What is probabilistic programming?
Probabilistic languages can free developers from the complexities of high-performance probabilistic inference.
 Probablistic program diagram
Probablistic program diagram
Probabilistic programming languages are in the spotlight. This is due to the announcement of a new DARPA program to support their fundamental research. But what is probabilistic programming? What can we expect from this research? Will this effort pay off? How long will it take?
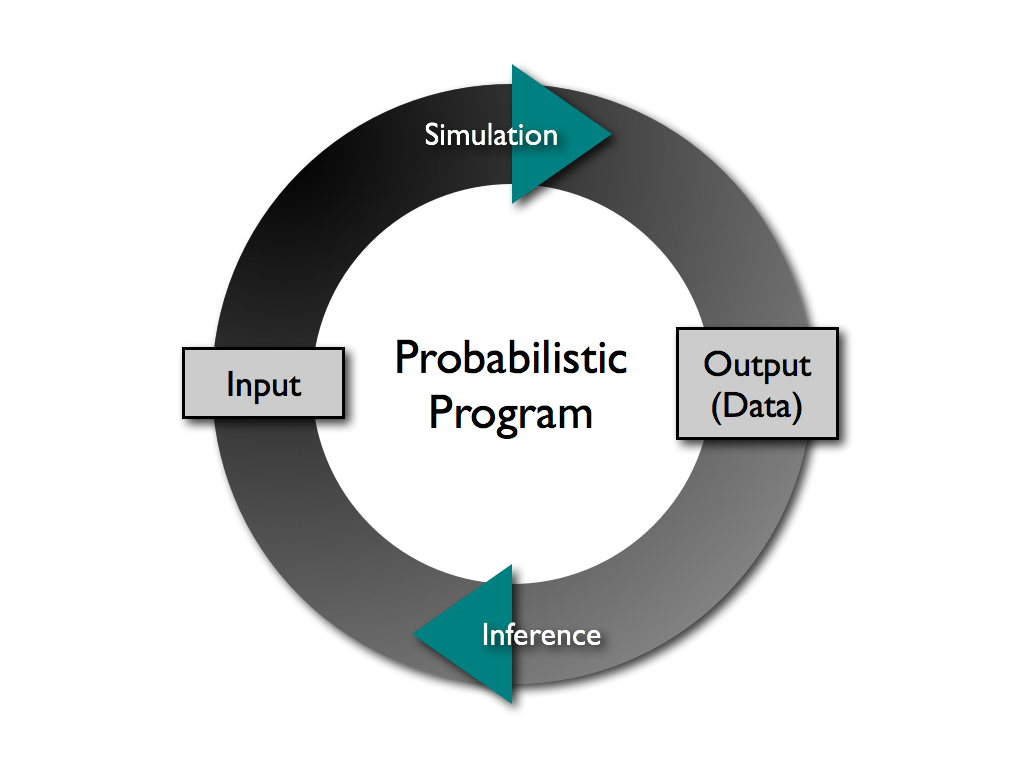
A probabilistic programming language is a high-level language that makes it easy for a developer to define probability models and then “solve” these models automatically. These languages incorporate random events as primitives and their runtime environment handles inference. Now, it is a matter of programming that enables a clean separation between modeling and inference. This can vastly reduce the time and effort associated with implementing new models and understanding data. Just as high-level programming languages transformed developer productivity by abstracting away the details of the processor and memory architecture, probabilistic languages promise to free the developer from the complexities of high-performance probabilistic inference.

Learn faster. Dig deeper. See farther.
What does it mean to perform inference automatically? Let’s compare a probabilistic program to a classical simulation such as a climate model. A simulation is a computer program that takes some initial conditions such as historical temperatures, estimates of energy input from the sun, and so on, as an input. Then it uses the programmer’s assumptions about the interactions between these variables that are captured in equations and code to produce forecasts about the climate in the future. Simulations are characterized by the fact that they only run in one direction: forward, from causes to hypothesized effects.
A probabilistic program turns this around. Given a universe of possible interactions between different elements of the climate system and a collection of observed data, we could automatically learn which interactions are most effective in explaining the observations — even if these interactions are quite complex. How does this work? In a nutshell, the probabilistic language’s runtime environment runs the program both forward and backward. It runs forward from causes to effects (data) and backward from the data to the causes. Clever implementations will trade off between these directions to efficiently home in on the most likely explanations for the observations.

Better climate models are but one potential application of probabilistic programming. Other models include: shorter and more humane clinical trials with fewer unneeded side effects and more accurate outcomes; machine perception that transcends the capabilities of the now-ubiquitous quadcopters and even Google’s self-driving cars; and “nervous systems” that fuse data from massively distributed and noisy sensor networks to better understand both the natural world and artificial environments.
Of course, any technology this general carries a lot of uncertainty around its development path and eventual impact. So much depends on complex interactions with other technology threads and, ultimately, social factors and regulation. With all possible humility, here is one sample from the predictive distribution, conditioned on what we know so far:
- Phase I — Probabilistic programming will transform the practice of data science by unifying anecdotal reasoning with more reliable statistical approaches. If data science is first and foremost about telling stories, then probabilistic programming is in many ways the perfect tool. Practitioners will be able to leverage the persuasive power of narrative, while staying on firm quantitative ground.
- Phase II — Practitioners will really start to push the boundaries of modeling in fundmental ways in order to address many applications that don’t fit well into the current machine learning, text mining, or graph analysis paradigms. Many real-world datasets are a mixture of tabular, relational, textual, geospatial, audiovisual, and other data types. Probabilistic programs can weave all of these pieces together in natural ways. Current solutions that claim to integrate heterogeneous data typically do so by beating it all into a similar form, losing much of the underlying structure along the way.
- Phase III — Probabilistic programming will push well into territory that is universally recognized as artificial intelligence. As we’re often reminded, intelligent systems are very application-specific. Good chess algorithms are unlike Google’s self-driving car, which is totally different from IBM’s Watson. But probabilistic programs can be layered and modularized, with subsystems that specialize in particular problem domains, but embedded in a shared fabric that recognizes the current context and brings appropriate modeling subsystems to bear.
What will it take to make all this real? The conceptual underpinnings of probabilistic programming languages are well in hand, thanks to trailblazing work by research groups at MIT, UMass Amherst, Microsoft Research, Harvard, and elsewhere. The core challenge at this point is developing performant inference engines that can efficiently solve the very wide range of models that these languages can express. We’ll also need new debugging, optimization, and visualization tools to help developers get the most from these systems.
This story will take years to play out in full, but I expect we’ll see real progress over the next three to four years. I’m excited.
Want to learn more? BUGS is a probabilistic programming language originally developed by statisticians more than 20 years ago. While it has a number of limitations around expressivity and dataset size, it’s a great way to get your feet wet. Also check out Rob Zinkov’s tutorial post, which includes examples of several models. Church is the most ambitious probabilistic programming language. Don’t miss the tutorials, though it may not be the most accessible or practical option until the inference engine and toolset mature. For that reason, factorie might be a better bet in the short term, especially if you like Scala, or Microsoft Research’s infer.net with C# and F# bindings. The proceedings from a recent academic workshop provide a great snapshot of the field as of late 2012. Finally, this video from a long-defunct startup that I co-founded contains one stab at explaining many of the concepts underlying probabilistic programming referred to under the more general term probabilistic computing: