Creating autonomous vehicle systems
Understanding AV technologies and how to integrate them.
 The original Benz Patent-Motorwagen, first built in 1885 and awarded the patent for the concept. (source: Wikimedia Commons)
The original Benz Patent-Motorwagen, first built in 1885 and awarded the patent for the concept. (source: Wikimedia Commons)
We are at the beginning of the future of autonomous driving. What is the landscape and how will it unfold? Let’s consult history to help us predict.
Information technology took off in the 1960s, when Fairchild Semiconductors and Intel laid the foundation by producing silicon microprocessors (hence Silicon Valley). Microprocessor technologies greatly improved industrial productivity; the general public had limited access to it. In the 1980s, with the Xerox Alto, Apple Lisa, and later Microsoft Windows, using the Graphical User Interface (GUI), the second layer was laid, and the vision of having a “personal” computer became a possibility.

Learn faster. Dig deeper. See farther.
With virtually everyone having access to computing power in the 2000s, Google laid the third layer, connecting people—indirectly, with information.
Beginning with Facebook in 2004, social networking sites laid the fourth layer of information technology by allowing people to directly connect with each other, effectively moving human society to the World Wide Web.
As the population of Internet-savvy people reached a significant scale, the emergence of Airbnb in 2008, followed by Uber in 2009, and others, laid the fifth layer by providing direct Internet commerce services.
Each new layer of information technology, with its added refinements, improved popular access and demand. Note that for most Internet commerce sites, where they provide access to service providers through the Internet, it is humans who are providing the services.

Now we are adding the sixth layer, where robots, rather than humans, provide services.
One example of this is the advent of autonomous vehicles (AVs). Autonomous driving technologies enable self-driving cars to take you to your destination without the involvement of a human driver. It’s not one technology, but an integration of many.
In this post, we’ll explore the technologies involved in autonomous driving and discuss how to integrate these technologies into a safe, effective, and efficient autonomous driving system.
An introduction to autonomous driving technologies
Autonomous driving technology is a complex system, consisting of three major subsystems: algorithms, including sensing, perception, and decision; client, including the robotics operating system and hardware platform; and the cloud platform, including data storage, simulation, high-definition (HD) mapping, and deep learning model training.
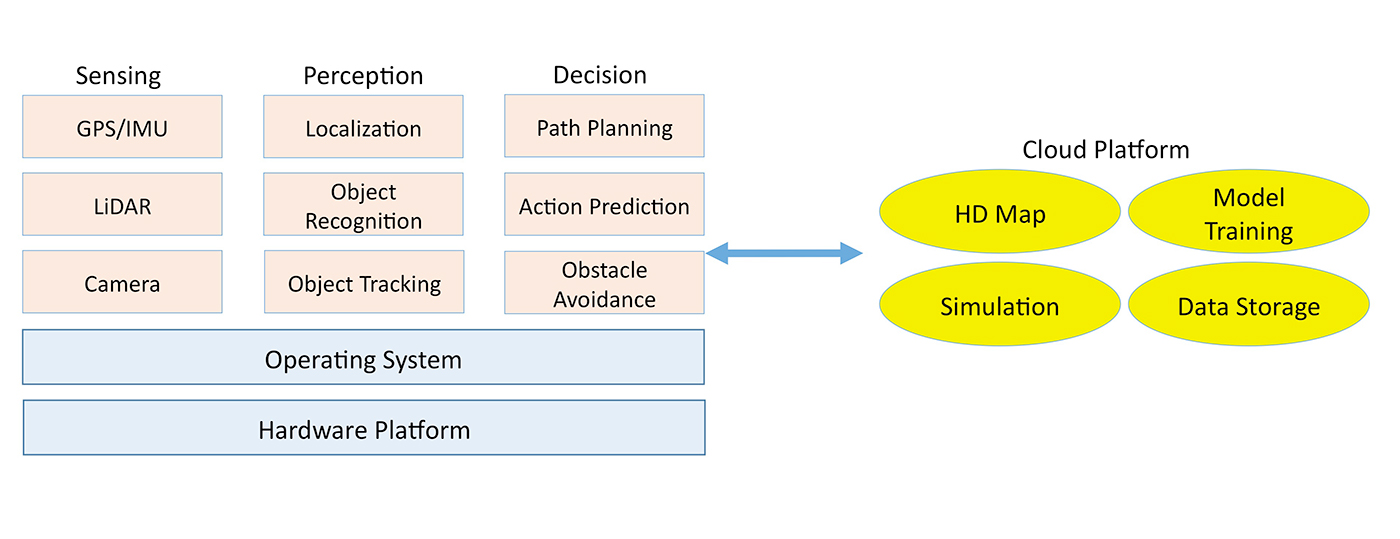
The algorithm subsystem extracts meaningful information from sensor raw data to understand its environment and make decisions about its actions. The client subsystem integrates these algorithms to meet real-time and reliability requirements. (For example, if the sensor camera generates data at 60 Hz, the client subsystem needs to make sure that the longest stage of the processing pipeline takes less than 16 milliseconds (ms) to complete.) The cloud platform provides offline computing and storage capabilities for autonomous cars. Using the cloud platform, we are able to test new algorithms and update the HD map—plus, train better recognition, tracking, and decision models.
Autonomous driving algorithms
The algorithms component consists of: sensing and extracting meaningful information from sensor raw data; perception, to localize the vehicle and understand the current environment; and decision, to take actions to reliably and safely reach destinations.
Sensing
Normally, an autonomous vehicle consists of several major sensors. Since each type of sensor presents advantages and drawbacks, the data from multiple sensors must be combined. The sensor types can include the following:
- GPS/IMU: The GPS/IMU system helps the AV localize itself by reporting both inertial updates and a global position estimate at a high rate, e.g., 200 Hz. While GPS is a fairly accurate localization sensor, at only 10 Hz, its update rate is too slow to provide real-time updates. Now, though an IMU’s accuracy degrades with time, and thus cannot be relied upon to provide accurate position updates over long periods, it can provide updates more frequently—at, or higher than, 200 Hz. This should satisfy the real-time requirement. By combining GPS and IMU, we can provide accurate and real-time updates for vehicle localization.
- LIDAR: LIDAR is used for mapping, localization, and obstacle avoidance. It works by bouncing a beam off surfaces and measuring the reflection time to determine distance. Due to its high accuracy, it is used as the main sensor in most AV implementations. LIDAR can be used to produce HD maps, to localize a moving vehicle against HD maps, detect obstacle ahead, etc. Normally, a LIDAR unit, such as Velodyne 64-beam laser, rotates at 10 Hz and takes about 1.3 million readings per second.
- Cameras: Cameras are mostly used for object recognition and object tracking tasks, such as lane detection, traffic light detection, pedestrian detection, and more. To enhance AV safety, existing implementations usually mount eight or more cameras around the car, such that we can use cameras to detect, recognize, and track objects in front, behind, and on both sides of the vehicle. These cameras usually run at 60 Hz, and, when combined, generate around 1.8 GB of raw data per second.
- Radar and Sonar: The radar and sonar system is used for the last line of defense in obstacle avoidance. The data generated by radar and sonar shows the distance from the nearest object in front of the vehicle’s path. When we detect that an object is not far ahead and that there may be danger of a collision, the AV should apply the brakes or turn to avoid the obstacle. Therefore, the data generated by radar and sonar does not require much processing and is usually fed directly to the control processor—not through the main computation pipeline—to implement such urgent functions as swerving, applying the brakes, or pre-tensioning the seatbelts.
Perception
Next, we feed the sensor data to the perception subsystem to understand the vehicle’s environment. The three main tasks in autonomous driving perception are localization, object detection, and object tracking.
Localization
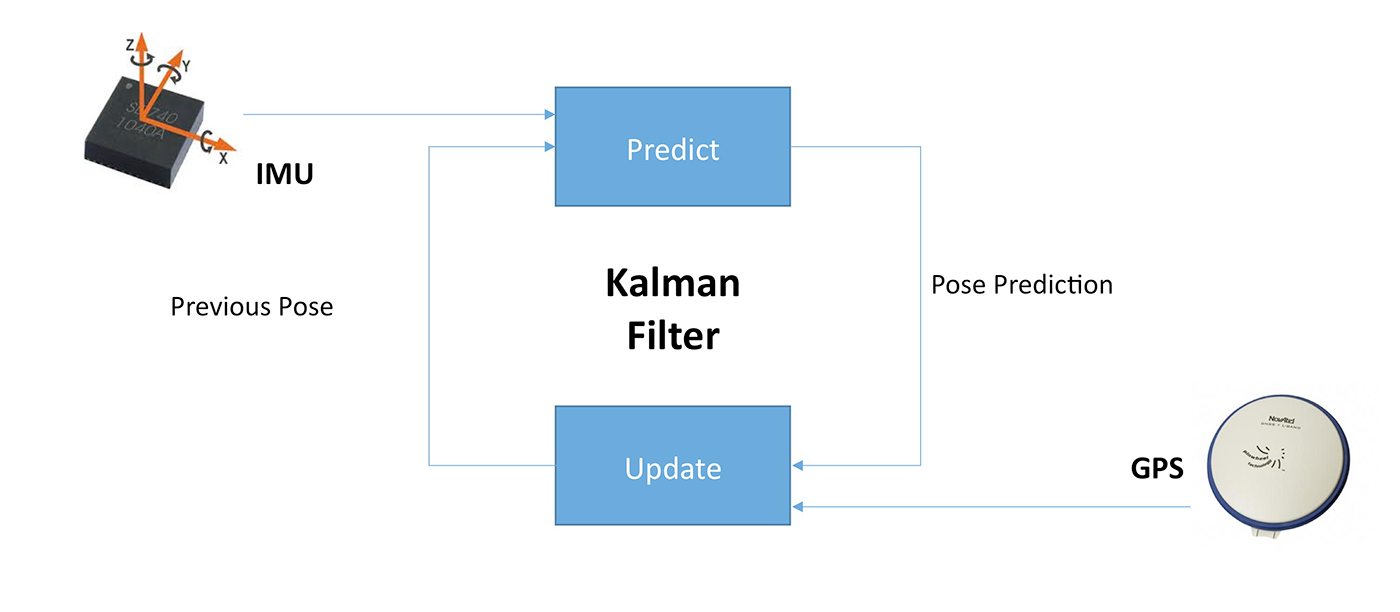
While GPS/IMU can be used for localization, GPS provides fairly accurate localization results but with a slow update rate; IMU provides a fast update with less accurate results. We can use Kalman filtering to combine the advantages of the two and provide accurate and real-time position updates. As shown in Figure 3, the IMU propagates the vehicle’s position every 5 ms, but the error accumulates as time progresses. Fortunately, every 100 ms, we get a GPS update, which helps us correct the IMU error. By running this propagation and update model, we can use GPS/IMU to generate fast and accurate localization results.
Nonetheless, we cannot solely rely on this combination for localization for three reasons: 1.) It has an accuracy of only about one meter; 2.) The GPS signal has multipath problems, meaning that the signal may bounce off buildings and introduce more noise; 3.) GPS requires an unobstructed view of the sky and thus does not work in closed environments such as tunnels.
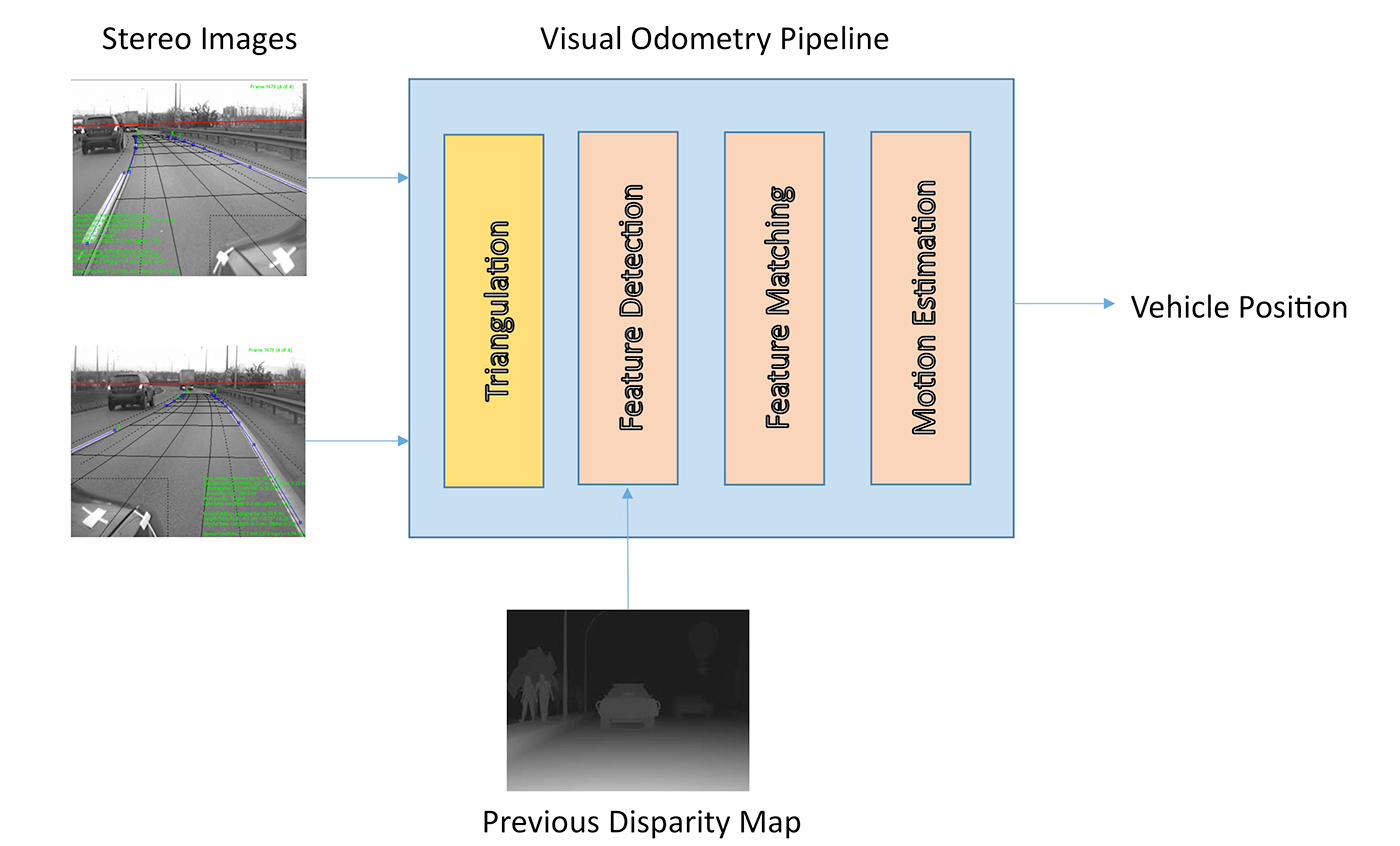
Cameras can be used for localization, too. Vision-based localization undergoes the following simplified pipeline: 1) by triangulating stereo image pairs, we first obtain a disparity map that can be used to derive depth information for each point; 2) by matching salient features between successive stereo image frames in order to establish correlations between feature points in different frames, we could then estimate the motion between the past two frames; and 3) we compare the salient features against those in the known map to derive the current position of the vehicle. However, since a vision-based localization approach is very sensitive to lighting conditions, this approach alone would not be reliable.
Therefore, LIDAR is usually the main sensor used for localization, relying heavily on a particle filter. The point clouds generated by LIDAR provide a “shape description” of the environment, but it is hard to differentiate individual points. By using a particle filter, the system compares a specific observed shape against the known map to reduce uncertainty.
To localize a moving vehicle relative to these maps, we apply a particle filter method to correlate the LIDAR measurements with the map. The particle filter method has been demonstrated to achieve real-time localization with 10-centimeter accuracy and is effective in urban environments. However, LIDAR has its own problem: when there are many suspended particles in the air, such as raindrops or dust, the measurements may be extremely noisy.
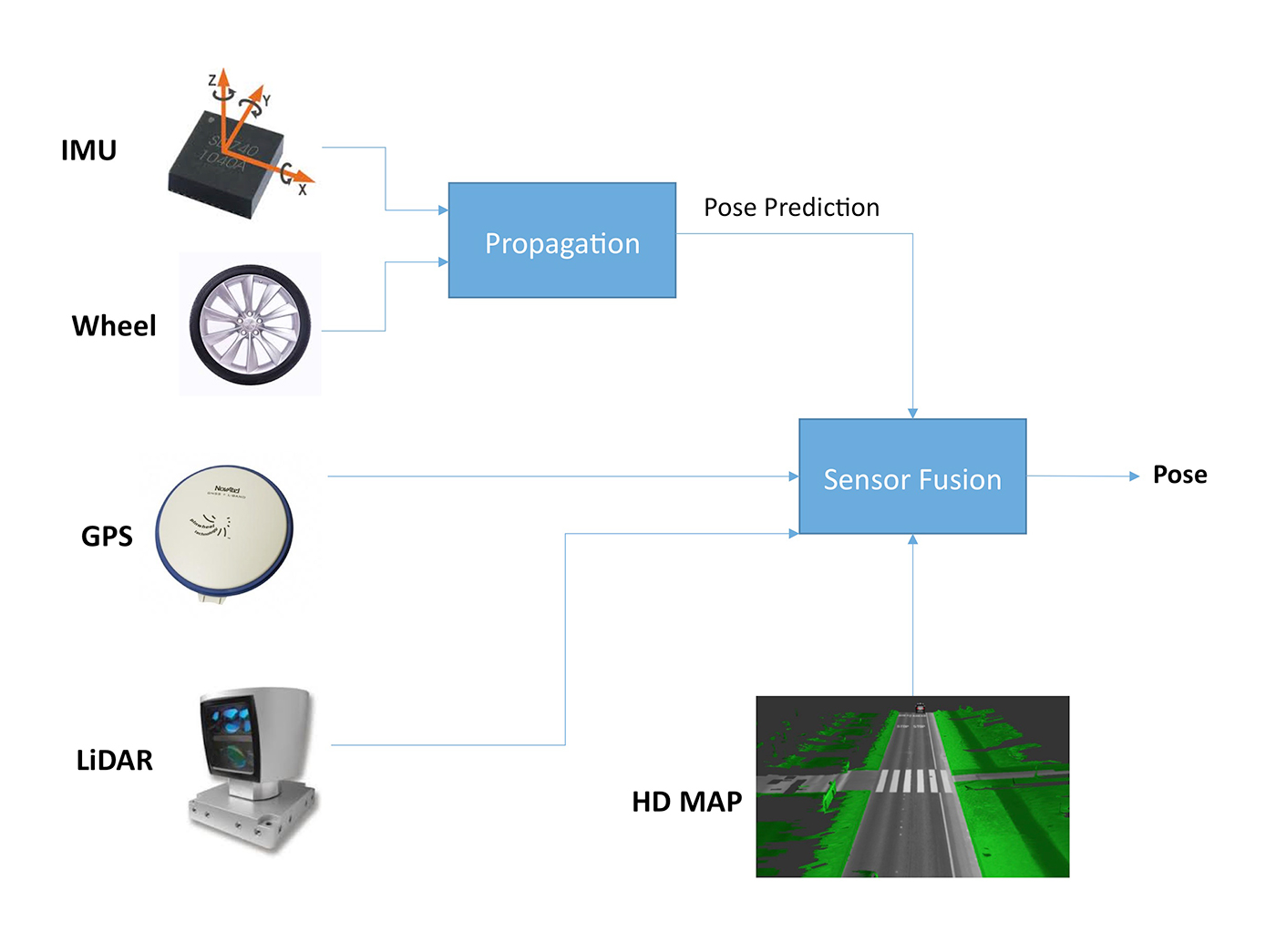
Therefore, to achieve reliable and accurate localization, we need a sensor-fusion process to combine the advantages of all sensors, as shown in Figure 5.
Object recognition and tracking
Since LIDAR provides accurate depth information, it was originally used to perform object detection and tracking tasks in AVs. In recent years, however, we have seen the rapid development of deep learning technology, which achieves significant object detection and tracking accuracy.
A convolution neural network (CNN) is a type of deep neural network that is widely used in object recognition tasks. A general CNN evaluation pipeline usually consists of the following layers: 1) the convolution layer uses different filters to extract different features from the input image. Each filter contains a set of “learnable” parameters that will be derived after the training stage; 2) the activation layer decides whether to activate the target neuron or not; 3) the pooling layer reduces the spatial size of the representation to reduce the number of parameters and consequently the computation in the network; and last, 4) the fully connected layer connects all neurons to all activations in the previous layer.
Once an object is identified using a CNN, next comes the automatic estimation of the trajectory of that object as it moves—or, object tracking.
Object tracking technology can be used to track nearby moving vehicles, as well as people crossing the road, to ensure the current vehicle does not collide with moving objects. In recent years, deep learning techniques have demonstrated advantages in object tracking compared to conventional computer vision techniques. By using auxiliary natural images, a stacked autoencoder can be trained offline to learn generic image features that are more robust against variations in viewpoints and vehicle positions. Then, the offline-trained model can be applied for online tracking.
Decision
In the decision stage, action prediction, path planning, and obstacle avoidance mechanisms are combined to generate an effective action plan in real time.
Action prediction
One of the main challenges for human drivers when navigating through traffic is to cope with the possible actions of other drivers, which directly influence their own driving strategy. This is especially true when there are multiple lanes on the road or at a traffic change point. To make sure that the AV travels safely in these environments, the decision unit generates predictions of nearby vehicles then decides on an action plan based on these predictions.
To predict actions of other vehicles, one can generate a stochastic model of the reachable position sets of the other traffic participants, and associate these reachable sets with probability distributions.
Path planning
Planning the path of an autonomous, responsive vehicle in a dynamic environment is a complex problem, especially when the vehicle is required to use its full maneuvering capabilities. One approach would be to use deterministic, complete algorithms—search all possible paths and utilize a cost function to identify the best path. However, this requires enormous computational resources and may be unable to deliver real-time navigation plans. To circumvent this computational complexity and provide effective real-time path planning, probabilistic planners have been utilized.
Obstacle avoidance
Since safety is of paramount concern in autonomous driving, we should employ at least two-levels of obstacle avoidance mechanisms to ensure that the vehicle will not collide with obstacles. The first level is proactive and based on traffic predictions. The traffic prediction mechanism generates measures like time-to-collision or predicted-minimum-distance. Based on these measures, the obstacle avoidance mechanism is triggered to perform local-path re-planning. If the proactive mechanism fails, the second-level reactive mechanism, using radar data, takes over. Once radar detects an obstacle ahead of the path, it overrides the current controls to avoid the obstacle.
The client system
The client system integrates the above-mentioned algorithms together to meet real-time and reliability requirements. There are three challenges to overcome: 1) the system needs to make sure that the processing pipeline is fast enough to consume the enormous amount of sensor data generated; 2) if a part of the system fails, it needs to be robust enough to recover from the failure; and 3), the system needs to perform all the computations under energy and resource constraints.
Robotics operating system
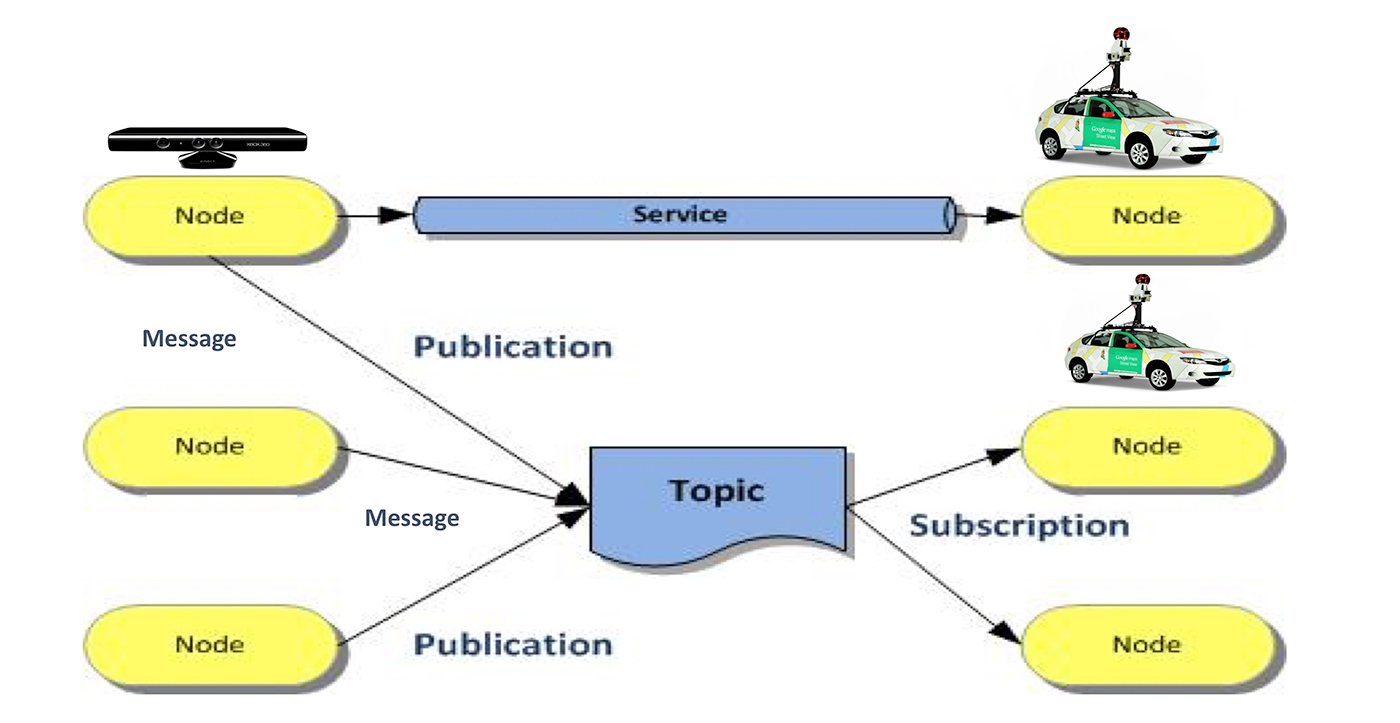
A robotics operating system (ROS) is a widely used, powerful distributed computing framework tailored for robotics applications (see Figure 6).
Each robotic task, such as localization, is hosted in an ROS node. These nodes communicate with each other through topics and services. It is a suitable operating system for autonomous driving, except that it suffers from a few problems:
- Reliability: ROS has a single master and no monitor to recover failed nodes.
- Performance: when sending out broadcast messages, it duplicates the message multiple times, leading to performance degradation.
- Security: it has no authentication and encryption mechanisms.
Although ROS 2.0 promised to fix these problems, it has not been extensively tested, and many features are not yet available.
Therefore, in order to use ROS in autonomous driving, we need to solve these problems first.
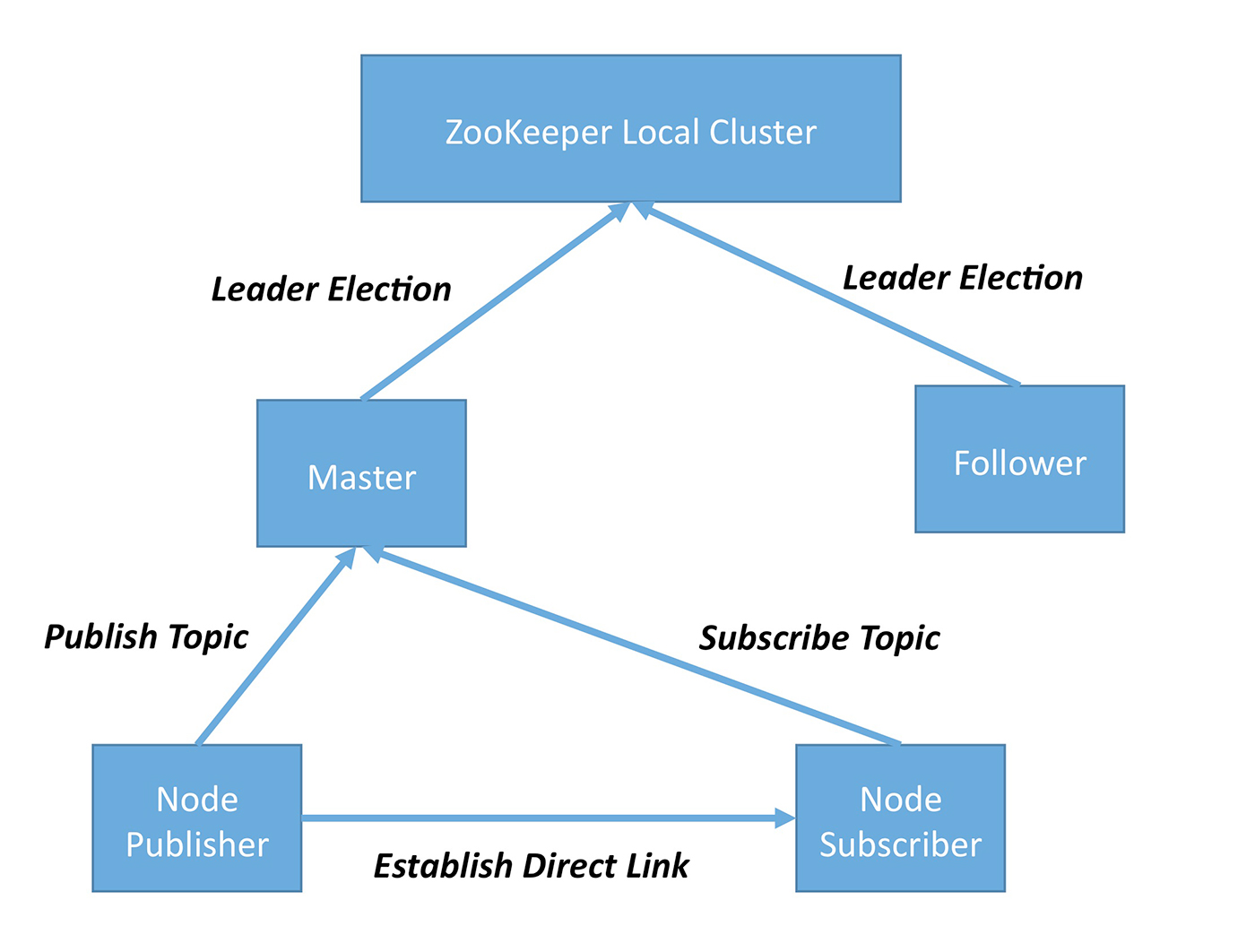
Reliability
The current ROS implementation has only one master node, so when the master node crashes, the whole system crashes. This does not meet the safety requirements for autonomous driving. To fix this problem, we implement a ZooKeeper-like mechanism in ROS. As shown in Figure 7, the design incorporates a main master node and a backup master node. In the case of main node failure, the backup node would take over, making sure the system continues to run without hiccups. In addition, the ZooKeeper mechanism monitors and restarts any failed nodes, making sure the whole ROS system stays reliable.
Performance
Performance is another problem with the current ROS implementation—the ROS nodes communicate often, as it’s imperative that communication between nodes is efficient. First, communication goes through the loop-back mechanism when local nodes communicate with each other. Each time it goes through the loopback pipeline, a 20-microsecond overhead is introduced. To eliminate this local node communication overhead, we can use a shared memory mechanism such that the message does not have to go through the TCP/IP stack to get to the destination node. Second, when an ROS node broadcasts a message, the message gets copied multiple times, consuming significant bandwidth in the system. Switching to a multicast mechanism greatly improves the throughput of the system.
Security
Security is the most critical concern for an ROS. Imagine two scenarios: in the first, an ROS node is kidnapped and is made to continuously allocate memory until the system runs out of memory and starts killing other ROS nodes and the hacker successfully crashes the system. In the second scenario—since, by default, ROS messages are not encrypted—a hacker can easily eavesdrop on the message between nodes and apply man-in-the-middle attacks.
To fix the first security problem, we can use Linux containers (LXC) to restrict the number of resources used by each node and also provide a sandbox mechanism to protect the node from each other, effectively preventing resource leaking. To fix the second problem, we can encrypt messages in communication, preventing messages from being eavesdropped.
Hardware platform
To understand the challenges in designing a hardware platform for autonomous driving, let us examine the computing platform implementation from a leading autonomous driving company. It consists of two compute boxes, each equipped with an Intel Xeon E5 processor and four to eight Nvidia Tesla K80 GPU accelerators. The second compute box performs exactly the same tasks and is used for reliability—if the first box fails, the second box can immediately take over.
In the worst case, if both boxes run at their peak, using more than 5000 W of power, an enormous amount of heat would be generated. Each box costs $20K to $30K, making this solution unaffordable for average consumers.
The power, heat dissipation, and cost requirements of this design prevent autonomous driving from reaching the general public (so far). To explore the edges of the envelope and understand how well an autonomous driving system could perform on an ARM mobile SoC, we can implement a simplified, vision-based autonomous driving system on an ARM-based mobile SoC with peak power consumption of 15 W.
Surprisingly, the performance is not bad at all: the localization pipeline is able to process 25 images per second, almost keeping up with image generation at 30 images per second. The deep learning pipeline is able to perform two to three object recognition tasks per second. The planning and control pipeline is able to plan a path within 6 ms. With this system, we are able to drive the vehicle at around five miles per hour without any loss of localization.
Cloud platform
Autonomous vehicles are mobile systems and therefore need a cloud platform to provide supports. The two main functions provided by the cloud include distributed computing and distributed storage. This system has several applications, including simulation, which is used to verify new algorithms, high-definition (HD) map production, and deep learning model training. To build such a platform, we use Spark for distributed computing, OpenCL for heterogeneous computing, and Alluxio for in-memory storage.
We can deliver a reliable, low-latency, and high-throughput autonomous driving cloud by integrating these three.
Simulation
The first application of a cloud platform system is simulation. Whenever we develop a new algorithm, we need to test it thoroughly before we can deploy it on real cars (where the cost would be enormous and the turn-around time too long).
Therefore, we can test the system on simulators, such as replaying data through ROS nodes. However, if we were to test the new algorithm on a single machine, either it would take too long or we wouldn’t have enough test coverage.
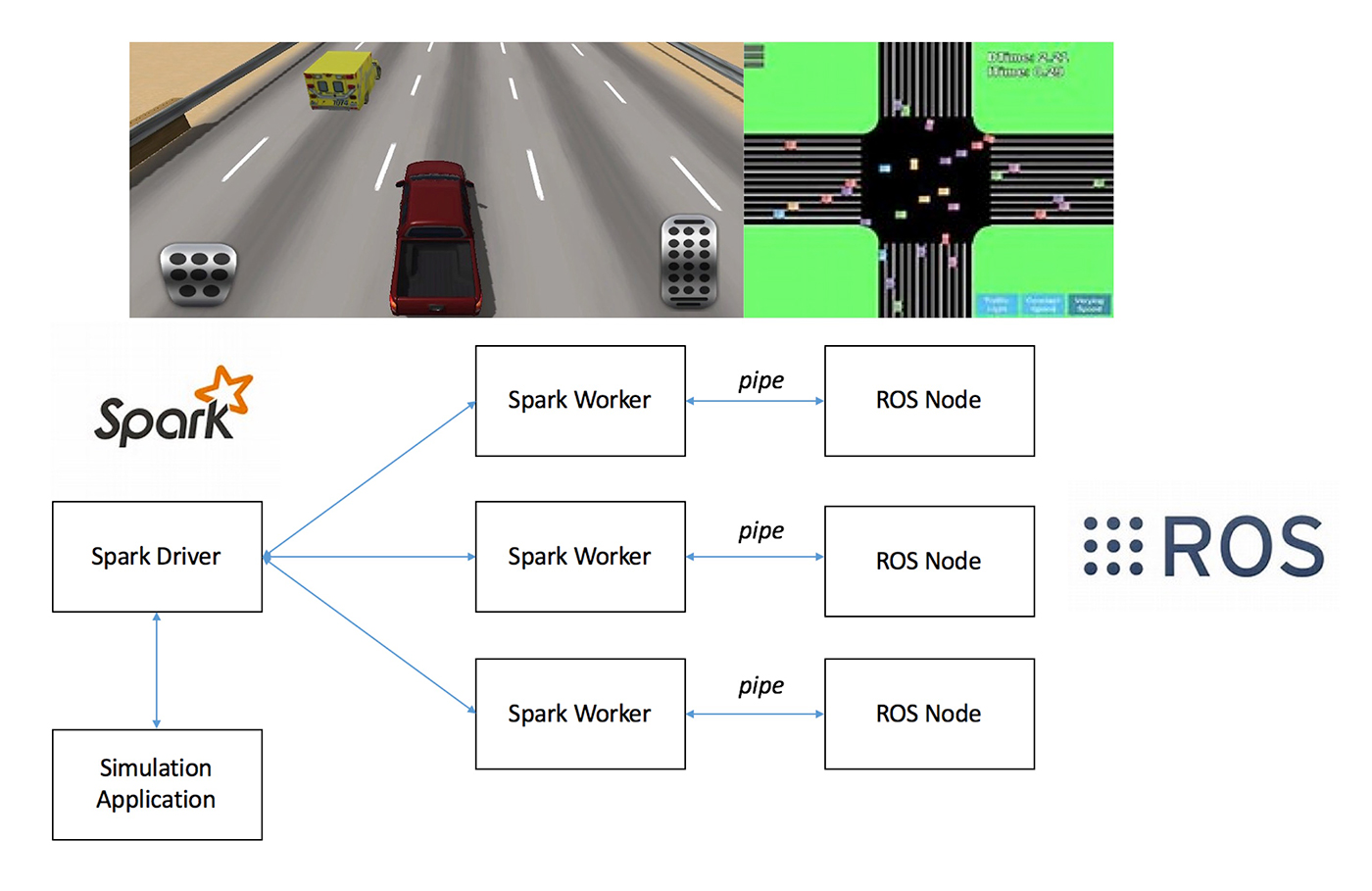
To solve this problem, we can use a distributed simulation platform, as shown in Figure 8.
Here, Spark is used to manage distributed computing nodes, and on each node, we can run an ROS replay instance. In one autonomous driving object recognition test set, it took three hours to run on a single server; by using the distributed system, scaled to eight machines, the test finished in 25 minutes.
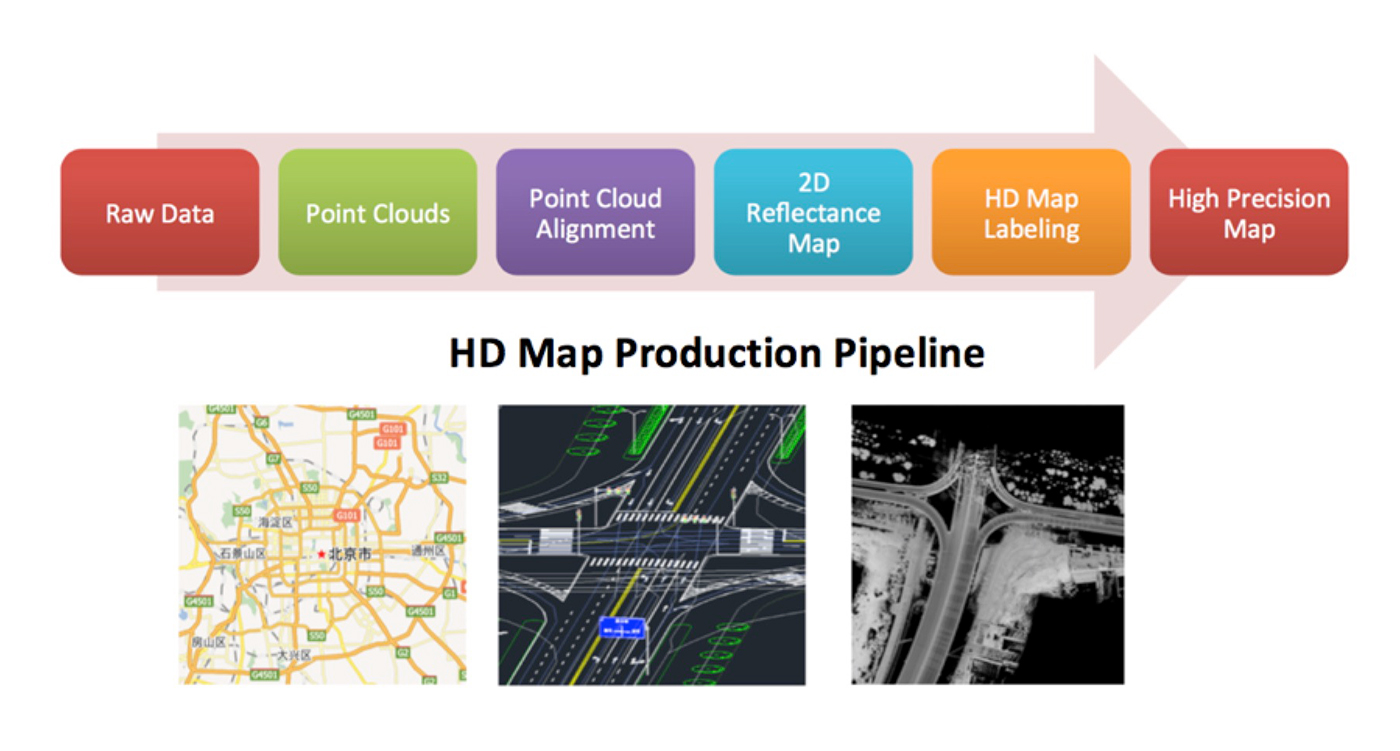
HD map production
As shown in Figure 9, HD map production is a complex process that involves many stages, including raw data processing, point cloud production, point cloud alignment, 2D reflectance map generation, HD map labeling, as well as the final map generation.
Using Spark, we can connect all these stages together in one Spark job. A great advantage is that Spark provides an in-memory computing mechanism, such that we do not have to store the intermediate data in hard disk, thus greatly reducing the performance of the map production process.
Deep learning model training
As we use different deep learning models in autonomous driving, it is imperative to provide updates that will continuously improve the effectiveness and efficiency of these models. However, since the amount of raw data generated is enormous, we would not be able to achieve fast model training using single servers.
To approach this problem, we can develop a highly scalable distributed deep learning system using Spark and Paddle (a deep learning platform recently open-sourced by Baidu).
In the Spark driver, we can manage a Spark context and a Paddle context, and in each node, the Spark executor hosts a Paddler trainer instance. On top of that, we can use Alluxio as a parameter server for this system. Using this system, we have achieved linear performance scaling, even as we add more resources, proving that the system is highly scalable.
Just the beginning
As you can see, autonomous driving (and artificial intelligence in general) is not one technology; it is an integration of many technologies. It demands innovations in algorithms, system integrations, and cloud platforms. It’s just the beginning, and there are tons of opportunities. I anticipate that by 2020, we will officially start this AI-era and see many AI-based products in the market. Let’s be ready.