Kapitel 4. Datenumwandlung mit dbt
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Der Hauptzweck von dbt ist es, dich dabei zu unterstützen, die Daten deiner Datenplattformen auf einfache und integrierte Weise zu transformieren, indem du einfach SQL-Anweisungen schreibst. Wenn wir dbt in einen ELT-Workflow einbinden, passt es zu den Aktivitäten während der Transformationsphase und bietet dir zusätzliche Komponenten wie Versionskontrolle, Dokumentation, Tests oder automatisierte Bereitstellung, die die Arbeit eines Datenspezialisten insgesamt vereinfachen. Erinnert dich das an die tatsächlichen Aktivitäten eines Analytikers? Das liegt daran, dass das dbt eines der modernen Tools ist, das die Arbeit von Analytikern definiert und ihnen die in die Plattform integrierten Instrumente an die Hand gibt, wodurch die Notwendigkeit, zusätzliche Dienste zur Beantwortung spezifischer Probleme einzurichten, reduziert und die Gesamtkomplexität des Systems verringert wird.
dbt unterstützt die beschriebenen Aufgaben eines Analytics Engineers und befähigt ihn, den Code in seiner Datenplattform kollaborativ auszuführen, um eine einzige Quelle der Wahrheit für Metriken und Geschäftsdefinitionen zu erhalten. Es fördert zentralen und modularen Analytics-Code, indem es DRY-Code mit der Templating-Sprache Jinja, Makros oder Paketen nutzt. Gleichzeitig bietet dbt die Sicherheit, die wir von den bewährten Methoden der Softwareentwicklung kennen, z. B. die Zusammenarbeit an Datenmodellen, die Versionierung und das Testen und Dokumentieren deiner Abfragen, bevor du sie sicher in die Produktion überführst, mit Überwachung und Transparenz.
Wir haben eine gründliche Einführung in dbt gegeben. In diesem Kapitel werden wir jedoch noch tiefer in die Besonderheiten von dbt eintauchen und seine Bedeutung in der Welt der Datenanalyse erläutern. Wir werden die Design-Philosophie von dbt, die Prinzipien dieses Transformationswerkzeugs und den Lebenszyklus von Daten mit dbt als Kernstück erörtern und zeigen, wie dbt Rohdaten in strukturierte Modelle umwandelt, die einfach zu nutzen sind. Wir werden die Projektstruktur von dbt erkunden, indem wir die verschiedenen Funktionen wie das Erstellen von Modellen, Dokumentation und Tests sowie andere dbt-Artefakte wie YAML-Dateien erläutern. Am Ende dieses Kapitels wirst du ein umfassendes Verständnis von dbt und seinen Möglichkeiten haben, so dass du es effektiv in deinem Datenanalyse-Workflow einsetzen kannst.
dbt Design Philosophie
Da die Arbeitsabläufe in der Datenverarbeitung und -analyse immer komplexer werden, sind Tools, die den Prozess rationalisieren und gleichzeitig die Datenqualität und -zuverlässigkeit aufrechterhalten, unverzichtbar. dbt hat sich als konzentrierte Lösung mit einer klar definierten Designphilosophie herauskristallisiert, die seinen Ansatz für die Datenmodellierung und das Analytics Engineering untermauert.
Zusammenfassend lässt sich sagen, dass die dbt-Designphilosophie auf den folgenden Punkten beruht:
- Code-zentrierter Ansatz
-
Der Kern der Designphilosophie von dbt ist ein codezentrierter Ansatz für die Datenmodellierung und -transformation. Anstatt sich auf GUI-basierte Schnittstellen oder manuelle SQL-Skripte zu verlassen, ermutigt dbt die Benutzer, Datentransformationen mithilfe von Code zu definieren. Dieser Wechsel zur codebasierten Entwicklung fördert die Zusammenarbeit, Versionskontrolle und Automatisierung.
- Modularität für Wiederverwendbarkeit
-
dbt fördert die Modularität und ermöglicht es Datenexperten, wiederverwendbaren Code Komponenten zu erstellen. Modelle, Makros und Tests können in Paketen organisiert werden, was die Wartung und Skalierbarkeit des Codes erleichtert. Dieser modulare Ansatz steht im Einklang mit bewährten Methoden und verbessert die Wiederverwendbarkeit von Code.
- Transformationen als SQL
SELECTAnweisungen -
dbt-Modelle sind als SQL
SELECT-Anweisungen definiert, sodass sie für Analysten und Ingenieure mit SQL-Kenntnissen zugänglich sind. Diese Entscheidung vereinfacht die Entwicklung und stellt sicher, dass die Datenmodellierung den bewährten Methoden von SQL entspricht. - Deklarative Sprache
-
dbt verwendet eine deklarative Sprache zur Definition von Datentransformationen. Analysten geben das gewünschte Ergebnis an, und dbt kümmert sich um die zugrunde liegende Implementierung. Diese Abstraktion reduziert die Komplexität beim Schreiben von komplexem SQL-Code und verbessert die Lesbarkeit.
- Inkrementelle Builds
-
Effizienz ist ein wichtiger Schwerpunkt des dbt-Designs. Es unterstützt inkrementelle Builds, so dass Dateningenieure nur die betroffenen Teile der Datenpipeline aktualisieren können, anstatt den gesamten Datensatz neu zu verarbeiten. Das beschleunigt die Entwicklung und verkürzt die Bearbeitungszeit.
- Dokumentation als Code
-
dbt setzt sich dafür ein, dass Datenmodelle und -transformationen als Code dokumentiert werden. Beschreibungen, Erklärungen und Metadaten werden zusammen mit dem Projektcode gespeichert und erleichtern den Teammitgliedern das Verständnis und die effektive Zusammenarbeit.
- Datenqualität, -prüfung und -validierung
-
dbt legt einen großen Schwerpunkt auf das Testen von Daten. Es bietet einen Testrahmen, mit dem Analysten Datenqualitätsprüfungen und Validierungsregeln definieren können. Dies umfasst die Zuverlässigkeit und Qualität der Daten in der gesamten Pipeline und stellt so sicher, dass die Daten die vordefinierten Kriterien erfüllen und die Geschäftsregeln einhalten.
- Integration der Versionskontrolle
-
Nahtlose Integration mit Versionskontrollsystemen wie Git ist ein grundlegender Aspekt des dbt. Diese Funktion ermöglicht die gemeinsame Entwicklung, die Nachverfolgung von Änderungen und die Möglichkeit, Änderungen rückgängig zu machen, um sicherzustellen, dass die Datenpipelines unter Versionskontrolle bleiben.
- Native Integration mit Datenplattformen
-
dbt wurde entwickelt, um nahtlos mit gängigen Datenplattformen wie Snowflake, BigQuery und Redshift zusammenzuarbeiten. Es nutzt die nativen Fähigkeiten dieser Plattformen für Skalierbarkeit und Leistung.
- Open Source und erweiterbar
-
dbt ist ein offenes Quellcode-Tool mit einer florierenden Community. Die Benutzer können die Funktionalität von dbt erweitern, indem sie eigene Makros und Pakete erstellen. Dank dieser Erweiterbarkeit können Unternehmen dbt an ihre spezifischen Datenanforderungen anpassen.
- Trennung von Umwandlung und Verladung
-
dbt trennt die Transformations- und Ladeschritte in der Datenpipeline. Die Daten werden in dbt transformiert und dann in die Datenplattform geladen.
Die Designphilosophie von dbt basiert auf der Schaffung einer kollaborativen, codezentrierten und modularen Umgebung für Data Engineers, Analysten und Data Scientists, um Daten effizient umzuwandeln, die Datenqualität zu gewährleisten und wertvolle Erkenntnisse zu gewinnen. dbt versetzt Unternehmen in die Lage, das volle Potenzial ihrer Daten zu nutzen, indem es die Komplexität der Datenmodellierung und des Analytics Engineering vereinfacht.
dbt Datenfluss
Abbildung 4-1 zeigt das Gesamtbild eines Datenflusses. Sie zeigt, wo das dbt und seine Funktionen in die gesamte Datenlandschaft von passen.

Abbildung 4-1. Typischer Datenfluss mit dbt, der dir dabei hilft, deine Daten u. a. aus BigQuery, Snowflake, Databricks und Redshift zu transformieren (siehe die dbt-Dokumentation für unterstützte Datenplattformen)
Wie bereits erwähnt, besteht der Hauptzweck von dbt darin, dir bei der Umwandlung der Daten deiner Datenplattformen zu helfen, und dafür bietet dbt zwei Werkzeuge:
-
dbt Wolke
-
dbt Core, ein Open-Source-CLI-Tool, das von dbt Labs gepflegt wird und das du in deinen verwalteten Umgebungen einrichten oder lokal ausführen kannst
Schauen wir uns ein Beispiel an, um zu sehen, wie dbt im wirklichen Leben funktioniert und was es leisten kann. Stell dir vor, wir arbeiten an einer Pipeline, die regelmäßig Daten von einer Datenplattform wie BigQuery extrahiert. Dann wandelt sie die Daten um, indem sie Tabellen kombiniert(Abbildung 4-2).
Wir werden die ersten beiden Tabellen zu einer einzigen Tabelle zusammenführen und dabei verschiedene Transformationstechniken anwenden, z. B. Datenbereinigung oder Konsolidierung. Diese Phase findet in dbt statt, also müssen wir ein dbt-Projekt erstellen, um diese Zusammenführung zu erreichen. Das werden wir schaffen, aber zuerst machen wir uns mit dbt Cloud vertraut und lernen, wie wir unsere Arbeitsumgebung einrichten.
Hinweis
In diesem Buch werden wir dbt Cloud verwenden, um unseren Code zu schreiben, da es der schnellste und zuverlässigste Weg ist, um mit dbt anzufangen, von der Entwicklung bis zum Schreiben von Tests, Scheduling, Deployments und der Untersuchung von Datenmodellen. Außerdem läuft dbt Cloud auf dbt Core. Während wir also mit dbt Cloud arbeiten, werden wir uns mit denselben Befehlen vertraut machen, die im CLI-Tool von dbt Core verwendet werden.

Abbildung 4-2. Anwendungsfall der Datenpipeline mit dbt
dbt Wolke
dbt Cloud ist eine Cloud-basierte Version von dbt, die eine breite Palette von Funktionen und Diensten bietet, um deinen Analytics-Code zu schreiben und zu produzieren. dbt Cloud ermöglicht es dir, deine dbt-Aufträge zu planen, ihren Fortschritt zu überwachen und Protokolle und Metriken in Echtzeit einzusehen. dbt Cloud bietet auch erweiterte Funktionen für die Zusammenarbeit, einschließlich Versionskontrolle, Tests und Dokumentation. Außerdem lässt sich dbt Cloud mit verschiedenen Cloud Data Warehouses wie Snowflake, BigQuery und Redshift integrieren, so dass du deine Daten ganz einfach transformieren kannst.
Du kannst dbt Core mit den meisten der genannten Funktionen nutzen, aber es muss auf deiner Infrastruktur konfiguriert und eingerichtet werden, ähnlich wie beim Betrieb eines eigenen Servers oder einer Amazon Elastic Compute Cloud (EC2) Instanz für Tools wie Airflow. Das bedeutet, dass du es eigenständig warten und verwalten musst, ähnlich wie eine virtuelle Maschine (VM) auf EC2.
Im Gegensatz dazu funktioniert die dbt Cloud wie ein verwalteter Service, ähnlich wie Amazon Managed Workflows for Apache Airflow (MWAA). Sie bietet Komfort und Benutzerfreundlichkeit, da viele betriebliche Aspekte für dich erledigt werden, sodass du dich mehr auf deine Analyseaufgaben und weniger auf die Verwaltung der Infrastruktur konzentrieren kannst.
Einrichten der dbt Cloud mit BigQuery und GitHub
Es gibt nichts Besseres, als eine bestimmte Technologie in der Praxis zu erlernen. Richten wir also die Umgebung ein, in der wir unser Wissen anwenden werden. Zu Beginn müssen wir uns für ein dbt-Konto registrieren.
Nach der Registrierung landen wir auf der Seite "Vollständige Projekteinrichtung"(Abbildung 4-3).

Abbildung 4-3. dbt Landing Page zur Fertigstellung der Projekteinrichtung
Diese Seite hat mehrere Abschnitte, um unser dbt-Projekt richtig zu konfigurieren, einschließlich der Verbindungen zu unserer gewünschten Datenplattform und zu unserem Code-Repository. Wir werden BigQuery als Datenplattform und GitHub zur Speicherung unseres Codes verwenden.
Der erste Schritt in BigQuery besteht darin, ein neues Projekt zu erstellen. In GCP suchst du in der Suchleiste nach Projekt erstellen und klickst darauf(Abbildung 4-4).
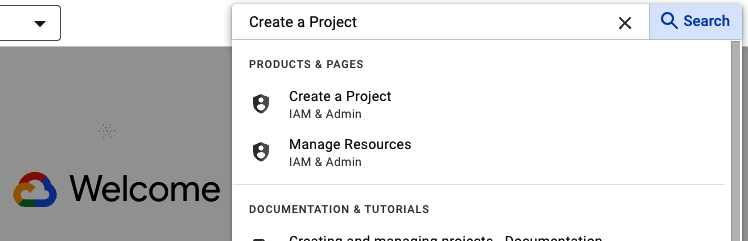
Abbildung 4-4. BigQuery-Projekt einrichten, Schritt 1
Es wird ein Bildschirm ähnlich wie in Abbildung 4-5 angezeigt, auf dem du das Projekt einrichten kannst. Wir haben es dbt-analytics-engineer genannt.
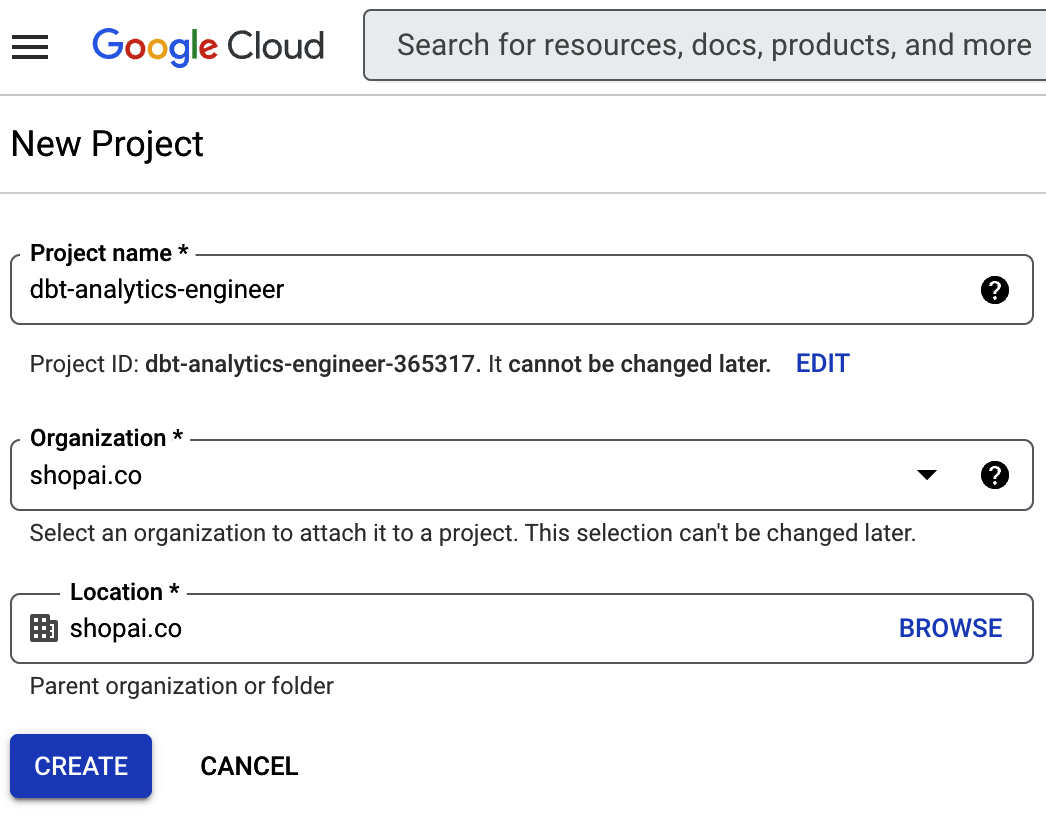
Abbildung 4-5. BigQuery-Projekt einrichten, Schritt 2
Nach der Konfiguration gehst du in deine BigQuery-IDE - du kannst wieder die Suchleiste verwenden. Sie sollte ähnlich aussehen wie in Abbildung 4-6.
Abbildung 4-6. BigQuery IDE
Teste abschließend das dbt public dataset, um sicherzustellen, dass BigQuery richtig funktioniert. Kopiere dazu den Code in Beispiel 4-1 in BigQuery und klicke dann auf Ausführen.
Beispiel 4-1. dbt public datasets in BigQuery
select*from`dbt-tutorial.jaffle_shop.customers`;select*from`dbt-tutorial.jaffle_shop.orders`;select*from`dbt-tutorial.stripe.payment`;
Wenn du die Seite in Abbildung 4-7 siehst, hast du es geschafft!
Hinweis
Da wir drei Abfragen gleichzeitig ausgeführt haben, sehen wir die Ausgabeergebnisse nicht. Klicke deshalb auf Ergebnisse anzeigen, um die Abfrageergebnisse einzeln einzusehen.
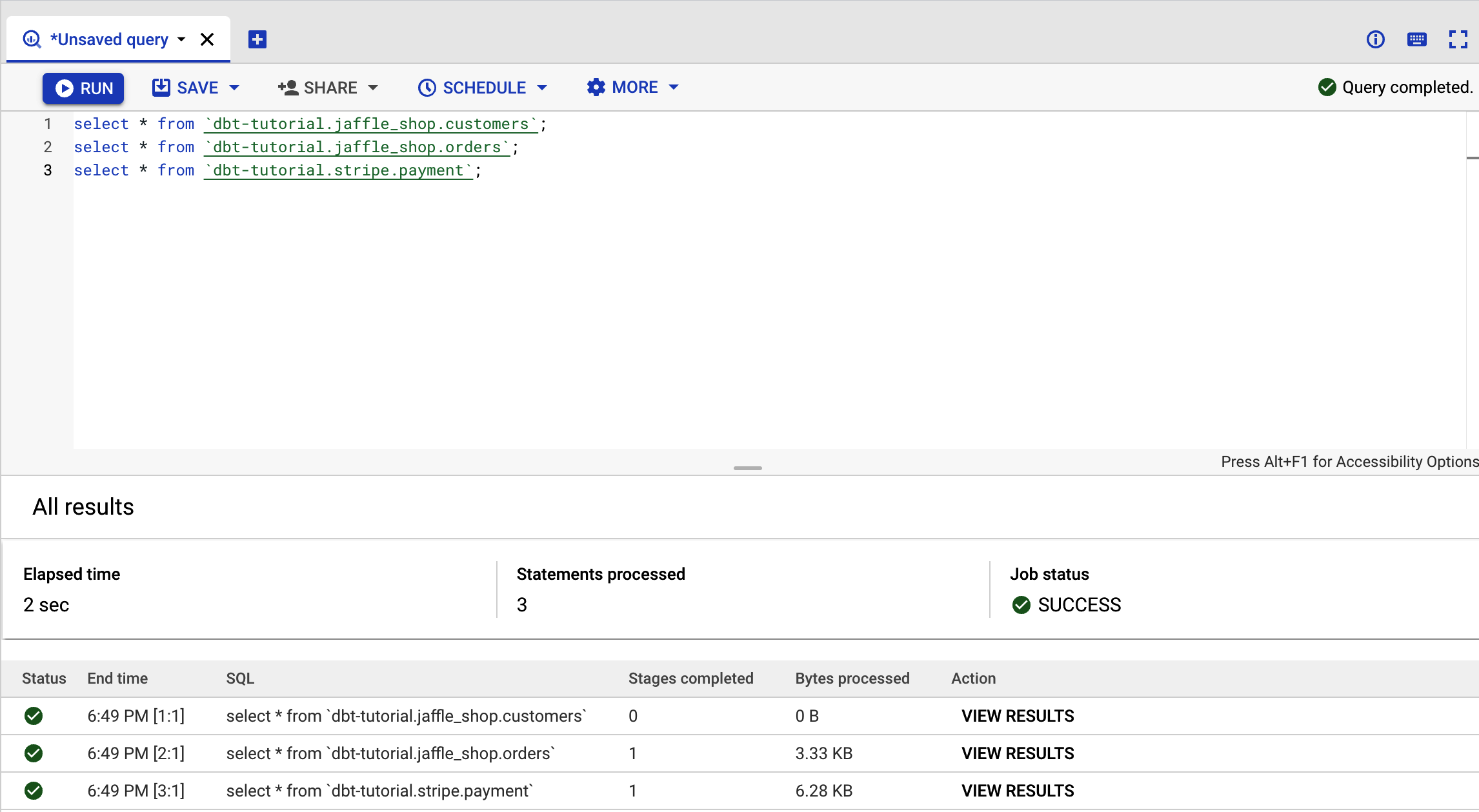
Abbildung 4-7. BigQuery-Datensatz-Ausgabe
Jetzt können wir dbt mit BigQuery verbinden und diese Abfragen in der dbt-IDE ausführen. Damit sich dbt mit deiner Datenplattform verbinden kann, musst du eine Schlüsseldatei erstellen, ähnlich wie bei den meisten anderen Datenplattformen mit einem Datenbank-Benutzernamen und einem Passwort.
Gehe zur BigQuery-Konsole. Bevor du mit den nächsten Schritten fortfährst, stelle sicher, dass du das neue Projekt in der Kopfzeile auswählst. Wenn du weder dein Konto noch dein Projekt siehst, klicke auf dein Profilbild auf der rechten Seite und überprüfe, ob du das richtige E-Mail-Konto verwendest:
-
Gehe zu IAM & Admin und wähle Servicekonten.
-
Klicke auf Servicekonto erstellen.
-
Gib in das Namensfeld ein
dbt-userein und klicke dann auf Erstellen und Weiter. -
Wähle bei "Diesem Dienstkonto Zugriff auf das Projekt gewähren" BigQuery Admin im Rollenfeld aus. Klicke auf Weiter.
-
Lass die Felder im Abschnitt "Benutzern Zugriff auf dieses Dienstkonto gewähren" leer und klicke auf "Fertig".
Der Bildschirm sollte wie in Abbildung 4-8 aussehen.

Abbildung 4-8. BigQuery Service Konten Bildschirm
Fahre nun mit den restlichen Schritten fort:
-
Klicke auf das Dienstkonto, das du gerade erstellt hast.
-
Tasten auswählen.
-
Klicke auf Schlüssel hinzufügen und wähle dann "Neuen Schlüssel erstellen".
-
Wähle JSON als Schlüsseltyp und klicke dann auf Erstellen.
-
Du solltest eine Eingabeaufforderung erhalten, die JSON-Datei herunterzuladen. Speichere sie lokal an einem leicht zu merkenden Ort mit einem eindeutigen Dateinamen, zum Beispiel dbt-analytics-engineer-keys.json.
Jetzt begeben wir uns für die endgültige Einrichtung zurück in die dbt Cloud:
-
Gib deinem Projekt auf dem Projekt-Setup-Bildschirm einen ausführlicheren Namen. In unserem Fall haben wir dbt-analytics-engineer gewählt.
-
Klicke auf dem Bildschirm "Lager auswählen" auf das BigQuery-Symbol und dann auf Weiter.
-
Lade die zuvor erstellte JSON-Datei hoch. Dazu klickst du auf die Schaltfläche "JSON-Datei des Servicekontos hochladen", die in Abbildung 4-9 zu sehen ist.
Zu guter Letzt, nachdem du die Datei hochgeladen hast, wende den letzten Schritt an:
-
Gehe ganz nach unten und klicke auf "Test". Wenn du siehst, dass dein Test erfolgreich abgeschlossen wurde (siehe Abbildung 4-10 ), bist du startklar! Klicke jetzt auf "Weiter". Wenn der Test jedoch fehlschlägt, ist es gut möglich, dass ein Problem mit deinen BigQuery-Anmeldedaten aufgetreten ist. Versuche, sie noch einmal neu zu generieren.

Abbildung 4-9. dbt Cloud, BigQuery Service Account übermitteln Bildschirm
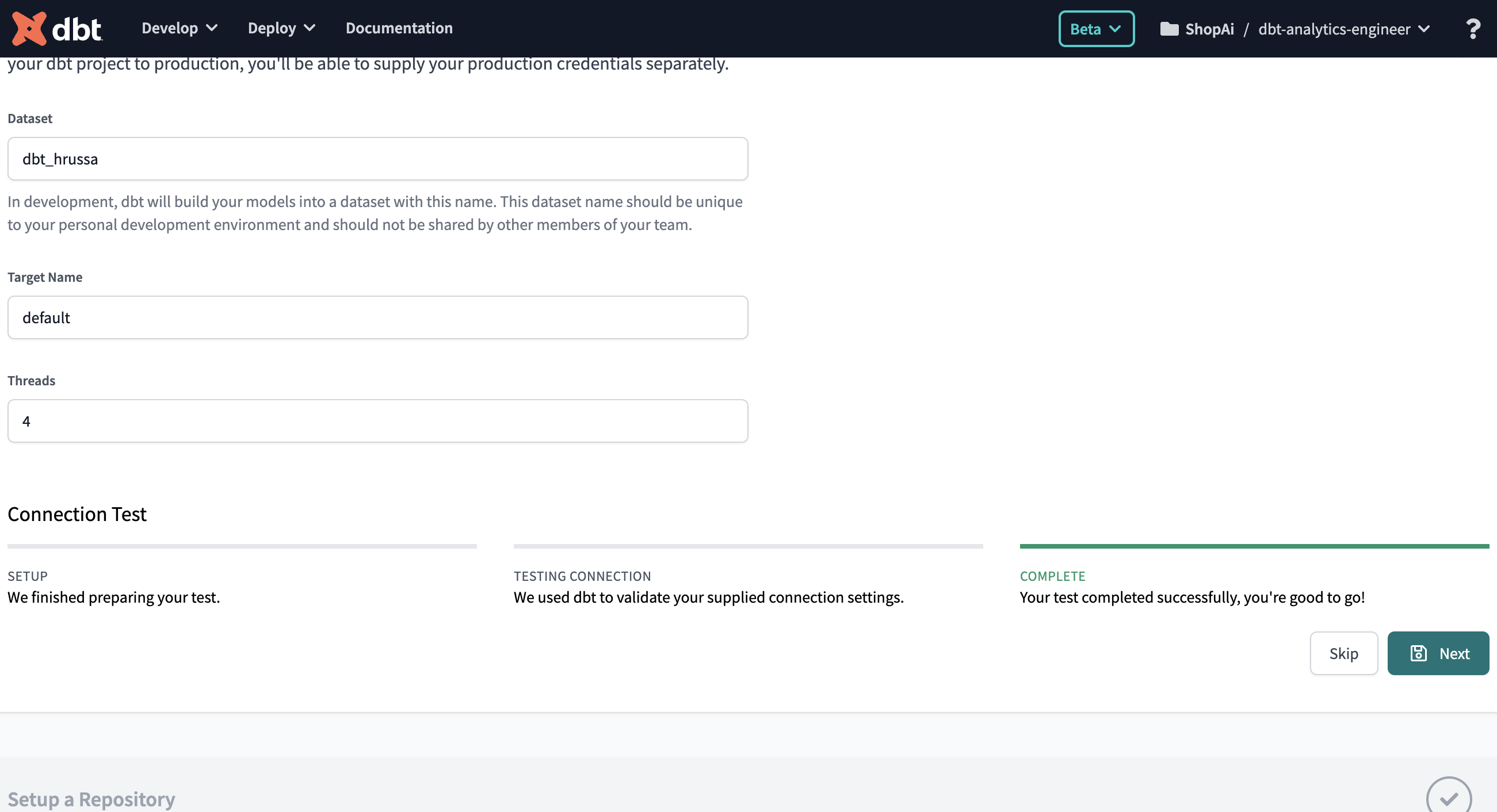
Abbildung 4-10. dbt und BigQuery Verbindungstest
Der letzte Schritt ist die Einrichtung von GitHub, aber zuerst müssen wir verstehen, worüber wir hier sprechen. GitHub ist eine beliebte Plattform für Versionskontrolle, die Git-Repositories bereitstellt, mit denen du Änderungen an deinem Code verfolgen und effektiv mit anderen zusammenarbeiten kannst. Um Git richtig zu nutzen, musst du dich an diese Grundsätze und bewährten Methoden halten:
- Engagiere dich oft, engagiere dich früh
-
Mache häufige Übertragungen, auch bei kleinen Änderungen. Das hilft dabei, deinen Fortschritt zu verfolgen und erleichtert die Fehlersuche. Jeder Commit sollte eine logische Änderung oder Funktion darstellen.
- Sinnvolle Commit-Meldungen verwenden
-
Schreibe prägnante und aussagekräftige Commit-Nachrichten. Eine gute Commit-Meldung sollte erklären, was geändert wurde und warum es geändert wurde.
- Verfolge eine Verzweigungsstrategie
-
Verwende Zweige für verschiedene Funktionen, Fehlerbehebungen oder Entwicklungsaufgaben.
- Ziehen vor Drücken
-
Ziehe immer die neuesten Änderungen aus dem entfernten Repository (z.B.
git pull), bevor du deine Änderungen veröffentlichst. So vermeidest du Konflikte und stellst sicher, dass deine Änderungen auf dem neuesten Code beruhen. - Überprüfe den Code vor der Übergabe
-
Wenn dein Team Codeüberprüfungen durchführt, solltest du sicherstellen, dass du deine Änderungen überprüfst und testest, bevor du sie festlegst. Das hilft, die Qualität des Codes zu erhalten.
- .gitignore verwenden
-
Erstelle eine .gitignore-Datei, um Dateien und Verzeichnisse anzugeben, die von der Versionskontrolle ausgeschlossen werden sollen (z. B. Build-Artefakte, temporäre Dateien).
- Atomic Commits verwenden
-
Konzentriere dich bei den Commits auf eine einzige, spezifische Änderung. Vermeide es, unzusammenhängende Änderungen im selben Commit zu mischen.
- Rebase statt Merge
-
Verwende
git rebase, um Änderungen aus einem Funktionszweig in den Hauptzweig zu integrieren, anstatt sie traditionell zusammenzuführen. Dies führt zu einer saubereren Commit-Historie. - Commit-Verlauf sauber halten
-
Vermeide es, "unfertige Arbeiten" oder Debugging-Anweisungen zu übertragen. Verwende Tools wie
git stash, um unfertige Arbeit vorübergehend zu speichern. - Tags verwenden
-
Erstelle Tags, wie z.B. Versions-Tags, um wichtige Punkte in der Geschichte deines Projekts zu markieren, wie z.B. Releases oder wichtige Meilensteine.
- Zusammenarbeiten und kommunizieren
-
Kommuniziere mit deinem Team über Git-Workflows und -Konventionen. Lege Richtlinien für den Umgang mit Problemen, Pull Requests und Konfliktlösungen fest.
- Wissen, wie du Änderungen rückgängig machen kannst
-
Lerne, wie du bei Bedarf Commits rückgängig machen (
git revert), Zweige zurücksetzen (git reset) und verlorene Arbeit wiederherstellen kannst (git reflog). - Dokument
-
Dokumentiere den Git-Workflow und die Konventionen deines Projekts in einem README oder in einem Leitfaden, um neue Teammitglieder effektiv einzubinden.
- Backup und Remote Repositories nutzen
-
Sichert regelmäßig eure Git-Repositories und nutzt Remote-Repositories wie GitHub für die Zusammenarbeit und Redundanz.
- Weiter lernen
-
Git ist ein großartiges Werkzeug mit vielen Funktionen. Lerne weiter und erforsche fortgeschrittene Git-Konzepte wie Cherry-Picking, interaktives Rebasing und benutzerdefinierte Hooks, um deinen Arbeitsablauf zu verbessern.
Um einige der gebräuchlichen Git-Begriffe und Befehle in der Praxis besser zu verstehen, werfen wir einen Blick auf Tabelle 4-1.
| Begriff/Befehl | Definition | Git-Befehl (falls zutreffend) |
|---|---|---|
Repository (repo) |
Dieser ist ähnlich wie ein Projektordner und enthält alle Dateien, den Verlauf und die Zweige deines Projekts. |
- |
Zweigstelle |
Ein Zweig ist eine separate Entwicklungslinie. Er ermöglicht es dir, an neuen Funktionen oder Fehlerbehebungen zu arbeiten, ohne die Hauptcodebasis zu beeinflussen. |
|
Pull Request (PR) |
Ein Pull Request ist ein Änderungsvorschlag, den du in den Hauptzweig einbringen möchtest. Auf diese Weise kannst du mit deinem Team zusammenarbeiten und Änderungen am Code überprüfen. |
- |
Versteck |
|
|
Commit |
Ein Commit ist ein Schnappschuss deines Codes zu einem bestimmten Zeitpunkt. Er stellt eine Reihe von Änderungen dar, die du an deinen Dateien vorgenommen hast. |
|
hinzufügen |
|
Der Git-Befehl für alle Änderungen lautet |
Gabel |
Ein Repository zu forken bedeutet, dass du eine Kopie des Projekts einer anderen Person auf GitHub erstellst. Du kannst Änderungen an deinem geforkten Projektarchiv vornehmen, ohne das Original zu verändern. |
- |
Klonen |
Das Klonen eines Repositorys bedeutet, eine lokale Kopie eines entfernten Repositorys zu erstellen. Du kannst lokal an deinem Code arbeiten und Änderungen in das entfernte Repository übertragen. |
|
Push |
|
|
Ziehen |
|
|
Status |
|
|
Logge |
|
|
Diff |
Der Befehl |
|
Zusammenführen |
Der Befehl |
|
Rebase |
Mit Rebase kannst du eine Reihe von Commits zu einem neuen Basis-Commit verschieben oder kombinieren. |
|
Checkout |
Der Befehl |
|
Diese Git-Befehle und Begriffe bilden die Grundlage für die Versionskontrolle in deinen Projekten. Die Git-Befehle verfügen jedoch oft über viele zusätzliche Argumente und Optionen, mit denen du deine Versionskontrolle noch genauer steuern kannst. Obwohl wir hier einige wichtige Befehle vorgestellt haben, ist es wichtig zu wissen, dass die Vielseitigkeit von Git weit über das hinausgeht, was wir hier beschrieben haben.
Für eine ausführlichere Liste der Git-Befehle und der verschiedenen Argumente, die sie akzeptieren können, empfehlen wir die offizielle Git-Dokumentation.
Nachdem du nun weißt, was Git und GitHub sind und welche Rolle sie im Projekt spielen, wollen wir eine Verbindung zu GitHub herstellen. Dazu musst du Folgendes tun:
-
Registriere dich für ein GitHub-Konto, wenn du noch keines hast.
-
Klicke auf Neu, um ein neues Repository zu erstellen, in dem du deinen Analytics-Code versionieren wirst. Auf dem Bildschirm "Neues Repository erstellen" gibst du deinem Repository einen Namen und klickst dann auf "Repository erstellen".
-
Nachdem du das Repository erstellt hast, kommst du zurück zu dbt. Im Abschnitt Repository einrichten wählst du GitHub aus und verbindest dann das GitHub-Konto.
-
Klicke auf GitHub-Integration konfigurieren, um ein neues Fenster zu öffnen, in dem du den Ort für die Installation der dbt Cloud auswählen kannst. Wähle dann das Repository aus, das du installieren möchtest.
Klicke nun auf "Entwicklung in der IDE starten". In Abbildung 4-11 siehst du, was du erwarten solltest.
Abbildung 4-11. dbt IDE
Wir geben einen Überblick über die integrierte Entwicklungsumgebung (IDE) von dbt Cloud in "Verwendung der dbt Cloud IDE" und gehen in "Aufbau eines dbt-Projekts" näher darauf ein.
Klicke oben links auf "dbt-Projekt initialisieren". Jetzt solltest du den Bildschirm wie in Abbildung 4-12 sehen können.
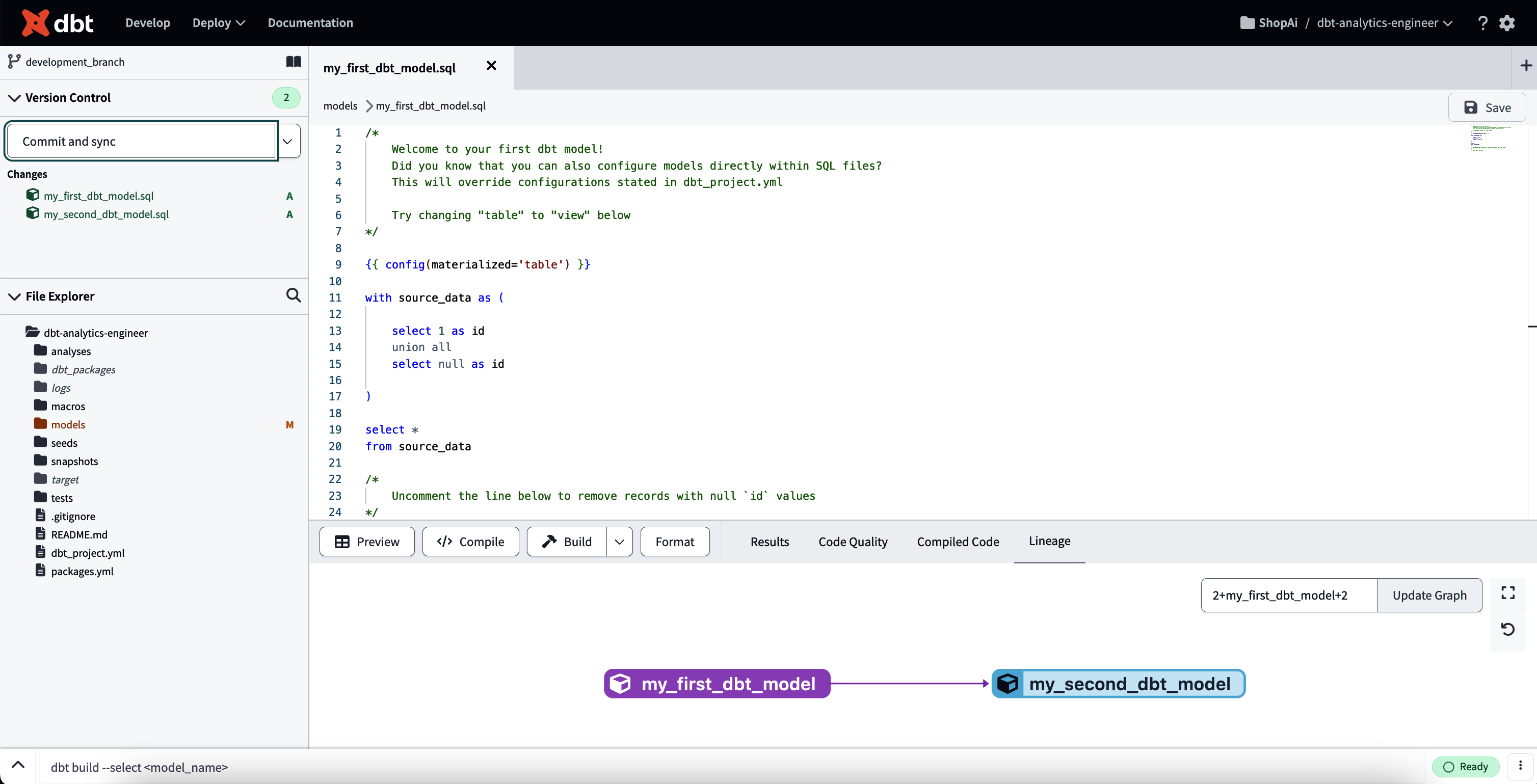
Abbildung 4-12. dbt nach der Projektinitialisierung
Wir werden die einzelnen Ordner und Dateien im Abschnitt "Struktur eines dbt-Projekts" genauer beschreiben . Jetzt wollen wir erst einmal sehen, ob die Abfragen funktionieren. Führe sie erneut aus, indem du den Code aus Beispiel 4-2 kopierst und auf Vorschau klickst.
Beispiel 4-2. dbt public datasets in BigQuery, dbt test
--select * from `dbt-tutorial.jaffle_shop.customers`;--select * from `dbt-tutorial.jaffle_shop.orders`;select*from`dbt-tutorial.stripe.payment`;
Wenn die Ausgabe ähnlich wie in Abbildung 4-13 aussieht, bedeutet das, dass deine Verbindung funktioniert. Du kannst dann Abfragen an deine Datenplattform senden, in unserem Fall an BigQuery.
Hinweis
Die hier beschriebenen Schritte sind Teil der Dokumentation für den BigQuery-Adapter in dbt. Da sich die Technologien weiterentwickeln und verbessern, können sich auch diese Schritte und Konfigurationen ändern. Um sicherzustellen, dass du die aktuellsten Informationen hast, solltest du die neueste dbt-Dokumentation für BigQuery lesen. In dieser Ressource findest du die aktuellsten Hinweise und Anleitungen für die Arbeit mit dbt und BigQuery.
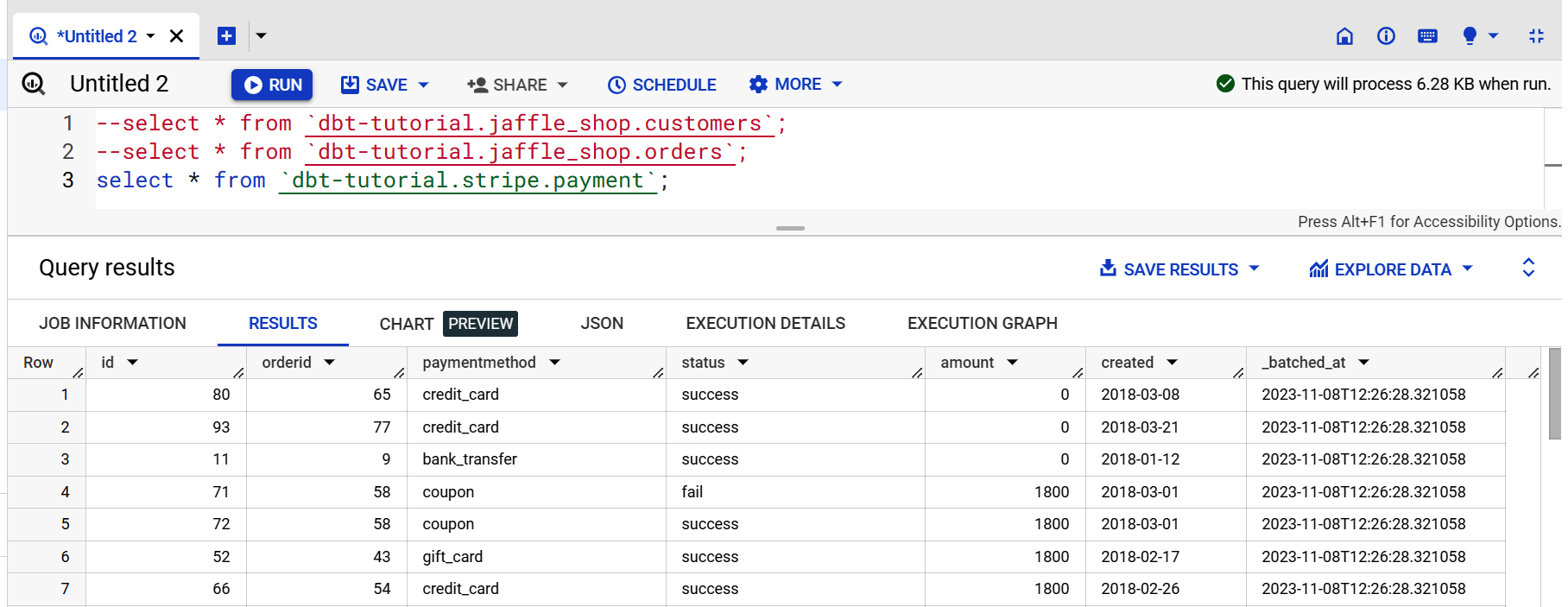
Abbildung 4-13. dbt-Ausgabe von BigQuery public dataset
Zum Schluss kannst du testen, ob deine GitHub-Integration wie erwartet funktioniert, indem du deinen ersten "Commit und Push" durchführst. Klicke auf die gleichnamige Schaltfläche, die in Abbildung 4-14 links zu sehen ist. Es erscheint ein Popup-Fenster (siehe Abbildung 4-14, rechts), in dem du deine Commit-Nachricht schreiben kannst. Klicke auf Änderungen festschreiben.
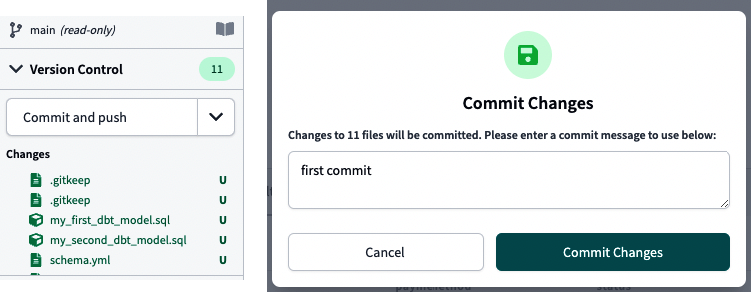
Abbildung 4-14. Commit und Push auf GitHub
Da wir keinen Git-Zweig erstellt haben, wird unser Code innerhalb des Hauptzweigs versioniert. Gehe in das GitHub-Repository, das du bei der Einrichtung angelegt hast, und sieh nach, ob dein dbt-Projekt existiert. Abbildung 4-15 sollte ähnlich aussehen wie das, was du in deinem GitHub-Repository siehst.
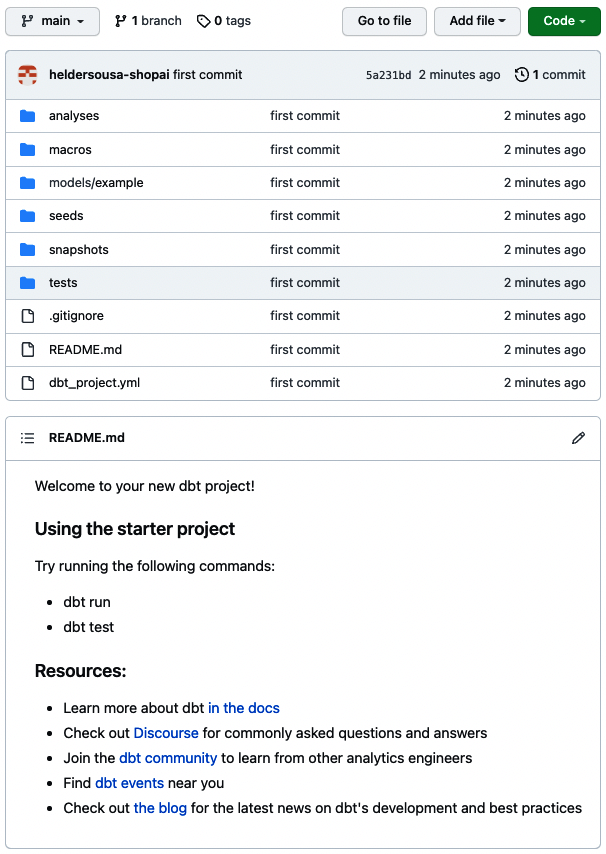
Abbildung 4-15. dbt GitHub-Repository, Überprüfung der ersten Übergabe
Verwendung der dbt Cloud UI
Wenn du dich bei der dbt Cloud anmeldest, zeigt auf der Startseite eine Willkommensnachricht und eine Zusammenfassung des Verlaufs deiner Aufträge an. Wie Abbildung 4-16 zeigt, ist die Seite zunächst leer, aber sobald wir unsere ersten Aufträge erstellt und ausgeführt haben, werden wir erste Informationen sehen. In "Aufträge und Einsatz" wird die Ausführung eines Auftrags genauer beschrieben.
Abbildung 4-16. dbt Landing Page
In der oberen Leiste siehst du verschiedene Optionen. Von der linken Seite aus kannst du auf die Seite Entwickeln zugreifen, auf der du deinen gesamten Analytics-Code entwickelst und deine Modelle, Tests und Dokumentation erstellst. Sie ist das Herzstück der dbt-Entwicklung. Wir geben dir weitere Einblicke in diesen Bereich unter "Verwendung der dbt-Cloud-IDE" und vertiefen die einzelnen Komponenten unter "Aufbau eines dbt-Projekts".
Direkt neben der Option Entwickeln befindet sich das Menü Bereitstellen, wie in Abbildung 4-17 dargestellt. In diesem Menü kannst du Aufträge konfigurieren und ihre Ausführung über den Ausführungsverlauf überwachen, die Entwicklungsumgebungen konfigurieren und die Aktualität der Snapshots über die Datenquellen überprüfen.
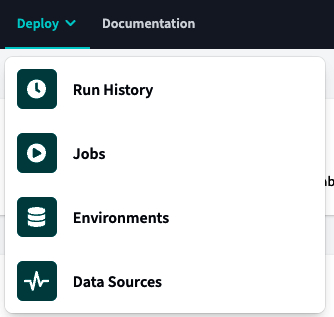
Abbildung 4-17. Menü dbt Deploy
Die erste Option des Verteilungsmenüs ist der Laufverlauf, der die in Abbildung 4-18 gezeigte Seite öffnet. Hier kannst du den Verlauf deines Auftrags sehen. Im Kontext von dbt sind Aufträge automatisierte Aufgaben oder Prozesse, die du so konfigurierst, dass sie bestimmte Aktionen ausführen, z. B. Modelle, Tests oder die Erstellung von Dokumentation. Diese Aufträge sind ein wesentlicher Bestandteil der Orchestrierung des dbt, die die Verwaltung und Automatisierung verschiedener Datenumwandlungs- und Analyseaufgaben umfasst.

Abbildung 4-18. dbt Run History Seite
Angenommen, du hast Aufträge konfiguriert, die bereits in diesem Abschnitt ausgeführt wurden. In diesem Fall kannst du den Aufruf und den Status der einzelnen Aufträge einsehen. Der Verlauf des Auftrags enthält eine Fülle von Informationen, darunter den Status, die Dauer, die Umgebung, in der der Auftrag ausgeführt wurde, und andere nützliche Details. Du kannst Informationen über die einzelnen Schritte abrufen, die der Auftrag durchlaufen hat, einschließlich der entsprechenden Protokolle für jeden Schritt. Außerdem kannst du die Artefakte finden, die der Auftrag erzeugt hat, z. B. Modelle, Tests oder Dokumentation.
Die nächste Option im Menü "Deploy" ist Aufträge. Damit öffnest du eine Seite, auf der du deine gesamte Automatisierung konfigurieren kannst, einschließlich CI/CD-Pipelines, Lauftests und andere spannende Verhaltensweisen, ohne dbt-Befehle manuell über die Kommandozeile auszuführen.
Abbildung 4-19 zeigt die leere Landing Page "Aufträge". Unter "Aufträge und Einsatz" ist ein ganzer Abschnitt den Aufträgen gewidmet .

Abbildung 4-19. Seite dbt Aufträge
Die dritte Option im Menü Deploy ist Environments. In dbt gibt es zwei Haupttypen von Umgebungen: Entwicklungs- und Bereitstellungsumgebungen. Standardmäßig konfiguriert dbt die Entwicklungsumgebung für dich, die direkt nach dem Einrichten deines dbt-Projekts sichtbar ist. Abbildung 4-20 zeigt dir die Landing Page Environments, die deiner ähnlich sein sollte, wenn du die Schritte in "Einrichten der dbt Cloud mit BigQuery und GitHub" befolgt hast .
Abbildung 4-20. dbt Environments Seite
Schließlich gibt es noch die Option Data Sources. Diese Seite, die in Abbildung 4-21 zu sehen ist, wird von dbt Cloud automatisch ausgefüllt, sobald du einen Auftrag für einen Snapshot der Quelldatenfrische konfigurierst. Hier siehst du den Stand der letzten Snapshots und kannst analysieren, ob die Aktualität deiner Quelldaten den Service Level Agreements (SLAs) entspricht, die du mit deinem Unternehmen vereinbart hast. Eine bessere Vorstellung von der Datenfrische bekommst du unter "Quelldatenfrische" und wie du sie testen kannst unter "Quellen testen".

Abbildung 4-21. dbt Data Sources Seite
Als Nächstes folgt die Option Dokumentation. Solange du und dein Team Routinen erstellen, um sicherzustellen, dass dein dbt-Projekt richtig dokumentiert wird, kommt diesem Schritt eine besondere Bedeutung zu. Eine ordnungsgemäße Dokumentation kann Fragen wie diese beantworten:
-
Was bedeuten diese Daten?
-
Woher kommen diese Daten?
-
Wie werden diese Kennziffern berechnet?
Abbildung 4-22 zeigt die Dokumentationsseite für dein Projekt. Wie du die Dokumentation innerhalb deines dbt-Projekts nutzen und schreiben kannst, während du deinen Code schreibst, erklären wir unter "Dokumentation".
Abbildung 4-22. dbt Dokumentationsseite
Mit dem Menü oben rechts kannst du dein dbt-Projekt auswählen(Abbildung 4-23). Dieses kurze Menü macht es einfach, zwischen dbt-Projekten zu wechseln.

Abbildung 4-23. dbt Menü "Konto auswählen
Das dbt-Hilfemenü(Abbildung 4-24) findest du, indem du unter auf das Fragezeichen-Symbol klickst. Hier kannst du im Chat direkt mit dem dbt-Team sprechen, Feedback geben und auf die dbt-Dokumentation zugreifen. Schließlich kannst du über das Hilfe-Menü auch der dbt-Community auf Slack oder den dbt-Diskussionen auf GitHub beitreten.
Abbildung 4-24. dbt-Hilfemenü
Im Menü Einstellungen, Abbildung 4-25, kannst du alles konfigurieren, was mit deinem Konto, deinem Profil und sogar mit Benachrichtigungen zu tun hat.
Abbildung 4-25. dbt-Einstellungsmenü
Wenn du auf eine der drei Optionen klickst, landest du unter auf der Seite Einstellungen, ähnlich wie in Abbildung 4-26. Auf der ersten Seite, den Kontoeinstellungen, kannst du dbt-Projekte bearbeiten und neu erstellen, Benutzer und deren Zugriffskontrolle (wenn du Eigentümer bist) verwalten und die Abrechnung verwalten.
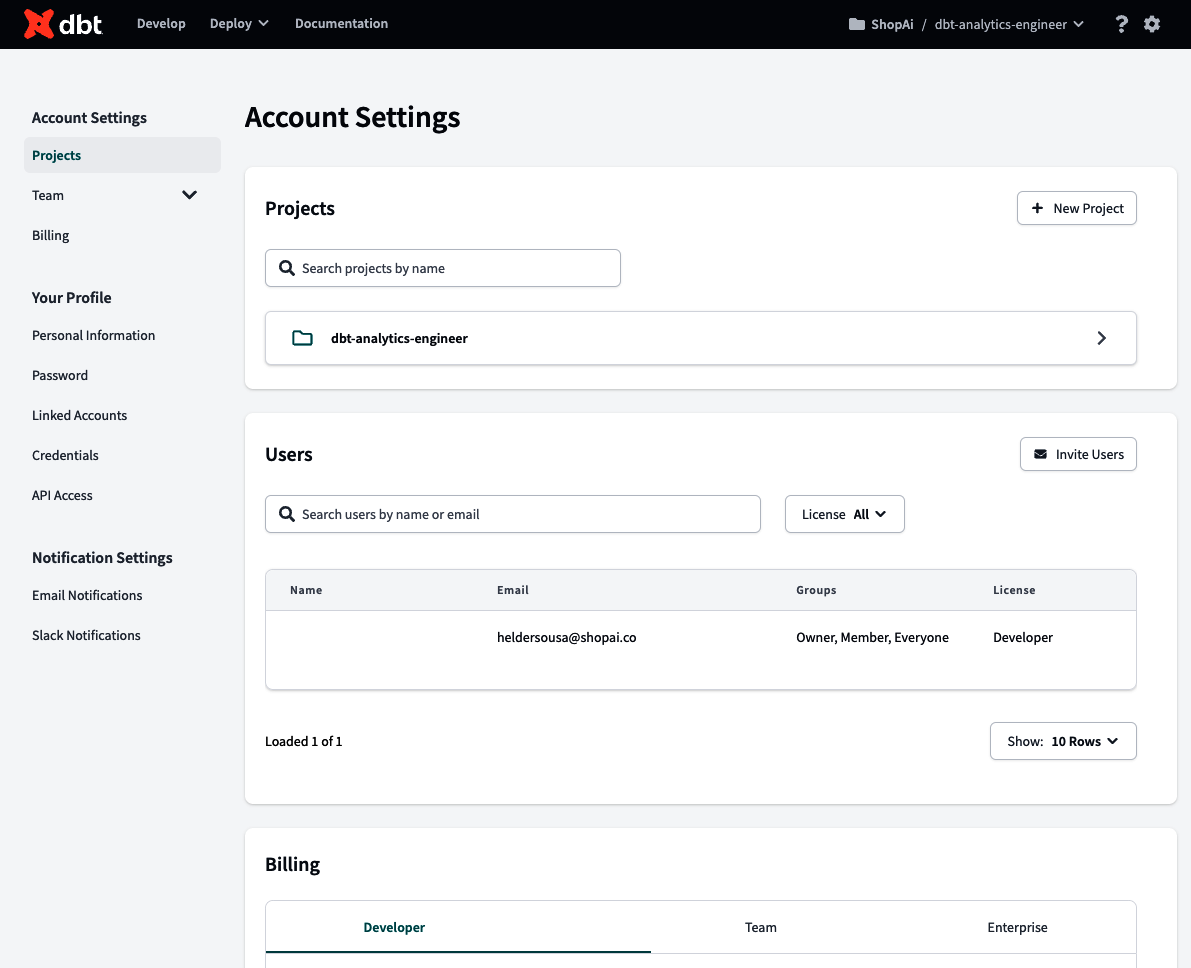
Abbildung 4-26. dbt Kontoeinstellungen Seite
Die zweite Menüoption, Profileinstellungen, ruft die Seite Dein Profil auf(Abbildung 4-27). Auf dieser Seite kannst du alle deine persönlichen Informationen einsehen und verknüpfte Konten wie GitHub oder GitLab, Slack und Single Sign-On (SSO) Tools verwalten. Außerdem kannst du die Anmeldeinformationen für deine Datenplattform und den API-Schlüssel überprüfen und bearbeiten.

Abbildung 4-27. dbt Dein Profil Seite
Über die Option Benachrichtigungseinstellungen gelangst du schließlich zum Zentrum für Benachrichtigungen (Abbildung 4-28), wo du Benachrichtigungen konfigurieren kannst, die du in einem ausgewählten Slack-Kanal oder per E-Mail erhältst, wenn ein Auftragslauf erfolgreich ist, fehlschlägt oder abgebrochen wird.
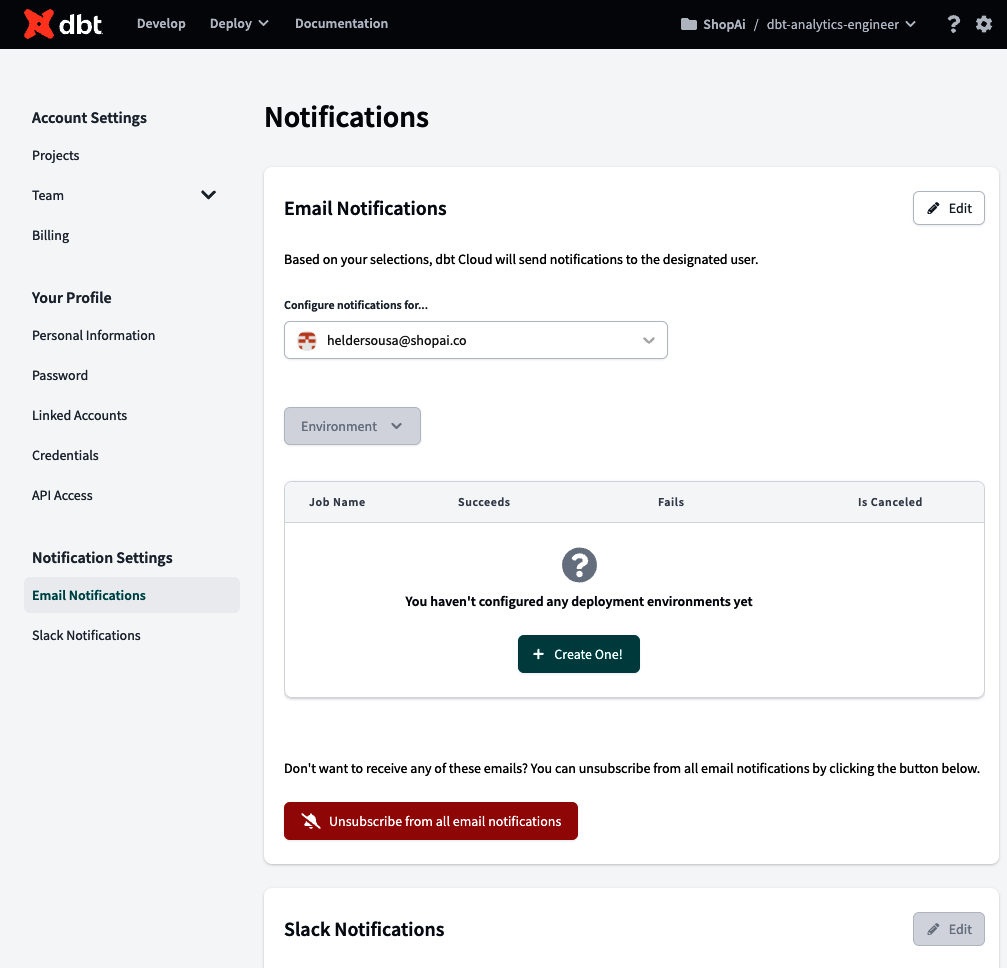
Abbildung 4-28. dbt Benachrichtigungszentrale
Verwendung der dbt Cloud IDE
Einer der wichtigsten Bestandteile von der dbt Cloud ist die IDE, in der der gesamte Analytics-Code zusammen mit Tests und Dokumentation geschrieben werden kann. Abbildung 4-29 zeigt die Hauptbereiche der dbt-IDE.

Abbildung 4-29. dbt IDE-annotiert
Im Folgenden findest du eine detaillierte Erklärung, was jeder Abschnitt bedeutet und welche Bedeutung er in der integrierten Entwicklungsumgebung hat:
-
Git-Kontrollen und Dokumentation
In diesem Menü kannst du mit Git interagieren. Hier kannst du sehen, was sich seit deiner letzten Übertragung geändert hat und was neu ist. Alle Git-Befehle in der IDE sind hier zu finden, und du kannst entscheiden, ob du deinen Code übertragen und pushen oder rückgängig machen willst. Außerdem siehst du oben rechts in diesem Fenster das Symbol für die Dokumentation. Sobald die Dokumentation erstellt ist, kannst du auf diese Verknüpfung klicken, um auf deine Projektdokumentation zuzugreifen.
-
Datei-Explorer
Der Datei-Explorer gibt dir den wichtigsten Überblick über dein dbt-Projekt. Hier kannst du sehen, wie dein dbt-Projekt aufgebaut ist - im Allgemeinen in Form von .sql, .yml und anderen kompatiblen Dateitypen.
-
Texteditor
In diesem Bereich der IDE wird dein Analytics-Code geschrieben und ausgereift. Hier kannst du auch andere relevante Dateien für dein Projekt bearbeiten und erstellen, z. B. die YAML-Dateien. Wenn du diese Dateien im Datei-Explorer auswählst, werden sie hier angezeigt. Es können mehrere Dateien gleichzeitig geöffnet werden.
-
Informationsfenster und Code Vorschau, Kompilieren und Erstellen
In diesem Menü werden deine Ergebnisse angezeigt, sobald du auf die Schaltflächen Vorschau oder Kompilieren klickst. Die Vorschau kompiliert deine Abfrage und führt sie gegen deine Datenplattform aus und zeigt die Ergebnisse auf der Registerkarte "Ergebnisse" am unteren Bildschirmrand an. Die Schaltfläche Kompilieren hingegen wandelt jede Jinja-Abfrage in reines SQL um. Die Ergebnisse werden im Informationsfenster auf der Registerkarte Kompilierter Code am unteren Rand des Bildschirms angezeigt. Die Schaltflächen Vorschau und Kompilieren gelten für Anweisungen und SQL-Dateien.
Build ist eine spezielle Schaltfläche, die nur in bestimmten Dateien angezeigt wird. Je nachdem, welche Art von Build du auswählst, enthalten die Laufergebnisse Informationen über alle Modelle, Tests, Seeds und Snapshots, die für den Build ausgewählt wurden, zusammengefasst in einer Datei.
Das Informationsfenster ist auch hilfreich bei der Fehlersuche während der Entwicklung oder bei der Verwendung der Registerkarte Abstammung, um die Datenabfolge des aktuell im Texteditor geöffneten Modells und seiner Vorfahren und Abhängigkeiten zu überprüfen.
-
Kommandozeile
In der Befehlszeile kannst du bestimmte dbt-Befehle wie
dbt runoderdbt testausführen. Während oder nach der Ausführung des Befehls wird außerdem ein Pop-up-Bildschirm angezeigt, der die Ergebnisse während der Verarbeitung anzeigt - klicke dazu auf den Pfeil am Anfang der Befehlszeile. Auch die Protokolle können hier eingesehen werden. Abbildung 4-30 zeigt die erweiterte Befehlszeile; der auszuführende Befehl steht oben und das Protokoll der Ausführung folgt.

Abbildung 4-30. dbt Befehlszeile erweitert
Struktur eines dbt-Projekts
Ein dbt-Projekt ist ein Verzeichnis, das aus Ordnern und Dateien, Programmiermustern und Namenskonventionen besteht. In diesen Dateien und Ordnern befinden sich der gesamte Analysecode, die Tests, die Dokumentation und die Parameter, die dbt vorgeben, wie es funktionieren soll. Es wird diese Namenskonventionen und Programmiermuster verwenden. Die Art und Weise, wie du deine Ordner und das Dateiverzeichnis organisierst, ist deine dbt-Projektstruktur.
Der Aufbau eines richtigen dbt-Projekts ist mühsam. Damit es gut umgesetzt werden kann, muss es die verschiedenen Bereiche und Abteilungen des Unternehmens zusammenbringen und ihre jeweiligen Fachkenntnisse nutzen, um die Ziele und Bedürfnisse des gesamten Unternehmens abzubilden. Daher ist es wichtig, klare, umfassende und konsistente Konventionen und Muster festzulegen. Dadurch wird sichergestellt, dass das Projekt auch dann zugänglich und pflegbar bleibt, wenn dein Unternehmen wächst, und dass das dbt so vielen Menschen wie möglich zugute kommt.
Die Art und Weise, wie du dein dbt-Projekt organisierst, kann variieren und unterliegt möglicherweise Änderungen, die von dir oder den Unternehmensrichtlinien festgelegt werden. Das ist kein Problem. Wichtig ist nur, dass du diese Änderungen explizit und für alle Mitwirkenden nachvollziehbar bekannt gibst und vor allem konsequent durchführst. In diesem Buch wollen wir die Grundstruktur des dbt-Projekts beibehalten, die du nach der Initialisierung vorfindest(Beispiel 4-3).
Beispiel 4-3. Anfangsstruktur eines dbt-Projekts
root/ ├─ analyses/ ├─ dbt_packages/ ├─ logs/ ├─ macros/ ├─ models/ │ ├─ example/ │ │ ├─ schema.yml │ │ ├─ my_second_dbt_model.sql │ │ ├─ my_first_dbt_model.sql ├─ seeds/ ├─ snapshots/ ├─ target/ ├─ tests/ ├─ .gitignore ├─ dbt_project.yml ├─ README.md
Jeder Ordner und jede Datei wird in den folgenden Abschnitten in diesem Kapitel und in Kapitel 5 erklärt. Einige haben mehr Gewicht und werden häufiger verwendet als andere. Dennoch ist es wichtig, eine Vorstellung von ihrem Zweck zu haben:
- Analysenordner
-
Wie unter "Analysen" beschrieben , wird dieser Ordner in der Regel verwendet, um Abfragen zu Prüfzwecken zu speichern. Du möchtest zum Beispiel Unstimmigkeiten bei der Migration von Logik aus einem anderen System in dbt finden und trotzdem die Möglichkeiten von dbt, wie die Verwendung von Jinja und Versionskontrolle, nutzen, ohne sie in deine erstellten Modelle innerhalb deiner Datenplattform aufzunehmen.
- dbt_packages Ordner
-
Hier installierst du deine dbt-Pakete. Wir werden das Konzept der Pakete in "dbt-Pakete" behandeln . Die Idee ist jedoch, dass Pakete eigenständige dbt-Projekte sind, die bestimmte Probleme lösen und wiederverwendet und in verschiedenen Organisationen eingesetzt werden können. Das fördert einen DRY-er Code, da du nicht immer wieder dieselbe Logik implementierst.
- Logs-Ordner
-
Hier werden alle Projektprotokolle standardmäßig gespeichert, es sei denn, du konfigurierst sie in deiner dbt_project.yml anders.
- Makro-Ordner
-
Hier wird dein DRY-ing up Transformationscode gespeichert. Makros sind, ähnlich wie Funktionen in anderen Programmiersprachen, Teile des Jinja-Codes, die mehrfach wiederverwendet werden können. Wir werden ihnen einen ganzen Abschnitt in "SQL-Makros verwenden" widmen, um sie genauer zu beschreiben.
- Modelle Ordner
-
Ist einer der Pflichtordner in dbt. Im Allgemeinen ist ein Modell eine SQL-Datei, die eine
SELECTAnweisung mit einer modularen Logik enthält, die deine Rohdaten in die endgültigen transformierten Daten umwandeln wird. In dbt gibt der Name des Modells den Namen einer zukünftigen Tabelle oder eines Views an, oder keines von beiden, wenn es als ephemeres Modell konfiguriert ist. Dieses Thema wird in "Modelle" näher erläutert . - Saatgut-Ordner
-
Hier werden unsere Nachschlagetabellen gespeichert. Wir werden das in "Seeds" besprechen . Der Grundgedanke ist, dass Seeds CSV-Dateien sind, die sich nur selten ändern und für die Modellierung von Daten verwendet werden, die in keinem Quellsystem vorhanden sind. Nützliche Anwendungsfälle sind z. B. die Zuordnung von Postleitzahlen zu Bundesländern oder eine Liste von Test-E-Mails, die wir von der Analyse ausschließen müssen.
- Snapshots-Ordner
-
Enthält alle Snapshot-Modelle für dein Projekt, die vom Ordner models getrennt sein müssen. Das dbt-Snapshot-Feature zeichnet Änderungen an einer veränderlichen Tabelle im Laufe der Zeit auf. Es wendet die langsam ändernde Dimension (SCDs) vom Typ 2 an, die angibt, wie sich eine Zeile in einer Tabelle im Laufe der Zeit ändert. Dies wird in "Schnappschüsse" ausführlich behandelt .
- Zielordner
-
Enthält die kompilierten SQL-Dateien , die geschrieben werden, wenn du die Befehle
dbt run,dbt compileoderdbt testausführst. Du kannst in der Datei dbt_project.yml optional festlegen, dass sie in einen anderen Ordner geschrieben werden. - Testordner
-
Dient dem Zweck, mehrere bestimmte Tabellen gleichzeitig zu testen . Dies ist nicht der einzige Ordner, in dem deine Tests geschrieben werden. Viele davon werden in den YAML-Dateien im Ordner deines Modells oder über Makros durchgeführt. Der Ordner "Tests" eignet sich jedoch eher für einzelne Tests, die die Ergebnisse der Interaktion zwischen mehreren bestimmten Modellen oder deren Beziehung zueinander aufzeigen. Wir werden dieses Thema im Abschnitt "Tests" ausführlich behandeln .
- dbt_project.yml
-
Ist der Kern von jedes dbt-Projekts. Daran erkennt dbt, dass es sich bei einem Verzeichnis um ein dbt-Projekt handelt, und sie enthält wichtige Informationen, die dbt sagen, wie es mit deinem Projekt arbeiten soll. Wir werden diese Datei im Laufe dieses Buches behandeln. Sie wird auch in "dbt_project.yml" behandelt .
- .gitignore und README.md
-
Sind Dateien, die typischerweise für deine Git-Projekte verwendet werden. Während gitignore absichtliche Dateien angibt, die Git bei deinem Commit und Push ignorieren soll, ist die README-Datei ein wichtiger Leitfaden, der anderen Entwicklern eine detaillierte Beschreibung deines Git-Projekts liefert.
Wir werden diese Ordner in diesem Kapitel und in Kapitel 5 ausführlicher behandeln, wenn wir uns mit dem dbt-Projekt und seinen Funktionen beschäftigen.
Jaffle Shop Datenbank
In diesem Buch geben wir eine Reihe von praktischen Beispielen, wie man mit den Komponenten und Funktionen von dbt arbeitet. In den meisten Fällen werden wir SQL-Abfragen entwickeln müssen, um die beste Vorstellung von dem zu bekommen, was wir zeigen wollen. Deshalb ist es wichtig, dass wir eine Datenbank haben, mit der wir arbeiten können. Diese Datenbank ist der Jaffle Shop.
Die Datenbank des Jaffle Shops ist eine einfache Datenbank, die aus zwei Tabellen besteht, für Kunden und Bestellungen. Um den Kontext zu verdeutlichen, werden wir eine weitere Datenbank von Stripe haben, in der die mit den Bestellungen verbundenen Zahlungen gespeichert sind. Alle drei Tabellen werden unsere Rohdaten sein.
Der Grund, warum wir diese Datenbank verwenden, ist, dass sie in BigQuery von dbt Labs bereits öffentlich verfügbar ist. Sie ist eine der Hauptdatenbanken, die für die Dokumentation und die Kurse verwendet werden. Wir hoffen, dass sie die Lernkurve der dbt-Plattform in diesem Stadium des Buches vereinfacht.
Abbildung 4-31 zeigt dir das ERD, das unsere Rohdaten mit Kunden, Bestellungen und Zahlungen darstellt.

Abbildung 4-31. Eine Jaffle Shop Rohdaten ERD, die wir wie folgt lesen: Ein einzelner Kunde (1) kann mehrere Bestellungen (N) haben, und eine einzelne Bestellung (1) kann mehrere Bearbeitungszahlungen (N) haben
YAML-Dateien
YAML ist eine menschenlesbare Sprache zur Daten-Serialisierung und wird häufig für Konfigurationsdateien und in Anwendungen verwendet, in denen Daten gespeichert oder übertragen werden. In dbt wird YAML verwendet, um Eigenschaften und einige Konfigurationen der Komponenten deines dbt-Projekts zu definieren: Modelle, Snapshots, Seeds, Tests, Quellen oder sogar das eigentliche dbt-Projekt, dbt_project.yml.
Abgesehen von den YAML-Dateien der obersten Ebene, wie dbt_project.yml und packages.yml, die speziell benannt und an bestimmten Orten abgelegt werden müssen, ist es dir überlassen, wie du die anderen YAML-Dateien in deinem dbt-Projekt organisierst. Erinnere dich daran, dass wie bei anderen Aspekten der Strukturierung deines dbt-Projekts die wichtigsten Richtlinien darin bestehen, konsistent zu bleiben, deine Absichten klar zu formulieren und zu dokumentieren, wie und warum es auf diese Weise organisiert ist. Es ist wichtig, ein Gleichgewicht zwischen Zentralisierung und Dateigröße zu finden, damit bestimmte Konfigurationen so einfach wie möglich zu finden sind. Im Folgenden findest du eine Reihe von Empfehlungen, wie du deine YAML-Dateien organisieren, strukturieren und benennen kannst:
-
Wie bereits erwähnt, ist die Balance zwischen der Zentralisierung der Konfiguration und der Dateigröße besonders wichtig. Wenn alle Konfigurationen in einer einzigen Datei gespeichert sind, kann es schwierig werden, eine bestimmte Konfiguration zu finden, wenn dein Projekt wächst (obwohl du technisch gesehen eine einzige Datei verwenden kannst). Auch die Änderungsverwaltung mit Git wird durch die sich wiederholende Datei erschwert.
-
Wie bereits erwähnt, ist es besser, alle Konfigurationen langfristig zu pflegen, wenn wir eine Konfiguration pro Ordner verwenden. Mit anderen Worten: Es wird empfohlen, in jedem Modellordnerverzeichnis eine YAML-Datei zu haben, die die Konfigurationen aller Modelle in diesem Verzeichnis erleichtert. Erweitere diese Regel, indem du die Konfigurationsdatei des Modells trennst und eine eigene Datei für die Konfigurationen deiner Quellen im selben Verzeichnis einrichtest(Beispiel 4-4).
In dieser Struktur haben wir die Staging-Modelle verwendet, um das zu repräsentieren, was wir besprechen, da sie die meisten Fälle abdecken, z. B. Quellen und YAML-Dateien. Hier siehst du das config per folder System, in dem source und model Konfigurationen unterteilt sind. Außerdem werden hier die Markdown-Dateien für die Dokumentation vorgestellt, auf die wir in "Dokumentation" näher eingehen werden. Der Unterstrich am Anfang stellt alle diese Dateien an den Anfang ihres jeweiligen Verzeichnisses, damit sie leichter zu finden sind.
Beispiel 4-4. dbt YAML-Dateien im Modellverzeichnis
root/ ├─ models/ │ ├─ staging/ │ │ ├─ jaffle_shop/ │ │ │ ├─ _jaffle_shop_docs.md │ │ │ ├─ _jaffle_shop_models.yml │ │ │ ├─ _jaffle_shop_sources.yml │ │ │ ├─ stg_jaffle_shop_customers.sql │ │ │ ├─ stg_jaffle_shop_orders.sql │ │ ├─ stripe/ │ │ │ ├─ _stripe_docs.md │ │ │ ├─ _stripe_models.yml │ │ │ ├─ _stripe_sources.yml │ │ │ ├─ stg_stripe_order_payments.sql ├─ dbt_project.yml
-
Wenn du Dokumentationsblöcke verwendest, gehst du genauso vor und erstellst eine Markdown-Datei (
.md) pro Modellverzeichnis. In "Dokumentation" werden wir diesen Dateityp besser kennenlernen.
Es wird empfohlen, dass du die Standardkonfigurationen deines dbt-Projekts in der Datei dbt_project.yml auf der Verzeichnisebene einrichtest und die kaskadierende Scope-Priorität nutzt, um Variationen dieser Konfigurationen zu definieren. So kannst du die Verwaltung deines dbt-Projekts vereinfachen und sicherstellen, dass deine Konfigurationen konsistent und leicht wartbar sind. Beispiel 4-4: Stell dir vor, dass alle unsere Staging-Modelle so konfiguriert sind, dass sie standardmäßig als View materialisiert werden. Das würde in deiner dbt_project.yml stehen. Wenn du jedoch einen speziellen Anwendungsfall hast, bei dem du die Materialisierungskonfiguration für deine jaffle_shop Staging-Modelle ändern musst, kannst du dies tun, indem du die Datei _jaffle_shop_models.yml änderst. Auf diese Weise kannst du die Materialisierungskonfiguration für diese spezielle Gruppe von Modellen anpassen, während der Rest deiner Projektkonfigurationen unverändert bleibt.
Die Möglichkeit, die Standardkonfigurationen für bestimmte Modelle außer Kraft zu setzen, wird durch die kaskadierende Scope-Priorität ermöglicht, die im dbt-Projekt-Build verwendet wird. Während alle Staging-Modelle als Views materialisiert werden, weil dies die Standardkonfiguration ist, werden die Staging-Modelle von jaffle_shop als Tables materialisiert, weil wir die Standardkonfiguration außer Kraft gesetzt haben, indem wir die spezifische YAML-Datei _jaffle_shop_models.yml aktualisiert haben.
dbt_project.yml
Eine der wichtigsten Dateien in dbt ist dbt_project.yml. Diese Datei muss sich im Stammverzeichnis des Projekts befinden und ist die Hauptkonfigurationsdatei für dein Projekt. Sie enthält wichtige Informationen, damit dbt richtig funktioniert.
Die Datei dbt_project.yml ist auch beim Schreiben deines DRY-er Analytics-Codes von Bedeutung. In der Regel werden hier die Standardkonfigurationen deines Projekts gespeichert, und alle Objekte erben davon, sofern sie nicht auf Modellebene überschrieben werden.
Hier sind einige der wichtigsten Felder, die du in dieser Datei finden wirst:
- Name
-
(Obligatorisch.) Der Name des dbt-Projekts. Wir empfehlen, diese Konfiguration in deinen Projektnamen zu ändern. Erinnere dich auch daran, ihn im Abschnitt des Modells und in der Datei dbt_project.yml zu ändern. In unserem Fall nennen wir es dbt_analytics_engineer_book.
- Version
-
(Obligatorisch.) Kernversion deines Projekts. Anders als die dbt-Version.
- config-version
-
(Obligatorisch.) Version 2 ist die derzeit verfügbare Version.
- Profil
-
(Obligatorisch.) Das Profil in dbt wird für die Verbindung mit deiner Datenplattform verwendet.
- [Ordner]-Pfade
-
(Optional.) Dabei ist [Ordner] die Liste der Ordner im dbt-Projekt. Das kann ein Modell, ein Seed, ein Test, eine Analyse, ein Makro, ein Snapshot, ein Log usw. sein. Die model-paths geben zum Beispiel das Verzeichnis deiner Modelle und Quellen an. Der Makro-Pfad ist das Verzeichnis, in dem sich dein Makro-Code befindet, und so weiter.
- Ziel-Pfad
-
(Optional.) In diesem Pfad wird die kompilierte SQL-Datei gespeichert.
- clean-targets
-
(Optional.) Liste der Verzeichnisse, die Artefakte enthalten, die mit dem Befehl
dbt cleanentfernt werden sollen. - Modelle
-
(Optional.) Standardkonfiguration der Modelle. In Beispiel 4-5 sollen alle Modelle im Staging-Ordner als Ansichten materialisiert werden.
Beispiel 4-5. dbt_project.yml, Modellkonfiguration
models:dbt_analytics_engineer_book:staging:materialized:view
packages.yml
Pakete sind eigenständige dbt-Projekte , die sich mit bestimmten Problemen befassen, wiederverwendet und organisationsübergreifend genutzt werden können. Sie sind Projekte mit Modellen und Makros. Wenn du sie zu deinem Projekt hinzufügst, werden diese Modelle und Makros Teil deines Projekts.
Um auf diese Pakete zuzugreifen, musst du sie zunächst in der Datei packages.yml definieren. Die detaillierten Schritte sind wie folgt:
-
Du musst sicherstellen, dass sich die Datei packages.yml in deinem dbt-Projekt befindet. Wenn nicht, erstelle sie bitte auf der gleichen Ebene wie deine dbt_project.yml-Datei.
-
In der Datei dbt packages.yml definierst du die Pakete, die du in deinem dbt-Projekt verwenden möchtest. Du kannst Pakete aus Quellen wie dem dbt Hub, aus Git-Repositories wie GitHub oder GitLab oder auch Pakete, die du lokal gespeichert hast, installieren. Beispiel 4-6 zeigt dir die Syntax, die für jedes dieser Szenarien erforderlich ist.
-
Führe
dbt depsaus, um die definierten Pakete zu installieren. Wenn du nichts anderes konfigurierst, werden diese Pakete standardmäßig in das Verzeichnis dbt_packages installiert.
Beispiel 4-6. Syntax zur Installation von Paketen aus dem dbt-Hub, Git oder lokal
packages:-package:dbt-labs/dbt_utilsversion:1.1.1-git:"https://github.com/dbt-labs/dbt-utils.git"revision:1.1.1-local:/opt/dbt/bigquery
profiles.yml
Wenn du dich entscheidest, die dbt CLI zu verwenden und dein dbt-Projekt lokal auszuführen, musst du eine profiles.yml einrichten, die nicht benötigt wird, wenn du die dbt Cloud verwendest. Diese Datei enthält die Datenbankverbindung, die dbt für die Verbindung mit der Datenplattform verwendet. Aufgrund ihres sensiblen Inhalts befindet sich diese Datei außerhalb des Projekts, um zu verhindern, dass die Anmeldeinformationen in deinem Code-Repository versioniert werden. Du kannst die Codeversionierung sicher verwenden, wenn deine Anmeldedaten in Umgebungsvariablen gespeichert sind.
Sobald du dbt von deiner lokalen Umgebung aus aufrufst, analysiert dbt deine dbt_project.yml-Datei und erhält den Profilnamen, den dbt für die Verbindung mit deiner Datenplattform benötigt. Du kannst je nach Bedarf mehrere Profile haben, aber es ist üblich, ein Profil pro dbt-Projekt oder pro Datenplattform zu haben. Auch wenn du für dieses Buch dbt Cloud benutzt und die Konfiguration der Profile nicht notwendig ist. Wir zeigen ein Beispiel für die profiles.yml, falls du neugierig bist oder lieber dbt CLI mit BigQuery verwenden möchtest.
Die typische YAML-Schemadatei für profiles.yml ist in Beispiel 4-7 dargestellt. Da wir in diesem Buch die dbt Cloud verwenden, ist die Konfiguration der Profile nicht notwendig. Wir zeigen dir jedoch ein Beispiel für die profiles.yml, falls du neugierig bist oder lieber die dbt CLI mit BigQuery verwenden möchtest.
Beispiel 4-7. profiles.yml
dbt_analytics_engineer_book:target:devoutputs:dev:type:bigquerymethod:service-accountproject:[GCP project id]dataset:[the name of your dbt dataset]threads:[1 or more]keyfile:[/path/to/bigquery/keyfile.json]<optional_config>:<value>
Die gängigste Struktur von profiles.yaml besteht aus den folgenden Komponenten:
- profil_name
-
Der Name des Profils muss mit dem Namen in deiner dbt_project.yml übereinstimmen. In unserem Fall haben wir es
dbt_analytics_engineer_bookgenannt. - Ziel
-
So hast du unterschiedliche Konfigurationen für verschiedene Umgebungen. Wenn du zum Beispiel lokal entwickelst, möchtest du mit verschiedenen Datensätzen/Datenbanken arbeiten. Wenn du aber in der Produktion arbeitest, ist es am besten, alle Tabellen in einem einzigen Dataset/einer einzigen Datenbank zu haben. Standardmäßig ist das Ziel auf
deveingestellt. - Typ
-
Die Art der Datenplattform, die du verbinden möchtest: BigQuery, Snowflake, Redshift und andere.
- Datenbankspezifische Verbindungsdetails
-
Beispiel 4-7 enthält Attribute wie
method,project,datasetundkeyfile, die erforderlich sind, um mit diesem Ansatz eine Verbindung zu BigQuery einzurichten. - Fäden
-
Anzahl der Threads, auf denen das dbt-Projekt laufen wird. Es erstellt ein DAG mit Verknüpfungen zwischen den Modellen. Die Anzahl der Threads steht für die maximale Anzahl von Pfaden durch den Graphen, die dbt parallel bearbeiten kann. Wenn du z. B.
threads: 1angibst, beginnt dbt nur mit dem Aufbau einer Ressource (Modelle, Tests usw.) und beendet diese, bevor es mit der nächsten weitergeht. Wenn du dagegenthreads: 4angibst, wird dbt an bis zu vier Modellen gleichzeitig arbeiten, ohne Abhängigkeiten zu verletzen.
Hinweis
Die allgemeine Idee der profiles.yml-Datei wird hier vorgestellt. Wir werden nicht weiter darauf eingehen und auch keine detaillierte Anleitung für die Konfiguration deines lokalen dbt-Projekts mit BigQuery geben. Die meisten Aufgaben, wie z. B. die Erstellung von Schlüsseldateien, wurden bereits in "Einrichten der dbt Cloud mit BigQuery und GitHub" beschrieben , aber es gibt vielleicht noch einige Feinheiten. Wenn du mehr erfahren möchtest, findest du unter dbt eine umfassende Anleitung.
Modelle
Modelle sind der Ort, an dem du als Datenspezialist die meiste Zeit im dbt-Ökosystem verbringen wirst. Sie werden in der Regel als select Anweisungen geschrieben und als .sql gespeichert und sind eines der wichtigsten Elemente in dbt, die dir helfen, deine Daten in deiner Datenplattform zu transformieren.
Um deine Modelle richtig aufzubauen und eine klare und konsistente Projektstruktur zu schaffen, musst du mit dem Konzept und den Techniken der Datenmodellierung vertraut sein. Das ist ein zentrales Wissen, wenn du Analytik-Ingenieur/in werden willst oder, allgemein gesprochen, jemand, der mit Daten arbeiten will.
Wie wir in Kapitel 2 gesehen haben, ist die Datenmodellierung der Prozess, der durch die Analyse und Definition der Datenanforderungen Datenmodelle erstellt, die die Geschäftsprozesse in deinem Unternehmen unterstützen. Dabei werden die Quelldaten, also die Daten, die dein Unternehmen sammelt und produziert, in transformierte Daten umgewandelt, die den Datenbedarf deiner Unternehmensbereiche und -abteilungen decken und einen Mehrwert schaffen.
Ähnlich wie bei der Datenmodellierung und wie in Kapitel 2 eingeführt, ist Modularität ein weiteres Konzept , das für die richtige Strukturierung deines dbt-Projekts und die Organisation deiner Modelle entscheidend ist, während dein Code DRY-er bleibt. Modularität bedeutet, dass ein Problem in eine Reihe von Modulen zerlegt wird, die getrennt und neu kombiniert werden können, wodurch die Gesamtkomplexität des Systems reduziert wird. In der Analytik ist das nicht anders. Wenn wir ein Datenprodukt erstellen, schreiben wir den Code nicht auf einmal. Stattdessen erstellen wir ihn Stück für Stück, bis wir die endgültigen Datenartefakte haben.
Da wir von Anfang an auf Modularität setzen wollen, werden auch unsere anfänglichen Modelle mit Blick auf die Modularität und in Übereinstimmung mit dem, was wir in Kapitel 2 besprochen haben, aufgebaut. Nach einem typischen dbt-Datenumwandlungsprozess gibt es drei Ebenen im Verzeichnis unseres Modells:
- Bereitstellungsebene
-
Unsere ersten modularen Bausteine befinden sich in der Staging-Schicht unseres dbt-Projekts. In dieser Schicht stellen wir eine Schnittstelle zu unseren Quellsystemen her, ähnlich wie eine API mit externen Datenquellen interagiert. Hier werden die Daten neu geordnet, bereinigt und für die Weiterverarbeitung vorbereitet. Dazu gehören Aufgaben wie die Standardisierung von Daten und kleinere Transformationen, die die Grundlage für eine weitergehende Datenverarbeitung bilden.
- Zwischenschicht
-
Diese Schicht besteht aus Modellen zwischen der Staging-Schicht und der Marts-Schicht. Diese Modelle bauen auf unseren Staging-Modellen auf und werden für umfangreiche Datentransformationen sowie für die Konsolidierung von Daten aus verschiedenen Quellen verwendet, wodurch verschiedene Zwischentabellen entstehen, die unterschiedlichen Zwecken dienen.
- Marts Schicht
-
Abhängig von deiner Datenmodellierungstechnik fügen Marts alle modularen Teile zusammen, um eine breitere Sicht auf die Entitäten zu erhalten, die für dein Unternehmen wichtig sind. Wenn du dich zum Beispiel für eine dimensionale Modellierungstechnik entscheidest, enthält die Kartierungsschicht deine Fakten- und Dimensionstabellen. In diesem Zusammenhang sind Fakten Ereignisse die im Laufe der Zeit immer wieder auftreten, wie z. B. Bestellungen, Seitenklicks oder Bestandsveränderungen, mit ihren jeweiligen Kennzahlen. Dimensionen sind Attribute wie Kunden, Produkte und Regionen, die diese Fakten beschreiben können. Marts können als Teilmengen von Daten innerhalb deiner Datenplattform beschrieben werden, die auf bestimmte Bereiche oder Abteilungen ausgerichtet sind, z. B. Finanzen, Marketing, Logistik, Kundenservice usw. Es kann auch sinnvoll sein, einen Mart mit der Bezeichnung "Core" zu haben, der nicht auf einen bestimmten Bereich ausgerichtet ist, sondern die wichtigsten Geschäftsdaten und Dimensionen enthält.
Nachdem wir uns vorgestellt haben, können wir jetzt unsere ersten Modelle erstellen, zunächst nur auf unserer Staging-Ebene. Erstelle einen neuen Ordner mit dem Namen staging innerhalb deines models-Ordners und die entsprechenden Ordner für source, jaffle_shop und stripe innerhalb des staging-Ordners. Erstelle dann die erforderlichen SQL-Dateien, eine für stg_stripe_order_payments.sql(Beispiel 4-8), eine weitere für stg_jaffle_shop_customers.sql(Beispiel 4-9) und schließlich eine für stg_jaffle_shop_orders.sql(Beispiel 4-10). Zum Schluss löschst du den Beispielordner innerhalb deiner Modelle. Er ist überflüssig und würde beim Programmieren nur unnötiges visuelles Rauschen erzeugen. Die Ordnerstruktur sollte ähnlich wie in Beispiel 4-11 sein.
Beispiel 4-8. stg_stripe_order_payments.sql
selectidaspayment_id,orderidasorder_id,paymentmethodaspayment_method,casewhenpaymentmethodin('stripe','paypal','credit_card','gift_card')then'credit'else'cash'endaspayment_type,status,amount,casewhenstatus='success'thentrueelsefalseendasis_completed_payment,createdascreated_datefrom`dbt-tutorial.stripe.payment`
Beispiel 4-9. stg_jaffle_shop_customers.sql
selectidascustomer_id,first_name,last_namefrom`dbt-tutorial.jaffle_shop.customers`
Beispiel 4-10. stg_jaffle_shop_orders.sql
selectidasorder_id,user_idascustomer_id,order_date,status,_etl_loaded_atfrom`dbt-tutorial.jaffle_shop.orders`
Beispiel 4-11. Ordnerstruktur der Staging-Modelle
root/ ├─ models/ │ ├─ staging/ │ │ ├─ jaffle_shop/ │ │ │ ├─ stg_jaffle_shop_customers.sql │ │ │ ├─ stg_jaffle_shop_orders.sql │ │ ├─ stripe/ │ │ │ ├─ stg_stripe_order_payments.sql ├─ dbt_project.yml
Führen wir nun aus, was wir getan haben, und überprüfen wir es. Normalerweise reicht es aus, dbt run in die Befehlszeile einzugeben, aber bei BigQuery musst du vielleicht noch Folgendes eingeben dbt run --full-refresh. Sieh dir danach deine Logs an, indem du den Pfeil links neben deiner Befehlszeile benutzt. Die Protokolle sollten ähnlich aussehen wie in Abbildung 4-32.
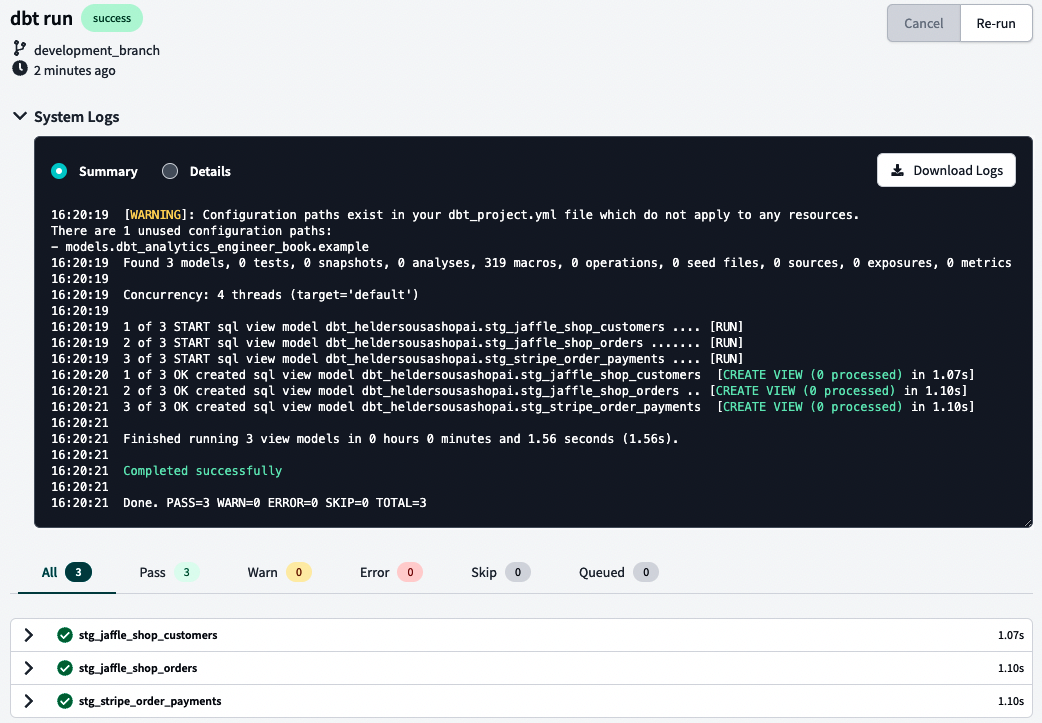
Abbildung 4-32. dbt-Systemprotokolle
Tipp
Deine Logs sollten dir auch einen guten Überblick über das Problem geben, wenn etwas schief läuft. In Abbildung 4-32 siehst du eine Zusammenfassung der Logs, aber du kannst dir auch die detaillierten Logs ansehen, um mehr zu erfahren.
In der Erwartung, dass du die Meldung "Erfolgreich abgeschlossen" erhalten hast, werfen wir nun einen Blick auf BigQuery, wo du alle drei Modelle materialisiert sehen solltest, wie Abbildung 4-33 zeigt.

Abbildung 4-33. dbt BigQuery-Modelle
Standardmäßig materialisiert dbt deine Modelle innerhalb deiner Datenplattform als Ansichten. Du kannst dies jedoch ganz einfach im Konfigurationsblock am Anfang der Modelldatei konfigurieren(Beispiel 4-12).
Beispiel 4-12. Materialisierungskonfiguration innerhalb der Modelldatei
{{config(materialized='table')}}SELECTidascustomer_id,first_name,last_nameFROM`dbt-tutorial.jaffle_shop.customers`
Jetzt, wo wir unsere ersten Modelle erstellt haben, können wir zu den nächsten Schritten übergehen. Ordne den Code mithilfe der YAML-Dateien neu an und befolge die bewährten Methoden, die in "YAML-Dateien" empfohlen werden . Wir nehmen den Codeblock von dort und konfigurieren unsere Materialisierungen in unseren YAML-Dateien(Beispiel 4-12). Die erste Datei, die wir ändern, ist dbt_project.yml. Sie sollte die zentrale YAML-Datei für die Standardkonfigurationen sein. Ändern wir also die Konfiguration des Modells mit dem Code in Beispiel 4-13 und führen dann dbt run erneut aus.
Beispiel 4-13. Modelle als Views und als Tabellen materialisieren
models:dbt_analytics_engineer_book:staging:jaffle_shop:+materialized:viewstripe:+materialized:table
Hinweis
Das Präfix + ist eine dbt-Syntaxerweiterung, die mit dbt v0.17.0 eingeführt wurde, um Ressourcenpfade und Konfigurationen in dbt_project.yml-Dateien zu verdeutlichen.
Da in Beispiel 4-13 alle Staging-Stripe-Modelle als Tabelle materialisiert werden mussten, sollte BigQuery wie in Abbildung 4-34 aussehen.
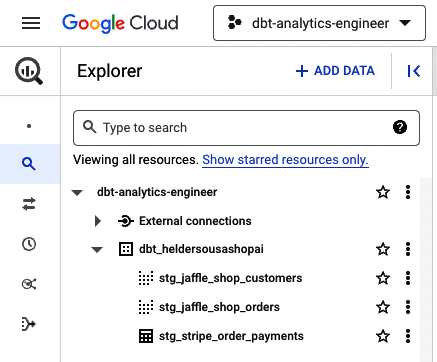
Abbildung 4-34. dbt BigQuery-Modelle mit materialisierter Tabelle
Beispiel 4-13 zeigt, wie du in der Datei dbt_project.yml für jeden Ordner die gewünschten Materialisierungen konfigurierst. Deine Staging-Modelle werden standardmäßig als Views gespeichert. Du kannst diese Konfiguration auf der Ordnerebene des Modells überschreiben, indem du die kaskadierende Scope-Priorität beim Projekt-Build nutzt. Ändern wir zunächst unsere dbt_project.yml so, dass alle Staging-Modelle als Views materialisiert werden, wie Beispiel 4-14 zeigt.
Beispiel 4-14. Bereitstellen von Modellen, die als Ansichten materialisiert werden sollen
models:dbt_analytics_engineer_book:staging:+materialized:view
Erstellen wir nun eine separate YAML-Datei für stg_jaffle_shop_customers, in der wir angeben, dass sie als Tabelle materialisiert werden soll. Dazu erstellst du die entsprechende YAML-Datei mit dem Namen _jaffle_shop_models.yml im Verzeichnis staging/jaffle_shop und kopierst den Code in Beispiel 4-15.
Beispiel 4-15. Festlegen, dass das Modell als Tabelle materialisiert werden soll
version:2models:-name:stg_jaffle_shop_customersconfig:materialized:table
Nachdem du dbt erneut ausgeführt hast, wirf einen Blick auf BigQuery. Sie sollte ähnlich aussehen wie in Abbildung 4-35.
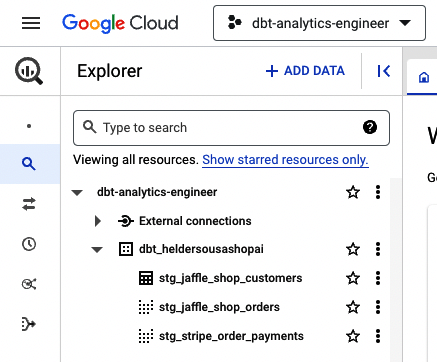
Abbildung 4-35. dbt BigQuery-Kundenmodell materialisiert in einer Tabelle
Dies ist ein einfaches Beispiel für die Verwendung von YAML-Dateien, für das Spielen mit Tabellenmaterialisierungen und dafür, was die kaskadierende Scope-Priorität in der Praxis bedeutet. Es gibt noch viel zu tun und zu sehen, und einiges von dem, was wir hier besprechen, wird im weiteren Verlauf noch mehr Anwendung finden. Für den Moment möchten wir dich bitten, dein Modell in der Datei _jaffle_shop_models.yml so zu ändern, dass es als View materialisiert wird. Das wird deineStandardkonfiguration sein.
Hoffentlich hast du jetzt deine ersten Modelle entwickelt und verstehst in etwa den allgemeinen Zweck der YAML-Dateien und die kaskadierende Scope-Priorität. In den folgenden Schritten werden wir unsere Zwischen- und Mart-Modelle erstellen und dabei die Funktionen von ref() kennenlernen. Dies wird unsere erste Anwendung von Jinja sein, die wir in "Dynamisches SQL mit Jinja" ausführlicher behandeln werden .
Das Wichtigste zuerst: unser Anwendungsfall. Wenn wir unsere Modelle in unserem Staging-Bereich haben, müssen wir wissen, was wir mit ihnen machen wollen. Wie wir zu Beginn dieses Abschnitts erwähnt haben, musst du die Datenanforderungen definieren, die die Geschäftsprozesse in deinem Unternehmen unterstützen. Als Geschäftsanwender können wir aus unseren Daten mehrere Ströme ableiten. Einer davon, unser Anwendungsfall, ist die Analyse unserer Bestellungen pro Kunde, wobei der Gesamtbetrag, der pro erfolgreicher Bestellung gezahlt wurde, und der Gesamtbetrag pro erfolgreicher Bestellart (Bargeld und Kredit) dargestellt werden.
Da wir hier einige Transformationen haben, die eine Änderung der Granularität von der Zahlungsartenebene bis hin zur Auftragskategorie erfordern, ist es gerechtfertigt, diese komplexe Operation zu isolieren, bevor wir die Kartierungsschicht erreichen. Genau hier landet die Zwischenschicht. Erstelle in deinem Modellordner einen neuen Ordner mit dem Namen intermediate. Erstelle darin eine neue SQL-Datei mit dem Namen int_payment_type_amount_per_order.sql und kopiere den Code aus Beispiel 4-16.
Beispiel 4-16. int_payment_type_amount_per_order.sql
withorder_paymentsas(select*from{{ref('stg_stripe_order_payments')}})selectorder_id,sum(casewhenpayment_type='cash'andstatus='success'thenamountelse0end)ascash_amount,sum(casewhenpayment_type='credit'andstatus='success'thenamountelse0end)ascredit_amount,sum(casewhenstatus='success'thenamountend)astotal_amountfromorder_paymentsgroupby1
Wie du bei der Erstellung der order_payments CTE sehen kannst, sammeln wir die Daten aus stg_stripe_order_payments mit der Funktion ref(). Diese Funktion verweist auf die vorgelagerten Tabellen und Ansichten, aus denen deine Datenplattform besteht. Wir werden diese Funktion als Standard verwenden, während wir unseren Analysecode implementieren, denn sie hat viele Vorteile:
-
Sie ermöglicht es dir, Abhängigkeiten zwischen Modellen auf flexible Weise zu erstellen, die in einer gemeinsamen Codebasis gemeinsam genutzt werden können, da sie den Namen des Datenbankobjekts während der
dbt runkompiliert und ihn aus der Umgebungskonfiguration beim Erstellen des Projekts entnimmt. Das bedeutet, dass der Code in deiner Umgebung unter Berücksichtigung deiner Umgebungskonfigurationen kompiliert wird, die in deiner speziellen Entwicklungsumgebung verfügbar sind, sich aber von denen deines Teamkollegen unterscheiden, der eine andere Entwicklungsumgebung verwendet, aber dieselbe Codebasis nutzt. -
Du kannst Lineage-Diagramme erstellen, in denen du den Datenfluss und die Abhängigkeiten eines bestimmten Modells visualisieren kannst. Darauf gehen wir später in diesem Kapitel ein, und es wird auch in "Dokumentation" behandelt .
Auch wenn der vorangegangene Code aufgrund der Wiederholbarkeit der CASE WHEN Bedingungen wie ein Gegenmuster erscheinen mag, ist es wichtig klarzustellen, dass der gesamte Datensatz alle Bestellungen enthält, unabhängig von ihrem Zahlungsstatus. Für dieses Beispiel haben wir uns jedoch entschieden, die Finanzanalyse nur für die Zahlungen durchzuführen, die mit den Bestellungen verbunden sind, die den Status "erfolgreich" erreicht haben.
Nachdem wir die Zwischentabelle erstellt haben, gehen wir zur letzten Ebene über. In dem beschriebenen Anwendungsfall müssen wir die Bestellungen aus der Sicht des Kunden analysieren. Das bedeutet, dass wir eine Kundendimension erstellen müssen, die mit unserer Faktentabelle verknüpft ist. Da der aktuelle Anwendungsfall mehrere Abteilungen erfüllen kann, erstellen wir keinen speziellen Abteilungsordner, sondern einen mit dem Namen Kern. Als Erstes erstellen wir also in unserem models-Ordner das Verzeichnis marts/core. Kopiere dann Beispiel 4-17 in eine neue Datei namens dim_customers.sql und Beispiel 4-18 in eine neue Datei namens fct_orders.sql.
Beispiel 4-17. dim_customers.sql
withcustomersas(select*from{{ref('stg_jaffle_shop_customers')}})selectcustomers.customer_id,customers.first_name,customers.last_namefromcustomers
Beispiel 4-18. fct_orders.sql
withordersas(select*from{{ref('stg_jaffle_shop_orders')}}),payment_type_ordersas(select*from{{ref('int_payment_type_amount_per_order')}})selectord.order_id,ord.customer_id,ord.order_date,pto.cash_amount,pto.credit_amount,pto.total_amount,casewhenstatus='completed'then1else0endasis_order_completedfromordersasordleftjoinpayment_type_ordersasptoONord.order_id=pto.order_id
Nachdem wir alle Dateien erstellt haben, setzen wir unsere Standardkonfigurationen in dbt_project.yml, wie in Beispiel 4-19 gezeigt, und führen dann dbt run oder möglicherweise dbt run --full-refresh auf BigQuery aus.
Beispiel 4-19. Modellkonfiguration, pro Schicht, in dbt_project.yml
models:dbt_analytics_engineer_book:staging:+materialized:viewintermediate:+materialized:viewmarts:+materialized:table
Tipp
Wenn du eine Fehlermeldung wie "Compilation Error in rpc request...depends on a node named int_payment_type_amount_per_order which was not found" erhältst, bedeutet dies, dass du ein Modell hast, das von dem Modell abhängt, das du versuchst, in der Vorschau anzuzeigen, und das sich noch nicht in deiner Datenplattform befindet - in unserem Fall int_payment_type_amount_per_order. Um das Problem zu lösen, gehst du zu dem betreffenden Modell und führst den dbt run --select MODEL_NAME aus und ersetze dabei MODEL_NAME durch den Namen des jeweiligen Modells.
Wenn alles erfolgreich gelaufen ist, sollte deine Datenplattform vollständig mit allen dbt-Modellen aktualisiert sein. Sieh dir einfach BigQuery an, das ähnlich wie in Abbildung 4-36 aussehen sollte.
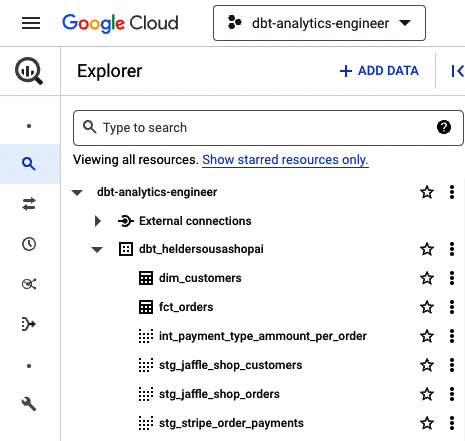
Abbildung 4-36. dbt BigQuery mit allen Modellen
Öffne schließlich fct_orders.sql und sieh dir die Option Lineage im Informationsfenster an(Abbildung 4-37). Dies ist eine der großartigen Funktionen, die wir in "Dokumentation" behandeln werden . Sie gibt uns einen guten Überblick über den Datenfluss, der ein bestimmtes Modell speist, sowie über seine vor- und nachgelagerten Abhängigkeiten.

Abbildung 4-37. dbt fct_orders data lineage
Quellen
In dbt sind Quellen die Rohdaten, die auf deiner Datenplattform verfügbar sind und mit einem generischen Extract-and-Load (EL)-Tool erfasst werden. Es ist wichtig, dbt-Quellen von traditionellen Datenquellen zu unterscheiden. Eine traditionelle Datenquelle kann entweder intern oder extern sein. Interne Datenquellen liefern die Transaktionsdaten, die den täglichen Geschäftsbetrieb innerhalb deines Unternehmens unterstützen. Kunden-, Verkaufs- und Produktdaten sind Beispiele für mögliche Inhalte aus einer internen Datenquelle. Externe Datenquellen hingegen liefern Daten, die von außerhalb deines Unternehmens stammen, z. B. Daten, die von deinen Geschäftspartnern, aus dem Internet oder aus der Marktforschung stammen. Oft handelt es sich dabei um Daten über Konkurrenten, Wirtschaftsdaten, demografische Daten von Kunden usw.
dbt-Quellen stützen sich auf interne und externe Daten, die vom Unternehmen benötigt werden, unterscheiden sich aber in ihrer Definition. Wie bereits erwähnt, sind dbt-Quellen die Rohdaten innerhalb deiner Datenplattform. Diese Rohdaten werden in der Regel von den Data-Engineering-Teams mithilfe eines EL-Tools in deine Datenplattform eingebracht und bilden die Grundlage für den Betrieb deiner analytischen Plattform.
In unseren Modellen unter "Modelle" haben wir unsere Quellen mit fest codierten Zeichenfolgen wie dbt-tutorial.stripe.payment oder dbt-tutorial.jaffle_shop.customers bezeichnet. Auch wenn das funktioniert, solltest du bedenken, dass es schwierig und zeitaufwändig sein kann, die Änderungen in mehreren Dateien vorzunehmen, wenn sich deine Rohdaten ändern, z. B. der Speicherort oder der Tabellenname, um bestimmten Namenskonventionen zu folgen. An dieser Stelle kommen die dbt-Quellen ins Spiel. Sie ermöglichen es dir, diese Quelltabellen in einer YAML-Datei zu dokumentieren, in der du auf deine Quelldatenbank, das Schema und die Tabellen verweisen kannst.
Setzen wir dies in die Praxis um. Befolgen wir die bewährten Methoden in "YAML-Dateien" und erstellen wir eine neue YAML-Datei im Verzeichnis models/staging/jaffle_shop mit dem Namen _jaffle_shop_sources.yml und kopieren den Code aus Beispiel 4-20. Dann erstellst du eine weitere YAML-Datei im Verzeichnis models/staging/stripe mit dem Namen _stripe_sources.yml und kopierst den Code aus Beispiel 4-21.
Beispiel 4-20. _jaffle_shop_sources.yml-sources-Parametrisierungsdatei für alle Tabellen unter dem Jaffle Shop Schema
version:2sources:-name:jaffle_shopdatabase:dbt-tutorialschema:jaffle_shoptables:-name:customers-name:orders
Beispiel 4-21. _stripe_sources.yml-sources Parametrisierungsdatei für alle Tabellen unter dem Stripe-Schema
version:2sources:-name:stripedatabase:dbt-tutorialschema:stripetables:-name:payment
Nachdem wir unsere YAML-Dateien konfiguriert haben, müssen wir eine letzte Änderung in unseren Modellen vornehmen. Anstatt unsere Quellen fest zu codieren, werden wir eine neue Funktion namens source() verwenden. Sie funktioniert wie die Funktion ref(), die wir im Abschnitt "Referenzierung von Datenmodellen" vorgestellt haben . Anstelle von {{ ref("stg_stripe_order_payments") }}, um eine Quelle zu konfigurieren, übergeben wir jetzt etwas wie {{ source("stripe", "payment") }}, das in diesem Fall die YAML-Datei referenziert, die wir in Beispiel 4-21 erstellt haben.
Machen wir uns jetzt die Hände schmutzig. Nimm den gesamten SQL Staging Model Code, den du zuvor erstellt hast, und ersetze ihn durch den entsprechenden Code in Beispiel 4-22.
Beispiel 4-22. Zahlungen, Aufträge und Kunden als Staging-Modelle mit der Funktion source()
-- REPLACE IT IN stg_stripe_order_payments.sqlselectidaspayment_id,orderidasorder_id,paymentmethodaspayment_method,casewhenpaymentmethodin('stripe','paypal','credit_card','gift_card')then'credit'else'cash'endaspayment_type,status,amount,casewhenstatus='success'thentrueelsefalseendasis_completed_payment,createdascreated_datefrom{{source('stripe','payment')}}-- REPLACE IT IN stg_jaffle_shop_customers.sql fileselectidascustomer_id,first_name,last_namefrom{{source('jaffle_shop','customers')}}-- REPLACE IT IN stg_jaffle_shop_orders.sqlselectidasorder_id,user_idascustomer_id,order_date,status,_etl_loaded_atfrom{{source('jaffle_shop','orders')}}
Nachdem du deine Modelle mit unserer Funktion source() umgestellt hast, kannst du überprüfen, wie dein Code in deiner Datenplattform ausgeführt wird, indem du dbt compile ausführst oder auf die Schaltfläche Kompilieren in deiner IDE klickst. Im Backend schaut dbt in die referenzierte YAML-Datei und ersetzt die Funktion source() durch den direkten Tabellenverweis, wie in Abbildung 4-38 dargestellt.
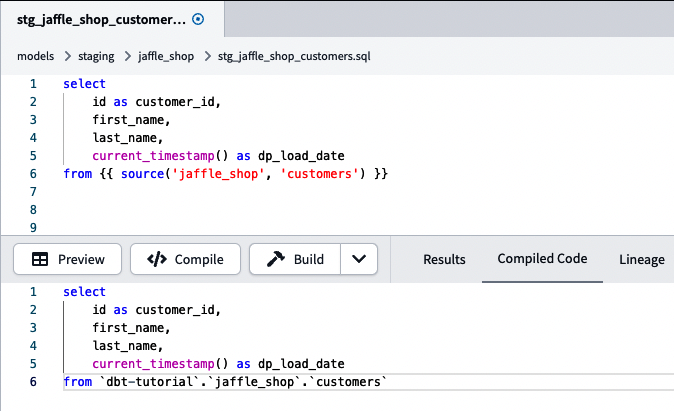
Abbildung 4-38. dbt customers staging model mit der Funktion source() und dem entsprechenden kompilierten Code. Der kompilierte Code wird in deiner Datenplattform ausgeführt.
Ein weiterer Vorteil der Funktion source() ist, dass du jetzt die Quellen in der Datenabfolge sehen kannst. Schau dir zum Beispiel unter die fct_orders.sql Lineage an. Die in Abbildung 4-37 gezeigte Lineage sollte jetzt wie Abbildung 4-39 aussehen.

Abbildung 4-39. dbt fct_orders data lineage mit Quellen
Frische der Quelle
Die Aktualität deiner Daten ist ein wesentlicher Aspekt der Datenqualität. Wenn die Daten nicht auf dem neuesten Stand sind, sind sie veraltet, was zu erheblichen Problemen im Entscheidungsprozess deines Unternehmens führen kann, da es zu ungenauen Erkenntnissen führen kann.
dbt ermöglicht es dir, diese Situation mit der Quellfrischeprüfung zu entschärfen. Dafür brauchen wir ein Audit-Feld, das den geladenen Zeitstempel eines bestimmten Datenartefakts in deiner Datenplattform angibt. Mit diesem Feld kann dbt prüfen, wie alt die Daten sind und je nach den festgelegten Bedingungen eine Warnung oder einen Fehler auslösen.
Um dies zu erreichen, müssen wir zu unseren YAML-Quelldateien zurückkommen. Für dieses Beispiel werden wir die Bestelldaten in unserer Datenplattform verwenden. Daraus ergibt sich, dass wir den Code in _jaffle_shop_sources.yml durch den Code in Beispiel 4-23 ersetzen.
Beispiel 4-23. _jaffle_shop_sources.yml-sources-Parametrisierungsdatei für alle Tabellen unter dem Jaffle Shop-Schema, mit Quellfreshness-Test
version:2sources:-name:jaffle_shopdatabase:dbt-tutorialschema:jaffle_shoptables:-name:customers-name:ordersloaded_at_field:_etl_loaded_atfreshness:warn_after:{count:12,period:hour}error_after:{count:24,period:hour}
Wie du sehen kannst, haben wir das Feld _etl_loaded_at in unserer Datenplattform verwendet. Wir mussten es nicht in unseren Transformationsprozess einbringen, da es keinen Mehrwert für Vorwärtsmodelle hat. Das ist kein Problem, denn wir testen unsere vorgelagerten Daten, die in unserem Fall unsere Rohdaten sind. In der YAML-Datei haben wir zwei zusätzliche Eigenschaften erstellt: loaded_at_field Die Eigenschaft freshness steht für das Feld, das im Rahmen des Frischetests überwacht werden soll, und die Eigenschaft für die eigentlichen Regeln zur Überwachung der Quellenfrische. In der Eigenschaft freshness haben wir festgelegt, dass eine Warnung ausgegeben wird, wenn die Daten 12 Stunden veraltet sind (Eigenschaft warn_after ), und dass ein Fehler ausgegeben wird, wenn die Daten in den letzten 24 Stunden nicht aktualisiert wurden (Eigenschaft error_after ).
Zum Schluss wollen wir sehen, was passiert, wenn wir den Befehl ausführen dbt source freshness. In unserem Fall erhalten wir eine Warnung, wie du in Abbildung 4-40 sehen kannst.

Abbildung 4-40. dbt bestellt Rohdaten und Quellfrische-Testprotokolle
Wenn du dir die Logdetails ansiehst, kannst du die in deiner Datenplattform ausgeführte Abfrage sehen und das Problem beheben. Diese spezielle Warnung war zu erwarten. Die _etl_loaded_at wurde so erstellt, dass sie 16 Stunden ab der aktuellen Uhrzeit benötigt, also wird alles, was darunter liegt, eine Warnung auslösen. Wenn du weiter herumspielen willst, ändere deine warn_after auf einen höheren Wert, z.B. 17 Stunden. Alle deine Tests sollten dann erfolgreich sein.
Hoffentlich ist das Konzept der Quellfrische jetzt klar. Wir werden im weiteren Verlauf des Buches darauf zurückkommen und dir zeigen, wie du die Quellfreshness-Tests automatisierst und mit Snapshots versiehst. In der Zwischenzeit ist es wichtig, seinen Zweck in der gesamten Testlandschaft zu verstehen, zu wissen, wie man ihn konfiguriert und wie wichtig dieser Test sein kann, um Probleme mit der Datenqualität zu entschärfen.
Tests
Als Analytiker musst du sicherstellen , dass die Daten genau und zuverlässig sind, damit du Vertrauen in die von dir gelieferten Analysen aufbauen und deinem Unternehmen objektive Erkenntnisse liefern kannst. Selbst wenn du alle bewährten Methoden befolgst, die dem Stand der Technik entsprechen, wird es immer wieder Ausnahmen geben - erst recht, wenn du mit der Unbeständigkeit von Daten, ihren Variationen, ihrer Art, ihrer Struktur usw. umgehen musst.
Es gibt viele Möglichkeiten, diese Ausnahmen zu erfassen. Wenn du jedoch mit großen Datenmengen arbeitest, musst du dir einen skalierbaren Ansatz überlegen, um große Datenmengen zu analysieren und diese Ausnahmen schnell zu identifizieren. Hier kommt dbt ins Spiel.
Mit dbt kannst du Tests schnell und einfach auf deinen gesamten Daten-Workflow ausdehnen, sodass du erkennen kannst, wenn etwas nicht funktioniert, bevor es jemand anderes tut. In einerEntwicklungsumgebung kannst du mit Tests sicherstellen, dass dein Analysecode die gewünschte Ausgabe erzeugt. In einer Deployment-/Produktionsumgebung kannst du Tests automatisieren und eine Warnung einrichten, die dich informiert, wenn ein bestimmter Test fehlschlägt, damit du schnell reagieren und das Problem beheben kannst, bevor es zu schwerwiegenderen Konsequenzen führt.
Als Datenexperte ist es wichtig zu verstehen, dass Tests in dbt als Behauptungen über deine Daten zusammengefasst werden können. Wenn du Tests auf deinen Datenmodellen durchführst, bestätigst du, dass diese Datenmodelle die erwarteten Ergebnisse liefern, was ein wichtiger Schritt ist, um die Qualität und Zuverlässigkeit der Daten zu gewährleisten. Diese Tests sind eine Form der Überprüfung, ähnlich wie die Bestätigung, dass deine Daten bestimmten Mustern folgen und vordefinierte Kriterien erfüllen.
Es ist jedoch wichtig zu wissen, dass dbt-Tests nur eine Art von Tests innerhalb der breiteren Landschaft der Datentests sind. Bei Softwaretests wird oft zwischen Verifizierung und Validierung unterschieden. dbt-Tests konzentrieren sich in erster Linie auf die Verifizierung, indem sie bestätigen, dass die Daten den festgelegten Mustern und Strukturen entsprechen. Sie sind nicht dafür gedacht, die Feinheiten der Logik in deinen Datentransformationen zu testen, wie es die Unit-Tests in der Softwareentwicklung tun.
Außerdem können dbt-Tests bis zu einem gewissen Grad bei der Integration von Datenkomponenten helfen, insbesondere wenn mehrere Komponenten zusammen ausgeführt werden. Dennoch ist es wichtig zu erkennen, dass dbt-Tests ihre Grenzen haben und nicht alle Anwendungsfälle abdecken können. Für umfassende Tests in Datenprojekten musst du unter Umständen andere Testmethoden und -werkzeuge einsetzen, die auf bestimmte Validierungs- und Überprüfungsanforderungen zugeschnitten sind.
In diesem Sinne wollen wir uns darauf konzentrieren, welche Tests mit dbt verwendet werden können. Es gibt zwei Hauptkategorien von Tests in dbt: singuläre und generische. Erfahren wir etwas mehr über beide Arten, ihren Zweck und wie wir sie nutzen können.
Generische Tests
Die einfachsten und dennoch hoch skalierbaren Tests im dbt sind generische Tests. Für diese Tests musst du in der Regel keine neue Logik schreiben, aber auch benutzerdefinierte generische Tests sind eine Option. In der Regel schreibst du jedoch ein paar Codezeilen in YAML und testest dann je nach Test ein bestimmtes Modell oder eine Spalte. dbt verfügt über vier eingebaute generische Tests:
uniqueTest-
Überprüft, ob jeder Wert in einer bestimmten Spalte eindeutig ist
not_nullTest-
Überprüft, ob jeder Wert in einer bestimmten Spalte nicht null ist
accepted_valuesTest-
Stellt sicher, dass jeder Wert in einer bestimmten Spalte in einer bestimmten vordefinierten Liste existiert
relationshipsTest-
Stellt sicher, dass jeder Wert in einer bestimmten Spalte in einer Spalte in einem anderen Modell vorhanden ist, so dass wir referenzielle Integrität gewährleisten
Da wir nun einige Informationen über die allgemeinen Tests haben, können wir sie ausprobieren. Wir können das Modell wählen, das wir wollen, aber der Einfachheit halber nehmen wir eines, auf das wir alle Tests anwenden können. Dafür haben wir das Modell stg_jaffle_shop_orders.sql gewählt. Hier können wir unique und not_null in Feldern wie customer_id und order_id testen. Mit accepted_values können wir prüfen, ob alle Bestellungen status in einer vordefinierten Liste sind. Schließlich werden wir den Test relationships verwenden, um zu prüfen, ob alle Werte aus customer_id im Modell stg_jaffle_shop_customers.sql enthalten sind. Beginnen wir damit, unsere _jaffle_shop_models.yml durch den Code in Beispiel 4-24 zu ersetzen.
Beispiel 4-24. _jaffle_shop_models.yml Parametrisierung mit generischen Tests
version:2models:-name:stg_jaffle_shop_customersconfig:materialized:viewcolumns:-name:customer_idtests:-unique-not_null-name:stg_jaffle_shop_ordersconfig:materialized:viewcolumns:-name:order_idtests:-unique-not_null-name:statustests:-accepted_values:values:-completed-shipped-returned-placed-name:customer_idtests:-relationships:to:ref('stg_jaffle_shop_customers')field:customer_id
Gib jetzt in deiner Befehlszeile ein dbt test ein und wirf einen Blick auf die Logs. Wenn der Test in der accepted_values fehlgeschlagen ist, hast du alles richtig gemacht. Er hätte eigentlich fehlschlagen müssen. Lass uns die Fehlerbehebung durchführen, um die mögliche Ursache des Fehlschlags zu verstehen. Öffne die Protokolle und erweitere den Test, der fehlgeschlagen ist. Klicke dann auf Details. Du siehst die Abfrage, die zum Testen der Daten ausgeführt wurde, wie Abbildung 4-41 zeigt.
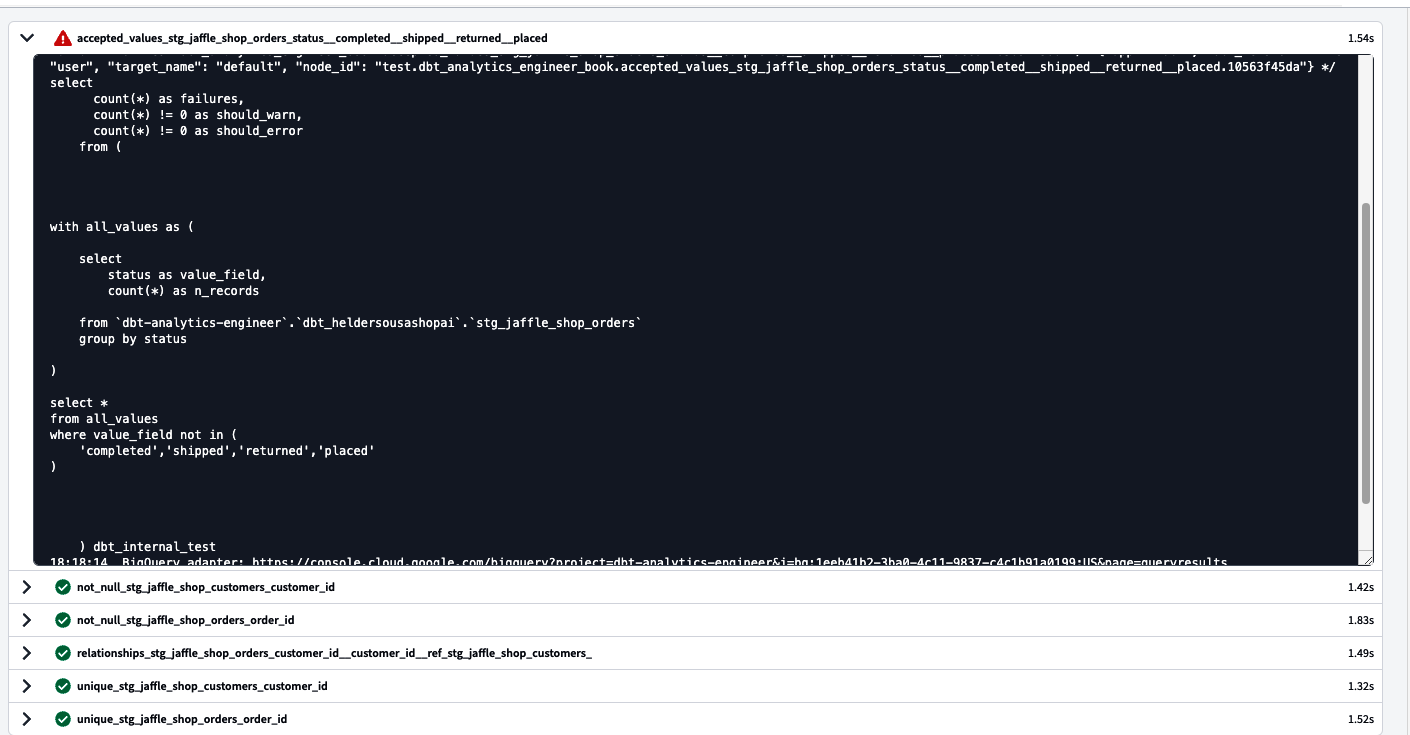
Abbildung 4-41. Generischer Test, dbt-Logs mit accepted_values fehlgeschlagener Test
Kopiere diese Abfrage in deinen Texteditor - behalte nur die innere Abfrage und führe sie dann aus. Du solltest eine ähnliche Ausgabe wie in Abbildung 4-42 erhalten.

Abbildung 4-42. Generisches Test-Debugging
Und voilá. Wir haben das Problem gefunden. Der zusätzliche Status return_pending fehlt in unserer Testliste. Fügen wir ihn hinzu und wiederholen unseren dbt test Befehl. Alle Tests sollten jetzt erfolgreich sein, wie in Abbildung 4-43 zu sehen ist.

Abbildung 4-43. Generischer Test, bei dem alle Tests erfolgreich durchgeführt wurden
Hinweis
Zusätzlich zu den generischen Tests in dbt Core gibt es noch viele weitere im dbt-Ökosystem. Diese Tests sind in dbt-Paketen zu finden, weil sie eine Erweiterung der allgemeinen Tests in dbt sind. In "dbt-Pakete" wird das Konzept der Pakete und ihre Installation im Detail erläutert. Für erweiterte Testmöglichkeiten sind Pakete wie dbt_utils vom dbt-Team oder dbt_expectations aus der Python-Bibliothek Great Expectations klare Beispiele für die hervorragende Nutzung von Paketen und ein Muss in jedem dbt-Projekt. Schließlich sind benutzerdefinierte generische Tests eine weitere dbt-Funktion, mit der du deine eigenen Datenvalidierungsregeln und -prüfungen definieren kannst, die auf deine spezifischen Projektanforderungen zugeschnitten sind.
Einzelne Tests
Im Gegensatz zu den generischen Tests sind singuläre Tests in .sql-Dateien im Verzeichnis tests definiert. In der Regel sind diese Tests hilfreich, wenn du ein bestimmtes Attribut in einem bestimmten Modell testen willst, aber die traditionellen Tests in dbt nicht deinen Bedürfnissen entsprechen.
Ein guter Test für unser Datenmodell ist es, zu prüfen, dass keine Bestellung einen negativen Gesamtbetrag aufweist. Wir können diesen Test in einer der drei Schichten durchführen - in der Vorstufe, der Zwischenschicht oder im Mart. Wir haben uns für die Zwischenschicht entschieden, da wir einige Transformationen vorgenommen haben, die die Daten beeinflussen könnten. Erstelle zunächst eine Datei namens assert_total_payment_amount_is_positive.sql im Verzeichnis tests und kopiere den Code aus Beispiel 4-25.
Beispiel 4-25. assert_total_payment_amount_is_positive.sql Einzeltest, um zu prüfen, ob das Attribut total_amount in int_payment_type_amount_per_order nur nicht-negative Werte hat
selectorder_id,sum(total_amount)astotal_amountfrom{{ref('int_payment_type_amount_per_order')}}groupby1havingtotal_amount<0
Jetzt kannst du einen der folgenden Befehle ausführen, um deinen Test zu starten, der erfolgreich sein sollte:
dbt test-
Führt alle deine Tests aus
dbt test --select test_type:singular-
Führt nur singuläre Tests aus
dbt test --select int_payment_type_amount_per_order-
Führt alle Tests für das Modell
int_payment_type_amount_per_orderaus. dbt test --select assert_total_payment_amount_is_positive-
Führt nur den spezifischen Test aus, den wir erstellt haben
Diese Befehle bieten dir die Möglichkeit, Tests nach deinen Anforderungen selektiv auszuführen. Ganz gleich, ob du alle Tests, Tests eines bestimmten Typs, Tests für ein bestimmtes Modell oder sogar nur einen einzelnen Test ausführen möchtest, dbt ermöglicht dir, verschiedene Auswahlsyntax-Optionen in deinen Befehlen zu nutzen. Diese Vielfalt an Möglichkeiten stellt sicher, dass du die Tests und andere dbt-Ressourcen, die du ausführen möchtest, genau auswählen kannst. In "dbt-Befehle und Auswahlsyntax" geben wir dir einen umfassenden Überblick über die verfügbaren dbt-Befehle und zeigen dir auf , wie du die Auswahlsyntax effizient zur Angabe von Ressourcen nutzen kannst.
Quellen testen
Um deine Modelle in deinem dbt-Projekt zu testen, kannst du diese Tests auch auf deine Quellen ausweiten. Das hast du bereits mit dem Test zur Quellfrische in " Quellfrische" getan . Du kannst aber auch generische und singuläre Tests für diesen Zweck potenzieren. Die Nutzung der Testmöglichkeiten in deinen Quellen gibt uns die Gewissheit, dass die Rohdaten so aufgebaut sind, dass sie unseren Erwartungen entsprechen.
Genauso wie du Tests in deinen Modellen konfigurierst, kannst du das auch für deine Quellen tun. Entweder in YAML-Dateien für allgemeine Tests oder in .sql-Dateien für einzelne Tests, die Norm bleibt die gleiche. Schauen wir uns ein Beispiel für jede Art von Test an.
Um mit den allgemeinen Tests zu beginnen, musst du die spezifische YAML-Datei der Quellen bearbeiten. Wir behalten dieselben unique, not_null und accepted_values Tests bei, wie wir sie für die Staging-Tabellen für Kunden und Bestellungen gemacht haben, aber jetzt wirst du ihre Quellen testen. Ersetze dazu den Code in _jaffle_shop_sources.yml durch den Code aus Beispiel 4-26.
Beispiel 4-26. _jaffle_shop_sources.yml-parametrizations mit generischen Tests
version:2sources:-name:jaffle_shopdatabase:dbt-tutorialschema:jaffle_shoptables:-name:customerscolumns:-name:idtests:-unique-not_null-name:ordersloaded_at_field:_etl_loaded_atfreshness:warn_after:{count:17,period:hour}error_after:{count:24,period:hour}columns:-name:idtests:-unique-not_null-name:statustests:-accepted_values:values:-completed-shipped-returned-placed-return_pending
Sobald du deinen neuen Code in der YAML-Datei hast, kannst du dbt test ausführen oder, genauer gesagt, den Befehl, der nur die Quelle testet, für die wir diese Tests erstellt haben, dbt test --select source:jaffle_shop. Alle deine Tests sollten erfolgreich sein.
Schließlich kannst du auch Einzeltests implementieren, wie du es zuvor getan hast. Wiederholen wir den Einzeltest, den wir in Beispiel 4-25 durchgeführt haben. Erstelle eine neue Datei namens assert_source_total_payment_amount_is_positive.sql in deinem Tests-Verzeichnis und kopiere den Code aus Beispiel 4-27. Dieser Test prüft, ob die Summe des Attributs amount pro Bestellung in der Tabelle der Zahlungsquelle nur nicht-negative Werte hat.
Beispiel 4-27. assert_source_total_payment_amount_is_positive.sql Einzeltest
selectorderidasorder_id,sum(amount)astotal_amountfrom{{source('stripe','payment')}}groupby1havingtotal_amount<0
Führe dbt test oder dbt test --select source:stripe aus, da wir in diesem Fall in die Stripe-Quelle schauen. Alles sollte ebenfalls funktionieren.
Auswertungen
Im Ordner analyses kannst du deine Ad-hoc-Abfragen, Audit-Abfragen, Trainingsabfragen oder Refactoring-Abfragen speichern, mit denen du z.B. überprüfen kannst, wie dein Code aussieht, bevor du deine Modelle veränderst.
Analysen sind Templating-SQL-Dateien, die du nicht unter dbt run ausführen kannst. Da du aber Jinja für deine Analysen verwenden kannst, kannst du dbt compile nutzen, um zu sehen, wie dein Code aussehen wird, und gleichzeitig deinen Code unter Versionskontrolle behalten. Schauen wir uns nun einen Anwendungsfall an, bei dem wir den Ordner Analysen nutzen können.
Stell dir vor, du willst kein komplett neues Modell erstellen, aber trotzdem eine Information für zukünftige Bedürfnisse behalten, indem du die Codeversionierung nutzt. Mit Analysen kannst du genau das tun. In unserem Anwendungsfall wollen wir die 10 wertvollsten Kunden in Bezug auf den gezahlten Gesamtbetrag analysieren und dabei nur die Aufträge mit dem Status "abgeschlossen" berücksichtigen. Dazu erstellst du im Verzeichnis analyses eine neue Datei namens most_valuable_customers.sql und kopierst den Code aus Beispiel 4-28.
Beispiel 4-28. most_valuable_customers.sql Analysen, die die Top 10 der wertvollsten Kunden auf Basis der abgeschlossenen Bestellungen ausgeben
withfct_ordersas(select*from{{ref('fct_orders')}}),dim_customersas(select*from{{ref('dim_customers')}})selectcust.customer_id,cust.first_name,SUM(total_amount)asglobal_paid_amountfromfct_ordersasordleftjoindim_customersascustONord.customer_id=cust.customer_idwhereord.is_order_completed=1groupbycust.customer_id,first_nameorderby3desclimit10
Führe den Code jetzt aus und überprüfe die Ergebnisse. Wenn alles gut läuft, erhältst du die 10 wertvollsten Kunden, wie Abbildung 4-44 zeigt.
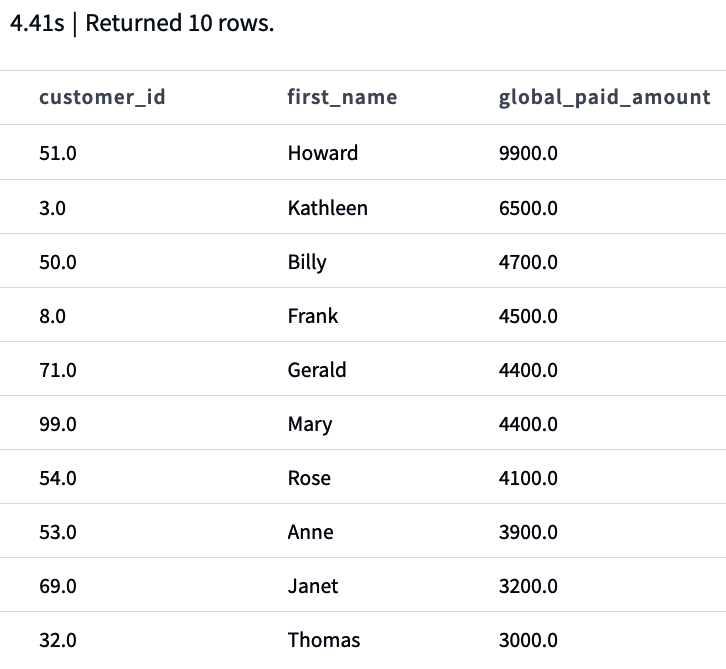
Abbildung 4-44. Top 10 der wertvollsten Kunden, basierend auf dem Gesamtbetrag, der mit abgeschlossenen Aufträgen bezahlt wurde
Saatgut
Seeds sind CSV-Dateien innerhalb deiner dbt-Plattform mit einer kleinen Menge nichtflüchtiger Daten, die als Tabelle in deiner Datenplattform materialisiert werden. Indem du einfach dbt seed in deine Befehlszeile eingibst, können Seeds in deinen Modellen wie alle anderen Modelle mit der Funktion ref() verwendet werden.
Es gibt zahlreiche Anwendungsmöglichkeiten für Seeds, z. B. die Zuordnung von Ländercodes (z. B. PT zu Portugal oder US zu den Vereinigten Staaten), Postleitzahlen zu Bundesstaaten, Dummy-E-Mail-Adressen, die von unseren Analysen ausgeschlossen werden sollen, oder sogar andere komplexe Analysen wie die Klassifizierung von Preisklassen. Wichtig ist, dass du dich daran erinnerst, dass das Saatgut keine großen oder häufig wechselnden Daten haben sollte. Wenn das der Fall ist, solltest du deinen Ansatz zur Datenerfassung überdenken - zum Beispiel mit SFTP (SSH File Transfer Protocol) oder einer API.
Um besser zu verstehen, wie man Seeds verwendet, schauen wir uns den nächsten Anwendungsfall an. Unter Berücksichtigung dessen, was wir in "Analysen" getan haben , wollen wir nicht nur die 10 wertvollsten Kunden auf der Grundlage der bezahlten Bestellungen sehen, sondern auch alle Kunden mit Bestellungen als regulär, Bronze, Silber oder Gold klassifizieren, und zwar unter Berücksichtigung der bezahlten total_amount. Beginnen wir damit, unseren Seed zu erstellen. Dazu erstellst du eine neue Datei mit dem Namen customer_range_per_paid_amount.csv in deinem Seeds-Ordner und kopierst die Daten aus Beispiel 4-29.
Beispiel 4-29. seed_customer_range_per_paid_amount.csv mit Bereichszuordnung
min_range,max_range,classification 0,9.999,Regular 10,29.999,Bronze 30,49.999,Silver 50,9999999,Gold
Nachdem du dies erledigt hast, führe aus dbt seed. Dadurch wird deine CSV-Datei in eine Tabelle in deiner Datenplattform umgewandelt. Schließlich erstellen wir im Verzeichnis analyses eine neue Datei namens customer_range_based_on_total_paid_amount.sql und kopieren den Code aus Beispiel 4-30.
Beispiel 4-30. customer_range_based_on_total_paid_amount.sql zeigt dir, basierend auf den abgeschlossenen Bestellungen und dem bezahlten Gesamtbetrag, den Kundenklassifizierungsbereich
withfct_ordersas(select*from{{ref('fct_orders')}}),dim_customersas(select*from{{ref('dim_customers')}}),total_amount_per_customer_on_orders_completeas(selectcust.customer_id,cust.first_name,SUM(total_amount)asglobal_paid_amountfromfct_ordersasordleftjoindim_customersascustONord.customer_id=cust.customer_idwhereord.is_order_completed=1groupbycust.customer_id,first_name),customer_range_per_paid_amountas(select*from{{ref('seed_customer_range_per_paid_amount')}})selecttac.customer_id,tac.first_name,tac.global_paid_amount,crp.classificationfromtotal_amount_per_customer_on_orders_completeastacleftjoincustomer_range_per_paid_amountascrpontac.global_paid_amount>=crp.min_rangeandtac.global_paid_amount<=crp.max_range
Führen wir nun unseren Code aus und sehen uns die Ergebnisse an. Für jeden Kunden wird der gezahlte Gesamtbetrag und der entsprechende Bereich angezeigt(Abbildung 4-45).
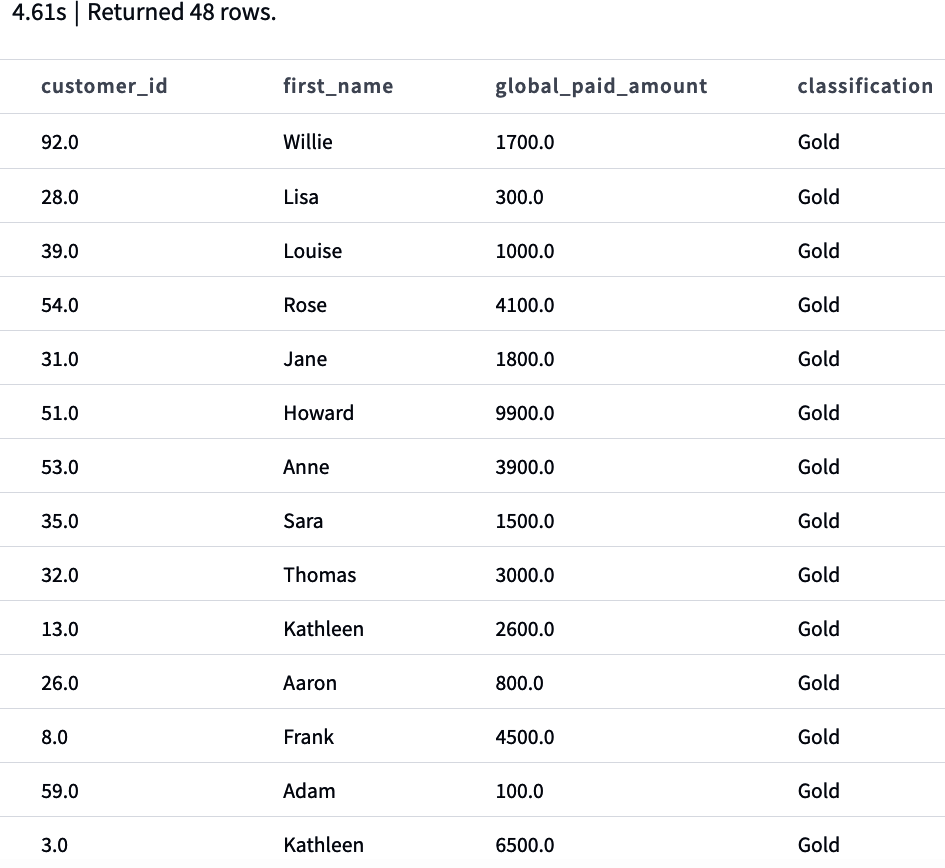
Abbildung 4-45. Reichweite der Kunden, basierend auf dem globalen Gesamtbetrag, der mit abgeschlossenen Bestellungen bezahlt wurde
Dokumentation
Dokumentation ist in der globalen Softwareentwicklung von entscheidender Bedeutung, doch sie scheint ein Tabu zu sein. Einige Teams dokumentieren, andere nicht, oder sie ist unvollständig. Sie kann zu bürokratisch oder komplex werden oder wird als zusätzlicher Aufwand auf der To-Do-Liste des Entwicklers angesehen und daher um jeden Preis vermieden. Du könntest eine riesige Liste von Gründen hören, die rechtfertigen, keine Dokumentation zu erstellen oder sie auf eine weniger anspruchsvolle Zeit zu verschieben. Niemand sagt, dass Dokumentation nicht notwendig ist. Es ist nur so, dass "wir es nicht tun", "nicht jetzt" oder "wir haben keine Zeit".
Hier sind einige Gründe, die für die Erstellung und Verwendung von Dokumentation sprechen:
-
Erleichtert den Einführungs-, Übergabe- und Einstellungsprozess. Mit einer ordnungsgemäßen Dokumentation hat jedes neue Teammitglied die Gewissheit, dass es nicht "den Wölfen zum Fraß vorgeworfen wird". Der neue Kollege hat den Onboarding-Prozess und die technische Dokumentation schriftlich vorliegen, was seine Lernkurve in Bezug auf die aktuellen Teamprozesse, Konzepte, Standards und technologischen Entwicklungen reduziert. Das Gleiche gilt für die Mitarbeiterfluktuation und den Übergang zum Wissensaustausch.
-
Sie ermöglicht eine einzige Quelle der Wahrheit. Von Geschäftsdefinitionen, Prozessen und Anleitungen bis hin zur Beantwortung von Self-Service-Fragen durch die Nutzerinnen und Nutzer - mit einer Dokumentation spart dein Team Zeit und Energie bei der Suche nach diesen Informationen.
-
Die gemeinsame Nutzung von Wissen durch die Dokumentation vermeidet doppelte oder überflüssige Arbeit. Wenn die Dokumentation bereits erstellt wurde, kann sie wiederverwendet werden, ohne dass man bei Null anfangen muss.
-
Sie fördert das Gefühl der gemeinsamen Verantwortung und stellt sicher, dass kritisches Wissen nicht auf eine einzelne Person beschränkt ist. Diese gemeinsame Verantwortung ist wichtig, um Störungen zu vermeiden, wenn wichtige Teammitglieder nicht verfügbar sind.
-
Sie ist unverzichtbar, wenn du Qualität und Prozesskontrolle sicherstellen und die Vorschriften einhalten willst. Eine Dokumentation ermöglicht es deinem Team, im gesamten Unternehmen zusammenzuarbeiten und sich abzustimmen.
Ein Grund für die mangelnde Motivation, eine Dokumentation zu erstellen, ist die Tatsache, dass sie parallel zum eigentlichen Entwicklungsfluss läuft, so als würde man ein Werkzeug für die Entwicklung und ein anderes für die Dokumentation verwenden. Bei dbt ist das anders. Du erstellst deine Projektdokumentation, während du unter anderem deinen Analysecode, die Tests und die Verbindung zu den Quellen entwickelst. Alles findet innerhalb von dbt statt, nicht in einer separaten Schnittstelle.
Die Art und Weise, wie dbt die Dokumentation handhabt, ermöglicht es dir, sie während der Erstellung deines Codes zu erstellen. In der Regel wird ein großer Teil der Dokumentation bereits dynamisch generiert, wie z. B. die Abstammungsdiagramme, die wir bereits vorgestellt haben. Dazu musst du nur deine Funktionen ref() und source() entsprechend konfigurieren. Der andere Teil ist teilweise automatisiert, du musst nur noch manuell eingeben, was ein bestimmtes Modell oder eine Spalte darstellt. Aber auch hier wird alles innerhalb von dbt gemacht, direkt in den YAML- oder Markdown-Dateien.
Fangen wir mit unserer Dokumentation an. Der Anwendungsfall, den wir erreichen wollen, ist die Dokumentation unserer Modelle und der entsprechenden Spalten von fct_orders und dim_customers. Wir werden die YAML-Dateien der Modelle verwenden und für eine umfangreichere Dokumentation werden wir doc-Blöcke innerhalb der Markdown-Dateien verwenden. Da wir noch eine YAML-Datei für die Core-Modelle im Marts-Verzeichnis erstellen müssen, tun wir dies mit dem Namen _core_models.yml.
Kopiere Beispiel 4-31. Erstelle dann im gleichen Verzeichnis eine Markdown-Datei mit dem Namen _code_docs.md und kopiere Beispiel 4-32.
Beispiel 4-31. _core_models.yml-YAML-Datei mit dem Parameter description
version:2models:-name:fct_ordersdescription:Analytical orders data.columns:-name:order_iddescription:Primary key of the orders.-name:customer_iddescription:Foreign key of customers_id at dim_customers.-name:order_datedescription:Date that order was placed by the customer.-name:cash_amountdescription:Total amount paid in cash by the customer with "success" paymentstatus.-name:credit_amountdescription:Total amount paid in credit by the customer with "success"payment status.-name:total_amountdescription:Total amount paid by the customer with "success" payment status.-name:is_order_completeddescription:"{{doc('is_order_completed_docblock')}}"-name:dim_customersdescription:Customer data. It allows you to analyze customers perspective linkedfacts.columns:-name:customer_iddescription:Primary key of the customers.-name:first_namedescription:Customer first name.-name:last_namedescription:Customer last name.
Beispiel 4-32. _core_doc.md - Markdown-Datei mit einem Doc-Block
{% docs is_order_completed_docblock %}Bevor wir die Dokumentation erstellen, wollen wir versuchen zu verstehen, was wir getan haben. Wenn du die YAML-Datei _core_models.yml analysierst, kannst du sehen, dass wir eine neue Eigenschaft hinzugefügt haben: description. Diese grundlegende Eigenschaft ermöglicht es dir, die Dokumentation durch deine manuellen Eingaben zu ergänzen. Diese manuellen Eingaben können Text sein, wie wir es in den meisten Fällen getan haben, aber sie können auch auf Doc-Blöcke innerhalb von Markdown-Dateien verweisen, wie in fct_orders, Spalte is_order_completed. Zuerst haben wir den Dokumentationsblock in der Markdown-Datei _code_docs.md erstellt und ihn is_order_completed_docblock genannt. Diesen Namen haben wir verwendet, um auf den Doc-Block im Beschreibungsfeld zu verweisen: "{{ doc('is_order_completed_docblock') }}".
Generieren wir unsere Dokumentation, indem wir dbt docs generate in deine Befehlszeile eingibst. Nach erfolgreicher Beendigung kannst du durch die Dokumentationsseite navigieren.
Die Dokumentationsseite zu erreichen, ist einfach. Nachdem du dbt docs generate erfolgreich ausgeführt hast, kannst du in der IDE oben links auf dem Bildschirm auf das Symbol für die Dokumentationsseite klicken, direkt neben den Informationen zum Git-Zweig(Abbildung 4-46).
Abbildung 4-46. Dokumentation anzeigen
Sobald du die Dokumentationsseite aufgerufen hast, siehst du die Übersichtsseite, ähnlich wie in Abbildung 4-47. Im Moment hast du die Standardinformationen von dbt zur Verfügung, aber auch diese Seite kann vollständig angepasst werden.
Abbildung 4-47. Dokumentation Landing Page
Auf der Übersichtsseite siehst du auf der linken Seite deine Projektstruktur(Abbildung 4-48) mit Tests, Seeds und Modellen, in denen du frei navigieren kannst.

Abbildung 4-48. dbt-Projektstruktur innerhalb der Dokumentation
Wähle nun eines der von uns entwickelten Modelle aus und sieh dir die dazugehörige Dokumentation an. Wir haben das Modell fct_orders ausgewählt. Wenn du auf die Datei klickst, werden dir auf dem Bildschirm mehrere Informationsebenen zu dem Modell angezeigt (siehe Abbildung 4-49).
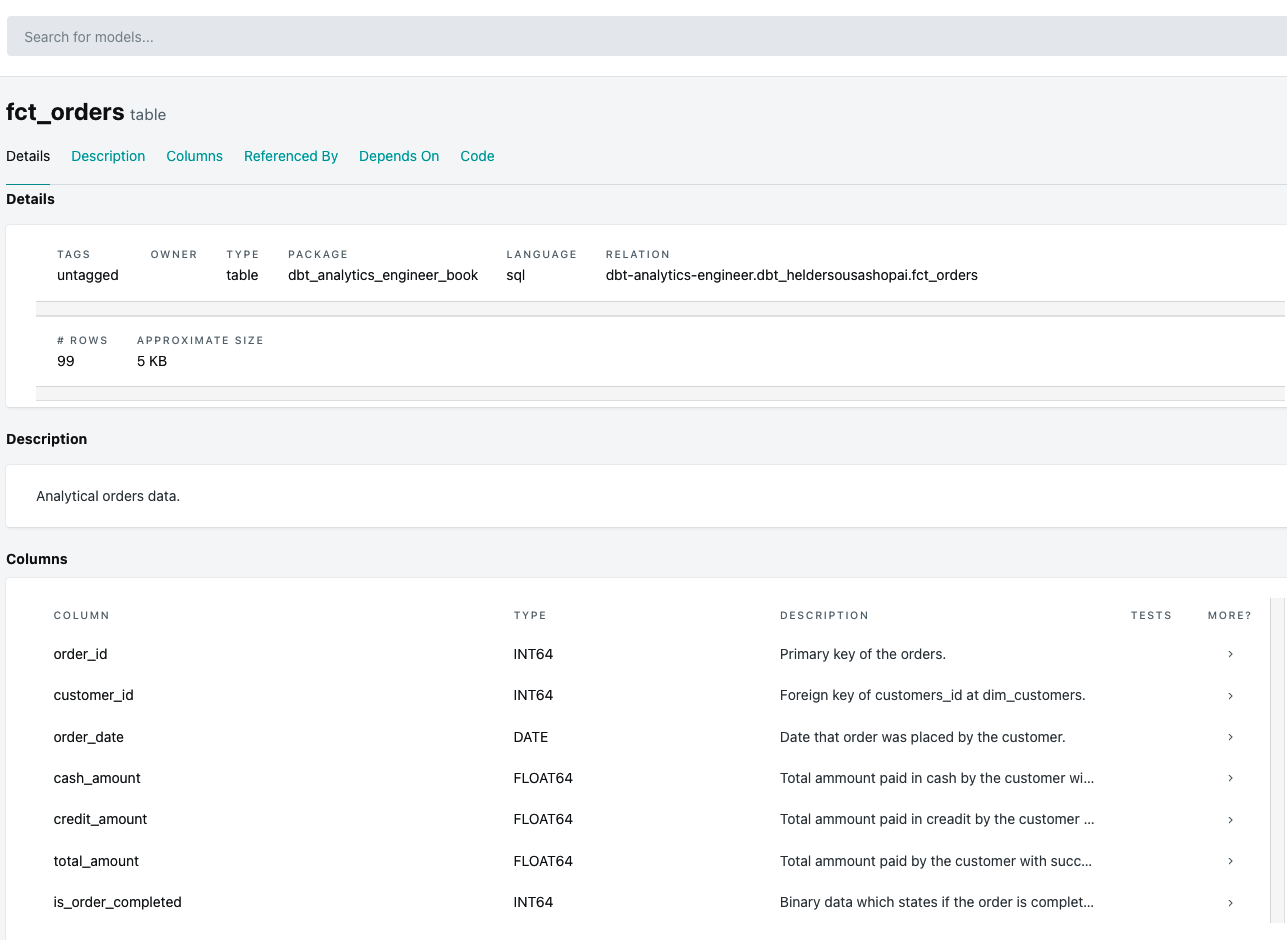
Abbildung 4-49. fct_orders Dokumentationsseite
Oben im Abschnitt Details findest du Informationen zu den Metadaten der Tabelle, z. B. den Tabellentyp (auch als Materialisierung bekannt). Die verwendete Sprache, die Anzahl der Zeilen und die ungefähre Größe der Tabelle sind weitere verfügbare Details.
Gleich danach folgt die Beschreibung des Modells. Wie du dich vielleicht erinnerst, war es das Modell, das wir in der Datei _core_models.yml für die Tabelle fct_orders konfiguriert haben.
Schließlich haben wir die Spalteninformationen zu fct_orders. Diese Dokumentation ist teilweise automatisiert (z. B. der Spaltentyp), wird aber auch manuell eingegeben (z. B. die Spaltenbeschreibungen). Wir haben diese Eingaben bereits beim Ausfüllen der Beschreibungseigenschaften gemacht und umfassende Informationen in Form von Dokumentationsblöcken für das Attribut is_order_completed bereitgestellt. Um den geschriebenen Doc-Block auf der Dokumentationsseite zu sehen, klicke in das Feld is_order_completed, das sich ausklappen und die gewünschten Informationen anzeigen sollte(Abbildung 4-50).

Abbildung 4-50. is_order_completed Spalte zeigt den konfigurierten Doc-Block
Nach den Spalteninformationen folgen die nachgelagerten und vorgelagerten Abhängigkeiten des Modells mit den Abschnitten Referenziert von bzw. Abhängig von. Diese Abhängigkeiten sind auch in Abbildung 4-51 dargestellt.

Abbildung 4-51. fct_orders Abhängigkeiten in der Dokumentation
Unten auf der Dokumentationsseite fct_orders findest du den Code, mit dem das jeweilige Modell erstellt wurde. Du kannst den Quellcode im Rohformat mit Jinja oder den kompilierten Code anzeigen lassen. Abbildung 4-52 zeigt die rohe Form.

Abbildung 4-52. fct_orders Quellcode
Unten rechts auf deiner Dokumentationsseite siehst du eine blaue Schaltfläche. Wenn du auf diese Schaltfläche klickst, wird das Abstammungsdiagramm für das jeweilige Modell, das du gerade visualisierst, angezeigt. Wir haben den fct_orders Liniengraphen ausgewählt, in dem du die vorgelagerten Abhängigkeiten, wie die Quelltabellen oder die Zwischentabellen, sowie die nachgelagerten Abhängigkeiten, wie die in Abbildung 4-53 gezeigten Analysedateien, sehen kannst. Das Lineage-Diagramm ist sehr aussagekräftig, da es einen ganzheitlichen Überblick über den Weg der Daten gibt, von dem Moment, in dem du sie konsumierst, bis zu ihrer Umwandlung und Bereitstellung.
Ein weiterer interessanter Aspekt der dbt-Dokumentation, den es zu erwähnen gilt, ist die Möglichkeit, Beschreibungen auf Spalten- und Tabellenebene mit Hilfe der Konfiguration persist_docs direkt in der Datenbank zu speichern. Diese Funktion ist für alle Nutzer deines DataWarehouse wertvoll, auch für diejenigen, die keinen Zugang zur dbt Cloud haben. Sie stellt sicher, dass wichtige Metadaten und Beschreibungen für die Datenkonsumenten leicht zugänglich sind, was ein besseres Verständnis und eine bessere Nutzung deiner Datenbestände ermöglicht.

Abbildung 4-53. fct_orders Abstammungsdiagramm
dbt-Befehle und Auswahlsyntax
Wir haben bereits einige dbt-Befehle vorgestellt, z. B. dbt run und dbt test, und erklärt, wie wir mit der CLI interagieren, um sie auszuführen. In diesem Abschnitt werden wir die wichtigsten dbt-Befehle und die Auswahlsyntax kennenlernen, mit denen du verschiedene Aspekte deines dbt-Projekts ausführen, verwalten und kontrollieren kannst. Ob du nun Transformationen ausführst, Tests durchführst oder Dokumentationen erstellst - diese Befehle sind dein Werkzeugkasten für effektives Projektmanagement.
Fangen wir ganz am Anfang an. Im Kern ist dbt ein Kommandozeilen-Tool, das deine Arbeitsabläufe bei der Datenumwandlung vereinfacht. Es bietet eine Reihe von Befehlen, mit denen du effizient mit deinem dbt-Projekt arbeiten kannst. Wir werden uns jeden dieser Befehle genauer ansehen.
dbt-Lauf
Mit dem Befehl dbt run kannst du unter die in deinen dbt-Modellen definierten Datentransformationen ausführen. Er arbeitet mit den Konfigurationsdateien deines Projekts, wie z.B. dbt_project.yml, um herauszufinden, welche Modelle in welcher Reihenfolge ausgeführt werden müssen. Dieser Befehl ermittelt die Modelle, die aufgrund ihrer Abhängigkeiten ausgeführt werden müssen, und führt sie in der richtigen Reihenfolge aus.
dbt-Dokumente
Eine angemessene Dokumentation ist für kollaborative Datenprojekte unerlässlich . dbt docs automatisiert die Erstellung der Dokumentation für dein dbt-Projekt, einschließlich Modellbeschreibungen, Spaltenbeschreibungen und Beziehungen zwischen Modellen. Um die Dokumentation zu erstellen, musst du dbt docs generate ausführen.
dbt bauen
Bevor du dein dbt-Projekt ausführst, ist es oft notwendig, es zu kompilieren. Der Befehl dbt build führt diese Aufgabe aus und erstellt die erforderlichen Artefakte für die Ausführung. Dieser Schritt ist wichtig, um den Ausführungsprozess zu optimieren und sicherzustellen, dass alles an seinem richtigen Platz ist. Sobald dein Projekt erfolgreich kompiliert wurde, kannst du mit anderen Befehlen wie dbt run mit mehr Zuversicht fortfahren.
Andere Befehle
Obwohl die oben genannten Befehle am häufigsten verwendet werden, solltest du auch die anderen Befehle von dbt kennen, wie zum Beispiel diese:
dbt seed-
Lädt Rohdaten oder Referenzdaten in dein Projekt
dbt clean-
Löscht Artefakte, die von
dbt build dbt snapshot-
Macht einen Schnappschuss deiner Daten für die Versionierung
dbt archive-
Archiviert Tabellen oder Modelle zur kalten Speicherung
dbt deps-
Installiert die in packages.yml definierten Projektabhängigkeiten
dbt run-operation-
Führt eine in deinem Projekt definierte benutzerdefinierte Operation aus
dbt source snapshot-freshness-
Überprüft die Aktualität deiner Quelldaten
dbt ls-
Listet die in einem dbt-Projekt definierten Ressourcen auf
dbt retry-
Führt den zuletzt ausgeführten dbt-Befehl an der Fehlerstelle erneut aus
dbt debug-
Führt dbt im Debug-Modus aus und liefert detaillierte Debugging-Informationen
dbt parse-
Analysiert dbt-Modelle, ohne sie auszuführen, was für die Syntaxprüfung hilfreich ist
dbt clone-
Klont ausgewählte Modelle aus dem angegebenen Zustand
dbt init-
Erzeugt ein neues dbt-Projekt im aktuellen Verzeichnis
Auswahlsyntax
Wenn deine dbt-Projekte wachsen, brauchst du , um bestimmte Modelle, Tests oder andere Ressourcen zur Ausführung, zum Testen oder zur Dokumentationserstellung auszuwählen, anstatt sie jedes Mal auszuführen. An dieser Stelle kommt die Auswahlsyntax ins Spiel.
Mit der Auswahlsyntax kannst du genau festlegen, welche Ressourcen du bei der Ausführung von dbt-Befehlen ein- oder ausschließen möchtest. Die Auswahlsyntax umfasst verschiedene Elemente und Techniken, wie zum Beispiel die folgenden.
Wildcard *
Das Sternchen (*) steht für ein beliebiges Zeichen oder eine Zeichenfolge. Schauen wir uns Beispiel 4-33 an.
Beispiel 4-33. Auswahlsyntax mit * Wildcard
dbtrun--selectmodels/marts/core/*
Hier verwenden wir den Platzhalter * zusammen mit dem Flag --select, um alle Ressourcen oder Modelle im Core-Verzeichnis zu erreichen. Dieser Befehl führt alle Modelle, Tests oder andere Ressourcen in diesem Verzeichnis aus.
Tags
Tags sind Bezeichnungen, die du Modellen, Makros oder anderen Ressourcen in deinem dbt-Projekt zuweisen kannst - insbesondere innerhalb der YAML-Dateien. Du kannst die Auswahlsyntax verwenden, um Ressourcen mit bestimmten Tags auszuwählen. Beispiel 4-34 zeigt, wie du Ressourcen anhand des Tags marketing auswählen kannst.
Beispiel 4-34. Auswahlsyntax mit einem Tag
dbtrun--selecttag:marketing
Modellname
Du kannst ein einzelnes Modell genau auswählen, indem du den Namen in der Auswahlsyntax verwendest, wie in Beispiel 4-35 gezeigt.
Beispiel 4-35. Auswahlsyntax mit einem Modell
dbtrun--selectfct_orders
Abhängigkeiten
Verwende die Symbole + und -, um Modelle auszuwählen, die von anderen abhängen oder von denen andere abhängen. Zum Beispiel wählt fct_orders+ die Modelle von aus, die von fct_orders abhängen, während +fct_orders die Modelle auswählt, von denen fct_orders abhängt(Beispiel 4-36).
Beispiel 4-36. Auswahlsyntax mit Abhängigkeiten
# run fct_orders upstream dependencies dbt run --select +fct_orders # run fct_orders downstream dependencies dbt run --select fct_orders+ # run fct_orders both up and downstream dependencies dbt run --select +fct_orders+
Pakete
Wenn du dein dbt-Projekt in Paketen organisierst, kannst du die Paketsyntax verwenden, um alle Ressourcen innerhalb eines bestimmten Pakets auszuwählen, wie in Beispiel 4-37 gezeigt.
Beispiel 4-37. Auswahlsyntax mit einem Paket
dbtrun--selectmy_package.some_model
Mehrere Auswahlen
Du kannst Elemente der Auswahlsyntax kombinieren, um komplexe Auswahlen zu erstellen, wie in Beispiel 4-38 gezeigt.
Beispiel 4-38. Auswahlsyntax mit mehreren Elementen
dbtrun--selecttag:marketingfct_orders
In diesem Beispiel haben wir Elemente wie Tagging und Modellauswahl kombiniert. Das dbt-Modell mit dem Namen fct_orders wird nur ausgeführt, wenn es das Tag marketing hat.
Mit der Auswahlsyntax kannst du steuern, welche dbt-Ressourcen anhand verschiedener Kriterien wie Modellnamen, Tags und Abhängigkeiten ausgeführt werden. Du kannst die Auswahlsyntax mit dem --select Flag verwenden, um deine dbt-Operationen auf bestimmte Teilmengen deines Projekts zuzuschneiden.
Darüber hinaus bietet dbt verschiedene andere auswahlbezogene Flags und Optionen, wie z.B. --selector, --exclude, --defer, und mehr, die dir eine noch feinere Kontrolle darüber geben, wie du mit deinem dbt-Projekt interagierst. Diese Optionen machen es einfacher, dbt-Modelle und -Ressourcen so zu verwalten und auszuführen, dass sie mit den Anforderungen und Arbeitsabläufen deines Projekts übereinstimmen.
Aufträge und Einsätze
Bis jetzt haben wir uns damit beschäftigt, wie man mit dbt entwickelt. Wir haben gelernt, was Modelle sind, wie man Tests implementiert und Dokumentationen schreibt und andere wichtige Komponenten von dbt kennengelernt. All das haben wir mit unserer Entwicklungsumgebung und durch das manuelle Ausführen unserer dbt-Befehle erreicht und getestet.
Die Verwendung einer Entwicklungsumgebung sollte nicht bagatellisiert werden. Sie ermöglicht es dir, mit der Entwicklung deines dbt-Projekts fortzufahren, ohne die Entwicklungs-/Produktionsumgebung zu beeinträchtigen, bis du bereit bist. Aber jetzt sind wir an dem Punkt angelangt, an dem wir unseren Code produktiv machen und automatisieren müssen. Dazu müssen wir unseren Analysecode in einen Produktionszweig, der normalerweise als Hauptzweig bezeichnet wird, und in ein spezielles Produktionsschema wie dbt_analytics_engineering.core in BigQuery oder das entsprechende Produktionsziel in deiner Datenplattform deployen.
Schließlich müssen wir einen Auftrag konfigurieren und planen, um das, was wir in die Produktion bringen wollen, zu automatisieren. Die Konfiguration eines Auftrags ist ein wichtiger Teil des CI/CD-Prozesses. Er ermöglicht es dir, die Ausführung deiner Befehle in einem Rhythmus zu automatisieren, der zu deinen Geschäftsanforderungen passt.
Zunächst müssen wir alles, was wir bis jetzt gemacht haben, in unseren Entwicklungszweig übertragen und synchronisieren und dann mit dem Hauptzweig zusammenführen. Klicke auf die Schaltfläche "Übertragen und synchronisieren"(Abbildung 4-54). Vergiss nicht, eine ausführliche Nachricht zu schreiben.
Abbildung 4-54. "Schaltfläche "Bestätigen und synchronisieren
Möglicherweise musst du einen Pull Request stellen. Wie in "Einrichten der dbt Cloud mit BigQuery und GitHub" kurz erklärt , spielen Pull Requests (PRs) eine wichtige Rolle bei der gemeinsamen Entwicklung. Sie dienen als grundlegender Mechanismus, um deinem Team deine Änderungsvorschläge mitzuteilen. Es ist jedoch wichtig zu verstehen, dass PRs nicht nur dazu dienen, deine Kollegen über deine Arbeit zu informieren, sondern dass sie ein wichtiger Schritt im Überprüfungs- und Integrationsprozess sind.
Wenn du einen PR erstellst, lädst du dein Team ein, deinen Code zu überprüfen, Feedback zu geben und gemeinsam zu entscheiden, ob die Änderungen mit den Zielen und Qualitätsstandards des Projekts übereinstimmen.
Um zu unserem Code zurückzukommen, musst du deinen PR mit deinem Hauptzweig auf GitHub zusammenführen. Dein letzter Bildschirm in GitHub sollte ähnlich aussehen wie Abbildung 4-55.

Abbildung 4-55. Pull Request Bildschirm nach dem Zusammenführen mit dem Hauptzweig
In diesem Stadium sollte dein Hauptzweig gleich deinem Entwicklungszweig sein. Jetzt ist es an der Zeit, ihn auf deiner Datenplattform einzusetzen. Bevor du einen Auftrag erstellst, musst du deine Bereitstellungsumgebung einrichten:
-
Klicke im Menü Verteilen auf die Option Umgebungen und dann auf die Schaltfläche Umgebung erstellen. Es öffnet sich ein Fenster, in dem du deine Einsatzumgebung konfigurieren kannst.
-
Behalte die neueste dbt-Version bei und aktiviere nicht die Option, auf einem eigenen Zweig zu laufen, da wir unseren Code in den Hauptzweig eingebunden haben.
-
Nenne die Umgebung "Einsatz".
-
In den Abschnitt Deployment Credentials schreibst du den Datensatz, der deine Deployment-/Produktionsumgebung verknüpfen soll. Wir haben ihn
dbt_analytics_engineer_prodgenannt, aber du kannst den Namen verwenden, der am besten zu deinen Bedürfnissen passt.
Wenn alles gut läuft, solltest du eine Bereitstellungsumgebung mit Konfigurationen ähnlich denen in Abbildung 4-56 haben.

Abbildung 4-56. Einstellungen der Einsatzumgebung
Jetzt ist es an der Zeit, deinen Auftrag zu konfigurieren. In der dbt Cloud UI klickst du auf die Option Aufträge in deinem Bereitstellungsmenü und dann auf die Schaltfläche Neuen Auftrag erstellen. Die Erstellung eines Auftrags kann von einfachen Konzepten bis hin zu komplexeren Konzepten reichen. Lass uns einen Auftrag einrichten, der die wichtigsten Ideen abdeckt, die wir besprochen haben:
-
Benenne den Auftrag(Abbildung 4-57).
Abbildung 4-57. Festlegen des Auftragsnamens
-
Im Abschnitt Umgebung verweisen wir auf die Einsatzumgebung. Konfiguriere die dbt-Version so, dass sie von der in der Einsatzumgebung definierten Version erbt. Lasse den Zielnamen als Standard eingestellt. Das ist hilfreich, wenn du Bedingungen für deine Arbeitsumgebung festlegen möchtest (z. B.: Wenn du dich in der Einsatzumgebung befindest, mach dies; wenn du dich in der Entwicklungsumgebung befindest, mach das). Schließlich haben wir die Threads in "profiles.yml" behandelt . Belassen wir es bei der Standardkonfiguration. Wir haben keine Umgebungsvariablen erstellt, daher bleibt dieser Abschnitt leer. Abbildung 4-58 zeigt die Gesamtkonfiguration des Abschnitts "Environment".
Abbildung 4-58. Definieren der Auftragsumgebung
-
Abbildung 4-59 zeigt die globalen Konfigurationen der Ausführungseinstellungen. Wir haben "Ausführungszeitlimit" auf 0 gesetzt, damit dbt den Auftrag nicht beendet, wenn er länger als eine bestimmte Zeitspanne läuft. Außerdem haben wir "nicht auf einen anderen Lauf verschieben" gewählt. Schließlich haben wir die Kästchen "Generate docs on run" und "Run source freshness" aktiviert. Diese Konfiguration reduziert die Anzahl der Befehle, die du in den Abschnitt Befehle schreiben musst. Für diesen Anwendungsfall haben wir nur die Standardeinstellungen
dbt buildbeibehalten.
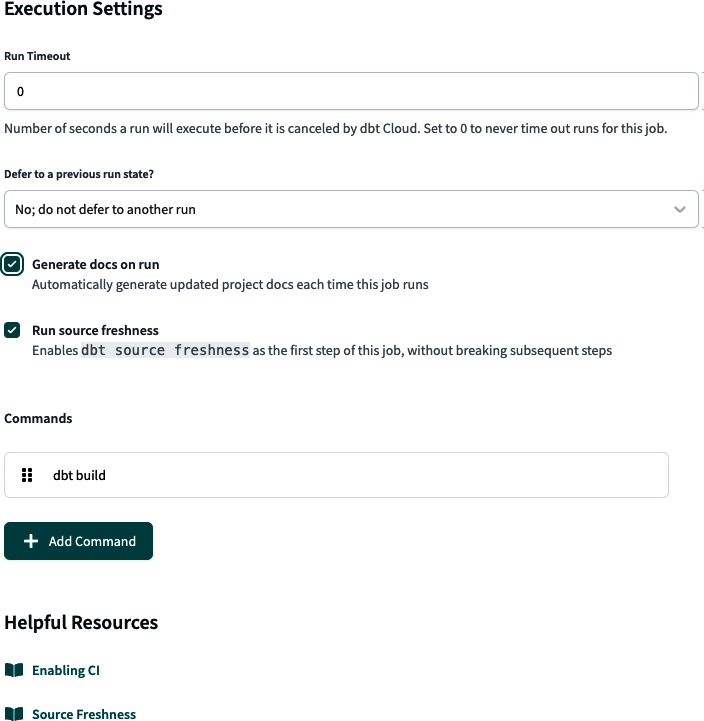
Abbildung 4-59. Definieren von Auftragseinstellungen
-
Die letzte Konfigurationseinstellung ist Auslöser, in der du festlegst, wie der Auftrag gestartet werden soll. Es gibt drei Möglichkeiten, einen Auftrag auszulösen:
-
Ein konfigurierter Zeitplan im dbt
-
Über Webhooks
-
Durch einen API-Aufruf
-
Für diesen Anwendungsfall haben wir die Option Zeitplan gewählt und den Zeitplan so eingestellt, dass er stündlich läuft, wie in Abbildung 4-60 dargestellt.
Abbildung 4-60. Definieren des Auftragsauslösers
Es ist an der Zeit, den Job auszuführen und zu sehen, was passiert. Speichere deinen Auftrag und wähle "Jetzt ausführen" oder warte darauf, dass der Auftrag automatisch ausgelöst wird, sobald er den konfigurierten Zeitplan erreicht hat.
Während der Auftrag läuft oder nachdem er beendet wurde, kannst du jederzeit den Status und die ausgeführten Aufgaben einsehen. Wähle im Menü Verteilen die Option Ausführungsverlauf. Dort siehst du die Ausführungen deiner Aufträge. Wähle einen aus und sieh dir die Ausführungsübersicht an. In Abbildung 4-61 siehst du, was du erwarten solltest.

Abbildung 4-61. Übersichtsbildschirm für die Auftragsausführung
In der Ausführungsübersicht erhältst du wichtige Informationen über die jeweilige Auftragsausführung, die bei der Fehlersuche hilfreich sein können. Ganz oben findest du eine Zusammenfassung des Ausführungsstatus, die Person oder das System, das den Auftrag ausgelöst hat, den Git-Commit, der mit dieser Auftragsausführung indiziert wurde, die erzeugte Dokumentation, die Quellen und die Umgebung, in der der Auftrag ausgeführt wurde.
Direkt nach der Auftragsübersicht findest du die Ausführungsdetails, z. B. die Zeit, die für die Ausführung des Auftrags benötigt wurde, und wann er gestartet und beendet wurde. Eine der wichtigsten Informationen, die dir die Ausführungsübersicht liefert, sind die Ausführungsschritte, in denen alle Befehle aufgeführt sind, die während der Ausführung des Auftrags ausgeführt wurden, und die es dir ermöglichen, jeden einzelnen Schritt und seine Protokolle einzusehen (siehe Abbildung 4-62). Wenn du die Protokolle der einzelnen Schritte untersuchst, kannst du nachvollziehen, was in den einzelnen Schritten gelaufen ist und nach Problemen während der Ausführung suchen.
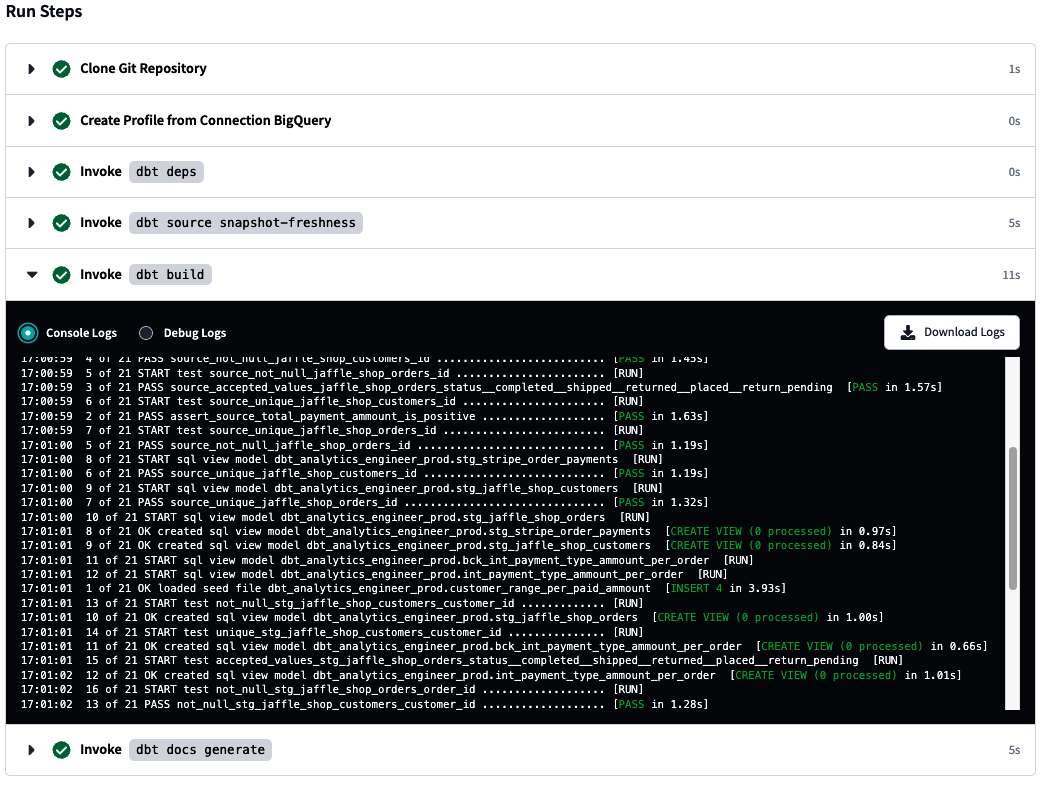
Abbildung 4-62. Details zu den Ausführungsschritten des Auftrags
Mit dbt-Aufträgen kannst du deine Transformationen ganz einfach automatisieren und deine Projekte auf effiziente und skalierbare Weise in die Produktion überführen. Egal, ob du Datenanalyst, Dateningenieur oder Analytiker bist, dbt kann dir helfen, die Komplexität deiner Datentransformationen zu bewältigen und sicherzustellen, dass deine Datenmodelle immer genau und aktuell sind.
Zusammenfassung
Dieses Kapitel zeigt, dass Analytics Engineering ein sich ständig weiterentwickelnder Bereich ist, der immer wieder von Innovationen beeinflusst wird. dbt ist nicht nur ein Aspekt dieser Geschichte, sondern ein entscheidendes Werkzeug in diesem Bereich.
Das Hauptziel von Analytics Engineering ist es, Rohdaten in wertvolle Erkenntnisse umzuwandeln. Dieses Tool spielt eine entscheidende Rolle dabei, die Komplexität der Datentransformation zu vereinfachen und die Zusammenarbeit zwischen einer Vielzahl von Interessengruppen zu fördern. dbt stellt sicher, dass die Datentransformation nicht nur eine technische Veränderung ist, sondern legt auch großen Wert auf Offenheit, Einbeziehung und Wissensaustausch.
dbt ist bekannt dafür, dass es komplizierte Prozesse durch die mühelose Integration mit großen Data Warehouses rationalisiert. Außerdem fördert es einen kollaborativen Ansatz bei der Datenumwandlung, indem es optimale Nachvollziehbarkeit und Genauigkeit gewährleistet. Außerdem unterstreicht es, wie wichtig es ist, Datenprozesse gründlich zu testen, um ihre Zuverlässigkeit zu gewährleisten. Die benutzerfreundliche Oberfläche unterstreicht den Gedanken, dass Analytik-Engineering ein inklusiver Bereich ist, der Beiträge von Menschen aller Kompetenzniveaus willkommen heißt.
Abschließend möchten wir allen Analytikern, die an der Spitze der Branche bleiben wollen, dringend empfehlen, sich mit diesem transformativen Werkzeug zu beschäftigen. Da dbt immer wichtiger wird und unbestreitbare Vorteile bringt, kann die Beherrschung dieses Tools nicht nur deine Fähigkeiten verbessern, sondern auch eine reibungslosere und kooperativere Datentransformation in der Zukunft ermöglichen.
Get Analytics Engineering mit SQL und dbt now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

