How do I configure Apache Spark on an Amazon Elastic MapReduce (EMR) cluster?
Learn how to manage Apache Spark configuration overrides for an AWS Elastic MapReduce cluster to save time and money.
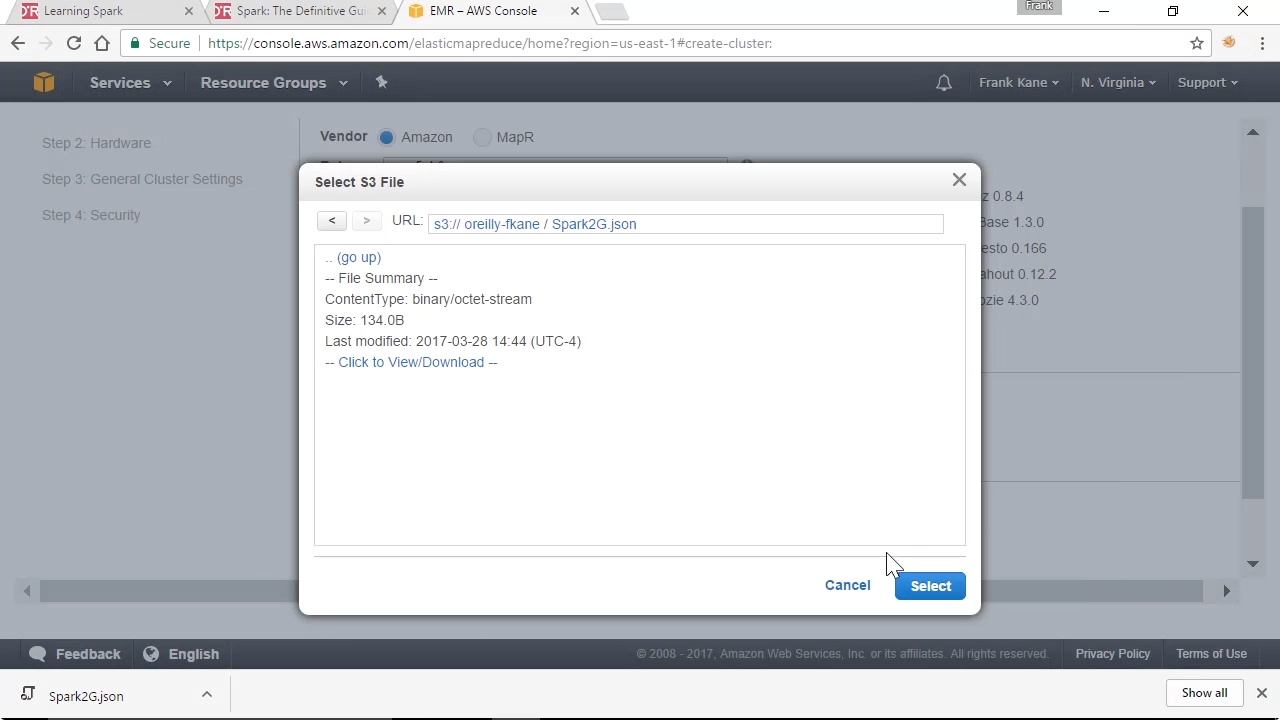 Screenshot from "How do I configure Apache Spark on an Amazon Elastic MapReduce (EMR) cluster?" (source: O'Reilly)
Screenshot from "How do I configure Apache Spark on an Amazon Elastic MapReduce (EMR) cluster?" (source: O'Reilly)
Specifying default configuration overrides for Spark ensures your clusters are consistent and large jobs will not fail. Amazon Web Services pro Frank Kane shows you how to set these overrides for your Apache Spark/Elastic MapReduce (EMR) cluster.
