What is neural architecture search?
An overview of NAS and a discussion on how it compares to hyperparameter optimization.
 Neurons (source: Pixabay)
Neurons (source: Pixabay)
Deep learning offers the promise of bypassing the process of manual feature engineering by learning representations in conjunction with statistical models in an end-to-end fashion. However, neural network architectures themselves are typically designed by experts in a painstaking, ad hoc fashion. Neural architecture search (NAS) has been touted as the path forward for alleviating this pain by automatically identifying architectures that are superior to hand-designed ones.
But with the field moving so fast both in terms of research progress and hype, it can be hard to get answers to basic questions: What exactly is NAS and is it fundamentally different from AutoML or hyperparameter optimization? Do specialized NAS methods actually work? Aren’t they prohibitively expensive to use? Should I be using specialized NAS methods? In this post, we’ll answer each of these questions. Our discussion touches upon a few key points:

Learn faster. Dig deeper. See farther.
- There is a false dichotomy between NAS and traditional hyperparameter optimization; in fact, NAS is a subset of hyperparameter optimization. Moreover, specialized NAS methods are not actually fully automated, as they rely on human-designed architectures as starting points.
- While exploring and tuning different neural network architectures is of crucial importance in developing high-quality deep learning applications, in our view specialized NAS methods are not ready for primetime just yet: they introduce significant algorithmic and computational complexities compared to high-quality hyperparameter optimization algorithms (e.g., ASHA) without demonstrating improved performance on standard benchmarking tasks.
- Specialized NAS methods have nonetheless exhibited remarkable advances in the past few years in terms of improved accuracy, reduced computational costs, and architecture size, and could eventually surpass human performance on neural architecture design.
To set the stage, let’s first discuss how NAS fits within the wider umbrella of AutoML (automated machine learning).
AutoML ⊃ hyperparameter optimization ⊃ NAS
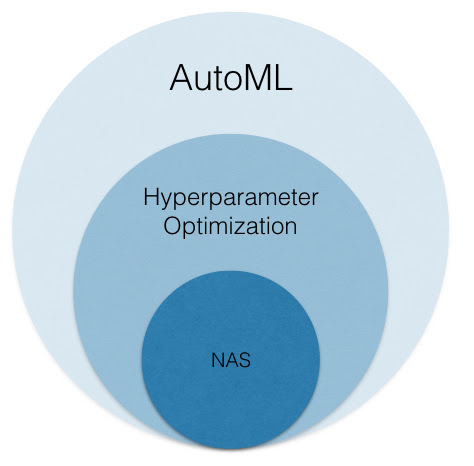
AutoML focuses on automating every aspect of the machine learning (ML) workflow to increase efficiency and democratize machine learning so that non-experts can apply machine learning to their problems with ease. While AutoML encompasses the automation of a wide range of problems associated with ETL (extract, transform, load), model training, and model deployment, the problem of hyperparameter optimization is a core focus of AutoML. This problem involves configuring the internal settings that govern the behavior of an ML model/algorithm in order to return a high-quality predictive model.
For example, ridge regression models require setting the value of a regularization term, random forest models require the user to set the maximum tree depth and minimum number of samples per leaf, and training any model with stochastic gradient descent requires setting an appropriate step size. Neural networks also require setting a multitude of hyperparameters, including (1) selecting an optimization method along with its associated set of hyperparameters; (2) setting the dropout rate and other regularization hyperparameters; and, if desired, (3) tuning parameters that control the architecture of the network (e.g., number of hidden layers, number of convolutional filters).
Although the exposition on NAS might suggest it is a completely new problem, our final example above hints at a close relationship between hyperparameter optimization and NAS. While the search spaces used for NAS are generally larger and control different aspects of the neural network architecture, the underlying problem is the same as that addressed by hyperparameter optimization: find a configuration within the search space that performs well on the target task. Hence, we view NAS to be a subproblem within hyperparameter optimization.
NAS is nonetheless an exciting direction to study, as focusing on a specialized subproblem provides the opportunity to exploit additional structure to design custom tailored solutions, as is done by many specialized NAS approaches. In the next section, we will provide an overview of NAS and delve more into the similarities and differences between hyperparameter optimization and NAS.
NAS overview
Interest in NAS ballooned after the work of Zoph, et. al., 2016 used reinforcement learning to design, at the time, state-of-the-art architectures for image recognition and language modeling. However, Zoph, et. al., 2016, in addition to other first generation specialized approaches for NAS, required a tremendous amount of computational power (e.g., hundreds of GPUs running for thousands (!) of GPU days in aggregate), making them impractical for all but the likes of companies like Google. More recent approaches exploit various methods of reuse to drastically reduce the computational cost, and new methods are being rapidly introduced in the research community.
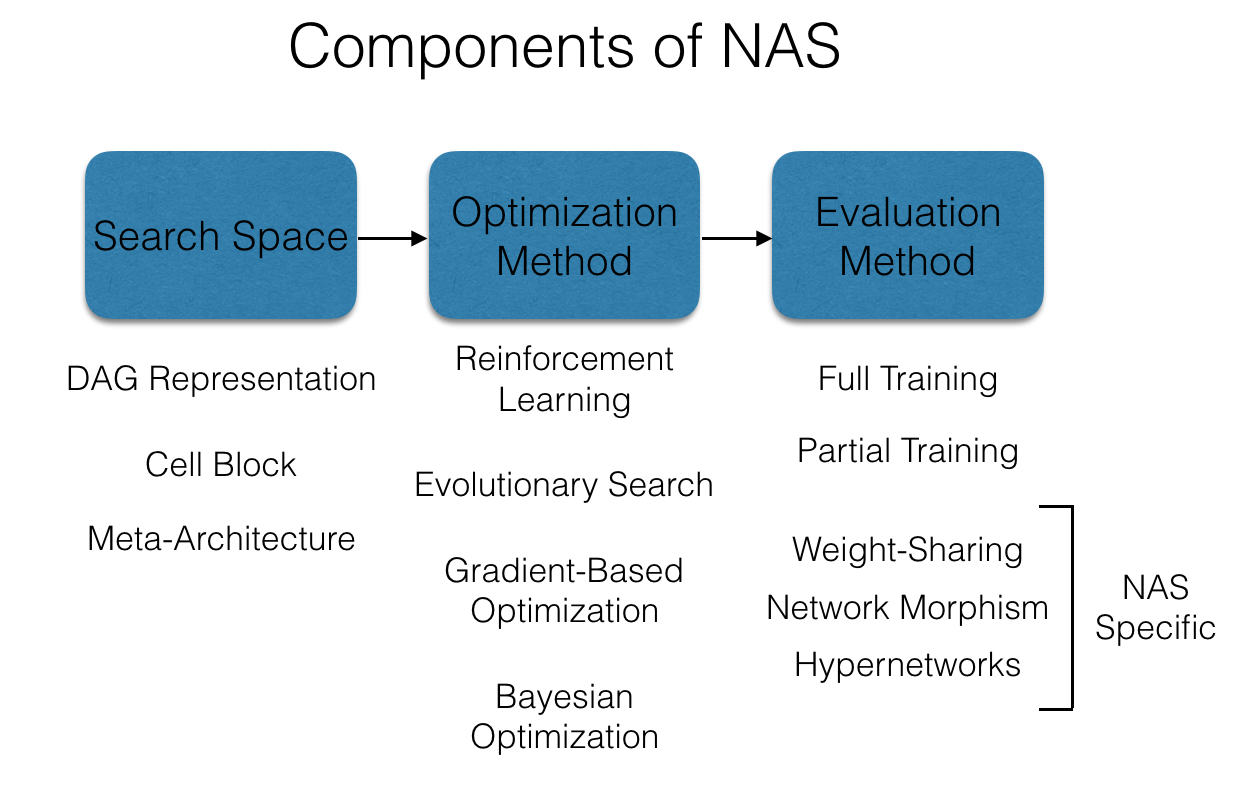
We’ll next dive a bit deeper into the core design decisions associated with all of these specialized NAS methods (for a detailed overview of NAS, we recommend the excellent survey by Elsken, et al., 2017). The three main components are:
- Search space. This component describes the set of possible neural network architectures to consider. These search spaces are designed specific to the application—e.g., a space of convolutional networks for computer vision tasks or a space of recurrent networks for language modeling tasks. Hence, NAS methods are not fully automated, as the design of these search spaces fundamentally relies on human-designed architectures as starting points. Even so, there are still many architectural decisions remaining. In fact, the number of possible architectures considered in these search spaces are often over 10^10.
- Optimization method. This component determines how to explore the search space in order to find a good architecture. The most basic approach here is random search, while various adaptive methods have also been introduced—e.g., reinforcement learning, evolutionary search, gradient-based optimization, and Bayesian optimization. While these adaptive approaches differ in how they determine which architectures to evaluate, they all attempt to bias the search toward architectures that are more likely to perform well. Unsurprisingly, all of these methods have counterparts that have been introduced in the context of traditional hyperparameter optimization tasks.
- Evaluation method. This component measures the quality of each architecture considered by the optimization method. The simplest, but most computationally expensive choice is to fully train an architecture. One can alternatively exploit partial training, similar in spirit to early-stopping methods commonly used in hyperparameter optimization like ASHA. NAS-specific evaluation methods—such as network morphism, weight-sharing, and hypernetworks—have also been introduced to exploit the structure of neural networks to provide cheaper, heuristic estimates of quality. Partial training approaches are typically an order-of-magnitude cheaper than full training, while NAS-specific evaluation methods are two to three orders of magnitude cheaper than full training.
Notably, these are the same three requisite ingredients for traditional hyperparameter optimization methods. The research community has converged on a few canonical benchmarking data sets and tasks to evaluate the performance of different search methods, and we’ll next use these benchmarks to report results on head-to-head comparisons between (1) human-designed architectures tuned via hyperparameter optimization methods, and (2) NAS-designed architectures identified via leading specialized NAS methods. (NAS focuses on the problem of identifying architectures, but nonetheless requires a secondary hyperparameter optimization step to tune the non-architecture-specific hyperparameters of the architecture it identifies. Our results show the test error after performing both steps.)
NAS models vs. human-designed models
The two most common tasks used to benchmark NAS methods are (1) designing convolutional neural network (CNN) architectures evaluated on the CIFAR-10 data set, and (2) designing recurrent neural network (RNN) architectures evaluated on the PennTree Bank (PTB) data set. We show the test error for different architectures on CIFAR-10 in the table below.
| Source | Number of Parameters (Millions) | Test Error | Search Method | Evaluation Method | |
|---|---|---|---|---|---|
| PyramidNet + ShakeDrop | Yamada et al., 2018 | 26 | 2.31 | Human designed | – |
| NASNet-A + cutout | Zoph et al., 2017 | 3.3 | 2.65 | Reinforcement Learning | Full Train |
| AmoebaNet-B + cutout | Real et al., 2018 | 34.9 | 2.13 | Evolutionary | Full Train |
| NAONET | Luo et al., 2018 | 28.6 | 2.98 | Gradient | Partial Train |
| DARTS + cutout | H. Liu et al., 2018 | 3.4 | 2.83 | Gradient | Weight Sharing |
For the CIFAR-10 benchmark, specialized NAS methods that use full training perform comparably to manually designed architectures; however, they are prohibitively expensive and take more than 1,000 GPU days. Although methods that exploit partial training or other NAS-specific evaluation methods require less computation to perform the search (400 GPU days and ~1 GPU day, respectively), they are outperformed by the manually designed architecture in Table 1. Notably, the NAS architectures have nearly an order of magnitude fewer parameters than the human-designed model, indicating promising applications of NAS to memory- and latency-constrained settings.
The test perplexity for different architectures on the PTB data set are shown in Table 2.
| Source | Test Perplexity | Search Method | Evaluation Method | |
|---|---|---|---|---|
| LSTM with MoS | Yang et al., 2017 | 54.4 | Human designed | – |
| NASNet | Zoph et al., 2016 | 62.4 | Reinforcement Learning | Full Train |
| NAONET | Luo et al., 2018 | 56.0 | Gradient | Partial Train |
| DARTS | H. Liu et al., 2018 | 55.7 | Gradient | Weight Sharing |
The specialized NAS results are less competitive on the PTB benchmark compared to manually designed architectures. It is surprising, however, that cheaper evaluation methods outperform full training on this benchmark; this is likely due to the additional advances that have been made in training LSTMs since the publication of Zoph, et.al., 2016.
Are specialized NAS methods ready for widespread adoption?
Not yet! To be clear, exploring various architectures and performing extensive hyperparameter optimization remain crucial components of any deep learning application workflow. However, in light of the existing research results (as highlighted above), we believe that while specialized NAS methods have demonstrated promising results on these two benchmarks, they are still not ready for prime time for the following reasons:
- Since highly tuned, manually designed architectures are competitive with computationally tractable NAS methods on CIFAR-10 and outperform specialized NAS methods on PTB, we believe resources are better spent on hyperparameter optimization of existing manually designed architectures.
- Most specialized NAS methods are fairly specific to a given search space and need to be retrained or retooled for each new search space. Additionally, certain approaches suffer from robustness issues and can be hard to train. These issues currently hinder the general applicability of existing specialized NAS methods to different tasks.
Related: