Comparing production-grade NLP libraries: Accuracy, performance, and scalability
A comparison of the accuracy and performance of Spark-NLP vs. spaCy, and some use case recommendations.
 Fractal complexity (source: Pixabay)
Fractal complexity (source: Pixabay)
This is the third and final installment in this blog series comparing two leading open source natural language processing software libraries: John Snow Labs’ NLP for Apache Spark and Explosion AI’s spaCy. In the previous two parts, we walked through the code for training tokenization and part-of-speech models, running them on a benchmark data set, and evaluating the results. In this part, we compare the accuracy and performance of both libraries on this and additional benchmarks, and provide recommendations on which use cases fit each library best.
Accuracy
Here are the accuracy comparisons from the models training in Part 1 of this blog series:

Learn faster. Dig deeper. See farther.
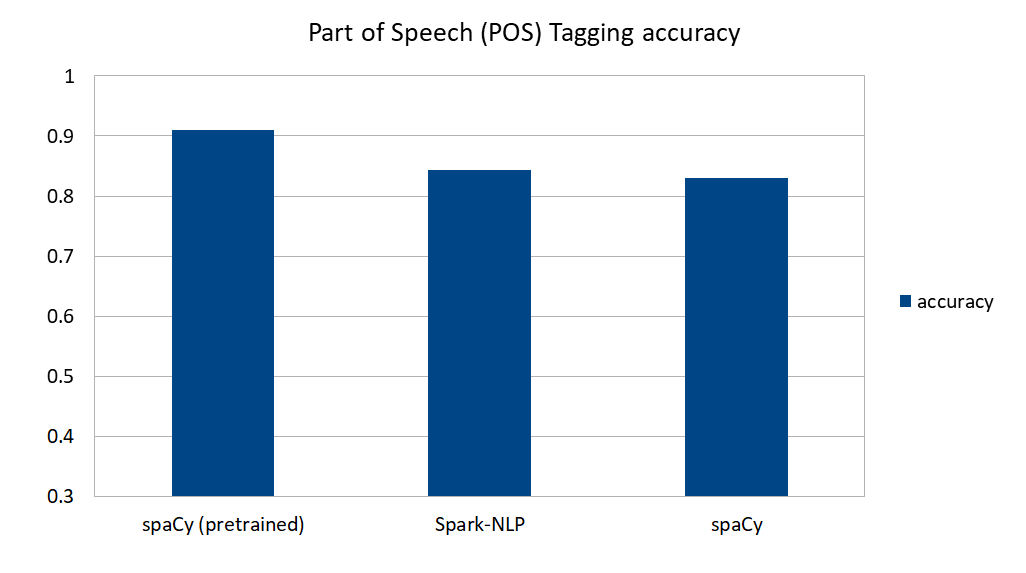
spaCy’s pre-trained model does a great job predicting part-of-speech tags in English text. If your text is standard, news- or article-based text (i.e., not domain-specific text like legal documents, financial statements, or medical records), and in one of the seven languages supported by spaCy, this is a great way to go. Note that pretrained results here include our custom tokenizer, otherwise accuracy (and particularly the ratio of matched tokens) would go down (see Figure 2).
spaCy’s self-trained model and Spark-NLP perform similarly when trained using the same training data, at about 84% accuracy.
A major impact of spaCy’s accuracy seems to come not from trained data but from the English vocab content, where Spark-NLP assumes nothing on language—it is fully language agnostic—and only learns from whatever the annotators on the pipeline get to know. This means that the same code and algorithms, on training data from another language, should work without change.
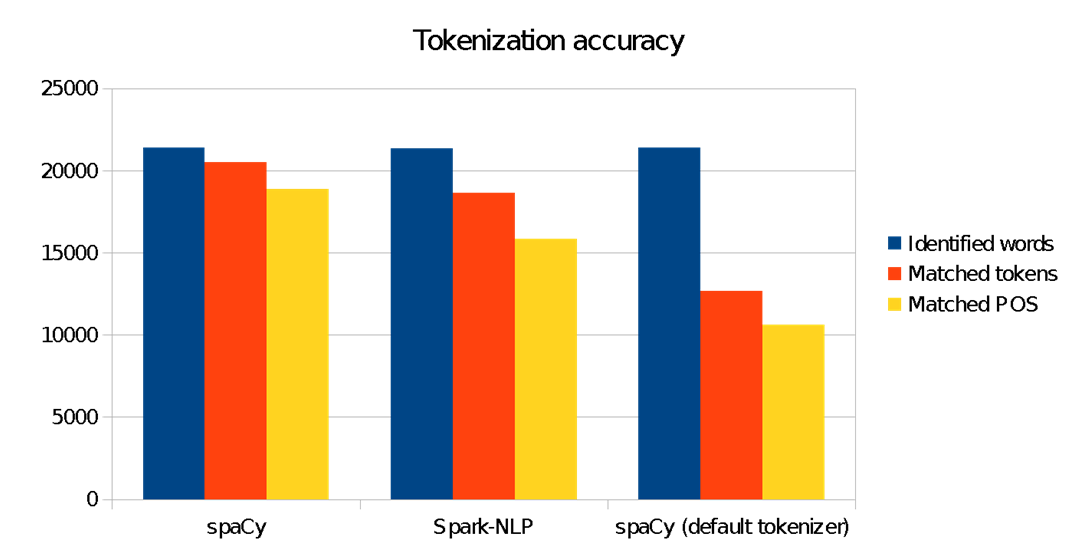
We see here that our modified spacy tokenizer makes significant impact to better match our target ANC corpus tokens. Using “out-of-the-box” spaCy for this benchmark would deliver inferior results. This is very common in natural language understanding: domain-specific models must be trained to learn the nuances, context, jargon, and grammar of the input text.
Performance
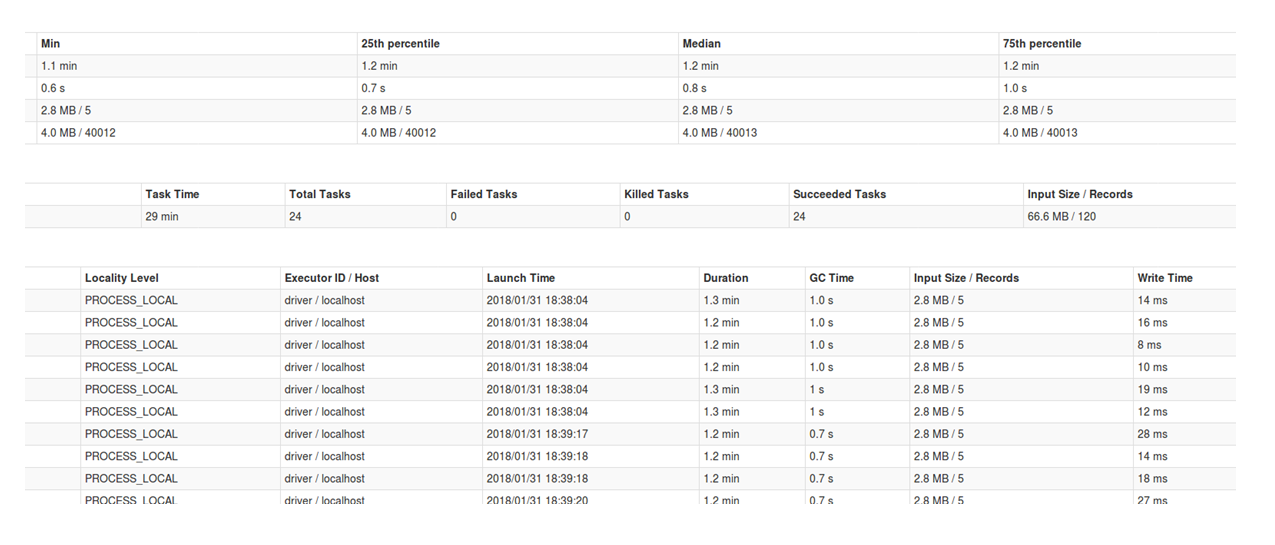
Although things looks happy when we train and predict about 77 KB of .txt files (resulting in 21,000 words to predict and compare), when we train against twice the number of files, and predict 9,225 files as opposed to 14, things don’t look so happy anymore. Of course, this isn’t “big data” by any measure, but more realistic than a toy/debugging scenario. Here are the facts:
Spark-NLP 75mb prediction Time to train: 4.798381899 seconds Time to predict + collect: 311.773622473 seconds Total words: 13,441,891
Training on spaCy was a little bit more troublesome because I faced several issues on weird characters and text format in training data—even though I’d already cleaned it in the training algorithm we saw before. After working it around, I got an exponential increase in the amount of time to train, so I had to estimate the amount of time it would take, based on how it scaled as I increased the number of files in the training folder, which returned about two hours or more.
SpaCy 75mb prediction Time to train: 386.05810475349426 seconds Time to predict + collect: 498.60224294662476 seconds Total words: 14,340,283
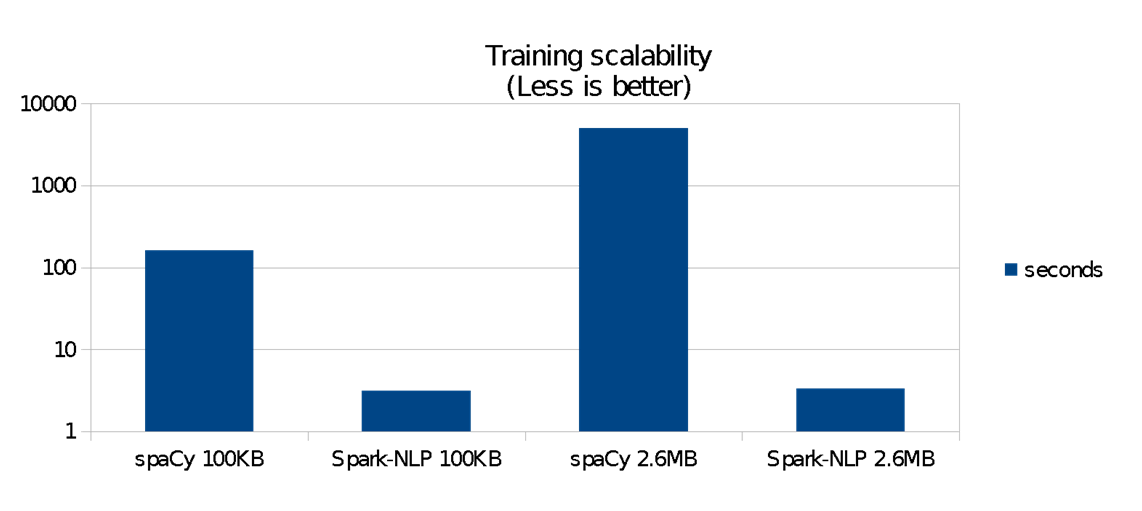
Figure 3 shows that for this 75mb benchmark:
- Spark-NLP was more than 38 times faster to train 100 KB of data and about 80 times faster to train 2.6 MB. Scalability difference is significant.
- Spark-NLP’s training itself did not grow significantly when data grew from 100 KB to 2.6 MB
- spaCy’s training time grows exponentially as we increase the data size
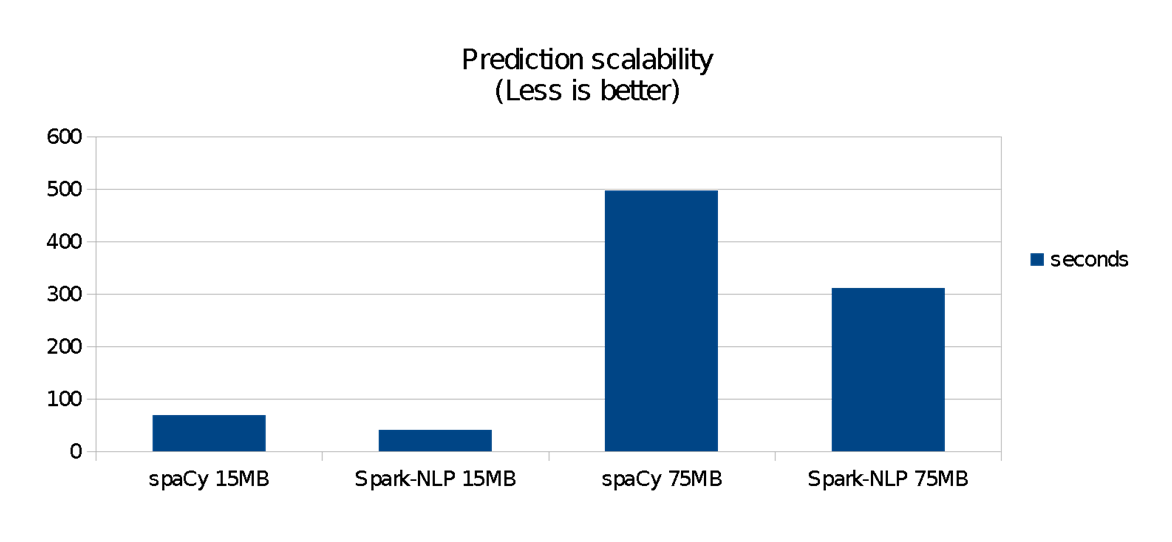
Figure 4 shows the runtime performance comparison of running the Spark-NLP pipeline—i.e., using the models after the training phase is done. spaCy is fast on small data sets, but it does not scale as well as Spark-NLP does. For these benchmarks:
- spaCy was faster on 140 KB data sets (both libraries finished in less than a second)
- Spark-NLP was 1.4 times faster on a 15 MB data set (roughly 40 versus 70 seconds)
- Spark-NLP was 1.6 times faster on a 75 MB data set, taking about half the time to complete (roughly five versus nine minutes)
spaCy is highly optimized for single-machine execution. It’s written from the ground up in Cython, and was validated in 2015 (two years before Spark-NLP became available) as having the fastest syntactic parser when compared to other libraries written in Python, Java, and C++. spaCy does not have the overhead of the JVM and Spark that Spark-NLP has, which gives it an advantage for small data sets.
On the other hand, the heavy optimization that was done on Spark over the years—especially for single-machine, standalone mode—shines here by taking the lead in data sets as small as a few megabytes. Naturally, this advantage becomes more substantial as the data size grows, or as the complexity of the pipeline (more naturl language processing (NLP) stages, adding machine learning (ML) or deep learning (DL) stages) grows.
Scalability
Outside of these benchmarks, Spark scales as Spark does. How well depends on how you partition your data, whether you have wide or tall tables (the latter are better in Spark), and most importantly, whether you use a cluster. Here, for example, everything is on my local machine, and I am running a groupBy filename operation, which means my table is wider than taller, since for every filename there is a large number of words. If I could, I would probably also avoid calling a collect(), which hits hard on my driver memory, as opposed to storing the result in distributed storage.
In this case, for example, if I performed the groupBy operation after the transform() step—basically merging the POS and tokens after the prediction—I’d be transforming a much taller table than the previous one (960,302 lines instead of 9,225, which was the number of files). I also have control over whether I oversubscribe my CPU cores into Spark (e.g., local[6]) and the number of partitions I inject into the transform operation. There is usually a bell shape in performance when tuning Spark performance; in my case, the optimum was about six subscribed cores and 24 partitions.
On spaCy, the parallel algorithm I showed in the previous sections doesn’t seem to significantly impact performance, while only gaining a few seconds out of the total prediction time.
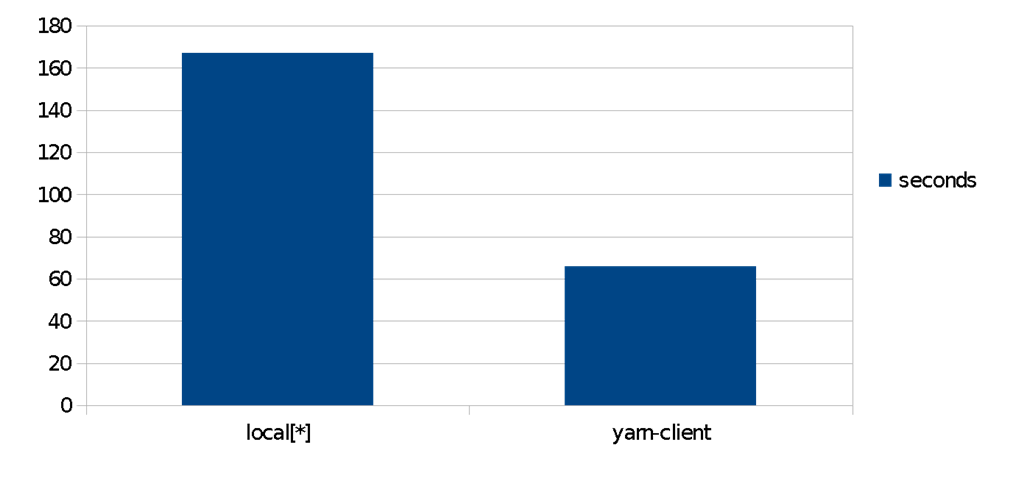
For an Amazon EMR cluster, in a simple comparison of the same algorithms, we notice a 2.5x speedup in the time for POS prediction when utilizing a distributed yarn cluster against a local-only counterpart on the same node. Data sets in this scenario have been put in HDFS datanodes. In practice, this means you can achieve different cost/performance tradeoffs, using configuration only, with linear scaling. This is a core benefit of Spark, Spark ML, and Spark-NLP.
Conclusion
The use cases for the two libraries are quite different. If your needs are toward plugging in a small data set and getting output quickly, then spaCy is a winner: you download your model per language, process the data, and pass it line by line to the NLP object. It contains a large vocabulary set of strategies on the language plus a bunch of state-of-the-art trained models that will respond back with highly optimized C++ (Cython) performance. If you want to parallelize your task, customize a component (like we did for the tokenizer), or train models to fit your domain-specific data, then spaCy makes you go through its API and write more code.
On the other hand, if you have a large task ahead, then Spark-NLP will be far faster, and from a certain scale, the only choice. It automatically scales as you plug in larger data sets or grow your Spark cluster. It is between one and two orders of magnitude faster for training NLP models, holding for the same level of accuracy.
spaCy comes with a set of superbly tuned models for a variety of common NLP tasks. Spark-NLP does not (at the time of writing this post) come with pre-trained models. spaCy models are “black box” and are usually within 1% of the state of the art, if your text is similar to what the models were trained on. When training domain-specific models with Spark-NLP, pipelines are language agnostic, and their result is strictly the sum of their parts. Every annotator works on the knowledge provided to it, and each one of them will communicate with other annotators to achieve a final result. You can inject a spell checker, a sentence detector, or a normalizer, and it will affect your outcome without having to write additional code or custom scripts.
We hope you have enjoyed this overview of both libraries, and that it will help you deliver your next NLP project faster and better. If you are interested in learning more, there will be hands-on, half-day tutorials on “Natural language understanding at scale with spaCy and Spark ML” at the upcoming Strata Data San Jose in March and Strata Data London in May.