The Snapchat leak
4.6 million phone numbers, is one of them yours?
While the site crumbled quickly under the weight of so many people trying to get to the leaked data—and has now been suspended—there isn’t really such a thing as putting the genie back in the bottle on the Internet.
Just before Christmas the Australian based Gibson Security published a report highlighting two exploits in the Snapchat API claiming that hackers could easily gain access to users’ personal data. Snapchat dismissed the report, responding that,

Learn faster. Dig deeper. See farther.
Theoretically, if someone were able to upload a huge set of phone numbers, like every number in an area code, or every possible number in the U.S., they could create a database of the results and match usernames to phone numbers that way.
Adding that they had various “safeguards” in place to make it difficult to do that. However it seems likely that—despite being explicitly mentioned in the initial report four months previously—none of these safeguards included rate limiting requests to their server, because someone seems to have taken them up on their offer.
Data Release
Earlier today the creators of the now defunct SnapchatDB site released 4.6 million records—both as an SQL dump and as a CSV file. With an estimated 8 million users (May, 2013) of the app this represents around half the Snapchat user base.
Each record consists of a Snapchat user name, a geographical location for the user, and partially anonymised phone number—the last two digits of the phone number having been obscured.
While Gibson Security’s find_friends exploit has been patched by Snapchat, minor variations on the exploit are reported to still function, and if this data did come from the exploit—or a minor variation on it—uncovered by Gibson, then the dataset published by SnapchatDB is only part of the data the hackers now hold.
In addition to the data already released they would have the full phone number of each user, and as well as the user name they should also have the—perhaps more revealing—screen name.
Data Analysis
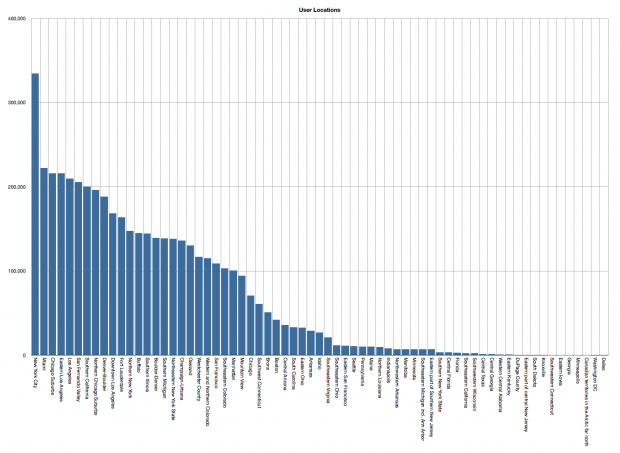
Taking an initial look at the data, there are no international numbers in the leaked database. All entries are US numbers, with the bulk of the users from—as you might expect—the greater New York, San Francisco and Bay areas.
However I’d assume that the absence of international numbers is an indication of laziness rather than due to any technical limitation. For US based hackers it would be easy to iterate rapidly through the fairly predictable US number space, while “foreign” numbers formats might present more of a challenge when writing a script to exploit the hole in Snapchat’s security.
Only 76 of the 322 area codes in the United States appear in the leaked database, alongside another two Canadian area codes, mapping to 67 discrete geographic locations—although not all the area codes and locations match suggesting that perhaps the locations aren’t derived directly from the area code data.
Despite some initial scepticism about the provenance of the data I’ve confirmed that this is a real data set. A quick trawl through the data has got multiple hits amongst my own friend group, including some I didn’t know were on Snapchat—sorry guys.
Since the last two digits were obscured in the leaked dataset the partial phone number string might—and frequently does—generate multiple matches amongst the 4.6 million records against a comparison number.
I compared the several hundred US phone numbers amongst my own contacts against the database—you might want to do that yourself—and generated several spurious hits where the returned user names didn’t really seem to map in any way to my contact. That said, as I already mentioned, I found several of my own friends amongst the leaked records, although I only knew it was them for sure because I knew both their phone number and typical choices of user names.
Conclusions
As it stands therefore this data release is not—yet—critical, although it is certainly concerning, and for some individuals it might well be unfortunate. However if the SnapchatDB creators choose to release their full dataset things might well get a lot more interesting.
If the full data set was released to the public, or obtained by a malicious third party, then the username, geographic location, phone number, and screen name—which might, for a lot of people, be their actual full name—would be available.
This eventuality would be bad enough. However taking this data and cross-correlating it with another large corpus of data, say from Twitter or Gravatar, by trying to find matching user or real names on those services—people tend to reuse usernames on multiple services after all—you might end up with a much larger aggregated data set including email addresses, photographs, and personal information.
While there would be enough false positives—if matching solely against user names—that you’d have a interesting data cleaning task afterwards, it wouldn’t be impossible. Possibly not even that difficult.
I’m not interested in doing that correlation myself. But others will.