What is hash partitioning in Kudu?
Learn how hash partitioning affects performance and stability in Kudu.
 Screen from "What is hash partitioning in Kudu?" (source: O'Reilly)
Screen from "What is hash partitioning in Kudu?" (source: O'Reilly)
Proper schema and partitioning design is essential for Kudu performance. In this video, Ryan Bosshart explains how hash partitioning paired with range partitioning can be used to improve operational stability. Architects, developers, and data engineers designing new tables in Kudu will learn:
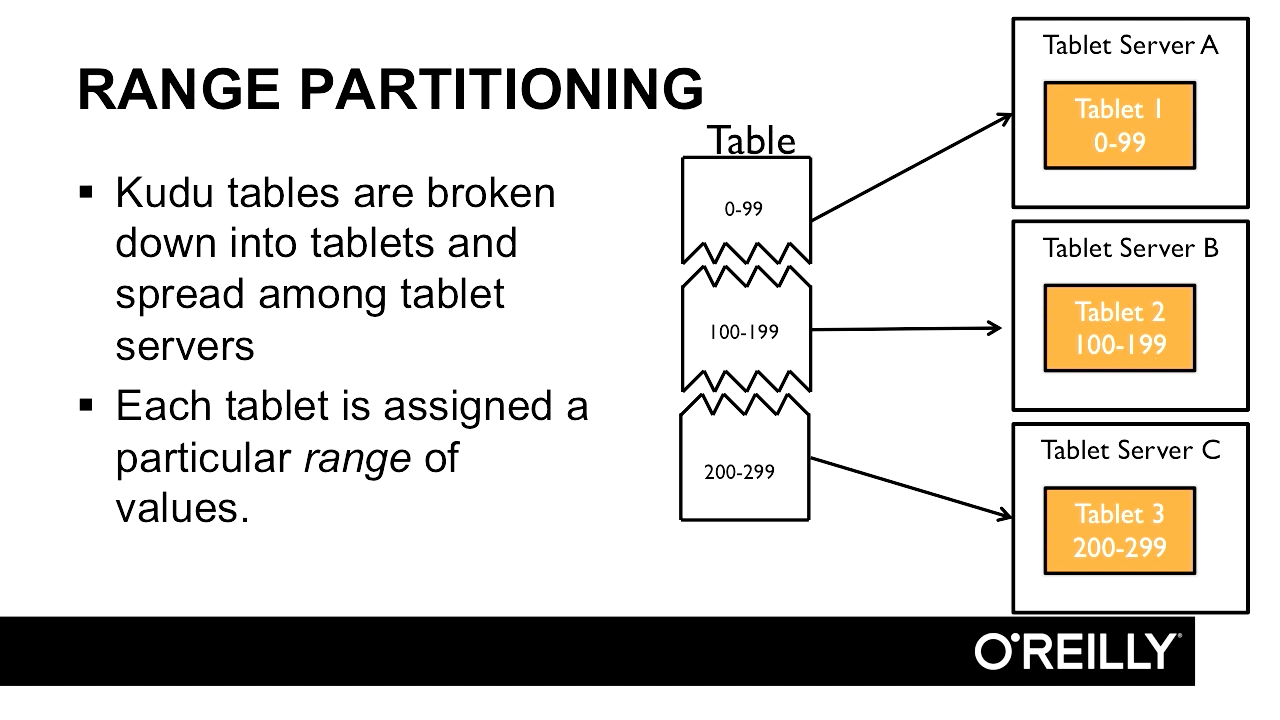
- How partitioning affects performance and stability in Kudu.
- The difference between hash and range partitioning.
- The advantages and drawbacks of each partitioning type.

Learn faster. Dig deeper. See farther.
Ryan Bosshart is a Principal Systems Engineer at Cloudera, where he leads a specialized team focused on Hadoop ecosystem storage technologies such as HDFS, Hbase, and Kudu. An architect and builder of large-scale distributed systems since 2006, Ryan is co-chair of the Twin Cities Spark and Hadoop User Group. He speaks about Hadoop technologies at conferences throughout North America and holds a degree in computer science from Augsburg College.