Building big data systems in academia and industry
The O'Reilly Data Show Podcast: Mikio Braun on stream processing, academic research, and training.
 Graz University Library reading room (source: Wikimedia Commons)
Graz University Library reading room (source: Wikimedia Commons)
Mikio Braun is a machine learning researcher who also enjoys software engineering. We first met when he co-founded a real-time analytics company called streamdrill. Since then, I’ve always had great conversations with him on many topics in the data space. He gave one of the best-attended sessions at Strata + Hadoop World in Barcelona last year on some of his work at streamdrill.
I recently sat down with Braun for the latest episode of the O’Reilly Data Show Podcast, and we talked about machine learning, stream processing and analytics, his recent foray into data science training, and academia versus industry (his interests are a bit on the “applied” side, but he enjoys both).

Learn faster. Dig deeper. See farther.
jblas: Evolution of a matrix library
Braun created and continues to maintain jblas, a linear algebra library for Java. When I started needing a matrix library for Hadoop (or for that matter, during the early days of Spark), jblas kept popping up as an option. Now that he has more time, Braun is going to add functions that users have been clamoring for. We talked about how jblas came about in the first place:
Ten years ago, everyone was just using MATLAB for research. Then they changed their licensing model, and you could only get the academic license if you were a university. … All the publicly funded research institutes couldn’t afford MATLAB anymore, so people said, ‘Okay, we have to use something else.’ … Now we know everyone switched to R and Python, but at that time, it was unclear what it was. I thought, actually, that a combination of Java and JRuby would be a good idea. The problem was that there was no matrix implementation for that. … I thought if you use Java, the JVM as the platform, then it’s much easier to do that because you need to do Java and not C — writing the C plugin is more difficult. That was the general idea. I looked at Jython at the time and JRuby, and JRuby looked much better, so I went with that. The first thing I had to do was write this matrix library, and that was jblas, so it could be based on the low level … implementations of BLAS and LAPACK, and then would wrap these nicely. … Later on, I found out with Hadoop, jblas was very interesting again, and people started to use it.
Stream processing
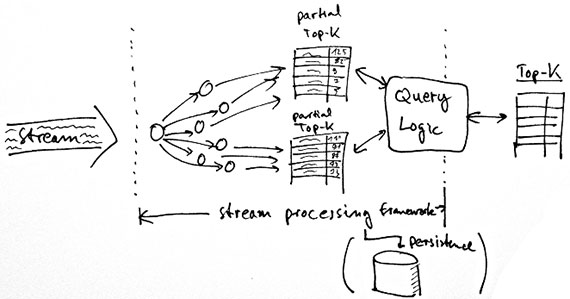
One topic Braun and I both follow closely is stream processing and analytics. Braun also co-created a system that shipped with many interesting (approximate) algorithms:
The basic idea was that we wanted to count elements — like in a Twitter stream, many, many elements — when we first started our databases. That was at some point too slow, so we started to do this thing ourselves, which was based on the streaming algorithms. I think it’s a bit different from the typical stream processing frameworks like Storm or Samza because we didn’t just rely on parallelization; instead, we used some approximate algorithms to do the counting. The whole system was always just on one machine, so it didn’t really scale out. Instead, we tried to find algorithms that were able to count millions of elements on one machine very efficiently. … For some applications, you really want to have exact answers. If you’re handling money or anything like that, you don’t want to have any approximate answers. What we found very early on was that for many applications, for example like trending [topics] in social networks, you don’t really care about the exact answers. You suddenly have many more possibilities, or you have access to algorithms that are very, very efficient.
Academia and industry
As I noted in an earlier podcast on the rise of Apache Spark, what’s remarkable about the UC Berkeley AMPLab are the software tools that have come out of it: aside from Spark, Apache Mesos and Tachyon have been embraced by industry. The usual pattern is for academic software tools to wither after accompanying papers have been published. As someone who loves to build software systems, Braun sometimes feels that academia isn’t the right fit for his interests. For now, he’s excited about working with other researchers in the new (cross-disciplinary) Berlin Big Data Center:
I think that my problem with a job in academia was that I always was too interested in actually building things and trying things out and programming. Somehow, academia is very much focused on creating new stuff. Even the software projects — some researchers, they’re open sourcing their software. In the long run, actually, I’m not sure it makes sense because such an open source project is something you have maintain for a long time. … If you want to do the stuff that counts toward your career progress in academia, there’s a conflict there somehow, right? I think on the one hand, if you think about, research at the university is publicly funded. They produce new knowledge that is for the good of society. It should be okay if they just produce … new technology and software for people. But if you do this, then you don’t fit in, right?
You can listen to our entire interview in the SoundCloud player above, or subscribe through SoundCloud, TuneIn, or iTunes.