Data liquidity in the age of inference
Probabilistic computation holds too much promise for it to be stifled by playing zero sum games with data.
 Water ripples (source: Blazing Firebug via Pixabay)
Water ripples (source: Blazing Firebug via Pixabay)
It’s a special time in the evolutionary history of computing. Oft-used terms like big data, machine learning, and artificial intelligence have become popular descriptors of a broader underlying shift in information processing. While traditional rules-based computing isn’t going anywhere, a new computing paradigm is emerging around probabilistic inference, where digital reasoning is learned from sample data rather than hardcoded with boolean logic. This shift is so significant that a new computing stack is forming around it with emphasis on data engineering, algorithm development, and even novel hardware designs optimized for parallel computing workloads, both within data centers and at endpoints.
A funny thing about probabilistic inference is that when models work well, they’re probably right most of the time, but always wrong at least some of the time. From a mathematics perspective, this is because such models take a numerical approach to problem analysis, as opposed to an analytical one. That is, they learn patterns from data (with various levels of human involvement) that have certain levels of statistical significance, but remain somewhat ignorant to any physics-level intuition related to those patterns, whether represented by math theorems, conjectures, or otherwise. However, that’s also precisely why probabilistic inference is so incredibly powerful. Many real-world systems are so multivariate, complex, and even stochastic that analytical math models do not exist and remain tremendously difficult to develop. In the meanwhile, their physics-ignorant, FLOPS-happy, and often brutish machine learning counterparts can develop deductive capabilities that don’t nicely follow any known rules, yet still almost always arrive at the correct answers.

Learn faster. Dig deeper. See farther.
This is exciting because it means even without fully understanding the underlying physics, we can replicate in software powerful functions like perception, planning, and decision making. In fact, studying the inputs and outputs of learning models may even help us develop some of the missing physical models for complex systems in biology, chemistry, environmental sciences and more. When considering these capabilities, it’s no wonder why academics and industrialists alike are flocking towards ways to apply artificial intelligence. However, the exciting promise of this impending age of inference comes with an indisputable Achilles’ heel. In this computing paradigm, running software applications requires data just as much as it needs memory and microprocessors. Data becomes a computing component as core as the physical parts that comprise actual computers. Suddenly, the notion of supply and value chains apply to not only physical goods, but also digital assets like data. Unfortunately, the economic ecosystems around data remain largely underdeveloped, and rather than being packaged and shipped seamlessly, data goods far too often stay raw and stuck.

Data fiefdoms
While the public web distributes information more freely and with more scale than ever before, sharing data valuable for training and running machine learning models runs contrary to how most internet business models have evolved. That makes sense and there is nothing wrong with that per se. If a company has invested in building valuable data sets that help differentiate its product or service, its motivation is to preserve that moat by protecting that data against competition. Data network effects are a particularly powerful business and technology strategy that emerged along these lines. When we zoom outside the lens of an individual company and its singular interests, however, we start seeing several industry-level benefits that breaking data silos would create for everyone. Here are just some of them.
Efficiency
Many redundant data sets are unnecessarily created because prior knowledge of their existence or accessibility are missing. The cost and time savings of reducing redundancy can be enormous.
Reproducibility
Sometimes it’s beneficial to purposely repeat data collection because reproducibility provides quality assurance. However, even in this case, data transparency and sharing is needed to actually compare independently collected data sets.
Multiplier effects
For narrow applications like cat recognition, the value of data can saturate rather quickly. For massive information spaces like genomics or driving around New York City, the value of data will continue to compound with aggregation for quite some time. Given that a culture of open source algorithms has already become widespread, data federation can have multiplicative effect as open models are combined with open data.
Unlocking discovery
Successfully solving many computational problems requires not just data, but also a critical mass of data, which can often be reached more quickly through aggregation or crowdsourcing. Different levels of critical mass unlock different levels of discovery, and we don’t even know what those levels are yet a priori.
Big innovation from small players
Economies of scale help large organizations amass data more efficiently, while smaller players are often on the outside looking in and find their innovative ideas data-starved. New tools giving small companies more leverage are needed to help close the data inequality gap so their innovations have a better chance of reaching markets.
Of primary concern here is not that all data should be fully federated. Forms of proprietary data will always exist because information asymmetry provides such strong strategic advantages. In fact, monopolistic ownership of data sometimes fosters innovation because it gives the innovator enough sense of security to invest in projects that require long time horizons. On the other hand, a plethora of data exhaust exists across fiefdoms that, when pooled and made accessible, could create a data commons that accelerates progress for everyone in an information intensive industry. These data sets usually create little value for individual owners when isolated, but aggregating them unlocks far greater value and grows the pie for everyone. The kind of data residing in a data commons is often necessary, but insufficient, and businesses require much more data and work to actually make their products competitive. Thus, competing by attempting to monopolize data at the data commons level seemingly amounts to a zero sum game, and resources spent doing so would likely be better used elsewhere. Instead, as machine learning proliferates across industries, sharing certain types of data can create a strong foundation on which everyone can build and drive progress. As data becomes more important than ever in the age of inference, it becomes imperative to create data liquidity cutting across organizational boundaries defined by corporations, universities, and even nation-states.

Models of data exchange
Sharing data for collective benefit is far from a novel concept. Calls for increasing information transparency have long existed, for example, in open science and open government. Industry has nonetheless shown limited initiative given understandable leeriness of competitors and hidden agendas. Yet, industrial markets scale to general populations, and forward-thinking altruism does not. Since markets operate according to supply and demand, market-driven incentives will likely need to take root for industry to widely adopt data sharing as it strives to incorporate machine learning competency. Here it’s worth exploring a few data exchange models to turn the gears on ways to design an industrial ecosystem that incentivizes sharing.
One way to think of data sharing is as a network where nodes represent data sets or repositories. From this perspective, the parameters that best define a data sharing network’s robustness would be its latency and uptime, where uptime corresponds to the visibility and accessibility of data nodes. Bandwidth would of course matter if real-time data sharing is critical, which it is in continuous learning applications, but here we will only consider batch learning applications where latency of procuring training data is more important. Using this framework helps us visualize the attributes and differences of three types of data exchange operating on different principles: open data, data brokerage, and data cooperative.
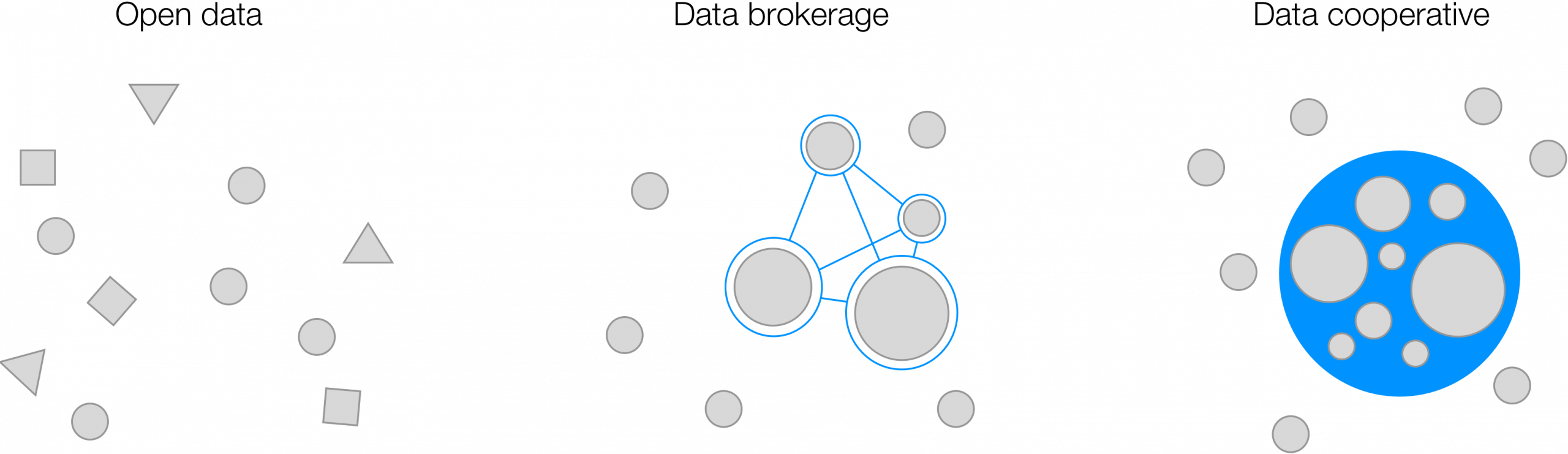
Open data
Open data ideals are commendable and implementing them has yielded great results such as the Allen Institute’s ongoing work with the Allen Brain Atlas. Visibility and accessibility of data are high, presuming the organization publishing the data successfully markets availability and maintains infrastructure for data hosting. Significant latency exists in usefully combining data from different organizations because of data heterogeneity. This is challenging for any data exchange model, but it’s particularly hard in open data where initiatives tend to be bottom-up and fragmented across many participants without strong top-down prescription and enforcement of how to organize data. This is solvable, for example, with government agencies that can use funding as leverage in implementing standards. However, that does not solve the even bigger challenge with open data around scalability. It takes considerable work and expense to build data sets, structure them, and then host them for free public consumption. While some admirably bear this burden out of conviction in the power of openness, they form a minority, and most would-be data contributors would not take on the extra work even if they understand and agree with the value of a data commons. Ultimately, there needs to be more incentive.
Data brokerage
An obvious way to create incentive is introducing financial reward. The ability to monetize data has the natural effect of encouraging business formation around collecting and selling data for profit. Since that business model aligns supremely well with data aggregation, data brokers inherently solve for scalability and amass far larger amounts of data than open data projects, and they do so on a continuous basis. Visibility of data can be high because brokers are also incentivized to market their offerings, but actual data accessibility hides behind paywalls. As a result, data can move around fast and often on this network, but only for paying customers and partners. Nonetheless, data brokerage networks have worked extremely well and effectively power modern finance and e-commerce by providing the data backbone for end applications.
The data brokerage model faces limitations though, particularly pertaining to the types of data they handle. Namely, data with high acquisition costs are less palatable to data brokers because of higher capital intensity. There is no doubt, for example, that increased sharing and exchange around healthcare data is incredibly valuable. However, the process of establishing provenance and securing patient consent appears prohibitively expensive compared to the massive amounts of consumer and financial data that can be scraped from the web for free. Thus, businesses shy away from healthcare and other industries with high data acquisition cost (DAC), leaving them with poor data sharing networks as a result. Consider for a moment that important scientific enterprises in fields like medicine, chemicals, and materials feature high DAC (because data is generated from running actual physical experiments). These fields feature exactly the kind of inferential science for which machine learning can drive tremendous progress, yet lack of data liquidity puts them at a serious disadvantage as they scramble to adopt machine learning techniques. The data brokerage model also works best in areas with heavily fragmented data ownership. It struggles to work in industries featuring data monopolies that ultimately have far too much leverage and far too little incentive to share.
Data cooperative
Data cooperatives reflect a sort of membership model that has powerful advantages around coordination and alignment. In the ideal scenario, a virtuous cycle emerges as members collectively benefit from coordinating efforts, which attracts new members, which drives even greater collective value for members, and the pattern repeats. Alignment on the upside of collaboration (or even coopetition) is a very powerful thing. For example, members can agree on standardization to help alleviate challenges in integrating heterogeneous data. Data liquidity can be even higher than in the brokerage model because members may more transparently coordinate data exchange than partner brokers with opaque agendas. Perhaps the most distinct advantage of the cooperative model though lies in the ability to coordinate efforts and invest collectively in data generation and acquisition. This provides a key lever for solving the challenges facing industries where DAC is high and thus data liquidity is low, as described above. The cooperative can collectively prioritize what data sets to collect and pool resources to reduce effort, cost, and redundancy in procuring that data.
Impactful industry consortia like the Semiconductor Research Corporation (SRC) offer examples of how well this dynamic can work. A supreme example of successful coopetition, the SRC is governed by partners and competitors along the value chain of the semiconductor industry. Each year, members collaboratively set direction on R&D focus areas to tackle the most critical technology challenges facing the industry. SRC funds some of those efforts and fosters knowledge transfer between member companies as they make progress. When a breakthrough is made, it is shared per membership agreement, with the notion that these technologies are pre-competitive. That is, their development is a common boon to everyone in the industry, and competition should ultimately focus on product offerings and differentiation. In the software world, the Linux Foundation provides another meaningful example. In the data world, this grow-the-pie mentality would be game-changing but has thus far been lacking. The primary challenge facing modern data cooperatives will be the cold start problem. Trust has to be established before companies will meaningfully contribute valuable data, but seeing others contribute data is what actually establishes trust.
The importance of data will continue to magnify, sometimes intensely so, as companies figure out how to derive value from data while privacy and security concerns simultaneously mount. I suspect we will soon see many innovative solutions to challenges around data ownership and exchange. However, we should not presuppose these issues will resolve themselves without considerable thought and effort, and there is too much on the line for us to get this wrong. The emerging paradigm of probabilistic computation holds too much promise for human progress and discovery to be stifled by playing zero sum games with data.