resources defined in a dbt project
dbt retry-
Re-runs the last run dbt command from the point of failure
dbt debug-
Runs dbt in debug mode, providing detailed debugging information
dbt parse-
Parses dbt models without running them, which is helpful for syntax checking
dbt clone-
Clones selected models from the specified state
dbt init-
Creates a new dbt project in the current directory
Selection syntax
As your dbt projects grow, you’ll need to target specific models, tests, or other resources for execution, testing, or documentation generation instead of running them all every time. This is where selection syntax comes into play.
Selection syntax allows you to precisely specify which resources to include or exclude when running dbt commands. Selection syntax includes various elements and techniques, such as the following.
Wildcard *
The asterisk (*) represents any character or sequence of characters. Let’s have a look at Example 4-33.
Example 4-33. Selection syntax with * wildcard
dbtrun--selectmodels/marts/core/*
Here, we’re using the * wildcard along with the --select flag to target all resources or models within the core directory. This command will execute all models, tests, or other resources located within that directory.
Tags
Tags are labels you can assign to models, macros, or other resources in your dbt project—in particular, inside the YAML files. You can use selection syntax to target resources with specific tags. For instance, Example 4-34 shows how to select resources based on the marketing tag.
Example 4-34. Selection syntax with a tag
dbtrun--selecttag:marketing
Model name
You can precisely select a single model by using its name in the selection syntax, as shown in Example 4-35.
Example 4-35. Selection syntax with a model
dbtrun--selectfct_orders
Dependencies
Use the + and - symbols to select models that depend on or are depended upon by others. For example, fct_orders+ selects models that depend on fct_orders, while +fct_orders selects models that fct_orders depends on (Example 4-36).
Example 4-36. Selection syntax with dependencies
# run fct_orders upstream dependencies dbt run --select +fct_orders # run fct_orders downstream dependencies dbt run --select fct_orders+ # run fct_orders both up and downstream dependencies dbt run --select +fct_orders+
Packages
If you organize your dbt project into packages, you can use package syntax to select all resources within a specific package, as shown in Example 4-37.
Example 4-37. Selection syntax with a package
dbtrun--selectmy_package.some_model
Multiple selections
You can combine elements of selection syntax to create complex selections, as shown in Example 4-38.
Example 4-38. Selection syntax with multiple elements
dbtrun--selecttag:marketingfct_orders
In this example, we combined elements such as tagging and model selection. It will run the dbt model named fct_orders only if it has the tag marketing.
Selection syntax allows you to control which dbt resources run based on various criteria, including model names, tags, and dependencies. You can use selection syntax with the --select flag to tailor your dbt operations to specific subsets of your project.
Additionally, dbt offers several other selection-related flags and options, such as --selector, --exclude, --defer, and more, which provide even more fine-grained control over how you interact with your dbt project. These options make it easier to manage and execute dbt models and resources in a way that aligns with your project’s requirements and workflows.
Jobs and Deployment
Until now, we’ve been covering how to develop using dbt. We’ve learned about models and how to implement tests and write documentation, among other relevant components that dbt provides. We accomplished and tested all of this by utilizing our development environment and manually executing our dbt commands.
Using a development environment shouldn’t be minimized. It allows you to continue building your dbt project without affecting the deployment/production environment until you are ready. But now we have reached the stage where we need to productionize and automate our code. For that, we need to deploy our analytics code into a production branch, typically named the main branch, and into a dedicated production schema, such as dbt_analytics_engineering.core in BigQuery, or the equivalent production target in your data platform.
Finally, we need to configure and schedule a job to automate what we want to roll into production. Configuring a job is an essential part of the CI/CD process. It allows you to automate the execution of your commands in a cadence that fits your business needs.
To begin, let’s commit and sync everything we did until now into our development branch and then merge with the main branch. Click the “Commit and sync” button (Figure 4-54). Don’t forget to write a comprehensive message.

Figure 4-54. “Commit and sync” button
You may need to make a pull request. As explained briefly in “Setting Up dbt Cloud with BigQuery and GitHub”, pull requests (PRs) play an essential role in collaborative development. They serve as a fundamental mechanism for communicating your proposed changes to your team. However, it’s crucial to understand that PRs are not just about notifying your colleagues of your work; they are a critical step in the review and integration process.
When you create a PR, you are essentially inviting your team to review your code, provide feedback, and collectively decide whether these changes align with the project’s goals and quality standards.
Getting back to our code, after your PR, merge it with your main branch in GitHub. Your final screen in GitHub should be similar to Figure 4-55.

Figure 4-55. Pull request screen after merging with the main branch
At this stage, your main branch should equal your development branch. Now it is time to deploy it into your data platform. Before creating a job, you need to set up your deployment environment:
-
From the Deploy menu, click the Environments option and then click the Create Environment button. A screen will pop up where you can configure your deployment environment.
-
Keep the latest dbt Version, and don’t check the option to run on a custom branch since we’ve merged our code into the main branch.
-
Name the environment “Deployment.”
-
In the Deployment Credentials section, write the dataset that will link your deployment/production environment. We’ve named it
dbt_analytics_engineer_prod, but you can use the name that best suits your needs.
If everything goes well, you should have a deployment environment set up with configurations similar to those in Figure 4-56.

Figure 4-56. Deployment environment settings
Now it is time to configure your job. Inside the dbt Cloud UI, click the Jobs option in your Deploy menu and then click the Create New Job button. Creating a job can range from simple concepts to more complex ones. Let’s set up a job that will cover the main ideas that we’ve discussed:
-
Name the job (Figure 4-57).
Figure 4-57. Defining the job name
-
In the Environment section, we will point to the Deployment environment. Configure the dbt version to inherit from the version defined in the Deployment environment. Then leave the Target Name set as default. This is helpful if you would like to define conditions based on your work environment (for example: if in the deployment environment, do this; if in development, do that). Finally, we covered the Threads in “profiles.yml”. Let’s keep it set to the default configuration. We didn’t create any Environment Variables, so this section will be left empty. Figure 4-58 presents the overall Environment section configuration.

Figure 4-58. Defining the job environment
-
Figure 4-59 shows the global configurations of the Execution Settings. We’ve set Run Timeout to 0, so dbt will never kill the job if it runs for more than a certain amount of time. Then we’ve also chosen “do not defer to another run.” Finally, we’ve selected the “Generate docs on run” and “Run source freshness” boxes. This configuration will reduce the number of commands you need to write in the Commands section. For this use case, we kept the default
dbt buildonly.

Figure 4-59. Defining job settings
-
The last configuration setting is Triggers, in which you configure how to launch the job. There are three options to trigger a job:
-
A configured schedule inside dbt
-
Through Webhooks
-
Through an API call
-
For this use case, we’ve chosen the Schedule option and set the schedule to run on an hourly basis, as shown in Figure 4-60.

Figure 4-60. Defining the job trigger
It’s time to execute and see what happens. Save your job; then select Run Now or wait for the job to be automatically triggered after it hits the configured schedule.
While the job runs, or after it finishes, you can always inspect the status and what was executed. From the Deploy menu, select the Run History option. You will see your job executions. Select one and take a look at the Run Overview. Figure 4-61 is what you should expect to see.
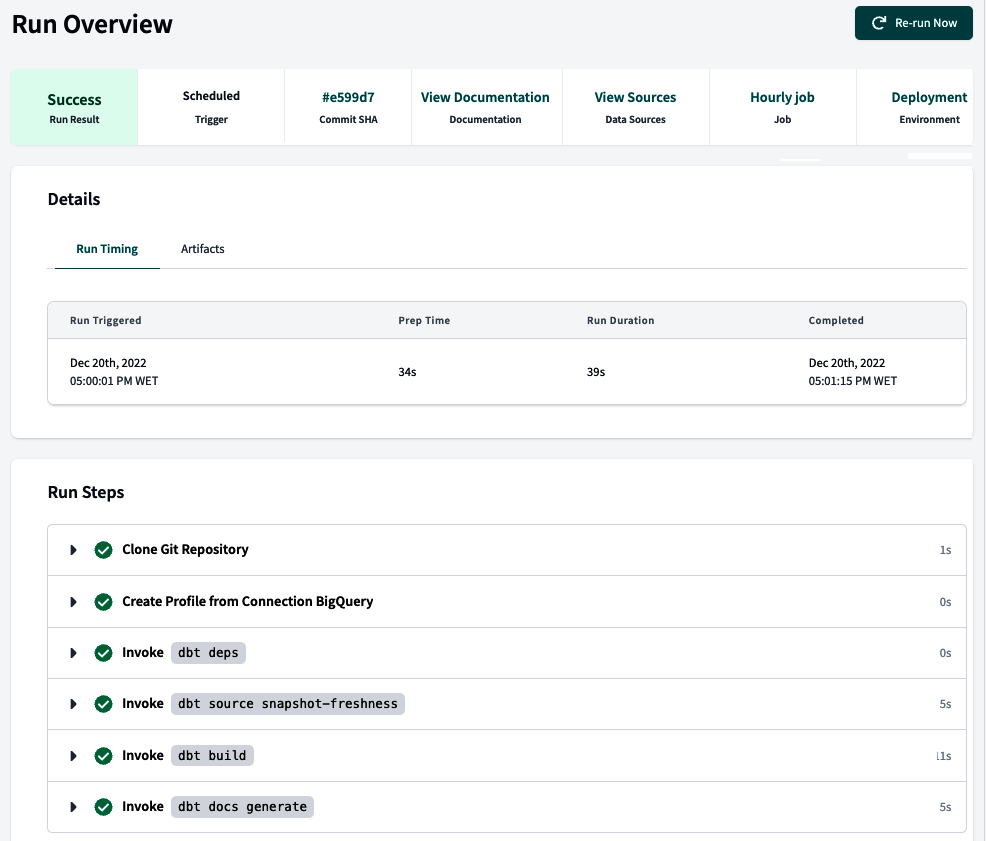
Figure 4-61. The job’s Run Overview screen
Once inside the Run Overview, you have relevant information about the specific job execution, which could be helpful with potential troubleshooting issues. At the top is a summary of the job execution status, the person or system who triggered the job, the Git commit indexed to this job execution, the generated documentation, sources, and the environment where this job ran.
Right after the job summary, you can find the execution details, such as the time it took to execute the job and when it started and finished. Finally, one of the essential pieces of information that the Run Overview gives you is the Run Steps, which detail all the commands executed during the job execution and allow you to inspect each isolated step and its logs, as shown in Figure 4-62. Exploring each step’s logs will enable you to understand what ran in each and look up issues during its execution.

Figure 4-62. The job’s Run Steps details
By using dbt jobs, you can easily automate your transformations and deploy your projects to production in an efficient and scalable way. Whether you are a data analyst, data engineer, or analytics engineer, dbt can help you address the complexity of your data transformations and ensure that your data models are always accurate and up-to-date.
Summary
This chapter demonstrates that analytics engineering is an ever-evolving field that is always influenced by innovations. dbt is not just one aspect of this story; it is a crucial tool in the field.
The primary objective of analytics engineering is to convert raw data into valuable insights, and this tool plays a crucial role in simplifying the complexities of data transformation and promoting cooperation among a wide range of stakeholders. dbt ensures that data transformation is not just a technical change but also places great emphasis on openness, inclusivity, and knowledge sharing.
dbt is renowned for its capacity to streamline complicated processes by effortlessly integrating with large data warehouses. It also promotes a collaborative approach to data transformation by ensuring optimal traceability and accuracy. Furthermore, it highlights the significance of thoroughly testing data processes to guarantee dependability. Its user-friendly interface reinforces the notion that analytics engineering is an inclusive field, welcoming contributions from individuals of all competency levels.
To conclude, we strongly encourage analytics engineers who want to stay at the forefront of the industry to take a deep dive into this transformational tool. As dbt is increasingly important and unequivocally beneficial, being proficient in this tool can not only improve your skill set but also facilitate smoother and more cooperative data transformations in the future.
Get Analytics Engineering with SQL and dbt now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

