How a RESTful API represents resources
Formats, linking, and versioning are important in well-formed RESTful APIs.
 Confluence (source: Picabel)
Confluence (source: Picabel)
In this series of posts on RESTful API design, we started from the spec of a bike rental application and we’re moving towards a fully functional API design. In the first article, we talked about how to identify the URL and HTTP method pairs we would need to implement the server-side API for the application. Then, in the second part, we explored how our server should react to incoming requests and communicate its state with status codes. We also learned how HTTP implements authentication, caching, and optimistic locking.
Now, in the third and last part of this example-guided tour, we will cover some of the most controversial topics among the REST community. They are actively debated and are always on the spot in the discussions about RESTful API design: resource representations, Media Types, HATEOAS, and versioning.

Learn faster. Dig deeper. See farther.
In our previous examples, our bike rental API sent and received data formatted as vanilla JSON. By “vanilla” we mean JSON as defined by the JSON standard: a simple format that supports collections of name/value pairs and arrays of strings, numbers, booleans and nulls. But RESTful APIs can send and receive any data type chosen by the developer. REST is not a protocol, it’s an architectural style. As such, it doesn’t limit the format of client-server interaction, i.e., the Media Type1. However, this flexibility is a double-edged sword. On the bright side, it gives applications liberty to define the format that best suits them. On the other side, this results in a lack of standardization. Working with a new RESTful API usually requires a bit of reading to understand how it accepts input data (the request, especially the query parameters and the body) and returns output data (the response, especially the body).
For example, the bike sharing application we’ve seen in our previous articles has a stations resource. There are many reasonable Media Types we can use to represent a list of stations. We’ve used vanilla JSON:
[{"id":1,"name":"John St","location":[40.7,-74]},{"id":2,"name":"Brooklyn Bridge","location":[40.7,-73]}]
But nothing prevents us from using another Media Type, such as XML:
<stations><stationid="1"name="John St"><location><latitude>40.7</latitude><longitude>-74</longitude></location></station><stationid="2"name="Brooklyn Bridge"><location><latitude>40.7</latitude><longitude>-73</longitude></location></station></stations>
Additionally, there are multiple ways of representing data in a single Media Type. For example, latitude and longitude can be shown as decimal degrees like [40.7, -74] or degrees, minutes and seconds like ["40 42 0", "-74 0 0"].
In the first article of this series, we considered which data the API clients needed in request and responses. Now we’ll discuss how to represent that data.
User centered design for representations
When deciding the way to represent API resources, try to imagine how clients will consume them. There are two important questions:
- Are the representation data fields in a format that’s easily processable by clients?
- Do these data fields precisely represent the resource state from the server?
Make the representation easy to process
Remember the GET /rents/ request from the first article? Its response includes each active rent start_date in a format like this:
"2017-06-08T19:30:39+00:00"
This is the ISO 8601 format for datetimes, which is a popular standardized format for representing dates as strings. It’s used by GitHub API, which is considered a well implemented API. Since the JSON spec is silent about how datetimes should be specified, web developers commonly use ISO 8601 for representing datetimes in JSON. Because it is a popular standard, most frameworks and languages have built-in functions to parse ISO 8601 and get datetime objects, thereby facilitating the work of API client. As always, there’s a relevant XKCD.
Now imagine if instead we represented start_date like this:
"08/06/2017 19:30:39"
This is a human readable format, but it isn’t standardized for machines to process. The API client programmer needs to check the programming language docs to know which format specifiers it must use to process this format. Besides, the custom representation introduces ambiguities, as we’ll see.
Another important example in GET /rents/ is how we represent rents that have no end_date:
end_date: null
Some APIs do this differently. They hide the empty field entirely, removing the end_date key from the JSON response body. This is a bad practice. It makes the API less explorable, less self-descriptive, less predictable, and more error-prone for clients.
Make the representation precise
There are other problems with start_date: "08/06/2017 19:30:39". First, it is ambiguous. 08/06/2017 is August 6th in the US. However, it’s June 8th in the UK and other countries. A badly implemented datetime parser might accept this format and interpret it wrongly. Second, the format lacks potentially crucial data: there’s no time zone info. The API client don’t know whether this date and time is in UTC or in the time zone where the bike rental service is operating. This imprecision could be remediated with ISO 8601.
Similar to the above problem is representing floating-point numbers. In our bike rental API, we represent the latitude and longitude of a location like this:
"location": [40.7, -74]
However, it’s important to note that floating point arithmetic is not exact. When a processor performs the floating-point addition 0.04 + 0.07, the result may be something like 0.11000000000000001. Such imprecise approximations are fine for latitude and longitude calculations, but they’re definitely insufficient for financial data. In JSON, the popular solution is to use strings of decimal numbers to represent exact currency values, for example:
"price_in_usd": "19.90"
Another solution is to use the smallest currency unit as an integer, which in dollars is cents. That’s what Stripe does. The previous example would then look like:
"price_in_usd_cents": 1990
In JSON, besides floats versus integers, a common mistake is not using Booleans to represent true or false values. Don’t use integers 1 or 0, or even worse, strings “1” or “0” to represent true or false. The string “0” is interpreted as truthy in a lot of programming languages. If your API client uses it in a “if” statement, it might introduce a bug that’s hard to catch. A bug like this might even happen on the server, if this bad data comes back to it via a request body. Just use JSON Booleans, as we’ve did on the first article with the is_active field in GET /rents/.
In the problems above, we gave examples and solutions in JSON. But those problems are mostly independent of Media Type, even though some specific Media Types might solve them (for example, by specifying a standard datetime format). Now let’s discuss how Media Types help us with important API features.
Sorting, filtering, paginating, linking with Media Types
Defining a Media Type for a RESTful API is more than choosing a data format like JSON or XML. It’s defining the whole format of interactions between clients and servers, i.e., the structure of requests and responses. As Roy Fielding, REST creator says, “a REST API should spend almost all of its descriptive effort in defining the Media Type(s) used for representing resources and driving application state”. In practice this means we must define how our API Media Type relates to features like sorting, filtering, paginating, and linking.
Sorting and filtering
Imagine if the mobile app that uses our bike rental API supports ordering stations by distance, name, or number of available bikes. You don’t want your API clients to fetch your whole set of stations to sort them client-side, because that could lead to huge, slow data transfers. Thus, you need to support sorting in the API-level.
Similarly, sometimes API clients or their users want only a subset of resources that match some condition. Better to filter server-side instead of passing the whole collection to be filtered by the client.
The most RESTful way to support sorting and filtering is using HTTP query parameters on each resource. The sortable/filterable fields must match the names used in resource representations. This is how the resource representation Media Type is related to sorting and filtering. So, when documenting your API Media Type, you must document how it supports sorting and filtering.
In our Bike rental API, we can implement sorting and filtering for /stations/ as following:
GET /stations/?sort=-available_bikes_quantity
- Get the stations with the most available bikes first.
GET /stations/?name_contains=Brooklyn
- Get the stations whose names contain Brooklyn.
GET /stations/?sort=-available_bikes_quantity,distance&name_not_contains=Park
- Get the stations with the most available bikes first, closest to the user and with names that do not contain the word “Park”.
Pagination and HATEOAS
In the first article, we defined GET /stations/ as the way to get all stations. Our example included only two stations. What if our bike service had thousands of stations? We could return them all in a huge JSON list, but is a good idea? Probably not. This would have a negative impact in the performance of our backend server and API clients. The solution is pagination.
The most straightforward way to paginate API responses is to return the page count and leave it up to the API client to specify the page through a query parameter. The response for a request like GET /stations/?page=2 looks like this:
{"page_number":2,"total_pages":102,"page_count":10,"total_count":1013,"results":[{"id":1,"name":"John St","location":[40.7,-74],"available_bikes_quantity":10},{"id":2,"name":"Brooklyn Bridge","location":[40.7,-73],"available_bikes_quantity":2}]}
Note that the results are now enveloped in the JSON results key. Everything we had before in our response body is there, but each request will have a part of the results since they’re paginated. To get the next page, the client would make the request GET /stations/?page=3. And the last page of results is at the URL /stations/?page=102.
This looks simple, but is not ideal, as you’re asking the API client to build the URL for the next resource. Why is the API server asking this if it already knows what’s the current page, what’s the next one, and the previous ones? Asking for clients to build URLs it’s the opposite of the HATEOAS principle. Simplifying a lot, this crazy acronym is a fancy way of saying that RESTful API responses need to include links to related resources. If the client needs a related resource, even if it’s the next page of results, the API should guide the client to it. How? By using Hypermedia: media with links. Hypermedia guides the client to the next page, the next application state. That’s why by linking our resources we’re using Hypermedia as the Engine of Application State (HATEOAS).
To update our example to use HATEOAS, we can send the following:
{"page_number":2,"total_pages":102,"total_count":1013,"previous_page":"/stations/?page=1","next_page":"/stations/?page=3","last_page":"/stations/?page=102","results":[…]}
Now the client doesn’t need to build URLs to get the previous, next, or last pages! HATEOAS makes our API easier to consume, more explorable, and less error-prone. However, there’s a more RESTful alternative. As someone once said, HTTP is your envelope already. You don’t need to add pagination metadata in the response body, you can use response headers! That’s what the GitHub API does on its paginated responses. It uses the Link header to hold the pagination links. Updating our example to be like GitHub API responses, we get this:
Status: 200 OK
Link: </stations/?page=3>; rel="next",
</stations/?page=1>; rel="previous",
</stations?page=102>; rel="last"
[
… results here …
]
But wait, we’ve lost the total_count! How can we return it if we’re not using an enveloped response? The solution is again using headers, but this time a custom application-specific one. We can call it Total-Count, as other APIs usually do. Thus, besides the Link header, we need to include the Total-Count header in our /stations/ responses.
It’s important to note that HATEOAS mandates linking not only when paginating, but any time when there are relations between the resources, especially when those other resources will help us to change the state of the application. For example, on GET /rents/ we may have an active rent that’s cancellable. We could link to it like this:
Link: </rents/321914/>; rel="active-rent".
Then, the API client can check whether there’s a rel="active-rent"2 URL on the Link header of GET /rents/ response. If so, it means the active rent is cancellable, and therefore the API client can show a “Cancel” button on the end user interface. This button makes a DELETE request to the rel="active-rent" URL, which specifies rent 321914. Again the API is the engine of application state, since it’s driving the client to the possible ways of changing the application state. For more information about HATEOAS, check the article How to GET a Cup of Coffee.
The key point for designing a great representation is to think about what’s best for the API client. Look for the good practices of the Media Type you’re using. Grab inspiration from good APIs like GitHub or Stripe. Avoid truncating data from the fields that your API exposes. And link resources to other resources.
However, note we’ve only used vanilla JSON in our examples. There are many other Media Types we could have used. Different Media Types have different features. Some of them will easily solve the problems we’ve just discussed, for example, by defining a standard for pagination or links. Let’s explore Media Types other than JSON.
Common Media Types for RESTful APIs
In the HTTP protocol, Media Types are specified with identifiers like text/html, application/json, and application/xml, which correspond to HTML, JSON, and XML respectively, the most common web formats. There are other more API-specific Media Types as well, such as application/vnd.api+json. This represents is JSON API, which we’ll cover later.
But web pages and APIs can render or respond much more than text. The contemporary web has images, audio, video, etc. There are many Media Types for each of those things too, like image/gif, audio/vorbis, video/mpeg, etc.
HTTP servers can support multiple Media Types for the same resource. In a request, the client specifies which Media Type it wants for the resource representation to be with the Accept header. You can imagine, then, an API that can respond either with JSON or XML, depending whether the client passed Accept: application/json or Accept: application/xml.
The first thing we must consider is to not roll out our own custom Media Type. Instead, we should choose an existing one. API consumers are used to deal with JSON, XML, or their derivations like JSON API. Those Media Types are standardized, which means they have extensive tooling we can use to facilitate the development of RESTful APIs.
XML
As we can see by the Google Trends chart in Figure 1, interest in XML APIs has dramatically decreased over time, with JSON taking their place by a long margin:
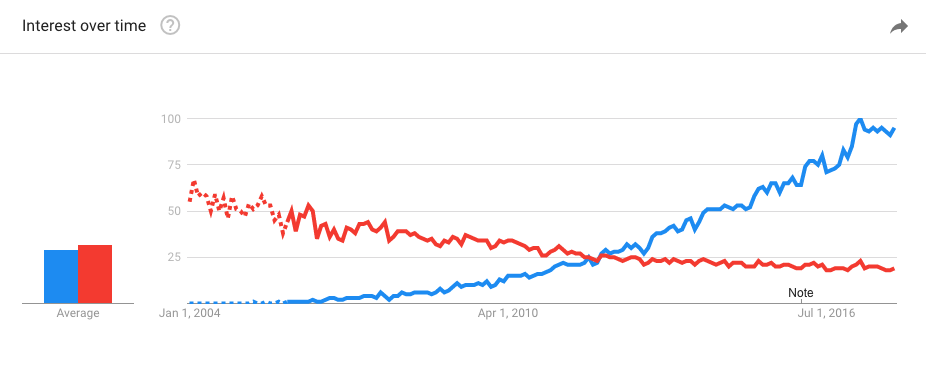
Basically, this tells us we should avoid XML for new APIs. Remember, we’re writing APIs for people to consume them. And people don’t like XML, mostly because it’s very verbose, difficult for a human to read and a computer to parse. Perhaps the problem actually is not XML syntax per-se (the example in the beginning of this post was readable), but the number of complexities introduced by dozens of extensions that clutter XML documents with schemas, namespaces, types, envelopes, etc.
For new APIs, we see no reason for using XML, except if there’s already a good XML-based standard you want to use in API responses like RSS or Atom, or if you need your API to be consumed by a legacy system that supports only XML3.
Vanilla JSON
Vanilla JSON is not Hypermedia, because there is no standard way of expressing links to other resources. JSON doesn’t mandate that links should go in a specific place. In fact, the standard is silent about links. Therefore, using vanilla JSON is not strictly RESTful, since REST mandates HATEOAS.
You can, however, add links to JSON by enveloping your data under a key like results as we did in an earlier example, and adding links and other metadata outside the envelope. While enveloping vanilla JSON is not standardized, it’s very common in the wild. For simpler or private APIs, it’s fine. A more RESTful alternative would be to use the Link header, as we’ve seen. But even the Link header is not enough for some cases. What if each station had related bike resources? How would we link each station to its bikes URL? We can’t add those links to the Link header because there’s no way of mapping each station to its bikes there. What most vanilla JSON APIs simply do is add the subordinate resource link inside the resource representation data, like this:
{…metadata…,"results":[{"id":1,"name":"John St","location":[40.7,-74],"available_bikes_quantity":10,"bikes_url":"/stations/1/bikes/"},{"id":2,"name":"Brooklyn Bridge","location":[40.7,-73],"available_bikes_quantity":2,"bikes_url":"/stations/2/bikes/"}]}
This is not ideal since it mixes resource data with metadata (links). A more RESTful solution is to use Media Types that have explicit support for Hypermedia, like JSON API. That said, more RESTful does not necessarily mean better for you and your API clients. For example, GitHub API sticks with linked vanilla JSON. Consider what you’ll really gain by separating data from metadata before introducing the complexity of a fully-featured Hypermedia Media Type.
JSON API
JSON API defines conventions about how JSON should be structured in APIs. The GET /stations/ response would be formatted like this in JSON API:
{"links":{"prev":"/stations/?page=1","self":"/stations/?page=2","next":"/stations/?page=3","last":"/stations/?page=102"},"meta":{"count":1013},"data":[{"type":"station","id":1,"attributes":{"name":"John St","location":[40.7,-74],"available_bikes_quantity":10},"relationships":{"bikes":{"links":{"related":"/stations/1/bikes/"}}},"links":{"self":"/stations/1/"}},{"type":"station","id":2,"attributes":{"name":"Brooklyn Bridge","location":[40.7,-73],"available_bikes_quantity":2},"relationships":{"bikes":{"links":{"related":"/stations/2/bikes/"}}},"links":{"self":"/stations/2/"}}]}
As you can see, this Media Type is more verbose than vanilla JSON, but it’s also more organized. Links, identifiers, data fields (attributes), and relationships are all properly separated, each of them in a standardized place. This facilitates the implementation of generic tools to deal with APIs that use JSON API as Media Type. In fact, there are many JSON API client and server libraries for most of the popular programming langagues.
Another great feature of JSON API is support for metadata on the top-level object, embedded resources or even links. The available_bikes_quantity can be thought as metadata of the station bikes. Thus, instead of putting the available_bikes_quantity inside attributes, we can move it next to the related bikes link:
{…"attributes":…,"relationships":{"bikes":{"links":{"related":{"href":"/stations/2/bikes/","meta":{"available_bikes_quantity":2}}}}},…}
Being a complete Media Type, JSON API decides not only how GET responses are represented, but also how to represent data on creations, updates, and deletions, as well as how to support partial representations, sorting, and filtering.
JSON API is a good choice for complex public APIs. It has been battle-tested by many real-world APIs (Patreon being a good example) and it’s opinionated in many aspects, thereby deciding for you how your API should expose and receive data. That’s great, because you can focus on what’s most important: which data fields you want to expose and receive. For more information about JSON API, check the official website.
HAL
As its friendly spec says, HAL (Hypermedia Application Language) is a simple format that offers a consistent and easy way to hyperlink between resources in your API. The same example we showed for JSON API can be represented like this in HAL
{"_links":{"prev":{"href":"/stations/?page=1"},"self":{"href":"/stations/?page=2"},"next":{"href":"/stations/?page=3"},"last":{"href":"/stations/?page=102"}},"count":1013,"_embedded":{"stations":[{"id":"1","name":"John St","location":[40.7,-74],"available_bikes_quantity":10,"_links":{"bikes":{"href":"/stations/1/bikes/"}}},{"id":"2","name":"Brooklyn Bridge","location":[40.7,-73],"available_bikes_quantity":2,"_links":{"bikes":{"href":"/stations/2/bikes/"}}}]}}
As you can see, the format is quite similar to JSON API. In fact, HAL has a few advantages over JSON API, but some drawbacks too:
- HAL is one of the simplest hypermedia response data formats, but it was not conceived originally as a request data format.
- The HAL specification is simpler than JSON API one, but it’s less complete. There’s no support for metadata on links, partial representations, sorting, or filtering.
- As the JSON API FAQ says, HAL embeds nested data recursively, while JSON API flattens the entire graph of objects at the top level. The JSON API approach avoids repeated nested data.
- HAL can be used either in JSON or XML, while JSON API is JSON only. But XML HAL is not much used in practice, which means there are not many resources about it.
- One unique feature HAL has is compact URIs (CURIEs), which are basically documentation links inside of the responses. This makes the documentation discoverable from within the API itself.
So when to use HAL? Ideally, when you want the benefits from hypermedia without the JSON API complexity. As with JSON API, there are HAL libraries for many programming languages. Also, you can grab inspiration from real-world public APIs that use HAL.
Other Hypermedia formats for APIs
There are other less common formats for APIs. One worth mentioning is JSON LD, which stands for JSON Linked Data and is related to Semantic Web concepts. It’s used by Google Knowledge Graph API.
Other formats include Collection+JSON, Mason, Siren, UBER, and CPHL. They are much less popular than JSON API and HAL.
Versioning
Versioning in REST is always a subject of hot debates. That’s because there are many ways to do it and the REST original article does not provide a clear solution for it. Developers of API clients hate unstable APIs, and are not keen to refactor code just to support a new API version. Updating clients cost time and money. If you want your API users to stay happy, try hard to avoid API changes. When updating is inevitable, keep the old versions online for some good amount of time. Regardless of what versioning option you’ll chose, always launch with a version and ask your API clients to specify it on requests. This will solve most of the problems of incompatibility, because it will allow you to have multiple versions online and safely launch new versions without breaking old clients.
The most RESTful way to version an API is to version the resource representations. For example, remember the problem we’ve discussed where some APIs don’t use Booleans for true/false fields? Imagine that on the first version of our Bike rental API we had "is_active": "0" in our GET /rents/ response. Then we learned that’s bad, and we decided to change to "is_active": false. How should we introduce that change? Ideally with a different Media Type, since the representation changed. To do that properly, we should publish our API from day 1 with a custom Media Type that includes the version, like: application/vnd.bikerental.v1+json. Then, our first API clients should use that Media Type on their Accept headers. That’s equivalent of saying “I want data formatted as the Bike rental JSON version 1”. Currently, GitHub API handles versioning in that way. Afterwards, we can deploy the change to "is_active": false and introduce a second Media Type: application/vnd.bikerental.v2+json. This allows us to keep both versions for some time and disable the older one once its traffic is minimal.
Sometimes, however, the API change is so large that it cause changes not only to the representation, but even the semantics. Imagine our service doesn’t want to support active rent cancellations via the API anymore. If you’ve just rent a bike and you don’t want it anymore, you can just return it to the station within 10 minutes and the station will automatically cancel the rent for you. This means we’ll have remove DELETE /rents/{id}/ from the API. In the new API version, the response for those requests should be 405 Method Not Allowed. Theoretically, old API clients that respect HATEOAS would not break. They would see that the link on the Link header with rel="active-rent" is now gone and thereby would remove the “Cancel” button from the end user UI. But it’s very rare for API clients to behave like that, especially clients of public APIs. In that case of a hard functionality change, probably it would be better to be more explicit about the API version by adding it to the URL. The conservative solution would be to keep supporting DELETE /v1/rents/{id}/ for some time to avoid breaking clients and launch a /v2/ API without this functionality.
The cases we’ve just suggested are good reasons for adding a new version to the API, but there are many cases where a new API version shouldn’t be necessary. For example, if you’re adding a new resource for newer clients to use, why bother deprecating the version of older clients? If they don’t know about that new resource, they shouldn’t be affected by it. Another reason not to update the API is when there’s a change in the backend technology. The whole point of REST is to be a uniform interface decoupled from the implementation, with clients using resource representations, not the resources themselves. So it shouldn’t matter if your backend resource changed from MongoDB to PostgreSQL, just return the same representation to the client. Don’t break your API because of updates that should be transparent for the client.
In practice, the most important thing about versioning is to launch with a version, either on the Media Type or the URL, and communicate well with API clients, documenting changes and giving them time to adapt to newer versions by deprecating older versions slowly. Your backend code might become a bit cluttered to support multiple versions online at the same time, but your API clients will be thankful.
In this series of posts we covered the most important aspects about RESTful APIs. The great thing is that we’ve started from scratch with a spec and learned a lot with practical examples related to it. There’s much more to learn about REST, since we couldn’t cover everything. We recommend taking a look at the Best Practices for Designing a Pragmatic RESTful API and Building Your API for Longevity. Those links have good advice that balances practicality and purity. Always look for that when studying REST. Also, we suggest you to explore API specification languages like RAML and Swagger, which facilitate the design of complex RESTful APIs.
- Some people confuse Media Types with API specification formats/languages. An API specification language is something much more complex. It describes the whole API, including resources, methods, schemas, and Media Types in a machine-readable language that generates mock servers, documentations, and tools, enabling the top-down development of an API. ↩
- Here we created a custom link relation (rel), but there is a number of standardized ones.↩
- Even that might not be a good reason, as it should not be very difficult to write a JSON parser in any language that already has a XML parser.↩