Building a natural language processing library for Apache Spark
The O’Reilly Data Show Podcast: David Talby on a new NLP library for Spark, and why model development starts after a model gets deployed to production.
 Richard March Hoe's printing press—six cylinder design (source: "History of the Processes of Manufacture," 1864 on Wikimedia Commons)
Richard March Hoe's printing press—six cylinder design (source: "History of the Processes of Manufacture," 1864 on Wikimedia Commons)
When I first discovered and started using Apache Spark, a majority of the use cases I used it for involved unstructured text. The absence of libraries meant rolling my own NLP utilities, and, in many cases, implementing a machine learning library (this was pre deep learning, and MLlib was much smaller). I’d always wondered why no one bothered to create an NLP library for Spark when many people were using Spark to process large amounts of text. The recent, early success of BigDL confirms that users like the option of having native libraries.
In this episode of the Data Show, I spoke with David Talby of Pacific.AI, a consulting company that specializes in data science, analytics, and big data. A couple of years ago I mentioned the need for an NLP library within Spark to Talby; he not only agreed, he rounded up collaborators to build such a library. They eventually carved out time to build the newly released Spark NLP library. Judging by the reception received by BigDL and the number of Spark users faced with large-scale text processing tasks, I suspect Spark NLP will be a standard tool among Spark users.

Learn faster. Dig deeper. See farther.
Talby and I also discussed his work helping companies build, deploy, and monitor machine learning models. Tools and best practices for model development and deployment are just beginning to emerge—I summarized some of them in a recent post, and, in this episode, I discussed these topics with a leading practitioner.
Here are some highlights from our conversation:
The state of NLP in Spark
Here are your two choices today. Either you want to leverage all of the performance and optimization that Spark gives you, which means you want to stay basically within the JVM, and you want to use a Java-based library. In which case, you have options that include OpenNLP, which is open source, or Stanford NLP, which requires licensing in order to use in a commercial product. These are older and more academically oriented libraries. So, they have limitations in performance and what they do.
Another option is to look at something like spaCy—a Python-based library that really has raised the bar in terms of usability, and the trade-offs between analytical accuracy and performance. But then your challenge is that you have your text in Spark, but to call the spaCy pipeline, you basically have to move the data from the JVM to a Python process, do some processing there, and send it back, which in practice means you take a huge performance hit because most of the processing you do is really moving strings between operating system processors.
… So, really what we were looking for is a solution to work on text directly, within a data frame. A tool that will take into account everything Spark gives in terms of caching, distributed computation, and the other optimizations. This enable users to basically run an NLP and machine learning pipeline directly on their text.
Enter Spark NLP
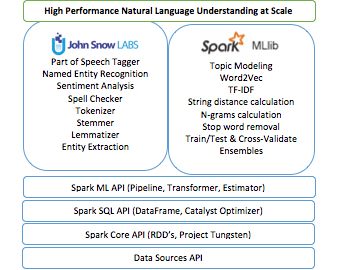
The core purpose of an NLP library is the ability to take text and then apply a set of annotations on the text. So, the basic annotations we ship in this initial version of Spark NLP include things like a tokenizer, a lemmatizer, sentence boundary detection, and paragraph boundary detection. Then on top of that, we include things like sentiment analysis, spell checker so we can auto-suggest corrections, and a dependency parser so we can not just know that we have a noun and a verb, but also that this verb talks about the specific noun, which is often semantically interesting. We also include named entity recognition algorithms.
Deploying and monitoring machine learning models in production
I think what’s happening is that people expect basic model development to be very similar to software development. When we started doing software development, we started it wrong. We assumed software engineering was a lot like civil engineering or mechanical engineering. It took a good 30 years until we said no, this is actually not the right model and we tried something different.
So, now I think we have the same paradigm error. People assume that, look, this is software. I build it, I deploy it on machine, I test it, I put it in production, therefore I should think of it like software, right? It’s something I build, I test it, it passes it, I deploy it, and it’s done, it moves to the ops team.
In reality, there really is a fundamental difference. What happens is once you put a machine learning model in production, at that point it starts degrading in terms of accuracy because of many, many things. Because the world changes, because the underlying population changes, the data you’re serving in production changes, because people react and basically try to game your model, because you have undocumented data dependencies on other systems. … I think you really need to be aware of the fact that when you deploy a machine learning model to production, in many cases really, you’re just starting your modeling process.
Related resources:
- Building pipelines for natural language understanding with Spark
- “Deep learning for Apache Spark”: Jason Dai on BigDL, a library for deep learning on existing data frameworks.
- When models go rogue: David Talby on hard-earned lessons about using machine learning in production
- “The current state of applied data science”
- “What are machine learning engineers?”: examining a new role focused on creating data products and making data science work in production.