How do I run an Apache Spark script on an Amazon Elastic MapReduce (EMR) cluster?
Learn how to use steps in the EMR console to schedule and run Spark scripts stored in Amazon S3, on both new and existing clusters.
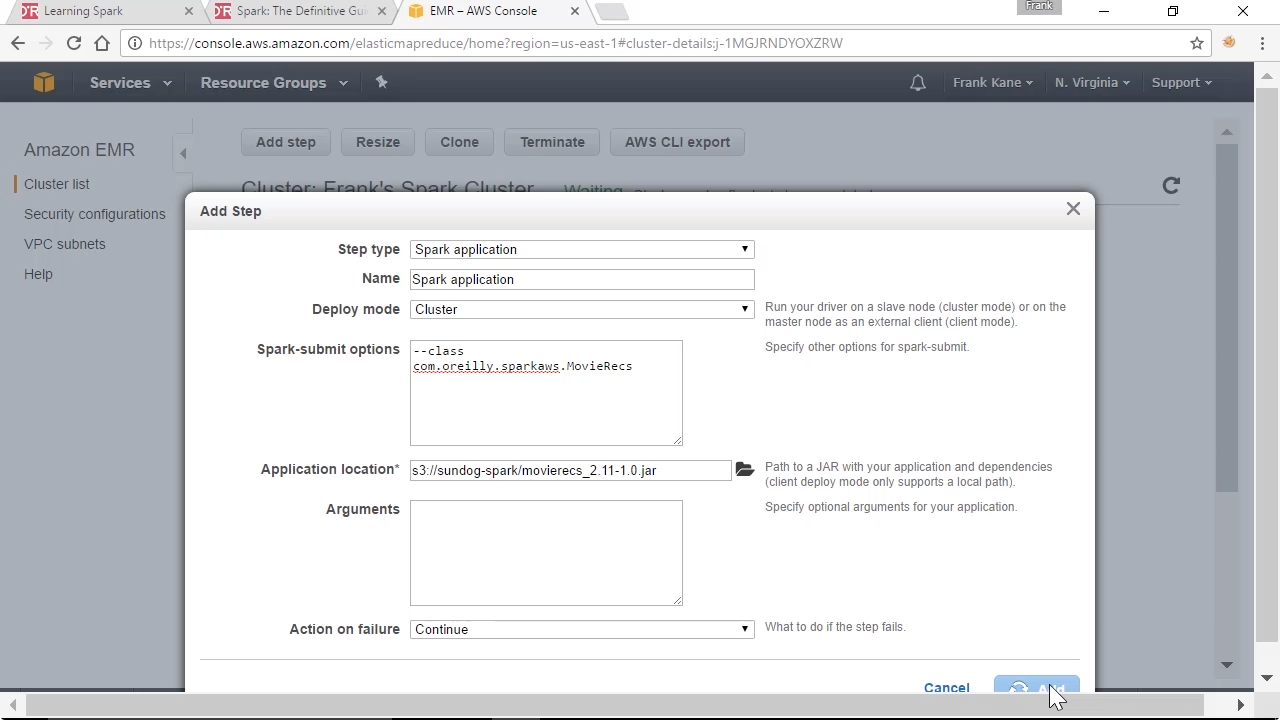 Screenshot from "How do I run an Apache Spark script on an Amazon Elastic MapReduce (EMR) cluster?" (source: O'Reilly)
Screenshot from "How do I run an Apache Spark script on an Amazon Elastic MapReduce (EMR) cluster?" (source: O'Reilly)
Amazon Web Services pro Frank Kane shows you how to use steps in the AWS Elastic MapReduce (EMR) console to quickly run your Spark scripts stored in S3. Learn how to save time and money by automating the running of a Spark driver script when a new cluster is created, saving the results in S3, and terminating the cluster when it is done.
