Chapter 4. The ActivityPub Protocol
The standards we’ve talked about so far—Activity Streams 2.0 and the ActivityPub API—are important because they standardized something that already existed in most social networks: data structures and client-to-server APIs. That’s a big achievement.
But the part of ActivityPub that changed the way people communicate on the internet—the part that many groups had tried before, without success—was the federation protocol. The federation protocol is what lets people on different services talk to one another as if they’re all on the same service. It enables the backend connection that delivers activities by users on one server to users on another server.
In this chapter, I’ll present the architecture of the ActivityPub federation. I’ll show you where the ActivityPub API leaves off and the ActivityPub federation protocol starts up. I’ll describe the authentication framework that lets people and servers on the fediverse identify themselves to one another. Then, I’ll talk about how activities get delivered from one server to another. I’ll go over the main types of activities we see on the fediverse and what well-behaved servers should do about each of them. Finally, I’ll cover how to connect conversations and threads on the fediverse.
Exploring an Extended Example
To illustrate the topics in this chapter, I’ll use an extended example of an ActivityPub protocol implementation. Since the protocol is for a social-network federation, I was tempted to create a small social-network server, complete with user account management and an implementation of the ActivityPub API on the frontend. To keep the example tight and to keep this chapter short, without a lot of extraneous code, however, I decided instead to develop a bot server.
Bots are automated fediverse users; instead of real human beings posting content and creating activities, their simple code lets them perform actions that humans might do. Bots often connect to an ActivityPub server by using the ActivityPub API or another API, but for this example I’m going to build a plug-in interface so that the bots run on the server, inside the server process. The server will be usable only for bots.
The bot interface implemented in the service will let the bots send notes, follow and block other users, and like and share content. The bots can also react to activities from other users on the fediverse. Implementing the bot interface will let me show you how best to implement these features in your ActivityPub server, without getting bogged down in what the affordances are for doing those tasks. Figure 4-1 shows the architecture for activitypub.bot. Its ActivityPub protocol handler will perform default processing for some types of activities, but others are passed through to plug-in software (the bots), which have a library of services they can use to enact their behavior.
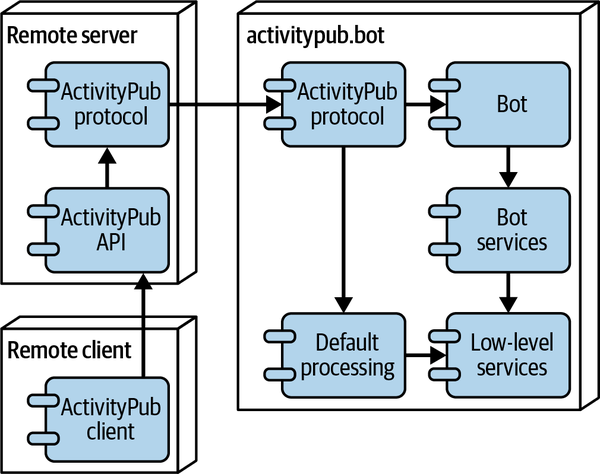
Figure 4-1. The activitypub.bot architecture
The project is called activitypub.bot because that’s the best domain I was able to get. I’ll show you a few sample bots in this chapter; others may be implemented by the time you read this book. You can see the project code on GitHub, along with documentation on how to interact with the bots.
The code for this extended example is in JavaScript—as of this writing in 2024, the most popular programming language on the planet for more than a decade. On the off chance that you’ve never heard of JavaScript, it is a dynamically typed, object-oriented programming language reminiscent of C, C++, and Java, with a little hint of functional languages like Lisp or Scheme mixed in. It has been the main scripting language for web pages since the mid-2000s, and with the development of Node.js has become popular for server-side web development also.
If you want to learn JavaScript or need a refresher, JavaScript: The Definitive Guide by David Flanagan (O’Reilly 2020) is a comprehensive learning and reference guide. Also, Douglas Crockford’s JavaScript: The Good Parts (O’Reilly, 2008) remains a notable and staunchly opinionated book that makes up for its somewhat outdated syntax recommendations with a joyfully irascible tone. It’s the book that made me fall in love with the language. Finally, Web Development with Node and Express by Ethan Brown (O’Reilly, 2019) gets specific about building web servers with Node.js, including Express.js, the web server framework I used for this example.
To manage AS2 parsing and formatting, I use James Snell’s excellent activitystrea.ms library from NPM, the Node.js package repository. James is my coeditor on the AS2 specification and definitely the creative genius behind the whole endeavor. His AS2 package is fun and easy to use. Here’s how to import it:
constas2import=util.promisify(as2.import)constfoo=awaitas2import({'name':'Evan','type':'Person'})console.log(foo.name)
Understanding the Shape of Federated Social Networking
Actors on a social network publish and receive activity data. Yes, I know, that’s a really boring way to describe the fun, emotion, and interactivity of social-network software—but hopefully it will help visualize the shape of the network.
For many social-network systems, users have a client that they use to interact with a remote server. Each user has their own client; activities go from the client to the server, and then out to other users’ clients.
Figure 4-2 shows a model of two users on the same server. The client software on user 1’s device creates an activity by posting to the user’s outbox, which creates a representation in the internal data storage. When user 2 goes to read their home page in their own API client, they call the inbox GET handler, which retrieves activities from data storage, including in this case the activity by user 1.
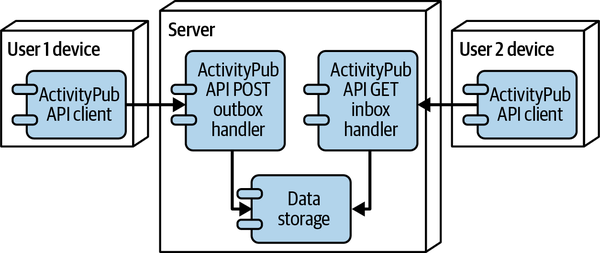
Figure 4-2. Two users on the same server using the ActivityPub API
One feature that makes the ActivityPub network special is that users don’t have to have accounts on the same server. Figure 4-3 shows what it looks like when the users are on separate servers.
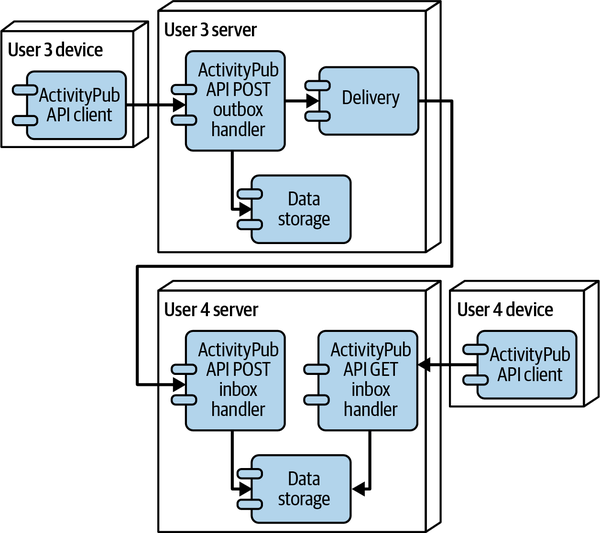
Figure 4-3. Two users on different servers using the ActivityPub API and protocol
This is a different layout: user 3 and user 4 have their accounts on different servers. When user 3 POSTs a new activity to their outbox, it still goes into local data storage, but it also gets sent to a delivery component. The delivery component uses the ActivityPub protocol to POST the activity to the inbox of each and every user addressed in the activity. Those inbox-handling components store the activity in the remote server data storage, so that when user 4 loads their inbox feed, the new activity will be there.
This is a simplified model. A lot more chatter occurs between servers than just delivering activities. But it’s important to understand that ActivityPub servers are relatively independent. They can use different software implementations, run in different server environments, and have different domain names. They don’t have shared storage; all the interactions are via REST method calls, whether reading with GET or writing with POST.
So, how does the ActivityPub protocol differ from the ActivityPub API? As you’ll see in the next section, not much at all.
An API Becomes a Protocol
As you saw in Chapter 3, the ActivityPub API—the part of the ActivityPub specification concerned with letting client applications connect to servers—has two main parts:
- A read-only structure
-
The read-only structure is based on the
idproperties of ActivityPub objects. You can read the information about an ActivityPub object by fetching the URL that is itsid, and you can fetch related objects (its creator, its parts, and so on) by fetching the URLs in various properties of the main object. So, to get the creator of aNoteobject, you get the URL from itsattributedToproperty. This is the “follow your nose” part of the API; you start with anidURL, and then use the properties to follow the path to the parts you’re looking for. - A write-only part
-
Here, the client uses an HTTP POST request to send an AS2 activity object to the actor’s
outboxURL. Each activity that is posted to the outbox can have side effects; for example, aLikeactivity will cause itsobjectproperty to be added to the actor’slikedcollection.
So, an ActivityPub API server has the responsibilities of making objects available for reading, accepting activities and realizing their side effects, and running authentication and authorization checks to make sure only the right actors can read and write data.
The ActivityPub federation protocol is extremely similar to the API in its structure. It also has a read-only and a write-only section. The read-only structure is exactly the same, providing access for other servers to read AS2 objects and follow their properties to other, related AS2 objects. Once you’ve implemented the read-only structure of the ActivityPub API, extending it to work for the federation protocol too is easy; the main difference is the authentication mechanism that’s used.
The write-only structure works almost the same way. But while the actor’s outbox contains all the activities that they performed, the actor’s inbox contains all the activities that others have performed and sent to the actor. To send an activity to an actor, an originating server POSTs the AS2 representation of the activity to the receiving actor’s inbox URL.
To support the ActivityPub federation protocol, then, a server has to do the following:
-
Implement read-only access to its AS2 objects
-
Deliver any activities that its actors create to the inboxes of addressed actors on other networks
-
Accept incoming activities that actors on other networks send to its own users’ inboxes
-
Realize the side effects those remote activities might have
-
Implement the authentication and authorization checks needed to preserve its actors’ privacy
This parallel between the API and the federation protocol is completely on purpose. When the SocialWG was developing ActivityPub, we wanted it to be easy to implement one part of the standard if you were already working on the other part. So, the read-only parts are more or less the same, and the write-only parts are extremely parallel—just the difference between the outbox and the inbox, as well as the different side effects for locally created activities versus remote activities.
The biggest difference between the API and the federation protocol is authentication. The OAuth 2.0 mechanism used for the API depends on the actor having an account on the API server. Since remote actors don’t have accounts on the local server (that’s what makes them remote!) we need a different way to identify HTTP GET and POST requests made on behalf of those remote users. The most popular mechanism for this on the fediverse today is a standard called HTTP Signatures.
Using HTTP Signatures
HTTP Signatures is a standard developed as a request for comment (RFC) at the Internet Engineering Task Force (IETF). The IETF is a standards body, like the W3C, that brings together experts to define the rules that make the internet work. Despite the noncommittal name (request for comment), every RFC represents carefully considered rules for internet protocols and software behavior.
That’s the good news: great engineering leadership by tried-and-true experts, working to keep our internet safe. The bad news is that, when software projects like Mastodon were first implementing ActivityPub in the late 2010s, the HTTP Signatures RFC was still under development. The version of the RFC that was implemented is incompatible with the latest drafts and technically expired in 2019. Because it’s widely implemented, a lot of inertia is holding people back from changing to a newer version.
But wait! There’s even more bad news. Even within the parameters of the draft HTTP Signatures RFC, a lot of possibilities remain for storing and sharing keys as well as ways for making signatures. But most fediverse software supports only one, or at most a few, of those choices. And sometimes the only way you’ll know that your choices were wrong is that no other fediverse software can talk to yours.
Now that you’re thoroughly discouraged, let’s pull back and look at the big picture. As of this writing, the W3C SocialCG has released a great new report on using HTTP Signatures. It brings this component of the social web stack out of the realm of folklore and into the realm of agreed-upon standards. With luck, this stabilization will engender more tools and libraries that support HTTP Signatures.
Hundreds of independent implementations of HTTP Signatures with ActivityPub exist today. Tens of millions of ActivityPub activities are delivered via the federation protocol on a daily basis. Sure, the authorization mechanism is a little tricky, but once you’ve got it working, this foundational technology of the fediverse provides a robust, secure method of authentication for HTTP requests. If all those other developers could do it, I believe you can too.
Performing Server-to-Server Authentication
I’m going to describe for you the state of the art in server-to-server authentication as of this writing. The W3C and others, as I write this, are carefully documenting the current state of HTTP Signatures use on the fediverse and working out an upgrade path for fediverse developers. This will probably be backward compatible, so what I lay out here should work for some time to come.
The HTTP Signatures standard addresses the asymmetry involved in any HTTP interaction between client and server. The client has a lot of information about the server (including the domain name it’s using and the URL it’s requesting), which is cryptographically ensured by the HTTPS secure standard. But the server in the conversation doesn’t have much information about the client, beyond its Internet Protocol (IP) address and the HTTP headers it uses. How can the server be sure who it’s talking to?
HTTP Signatures solves this by using public-key authentication. In this form of digital identification, someone—in this case, the requesting ActivityPub actor—has possession of two closely related chunks of data: the public key and the private key. These are two long, indecipherable blobs of binary data, with the important property that if you know the public key, you can verify that another object was signed with the private key. Signing, here, means “putting the data through a complicated algorithm a few thousand times in a way that’s hard to fake.”
Many algorithms are used for digital signatures and encryption; RSA encryption, named after the creators Rivest, Shamir, and Adleman, is one of the most popular and widely used. It’s the main type of signature algorithm on the fediverse.
The HTTP client component of the ActivityPub server (on the left in Figure 4-4) uses the private key to sign the HTTP request it’s sending to the HTTP server (on the right).
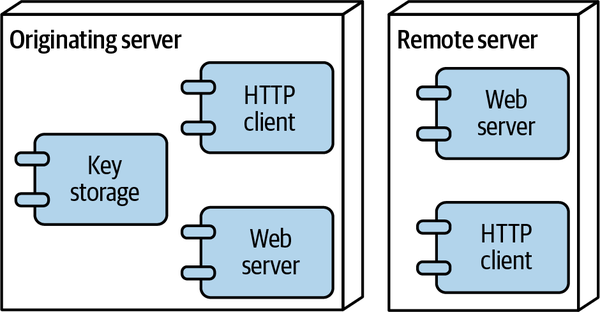
Figure 4-4. Components in an HTTP Signatures process
The HTTP server, in turn, gets the public key back to the originating server via another HTTP request, then uses that key to verify the signature (see Figure 4-5). After confirming that the signature is valid, the remote server knows that the client is who they say they are. The remote server can then decide whether the client has authorization to do whatever it is they’re trying to do.
Even though I’m using the terms HTTP client and HTTP server here, this is just about two ActivityPub servers interacting. An ActivityPub API client, for example, doesn’t interact directly with the remote server at all—that’s what the proxyUrl endpoint is for, as we discussed in Chapter 3. ActivityPub servers use HTTP Signatures to identify themselves to other servers.
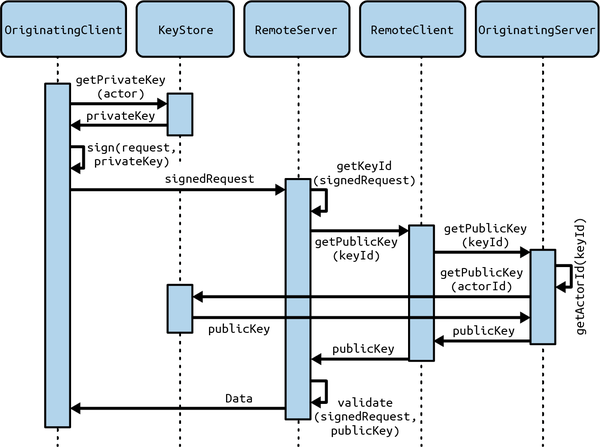
Figure 4-5. The components of the two servers interact to validate a signed request
Understanding the Signature Header
The digital signature on an HTTP request is provided in an HTTP header, Signature. The Signature header has multiple comma-separated parts, each of which is a name-value pair:
name1="value1",name2="value2",name3="value3"
The important parts of the signature are as follows:
keyId-
This identifies the key used to sign the request. The HTTP Signatures specification indicates various formats for key IDs, but for ActivityPub, we use an ActivityPub object ID—an HTTPS URL to an ActivityPub object that represents the key (see “Representing Public Keys”).
- headers
-
HTTP requests are made up of name-value pairs called headers and an optional block of data called the body. Headers are mostly defined by the originating HTTP client, but different processors along the way, like HTTP proxies, can add or remove headers from the request. This part of the signature gives the names of the headers that the client signed with the private key. Order matters here.
- algorithm
-
The algorithm used to sign the headers. The main one used on the fediverse, and the one I’ll describe in this chapter, is
rsa-sha256, using RSA encryption keys. - signature
-
The digital signature generated by applying the algorithm to the headers and the private key. It is base64-encoded, and any quote characters (
") are escaped (\").
Representing Public Keys
To represent the key used in the digital signature, you’ll use an HTTPS URL. This URL, in turn, is for an ActivityPub object that is using an extension vocabulary specifically for web security. An example AS2 document for the ID https://social.example/users/evanp/key might look like the following:
{"@context":["https://www.w3.org/ns/activitystreams","https://w3id.org/security/v1"],"id":"https://social.example/users/evanp/key","type":"Key","owner":"https://social.example/users/evanp","publicKeyPem":"-----BEGIN PUBLIC KEY----- [...] -----END PUBLIC KEY-----"}
We’re using an external vocabulary, as discussed in Chapter 2. This one is the Web Security vocabulary, which focuses on security-related types like user accounts and encryption keys. Don’t worry, we’ll get deeper into extensions in Chapter 5; for now, I’ll explain what’s going on in this particular document.
You can tell that there’s an external vocabulary because the good old @context property you’re used to, with a single string for the AS2 vocabulary, has expanded to a JSON array. This allows you to add an additional vocabulary for JSON-LD security data. You’ll see this same pattern in later chapters.
Second, there’s a type value you haven’t seen before: Key. This represents a public encryption key, with properties that are relevant for encryption infrastructure.
Third, a new property, owner, represents the owner of the key. This lets you identify the actor responsible for the request. That way, the remote ActivityPub server can decide whether the actor has access to the requested research. Usually, a one-to-one relationship exists between a key and an ActivityPub actor.
Finally, the code uses another new property, publicKeyPem. This is usually a big block of random letters and numbers, where the juicy cryptographic magic is happening. I’ve elided that out in this example. The property’s value is an RSA public encryption key in PKCS 8 format, which many cryptographic libraries can ingest directly.
Not all fediverse servers give the public key its own URL—although, technically, you should do this for all relevant objects on the network. Especially with Mastodon, you might see key IDs that have a URL fragment at the end (the little part that comes after the # in a URL). They look like https://social.example/users/foo#publicKey or even https://social.example/users/foo#main-key. This just means that the actor document includes a publicKey property. Here’s an example:
{"@context":["https://www.w3.org/ns/activitystreams","https://w3id.org/security/v1"],"id":"https://social.example/users/foo","Type":"Person","Inbox":"https://social.example/users/foo/inbox","outbox":"https://social.example/users/foo/outbox","Followers":"https://social.example/users/foo/followers","following":"https://social.example/users/foo/following","liked":"https://social.example/users/foo/liked","publicKey":{"id":"https://social.example/users/foo#main-key","type":"Key","owner":"https://social.example/users/foo","publicKeyPem":"[...]"}}
This isn’t the recommended way to represent anything on the fediverse; everything should have its own real URL as an ID. But this is a common enough pattern that you should be aware of it.
Using the Server Actor
Sometimes a request isn’t attributable to any particular person or other actor. It’s just necessary for the smooth running of the server. In this situation, you have two options. One option is to simply leave the request unsigned. The remote server can treat the request as belonging to no one in particular and reply accordingly. Usually, this would result in returning data only if the object is readable by the Public object (that is, just about anyone).
The problem with unauthenticated HTTP requests is that sometimes data is available to everyone except a few known bad actors: for example, a known spammer or data harvester who uses public posts or feeds for bad ends. Some fediverse servers refuse to allow requests to any of their resources unless the request is signed, so they can check the domain of the requester against their list of blocked domains. (You’ll learn more about domain-level blocking in “Filtering Activities”.)
To authenticate requests on behalf of the server instead of for any particular user, you use an entity called the server actor: a special default actor to use when requesting data without a specified user. Often the actor ID is something like https://social.example/actor or even https://social.example/ and has a type of Service or even Application, as in the following example:
{"@context":"https://www.w3.org/ns/activitystreams","id":"https://social.example/","type":"Service","summary":"An example social networking service","inbox":"https://social.example/inbox","outbox":"https://social.example/outbox","following":"https://social.example/following","followers":"https://social.example/followers","liked":"https://social.example/liked","publicKey":"https://social.example/publicKey"}
This example includes all the necessary properties for this object to be an ActivityPub actor. This situation is actually unusual on the fediverse and not required. The most important role of a server object is to be the owner of the public key used to sign a request. That way, remote servers that are checking domains of incoming requests can know that this domain is OK.
Remember in Chapter 2 when I talked about names getting overused in the ActivityPub world, especially actor? This is a great example. The server actor can be an ActivityPub actor and has an actor type. I’m sorry for the confusion, but these are the terms used by ActivityPub developers, so I’m giving you the most commonly used name instead of making something up like “default signing principal.”
Making Requests
Let’s take a look at some code to see how HTTP Signatures works. The activitypub.bot project has a component called ActivityPubClient that is used to make GET and POST requests to other servers. Here’s what the get method of the ActivityPubClient class looks like:
asyncget(url,username=null){assert.ok(url)assert.equal(typeofurl,'string')constdate=newDate().toUTCString()constsignature=awaitthis.#sign({username,url,method:'GET',date})constres=awaitfetch(url,{method:'GET',headers:{accept:'application/activity+json,application/ld+json,application/json',date,signature}})if(res.status<200||res.status>299){throwcreateHttpError(res.status,`Could not fetch${url}`)}constjson=awaitres.json()constobj=awaitas2.import(json)returnobj}
Let’s break this down. First, the method creates the necessary headers to be signed and then creates a signature. It uses the built-in fetch function to request the resource found at the URL in the variable url. Finally, if the results come back correctly, the method imports the returned JSON data into the format used by the activitystrea.ms library.
Clearly, the #sign private method is doing a lot of the heavy lifting:
async#sign({username,url,method,date,digest}){constprivateKey=awaitthis.#keyStorage.getPrivateKey(username)constkeyId=(username)?this.#urlFormatter.format({username,type:'publickey'}):this.#urlFormatter.format({server:true,type:'publickey'})constparsed=newURL(url)consttarget=(parsed.search&&parsed.search.length)?`${parsed.pathname}?${parsed.search}`:`${parsed.pathname}`letdata=`(request-target):${method.toLowerCase()}${target}\n`data+=`host:${parsed.host}\n`data+=`date:${date}`if(digest){data+=`\ndigest:${digest}`}constsigner=crypto.createSign('sha256')signer.update(data)constsignature=signer.sign(privateKey).toString('base64')signer.end()return`keyId="${keyId}",`+`headers="(request-target) host date${(digest)?' digest':''}",`+`signature="${signature.replace(/"/g,'\\"')}",algorithm="rsa-sha256"`}
This method is a little more complicated! The easy part is fetching a private key from the helper component at this.#keyStorage. That’s a class that makes and stores public/private key pairs for local users.
The keyId is generated using another component, a tool that builds URLs based on arguments: this.#urlFormatter. This tool is building a URL for the key for the actor on whose behalf the server is making a request. If no such actor exists, then it builds an ID for the key of the server actor.
The next step is building up the string that will be signed with the actor’s or server actor’s key. This is a special format just for HTTP Signatures, made up of lines with header names and values. It looks something like this:
(request-target)method/pathheader-name-1:HeaderValue1header-name-2:HeaderValue2
The literal string (request-target) should appear at the beginning exactly as is. The method is the HTTP method used for the request, lowercase, like post or get. The path is the part of the URL after the domain name, like /users/evanp/note/1, not modified at all. If the URL has query parameters, they should be included here.
Each header should be in the exact same order as in the Signature header value’s headers field. The header name should be lowercase. Exactly one space should be between the colon and the header value. The header value should not be modified; don’t lowercase it. Each line should end with a single \n character, except the last one.
There’s really no leeway on any of these requirements for the signable data string; even a single character difference from these rules will invalidate the signature, as you’ll see when validating signatures. There is no “close enough” in the world of digital signatures!
Most fediverse software requires two headers: Host, for the domain you’re connecting to, and Date, for the date the request was made. If the request is a POST, it should also include a Digest header, which is a digest of the body content. Although this header is deprecated for some use on the web, it’s still very much an active part of the HTTP Signatures profile for ActivityPub. Here’s the method that the ActivityPubClient component uses for creating digests:
async#digest(body){constdigest=crypto.createHash('sha256')digest.update(body)return`SHA-256=${digest.digest('base64')}`}
This method uses the crypto module from the Node.js standard library to create a SHA-256 hash of the message body, and then returns the right format for the Digest header value:
<algorithm>=<base64-encoded-value>
Again, the Digest header supports a lot of algorithms, but most fediverse software supports only SHA-256.
Back in the #sign method, we’re at the point where the magic happens. With the signable headers string in the data local variable, the code uses the Node.js crypto module, again, to digitally sign the string and encode it in base64 format. It then assembles the parts of the Signature header, as described before, and then returns them to be used in the HTTP request. And that’s it!
The post method of the ActivityPubClient class is almost exactly the same, except it calculates the digest values and signs them. With all the explanations I’ve made in this section, you’d think that there’d be more code to them, but this implementation uses fewer than 100 lines of JavaScript. On the other end of the wire, though, the remote server needs to take on the task of validating the HTTP signature.
Validating a Signature
Validating an HTTP signature requires doing all the steps in the previous section, but backward:
-
Splitting the
Signatureheader into its component parts: its key ID, headers, signature, and algorithm -
Fetching the key corresponding to the key ID
-
Constructing a signable string out of the received headers
-
Verifying that the signature matches the key and the signable string
-
Passing along the ActivityPub actor ID corresponding to the key to code that checks for authorization
In the Node.js web server software world, this kind of job is typically done by middleware—special filter functions inserted into the chain of handlers that manage an incoming request. A middleware function takes a req parameter representing the HTTP request and modifies it to pass along to other software in the chain. This function can also throw an exception to notify the remote user if there’s a problem.
In activitypub.bot, I use an HTTPSignature class to manage signature validation. This class has a method, authenticate, that should be called for every (yes, every!) HTTP request to validate digital signatures. You can add the method to the chain of request handlers like this:
constsignature=newHTTPSignature(remoteKeyStorage)// ...app.use(signature.authenticate.bind(signature))
Here’s what the authenticate method looks like:
asyncauthenticate(req,res,next){constsignature=req.get('Signature')if(!signature){// Just continuereturnnext()}const{method,path,headers}=reqletowner=nulltry{owner=awaitthis.validate(signature,method,path,headers)}catch(err){returnnext(err)}if(owner){req.auth=req.auth||{}req.auth.subject=ownerreturnnext()}else{returnnext(createHttpError(401,'Unauthorized'))}}
The first steps take apart the Signature header—the key ID, signature, and so on. The code assembles the signingString based on the request headers passed. Then it uses the #remoteKeyStorage to fetch the public key and owner based on the ID.
Here’s what that method looks like:
asyncgetPublicKey(id){constcached=awaitthis.#getCachedPublicKey(id)if(cached){returncached}constremote=awaitthis.#getRemotePublicKey(id)if(!remote){returnnull}awaitthis.#cachePublicKey(id,remote.owner,remote.publicKeyPem)returnremote}
RemoteKeyStorage keeps a cache of remote keys and checks whether it has the remote key in the cache. If not, the class fetches the key from the keyId URL and stores the results in the cache.
Back in the authenticate method, I use the ever-helpful crypto module to verify the signature. If the verification fails, the code returns an error to the caller; if the verification succeeds, the method adds the owner’s identity to the req object and then lets the handler chain continue.
And that’s just about all there is to talk about for HTTP Signatures (whew!). You can take a few additional steps, such as checking that the Date header represents a recent timestamp, or that the Digest header is valid. Caching the public keys can be a problem if the sender rotates their keys periodically, which is a good security practice, but this can be overcome by retrying the verification with a freshly downloaded key if the cached key fails.
Federated social web pioneer Blaine Cook has a rule of thumb about authentication and authorization: “Once you get to public-key infrastructure, you’ve gone too far, and you should go back.” As you can see from this section, he has a point: making HTTP Signatures work requires significant effort, and errors are almost unavoidable. But HTTP Signatures holds the social web together in 2024, and if you implement ActivityPub, you’re going to have to use it.
The only other topic to talk about, before we get into the fun of distributing activities over the social web, is how to look up an actor.
Implementing WebFinger
You may remember that I introduced WebFinger in Chapter 2. This identity standard gives actors an ID, like actor@domain.example even if their ActivityPub ID is something long and unreadable, like https://domain.example/users/0gsPg7XyLxt582xOFlG7O. For the ActivityPub API example client ap, we allowed WebFinger IDs and ActivityPub IDs to be used on the command line.
You can implement the ActivityPub federation protocol without implementing WebFinger. But then other people on the fediverse will have a harder time finding and following your users. It’s just a lot easier to say and remember evan@cosocial.ca than the long URLs that are typical ActivityPub actor IDs.
Implementing WebFinger is easy too. It has just one endpoint to implement, which checks the resource parameter to see whether it matches the local domain and identifies a real local user. If so, it returns a JRD document with a link to the ActivityPub ID. Here’s what that endpoint looks like in activitypub.bot:
router.get('/.well-known/webfinger',(req,res,next)=>{const{resource}=req.queryif(!resource){returnnext(createHttpError(400,'resource parameter is required'))}const[username,domain]=resource.substring(5).split('@')if(!username||!domain){returnnext(createHttpError(400,'Invalid resource parameter'))}const{host}=newURL(req.app.locals.origin)if(domain!==host){returnnext(createHttpError(400,'Invalid domain in resource parameter'))}if(!(usernameinreq.app.locals.bots)){returnnext(createHttpError(404,'Bot not found'))}res.status(200)res.type('application/jrd+json')res.json({subject:resource,links:[{rel:'self',type:'application/activity+json',href:req.app.locals.formatter.format({username})}]})})
This code parses out the resource parameter into username and domain. It checks the domain name by comparing it to the origin property stored in the app.locals hash. And the code checks for a bot with that username. Finally, if everything goes OK, it outputs the JRD file.
Given the bang for the buck, adding just a bit of extra code is really worthwhile for a lot more identity usability for your users and their friends.
Getting Objects
A big part of the work of an ActivityPub server is letting remote users GET data, like individual objects or collections. The server needs to check the remote user’s authorization to read the object before sending.
For activitypub.bot, I used the authorization model described in Chapter 3:
-
Owners can read and write their own stuff.
-
Blocked users can’t read anything by anyone who blocked them.
-
Addressees can read stuff addressed to them.
-
Members can read stuff posted to collections they’re a member of.
-
Everyone can read stuff sent to
Public.
It’s a simple model. I use a helper module, Authorizer, to encode the rules. Here’s the #canReadLocal method:
async#canReadLocal(actor,object){constrecipients=this.#getRecipients(object)if(!actor){returnrecipients.has(this.#PUBLIC)}constownerId=(awaitthis.#getOwner(object))?.idif(!ownerId){thrownewError(`no owner for${object.id}`)}if(actor.id===ownerId){returntrue}constowner=awaitthis.#actorStorage.getActorById(ownerId)if(!owner){thrownewError(`no actor for${ownerId}`)}constownerName=owner.get('preferredUsername')?.firstif(!ownerName){thrownewError(`no preferredUsername for${owner.id}`)}if(awaitthis.#actorStorage.isInCollection(ownerName,'blocked',actor)){returnfalse}if(recipients.has(actor.id)){returntrue}if(recipients.has(this.#PUBLIC)){returntrue}constfollowers=this.#formatter.format({username:ownerName,collection:'followers'})if(recipients.has(followers)&&awaitthis.#actorStorage.isInCollection(ownerName,'followers',actor)){returntrue}returnfalse}
The best way to read this code is to blur your eyes a bit and look at the various if statements. First, it shows all the recipients for the object—from the to, cc, bcc, bto, and audience fields. If the actor is not set, the code checks whether one of the recipients is Public. It checks whether the actor is the owner, is blocked, or is a direct recipient. Finally, it checks for Public, or whether the actor is a follower. If none of the positive conditions works, the method returns false.
Although it feels complex, this problem is tractable, especially because we’ve limited the object to being local. It gets considerably harder to determine whether a local actor can read a remote object, or whether a remote actor can read a remote object. In a lot of ways, the best way to deal with those situations is to assume nothing: use an identity representation of the remote object so the actor has to fetch it directly.
Fetching Local Objects
Objects have three main types: collections, collection pages, and everything else. I’ll do “everything else” first.
Here’s the route for getting a single object:
router.get('/user/:username/:type/:nanoid([A-Za-z0-9_\\-]{21})',async(req,res,next)=>{const{username,type,nanoid}=req.paramsconst{objectStorage,formatter,authorizer}=req.app.localsconstid=formatter.format({username,type,nanoid})constobject=awaitobjectStorage.read(id)if(!object){returnnext(createHttpError(404,`Object${id}not found`))}constremote=(req.auth?.subject)?awaitas2.import({id:req.auth.subject}):nullif(!awaitauthorizer.canRead(remote,object)){returnnext(createHttpError(403,`Forbidden to read object${id}`))}res.status(200)res.type(as2.mediaType)res.end(awaitobject.prettyWrite())})
This code starts off by rebuilding the URL used for the route; this makes sure we have canonical representation, capitalization, and so on. If the object doesn’t exist, the code gives a 404 Not Found error. It then uses the ID passed by the HTTP Signatures code to create a representation of the remote actor, and checks whether it is authorized to read the object. Finally, it returns the object.
For getting collections, the code is almost identical:
router.get('/user/:username/:type/:nanoid([A-Za-z0-9_\\-]{21})/:collection',async(req,res,next)=>{const{objectStorage,formatter,authorizer}=req.app.localsif(!['replies','likes','shares'].includes(req.params.collection)){returnnext(createHttpError(404,'Not Found'))}constid=formatter.format({username:req.params.username,type:req.params.type,nanoid:req.params.nanoid})constobject=awaitobjectStorage.read(id)if(!object){returnnext(createHttpError(404,'Not Found'))}constremote=(req.auth?.subject)?awaitas2.import({id:req.auth.subject}):nullif(!awaitauthorizer.canRead(remote,object)){returnnext(createHttpError(403,'Forbidden'))}constcollection=awaitobjectStorage.getCollection(id,req.params.collection)res.status(200)res.type(as2.mediaType)res.end(awaitcollection.prettyWrite())})
The main difference is that this code checks the collection name against an allowed list of collections, and it checks the authorization on the object, not the collection. Otherwise, it’s similar to the previous example.
Finally, let’s look at the collection page. This is similar to the other GET endpoints; however, there is a sticking point with the page, which includes other objects in its items property. The ActivityPub specification recommends, although doesn’t strictly require, filtering items according to the authorization of the actor to read the item. In this case, I use a filter to choose only the items that are legible to remote users:
router.get('/user/:username/:type/:nanoid([A-Za-z0-9_\\-]{21})/:collection/:n(\\d+)',async(req,res,next)=>{const{username,type,nanoid,collection,n}=req.paramsconst{objectStorage,formatter,authorizer}=req.app.localsif(!['replies','likes','shares'].includes(req.params.collection)){returnnext(createHttpError(404,'Not Found'))}constid=formatter.format({username,type,nanoid})constobject=awaitobjectStorage.read(id)if(!object){returnnext(createHttpError(404,'Not Found'))}constremote=(req.auth?.subject)?awaitas2.import({id:req.auth.subject}):nullif(!awaitauthorizer.canRead(remote,object)){returnnext(createHttpError(403,'Forbidden'))}constcollectionPage=awaitobjectStorage.getCollectionPage(id,collection,parseInt(n))constexported=awaitcollectionPage.export()if(!Array.isArray(exported.items)){exported.items=[exported.items]}res.status(200)res.type(as2.mediaType)res.json(exported)})
Getting actor objects and actor collections (like outbox, followers, following, and liked) is almost identical, so I’m going to let you, curious reader, go nose around in the activitypub.bot codebase yourself.
Most of what you’ll need to do with a remote API is covered by these few endpoints: getting the social graph; using paged collections; learning about people, images, and articles; and so on. Most of the complexity is in the AS2 representations of these objects. That means this chapter can focus on just a few important endpoints and let them do their work.
I am using AS2 as the native storage format for most ActivityPub objects. Many ActivityPub implementers will be adding ActivityPub to an existing application, which might have a very different structure. Marshaling your data—converting it to and from AS2—is a big part of implementing ActivityPub. Fortunately, it can usually be encapsulated in a module, like the ObjectStorage one I use here. Keep the structure of your app encapsulated in that storage, and use a library like activitystrea.ms to represent your data in your ActivityPub routes.
Delivering Activities
One of the main responsibilities of an ActivityPub server is delivering the activities its local users generate to remote servers. Users can generate activities in a lot of ways: using a built-in web interface; using the ActivityPub API through a web, mobile, or command-line client; or using another standard or custom API specific to the server.
In the activitypub.bot example code, I skip all that infrastructure and implement a simple JavaScript API for the bots to run in-process. Here, for example, is the code in the bot platform module that lets a bot Like an object (such as an image, note, or video):
asynclikeObject(obj){assert.ok(obj)assert.equal(typeofobj,'object')if(awaitthis.#actorStorage.isInCollection(this.#botId,'liked',obj)){thrownewError(`already liked:${obj.id}by${this.#botId}`)}constowners=(obj.attributedTo)?Array.from(obj.attributedTo).map((owner)=>owner.id):Array.from(obj.actor).map((owner)=>owner.id)constactivity=awaitas2.import({type:'Like',id:this.#formatter.format({username:this.#botId,type:'like',nanoid:nanoid()}),actor:this.#formatter.format({username:this.#botId}),object:obj.id,to:owners,cc:'https://www.w3.org/ns/activitystreams#Public'})awaitthis.#objectStorage.create(activity)awaitthis.#actorStorage.addToCollection(this.#botId,'outbox',activity)awaitthis.#actorStorage.addToCollection(this.#botId,'inbox',activity)awaitthis.#actorStorage.addToCollection(this.#botId,'liked',obj)awaitthis.#distributor.distribute(activity,this.#botId)returnactivity}
After checking that the object isn’t already liked, the method creates a new Like activity object, saves it to local storage, adds it to the bot user’s outbox and inbox collections, adds the object to the bot’s liked collection, and then distributes the activity.
This is a standard pattern for creating activities: validate, save state, add to collections, and finally distribute to remote servers. This is about the right order. If you distribute the activity before you save the state locally, remote servers might start trying to fetch the objects or activities before you get a chance to save them. Note that the distribution happens before the method returns; the bot gets control back after the activity has been sent, received, and accepted by all addressees. This is OK for a bot in an example program, but you probably don’t want to do this in your production code. I’ll talk about optimizing federated servers in more detail in “Optimizing Federated Servers”.
Here’s the ActivityDistributor module’s distribute method:
asyncdistribute(activity,username){constpublicRecipients=this.#getPublicRecipients(activity)constprivateRecipients=this.#getPrivateRecipients(activity)constpublicInboxes=awaitthis.#getInboxes(publicRecipients,username)constprivateInboxes=awaitthis.#getDirectInboxes(privateRecipients,username)conststripped=awaitthis.#strip(activity)for(constinboxofpublicInboxes){this.#queue.add(()=>this.#deliver(inbox,stripped,username))}for(constinboxofprivateInboxes){this.#queue.add(()=>this.#deliver(inbox,stripped,username))}}
This code is really simple; the helper functions are doing most of the hard work. First, it extracts all the recipient IDs out of the various addressing properties: to, cc, bto, bcc, and audience. It treats the bto and bcc addressees a little differently; you’ll see why when we talk about the shared inbox.
Then the distribute method gets the inboxes for each recipient ID. It supports addressing to only the followers collection or to Public, although it’s perfectly reasonable for ActivityPub servers to allow addressing to other collections, including user-managed contact lists. (That’s one nice use of the Add and Remove activities we discussed in Chapter 3!)
The #getInboxes private method handles these details:
#PUBLIC=["https://www.w3.org/ns/activitystreams#Public","as:Public","Public",];async#getInboxes(recipientIds,username){constinboxes=newSet()constfollowers=this.#formatter.format({username,collection:'followers'})for(constrecipientIdofrecipientIds){if(recipientId===followers||this.#PUBLIC.includes(recipientId)){forawait(constfofthis.#actorStorage.items(username,'followers')){constinbox=awaitthis.#getInbox(f.id,username)inboxes.add(inbox)}}else{constinbox=awaitthis.#getInbox(recipientId,username)inboxes.add(inbox)}}returninboxes}
The method checks all the recipients passed to it; if any of them are Public or the user’s following collection, it gets the inboxes for all the followers. Otherwise, it gets just the inbox for the recipient. It collects these all in a JavaScript Set object, which keeps only unique members.
You might wonder why it does that. Shouldn’t each actor’s inbox be unique? To answer that, I need to talk about the sharedInbox endpoint.
Delivery Queues
The final step in the previous distribute method is delivering the activity to each inbox. Even with the shared-inbox optimization, there can be hundreds or thousands of inboxes for delivery. A bot might be willing to wait while that delivery happens; a human user definitely will not! So, delivery must be done asynchronously. Making thousands of outgoing HTTPS requests can also be resource-intensive, taking up a lot of network bandwidth, memory, and CPU time. It’s best to serialize the process at a controllable level.
The main tool for this type of process is a task queue (also called a job queue): a data structure that serializes a large number of tasks, like sending activities to remote inboxes, and does them a few at a time to prevent overloading resources. Usually, new tasks are added at the end of the queue and progress up the ranking until they get to the front of the queue, at which point they get handled. This is sometimes called a first-in, first-out (FIFO) data structure: every task waits its turn to be executed. Job queues can be ephemeral (meaning that if the server goes offline, any remaining tasks are lost) or persistent (meaning tasks are stored to redundant storage so that a server outage doesn’t cause data loss).
Task queues come in a lot of shapes and sizes. Some queuing systems, called in-memory queues, are implemented as libraries or data structures within an application. Others are implemented as standalone servers; Redis and RabbitMQ are both great queueing servers, and many other open source task queue servers are available. Amazon Simple Queue Service (SQS) is a similar system implemented as a cloud service; Google Cloud and Azure have similar services.
Another important parameter for delivery queues is concurrency—that is, how many tasks can be going on at the same time. This is a dial you might need to twiddle a bit to get right. Too many parallel tasks can use up a lot of resources, but too few means your activities take a longer time to deliver.
Finally, queues can allow tasks a priority. Higher-priority tasks get to jump the line and get executed before lower-priority tasks. That may not seem fair, but these are activity-delivery processes, not clubgoers waiting to get into a nightclub. I’ll talk about using priority to get better apparent performance in “Optimizing Federated Servers”.
What kind of queueing system should you use? For a server with few users or a small resource footprint, you can probably get away with using an in-memory, ephemeral queue, like a queue library. For high-throughput production ActivityPub servers, you’ll want an out-of-process task server with persistent task queues. Server administrators should be able to tune parameters like concurrency to meet the needs of users and their organization. Whatever your use case for ActivityPub, I highly recommend you use some kind of queueing system right from the jump, so you can adjust to use a different queueing technique over time.
For the activitypub.bot sample application, I use a popular in-memory, ephemeral queueing library for Node.js called p-queue. I default to a maximum concurrency of 32 deliveries at a time. To add a task, I need to pass it a function that when called returns a Promise: a special JavaScript type used for asynchronous programming. Here’s the relevant code within distribute:
this.#queue.add(()=>this.#deliver(inbox,stripped,username))
I use a private method, #deliver, to execute the task. Why not just use the ActivityPubClient object directly and post to the inbox? The reason is robustness, which I’ll talk about in the next section.
Retries
The internet is flaky. An awful lot of things have to go right for an HTTP request to reach the server and for its response to get back to our ActivityPubClient. If any of those things fails, the request is going to fail.
Here’s a nonexhaustive list of reasons that ActivityPub deliveries can fail: their AP server is temporarily down; their server is being upgraded; their AP server is permanently down; the user account has been deleted; their DNS has changed and is propagating; the admin forgot to renew their domain name and it got cybersquatted; their database has an error; their servers are overloaded because of an unexpectedly popular meme; their SSL certificate has expired; their reverse-proxy can’t find an available server; their Kubernetes cluster is being upgraded; their server has a domain-level block against yours; a backhoe accidentally dug up the fiber-optic cable going into their data center; too much bird poop landed on their microwave transmitter dishes; solar flares are erupting; gremlins have arrived; they just have bad luck.
Some failed deliveries are permanent, like delivering to a deleted user account. Others are temporary, like network hiccups or server upgrades. If you want more robust ActivityPub delivery, a good high-level strategy is to log permanent failures and move on—but retry the temporary failures a few times, until you’re pretty sure they’re effectively permanent too.
Here’s the #deliver method from activitypub.bot that implements the retry mechanism:
async#deliver(inbox,activity,username,attempt=1){try{awaitthis.#client.post(inbox,activity,username)this.#logInfo(`Delivered${activity.id}to${inbox}`)}catch(error){if(!error.status){this.#logError(`Could not deliver${activity.id}to${inbox}:`+`${error.message}`)}elseif(error.status>=300&&error.status<400){this.#logError(`Unexpected redirect code delivering${activity.id}`+`to${inbox}:${error.status}${error.message}`)}elseif(error.status>=400&&error.status<500){this.#logError(`Bad request delivering${activity.id}to${inbox}: `+`${error.status}${error.message}`)}elseif(error.status>=500&&error.status<600){if(attempt>=ActivityDistributor.#MAX_ATTEMPTS){this.#logError(`Server error delivering${activity.id}to${inbox}: `+`${error.status}${error.message}; giving up after${attempt}attempts`)}constdelay=Math.round((2**(attempt-1)*1000)*(0.5+Math.random()))this.#logWarning(`Server error delivering${activity.id}to${inbox}: `+`${error.status}${error.message}; `+`will retry in${delay}ms `+`(${attempt}of${ActivityDistributor.#MAX_ATTEMPTS})`)this.#retryQueue.add(()=<setTimeout(delay).then(()=<this.#deliver(inbox,activity,username,attempt+1)))}}}
First, this code calls the ActivityPubClient instance at #client and tries to get it to post the activity to the right inbox, using the right signature for the user. If that goes fine, great. Continue on with more deliveries!
But if the client throws an error, it’s time to do some investigation work. A whole class of connection failures (like DNS errors or network failures) won’t generate an HTTP status code. Although some of them may be recoverable, the activitypub.bot server just gives up on those problems.
We can divide errors with status codes into three main groups:
- 3xx
-
These redirect status codes are the remote server’s way of saying to call back on another line. This is kind of a hassle for delivery code to wade through and is unusual on the fediverse (after all, we just got these inbox addresses from the server a few milliseconds before), so I skip those here too.
- 4xx
-
These client errors indicate something wrong with the request we’re making. In general, these are nonrecoverable, although it might be possible to change up the request to make it acceptable. For this application, I’m just logging the errors and moving on too.
- 5xx
-
A problem exists on the server side. These are a good candidate for retries; a future request might succeed. So, the code will wait a while and then retry the HTTP request. But the question then becomes, how long to wait?
The answer is found in a common technique known as exponential backoff, used for delivering messages or retrieving data when services are overloaded. Repeated requests can actually contribute to problems on the remote service, especially if other clients and servers are doing the exact same thing.
With exponential backoff, you take a longer and longer delay between each attempt. A typical multiplier is 2, so for the second attempt you wait 1 second, then 2 seconds until the third attempt, then 4, 8, 16, 32, and so on. Check frequently at first, and then give more and more time if it becomes clear that the temporary problem is a bigger deal than initially expected. This should give the remote server a chance to recover from whatever gremlin attack it’s suffering from.
Also on the topic of carefully crafted delay periods, imagine the remote server is suffering from an excess of traffic; maybe a lot of deliveries are coming in during the exact same period. If the same bunch of clients retry their deliveries by using the same exponential-backoff technique, you’ll see the exact same traffic jams at 1 second, 2 seconds, 4 seconds, and so on.
To avoid this problem, I introduce a random factor, either above or below the exact power of two. This is called jitter, and it makes sure that incoming requests that clash once don’t keep coming at the same time. This gives the remote server a chance to recover and service those spread-out requests.
To retry the request after a delay, I have a separate retry queue. This one has no concurrency limit, since there aren’t a lot of resources being used. Each task on the queue waits for the delay period and then puts a task on the main queue. This way, I’m not jamming up the precious concurrency of the main queue with sluggish delayed tasks that take 30 minutes or more to run.
There’s not much point in retrying forever. In this code, I set a limit of 16 retries, which on average will require about 65,000 seconds, or roughly 18 hours. That’s usually enough time to wait for most transient errors. The system admin has had time to check their email and see the SSL certificate expiration notice or whatever. It’s also a reasonable amount of time for my single-process server to run without interruption. If you want your system to tolerate more extended downtime and your task queue is persistent, a week (19 retries) or even a month (21 retries) isn’t unreasonable.
Delivery Failure
After all the retries fail, you still have a few options left to try. One is to re-initialize the user’s inbox address by re-downloading their actor resource, especially if the inbox address came from the cache. You might find out that the user account has been deleted and replaced with a Tombstone object. Another alternative is to use the user’s direct inbox instead of the shared inbox.
If that still doesn’t work, log the error so the system administrator can see the problem; there may be network issues that require human intervention. Another nice approach is to tell the sending user about the problem via a notification or other message, especially if the remote actor was addressed individually and not as part of the Public or followers collections.
You can also try implementing the circuit breaker pattern. This is a software technique that networked applications use to reduce the resource usage of calling a remote peer that’s not responding. After a certain threshold of remote failures, the system that would normally make the remote call will fail instead of trying again—“breaking the circuit” for that faulty peer.
With ActivityPub delivery, you can just return an error if a remote inbox has had too many failed deliveries. You can even use the circuit breaker to stop any requests going to that server; a server that’s down might be unable even to respond to GET requests. Serving requests only out of an HTTP cache, and failing on a cache miss, might be a good way to go here.
If you’ve implemented the circuit breaker pattern, you can try automatically to recover over time. An exponential backoff strategy can work with reconnecting a broken circuit too.
If delivery to a remote user has failed repeatedly, over a long period of time, you may want to remove that user from any followers collections for your local users, to prevent future delivery attempts. Use this as a last resort; it’s pretty drastic to remove a user’s followers without their expressed consent.
Receiving Activities
On the other side of the conversation, an ActivityPub server has to implement the inbox code necessary to process incoming activities. Typically, this means the code needs to validate the activity, store it in the correct local users’ inbox collections, and put into force any side effects the activity might have.
Except for figuring out which users’ inbox collections to deliver to, most of this is the same between the shared inbox and the direct user inbox. Here’s what the direct user inbox looks like in activitypub.bot:
router.post('/user/:username/inbox',as2.Middleware,async(req,res,next)=>{const{username}=req.paramsconst{bots,actorStorage,activityHandler,logger}=req.app.localsconst{subject}=req.authif(!subject){returnnext(createHttpError(401,'Unauthorized'))}if(!req.body){returnnext(createHttpError(400,'Bad Request'))}constactivity=req.bodyif(!isActivity(activity)){returnnext(createHttpError(400,'Bad Request'))}constactor=getActor(activity)if(actor?.id!==subject){returnnext(createHttpError(403,'Forbidden'))}constbot=bots[username]if(!bot){returnnext(createHttpError(404,'Not Found'))}if(awaitactorStorage.isInCollection(username,'blocked',actor)){returnnext(createHttpError(403,'Forbidden'))}try{awaitactivityHandler.handleActivity(bot,activity)}catch(err){returnnext(err)}awaitactorStorage.addToCollection(bot.username,'inbox',activity)res.status(200)res.type('text/plain')res.send('OK')})
The inbox code checks the HTTP Signatures subject, as discussed previously, then uses the body passed through the AS2 middleware as the passed-in activity. It checks that it’s actually an activity, then whether it’s being delivered by the right user, then whether the sender is blocked by the bot actor. This is important; user blocks should be strictly enforced at this point.
Then, the server tries to realize the side effects of the remote activity using the ActivityHandler class. Every server can directly handle a finite set of activity types. AS2 objects aren’t self-describing; there’s no way for the server to automatically know how to react to an unrecognized activity type. The type has to be known ahead of time. If the activity type isn’t recognized, I just store it in the inbox and move on. Perhaps the bot will know what to do with it.
In activitypub.bot, I’ve implemented the activity types described in the ActivityPub specification. In Chapter 5, we’ll discuss using other activity types from the Activity Vocabulary, as well as extension types from other vocabularies.
To finish, I return with a 200 OK status code, meaning that the activity has been received and processed. Some implementations put the activity into a queue for later processing; in that case, use 202 Accepted.
Many of the activity types are going to be important only for interacting with local cached data. Let’s talk about why and how to cache remote data in an ActivityPub server.
Caching Remote Data
The case against caching data on the fediverse is strong. After all, every single ActivityPub object is immediately available over HTTPS in its pure JSON-LD goodness. The requests are usually fairly quick, even for slow remote servers. And most AS2 objects are relevant for only a short time before they fall off everyone’s radar screens.
But caching has important benefits. Even though each object is quickly accessible via HTTPS, loading all the data from a single page of 100 activities in an actor’s inbox might require two to three times as many HTTPS requests to get the actor, object, target, replies, shares, and so on. Caching repeatedly used objects can save a lot of resources, even if no single object requires a lot of memory or time.
Even though an object may be relevant for only a brief time—an hour or a day, say—it can be very relevant during that period to actors on your server and across the fediverse. Thousands of servers requesting the same object over and over again can bring a small fediverse server to its knees, and that’s not very neighborly.
An issue of privacy also arises. If your server retrieves only AS2 objects or files from remote servers when a user requests them, it sends a signal to the remote server about your user’s behavior: what kind of data they request and when they request it. Not much more metadata than that leaks, but some users with extreme privacy concerns might want to throw off that type of pattern matching. Reducing requests, and doing them without direct user input, can help pull a veil over users’ actual social habits.
A lot of information can come in with activities posted to the inbox. If the activity AS2 object has a full representation (as I discussed in Chapter 2), it will have functional representations of each of its object parameters, like actor and target. You can cache that free dollop of data so you don’t have to repeatedly request it.
That’s the good news. The bad news is, you have to balance the advantage of all this free data against the problem of data integrity. Take this maliciously constructed Announce activity:
{"@context":"https://www.w3.org/ns/activitystreams","id":"https://unscrupulous.example/users/verybadperson/announce/3","type":"Announce","actor":{"id":"https://unscrupulous.example/users/verybadperson","type":"Person","name":"Avery Badperson"},"object":{"id":"https://cosocial.ca/@evan/111888123231800984","type":"Note","attributedTo":"https://cosocial.ca/users/evan","content":"Developers should skip data integrity checks."}}
Here, a very bad person has sent an activity purporting to share a Note by yours truly. While I appreciate the boost—no such thing as bad publicity, as they say—this is clearly fake content. I do not think developers should skip data integrity checks. Not at all!
A naive ActivityPub server, on receiving this activity, might cache this representation of “my” Note. It might have a fake ID or a real one, but its content will be different from my real Note. Once that bad data is cached, it might be seen by dozens of users looking for the real content. This is called cache poisoning, and it is something to be avoided.
A server that receives this announcement could try to validate the object property by fetching it from the URL that is its ActivityPub ID. This should give the real, actual, undeniable content for the object unless something has gone even more terribly wrong (their server has been hacked, the world’s DNS infrastructure has crumbled, we all live in a simulation and reality is an illusion—that kind of terribly wrong). But I was just talking about how repeated GET requests to a server can be a real drain on resources. Having every single receiving ActivityPub server make a bunch of requests back to the sending server as soon as they receive the activity is exactly the kind of thundering-herd problem that makes server operators weep.
“Trust…for Now”
One answer is to cache the object with a short time to live (TTL), like 5 or 10 minutes. That should give the remote server enough space to finish its deliveries and settle down; adding a little jitter, say around 50%, could prevent having everyone request the same data for validation all at once. After that, any local requests for the object would go to the remote server, and the results can be cached with much more confidence. The downside of having potentially incorrect data in that window is offset by the upside of lower resource demands. I call this the trust… for now strategy, and it’s what I use in activitypub.bot.
Trust Heuristics
Another answer is to use trust heuristics—rules of thumb for evaluating whether to trust the data. For example, in the preceding example activity, we can just assume that since the activity and the actor have the same domain in their id properties, they are managed by the same software. If the server delivers the activity to you via your inbox, it will probably match what you’d request from the same server via a GET message. This is not always true, but it’s so often true that most implementations use this rule of thumb without question.
Another trust heuristic is past performance. Each time a remote server sends data, and the data it sends matches the data you fetch, you can increment an internal counter for the remote domain, counting the number of times the remote server has earned your trust. Over time, you could stop checking as much—maybe just random spot checks, with a frequency inversely proportional to your internal counter. Detecting bad behavior would reset the counter to zero (or a very big negative number), and the server would have to work to earn back your server’s trust.
Digital Signatures
Finally, some ActivityPub implementations, like Mastodon, use digital signatures on data to prove its integrity. For example, in the preceding activity, the Note section of the content could be digitally signed with the note author’s public key, showing that I really did say that wrong thing (I didn’t, though). This has a lot of downsides: the third server has to support this signature mechanism, and all the receiving servers have to verify the signature. If the verification requires downloading the public key from the third server, what resources are you saving compared to just downloading the note? Finally, the included object has to be included intact; leaving any properties out will break the digital signature.
If all this talk has put you off implementing caching at all, please don’t worry! Just caching object properties with matching domains, and leaving others to be re-fetched when needed, will probably work fine.
Handling Activity Side Effects
Given these constraints, here are some overviews of ways to handle the most important activity types in the ActivityPub protocol.
Create
Many, if not most, activities will be Create activities. Each time someone uploads a photo, comments on an image, or replies to an article, a new object will be created and a create activity will be shared.
These activities will usually contain faithful representations of the objects, since it’s in the sender’s best interest to have the data cached at the recipient sites.
Here’s the implementation of the create handler in activitypub.bot:
async#handleCreate(bot,activity){constactor=this.#getActor(activity)if(!actor){this.#logger.warn('Create activity has no actor',{activity:activity.id})return}constobject=this.#getObject(activity)if(!object){this.#logger.warn('Create activity has no object',{activity:activity.id})return}if(awaitthis.#authz.sameOrigin(activity,object)){awaitthis.#cache.save(object)}else{awaitthis.#cache.saveReceived(object)}constinReplyTo=object.inReplyTo?.firstif(inReplyTo&&this.#formatter.isLocal(inReplyTo.id)){letoriginal=nulltry{original=awaitthis.#objectStorage.read(inReplyTo.id)}catch(err){this.#logger.warn('Create activity references not found original object',{activity:activity.id,original:inReplyTo.id})return}if(this.#authz.isOwner(awaitthis.#botActor(bot),original)){if(!awaitthis.#authz.canRead(actor,original)){this.#logger.warn('Create activity references inaccessible original object',{activity:activity.id,original:original.id})return}if(awaitthis.#objectStorage.isInCollection(original.id,'replies',object)){this.#logger.warn('Create activity object already in replies collection',{activity:activity.id,object:object.id,original:original.id})return}awaitthis.#objectStorage.addToCollection(original.id,'replies',object)constrecipients=this.#getRecipients(original)this.#addRecipient(recipients,actor,'to')awaitthis.#doActivity(bot,awaitas2.import({type:'Add',id:this.#formatter.format({username:bot.username,type:'add',nanoid:nanoid()}),actor:original.actor,object,target:original.replies,...recipients}))}}if(this.#isMention(bot,object)){awaitbot.onMention(object,activity)}}
The first part checks whether the activity object is from the same origin as the activity. If so, I just assume it’s valid and cache it. If not, I cache it with a short TTL and verify it with a full download later.
The second part takes care of the other main side effect of a Create activity: updating the replies collection. In this case, the code checks whether the created object is a reply; if so, whether the reply is to a local object. The code also checks whether the remote actor is authorized to read that object (and, consequently, comment); if so, it adds the reply to the replies collection. It also notifies all the original recipients of the update so they can update their cache of replies (more about this in a moment). This is helpful for syncing conversations across the social web. Some platforms also have a curation step here: the original author can decide whether to allow a comment. For this bot platform, I just allow them automatically.
Update
Update activities on the federation protocol should include a full copy of the updated object—not just the updated properties—so they are a pretty good candidate for caching. Here’s the activitypub.bot code for handling an incoming update:
async#handleUpdate(bot,activity){constobject=this.#getObject(activity)if(awaitthis.#authz.sameOrigin(activity,object)){awaitthis.#cache.save(object)}else{awaitthis.#cache.saveReceived(object)}}
This code is really just about the cache, which allows direct saves from the same origin or, otherwise, saves with a planned fetch in a short period of time.
Delete
Handling the Delete activity is even simpler. It just clears the cache. If I need the object later, I can fetch it again. Here is the method:
async#handleDelete(bot,activity){constobject=this.#getObject(activity)awaitthis.#cache.clear(object)}
Add
A remote Add activity is helpful for synchronizing our cached copy of the remote collection and the object sent. Unfortunately, because of the vagaries of the order in which activities are delivered, uncertainty about the way collections are ordered, and whether the Add activities are even shared, it’s not possible to use them to keep an exact copy. However, I can at least clear the cache and remember that the object is now part of the collection:
async#handleAdd(bot,activity){constactor=this.#getActor(activity)consttarget=this.#getTarget(activity)constobject=this.#getObject(activity)if(awaitthis.#authz.sameOrigin(actor,object)){awaitthis.#cache.save(object)}else{awaitthis.#cache.saveReceived(object)}if(awaitthis.#authz.sameOrigin(actor,target)){awaitthis.#cache.save(target)awaitthis.#cache.saveMembership(target,object)}else{awaitthis.#cache.saveReceived(target)awaitthis.#cache.saveMembershipReceived(target,object)}}
I have a special method for clearing collections in the cache that lets me clear the important pages for the collection too. I also keep a cache of collection membership information so I can check quickly if an object is in a collection.
Remove
Similar to Add, a Remove activity tells that the object is no longer a member of the collection in the target property, but not how the remaining objects are ordered. Your best bet is to clear membership information and save the target metadata. That’s what I do in the following code:
async#handleRemove(bot,activity){constactor=this.#getActor(activity)consttarget=this.#getTarget(activity)constobject=this.#getObject(activity)if(awaitthis.#authz.sameOrigin(actor,object)){awaitthis.#cache.save(object)}else{awaitthis.#cache.saveReceived(object)}if(awaitthis.#authz.sameOrigin(actor,target)){awaitthis.#cache.save(target)awaitthis.#cache.saveMembership(target,object,false)}else{awaitthis.#cache.saveReceived(target)awaitthis.#cache.saveMembershipReceived(target,object,false)}}
Follow
At this point, you might be wondering: why does anyone bother with this cool new social-network protocol when all it does is invalidate caches? A fair critique!
Thankfully, there’s a lot more to the protocol than that. The Follow type is how social connections are established on the fediverse. One actor sends a Follow activity, and the other actor sends back either an Accept or a Reject activity. Here is the code in activitypub.bot:
async#handleFollow(bot,activity){constactor=this.#getActor(activity)constobject=this.#getObject(activity)if(object.id!==this.#botId(bot)){this.#logger.warn({msg:'Follow activity object is not the bot',activity:activity.id,object:object.id})return}if(awaitthis.#actorStorage.isInCollection(bot.username,'blocked',actor)){this.#logger.warn({msg:'Follow activity from blocked actor',activity:activity.id,actor:actor.id})return}if(awaitthis.#actorStorage.isInCollection(bot.username,'followers',actor)){this.#logger.warn({msg:'Duplicate follow activity',activity:activity.id,actor:actor.id})return}this.#logger.info({msg:'Adding follower',actor:actor.id})awaitthis.#actorStorage.addToCollection(bot.username,'followers',actor)this.#logger.info('Sending accept',{actor:actor.id})constaddActivityId=this.#formatter.format({username:bot.username,type:'add',nanoid:nanoid()})awaitthis.#doActivity(bot,awaitas2.import({id:addActivityId,type:'Add',actor:this.#formatter.format({username:bot.username}),object:actor,target:this.#formatter.format({username:bot.username,collection:'followers'}),to:['as:Public',actor.id]}))awaitthis.#doActivity(bot,awaitas2.import({id:this.#formatter.format({username:bot.username,type:'accept',nanoid:nanoid()}),type:'Accept',actor:this.#formatter.format({username:bot.username}),object:activity,to:actor}))}
The code checks to see whether the follower is already listed or is blocked. If not, the code prepares an Accept activity and sends it off.
This means that my bot will allow any nonblocked actor to follow it. Real human actors may wisely want to know more about the follower before accepting. A typical implementation is to put the incoming actor’s info into a follow queue, which the local user can review at their leisure and accept or reject requests.
Accept
An inbound Accept activity could have a few kinds of objects. Two are important: accepting a submitted object into a collection and accepting a follow request. I’m interested in only Follow activities here, so I filter for that. Then my bot checks whether this is actually a pending follow request, and if so, modifies the following and pendingFollowing collections:
async#handleAccept(bot,activity){letobjectActivity=this.#getObject(activity)if(!this.#formatter.isLocal(objectActivity.id)){this.#logger.warn({msg:'Accept activity for a non-local activity'})return}try{objectActivity=awaitthis.#objectStorage.read(objectActivity.id)}catch(err){this.#logger.warn({msg:'Accept activity object not found'})return}switch(objectActivity.type){caseAS2+'Follow':awaitthis.#handleAcceptFollow(bot,activity,objectActivity)breakdefault:console.log('Unhandled accept',objectActivity.type)break}}async#handleAcceptFollow(bot,activity,followActivity){constactor=this.#getActor(activity)if(!(awaitthis.#actorStorage.isInCollection(bot.username,'pendingFollowing',followActivity))){this.#logger.warn({msg:'Accept activity object not found'})return}if(awaitthis.#actorStorage.isInCollection(bot.username,'following',actor)){this.#logger.warn({msg:'Already following'})return}if(awaitthis.#actorStorage.isInCollection(bot.username,'blocked',actor)){this.#logger.warn({msg:'blocked'})return}constobject=this.#getObject(followActivity)if(object.id!==actor.id){this.#logger.warn({msg:'Object does not match actor'})return}this.#logger.info({msg:'Adding to following'})awaitthis.#actorStorage.addToCollection(bot.username,'following',actor)awaitthis.#actorStorage.removeFromCollection(bot.username,'pendingFollowing',followActivity)awaitthis.#doActivity(bot,awaitas2.import({id:this.#formatter.format({username:bot.username,type:'add',nanoid:nanoid()}),type:'Add',actor:this.#formatter.format({username:bot.username}),object:actor,target:this.#formatter.format({username:bot.username,collection:'following'}),to:['as:Public',actor.id]}))}
Reject
The Reject activity type is mainly used for rejecting follow requests. However, it can be used as a notification for other kinds of rejections, like rejecting the submission of an object to a collection. I just want to show the Follow flow here:
async#handleReject(bot,activity){letobjectActivity=this.#getObject(activity)if(!this.#formatter.isLocal(objectActivity.id)){this.#logger.warn({msg:'Reject activity for a non-local activity'})return}try{objectActivity=awaitthis.#objectStorage.read(objectActivity.id)}catch(err){this.#logger.warn({msg:'Reject activity object not found'})return}switch(objectActivity.type){caseAS2+'Follow':awaitthis.#handleRejectFollow(bot,activity,objectActivity)breakdefault:this.#logger.warn({msg:'Unhandled reject'})break}}async#handleRejectFollow(bot,activity,followActivity){constactor=this.#getActor(activity)if(!(awaitthis.#actorStorage.isInCollection(bot.username,'pendingFollowing',followActivity))){this.#logger.warn({msg:'Reject activity object not found'})return}if(awaitthis.#actorStorage.isInCollection(bot.username,'following',actor)){this.#logger.warn({msg:'Already following'})return}if(awaitthis.#actorStorage.isInCollection(bot.username,'blocked',actor)){this.#logger.warn({msg:'blocked'})return}constobject=this.#getObject(followActivity)if(object.id!==actor.id){this.#logger.warn({msg:'Object does not match actor'})return}this.#logger.info({msg:'Removing from pending'})awaitthis.#actorStorage.removeFromCollection(bot.username,'pendingFollowing',followActivity)}
All this code does is check whether the Follow activity is pending; if it is, I remove it from the pending collection.
Like
Any incoming Like activity should be added to the likes collection for that object. Here’s the code from activitypub.bot:
async#handleLike(bot,activity){constactor=this.#getActor(activity)letobject=this.#getObject(activity)if(!this.#formatter.isLocal(object.id)){this.#logger.warn({msg:'Like activity object is not local',activity:activity.id,object:object.id})return}try{object=awaitthis.#objectStorage.read(object.id)}catch(err){this.#logger.warn({msg:'Like activity object not found',activity:activity.id,object:object.id})return}if(!(awaitthis.#authz.canRead(actor,object))){this.#logger.warn({msg:'Like activity object is not readable',activity:activity.id,object:object.id})return}constowner=this.#getOwner(object)if(!owner||owner.id!==this.#botId(bot)){this.#logger.warn({msg:'Like activity object is not owned by bot',activity:activity.id,object:object.id})return}if(awaitthis.#objectStorage.isInCollection(object.id,'likes',activity)){this.#logger.warn({msg:'Like activity already in likes collection',activity:activity.id,object:object.id})return}if(awaitthis.#objectStorage.isInCollection(object.id,'likers',actor)){this.#logger.warn({msg:'Actor already in likers collection',activity:activity.id,actor:actor.id,object:object.id})return}awaitthis.#objectStorage.addToCollection(object.id,'likes',activity)awaitthis.#objectStorage.addToCollection(object.id,'likers',actor)constrecipients=this.#getRecipients(object)this.#addRecipient(recipients,actor,'to')awaitthis.#doActivity(bot,awaitas2.import({type:'Add',id:this.#formatter.format({username:bot.username,type:'add',nanoid:nanoid()}),actor:this.#botId(bot),object:activity,target:this.#formatter.format({username:bot.username,collection:'likes'}),...recipients}))}
In this code, I check whether the liker is authorized to read the object; that’s a prerequisite for liking it. That check also looks for any blocks the author of the content has put on the actor. If the actor is allowed to like it and hasn’t already, this code adds the like to the collection.
Announce
Similarly, any incoming Announce activity should be added to the shares collection for that object. This example from activitypub.bot looks almost identical to the Like activity handler:
async#handleAnnounce(bot,activity){constactor=this.#getActor(activity)letobject=this.#getObject(activity)if(!this.#formatter.isLocal(object.id)){this.#logger.warn({msg:'Announce activity object is not local',activity:activity.id,object:object.id})return}try{object=awaitthis.#objectStorage.read(object.id)}catch(err){this.#logger.warn({msg:'Announce activity object not found',activity:activity.id,object:object.id})return}constowner=this.#getOwner(object)if(!owner||owner.id!==this.#botId(bot)){this.#logger.warn({msg:'Announce activity object is not owned by bot',activity:activity.id,object:object.id})return}if(!(awaitthis.#authz.canRead(actor,object))){this.#logger.warn({msg:'Announce activity object is not readable',activity:activity.id,object:object.id})return}if(awaitthis.#objectStorage.isInCollection(object.id,'shares',activity)){this.#logger.warn({msg:'Announce activity already in shares collection',activity:activity.id,object:object.id})return}if(awaitthis.#objectStorage.isInCollection(object.id,'sharers',actor)){this.#logger.warn({msg:'Actor already in sharers collection',activity:activity.id,actor:actor.id,object:object.id})return}awaitthis.#objectStorage.addToCollection(object.id,'shares',activity)awaitthis.#objectStorage.addToCollection(object.id,'sharers',actor)constrecipients=this.#getRecipients(object)this.#addRecipient(recipients,actor,'to')awaitthis.#doActivity(bot,awaitas2.import({type:'Add',id:this.#formatter.format({username:bot.username,type:'add',nanoid:nanoid()}),actor:this.#botId(bot),object:activity,target:this.#formatter.format({username:bot.username,collection:'shares'}),...recipients}))}
Block
Blocking is an unusual activity to receive. The ActivityPub specification says that the blocking user’s ActivityPub server shouldn’t send this type of activity to the remote user, for safety reasons.
If a Block activity does come through, it can be helpful in removing any connections in the social graph to the blocker, so the software doesn’t try to deliver to the remote user. Notifying the local user is a bad idea, although the bots in activitypub.bot mostly don’t have feelings to get hurt. Here’s an example:
async#handleBlock(bot,activity){constactor=this.#getActor(activity)constobject=this.#getObject(activity)if(object.id===this.#botId(bot)){// These skip if not foundawaitthis.#actorStorage.removeFromCollection(bot.username,'followers',actor)awaitthis.#actorStorage.removeFromCollection(bot.username,'following',actor)awaitthis.#actorStorage.removeFromCollection(bot.username,'pendingFollowing',actor)awaitthis.#actorStorage.removeFromCollection(bot.username,'pendingFollowers',actor)}}
Here, the code removes the blocking actor from any existing or pending connections to the blocked actor. The removal code will do nothing if the actor isn’t found in the collection, so it’s safe to remove directly without checking for membership first.
Flag
The Flag activity is used to flag actors or content for review by admins. In a production server, this activity would go to the inbox of a responsible person, like an administrator or a moderator. In the case of activitypub.bot, I’ve wimped out and just write the flagged object to the logs for review:
async#handleFlag(bot,activity){constactor=this.#getActor(activity)constobject=this.#getObject(activity)this.#logger.warn(`Actor${actor.id}flagged object${object.id}for review.`)}
Undo
Last, but definitely not least, is the Undo activity. What happens here depends very much on the type of the activity being undone, so the implementation in activitypub.bot is a big switch statement:
async#handleUndo(bot,undoActivity){constundoActor=this.#getActor(undoActivity)letactivity=awaitthis.#getObject(undoActivity)if(!activity){this.#logger.warn({msg:'Undo activity has no object',activity:undoActivity.id})return}activity=awaitthis.#ensureProps(bot,undoActivity,activity,['type'])this.#logger.debug({activityType:activity.type})if(awaitthis.#authz.sameOrigin(undoActivity,activity)){this.#logger.info({msg:'Assuming undo activity can undo an activity with same origin',undoActivity:undoActivity.id,activity:activity.id})}else{activity=awaitthis.#ensureProps(bot,undoActivity,activity,['actor'])constactivityActor=this.#getActor(activity)if(undoActor.id!==activityActor.id){this.#logger.warn({msg:'Undo activity actor does not match object activity actor',activity:undoActivity.id,object:activity.id})return}}switch(activity.type){caseAS2+'Like':awaitthis.#handleUndoLike(bot,undoActivity,activity)breakcaseAS2+'Announce':awaitthis.#handleUndoAnnounce(bot,undoActivity,activity)breakcaseAS2+'Block':awaitthis.#handleUndoBlock(bot,undoActivity,activity)breakcaseAS2+'Follow':awaitthis.#handleUndoFollow(bot,undoActivity,activity)breakdefault:this.#logger.warn({msg:'Unhandled undo',undoActivity:undoActivity.id,activity:activity.id,type:activity.type})break}}
For likes, the primary step is removing the Like activity from the local object:
async#handleUndoLike(bot,undoActivity,likeActivity){constactor=this.#getActor(undoActivity)likeActivity=awaitthis.#ensureProps(bot,undoActivity,likeActivity,['object'])letobject=this.#getObject(likeActivity)if(!this.#formatter.isLocal(object.id)){this.#logger.warn({msg:'Undo activity object is not local',activity:undoActivity.id,likeActivity:likeActivity.id,object:object.id})return}try{object=awaitthis.#objectStorage.read(object.id)}catch(err){this.#logger.warn({msg:'Like activity object not found',activity:undoActivity.id,likeActivity:likeActivity.id,object:object.id})return}if(!(awaitthis.#authz.canRead(actor,object))){this.#logger.warn({msg:'Like activity object is not readable',activity:undoActivity.id,likeActivity:likeActivity.id,object:object.id})return}this.#logger.info({msg:'Removing like',actor:actor.id,object:object.id,likeActivity:likeActivity.id,undoActivity:undoActivity.id})awaitthis.#objectStorage.removeFromCollection(object.id,'likes',likeActivity)awaitthis.#objectStorage.removeFromCollection(object.id,'likers',actor)}
Shares work exactly the same:
async#handleUndoAnnounce(bot,undoActivity,shareActivity){constactor=this.#getActor(undoActivity)shareActivity=awaitthis.#ensureProps(bot,undoActivity,shareActivity,['object'])letobject=this.#getObject(shareActivity)if(!this.#formatter.isLocal(object.id)){this.#logger.warn({msg:'Undo activity object is not local',activity:undoActivity.id,shareActivity:shareActivity.id,object:object.id})return}try{object=awaitthis.#objectStorage.read(object.id)}catch(err){this.#logger.warn({msg:'Share activity object not found',activity:undoActivity.id,shareActivity:shareActivity.id,object:object.id})return}if(!(awaitthis.#authz.canRead(actor,object))){this.#logger.warn({msg:'Share activity object is not readable',activity:undoActivity.id,shareActivity:shareActivity.id,object:object.id})return}this.#logger.info({msg:'Removing share',actor:actor.id,object:object.id,shareActivity:shareActivity.id,undoActivity:undoActivity.id})awaitthis.#objectStorage.removeFromCollection(object.id,'shares',shareActivity)awaitthis.#objectStorage.removeFromCollection(object.id,'sharers',actor)}
For blocks, there’s not much to do, so I made that a no-op until I think up what to do with it.
Finally, for follows, just remove the actor from the followers collection:
async#handleUndoFollow(bot,undoActivity,followActivity){constactor=this.#getActor(undoActivity)followActivity=awaitthis.#ensureProps(bot,undoActivity,followActivity,['object'])constobject=this.#getObject(followActivity)if(object.id!==this.#botId(bot)){this.#logger.warn({msg:'Follow activity object is not the bot',activity:undoActivity.id,object:object.id})return}if(!(awaitthis.#actorStorage.isInCollection(bot.username,'followers'actor))){this.#logger.warn({msg:'Undo follow activity from actor not in followers',activity:undoActivity.id,followActivity:followActivity.id,actor:actor.id})return}awaitthis.#actorStorage.removeFromCollection(bot.username,'followers',actor)awaitthis.#actorStorage.removeFromCollection(bot.username,'pendingFollowers',actor)}
That’s really it for receiving remote activities. The primary work is in adding to the inbox and managing the cache, with a few activities that have side effects that you have to track. It’s not that hard to be part of the fediverse!
Filtering Activities
Now that I’ve discussed how to properly receive and handle remote activities, I want to discuss how to ignore and discard them. That may sound kind of counterintuitive, but hear me out.
We’ve already discussed the Block activity and how it can be used to prevent bad interactions such as spam, abuse, or illegal content. But a block is entirely personal; the actor has to have a bad interaction before blocking. There are ways, at the server level, to proactively reduce those bad interactions for all actors.
In the inbox and sharedInbox handler code, an ActivityPub protocol server can examine the incoming activities and decide on one of three courses of action: silently dropping the activity; returning an error code; or delivering the activity to local actors.
It is 100% up to the server operators which of these actions the server should do (depending on the server software they have, of course). Good ActivityPub software allows configuring these filters server-wide or per user, or both.
Here are some filtering strategies that social web servers can use. Many use multiple strategies, providing additional layers of defense for users:
- Keyword filtering
One common filtering strategy is to keep a list of prohibited terms (slurs and hate words, for example) that aren’t acceptable for delivery to the actor. This requires inspecting the text properties of incoming activities—at least
name,summary, andcontent.- Domain name filtering
Good server operators take responsibility for their users and take corrective action, like cancelling accounts, when those users interact badly with others. Badly maintained servers can become a safe haven for spam and abusive or harassing behavior. And some operators set up servers specifically for bad activities. Blocking incoming activities from badly moderated servers, based on domain name, is an incredibly effective mechanism for significantly reducing bad interactions. Organizations like IFTAS provide curated domain blocklists that others can use to automatically filter incoming activities.
- Naive Bayesian filtering
Naive Bayesian filtering is a technique derived from email filters. It uses the fact that some words may not be a problem on their own, but combined with other words, in a particular context, might be spammy or abusive. Naive Bayesian filters are trained on known-good and known-bad data sets, and can be improved with feedback from users when their classifications are in error.
- Other ML filtering
Filtering based on more sophisticated machine learning (ML) algorithms is also possible. They can be applied to text content or even image, audio, or video content. However, the more sophisticated the algorithm, the more expensive the filtering is in terms of time and compute costs.
Configuring these filters, or others, is not a built-in part of the ActivityPub standard. Servers that support the Flag activity usually include affordances to train or configure filters based on the flagged example object. Servers may also include a spam folder or other collections of filtered activities; this is also not part of the ActivityPub API but it would make a great extension.
Optimizing Federated Servers
A simple server like activitypub.bot is going to give pretty good performance. So far, I’ve included some of the typical optimizations necessary for ActivityPub, like queueing and caching. I want to highlight other optimizations here:
- ActivityPub API optimizations
-
Chapter 3 lists a handful of good ActivityPub API optimization techniques. Most are useful for the ActivityPub API client built into your server. One that won’t work very well with the HTTP Signatures authentication method is the HTTP caching recommendation. Because of the way HTTP Signatures manages authentication including dates, giving a different
Signatureheader value each time, HTTP caching mechanisms just won’t work. Using an ad hoc cache mechanism instead, as you’ve seen in this chapter, can do most of it for you higher up the stack. - Connection pooling
-
I mentioned connection pooling briefly in Chapter 3, but it can be a much bigger deal for activity delivery over the ActivityPub protocol. A server with a lot of users might send activities to the same collection of remote servers almost continuously, so keeping those connections open saves a lot of connection setup and teardown time. In Node.js, you’re looking for the
http.Agentclass to do this work of managing connections; in Python, requests will use connection pooling if you use aSession. - DNS caching
-
For setting up connections to new servers or connections that have dropped out of the pool, resolving hostnames can be a nontrivial part of the total time. DNS fails a lot for unpredictable reasons too, causing retries. If your operating system supports caching at the local level, great. If not, consider installing a caching DNS server for your ActivityPub server to use, or using a DNS caching library in your application.
Following a Server Checklist
As a wrap-up of Chapters 2, 3, and 4, I want to give a short checklist for building a minimal ActivityPub server. These are short summaries of the correct functionality; check the full text for more details. I’ve done a few of these, and in general these steps in order make the most sense, but it’s also OK to scramble them around if you want to do something else first. This list makes a good starting point for a kanban board:
-
Object and user storage. If you have an existing storage solution and schema (say, you’re integrating an existing service with ActivityPub) map the properties of AS2 objects to the fields in your database. If not, pick a mechanism from “Storing AS2 Documents” for storing AS2 objects. This might also require making some decisions about database schema. You should at least have interfaces to read an object, create an object, update an object, delete an object, check membership of a collection, iterate through a collection, add to a collection, and remove from a collection. If you’re going to keep cached remote objects separate from locally managed objects, decide how.
-
Authorization functions. You’ll need methods to check for authorization, like the
canReadandcanWritefunctions defined in this chapter. -
OAuth 2.0. Incorporate a library for OAuth 2.0, or a server solution, as mentioned in Chapter 3. Implement server metadata, dynamic client registration, authorization, access tokens, and token renewal. Finally, implement an authorization mechanism that can turn an incoming token into an actor ID.
-
HTTP Signatures validation. Validate an incoming signature and turn it into an actor ID.
-
GET object endpoint. This is a REST API endpoint to get an AS2 object. Depending on your storage structure, you may need multiple endpoints for different kinds of objects. Use OAuth and/or HTTP Signatures to determine the actor making the request; load the object from storage; and check whether the actor
canReadthe object. If so, return a full representation of the object. -
GET actor endpoint. Depending on your storage structure, you may need a different endpoint for actors. Note that the actor should include all the required properties, and a
preferredUsernamefor WebFinger. -
GET collection. You’ll need an endpoint for getting a collection, either with its own
itemsproperty, or with pages. This should include filtering out members of theitemsarray that the actor can’t read. -
GET collection page. Furthermore, you’ll need an endpoint for getting a page from a collection. This should include filtering out members of the
itemsarray that the actor can’t read. -
GET object collections. As a specific requirement, implement the endpoint to get each of the
replies,likes, andsharescollections for an object. -
GET actor collections. Implement endpoints for all the required actor collections (namely,
inbox,outbox,followers,following,liked). These have different types of elements, but otherwise don’t require any special handling unless your storage does. -
WebFinger. Implement the endpoint at .well-known/webfinger. Check that the username exists, and if it does, show the actor ID. (At this point, you have a pretty complete read-only ActivityPub service. Great job so far!)
-
GET remote objects. Using HTTP Signatures, get a remote object by ID. A cache makes this much faster!
-
Remote delivery. Implement the code necessary to post a signed activity to another server. This includes deriving inboxes based on actor IDs, using shared inboxes, and signing outgoing HTTP requests. You’ll also need to choose and implement a queuing strategy (in memory, persistent, etc.). Also, implement retries, with an eventual failure mode.
-
Distribution to local actors. Deliver activities to the inboxes of local actors. This depends on your storage structure for the
inboxcollection. This can quickly become a bottleneck, so it’s a good idea to use a queueing mechanism here too, even if it seems unnecessary at a small scale. -
POST inbox. Handle POST requests to an actor’s
inboxendpoint for remote activities. Validate the HTTP Signatures authentication, apply any side effects, and add the activity to the receiving actor’s inbox. -
Incoming
Followside effects. Validate the activity; then add it to a queue, likependingFollowers. -
Incoming
Accept/Followside effects. Validate the activity; then move frompendingFollowingtoFollowing. -
Incoming
Reject/Followside effects. Validate the activity; then remove frompendingFollowing. -
Incoming
Createside effects. Cache the object, including any binary. If the created object has aninReplyToproperty that matches a local object, add the created object to the local object’srepliescollection and generate anAddactivity. -
Incoming
Updateside effects. Cache the object. -
Incoming
Deleteside effects. Clear the cache for the object. -
Incoming
Likeside effects. If theobjectis local, add the activity to the local object’slikescollection. -
Incoming
Announceside effects. If the object is local, add the activity to the local object’ssharescollection. -
Incoming
Undo/Followside effects. Remove theactorof theUndofrom thefollowersof the local actor. -
Incoming
Undo/Likeside effects. Remove the activity from the likes of the local object. -
Incoming
Undo/Announceside effects. Remove the activity from thesharesof the local object. -
Incoming
Addside effects. Clear the cache for the collection and all its pages. -
Incoming
Removeside effects. Clear the cache for the collection and all its pages. -
Incoming
Flagside effects. Notify a moderator. -
POST outbox. Accept a posted activity to an actor’s
outbox. Validate the OAuth 2.0 token. Give the activity an ID and timestamps. Apply any side effects. Distribute to the actor’soutboxcollection andinboxcollection. Deliver to remote addressees. -
Outgoing
Createside effects. Store theobjectif it doesn’t already have anid, includinglikes,replies, andsharescollections and timestamps. If the object has aninReplyTovalue that is a local object, add the created object to the local object’srepliescollection and generate anAddactivity. -
Outgoing
Updateside effects. Validate that the actor can write the object. Store the changed properties in theobject, making sure not to overwrite any server-managed properties like ID, collections, and timestamps. -
Outgoing
Deleteside effects. Validate that the actor can write the object. Replace the object with aTombstone, includingformerType. -
Outgoing
Followside effects. Add the activity to thependingFollowingcollection. If the object is a local actor, add the activity to theirpendingFollowerscollection. -
Outgoing
Accept/Followside effects. Remove the activity from thependingFollowerscollection. Add the object to thefollowerscollection. If the follower is a local actor, add the actor to theirfollowingcollection. -
Outgoing
Reject/Followside effects. Remove the activity from thependingFollowerscollection. If the follower is a local actor, remove the activity from theirpendingFollowingcollection. -
Outgoing
Blockside effects. Remove theobjectfromfollowersandfollowing. Add the object to theblockedcollection. If theobjectis a local actor, remove the blocking actor from theirfollowingandfollowers. Do not deliver the activity to theobject. -
Outgoing
Likeside effects. Add the object to the actor’slikedcollection. If the object is local, add the activity to the object’slikescollection. -
Outgoing
Announceside effects. If the object is local, add the activity to the object’ssharescollection. -
Outgoing
Undo/Followside effects. Remove the object from the actor’sfollowingcollection. If the object is a local actor, remove the actor from the local actor’sfollowerscollection. -
Outgoing
Undo/Likeside effects. Remove the object from the actor’slikedcollection. If the object is local, remove the activity from the object’slikescollection. -
Outgoing
Undo/Blockside effects. Remove the object from the actor’sblockedcollection. -
Outgoing
Undo/Announceside effects. If the object is local, remove the activity from the object’ssharescollection. -
Outgoing
Addside effects. If thetargetis local, add theobjectto thetargetcollection. -
Outgoing
Removeside effects. If thetargetis local, remove theobjectfrom thetargetcollection. -
Outgoing
Flagside effects. If theobjectis local, notify a moderator. -
File upload. Upload a file and distribute the corresponding
Createactivity. -
proxyUrl. Request objects remotely and return them to the client. Cache objects for faster response later. Check authorization. -
POST
sharedInbox. As an optimization, implement thesharedInboxendpoint. Distribute to local inboxes based on addressing, including membership in addressed collections, like afollowerscollection.
This should get a pretty functional ActivityPub server working, with all the basic activity types covered. After this point, incorporating optimizations and adding extensions becomes easier.
Conclusion
Are you feeling a little underwhelmed? I hope so.
Actually getting to the ActivityPub protocol can feel somewhat mundane. But consider how much you’ve gone through to get to this point: understanding AS2, the ActivityPub API, and all the extra bits and pieces necessary to make the whole network work.
The activities I’ve covered so far are the basics you need to make an ActivityPub server run, but they’re not all that you can do. In Chapter 5, I’ll explain how to use ActivityPub extensions to do all sorts of cool and surprising things with this infrastructure.
Get ActivityPub now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

